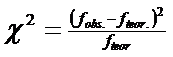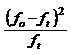| CATEGORII DOCUMENTE |
| Astronomie | Biofizica | Biologie | Botanica | Carti | Chimie | Copii |
| Educatie civica | Fabule ghicitori | Fizica | Gramatica | Joc | Literatura romana | Logica |
| Matematica | Poezii | Psihologie psihiatrie | Sociologie |
Distributia probabilitatilor si modelul de distributie (dispersie) a populatiilor
Modelul spatial al populatiilor de plante si animale.
Cuprins
Teoria probabilitatii. Distributia statistica. Distributia probabilitatii. Distributia probabilitatii uniforme, distributia probabilitatii Poisson, distributia probabilitatii binomial negative. Distributia probabilitatii, ca model de distributie a populatiilor (modelul uniform, modelul Poisson, modelul binomial negativ), indicele de dispersie (agregare). Distributia normala. Abundenta si distributia statistica. Samplingul, marimea probelor si tipurile de distributie
(K-4,6,7; J-7,8,9)
Bibliografie selectiva referitoare la distributia probabilitatii si populatiilor
Anscombe F.J., 1948. The transformation of Poisson, binomial and negative binomial data. Biometrika, 35, 246-254.
Anscombe F.J., 1950. Sampling theory of the negative binomial and logarithmic series distribution. Biometrika, 37: 358-382.
Bliss, VC.I., FisherR.A., 1953. Fittingthe negative binomial distributionto biological data and noteon the efficientfitting of the negative binomial. Biometrics, 9: 176-200.
Bulmer M.G., 1974. On fitting the Poisson lognormal distribution to species-abundance data. Biometrcs, 30: 101-110.
Diggle P.J., 1983. Statistical Analysis of Spatial Point
Patterns. Acad. Press,
Gaston K.J.,
Johnson N.L.,
Kotz S., 196 Distributions in Statistics:
Discrete Distributions. Houghton Mifflin,
Manly B.F.J., 1991. Randomization and
Patil G.P.,
Pielou E.C., Walters W.E., 1971. Spatial
Patternsand Statistical Distributions.
Perry J.N., 1988. Some models for spatial variabilityof animal species. Oikos 51: 124-130.
Perry J.N., 1995b. Spatial aspects of animal and plants
distributionin patchy farmland habitats. Pp. 221-242. In: Glen D.M., Greaves
M.P.,
Pielou E.C., 1984. The interpretation of Ecological Data.
Wiley,
Southwood T.R.E., 1978. Ecological Methods. 2-nd.ed.
Stan Gh., 1993. Metode statistice cu aplicatii in cercetari entomologice (I). Bul.Inf.Soc.Lepidopter.Rom., 4 (2): 83-112.
Underwood A.J., 1997. Experiments in Ecology: Their Logical
Design and Interpretation using analysis of Variance.
Zar J.H., 1996. Biostatistical analysis.3-rd.ed.
Prentice-Hall,
Calculul probabilitatilor este un domeniu al matematicii deosebit de important ocupandu-se cu metodele de cercetare asupra problemelor in care intervin evenimente (observatii, masuratori etc) care nu sunt nici cu totul imposibile dar nici absolut sigure (deci nu apare cu certitudine, dar aparitia nu este imposibila). Cu alte cuvinte, se studiaza niste evenimente intamplatoare care se numesc probabile. In calculul probabilitatilor este vorba despre studiul unor fenomene in masa, colectivitati, ansambluri.
Datorita faptului ca fenomenele biologice sunt prin excelenta probabile face posibila aplicarea acestei ramuri ale matematicii in biologie.
Matematic, probabilitatea este un raport dintre 2 numere si se exprima printrun numar pozitiv, subunitar (0<p<1).
a. Sa pornim de la aruncatul zarului. Probabilitatea de aparitie a celor 6 fete este egala. Probabilitatea de aparitie a uneia este de 1/6 (1:6) = 0,167. Valoarea de mai sus a probabilitatii se mai poate scrie si sub forma procentuala (16,7%).Dar, care este probabilitatea altor variante ?
- ca sa cada numai una din doua fete a celor 6 ale zarului, probabilitatea va fi: 1/6 + 1/6 = 2/6 = 1/3 = 0,3;
- ca sa cada una din 3 fete ale zarului, p = 1/6 + 1/6 + 1/6 = 3/6 = 1/2 = 0,5;
- ca sa cada una din 4 fete ale zarului, p = 1/6 + 1/6 + 1/6 + 1/6 = 4/6 = 2/3 = 0,6;
- ca sa cada una din 5 fete ale zarului, p = 1/6+1/6+1/6+1/6+1/6 = 5/6 = 0,8.
Prin exemplul de mai sus s-a ilustrat teorema adunarii probabilitatilor.
In al doile caz, sansa ca la aruncarea zarului sa cada de 2 ori la rand aceeiasi fata (de exemplu cea cu 6 puncte) este p = 1/6 1/6 = 1/36 = 0,03. Aceasta sana este egala de fapt si cu aceea de a iesi"sase - sase" cand se arunca cu 2 zaruri.
In cazul acesta este vorba despre teorema inmultirii probabilitatilor. Daca probabilitatea ca sa se produca evenimentul E1 este p1 iar probabilitatea ca sa se produca evenimentul E2 este p2 si evenimentele sunt reciproc independente, probabilitatea ca sa se produca succesiv E1 si E2 este P = p1 p2.
b. Aruncand in aer o moneda spunem ca exista 2 eventualitati, egal de probabile, de a cadea stema sau banul: p1 = p2 = 1/2 = 1:2 = 0,50 (50%)
c. Daca intr-o urna avem 25 bile albe si 75 bile rosii, frecventa relativa a celor doua categorii de bile este urmatoarea:
- pentru bilele albe: Fr = A / (A + R) = 25 / (25 + 75) = 25 / 100 = 0,25 = 25%;
- pentru bilele rosii: Fr = R / (R + A) = 75 / (75 + 25) = 75 / 100 = 0,75 = 75%.
Valorile finale de mai sus sunt deci tocmai probabilitatile cautate. Astfel:
p1 = 0,25; p2 = 0,75; p1 + p2 = 0,25 + 0,75 = 1,00.
Deci bila scoasa din urna trebuie sa fie ori alba ori rosie. Daca a scoate o bila alba este evenimentul E cu probabilitatea p,; a scoate o bila rosie este evenimentul contrar (E) si cu probabilitatea p.
Daca din statistici efectuate pe esantioane mari s-a evidentiat ca la 100 de nou nascuti 55 sunt fete si 45 baieti, probabilitatea sa se nasca o fata este egala deci cu 55 / (55 + 45) = 55 / 100 = 0,55. Dar, din 100 de nou nascuti luati la intamplare (randomizat) nu vom gasi acelasi raport iar sansa de a se naste 55 fete inseamna numai ca pe esantioane suficient de mari frecventa relativa a fetelor va fi in jur de 55%.
Situatiile statistice sau de probabilitate se pot evident reprezenta grafic. Se porneste de la un tabel de frecvente realtive stabilit intial (sau de probabilitati), de tipul:
![]() Eventualitatile (E) A B C D E F...
Eventualitatile (E) A B C D E F...
![]()
Probabilitatea (p) 0,10 0,20 0,60 0,10 0,80 0,30
Reprezentarea grafica care se poate face este aleasa de cercetator in asa fel cat sa fie cea mai veridica (ex. fie sub forma de grafic, situatie in care pe abscisa sunt trecute eventualitatile (E), iar pe ordonata valorile p si se obtine o histograma; fi o reprezentare de tip "placinta" in care probabilitatile sunt calculate proportional pentru diferite sectoare de cerc)
![]()
![]() Teoria
probabilitatilor ocupandu-se cu studiul fenomenelor de masa ea
se supune "legii numerelor mari
Teoria
probabilitatilor ocupandu-se cu studiul fenomenelor de masa ea
se supune "legii numerelor mari
- pe baza considerentelor de mai sus legea numerelor mari se mai numeste si legea cifrelor medii (adica, valorile individuale se abat mai mult sau mai putin de la aceasta medie deci valoarea medie nu este caracteristica individului ci unei colectivitati mari omogene - lot, grup - luata la intamplare).
Supunandu-se acestei legi se intelege ca probabilitatea sau "sansa" de a ne apropia de media generala, sau ca un eveniment sa aiba loc, este mai mare cu cat numarul de evenimente cercetate este mai mare (de ex. se amesteca 500 bile albe si 500 bile albastre; asa cum am aratat anterior, sansa de a scoate o bila albastra este de 1:2, dar una este situatia daca facem 3 incercari si alta daca se fac 200 de incercari; se deduce clar: cu cat se mareste numarul de operatii de scoatere a unei bile din urna cu atat proportia se va apropia de 1:1 (retineti: dupa fiecare scoatere bila se noteaza si se reintroduce in urna !).
Sa mai retinem ca probabilitatea nu poate rezolva totul, deci nu poate fi o dogma. Cu atat mai mult in biologie, unde fenomenele respective trebuie analizate sa existe omogenitate si sa se stabileasca cauzele corecte; cu cat cercetarea se face pe un numar mai mare cu atat rezultatele vor fi mai sigure.
2. Distributia probabilitatii
Distributiile empirice obtinute in mod obisnuit la prelucrarea datelor experimentale, pot fi comparate cu distributii teoretice (ideale). Asemanarea cu una dintre acestea are menirea de a usura munca ercetatorului si de a sugera o serie de explicatii. Distributia se refera la modul de repartitie (dispersie) a caracterelor sau al organismelor (indivizi, specii) intr-un habitat (sol, apa, aer) sau la nivelul la care se fac prelevarile de probe. Cunoasterea modelului de distributie este de exemplu deosebit de necesara pentru studiile de ecologie si etologie, in vederea caracterizarii dinamicii si structurii populatiilor, iar in paralele, pentru alegerea celei mai corecte metode de sampling. Datele obtinute sunt de asemenea importante pentru estimarea corecta a abundentei si a densitatii. Dupa modelulul de distributie exista 3 tipuri fundamentale:
- uniforma: ceea ce ar corespunde unor distante relativ egale intre indivizi:
- grupata (aglomerata): cind indivizii populatiilor formeaza grupari mai mari sau mai mici;
- intamplatoare: situatie in care indivizii sunt repartizati neuniform in suprafata respectiva de areal.
Sa pornim de la un exemplu de sampling. Doua specii de lepidoptere (Mamestra brassicae si Lacanobia oleracea) au pupele distribuite intamplator in habitat. Se recolteaza 100 de pupe si se urmareste emergenta in laborator. In urma emergentei se constata ca 80 pupe au apartinut speciei M. brassicae (restul de 20 speciei L. oleracea). In ceea ce priveste sexul, se stie ca acesta este in general de 1:1 (masculi:femele) (deci 1 din 2 este mascul, iar celalalt este femela). Pornind de aici, sa vedem:
- care este probabilitatea (P) ca pupele emerse sa apartina speciei M. brassicae ?
![]() ; probabilitatea = frecventa
; probabilitatea = frecventa
- care este probabilitatea (P) ca pupele emerse sa apartina speciei L. oleracea ?
![]() ; probabilitatea =
frecventa
; probabilitatea =
frecventa
- care este probabilitatea (P) ca pupele emerse sa fie de sex masculin ?
![]()
Daca vom descrie emergenta la nivel de specie si sex, suma probabilitatilor pentru toate evenimentele posibile va fi = 1
|
Probabilitatea de emergenta |
|||
|
Mamestra brassicae |
Lacanobia oleracea |
||
|
masculi |
femele |
masculi |
femele |
|
0,8 x 0,5 =0,4 |
0,8 x 0,5 = 0,4 |
0,2 x 0,5 = 0,1 |
0,2 x 0,5 =0,1 |
O asemenea impartire care arata probabilitatile individuale pentru toate situatiile posibile si care insumate dau valoarea 1 se cheama distributia probabilitatii.
Distributia probabilitatii este folosita din doua puncte de vedere:
- pentru a arata probabilitatea de producere a unui eveniment;
- pentru a genera o distributie a frecventelor anticipate (presupuse, asteptate).
Probabilitatea = frecventa observatiilor particulare / nr. total de observatii.
Frecventa asteptata = probabilitatea x numarul de observatii
Sa revenim la cazurile prezentate anterior de catre noi pentru speciile M. brassicae si L. oleracea. Sa vedem care ar putea fi frecventa asteptata daca am recolta 200 de pupe:
- frecventa asteptata pentru M. brassicae (♀♀) = 0,4 x 200 = 80
- frecventa asteptata pentru M. brassicae (♂♂) = 0,4 x 200 = 80
- frecventa asteptata pentru L. oleracea (♀♀) = 0,1 x 200 = 20
- frecventa asteptata pentru L. oleracea (♂♂) = 0,1 x 200 = 20
Total frecventa asteptata: 80 + 80 + 20 + 20 = 200
5.3. Modele de distributia probabilitatii
Am analizat mai sus cum poate fi reprezentata probabilitatea. Dar, xista si modalitatea matematica de a genera distributia probabilitatii, prin modelare matematica. Aceasta este o aplicatie in investigatia experimentala. Astfel, daca exista niste date preliminare, ele pot fi generalizate. Pe de alta parte, este posibil ca datele experimentale sa nu concorde cu predictia si atunci cercetarile ori se reiau ori se reverifica.
Exista mai multe modele matematice disponibile pentru a genera distributia probabilitatii, dar totusi putine sunt valabile pentru studiile ecologice experimentale din camp. Vom analiza in continuare cele 3 tipuri de distributii existente: binomiala, Poisson si binomial negativa.
A. Distributia probabilitatii binomiale (Bin) (uniforma, binomial pozitiva)
Distributia binomiala este folosita atunci cand:
- observatiile consista din masurarea lucrurilor;
- o observatie este clasificata intr-una din doua categorii posibile (masculi sau femele; specia X sau specia Y; adult sau juvenil; un succes sau insucces al unui event etc);
Vom mai vedea in continuare ca vorbim despre o distributie binomiala atunci cand:
- varianta (dispersia) evaluata pentru proba luata est mai mica decat media (s2 < ‾x);
- obiectele (indivizii) analizate sunt dispersate intr-un mod regulat, uniform
Matematic, in cadrul distributiei binomiale ne vom referi la situatii in care exista doar doua posibile eventualitati (am aratat acest lucru si la inceput atunci cand am vorbit despre probabilitati). Daca luam: p = probabilitatea de a avea loc a unui event si q = probabilitatea altui eveniment; atunci p + q =1; q = 1 - p; p = q = 0,5.
Acesta este cazul ilustrat la inceputul acestui capitol cu speciile M. brassicae si L. oleracea (nr. de pupe recoltate din cimp = k; probabilitatea de a fi masculi = p; probabilitatea de a fi femele = q). Posibilitatea obtinerii unui singur event (p-1) este ilustrata in tabelul 22:
Tabelul 22
Distributia binomiala - un singur eveniment
|
Nr. cazuri (k) |
Eventualitati posibile = 2 |
Nr. combinatii |
Probabilitatea totala |
|
|
M p |
F q |
p + q = 1 |
||
Daca se iau 2 pupe (k=2), numarul de rezultate posibile creste la 4: 2 masculi (MM), 1 mascul si 1 femela (MF); 1 femela si 1 mascul (FM); 2 femele (FF). Deoarece exista 4 eventualitati posibile, probabilitatea de a avea loc unul singur este de = 0,25 (Observati: combinatia FM si MF este aceeasi doar ca ordinea este diferita, in acest caz numarul de combinatii nu este 4 ci 3 - Tabelul 23).
Tabelul 23
Distributia binomiala - 2 evenimente
|
Nr. cazuri (k) |
Eventualitati posibile = 3 |
Nr. combinatii |
Probabilitatea totala |
||
|
MM (2M =1/4) p x p =p2 |
MF FM (1M, 1F = 1/4+1/4 = 2/4) pq + qp = 2 pq |
FF (2F = 1/4) q x q = q2 |
p2+2pq+q2 |
||
In mod asemanator sa mergem mai departe in situatia cu 3 pupe (k=3), atunci nr. eventualitati cresc la 8 (Tabelul 24). Combinatii vor fi insa 4: numai masculi; numai femele: masculi si femele (in doua variante; de 2 ori mai julti masculi, respectiv, de 2 ori femele).
Tabelul 24
Distributia binomiala - 3 evenimente
|
k |
Eventualitati posibile = 8 |
Comb. |
Probabil.totala |
|||
|
MMM (3M, 1/8) ppp p3 |
MMF MFM FMM (2M,1F=3/8) p2q+pqp+qp2 3p2q |
FFM FMF MFF (2F,1M=3,8) q2p+qpq+pq2 = 3pq2 |
FFF (3F, 1/8) qqq = q3 |
p3+3p2q+3pq2+q3=1 |
||
Daca vom lua 4 pupe (k=4), numarul de eventuri creste la 16, in 5 combinatii posibile (Tabel 25).
Tabelul 25
Distributia binomiala - 4 eventuri
|
k |
Eventualitati posibile = 16 |
Comb. |
Probabil.totala |
||||
|
MMMM (4M,1/16) pppp =p4 |
MMMF MMFM MFMM FMMM (3M,1F=4/16) p3q+p2qp+ pqp2+qp3 =4p3q |
MMFF MFMF MFFM FMMF FMFM FFMM (2M,2F=6/16) p2q2+pqpq+ pq2p+qp2q+ qpqp+q2p2 =6p2q2 |
FFFM FFMF FMFF MFFF (3F,1M=4/16) q3p+q2pq+ qpq2+pq3 =4pq3 |
FFFF (4F=1/16) qqqq =q4 |
p4+4p3q+6p2q2+ 4pq3+q4 = 1 |
||
Distributia
binomiala (discontinua; a lui Bernoulli) are asadar loc in
conditiile existentei unei alternative (ori bila alba, ori
bila albastra) si a probabilitatii de aparitie a
fiecarei eventualitati care este
→ (1 + 1)0.
1 1 → (1 + 1)1
1 3 3 1 → (1 + 1)3
1 5 10 10 5 1 → (1 + 1)5
1 6 15 20 15 6 1 → (1 + 1)6.
![]()
![]() Distributia
binomiala (discontinua) este
o distributie discreta, ea se refera la
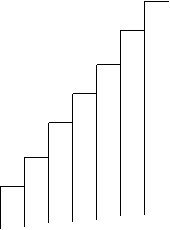
caractere ce variaza in salt. Ea poate trece intr-una continua (normala) daca n ∞, iar p = q = . Histograma unei distributii binomiale
este de felul celei prezentate in Fig. LP3-1
Distributia
binomiala (discontinua) este
o distributie discreta, ea se refera la
caractere ce variaza in salt. Ea poate trece intr-una continua (normala) daca n ∞, iar p = q = . Histograma unei distributii binomiale
este de felul celei prezentate in Fig. LP3-1
![]()
![]()
![]() P
P
![]() k
k
Fig. LP3-1. Histograma distributiei binomiale pozitive
Media unei astfel de distributii se calculeaza dupa relatia:
![]()
iar abaterea standard dupa relatia:
![]()
Formulele prezentate in Tabelele 12-15 si care compun triunghiul lui Pascal pot fi generalizate pentru aplicatiile practice si astfel, pentru valori date pentru k si q se poate evalua probabilitatea pentru orice combinatie. Daca folosim notatia urmatoare: p = probabilitatea ca o populatie (individ etc) sa fie prezenta in proba si q = probabilitatea ca si alta populatie (individ etc) sa fie absenta din proba si daca probabilitatile raman constante in fiecare din k=n extrageri (probe prelevate) atunci seria de probabilitati este data de desfasurarea binomului:
![]()
Formula generala este:
![]()
(P(x) = probabilitatea ca populatia respectiva sa fie reperezentata prin x indivizi in unitatea de proba; k = numarul de eventuri, probe etc; k! = k factorial; ex. 0! = 1; 1!=1; 2! = 2∙1; 3! = 3∙2∙1; 4! = 4∙3∙2∙1; 5! = 5∙4∙3∙2∙1; x = numarul unui eveniment particular (ex. masculi etc); p = probabilitatea unui eveniment particular (ex. masculi); q = probabilitatea unui alt eveniment particular (ex. femele).
Daca se cunoaste media ( x) si numarul maxim de indivizi continut in probe (k), atunci probabilitatea (p) ca popuplatia sa fie prezenta in proba va fi:
![]()
Probabilitatea celeilalte populatii (q) va fi:
q = 1- p
Exercitiu 1 Daca probabilitatea probabilitatea de emergenta a unui mascul din pupe selectate randomizat, este p=0,5, care este probabilitatea ca 4 pupe sa dea 1 mascul si 3 femele ?. Daca ne uitam in Tab. 15, coloana 4 (pentru 3F,1M vedem ca probabilitatea este 4/16 = 0,25).
Avand datele: k = 4; x = 1 mascul; p = 0,5; q = (1-p) = 0,5, aplicand formula generala obtinem:
![]()
Exercitiu 2. p=q. Sa se calculeze distributia completa a probabilitatii, pentru toate combinatiile, cand k=8 si p = 0,5.
Daca p = 0,5, rezulta ca si q = 0,5; daca k =8 rezulta urmatoarele combinatii posibile:
|
Masculi | |||||||||
|
femele |
Sunt deci 9 combinatii posibile (Observatie: deoarece p = q = 0,5 distributiile vor fi simetrice; asa ca mai jos vom calcula probabilitatile doar pentru primele 5 combinatii, ultimele 4 fiind similare ca valoare cu primele 4)
* pentru 8 masculi (deci la fel si pentru 8 femele); combinatia 8:0, respectiv 0:8
![]()
* pentru 7 masculi (respectiv 7 femele); combinatia 7:1, respectiv 1:7
![]()
* pentru 6 masculi (respectiv, 6 femele); combinatia 6:2, respectiv 2:6
![]()
* pentru 5 masculi (respectiv, 5 femele); combinatia 5:3, respectiv 3:5
![]()
* pentru 4 masculi (respectiv 4 femele); combinatia 4:4
![]()
Acum trecem distributiile, cu toate probabilitatile, intr-un tabel similar cu cel anterior:
|
Masculi | |||||||||
|
Femele | |||||||||
|
Probabilitate |
Rezultatul sumei probabilitatilor = 1.Reprezentarea grafica este ilustrata in Fig. LP3-2.
Exercitiu 3. p≠q. Sa se reprezinte distributia probabilitatii pentru toate eventualitatile unei distributii binomiale in conditiile in care k = 8; p = 0,8 (deci q =0,2).
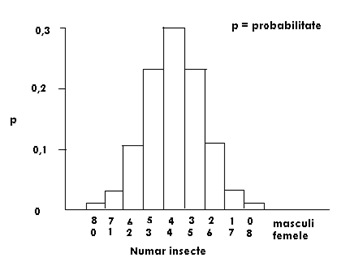
Fig. LP3-2. Distributia probabilitatii binomiale in situatia in care k=8 si p=q=0,5. Inaltimea fiecarei coloane a histogramei este probabilitatea pentru fiecare combinatie dintre masculi si femele considerand ca emergenta are loc din 5 pupe recoltate din habitat, la intamplare
Acesta este cazul descris anterior pentru M. brassicae si L. oleracea si practic avem aceleasi combinati ca si in cazul ex. 2. Avand asadar, x=6 (numarul pentru M. brassicae); p=0,8; q=0,2 (nr. pentru L. oleracea) si inlocuind in formula generala (calculand dupa procedeul de mai sus), obtinem toate valorile probabilitatilor (P) pe care le trecem de asemnea intr-un tabel asemanator:
|
M.br. | |||||||||
|
L.oler. | |||||||||
|
P |
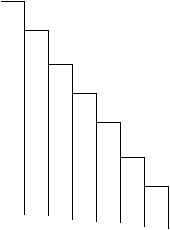
Reprezentarea grafica (Fig. LP3-3) se observa ca indica un model asimetric
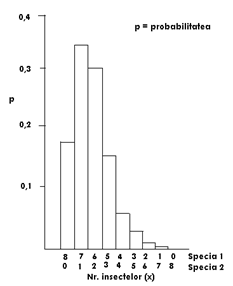
Fig. LP3-3. Distributia probabilitatii binomiale pentru k=8; p = 0,8. Inaltimea fiecarei coloane a histogramei reprezinta probabilitatea fiecarei combinatii dintre M. brassicae si L. oleracea care ar emerge din 8 pupe colectate la intamplare dintr-un habitat specific.
Exercitiu 4 (varianta exercitiu 3) (p≠q). x =3; k=4; atunci: p = 3 / 4 = 0,75; q = 1- 0,75 = 0,25; iar p + q = 1.
Probabilitatile seriei binomial pozitive vor fi, asa cum am aratat anterior, obtinute din desfasurarea binomului (p + q)k concret pentru exemplul dat: (0,25 + 0,75)4. In acest caz, probabilitatea de prezenta in proba a 0, 1, 2, 3, 4 indivizi este urmatoarea:
![]()
![]()
![]()
![]()
![]()
Daca se face suma probabilitatilor calculate (0,039 + 0,0469 + 0,2109 + 0,4219 + 0,3164 = 1.
Daca am extras 20 de probe (n = 20) atunci, probabilitatile calculate se inmultesc cu 20 si se afla frecventa teoretica cu care pot sa apara in probe 0, 1, 2, 3, 4 indivizi.
B. Distributia probabilitatii Poisson (Poisson;intamplatoare)
Acest model de distributie se supune Legii evenimentelor rare sau Legii numerelor mici. Este un caz al modelului distributiei binomial-pozitive. Exista cazuri cand probabilitatea ca un eveniment oarecare sa se produca este foarte mica sau la un numar oarecare de observatii este chiar 0 (desi stim ca la un numar mai mare de observatii acest eveniment ar putea sa survina). In cazul probabilitatii de aparitie a evenimentelor rare (sau a evenimentelor care nu apar din cauza unui numar mic de observatii) in locul distributiei normale se utilizeaza distributia Poisson.
Despre probabilitatea distributiei Poisson vorbim in urmatoarele situatii:
- evenimentele (lucrurile) pot fi evaluate cantitativ;
- datele cantitative se obtin de pe unitati de proba bine definite (ex. patrate de proba; probe luate la intervale fixe de timp etc) si pot fi organizate intr-o distributie a frecventelor, valoarea mediei fiind aproximativ egala cu varianta (dispersia);
- obiectele numarate sunt rare (adica, in probe sunt putine elemente fata de cit ar putea fi);
- indivizii sunt dispersati randomizat in spatiu si timp, ei sunt independenti unul de altul; ei nu sunt nici atrasi nici indepartati unul de altul.
Acest model de distributie impune cateva observatii. Este un model greu de gasit in realitate in natura, dar este folosit pentru a descrie dispersia aproximativ randomizata. Mai degraba include evenimente decit indivizi (obiecte) (ex. dezintegrarea radioactiva/unitatea de timp; golurile intr-un meci de fotbal; globulele de sange pe unitatea de suprafata a unui hematocrit; migratia pasarilor care trec pe la capatul unui loc/unitatea de timp; dezvoltarea coloniilor bacteriene rezistente la antibiotice; aparitia unor boli rare etc).
Am vazut ca distributia binomiala este definita de 2 parametrii (p si q). Distributia Poisson este determinata de un parametru ( El este egal cu media populatiei ( si cu varianta = dispersia (s2;
Distributia Poisson este o discreta distributie a frecventei astfel ca termenii acestei distributii sunt definiti astfel: frecventa relativa = proportie = probabilitate. Formula generala a distributiei Poisson pentru determinarea probabilitatii (P), atunci cand unitatea de proba contine un numar specific de indivizi (x) pentru o valoare data a mediei (‾x) va fi:
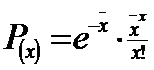
(P(x) = probabilitatea de a observa x indivizi in patratul de proba; x = m = media numarului de indivizi/proba; este vorba de media estimata pe baza sampling-ului, altfel, matematic, media este reprezentata de μ ; e = baza log. natural; 2 = 2,7183; x = numarul specific de indivizi / unitatea de proba; x! = x factorial; e-m = functia exponentiala negativa a lui e)
Retineti pentru parametrul e-m exista tabele matematice, cu valori gata calculate
Exercitiu 5. Sa se estimeze probabilitatea distributiei Poisson pentru x = 0-10; x = 4,0. Cu alte cuvinte noi vom calcula probabilitatea de a gasi un numar dat (x) de indivizi intr-o unitate de sampling unde x poate fi un numar intre intre 0 si 10. Stim ca x = 4,0; e = 2,7183; x = 0-10. Aplicand relatia pentru fiecare caz, obtinem:
![]()
(0! =1; e-4 = 0,0183 - din tabelul valorilor lui e-m)
![]()
![]()
![]()
Si astfel se procedeaza in continuare pana la 10, iar toate valorile probabilitatii vor fi:
P(x=0) = 0,0183; P(x=1) = 0,073; P(x=2) = 0,146; P(x=3) = 0,195; P(x=4) = 0,195; P(x=5) = 0,156; P(x=6) = 0,104; P(x=7) = 0,059; P(x=8) = 0,030; P(x=9) = 0,013; P(x=10) = 0,005.
Suma probabilitatilor = 0,994 (≈ 1)
Distributia probabiltatii este ilustrata in Fig. LP3-4.
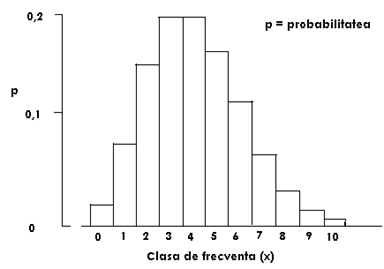
Fig. LP3-4. Distributia probabilitatii Poisson, estimata pentru x = 4,0. Inaltimea fiecarei bare a histogramei reprezinta probabilitatea estimata pentru o unitate de proba selectata care va contine x indivizi.
C. Distributia probabilitatii binomial negative (NegBin)(in agregate)
In natura nu snt multe specii care care sa aiba un model de distributie spatial randomizat, majoritatea speciilor respectand modelul in agregate. Pentru a descrie acest model exista o varietate de distributii statistice (Patil si colab., 1971; Krebs, 1999). Cel mai comun este cel al distributiei binomial negative, iar in literatura ecologica de azi, terminologia binomial negativ si model in agregate, sunt sinonime. Sa mai amintim ca acest model are un numar mare de variatii (vezi Fig. LP2-14,b)
Distributia binomial negativa este adecvata cand:
- observatiile constau in numararea de lucruri (obiecte, indivizi etc);
- valorile sunt obtinute de pe o unitate de sampling definita (patrate, filee, capcane etc) si pot fi organizate intr-o distributie de frecvente si in care varianta=(dispersia este mai mare decat media (s2 > ‾x);
- indivizii nu sunt dispersati randomizat dar nici nu sunt independenti ci sunt dispusi in grupe (aglomerari) de indivizi
Spre deosebire de distributia Poisson, distributia binomial negativa este un model robust care poate descrie o serie larga de situatii din natura (ex. dispersia plantelor in camp; distributia ectoparazitilor pe gazde; gaurile de iesire ale cariilor de lemn; dispunerea oualor de insecte pe substrat; dispozitia galelor pe frunzele de stejar etc).
Matematic, probabilitatea distributiei binomial negative este definita de 2 parametrii (ca si cea binomial pozitiva): un exponent (k) si media populatiei ( ). Atentie: spre deosebire de distributia binomial pozitiva unde k este un numar intreg, aici valoarea lui k este o variabila continua.
Expresia matematica este:
![]()
![]()
In practica ecologica, cele doua variabile pot fi determinate pe baza datelor furnizate de probe. Valoarea medie a probei (‾x ) este o estimare satisfacatoare pentru , iar k poate fi estimat pe baza mediei si variantei (s2), dupa relatia
![]()
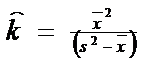
(semnul ^ indica faptul ca este vorba despre un parametru estimat al populatiei).
Probabilitatile individuale ale lui P(x), adica probabilitatea ca un numar specific de indivizi (x) sa apara in unitatea de proba selectata randomizat (ex. un patrat) sunt deduse astfel din desfasurarea expresiei de mai sus:
![]()
unde: p = μ ∙ k
si: q = (1 + p)
Exercitiu 6 Sa se estimeze distributia binomiala negativa pentru: x = 0 - 5; ‾x= 2,0; s2 = 5,0
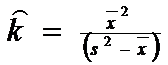
![]()
Urmeaza apoi o secventa constituita din mai multi pasi:
* Pasul 1. Se calculeaza probabilitatea pentru x = 0
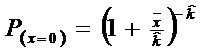
![]()
* Pasul 2. Se calculeaza un factor F dupa relatia:
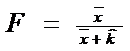
![]()
* Pasul 3. Se calculeaza probabilitatea pentru x = 1, dupa relatia:
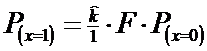
![]()
* Pasul 4. Probabilitatea pentru x = 2 este data de relatia:
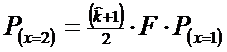
![]()
* Pasul 5. Probabilitatea pentru x = 3 se calculeaza dupa relatia:
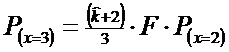
![]()
* Pasul 6. Probabilitatea pentru x = 4 se estimeaza dupa relatia:
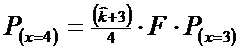
![]()
* Pasul 7. Probabilitatea pentru x = 5 va fi estimata dupa relatia:
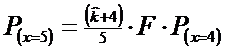
![]()
Observand relatiile de mai sus se poate observa
ca pentru fiecare caz urmator probabilitatea poate fi evaluata
din cea anteriora prin multiplicare cu 2 termeni (x-1) si ![]()
Adunand cele 5 valori ale probabilitatilor se obtine rezultatul 0,91 Deci ar mai trebui continuat pana la x = 6..Astfel prin calcule am mai obtinut: P(x=6) = 0,029; P(x=7) = 0,018; P(x=8) = 0,011. Insumand:
Probabilitatile distributiei binomial negative pentru x = 0 - 8 sunt prezentate in Fig. LP2-5.
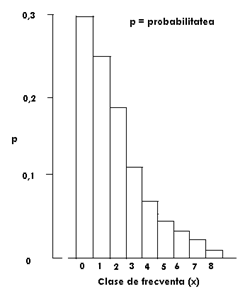
Fig. LP2-5. Distributia probabilitatii binomial negative estimate pentru ‾x= 2,0 si k = 1,33. Inaltimea fiecarei coloane a histogramei reprezinta probabilitatea pentru o unitate de proba selectata randomizat ca sa contina x indivizi.
Modalitatea de calculare descrisa mai sus este simpla altfel folosirea formulei generale pentru distributia binomial negativa este greoaie:
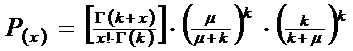
(P(x) = probabilitatea ca un patarat sa contina x indivizi; x = numarul - 0, 1, 2, 3, 4..; μ = media distributiei; k = exponentul binomial negativ; Γ = functia gamma - vezi in continuare).
Functia Gamma se estimeaza dupa formula lui Stirling:
![]()
Cel mai dificil este insa de estimat exponentul k (Bliss si Fisher, 1953). Un calcul aproximativ este dat de relatia prezentata mai sus:
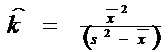
Exista mai multe situatii. Ne referim pe scurt la cele mai importante:
☻ - varianta cu probe mici (n < 20); valorile putine sunt aranjate in frecvente de distributie
a. METODA 1: mai mult de 1/3 din patrate sunt goale. k este dedus din rezolvarea ecuatiei:
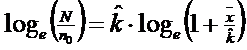
(N = numarul total de
patrate numarate; n0 = numarul de patrate continand 0 indivizi;
‾x = media observata; ![]() = exponentul
binomial negativ estimat)
= exponentul
binomial negativ estimat)
b. METODA 2: mai putin de 1/3 patrate sunt goale. k este estimat dupa relatia:
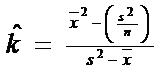
c. Metoda 3: cind media > 4,0 si mai putin de 1/3 din patrate sunt goale. Este mai greoaie (Elliott, 1974).
☻ - varianta cu probe mari (n > 20); valorile sunt aranjate in frecvente de distributie. Exista doua variante de lucru, in functie de aceste frecvente. Relatiile sunt de asemenea complicate. Pentru a usura calculele, cu cele 2 metode s-a intocmit un grafic (Fig. LP3-6).
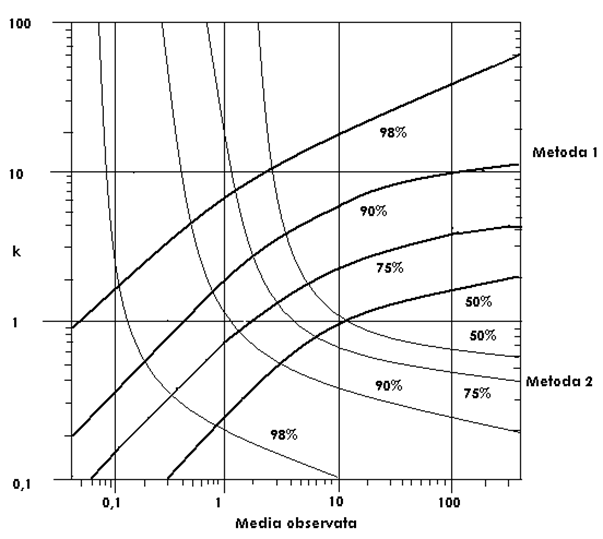
Fig. LP3-6. Grafic sintetic pentru estimarea parametrului k, bazat pe relativa eficient[ a Metodelor 1 si 2 descrise in text. Daca insa varianta de lucru are probe multe (n > 20) si nu se foloseste metoda 3 atunci se poate folosi graficul pentru a localiza media observata si valoarea aproximativa a lui k, estimata prin una din metodele 1 sau 2. Metoda are o relativa eficacitate (dupa Anscombe, 1950; din Krebs, 1999).
Un alt aspect deosebit de interesant referitor la modelul de distributie binomial negativa, legat tot de parametrul k arata urmatorul aspect: cu cat k creste graficul care ilustreaza distributia binomial negativa se modifica in sensul ca la un k cu o valoare mare, apropiata teoretic de infinit, modelul binomial negativ se apropie de distributia Poisson (Fig. LP3-7)
Pentru compararea distributiei binomial negative cu distributia Poisson, in conditile in care media variaza, forma curbelor este distincta. Modificarea valorilor mediei (μ) modifica forma distributiei in ambele cazuri (pentru distributia Poisson, cresterea valorii mediei apropie curba de cea normala, iar la distributia binomial negativa o apropie de Poisson) (Fig. LP3-8).
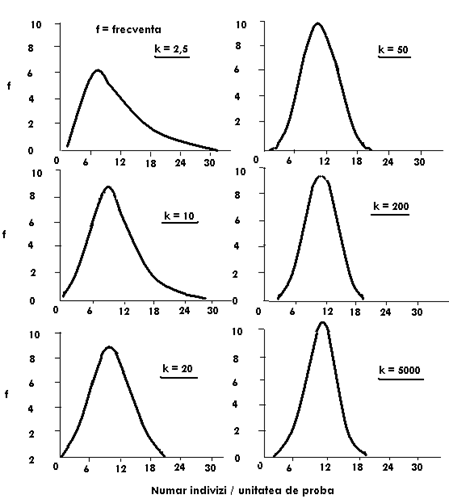
Fig. LP3-7. Efectul valorii lui k asupra formei curbelor distributiei binomial negative. In toate cele 6 cazuri prezentate in imagine, media celor 6 frecvente este 10. Variatia valorii lui k de la 2,5 la o valoare foarte mare modifica forma curbei, apropiind-o de distributia Poisson (dupa Elliott, 1977; din Krebs, 1999).
6. Distributia normala (distributie fundamentala; continua)
(distributia Gauss - Laplace)
a. Curba normala
Acest tip de functie se considera ca joaca in statistica matematica, acelasi rol ca si cel al functiei liniare din analiza. Grafic se reprezinta printr-o curba in forma de clopot, cu ramuri care se intind intre -∞ si +∞. Deschiderea clopotului pana la punctele de inflexiune cu axele este masurata de valoarea (s) (abaterea standard). Dupa curba normala se distribuie si variatiile intamplatoare ale indivizilor dintr-o populatie. Daca studiem un anume eveniment si consideram ca normal ceea ce se intalneste la 95% dintre indivizii populatiei atunci intervalul de normalitate este ‾x 2s (Fig. LP3-9).
Astfel, in intervalul:
* ‾x 1s - se afla 66 -68% din date (68,26%);
* ‾x 2s - se afla 95 % din date (95,45%);
* ‾x 3s - se afla 99% din date (99,73%).
Cu alte cuvinte, ceea ce se incadreaza in acest interval face parte din populatie iar restul nu.
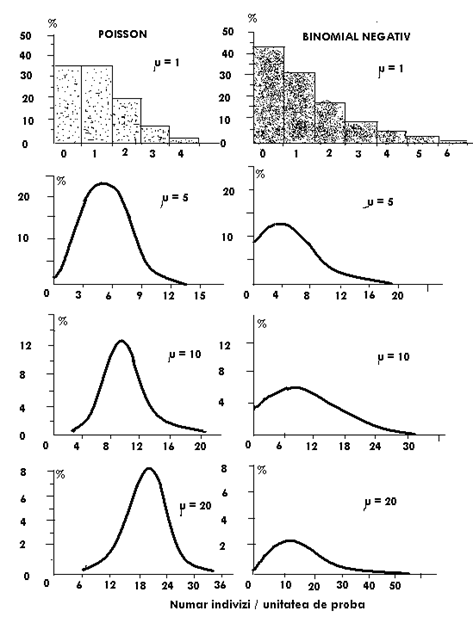
Fig. LP3-8. Forma distributiei frecventelor Poisson si binomial negativa in functie de valoarea mediei (μ). In toate cazurile, k este constant (k = 2,5)
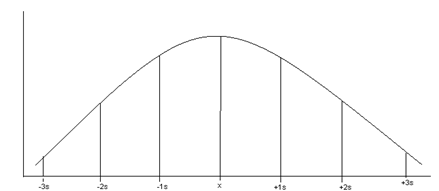
Fig. LP3- Reprezentarea curbei normale si intervalele de normalitate
In cazul studiului coeficientului de asimetrie am aratat ca acesta se refera la deviatiile curbei de distributie pentru valorile noastre, fata de modelul de distributie teoretic (adica fata de distributia normala). Prin distributie statistica se intelege modalitatea de repartitie a valorilor individuale ale variabilei x in cadrul unei serii.. In biologie si mai ales in ecologie, majoritatea distributiilor au caracter simetric adica, valorile situate de o parte si de alta a mediei (respectiv, valorile frecventelor situate de o parte si de alta a clasei de frecventa maxima) sunt aproximativ egale intre ele.
variaza pe intervalul: -1........+1.
![]()
Exemplu: Presupune urmatorul sir de valori, ordonat crescator: 0, 0, 0, 1, 3, 3, 3, 4, 4, 4, 4, 5, 5, 5, 6, 6, 7, 7, 7, 8. Pentru acest sir dupa calcule, vom avea urmatoarele valori:
n = 20; ∑ = 82; ‾x = 4,1; Mod = 4; Mdn = 4; s2 = 5,9844; s = 2,4473.
Conform relatiei, valoarea coeficientului de asimetrie va fi:
Semnificatie: Valoarea obtinuta indica o asimetrie pozitiva; de asemenea, valoarea mica arata ca exista o tendinta foarte mica de grupare a datelor spre valorile mari.
Vorbind de valori mari, ne referim la valorile care se gasesc cat mai apropiat de medie, ceea ce intr-o reprezentare grafica a unei distributii normale (Gauss), cu forma de "clopot" valorile mari sunt la "varful clopotului". Se intelege ca abaterile standard (s) vor fi de o parte si de alta a mediei.
Intr-un experiment privind masurarea lungimii a 100 de muguri, datele obtinute s-au grupat pe clase de frecventa. Intervalul de clasa a fost 1. Reprezentarea grafica combinata (poligon de frecvente si curba de frecvente) indica o distributie simetrica (Fig. LP3-10):
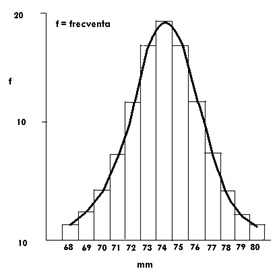
Fig. LP3-10. Curba frecvetelor pentru 100 muguri, reprezentate grafic prin poligon de frecventa si curba de frecvente.
Asadar intervalul de clasa este foarte mic. Pe de ala parte, daca se mareste numarul de observatii creste gradul de precizie iar o histograma trece spre o curba, la fel, simetrica si ea (Fig. LP3-11):
Fig. LP3-11. Trecerea gradata a unei histograme spre o curba normala.
Pe baza unui numar foarte mare de probe luate dintr-o aceeasi populatie, matematicianul Gauss a definit moelul pentru curba normala, care este de tipul:
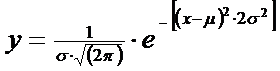
Aceasta este ecuatia unei curbe normale unde y = f(x). π si e = constante; μ = media; σ = abaterea standard a populatiei. Uzual noi nu cunoastem pe μ si σ, si ii estimam pe baza datelor de sampling prin ‾x si s Daca numarul de observatii este >30 cei doi parametrii vor fi corect apreciati de datele de sampling.
Ca orice variabila continua, x isi poate asuma orice grad de precizie si implici si y va fi continuu. Aceasta contrasteaza cu cele 3 distributii descrise anterior unde valorile lui x erau numere intregi.
Se poate genera o infinitate de forme ale curbei normale prin valorile practic nelimitate ale lui si (Fig. LP3-12)
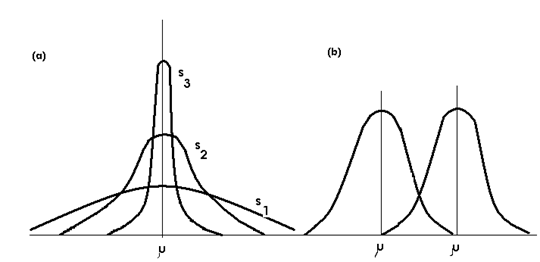
Fig. LP3-12. Curba normala reprezentata in diferite moduri, dependent de valorile celor 2 parametrii (μ si σ).
b. Proprietati matematice ale curbei normale
O curba normala este simetrica iar axa de simetrie trece prin punctul ‾x = μ. De o parte si de alta a punctului de inflexiune directia curbei se schimba de la forma concava la cea convexa. Pe axa Ox se pot marca, de o parte si de alta a punctului de inflexiune valori ale lui σ. Axele verticale ale distributiei fot fi rescalate de numarul de observatii si efectiv devin o distributie a probabilitatii sau mai corect o densitate a probabilitatii. Probabilitatea totala cuprinsa in curba este de 100% iar de o parte si de alta a mediei, valorile abaterii standard definesc niste suprafete in care sunt cuprinse 68,26% din observatii (pentru x 1s), 95,45% (pentru ‾x 2s) si 99,73% (pentru ‾x 3s) (vezi Fig. I). Cu alte cuvinte, exista o probabilitate P = 0,68 ca o singura observatie randomizata sa fie gasita in intervalul ‾x 1s (32% vor fi in afara acestei limite: 16% in dreapta si 16% in stanga fata de abaterea standard 1). Similar, extinzand limitele la 2s si 3s vom putea spune ca exista o probabilitate P = 0,95, respectiv, P = 0,9 Din punct de vedere practic este mai usor de lucrat cu aceste valori, ele putand fi calculate caci aceste valori ale probabilitatii vin de la ‾x 1,96s (1,960 = valoarea teoretica a lui "t" pentru P = 0,05) si respectiv ‾x 2,58s (2,580 = valoarea teoretica a lui "t" pentru P = 0,01) Aceasta inseamna ca probabilitatea unei observatii sa se gaseasca in afara acestei limite este de P = 0,05, respectiv P = 0,01.
Orice valoare de observare x de pe linia bazala a curbei normale poate fi standardizata ca un numar de unitati de abatere standard, valorile fiind mai indepartate de medie. Aceasta expresie se cheama z-score. Pentru a transforma pe x in z se aplica formula:
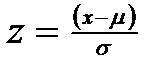
(daca μ este mai mare x atunci z este negativ).
Adesea nu se cunosc valorile lui μ si σ si atunci, in probele care provin din observatii cu n > 30, valoarea lui z este data de relatia:
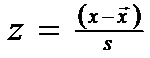
Daca valoarea calculata a lui z este > 1,960 (pentru care P = 0,05), atunci probabilitatea fiecarei observatii aleasa la intamplare este mai < 0,05. Ea este privita ca improbabila sau statistic semnificativa (daca "t" empiric = calculat > "t" teoretic = diferente semnificative)
Exemplu. Pe baza uni numar mare de probe s-a evaluat media unei populatii de seminte (‾x = 3,8mm) iar σ = 0,15 mm. Daca se gaseste o seminta de 4,3 mm, ea va apartine acestei populatii ?.
Se converteste observatia x in z-score:
![]()
Valoarea z > 1,960 (pentru care P = 0,05). Mai mult z > 2,580 (pentru care P = 0,01). Deci, diferentele sunt puternic semnificative, cu alte cuvinte: este foarte putin probabil ca acest individ sa apartina acestei populatii.
c. Curba normala cu distributia la o extremitate sau la ambele extremitati
Am zis ca in cazul unei curbe normale, 95% din observatii sunt continute pe intervalul ‾x 2s (sau ‾x 1,960s). Restul de 5% sunt impartite egal in afara acestei limite, de o parte si de alta (partea "superioara"; cea cu +; partea "inferioara"; cea cu -) (Fig. LP3-13,a). Exista deci o alternativa in care 5% poate fi considerat intr-o singura parte, iar in acest caz punctul de oprire pe abscisa este la valoarea 1,65 (Fig. LP3-13,b).
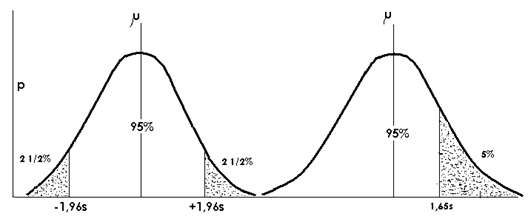
Fig. LP3-13. (a) - Curba normala cu rezidual de 5% considerat impartit in afara intervalului ‾x 1,960s, impartit in ambele parti ale curbei; (b) - Curba normala cu rezidual de 5% considerat doar in partea "superioara" a curbeiimpartit in afara intervalului ‾x 1,960s
In cercetari experimentale se poate spune ca o observatie randomizata poate sa nu apartina unei populatii de medie si abatere data ci unei populatii care are o medie mai mare (sau alternativa). In acest caz valoarea critica a lui z este mai mica (1,65σ ) si zicem ca este o curba normala unilaterala (one-tailed).
Exemplu. Pe baza unui numar mare de probe, media lungimii corpului la masculii unei specii de insecta a fost de 5,6 mm; abaterea standard = 0,26 mm. Femelele se cunosc a avea in medie dimensiuni mai mari. Se pune intrebarea: un individ recoltat randomizat si cu L = 6,1 mm, poate fi mascul ?.
In prima faza spunem ca o asemenea dimensiune este improbabila sa apartina unei populatii distribuita normal, cu parametrii respectivi, deci trebuie sa parvina de la o populatie cu media mai mare, deci ar fi o femela. Curba normala este unilaterala si valoarea lui z = 1,65.
Se converteste observatia individuala x in z-score:
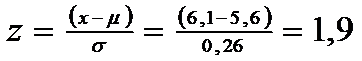
z < 1,960 pentru curba normala bilaterala, dar z > 1,650, pentru curba normala unilaterala. Daca testul este pentru curba normala unilaterala atunci diferentele sunt semnificative si deci este improbabil ca individul sa fie mascul ci este probabil o femela.
d. Distributia "t" pentru probe mici
In distributia normala valorile lui z (z=1,96 si z = 2,58) indica limitele mediei populatiei unde sunt cuprinse 95, respectiv 99% din date (observatii). Cum nu cunoastem valorile lui μ si σ noi trebuie sa le calculam pe baza datelor noastre de sampling. Mai spunem de asemenea, ca trebuie sa luam foarte multe probe pentru ca datele sa fie corecte.
Cind numarul de probe este mic (n < 30),"z" este inlocuit cu "t . Cu cat scade numarul de probe cu atat va scadea si siguranta. Deci valoarea lui t trebuie sa creasca. Si implicit media si abaterea deoarece distributia "t" este dependenta de marimea probei (n). Dar nu valoarea n masoara pe "t" ci n-1 (gradele de libertate). In acest caz exista modalitatile matematice de compensatie iar valorile teoretice ale lui "t" se afla in tabele si ele vor fi comparate cu valorile "t" empirice (calculate din datele noastre de sampling).
Convertirea lui z in t, in cazul numarului mic de probe, se face dupa relatia:
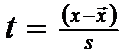
daca "t" empiric (calculat) > "t" teoretic (tabelar) .... = diferente semnificative
Exemplu Din 12 exemplare de Poa sp. s-au masurat florile. Datele (in mm) sunt urmatoarele:
S-a gasit in herbar un exemplar care masoara 4,4 mm. Este acest specimen incadrat in populatia de mai sus pentru care ‾x = 5,43 si s = 0,62 mm ?.
Convertim valoarea lui x in t-score:
![]()
(Atentie: se ignora semnul - deoarece noi folosim modelul de curba normala bilaterala)
"t" calculat (=1,66) se compara cu "t" teoretic (din Tabelul cu valorile lui "t"), pentru n-1 grade de libertate (=11). Pentru P =0,05 gasim valoarea 2,201. In acest caz "t" calc. < "t' teoretic. Deci sunt diferente nesemnificative (x apartine asadar aceleiasi populatii).
Observatie Din Tabelul cu valorile lui "t" se constata ca cu cat creste n, scade "t". Pentru n = ∞ "t" = 1,96 (pt. P = 0,05) si "t" = 2,58 (pt. P = 0,01). Cand spunem ca ne referim la numar de probe < sau > de 30 o facem deoarce peste 30 schimbarile relative ale valorii lui "t" devin foarte mici, odata cu cresterea numarului de probe. Astfel, valoarea lui "t" pentru P=0,05 este doar cu foarte-foarte putin < 2
e. Sunt datele noastre "normale" ?
Multi dintre parametrii statistici descrisi depind de proprietatile curbei normale. Ei de fapt arata ca probele au fost bine luate din populatia care are o distributie normala. Atunci cand probele sunt putine este greu in a recunoaste daca populatia parentala este normala, iar in acest caz, tehnicile distributiei libere (non-parametrica) sunt cele mai indicate.Pentru ca o curba normala este continua probele care vor cuprinde obiectele numarate nu vor putea niciodata sa fie "noemale" ci ele pot sa fie cel mult in conformitate cu curba binomiala, Poisson sau distributia binomial negativa. Cu toate acestea, erorile datorate pierderii continuitatii, adica, faptul ca sunt cauzate de niste "pasi" existenti in distributia frecventelor nu trebuie sa fie ceva de luat prea in serios daca distributia este destul de simetrica. Noi am vazut ca acesta este cazul distributiei binomiale cand P ≈0,5 si distributia Poisson, cand P > 0,5. Deci putem privi distributia ca fiind aproximativ normala.Erorile sunt mari mai ales atunci cand prelucrand datele de sampling varianta > decat media. In acest caz datele nu pot fi utilizate fara ajustarea (transformarea) sau normalizarea datelor.
Adesea probele se pot indeparta foarte mult de normalitate. Multe organisme sunt polimorfice (ex. cazul dimorfismului sexual). Masuratorile efectuate in probele de indivizi vor fi polimodale, fiecare mod corespunzand unei anumite clasa de populatie (de sex, de varsta etc). Cum se poate sti daca probele provin dintr-o populatie distribuita normal ?. Ar fi doua modalitati:
- ori se aplica relatia lui Gauss si dupa aceea se aplica testul bunei-corespondente (goodness-of-fit test) (frecvent insa nu este nevoie de aceasta);
- se reprezinta grafic si se observa daca exista "normalitate"; se calculeaza media si abaterea standard a probei iar daca 70% din observatii sunt cuprinse in intervalul ‾x 1s este o distributie normala.
Exemplu In 3 loturi experimentale s-au facut cate 10 observatii de sampling in fiecare. Apartin acestea de popultii distribuite normal?.
a. din cele 10 se iau 6 pentru care se noteaza frecventa, astfel: 6(1); 7(1); 8(3); 9(2); 10(2); 11(1).
‾x = 8,6; s=1,5; ‾x 1s = 7,1...10,1. Observatiile sunt usor diferentiate si 7 din 10 sunt cuprinse pe intervalul ‾x 1s deci nu ar exista nici o ratiune de a sta la indoiala ca probele provin dintr-o populatie normala.
b. se iau numai 5 din lotul 2: 5(3); 6(3); 7(2); 8(1); 9(1).
‾x = 6,4; s=1,35; ‾x 1s = 5,1...7,8. In acest caz exista o usoara diferentiere a datelor si numai jumatate din ele cad in intervalul ‾x 1s. De data aceasta se poate sta la indoiala ca probele provin dintr-o populatie normala.
c. in acest caz se iau urmatoarele valori: 5(3); 6(2); 791); 8(2); 9(2).
‾x = 6,8; s=1,62; ‾x 1s = 5,2...8,4. In acest caz exista un bimodalism evident; numai jumatate din ele cad in intervalul ‾x 1s. De data aceasta se poate sta la indoiala ca probele provin dintr-o populatie normala.
Modul in care organismele sunt dispersate in natura prezinta o deosebita importanta pentru biologi si ecologi. Modul in care indivizii sunt dispersati reprezinta un prim pas in intelegerea relatiilor existente intre ei, precum si relatiile dintre indivizi si mediu. In orice areal geografic, asadar, plantele si animalele sunt distribuite in unul din cele 3 modele spatiale: regulat (uniform), la intamplare (randomizat) si aglomerat (agregat, contagios) (Fig. LP3-14,a). Pe de alta parte exista diferite gradatii in cadrul fiecarui model.
Retineti Terminologia acestor modele de distributie (dispersie) poate fi uneori confuza. Iata de exemplu o serie de sinonimii:Uniform = regular = even = pozitive contagion = under-dispersed;Aggregated = contagious = clustered = clumped = patchy = negative contagion = over-dispersed
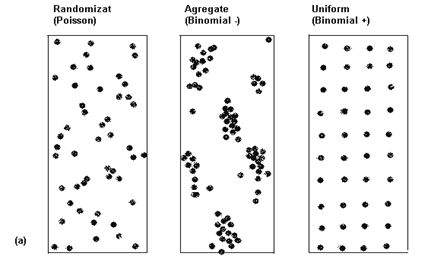
s2 = ‾x s2 > ‾x s2 < ‾x
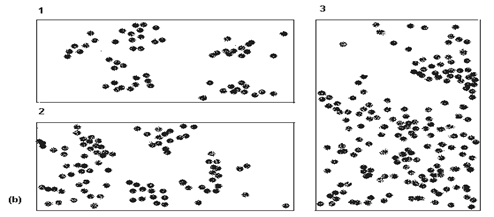
Fig. LP3-14. Modelele de distributie (dispersie) a indivizilor in natura. (a) cele 3 modele clasice: intamplator (randomizat, Poisson), in agregate (contagios, binomial negativ) si uniform (binomial pozitiv); este prezentata si relatia dintre medie si varianta (dispersie) in cadrul fiecarui model; (b) - variatii ale modelului de distributie in agregate: 1 - slab (usor agregat; 2 - larg (puternic) agregat, cu indivizi dispusi randomizat; 3 - larg agregat cu indivizi uniform distribuiti (dupa Jarvis si colab., 1998; Krebs, 1999).
In acest gen de cercetari, tehnicile statistice pot fi de ajutor in 2 moduri:
-formarea unei opinii obiective daca datele valorice dintr-o proba cuprind indivzi care sunt dispersati in natura in una din cele 3 modalitati;
- daca am obtinut un numar suficient de mare de unitati de proba ele ar putea sa ne permita sa determinam mult mai precis daca distributia in proba este in acord cu unul din modelele de probabilitatea distributiei.
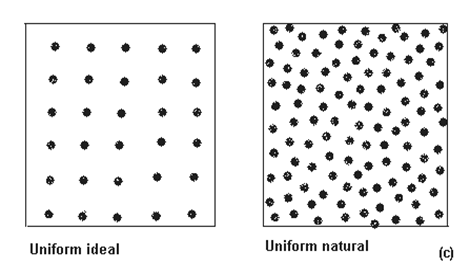
Fig. LP3-14, continuare. Variatii ale modelului de distributie uniform (binomial pozitiv) a indivizilor populatiilor in camp: uniform ideal si uniform natural (c); dupa alti autori nu ar exista un model de distributie uniform ideal decat artificial (cultura de viata de vie; pomii dintr-o livada), in realitate fiind vorba de o distributie uniforma a unor "agregate de indivizi" si nu de indivizi izolati (dupa Jarvis si colab., 1998; Krebs, 1999).
Daca dispersia este imaginata ca modul in care obiectele sunt imprastiate pe o suprafata (ex. sol), in acest caz un patrat de proba este o unitate de sampling corespunzatoare. Dar, de foarte multe ori se urmareste dispersia ca eveniment derulat in timp, caz in care o anumita perioada de timp este o unitate de sampling corespunzatoare.
7.1. Teste adecvate de verificare a corectitudinii distributiei (Goodness-of-Fit Tests)
Exista doua metode pentru a testa corectitudinea distributiei Poisson: testul indicelui de dispersie si testul adecvat "chi patrat' (chi square goodnes-of-fit test)
7.1.1. Indicele de dispersie
Daca ne referim la un model de dispersie de tipul A(1) acesta este neuzual in natura dar arborii plantati intr-o livada pot reflecta acest model. Daca mai multe unitati de sampling contin exact acelasi numar de obiecte (indivizi), le-am putea presupune ca fiind o dispersie extrem de regulata (uniforma). De asemenea, s-ar putea ca media probei sa aiba aceeasi valoare ca oricare singura observatie, iar abaterea standard si dispersia sa fie 0. In modelul de dispersie de tip A(2), am putea deduce ca exista totusi o mica variatie intre "observatiile" dintr-o proba, dar varianta va fi inca mica.
Trecand la polul opus, la dispersia in agregate, aceasta va contine cateva unitati de proba cu putini indivizi (0, 1), dar si unitate de proba cu foarte multi. In acest caz abaterea standard si dispersia sunt mari.
Intre aceste doua extreme se afla distributia intamplatoare. Generalizand se pot spune urmatoarele:
- o proba cu o mica varianta sugereaza o dispersie regulata (uniforma);
- o proba cu varianta intermediara sugereaza o dispersie randomizata (intamplatoare);
- o proba cu varianta larga sugereaza o dispersie contagioasa ( in agregate)
Este asadar nevoie de o scara cantitativa care care sa indice sectiunile cu cele 3 tipuri de dispersie. Distributia Poisson descrie cel mai bine dispersia randomizata a obiectelor. Matematic, in acest model, vaianta (dispersia) este egala cu media (s2 = ‾x). Dar in probele cu obiecte dispersate randomizat presupunem o varianta aproximativ agala cu media (s2 ≈ ‾x) sau s2 / ‾x ≈ 1.
Daca se face raportul dintre dispersie si medie se obtine indicele de dispersie (agregare). In functie de valoarea acestuia se poate estima si tipul de distributie (se va tine cont ca in cazul distributiei Poisson, raportul dispersie / medie ≈ 1).
Astfel:
![]() indivizii prezinta o
dispersie intamplatoare;
indivizii prezinta o
dispersie intamplatoare;
![]() indivizii prezinta o dispersie in
agregate;
indivizii prezinta o dispersie in
agregate;
![]() indivizii au o dispersie uniforma
indivizii au o dispersie uniforma
In urma prelucrarii datelor experimentale se poate obtine un raport varianta / medie ≈ 1 situatie in care, pentru a avea ceritudinea unei distributii intamplatoare (concret, pentru a vedea daca deviatia fata de valoarea 1 este semnificativa sau nu) se foloseste testul de semnificatie urmator:
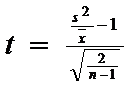
![]() = eroarea standard
a abaterii; n = numarul de probe; n-1 = grade libertate)
= eroarea standard
a abaterii; n = numarul de probe; n-1 = grade libertate)
Semnificatia o vom gasi din tabelul valorilor lui t, pentru pragul de semnificatie propus (P = 0,05 sau P = 0,01), pe randul corespunzator gradelor de libertate.
7.1.2. Testul "chi patrat"
Daca se reprezinta relatia dintre "χ2" si numarul de "grade de libertate" (n-1) se poate imagina un grafic (Fig. LP2-15) care prezinta zonele pentru cele 3 tipuri de dispersie.
Exercitiu 7 In cadrul unui program de monitorizarea poluarii marine langa o rafinarie, s-a investigat annual de catre ecologi densitatea populatiilor de Patella sp. (Mollusca). Unitatea de sampling reprezenta un patrat de 20 x 20 cm (0,04 m2) iar obserbatiile s-au facut pe 20 unitati de sampling. S-au obtinut urmatoarele date:
6, 8, 9, 9, 10, 7, 8, 7, 7, 9, 8, 10, 7, 8, 8, 9, 11, 9, 8
Se pune intrebarea care este modelul de dispersie al indivizilor acestei specii ?.
Exista urmatorii pasi de a proceda:
- se calculeaza media (‾x= 8,45), varianta = dispersia (s2=1,84) si abaterea standard (s=1,356);
- se calculeaza indicele de dispersie (Id = s2 / ‾x); (Id = 0,218); valoarea fiind <1 suspectam a fi o dispersie regulata;
- se calculeaza multiplicand pe Id cu nr. grade de libertate ( ) (n-1);
= Id ∙
- pe graficul din Fig. LP3-12 se cauta punctul de intersctie dintre si (4,14 si 19);
- punctul respectiv este sub linia de demarcatie sub dispersia randomizata, in sectorul dispersiei uniforme (regulate).
Exercitiu 8 Un program de studiu a polenizarii a evidentiat ca frecventa de vizitare a florilor de catre albine. Unitatile de sampling s-au facut la intervale de 1 minut si in cele 10 intervale s-au obtinut urmatoarele valori:
6, 3, 3, 9, 4, 6, 2, 5, 2
Cum sunt dispersate vizitele albinelor ?. Procedand conform etaplor de lucru prezentate pentru Exercitiu 10, obtinem: (‾x = 4,4; s2 = 4,71; s = 2,17; Id = 1,07; ; punctul de intersectie este 9,63: Punctul este in sectorul dispersiei randomizate (intamplatoare).
Exercitiu A fost investigata dispersia speciei Orchis morio (Orchidee) intr-o rezervatie naturala Un numar de 12 patrate de 1 / 1 m (unitati de sampling) s-au plasat randomizat si s-au numarat plantele tinta. S-au obtinut urmatoarele date
Cum este dispersata aceasta specie ?. Se parcurg toate etapele descrise in ex. 7. Astfel, printre altele, valoarea lui Id = s2 / ‾x (Id = 28,8). Valoarea fiind >1, putem presupune o distributie (dispersie) in agegate. Dupa ce s-a calculat (316,8) si s-a urmarit pe grafic locul de intersectie cu valoarea lui (11) se constata ca acest punct este situat an domeniul dispersiei in agregate.
7.2. Modele de dispersie si alegerea modelelor de dispersie (distributie)
In exemplele anterioare au fost prezentate cateva situatii in care numarul de probe a fost < 30. Pe baza datelor obtinute s-a calculat indicele de dispersie, in functie de varianta si medie. Daca probele sunt > 30 atunci observatiile pot fi grupate in interiorul unei distributii a frecventelor. Trebuie apoi de urmarit daca distributia obtinuta este in concordanta cu cea asteptata conform cu ceea ce am prezentat la distributia probabilitatilor. In alegerea modelului trebuie abut in vedere doua aspecte:
- modelul nimerit trebuie ales ca sa fie acceptabilrezonabil din punct de vedere statistic;
- distruibutia asteptata sa fie realizabila
Liniile directoare in alegerea modelului sunt: - daca indicele de dispersie sugereaza o dispersie uniforma, se alege modelul binomial pozitiv;
- daca indicele de dispersie sugereaza o dispersie randomizata, se alege modelul Poisson;
- daca indicele de dispersie sugereaza o dispersie in agregate, se alege modelul binomial negativ.
Daca rezultatele empirice (calculate) se suprapun (cel putin partial) cu cele teoretice, avem certitudinea ca distributia populatiei corespunde modelului teoretic ales.
Distributiile de tip uniform si uniform aglomerat se pot in general aprecia usor chiar numai prin observarea frecventelor din probe asemanatoare. Astfel, o distributie uniforma va avea frecventele asemanatoare in grad inalt, pe probe comparative. O distributie uniform aglomerata va avea multe probe cu multi indivizi, multe probe fara indivizi si foarte putine (sau chiar deloc) probe cu putini indivizi. In cazul unei distributii intimplatoare vor fi probe multe cu frecvente mari, multe cu frecvente mici dar si probe fara indivizi. Exista astfel riscul ca o distributie intimplatoare sa fie confundata cu una in agregate.
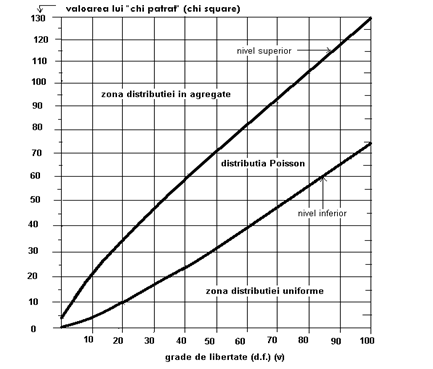
Fig. LP2-15. Zonele celor 3 tipuri de dispersie, ilustrate grafic pe baza relatiei dintre valorile calculate ale lui "χ2" si υ (grade de libertate; n-1). P = 0,05.
Pornind de la cele afirmate mai sus, in cazul repetarii unui experiment (sampling), se pune intrebarea firesca: ce probabilitatea de aparitie o au probele cu numere mici, stiind ca cea mai mare probabilitate o au probele cu numere mari (adica evenimentele comune). Dar, exista si probabilitatea numerelor mici, care arata ca sansa de repetare este un eveniment rar. Ori, in acest caz se calculeaza distributia Poisson care se refera la distributia evenimentelor rare, intamplatoare. Metoda aceasta consta in calcularea frecventelor teoretice (posibile), in limitele acelorasi medii si frecvente ca cele din probele analizate (observate). Dupa gradul de corespondenta dintre frecvente (observate si calculate teoretic) se poate deduce modelul de distributie.
Procedura de lucru pentru evaluarea distributiei asteptate (presupuse, teoretice) este aceeasi pentru fiecare model si cuprinde urmatoarele etape:
|
- se estimeaza parametrii distributiei pe baza datelor de sampling (k, p, q;f); - parametrii astfel estimati se vor folosi pentru estimarea distributiei probabilitatii pentru un numar convenabil de clase de frecventa; deci, se vor grupa datele in clase de frecventasi se noteaza frecventa; - frecventa teoretica a probelor = probabilitatea fiecarei clase x nr. total de probe; - se converteste distributia probabilitatii asteptate intr-o distributie a frecventei asteptate, multiplicand probabilitatea cu fiecare frecventa a marimii probei;- se suprapun frecventele asteptate (teoretice) peste frecventele observate pentru a vedea cum se potrivesc de bine si pentru a estima tipul de distributie, astfel: ☼ - f. observate < f. teoretice = distributie uniforma; ☼ - f. observate > f. teoretice = distributie in agregate; ☼ - f. observate ≈ f. teoretice = distributie intamplatoare - se
verifica semnificatia dintre fr. observate (fobs.) si
cele teoretice (fteor.),
utilizand testul "χ2"
dupa relatia: |
In continuare, aceste proceduri vor fi descrise pentru fiecare model.
Exercitiu 10 Aprecierea modelului de distributie (cu ajutorul distributiei Poisson) pentru frecventa capturilor de masculi de Mamestra brassicae din 100 de capcane feromonale, iar datele de captura s-au grupat in 5 clase de frecventa, dupa modelul tabelului de mai jos (completati rubricile !).
|
Nr.ind./proba xi |
Frecv. observata fo |
xi ∙ fi |
Probabilitatea p |
Nr. probe n |
Frecv. teoretica (p x n) |
Pentru calcularea valorilor lui χ2 se aranjeaza datele intr-un tabel de forma urmatoare:
|
Clasa de frecventa |
Frecventa |
Diferenta (fo - ft) |
(fo - ft)2 |
|
|
|
Observate fo |
Teoretice ft |
||||
7.2.1. Modelul binomial (uniform, binomial pozitiv)
Evaluarea probabilitatii teoretice a distributiei binomiale are la baza procedura descrisa anterior la acest tip de probabilitate. Se cere estimarea parametrilor k si p. Anterior, parametrul k a fost decis arbitrar ca un numar intreg ce reprezinta probele sau evenimentele. In cazul folosirii distributiei binomiale ca model al dispersiei regulate (uniforme), parametrul k este echivalent cu numarul cel mai mare de indivizi ce pot fi continuti intr-o unitate de sampling. Alteori insa parametrul k se estimeaza pe baza tuturor datelor obtinute din sampling, dupa relatia:
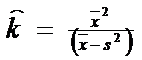
(atentie: numitorul este "invers" fata de relatia de la distributia in agregate)
De asemenea, anterior, am aratat ca p = probabilitatea ca una din doua posibilitati ale unui event sa se produca, iar q = probabilitatea evenimentului opus.
In dispersia uniforma p reprezinta probabilitatea ca fiecare punct din unitatea de sampling sa fie ocupat de 1 individ. O valoare estimata a lui pe este obtinuta din relatia:
![]() iar
q = 1 - p
iar
q = 1 - p
Exercitiu 11. Reluam exemplul dat cu Patella sp (Mollusca). Unele detalii au fost prezentate anterior (vezi Exercitiu 7). Un tabel de frecvente pentru scoicile numarate in 50 unitati de sampling (patrate de 20/20 cm) (grupate in 6 clase de frecventa) au aratat urmatoarele date:
|
Nr. scoici (x) | ||||||
|
Frecventa (f) |
- Se estimeaza apoi urmatorii parametrii: n = 50; ‾x = 8,64; s2 = 1,828; s = 1,352; se vede ca s2 < ‾x) (deci este vorba despre un model binomial negativ).
- Se estimeaza apoi valoarea lui k, dupa relatia de mai sus:
![]()
- se calculeaza valoarea lui p: p = 8,64 / 11 = 0,785; p = 0,785
- valoarea lui q: q = 1 - p; q = 0,215
- se utilizeaza relatia data pentru distributia probabilitatii binomiale:
![]()
- pentru valori ale lui x cuprinse pe intervalul 0-4, probabilitatea este mica asa ca vom neglija aceste valori si vom porni numai de la x = 5. Dupa efectuarea calculelor dupa acelasi tipic obtinem valorile lui P(x) si corespunzator vom calcula valorile frecventei (f). Le trecem intr-un tabel de forma celui de mai jos:
|
Categoria de probabilitate P(x) |
Valorile probabilitatii |
Categoria de frecventa (f) f = P(x) ∙ n |
Valorile frecventei |
|
P(x=5) |
f(x=5) | ||
|
P(x=6) |
f(x=6) | ||
|
P(x=7) |
f(x=7) | ||
|
P(x=8) |
f(x=8) | ||
|
P(x=9) |
f(x=9) | ||
|
P(x=10) |
f(x=10) | ||
|
P(x=11) |
f(x=11) |
- urmeaza compararea frecventelor: observata (din tabelul anterior) si cea estimata (din acest ultim tabel), pe care le vizualizam grafic (Fig. LP3-16).
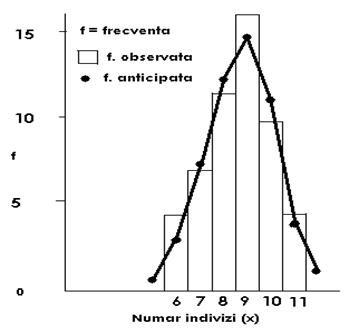
Fig. LP3-16. Reprezentarea grafica a unui model de distributie binomiala pozitiva (uniforma) pe baza distributiei frecventelor pentru specia Patella sp, (Mollusca) pe baza datelor de sampling din 50 unitati de sampling. Coloanele histogramei reprezinta frecventele observate; punctele (●) de pe curba reprezinta frecventele estimate (calculate).
7.2.2. Modelul Poisson (randomizat, intamplator)
Detalii au fost prezentate anterior in cadrul distributiei probabilitatii Poisson. Ca si pentru modelul binomial si aici, pentru modelul Poisson, vom prezenta si aici etapele de lucru avand ca model un studiu al populatiilor de nematode.
Exercitiu 13. In 60 patrate de proba (sau volume) sunt evaluate numarul de nematode si frecventa lor pe clase de frecventa. Datele obtinute arata astfel
|
Nr. nematode (x) | |||||||||
|
Frecventa obs. (f) |
- celelalte valori calculate sunt: n = 60; x = 2,6; s2 = 2,446; s = 1,564.
- se observa ca valoarea dispersiei este apropiata de cea a mediei (2,4 si 2,6) si acesta ar indica un model Poisson. Aceasta distributie este determinata de un singur parametru ( ) care este estimat pentru o proba de catre medie ( x Urmand modalitatea de lucru prezentata in Exercitiul 4, se calculeaza probabilitatea pentru fiecare clasa de frecventa, pe baza relatiei:
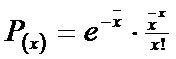
-Calculam probabilitatea (p) si apoi frecventa (f). Datele vor fi trecute intr-un tabel similar cu cel anterior:
|
Categoria de probabilitate P(x) |
Valorile probabilitatii |
Categoria de frecventa (f) f = P(x) ∙ n |
Valorile frecventei |
|
P(x=0) |
f(x=0) | ||
|
P(x=1) |
f(x=1) | ||
|
P(x=2) |
f(x=2) | ||
|
P(x=3) |
f(x=3) | ||
|
P(x=4) |
f(x=4) | ||
|
P(x=5) |
f(x=5) | ||
|
P(x=6) |
f(x=6) | ||
|
P(x=7) |
f(x=7) | ||
|
P(x=8) |
f(x=8) |
- urmeaza compararea frecventelor: observata (din tabelul anterior) si cea estimata (din acest ultim tabel), pe care le vizualizam grafic (Fig. LP3-17).
7.2.3. Modelul binomial negativ
Anterior am aratat ca distributia negativ binomiala reprezinta un model robust care descrie majoritatea situatiilor din natura, conform carora obiectele sunt dispuse aglomerat (agregat, contagios). Un asemenea model il prezinta dispersia parazitilor pe gazde. Ne vom referi in cele ce urmeaza la studiul samplingului la nivelul populatiilor de Clethrionomys glarcolus (Mamifera: Soricidae), animale mici capturate cu ajutorul unor capcane. Pe acestea s-au inregistrat numarul de paraziti (purici)
Exercitiu 14 Un banc (grup, colonie) de 80 animale s-au capturat si s-au examinat de purici. Dupa inregistrarea numarului de paraziti, fiecare animal a fost marcat pentru a nu fi recapturat la urmatoarea actiune. Datele referitoare la numarul de purici si frecventa pe clase de frecventa s-au trecut intr-un tabel de forma celui urmator:
|
Nr. purici (x) | |||||||||
|
Frecventa obs. (f) |
- celelalte valori calculate sunt: n = 80; x = 1,78; s2 = 2,59; s = 1,61.
- se observa ca valoarea dispersiei > decat cea a mediei (2,59 si 1,78) si acesta indica un model binomial negativ. Media este satisfacator estimata de (=1,78) Urmand modalitatea de lucru prezentata in Exercitiul 5, se calculeaza k (estimat) dupa relatia:
F = 0,313
Pornind de la P(x=1) pentru urmatoarele valori ale lui x ultima relatie se deduce din cea anterioara prin multiplicare cu 2 termeni
(x-1) si ![]()
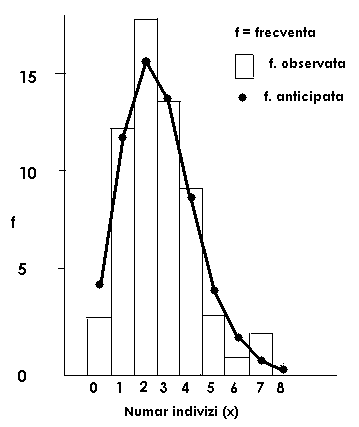
Fig. LP3-17. Reprezentarea grafica a unui model de distributie Poisson pe baza distributiei frecventelor pentru speciile de Nematoda (Nemathelmintha) pe baza datelor de sampling din 60 unitati de sampling. Coloanele histogramei reprezinta frecventele observate; punctele (●) de pe curba reprezinta frecventele estimate (calculate)
-Calculam probabilitatea (p) si apoi frecventa (f). Datele vor fi trecute intr-un tabel:
|
Categoria de probabilitate P(x) |
Valorile probabilitatii |
Categoria de frecventa (f) f = P(x) ∙ n |
Valorile frecventei |
|
P(x=0) |
f(x=0) | ||
|
P(x=1) |
f(x=1) | ||
|
P(x=2) |
f(x=2) | ||
|
P(x=3) |
f(x=3) | ||
|
P(x=4) |
f(x=4) | ||
|
P(x=5) |
f(x=5) | ||
|
P(x=6) |
f(x=6) | ||
|
P(x=7) |
f(x=7) | ||
|
P(x=8) |
f(x=8) |
- urmeaza compararea frecventelor: observata (din tabelul anterior) si cea estimata (din acest ultim tabel), pe care le vizualizam grafic (Fig. LP3-18).
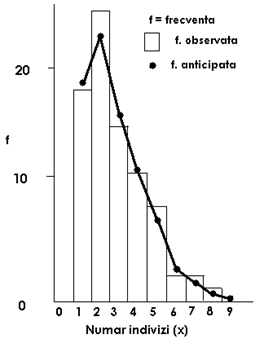
Fig. LP3-18. Reprezentarea grafica a unui model de distributie binomial negativ pe baza distributiei frecventelor pentru speciile de Clethrionomys glarcolus (Mamifera: Soricidae) parazitate de purici, in cadrul unei relatii gazda - parazit, pe baza datelor de sampling dintr-o colonie de 80 indivizi. Coloanele histogramei reprezinta frecventele observate; punctele (●) de pe curba reprezinta frecventele estimate (calculate)
7.3. Studiul modelului de distributie a populatiilor pe baza relatiei dintre varianta (dispersie) (s2) si medie (‾x).
Anterior am precizat in cazul prezentarii celor 3 modele de distributie (dispersie) ca exista o relatie stransa intre media populatiei si dispersie (varianta). Reamintim acest aspect:
a. distributia binomial pozitiva (uniforma) (s2 < ‾x)
b. distributia binomiala negativa (in agregate) (s2 > ‾x)
c. distributia Poisson (intamplatoare) (s2 = ‾x)
Modelul matematic descris pentru cele 3 tipuri de distributii il completam cu modalitatea folosita in studiile ecologice de a studia tipul de distributie a populatiilor unor specii pe baza relatiei amintite, dintre varianta si medie, respectiv, s2 < ‾x; s2 > ‾x; s2 = ‾x (Fig. 41)
Cele doua valori, stau la
baza relatiei care se mai numeste si Legea puterii a lui
Precizare. Mai jos prezentam un exemplu concret de lucru, in cazul unui studiu pe populatiile unei specii de insecte daunatoare. Aceste studii sunt deosebit de dificile, comportamentul si distanta de zbor fiind sub dependenta a o serie de factori. Cu totul alta este situatia la specii care au un comportament locomotor redus.
Exemplu: s-a studiat modelul de distributie a unor populatii apartinand unor specii de lepidoptere daunatoare, pe baza datelor provenite din capturarea masculilor cu capcane feromonale. Modelul pentru care sunt prezentate datele din tabelul 8 se refera la specia Mamestra brassicae (o specie cu un nivel redus al populatiilor in camp deoarece prezinta un comportament special
Metoda de lucru. Se aleg 3-5 loturi experimentale (dupa ce in prealabil s-a studiat ecologia si comportamentul speciei, deci, se stie cat de cat despre distanta de zbor, dispersie, relatia cu planta gazda etc). In fiecare lot se folosesc 8 - 10 -15 capcane feromonale dispuse la distante variabile 50, 100 sau 200 m (de asemenea in functie de o serie de parametrii - marimea lotului, relief, cultura cu specia gazda etc). Capcanele se instaleaza in perioada in care zborul este maxim (durata de observare fiind variabila, in functie de perioada de zbor activ. Capcanele se controleaza zilnic, se inregistreaza captura, se fac schimbari de baze adezive. Lotul experimental se poate si caroia si zilnic capcanele se pot deplasa ca pe o tabla de sah, astfel acoperind o suprafata optima (se pot folosi si variante atractive diferite situatie in care capcanele se deplaseaza dupa modelul patratului Latin).
Datele obtinute (numarul de masculi capturati) reprezentand un sir de valori, se trec intr-un tabel (Tabelul 26).In exemplul de jos complicam putin acest tabel entru a arata cum se procedeaza in situatiile in care observatiile nu se fac zilnic ci la un interval de 2-3 zile (atunci cand durata de zbor este mai lunga).
Tabelul 26
Forma initiala tabelara pentru includerea datelor observatiilor din camp in vederea analizarii modelului de distributie a populatiilor. Datele se refera la populatiile de Mamestra brassicae, analizate pe baza capturilor cu ajutorul capcanelor feromonale (detalii in text) (dupa Stan, 1994).
|
Nr. cap. | |||||||||||
|
I |
II |
III |
IV |
V |
VI |
VII |
VIII |
IX |
Total |
‾x/cap** |
|
* - cifrele dintre paranteze reprezinta numarul de zile dintre 2 observatii consecutive; cele 3 zile pentru observarea I reprezinta intervalul dintre instalarea capcanelor si prima verificare;
** media/capcana (se imparte numarul total la cele 22 zile cat a durat capturarea (aceste valori nu intra in calcule ci sunt orientative atunci cand se compara cu media pe verticala (adica media / capcana / noapte, pentru fiecare observare - vezi continuarea tabelului).
Tabelul de mai sus se continua calculand paramterii care ne intereseaza [x2, ∑ x, ∑x2, ( ∑x)2, ‾x, s2].
n = 9 (numar de observatii; n-1 = 8
continuare Tabel 26 (pentru primele 5 observatii
|
Nr. Cap. |
Numarul masculilor capturati / zile de verificare a capcanelor |
|||||||||
|
I |
II |
III |
IV |
V |
||||||
|
xi |
xi2 |
xi |
xi2 |
xi |
xi2 |
xi |
xi2 |
xi |
xi2 |
|
|
2,00 |
1,00 |
1,00 |
0 |
1 |
2,00 |
4,00 |
0,67 |
0,44 |
||
|
3,00 |
7,00 |
49,00 |
5,50 |
30,25 |
0,33 |
0,11 |
3,00 |
9,00 |
||
|
1,33 |
2,00 |
4,00 |
1,00 |
1,00 |
2,00 |
4,00 |
1,67 |
2,78 |
||
|
0,67 |
1,00 |
1,00 |
0,50 |
0,25 |
2,00 |
4,00 |
1,67 |
2,78 |
||
|
1,33 |
2,50 |
6,25 |
3,50 |
12,25 |
2,33 |
5,44 |
1,67 |
2,78 |
||
|
2,67 |
3,50 |
12,25 |
3,50 |
12,25 |
3,33 |
11,11 |
2,67 |
7,11 |
||
|
1,67 |
3,50 |
12,25 |
1,00 |
1,00 |
4,00 |
16,00 |
0 |
0 |
||
|
2,33 |
2,00 |
4,00 |
1,50 |
2,25 |
3,67 |
13,44 |
3,00 |
9,00 |
||
|
∑x |
15,00 |
16,5 |
19,7 |
14,3 | ||||||
|
∑x2 | ||||||||||
|
(∑x)2 | ||||||||||
|
‾x/c/n | ||||||||||
|
s2 | ||||||||||
continuare Tabel 26 (pentru urmatoarele 5 observatii
|
Nr. cap. |
Numarul masculilor capturati / zile de verificare a capcanelor |
|||||||
|
VI |
VII |
VIII |
IX |
|||||
|
xi |
xi2 |
xi |
xi2 |
xi |
xi2 |
xi |
xi2 |
|
|
0 |
1 |
0,50 |
0,25 |
2,67 |
7,11 |
0 |
1 |
|
|
3,00 |
9,00 |
1,50 |
2,25 |
1,67 |
2,78 |
1,00 |
1,00 |
|
|
7,50 |
56,25 |
1,00 |
1,00 |
2,67 |
7,11 |
1,00 |
1,00 |
|
|
4,50 |
20,25 |
4,50 |
20,25 |
1,00 |
1,00 |
0 |
0 |
|
|
2,50 |
6,25 |
1,00 |
1,00 |
0,67 |
0,44 |
0 |
0 |
|
|
1,50 |
2,25 |
1,00 |
1,00 |
1,67 |
2,78 |
0,33 |
0,11 |
|
|
2,50 |
6,25 |
1,00 |
1,00 |
0,67 |
0,44 |
0,33 |
0,11 |
|
|
4,00 |
16,00 |
1,50 |
2,25 |
1,00 |
1,00 |
0,67 |
0,44 |
|
|
∑x |
25,50 |
12,00 |
12,00 |
3,33 | ||||
|
∑x2 | ||||||||
|
(∑x)2 | ||||||||
|
‾x/c/n | ||||||||
|
s2 | ||||||||
Relatia exponentiala de mai sus se transforma intr-una de tip logaritmic, astfel:
log s2 = log a + b . log ‾x
In acest fel in reprezentare pe scara logaritmica se reprezinta o functie liniara. Cele doua valori (‾x si s2) vor fi transpuse aici (pe abscisa valorile mediei; pe ordonata valorile variantei) (Fig. LP3-19).
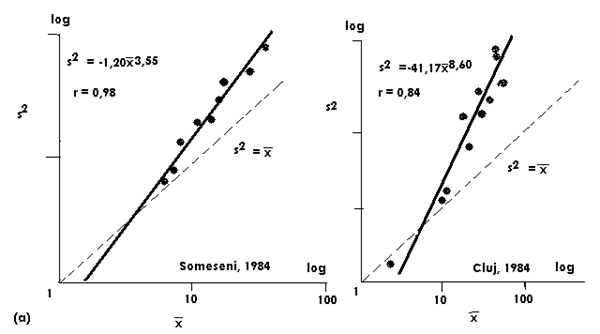
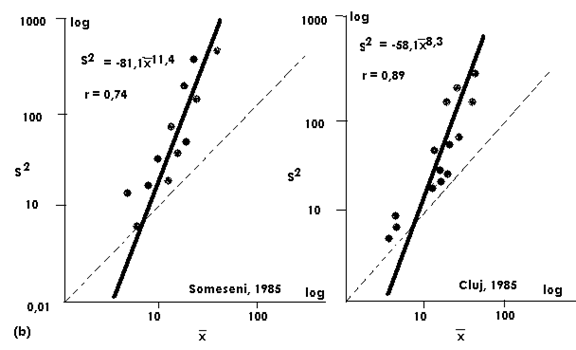
Fig. LP3-1 Modelul de distributie a populatiilor de Xestia c-nigrum (Lepidoptera: Noctuidae) (a, b). Se observadistributia (dispersia) in agregate, model care a fost similar an zone diferite si ani succesivi. In schimb, pentru alte specii, pentru care a fost suspectat un model de distributie de tip Poisson folosirea numai a relatiei T'sPL nu a fost suficienta (dupa Stan, 1993).
In derularea calculelor, urmatoarea etapa este substituirea (x = ‾x si y = s2 ), datele fiind trecute intr-un alt tabel, de forma:
|
Obs. (Citiri) |
x (=‾x) |
y (=s2) |
x2 |
y2 |
x . y |
|
I | |||||
|
II | |||||
|
III | |||||
|
IV | |||||
|
V | |||||
|
VI | |||||
|
VII | |||||
|
VIII | |||||
|
IX | |||||
|
Sx, y | |||||
|
Sx, y) | |||||
|
S x2, y2 | |||||
|
Sx . y |
In continuare se calculeaza valorile lui a si b (vezi functia liniara de tipul y = a + bx; reamintim aici relatiile de calcul, pe care le vom aborda pe larg in cadrul lucrarilor practice pentru Relatii si Functii:
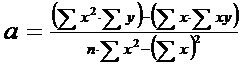
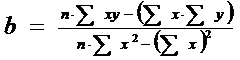
Se inlocuiesc toti parametrii calculati in tabel si dupa calcule se obtine:
a = - 1,4642; b = 1,8858
Deci, ecuatia de regresie va fi:
y = -1,4642 + 1,8858 . x
sau in forma exponentiala initiala a relatiei:
![]()
Observatie: In figurile prezentate anterior, in dreptul liniei de regresie este prezentata ecuatia dreptei dar si valoarea coeficientului de corelatie (r) (prezentam aici relatia deoarece cunoastem toate valorile care sunt incluse in ea dar vom reveni asupra semnificatiei in Cap.Relatii si Functii)
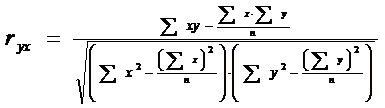
Dupa efectuarea tuturor calculelor se obtine r = 0,8554 (altfel spus, intre cele doua variante exista o buna corelatie, de 85,5%; dar pentru a fi reprezentativa corelatia trebuie sa fie > 95%, sau cel putin 90 - 92%).
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 4616
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2024 . All rights reserved