| CATEGORII DOCUMENTE |
Operatiuni executate asupra variabilelor si bazelor de date
Complexitatea si varietatea calculelor statistice din programu SPSS sunt amplificate de numeroasele facilitati de lucru in cadrul bazelor de date. O parte din ele sunt intalnite si in diverse programe altele sunt specifice. Pentru a trece in revista aceste facilitati ni s-a parut mai simplu de a prezenta meniuri intregi de comenzi cu precizarea ca nu vom detalia toate utilitatile specifice; vom detalia doar acele aspecte pe care le consideram findamentale sau oricum sunt mai des intalnite. Vom incepe cu meniul Data care este compus din urmatoarele submeniuri:
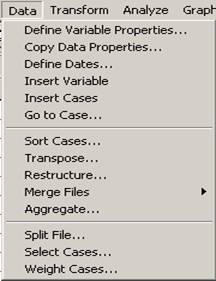 1. Define
Variable Properties- ajuta la schimbari de nume sau atribute ale
variabilelor din Data Editor. Dupa
ce am trecut o variabila din coloana din stanga in dreapta se va deschide
fereastra care poarta chiar numele submeniului, fereastra in care avem o
descriere amanuntita a variabilei. Aici putem face si schimbarile pe
care le consideram necesare. Daca Data Editor nu contine o baza de date
submeniul nu poate fi activ.
1. Define
Variable Properties- ajuta la schimbari de nume sau atribute ale
variabilelor din Data Editor. Dupa
ce am trecut o variabila din coloana din stanga in dreapta se va deschide
fereastra care poarta chiar numele submeniului, fereastra in care avem o
descriere amanuntita a variabilei. Aici putem face si schimbarile pe
care le consideram necesare. Daca Data Editor nu contine o baza de date
submeniul nu poate fi activ.
2. Copy Data Properties- ajuta la transferul datelor intre diverse baze de date
3. Define Dates-ajuta la definirea datelor calendaristice mai ales pentru lucrul cu serii de timp
4. Insert Variable-ajuta la inserarea unei
noi variabile in baza de date. Sa presupunem ca celula activa dintr-o baza de
date este pozitionalta pe o coloana (variabila):
ca in situatia de mai jos. Dupa activarea comenzii in partea dreapta va
apare o noua variabila care trebuie definita (aceeasi operatie putea
fi setata daca ne opream cu mausul pe numele variabilei marital clic dreapta
si alegeam Insert Variable sau
direct de pe bara de instrumente cu
butonul ![]() ):
):
![]()

5. Insert Cases-ajuta la inserarea
unor noi cazuri (linii orizontale). Daca celula activa este plasata pe un
anumit rand atunci va apare un nou rand imediat deasupra acestuia. Se poate
apela si la plasarea mausului pe rindul respectiv si clic dreapta sau
direct de pa bara su instrumente actionand butonul ![]() .
.
6. Go to Case- se poate indica un anumit caz din baza pentru a se ajunge imediat la acesta.
7. Sort Cases-ajuta la sortarea (ordonarea) valorilor seriei dupa valorile dintr-una sau mai multe variabile. Aici un exemplu de reordonare a bazei dupa valorile crescatoare din variabila age:


8. Transpose-ajuta la inversarea coloanelor cu liniile din baza de date. Ariabilele neselectate vor fi pierdute!
9. Restructure-ajuta la transformari complexe in interiorul bazelor de date. Sunt trei optiuni: restructurarea anumitor variabile in cazuri, restructurarea unor cazuri in variabile sau inversarea intrecazuri si variabile tuturor datelor.
10. Merge files-ajuta la unirea mai multor date din baze diferite. Sa presupunem ca am aplicat un chestionar in orasul X si apoi acelasi chestionar in orasul Z. Datele respective sunt in baze diferite desi au acelasi numar de variabile. Reunirea intr-o singura baza se face plecand de la una dintre ele (baza1) la care se adauga cea de a doua baza . Sa presupunem ca am construit o baza cu doar zece cazuri la care vom adauga alte 10 cazuri din cealalta baza :
Vom actiona comenzile Data Merge Files Add Cases iar dupa
ce vom selecta noua baza se va
deschide urmatoarea fereastra. Sa presupunem ca in noua baza variabila religie a fost scrisa gresit relig.
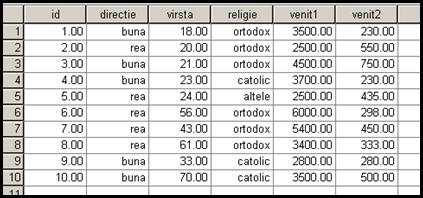
In aceasta fereastra
variabilele cu semnul (*) fac parte din baza initiala iar cele cu
semnul (+) din baza adaugata. Numele celei de-a doua variabile poate fi
schimbat din butonul Rename sau
pot fi selectate ambele si trecute in partea dreapta cu butonul Pair. Butonul Paste este consevarea lucrului in limbaj sintaxa. Dupa OK
rezulta:
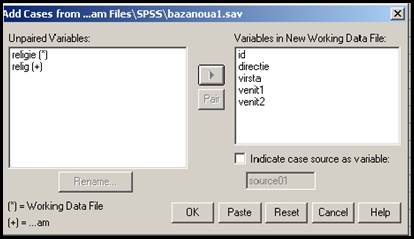
Noua baza (baza2) cuprinde acum toate cele 20 de cazuri iar numele
acesteia este cel al primei baze de la care s-a plecat. O putem salva in
aceasta forma File Save as

Comanda Merge
Files ajuta si la conectarea cu alte baze de date care au
variabile diferite. Sa presupunem ca avem prima baza cu cele 10 cazuri
si in alta baza de date avem situatia respectivilor subiecti
privind numarul de copii. Se observa ca subiectii au aceleasi
numere de identificare dar nu sunt in ordine. Apland la Sort Cases dupa variabila id rezulta:



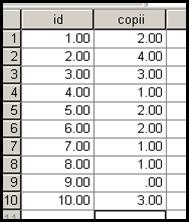
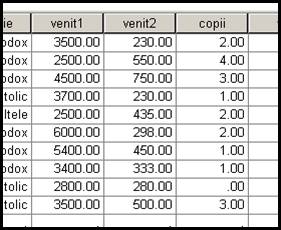
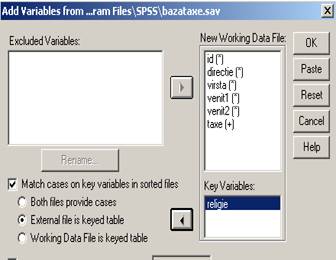
Dupa ce am salvat noua baza (sortata!) am formulat comenzile Data→Merge File→Add Variables si dupa OK observam ca noua variabila a intrat in prima baza. Sa presupunem ca in cea de a doua baza aveam numai cinci observatii dupa cum urmeaza:
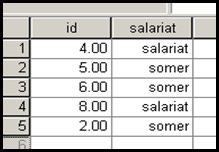 Aceasta noua baza va trebui sa fie sortata
ascendent dupa variabila id deoarece
cazurile nu sunt in ordine. Dupa sortare, salvam fisierul. Baza de date de
la care se va pleca este baza1 din
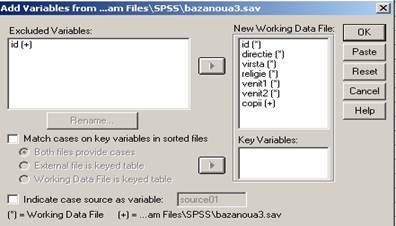
exemplul precedent. Dupa ce am deschis aceasta baza vom parcurge Data Merge Files Add Variable si va apare urmatoarea feereastra:
Aceasta noua baza va trebui sa fie sortata
ascendent dupa variabila id deoarece
cazurile nu sunt in ordine. Dupa sortare, salvam fisierul. Baza de date de
la care se va pleca este baza1 din
exemplul precedent. Dupa ce am deschis aceasta baza vom parcurge Data Merge Files Add Variable si va apare urmatoarea feereastra:
Initial variabila id se afla in coloana din dreapta (Excluded Variables)
dar a fost desemnata drept key variable dupa setarea optiunii Match Case. Both files
provide cases. Se observa ca valorile din baza externa s-au atasat in baza de plecare
pentru cazurile corespunzatoare.


Practic au aparut in final toate varibilele
dar acolo unde au fost mai putine observatii s-au salvat doar
acele date. Obs1. Dupa ce au fost luate toate setarile
inainte de OK se poate da comanda Paste care salveaza in limbaj sintaxa
comenzile de pana acum intr-un fisier separa care poate fi salvat
si folosit alta data.

Obs2. Exista si alte doua optiuni in fereastra de mai inainte: External file is keyed table Working Data File is keyed table.
Sa presupunem ca in localitatea X in functie de religie cetatenii trebuie sa plateasca o taxa anuala exprimata in sute de mii de lei astfel:
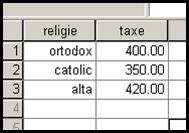 Se cere ca in baza2 unde sunt inregistrati 20 de subiecti sa se
ataseze fiecaruia dupa religia proprie taxa pe care o va plati. Practic
trebuie sa reunim baza2 cu aceasta
din urma. Pentru inceput ambele baze vor fi sortate ascendent dupa variabila
religie si vor fi salvate in aceasta forma. Apoi vom deschide baza2 si vom urma comenzile Data Merge File Add Variable dupa care vom seta
optiunea External file is keyed
table, iar variabila cheie este religia:
Se cere ca in baza2 unde sunt inregistrati 20 de subiecti sa se
ataseze fiecaruia dupa religia proprie taxa pe care o va plati. Practic
trebuie sa reunim baza2 cu aceasta
din urma. Pentru inceput ambele baze vor fi sortate ascendent dupa variabila
religie si vor fi salvate in aceasta forma. Apoi vom deschide baza2 si vom urma comenzile Data Merge File Add Variable dupa care vom seta
optiunea External file is keyed
table, iar variabila cheie este religia:
![]()

Se observa ca in baza initila a aparut o noua variabila care atribuie fiecarei categorii valoarea taxelor respective. Practic apar toate varibilele din cele doua fisiere iar criteriul de alipire ramane alocare unor valori-perechi.
Obs. 3. Optiunea Working Data File is keyed table o vom alege daca drumul parcurs este invers: de la ultima baza cu cele trei cazuri la baza mare: deci baza de plecare (Working Data File) va da criteriul de alipire a bazelor.
Obs4. Operatiile de alipire a bazelor de date trebuie sa respecte conditiile: trebuie sa existe in ambele baze o variabila comuna dupa care se face alipirea; trebuie o atentie sporita la variabilele care au acelasi nume si care nu sunt criterii de alipire; variabilele trebui8e sortate ambele in acelasi sens inainte de a fi alipite.
8. Agregarea datelor
Uneori este nevoie de a sintetiza anumite informatii despre valorile dintr-o baza de date grupindu-le dupa o serie de categorii care sunt specifice unei variabile alese. Sa luam de exemplu baza de date Cars.sav:

In aceasta baza de date sunt diverse informatii despre autoturisme: cilindree (variabila engine)
puterea motorului (horse), greutate (weight), acceleratie (accel), an de fabricatie (year). Plecind de la aceasta baza de date dorim sa obtinem pentru toate aceste caracteristici marimi medii sau alte marimi, grupate dupa anii de fabricatie. Pentru aceasta vom apela comenzile Data Aggregate dupa care va apare fereastra urmatoare:

Se impun unele precizari privind aceasta fereastra:
-variabila in functie de care se vor face calcule separate o trecem in rubrica Break Variable
-variabilele asupra carora se vor face calculele se trec in cea de a doua rubrica iar operatiile in sine sunt optionale si se port alege din butonul Function:

-optiunea Save number of casesva introduce o noua variabila care contorizeaza numarul de cazuri din fiecare categorie
-optiunea Create new data file va indica o noua baza de date care va fi salvata de program si in care vom avea rezultatele agregarii. Din butonul File putem sa denumim baza respectiva! Pentru acest caz vom lasa denumirea aggr.sav
-optiunea Replace Working data file va elimina datele din baza curenta!
Dupa ce vom da OK trebuie sa cautam si sa deschidenm noul fisier creat de catre program si care se afla de obicei in Program files SPSS. Noua baza de date este urmatoarea:
Se observa categoriile generate de catre
variabila year si pentru
fiecare categorie (an de fabricatie) sunt calculate mediile respective.
Pentru accel sunt specificate
doar valorile maxime. Ultima variabila contine numarul de cazuri din
fiecare categorie. Se pot apoi face analize plecand de la aceste date.

Variabila dupa care vom impati subiectii in grupuri
disticte region4 este trecuta in
dreapta iar ca varianta de vizualizare a rezultatelor am ales optiunea
Compare Groups. Dupa OK in Data Editor va apare in coltul din dreapta jos
mentiunea Split File On
care ne avertizeaza ca baza este filtrata si orice rezultat viitor va fi definit de filtrarea
respectiva:
9. Split File-comanda des utilizata care permite analizarea
diverselor valori statistice pentru grupuri intregi de subiecti generate
tocmai de categoriile din variabile. Sa presupunem ca in baza GSS93 subset.sav dorim sa cunoastem in care dintre
regiunile americane respondentii au in medie, un nivel de educatie
mai mare. Conform variabilei region4 subiectii
din ancheta sunt divizati in 4 regiuni iar variabila educ reprezinta anii de
studiu pentru o scoala incheiata. Vom apela la comanda Data Split file pentru a
produce filtrarea bazei conform unui criteriu impus:
![]()

![]()
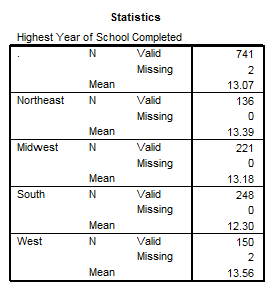
Urmeaza sa calculam media anilor de studiu cu comenzile Analyze→Descriptive Statistics→Frequencies iar din meniul Statistics vom alege doar media (mean). Rezultatul in Output este urmatorul:
Dupa cum se observa din tabelul alaturat cei
ce nu au declarata regiunea au in medie 13.07 ani de scoala. Media cea
mai mare se intalneste printre cei din vestul SUA. Restul
comparatiilor sunt evidente. Obs. Daca trebuie sa facem alte analize
statistice care nu privesc impartirea populatiei pe categorii
atunci trebuie sa eliminam comenzile anterioare astfel: Data Split File Reset OK sau prin alegerea optiunii Analyze
all cases
Obs: rezultatele pot fi afisate si separat daca setam optiunea Organize output by groups.
10. Select Cases-dintr-o baza de date se pot analiza anumite cazuri selectate dupa un criteriu necesar cercetarii statistice. Procedura urmeaza comenzile Data Select Cases Sa presupunem ca in baza de date BOP_mai/2003_Gallup.sav dorim sa vedem care sunt optiunile persoanelor de sex masculine privind directia in care se indreapta Romania: este vorba de variabilele sex0 (genul respondentilor) si a1 (directia in care se indreapta tara noastra). Prima variabila este variabila criteriu cu valorile: 1. masculin, 2.feminin. Vom selecta doar respondentii de sex masculin prin If condition is satisfied If:


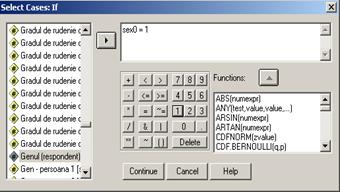
Se va deschide o noua fereastra in care am pus conditia de
selectie: sex0=1. Dupa Continue
se va reveni in baza de date care are acum, in dreapta jos precizarea Filter On. In baza de date vor apare in
partea dreapta o serie de "taieturi" semn ca liniile ce cpurind sexul feminin
au fost -pentru moment-eliminate. Din acest moment orice calcule statistice
efectuate vor tine cont de selectarea efectuata. La final respectiva setare
trebuie anulata daca se intentioneaza alte calcule. 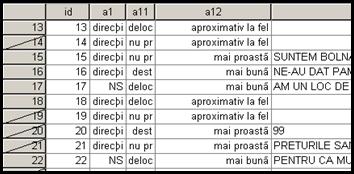
Numarul de cazuri valide sunt doar
respondentii de sex masculin dintr-un esantion de 2100 de
persoane. Rezultatele finale sunt urmatoarele:
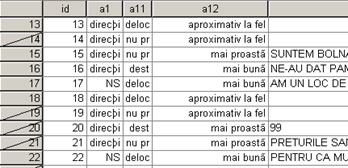


Obs: Metodele de selectie sunt foarte diverse: selectarea unui esantion din baza (Random sample of cases), selectie in functie de date sau ore (Based on time or case range), selectie in functie de o variabila filtru (Use filtre variable). In cadrul ferestrei Select Cases If se pot folosi butoanele cu cifre sau semne matematice pentru conditiile impuse si chiar o serie de functii care sunt listate in tabelul din dreapta ferestrei. Acestea pot fi: functii aritmetice (ABS[modul], LN[log. natural], SQRT [radical], etc,) functii statistice (MEAN, SUM, VARIANCE, etc.) functii de lucru cu variabile nominale, functii pentru date temporale, functii logice, functii referitoare la valorile lipsa etc. O parte din aceste functii le regasim si in programul Excel.
11. Weight Cases-ajuta la ponderarea observatiilor adica la repetarea unei observatii de un anumit numar de ori. Aceasta operatie este necesara in cazurile in care anumite subgrupuri din populatie nu sunt bine reprezentate in esantion. De exemplu proportia de tineri intre 18-25 de ani este de 30% in esantion iar in populatia mare este de 25%. Esantionarea poate introduce distorsiuni si de aceea se cere ponderarea acelor cazuri care sunt supra/sub-evaluate. Se defineste o variabila de ponderare conform careia se vor aplica respectivele ponderari. Procedura impusa de catre program pleaca de la o pondrare egala a fiecarui caz ca si cum sansele de intra in esantion sunt egale (esantionare simpla aleatoare). Aceste sanse sunt insa inegale atunci cand esantionul tine cont de o anumita stratificare.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 1198
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2024 . All rights reserved