| CATEGORII DOCUMENTE |
Structura unui fisier - UNIX
Dupa cum s-a mentionat anterior, inodul are o tabela de cuprins prin care localizeaza datele fisierului pe disc. Intrucat fiecare bloc de pe disc este adresabil prin numar, tabela de cuprins contine un set de numere de blocuri disc. Daca datele unui fisier ar fi stocate intr-o sectiune contigua pe disc (fisierul ocupa o secventa liniara de blocuri disc), atunci memorarea adresei blocului de start si dimensiunea fisierului ar fi suficiente pentru a accesa toate datele din fisier. Insa, o astfel de strategie de alocare nu permite o dinamica a marimii fisierului in sistemul de fisiere fara riscul fragmentarii spatiului liber de memorare de pe disc. In plus, nucleul trebuie sa aloce si sa rezerve spatiu contiguu in sistemul de fisiere inainte de a permite efectuarea operatiunilor de marire a dimensiunii fisierului.
De exemplu, sa presupunem ca un utilizator creeaza trei fisiere A, B si C, fiecare ocupand cate 10 blocuri disc si ca sistemul aloca spatiu contiguu pentru cele trei fisiere.
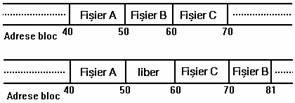
Figura 4. 5. Alocarea de fisiere in blocuri contigue si fragmentarea
spatiului liber
Daca dupa aceea utilizatorul doreste sa adauge 5 blocuri de date la fisierul din mijloc ,B, nucleul trebuie sa copieze fisierul B intr-un spatiu din sistemul de fisiere care permite stocarea a 15 blocuri.
O astfel de metoda care presupune costuri de executie ridicate, nu ar permite, in cazul de fata, utilizarea blocurilor disc ocupate anterior de datele fisierului B pentru a stoca fisiere ce necesita mai mult de 10 blocuri(figura 4.5.). Nucleul poate minimiza fragmentarea spatiului de memorare prin executarea periodica a unui set de proceduri destinate compactarii spatiului disponibil, insa aceasta operatie ar diminueaza din puterea de procesare.
Pentru o mai mare flexibilitate, nucleul aloca unui fisier cate un bloc la un moment dat, si elimina necesitatea pastrarii contigue a datelor fisierului, permitand ca acestea sa fie memorate peste tot in sistemul de fisiere. Dar aceasta schema de alocare complica sarcina localizarii datelor. Tabela de cuprins poate stoca o lista a numerelor de blocuri ce contin datele apartinand fisierului, dar calculele arata ca gestiunea unei liste liniare a blocurilor disc ale unui fisier in inod este dificila. Daca un bloc logic contine 1 ko, atunci un fisier de dimensiune 10 ko va avea nevoie de un index de 10 numere de bloc. Aceasta ar presupune fie variatia dimensiunii inodului in conformitate cu dimensiunea fisierului, fie necesitatea plasarii unei limite inferioare relative pentru dimensiunea fisierului.
Tabela de cuprins a blocurilor disc arata conform reprezentarii din figura 4.6, si asigura posibilitatea de a avea fisiere de dimensiuni mari.
UNIX system V are 13 intrari in tabela de cuprins a inodului. Intrarile marcate 'direct' contin numere de blocuri disc care contin date din fisier. Intrarea marcata 'simpla indirectare' refera un bloc ce contine o lista de numere de blocuri directe. Pentru a accesa date prin intermediul blocului de indirectare, nucleul trebuie sa-l citeasca, sa gaseasca intrarea corespunzatoare blocului direct in care se gasesc datele solicitate, si dupa aceea sa citeasca blocul direct. Blocul corespunzator intrarii marcate 'dubla indirectare' contine o lista de numere de blocuri de indirectare, iar blocul corespunzator intrarii 'tripla indirectare' contine o lista de numere de blocuri de dubla indirectare.
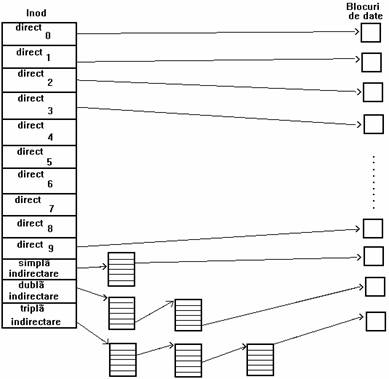
Figura 4. 6. Blocuri directe si de indirectare ale unui nod
In principiu metoda poate fi extinsa la structuri cu mai multe nivele de indirectare, insa structura prezentata este suficienta in practica. De exemplu, presupunand ca un bloc logic din sistemul de fisiere ocupa 1ko si ca un numar de bloc este adresabil pe 32 de biti, un bloc poate contine pana la 256 numere de bloc. Dimensiunea maxima a unui fisier poate depasi 16 Go prin utilizarea tuturor celor 13 intrari, dupa cum arata si calculul din figura 4.7.
Intrucat campul din inod in care se pastreaza dimensiunea fisierului este are 32 biti, dimensiunea unui fisier este limitata practic la 4 Go (232).
10 blocuri directe a cate 1ko fiecare ___________ 10 ko
1 bloc indirect de 256 blocuri directe ___________ 256 ko
1 bloc dublu de 256 blocuri indirecte___________ 64 Mo
1 bloc triplu de 256 blocuri duble ______________ 16 Go
Figura 4.7. Capacitatea unui fisier - blocuri de 1ko
Procesele acceseaza datele unui fisier specificand deplasamentul. Daca utilizatorul vede fisierul ca pe un sir de octeti, nucleul il vede ca un sir de blocuri, realizand in acest sens si o conversie. Fisierul incepe de la blocul logic 0 si continua pana la un numar de bloc logic corespunzator dimensiunii fisierului.
algoritm bmap
intrari: (1) inod
(2) deplasamentul
iesiri: (1) numarul blocului in sistemul de fisiere
(2) deplasamentul din bloc
(3) numar de octeti din bloc transferati prin operatii de I/O
(4) numarul blocului citit in avans
Figura 4.8. Obtinerea numarului blocului din sistemul de fisiere pe
baza deplasamentului
Nucleul acceseaza inodul si converteste numarul de bloc logic in numarul de bloc disc. Figura 4.8 prezinta algoritmul bmap care determina blocul fizic de disc corespunzator deplasamentului in fisier.
Consideram ca un fisier are blocurile dispuse conform figurii 4.9 si ca un bloc disc contine 1ko(1024octeti). Daca un proces intentioneaza sa acceseze octetul cu deplasamentul 9000, nucleul calculeaza ca octetul este in blocul direct 8 al fisierului (numarand de la 0). Apoi acceseaza (conform tabelei de cuprins a inodului) blocul cu numarul 367, iar octetul 808 din acesta reprezinta octetul 9000 din fisier.
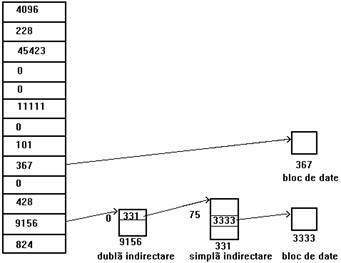
Figura 4. 9. Inodul si dispunerea blocurilor unui fisier
Daca un proces intentioneaza sa acceseze octetul cu deplasamentul 350 000 al unui fisier, el trebuie sa acceseze un bloc de dubla indirectare (conform figurii, numarul 9156). Deoarece un bloc de indirectare poate contine cel mult 256 numere de bloc, primul octet accesat prin blocul de dubla indirectare este octetul 272 384 (256 ko+10 ko) al fisierului. Astfel, octetul numarul 350 000 din fisier este octetul cu numarul 77 616 in blocul de dubla indirectata. Intrucat fiecare bloc de simpla indirectare acceseaza 256 ko, octetul numarul 350 000 trebuie sa fie in blocul de simpla indirectare cu numarul 331, corespunzator intrarii 0 in blocul de dubla indirectare. Deoarece fiecare bloc direct corespunzator unui bloc de simpla indirectare contine 1 ko, octetul numarul 77 616 al blocului de simpla indirectare este in blocul direct 75 al blocului de simpla indirectare, care are numarul 3333. In final, se determina ca octetul cu numarul 350 000 in fisier este octetul cu numarul 816 in blocul 3333.
Examinand mai atent figura, mai multe intrari de blocuri din inod sunt 0, ceea ce inseamna ca intrarile blocurilor logice nu contin date. Aceasta se intampla daca nici un proces nu a scris date in fisier la deplasamentul corespunzator acelor blocuri, si din acest motiv numerele de bloc raman la valoarea lor initiala, 0. Pentru aceste blocuri nu se aloca spatiu pe disc. Procesele pot realiza o astfel de dispunere a blocurilor unui fisier utilizand apelurile sistem lseek si write (descrise in capitolul urmator).
Conversia unui deplasament de valoare mare, de exemplu unul care implica o tripla indirectare, este o procedura dificila care poate cere nucleului sa acceseze pe langa inod si blocul de date cautat, inca trei blocuri disc. Chiar daca nucleul gaseste blocurile in buffer-ul cache, operatia este totusi consumatoare (de timp si resurse), deoarece nucleul trebuie sa faca multiple cereri de acces la buffere care pot fi blocate, trebuind in acest caz sa astepte deblocarea lor. In practica, eficienta algoritmului depinde de modul de utilizare a sistemului si de frecventa cu care utilizatorii acceseaza fisiere de dimensiuni mici sau mari. S-a observat ca majoritatea fisierelor intr-un sistem UNIX contin mai putin de 10 ko, si o parte insemnata dintre acestea chiar mai putin de 1 ko. Pentru ca cei 10 ko ai unui fisier sunt stocati in blocuri directe, majoritatea datele din fisier pot fi accesate printr-un singur acces la disc. In ciuda faptului ca accesarea fisierelor mari este o operatiune costisitoare, accesul la fisiere de dimensiuni obisnuite este rapid.
Accesul la sistemul de fisiere este cu atat mai rapid cu cat nucleul acceseaza mai multe date de pe disc in decursul unei operatii, altfel spus, cu cat dimensiunea blocurilor disc este mai mare. Folosirea blocurilor de dimensiuni mari (4 ko, 8 ko) aduce pe langa avantajul cresterii vitezei, si un dezavantaj: cresterea fragmentarii blocurilor (mari portiuni de spatiu de pe disc nu pot fi utilizate). De exemplu, daca dimensiunea blocului logic este de 8 o, atunci un fisier de dimensiune 12 o va folosi complet un bloc si unul pe jumatate. Cei 4 ko ramasi se irosesc, deoarece nu pot fi folositi ca spatiu de stocare.
Implemetarea Berkeley BSD 4.2 remediaza situatia prezentata anterior prin introducerea blocurilor fragment ce contin ultimele date (care nu completeaza un bloc) din diferite fisiere. Aceste blocuri au tot dimensiunea de 4 ko sau 8 ko, dar sunt organizate ca o succesiune antet-date, unde antetul pastreaza informatii referitoare la fisierul caruia ii apartine fragmentul de date care-l urmeaza. Pentru a identifica blocul fragment care-i pastreaza partea finala, fisierul pastreaza in ultima intrare adresa acestui bloc. Aceasta solutie va introduce o incetineala la accesul ultimului fragment.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 1336
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2024 . All rights reserved