| CATEGORII DOCUMENTE |
DOCUMENTE SIMILARE |
|
TERMENI importanti pentru acest document |
|
| : | |
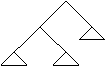
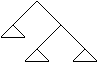
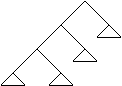
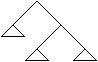
Arbori
1 Structuri arborescente
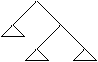
Un arbore cu radacina ('rooted tree') este o structura neliniara, in care fiecare nod poate avea mai multi succesori, dar un singur predecesor, cu exceptia unui nod special, numit radacina si care nu are nici un predecesor.
Structura de arbore se poate defini recursiv astfel: Un arbore este fie:
- nimic (arbore vid)
- un singur nod (radacina)
- un nod care are ca succesori un numar finit de arbori.
![]()
![]()
![]()
![]()
![]()
![]()
Altfel spus, daca se elimina radacina unui arbore rezulta mai multi arbori, care erau subarbori in arborele initial (dintre care unii pot fi arbori fara nici un nod).
Definitia recursiva este importanta pentru ca multe operatii cu arbori pot fi descompuse recursiv in cateva operatii componente:
- prelucrare nod radacina
- prelucrare succesori nod (subarbori), repetata pentru fiecare fiu.
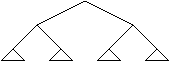
Intr-un arbore ordonat este importanta ordinea memorarii succesorilor fiecarui nod deci intr-un arbore binar este important care este fiul stanga si care este fiul dreapta.
Un arbore poate fi privit ca o extindere a listelor liniare. Un arbore binar in care fiecare nod are un singur succesor, pe aceeasi parte, este de fapt o lista liniara.
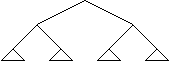
Structura de arbore este o structura ierarhica, cu noduri asezate pe diferite niveluri, cu relatii de tip parinte - fiu intre noduri. Fiecare nod are o anumita inaltime fata de radacina; toti succesorii unui nod se afla pe acelasi nivel si au aceeasi inaltime.
Nodurile terminale, fara succesori, se numesc si
'
Inaltimea (adancimea) unui arbore este data de calea cea mai lunga de la radacina la o frunza. Un arbore cu un singur nod (radacina) are inaltimea zero.
Structurile arborescente se folosesc in programare deoarece:
- Reprezinta un model natural pentru o ierarhie de obiecte (entitati, operatii etc).
- Sunt structuri de cautare cu performante foarte bune, permitand si mentinerea in ordine a unei colectii de date dinamice (cu multe adaugari si stergeri).
De cele mai multe ori legaturile unui nod cu succesorii sai se reprezinta prin pointeri, dar sunt posibile si reprezentari fara pointeri ale arborilor, prin vectori. Un vector de structuri (sau mai multi vectori paraleli), unde fiecare structura corespunde unui nod, iar adresele de legatura intre noduri sunt indici in vector. Este posibil si ca in loc de indici sa se foloseasca chiar valorile din nodurile fii (daca sunt intregi).
De obicei se intelege prin arbore o structura cu pointeri, deoarece aceasta este mai eficienta in cazul unor colectii cu numar necunoscut sau variabil de elemente, dar nu foarte mare.
O reprezentare liniara posibila a unui arbore este o expresie cu paranteze complete, in care fiecare nod este urmat de o paranteza ce grupeaza succesorii sai. Exemple:
1) a (b,c)
este un arbore binar cu 3 noduri: radacina 'a', avand la stanga pe 'b' si la dreapta pe 'c'
5 (3 (1,), 7(,9))
este un arbore binar ordonat cu radacina 5. Nodul 3 are un singur succesor, la stanga, iar nodul 7 are numai succesor la dreapta.
5
_______|_______
3 7
___|___ ___|___
1 9
Uneori relatiile dintre nodurile unui arbore sunt impuse de semnificatia datelor memorate in noduri (ca in cazul arborilor ce reprezinta expresii aritmetice sau sisteme de fisiere), dar alteori distributia valorilor memorate in noduri nu este impusa, fiind determinata de valorile memorate ( ca in cazul arborilor de cautare, unde structura depinde de ordinea de adaugare si poate fi modificata prin reorganizarea arborelui).
Ca exemplu de arbore binar reprezentat prin vectori si a carei structura este determinata de relatiile dintre datele memorate vom prezenta arborii Huffman folositi in compresia datelor.
Compresia datelor se face de obicei prin recodificarea lor. Una din metodele de compresie a unui fisier de caractere foloseste coduri de lungime variabila in functie de frecventa de aparitie a caracterelor; cu cat un caracter apare mai des intr-un fisier cu atat se folosesc mai putini biti pentru codificarea lui. De exemplu, intr-un fisier apar 6 caractere cu urmatoarele frecvente:
a (45), b(13), c(12), d(16), e(9), f(5)
Codurile Huffman pentru aceste caractere sunt:
a= 0, b=101, c=100, d=111, e=1101, f=1100
Numarul de biti necesari pentru un fisier de 1000 caractere va fi 3000 in cazul codificarii cu cate 3 biti pentru fiecare caracter si 2240 in cazul folosirii de coduri Huffman, deci se poate realiza o compresie de cca. 25% (in cele 1000 de caractere vor fi 450 de litere 'a', 130 de litere 'b', 120 litere 'c', s.a.m.d).
Fiecare cod Huffman incepe cu un prefix distinct, ceea ce permite recunoasterea lor la decompresie; de exemplu fisierul comprimat 001011101 va fi decodificat ca 0/0/101/1101 = aabe.
Problema este de a stabili codul fiecarui caracter functie de probabilitatea lui de aparitie astfel incat numarul total de biti folositi in codificarea unui sir de caractere sa fie minim. Este o problema de optimizare abordabila printr-un algoritm de tip greedy. Pentru generarea codurilor de lungime variabila se foloseste un arbore binar in care fiecare nod neterminal are exact doi succesori.
Pentru exemplul dat arborele optim de codificare cu frecventele de aparitie in nodurile neterminale si cu literele codificate in nodurile terminale este :
5(100)
/
a(45) 4(55)
/
2(25) 3(30)
c(12) b(13) 1(14) d(16)
/
f(5) e(9)
Se observa introducerea unor noduri intermediare care nu corespund unor litere.
Pentru codificare se parcurge arborele incepand de la radacina si se adauga cate un bit 0 pentru un succesor la stanga si cate un bit 1 pentru un succesor la dreapta.
Algoritmul genereaza arborele de codificare incepand de jos in sus, folosind o coada cu prioritati de perechi caractere-frecvente, ordonata crescator dupa frecventa lor de aparitie. La fiecare pas se extrag primele doua elemente din coada (cu frecvente minime), se creaza cu ele un subarbore si se introduce in coada un element a carui frecventa este egala cu suma frecventelor elementelor extrase.
Evolutia acestei cozi pentru exemplul dat este :
f(5), e(9), c(12), b(13), d(16), a(45)
c(12), b(13), 1(14), d(16), a(45)
1(14), d(16), 2(25), a(45)
2(25), 3(30), a(45)
a(45), 4(55)
5(100)
Elementele noi adaugate la coada au fost numerotate in ordinea producerii lor.
Daca sunt n caractere de codificat atunci sunt necesari n-1 pasi de forma:
- initializare subarbore
- extrage si sterge din coada element cu valoare minima
- introduce element in succesor stanga
- extrage din coada element cu valoare minima
- introduce element in succesor dreapta
- introduce in coada element cu suma frecventelor si cu o valoare generata
Varianta de program prezentata in continuare foloseste numai vectori alocati la compilare pentru implementarea tipurilor de date abstracte 'arbore binar' si 'coada cu prioritati' (numarul de caractere este cunoscut de la inceput si este relativ mic).
// date memorate in arborele de codificare
typedef struct cf; // pereche caracter-frecventa
// coada cu prioritati ca vector
typedef struct pq; // coada ordonata
// arbore binar reprezentat prin vectori
typedef struct bt; // arbore binar
Pentru datele considerate vectorii ce reprezinta arborele binar arata astfel:
ch: a b c d e f 1 2 3 4 5
fr: 45 13 12 16 9 5 14 25 30 55 100
st: -1 -1 -1 -1 -1 -1 5 2 6 7 0
dr: -1 -1 -1 -1 -1 -1 4 1 3 8 9
Functia urmatoare construieste arborele de codificare:
int build (bt & a )
i=n=q.nc;
while ( ! pqempty(q))
return i-1; // nr de noduri in arbore
}
Pentru codificarea caracterelor se parcurge arborele infixat pornind de la radacina, adaugand la fiecare nou nivel un bit in plus la cod (0 pe stanga, 1 pe dreapta):
void gencod (bt a, int k, int cod)
}
2 Arbori partial ordonati. Vectori Heap.
Un 'Heap' este un vector care reprezinta un arbore binar partial ordonat de inaltime minima, completat de la stanga la dreapta pe fiecare nivel. Un max-heap are urmatoarele proprietati:
- Toate nivelurile sunt complete, cu posibila exceptie a ultimului nivel, completat de la stanga spre dreapta.
- Valoarea oricarui nod este mai mare sau egala cu valorile succesorilor sai.
O definitie mai scurta a unui (max)heap este: un arbore binar complet in care orice fiu este mai mic decat parintele sau.
Rezulta de aici ca radacina arborelui contine valoarea maxima dintre toate valorile din arbore (pentru un max-heap). Uneori este utila ordonarea crescatoare a valorilor dintr-un heap, cu valoarea minima in radacina (min-heap).
Vectorul contine valorile nodurilor, iar legaturile unui nod cu succesorii sai sunt reprezentate implicit prin pozitiile lor in vector :
- Radacina are indicele 1 (este primul element din vector).
- Pentru nodul din pozitia k nodurile vecine sunt:
- Fiul stanga in pozitia 2*k
- Fiul dreapta in pozitia 2*k + 1
- Parintele in pozitia k/2
Exemplu de vector max-heap :
Indice 1 2 3 4 5 6 7 8 9 10
Valoare 16 14 10 8 7 9 3 2 4 1
16
___________|___________
| |
14 10
_____|______ ______|______
| | | |
8 7 9 3
De observat ca valorile din noduri depind de ordinea introducerii lor in heap, dar structura arborelui cu 10 valori este aceeasi (ca repartizare pe fiecare nivel). Altfel spus, cu aceleasi n valori se pot construi mai multi vectori max-heap (sau min-heap).
Vectorii heap au cel putin doua utilizari importante:
- (Max-Heap) o metoda eficienta de sortare ('HeapSort');
- (Min-Heap) o implementare eficienta pentru tipul 'Coada cu prioritati';
Operatiile de introducere si de eliminare dintr-un heap necesita un timp de ordinul O(lg n), dar citirea valorii minime (maxime) este O(1) si nu depinde de marimea sa.
Operatiile de baza asupra unui heap sunt :
- Transformare heap dupa aparitia unui nod care nu este mai mare ca succesorii sai, pentru mentinerea proprietatii de heap ("heapify" = ajustare, cernere);
- Crearea unui heap dintr-un vector oarecare;
- Extragere valoare maxima (minima);
- Inserare valoare noua in heap, in pozitia corespunzatoare.
- Modificarea valorii dintr-o pozitie data.
Primul exemplu este cu un max-heap de numere intregi, definit astfel:
typedef struct heap;
Numele de "reajustare" al operatiei "heapify" vine de la faptul ca ea reface un heap dintr-un arbore la care elementul k nu respecta conditia de heap, dar subarborii sai respecta aceasta conditie; la aceasta situatie se ajunge dupa inlocuirea sau dupa modificarea valorii din radacina unui arbore heap. Aplicata asupra unui vector oarecare functia "heapify(k)" nu creeaza un heap, dar aduce in pozitia k cea mai mare dintre valorile subarborelui cu radacina in k : se muta succesiv in jos pe arbore valoarea v[k], daca este mai mare decat fii sai. Functia recursiva 'heapify' din programul urmator face aceasta transformare propagand in jos pe arbore valoarea din nodul 'i', astfel incat arborele cu radacina in 'i' sa fie un heap. In acest scop se determina valoarea maxima dintre v[i], v[st] si v[dr] si se aduce in pozitia 'i', pentru ca sa avem v[i] >= v[st] si v[i] >= v[dr], unde 'st' si 'dr' sunt adresele (indicii) succesorilor la stanga si la dreapta ai nodului din pozitia 'i'. Valoarea coborata din pozitia 'i' in 'st' sau 'dr' va fi din nou comparata cu succesorii sai, la un nou apel al functiei 'heapify'.
// ajustare max-heap
void heapify (heap & h,int i)
}
Urmeaza o varianta iterativa pentru functia "heapify" , care foloseste o functie "swap" de interschimb a doua elemente dintr-un vector:
void heapify (heap& h, int i)
}
Transformarea unui vector
dat intr-un vector heap se face treptat, pornind de la
void makeheap (heap & h)
Vom ilustra actiunea functiei 'makeheap' pe exemplul urmator:
operatie vector arbore
initializare 1 2 3 4 5 6 1
2 3
4 5 6
heapify(3) 1 2 6 4 5 3 1
2 6
4 5 3
heapify(2) 1 5 6 4 2 3 1
4 2 3
heapify(1) 6 5 3 4 2 1 6
5 3
4 2 1
Programul de mai jos arata cum se poate ordona un vector prin crearea unui heap si interschimb intre valoarea maxima si ultima valoare din vector.
// sortare prin creare si ajustare heap
void heapsort (int a[],int n)
for (i=0;i<n;i++) // scoate din heap in vectorul a
a[i]= h.v[i+1];
}
In functia de sortare se repeta urmatoarele operatii:
- schimba valoarea maxima a[1] cu ultima valoare din vector a[n],
- se reduce dimensiunea vectorului
- se 'ajusteaza' vectorul ramas
Vom arata actiunea procedurii 'heapSort' pe urmatorul exemplu:
dupa citire vector 4,2,6,1,5,3
dupa makeheap 6,5,4,1,2,3
dupa schimbare 6 cu 3 3,5,4,1,2,6
dupa heapify(1,5) 5,3,4,1,2,6
dupa schimbare 5 cu 2 2,3,4,1,5,6
dupa heapify(1,4) 4,3,2,1,5,6
dupa schimbare 4 cu 1 1,3,2,4,5,6
dupa heapify(1,3) 3,1,2,4,5,6
dupa schimbare 3 cu 2 2,1,3,4,5,6
dupa heapify(1,2) 2,1,3,4,5,6
dupa schimbare 2 cu 1 1,2,3,4,5,6
Extragerea valorii maxime dintr-un heap se face eliminand radacina (primul element din vector), aducand in locul ei un nod frunza si aplicand functia 'heapify' (ajustare) pentru mentinerea vectorului ca heap:
// extragere valoare maxima din coada
int delmax ( heap & h)
Adaugarea unei noi valori la un heap se poate face in prima pozitie libera (de la sfarsitul vectorului), urmata de deplasarea ei in sus cat este nevoie, pentru mentinerea calitatii de heap:
// introducere in heap
void insH (heap & h, int x )
h.v[i] = x; // valoarea din i se mutase in jos
}
Modul de lucru al functiei insH este aratat pe exemplul de adaugare a valorii val=7 la vectorul a=[ 8,5,6,3,2,4,1 ]
n=8
i=8, a[4]=3 < 7 , a[8]=a[4] a= [ 8,5,6,3,2,4,1,3 ]
i=4, a[2]=5 < 7 , a[4]=a[2] a= [ 8,5,6,5,2,4,1,3 ]
i=2, a[1]=8 > 7 , a[2]=7 a= [ 8,7,6,5,2,4,1,3 ]
Intr-un heap folosit drept coada cu prioritati se memoreaza obiecte ce contin o cheie, care determina prioritatea obiectului, plus alte date asociate acestei chei. De exemplu, in heap se memoreaza arce dintr-un graf cu costuri, iar ordonarea lor se face dupa costul arcului. In limbajul C avem de ales intre un heap de pointeri la void si un heap de structuri. Exemplu de min-heap generic folosit pentru arce cu costuri:
typedef struct Arc;
typedef Arc T; // tip obiecte puse in heap
typedef int Tk; // tip cheie
typedef int (* fcomp)(T,T); // tip functie de comparare
typedef struct heap;
// compara arce dupa cost
int cmparc (Arc a, Arc b)
// ajustare heap
void heapify (heap & h,int i)
}
// micsorare cheie din pozitia i
void decrkey (heap & h, int i, Tk key)
}
3 Operatii cu arbori binari
Un caz particular important de arbori il constituie arborii binari, in care un nod poate avea cel mult doi succesori: un succesor la stanga si un succesor la dreapta.
Definitia unui nod dintr-un arbore binar seamana cu definitia unui nod dintr-o lista inlantuita, dar contine doua adrese de legatura, catre cei doi succesori posibili :
typedef struct tnod tnod;
r
![]()
![]()
![]()
![]() st dr
st dr
Uneori
se memoreaza in fiecare nod si adresa nodului parinte, pentru a ajunge repede
la parintele unui nod (pentru parcurgere de la
Un arbore este complet definit printr-o singura variabila pointer, care contine adresa nodului radacina; pornind de la radacina se poate ajunge la orice nod. Radacina poate fi un nod special sentinela sau poate contine date, la fel ca si celelalte noduri din arbore.
Operatiile uzuale cu arbori sunt aceleasi cu operatiile descrise la alte colectii:
- Initializare arbore (creare arbore vid);
- Adaugarea unui nod la un arbore;
- Cautarea unei valori date intr-un arbore;
- Eliminarea (stergerea) unui nod cu valoare data;
- Enumerarea tuturor nodurilor din arbore intr-o anumita ordine (asociata cu aplicarea anumitor operatii asupra nodurilor enumerate).
Alte operatii cu arbori, utile in anumite aplicatii :
- Determinarea valorii minime sau maxime dintr-un arbore
- Determinarea valorii imediat urmatoare valorii dintr-un nod dat
- Determinarea radacinii arborelui ce contine un nod dat
- Adaugarea unui subarbore la un arbore
- Eliminarea unui subarbore dintr-un arbore ("pruning")
- Rotatii la stanga sau la dreapta in jurul unui nod
O situatie speciala o
prezinta operatia de adaugare a unui nod la un arbore: nodul nou devine o frunza, deci arborele
creste prin
Initializarea unui arbore vid se poate reduce la atribuirea valorii NULL pentru variabila radacina, sau la crearea unui nod sentinela, fara date. Poate fi luata in considerare si o initializare a radacinii cu prima valoare introdusa in arbore, astfel ca adaugarile ulterioare sa nu mai modifice radacina (daca nu se face modificarea arborelui pentru reechilibrare, dupa fiecare adaugare ).
Functiile pentru operatii cu arbori binari sunt natural recursive, pentru ca orice operatie (afisare, cautare etc) se reduce la operatii similare cu subarborii stanga si dreapta, plus operatia asupra radacinii. Reducerea (sub)arborilor continua pana se ajunge la un (sub)arbore vid.
Una dintre cele mai simple operatii cu un arbore binar este determinarea inaltimii unui arbore (celei mai lungi cai de la radacina la orice frunza); inaltimea unui arbore este egala cu cea mai mare dintre inaltimile subarborilor sai, plus unu pentru radacina, pentru un arbore nevid si zero pentru arborele vid.
// calcul inaltime arbore binar cu radacina r
int maxpath (tnod * r)
if (r == NULL)
return 0; // inaltime arbore vid
else return max (maxpath (r st), maxpath(r dr))+1;
}
In mod similar se poate scrie o functie care sa numere nodurile dintr-un arbore.
Cautarea unei valori intr-un arbore binar se reduce la cautarea succesiva in fiecare din cei doi subarbori:
// cautare in arbore oarecare
tnod * findAB ( tnod * r, int x)
Vizitarea nodurilor unui arbore binar inseamna de fapt liniarizarea arborelui, adica stabilirea unei secvente liniare de noduri. Aceasta operatie se poate face in mai multe feluri, in functie de ordinea in care se iau in considerare radacina, subarborele stanga si subarborele dreapta :
- Ordine prefixata (preordine sau RSD) : radacina, stanga, dreapta
- Ordine infixata (inordine sau SRD) : stanga, radacina, dreapta
- Ordine postfixata (postordine sau SDR): stanga, dreapta, radacina
Fie arborele binar descris prin expresia cu paranteze:
5 ( 2 (1,4(3,)), 8 (6 (,7),9) )
Traversarea prefixata produce secventa de noduri: 5 2 1 4 3 8 6 7 9
Traversarea infixata produce secventa de noduri: 1 2 3 4 5 6 7 8 9
Traversarea postfixata produce secventa de noduri: 1 3 4 2 7 6 9 8 5
O expresie se scrie uzual in forma 'infixata' (cu operatorul intre operanzi), dar se poate rescrie si in forma prefixata (utilizata pentru functii) sau in forma postfizata. De exemplu, restul impartirii a doi intregi a si b se scrie infixat in C (a%b) dar prefixat in Pascal ( mod(a,b)); forma postfixata ar fi ab%.
Exemplu de functie pentru afisare infixata a valorilor dintr-un arbore binar:
// traversare infixata arbore binar
void infix (tnod * r)
}
Functia 'infix' poate fi usor modificata pentru o alta strategie de vizitare. Exemplu
// traversare prefixata arbore binar
void prefix (tnod * r)
}
Pornind de la functia minimala de afisare se pot scrie si alte variante de afisare: ca o expresie cu paranteze sau cu evidentierea structurii de arbore:
// afisare structura arbore (cu indentare)
void printAB (tnod * r, int ns)
else
}
De asemenea se pot realiza alte operatii care se aplica asupra tuturor nodurilor, cum ar fi insumarea valorilor din nodurile unui arbore binar. Exemplu:
// suma valorilor din noduri
int sum (tnod* r)
Desi operatiile cu arbori prezentate anterior sunt suficiente pentru multe aplicatii, ele nu pot acoperi toata diversitatea de aplicatii ale arborilor. De aceea, s-au propus operatii primitive, la nivel de nod de arbore, necesare si suficiente pentru a programa orice aplicatie cu arbori:
- Creare nod de arbore, cu o valoare data:
tnod* build (T x); // creare nod cu valoarea x
- Adaugare fiu la un nod dat:
void addLeft (tnod* p, tnod* left); // adauga lui p un fiu stanga
void addRight (tnod* p, tnod* right); // adauga lui p un fiu dreapta
Eliminarea unui nod din arbore se poate face prin modificarea unei legaturi in nodul parinte. Pentru a realiza eficient aceste operatii fiecare nod din arbore trebuie sa memoreze si adresa nodului parinte.
In exemplul urmator se considera ca datele folosite la construirea arborelui se dau sub forma unor tripleti de valori: valoare nod parinte, valoare fiu stanga, valoare fiu dreapta. O valoare zero marcheaza absenta fiului respectiv. Exemplu de date:
5 3 7 / 7 6 8 / 3 2 4 / 2 1 0 / 8 0 9
(un arbore de cautare, cu ordinea infixata a nodurilor:
// cauta valoarea x in arborele cu radacina r
tnod * find (tnod *r, T x)
// creare si afisare arbore binar
void main ()
infix (r); // afisare infixata
}
Operatiile la nivel de arbore sunt necesare de exemplu la crearea unui arbore binar ce corespunde unei expresii aritmetice. Fiecare nod din arbore contine un un intreg care codifica tipul nodului (operand sau operator) si un pointer catre valoarea operandului sau catre codul operatorului, sau chiar valoarea operandului si codul operatorului:
enum ; // OP=0, VAL=1
typedef struct Info ;
Pentru simplificarea codului vom considera aici numai expresii cu operanzi dintr-o singura cifra, cu operatorii aritmetici '+', '-', '*', '/', cu sau fara paranteze si fara spatii albe intre operanzi si operatori. Eliminarea acestor restrictii nu modifica esenta problemei si nici solutia discutata, dar complica implementarea ei.
Problema evaluarii expresiilor aritmetice este aceea ca ordinea de calcul difera in general de ordinea aparitiei operatorilor respectivi in expresie. De exemplu, expresia:
1 + 3*2 - 8 / 4
se calculeaza in ordinea *, /, +, - : 3*2 =6; 8/4=2; 1+6 =7; 7-2=5;
O solutie este crearea unui arbore binar echivalent expresiei si evaluarea pe arbore. Pentru expresia anterioara arborele echivalent arata astfel:
_
____________|___________
| |
Exemplu de creare a arborelui pentru expresia
void main () , prod=, div=;
Info v2=, v3=, v8=, v4=;
rad=build(minus);
addLeft(rad,s=build(prod)); addRight (rad,d=build(div));
addLeft(s,build(v2)); addRight(s,build(v3)); // 2*3
addLeft(d,build(v8)); addRight(d,build(v4)); // 8/4
printf('%f n',eval(rad));
}
Evaluarea recursiva a unui arbore expresie se poate face cu functia urmatoare.
float eval(tnod * r)
}
4 Arbori binari de cautare
Un arbore binar de cautare (BST=Binary Search Tree), numit si arbore de sortare, este un arbore binar cu proprietatea ca orice nod are valoarea mai mare decat orice nod din subarborele stanga si mai mica decat orice nod din subarborele dreapta. Exemplu de arbore binar de cautare:
5 ( 2 (1,4(3,)), 8 (6 (,7),9) )
![]()
![]() 5
5
![]()
![]()
![]()
![]()
![]()
![]() 1 4 6 9
1 4 6 9
3 7
Arborii BST permit mentinerea datelor in ordine si o cautare rapida a unei valori, ceea ce ii recomanda pentru implementarea de multimi si dictionare ordonate. In plus, afisarea infixata a unui arbore binar de cautare produce un vector ordonat cu valorile din nodurile arborelui.
Cautarea intr-un arbore BST este comparabila cu cautarea binara pentru vectori ordonati: dupa ce se compara valoarea cautata cu valoarea din radacina se poate decide in care din cei doi subarbori se afla (daca exista) valoarea cautata. Fiecare noua comparatie elimina un subarbore din cautare si reduce cu 1 inaltimea arborelui in care se cauta. Procesul de cautare intr-un arbore binar ordonat poate fi exprimat recursiv sau nerecursiv.
// cautare recursiva in arbore ordonat
tnod * findABC ( tnod * r, int x)
// cautare nerecursiva in arbore ordonat
tnod * findABC ( tnod * r, int x)
return NULL;
}
Timpul minim de cautare se realizeaza pentru un arbore BST echilibrat (cu inaltime minima), la care inaltimile celor doi subarbori sunt egale sau difera cu 1. Acest timp este de ordinul log2n, unde n este numarul total de noduri din arbore. Valoarea maxima dintr-un arbore binar de cautare se afla in nodul din extremitatea dreapta, iar valoarea minima in nodul din extremitatea stanga. Exemplu de functie:
int maxABC ( tnod * r)
Adaugarea
unui nod la un arbore BST seamana cu
cautarea, pentru ca se cauta nodul frunza cu valoarea cea mai apropiata de
valoarea care se adauga. Nodul nou se adauga ca frunza (arborele creste prin
// adaugare nod la arbore binar ordonat
void addABC (tnod *& r, int x) // daca arbore nevid
if (x < r val) // daca x mai mic ca valoarea din radacina
addABC (r st,x); // se adauga la subarborele stanga
else // daca x mai mare ca valoarea din radacina
addABC (r dr,x); // se adauga la subarborele dreapta
}
Eliminarea unui nod cu valoare data dintr-un arbore BST trebuie sa considere urmatoarele situatii:
- Nodul de sters nu are succesori (este o frunza);
- Nodul de sters are un singur succesor;
- Nodul de sters are doi succesori.
Eliminarea unui nod cu un succesor sau fara succesori se reduce la inlocuirea legaturii la nodul sters prin legatura acestuia la succesorul sau (care poate fi NULL).
Eliminarea unui nod cu 2 succesori se face prin inlocuirea sa cu un nod care are cea mai apropiata valoare de cel sters; acesta poate fi nodul din extremitatea dreapta a subarborelui stanga sau nodul din extremitatea stanga a subarborelui dreapta (este fie predecesorul, fie succesorul in ordine infixata). Acest nod are cel mult un succesor
Fie arborele BST urmator
![]()
![]() 5
5
![]()
![]()
![]()
![]()
![]()
![]()
3 7
Eliminarea nodului 5 se face fie prin inlocuirea sa cu nodul 4, fie prin inlocuirea sa cu nodul 6. Acelasi arbore dupa inlocuirea nodului 5 prin nodul 4 :
![]()
![]() 4
4
![]()
![]()
![]()
![]()
![]() 1 3 6 9
1 3 6 9
Operatia de eliminare nod se poate exprima nerecursiv sau recursiv, iar functia se poate scrie ca functie de tip 'void' cu parametru referinta sau ca functie cu rezultat pointer (adresa radacinii arborelui se poate modifica in urma stergerii valorii din nodul radacina). Exemplu de functie nerecursiva pentru eliminare nod:
void delABC (tnod*& r, int x)
if (p==0) return; // nu exista nod cu val. x
if (p st != 0 && p dr != 0)
// muta valoarea din s in p
p val=s val;
p=s; pp=ps; // p contine adresa nodului de eliminat
}
// p are cel mult un fiu q
q= (p st == 0)? p dr : p st;
// elimina nodul p
if (p==r) r=q; // daca se modifica radacina
else
free (p);
}
Timpul necesar operatiei de eliminare nod este proportional cu inaltimea arborelui, iar pentru un arbore dezechilibrat (cazul cel mai rau), proportional cu numarul de noduri O(n).
5 Arbori binari echilibrati
Cautarea intr-un arbore binar ordonat este eficienta daca arborele este echilibrat. Un arbore perfect echilibrat este un arbore in care numarul de noduri din cei doi subarbori ai fiecarui nod difera cel mult cu 1. Timpul de cautare intr-un arbore este determinat de inaltimea arborelui, iar aceasta inaltime este minima (pentru un numar dat de noduri) daca inaltimile celor doi subarbori difera cu cel mult 1. Un astfel de arbore binar se numeste arbore echilibrat in inaltime.
In functie de ordinea adaugarilor de noi noduri (si eventual de stergeri) se poate ajunge la arbori foarte dezechilibrati; cazul cel mai defavorabil este un arbore cu toate nodurile pe aceeasi parte. Timpul de cautare intr-un arbore foarte dezechilibrat este de ordinul O(n) dar timpul de cautare intr-un arbore echilibrat este de ordinul O(lg n).
Ideea generala este ajustarea arborelui dupa operatii de adaugare sau de stergere, daca aceste operatii strica echilibrul existent. Structura arborelui se modifica, dar se mentin relatiile dintre valorile continute in noduri. Exemple de arbori binari de cautare echivalenti (cu acelasi continut), dar cu structuri si inaltimi diferite:
/ /
Restructurarea unui arbore de cautare se face prin rotatii; o rotatie modifica structura unui (sub)arbore, dar mentine relatiile dintre valorile din noduri.
Adaugarea si stergerea de noduri la un arbore colorat se face la fel ca la arborii de cautare, dar dupa aceste operatii se verifica respectarea proprietatilor mentionate si, daca este necesar se fac una sau doua rotatii de arce pentru mentinerea acestora dar si pentru pastrarea relatiei de ordine intre noduri.
Rotatia la stanga in subarborele cu radacina A aduce in locul lui A fiul sau dreapta B, iar A devine fiu stanga al lui B ( B > A).
Rotatia la dreapta a subarborelui cu radacina B poate fi privita ca operatie inversa rotatiei la stanga in jurul lui A; B devine fiu dreapta al lui A.
A Rot. stanga B
![]()
![]()
![]()
![]() B Rot. dreapta A
B Rot. dreapta A
![]() x z
x z
y z x y
Se observa ca prin rotatii se mentin relatiile dintre valorile nodurilor:
x < A < B < z ; A < y < B ;
Functiile care realizeaza aceste rotatii sunt simetrice:
// Rotatie spre stanga in jurul lui b
void rotateLeft ( Node*& b)
// Rotatie spre dreapta in jurul lui a
void rotateRight ( Node*& a)
Rotatiile pot avea ca efect ridicarea (coborarea) unor noduri in arbore si reducerea inaltimii arborelui, ca in exemplul urmator:
7 5
5 Rot. dreapta 7 -> 3 7
/
3
S-au propus cateva variante de arbori de cautare pentru noduri cu probabilitati egale de cautare si altele pentru noduri cu probabilitati diferite de solicitare.
Algoritmii de inserare si de stergere noduri in arbori echilibrati realizeaza o reechilibrare automata a arborelui, daca ea devine necesara dupa adaugarea sau dupa stergerea unui nod.
Principalele variante de arbori cu autoechilibrare sunt:
- Arbori Treap (Tree-Heap)
- Arbori AVL
- Arbori cu noduri colorate ("red-black").
- Arbori "scapegoat"
- Arbori 2-3 (sau 2-3-4)
Toate aceste variante au in comun faptul ca nu sunt arbori perfect echilibrati ci sunt arbori (aproape) echilibrati in inaltime.
Diferentele dintre acesti arbori se manifesta prin criteriul folosit pentru aprecierea gradului de echilibru si prin valoarea suplimentara memorata in fiecare nod.
In cazul arborilor AVL criteriul este diferenta dintre inaltimilor subarborilor ce au ca radacina acel nod. Daca acest numar, memorat in fiecare nod, are o valoare absoluta mai mare ca 1, se considera ca arborele s-a dezechilibrat. Arborii AVL au fost primii in ordine istorica, dar isi pastreaza importanta si in prezent, pentru ca asigura performante bune ( lg(n) ) in medie si o programare relativ simpla.
In cazul arborilor RBT nodurile sunt colorate fie cu rosu, fie cu negru. Criteriul de echilibru este ca fiecare cale de la radacina la o frunza sa aiba acelasi numar de noduri negre. Deoarece un nod rosu trebuie sa aiba fii colorati negru, rezulta ca pe fiecare cale exista cel putin jumatate din noduri negre; de aici si criteriul de echilibru: cea mai lunga cale nu poate avea mai mult decat de doua ori mai multe noduri decat cea mai scurta cale. Arborii RBT asigura performante bune si in cazul mediu si in cazul cel mai defavorabil, ceea ce explica de ce sunt utilizati in bibliotecile de clase.
In cazul arborilor Treap se memoreaza in fiecare nod si o prioritate (numar intreg generat aleator), iar arborele de cautare (ordonat dupa valorile din noduri) este obligat sa respecte si conditia de heap relativ la prioritatile nodurilor. Un treap nu este un heap deoarece nu are toate nivelurile complete, dar in medie inaltimea sa nu depaseste dublul inaltimii minime (realizata de un heap).
Arborii "scapegoat" memoreaza in fiecare nod atat inaltimea cat si numarul de noduri din subarborele cu radacina in acel nod. Ideea principala este de a nu proceda la restructurarea arborelui prea frecvent, ea se va face numai dupa un numar de adaugari sau de stergeri de noduri. Stergerea unui nod nu este efectiva ci este doar o marcare a nodurilor respective ca invalidate. Eliminarea efectiva si restructurarea se va face numai cand in arbore sunt mai mult de jumatate de noduri marcate ca sterse. La adaugarea unui nod se actualizeaza inaltimea si numarul de noduri pentru nodurile de pe calea ce contine nosul nou si se verifica (pornind de la nodul adaugat in sus, spre radacina) daca exista un arbore prea dezechilibrat (cu inaltime mai mare ca logaritmul numarului de noduri: h(v) > m + log(|v|) ). Se va restructura numai acel subarbore gasit vinovat de dezechilibrarea intregului arbore.
Fie urmatorul subarbore dintr-un arbore BST:
15
/
Dupa ce se adauga valoarea 8 nu se face nici o modificare, desi subarborele devine "putin" dezechilibrat. Daca se adauga si valoarea 5, atunci subarborele devine "mult" dezechilibrat si se va restructura, fara a fi nevoie sa se propage in sus modificarea (parintele lui 15 era mai mare ca 15, deci va fi mai mare si ca 10). Exemplu:
15 10
/ /
/ /
Costul amortizat al operatiilor de insertie si stergere intr-un arbore "scapegoat" este tot O( log(n) ).
6 Arbori Treap
Numele "Treap" provine din "Tree Heap" si desemneaza o structura care combina caracteristicile unui arbore binar de cautare cu caracteristicile unui Heap.
Fiecare nod din arbore contine o valoare (o cheie) si o prioritate. In raport cu cheia nodurile unui treap respecta conditia unui arbore de cautare, iar in raport cu prioritatea este un mini-heap.
typedef struct th Node;
Sa consideram ca exemplu cheile a,b,c,d,e,f. Sa presupunem ca acestor chei li se asociaza urmatoarele prioritati:
Cheie a b c d e f
Prior 6 5 8 2 12 10
Un treap construit cu aceste chei si aceste prioritati arata astfel :
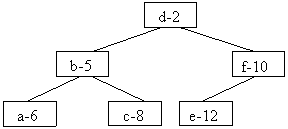
Principala utilizare a unui treap este aceea de arbore relativ echilibrat, folosit pentru realizarea de dictionare. Echilibrarea se asigura prin generarea aleatoare de prioritati si rearanjarea arborelui binar de cautare pentru a respecta si conditia de min-heap. Un astfel de treap se numeste si arbore binar de cautare cu randomizare.
Adaugarea unei valori la un treap se face in doua etape:
- In prima etapa se adauga o frunza, la fel ca la orice arbore binar de cautare
- In a doua etapa se ajusteaza arborele pentru a respecta conditia de heap (pentru prioritati).
// creare nod frunza cu cheia x si prioritatea p
Node* make (int x, int pr)
// insertie nod
void insert( Node*& r, int x, int p)
else if( x > r val )
// else duplicat; nu se adauga
}
La adaugarea unui nod se pot efectua mai multe rotatii (dreapta si/sau stanga), dar numarul lor nu poate depasi inaltimea arborelui. Exemplul urmator ilustreaza etapele prin care trece un treap cu prioritatea din radacina egala cu 3 la adaugarea cheii G cu prioritatea 2:
E3 E3 E3 E3 G2
/ / / / /
B5 H7 B5 H7 B5 H7 B5 G2 E3 H7
A6 F9 K8 A6 F9 K8 A6 G2 K8 A6 F9 H7 B5 F9 K8
/ /
G2 F9 K8 A6
initial adauga G2 Rot.st. F9 Rot.dr. H7 Rot.st. G2
S-a aratat ca pentru o secventa de chei generate aleator si adaugate la un arbore binar de cautare, arborele este relativ echilibrat; mai exact, calea de lungime minima este 1.4 lg(n)-2 iar calea de lungime maxima este 4.3 lg(n). Din acest motiv prioritatile sunt generate aleator.
Node * root = NULL; // initializare arbore
for (i=0; i<n; i++) // adauga n noduri cu valori x[i]
insert (root, x[i], rand());
Eliminarea unui nod dintr-un treap nu este mult mai complicata decat eliminarea dintr-un arbore binar de cautare; numai dupa eliminarea unui nod cu doi succesori se compara prioritatile fiilor nodului sters si se face o rotatie in jurul nodului cu prioritate mai mare (la stanga pentru fiul stanga si la dreapta pentru fiul dreapta).
O alta utilizare posibila a unui treap este ca structura de cautare pentru chei cu probabilitati diferite de cautare; prioritatea este in acest caz determinata de frecventa de cautare a fiecarei chei, iar radacina are prioritatea maxima (este un max-heap).
7 Arbori AVL
Arborii AVL (Adelson-Velski, Landis) sunt arbori binari de cautare in care fiecare subarbore este echilibrat in inaltime. Pentru a recunoaste rapid o dezechilibrare a arborelui s-a introdus in fiecare nod un camp suplimentar, care sa arate fie inaltimea nodului, fie diferenta dintre inaltimile celor doi subarbori pentru acel nod (dreapta minus stanga). Acest camp poate contine valorile -1, 0, 1 pentru noduri "echilibrate".
La adaugarea unui nou nod (ca frunza) factorul de echilibru al unui nod interior se poate modifica la -2 (adaugare la subarborele stanga) sau la +2 (adaugare la subarborele dreapta), ceea ce va face necesara modificarea structurii arborelui.
La fiecare adaugare (sau stergere) se recalculeaza factorii de echilibru la fiecare nod intalnit parcurgand arborele de jos in sus, de la nodul adaugat spre radacina.
Exemplu de arbore AVL (in paranteze factorul de echilibrul al nodului):
80 (-1)
/ /
10(0) 20(0)
Adaugarea valorilor 120 sau 35 sau 50 nu necesita nici o ajustare in arbore pentru ca factorii de echilibru raman in limitele [-1,+1].
Dupa adaugarea unui nod cu valoarea 5, arborele se va dezechilibra astfel:
80 (-2)
10(-1) 20(0)
Primul nod dezechilibrat (de jos in sus) este 30, iar solutia este o rotatie la dreapta a acestui nod:
/
Uneori sunt necesare doua rotatii (o dubla rotatie) pentru corectia dezechilibrului creat, ca in exemplul urmator, dupa adaugarea valorii 55:
/ /
/
55(0)
Mai intai se face o rotatie la stanga a nodului 30 si apoi o rotatie la dreapta a nodului 80 :
Inaltimea maxima a unui arbore AVL este 1.44*log(n), deci in cazul cel mai rau cautarea intr-un arbore AVL nu necesita mai mult de 44% comparatii fata de cele necesare intr-un arbore perfect echilibrat. In medie, este necesara o rotatie (simpla sau dubla) cam la 46,5% din adaugari si este suficienta o singura rotatie pentru refacere.
Implementarea care urmeaza memoreaza in fiecare nod din arbore inaltimea sa, deci distanta fata de radacina arborelui. Un nod vid are inaltimea -1.
typedef struct node Node;
// determina inaltime nod cu adresa t
int th (Node* t)
Operatiile de rotatie simpla sunt cele din 5 dar in plus modifica si inaltimea:
void rotateLeft( Node * & b )
// rotatie simpla la dreapta
void rotateRight( Node * & a )
Pentru arborii AVL sunt necesare si rotatii duble:
// rotatie dubla la stanga
void doubleLeft( Node * & c )
// rotatie dubla la dreapta
void doubleRight( Node * & c )
Operatia de adaugare a unei valori x la un arbore AVL este relativ simpla:
void insert( Node* & t, int x )
else if( x < t->value )
else if( t->value < x )
else
; // nimic daca x exista deja in arbore
t->h = max( th( t->left ), th( t->right ) ) + 1;
}
Evolutia unui arbore AVL la adaugarea valorilor 1,2,3,4,5,6,7 este urmatoarea:
4 3 5 1 3 6 1 3 5 7
8 Arbori RBT
Arborii de cautare cu noduri colorate ('Red Black Trees'= RBT) realizeaza un bun compromis intre gradul de dezechilibru al arborelui si numarul de operatii necesare pentru mentinerea acestui grad, fiind folositi in bibliotecile de clase C++ (STL) si Java pentru implementarea de multimi si dictionare ordonate.
Un arbore RB are urmatoarele proprietati:
- Orice nod este colorat fie cu negru fie cu rosu.
- Succesorii (inexistenti) ai nodurilor frunza se considera colorati in negru
- Un nod rosu nu poate avea decat succesori negri
- Orice cale de la radacina la o frunza are acelasi numar de noduri negre.
Se considera ca toate frunzele au ca succesor un nod sentinela negru.
De observat ca nu este necesar ca pe fiecare cale sa alterneze noduri negre si rosii si nici nu este impusa culoarea nodului radacina.
Consecinta acestor proprietati este ca cea mai lunga cale din arbore este cel mult dubla fata de cea mai scurta cale din arbore; cea mai scurta cale poate avea numai noduri negre, iar cea mai lunga are noduri negre si rosii care alterneaza.
O definitie posibila a unui nod dintr-un arbore RBT:
typedef struct Node Node;
#define NIL &sentinel // adresa memorata in nodurile frunza
Node sentinel = ; // santinela este un nod negru
Operatia de rotatie la stanga in jurul nodului a este ceva mai complicata din cauza modificarii legaturilor catre noduri paruinte si este realizata de functia urmatoare:
Node *root = NIL; // radacina arbore este variabila externa
void rotateLeft(Node *a) else
// leaga pe a la b
b left = a;
if (a != NIL) a parent = b;
}
Orice nod adaugat primeste culoarea rosie si apoi se verifica culoarea nodului parinte si culoarea 'unchiului' sau (frate cu parintele sau, pe acelasi nivel).
La adaugarea unui nod (rosu) pot apare doua situatii care sa necesite modificarea arborelui:
- Parinte rosu si unchi rosu.
- Parinte rosu dar unchi negru.
Prima situatie este ilustrata in figura urmatoare:
7(N) 7(R)
5(R) 9(R) 5(N) 9(N)
3(R) 3(R)
Dupa ce se adauga nodul rosu cu valoarea 3 se modifica culorile nodurilor cu valorile 5 (parinte) si 9 (unchi) din rosu in negru si culoarea nodului 7 din negru in rosu. Daca 7 nu este radacina atunci modificarea culorilor se propaga in sus.
A doua situatie este ilustrata de figura urmatoare:
![]()
![]()
7(N) 5(N)
5(R) 9(N) 3(R) 7(R)
/ /
3(R) 6(N) 6(N) 9(N)
In acest caz se roteste la dreapta muchia ce uneste nodurile 5 si 7, cu ajustare subarbori, dar modificarea nu se propaga in sus deoarece radacina subarborelui are aceeasi culoare dinainte (negru).
Daca noul nod se adauga ca succesor dreapta (de ex. valoarea 6, daca nu ar fi existat deja), atunci se face mai intai o rotatie la stanga a muchiei 5-6, astfel ca 6 sa ia locul lui 5, iar 5 sa devina fiu stanga a lui 6.
// reechilibrare dupa insertie nod
void insertFixup(Node *x) else
// recolorare si rotatie
x parent color = BLACK; x parent parent color = RED;
rotateRight(x parent parent);
}
} else else
x parent color = BLACK; x parent parent color = RED;
rotateLeft(x parent parent);
}
}
}
root color = BLACK;
}
Functia de mai sus este apelata de functia de adaugare nod la arbore RBT:
Node *insert (T data)
// creare nod nou
if ((x = malloc (sizeof(*x))) == 0)
x value = data;
x parent = parent;
x left = NIL;
x right = NIL;
x color = RED;
// legare nod nou la arbore
if(parent) else
root = x;
insertFixup(x);
return(x);
}
Pentru a intelege modificarile suferite de un arbore RB vom arata evolutia sa la adaugarea valorilor 1,2,8 (valori ordonate, cazul cel mai defavorabil):
1(N) 1(N) 2(N) 2(N) 2(N)
2(R) 1(R) 3(R) 1(N) 3(N) 1(N) 4(N)
/
4(R) 3(R) 5(R)
2(N) 2(N) 4(N)
1(N) 4(R) 1(N) 4(R) 2(R) 6(R)
3(N) 5(N) 3(N) 6(N) 1(N) 3(N) 5(N) 7(N)
/
6(R) 5(R) 7(R) 8(R)
Si dupa operatia de eliminare a unui nod se apeleaza o functie de ajustare pentru mentinerea conditiilor de arbore RB.
Este posibila si o varianta de arbori RBT fara legaturi in sus, la noduri parinte, pentru ca la cautarea locului unde se va adauga noul nod (functia "insert") se trece prin nodurile parinte si "bunic" ale noului nod si se pot retine adresele lor.
9 Arbori optimi la cautare
Pana acum am presupus ca toate valorile memorate intr-un arbore de cautare au aceeasi probabilitate de cautare, sau ca nu exista informatii despre acest subiect.
Un arbore optim la cautare ("Best Search Tree") este un arbore binar de cautare in care fiecare valoare din arbore are o probabilitate cunoscuta de cautare. Timpul mediu de cautare a unor valori date in arbore depinde atat de de distanta sa fata de radacina arborelui cat si de probabilitatea de a cauta fiecare valoare. Problema consta in construirea unui arbore pentru care timpul mediu de cautare sa fie minim.
Fie c[i] o valoare (o cheie) si p[i] probabilitatea de cautare a valorii c[i]. Vom considera varianta mai simpla a problemei, in care nu se cauta decat valori care exista sigur in arbore si deci suma probabilitatilor p[i] este 1. La calculul numarului mediu de comparatii necesare pentru gasirea unei valori vom aduna contributia fiecarei chei la acest numar, adica produsul dintre adancimea cheii si probabilitatea de cautare. Vom considera cheile ordonate crescator dupa valorile lor.
Exemplu de date initiale:
c[i] 1 2 3 4 5
p[i] 0.25 0.20 0.05 0.20 0.30
Un algoritm greedy pentru aceasta problema se bazeaza pe observatia ca valorile care se cauta frecvent (cu probabilitate mare) ar trebui sa fie cat mai aproape de radacina arborelui. La fiecare pas se alege cheia k cu probabilitate maxima de cautare, dupa care se repeta acelasi algoritm pentru cheile mai mici decat c[k] (aflate in subarborele stanga) si pentru cheile mai mari decat c[k] (din subarborele dreapta).
Pentru datele anterioare cheia 5 va fi aleasa ca radacina a arborelui, iar arborele optim la cautare poate fi descris prin expresia cu paranteze urmatoare:
Notand cu d[i] distanta cheii i fata de radacina putem calcula contributia fiecarei chei si numarul mediu de comparatii:
c[i] 1 2 3 4 5
p[i] 0.25 0.20 0.05 0.20 0.30
d[i] 2 3 5 4 1
contrib 0.50 + 0.60 + 0.25 + 0.80 + 0.30 = 2.45
Pentru aceste date solutia greedy nu este si solutia optima. O solutie mai buna este arborele descris prin expresia cu paranteze 2 ( 1 , 4 ( 3, 5) ) :
c[i] 1 2 3 4 5
p[i] 0.25 0.20 0.05 0.20 0.30
d[i] 2 1 3 2 3
contrib 0.50 + 0.20 + 0.15 + 0.40 + 0.90 = 2.15
Functia care creeaza arborele binar optim la cautare pe baza algoritmului greedy:
tnod * greedy (int i, int j)
O alta abordare a arborilor de cautare cu probabilitati diferite de cautare, dar necunoscute inainte de crearea arborelui, este modificarea automata a structurii dupa fiecare operatie de adaugare sau de stergere, astfel ca valorile cele mai cautate sau cautate cel mai recent sa fie cat mai aproape de radacina.
Un arbore "splay" este un arbore binar, care se modifica automat pentru aducerea ultimei valori accesate in radacina arborelui, ceea ce il recomanda pentru memorii "cache". Timpul necesar aducerii unui nod in radacina depinde de distanta acestuia fata de radacina, dar in medie sunt necesare O( n*log(n) + m*log(n)) operatii pentru m adaugari la un arbore cu n noduri, iar fiecare operatie de "splay" costa O(n*log(n)).
Daca N are doar parinte P si nu are "bunic"atunci se face o singura rotatie pentru a-l aduce pe N in radacina arborelui.
![]()
![]()
 P N P N
P N P N
N P N P
( N<P) rot. la dreapta ( zig) (N>P) rot. la stanga (zag)
Daca N are si un bunic B (parintele lui P) atunci se deosebesc 4 cazuri, functie de pozitia nodului (nou) accesat N fata de parintele sau P si a parintelui P fata de "bunicul" B al lui N :
N < P < B Se face o dubla rotatie la dreapta astfel ca P sa devina fiu dreapta al lui N si B fiu dreapta al lui P (zig zig)
B N
![]()
 P P
P P
1 3
![]() N 2 4 B
N 2 4 B
3 4 zig zig 2 1
2: N > P > B Se face o dubla rotatie la stanga astfel ca P sa devina fiu stanga al lui N si B fiu stanga al lui P (zag zag)
B N
![]() zag zag
zag zag
![]()
 P P
P P
1 4
2 N B 3
3: P < N < B Se face o rotatie astfel ca B sa devina fiu dreapta al lui N si P fiu stanga al lui N (zig zag)
B N
![]()
![]()
 zig zag
zig zag
![]()
![]()
![]()
![]() P P B
P P B
1
![]()
![]()
![]() 2 N
2 N
![]()
![]()
3 4
4: B < N < P Se face o rotatie astfel ca P sa devina fiu dreapta al lui N si B fiu stanga al lui N (zag zig)
B N
![]()
![]()
![]()
![]() P zag zig B P
P zag zig B P
![]()
![]()
![]()
![]() 1 N
1 N
![]()
![]()
3 4
Daca valoarea cautata x nu exista in arbore, atunci se aduce in radacina nodul cu valoarea cea mai apropiata de x, ultimul pe calea de cautare a lui x. Dupa eliminarea unui nod cu valoarea x se aduce in radacina valoarea cea mai apropiata de x.
Ca si in exemplul cu arbori RBT vom folosi un nod santinela in locul unui pointer nul, pentru noduri frunza:
// nod sentinela
Node NN =;
// initializare arbore
void init ( Node* & t)
Functia urmatoare realizeaza operatia de "splay", necesara dupa cautare, insertie si stergere de noduri:
// x este valoarea accesata din arborele cu radacina t
void splay( Node* & t, int x )
else if( t element < x )
else
break;
leftTreeMax right = t left;
rightTreeMin left = t right;
t left = header.right;
t right = header.left;
}
Functiile care fac rotatii in arbore (noduri fara legaturi la nodul parinte) sunt aceleasi din subcapitolul 5 (Arbori echilibrati).
Cautarea unei valori intr-un arbore "splay" :
int find ( Node*& t, int x )
Insertia unei noi valori intr-un arbore "splay":
void insert( Node* & t, int x )
else
else
if( t element < x )
else
return;
}
newNode = NULL; // pentru apel new la urmatoarea adaugare
}
Evolutia unui arbore "splay" dupa cateva operatii de adaugare a unor valori:
3 9 6 2 4 5
/ / / /
/ /
/
9 2
+3 +9 +6 +2 +4 +5
Eliminarea unei valori dintr-un arbore "splay":
void remove( Node* & t, int x )
free(t);
t = newTree;
}
10 Arbori multicai
Un arbore multicai ("Multiway Tree") este un arbore in care fiecare nod poate avea un numar oarecare de succesori, de obicei nelimitat.
Arborii multicai pot fi clasificati in doua grupe:
- Arbori de cautare, echilibrati folositi pentru multimi si dictionare (arbori 2-3-4);
- Arbori care exprima relatiile dintre elementele unei colectii si a caror structura nu poate fi modificata.
Arborii 2-3-4 sunt arbori ordonati si echilibrati, cu toate caile de aceeasi lungime si cu urmatoarele caracteristici:
- Un nod contine n valori ( n intre 2 si 4 ) si n+1 pointeri catre noduri fii (subarbori);
- Valorile dintr-un nod sunt ordonate crescator;
- Toate valorile dintr-un nod sunt mai mari decat valorile din nodurile aflate in stanga sa si mai mici decat valorile aflate in noduri din dreapta sa.
- Valorile noi pot fi adaugate numai in noduri frunza.
- Prin adaugarea unei noi valori la un nod plin, acesta este spart in alte doua noduri cu cate doua valori, iar valoarea mediana este trimisa pe nivelul superior;
- Arborele poate creste numai in sus, prin crearea unui nou nod radacina.
Sa consideram urmatoarea secventa de chei (valori) adaugate la un arbore 2-3-4:
Evolutia arborelui dupa fiecare valoare adaugata este prezentata mai jos:
[4, , , ] [4, , , ] [4, , , ] [4, , , ]
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Fiecare nod dintr-un arbore 2-3-4 contine un vector de 4 chei si un vector de 5 pointeri; exemplu pentru nodul radacina din arborele de mai sus:
![]()
![]()
![]()
![]()
Cautarea unei valori si cautarea nodului la care trebuie adaugata o noua valoare se face la fel ca la arborii binari de cautare: se pleaca de la radacina si se compara cheia cautata cu cheile din nod; se continua cautarea pe calea indicata de adresa de la stanga valorii imediat urmatoare celei cautate (sau de la dreapta ultimei valori din nod daca valoarea cautata este mai mare decat ultima valoare din nod).
Din cauza numarului mare de pointeri pe nod arborii 2-3-4 sunt mai putin folositi decat arborii binari echilibrati, dar varianta numita arbore B este cea mai folosita structura de cautare memorata pe un suport extern.
Multe structuri arborescente "naturale" (care modeleaza situatii reale) nu sunt arbori binari, iar numarul succesorilor unui nod nu este limitat la o valoare mica si cunoscuta. Un exemplu este arborele de fisiere si subdirectoare care reprezinta continutul unui volum disc: nodurile interne sunt subdirectoare, iar nodurile frunza sunt fisiere "normale" (care contin date). Exemplu:
Program Files
Adobe
Acrobat 0
Reader
. . .
Internet Explorer
. . .
iexplorer.exe
WinZip
winzip.txt
wz.com
wz.pif
. . .
WINDOWS
. . .
Un alt exemplu este arborele DOM creat de un parser XML pe baza unui document XML: fiecare nod corespunde unui element XML (delimitat prin tag-uri de inceput si de sfarsit). Exemplu de mic fisier XML:
<priceList>
<computer>
<name> CDC </name>
<price> 540 </price>
</ computer >
<computer>
<name> SDS </name>
<price> 495 </price>
</ computer >
</priceList>
Arborele DOM (Document Object Model) corespunzator acestui document XML:
![]()
![]()
![]()
![]()
CDC 540 SDS 495
Un arbore multicai, numit arbore sintactic ("parser tree"), este creat de un analizor sintactic ("parser") pentru a reflecta relatiile dintre elementele sintactice ale unei fraze (din limbajul natural) sau ale unei instructiuni (dintr-un limbaj de programare).
Un arbore multicai cu radacina se poate reprezenta in mai multe moduri:
Fiecare nod contine un vector de pointeri la nodurile fii (succesori, descendenti) si, eventual, un pointer la nodul parinte (vectorul poate fi alocat dinamic).
De exemplu, arborele descris prin expresia cu paranteze urmatoare:
a ( b (c,d (e), f (g, h (k, l), i, j), m (n,p) )
se va reprezenta prin vectori de pointeri la fii astfel:
![]()
![]() a
a
![]()
![]()
b f m
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
c d g h i j n p
![]()
![]()
![]()
e k l
Fiecare nod contine 3 pointeri: la nodul parinte, la fiul stanga si la fratele imediat.
De exemplu, arborele descris prin expresia cu paranteze urmatoare:
a ( b (c,d (e), f (g, h (k, l), i, j), m (n,p) )
se va reprezenta prin legaturi la fiul stanga si la fratele dreapta astfel:
a
|
![]()
![]() b f m
b f m
| | |
![]()
![]()
![]()
![]()
![]() c d g h i j n p
c d g h i j n p
e k l
![]()
Un nod de arbore multicai cu vector de fii poate fi definit astfel:
typedef struct tnode tnode;
Operatiile de adaugare a unui fiu si de afisare a unui arbore multicai cu vectori:
// adaugare fiu la un nod crt
void addChild (tnode*& crt, tnode* & child)
crt kids[crt
child parent=crt; // legatura de la fiu la parintele sau
}
// afisare prefixata (sub)arbore
void print (tnode* r, int ns)
}
In reprezentarea fiu-frate un nod de arbore poate fi definit astfel:
typedef struct tnode tnode;
Functiile pentru operatiile de adaugare fiu si de afisare arbore fiu-frate sunt:
// adaugare fiu la un nod crt
void addChild (tnode* crt, tnode* child)
}
// afisare arbore fiu-frate
void print (tnode* r, int ns)
}
}
Afisarea arborelui se face cu indentare la fiecare nivel, pentru a pune in evidenta structura ierarhica.
Folosirea unui pointer catre parinte in fiecare nod permite afisarea caii de la radacina la un nod dat si simplificarea operatiei de eliminare a unui nod.
De obicei nu exista o relatie de ordine intre valorile din nodurile unui arbore multicai, dar cautarea unei valori date intr-un arbore multicai este o operatie uzuala. Exemplu de functie de cautare intr-un arbore multicai cu vector de pointeri:
tnode* find (tnode* r, T x)
Relatiile dintre nodurile unui arbore multicai nu pot fi modificate pentru a reduce inaltimea arborelui (ca in cazul arborilor binari de cautare), deoarece aceste relatii sunt impuse de aplicatie si nu de valorile din noduri.
Ca si in cazul arborilor binari se poate folosi o reprezentare mai compacta prin vectori in locul utilizarii de pointeri (pentru un numar mare de noduri).
Modelul DOM (Document Object Model), elaborat de consortiul W3C pentru unificarea modului de acces la arborele ce reprezinta structura unui fisier XML, defineste cateva interfete pentru programatorul de aplicatii, indiferent de limbajul folosit si de aplicatia concreta. Folosind aceste operatii, un program poate extrage din arborele DOM creat de parser informatiile care sunt de interes pentru acel program.
Pentru limbajul C aceste interfete contin prototipuri (declaratii) de functii pentru acces la nodurile arborelui, care nu sunt legate de o anumita implementare pentru arborele DOM. Fiecare nod din arbore are un tip, un nume si o valoare.
Dintre operatiile componente ale interfetei "Node" mentionam pe cele care pot fi utilizate si pentru alti arbori multicai, cu alt continut si alta semnificatie decat XML:
char* getNodeValue(Node* t) ; // are ca rezultat valoarea din nodul t
void setNodeValue(Node * t, char* nodeValue) ; // modificare valoare nod
Node* getParentNode(Node * t); // adresa nodului parinte al nodului t
NodeList getChildNodes(Node * t); // obtine lista fiilor nodului t
Node* getFirstChild(Node* t); // adresa primului fiu al nodului t
Node* getNextSibling(Node * t); // adresa fiului urmator al nodului t
Node* removeChild(Node* t, Node* oldChild) ; // eliminarea unui fiu dat al lui t
Node* appendChild(Node* t, Node* newChild) ; // adauga un fiu nodului t
int hasChildNodes(Node* t); // daca nodul t are succesori sau este frunza
Tipul abstract "NodeList" suporta urmatoarele operatii:
Node* item(NodeList *list, int index); // adresa elementului din pozitia "index"
int getLength(NodeList* list) ; // lungimea listei abstracte "list"
Accesul la succesorii unui nod se poate face deci in doua moduri, ilustrate printr-o functie care creeaza un vector cu acesti succesori:
// varianta 1
int children (Node * t, Node * kids[])
// varianta 2
int children (Node * t, Node * kids[])
Un parser DOM citeste un fisier XML si creeaza un arbore DOM cu elementele componente ale fisierului. Programul parser foloseste o stiva pentru marcaje de inceput ("start tag"), stiva care permite si verificarea corectitudinii formale a fisierului XML. Considerand ca toate marcajele se folosesc numai in perechi (start tag - end tag), algoritmul unui parser DOM fara verificari se poate descrie astfel:
initializari
repeta pana la sfarsit fisier XML
extrage urmatorul marcaj
daca este marcaj de inceput atunci
creeaza nod
adauga nod creat ca fiu al nodului din varful stivei
pune adresa nod pe stiva
altfel // marcaj de sfarsit
scoate adresa nod din stiva
11 Arbori Trie
Un arbore "Trie" (de la "retrieve" = regasire) este un arbore folosit pentru memorarea unor siruri de caractere sau unor siruri de biti de lungimi diferite, dar care au in comun unele subsiruri, ca prefixe.
Nodurile unui trie nu contin date, iar un sir este o cale de la radacina la un nod frunza sau la un nod interior. Pentru siruri de biti arborele trie este binar, dar pentru siruri de caractere arborele trie nu mai este binar (numarul de succesori ai unui nod este egal cu numarul de caractere distincte din sirurile memorate).
In exemplul urmator este un trie construit cu sirurile (cuvintele): cana, cant, casa, dop, mic, minge. Nu toate nodurile interioare din arbore au asociate valori.
/ |
c d m
/ |
a o i
/ | /
n s p c n
a t a g
|
e
Avantajele unui arbore trie sunt:
- Regasirea rapida a unui sir dat sau verificarea apartenentei unui sir dat la dictionar; numarul de comparatii este determinat numai de lungimea sirului cautat, indiferent de numarul de siruri memorate in dictionar (deci este un timp constant O(1) in raport cu dimensiunea colectiei). Acest timp poate fi important intr-un program "spellchecker" care verifica daca fiecare cuvant dintr-un text apartine sau nu unui dictionar.
- Determinarea celui mai lung prefix al unui sir dat care se afla in dictionar (operatie necesara in algoritmul de compresie LZW).
- O anumita reducere a spatiului de memorare, daca se folosesc vectori in loc de arbori cu pointeri.
Exemplul urmator este un trie binar in care se memoreaza numerele 2,3,4,5,6,7,8,9,10 care au urmatoarele reprezentari binare pe 4 biti : 0010, 0011, 0100, 0101, 0110, 1010
0/ 1 bit 0
0/ 1 0/ 1 bit 1
- 2 - -
0/ 1 0/ 1 0/ 1 0/ 1 bit 2
1 1 1 bit 3
Este de remarcat ca structura unui arbore trie nu depinde de ordinea in care se adauga valorile la arbore, iar arborele este in mod natural relativ echilibrat. Inaltimea unui arbore trie este determinata de lungimea celui mai lung sir memorat si nu depinde de numarul de valori memorate.
Arborele Huffman de coduri binare este un exemplu de trie binar, in care codurile sunt cai de la radacina la frunzele arborelui (nodurile interne nu sunt semnificative).
Pentru arbori trie este avantajoasa memorarea lor ca vectori (matrice) si nu ca arbori cu pointeri (un pointer ocupa uzual 32 biti, un indice de 16 biti este suficient pentru vectori de 64 k elemente).
Dictionarul folosit de algoritmul de compresie LZW poate fi memorat ca un "trie". Exemplul urmator este arborele trie, reprezentat prin doi vectori "left" si "right", la compresia sirului 'abbaabbaababbaaaabaabba' :
i 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14
w - a b ab bb ba aa abb baa aba abba aaa aab baab bba
left 1 6 5 9 14 7 11 - - - - - - - -
right 2 3 4 7 - - 12 13 - - - - - - -
In acest arbore trie toate nodurile sunt semnificative, pentru ca reprezinta secvente codificate, iar codurile sunt chiar pozitiile in vectori (notate cu 'i'). In pozitia 0 se afla nodul radacina, care are la stanga nodul 1 ('a') si la dreapta nodul 2 ('b'), s.a.m.d.
Cautarea unui sir 'w' in acest arbore arata astfel:
// cautare sir in trie
int get ( short left[], short right[],int n, char w[])
return j; // ultimul nivel din trie care se potriveste
}
Adaugarea unui sir 'w' la arborele trie incepe prin cautarea pozitiei (nodului) unde se termina cel mai lung prefix din 'w' aflat in trie si continua cu adaugarea la trie a caracterelor urmatoare din 'w'.
Pentru reducerea spatiului de memorare in cazul unor cuvinte lungi, cu prea putine caractere comune cu alte cuvinte in prefix, este posibila comasarea unei subcai din arbore ce contine noduri cu un singur fiu intr-un singur nod; acesti arbori trie comprimati se numesc si arbori Patricia (Practical Algorithm to Retrieve Information Coded in Alphanumeric).
Intr-un arbore Patricia nu exista noduri cu un singur succesor si in fiecare nod se memoreaza indicele elementului din sir (sau caracterul) folosit drept criteriu de ramificare.
Un arbore de sufixe (suffix tree) este un trie format cu toate sufixele cu sens ale unui sir dat; el permite verificarea rapida (intr-un timp proportional cu lungimea lui q) a conditiei ca un sir dat q sa fie un suffix al unui sir dat s.
12 Arbori KD si arbori QuadTree
Arborii kD sunt un caz special de arbori binari de cautare, iar arborii QuadTree (QT) sunt arbori multicai, dar utilizarea lor este aceeasi: pentru descompunerea unui spatiu k-dimensional in regiuni dreptunghiulare (hiperdreptunghiulare pentru k >2).
Vom exemplifica cu cazul unui spatiu bidimensional (k=2) deoarece arborii "QuadTree" (QT) reprezinta alternativa arborilor 2D (pentru arborii 3D alternativa multicai se numeste "OctTree", pentru ca fiecare nod are 8 succesori). Intr-un arbore QT fiecare nod care nu e o frunza are exact 4 succesori.
Arborii QT sunt folositi pentru reprezentarea compacta a unor imagini fotografice care contin un numar mare de puncte diferit colorate, dar in care exista regiuni cu puncte de aceeasi culoare. Fiecare regiune apare ca un nod frunza in arborele QT.
Construirea unui arbore QT se face prin impartire succesiva a unui dreptunghi in 4 dreptunghiuri egale (stanga, dreapta, sus, jos) printr-o linie verticala si una orizontala. Cei 4 succesori ai unui nod corespund celor 4 dreptunghiuri (celule) componente. Operatia de divizare este aplicata recursiv pana cand toate punctele dintr-un dreptunghi au aceeasi valoare.
O aplicatie pentru arbori QT este reprezentarea unei imagini colorate cu diferite culori, incadrata intr-un dreptunghi ce corespunde radacinii arborelui. Daca una din celulele rezultate prin partitionare contine puncte de aceeasi culoare, atunci se adauga un nod frunza etichetat cu acea culoare. Daca o celula contine puncte de diferite culori atunci este impartita in alte 4 celule mai mici, care corespund celor 4 noduri fii.
Exemplu de imagine si de arbore QT asociat acestei imagini.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
5 5 6 7 4 5
5 5 8 7 1 1 2 1 6 7 8 7
Nodurile unui arbore QT pot fi identificate prin numere intregi (indici) si/sau prin coordonatele celulei din imagine pe care o reprezinta in arbore.
Reprezentarea unui quadtree ca arbore cu pointeri necesita multa memorie (in cazul unui numar mare de noduri) si de aceea se folosesc si structuri liniare cu legaturi implicite (vector cu lista nodurilor din arbore), mai ales pentru arbori statici, care nu se modifica in timp.
Descompunerea spatiului 2D pentru un quadtree se face simultan pe ambele directii (printr-o linie orizontala si una verticala), iar in cazul unui arbore 2D se face succesiv pe fiecare din cele doua directii (sau pe cele k directii, pentru arbori kD).
Un arbore kD este un arbore binar care reprezinta o descompunere ierarhica a unui spatiu cu k dimensiuni (de unde si numele) in celule, fiecare celula continand un singur punct sau un numar redus de puncte dintr-o portiune a spatiului k-dimensional. Impartirea spatiului se face prin (hiper)plane paralele cu axele.
Arborii kD se folosesc pentru memorarea coordonatelor unui numar relativ redus de puncte, folosite la decuparea spatiului in subregiuni. Intr-un arbore 2D fiecare nod din arbore corespunde unui punct sau unei regiuni ce contine un singur punct.
Fie punctele de coordonate intregi : (2,5), (6,3), (3,8), (8,9)
O regiune plana dreptunghiulara delimitata de punctele (0,0) si (10,10) va putea fi descompusa astfel:

Prima linie a fost orizontala la y=5 prin punctul (2,5), iar a doua linie a fost semi-dreapta verticala la x=3, prin punctul (3,8). Arborele 2D corespunzator acestei impartiri a spatiului este urmatorul:
(2,5)
/
(8,9)
Punctul (6,3) se afla in regiunea de sub (2,5) iar (3,8) in regiunea de deasupra lui (2,5); fata de punctul (3,8) la dreapta este punctul (8,9) dar la stanga nu e nici un alt punct (dintre punctele aflate peste orizontala cu y=5).
Alta secventa de puncte sau de orizontale si verticale ar fi condus la un alt arbore, cu acelasi numar de noduri dar cu alta inaltime si alta radacina. Daca toate punctele sunt cunoscute de la inceput atunci ordinea in care sunt folosite este importanta si ar fi de dorit un arbore cu inaltime cat mai mica .
In ceea ce priveste ordinea de "taiere" a spatiului, este posibila fie o alternanta de linii orizontale si verticale (preferata), fie o secventa de linii orizontale, urmata de o secventa de linii verticale, fie o alta secventa. Este posibila si o varianta de impartire a spatiului in celule egale (ca la arborii QT) in care caz nodurile arborelui kD nu ar mai contine coordonatele unor puncte date.
Fiecare nod dintr-un arbore kD contine un numar de k chei, iar decizia de continuare de pe un nivel pe nivelul inferior (la stanga sau la dreapta) este dictata de o alta cheie (sau de o alta coordonata). Daca se folosesc mai intai toate semidreptele ce trec printr-un punct si apoi se trece la punctul urmator, atunci nivelul urmator celui cu numarul j va fi (j+1)% k unde k este numarul de dimensiuni.
Pentru un arbore 2D fiecare nod contine ca date 2 intregi (x,y), iar ordinea de taiere in ceea ce urmeaza va fi y1, x1, y2, x2, y3, x3, . Cautarea si inserarea intr-un arbore kD seamana cu operatiile corespunzatoare dintr-un arbore binar de cautare BST, cu diferenta ca pe fiecare nivel se foloseste o alta cheie in luarea deciziei.
typedef struct kdNode kdNode;
// insertie in arbore cu radacina t a unui vector de chei d pe nivelul k
void insert( kdNode* & t, int d[ ], int k )
else if( d[k] < t x[k] ) // daca se continua spre stanga sau spre dreapta
insert(t left,d,(k+1)%2 ); // sau 1-k ptr 2D
else
insert(t right,d,(k+1)%2 ); // sau 1-k ptr 2D
// creare arbore cu date citite de la tastatura
void main()
Un arbore kD poate reduce mult timpul anumitor operatii de cautare intr-o imagine sau intr-o baza de date (unde fiecare cheie de cautare corespunde unei dimensiuni): localizarea celulei in care se afla un anumit punct, cautarea celui mai apropiat vecin, cautare regiuni (ce puncte se afla intr-o anumita regiune), cautare cu informatii partiale (se cunosc valorile unor chei dar nu se stie nimic despre unul sau cateva atribute ale articolelor cautate).
Vom exemplifica cu determinarea punctelor care se afla intr-o regiune dreptunghiulara cu punctul de minim "low" si punctul de maxim "high", folosind un arbore 2D:
void printRange( kdNode* t, int low[], int high[], int k )
Cautarea celui mai apropiat vecin al unui punct dat folosind un arbore kD determina o prima aproximatie ca fiind nodul frunza (regiunea) care ar putea contine punctul dat. Functie de cautare a punctului in a carui regiune s-ar putea gasi un punct dat.
// cautare (nod) regiune care (poate) contine punctul (c[0],c[1])
// t este nodul (punctul) posibil cel mai apropiat de (c[0],c[1])
int find ( kdNode* r, int c[], kdNode * & t)
return 0; // negasit cand r==NULL
De exemplu, intr-un arbore cu punctele (2,5),(6,3),(3,9),(8,7), cel mai apropiat punct de (8,8) este (8,7), dar cel mai apropiat punct de (4,6) este (2,5) si nu (8,7), care este indicat de functia "find"; la fel (2,4) este mai apropiat de (2,5) desi este continut in regiunea definita de punctul (6,3).
De aceea, dupa ce se gaseste nodul cu "find", se cauta in apropierea acestui nod (in regiunile vecine), pana cand se gaseste cel mai apropiat punct. Nu vom intra in detaliile acestui algoritm, dar este sigur ca timpul necesar va fi mult mai mic decat timpul de cautare a celui mai apropiat vecin intr-o multime de N puncte, fara a folosi arbori kD. Folosind un vector de puncte (o matrice de coordonate) timpul necesar este de ordinul O(n), dar in cazul unui arbore kD este de ordinul O(log(n)), adica este cel mult egal cu inaltimea arborelui.
Reducerea inaltimii unui arbore kD se poate face alegand la fiecare pas taierea pe dimensiunea maxima in locul unei alternante regulate de dimensiuni; in acest caz mai trebuie memorat in fiecare nod si indicele cheii (dimensiunii) folosite in acel nod.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 2916
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2024 . All rights reserved