| CATEGORII DOCUMENTE |
Linux Software RAID
Introduction
The main goals of using redundant arrays of inexpensive disks (RAID) are to improve disk data performance and provide data redundancy.
RAID can be handled either by the operating system software or it may be implemented via a purpose built RAID disk controller card without having to configure the operating system at all. This chapter will explain how to configure the software RAID schemes supported by RedHat/Fedora Linux.
For the sake of simplicity, the chapter focuses on using RAID for partitions that include neither the /boot or the root (/) filesystems.
RAID Types
Whether hardware- or software-based, RAID can be configured using a variety of standards. Take a look at the most popular.
Linear Mode RAID
In the Linear RAID, the RAID controller views the RAID set as a chain of disks. Data is written to the next device in the chain only after the previous one is filled.
The aim of Linear RAID is to accommodate large filesystems spread over multiple devices with no data redundancy. A drive failure will corrupt your data.
Linear mode RAID is not supported by Fedora Linux.
RAID 0
With RAID 0, the RAID controller tries to evenly distribute data across all disks in the RAID set.
Envision a disk as if it were a plate, and think of the data as a cake. You have four cakes- chocolate, vanilla, cherry and strawberry-and four plates. The initialization process of RAID 0, divides the cakes and distributes the slices across all the plates. The RAID 0 drivers make the operating system feel that the cakes are intact and placed on one large plate. For example, four 9GB hard disks configured in a RAID 0 set are seen by the operating system to be one 36GB disk.
Like Linear RAID, RAID 0 aims to accommodate large filesystems spread over multiple devices with no data redundancy. The advantage of RAID 0 is data access speed. A file that is spread over four disks can be read four times as fast. You should also be aware that RAID 0 is often called striping.
RAID 0 can accommodate disks of unequal sizes. When RAID runs out of striping space on the smallest device, it then continues the striping using the available space on the remaining drives. When this occurs, the data access speed is lower for this portion of data, because the total number of RAID drives available is reduced. For this reason, RAID 0 is best used with drives of equal size.
RAID 0 is supported by Fedora Linux. Figure 26.1 illustrates the data allocation process in RAID 0.
RAID 1
With RAID 1, data is cloned on a duplicate disk. This RAID method is therefore frequently called disk mirroring. Think of telling two people the same story so that if one forgets some of the details you can ask the other one to remind you.
When one of the disks in the RAID set fails, the other one continues to function. When the failed disk is replaced, the data is automatically cloned to the new disk from the surviving disk. RAID 1 also offers the possibility of using a hot standby spare disk that will be automatically cloned in the event of a disk failure on any of the primary RAID devices.
RAID 1 offers data redundancy, without the speed advantages of RAID 0. A disadvantage of software-based RAID 1 is that the server has to send data twice to be written to each of the mirror disks. This can saturate data busses and CPU use. With a hardware-based solution, the server CPU sends the data to the RAID disk controller once, and the disk controller then duplicates the data to the mirror disks. This makes RAID-capable disk controllers the preferred solution when implementing RAID 1.
A limitation of RAID 1 is that the total RAID size in gigabytes is equal to that of the smallest disk in the RAID set. Unlike RAID 0, the extra space on the larger device isn't used.
RAID 1 is supported by Fedora Linux. Figure 26.1 illustrates the data allocation process in RAID 1.
Figure 26-1 RAID 0 And RAID 1 Operation
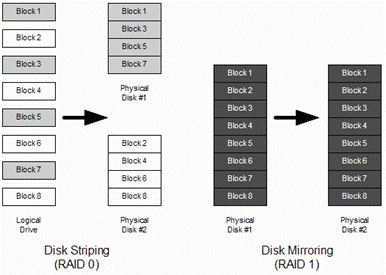
RAID 4
RAID 4 operates likes RAID 0 but inserts a special error-correcting or parity chunk on an additional disk dedicated to this purpose.
RAID 4 requires at least three disks in the RAID set and can survive the loss of a single drive only. When this occurs, the data in it can be recreated on the fly with the aid of the information on the RAID set's parity disk. When the failed disk is replaced, it is repopulated with the lost data with the help of the parity disk's information.
RAID 4 combines the high speed provided of RAID 0 with the redundancy of RAID 1. Its major disadvantage is that the data is striped, but the parity information is not. In other words, any data written to any section of the data portion of the RAID set must be followed by an update of the parity disk. The parity disk can therefore act as a bottleneck. For this reason, RAID 4 isn't used very frequently.
RAID 4 is not supported by Fedora Linux.
RAID 5
RAID 5 improves on RAID 4 by striping the parity data between all the disks in the RAID set. This avoids the parity disk bottleneck, while maintaining many of the speed features of RAID 0 and the redundancy of RAID 1. Like RAID 4, RAID 5 can survive the loss of a single disk only.
RAID 5 is supported by Fedora Linux. Figure 26.2 illustrates the data allocation process in RAID 5.
Linux RAID 5 requires a minimum of three disks or partitions.
Figure 26-2 RAID 5 Operation
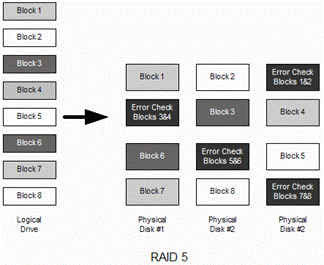
Before You Start
Specially built hardware-based RAID disk controllers are available for both IDE and SCSI drives. They usually have their own BIOS, so you can configure them right after your system's the power on self test (POST). Hardware-based RAID is transparent to your operating system; the hardware does all the work.
If hardware RAID isn't available, then you should be aware of these basic guidelines to follow when setting up software RAID.
IDE Drives
To save costs, many small business systems will probably use IDE disks, but they do have some limitations.
The total length of an IDE cable can be only a few feet long, which generally limits IDE drives to small home systems.
IDE drives do not hot swap. You cannot replace them while your system is running.
Only two devices can be attached per controller.
The performance of the IDE bus can be degraded by the presence of a second device on the cable.
The failure of one drive on an IDE bus often causes the malfunctioning of the second device. This can be fatal if you have two IDE drives of the same RAID set attached to the same cable.
For these
reasons, I recommend you use only one IDE drive per controller when using RAID,
especially in a corporate environment. In a home or
Serial ATA Drives
Serial ATA type drives are rapidly replacing IDE, or Ultra ATA, drives as the preferred entry level disk storage option because of a number of advantages:
The drive data cable can be as long as 1 meter in length versus IDE's 18 inches.
Serial ATA has better error checking than IDE.
There is only one drive per cable which makes hot swapping, or the capability to replace components while the system is still running, possible without the fear of affecting other devices on the data cable.
There are no jumpers to set on Serial ATA drives to make it a master or slave which makes them simpler to configure.
IDE drives have a 133Mbytes/s data rate whereas the Serial ATA specification starts at 150 Mbytes/sec with a goal of reaching 600 Mbytes/s over the expected ten year life of the specification.
If you can't afford more expensive and faster SCSI drives, Serial ATA would be the preferred device for software and hardware RAID
SCSI Drives
SCSI hard disks have a number of features that make them more attractive for RAID use than either IDE or Serial ATA drives.
SCSI controllers are more tolerant of disk failures. The failure of a single drive is less likely to disrupt the remaining drives on the bus.
SCSI cables can be up to 25 meters long, making them suitable for data center applications.
Much more than two devices may be connected to a SCSI cable bus. It can accommodate 7 (single-ended SCSI) or 15 (all other SCSI types) devices.
Some models of SCSI devices support 'hot swapping' which allows you to replace them while the system is running.
SCSI currently supports data rates of up to 640 Mbytes/s making them highly desirable for installations where rapid data access is imperative.
SCSI drives tend to be more expensive than IDE drives, however, which may make them less attractive for home use.
Should I Use Software RAID Partitions Or Entire Disks?
It is generally a not a good idea to share RAID-configured partitions with non-RAID partitions. The reason for this is obvious: A disk failure could still incapacitate a system.
If you decide to use RAID, all the partitions on each RAID disk should be part of a RAID set. Many people simplify this problem by filling each disk of a RAID set with only one partition.
Backup Your System First
Software RAID creates the equivalent of a single RAID virtual disk drive made up of all the underlying regular partitions used to create it. You have to format this new RAID device before your Linux system can store files on it. Formatting, however, causes all the old data on the underlying RAID partitions to be lost. It is best to backup the data on these and any other partitions on the disk drive on which you want implement RAID. A mistake could unintentionally corrupt valid data.
Configure RAID In Single User Mode
As you will be modifying the disk structure of your system, you should also consider configuring RAID while your system is running in single-user mode from the VGA console. This makes sure that most applications and networking are shutdown and that no other users can access the system, reducing the risk of data corruption during the exercise.
[root@bigboy tmp]# init 1
Once finished, issue the exit command, and your system will boot in the default runlevel provided in the /etc/inittab file.
Configuring Software RAID
Configuring RAID using Fedora Linux requires a number of steps that need to be followed carefully. In the tutorial example, you'll be configuring RAID 5 using a system with three pre-partitioned hard disks. The partitions to be used are:
/dev/hde1
/dev/hdf2
/dev/hdg1
Be sure to adapt the various stages outlined below to your particular environment.
RAID Partitioning
You first need to identify two or more partitions, each on a separate disk. If you are doing RAID 0 or RAID 5, the partitions should be of approximately the same size, as in this scenario. RAID limits the extent of data access on each partition to an area no larger than that of the smallest partition in the RAID set.
Determining Available Partitions
First use the fdisk -l command to view all the mounted and unmounted filesystems available on your system. You may then also want to use the df -k command, which shows only mounted filesystems but has the big advantage of giving you the mount points too.
These two commands should help you to easily identify the partitions you want to use. Here is some sample output of these commands.
[root@bigboy tmp]# fdisk -l
Disk /dev/hda: 12.0 GB, 12072517632 bytes
255 heads, 63 sectors/track, 1467 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/hda1 * 1 13 104391 83 Linux
/dev/hda2 14 144 1052257+ 83 Linux
/dev/hda3 145 209 522112+ 82 Linux swap
/dev/hda4 210 1467 10104885 5 Extended
/dev/hda5 210 655 3582463+ 83 Linux
/dev/hda15 1455 1467 104391 83 Linux
[root@bigboy tmp]#
[root@bigboy tmp]# df -k
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/hda2 1035692 163916 819164 17% /
/dev/hda1 101086 8357 87510 9% /boot
/dev/hda15 101086 4127 91740 5% /data1
/dev/hda7 5336664 464228 4601344 10% /var
[root@bigboy tmp]#
Unmount the Partitions
You don't want anyone else accessing these partitions while you are creating the RAID set, so you need to make sure they are unmounted.
[root@bigboy tmp]# umount /dev/hde1
[root@bigboy tmp]# umount /dev/hdf2
[root@bigboy tmp]# umount /dev/hdg1
Prepare The Partitions With FDISK
You have to change each partition in the RAID set to be of type FD (Linux raid autodetect), and you can do this with fdisk. Here is an example using /dev/hde1.
[root@bigboy tmp]# fdisk /dev/hde
The number of cylinders for this disk is set to 8355.
There is nothing wrong with that, but this is larger than 1024,
and could in certain setups cause problems with:
1) software that runs at boot time (e.g., old versions of LILO)
2) booting
and partitioning software from other
(e.g., DOS FDISK, OS/2 FDISK)
Command (m for help):
Use FDISK Help
Now use the fdisk m command to get some help:
Command (m for help): m
p print the partition table
q quit without saving changes
s create a new empty Sun disklabel
t change a partition's system id
Command (m for help):
Set The ID Type To FD
Partition /dev/hde1 is the first partition on disk /dev/hde. Modify its type using the t command, and specify the partition number and type code. You also should use the L command to get a full listing of ID types in case you forget.
Command (m for help): t
Partition number (1-5): 1
Hex code (type L to list codes): L
16 Hidden FAT16 61 SpeedStor f2 DOS secondary
17 Hidden HPFS/NTF 63 GNU HURD or Sys fd Linux raid auto
18 AST SmartSleep 64 Novell Netware fe LANstep
1b Hidden Win95 FA 65 Novell Netware ff BBT
Hex code (type L to list codes): fd
Changed system type of partition 1 to fd (Linux raid autodetect)
Command (m for help):
Make Sure The Change Occurred
Use the p command to get the new proposed partition table:
Command (m for help): p
Disk /dev/hde: 4311 MB, 4311982080 bytes
16 heads, 63 sectors/track, 8355 cylinders
Units = cylinders of 1008 * 512 = 516096 bytes
Device Boot Start End Blocks Id System
/dev/hde1 1 4088 2060320+ fd Linux raid autodetect
/dev/hde2 4089 5713 819000 83 Linux
/dev/hde4 6608 8355 880992 5 Extended
/dev/hde5 6608 7500 450040+ 83 Linux
/dev/hde6 7501 8355 430888+ 83 Linux
Command (m for help):
Save The Changes
Use the w command to permanently save the changes to disk /dev/hde:
Command (m for help): w
The partition table has been altered!
Calling ioctl() to re-read partition table.
WARNING: Re-reading the partition table failed with error 16: Device or resource busy.
The kernel still uses the old table.
The new table will be used at the next reboot.
Syncing disks.
[root@bigboy tmp]#
The error above will occur if any of the other partitions on the disk is mounted.
Repeat For The Other Partitions
For the sake of brevity, I won't show the process for the other partitions. It's enough to know that the steps for changing the IDs for /dev/hdf2 and /dev/hdg1 are very similar.
Preparing the RAID Set
Now that the partitions have been prepared, we have to merge them into a new RAID partition that we'll then have to format and mount. Here's how it's done.
Create the RAID Set
You use the mdadm command with the --create option to create the RAID set. In this example we use the --level option to specify RAID 5, and the --raid-devices option to define the number of partitions to use.
[root@bigboy tmp]# mdadm --create --verbose /dev/md0 --level=5
--raid-devices=3 /dev/hde1 /dev/hdf2 /dev/hdg1
mdadm: layout defaults to left-symmetric
mdadm: chunk size defaults to 64K
mdadm: /dev/hde1 appears to contain an ext2fs file system
size=48160K mtime=Sat Jan 27
mdadm: /dev/hdf2 appears to contain an ext2fs file system
size=48160K mtime=Sat Jan 27
mdadm: /dev/hdg1 appears to contain an ext2fs file system
size=48160K mtime=Sat Jan 27
mdadm: size set to 48064K
Continue creating array? y
mdadm: array /dev/md0 started.
[root@bigboy tmp]#
Confirm RAID Is Correctly Inititalized
The /proc/mdstat file provides the current status of all RAID devices. Confirm that the initialization is finished by inspecting the file and making sure that there are no initialization related messages. If there are, then wait until there are none.
[root@bigboy tmp]# cat /proc/mdstat
Personalities : [raid5]
read_ahead 1024 sectors
md0 : active raid5 hdg1[2] hde1[1] hdf2[0]
4120448 blocks level 5, 32k chunk, algorithm 3 [3/3] [UUU]
unused devices: <none>
[root@bigboy tmp]#
Notice that the new RAID device is called /dev/md0. This information will be required for the next step.
Format The New RAID Set
Your new RAID partition now has to be formatted. The mkfs.ext3 command is used to do this.
[root@bigboy tmp]# mkfs.ext3 /dev/md0
mke2fs 1.39
(
Filesystem label=
OS type: Linux
Block size=1024 (log=0)
Fragment size=1024 (log=0)
36144 inodes, 144192 blocks
7209 blocks (5.00%) reserved for the super user
First data block=1
Maximum filesystem blocks=67371008
18 block groups
8192 blocks per group, 8192 fragments per group
2008 inodes per group
Superblock backups stored on blocks:
8193, 24577, 40961, 57345, 73729
Writing inode tables: done
Creating journal (4096 blocks): done
Writing superblocks and filesystem accounting information: done
This filesystem will be automatically checked every 33 mounts or
180 days, whichever comes first. Use tune2fs -c or -i to override.
[root@bigboy tmp]#
Create the mdadm.conf Configuration File
Your system doesn't automatically remember all the component partitions of your RAID set. This information has to be kept in the mdadm.conf file. The formatting can be tricky, but fortunately the output of the mdadm --detail --scan --verbose command provides you with it. Here we see the output sent to the screen.
[root@bigboy tmp]# mdadm --detail --scan --verbose
ARRAY /dev/md0 level=raid5 num-devices=4
UUID=77b695c4:32e5dd46:63dd7d16:17696e09
devices=/dev/hde1,/dev/hdf2,/dev/hdg1
[root@bigboy tmp]#
Here we export the screen output to create the configuration file.
[root@bigboy tmp]# mdadm --detail --scan --verbose > /etc/mdadm.conf
Create A Mount Point For The RAID Set
The next step is to create a mount point for /dev/md0. In this case we'll create one called /mnt/raid
[root@bigboy mnt]# mkdir /mnt/raid
Edit The /etc/fstab File
The /etc/fstab file lists all the partitions that need to mount when the system boots. Add an Entry for the RAID set, the /dev/md0 device.
/dev/md0 /mnt/raid ext3 defaults 1 2
Do not use labels in the /etc/fstab file for RAID devices; just use the real device name, such as /dev/md0. In older Linux versions, the /etc/rc.d/rc.sysinit script would check the /etc/fstab file for device entries that matched RAID set names listed in the now unused /etc/raidtab configuration file. The script would not automatically start the RAID set driver for the RAID set if it didn't find a match. Device mounting would then occur later on in the boot process. Mounting a RAID device that doesn't have a loaded driver can corrupt your data and produce this error.
Starting up RAID devices: md0(skipped)
Checking filesystems
/raiddata: Superblock has a bad ext3 journal(inode8)
CLEARED.
***journal has been deleted - file system is now ext 2 only***
/raiddata: The filesystem size (according to the superblock) is 2688072 blocks.
The physical size of the device is 8960245 blocks.
Either the superblock or the partition table is likely to be corrupt!
/boot: clean, 41/26104 files, 12755/104391 blocks
/raiddata: UNEXPECTED INCONSISTENCY; Run fsck manually (ie without -a or -p options).
If you are not familiar with the /etc/fstab file use the man fstab command to get a comprehensive explanation of each data column it contains.
The /dev/hde1, /dev/hdf2, and /dev/hdg1 partitions were replaced by the combined /dev/md0 partition. You therefore don't want the old partitions to be mounted again. Make sure that all references to them in this file are commented with a # at the beginning of the line or deleted entirely.
#/dev/hde1 /data1 ext3 defaults 1 2
#/dev/hdf2 /data2 ext3 defaults 1 2
#/dev/hdg1 /data3 ext3 defaults 1 2
Mount The New RAID Set
Use the mount command to mount the RAID set. You have your choice of methods:
The mount command's -a flag causes Linux to mount all the devices in the /etc/fstab file that have automounting enabled (default) and that are also not already mounted.
[root@bigboy tmp]# mount -a
You can also mount the device manually.
[root@bigboy tmp]# mount /dev/md0 /mnt/raid
Check The Status Of The New RAID
The /proc/mdstat file provides the current status of all the devices.
[root@bigboy tmp]# raidstart /dev/md0
[root@bigboy tmp]# cat /proc/mdstat
Personalities : [raid5]
read_ahead 1024 sectors
md0 : active raid5 hdg1[2] hde1[1] hdf2[0]
4120448 blocks level 5, 32k chunk, algorithm 3 [3/3] [UUU]
unused devices: <none>
[root@bigboy tmp]#
Conclusion
Linux software RAID provides redundancy across partitions and hard disks, but it tends to be slower and less reliable than RAID provided by a hardware-based RAID disk controller.
Hardware RAID configuration is usually done via the system BIOS when the server boots up, and once configured, it is absolutely transparent to Linux. Unlike software RAID, hardware RAID requires entire disks to be dedicated to the purpose and when combined with the fact that it usually requires faster SCSI hard disks and an additional controller card, it tends to be expensive.
Remember to take these factors into consideration when determining the right solution for your needs and research the topic thoroughly before proceeding. Weighing cost versus reliability is always a difficult choice in systems administration.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 1173
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2024 . All rights reserved