| CATEGORII DOCUMENTE |
| Agricultura | Asigurari | Comert | Confectii | Contabilitate | Contracte | Economie |
| Transporturi | Turism | Zootehnie |
In integrarea orientata pe date un rol important il au instrumentele. Aceste instrumente le putem clasifica in doua categorii:
instrumente pentru gestiunea datelor, in cazul in care datele sunt deja stocate in baze de date sau in depozite de date si
instrumente pentru extragerea datelor din diferitele surse si incarcarea acestora intr-o baza de date consolidata.
In acest capitol vor fi prezentate principalele sisteme de gestiune a bazelor de date si a depozitelor de date si cateva teste realizate cu instrumentele folosite pentru migrarea datelor.
Un sistem de gestiune a bazelor de date este un ansamblu complex de programe care asigura interfata intre o baza de date si utilizatorii acesteia.
Sistemul de gestiune a bazelor de date este componenta software a unui sistem de baza de date care interactioneaza cu toate celelalte componente ale acestuia, asigurand legatura si interdependenta intre elementele sistemului.
Rolul unui SGBD intr-un context de sistem de baza de date este de:
1. a defini si descrie structura bazei de date, lucru care se realizeaza printr-un limbaj propriu specific, conform unui anumit model de date;
2. a incarca/valida datele in baza de date respectand niste restrictiile de integritate impuse de modelul de date utilizat;
a realiza accesul la date pentru diferite operatii (consultare, interogare, actualizare, editare situatii de iesire), utilizand operatorii modelului de date;
4. a intretine baza de date cu ajutorul unor instrumente specializate (editoare, utilitare (shells), navigatoare, convertoare etc.);
5. a asigura protectia bazei de date sub aspectul securitatii si integritatii datelor.
Obiectivul general al unui SGBD este de a furniza suportul software complet pentru dezvoltarea de aplicatii informatice cu baze de date. Fiind un mediu specializat, SGBD satisface cerintele informationale ale utilizatorului intr-un mod optim. Astfel, el asigura minimizarea costului de prelucrare a datelor, reduce timpul de raspuns (timp util), asigura o mai buna flexibilitate si deschidere a aplicatiei, asigura protectie ridicata a datelor.
Cele mai utilizate SGBD-uri sunt:
ORACLE - realizat de firma Oracle Corporation USA, produs complet relational, robust, bazat pe SQL standard extins, ajuns la versiunea 10G, extensie orientata obiect, arhitectura client/server, lucrul distribuit, BD Internet, optimizator de regasire;
DB2 - realizat de firma IBM, bazat pe SQL, optimizator de regasire, respecta teoria relationala, lucrul distribuit, robust;
INFORMIX - realizat de firma Informix, respecta teoria relationala, lucru distribuit, robust;
PROGRESS - realizat de firma Progress Software, are limbaj propriu (Progress 4GL), suporta SQL, ruleaza pe o gama larga de calculatoare sub diferite sisteme de operare;
SQLServer - realizat de firma Microsoft, bazat pe SQL, ruleaza in arhitectura client/server;
INGRES II - realizat de firma Computer Associates, este un SGBDR complet, implementeaza doua limbaje relationale (intai Quel si apoi SQL), este suportat de diferite sisteme de operare (Windows, VMS, UNIX), lucreaza distribuit in arhitectura client/server, extensie cu facilitati orientate obiect, permite aplicatii tip Internet, protectia ridicata a datelor, organizarea fizica a tabelelor se face prin sistemul de operare, are numeroase componente;
VISUAL FOXPRO - realizat de firma Microsoft, are un limbaj procedural propriu foarte puternic, extensie orientata obiect, programare vizuala, nucleu extins de SQL, rapid;
ACCESS - realizat de firma Microsoft, bazat pe SQL, are limbajul procedural gazda (Basic Access), are generatoare puternice;
PARADOX - realizat de firma Borland, are limbaj procedural propriu (PAL) si suporta SQL.
Instrumentele oferite de Oracle Discoverer cuprind: elemente de analiza multidimensionala a datelor care implementeaza operatiile specifice (navigare in cadrul ierarhiilor, rotatii, sectiuni) si functii de analiza (de previziune, de construire a scenariilor "ce se intampla daca?"); elemente de vizualizare a datelor prin construirea de rapoarte si grafice flexibile si usor de modificat de catre utilizatorul final.
Oracle Discoverer 9.0.4. este alcatuit din doua componente majore (figura 1):
Arhitectura Oracle
Discoverer este compusa din trei niveluri distincte: nivelul datelor, nivelul End
User Layer (EUL V5 pentru
versiunea Oracle Discoverer 9.0.4) care contine metadatele si
structurile specifice utilizate in analiza si nivelul interfetei cu
utilizatorul. 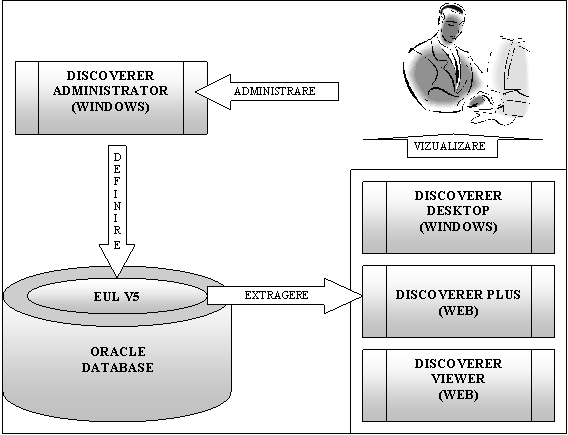

Figura 1. Arhitectura Oracle Discoverer
Accesul la date se realizeaza prin intermediul nivelului EUL si este un acces direct, fara construirea unui depozit de date suplimentar. Structurile multidimensionale de tipul dimensiunilor si a tabelelor de fapte sunt transformate automat din sursele relationale in obiecte de tipul Folder si grupate si incarcate in obiectele de tipul Business Area ale nivelului EUL. Din acest motiv, pe baza de date relationala trebuie construite mai intai o serie de view-uri care sa faciliteze maparea datelor pe obiectele din Oracle Discoverer.
Pentru construirea unei aplicatii de analiza de tipul Business Intelligence sunt necesare doua etape:
definirea obiectelor in Oracle Discoverer Administrator si
construirea prezentarilor in Oracle Discoverer Desktop sau Oracle Discoverer Plus sau Viewer.
Oracle Discoverer ofera posibilitatea construirii unui depozit virtual de date, centralizat sau bazat pe data marts, folosind surse de date diferite, extrase de obicei din bazele de date relationale. Depozitul se bazeaza pe tabele sau pe un set de viziuni construite pe baza de date. Integrarea datelor se poate realiza prin acest nivel de tabele virtuale care pot fi construite pe baze de date diferite prin intermediul data link-urilor.
Solutia cea mai complexa oferita de compania Oracle pentru analiza, proiectarea, dezvoltarea si implementarea unui depozit de date este Warehouse Builder 10g. Este conceput ca un mediu integrat care sa asiste intregul ciclu de dezvoltare a depozitelor de date. Acesta permite si migrarea datelor obtinute in alte medii cum ar fi OLAP Analytic Workspace Manager sau Oracle Discoverer sau chiar versiunile anterioare de Oracle Express.
Spre deosebire de Oracle Discoverer in care se realiza un depozit virtual, in Warehouse Buider datele sunt stocate fizic intr-un repository special construit pe baza de date.
Principalele obiecte cu care lucreaza Warehouse Builder sunt prezentate in continuare:
colectiile (collections) reprezinta un mecanism generic de grupare. Ele sunt o cale de acces mai usoara la definitiile obiectelor folosita pentru a realiza activitati la nivel de grup, de exemplu validarea sau generarea de cod;
bazele de date (databases) reprezinta maparea unor date din baze de date Oracle sau non-Oracle. Se introduc notiunile de "modul" si "locatie";
Modulul reprezinta un mod logic de grupare a definitiilor de obiecte. De exemplu, un modul de baza de date Oracle reprezinta o grupare logica de obiecte care apartin unei baze de date (scheme) Oracle. Atat bazele de date (databases), fisierele (files), aplicatiile (applications), cat si fluxurile de procese (process Flows) sunt grupate din punct de vedere logic in module.
Locatia defineste informatii referitoare la schema bazei de date sau la instrumente destinatie. Locatiile sunt specifice tipurilor de module: baze de date Oracle, baze de date non-Oracle, SAP sau fisiere. Atunci cand se creeaza o locatie, se memoreaza o definitie logica ce contine tipul de locatie si versiunea.
fisierele (files). Un modul de fisiere defineste o "legatura" catre un director ce contine un numar de fisiere text. Putem folosi un wizard pentru a importa aceste fisiere, ele putand contine tipuri multiple de inregistrari, inregistrari separate prin caractere etc.;
aplicatiile (applications) contin definitii ale pachetelor de aplicatii. Oracle Warehouse Builder asigura un instrument de integrare pentru sistemele SAP;
fluxul de date (process flow) contine definitii ale fluxurilor de procese. Acestea sunt continute in module, iar in cadrul modulului sunt continute in pachetele de fluxuri de date. Codul pe care Warehouse Builder-ul il genereaza pentru a reprezenta definitiile fluxurilor de date respecta standardul XML Process Definition Language(XPDL);
transformarile publice (public transformations) reprezinta transformari ce pot fi folosite in cadrul proiectului. Acestea sunt divizate in transformari obisnuite si transformari predefinite. Cele obisnuite pot fi definite sau importate de catre utilizator, in timp ce, cele predefinite sunt legate de instalarea Warehouse Builder. Toate acestea sunt disponibile in schema destinatie. Transformarile publice sunt divizate in urmatoarele categorii:
"Administration" - de exemplu: activarea/anularea restrictiilor, analizare tabela/schema,etc;
"Character"- de exemplu CHR, CONCAT, LDAP,LTRIM,etc;
"Conversion" - pentru realizarea conversiilor dintre tipurile de date;
"Date" - asigura un numar de transformari specifice pentru datele de tip "date" ;
"Numeric" - de exemplu ABS, SIN,FLOOR, etc;
"OLAP" - asigura accesul la procedurile de incarcare a cubului si dimensiunilor
"Other" - inclusiv transformari NVL;
"XML" - pentru a expune transformarile de incarcare XML;
conexiunea la Runtime Repository (Runtime Repository Connections) contine specificatiile de conectare la depozitul central de rulare (runtime repository).
Datele provenite din surse multiple, atat din fisiere, cat si din baze de date de diferite generatii si producatori, sunt preluate si incarcate intr-un modul centralizat, numit modul sursa si apoi acestuia i se aplica procesul de extragere, transformare si incarcare (ETL) intr-un modul destinatie, din care vor fi utilizate pentru analiza. Iata, pe scurt, obiectele acestor doua module:
1) Modulul sursa se defineste pe baza tabelelor din sistemelor tranzactionale existente in cadrul institutiei. Pentru simplificarea procesului de extragere si incarcare a datelor in depozit se pot construi view-uri sau tabele suplimentare care sa prezinte datele intr-o forma asemanatoare celor din dimensiuni si fapte. Datele pot proveni fie din diverse fisiere, fie din tabelele aplicatiilor operationale pe diferite platforme ca Oracle, Microsoft, SAP, Informix, Hyperion etc. Ele sunt centralizate si integrate in acest modul pe care se va aplica procesul ETL.
2) Modulul destinatie va contine dimensiunile, tabelele de fapte, cuburile si maparile necesare depozitului de date. In cadrul acestui modul se pot defini urmatoarele elemente:
dimensiunile - Warehouse Builder permite proiectarea dimensionala (acesta reprezinta un avantaj fata de cei mai importanti concurenti). Dimensiunile constau in unul sau mai multe niveluri si ierarhii si contin atribute;
cuburile - sunt descrise de dimensiuni. Cuburile fac parte din modelarea dimensionala. In mod obisnuit, un cub are legaturi cu una sau mai multe dimensiuni si contine masuri ale datelor care ne intereseaza. Intr-o implementare relationala, cubul este realizat ca o tabela relationala, in timp ce in mediul OLAP cubul este creat ca o structura separata;
maparile - reprezinta fluxuri de date necesare modelarii procesului ETL (Extract, Transform and Load). Warehouse Builder genereaza cod pentru implementarea maparilor in mediul de rulare (runtime). Se poate genera cod in trei tipuri de limbaje in functie de natura sursei: PL/SQL, SQL Loader (in cazul in care sursa o reprezinta fisierele text) si ABAP (in cazul in care sursa e reprezentata de tabelele din cadrul pachetelor de aplicatii SAP);
transformarile - se prezinta sub forma de cod PL/SQL implementat ca si functie, procedura sau pachet. Warehouse Builder asigura utilizatorului posibilitatea de a defini cod PL/SQL si de a-l include intr-o mapare pentru a implementa orice tip de transformare;
tabelele - definitii de tabele sunt folosite deseori in proiectarea unui sistem de inteligenta a afacerilor;
viziunile se pot folosi viziuni pentru a simplifica eventualele interogari de regasire;
viziunile materializate - pot fi foarte importante pentru a usura cererile de regasire. Warehouse Builder permite definirea de viziuni materializate;
tabelele externe - Warehouse Builder permite proiectarea tabelelor externe in cadrul sistemului destinatie (target). Pentru a nu folosi direct un fisier text ca si sursa intr-o mapare si a rula programul de incarcare SQL, se poate defini o tabela externa. Avantajele folosirii definitiei unei tabele externe comparativ cu folosirea definitiei unui fisier text sunt: rularea select-urilor in paralel si flexibilitate in cadrul transformarilor PL/SQL, datorata posibilitatii realizarii unui join eterogen intre tabelele externe si tabelele relationale;
listele avansate (advanced queues) - pot fi folosite atat ca sursa cat si ca destinatie intr-o mapare;
secvente - definitiile de secvente pot fi folosite ca obiect sursa intr-o mapare pentru a genera o valoare numerica in secventa.
Dupa realizarea procesului de incarcare in modulul destinatie, Warehouse Builder valideaza obiectele si genereaza urmatoarele tipuri de script-uri:
script-uri DDL - pentru crearea si stergerea obiectelor de tipul dimensiunilor, tabelelor de fapte, ierarhiilor;
fisiere de control SQL*Loader - pentru extragerea si transportul datelor pornind de la fisierul sursa;
script-uri TCL pentru programarea si conducerea job-urilor - Enterprise Manager.
Prin intermediul utilitarului de transfer, Warehouse Builder Transfer Wizard se permite exportul metadatelor catre urmatoarele tipuri de destinatie: un fisier in conformitate cu standardul OMG CWM, Oracle Discoverer, Oracle Express si OLAP Server.
Datorita facilitatilor sale, a posibilitatilor de integrare a datelor din surse multiple si diferite, dar si a mediului integrat de dezvoltare oferit, se poate spune ca Oracle Warehouse Builder 10g este cel mai potrivit instrument de realizare a unui depozit de date.
Prin instrumentele Analysis Services, Microsoft SQL Server 2005 integreaza solutii avansate pentru depozite de date si Business Intelligence. In prezentarea oficiala a produsului, compania Microsoft [NET01] precizeaza ca Analysis Services ofera instrumente pentru realizarea unor analize complexe asupra informatiilor stocate in baze de date de mari dimensiuni.
Componenta Online Analytical Processing (OLAP) integrata in cadrul acestei solutii, ofera posibilitati avansate de realizarea a analizelor multidimensionale asupra datelor. Suplimentar, OLAP permite realizarea analizei pe baza unor surse eterogene de informatie, componenta OLE DB oferind posibilitatea de conectare la diverse alte sisteme de gestiune a bazelor de date.
OLAP Actions, o noua facilitate din cadrul Analysis Services, permite declansarea diverselor actiuni pe baza rezultatelor analizelor. Analizele realizate prin intermediul instrumentelor OLAP pot deveni accesibile prin intermediul Web-ului, fiind asigurat in acest mod un nivel deosebit de mobilitate in accesarea informatiilor.
SQL Server dispune de doi algoritmi (Microsoft Decision Trees si Microsoft Clustering) care permit realizarea unor analize complexe prin data mining.
Pentru realizarea analizelor si exploatarea avantajelor oferite de Analysis Services este posibila integrarea cu diverse aplicatii. Instrumentele Pivot Table si Pivot Chart, accesibile in cadrul suitei Microsoft Office, pot fi utilizate pentru sintetizarea datelor rezultate in urma analizelor OLAP sau data mining. Microsoft Data Analyzer este un instrument specializat dedicat managerilor, care permite realizarea simpla a unor rapoarte si grafice pe baza datelor furnizate de Analysis Services.
SQL Server 2005 Reporting Services este un instrument destinat realizarii de rapoarte clasice si automate, disponibile la cerere sau generate periodic intr-o multitudine de formate de raportare (HTML, PDF, Excel).
Pentru o analiza comparativa prezentam in continuare un tabel cu cateva solutii si instrumente existente de realizare si prelucrare a datelor multidimensionale.
Tabel 1 Optiuni de stocare si prelucrare a datelor multidimensionale
|
Optiuni de procesare multidimensionala |
Baza de date relationala |
Baza de date multidimensionala |
Fisiere |
|
Motorul server Multidimensional |
Oracle Express (ROLAP mode) Oracle AWM Oracle Warehouse Builder Crystal Holos (ROLAP mode) |
Oracle Express Oracle Warehouse Builder SAS CFO Vision |
Oracle Warehouse Builder |
|
Motorul client Multidimensional |
Oracle Discoverer |
Comshare FDC |
Oracle Personal Express Brio.Enterprise |
Dupa cum se poate observa, instrumentele oferite de Oracle acopera intreaga gama a posibilitatilor de stocare si prelucrare a unui depozit de date, iar prin facilitatile de transfer si comunicare intre aceste instrumente se poate dezvolta o solutie complexa de depozit de date in functie de necesitatile de realizare.
Migrarea datelor se poate face manual sau folosind anumite instrumente. Pornind de la baza de date sursa se exporta structura, obiectele si datele acesteia in scripturi SQL. Acestea sunt apoi adaptate la sintaxa bazei de date destinatie, pentru a putea fi rulate pe aceasta, proces care poate fi unul deosebit de anevoios. De aceea, se recomanda folosirea unui asistent de migrare, care sa faciliteze acest proces. El trebuie sa indeplineasca cat mai multe din urmatoarele cerinte:
Sa ofere o solutie cuprinzatoare si integrata
Asistentul de migrare trebuie sa asigure nu doar conversia datelor, ci intregii scheme a bazei de date si algoritmului. Trebuie convertite si datele de tip LOB (imagini, video), definitiile de tabele incluzand si tipurile de date, tipul NULL, valorile implicite si comentariile, cheile primare, unice si externe, viziunile, functiile/ procedurile/pachetele stocate. Daca aceste facilitati nu sunt oferite de baza de date, asistentul trebuie sa poata oferi solutii alternative (spre exemplu, conversia pachetelor in functii si proceduri, daca baza de date destinatie nu are suport nativ pentru pachete). Pe langa diferentele de sintaxa, software-ul trebuie sa rezolve problemele legate de cuvinte rezervate si de conflicte de identificatori. Daca se schimba numele unei tabele sau unei coloane, modificarea trebuie reflectata automat in toate functiile sau tabelele care refera acea tabela sau coloana. Software-ul de migrare trebuie sa cunoasca particularitatile fiecarei baze de date. Spre exemplu, MySQL impune definirea de indecsi pe coloanele care sunt folosite ca si chei externe pentru alte tabele. Daca aceste cerinte nu sunt indeplinite si se convertesc doar datele, restul de obiecte trebuiesc convertite manual sau cu un alt asistent de migrare.
Sa ofere o solutie flexibila pentru definirea regulilor globale
Structura bazei de date nu trebuie modificata prea mult in timpul conversiei, deoarece ar trebui rescrise aplicatiile, ceea ce ar face migrarea foarte scumpa. Exista cazuri in care trebuie schimbatmodul implicit de conversie intre doua tipuri de date sau modul de redenumire a coloanelor/tabelelor/functiilor care in noua baza de date sunt nume rezervate. Implicit, aceste nume sunt puse intre ghilimele sau apostroafe, dar pentru multi dezvoltatori acest lucru poate fi un inconvenient, deoarece vor trebui sa fie folosite ghilimelele de fiecare data cand este referita tabela/coloana respectiva. Toate aceste reguli trebuie sa poata fi definite global si sa fie aplicate pentru toate obiectele.
Sa faciliteze migrarea aplicatiilor
Dupa migrarea bazei de date, aplicatiile sunt de obicei modificate, fara a afecta insa structura bazei de date. Aceste modificari vor conduce la schimbarea sintaxei comenzilor SQL in cazul in care acest lucru este impus de noul SGBD,dar si rezolvarea de incompatibilitati de interfata. Aplicatiile scrise doar in SQL sunt in general usor de migrat. E mai dificil in cazul unei aplicatii scrise, spre exemplu in Visual C+, care apeleaza o baza de date Oracle printr-un ODBC. Sunt imposibil de migrat aplicatiile scrise intr-un mediu proprietar (spre exemplu Orace Developer Suite). Pentru ca acest lucru sa se desfasoare cat mai usor asistentul, trebuie sa raporteze modificarile realizate in structura bazei de date in timpul conversiei cat si posibilele incompatibilitati de interfata intre aplicatii si noua baza de date.
Sa ofere performante ridicate
Deoarece bazele de date stocheaza volume mari de date, migrarea trebuie sa se realizeze in cel mai rapid mod posibil. Comenzile LOAD DATA INFILE din MySQL si IMP din Oracle sunt de 20 de ori mai rapide decat importul folosind INSERT din SQL. Asistentul de migrare trebuie sa foloseasca aceste facilitati si sa recurga la INSERT din SQL prin interfata ODBC doar daca nu exista alta alternativa mai rapida. Este necesar insa si exportul structurii tabelelor in scripturi SQL si a datelor in formate ASCII (CSV, Tab Delimited, SQL Insert).
Sa ofere posibilitati de personalizare
Se doreste ca migrarea sa fie automatizata in procent de 100%, dar asistentii de migrare existenti pot oferi o automatizare de pana la 95%. Dar, chiar si numai 5% de obiecte care nu au fost migrate automat pot genera mari probleme. De aceea, este foarte important ca producatorul asistentului sa ofere servicii de personalizare pentru fiecare proiect in parte, pentru a micsora la minim conversia manuala.
Sa ofere posibilitati de migrare intre cat mai multe sisteme de baze de date, inclusiv pentru bazele de date distribuite
Fiecare producator de SGBD pune la dispozitie un asistent pentru preluarea de date din alte baze de date. Exista insa si asistenti mai generali, care suporta mai multe baze de date ca sursa si ca destinatie.
Acest utilitar asigura migrarea datelor si procedurilor stocate in Oracle din alte baze de date. Cea mai recenta versiune aparuta este 10.1.0.4.
Tabel 2 : Migrare folosind Oracle WorkBench (D=DA, N=NU, I=INDISPONIBIL)
|
Oracle Database Server are trei utilitare incarcarea si descarcarea datelor dintr-o baza de date: Export, Import si SQL*Loader. Utilitarele Import si Export lucreaza impreuna: Export trimite definitiile bazei de date si datele efective unui fisier de export si Import poate citi fisierul pentru a efectua diferite activitati. Se poate utiliza Import si Export pentru diverse activitati importante ale bazei de date: restaurarea unei tabele, generarea de comenzi script CREATE, copierea datelor intre baze de date Oracle, migrarea intre versiuni Oracle, mutarea tabelelor dintr-o schema in alta.
SQL*Loader este asemanator cu Import in modul in care incarca datele, diferenta principala este aceea ca utilitarul Import poate citi numai fisiere de export Oracle, iar SQL*Loader poate citi si fisiere text generate de baze de date non-Oracle. SQL*Loader utilizeaza un fisier de control pentru a comunica utilitarului cum sa incarce datele.
Utilitarele Import si Export pot efectua urmatoarele operatii:
Arhivarea si recuperarea datelor. Probabil cea mai folosita caracteristica a acestor utilitare este capacitatea de a servi ca o solutie de arhivare. Majoritatea solutiilor Oracle utilizeaza arhivari on-line sau hot pentru a arhiva intreaga baza de date, in eventualitatea unui defect hardware sau software. Acestea functioneaza bine, deoarece toate datele pot fi restaurate la o miime de secunda fata de momentul prabusirii bazei de date. Daca o singura tabela din intreaga baza de date are nevoie de recuperare in timpul unei arhivari complete, intreaga baza de date va trebui recuperata pe un alt calculator, iar tabela respectiva sa fie copiata la loc. Export permite ca dintr-un fisier ce contine intreaga baza de date, sa poata fi extrase un utilizator, o tabela sau orice alt obiect.
Copierea obiectelor intre scheme (utilizatori) Utilitarele pot fi utilizate pentru a copia de la o schema la alta toate tipurile de obiecte: tabele, indecsi, drepturi, proceduri, viziuni. Se pot specifica obiectele care se doresc mutate, specificand schemele sursa si destinatie prin (utilizatorii) prin FROM si TO. Pentru a copia tabele intre utilizatori, acestea trebuie sa aiba permisiunile corecte. CREATE ANY TABLE este necesar pentru a crea tabele in contul destinatie. In plus, oricare din permisiunile SELECT sau EXP_ANY_TABLE trebuie acordate utilizatorului care efectueaza exportul. Spatiile de tabele trebuie sa fie suficient de mari pentru ca tabelele sa poata fi create.
Exemplu
Pentru a exporta datele din tabelele departamente si angajati din utilizatorul datef, se poate utiliza urmatoarea comanda:
Exp userid=system/manager@oracle9i tables=datef.departamente, datef.angajati
La importarea datelor, poate aparea una din urmatoarele situatii:
Daca tabelele departamente si angajati nu exista in utilizatorul test, se poate folosi urmatoarea sintaxa:
imp userid=system/manager@oracle9i from user=datef to user=test tables=departamente, angajati
Daca tabele exista deja in userul test, dar nu contin date se poate utiliza parametrul IGNORE=Y:
imp userid=system/manager@oracle9i from user=datef touser=test tables=departamente, angajati IGNORE=Y
Daca exista in utilizatorul test una din tabelele departamente sau angajati, acestea trebuie trunchiate inainte de import pentru a evita sa existe date duplicate sau respinse (din cauza cheilor primare sau unice).
Copierea obiectelor intre baze de date Oracle. O tabela se poate exporta dintr-o baza de date si sa fie importata in alta (chiar si de alta versiune). Sunt situatii in care sunt exportate tabele cheie (sau cele ce se modifica) si sunt trimise catre o locatie indepartata unde se poate utiliza Import pentru a incarca datele in baza de date locala. Aceasta este o forma de replicare a datelor la distanta cu o singura directie.
Generarea comenzilor script de tip CREATE Export si Import contin optiuni puternice ce permit generarea de comenzi script pentru crearea de tabele, viziuni, indecsi, proceduri/functii/pachete stocate sau orice alt obiect, spatii de tabele, segmente rollback, acordare de drepturi, etc. Acestea sunt folositoare pentru refacerea structurii bazei de date. Generarea de fisiere script se face folosind optiunile SHOW si LOG pentru a salva comenzile SQL intr-un fisier script, listat in ordinea corecta a dependentelor (adica o tabela este creata inaintea unui index, cheile primare inaintea cheilor externe, samd). Formatarea rezultatului nu este corecta din punct de vedere sintactic, aparand ghilimele asezate necorespunzator, sau cuvinte despartite pe doua linii, rezultate care necesita modificare manuala.
Migrarea bazei de date de la o versiune Oracle la alta. Se poate efectua upgrade, iar uneori downgrade folosind Import si Export. De exemplu, se poate exporta o baza de date Oracle8i, copia fisierul pe un calculator avand Oracle9i si importa fisierul. Se recomanda ca importul si exportul sa se faca cu utilitarele versiunii de baza de date destinatie.
Defragmentarea unui spatiu de tabela Fragmentarea se produce atunci cand tabelele si indecsii sunt creati, stersi, mariti si redusi de mai multe ori intr-o perioada de timp. Acest fapt determina ca spatiul liber sa fie despartit in mai multe bucati. Daca sunt mai multe blocuri mici de spatiu liber in loc de cateva spatii mari, s-ar putea ca anumite obiecte sa nu poata fi create sau anumite tabele sa nu poata fii populate. Defragmentand tabelele de spatiu, datele sunt reorganizate, astfel incat tot spatiul liber este asezat intr-o singura zona, iar spatiile obiectelor sunt grupate alaturat. Utilitarele Import si Export pot rezolva fragmentarea in doua feluri: fie proceseaza o tabela cu spatii multiple pentru a o redimensiona intr-o tabela cu un singur spatiu mai mare care va avea dimensiunea totala a spatiilor anterioare, fie alipeste obiectele din spatiile de tabele, in timp ce transforma spatiile libere intr-un spatiu liber mai mare. Metoda cea mai usoara de rezolvare a problemei este urmatoarea: Se exporta baza de date, specificand FULL=Y si COMPRESS=Y. FULL=Y exporta intreaga baza de date, iar COMPRESS=Y indica compresarea spatiilor. Dupa aceea se sterge si se recreeaza intreaga baza de date, iar importul se face cu parametrul FULL=Y.
SQL*Loader poate efectua urmatoarele operatii:
a. Incarcarea datelor intr-o baza de date Oracle dintr-o baza de date non-Oracle Utilitarul SQL*Loader este folosit pentru analizarea si incarcarea fisierelor text in tabele Oracle. Multe produse non-Oracle - cum ar fi Microsoft Excel, Acces, SQL Server, Lotus 1-2-3, SyBase, Informix pot salva date intr-un fisier cu lungime fixa, variabila sau intr-un fisier delimitat. Un fisier cu lungime fixa are un numar de caractere specificat pentru fiecare coloana in tabel. De exemplu, daca specificarea este de 50 de bytes si exista doar 20 de bytes in coloana inregistrari, vor fi adaugate 20 de spatii libere. In acest fel Oracle stie unde sa caute fiecare coloana. Intr-un fisier delimitat existanun caracter special (de obicei, un tab sau o virgula) care separa fiecare coloana pentru fiecare inregistrare. In general, datele de tip sir de caractere sunt puse intre ghilimele, iar daca delimitatorul se regaseste intre acestea el este ignorat.
b. Inlocuirea datelor existente cu date noi. SQL*Loader poate sa inlocuiasca inregistrarile existente intr-o tabela cu inregistrarile care sunt incarcate. Acesta metoda este cunoscuta sub denumirea de REPLACE. O metoda asemanatoare este TRUNCATE, mai rapida decat REPLACE, in care toate inregistrarile sunt indepartate din tabel inainte ca noile date sa fie introduse.
c. Obtinerea unui set cu datele invalide SQL*Loader poate crea fisiere ce listeaza toate inregistrarile care nu indeplinesc conditiile specificate, sau datele formatate in mod incorect. Aceste fisiere pot fi analizate dupa incarcare, si, daca se doreste acest lucru, datele pot fi sterse si reincarcate.
d. Lucrul la nivel logic cu datele in timpul incarcarii Se pot specifica conditii WHEN astfel incat numai anumite tipuri de inregistrari sa fie incarcate.
e. Incarcarea datelor din surse multiple in mod simultan. Inregistrarile fizice multiple se pot combina intr-o singura inregistrare a bazei de date, utilizand clauza CONTINUE IFTHIS in fisierul de control din SQL*Loader. Pentru ca acesta sa functioneze, fisierul text trebuie setat intr-un mod special. Alta metoda este incarcarea surselor multiple in tabele temporare in baza de date si apoi unirea acestora folosind SQL.
f. Incarcarea datelor in tabele multiple Aceasta optiune din SQL*Loader permite specificarea coloanelor care merg intr-o tabela si coloanelor care merg in alta. Se pot chiar repeta coloanele de incarcare in mai multe tabele ale bazei de date. Un avantaj este faptul ca setul de tabele al bazei de date sa fie normalizat, fiecare tabela cu o cheie primara folosita pentru jonctiune, caz in care SQL*Loader poate incarca coloanele adecvate in fiecare tabela in timp ce copiaza cheia primara in fiecare tabela pentru fiecare inregistrare din fisierul text.
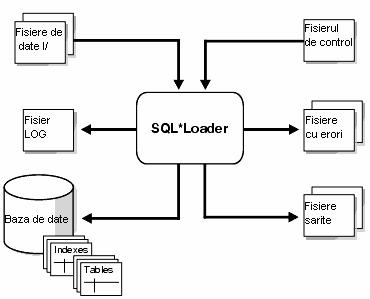
Figura 2. SQL* Loader
SQL Loader este invocat folosind comanda sqlldr, eventual cu parametrii pentru a stabili caracteristicile sesiunii. In situatia in care parametrii se modifica rar, este mai eficient a se specifica parametrii, grupandu-i intr-un fisier de parametrii specificat mai apoi in linia de comanda folosind parametrul PARFILE. Anumiti parametrii pot fi inclusi in fisierul de control al SQL*Loader-ului folosind clauza OPTIONS. Totusi valorile parametrilor specificate in linia de comanda suprascriu valorile din fisierele din parametri sau cei din clauza OPTIONS.
Fisierul de control este un fisier text scris dupa o structura pe care SQL*Loader-ul o intelege. Acest fisier ii spune unde se gasesc datele, cum sa le citeasca si cum sa le interpreteze, unde sa le insereze si inca cateva alte lucruri. Se poate spune ca fisierul de control are trei sectiuni, desi acestea nu sunt definite prea precis:
Prima sectiune contine informatii generale despre sesiune, printre acestea: optiuni globale, cum ar fi numarul de randuri, numarul de randuri peste care sa sara, clauza INFILE (care specifica unde sunt localizate datele).
A doua sectiune este alcatuita din unul sau mai multe blocuri INTO TABLE. Fiecare dintre aceste blocuri contine informatii despre tabele in care se incarca datele, cum ar fi numele acesteia si coloanele care o alcatuiesc.
A treia sectiune este optionala si poate contine datele efectiv de incarcat. Sintaxa fisierului de control este libera, comenzile putandu-se extinde pe mai multe linii si nu se face diferenta intre literele mari si cele mici (case insensitive), cu exceptia sirurilor de caractere aflate intre ghilimele, care sunt luate ca atare. Cuvintele CONSTANT si ZONE au o semnificatie aparte pentru SQL*Loader si de aceea nu se recomanda folosirea acestor denumiri pentru tabele sau coloane.
Fisierele de date de intrare. SQL*Loader citeste datele din unul sau mai multe fisiere specificate in fisierul de control. Din punctul lui de vedere, datele din fisierele de intrare sunt organizate in inregistrari. O inregistrare poate fi in format fix, variabil sau stream. Formatul inregistrarilor este specificat in fisierul de control, mai exact prin parametrul INFILE. Daca nu este specificat nici un format, implicit se foloseste tipul delimitat (stream).
a. Un fisier este in format fix cand toate inregistrarile au aceeasi lungime. Desi acest format este cel mai putin flexibil, este in schimb cel mai performant. Se specifica faptul ca fisierul de date este in format fix astfel: INFILE 'nume_fisier_date ' 'fix n', unde "n" este lungimea in octeti a fiecarei inregistrari.
Fisierul de date din urmatorul exemplu contine cinci inregistrari, prima inregistrare cd,] avand 11 octeti considerandu-se ca fiecare caracter ocupa un octet, iar delimitatorul de rand inca un octet.
Ldr.sqlImportul se lanseaza astfel:
sqlldr userid=user/parola@bazadate control=ldr.sql log=log.txt
b. Un fisier este in format variabil cand lungimea fiecarei inregistrari, in cazul unui camp de tip caracter, se afla la inceputul fiecarei inregistrari din fisierul de date. Formatul acesta este mai flexibil decat cel anterior si aduce un spor de performanta fata de cel de tip stream. Spre exemplu, se poate specifica ca un fisier de date sa fie interpretat in format variabil astfel: INFILE 'nume_fisier_date' 'var n', unde "n" reprezinta numarul de octeti ai fiecarui camp de specificare a lungimii inregistrarii. Daca "n" nu este specificat, i se atribuie valoarea implicita 5, iar daca ii este atribuita o valoare mai mare de 40 va rezulta o eroare.
In exemplul urmator, fisierul de control spune SQL*Loader-ului sa caute datele in fisierul example.dat si se asteapta un format variabil, in care campurile au maxim 3 octeti. Fisierul de date example.dat contine trei inregistrari. Prima inregistrare este de 009 octeti, a doua este de 010 octeti (include si caracterul de rand nou), iar a treia de 012 octeti (de asemenea, e inclus caracterul de rand nou).
load datac. Un fisier este in format delimitat (stream), cand nu se specifica lungimea inregistrarilor. SQL*Loader formeaza inregistrari, cautand terminatorul de inregistrare. Acest format este cel mai flexibil, dar si cel mai putin performant. Pentru ca un fisier de date sa fie prelucrat ca fiind in format delimitat se specifica: INFILE nume_fisier_date ['str terminator_sir']. Terminatorul poate fi specificat in format caracter, intre ghilimele (de exemplu ',') sau ca un octet in baza 16. Cand un terminator contine un caracter special, neimprimabil, el trebuie specificat in format hexa. Totusi exista anumite caractere neimprimabile care pot fi specificate in format caracter astfel:
n indica linia noua;
t indica tabul orizontal;
f indica form feed;
v indica tab vertical;
r indica carriage return.
Daca setul de caractere nu este specificat prin parametrul NLS_LANG, iar setul de caractere a sesiunii curente este diferit fata de cel din fisierul de date, caracterele sunt convertite in setul de caractere a acestuia. Aceasta conversie se realizeaza inainte de cautarea terminatorului de inregistrare. Pe platformele Unix, daca nu este specificat nici un terminator, cel implicit este 'n'. Pe o platforma Windows, daca nu este specificat terminatorul, SQL*Loader foloseste n sau rn, mai exact pe care il gaseste primul. Daca terminatorul dorit este rn si n se afla mai inainte, trebuie specificat explicit terminatorul. In exemplul urmator este specificat terminatorul '|n'.
load data
infile 'example.dat' 'str '|n''
into table example
fields terminated by ',' optionally enclosed by '''
(col1 char(5),
col2 char(7))
example.dat:
hello,world,|
ileana,alina,|
SQL*Loader organizeaza datele de intrare in inregistrari fizice, in functie de formatul specificat. Implicit, o inregistrare fizica este echivalenta cu una logica, dar SQL*Loader-ul poate combina mai multe inregistrari fizice intr-una logica. El poate combina un numar fix de inregistrari fizice pentru a forma fiecare inregistrare logica sau poate combina inregistrarile fizice in cele logice, atat timp cat o anumita conditie este adevarata. Incepand cu Oracle9i, sunt suportate inregistrari mai mari decat 64KB. Acest lucru reduce nevoia de a se desparti inregistrarile logice in mai multe inregistrari fizice. Pentru asamblarea la loc a inregistrarilor fizice in inregistrari logice se pot folosi CONCATENATE sau CONTINUEIF. Se va folosi CONCATENATE cand se doreste ca SQL*Loader sa combine mereu acelasi numar de inregistrari fizice pentru a forma o inregistrare logica. In exemplul urmator, integer specifica numarul de inregistrari fizice de combinat: CONCATENATE integer. Valoarea integer specificata determina numarul de structuri de inregistrari fizice pe care SQL*Loader le aloca pentru fiecare rand din vectorul coloanelor. Deoarece valoarea implicita pentru COLUMNARRAYROWS este mare, daca se va specifica o valoare mare si pentru CONCATENATE este posibil sa apara erori din cauza memoriei insuficiente. Performanta se poate imbunatati prin reducerea valorii parametrului COLUMNARRAYROWS (reducand numarul de randuri intr-un vector de coloane).
Se poate folosi si CONTINUEIF, daca numarul de inregistrari fizice ce trebuie combinate variaza. Clauza CONTINUEIF este urmata de o conditie, care va fi evaluata pentru fiecare inregistrare fizica, in timp ce este citita. Spre exemplu, doua inregistrari pot fi combinate daca semnul diez (#) se afla pe pozitia 80 a primei inregistrari. Daca la aceasta pozitie se afla orice alt caracter, a doua inregistrare nu este concatenata cu prima. Pozitiile specificate in clauza se refera la pozitia din fiecare inregistrare fizica, aceasta fiind singura situatie in care sunt referite pozitii din inregistrarile fizice. Orice alte referinte au in vedere inregistrarile logice. Pentru CONTINUEIF THIS si CONTINUEIF LAST, daca parametrul PRESERVE nu este specificat, campul de continuare este sters din toate randurile fizice unde inregistrarea logica este asamblata. Spre exemplu, daca se specifica CONTINUEIF THIS(3:5)='***' este specificat, atunci pozitiile de la 3 la 5 sunt sterse din toate inregistrarile, chiar daca pe aceste pozitii se afla caracterele de continuare (***). In cazul CONTINUEIF THIS si CONTINUEIF LAST, daca este specificat parametrul PRESERVE, campul de continuare este mentinut.
Exemplu (CONTINUEIF THIS fara parametrul PRESERVE)
Se presupune cazul unor inregistrari fizice de 14 octeti, in care punctul reprezinta un spatiu:
%%aaaaaaaa.
%%bbbbbbbb.
..cccccccc.
%%dddddddddd..
%%eeeeeeeeee..
..ffffffffff..
Daca clauza CONTINUEIF THIS nu contine parametrul PRESERVE:
CONTINUEIF THIS (1:2) = '%%'
In acest caz daca, '%%' se afla pe primele doua pozitii ale unei inregistrari fizice (rand), urmatoarea inregistrare este concatenata dupa aceasta, nementinandu-se caracterele de continuare:
aaaaaaaa.bbbbbbbb.cccccccc.
dddddddddd..eeeeeeeeee..ffffffffff..
Daca clauza CONTINUEIF THIS foloseste parametrului PRESERVE caracterele de continuare '%%'
sunt mentinute si dupa concatenare:
CONTINUEIF THIS PRESERVE (1:2) = '%%'
In acest caz, inregistrarile logice sunt asamblate astfel:
%%aaaaaaaa.%%bbbbbbbbcccccccc.
%%dddddddddd..%%eeeeeeeeee.ffffffffff..
Dupa formarea inregistrarilor logice, sunt setate campurile de date din cadrul acestora. Setarea campurilor este un proces in care SQL*Loader foloseste specificatiile din fisierul de control pentru a determina care parte a inregistrarilor logice corespunde fiecarui camp din fisierul de control. Este posibil ca pentru doua sau multe specificatii, sa se refere la aceleasi date. De asemenea, este posibil ca o inregistrare logica sa contina date care nu sunt referite de nici o specificatie a fisierului de control. De cele mai multe ori, specificatiile campurilor din fisierul de control se refera la o parte din inregistrarile logice.
Fisierele de tip LOB si cele secundare Fisierele de tip LOB sunt suficient de mari pentru a fi incarcate din fisiere speciale: LOBFILE. In aceste fisiere datele, campurile nu sunt organizate in inregistrari si de aceea lucrul destul de anevoios cu acestea este evitat. Spre exemplu se pot folosi fisiere LOBFILE pentru a incarca marcile, numele si CV-urile angajatilor. In acest caz marca si numele pot fi citite din fisierul normal de date, iar CV-urile, care sunt mai voluminoase, din fisierele LOBFILE. Aceste fisiere pot fi folosite si pentru o incarcare mai facila a datelor de tip XML.
Fisierele secundare de date (SDF) sunt similare celor principale: o colectie de inregistrari, fiecare inregistrare fiind alcatuita din campuri. Acestea trebuie specificate in fisierul de control (folosind parametrul SDF) si sunt folosite in special pentru a incarca tabele imbricate.
LOAD DATA
INFILE 'sample.dat'
INTO TABLE person_table
FIELDS TERMINATED BY ','
(name CHAR(20),
'RESUME' LOBFILE(CONSTANT 'jqresume') VARCHARC(4,2000))
Datafile (sample.dat)
Johny Quest,
Speed Racer,
Secondary Datafile (jqresume.txt)
0501Johny Quest
500 Oracle Parkway
0000
VARCHARC(4,2000) arata ca primii patru octeti (caractere) trebuie sa fie interpretati ca lungimea fisierului (spre exemplu, 0501 arata ca fisierul LOB contine 501 de caractere, iar 0000 arata ca fisierul LOB nu contine date) si ca dimensiunea maxima a campului este de 2000 de caractere.
Conversia datelor. In timpul unei incarcari obisnuite, campurile din fisiere sunt copiate si convertite in coloanele din baza de date. Conversia se face in doi pasi:
SQL*Loader foloseste specificatiile campurilor din fisierul de control pentru a interpreta formatul fisierului de date, pentru a analiza fisierele de intrare si pentru a popula vectorii ce corespund unei comenzi INSERT.
Baza de date accepta datele si executa comenzile INSERT.
Baza de date foloseste tipul de data a coloanei pentru a converti datele in formatul in care vor fi stocate. Trebuie tinut cont de faptul ca exista o diferenta intre tipurile de date ale campurilor definite in fisierul de control al SQL*Loader-ului si cele ale coloanelor din baza de date.
Inregistrarile cu erori Inregistrarile citite din fisierele de date pot sa nu fie inserate in baza de date, ele regasindu-se intr-un fisier cu inregistrari eronate (bad file) sau intr-un fisier cu inregistrari ignorate (rejected file). Fisierul cu inregistrari eronate contine inregistrarile care au fost respinse fie de Loader, fie de baza de date. Fisierele de date sunt respinse de SQL*Loader cand formatul de intrare este eronat. Spre exemplu, daca nu exista un caracter delimitator, sau daca un camp este mai mare decat dimensiunea maxima. Un fisier de date procesat de SQL*Loader este trimis bazei de date pentru a fi inserat intr-o tabela ca o inregistrare. Daca baza de date determina ca inregistrarea este valida, ea este introdusa in tabela, iar daca nu, ea este respinsa si SQL*Loader-ul o introduce in fisierul cu date eronate. O inregistrare poate fi invalida deoarece: o cheie nu este unica, un camp obligatoriu este NULL sau nu este indeplinita alta conditie de integritate, datele sunt invalide pentru tipul de data al coloanei din baza de date, etc. SQL*Loader poate crea, la cerere, un fisier cu datele ignorate. Aceste date sunt cele care nu au trecut de filtrare pentru ca nu au corespuns nici unui criteriu de selectie specificat in fisierul de control. Se poate specifica numarul maxim de inregistrari care sa fie inserate in acest fisier.
Fisierul de log Cand SQL*Loader incepe executia, el creeaza un fisier de log care va contine detalii despre incarcarea datelor si despre erorile aparute. Daca acest fisier nu poate fi creat, executia nu se mai desfasoara. Acest fisier este creat implicit in acelasi director cu fisierul de control.
Este un asistent de migrare foarte bun pentru importul datelor in MySQL, el suportand numeroase baze de date, atat ca sursa (DB2, Oracle, SQL Server, SyBase, SAP, Access, Lotus Notes, Foxpro, Dbase), cat si ca destinatie (DB2, SqlServer, Oracle, SyBase, Pervasive SQL). Cea mai recenta versiune aparuta este 9 si suporta ca sursa si destinatie cele mai recente versiuni ale SGBD-urilor (DB/2 8.2, Oracle 10g, MySql 5.x, MS SQL Server 2005, s.a.). Acest utilitar da posibilitatea administratorului de baza de date sa intervina in convertirea implicita a tipurilor de date prin definire unor reguli globale.
SQLWays rezolva situatiile aparute datorita conflictelor de identificatori sau datorita unei denumiri de obiect din baza de date sursa care este cuvant rezervat in baza de date destinatie. Cand se redenumeste un astfel de obiect, asistentul realizeaza modificarile necesare in toate obiectele care il refereau. SQLWays poate exporta baza de date sursa in script SQL, ceea faciliteaza folosirea altor utilitare sau limbaje de script (Perl spre exemplu). SQLWays realizeaza rapoarte despre modificarile suferite in timpul conversiei si faciliteaza conversia aplicatiilor. Ca si utilitarele pentru migrare oferite de Oracle sau IBM pentru propriile lor baze de date, SQLWays realizeaza exportul si importul in modul cel mai rapid disponibil.
Este optimizat pentru folosirea in cazul depozitelor de date si este orientat mai ales pe transferul si transformarea de date. Suporta, de asemenea, modelarea datelor si ingineria inversa (pentru a converti si schema bazei de date) poate converti si schema bazei de date. DT/Studio este recomandat in cazul cand este necesara o reproiectare importanta a bazei de date, deoarece pune la dispozitie numeroase functii si facilitati de transformare. DT/Studio nu suporta conversia functiilor/procedurilor/pachetelor stocate in baza de date.
Si acest utilitar se concentreaza pe transferul de date si pune la dispozitie scripturi, Visual Basic pentru transformari de date. Se pot redefini tipurile de date pentru fiecare tabela si se pot schimba denumirile de tabele sau de coloane, dar este necesara o interventie importanta din partea utilizatorului pentru ca migrarea sa se faca complet. DTS ofera facilitati limitate de conversie a schemei bazei de date, nesuportand chei primare, unice sau externe, valori implicite sau comentarii.
Se da tabela Sarbatori cu urmatoarea structura (in Oracle 10g): Name Type Nullable Comments DATA DATE Data calendaristica TIP VARCHAR2(1) Y R -Religioasa,L-Legala DEN VARCHAR2(25) Y Denumire In tabela temp_clob_tab obtinem doua inregistrari, una cu documentul: si cealalta cu o singura inregistrare. Se poate schimba denumirea nodului principal din ROWSET folosind functia setRowsetTag, spre exemplu: dbms_xmlgen.setRowsetTag(qryCtx,'RANDURI'). Documentul astfel obtinut poate fi
usor exportat in alta baza de date cu suport nativ de XML.
Se da tabela nomenclator_prenume avand 66841 de inregistrari cu urmatoarea structura. Rularea procedurii de mai sus a durat 5,875 de secunde pe un calculator Barton 2500+ cu 1GB RAM, obtinandu-se un singur document XML.
Name Type Comments
----- ----- -------------
PRENUME_CD VARCHAR2(40) Prenume cu diacritice
ID_PRENUME NUMBER(8) Id prenume
PRENUME_FD VARCHAR2(40) Prenume fara diacritice
Pe tabela acte_identitate avand 316.562 de inregistrari si structura de mai jos; rularea procedurii a durat 55,784 de secunde.
Name Type Comments
ID_P NUMBER(12) ID Partener
NR_CRT NUMBER(2) Numar curent
TIP_ACT_ID VARCHAR2(2) Tip AI
SERIE VARCHAR2(15) Serie AI
NUMAR NUMBER(15) Numar AI
ELIBERAT_DE VARCHAR2(128) Eliberat de
VALABIL_PANA_LA DATE Valabil pana la
ELIBERAT_LA DATE Data eliberarii
STARE VARCHAR2(1) A-Activ, D - Dezafectat
Acest lucru arata ca exportul in format XML este rentabil ca timp si in cazul unui volum mai mare de date.
Daca se doreste obtinerea de documente imbricate in cazul de fata listarea angajatilor pe departamente, trebuie folosite TYPE-uri cat si operatorul CAST.
CREATE OR REPLACE TYPE ang_t AS OBJECT('@angajat_id' NUMBER, nume VARCHAR2(20)); Pentru demonstrarea migrarii intre Oracle si MySQL se foloseste o baza de date Oracle 10g ruland pe un calculator Barton 2500+ cu 1GB RAM si o baza de date MySQL 5.0.3 ruland pe un calculator Barton 2400+ cu 512 MB RAM, legate in retea (10 Mbps). Folosind Ispirer SQLWays 8 se va incerca migrarea unui utilizator din Oracle in MySQL. Utilizatorul are 8 Functii, 1 pachet, 6 tabele, 1 viziune si 3 declansatori. Structura lui se afla pe CD in directorul Demo/Oracle. Exportul se face rapid si fara erori, folosind wizard-ul, conform documentatiei [ISPI05], scripturile rezultate aflandu-se pe CD in directorul DemoMigrare/Mysql. La import apar insa erori, doar 5 tabele sunt create si incarcate corect din start, iar pentru una dintre ele trebuie modificat script-ul CREATE, schimband DEFAULT(0) in DEFAULT 0 pentru a functiona. Nici un declansator nu se compileaza corect si apar erori la una din functii si la pachet. De asemenea, noul utilizator a trebui sa fie creat manual, script-ul generat automat nefunctionand. 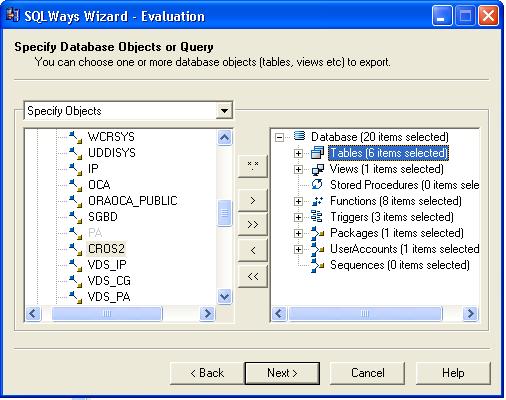
Figura 3 Exportul folosind SQL WaysWizard Din cele 20 obiecte, au aparut erori la 7 dintre ele rezultand In concluzie, aceasta metoda de migrare, bazata asistentul Ispirer SQLWays, intre aceste doua sisteme de gestiune a bazelor de date trebuie sa se limiteze la exportul de date, exportul altor obiecte putand duce la erori. Exportarea unei tabele avand 9 coloane si 316.562 de inregistrari (tabela acte_identitate descrisa si la paragraful anterior) dureaza 27 de secunde, iar importul in MYSQL folosind LOAD INFILE dureaza mai putin de 10 secunde, mai putin chiar decat in cazul generarii de fisiere XML folosind pachetul DBMS_XMLGEN din Oracle. S-a incercat, de asemenea, migrarea unei baze de date continand 28 de tabele din MySQL 5.0.3 in Oracle 10g. Daca structura tabelelor a fost migrata cu succes, datele in sine nu au fost migrate, din cauza unei folosiri defectuoase a SQL*Loader-ului de catre SQL Ways. CAPITOLUL ANALIZA COMPARATIVA A DIFERITELOR INSTRUMENTE UTILIZATE PENTRU INTEGRAREA DATELOR 1
1. Sisteme de gestiune a bazelor de date 1
2. Sisteme pentru gestiunea depozitelor de date 3
2.1 Oracle Discoverer 3
2.2 Oracle Warehouse Builder 4
2. Microsoft SQL Server 2005 Business Intelligence 8
Instrumente utilizate pentru migrarea datelor 9
1. Oracle Migration Workbench 11
2. Utilitarele SQL*Loader si Import/Export 12
Ispirer SQLWays 22
4. Embarcadero DT/Studio 23
5. Microsoft DTS 23
4. Testarea instrumentelor 23
4.1. Migrarea din Oracle folosind XML 23
4.2. Migrarea folosind Ispirer SQLWays 8 26
[NET05].
[NET01]
[ISPI05].
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 2490
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2024 . All rights reserved