| CATEGORII DOCUMENTE | ||
|
||
baze de date
informatie faptica (rezultata in urma unor masuratori sau statistici) folosita ca baza pentru rationamente, discutii sau calcule;
informatie perceputa cu un organ de simt sau preluata cu un dispozitiv specializat, care include pe langa informatiile utile, informatii inutile si/sau informatii redundante; informatie care trebuie procesata pentru a dobandi un inteles;
informatie in forma numerica care poate fi transmisa digital sau procesata.
Baza de date (BD) - 1967
sistem computerizat de pastrare a unei colectii de date organizate sub forma de fisiere, date asupra carora sunt permise operatii precum:
adaugarea unui nou fisier (initial gol) la baza de date;
inserarea de noi date in fisierele existente;
regasirea datelor din fisierele existente;
actualizarea datelor din fisierele existente;
stergerea datelor din fisierele existente;
indepartarea fisierelor existente (goale sau nu) in mod permanent din baza de date, etc.
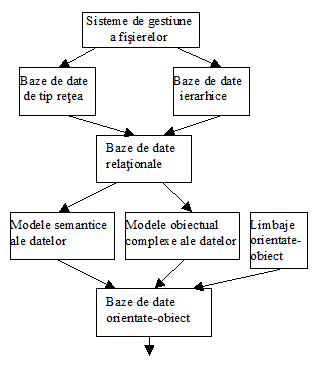
Sistem de gestiune a bazelor de date (SGBD)
o colectie de programe care:
gestioneaza structura bazei de date
controleaza accesul la datele memorate in baza de date
partajeaza datele intre multiple aplicatii sau utilizatori
 translateaza cererile utilizatorilor
in codul complex necesar pentru a procesa acele cereri, le
proceseaza si returneaza raspunsul catre utilizatori
translateaza cererile utilizatorilor
in codul complex necesar pentru a procesa acele cereri, le
proceseaza si returneaza raspunsul catre utilizatori
Sistemul de gestiune a fisierelor (SGF)
prelucrari asupra fisierelor
independente de datele memorate in fisiere
preoarele bazelor de date
Modelul ierarhic al datelor (BD ierarhice)
colectie de arbori
nod radacina, noduri copil, noduri frunza
relatii de tip 1-N, nod copil cu un singur nod parinte
structura navigationala
IMS (IBM)
Modelul retea al datelor (BD retea)
relatii de tip 1-N, nod copil cu mai multi parinti
structura navigationala
IDS, IDMS
Modelul relational al datelor (BD relationale)
bazat pe algebra relationala si calculul predicatelor
atribute, tupluri, relatii
limbaj de definire a datelor DDL
limbaj de manipulare a datelor DML
restrictii de integritate
DB2, ORACLE, SQL Server, dBASE, FoxPro, etc.
Modelul semantic al datelor
modelul entitate-relatie
modele de laborator
folosite pentru proiectarea bazei de date
Modelul obiectual complex al datelor (BD orientate-obiect)
tipuri de date abstracte
obiecte, clase, metode, mesaje
mostenire simpla si multipla
incapsulare, polimorfism
identitate obiectuala
POET, Versant, ObjectStore - SGBDOO
DB2, ORACLE9, Informix, Visual FoxPro - SGBDRO
2
BAZE DE DATE
RELATIONALE
Modelul relational al datelor:
1970 - mat. dr. E.F. Codd
bazat pe teoria matematica a relatiilor (multimilor)
Structuri de date relationale:
tuplu - set ordonat de valori care descriu anumite caracteristici ale datelor la un anumit moment in timp Termenii neformali rand, articol, inregistrare
atribut - evidentiaza o anumita caracteristica a datelor Termenii neformali coloana camp)
domeniu - setul de valori pe care le poate lua un atribut Toate valorile unui domeniu sunt de acelasi tip
STUDENT

O relatie R asupra domeniilor D1, D2, D3,., Dn, nu neaparat distincte, este construita dintr-un header si un corp al relatiei.
Header-ul contine un set fix de atribute A1, A2, A3, ., An, astfel incat fiecare atribut Ai este definit exact pe unul dintre domenii, si anume Di, unde i=1,n
Corpul consta dintr-un set variabil in timp de tupluri, unde fiecare tuplu la randul sau consta dintr-un set de perechi atribut-valoare (Ai:vi), unde i=1,n. Exista cate o astfel de pereche pentru fiecare atribut Ai din header. Pentru oricare pereche atribut-valoare (Ai:vi), vi este o valoare din domeniul unic Di asociat cu atributul Ai.
STUDENT

Gradul unei relatii este dat de numarul de atribute ale relatiei.
grad unu unara, grad doi binara, grad trei ternara grad n n-ara. Gradul relatiei STUDENT este 3.
Cardinalitatea unei relatii este data de numarul de tupluri ale relatiei. Cardinalitatea unei relatii se modifica in timp. Cardinalitatea actuala a relatiei STUDENT este 4.
Universul relational U(R) este alcatuit din toate combinatiile posibile ale valorilor atributelor unei relatii.
Orice relatie R este o submultime a universului relational U(R).
Proprietati
Tuplurile unei relatii sunt neordonate (set de tupluri)
Atributele unei relatii sunt neordonate set de perechi (atribut, valoare)
Toate valorile atributelor sunt atomice (valoare indivizibila
Intr-o relatie nu exista tupluri duplicat. (set de tupluri)
Baza de date relationala baza de date perceputa de utilizatori sub forma unei colectii variabile in timp de relatii normalizate
Relatie -> fisier de date
Tuplu -> inregistrare
Atribut -> camp
Fisierele relationale trebuie sa indeplineasca urmatoarele conditii:
sa contina doar un singur tip de inregistrari;
campurile nu au o ordine specifica in cadrul inregistrarii, de la stanga la dreapta;
inregistrarile nu au o ordine specifica in cadrul fisierului, de sus in jos;
fiecare camp contine o singura valoare, atomica;
inregistrarile au un camp sau o combinatie de campuri care le identifica in mod unic, numita cheie primara.
Reguli de integritate relationala
ü doua reguli de integritate (regula de integritate a entitatii si regula de integritatete referentiala)
ü regulile sunt generale se aplica oricarei baze de date care pretinde ca se conformeaza modelului relational
ü regulile de integritate relationala sunt specificate pentru o schema a bazei de date si trebuie sa fie respectate de orice instanta a acelei scheme
Se bazeaza pe notiunile de:
Cheie candidata
Cheie primara
Cheie externa (straina
Reguli de integritate relationala
Cheie candidata (candidate key)
Fiind data o relatie R cu atributele A1, A2, ., An, setul de atribute K=(Ai, Aj, .,Ak) din R, este o cheie candidata a lui R daca si numai daca satisface urmatoarele doua proprietati:
Unicitate - nu exista nici un moment in timp in care doua tupluri distincte ale relatiei R sa aiba aceeasi valoare pentru atributul Ai, aceeasi valoare pentru atributul Aj, ., si aceeasi valoare pentru atributul Ak.
Forma minimala - nici unul din atributele Ai, Aj, ., Ak ale cheii K nu pot fi inlaturate din aceasta fara a distruge proprietatea de unicitate.
Daca o relatie are mai multe chei candidate, cea aleasa pentru a reprezenta relatia se va numi cheie primara, iar celelalte chei alternative.
EX. Daca extindem relatia STUDENT adaugandu-i si atributele Data_Nasterii si Buletin_Identitate, atunci chei candidate pentru aceasta relatie pot fi: Legitimatie, Nume+Data_Nasterii sau Buletin_Identitate.
Cheie primara (primary key)
Cheia primara este un identificator unic la nivelul relatiei, formata dintr-un atribut sau dintr-o combinatie de atribute ale relatiei, care are proprietatea ca la orice moment de timp nu exista doua tupluri ale relatiei care sa aiba exact aceeasi valoare pentru acel atribut sau acea combinatie de atribute.
ü o relatie are intotdeauna o cheie primara
ü cel putin combinatia tuturor atributelor relatiei formeaza o cheie primara (proprietatea de unicitate a tuplurilor la nivelul relatiei)
ü de obicei, cheia primara formata dintr-un singur atribut sau din cel mult doua, trei atribute ale relatiei
ü se specifica prin intermediul limbajului de descriere a datelor (DDL)
ü de regula, la crearea tabelei se specifica cheia primara cu ajutorul constructiei PRIMARY KEY sau anumite coloane pot fi restrictionate de la a accepta valori duplicat, prin crearea de indecsi cu optiunea UNIQUE, si valori nule, prin folosirea restrictiei NOT NULL.
EX. Cheia primara a relatiei STUDENT este, de exemplu, Legitimatie.
Cheie externa (foreign key)
O cheie externa sau straina este un atribut sau o combinatie de atribute ale unei relatii R2 ale caror valori trebuie sa se potriveasca cu cele ale unei chei primare dintr-o alta relatie R1. Relatiile R1 si R2 nu sunt neaparat distincte. Cheia externa si cheia ei primara corespondenta trebuie sa fie definite pe acelasi domeniu de valori.

|
Nota |
Disciplina |
Legitimatie (FK) |
|
BD | ||
|
CN | ||
|
BD | ||
|
CN | ||
|
PROG |
relatia STUDENT => relatie NOTA (atribute Disciplina, Nota, Legitimatie)
cheie externa (FK)(atributul Legitimatie din relatia NOTA ) => cheie primara (PK) (atributul Legitimatie din relatia STUDENT)
Pentru fiecare cheie externa din baza de date, proiectantul bazei de date trebuie sa stabileasca raspunsul la urmatoarele trei intrebari:
ü Poate accepta cheia externa valorea null?
ü Ce se intampla daca se incearca stergerea unei inregisrari catre care o cheie externa face referinta?
Stergerea in cascada
Stergerea este interzisa
Umplerea cu valoarea NULL
ü Ce se intampla daca se incearca modificarea valorii cheii primare catre care o cheie externa face referinta?
Modificarea in cascada
Modificarea este interzisa
Umplerea cu valoarea NULL
ü se specifica prin intermediul limbajului de descriere a datelor (DDL)
ü de regula, la crearea tabelei se specifica cheia externa cu ajutorul constructiei FOREIGN KEY la nivelul careia se indica cheia primara catre care va referi aceasta.
Reguli de integritate
Cele doua reguli sau restrictii de integritate suportate de modelul relational al datelor sunt urmatoarele:
Regula de integritate a entitatii - atributele care fac parte din cheia primara a unei relatii nu pot avea valoarea NULL
Regula de integritate referentiala - daca relatia R2 contine o cheie straina FK care are ca si corespondent cheia primara PK a relatiei R1, atunci fiecare valoare a lui FK trebuie fie sa fie egala cu o valoare a lui PK dintr-unul din tuplurile relatiei R1, fie sa aiba valoarea NULL (valorile tuturor atributelor care formeaza cheia straina trebuie sa fie NULL). Relatiile R1 si R2 nu sunt neaparat distincte.
ü trebuie obligatoriu indeplinite pentru ca o baza de date relationala sa fie corect definita
ü sunt specificate pentru o schema a bazei de date
ü trebuie respectate de orice instanta a acelei scheme
ü DDL trebuie sa includa facilitati de specificare a restrictiilor de integritate pentru ca SGBD-ul sa le aplice in mod automat
ü majoritatea SGBD-urilor suporta restrictia de integritate a entitatii prin specificarea la nivelul cheii primare a optiunii NOT NULL
ü restrictia de integritate referentiala nu este suportata de toate SGBD-urile
ü cele care o suporta o specifica de regula prin constructia FOREIGN KEY
ü la cele care nu o suporta ea trebuie implementata la nivelul programelor de aplicatii pentru a asigura integritatea bazei de date
ü restrictii generale numite restrictii de integritate semantica
EX. salariul unui angajat nu poate depasi salariul sefului sau direct, sau numarul maxim de ore lucrate de un angajat intr-o zi nu poate fi mai mare de 24
ü nu este in general disponibil la nivelul SGBD-ului
ü ele trebuie implementate la nivelul aplicatiei
ü exista, insa, si SGBD-uri care dispun si de acest tip de restrictii de integritate (se pot specifica la crearea structurii tabelei cu ajutorul optiunii CHECK)
Violarea (incalcarea) restrictiilor de integritate poate apare in situatia operatiilor de actualizare a relatiilor:
inserarii - violarea oricareia dintre cele trei tipuri de restrictii de integritate
stergerii - numai restrictia de integritate referentiala poate fi afectata
modificarii - violarea oricareia dintre cele trei restrictii de integritate
3
Algebra relationala
ü o colectie de operatii care sunt utilizate pentru a manipula relatii
ü operatiile sunt utilizate pentru a selecta tupluri din relatii individuale si pentru a combina tupluri infratite din mai multe relatii, cu scopul de a satisface cerintele de interogare ale bazei de date
ü rezultatul oricarei operatii este o noua relatie, care poate fi manipulata apoi cu operatorii algebrei relationale
Operatorii algebrei relationale se impart in doua mari grupe:
setul traditional de operatori - cei proveniti din algebra relationala, pe care ii cunoasteti din lectiile de matematica, si anume: reuniunea, intersectia, diferenta si produsul cartezian;
setul special de operatori - operatori creati specific pentru modelul relational al datelor, si anume: selectia, proiectia, reunirea si divizarea.
Reuniunea - U (union)
Fiind date relatia R1 si R2, reuniunea celor doua relatii, R1 U R2, este o noua relatie care contine toate tuplurile care apar fie in cel putin una dintre relatii fie in ambele.
De exemplu, fiind date relatiile R1 si R2 de mai jos:
R1 R2

R1 U R2
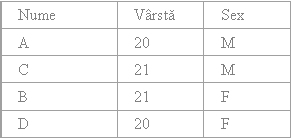
Cele doua relatii care se reunesc trebuie sa aiba acelasi fel de tupluri, adica tupluri care au aceleasi atribute. Aceasta conditie se numeste compatibilitatea reuniunii.
Doua relatii R1, avand atributele A1, A2, ., An, si R2, avand atributele B1, B2, ., Bn, sunt compatibile la reuniune daca au acelasi grad n si daca dom(Ai)=dom(Bi) pentru 1 ≤ i ≤ n.
Reuniunea este comutativa, adica R1 U R2 = R2 U R1.
Reuniunea este asociativa, adica R1 U ( R2 U R3 ) = (R1 U R2 ) U R3
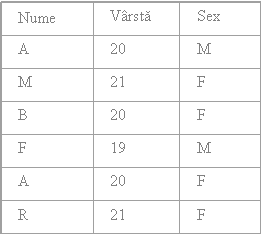
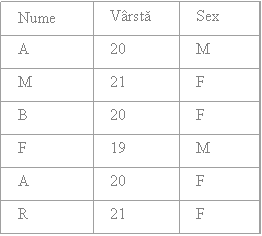
Intersectia ∩ (intersection)
Fiind date doua relatii R1 si R2, intersectia celor doua este o relatie care contine numai tuplurile comune celor doua relatii
De exemplu, fiind date relatiile R1 si R2 de mai jos:
R1 ∩ R2
|
Nume |
Varsta |
Sex |
|
A |
M |
|
|
B |
F |
Relatiile R1 si R2 trebuie sa fie compatibile la reuniune.
Intersectia este comutativa, adica R1 ∩ R2 = R2 ∩ R1.
Intersectia este asociativa, adica R1 ∩ ( R2 ∩ R3 ) = ( R1 ∩ R2 ) ∩ R3.
Diferenta - (difference)
Fiind date doua relatii R1 si R2, diferenta dintre R1 si R2 este o relatie care contine toate tuplurile care apartin lui R1 si care nu apartin si lui R2.
De exemplu, fiind date relatiile R1 si R2 de mai jos: R1-R2, R2-R1
|
Nume |
Varsta |
Sex |
|
C |
M |
|
Nume |
Varsta |
Sex |
|
D |
F |
Relatiile R1 si R2 trebuie sa fie compatibile la reuniune.
Diferenta nu este comutativa, adica R1 R2 ≠ R2 R1.
Produsul cartezian X (cartesian product)
Fiind date relatiile R1, avand atributele A1, A2, ., An, si R2, avand atributele B1, B2, ., Bm, produsul cartezian al celor doua relatii este tot o relatie, avand atributele A1, A2, ., An, B1, B2, ., Bm, care contine toate tuplurile posibile rezultate ca urmare a combinarii unui tuplu al relatiei R1 cu un tuplu al relatiei R2.
Relatiile R1 si R2 nu trebuie sa fie compatibile la reuniune.
Relatia rezultata in urma produsului cartezian are (n+m) atribute, si daca relatia R1 are N1 tupluri, iar relatia R2 are N2 tupluri, ea va avea (N1*N2) tupluri.
De exemplu, fiind date relatiile R1 si R2 de mai jos:
|
Nume |
Prenume |
|
Pop |
Ana |
|
Pop |
Ion |
|
Bucur |
Ana |
|
Bucur |
Ion |
R1 R2 R1XR2
|
Nume |
|
Pop |
|
Bucur |
|
Prenume |
|
Ana |
|
Ion |
Selectia σ(select)
Selectia este utilizata pentru a selecta un subset de tupluri ale unei relatii.
Acest subset de tupluri trebuie sa satisfaca o conditie de selectie.
σ<conditie_selectie> (<nume_relatie>)
unde,
<conditie_selectie> este o conditie logica de tipul:
<nume_atribut> <operator_comparatie> <valoare_constanta> AND/OR/NOT
<nume_atribut> <operator_comparatie> <nume_atribut>
Operatorul de comparatie depinde de tipul de data al domeniului atributului si poate fi, de exemplu: <, >, ≤, ≥, =, ≠ pentru valori numerice ale atributului.
Operatorul de selectie este unar, adica se aplica unei singure relatii.
Relatia rezultata in urma selectiei are aceleasi atribute ca si relatia asupra careia s-a aplicat operatorul de selectie.
Gradul relatiei rezultate in urma selectiei = gradul relatiei initiale asupra careia s-a aplicat operatorul de selectie
Numarul de tupluri ale relatiei rezultat ≤ numarul de tupluri ale relatiei initiale
Numarul de tupluri rezultate in urma operatiei de selectie se mai numeste si selectivitatea acelei conditii de selectie.
Operatia de selectie este comutativa, adica
σ<cond1>( σ<cond2>(R)) = σ<cond2>( σ<cond1>(R))
Fie relatia R1 <Varsta=20>(R1)= R
 R2
R2
< (Sex=M) AND (Varsta>19) >(R1)= R
R3
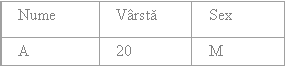
Proiectia π(project)
Operatia de proiectie construieste o noua relatie, prin selectarea anumitor atribute ale unei relatii existente. Tuplurile duplicat sunt eliminate.
π<lista_atribute> (<nume_relatie>)
Noua relatie are ca atribute doar atributele specificate in <lista_atribute> pastrand aceeasi ordine ca si cea din lista.
Gradul relatiei rezultat cu numarul elementelor din lista.
Numarul de tupluri ale relatiei rezultate in urma proiectiei ≤ numarul de tupluri ale relatiei initiale.
Numarul de tupluri ale relatiei rezultat numarul tuplurilor relatiei initiale (daca un atribut din lista este cheie primara a relatiei
Numarul de tupluri ale relatiei rezultat < numarul tuplurilor relatiei initiale (daca atributele din lista nu sunt chei candidate apare fenomenul de eliminare a duplicatelor la nivelul tuplurilor
Operatorul de proiectie este tot un operator unar.
Proiectia nu este comutativa.
Fie relatia R1
 R2
R2
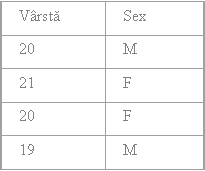 R3
R3
<Nume,Sex>(R1)=R2
<Varsta Sex>(R1)=R3
Reunirea ►◄ (join)
Operatia de reunire are ca scop alaturarea a doua relatii R1si R2, cu scop de a forma o noua relatie R3.
Relatiile R1si R2 trebuie sa aiba un atribut comun sau un grup de atribute comune, atribute ce sunt definite pe aceleasi domenii de valori.
Intre valorile atributelor comune trebuie sa se stabileasca o relatie de comparatie pe baza careia se vor concatena tuplurile celor doua relatii initiale intr-unul singur.
Operatia mai este denumita si compunere.
Notatia formala folosita pentru join este urmatoarea:
R►◄<conditie_join>S
Fiind date relatiile R1(A1, A2, ., An) si R2(B1, B2, ., Bm), prin reunirea celor doua relatii rezulta tot o relatie, R3(A1, A2, ., An, B1, B2, ., Bm) avand (n+m) atribute ordonate dupa cum s-a precizat. Relatia R3 are un tuplu pentru fiecare combinatie de tupluri de tipul : un tuplu din relatia R1 si un tuplu din relatia R2, daca combinatia satisface conditia de join.
Conditia de join este de forma:
<conditie1> AND <conditie2> AND.AND <conditie n >
unde, fiecare conditie este de forma:
Ai θ Bj
unde, Ai este un atribut al lui R1, Bj este un atribut al lui R2, Ai si Bj au acelasi domeniu si θ este un operator de comparatie precum: =, ≠, <, >, ≤, ≥. Conditia de join este specificata asupra atributelor apartinand celor doua relatii R1 si R2 si este evaluata pentru fiecare combinatie de tupluri. Fiecare combinatie de tupluri care satisface conditia de join este inclusa in relatia rezultat R3 ca un tuplu singular. Daca un tuplu al relatiei R1 nu are corespondent in relatia R2, atunci acesta nu apare in relatia rezultat R3.
Daca se utilizeaza orice alt operator de comparatie in afara celui de egalitate, join-ul se numeste theta join. Tuplurile ale caror atribute de join au valoarea null nu apar in rezultat.
Cel mai des utilizat join este cel care foloseste ca operator de comparatie semnul '='. Acesta se numeste si equijoin. Equijoin-ul nu elimina coloanele duplicat. In acest caz, relatia rezultata ar avea de doua ori acelasi atribut, adica valorile atributului apar de doua ori, chiar daca numele atributelor este diferit.
Din acest motiv s-a introdus natural join, care elimina aceasta dublare a valorilor atributului. In acest caz, fiecarui tuplu al relatiei R1 i se concateneaza tuplurile relatiei R2 care au aceeasi valoare pentru atributul comun, si se inlatura a doua aparitie in tuplu a atributului comun.
Relatia rezultata in urma unui join poate avea intre 0 si NR1 * NR2 tupluri, unde NR1 este numarul de tupluri al relatiei R1 si NR2 este numarul de tupluri al relatiei R2.
Fie relatiile R1 si R2
R1 R2
|
Nume |
Prenume |
|
A |
Ana |
|
B |
Ion |
|
C |
Vasile |
|
Prenumele |
Sex |
|
Ana |
F |
|
Ion |
M |
|
Vasile |
M |
Equijoin
R3 = R1 ►◄(Prenume=Prenumele) R2
R3

Natural join
R'3 (eliminarea coloanei cu valori duplicat
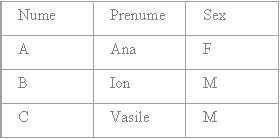
In cazul operatiei de join natural numai tuplurile din relatia R1 care au corespondent in relatia R2 apar in relatia rezultat.
Daca este necesar ca toate tuplurile relatiei R1 sa se regaseasca in relatia rezultat se va folosi operatia de join extern (outer join). In cazul join-ului extern toate tuplurile din relatiile R1 si R2 se vor regasi in relatia rezultat, fie ca au sau nu corespondent in cealalta relatie. Acest tip de join se mai numeste si join extern complet (full outer join).
Exista si notiunea de join extern la stanga (left outer join), caz in care toate tuplurile din relatia R1 apar in relatia rezultat, indiferent daca au sau nu un tuplu corespondent in relatia R2. Daca un tuplu din relatia R1 nu are corespondent in relatia R2, atunci atributelor din relatia rezultat care apartin relatiei R2 li se atribuie valoarea null.
Exista si notiunea de join extern la dreapta (right outer join), caz in care toate tuplurile din relatia R2 apar in relatia rezultat, indiferent daca au sau nu un tuplu corespondent in relatia R1. Daca un tuplu din relatia R2 nu are corespondent in relatia R1, atunci atributelor din relatia rezultat care apartin relatiei R1 li se atribuie valoarea null.
Divizarea (division)
Divizarea sau diviziunea este o operatie inversa produsului cartezian.
Daca o relatie R1 de grad (m+n) se divide cu o relatie R2 de grad n rezulta o relatie R3 de grad m. Atributul cu indicele (m+i) din relatia R1 si atributul cu indicele i din relatia R2 trebuie sa fie definite pe acelasi domeniu.
Rezultatul divizarii relatiei R1 cu relatia R2 este o relatie R3, care contine acele tupluri ale caror valori se regasesc in relatia R1 in combinatie cu toate tuplurile relatiei R2.
EX. rezultatul divizarii relatiei R1 cu relatia R2 este relatia R3
R1 R2 R3
|
Nume |
|
A |
|
C |
|
Sex |
|
M |
|
F |

4
Calcul relational
ü Este o alternativa a algebrei relationale in ceea ce priveste partea de manipulare a datelor .
ü algebra relationala furnizeaza o colectie de operatii explicite de tip selectie, proiectie, reuniune, etc., care pot fi utilizate pentru a construi noi relatii pornind de la cele deja existente in baza de date
ü calculul relational furnizeaza o notatie necesara pentru a formula definitia noii relatii in termenii acelor relatii deja existente in baza de date
ü Calculul relational stabileste practic care este problema ce trebuie rezolvata.
ü Algebra relationala ne furnizeaza o modalitate de rezolvare a acestei probleme.
ü Se poate spune ca algebra relationala este procedurala, in timp ce calculul relational este neprocedural.
ü Pentru fiecare expresie a algebrei relationale exista o expresie echivalenta a acesteia in calculul relational si viceversa. Exista o echivalenta de tip unu-la-unu intre cele doua expresii.
ü Calculul relational este mai apropiat de limbajul natural.
ü Algebra relationala este mai apropiata de un limbaj de programare.
ü Ambele reprezinta o modalitate formala de reprezentare a manipularii datelor.
ü Algebra si calculul relational sunt echivalente unul cu altul.
ü Calculul relational se bazeaza pe teoria calculului predicatelor din logica matematica.
ü Ideea isi are originea intr-un articol al lui J.L. Kuhns
ü Conceptul de calcul relational ii apartine lui E.F. Codd.
ü Acesta, in 1972, a imaginat calculul relational ca o forma speciala de calcul al predicatelor aplicat la bazele de date relationale.
ü El a creat chiar un limbaj bazat explicit pe calculul relational, numit sublimbajul de date ALPHA, care nu a fost insa implementat niciodata in forma lui initiala, dar care sta la baza limbajului QUEL din INGRES.
ü Tot Codd a creat un algoritm pe baza caruia o expresie arbitrara a calculului relational poate fi redusa la o expresie semantic echivalenta a algebrei relationale.
Modelul relational al datelor
Modelul relational al datelor implica urmatoarele trei aspecte:
structura datelor - datele au o structura tabelara, formata din relatii de grad n, adica cu n atribute, si cardinalitate m, adica m tupluri intr-o relatie. Valorile tuturor atributelor relatiilor sunt atomice.
integritatea datelor - datele trebuie sa respecte cele doua reguli de integritate relationala, si anume:
1.Regula de integritate a entitatii.
2.Regula de integritate referentiala
manipularea datelor - trebuie sa existe operatorii algebrei relationale, reuniunea, intersectia, diferenta, produsul cartesian, selectia, proiectia, reunirea si divizarea, sau echivalentele acestora in calculul relational, precum si un opeartor de atribuire relationala.
Sisteme relationale de baze de date
Sunt acele sisteme care au la baza modelul relational al datelor.
Un sistem de baze de date este relational daca suporta cel putin urmatoarele doua conditii:
baza sa de date este relationala, adica datele sunt percepute de utilizatori sub forma unor tabele relationale si nimic altceva;
cel putin operatorii de selectie, proiectie si join natural sunt implementati la nivelul sistemului, fara a fi necesare alte predefiniri ale cailor de acces fizic pentru a se realiza aceste operatii.
In functie de gradul de respectare a modelului relational, sistemele se pot clasifica astfel:
sistem tabelar - cel care suporta numai date cu structura tabelara;
sistem relational minimal - cel care suporta structura tabelara pentru date si in plus si cei trei operatori relationali (selectia, proiectia si join-ul);
sistem relational complet - cel care suporta structura tabelara pentru date plus cei opt operatori relationali (reuniunea, intersectia, diferenta, produsul cartezian, selectia, proiectia, join-ul si divizarea);
sistem in totalitate relational - cel care suporta structura tabelara pentru date plus cei opt operatori relationali plus cele doua reguli de integritate relationala.
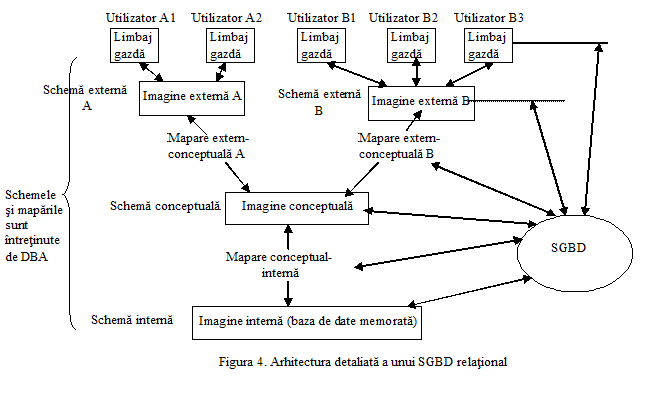
Arhitectura unui sistem de gestiune a bazelor de date relational
Arhitectura unui SGBD relational este divizata pe trei nivele generale:
nivelul intern - este cel mai apropiat de suportul fizic de memorare a datelor, el este preocupat de modul cum sunt memorate efectiv datele pe acest suport.
nivelul extern - este cel mai apropiat de utilizatorii sistemului, el fiind preocupat de modul cum sunt vazute datele de utilizatorii individuali.
nivelul conceptual - este un nivel intermediar intre celelalte doua.
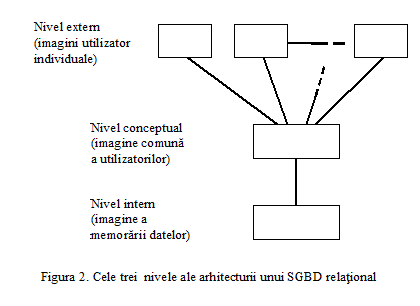
Nivelul extern - este preocupat de imaginea utilizatorilor individuali asupra datelor
Nivelul conceptual - este preocupat de asigurarea unei imagini comune asupra datelor pentru toti utilizatorii
Nivelul intern - este preocupat de modul cum sunt memorate efectiv datele pe suportul extern de memorare
ü Vor fi mai multe imagini externe, distincte, fiecare constituind o reprezentare a unei portiuni a bazei de date intr-un mod mai mult sau mai putin abstract.
ü Va fi doar o imagine conceptuala, continand o reprezentare a tuturor datelor din baza de date.
ü Va exista doar o imagine interna a bazei de date, reprezentand baza de date in totalitatea ei, asa cum este ea memorata pe suportul fizic.
Exemplu BD intreprindere -> prelucrata de doi utilizatori finali individuali. Unul foloseste pentru a prelucra baza de date FoxPro, iar celalalt SQL.
Vor exista 2 imagini externe + 1 imagine conceptuala + 1 imagine interna a BD.
Imagine externa 1 (FoxPro) Imagine externa 2 (SQL)
ANGAJATI ANG
MARCA C 6 NR_ANG N 6
SALAR N 9 2 SECTIE N 2
-------- ----- ------ -------- ----- ------ ----- ----- ----- ----- ------
Imagine conceptuala
ANGAJAT
ANG_NR C 6
ANG_SECTIE N 2
ANG_SALAR N 9 2
-------- ----- ------ -------- ----- ------ ----- ----- ----- ----- ------
Imagine interna
INREG_ANG Lungime = 16
ANG# TIP = BYTE(6) , OFFSET = , INDEX =ANGX
SECTIE TIP = BYTE(2) , OFFSET =
PLATA TIP = WORD , OFFSET =
Nivelul extern
ü Nivelul extern este nivelul utilizatorilor individuali.
programatori de aplicatii
utilizatori finali
DBA (administratorul bazei de date) - caz particular de utilizator individual, el fiind interesat deopotriva si de nivelul conceptual si de cel intern al bazi de date.
ü Fiecare utilizator are la dispozitie un limbaj gazda cu ajutorul caruia poate prelucra datele bazei de date.
Pentru programatorii de aplicatii, acest limbaj poate fi fie un limbaj de programare conventional (de exemplu: C, C++, Delphi, Visual Basic, Smalltalk, etc.) fie un limbaj de programare creat special pentru baze de date (de exemplu: dBASE, FOX, PL/SQL).
Pentru utilizatorii finali, acest limbaj poate fi un limbaj de interogare de tipul 'query language' (QL) sau 'query - by - example' (QBE) sau se mai poate utiliza si varianta selectiei din meniuri.
ü Limbajul gazda incorporeaza un sublimbajul de date (DSL)
ü DSL - este un subset al limbajului bazei de date ce este preocupat in special de obiectele si operatiile bazei de date.
ü Limbajul gazda furnizeaza si o serie de alte facilitati care nu sunt specifice obiectelor si operatiilor bazei de date, spre exemplu: variabilele locale, operatiile de calcul matematic, logica de tip if-then-else, etc.
ü Un sistem de baze de date poate suporta mai multe limbaje gazda si mai multe sublimbaje de date.
ü In principiu, fiecare DSL este o combinatie a cel putin doua sublimbaje subordonate si anume:
ü limbajul de definire a datelor (DDL) care furnizeaza definitia sau descrierea obiectelor bazei de date
ü limbajul de manipulare a datelor (DML) care permite manipularea si procesarea acestor obiecte.
ü Un utilizator individual va fi interesat in general doar de o anumita portiune a bazei de date, care adesea va fi ceva abstract in comparatie cu modul cum sunt datele memorate pe suportul fizic.
ü Termenul ANSI (American National Standard Institute) pentru imaginea unui utilizator individual asupra bazei de date este de imagine externa.
ü O imagine externa este continutul bazei de date asa cum este el vazut de un utilizator particular.
ü De exemplu, departamentul Personal al unei intreprinderi poate sa priveasca baza de date ca pe o colectie de articole despre departamente plus o colectie de articole despre angajati, fara sa aiba cunostinta despre colectia de articole cu privire la furnizori sau la piesele furnizate de acestia, care sunt vazute numai de utilizatorii din departamentul Aprovizionare.
ü O imagine externa contine multiple aparitii de multiple tipuri de inregistrari externe.
ü O inregistrare externa nu este neaparat identica cu o inregistrare memorata.
ü Sublimbajul de date al utilizatorului este definit in termenii inregistrarilor externe. De exemplu, o operatie DML de cautare a unei inregistrari va regasi o inregistrare externa, nu una memorata pe suportul fizic.
ü Fiecare imagine externa este definita in termenii unei scheme externe
ü Schema externa contine definitiile de baza ale fiecarui tip, din variatele tipuri de inregistrari externe posibile la nivelul acelei imagini externe.
ü Schema externa este scrisa utilizand portiunea DDL din sublimbajul de date al utilizatorului, numita si DDL extern.
ü De exemplu, inregistrarea externa specifica unui angajat poate fi definita ca fiind alcatuita dintr-un camp numit Marca, de tip caracter cu lungime 6 caractere, plus un camp Salar, de tip numeric de lungime de 6 cifre, plus etc.
ü Pe langa aceasta schema externa trebuie sa existe si o definitie a corespondentelor existente intre schema externa si schema conceptuala.
Nivelul conceptual
ü Imaginea conceptuala este o reprezentare a intregului continut informational al bazei de date.
ü Este o modalitate de reprezentare abstracta in comparatie cu modul in care datele sunt memorate pe suportul fizic.
ü Ea poate sa fie diferita si de modul in care datele sunt vazute de un utilizator individual particular.
ü Imaginea conceptuala incearca sa ofere o imagine a datelor asa cum sunt ele de fapt, mai degraba decat asa cum sunt utilizatorii fortati sa vada aceste date datorita constrangerilor impuse de limbajul gazda folosit sau de capacitatea hardware-ul pe care il utilizeaza.
ü Imaginea conceptuala este alcatuita din multiple aparitii ale multiplelor tipuri de inregistrari conceptuale.
ü De exemplu, imaginea conceptuala poate contine o colectie de inregistrari cu privire la departamente plus o colectie de inregistrari cu privire la angajati plus o colectie de inregistrari cu privire la furnizori plus o colectie de inregistrari cu privire la piesele furnizate.
ü O inregistrare conceptuala nu este neaparat identica cu o inregistrare externa sau cu o inregistrare memorata.
ü Imaginea conceptuala este definita in termenii unei scheme conceptuale care include definitii pentru fiecare din tipurile variate de inregistrari conceptuale.
ü Schema conceptuala este scrisa utilizand un limbaj de definire a datelor numit DDL conceptual.
ü Daca se urmareste respectarea independentei datelor:
ü definitiile DDL conceptuale nu trebuie sa implice nici un fel de considerente legate de structura de memorare a datelor sau de strategia de acces la acestea
ü ele trebuie sa fie doar definitii cu privire la continutul informatiilor din baza de date
ü Daca schema conceptuala este construita astfel incat sa asigure independenta datelor, atunci si schemele externe definite in termenii acestei scheme conceptuale, vor asigura independenta datelor.
ü Deci, in schema conceptuala nu trebuie sa se faca referiri la modul cum sunt reprezentate campurile memorate, care este secventa in care sunt memorate inregistrarile sau orice alt detaliu cu privire la modalitatile de memorare a datelor sau de accesare a lor (prin indexare, pointeri, hashing, etc).
ü Imaginea conceptuala este o imagine a intregului continut informational al bazei de date.
ü Schema conceptuala este o definitie a acestei imagini.
ü Definitiile din cadrul schemei conceptuale contin:
ü definitiile datelor bazei de date
ü verificarile de securitate si de integritate ale datelor
Nivelul intern
ü Imaginea interna este reprezentarea la nivelul cel mai de jos al intregii baze de date.
ü Imaginea interna contine multiple aparitii de multiple tipuri de inregistrari interne (inregistrari memorate).
ü Imaginea interna este descrisa in termenii unei scheme interne.
ü Schema interna specifica si defineste diferitele tipuri de inregistrari memorate, specifica de asemenea si ce indecsi exista, cum sunt reprezentate campurile, care este secventa fizica a inregistrarilor memorate, etc.
ü Schema interna este scrisa utilizand un alt limbaj de definire a datelor numit DDL intern.
ü Nivelul intern al unei baze de date este nivelul preocupat de modul in care datele sunt efectiv memorate in baza de date.
ü Bazele de date sunt memorate pe medii care suporta acces direct.
ü Folosim termeni precum timp de cautare, intarziere de rotatie, cilindru, pista, cap de citire/scriere.
ü Timpul de accces la date este mult mai mare in cazul discurilor decat in cazul accesului la memoria interna ( accesul la disc - <400 milisecunde penru floppy discurilor de pe microsisteme si >30 milisecunde pentru discurile de pe mainframe-uri, accesul la memoria interna este cu cel putin 4-5 ordine de marime mai rapid decat accesul la disc).
ü Obiectiv major - minimizarea numarului de accese la disc (localizarea unei inregistrari memorate prin cat mai putine accese de citire/scriere pe disc).
ü Orice tip de aranjament al datelor pe suportul de memorare fizica este referit ca structura de memorare.
ü Nu exista o stuctura de memorare optima pentru orice tip de aplicatie.
ü Un sistem bun poate suporta mai multe tipuri de structuri de memorare (diferite portiuni ale bazei de date sa poata fi memorate in moduri diferite, structura de memorare pentru o anumita portiune sa poata fi schimbata dupa cum se modifica cerintele de performanta ale sistemului).
ü Procesul de alegere a unei structuri de memorare a datelor cat mai potrivita pentru baza de date este denumit proiecterea fizica a bazei de date.
Conversii intre nivele (mapari)
ü Exista doua nivele de conversie sau mapare intre cele trei nivele ale unui SGBD:
ü un nivel de mapare intre nivelul extern si nivelul conceptual
ü un nivel de mapare intre nivelul conceptual si cel intern
ü Conversia conceptual-interna defineste corespondenta dintre imaginea conceptuala si baza de date memorata.
ü specifica cum inregistrarile conceptuale si campurile acestora sunt reprezentate la nivel intern
ü Daca structura bazei de date memorate se modifica, atunci corespondentele conceptual-interne trebuie de asemenea sa se modifice in conformitate cu aceste modificari, astfel incat schema conceptuala sa ramana invarianta.
ü Este responsabilitatea DBA-ului sa controleze aceste schimbari, astfel incat efectele lor sa fie izolate dedesuptul nivelului conceptual pentru ca independenta fizica a datelor sa fie asigurata.
ü Conversia extern-conceptuala defineste corespondenta dintre o imagine externa particulara si imaginea conceptuala a bazei de date.
ü Diferentele care pot sa existe intre cele doua nivele sunt similare cu cele care pot exista intre inregistrarea conceptuala si baza de date memorata. De exemplu, campurile pot sa fie de tipuri de date diferite, numele campurilor pot sa fie modificate, mai multe campuri conceptuale pot fi combinate intr-un singur camp extern (virtual), etc.
ü La un moment dat in timp pot sa existe oricate imagini externe si orice numar de utilizatori pot sa imparta aceeasi imagine externa.
ü Diferitele imagini externe se pot suprapune. Exista anumite limbaje care permit definirea unei imagini externe in termenii altei imagini externe folosind o conversie extern/externa.
5
Administratorul bazei de date
ü Administratorul bazei de date (DBA) este persoana, sau grupul de persoane, responsabila cu controlul intregului sistem de baze de date.
ü Administratorul bazei de date are mai multe sarcini:
ü sa decida care este continutul informational al bazei de date
ü sa decida structura de memorare si strategiile de acces la date
ü asigurarea legaturii cu utilizatorii
ü definirea de verificari de securitate si integritate
ü definirea unei strategii pentru salvarea si recuperarea datelor
ü modificarea performantelor si a altor cerinte necesare in prelucrarea datelor
ü Unul dintre cele mai importante instrumente care stau la dispozitia DBA-ului este catalogul sistem sau dictionarul de date.
ü Catalogul sistem poate fi privit ca o baza de date sistem nu una utilizator. Continutul acestui dictionar este de tipul 'date despre datele bazei de date',
ü Pentru a realiza toate sarcinile care ii revin, administratorul bazei de date are nevoie de o serie de programe utilitare.
ü rutinele de salvare a datelor si de refacere a lor in caz de accident - salvarea periodica a datelor bazei de date si refacerea automata a acestora in cazul in care in sistem s-au semnalat erori;
ü rutinele de reorganizare a datelor - rearanjarea datelor din baza de date astfel incat sa se obtina performanta maxima in prelucrarea acestora (de exemplu, memorarea datelor intre care exista legaturi in acelasi cluster sau eliberarea spatiului fizic de memorare de catre acele date care nu mai sunt necesare).
ü rutinele statistice - analiza statistica a performantelor sistemului, ca de exemplu: analiza marimii fisierelor, distibutia valorii datelor, etc.
Scenariul accesului la o baza de date
ü SGBD-ul furnizeaza interfata dintre utilizatorii finali si baza de date.
ü Aceasta interfata este invizibila pentru utilizator.
ü Utilizatorii interfereaza cu sistemul de baze de date la nivel extern, celelalte nivele si maparile dintre ele netrebuind a fi luate in calcul de acestia.
ü Cererile adresate bazei de date ce catre un utilizator final sunt transmise de la un terminal, care poate chiar sa fie fizic detasat de sistemul de baze de date.
ü Cererea este transmisa unei aplicatii, incorporate sau nu in sistem, si prin intermediul acesteia sistemului de gestiune al bazei de date.
ü Cererile sunt transmise sub forma unor mesaje de comunicatie.
ü De asemenea, raspunsurile ce vin de la SGBD sunt transmise la utilizatorul final, prin intermediul aplicatiei, tot sub forma unor mesaje de comunicatie.
ü Toate aceste transmisii de mesaje au loc sub controlul gestionarului de comunicatii (Data Communications Manager) care este practic un sistem separat de SGBD, dar care trebuie sa lucreze in armonie cu acesta pentru a satisface cererile utilizatorilor.
ü SGBD-ul este software-ul care gestioneaza toate accesele la baza de date. Conceptual ceea ce se intampla este prezentat in continuare:
ü un utilizator lanseaza o cerere de acces la datele bazei de date - el utilizeaza in acest scop un sublimbaj de date particular, de exemplu SQL.
ü SGBD-ul intercepteaza acea cerere si o analizeaza - dupa ce cererea este interceptata se face o analiza sintactica si semantica a acesteia pentru a descoperi daca o poate satisface.
ü SGBD-ul inspecteaza schema externa a utilizatorului care a lansat cererea, maparile extern/conceptuale corespunzatoare acesteia, schema conceptuala a bazei de date, maparea conceptual/interna si modul de definire a structurii de memorare a datelor.
ü 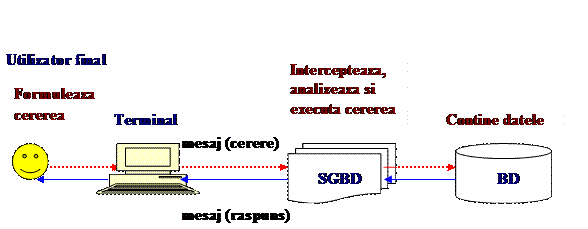 SGBD-ul executa operatiile necesare asupra bazei de date memorate - dupa executia operatiilor necesare asupra bazei de
date este obtinut raspunsul dorit care este livrat expeditorului
cererii
SGBD-ul executa operatiile necesare asupra bazei de date memorate - dupa executia operatiilor necesare asupra bazei de
date este obtinut raspunsul dorit care este livrat expeditorului
cererii
De exemplu
ü Cererea implica regasirea unor inregistrari externe particulare.
ü Campurile ce ne intereseaza apartin, in general, mai multor inregistrari conceptuale.
ü Fiecare inregistrare conceptuala, in schimb, poate necesita campuri din mai multe inregistrari memorate.
ü Conceptual, atunci cand SGBD-ul opereaza cererea trebuie in primul rand sa regaseasca toate aparitiile inregistrarilor memorate cerute, apoi sa construiasca inregistrarile conceptuale cerute, dupa care sa construiasca inregistrarile externe cerute. La fiecare nivel sunt necesare conversii ale tipului de data, ale identificatorilor anumitor atribute ale datelor, s.a.m.d.
Limbaje pentru definirea si manipularea datelor relationale
Limbajul SQL
ü SQL (Structured Query Language), initial scris si pronuntat SEQUEL, a fost proiectat pentru prima data in anii '70 de D.D. Chamberlin impreuna cu un colectiv de cercetatori de la Laboratorul de Cercetari al firmei IBM din San Jose California.
ü O implementare prototip a acestui limbaj a fost construita, la laboratorul amintit, sub denumirea de System-R si a fost supusa unui numar de teste de utilizare si de performanta, atat in cadrul firmei IBM cat si in exteriorul acesteia.
ü Si alti producatori au realizat sisteme care suporta limbajul SQL sau unul foarte apropiat de acesta.
ü S-au creat interfete SQL pentru o serie de alte produse relationale care nu erau de tip SQL.
ü Comitetul National American pentru Baze de Date Standard a stabilit definitia unui limbaj de baze de date relationale standard foarte apropiata de cea a SQL-ului firmei IBM.
ü SQL este un limbaj de date relational non-procedural, deoarece utilizatorii specifica ce anume doresc sa obtina din baza de date si nu cum sa se faca aceasta. Procesul de navigare prin baza de date fizica, pentru a obtine datele dorite, este realizat automat de sistem, nu manual de catre utilizator.
ü SQL include atat un limbaj de definire a datelor (DDL) cat si un limbaj de manipulare a datelor (DML).
ü DML poate opera atat la nivel extern, cat si la nivel conceptual.
ü DDL poate fi folosit pentru a defini obiecte la nivel extern (view-uri), la nivel conceptual (tabele), cat si la nivel intern (indecsi).
ü SQL furnizeaza si anumite facilitati de control al datelor care nu apartin nici DDL-ului nici DML-ului. Acestea formeaza asa numitul limbaj de control al datelor (DCL).
ü Toate declaratiile SQL sunt declaratii executabile. Ele pot fi introduse de la un terminal, caz in care se executa imediat, sau pot fi incorporate in alte limbaje de programare sau pentru baze de date, precum C, C++, Delphi, Visual Basic, PL/SQL, FoxPro, dBASE, etc.
SQL - Declaratii de definire a datelor (DDL)
Declaratiile de definire a datelor sunt declaratiile care alcatuiesc limbajul de definire a datelor DDL.
La nivelul SQL-ului acest limbaj este compus din urmatoarele declaratii:
Pentru tabele Pentru tabele virtuale Pentru indecsi
CREATE TABLE CREATE VIEW CREATE INDEX
ALTER TABLE
DROP TABLE DROP VIEW DROP INDEX
DDL - Tabele
ü O tabela este un sistem relational continand un rand cu antete de coloana impreuna cu zero sau mai multe randuri cu valori de date. Numarul randurilor cu date variaza in timp.
ü Randul cu antete de coloana specifica una sau mai multe coloane, iar pentru fiecare coloana se precizeaza numele pe care il va purta si tipul de data permis in acea coloana.
ü Fiecare rand cu date contine exact o singura valoare pentru fiecare coloana specificata in randul cu antetele de coloane.
ü Toate valorile unei coloane sunt de acelasi tip de data cu cel specificat pentru acea coloana in randul cu antele de coloana.
O tabela poarta un nume, prin intermediul caruia se fac referirile la ea, si este intotdeauna memorata pe suportul fizic de memorare intr-un fisier.
Declaratia prin intermediul careia se creaza tabelele este:
CREATE TABLE nume_tabela (nume_coloana1 tip_data [NOT NULL],
nume_coloana2 tip_data [NOT NULL ;
ü Se creaza o noua tabela.
ü Tabela initial nu contine date (este goala).
ü Datele sunt introduse in tabela cu ajutorul unor declaratii de manipulare a datelor.
Tipurile de date posibile sunt:
CHAR(n) - sir de caractere de lungime fixa n
VARCHAR(n) - sir de caractere de lungime variabila cu lungimea maxima n
INTEGER - numere intregi cu semn cu precizie de 31 biti
SMALLINT - numere intregi cu semn cu precizie de 15 biti
DECIMAL (p,q) - numere zecimale cu semn avand lungimea totala p biti si
partea zecimala de q biti
FLOAT - numere in virgula flotanta
MONEY - valori numerice reprezentate in diverse monede
DATE - date calendaristice in diverse formate
TIME - timpul exprimat in ore:minute:secunde
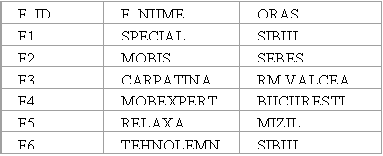
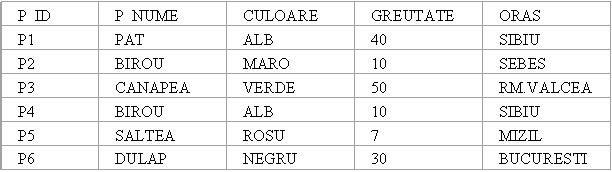
Exemplu:
Furnizori
Produse
CREATE TABLE FURNIZORI
(F_ID CHAR(5) NOT NULL,
F_NUME CHAR(20),
ORAS CHAR(15));
CREATE TABLE PRODUSE
(P_ID CHAR(6) NOT NULL,
P_NUME CHAR(20),
CULOARE CHAR(10),
GREUTATE INTEGER,
ORAS CHAR(15));
Declaratia de modificare a structurii unei tabele este urmatoarea:
ALTER TABLE nume_tabela
ADD nume_coloana tip_data;
ü Modificarea structurii unei tabele prin adaugarea de noi coloane acesteia. Vechile coloane ale structurii raman nemodificate.
ALTER TABLE nume_tabela
MODIFY nume_coloana tip_data;
ü Modifica caracteristicile coloanelor deja existente in tabela. Nu sunt permise decat modificarile care nu altereaza continutul informational al tabelei (marirea lungimii unui camp sau conversiile de tip de data care nu duc la pierderea datelor).
ALTER TABLE nume_tabela
DELETE nume_coloana;
ü Sterge coloana specificata din tabela. Atentie! datele existente la nivelul coloanei se pierd.
Declaratia de distrugere (stergere) a unei tabele este urmatoarea:
DROP TABLE nume_tabela;
ü Tabela specificata este inlaturata in mod permanent din sistem (mai precis declaratia acesteia este inlaturata din catalogul sistem).
ü De asemenea, toti indecsii si toate view-urile definite pe aceasta tabela sunt si ele automat inlaturate din sistem.
DDL - Indecsi
Indexul este o structura de date auxiliara unei tabele de baza care permite regasirea mult mai rapida a informatiei din tabela.
Declaratia de creare a unui index este urmatoarea:
CREATE [UNIQUE] INDEX nume_index
ON nume_tabela (nume_coloana1 [ASC/DESC],
nume_coloana2 [ASC/DESC], .);
ü Declaratia creaza un index cu numele nume_index pentru tabela nume_tabela.
ü Criteriul de indexare este indicat intre paranteze.
ü Ordonarea se poate face ascendent (implicit) sau descendent
ü Cheia de indexare se obtine concatenand continutul coloanelor dintre paranteze de la stanga la dreapta.
ü Coloanele cheii de indexare nu trebuie sa aiba acelasi tip de data, sau sa fie neaparat de lungime fixa.
ü In SQL indecsii sunt creati de utilizatori, dar folosirea lor nu intra in sarcina acestora.
ü Indecsii nu sunt mentionati niciodata in declaratiile SQL de manipulare a datelor.
ü Decizia de a folosi sau nu un anumit index, ca urmare a unei operatii de interogare a bazei de date, este luata intotdeauna de catre sistem nu de catre utilizator.
ü Indexul este automat actualizat pentru a reflecta orice actualizare facuta asupra datelor tabelei de baza, pana in momentul in care el sau tabela pentru care a fost construit este inlaturata din sistem.
ü Optiunea UNIQUE indica faptul ca nu sunt admise doua tupluri in tabela de baza care sa aiba aceeasi valoare pentru cheia de indexare.
De exemplu,
CREATE UNIQUE INDEX IF ON FURNIZORI (F_ID);
CREATE UNIQUE INDEX IP ON PRODUSE (P_ID);
ü In general, indecsii, ca si tabelele pot fi creati in orice moment in timp.
ü Restrictii pot sa apara in cazul in care se doreste crearea unor indecsi cu optiunea UNIQUE si tabela contine deja valori care violeaza aceasta cerinta. In acest caz, indecsii nu pot fi creati.
ü Este indicat ca indecsii cu optiunea UNIQUE sa fie creati odata cu crearea tabelei.
ü Pentru o tabela pot fi construiti oricati indecsi este nevoie pentru a mari viteza de executie a interogarilor.
ü Nu trebuie abuzat de numarul indecsilor, pentru ca si timpii de executie ai operatiilor de actualizare cresc deoarece sistemul trebuie sa intretina in mod automat acesti indecsi.
De exemplu, pentru tabela FURNIZORI se mai poate crea si indexul urmator:
CREATE INDEX IF1 ON FURNIZOR (ORAS DESC);
ü Daca un index nu mai este necesar este indicat ca el sa inlaturat din sistem.
Declaratia de inlaturare (stergere) a unui index este:
DROP INDEX nume_index;
ü Indexul este distrus in mod permanent, adica descrierea lui este inlaturata din catalogul sistem.
ü CREATE INDEX si DROP INDEX sunt singurele declaratii SQL referitoare la indecsi. Nici o alta declaratie SQL de manipulare a datelor nu face referire la indecsi.
ü Decizia de a folosi sau nu un index, ca urmare a unei cereri SQL, nu este luata de utilizator ci de optimizatorul sistemului.
DDL - Vizualizari (view)
O vizualizare sau o imagine (view) poate fi considerata o tabela virtuala, adica o tabela care nu exista de sine statator in baza de date, dar care pare astfel pentru utilizatori.
ü Vizualizarile nu contin date memorate pe suportul fizic.
ü Doar definitia lor, exprimata in termenii altor tabele ale bazei de date, este memorata in catalogul sistem.
Declaratia de creare a unei vizualizari este:
CREATE VIEW nume_vizualizare [(nume_coloana1, nume_coloana2, .)]
AS subinterogare;
ü Subinterogarea din definitia vizualizarii este de forma SELECT-FROM-WHERE si nu poate sa includa clauza ORDER BY. Definitia ei este salvata de catre sistem in catalogul sistem, iar utilizatorii vad vizualizarea ca si pe o tabela de baza.
ü Daca nu se specifica nici un nume de coloana la crearea vizualizarii sunt mostenite numele coloanelor din tabela pe baza careia s-a construit vizualizarea.
ü Numele coloanelor trebuie sa fie specificate explicit doar daca una dintre coloanele vizualizarii este derivata dintr-o functie SQL, o expresie aritmetica sau o constanta, sau daca doua sau mai multe dintre coloanele vizualizarii ar avea acelasi nume.
De exemplu, se va crea o vizualizare care va contine toate tipurile de produsele livrate si cantitatea totala livrata. Livrari
CREATE VIEW PT (P_ID, TOTAL)
AS SELECT P_ID, SUM(CANTITATE)
FROM LIVRARI
GROUP BY P_ID;
ü Un view restrictioneaza accesul la datele unei tabele.
ü De exemplu, se poate crea o vizualizare care va contine doar produsele de culoare alba.
CREATE VIEW PRODUSE_ALBE
AS SELECT P_ID, P_NUME, GREUTATE, ORAS
FROM PRODUSE
WHERE CULOARE = 'ALB';
ü Se poate crea o vizualizare in termenii altei vizualizari.
ü De exemplu, se poate crea o vizualizare care va contine produsele de culoare alba executate in SIBIU.
CREATE VIEW SIBIU_PRODUSE_ALBE
AS SELECT P_ID, P_NUME, GREUTATE
FROM PRODUSE_ALBE
WHERE ORAS = '
ü Declaratia prin care o vizualizare este inlaturata (stearsa) din sistem este:
DROP VIEW nume_vizualizare;
ü Definitia vizualizarii este inlaturata in mod permanent din catalogul sistem.
ü Orice alta vizualizare definita in termenii acestei vizualizari este si ea automat eliminata din sistem.
ü De exemplu
DROP VIEW PRODUSE_ALBE
DROP VIEW SIBIU_PRODUSE_ALBE
6
SQL - Declaratii de manipulare a datelor (DML)
Declaratiile de manipulare a datelor permit, pe de o parte, regasirea anumitor informatii din baza de date, pe de alta parte, inserarea, modificarea sau stergerea acestora.
SQL dispune de patru declaratii DML si anume:
SELECT UPDATE DELETE INSERT
Aceste declaratii se pot aplica, in general, atat tabelelor cat si vizualizarilor.
DML - Regasirea datelor (SELECT)
Forma generala a declaratiei de regasire a datelor in SQL, numita si bloc de interogare SQL, este urmatoarea:
SELECT [ALL/DISTINCT] lista_coloane
FROM lista_tabele
[WHERE conditie_selectie]
[GROUP BY lista_coloane [HAVING conditie_selectie]]
[ORDER BY lista_coloane];
SELECT specifica coloanele ce vor apare in raspunsul returnat ca urmare a interogarii.
FROM - specifica tabelele din care se vor extrage rezultatele.
WHERE - restrictioneaza numarul de randuri care vor apare in rezultat. Numai randurile care satisfac conditia de selectie vor apare in rezultat.
GROUP BY - gruparea randurilor de date care au aceeasi valoare pentru coloana sau coloanele specificate in lista_coloane si evaluarea anumitor caracteristici la nivelul grupurilor create. Clauza HAVING permite eliminarea din rezultat a acelor grupuri care nu satisfac conditia de selectie.
ORDER BY- ordoneaza rezultatele obtinute in urma interogarii dupa continutul coloanelor specificate in lista_coloane.
In continuare vom prezenta mai multe exemple de utilizare a clauzei SELECT.
Afisati informatiile complete cu privire la furnizori.
SELECT *
FROM FURNIZORI;
Afisati identificatorul si numele furnizorilor localizati in SIBIU.
SELECT F_ID, F_NUME
FROM FURNIZORI
WHERE ORAS
= '
Afisati toate produsele din care s-au efectuat livrari.
SELECT DISTINCT P_ID
FROM LIVRARI;
Afisati alfabetic dupa nume toate
produsele depozitate in
SELECT P_ID, P_NUME, 'Greutate in grame = ', GREUTATE*1000
FROM PRODUSE
WHERE ORAS
= '
ORDER BY P_NUME;
O categorie aparte de interogari sunt interogarile de compunere sau de reunire. In urma unui join datele pot fi extrase simultan din doua sau mai multe tabele.
Afisati date despre furnizorii si produsele localizate in acelasi oras numai pentru acele produse care nu au culoarea alba.
SELECT FURNIZORI.ORAS, F_NUME, P_NUME, CULOARE
FROM FURNIZORI, PRODUSE
WHERE FURNIZORI.ORAS = PRODUSE.ORAS
AND CULOARE <> 'ALB';
Functii incorporate
SQL dispune si de un set de functii incorporate care fac posibile rezolvarea unor probleme simple de calcul.
Aceste functii sunt urmatoarele:
COUNT (*/[DISTINCT] nume_coloana ) - returneaza numarul valorilor din
acea coloana
SUM ([DISTINCT] nume_coloana) - returneaza suma valorilor din acea coloana
AVG ([DISTINCT] nume_coloana) - returneaza media aritmetica a valorilor
din acea coloana
MAX (nume_coloana) - returneaza valoarea maxima din acea coloana
MIN (nume_coloana) - returneaza valoarea minima din acea coloana
De exemplu, aceste functii ar putea fi utilizate in astfel de scopuri:
Care este numarul total al furnizorilor?
SELECT COUNT (*)
FROM FURNIZORI;
Care este cantitatea totala livrata pentru produsul P1?
SELECT SUM (CANTITATE)
FROM LIVRARI
WHERE P_ID = 'P1';
Functiile incorporate se aplica foarte mult la nivelul grupurilor create cu GROUP BY pentru a evalua anumite caracteristici ale acestor grupuri.
Care sunt cantitatile totale livrate din fiecare produs in parte?
SELECT P_ID, SUM (CANTITATE)
FROM LIVRARI
GROUP BY P_ID;
Afisati in ordine descrescatoare cantitatile totale livrate din fiecare produs in parte?
SELECT P_ID, SUM (CANTITATE)
FROM LIVRARI
GROUP BY P_ID
ORDER BY 2;
Precizati identificatorul produselor livrate de mai mult de un furnizor.
SELECT P_ID
FROM LIVRARI
GROUP BY P_ID
HAVING COUNT (*) > 1;
Afisati identificatorul furnizorilor care au livrat mai mult de trei tipuri de produse
SELECT F_ID
FROM LIVRARI
GROUP BY F_ID
HAVING COUNT (*) >
Subinterogari
O subinterogare este o secventa SELECT-FROM-WHERE care este inclusa intr-o alta secventa de acelasi tip.
ü Teoretic sunt posibile oricate nivele de imbricare a subinterogarilor.
ü Practic, numarul nivelelor de imbricare posibile difera de la sistem la sistem.
ü Sistemul evalueaza intai interogarea de pe nivelul cel mai de jos, returneaza un set de rezultate care sunt utilizate in evaluarea interogarii de pe nivelul imediat urmator.
Precizati numele furnizorilor care livreaza cel putin un produs de culoare alba.
SELECT F_NUME
FROM FURNIZORI
WHERE F_ID IN
( SELECT F_ID
FROM LIVRARI
WHERE P_ID IN
( SELECT P_ID
FROM PRODUSE
WHERE CULOARE = 'ALB'));
Precizati numele produselor a caror greutate este mai mare decat greutatea produselor de culoare alba.
SELECT P_NUME
FROM PRODUSE
WHERE GREUTATE > ALL
( SELECT GREUTATE
FROM PRODUSE
WHERE CULOARE = 'ALB');
Precizati numele produselor a caror greutate este mai mare decat oricare dintre greutatile produselor de culoare alba.
SELECT P_NUME
FROM PRODUSE
WHERE GREUTATE > ANY
( SELECT GREUTATE
FROM PRODUSE
WHERE CULOARE = 'ALB');
DML - Modificarea datelor (UPDATE)
Modificarea datelor permite inlocuirea valorilor uneia sau a mai multor coloane ale unei tabele cu noi valori.
Forma generala a declaratiei SQL de modificare a datelor este:
UPDATE nume_tabela
SET nume_coloana1 = expresie1 nume_coloana2 = expresie2, .]
[WHERE conditie_selectie];
Toate randurile din tabela specificata prin nume_tabela, care satisfac conditia de selectie din clauza WHERE, sunt modificate in acord cu specificatia din clauza SET.
De exemplu, se pot efectua urmatoarele modificari:
Modificati culoarea produsului P2 de la 'MARO' la 'ALB' si majoratii greutatea cu 2 kg.
UPDATE PRODUSE
SET CULOARE = 'ALB', GREUTATE = GREUTATE+2
WHERE P_ID = 'P2';
Dublati cantitatile livrate de furnizorii localizati in SIBIU.
UPDATE LIVRARI
SET CANTITATE = CANTITATE * 2
WHERE F_ID IN
( SELECT F_ID
FROM FURNIZORI
WHERE ORAS = '
Nu este posibil sa se modifice mai mult de o tabela intr-o singura declaratie SQL UPDATE.
NOTA!!!! In cazul in care o informatie apare de mai multe ori in baza de date, daca i se modifica valoarea, aceasta modificare trebuie sa se reflecte in toate aparitiile acesteia in baza de date.
De exemplu, identificatorul furnizorului F_ID apare atat in tabela FURNIZORI cat si in tabela LIVRARI. Daca trebuie modificat identificatorul furnizorului F3, de la aceasta valoare la F7, atunci aceasta modificare trebuie facuta in ambele tabele pentru ca altfel ar apare fenomenul de inconsistenta a datelor in baza de date.
UPDATE FURNIZORI UPDATE LIVRARI
SET F_ID = 'F7' SET F_ID = 'F7'
WHERE F_ID = 'F3'; WHERE F_ID = 'F3';
DML - Stergerea datelor (DELETE)
Declaratia SQL ce permite stergerea randurilor dintr-o tabela este urmatoarea:
DELETE
FROM nume_tabela
[ WHERE conditie_selectie];
ü Toate randurile tabelei, specificate prin nume_tabela, care satisfac conditia de selectie sunt indepartate in mod permanent din tabela.
ü La nivelul unei declaratii DELETE se pot sterge randuri doar dintr-o singura tabela.
ü Daca clauza WHERE lipseste din declaratie, toate randurile tabelei sunt sterse.
ü Tabela continua sa existe, definitia ei nu este indepartata din catalogul sistem, chiar daca pentru moment nu mai contine nici o data.
Stergeti toti furnizorii localizati in SIBIU.
DELETE
FROM FURNIZORI
WHERE ORAS
= '
Stergeti toate livrarile efectuate pana in prezent.
DELETE
FROM LIVRARI;
Stergeti toate livrarile efectuate de furnizori localizati in BUCURESTI
DELETE
FROM LIVRARI
WHERE F_ID IN
( SELECT F_ID
FROM FURNIZORI
WHERE ORAS = 'BUCURESTI ;
DML - Inserarea datelor (INSERT)
Inserarea de noi randuri intr-o tabela se poate face in SQL in urmatoarele doua moduri:
INSERT INTO nume_tabela [(nume_coloana1, nume_coloana2, .)]
VALUES (valoare1, valoare2, .);
ü In prima versiune se insereaza un singur rand in tabela.
ü Coloanele specificate intre paranteze primesc valorile indicate.
ü Atribuirile se fac in felul urmator:
valoare1 -> nume_coloana1
valoare2 -> nume_coloana2
ü Coloanele tabelei care nu sunt indicate intre paranteze primesc valoarea NULL.
ü Daca lista de coloane dintre paranteze lipseste sunt luate in calcul toate coloanele tabelei in ordinea in care au fost ele definite la crearea acesteia, prin urmare lista valorilor trebuie sa se conformeze acestei ordini.
Inserarea de noi randuri intr-o tabela se poate face in SQL in urmatoarele doua moduri:
INSERT INTO nume_tabela [(nume_coloana1, nume_coloana2, .)]
( SELECT.
FROM.
WHERE.);
ü Se insereaza, de regula, mai multe randuri simultan in tabela.
ü Clauza SELECT.FROM.WHERE este evaluata si o copie a rezultatului este inserata in tabela.
ü Trebuie avut de grija ca lista coloanelor din clauza SELECT sa se potriveasca cu lista coloanelor specificate intre paranteze, ca tip de data si ca sens al informatiei pe care o stocheaza.
ü Daca lista de coloane dintre paranteze lipseste sunt luate in calcul toate coloanele tabelei in ordinea in care au fost ele definite la crearea acesteia, prin urmare lista coloanelor din clauza SELECT trebuie sa se conformeze acestei ordini.
Adaugati produsul P7 cu denumire 'CANAPEA' si localizare 'SEBES'.
INSERT INTO PRODUSE (P_ID, P_NUME, ORAS)
VALUES ('P_ID', 'CANAPEA', 'SEBES');
Adaugati un nou furnizor avand urmatoarele caracteristici: identificator F8, nume NEOSET, oras BUCURESTI.
INSERT INTO FURNIZORI VALUES ('F8', 'NEOSET', 'BUCURESTI');
Pentru fiecare produs livrat, determinati codul produsului si cantitatea totala livrata si salvati rezultatele obtinute in tabela TEMP.
CREATE TABLE TEMP
( P_ID CHAR(6),
TOTAL INTEGER);
INSERT INTO TEMP (P_ID, TOTAL)
( SELECT P_ID, SUM (CANTITATE)
FROM LIVRARI
GROUP BY P_ID );
7
SQL - Declaratii de control a datelor (DCL)
Declaratiile de control a datelor permit controlul accesului la datele bazei de date
SQL dispune de doua declaratii DCL si anume:
GRANT REVOKE
Aceste declaratii alcatuiesc subsistemul de autorizare
DCL - Cedarea drepturilor de acces (GRANT)
Forma generala a declaratiei GRANT prin care se cedeaza drepturi este urmatoarea:
GRANT ALL/lista_privilegii ON nume_tabela TO
PUBLIC/lista_utilizatori [WITH GRANT OPTION];
unde
lista_privilegii poate cuprinde:
SELECT - pentru tabele
UPDATE [ (lista_coloane) ] si
INSERT vizualizari
DELETE
CREATE
ALTER - pentru tabele
INDEX
ü De regula, procedura de instalare a sistemului de gestiune a bazei de date implica desemnarea unui utilizator special, privilegiat, denumit administrator al bazei de date (DBA).
ü Acesta este initial singurul utilizator al sistemului si are drepturi depline asupra acestuia.
ü DBA-ul poate crea noi utilizatori, identificati intotdeauna prin nume si parola, si le poate ceda acestora drepturi asupra obiectelor bazei de date.
ü Initial doar creatorul unei tabele sau al unei vizualizari are drepturi asupra acesteia.
ü El poate ceda toate sau numai o parte a drepturilor pe care le detine si altor utilizatori din sistem.
ü Daca cedarea drepturilor se face folosind clauza WITH GRANT OPTION acestia la randul lor pot ceda drepturile primite si altor utilizatori.
ü De exemplu, se pot ceda drepturi unor utilizatori astfel:
GRANT
SELECT ON FURNIZORI TO
GRANT SELECT, UPDATE(F_NUME, ORAS) ON FURNIZORI TO ION, FLORINA, DAN;
GRANT INSERT, DELETE ON LIVRARI TO PUBLIC;
GRANT ALL ON FURNIZORI TO VASILE;
ü Sunt SGBD-uri la care se pot crea roluri de utilizator care contin mai multe drepturi de acces la obiectele bazei de date.
ü Rolurile pot fi apoi cedate utilizatorilor din sistem.
GRANT ROLE <nume_rol>TO <nume_utilizator>;
DCL - Revocarea drepturilor de acces (REVOKE)
Drepturile primite pot fi retrase cu ajutorul declaratiei REVOKE.
Forma generala a acesteia este urmatoarea:
REVOKE ALL/lista_privilegii ON nume_tabela
FROM PUBLIC/lista_utilizatori;
ü Retragerea drepturilor se poate face la orice moment de timp ulterior aceluia cand au fost acordate.
ü Pot fi retrase toate drepturile acordate sau numai o parte a acestora.
ü La nivelul unei declaratii de tip REVOKE aceleasi drepturi pot fi retrase unui singur utilizator sau mai multor utilizatori.
ü Daca cedarea drepturilor a fost facuta folosind clauza WITH GRANT OPTION retragerea acestor drepturi se propaga in cascada catre toti utilizatorii care le primisera.
Mai jos sunt prezentate cateva exemple de revocare de drepturi:
REVOKE SELECT ON FURNIZORI FROM
REVOKE UPDATE ON FURNIZORI FROM ION;
REVOKE INSERT, DELETE ON FURNIZORI FROM VASILE;
REVOKE ALL ON FURNIZORI FROM FLORINA;
REVOKE ALL ON LIVRARI FROM PUBLIC;
Optimizarea interogarilor
Procesul prin care se alege calea cea mai facila si mai rapida de a obtine rezultatele unei interogari.
Exista sisteme relationale care realizeaza o optimizare automata a interogarilor (sistemul face analiza cererii si hotaraste care va fi succesiunea operatiilor relationale ce se vor executa pentru a satisface acea cerere cat mai rapid).
Pentru a intelege mai bine ce inseamna optimizarea interogarilor vom considera un exemplu de interogare:
Afisati numele furnizorilor care livreaza produsul cu cod P2.
SELECT DISTINCT F_NUME
FROM FURNIZORI, LIVRARI
WHERE FURNIZORI.F_ID = LIVRARI.F_ID
AND LIVRARI.P_ID = 'P2';
Sa presupunem ca tabela FURNIZORI are 100 de inregistrari, in timp ce tabela LIVRARI are 10.000 de inregisrari, din care 50 de inregistrari corespund produsului cu cod P2, adica au P_ID="P2".
Interogarea de mai sus se executa in mod neoptimizat astfel:
se executa produsul cartezian al relatiei FURNIZORI cu relatia LIVRARI. Aceasta inseamna citirea a 10.100 de inregistrari, adica a 100 de inregistrari din tabela FURNIZORI si a 10.000 de inregistrari din tabela LIVRARI. In urma produsului cartezian al celor doua relatii rezulta o relatie ce va avea 1.000.000 de tupluri , adica 100 * 10.000, care va trebui sa fie memorata temporar pe disc.
se selecteaza din relatia rezultata tuplurile care satisfac conditia din clauza WHERE. Plecand de la presupunerea facuta, vor rezulta 50 de tupluri ce vor fi pastrate in memoria centrala.
se efectueaza proiectia dupa numele furnizorului pe relatia rezultata anterior. Deoarece s-a folosit clauza DISTINCT vor rezulta in final cel mult 50 de tupluri.
Interogarea optimizata se executa astfel:
se selecteaza din relatia LIVRARI tuplurile care satisfac conditia P_ID = 'P2'. Plecand de la presupunerea facuta, vor rezulta 50 de tupluri ce vor fi pastrate in memoria centrala.
se reunesc, prin join pe conditia FURNIZORI.F_ID = LIVRARI.F_ID, tuplurile rezultate anterior cu cele din relatia FURNIZORI. Aceasta implica citirea celor 100 de tupluri ale relatiei FURNIZORI si compunerea lor cu cele 50 de tupluri deja existente in memorie. Vor rezulta 50 de tupluri care vor fi pastrate tot in memorie.
se efectueaza proiectia dupa numele furnizorului pe relatia rezultata anterior. Deoarece s-a folosit clauza DISTINCT vor rezulta in final cel mult 50 de tupluri
Din cele prezentate mai sus, se observa ca imbunatatirea performantelor este evidenta.
Procesul de optimizare presupune in general parcurgerea urmatoarelor etape:
1.Transformarea interogarii intr-o anumita forma de reprezentare interna.
ü Modalitatea de reprezentare interna este specifica fiecarui sistem in parte.
ü Ea trebuie sa fie un formalism suficient de puternic pentru a putea reprezenta toate interogarile posibile din limbajului de interogare al sistemului respectiv.
ü Ea trebuie sa fie cat mai neutra cu putinta, adica sa nu prejudicieze niciuna din alegerile ulterioare facute in ceea ce priveste optimizarea.
ü Forma de reprezentare interna utilizata in mod tipic este cea a arborilor de sintaxa abstracta sau a arborilor de interogare.
Procesul de optimizare presupune in general parcurgerea urmatoarelor etape:
1.Transformarea interogarii intr-o anumita forma de reprezentare interna.
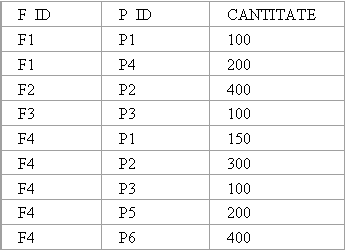
ü Mai jos este prezentat un arbore de interogare posibil pentru interogarea urmatoare:
'Gasiti numele furnizorilor care livreaza produsul P2.'
2. Conversia reprezentarii interne la forma ei canonica.
Deoarece mai toate limbajele de interogare permit exprimarea unei interogari intr-o varietate de moduri, putin diferite unele de altele, este necesara conversia reprezentarii interne a interogarii intr-o forma canonica echivalenta, care sa elimine aceste diferente si care sa constituie o modalitate de reprezentare mai eficienta decat cea originara.
Notiunea de forma canonica este preluata din matematica si poate fi definita astfel:
Fiind dat un set Q de obiecte (sa zicem interogari) si un operator de echivalenta intre aceste obiecte (adica interogarile q1 si q2 sunt echivalente daca si numai daca produc acelasi rezultat), subsetul C al lui Q se zice a fi setul formelor canonice ale lui Q daca si numai daca oricare obiect q din Q este echivalent cu doar un singur obiect c din C. Obiectul c se spune ca este forma canonica a obiectului q. Toate proprietatile care se aplica unui obiect q se aplica de asemenea si formei sale canonice c.
Transformarea interogarilor in forma lor canonica echivalenta se face in concordanta cu anumite reguli de transformare care sunt foarte bine definite.
Unele dintre aceste reguli sunt urmatoarele:
● WHERE cond_1 OR (cond_2 AND cond_3)
se transforma in
WHERE (cond_1 OR cond_2) AND (cond_1 OR cond_3)
( A JOIN B ) WHERE restrictie_pe_B
se transforma in
( A JOIN (B WHERE restrictie_pe B ) )
Unele dintre aceste reguli sunt urmatoarele:
( A JOIN B ) WHERE restrictie_pe_A AND restrictie_pe_B
se transforma in
( A WHERE restrictie_pe A ) JOIN ( B WHERE restrictie_pe_B)
A WHERE restrictie_1 ) WHERE restrictie_2
se transforma in
A WHERE restrictie_1 AND restrictie_2
Unele dintre aceste reguli sunt urmatoarele:
( A [ lista_atribute_1 ] ) [ lista_atribute_2 ]
se transforma in
A [ lista_atribute_2]
( A [ lista_atribute_1 ] ) WHERE restrictie_1
se transforma in
( A WHERE restrictie_1 ) [ lista_atribute_1 ]
3. Alegerea procedurilor elementare potrivite pentru a executa interogarea.
ü Dupa ce interogarea a fost transformata in forma sa canonica sistemul trece la alegerea procedurilor elementare care sa execute aceasta interogare.
ü La acest nivel se tine cont de existenta indecsilor sau a altor cai de acces, de distributia valorilor memorate ale datelor, de clusterarea fizica a inregistrarilor, s.a.m.d.
ü Expresia de interogare este considerata ca fiind alcatuita dintr-o succesiune de operatii elementare (join-uri, selectii, proiectii, etc.) intre care exista anumite interdependente.
ü Pentru fiecare astfel de operatie elementara, optimizatorul are la dispozitie un set de proceduri prin care se poate implementa operatia.
De exemplu, pentru operatia de selectie pot exista urmatoarele proceduri:
o procedura pentru cazul in care selectia se face pe baza unei conditii de egalitate asupra continutului unui singur camp;
ü o procedura pentru cazul in care campul implicat in conditia de selectie este indexat;
ü o procedura pentru cazul in care campul implicat in conditia de selectie nu este indexat, dar datele din acest camp sunt memorate fizic in acelasi cluster;
Fiecarea dintre aceste proceduri are asociat un cost implicat de executia sa in anumite conditii.
ü Utilizand informatiile din catalogul sistem cu privire la starea curenta a bazei de date, adica cu privire la indecsii existenti, la cardinalitatea relatiilor, etc., si tinand cont si de informatiile de interdependenta mentionate anterior, optimizatorul va alege una sau mai multe proceduri pentru implementarea fiecarei operatii elementare din expresia de interogare. Acest proces este adesea denumit si selectia cailor de acces.
4. Generare planurilor de interogare si alegerea celui mai ieftin.
ü Avand procedurile prin care poate fi implementata fiecare operatie elementara implicata de expresia de interogare, se construiesc planurile de interogare posibile si se alege cel mai ieftin.
ü Construirea tuturor combinatiilor posibile de proceduri asociate operatiilor elementare si evaluarea costului acestora este uneori destul de anevoioasa, deoarece necesita mult timp, de aceea de cele mai multe ori se aleg metode euristice de generare a planurilor de interogare.
ü Evaluarea costului unei interogari se poate face, de asemenea, prin mai multe metode.
ü Cea mai des folosita metoda este cea a contorizarii numarului de accese la disc pentru citire si scriere necesare pentru a executa acea interogare, deoarece de obicei acestea implica cele mai mari costuri.
ü Unele sisteme iau in considerare si gradul de utilizare al UCP-ului la executarea unor operatii asupra datelor din bufferele de memorie, precum si costurile de comunicatie implicate de transmiterea interogarii de la terminal catre baza de date si a rezultatului de la baza de date spre terminalul de unde a fost lansata interogarea.
ü In estimarea corecta a costului unei interogari, o problema importanta care poate sa apara este aceea a estimarii dimensiunii rezultatelor intermediare.
ü In majoritatea interogarilor sunt necesare generari de rezultate intermediare si pentru a estima corect numarul de operatii de citire/scriere pe disc trebuie sa se tina cont de marimea acestor rezultate intermediare care este data de dimensiunea actuala a datelor.
ü O estimare foarte exacta a costului unei interogari este greu de realizat.
8
Tranzactii si concurenta la nivelul bazei de date
Una dintre cele mai puternice caracteristici a SGBD-urilor este aceea ca:
permite mai multor utilizatori sa foloseasca in comun, in mod simultan, aceleasi date.
Pentru a preveni conflictele si a pastra integritatea bazei de date, sistemele de gestiune a bazelor de date trebuie sa dispuna de mecanisme de control al concurentei si de gestiune a tranzactiilor.
Tranzactii
ü Pastrarea starii de consistenta a bazei de date este unul din obiectivele majore ale oricarui SGBD.
ü De regula, pentru a pastra starea de consistenta a sistemului, este necesar ca operatiile de manipulare a datelor sa se execute intr-o anumita succesiune.
ü Orice intrerupere a acestei succesiuni poate duce la pierderea consistentei datelor.
De exemplu, modificarea identificatorului furnizorului F1 de la valoarea F1 la F8 implica, de fapt, doua operatii de actualizare UPDATE asupra bazei de date, si anume:
UPDATE FURNIZORI UPDATE LIVRARI
SET F_ID = 'F8' SET F_ID = 'F8'
WHERE F_ID = 'F1'; WHERE F_ID = 'F1';
Intre cele doua operatii de actualizare baza de date nu va fi intr-o stare consistenta, deoarece tabela LIVRARI va contine temporar unele inregistrari referitoare la livrari de produse efectuate de un furnizor care nu are inregistrare corespondenta in tabela FURNIZORI.
O tranzactie este o secventa de actiuni dintr-un program, considerata ca fiind o unitate logica de lucru, care citeste si/sau scrie date in baza de date si care satisface testul ACID, adica proprietatile de atomicitate, consistenta, izolare si durabilitate.
Testul ACID
Testul ACID contine de fapt cele patru proprietati pe care trebuie sa le satisfaca o tranzactie, si anume:
A - atomicitate,
C - consistenta,
I - izolare,
D - durabilitate.
Atomicitatea - o tranzactie este executata fie in intregime fie nu se executa deloc.
- Fie intreaga secventa de operatii de la nivelul tranzactiei se aplica bazei de date, fie nici o operatie nu este aplicata bazei de date.
(Referitor la exemplul de mai sus, fie toate actualizarile sunt vizibile lumii exterioare, fie nicio actualizare nu este vizibila.)
- In primul caz se spune ca tranzactia a fost comisa (commit).
- In al doilea caz se spune ca tranzactia a fost abandonata (abort).
SGBD-ul trebuie sa se asigure ca toate operatiile realizate de o tranzactie comisa cu succes sunt reflectate in baza de date si ca efectele tranzactiilor abandonate sunt complet eliminate din baza de date.
Consistenta - implica conservarea integritatii semantice a bazei de date.
- O baza de date se spune ca este consistenta daca toate restrictiile de integritate asupra bazei de date sunt satisfacute.
- Executia unei tranzactii trebuie sa asigure transferul bazei de date dintr-o stare consistenta intr-o alta stare consistenta.
Izolarea - implica protejarea rezultatelor intermediare ale operatiilor din cadrul unor tranzactii concurente.
- Izolarea este legata de executia tranzactiilor concurente.
- Tranzactiile concurente manipuleaza in mod partajat aceleasi date ale bazei de date.
- Daca operatiile din interiorul acestor tranzactii se suprapun si nu sunt protejate unele de altele pot sa apara anomalii.
- Izolarea presupune protejarea rezultatelor intermediare ale operatiilor din cadrul unor tranzactii concurente.
- Aceste rezultate devin vizibile in exteriorul tranzactiei numai in momentul in care tranzactia s-a incheiat cu succes.
Izolarea
SGBD-urile pot furniza mai multe nivele de izolare intre tranzactiile executate concurent.
Unul dintre acestea este serializabilitatea tranzactiilor care asigura cel mai puternic nivel de izolare.
Tranzactiile sunt serializabile daca executarea intretesuta a operatiilor lor produce acelasi efect asupra bazei de date ca si atunci cand sunt executate intr-o oarecare ordine seriala.
O alta modalitate, mai putin stricta, este aceea de a garanta ca actualizarile tranzactiilor incheiate cu succes nu vor fi niciodata pierdute.
- Tranzactiile trebuie sa fie corect sincronizate, astfel incat sa nu apara situatii in care actualizarile efectuate in baza de date de o tranzactie vor fi rescrise de o alta tranzactie, dupa care ambele tranzactii sunt comise.
- In aceasta situatie actualizarile primei tranzactii sunt pierdute, cu toate ca initiatorul tranzactiei nu este constient de acest lucru.
- Aceasta situatie se rezolva de regula printr-un mecanism de check-out. Utilizatorii verifica daca datele din baza de date pe care doresc sa le actualizeze pot fi modificate. Actualizarea este permisa doar daca nici un alt utilizator nu mai actualizeaza aceste date.
OBS: In multe aplicatii, imbunatatirea gradului de concurenta este mult mai importanta decat garantarea unui nivel ridicat de izolare a tranzactiilor, de aceea aceste aplicatii permit citirea rezultatelor intermediare ale tranzactiilor. Aceasta situatie este frecvent intalnita in aplicatiile de baze de date orientate-obiect care suporta tranzactii de durate foarte mari si care prelucreaza date statistice.
Durabilitatea - actualizarile tranzactiilor incheiate cu succes nu sunt niciodata pierdute.
Actualizarile pot fi recuperate in cazul in care apar defectari ale sistemului sau ale mediilor de memorare externa.
Odata ce un utilizator a fost informat ca tranzactia pe care a initiat-o s-a incheiat cu succes (a fost comisa), baza de date contine suficient de multa informatie redundanta, astfel incat, actualizarile efectuate pe durata tranzactiei sa poata fi refacute in cazul unor defectari aparute la nivelul sistemului.
Durabilitatea tranzactiilor este stans legata de refacerea datelor in caz de accident si va fi mai detaliat discutata in subcapitolul dedicat refacerii datelor.
Specificarea tranzactiilor
ü Tranzactiile implica un numar de actualizari (modificari, inserari, stergeri) care trebuie sa se realizeze fie in totalitate fie deloc asupra unei baze de date.
ü Utilizatorilor trebuie sa li se permita sa grupeze impreuna un numar de mai multe declaratii de manipulare a bazei de date.
ü Aceasta delimitare a unui numar de accese la baza de date si a unor declaratii de manipulare a bazei de date este in general facuta prin constructori de tipul Begin Transaction.End Transaction.
Constructorul Begin Transaction indica inceputul unei tranzactii.
Constructorul End Transaction indica sfarsitul unei tranzactii.
Sectiunea de cod dintre Begin TransactionEnd Transaction va fi executata atomic.
Atunci cand declaratia Begin Transaction End Transaction este executata cu succes (comisa toate operatiile de pe durata ei devin permanente in baza de date si sunt vizibile la nivelul altor tranzactii din sistem.
Utilizatorul poate decide sa anuleze efectul unei tranzactii si sa incheie tranzactia fara a o comite. SGBD-urile dispun in acest scop de un mecanism de abandon al tranzactiei cunoscut sub numele de abort, rollback sau undo.
De exemplu
Visual FoxPro
inceputul unei tranzactii este specificat prin BEGIN TRANSACTION,
sfarsitul tranzactiei se indica prin END TRANSACTION,
in situatia in care se doreste intreruperea fortata a unei tranzactii si revenirea la starea de dinaintea inceperii tranzactiei se poate folosi ROLLBACK.
Visual dBASE
inceputul unei tranzactii va fi specificat cu ajutorul sintaxei BEGINTRANS( ),
sfarsitul tranzactiei este precizat folosind COMMIT( ),
anularea unei tranzactii si refacerea starii de dinaintea inceperii tranzactiei se face cu ajutorul lui ROLLBACK( ).
Oracle Server
tranzactia incepe cand prima declaratie SQL executabila este executata.( Nu exista o declaratie explicita de tip Begin Transaction
tranzactia se incheie cand apare unul dintre urmatoarele evenimente:
. o declaratie COMMIT sau ROLLBACK;
se executa o declaratie SQL apartinand limbajului DDL sau DCL, caz in care se genereaza automat un COMMIT;
utilizatorii parasesc mediul SQL*Plus;
se produce o eroare la nivelul masinii sau al sistemului.
Dupa ce o tranzactie s-a incheiat, urmatoarea declaratie SQL executabila initiaza o noua tranzactie.
 Logica de executie a
declaratiilor de la nivelul tranzactiilor poate fi controlata cu
ajutorul comenzilor COMMIT, SAVEPOINT si ROLLBACK.
Logica de executie a
declaratiilor de la nivelul tranzactiilor poate fi controlata cu
ajutorul comenzilor COMMIT, SAVEPOINT si ROLLBACK.
Concurenta
ü SGBD-urile sunt sisteme multiuser
ü este permis ca orice numar de tranzactii sa acceseze aceleasi date ale bazei de date in acelasi timp
ü este necesar un mecanism de control al accesului concurent pentru a se asigura ca tranzactiile concurente nu se influenteaza negativ unele pe altele
ü altfel pot apare o serie de probleme deloc de neglijat
Problemele accesului concurent
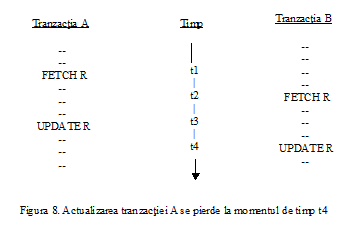 1. Problema actualizarilor
pierdute
1. Problema actualizarilor
pierdute
2. Problema dependentei de nevalidarea tranzactiei
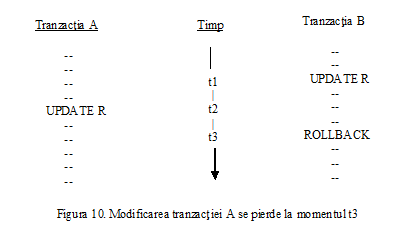 pierderea unei modificari
raportate ca incheiate cu succes
pierderea unei modificari
raportate ca incheiate cu succes 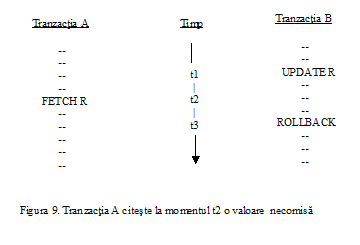
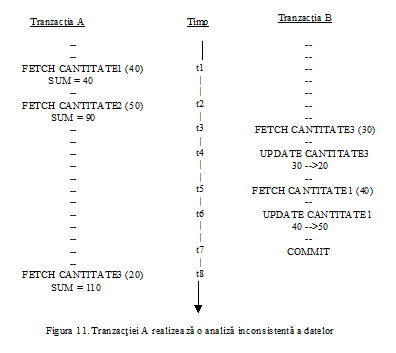 3. Problema analizei inconsistente a
datelor
3. Problema analizei inconsistente a
datelor
Blocarea inregistrarilor
Blocarea inregistrarilor este un mecanism care permite pastrarea starii de consistenta a sistemului in cazul unor accese concurente la baza de date.
Ideea de baza a blocarii este simpla:
cand o tranzactie trebuie sa se asigure ca un obiect de care este interesata (de obicei o inregistrare a bazei de date) nu va fi modificat intr-un mod imprevizibil de o alta tranzactie instituie o blocare la nivelul acelui obiect,
blocarea inseamna ca nu se va permite altei tranzactii sa modifice sau sa blocheze la randul ei acel obiect,
prima tranzactie este astfel capabila sa constientizeze sistemul ca obiectul de care este interesata va ramane intr-o stare stabila atata timp cat tranzactia doreste acest lucru.
Granularitatea blocarii, adica marimea obiectului care trebuie blocat, poate varia.
Sunt posibile urmatoarele tipuri de granularitati:
blocare la nivelul intregii baze de date - Acest tip de blocare incetineste foarte mult lucrul cu baza de date si nu este indicata sa se adopte decat atunci cand se fac prelucrari de tip batch (in loturi de inregistrari) la nivelul tranzactiei.
blocare la nivelul tabelei - Aceasta granularitate a blocarii este mai buna decat precedenta, dar si ea poate cauza intarzieri ale accesului la date mult prea mari pentru a putea fi intotdeauna acceptate, de aceea si ea se foloseste cu precadere tot atunci cand se prelucreaza la nivelul unei tranzactii blocuri de inregistrari ale tabelei.
blocare la nivelul unei pagini de date - Aceasta granularitate a blocarii este mult mai acceptabila decat precedentele si este si cea mai des utilizata de catre SGBD-uri.
Sunt posibile urmatoarele tipuri de granularitati:
blocare la nivelul unui rand de date din tabela Acest nivel de blocare este mult mai putin restrictiv decat precedentele permitand un grad mai mare de concurenta, dar este mai complicat de implementat si de gestionat de catre SGBD. El este, insa, unul dintre cele mai utilizate nivele de blocare la nivelul SGBD-urilor.
blocare la nivelul unei coloane dintr-o tabela - Acest tip de blocare este cel mai flexibil din punctul de vedere al accesului concurent la date, dar necesita mult prea multe prelucrari din partea sistemului pentru a fi implementat, de accea nu se foloseste si in practica.
Protocolul prin care blocarile sunt instituite si apoi eliberate la nivelul obiectelor bazei de date poarta numele de blocare in doua-faze.
Blocarea in doua-faze garanteaza serializabilitatea tranzactiilor concurente si dupa cum o sugereaza si numele este alcatuita din doua etape, si anume:
1. faza de crestere - in care tranzactia instituie toate blocarile de care are nevoie, fara a debloca vreuna din datele blocate anterior. Dupa ce tranzactia a instituit toate blocarile de care avea nevoie, se considera ca ea se afla in punctul de blocare si abia acum poate sa prelucreze datele dupa dorinta. Dupa ce prelucrarile se incheie incepe cea de a doua faza a blocarii.
2. faza de descrestere - in care tranzactia elibereaza toate blocarile pe care le instituise anterior si in care nu mai poate obtine alte blocari.
Exista doua tipuri de blocari ale accesului la date:
blocarea exclusiva (X) - daca tranzactia A detine o blocare exclusiva asupra inregistrarii R, atunci o cerere din partea tranzactiei B de blocare de orice tip asupra inregistrarii R va cauza intrarea tranzactiei B intr-o stare de asteptare pana cand blocarea instituita de tranzactia A asupra lui R este eliberata.
blocarea partajata (S) - daca tranzactia A detine o blocare partajata asupra inregistrarii R, atunci:
o cerere din partea tranzactiei B de blocare exclusiva a inregistrarii R va cauza intrarea tranzactiei B intr-o stare de asteptare pana cand tranzactia A va elibera acea blocare;
o cerere din partea tranzactiei B de blocare partajata a inregistrarii R va fi acceptata, atat tranzactia A cat si tranzactia B vor detine o blocare asupra inregistrarii R.
Compatibilitatile dintre cele doua tipuri de blocari, care pot exista la nivelul unei inregistrari R a bazei de date, in cazul a doua tranzactii concurente A si B (N - nu sunt compatibile, Y sunt compatibile).

ü Cererea de blocare a inregistrarilor este in mod normal implicita la nivelul tranzactiilor.
ü In mod automat, atunci cand o tranzactie citeste cu succes o inregistrare, o blocheaza partajat.
ü In mod automat, atunci cand o tranzactie modifica cu succes o inregistrare, o blocheaza in mod exclusiv.
ü Daca o tranzactie a blocat deja in mod partajat o inregistrare, datorita unei operatii de tip FETCH, si aceasta operatie este urmata de o operatie de tip UPDATE, atunci blocarea se va transforma din partajata in exclusiva.
Cum rezolva blocarile cele trei probleme prezentate anterior cu privire la accesul concurent la datele unei baze de date.
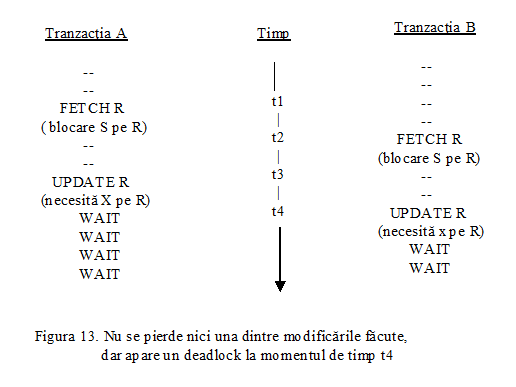 1. Problema actualizarilor
pierdute
1. Problema actualizarilor
pierdute
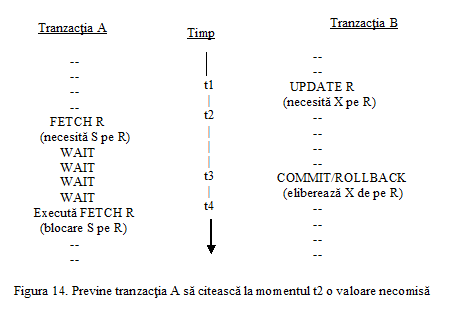 2. Problema dependentei de
nevalidarea tranzactiei
2. Problema dependentei de
nevalidarea tranzactiei
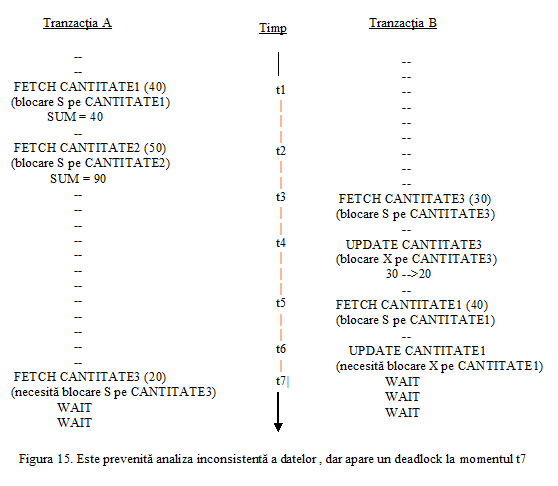 3. Problema analizei inconsistente a
datelor
3. Problema analizei inconsistente a
datelor
ü Problema accesului concurent la date poate fi rezolvata cu ajutorul blocarilor de tip exclusiv (X) si partajat (S), dar ele pot introduce noi probleme, si anume acelea ale intrarii simultane in stare de asteptare a mai multor tranzactii.
ü Tranzactiile aflate simultan in stare de asteptare, asteapta unele dupa altele sa-si elibereze blocarile instituite anterior.
ü Apare o blocare generala la nivelul sistemului in care tranzactiile asteapta unele dupa altele eliberarea blocarilor instituite la nivelul acelorasi inregistrari.
ü
 O
astfel de blocare generala se numeste deadlock.
O
astfel de blocare generala se numeste deadlock.
Teoretic un deadlock poate sa implice oricat de multe tranzactii
In practica s-a observat ca aproape niciodata el nu implica mai mult de doua tranzactii.
Sistemul trebuie sa fie capabil sa detecteze situatia de deadlock si sa o inlature.
Detectarea acestor stari implica detectarea unui ciclu in graful 'cine pe cine asteapta'.
Inlaturarea acestei stari implica alegerea uneia dintre tranzactiile acelui ciclu al grafului ca 'victima' si anularea ei prin ROLLBACK, eliberand astfel blocarile instituite de ea si permitand altor tranzactii sa se execute.
Se observa ca 'victima' a fost anulata cu toate ca nici o eroare nu a aparut la nivelul ei.Unele sisteme vor reporni automat aceasta tranzactie de la inceput, presupunand ca acele conditii care au cauzat intreruperea in primul caz nu vor mai aparea. Alte sisteme doar semnalizeaza aparitia si rezolvarea partiala a deadlock-ului, de regula, prin anuntarea aplicatiei care rula tranzactia care a fost aleasa 'victima'. Este problema programatorului sa hotarasca in continuare daca va reexecuta sau nu aceasta tranzactie.
Blocarea inregistrarilor - metoda pesimista de control a accesului concurent
Exista si mecanisme bazate pe algoritmi optimisti:
ü Metodele optimiste de control al concurentei se bazeaza pe presupunerea ca, doua sau mai multe tranzactii cer acces simultan la aceeasi inregistrare a bazei de date destul de rar in practica.
ü Probabilitatea aparitiei conflictelor de acest tip este destul de mica.
ü Metodele optimiste opereaza astfel incat permit tranzactiilor sa se execute nestingherite pana la momentul comiterii, moment in care se produce o verificare pentru a se vedea daca nu au aparut conflicte.
ü Daca s-au detectat conflicte, tranzactiile implicate sunt repornite de la inceput si se incearca o noua executie a lor in speranta ca de data aceasta ele vor fi incheiate cu succes.
ü Cum nici o modificare nu este scrisa in baza de date inainte ca tranzactia sa se incheie cu succes prin COMMIT, la repornirea tranzactiei nu trebuie sa se efectueze nici o operatie suplimentara de anulare a prelucrarilor tranzactiei abandonate.
ü Controlul optimist al concurentei permite accesarea inregistrarilor bazei de date fara nici un control prealabil.
ü La starsitul unei tranzactii, o procedura de validare este utilizata pentru a abandona toate tranzactiile care au accesat intr-un mod incompatibil inregistrari ale bazei de date.
ü O alta metoda optimista este cea a marcilor de timp (timestamps) la nivelul careia fiecarei tranzactii i se asociaza o astfel de marca de timp.
ü Pentru orice cerere de acces la baza de date, sistemul compara timestamp-ul tranzactiei care a lansat cererea cu timestamp-ul tranzactiei care a citit sau modificat ultima data inregistrarea dorita.
ü Daca este vreun conflict, atunci tranzactia care a lansat cererea este repornita avand de data aceasta un nou timestamp care probabil ca nu va mai genera conflicte.
ü Avantajul acestor tehnici este lipsa timpilor de asteptare (asteptare pentru eliberarea blocarilor) la nivelul tranzactiilor si simplitatea validarii.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 2103
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2024 . All rights reserved