| CATEGORII DOCUMENTE |
Subinterogari
Sunteti patronul unei firme. In ultima perioada unul dintre salariatii firmei, pe nume Ionescu, s-a remarcat in mod deosebit prin activitatea sa. Ati decis de aceea sa ii mariti salariul si pentru a decide cu cat sa-l mariti doriti sa aflati care sunt persoanele cu salariu mai mare decat salariul lui Ionescu si care sunt salariile castigate de acestia. Cum faceti acest lucru?
Mai intai veti determina salariul angajatului Ionescu:
SELECT salariul
FROM angajati
WHERE nume='Ionescu'
Sa notam cu S salariul returnat de aceasta comanda. Acum putem afisa foarte simplu angajatii cu salariu mai mare decat S
SELECT nume, prenume
FROM angajati
WHERE salariul>S
Intrebarea care se pune acum este daca nu exista posibilitatea de a uni aceste doua comenzi in una singura. Raspunsul este afirmativ. Vom inlocui in a doua comanda valoarea S cu comanda care a generat aceasta valoare astfel:
SELECT nume, prenume
FROM angajati
WHERE salariul > ( SELECT salariul
FROM angajati
WHERE nume='Ionescu' )
Asadar am inclus prima interogare in interiorul celei de a doua interogari. O astfel de interogare aflata in interiorul unei alte comenzi SQL se numeste subinterogare. Subinterogarile sunt intotdeauna rulate inaintea comenzii in care sunt incluse, doar pe baza rezultatelor returnate de subinterogari putandu-se obtine rezultatele interogarii exterioare subinterogarii.
Un proces similar cu modul de rulare al subinterogarilor este modul in care calculam expresiile cu paranteze (figura II.5.1).
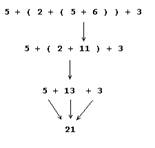
Figura II.5.1.
Subinterogarile sunt in general folosite atunci cand dorim sa afisam informatii dintr-o tabela pe baza unor informatii pe care le preluam din aceeasi tabela sau din alte tabele. De exemplu putem afisa angajatii care lucreaza in acelasi departament cu angajatul X si sunt mai tineri decat persoana X
Exista doua tipuri de subinterogari:
subinterogari simple care returneaza o singura linie;
subinterogari multiple care returneaza mai multe linii si/sau mai multe coloane.
Inainte de a prezenta fiecare din aceste tipuri de subinterogari trebuie sa subliniem cateva restrictii de utilizare a subinterogarilor:
o subinterogare va fi intotdeauna inclusa in paranteza
subinterogarea nu poate contine clauza ORDER BY
Subinterogarile simple, asa cum am precizat, vor returna intotdeauna o singura valoare.
Ele pot sa apara in clauza WHERE sau in clauza HAVING si sunt folosite impreuna cu operatorii < > <= >= <>
Vom prezenta cateva exemple folosind urmatoarele tabele:
Persoane (Id, IdFirma, Nume, Localitate, DataN)
Firme (Id, Nume, Localitate)
Dorim sa afisam toate persoanele care lucreaza la aceeasi firma la care lucreaza si Ionescu:
SELECT Nume FROM persoane
WHERE IdFirma = ( SELECT IdFirma
FROM angajati
WHERE nume = 'Ionescu')
Acelasi rezultat l-am putea obtine cu ajutorul unui selfjoin astfel:
SELECT p.nume
FROM persoane p, persoane i
WHERE p.IdFirma = i.IdFirma AND
i.nume = 'Ionescu'
insa folosirea subinterogarilor este mult mai usoara si mai naturala si in general este mai rapida.
Iata un exemplu de folosire a operatorului <> impreuna cu o subinterogare:
SELECT nume
FROM persoane
WHERE localitatea <> (SELECT localitatea FROM persoane
WHERE nume='Ionescu')
Comanda afiseaza toate persoanele care nu locuiesc in aceeasi localitate cu Ionescu.
Subinterogarile pot folosi functii de grup ca in exemplul urmator:
SELECT nume FROM persoane
WHERE DataN = (SELECT max(DataN) FROM persoane)
Aceasta comanda va afisa cea mai tanara persoana din tabela persoane, data sa de nastere este cea mai mare, adica este cea mai recenta data de nastere.
Similar putem utiliza subinterogarile simple in clauza HAVING. Sa vedem de exemplu cum putem afisa codul firmei cu cei mai multi angajati:
SELECT IdFirma FROM persoane
GROUP BY IdFirma
HAVING count(*) = ( SELECT max(count(*))
FROM persoane
GROUP BY IdFirma )
Subinterogarea determina mai intai numarul maxim de persoane angajate la o firma, iar apoi afiseaza Id-ul firmei care are numarul de angajati egal cu acest maxim.
Atentie! Am fi tentati sa scriem o comanda de forma:
SELECT DISTINCT IdFirma
FROM persoane
WHERE count(*) = ( SELECT max(count(*))
FROM persoane
GROUP BY IdFirma )
dar am precizat in capitolul anterior functiile de grup NU pot sa apara in clauza WHERE
Subinterogarile pot fi imbricate una in alta pe oricate nivele. Numarul maxim de nivele de imbricare a interogarilor este teoretic nelimitat. Singura limitare care poate interveni este data de dimensiunea bufferelor.
In exemplul urmator, am construit o interogare care afiseaza numele firmei care are numarul maxim de angajati. Aceasta interogare foloseste interogarea din exemplul anterior pentru a determina Id-ul firmei cu numar maxim de angajati, iar apoi cauta in tabela firme numele acestei firme.
SELECT nume
FROM firme
WHERE Id = (SELECT IdFirma
FROM persoane
GROUP BY IdFirma
HAVING count(*) = ( SELECT max(count(*))
GROUP BY IdFirma
Interesant este faptul ca in cadrul unei subinterogari se poate face referire la tabelele din clauza WHERE a interogarii parinte. Astfel daca dorim sa afisam toate persoanele care lucreaza in aceeasi localitate in care si locuiesc vom scrie astfel:
select nume
from persoane p
where localitate = ( select localitate
from firme f
where p.idfirma=f.id
Am folosit subinterogarea pentru a afla localitatea in care se gaseste firma la care lucreaza fiecare angajat in parte. Acest tip de subinterogari se numesc subinterogari corelate.
Am vazut cum putem utiliza subinterogarile simple. Vom studia acum cum utilizam subinterogarile care returneaza mai multe linii. Cand o subinterogare returneaza mai mult de o linie, nu mai este posibil sa folosim operatorii de comparatie < > <= >= <> , deoarece o valoare simpla nu poate fi comparata direct cu un set de valori. Va trebui sa comparam o valoare simpla cu fiecare valoare din setul de valori returnate de subinterogare. Pentru a realiza acest lucru vom folosi cuvintele cheie ANY si ALL impreuna cu operatorii de comparatie, pentru a determina daca o valoare este egala, mai mica sau mai mare decat orice valoare sau decat una din valorile din setul de date returnat de subinterogare.
Pentru a exemplifica modul de folosire a subinterogarilor multiple vom utiliza tabela jucatori cu urmatorul continut: Tabelul II.5.1. Tabela Jucatori
|
ID |
NUME |
RATING |
VARSTA |
LOCALITATE |
|
Ion |
Sibiu |
|||
|
Iulian |
Brasov |
|||
|
George |
Bucuresti |
|||
|
Paul |
Bucuresti |
|||
|
Andrei |
Sibiu |
|||
|
Marian |
Cluj-Napoca |
|||
|
Ilie |
Sibiu |
|||
|
Alin |
Brasov |
|||
|
Radu |
Cluj-Napoca |
|||
|
Vasile |
Iasi |
Cum aflam oare numele si localitatea jucatorilor a caror rating este egal cu al unui jucator sub de ani? Vom afla mai intai care sunt ratingurile jucatorilor sub de ani:
SELECT rating
FROM jucatori
WHERE varsta<21
Vom obtine trei valori ale ratingului si anume si respectiv : Tabelul II.5.2.
|
RATING |
apoi vom afisa persoanele a caror rating este sau
SELECT * FROM jucatori
WHERE rating IN ( 6, 2, 4 )
Rezultatul va fi cel din tabelul II.5.3. Tabelul II.5.3.
|
ID |
NUME |
RATING |
VARSTA |
LOCALITATE |
|
Iulian |
Brasov |
|||
|
Alin |
Brasov |
|||
|
Paul |
Bucuresti |
|||
|
Andrei |
Sibiu |
Aceste doua comenzi se pot scrie impreuna in una singura prin folosirea unei subinterogari multiple astfel:
SELECT * FROM jucatori
WHERE rating IN ( SELECT rating FROM jucatori
WHERE varsta<21 )
Ce se intampla daca o subinterogare multipla returneaza o valoare nula iar operatorul folosit este IN? De exemplu ce va afisa comanda:
SELECT * FROM jucatori
WHERE rating IN ( SELECT rating FROM jucatori
WHERE localitate='Sibiu')
Mai intai subinterogarea va afisa ratingurile tuturor persoanelor din Sibiu: Tabelul II.5.4.
|
RATING |
deci interogarea anterioara este echivalenta cu
SELECT * FROM jucatori WHERE rating IN ( 3, 4, NULL)
Sau SELECT * FROM jucatori
WHERE rating=3 OR rating=4 OR rating=NULL
insa din comparatia cu NULL nu rezulta nimic (NULL nu poate fi comparat decat cu operatorii IS NULL sau IS NOT NULL in rest nu vom obtine nici un rezultat), asadar se vor afisa doar jucatorii cu ratingul egal cu sau
|
ID |
NUME |
RATING |
VARSTA |
LOCALITATE |
|
Marian |
Cluj-Napoca |
|||
|
George |
Bucuresti |
|||
|
Ion |
Sibiu |
|||
|
Andrei |
Sibiu |
Tabelul II.5.5.
Daca insa subinterogarea va returna doar o singura valoare nula ca de exemplu comanda:
SELECT rating FROM jucatori
WHERE nume='Ilie'
Tabelul II.5.6.
|
RATING |
atunci interogarea exterioara, neavand cu ce alta valoare sa compare, nu va returna nici o linie:
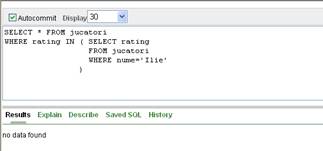
Figura II.5.2.
Fie urmatoarea comanda:
SELECT * FROM jucatori
WHERE rating > ALL ( SELECT rating FROM jucatori
WHERE varsta<21 )
Interogarea interioara returneaza multimea valorilor ratingurilor tuturor persoanelor cu varsta mai mica decat , iar interogarea exterioara va verifica fiecare persoana din tabela pentru a vedea daca ratingul sau este mai mare decat fiecare valoare returnata de catre interogarea interioara.
Interogarea interioara va returna valorile (tabelul II.5.2), deci comanda anterioara este echivalenta cu
SELECT * FROM jucatori
WHERE rating > ALL ( 2, 4, 6 )
sau
SELECT * FROM jucatori
WHERE rating>2 AND rating>4 AND rating>6
In concluzie am afisat toate persoanele al caror rating este mai mare decat ratingul tuturor persoanelor mai mici de 21 de ani.
Deci operatorul >ALL se poate interpreta ca mai mare decat valoarea maxima din multimea de valori returnata de catre subinterogare. Similar operatorul <ALL se poate interpreta ca mai mic decat valoarea minima din multimea valorilor returnate de catre subinterogare
Daca una dintre valorile returnate de catre interogarea interioara este nula atunci interogarea exterioara nu va afisa nici o linie daca este folosita optiunea ALL. Sa vedem un exemplu. Dorim sa afisam toate persoanele cu rating mai mare decat ratingurile tuturor persoanelor din Sibiu:
select * from jucatori
where rating >ALL ( select rating
from jucatori
where localitate='Sibiu' )
Interogarea interioara returneaza urmatoarele valorile si NULL (tabelul II.5.4.) si interogarea exterioara se poate scrie echivalent:
select * from jucatori
where rating>3 AND rating>6 AND rating>NULL
Conditia din clauza where are valoarea true doar daca toate cele trei conditii sunt adevarate. Insa expresia 'rating>NULL' are valoarea NULL, adica nu este nici adevarata nici falsa. Asadar conditia din clauza WHERE nu este adevarata niciodata si comanda nu afiseaza nici o linie.
Daca folosirea optiunii ALL se putea traduce printr-o conditie compusa cu operatorul AND, in cazul optiunii ANY se va putea traduce conditia in alta conditie care foloseste operatorul OR
Fie urmatoarea comanda:
select * from jucatori
where rating >ANY ( SELECT rating FROM jucatori
WHERE varsta<21 )
Am vazut ca interogarea interioara returneaza valorile si (tabelul II.5.2) Comanda exterioara va afisa toti jucatorii care au un rating mai mare decat a oricarui jucator sub 21 de ani, sau altfel spus se afiseaza persoanele cu rating mai mare decat a cel putin unei persoane cu varsta sub de ani.
Tabelul II.5.7.
|
ID |
NUME |
RATING |
VARSTA |
LOCALITATE |
|
Vasile |
Iasi |
|||
|
Iulian |
Brasov |
|||
|
Andrei |
Sibiu |
|||
|
Ion |
Sibiu |
|||
|
Marian |
Cluj-Napoca |
|||
|
George |
Bucuresti |
Putem spune ca operatorul >ANY poate fi interpretat ca mai mare decat valoarea minima din multimea de valori returnata de catre subinterogare. Similar operatorul <ANY se poate interpreta ca mai mic decat valoarea maxima din multimea valorilor returnate catre subinterogare
Daca una din valorile returnate de catre interogarea interioara este nula, interogarea exterioara poate afisa totusi ceva. De exemplu comanda
SELECT * FROM jucatori
WHERE rating >ANY ( SELECT rating FROM jucatori
WHERE localitate='Sibiu' )
va afisa Tabelul II.5.8.
|
ID |
NUME |
RATING |
VARSTA |
LOCALITATE |
|
Vasile |
Iasi |
|||
|
Iulian |
Brasov |
|||
|
Andrei |
Sibiu |
Acest lucru se intampla deoarece comanda data se poate scrie echivalent
SELECT * FROM jucatori
WHERE rating >ANY ( 3, 4, NULL )
deoarece subinterogarea returneaza valorile si NULL (tabelul II.5.4.), si aceasta comanda se poate scrie si
SELECT * FROM jucatori
WHERE rating>3 OR rating>4 OR rating>NULL
Conditia din WHERE este adevarata daca cel putin una din cele trei conditii este adevarata. Cum ultima conditie, rating>NULL, nu va fi niciodata adevarata, este suficient ca ratingul jucatorului sa fie mai mare decat sau mai mare decat , pentru ca el sa fie afisat.
Daca insa subinterogarea va returna o singura valoare nenula, si nimic altceva, atunci comanda exterioara nu va afisa nimic:
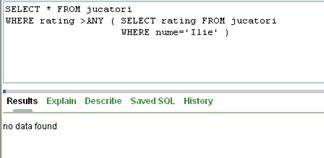
Figura II.5.3.
Modul in care se pot folosi optiunile ANY IN si ALL se pot rezuma in figura II.5.4.
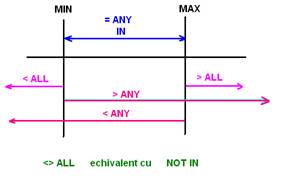
Figura II.5.4.
Echivalentele ce se pot folosi cu aceste optiuni sunt rezumate in tabelul urmator:
Tabelul II.5.9.
|
IN |
=ANY |
|
NOT IN |
<> ALL |
|
< ANY |
< maxim |
|
> ANY |
> minim |
|
< ALL |
< minim |
|
> ALL |
> maxim |
Putem folosi operatorul EXISTS pentru a verifica daca o subinterogare returneaza vreo linie. De obicei se foloseste acest operator impreuna cu subinterogari corelate. De exemplu comanda urmatoare afiseaza toti angajatii care sunt managerii altor angajati:
SELECT employee_id, first_name, last_name
FROM employees a
WHERE EXISTS (SELECT employee_id FROM employees b
WHERE b.manager_id=a.employee_id)
In subinterogare am determinat angajatii coordonati de catre un angajat afisat de catre interogarea exterioara.
Evident aceasta comanda o putem transcrie cu ajutorul operatorului IN astfel:
SELECT employee_id, first_name, last_name
FROM employees a
WHERE employee_id IN
(SELECT employee_id FROM employees b
WHERE a.employee_id=b.employee_id)
Este destul de usor de dedus ca folosirea operatorului EXISTS ofera performante mai mari intrucat IN compara fiecare valoare returnata de catre interogarea exterioara cu fiecare valoare returnata de subinterogare, pe cand operatorul EXISTS verifica doar existenta a cel putin unei linii returnata de subinterogare, fara a face nici o comparatie.
O subinterogare multipla poate fi folosita si in clauza FROM a unei interogari ca in exemplul urmator:
SELECT a.employee_id, first_name, last_name, nrang
FROM employees a, (SELECT manager_id, count(*) nrang
FROM employees GROUP BY manager_id
HAVING count(*)>0) b
WHERE a.employee_id=b.manager_id
care afiseaza id-ul, numele, prenumele si numarul de subalterni ai tuturor managerilor (tabelul II.5.10).
Tabelul II.5.10.
EMPLOYEE_ID |
FIRST_NAME |
LAST_NAME |
NRANG |
|
Steven |
King | ||
|
Neena |
Kochhar | ||
|
Lex |
De Haan | ||
|
Alexander |
Hunold | ||
|
Kevin |
Mourgos | ||
|
Eleni |
Zlotkey | ||
|
Michael |
Hartstein | ||
|
Shelley |
Higgins |
Dupa etapa de modelare a bazelor de date, primul pas in realizarea unei aplicatii de baze de date consta in crearea obiectelor ce compun baza de date: tabele, indexi, vederi, sinonime etc.
Crearea tabelelor, presupune stabilirea numelor tabelelor si a coloanelor ce le compun, stabilirea tipurilor de date pe care le au coloanele tabelei, dar si declararea restrictiilor (constrangerilor) care asigura integritatea si coerenta informatiilor din baza de date.
Pentru crearea unei tabele se foloseste comanda CREATE TABLE. Cea mai simpla forma a acestei comenzi, in care pentru moment nu se definesc valori implicite pentru coloane si nu definim nici o restrictie este:
CREATE TABLE numetabel
( coloana1 tip1,
coloana2 tip2,
coloanan tipn )
unde - numetabel este numele atribuit tabelului nou creat. Acest nume trebuie sa respecte restrictiile privind definirea numelor despre care a discutat in capitolul II.1.
coloana1, coloana2, ., coloanan sunt numele coloanelor din tabela nou creata
tip1, tip2, ., tipn reprezinta tipul datelor ce vor fi retinute in coloanele tabelei nou create si dimensiunea (daca este cazul). Principalele tipurile de date existente in Oracle au fost prezentate in capitolul I.3. Pe langa numele tipului respectiv se precizeaza in paranteza lungimea tipului, respectiv numarul de caractere pentru un sir de caractere, sau numarul total de cifre si numarul de cifre de dupa virgula pentru valorile numerice.
De exemplu, pentru crearea tabelei corespunzatoare entitatii Jucator despre care am discutat in capitolul I.3 folosim comanda:
CREATE TABLE jucatori (
nr_legitimatie NUMBER(3),
nume VARCHAR2(30), prenume VARCHAR2(30),
data_nasterii DATE, adresa VARCHAR2(50),
telefon CHAR(13), email VARCHAR2(30),
cod_echipa NUMBER(3) )
Deocamdata nu am definit cheia primara si cheia straina.
Pentru crearea tabelei ECHIPE folosim comanda:
CREATE TABLE jucatori (
cod NUMBER(3),
nume VARCHAR2(30), localitate VARCHAR2(30),
adresa_club VARCHAR2(50) )
Iata inca un exemplu:
CREATE TABLE elevi (
id NUMBER(5),
nume VARCHAR2(30), prenume VARCHAR2(30),
bursier CHAR(1), media NUMBER(4,2) )
In acest exemplu, pentru tipul campului media s-au precizat doua valori. Prima ( ) reprezinta numarul total de cifre ale numarului, iar al doilea numar reprezinta numarul de cifre zecimale ( ). Daca sunt introduse mai mult de doua zecimale se va face rotunjire la doua zecimale. La partea intreaga pot exista doua cifre. Daca numarul introdus are mai mult de doua cifre la partea intreaga se va semnala o eroare. De asemenea, am declarat un camp bursier, care ne va ajuta sa memoram daca un elev este sau nu bursier. Insa, in Oracle nu exista tipul logic (sau boolean), motiv pentru care am optat pentru tipul CHAR(1), pentru un elev bursier vom memora in acest camp valoarea 'D', pentru ceilalti elevi acest camp ramanand necompletat.
O alta metoda de creare a unei tabele defineste structura pe baza structurii unei tabele deja existente si in acelasi timp copiaza datele din tabela deja existenta. Datele care se copiaza din tabela deja existenta (liniile dar si coloanele ce se copiaza) se precizeaza prin clauza AS urmata de o subinterogare. De exemplu comanda urmatoare creeaza tabela bursieri pe baza tabelei elevi deja existenta:
CREATE TABLE bursieri
AS SELECT id, nume, prenume FROM elevi
WHERE bursier='D'
Se observa ca nu sunt copiate coloanele media si bursier din tabela elevi
Sintaxa comenzii CREATE TABLE prezentata anterior este una mult simplificata. In cadrul acestei comenzi putem utiliza clauza DEFAULT pentru a defini o valoare implicita pentru o coloana a tabelei. Aceasta clauza precizeaza ce valoare va lua un atribut atunci cand, la inserarea unei linii in tabela, nu se specifica in mod explicit valoarea atributului respectiv. Clauza DEFAULT apare dupa precizarea tipului coloanei si este urmata de constanta care defineste valoarea implicita:
CREATE TABLE angajati
( nume varchar2(30), prenume varchar2(30),
adresa varchar2(50) DEFAULT 'Necunoscuta',
localitate varchar2(20) DEFAULT 'Bucuresti',
data_ang date DEFAULT SYSDATE,
salar NUMBER(5) DEFAULT 800 )
Dupa cum se vede in exemplul anterior valoarea implicita poate fi o constanta dar poate fi de asemenea o expresie, sau o una din functiile speciale SYSDATE si USER (care returneaza numele utilizatorului curent) dar nu poate fi numele altei coloane sau al unei functii definite de utilizator.
Pentru o coloana pentru care nu s-a definit o valoare implicita, si nu face parte din cheia primara sau dintr-o restrictie NOT NULL sau UNIQUE (despre care povestim mai tarziu), sistemul va considera ca valoare implicita valoarea NULL
Dupa cum am precizat in prima parte a manualului, orice baza de date trebuie sa stabileasca regulile de integritate care sa garanteze ca datele introduse in baza de date sunt corecte si valide.
Aceasta inseamna ca daca exista o regula sau restrictie asupra unei entitati, atunci datele introduse in baza de date respecta aceste restrictii.
Regulile de integritate se definesc la crearea tabelelor folosind constrangerile. Constrangerile pot fi clasificate in:
constrangeri de domeniu, care definesc valorile pe care le poate lua un atribut (NOT NULL UNIQUE CHECK
constrangeri de integritate a tabelei, precizand cheia primara a acesteia
constrangeri de integritate referentiala, care asigura coerenta intre cheile primare (sau unice) si cheile straine corespunzatoare (FOREIGN KEY
Pe de alta parte constrangerile se pot clasifica dupa nivelul la care sunt definite in:
contrangeri la nivel de tabela care pot actiona asupra unei combinatii de coloane
constrangeri la nivel de coloana.
Constrangerile NOT NULL se pot defini doar la nivel de coloana.
Constrangerile UNIQUE PRIMARY KEY FOREIGN KEY si CHECK pot fi definite atat la nivel de coloana cat si la nivel de tabela. Totusi daca aceste constrangeri implica mai multe coloane atunci trebuie sa fie definite obligatoriu la nivel de tabela.
Daca o restrictie se defineste la nivel de coloana se va folosi sintaxa:
nume_coloana tip_data tip_constr
sau
nume_coloana tip_data CONSTRAINT nume_constr tip_constr
La nivel de tabela folosim sintaxa
tip_constr
sau
CONSTRAINT nume_constr tip_constr
Se observa ca putem decide sa dam un nume explicit unei constrangeri, ceea ce usureaza referirea ulterioara la acea constrangere, sau putem sa nu definim un nume explicit, caz in care sistemul va genera un nume implicit. Daca se foloseste cuvantul CONSTRAINT, atunci obligatoriu acesta va fi urmat de numele dat explicit constrangerii.
Vom prezenta in continuare modul de definire al fiecareia dintre aceste constrangeri.
Dupa cum am vazut in capitolele anterioare, NULL este o valoare speciala. Necompletarea in tabela a unei celule conduce la completarea ei cu valoarea NULL, semnificand faptul ca celula respectiva are de fapt o valoare nedefinita.
Intr-un ERD, un atribut poate fi obligatoriu, lucru pe care il marcam cu o steluta in fata atributului respectiv. In baza de date aceasta conditie se traduce prin faptul ca valoarea coloanei respective trebuie obligatoriu completata, adica nu poate contine valoarea NULL. Pentru definirea acestui tip de restrictii folosim restrictia NOT NULL pentru coloana respectiva, fie la crearea tabelei fie mai tarziu la modificarea structurii acesteia.
La crearea tabelei, restrictia NOT NULL se precizeaza pentru fiecare coloana ce trebuie sa respecte aceasta restrictie, dupa precizarea tipului coloanei respective astfel:
CREATE TABLE angajati
( nume varchar2(30) NOT NULL,
prenume varchar2(30),
localitate varchar2(20) DEFAULT 'Iasi' NOT NULL
Se observa ca restrictia NOT NULL a putut fi folosita in combinatie cu clauza DEFAULT
Cheia primara este o coloana sau o combinatie de coloane care identifica in mod unic liniile unei tabele. Coloanele care fac parte din cheia primara vor fi automat de tip NOT NULL fara ca acest lucru sa mai trebuiasca precizat explicit. Cand cheia primara este compusa dintr-o singura coloana, definirea acesteia se poate face la nivel de coloana ca in exemplul urmator:
CREATE TABLE angajati
( cnp number(13) PRIMARY KEY
nume varchar2(30),
sau daca dorim sa atribuim un nume constrangerii putem scrie
CREATE TABLE angajati
( cnp number(13) CONSTRAINT angajati_pk PRIMARY KEY
nume varchar2(30),
Definirea cheii primare la nivel de tabela se poate face si atunci cand cheia este compusa dintr-un singur camp, dar este obligatorie atunci cand este compusa din mai multe coloane.
De exemplu tabela carti are cheia primara compusa din combinatia coloanelor titlu autor data_aparitie. Comanda de creare a acestei tabele se poate scrie:
CREATE TABLE carti
( titlu VARCHAR2(30),
autor VARHAR2(30),
data_ap DATE,
format VARCHAR2(10),
nr_pag NUMBER(3),
CONSTRAINT carti_pk
PRIMARY KEY (titlu, autor, data_ap)
sau simplu
CREATE TABLE carti
( titlu VARCHAR2(30),
autor VARCHAR2(30),
data_ap DATE,
format VARCHAR2(10),
nr_pag NUMBER(3),
PRIMARY KEY (titlu, autor, data_ap)
Sintaxa generala de definire a cheii primare este deci
PRIMARY KEY (lista_coloane)
Similar se poate defini si restrictia UNIQUE care precizeaza ca valoare coloanei definita ca UNIQUE, sau combinatia valorilor coloanelor ce definesc restrictia UNIQUE trebuie sa fie unica pentru toate liniile din tabela. Cu alte cuvinte, intr-o coloana definita ca UNIQUE nu pot exista valori duplicate.
Atentie! Coloanele definite ca UNIQUE pot contine valori NULL, iar acestea pot fi oricate, adica valoare NULL este singura valoare ce poate fi duplicata intr-o coloana UNIQUE
Exemple:
CREATE TABLE elevi
( nr_matr NUMBER(5) PRIMARY KEY,
cnp NUMBER(13) UNIQUE,
nume VARCHAR2(30),
prenume VARHAR2(30)
sau
CREATE TABLE elevi
( nr_matr NUMBER(5) PRIMARY KEY,
cnp NUMBER(13) CONSTRAINT cnp_uk UNIQUE,
nume VARCHAR2(30),
prenume VARHAR2(30)
sau
CREATE TABLE carti
( ISBN varchar2(20) PRIMARY KEY,
titlu VARCHAR2(30),
autor VARCHAR2(30),
data_ap DATE,
format VARCHAR2(10),
nr_pag NUMBER(3),
UNIQUE (titlu, autor, data_ap)
sau
CREATE TABLE carti
( ISBN varchar2(20) PRIMARY KEY,
titlu VARCHAR2(30),
autor VARCHAR2(30),
data_ap DATE,
format VARCHAR2(10),
nr_pag NUMBER(3),
CONSTRAINT carti_uk UNIQUE (titlu, autor, data_ap)
Restrictiile referentiale sunt categoria de restrictii care creeaza cele mai mari probleme in gestiunea bazelor de date.
Pentru exemplificarea modului de definire a chei straine vom relua un exemplu de ERD din capitolul I.3 si anume cel din figura II.6.1.
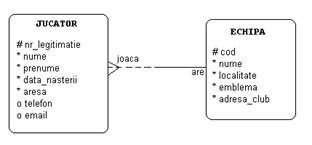
Crearea tabelei jucatori corespunzatoare entitatii JUCATOR din acest ERD se va scrie:
CREATE TABLE jucatori
( nr_legitimatie NUMBER(5) PRIMARY KEY,
cod_echipa NUMBER(3)
REFERENCES echipe(cod)
nume VARCHAR2(30) NOT NULL,
prenume VARCHAR2(30) NOT NULL,
datan DATE NOT NULL,
adresa VARCHAR2(60) NOT NULL,
telefon NUMBER(3),
email VARCHAR2(30)
sau
CREATE TABLE jucatori
( nr_legitimatie NUMBER(5) PRIMARY KEY,
cod_echipa NUMBER(3) CONSTRAINT ech_fk
REFERENCES echipe(cod),
nume VARCHAR2(30) NOT NULL,
prenume VARCHAR2(30) NOT NULL,
datan DATE NOT NULL,
adresa VARCHAR2(60) NOT NULL,
telefon NUMBER(3),
email VARCHAR2(30)
sau la nivel de tabela
CREATE TABLE jucatori
( nr_legitimatie NUMBER(5) PRIMARY KEY,
cod_echipa NUMBER(3),
nume VARCHAR2(30) NOT NULL,
prenume VARCHAR2(30) NOT NULL,
datan DATE NOT NULL,
adresa VARCHAR2(60) NOT NULL,
telefon NUMBER(3),
email VARCHAR2(30),
FOREIGN KEY (cod_echipa)
REFERENCES echipe(cod)
sau
CREATE TABLE jucatori
( nr_legitimatie NUMBER(5) PRIMARY KEY,
cod_echipa NUMBER(3),
nume VARCHAR2(30) NOT NULL,
prenume VARCHAR2(30) NOT NULL,
datan DATE NOT NULL,
adresa VARCHAR2(60) NOT NULL,
telefon NUMBER(3),
email VARCHAR2(30),
CONSTRAINT test_fk FOREIGN KEY (cod_echipa)
REFERENCES echipe(cod)
Sintaxa generala este asadar la nivel de tabela:
[CONSTRAINT nume_const] FOREIGN KEY (lista_coloane)
REFERENCES tabela_parinte(lista_coloane_referite)
iar la nivel de coloana
[CONSTRAINT nume_const]
REFERENCES tabela_parinte(lista_coloane_referite)
La definirea unei chei straine se poate utiliza o clauza suplimentara ON DELETE CASCADE care precizeaza ca la stergerea unei linii din tabela parinte se vor sterge automat din tabela copil acele linii care fac referire la linia ce se sterge din tabela parinte. De exemplu, prin folosirea acestei optiuni, la stergerea unei echipe se vor sterge automat toti jucatorii de la acea echipa.
Aceasta clauza se foloseste astfel:
CREATE TABLE jucatori
( nr_legitimatie NUMBER(5) PRIMARY KEY,
cod_echipa NUMBER(3) CONSTRAINT ech_fk
REFERENCES echipe(cod) ON DELETE CASCADE,
nume VARCHAR2(30) NOT NULL,
prenume VARCHAR2(30) NOT NULL,
datan DATE NOT NULL,
adresa VARCHAR2(60) NOT NULL,
telefon NUMBER(3),
email VARCHAR2(30)
O alta optiune este ON DELETE SET NULL care face ca la stergerea unui parinte, valorile cheii straine din liniile tabelei copil care fac referire la linia stearsa vor fi setate pe NULL. De exemplu la stergerea unei echipe, jucatorii acesteia vor deveni liberi de contract, deci codul echipei la care joaca va fi setat pe NULL
CREATE TABLE jucatori
( nr_legitimatie NUMBER(5) PRIMARY KEY,
cod_echipa NUMBER(3) CONSTRAINT ech_fk
REFERENCES echipe(cod) ON DELETE SET NULL,
nume VARCHAR2(30) NOT NULL,
prenume VARCHAR2(30) NOT NULL,
datan DATE NOT NULL,
adresa VARCHAR2(60) NOT NULL,
telefon NUMBER(3),
email VARCHAR2(30)
Implicit, fara precizarea uneia din aceste doua optiuni, Oracle va interzice stergerea unei linii din tabela parinte atata timp cat mai exista macar o linie in tabela copil care face referire la ea.
Sa vedem acum cum cream tabela inscrieri corespunzatoare entitatii inscriere din figura II.6.2. Observam ca in cheia primara intra si coloanele ce fac parte din cheia straina.
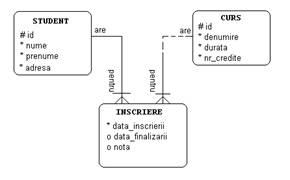
CREATE TABLE inscriere (
id_student NUMBER(5) NOT NULL
REFERENCES studenti(id),
id_curs NUMBER(5) NOT NULL REFERENCES cursuri(id),
data_inscrierii DATE DEFAULT sysdate NOT NULL,
data_finalizarii DATE,
nota NUMBER (4,2),
PRIMARY KEY (id_student, id_curs, data_inscrierii)
Acest tip de constrangeri specifica o conditie ce trebuie sa fie indeplinita de datele introduse in coloana (sau coloanele) asupra careia actioneaza. O astfel de constrangere poate limita valorile care pot fi introduse in cadrul unei coloane.
Iata cateva exemple de reguli de validare pentru tabela elevi care pot fi implementate cu ajutorul constrangerilor de tip CHECK
numele si prenumele unui elev trebuie sa inceapa cu o majuscula restul literelor fiind litere mici
nota unui elev nu poate fi mai mare de
campul bursier poate avea doar valorile 'D' si NULL
numarul de absente nemotivate va fi cel mult egal cu numarul total de absente
Crearea tabelei elevi in aceasta situatie se poate scrie astfel:
CREATE TABLE elevi
( nr_matr NUMBER(5) PRIMARY KEY,
cnp NUMBER(13) CONSTRAINT cnp_uk UNIQUE,
nume VARCHAR2(30) NOT NULL
CHECK nume=LTRIM(INITCAP(nume)),
prenume VARHAR2(30) NOT NULL
CHECK nume=LTRIM(INITCAP(nume))
bursier CHAR(1) CHECK bursier='D',
nota NUMBER(4,2)
CONSTRAINT nota_ck CHECK nota<=10
total_abs NUMBER(3),
abs_nemotiv NUMBER(3),
CHECK (abs_nemotiv<=total_abs)
Modificarea structurii unui tabel se realizeaza cu ajutorul comenzii ALTER TABLE, permitand adaugarea sau stergerea unei coloane, modificarea definitiei unei coloane, crearea unei noi constrangeri sau stergerea unor constrangeri existente.
Vom prezenta in continuare, pe scurt, fiecare dintre aceste operatii.
Se realizeaza folosind clauza ADD a comenzii ALTER TABLE. Sintaxa este similara cu cea a crearii unei coloane in cadrul comenzii CREATE TABLE. De exemplu comenda urmatoare adauga o colona nrgoluri la tabela jucatori
ALTER TABLE jucatori
ADD nrgoluri NUMBER(4)
Coloana nou creata va deveni ultima coloana a tabelei. Daca tabela contine deja date, coloana adaugata va fi completata cu NULL in toate liniile existente. De aceea nu vom putea adauga o coloana cu restrictia NOT NULL la o tabela ce contine deja date.
Asadar o comanda de forma:
ALTER TABLE test ADD ex NUMBER(3) NOT NULL
sau
ALTER TABLE test ADD ex NUMBER(3) PRIMARY KEY
Sunt permise doar daca tabela nu contine deja date.
Insa comanda
ALTER TABLE test ADD ex NUMBER(3) UNIQUE
poate fi folosita in orice moment, deoarece dupa cum am precizat o coloana UNIQUE poate contine oricate valori NULL
Se realizeaza folosind clauza DROP COLUMN a comenzii ALTER TABLE
ALTER TABLE elevi DROP COLUMN bursier
Asa cum este si normal, stergerea unei coloane duce automat si la stergerea restrictiilor definite pentru aceasta si care nu implica si alte coloane.
De exemplu daca tabela elevi a fost creata cu ajutorul comenzii de la pagina , putem sterge fara probleme coloana nume
ALTER TABLE elevi DROP COLUMN nume
chiar daca avem definita o restrictie de tip CHECK la nivelul acestei coloane. De asemenea putem sterge coloana nr_matr, chiar daca aceasta este cheia primara a tabelei:
insa se va genera o eroare daca incercam sa stergem coloana abs_nemotiv, din cauza restrictiei definita la nivel de tabela si care implica coloanele abs_nemotiv si total_abs
O varianta ar fi sa stergem mai intai toate restrictiile in care apare coloana ce dorim sa o stergem, sau sa folosim clauza CASCADE CONSTRAINTS astfel:
Poate fi facuta cu clauza MODIFY ca in exemplul urmator:
ATLER TABLE elevi MODIFY prenume VARCHAR2(50)
Prin care am modificat tipul coloanei prenume de le VARCHAR2(30) la VARCHAR2(50), deoarece am descoperit la un moment dat ca exista elevi al caror prenume (compus) are mai mult de 30 de caractere.
Marirea numarului de caractere pentru o coloana de tip sir de caractere se poate face fara nici o problema, insa micsorarea acestei dimensiuni se poate face doar daca tabela este goala, sau coloana respectiva contine doar valori NULL
Tot cu optiunea MODIFY se poate modifica, sau se poate stabili o valoare implicita, daca nu exista deja una astfel:
ALTER TABLE elevi MODIFY bursier CHAR(1)
DEFAULT 'D'
insa aceasta valoare implicita nu va afecta liniile deja existente in tabela, ci doar liniile ce vor fi introduSe in continuare.
Sintaxa comenzii pentru adaugarea unei constrangeri la nivel de tabela este:
ALTER TABLE nume_tabela
ADD CONSTRAINT nume_constr definitie_constr
sau
ALTER TABLE nume_tabela
ADD definitie_constr
De exemplu comanda urmatoare defineste cheia primara pentru o tabela fictiva
ALTER TABLE tabelaexemplu
ADD PRIMARY KEY (coloana1)
Aceasta comanda poate fi scrisa echivalent si
ALTER TABLE tabelaexemplu
ADD CONSTRAINT tabelaexemplu_pk PRIMARY KEY (coloana1)
Singura constrangere ce nu poate fi adaugata in acest fel este NOT NULL, care poate fi adaugata doar prin modificarea coloanei restective folosind MODIFY:
ALTER TABLE tabelaexemplu
MODIFY coloana2 VARCHAR2(20) NOT NULL
Stergerea unei constangeri se face folosind optiunea DROP CONSTRAINT astfel:
ALTER TABLE nume_tabela
DROP CONSTRAINT nume_constrangere
sau
ALTER TABLE nume_tabela DROP PRIMARY KEY
sau
ALTER TABLE nume_tabela
DROP UNIQUE(lista_coloane)
In unele situatii, este necesara o dezactivare temporara si apoi reactivarea unei constrangeri. Acest lucru se realizeaza astfel:
ALTER TABLE nume_tabela DISABLE/ENABLE
sau
ALTER TABLE nume_tabela DISABLE/ENABLE
sau
ALTER TABLE nume_tabela DISABLE/ENABLE
Clauza CASCADE precizeaza ca si constrangerile dependente sunt deasemenea afectate.
Pana in acest moment am exemplificat diverse comenzi pe tabele care am presupus ca exista deja in baza de date si sunt deja incarcate cu date. Insa atunci cand veti face propriile voastre aplicatii va trebui sa stiti sa introduceti singuri date in tabele, sa modificati unele dintre aceste date, sa stergeti la un moment dat o parte dintre ele etc.
Pentru a adauga linii intr-o tabela se utilizeaza comanda INSERT. Forma generala a acestei comenzi este urmatoarea:
INSERT INTO nume_tabela (lista_coloane)
VALUES (lista_valori);
unde nume_tabela este numele tabelei in care vom insera noua linie,
lista_coloane precizeaza exact coloanele pe care dorim sa le populam. Aceasta lista este optionala (ea poate lipsi).
lista_valori specifica valorile pe care le va lua, pe rand, coloanele din lista de coloane.
Lista de coloane si lista de valori trebuie sa aiba acelasi numar de elemente, si in plus coloanele si valorile din cele doua liste trebuie sa corespunda ca ordine si tip.
Valorile specificate in lista (sau cele implicite) intr-o comanda INSERT, trebuie sa satisfaca toate constrangerile aplicabile coloanelor respective (ca de exemplu PRIMARY KEY CHECK NOT NULL
Daca la rularea unei comenzi INSERT este generata o eroare de sintaxa, sau a fost incalcata o constrangere, linia nu este adaugata la tabela ci se va genera un mesaj de eroare.
Atunci cand din lista de coloane este omisa o coloana, Oracle va completa valoarea acelei coloane cu NULL, cu exceptia situatiei cand a fost definita o valoare implicita pentru coloana respectiva. In acest caz, Oracle completeaza coloana cu valoarea implicita. Daca omiteti din lista de coloane o coloana care nu poate avea valoarea NULL (s-a definit o restrictie NOT NULL sau PRIMARY KEY), si nu este definita o valoare implicita pentru acea coloana, se va genera o eroare.
Pentru a exemplifica modul de functionare a comenzii INSERT vom crea tabela jucatori
create table jucatori(
id NUMBER(5) PRIMARY KEY,
nume VARCHAR2(30) NOT NULL,
prenume VARCHAR2(30),
rating NUMBER(1) CHECK (rating between 1 and 5),
varsta NUMBER(2),
localitatea VARCHAR2(30) DEFAULT 'Timisoara',
email VARCHAR2(30) UNIQUE
O comanda completa de inserare a unei linii in aceasta tabela se poate scrie:
insert into jucatori (id, nume, prenume, rating, varsta,
localitatea, email)
values (18, 'Ionescu', NULL, 3, 30,
'Sibiu', 'user18@games.ro')
Fara a mai specifica coloanele putem scrie urmatoarea comanda, in care am tinut cont de ordinea coloanelor in tabela:
insert into jucatori values (11, 'Georgescu',
'Valeriu', 1, 18, 'Bucuresti', 'user11@games.ro')
Comanda urmatoare are ca efect completarea coloanelor id, nume, prenume cu valorile specificate in lista de valori iar coloanele rating, varsta, localitatea, email cu valorile implicite pentru aceste coloane, adica 'Timisoara' pentru localitate si respectiv NULL pentru rating, varsta, email
insert into jucatori (id, nume, prenume)
values (22, 'Vasilescu', 'Anca')

Figura II.7.1
Desi campul email are definita o restrictie UNIQUE, putem insera inca o valoare NULL in aceasta coloana, doar valorile nenule trebuind sa fie unice. Observati in comanda urmatoare cum s-a precizat ca dorim setarea valorii implicite si a valorii NULL pentru campurile localitate, rating si email
insert into jucatori (id, nume, prenume, rating, varsta,
localitatea, email)
values (37, 'Enescu', 'Monica', NULL, 26,
DEFAULT, NULL)

Figura II.7.2
Nu putem insa initializa coloanele id sau nume cu o valoare implicita, aceasta valoare implicita fiind in acest caz valoare NULL, care nu este permisa pentru cheia primara sau pentru o coloana avand restrictia NOT NULL
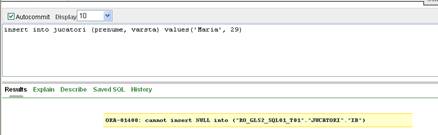
Figura II.7.3.
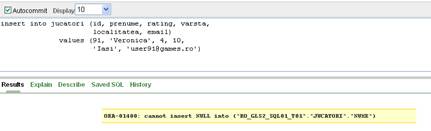
Figura II.7.4.
Pentru completarea unui camp putem folosi o subinterogare ca in urmatorul exemplu:
insert into jucatori (id, nume, prenume)
values ((select max(id)+1 from jucatori),
'Plesca','Ovidiu')
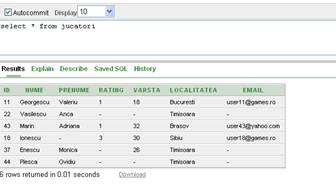
Figura II.7.5.
In Oracle este permisa adaugarea mai multor linii simultan prin preluarea datelor din alte tabele, cu ajutorul unei subinterogari. Comanda urmatoare, de exemplu, preia toti angajatii din tabela employees care au job_id-ul egal cu 'IT_PROG' si ii insereaza in tabela jucatori
insert into jucatori (id, nume)
select employee_id, last_name from employees
where job_id='IT_PROG'
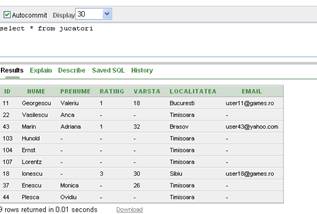
Figura II.7.6.
Stergerea uneia sau mai multor linii dintr-o tabela se face utilizand comanda DELETE a carei sintaxa este:
DELETE FROM nume_tabela WHERE conditie
Liniile care se vor sterge sunt selectate folosind clauza WHERE
DELETE FROM jucatori WHERE id>100
Stergerea liniilor se poate face si pe baza valorilor returnate de catre o subinterogare:
DELETE FROM jucatori WHERE id <
(SELECT id FROM jucatori WHERE nume='Ionescu')
Daca este omisa clauza WHERE, se vor sterge toate liniile din tabela, insa structura tabelei ramane (se sterge doar continutul tabelei, nu si tabela propriu-zisa). Deci comanda:
DELETE FROM jucatori
sterge toate liniile din tabela jucatori. Atentie! Aceste linii nu vor mai putea fi recuperate.
Modificarea uneia sau mai multor inregistrari (linii) dintr-o tabela se realizeaza cu comanda UPDATE care are sintaxa:
UPDATE nume_tabela
SET coloana1 = valoare1,
coloana2 = valoare2,
WHERE conditie
ca in urmatorul exemplu:
update jucatori
SET prenume='Emilian' WHERE id=18
care modifica (completeaza) prenumele jucatorului cu id-ul
Modificarea valorilor unei linii se poate face pe baza valorilor returnate de catre o subinterogare. Astfel, daca dorim sa ii atribuim jucatorului cu id-ul acelasi rating ca cel al jucatorului cu codul , iar varsta sa fie cu mai mare decat varta jucatorului cu codul , vom scrie:
UPDATE jucatori
SET rating=(SELECT rating FROM jucatori WHERE id=18),
varsta=(SELECT varsta+5 FROM jucatori WHERE id=43)
WHERE id=44
Daca o subinterogare utilizata la actualizarea valorilor dintr-o coloana nu returneaza nici o valoare, atunci campul respectiv va fi initializat cu NULL
UPDATE jucatori
SET rating = (SELECT rating FROM jucatori WHERE id=200)
WHERE id=44
Inaintea rularii acestei comenzii continutul tabelei jucatori era cea din figura II.7.7, iar dupa rularea sa continutul este cel din figura II.7.8. Se observa ca initial ratingul jucatorului era , iar dupa rularea comenzii acesta a devenit NULL
Figura II.7.7.
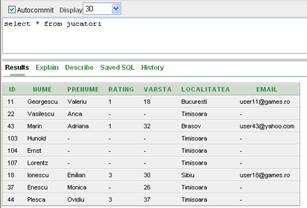
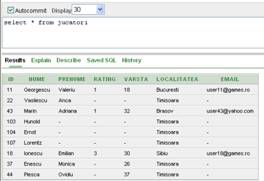
Figura II.7.7.
Interesant este ca o comanda de forma:
UPDATE jucatori
SET rating = (SELECT rating FROM jucatori WHERE id=18),
varsta = (SELECT varsta+5 FROM jucatori WHERE id=18)
WHERE id=44
se poate scrie si astfel:
UPDATE jucatori
SET (rating, varsta) =
(SELECT rating, varsta FROM jucatori WHERE id=18)
WHERE id=44
View-vederi
Uneori, din motive de securitate, ati dori sa nu permiteti anumitor utilizatori sa aiba acces nelimitat la o tabela, ci doar la datele ce se gasesc in anumite coloane ale acestei tabele.
De exemplu, intr-o firma, contabila firmei nu va avea acces la coloanele ce se refera la proiectele in care sunt implicati la momentul actual fiecare angajat al firmei, insa va avea cu siguranta acces la date privind salariul, tariful orar cu care este platit fiecare angajat, numarul de ore lucrate etc. Pe de alta parte, bibliotecara de la biblioteca firmei, nu va avea acces la datele privind salarizarea personalului ci doar la datele personale ale angajatilor (adresa, telefon, email etc).
Pentru a putea da acces partial la o tabela utilizatorilor vom folosi ceea ce numim vederi (sau views). O vedere este o tabela virtuala, pentru care nu sunt memorate date propriu-zise ci doar definitia vederii, care are rolul de filtrare a datelor.
Vederile sunt reprezentari logice ale tabelelor existente si functioneaza ca niste ferestre prin intermediul carora pot fi vizualizate si modificate datele din tabelele fizice (fig. II.8.1).
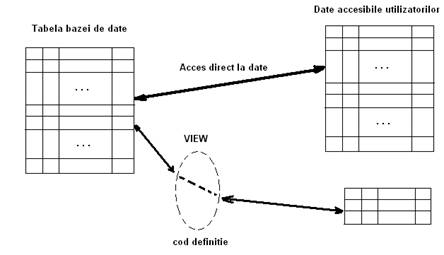
Figura II.8.1. Acces direct si indirect (printr-o vedere) la o tabela
Pe langa faptul ca ofera protectie marita a datelor, vederile mai au un mare avantaj: ele reduc in mod considerabil complexitatea interogarilor pe care utilizatorii trebuie sa le scrie. O vedere poate fi construita folosind operatii complexe de join, care raman 'ascunse' utlizatorului vederii respective, care va folosi interogari simple.
La crearea unei vederi se va folosi o subinterogare, oricat de complexa, insa aceasta NU poate folosi clauza ORDER BY
Sintaxa generala de a comenzii pentru crearea unei vederi este:
CREATE OR REPLACE VIEW nume_nedere
AS subinterogare
Optiunea OR REPLACE poate lipsi, aceasta fiind utila atunci cand dorim sa modificam o vedere deja existenta.
De exemplu, urmatoarea comanda creeaza o vedere simpla pe baza tabelei employees
CREATE OR REPLACE VIEW v1 AS
( SELECT first_name||' '||last_name as Nume,
salary
FROM employees WHERE department_id=20)
Dupa cum am precizat, o vedere se poate construi folosind mai multe tabele, ca in exemplul urmator:
CREATE OR REPLACE VIEW v2 AS
( SELECT a.nume ||' '|| a.prenume AS Angajat,
b.nume ||' '|| b.prenume AS Sef,
c.nume as Firma, d.nume as Job
FROM angajat a, angajat b
WHERE a.id_manager = b.id(+) and
a.idFirm=c.idFirm(+) and a.idJob=d.idJob(+)
Observatie. In subinterogarea care defineste o vedere, toate expresiile (nu si coloanele simple) trebuie sa aiba asociate un alias pentru a putea fi ulterior referite in interogari.
Cum putem interoga aceste vederi? Ele pot fi folosite ca orice tabela obisnuita, atat in interogari cat si in operatiile de actualizare (adaugare, modificare, stergere), asupra acestora din urma insa vom reveni in paragrafele urmatoare. Putem scrie de exemplu:
SELECT nume, salary FROM v1
WHERE nume like '%a%'
sau
SELECT angajat, sef, firma, job
FROM v2
O vedere poate fi sterasa cu comanda
DROP VIEW nume_vedere
Atentie! Stergerea unei vederi nu afecteaza in nici un fel datele din tabelele pe baza carora s-a creat vederea. Toate modificarile realizate asupra tabelelor prin intermediul vederii raman valabile si dupa stergerea acesteia.
In acest paragraf vom folosi pentru exemplificare tabelele jucatori si echipe create cu ajutorul urmatoarelor comenzi:
CREATE TABLE jucatori(
id NUMBER(5) PRIMARY KEY,
nume VARCHAR2(30) NOT NULL,
prenume VARCHAR2(30),
rating NUMBER(1) CHECK (rating BETWEEN 1 AND 5),
varsta NUMBER(2),
localitatea VARCHAR2(30) DEFAULT 'Timisoara',
email VARCHAR2(30) UNIQUE
Sa cream acum urmatoarele vederi:
CREATE OR REPLACE VIEW v1_JucatoriTm AS
( SELECT id, nume, varsta, localitatea FROM jucatori
WHERE localitatea = 'Timisoara' )
si
CREATE OR REPLACE VIEW v2_Jucatori AS
( SELECT nume, prenume FROM jucatori
WHERE rating IS NOT NULL)
Asadar am creat o vedere pentru toti jucatorii din Timisoara. Putem interoga simplu aceasta vedere:
SELECT * FROM v1_JucatoriTm
rezultatul fiind cel din tabelul urmator:
Tabelul II.8.1.
|
ID |
NUME |
VARSTA |
LOCALITATEA |
|
Vasilescu |
Timisoara |
||
|
Hunold |
Timisoara |
||
|
Ernst |
Timisoara |
||
|
Lorentz |
Timisoara |
||
|
Enescu |
Timisoara |
||
|
Plesca |
Timisoara |
iar comanda
SELECT * FROM v2_Jucatori
va afisa
Tabelul II.8.2.
|
NUME |
PRENUME |
|
Georgescu |
Valeriu |
|
Marin |
Adriana |
|
Ionescu |
Emilian |
Vom incerca acum, pe rand, sa vedem cum functioneaza fiecare operatie de actualizare a datelor.
O vedere poate fi creata folosind optiunea WITH READ OPTION, prin intermediul unei astfel de vederi neputandu-se efectua nici o operatie de actualizare. Aceste vederi sunt folosite doar pentru vizualizarea datelor:
CREATE OR REPLACE VIEW v4_JucatoriTm AS
( SELECT id, nume, varsta, localitatea
FROM jucatori
WHERE localitatea = 'Timisoara' )
WITH READ ONLY

Figura II.8.2.
Incercam sa inseram cate o inregistrare in tabela jucatori prin intermediul celor doua vederi create anterior:
insert into v1_JucatoriTm
values(210, 'Alexandrescu',41,'Iasi')
Comanda functioneaza perfect (fig. II.8.3), desi jucatorul nou inserat nu respecta domeniul vederii v1_JucatoriTm, adica desi putem vizualiza prin intermediul acestei vederi doar jucatorii din Timisoara, am reusit totusi sa inseram un jucator din alta localitate. Acest lucru ar putea crea probleme de securitate (am creat vederea tocmai pentru a restrictiona drepturile utilizatorilor).
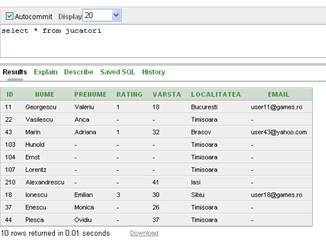
Figura II.8.3.
Aceasta problema poate fi rezolvata prin folosirea optiunii WITH CHECK OPTION la crearea vederii. Vom crea o noua vedere v3_jucatoriTm folosind aceasta optiune:
CREATE OR REPLACE VIEW v3_JucatoriTm AS
( SELECT id, nume, varsta, localitatea FROM jucatori
WHERE localitatea = 'Timisoara' )
WITH CHECK OPTION
De aceasta data nu mai putem insera valori care sunt in afara domeniului vederii (fig. II.8.4).
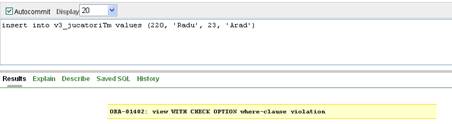
Figura II.8.4.
Prin intermediul vederii v2_jucatori nu vom putea insera linii in tabela jucatori, deoarece prin intermediul vederii nu avem acces la campul id, care fiind cheie primara nu poate fi initializata cu valoarea implicita NULL (fig. II.8.5)
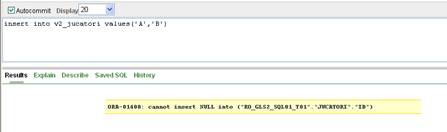
Figura II.8.5.
La stergerea unei inregistrari vom folosi comanda DELETE cu formatul deja cunoscut. Evident nu vom putea sterge din tabela decat liniile accesibile prin vederea respectiva. De aceea comanda:
DELETE FROM v1_jucatoriTm WHERE id=43
nu va genera nici o eroare, insa nu va sterge nici o linie intrucat jucatorul avand id-ul este din Brasov, deci nu avem acces la el prin intermediul vederii v1_jucatoriTm
Similar, nu vom putea folosi in clauza WHERE a comenzii DELETE coloane care nu sunt vizibile din vederea respectiva. De exemplu comanda
DELETE FROM v2_jucatori WHERE id=43
va genera o eroare, deoarece campul id este inaccesibil vederii (fig. II.8.6.)
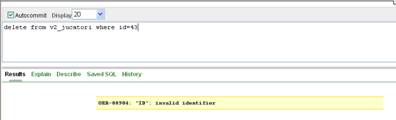
Figura II.8.6.
Comenzile
delete from v2_jucatori where prenume='Emilian'
si
delete from jucatori where id=107
sunt perfect functionale.
Ca si in cazul celorlaltor operatii de actualizare vom putea modifica doar valorile liniilor si coloanelor care sunt vizibile din vederea respectiva:
update v1_jucatoriTm
set varsta=13
where id=103
Operatiile de actualizare a datelor prin intermediul vederilor NU pot fi realizate in urmatoarele conditii:
actualizarea datelor (stergere, modificare, inserare) nu se poate efectua daca subinterogarea cu care s-a creat vederea foloseste:
o functii de grup
o clauza GROUP BY
o clauza DISTINCT
o pseudocoloanele ROWNUM sau ROWID
nu se poate modifica un camp calculat al unei vederi:
De exemplu, daca s-a creat vederea
CREATE VIEW v5 AS
( SELECT id, nume, nvl(rating,0) rating
FROM jucatori)
vom putea actualiza campurile id si nume:
UPDATE v5
SET nume='Eminescu'
WHERE id=37
dar nu putem modifica valoarea din campul rating (fig. II.8.7.)
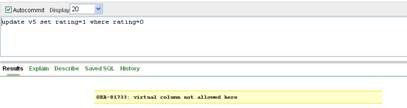
Figura II.8.7.
Nu se poate insera o linie intr-o tabela prin intermediul unei vederi decat daca toate coloanele NOT NULL ale tabelei sunt prezente in vedere.
Imaginati-va ca trebuie sa adaugati in baza de date a scolii, datele persoanele ale noilor elevi veniti in scoala voastra in clasa a IX-a. Fiecarui elev trebuie sa-i asociati un id unic in intreaga baza de date. Nu stiti insa exact care sunt id-urile elevilor deja existenti in baza de date, pentru a sti care sunt id-urile "libere". Cum rezolvati oare aceasta problema?
O varianta ar fi ca la inserarea unui nou elev sa determinati cel mai mare id existent in baza de date, si sa-i asociati elevului nou inserat un id cu o unitate mai mare decat cel mai mare id. Veti scrie o comanda de forma:
INSERT INTO elevi (id, nume, prenume, .)
VALUES ( SELECT max(id)+1 FROM elevi,
'Ionescu', 'Ioan', .)
O astfel de solutie poate genera probleme in cazul accesului concurent la baza de date, cand este posibil ca doi utilizatori diferiti sa incerce sa insereze doi elevi cu acelasi id
Solutia este folosirea secventelor. Secventele sunt obiecte ale bazei de date cate genereaza automat, in mod secvential, liste de numere. Acestea sunt utile cand o tabela foloseste o cheie primara artificiala, ale carei valori dorim sa le generam automat.
Sintaxa pentru crearea unei secvente este urmatoarea:
CREATE SEQUENCE nume_secventa
START WITH n1
INCREMENT BY n2
MAXVALUE n3 | NOMAXVALUE
MINVALUE n4 | NOMINVALUE
CACHE n5 | NOCHACE
CYCLE | NOCYCLE
Sa explicam pe rand care este rolul fiecarei optiuni din aceasta comanda:
START WITH n1 - precizeaza de la ce valoare va incepe generarea valorilor. Aceasta optiune este utila atunci cand campul pentru care dorim sa generam valori folosind aceasta secventa contine deja valori. In acest caz, vom preciza in n1 o valoare mai mare decat toate valorile deja existente in coloana respectiva. Daca aceasta optiune nu este prezenta, se va incepe implicit de la valoarea
INCREMENT BY n2 - precizeaza intervalul dintre doua numere din secventa. Poate fi un numar intreg pozitiv sau negativ, dar nu poate fi zero. Daca se precizeaza o valoare negativa, atunci valorile se vor genera in ordine descrescatoare, altfel se vor genera in ordine crescatoare. Daca omiteti aceasta optiune valoarea implicita a incrementului va fi
MAXVALUE n3 si respectiv MINVALUE n4 - aceste clause specifica cea mai mare, respectiv cea mai mica valoare returnata de catre secventa. n3 si respectiv n4 trebuie sa fie numere intrege cu maxim cifre.
NOMAXVALUE - valoarea maxima generata va fi pentru o secventa cu increment pozitiv, respectiv pentru o secventa cu increment negativ.
NOMINVALUE - valoarea maxima generata va fi pentru o secventa cu increment pozitiv, respectiv pentru o secventa cu increment negativ.
CACHE n5 - aceasta optiune este folosita din considerente de eficienta. Cu aceasta optiune se vor genera simultan n5 valori din secventa, si numai atunci cand acestea se vor epuiza se vor genera urmatoarele n5 valori. In acest fel se vor face mai putine modificari asupra bazei de date.
CYCLE | NOCYCLE - daca specificati optiunea CYCLE atunci cand secventa a ajuns la valoarea maxima (respectiv minima pentru o secventa cu increment negativ), secventa va reincepe sa genereze valori incepand cu MINVALUE (respectiv MAXVALUE pentru o secventa cu increment negativ). Evident, daca utilizati optiunea CYCLE nu exista nici o garantie privind unicitatea valorilor generate.
De exemplu, comanda:
CREATE SEQUENCE sec1
START WITH 1 INCREMENT BY 1
creeaza o secventa care va genera valori din in , incepand cu , adica va genera in ordine valorile , etc.
Comanda
CREATE SEQUENCE sec2
START WITH 120 INCREMENT BY -3
creeaza o secventa care va genera valori descrescatoare din in , incepand cu , adica va genera in ordine valorile , etc.
Stergerea unei secvente se face simplu cu comanda DROP SEQUENCE
Sa vedem acum cum generam efectiv valorile din secventa. Vom folosi doua pseudocoloane speciale numite NEXTVAL si respectiv CURRVAL NEXTVAL genereaza urmatoarea valoare din secventa, in timp ce CURVAL este folosita pentru a afla care a fost valoarea care tocmai a fost generata.
Pentru exemplificare, cream secventa
CREATE SEQUENCE sec3
START WITH 5 INCREMENT BY 3
si tabela
CREATE TABLE test(nr number(3))
si rulam de ori comanda:
INSERT INTO test values(sec3.NEXTVAL)
In acest fel continutul tabelei este (fig. II.9.1)
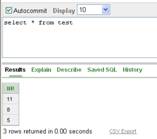
Figura II.9.1.
Daca rulam acum comanda
SELECT sec3.currval FROM dual
se va afisa valaoarea , adica exact ultima valoare generata de catre secventa.
Atentie! Pseudocoloanele NEXTVAL si CURRVAL nu pot fi folosite in urmatoarele contexte:
in clauza SELECT a unei vederi
intr-o comanda SELECT care foloseste optiunea DISTINCT
intr-o comanda SELECT care foloseste clauzele GROUP BY HAVING, sau ORDER BY
intr-o subinterogare din cadrul unei comenzi SELECT DELETE sau UPDATE
Intr-o optiune DEFAULT a comenzii CREATE TABLE sau ALTER TABLE
Comanda ALTER SEQUENCE care permite modificarea unei secvente are sintaxa similara cu cea a comenzii CREATE SEQUENCE
CREATE SEQUENCE nume_secventa
INCREMENT BY n2
MAXVALUE n3 | NOMAXVALUE
MINVALUE n4 | NOMINVALUE
CACHE n5 | NOCHACE
CYCLE | NOCYCLE
Modificarea unei secvente va afecta doar valorile ce se vor genera ulterior. La modificarea unei secvente trebuie sa se tina cont de cateva restrictii. De exemplu nu se poate stabili o valoare in clauza MAXVALUE care sa fie mai mica decat ultima valoare care a fost deja generata de catre secventa.
Sa experimentam putin optiunea de modificare a unei secvente. Sa rulam, pe rand, urmatoarele comenzi:
CREATE SEQUENCE sec4;
CREATE TABLE test1 (n NUMBER(2), v NUMBER(2));
INSERT INTO test1 values(1, sec4.NEXTVAL);
INSERT INTO test1 values(2, sec4.NEXTVAL);
INSERT INTO test1 values(3, sec4.NEXTVAL);
INSERT INTO test1 values(4, sec4.CURRVAL);
ALTER SEQUENCE sec4 INCREMENT BY -5 MINVALUE -200;
INSERT INTO test1 values(5, sec4.NEXTVAL);
INSERT INTO test1 values(6, sec4.NEXTVAL);
INSERT INTO test1 values(7, sec4.NEXTVAL);
Dupa aceste comenzi, continutul tabelei test va fi cel din tabelul urmator:
Tabelul II.9.1.
|
N |
V |
Atentie! In Oracle Database Express Edition este posibil ca referirea la pseudocoloana CURRVAL sa nu functioneze in mod corespunzator.
Sa presupunem ca am creat o tabela cu comanda:
CREATE TABLE test ( id integer, content varchar )
si am inserat o multime de linii in aceasta tabela. La un moment dat avem nevoie sa rulam o interogare de forma:
SELECT content FROM test WHERE id =
Serverul bazei de date va trebui sa parcurga intreaga tabela test, linie de linie, pentru a cauta toate liniile pentru care id-ul este 5. Daca tabela contine foarte multe linii si doar putine linii (poate chiar nici una) for fi returnate de catre interogarea anterioara, aceasta metoda este clar ineficienta.
Pentru a un acces direct si rapid la liniile unei tabele, se vor folosi indecsii.
Indecsii unei tabele functioneaza similar cu indexul unei carti de specialitate. Intr-un astfel de index, aflat de obicei la sfarsitul unei carti se gasesc principalii termeni si concepte intalnite in cartea respectiva, sortati alfabetic, indicandu-se in dreptul fiecarui termen pagina sau paginile la care poate fi intalnit termenul respectiv in carte. O persoana interesata de un anumit termen, nu va citi intreaga carte, ci va cauta in index pagina sau paginile corespunzatoare.
Exista doua tipuri de indecsi:
indecsi unici - sunt generati automat pentru coloanele ce fac parte din cheia primara sau asupra carora s-a definit o constrangere UNIQUE
indecsi non-unici - care sunt definiti de catre utilizator.
Crearea unui index se realizeaza cu comanda:
CREATE INDEX nume_index
ON nume_tabela(coloana1, coloana2, , coloanan)
De exemplu, daca dorim sa crestem viteza operatiilor de cautare dupa coloana nume din tabela elevi vom crea urmatorul index:
CREATE INDEX elevi_idx1
ON carti(nume)
Intr-un index putem include mai multe coloane ale unei tabele, ca in urmatorul exemplu:
CREATE INDEX elevi_idx2
ON carti(nume, prenume)
De asemenea pot fi incluse in index expresii, nu doar coloane ale unei tabele:
CREATE INDEX elevi_idx3
ON carti(UPPER(nume), UPPER(prenume))
Pentru a sterge un index folositi comanda DROP INDEX. Indecsii pot fi adaugati si stersi in orice moment fara a afecta tabela pe care o indexeaza in nici un fel, ei fiind fizic si logic independenti de tabela pe care o indexeaza. Totusi, atunci cand veti sterge o tabela, se vor sterge automat toti indecsii definiti pe tabela respectiva.
Odata creat un index, nu mai este necesara nici o interventie, acesta fiind actualizat automat dupa fiecare modificare efectuata asupra tabelei. De asemenea indexul va fi folosit automat in interogari care pot castiga de pe urma folosirii sale.
Un index definit pe o coloana care face parte dintr-o conditie de join, poate duce la cresterea semnificativa a vitezei de executare a join-ului respectiv.
Asadar, este indicata crearea unui index atunci cand:
coloana care se indexeaza contine o plaja mare de valori
coloana care se indexeaza contine multe valori nule (valorile nule nu sunt incluse in index)
una sau mai multe coloane sunt frecvent folosite impreuna in clauza WHERE sau in conditiile de join.
Tabela este mare si majoritatea interogarilor returneaza un numar mic de linii din aceasta tabela ( din numarul total de inregistrari)
Cand NU este indicat sa creati un index? Atunci cand:
tabela este mica, in acest caz cautarea secventiala este acceptabila
Coloanele nu sunt foarte des folosite in clauza WHERE a interogarilor
majoritatea interogarilor returneaza un numar mare de inregistrari (mai mult de din numarul total de inregistrari)
se efectueaza multe operatii de inserare, stergere sau modificare asupra tabelei. Dupa fiecare astfel de operatie sistemul trebuie sa actualizeze indexul, operatie consumatoare de timp
Coloanele indexate sunt referite cel mai ades ca parte a unor expresii.
Dupa cum stiti sinonimul este un cuvant cu exact acelasi inteles cu un alt cuvant, adica un cuvant care poate fi folosit in locul altui cuvant
Similar in dialectul bazelor de date, administratorul unei baze de date poate defini nume echivalente pentru un obiect al bazei de date.
In principal vom defini un sinonim pentru un obiect al bazei de date pentru a simplifica referirea la acel obiect.
De exemplu pentru a interoga tabela1 din schema unui alt utilizator, fie acesta user1, atunci vom referi aceasta tabela prin prefixarea numelui tabelei cu numele utilizatorului in a carui schema se gaseste tabela, adica vom scrie user1.tabela1. Daca numele utilizatorului este insa RO_L2_SQL01_S12 iar tabela se numeste d_track_listings, va trebui sa scriem RO_L2_SQL01_S12.d_track_listings pentru a ne referi la acea tabela, ceea ce este destul de neplacut. Pentru aceasta vom defini un sinonim mai scurt pentru tabela respectiva.
Sintaxa comenzii de creare a unui sinonim este
CREATE [PUBLIC] SYNONYM nume_sinonim
FOR obiect
De exemplu
CREATE SYNONYM ana_track
FOR RO_L2_SQL01_S12.d_track_listings
In continuare, vom putea folosi acest sinonim in locul numelui complet al tabelei.
Se pot defini sinonime pentru tabele, vederi, secvente, proceduri sau alte obiecte ale bazei de date.
Optiunea PUBLIC este folosita de catre administratorul bazei de date pentru a crea un sinonim accesibil tuturor utilizatorilor bazei de date. In mod implicit un sinonim este privat.
Stergerea unui sinonim se face cu comanda DROP SYNONYM
V-ati intrebat vreodata ce ar insemna ca elevii dintr-o scoala sa aiba acces liber la catalog si sa poata face orice modificare doresc in catalog? Dar daca orice utilizator conectat la internet ar avea acces nerestrictionat la baza de date a CIA, NASA, a unei banci si asa mai departe?
Evident, in viata reala accesul in anumite locuri este restrictionat. Daca faci parte dintr-un anumit grup restrans de persoane, ca de exemplu angajatii bancii, poti avea acces in anumite zone restrictionate sau la anumite resurse la care alte persoane nu au acces.
Ca si in lumea reala si in cazul bazelor de date trebuie sa putem defini o serie de drepturi pentru utilizatorii bazei de date, sau sa restrictionam accesul acestora la anumite obiecte ale bazei de date.
Controlul securitatii in Oracle se asigura prin specificarea: utilizatorilor bazei de date, schemelor, privilegiilor (drepturilor) si rolurilor.
Utilizatorii bazei de date si schemele
Fiecare baza de date are o lista de nume de utilizatori. Pentru a accesa baza de date un utilizator trebuie sa foloseasca o aplicatie si sa se conecteze cu un nume potrivit. Fiecarui nume de utilizator ii este asociata o parola. Orice utilizator are un domeniu de securitate care determina privilegiile si rolurile, cota de spatiu pe disc alocat si limitele de resurse ce le poate utiliza (timp CPU etc).
Privilegiile
Privilegiul este dreptul unui utilizator de a executa anumite instructiuni SQL. Privilegiile pot fi:
privilegii de sistem - permit utilizatorilor sa execute o gama larga de instructiuni SQL, ce pot modifica datele sau structura bazei de date. Aceste privilegii se atribuie de obicei numai administratorilor bazei de date.
privilegii de obiecte - permit utilizatorilor sa execute anumite instructiuni SQL numai in cadrul schemei sale, si nu asupra intregii baze de date.
Acordarea privilegiilor reprezinta modalitatea prin care acestea pot fi atribuite utilizatorilor. Exista doua cai de acordare explicit (privilegiile se atribuie in mod direct utilizatorilor) si implicit (prin atribuirea acestora unor roluri, care la randul lor sunt acordate utilizatorilor).
Rolurile
Rolurile sunt grupe de privilegii, care se atribuie utilizatorilor sau altor roluri. Rolurile permit:
Reducerea activitatilor de atribuire a privilegiilor. Administratorul bazei de date in loc sa atribuie fiecare privilegiu tuturor utilizatorilor va atribui aceste privilegii unui rol, care apoi va fi disponibil utilizatorilor;
Manipularea dinamica a privilegiilor. Daca se modifica un privilegiu de grup, acesta se va modifica in rolul grupului. Automat modificarea privilegiului se propaga la toti utilizatorii din grup;
Selectarea disponibilitatilor privilegiilor. Privilegiile pot fi grupate pe mai multe roluri, care la randul lor pot fi activate sau dezactivate in mod selectiv;
Proiectarea unor aplicatii inteligente. Se pot activa sau dezactiva anumite roluri functie de utilizatorii care incearca sa utilizeze aplicatia.
Un rol poate fi creat cu parola pentru a preveni accesul neautorizat la o aplicatie. Aceasta tehnica permite utilizarea parolei la momentul pornirii aplicatiei, apoi utilizatorii pot folosi aplicatia fara sa mai cunoasca parola.
Pentru acordarea unui drept unui anumit utilizator vasile se va folosi comanda GRANT. De exemplu, pentru a se conecta la baza de date, un utilizator trebuie sa aiba permisiunea de a crea o sesiune. Acest drept se aloca de catre un utilizator privilegiat (utilizatorul system de exemplu) prin comanda
GRANT CREATE SESSION TO vasile
Acum utilizatorul vasile se poate conecta la baza de date.
Revocarea unui drept unui anumit utilizator se face folosind comanda REVOKE ca in exemplul urmator:
REVOKE CREATE SESSION FROM vasile
Un drept de system permite unui utilizator sa efectueze anumite operatii asupra bazei de date precumexecutarea comenzilor DDL. Cele mai uzuale drepturi system sunt prezentate in tabelul urmator.
Tabelul II.10.1. Privilegii sistem
|
Permite. |
|
|
CREATE SESSION |
conectarea la baza de date |
|
CREATE SEQUENCE |
crearea secventelor |
|
CREATE SYNONYM |
crearea sinonimelor |
|
CREATE TABLE |
crearea tabelelor |
|
CREATE ANY TABLE |
crearea unor tabele in orice schema, nu doar in propria schema |
|
DROP TABLE |
stergerea tabelelor |
|
DROP ANY TABLE |
stergerea unor tabele din orice schema nu doar din schema proprie |
|
CREATE PROCEDURE |
crearea de proceduri memorate |
|
EXECUTE ANY PROCEDURE |
executarea unei proceduri in orice schema |
|
CREATE USER |
crearea de utilizatori |
|
DROP USER |
stergerea utilizatorilor |
|
CREATE VIEW |
crearea vederilor |
Dupa cum am precizat acordarea drepturilor se face folosind comanda GRANT. In exemplul urmator se acorda cateva drepturi sistem utilizatorului ion
GRANT CREATE SESSION, CREATE USER, CREATE TABLE TO ion
Se poate de asemenea folosi optiunea WITH ADMIN OPTION care permite unui utilizator sa aloce si el drepturile primite cu aceasta optiune, mai departe, altor utilizatori:
GRANT EXECUTE ANY PROCEDURE TO ion WITH ADMIN OPTION;
Dreptul acordat utilizatorului ion, de a executa orice procedura poate fi acordata de acesta mai departe utilizatorului george. Pentru aceasta ion se va conecta la baza de date folosind comanda
CONNECT ion/test
unde ion este username-ul iar test este parola si apoi va acorda dreptul lui george
GRANT EXECUTE ANY PROCEDURE TO george;
Un drept se poate aloca tuturor utilizatorilor bazei de date folosin optiunea PUBLIC ca in urmatorul exemplu:
CONNECT system/manager
GRANT EXECUTE ANY PROCEDURE TO PUBLIC;
In acest moment orice utilizator al bazei de date are dreptul de a executa o procedura in orice schema.
Un drept la nivel de obiect permite unui utilizator sa execute anumite actiuni asupra obiectelor bazei de date, ca de exemplu executarea anumitor comenzi DML pe tabelele bazei de date. De exemplu GRANT INSERT ON adm.elevi permite unui utilizator sa insereze linii noi in tabela elevi din schema adm. Cele mai des intalnite drepturi la nivel de obiect sunt prezentate in tabelul urmator:
Tabelul II.10.2. Privilegii la nivel de obiect
|
Permite . |
|
|
SELECT |
Interogarea tabelei |
|
INSERT |
Inserarea de noi linii in tabela |
|
UPDATE |
Modificarea valorilor din tabela |
|
DELETE |
Stergerea datelor din tabela |
|
EXECUTE |
Executarea unor proceduri memorate |
Veti utiliza de asemenea comanda GRANT. Exemplul urmator acorda utilizatorului ion dreptul de SELECT INSERT, si UPDATE pe tabela elevi si dreptul de SELECT asupra tabelei angajati
GRANT SELECT, INSERT, UPDATE ON adm.elevi TO ion;
GRANT SELECT ON profesori.angajati TO ion;
Urmatoarea comanda permite utilizatorului ion sa modifice doar valorile din coloanele prenume si adresa, din tabela elevi, utilizatorului ion
GRANT UPDATE (prenume,adresa) ON adm.elevi TO ion;
Folosind optiunea WITH GRANT OPTION veti permite utilizatorului sa acorde mai departe dreptul primit si altor utilizatori:
GRANT SELECT ON adm.elevi TO ion WITH GRANT OPTION;
Dreptul de a interoga tabela adm.elevi poate fi acum acordat de catre ion oricarui alt utilizator:
CONNECT ion/test
GRANT SELECT ON adm.elevi TO george;
Revocarea drepturilor la nivel de obiect se va face folosind comanda REVOKE. Urmatoarea comanda revoca dreptul de inserare de noi linii la tabela elevi utilizatorului ion
REVOKE INSERT ON elevi FROM ion;
Comanda va fi rulata din contul adm
Observatie! Daca am acordat un drept unui utilizator A folosind optiunea WITH GRANT OPTION, iar acest utilizatorul A a acordat si el la randul lui dreptul altor utilizatori B C si D, atunci cand vom revoca dreptul utilizatorului A, va fi revocat automat acel drept si tuturor utilizatorilor carora utilizatorul A le-a acordat acel drept, respectiv utilizatorilor B C si D
Dupa cum am precizat la inceputul capitolului, putem crea un rol, prin intermediul caruia vom putea acorda drepturi unui grup de utilizatori avand rolul respectiv, lucru mult mai usor decat acordarea drepturilor fiecarui utilizator separat.
De exemplu, in loc sa acordam drepturi de select insert si update mai multor utilizatori
GRANT SELECT, INSERT, UPDATE ON adm.elevi TO ion;
GRANT SELECT, INSERT, UPDATE ON adm.elevi TO vasile;
GRANT SELECT, INSERT, UPDATE ON adm.elevi TO gheorghe;
GRANT SELECT, INSERT, UPDATE ON adm.elevi TO maria;
GRANT SELECT, INSERT, UPDATE ON adm.elevi TO alin;
E mai comod sa cream un rol, sa acordam drepturi pentru acest rol si apoi sa acordam rolul respectiv celor cinci utilizatori. Vom scrie asadar
CREATE ROLE profi;
GRANT SELECT, INSERT, UPDATE ON adm.elevi TO profi;
GRANT profi TO ion, vasile, gheorghe, maria, alin;
In orice moment putem sterge un rol folosind comanda DROP ROLE. Aceasta va duce la revocarea tuturor drepturilor acordate utilizatorilor prin intermediul acestui rol.
Sa dam un exemplu mai complex de acordare a drepturilor si privilegiilor. Sa presupunem ca rulam pe rand urmatoarele comenzi
CONNECT hr/test;
CREATE ROLE r1;
CREATE ROLE r2;
GRANT SELECT, INSERT, DELETE ON hr.elevi TO r1
WITH GRANT OPTION;
GRANT DELETE, UPDATE ON hr.elevi TO r2
WITH GRANT OPTION;
GRANT r1 TO user1
GRANT r2 TO user2
GRANT CREATE VIEW TO user3 WITH GRANT OPTION
GRANT DELETE ON hr.elevi TO user3
GRANT UPDATE ON hr.elevi TO user4
CONNECT user2/pas2
GRANT DELETE ON hr.elevi TO user4
GRANT UPDATE ON hr.elevi TO user4
In acest moment utilizatorii au urmatoarele drepturi (figura II.10.1.):
Tabelul II.10.3.
|
UTILIZATOR |
DREPT |
|
user1 |
SELECT, INSERT, DELETE ON hr.elevi |
|
user2 |
DELETE, UPDATE ON hr.elevi |
|
user3 |
DELETE ON hr.elevi CREATE VIEW |
|
user4 |
DELETE, UPDATE ON hr.elevi |
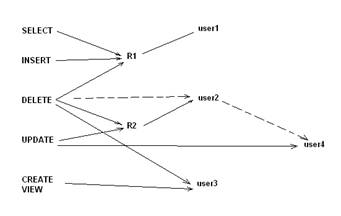
Figura II.10.1. Schema de acordare a drepturilor
Daca acum stergem rolul r2
DROP ROLE r2
utilizatorul user2 va pierde dreptul de DELETE si UPDATE asupra tabelei hr.elevi, si prin intermediul sau va pierde dreptul de DELETE si utilizatorul user4, care a primit acest drept de la user2. Desi user4 a primit de la user2 si dreptul de UPDATE, el nu va pierde acest drept deoarece a primit acest drept si direct de la utilizatorul SYSTEM Asadar dupa stergerea rolului r2, drepturile utilizatorilor sunt urmatoarele:
Tabelul II.10.4.
|
UTILIZATOR |
DREPT |
|
user1 |
SELECT, INSERT, DELETE ON hr.elevi |
|
user2 | |
|
user3 |
DELETE ON hr.elevi CREATE VIEW |
|
user4 |
UPDATE ON hr.elevi |
O tranzactie este un grup de comenzi SQL care sunt vazute ca o singura unitate. Imaginati-va o tranzactie ca un grup de comenzi SQL care nu pot fi separate, si al caror efect este in intregime salvat in baza de date, fie este in intregime anulat. Sa ne gandim de exemplu la efectuarea unui transfer bancar dintr-un cont in alt cont. O comanda UPDATE va efectua operatia de scadere a sumei de bani tranzactionata dintr-un cont, iar o alta comanda UPDATE va adauga suma respectiva la cel de al doilea cont. Daca ambele operatii decurg normal fara probleme, atunci ele vor deveni ambele permanente. Daca una dintre aceste doua comenzi esueaza (de exemplu nu poate fi contactata banca in care se depun banii) atunci ambele comenzi vor fi anulate. E normal sa renuntam la scaderea sumei de bani dintr-un cont, daca acestia nu pot fi depusi in celalalt cont, in caz contrar ar duce la pierderea banilor respectivi.
In general o tranzactie poate fi formata din mai multe comenzi INSERT UPDATE, si DELETE
Pentru a face permanenta o tranzactie folositi comanda COMMIT. Daca doriti sa renuntati la modificarile efectuate in cadrul unei tranzactii trebuie sa rulati o comanda ROLLBACK
Comanda ROLLBACK fara nici un parametru, incheie tranzactia curenta si renunta la toate modificarile facute in cadrul acestei tranzactii. Aveti insa posibilitatea definirii in cadrul unei tranzactii a unui asa numit punct de intoarcere, sau punct de salvare. Odata definit un astfel de punct de salvare, veti putea renunta doar la o parte din modificarile facute in cadrul tranzactiei curente.
Definirea unui punct de revenire se face cu comanda SAVEPOINT avand sintaxa:
SAVEPOINT nume_punct_de_revenire
Revenirea la un punct de revenire se face cu comanda ROLLBACK astfel:
ROLLBACK TO nume_punct_de_revenire
Definirea punctelor de revenire este utila in cazul unor tranzactii mari, cand in cazul in care faceti o greseala nu trebuie sa renuntati la toate operatiile din cadrul tranzactiei ci doar la o parte dintre acestea.
O tranzactie fiind un grup de comenzi SQL tratate ca un intreg, trebuie sa stabilim unde incepe o tranzactie si unde se termina aceasta.
O tranzactie incepe la intalnirea unuia dintre urmatoarele evenimente:
In momentul conectarii la baza de date si la inceperea rularii primei comenzi DML (INSERT UPDATE DELETE
La terminarea unei tranzactii anterioare si rularea urmatoarei comenzi DML.
O tranzactie se termina cand apare unul dintre urmatoarele evenimente:
La executarea unei comenzi COMMIT sau ROLLBACK (fara nici un parametru, intrucat ROLLBACK TO nu termina tranzactia ci doar revine la un punct precizat din cadrul tranzactiei curente)
La executarea unei comenzi DDL (CREATE ALTER DROP RENAME TRUNCATE), caz in care este executata automat comanda COMMIT
La executarea unei comenzi DCL (GRANT sau REVOKE) caz in care este executata automat comanda COMMIT
Va deconectati de la baza de date. Daca iesiti normal din SQL*Plus cu comanda Exit, sau dati Logout din Oracle Database Express Edition atunci are loc un COMMIT automat. Daca iesirea se face anormal, de exemplu in cazul unei pene de curent, atunci se executa in mod automat o comanda ROLLBACK
Executati o comanda DML care esueaza, caz in care are loc un ROLLBACK automat pentru acea singura comanda.
Sa experimentam acum modul de folosire a tranzactiilor.
Atentie In Oracle Database Express Edition toate comenzile sunt autocommit, si nu vor fi recunoscute comenzile COMMIT ROLLBACK sau SAVEPOINT. Pentru acest exercitiu puteti rula comenzile SQL in linia de comanda. Pentru aceasta alegeti din meniul Start Programs Oracle Database 10g Express Edition optiunea Run SQL Command Line. Se va deschide o fereastra in care va veti conecta la baza de date folosind comanda
CONECT
Introduceti username-ul (hr) si parola si in acest moment puteti rula orice comanda SQL.
Pentru a experimenta folosirea tranzactiilor vom crea urmatoarea tabela
create table savepoint_test ( n number )Inseram acum cateva linii in aceasta tabela:
insert into savepoint_test values (1);Definim acum un punct de salvare
savepoint sp1;si mai inseram cateva linii in tabela
insert into savepoint_test values (10);Definim un nou punct de salvare
savepoint sp2;si inseram in final inca trei linii
insert into savepoint_test values (100);Verificam acum daca datele au fost inserate in tabela
select * from savepoint_test;si vedem ca toate datele au fost inserate

Figura II.11.1.
Revenim acum la punctul de revenire sp2
ROLLBACK TO sp2si verificam continutul tabelei:
select * from savepoint_test;Observati ca ultimele linii inserate dupa definirea punctului de salvare sp2 au fost sterse din tabela (figura II.11.2.).
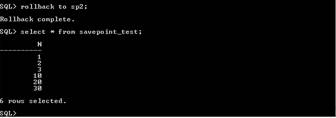
Figura II.11.2.
Inseram alte trei linii
insert into savepoint_test values (111);testam continutul tabelei:
select * from savepoint_test;
Figura II.11.3.
Revenim la punctul de salvare sp2
ROLLBACK TO sp2si verificam continutul tabelei:
select * from savepoint_test;Evident ultimele trei linii nu se mai gasesc in tabela continutul tabelei fiind acelasi cu cel din figura II.11.2. Daca revenim acum la punctul de salvare sp1, in tabela nu mai raman decat trei linii (figura II.11.4.)
ROLLBACK TO sp1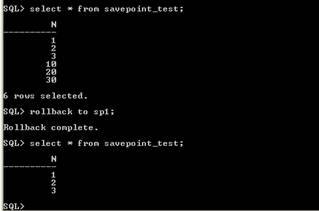
Figura II.11.4.
Schematic tranzactia anterioara arata ca in figura II.11.5.
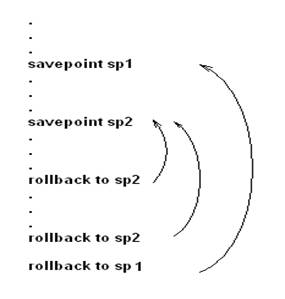
Figura II.11.5.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 3132
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2024 . All rights reserved