| CATEGORII DOCUMENTE |
| Astronomie | Biofizica | Biologie | Botanica | Carti | Chimie | Copii |
| Educatie civica | Fabule ghicitori | Fizica | Gramatica | Joc | Literatura romana | Logica |
| Matematica | Poezii | Psihologie psihiatrie | Sociologie |
Statistica - descriptiva (sinteza in urma acumularii unor date)
- deductiva ( model teoretic care poate fi exprimat printr-un model statistic)
Modelul teoretic (empiric) - consta intr-o serie de afirmatii sau formule prin care se da o
explicatie pentru observatia efectuata anterior
Ipoteze logice predictii care se emit pe baza modelelor teoretice
Faza analitica a metodei deductibile de cercetare:
- se folosesc diferite teste pentru evaluarea teoriilor prin falsificarea ipotezelor deoarece o teorie sau un model nu poate fi demonstrat logic ci doar prin respingerea tuturor alternativelor
Ipoteza nula - sustine o idee opusa teoriei logice, pe care dorim s-o validam
Se testeaza ipoteza nula:
daca se respinge → ipoteza logica este acceptata (nu exclude ajustari, completari ulterioare)
daca nu poate fi respinsa → modelul propus nu poate fi validat (date insuficiente, incorecte)
Ipoteza statistica ≠ ipoteza logica
Emisa doar in contextul populatiei statistice analizate; e folosita pentru testarea unei predictii derivate din ipoteza logica.
Importanta analizelor statistice deriva din faptul ca:
detectarea si descrierea modelelor in lumea vie trebuie facuta in mod riguros (streng, grndlich)
asigurarea unei acoperiri probabilistice pentru toti parametrii modelelor testate, ceea ce permite
generalizarea rezultatelor
diminuarea subiectivismului uman in interpretarea observatiilor si designul experimentelor
(cercetatorii au tendinta de a ignora dovezile ce contravin teoriilor proprii, au preconcepte)
Date - o colectie de observatii care pot fi unitati de esantionaj (suprafete de proba) sau unitati
experimentale (organisme)
Variabile - observatii individuale (lungime, nr. de indivizi)
- valoarea lor poate fi cunoscuta in urma unui esantion
- sunt aleatorii (nu se stie cum variaza)
Tipuri de variabile:
- calitative (nominale) - exprimat prin coduri
- reprezinta stari sau categorii ex: culoarea solului
- operatii matematice folosite: =, ≠
- cantitative - ordinale exprimat prin corpuri sau nr. intregi care definesc ranguri
- intervalul e inegal
- operatii: =, ≠, >, <
- de interval - se exprima prin nr. intregi (dar nu numai) care definesc tot ranguri
intervalul e egal ex: scara Celsius
- operatii: =, ≠, >, <, +,
- de ratie - exprimate prin nr. rationale, sunt veritabile variabilelor continue
- toti operatorii matematici ex: biomasa, intensitatea fotosintezei
- discontinue - nominale
- ordinale
- de interval
- continue
Probabilitati:
Incertitudinea: cea mai importanta caracteristica singulara a datelor biologice => mediile calculate in urma unui esantionaj repetat vor fi diferite din cauza diversitatii biologice (genotipica, fenotipica) si varietate temporala.
In analizele statistice incertitudinea este manipulata prin probabilitati (= are valori intre 0 = imposibilitate si 1 = certitudine).
Orice variabila aleatoare prezinta o distributie de probabilitate care se poate reprezenta grafic
intr-un sistem ortogonal de axe.
Pe abscisa fiind valorile pe care le are variabila respectiva.
Pe ordonata probabilitatiile relative. Suma acestora = 1.
Ex : am aruncat cu zarul de 100 de ori
 In cazul unei variabile continue se
vorbeste de functie de densitate a probabilitatii.
In cazul unei variabile continue se
vorbeste de functie de densitate a probabilitatii.
![]()
De multe ori suntem interesati de probabilitatea unui
interval de valori. Probabilitatea = aria de sub grafic
Tipuri de distributie pentru variabile
Procedurile statistice se bazeaza pe cunoasterea distributiei de probabilitate a variabilelor.
Distributia normala (gaussiana): Forma de clopot perfect simetrica fata de medie
= ![]() f(x, ,σ) - parametrii
f(x, ,σ) - parametrii
Distibutia normala standard: e folosita pentru comparatie,
Distributia logic- normala: multe variabile biologice care nu pot lua valori negative pot avea o
distributie asimetrica, o coada lunga in dreapta.
- logaritmul variabilelor este distribuit conform curbei Gauss.
f(logx, ,σ) - parametrii
Distributia exponentiala: - asimetrica, intalnita in cazul variabilelor temporale, care se refera la
momentul aparitiei unui fenomen
Ex: moartea unui individ, inflorirea
1 / λ = timpul mediu pana la prima manifestare a fenomenului
Distributia Weibull: - foarte flexibila (are forme
diferite) ![]() poate imita distributia normala sau
poate imita distributia normala sau
exponentiala in functie de parametrii functiei.
f(x, k/, λ/ k() > 0 - parametru de forma λ( - parametru de scara
- des folosita in analiza supravietuirii organismelor
Prin calcularea frecventelor si compararea lor cu frecventele observate cu ajutorul unui test de calitate a ajustarii( goodness-of-fit), se poate evalua daca (in ce masura) o variabila prezinta una din aceste distributii teoretice.
Curs II
Distributii ale indicilor statistici
Sunt folosite pentru a estima probabilitatea de a obtine anumite valori ale indicilor statistici, intr-un interval dat. IS= variabile aleatoare in comparatie cu parametrii (e fix)
Ex.: media reala= parametru populational
media estimata prin esantionaj= indice statistic
indicele z= corespunde distributiei normale standard
a. Media: cel mai simplu indicele statistic, media aritmetica a valorilor variabilelor respective.
b. Mediana: - valoarea mijlocie a unui set de date
- estimator mai bun decat media al centrelor distributiilor asimetrice, mai robust in raport cu prezeta valorilor extreme
c. Variabilitatea: imprastierea valorilor unei variatii in jurul
mediei, este masurata prin varianta
![]()
d. Deviatia standard: ![]()
e. Eroarea standard: ![]()
In cazul unei distributii normale (box-plot) mediana= medie= modul, cad in acelasi punct.
Testarea ipotezelor statistice:
Elaborarrea ipotezei nule si alegerea testului statistic corespunzator.
Specificarea nivelului critic de semnificativitate prin intermediu
probabilitatii de transgresiune ![]()
Colectarea datelor printr-un esantionaj aleatoriu si calcularea ipotezei statistice
Compararea valorii IS cu distributia standard (tabel), presupunem ca ipoteza nula este adevarata.
Daca probabilitatea este mica de a obtine o valoare
egala (a IS) sau mai mare decat pragul minim prestabilit a
probabilitatii de transgresiune![]() , se poate respinge ipoteza nula si se accepta
alternativa ei. Daca probabilitatea e egala sau mai mare decat nivelul critic
de semnificativitate se accepta ipoteza nula (ipoteza nula nu se
poate respinge fiind probabilitatea adevarata
, se poate respinge ipoteza nula si se accepta
alternativa ei. Daca probabilitatea e egala sau mai mare decat nivelul critic
de semnificativitate se accepta ipoteza nula (ipoteza nula nu se
poate respinge fiind probabilitatea adevarata ![]() test nesemnificativ. Nu inseamna ca
test nesemnificativ. Nu inseamna ca
ipoteza nula e adevarata, nr. prea mic de esantioane, alegerea gresita a populatiilor, erori de masurare
Distributia normala
media= mediana ![]() = cea mai comuna valoare
= cea mai comuna valoare
Testul cu 1 si 2 cozi:
- ipoteza nula corespunde lipsei vreunui efect asupra variabilei de raspuns, ipoteza alternativa poate fi in orice directie; pozitv sau negativ
Daca ipoteza e neclara se aplica un test cu 2 cozi, valorile extreme ale indicelui (din orice capat al distributiei standard) va determina respingerea ipotezei nule.
Test cu o coada: - valorile extreme din un capat al distributiei standard determina respingerea ipotezei nule
- uneori ipoteza nula indica daca efectul variabilelor independente conduce la cresterea sau scaderea variabilei de raspuns;
Teste parametrice si prezumtia lor
Toate testele statistice se bazeaza pe prezumtii.
Teste neparametrice
iau in considerare rangul datelor numerice, nu si valoarea lor
se bazeaza pe prezumtia 2 si 3, distributia datelor putand lua orice forma
mai robuste fata de valorile extreme
Transformarea datelor
Obiective:
sa aduca datele mai aproape de distributia normala
sa mareasca omogenitatea variantei
sa reduca influenta valorilor extreme
sa imbunatateasca liniaritatea in regresii
sa reduca efectul de interactiune dintre variante astfel ca acestea sa aibe efecte aditive, nu multiplicative.
Modalitati de transformare:
logaritmare: datele au o asimetrie pozitiva, coada lunga in
dreapta ln(x+1) x= 0 ![]() ln1= 0
ln1= 0
radacina patrata: variabilele exprima un nr.
de indivizi, celule ![]()
asimetrie negativa, coada spre stanga x' ![]()
comuna in fitosociologie x' = arc sin (![]() )
)
Date truncate
se intalnesc rar, impun teste specifice
pot aparea cand se inregistreaza intervalul de timp scurs pana la producerea unui eveniment ce se produce o singura data (moarte, disparitie, pierdere)
daca observatiile au fost inregistrate ca fiind mai mici atunci e vorba de date truncate
instrumentele de masura au ajuns la limita superioara sau inferioara de detectivitate
Corelatii
- iau valori intre -1 si 1 corelatie perfecta pozitiva
corelatie perfecta 0 = absenta corelatiilor
- semnificativitatea statistica a unui coeficient de corelatie poate fi estimata prin probabilitatea asociativa.
Ipoteza nula ar fi: cele 2 variabile sunt independente corelatia poate fi liniara sau neliniara
Coeficientul lui Pearson:
cel mai cunoscut coeficient parametric (distributia trebuie sa fie normala)
masoara doar corelatia liniara dintre 2 variabile
Coeficientul lui Spearman:
neparametric (pentru ca ia doar rangurile in calcul si nu valoarea absoluta)
! poate pune in evidenta corelatii neliniare, dar monotonice (crescatoare/ descrescatoare)
Corelatii partiale: iau in considerare efectul unor forte variabile
O variabila poate sa mascheze corelatia dintre 2 variabile daca efectul nu este luat in calcul.
Curs III
Modele liniare
- consta intr-o variabila dependenta (de raspuns) y si de una/ mai multe variabile independente (de predictie)
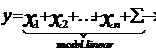 termen rezidual y- o variabila de ratie, de interval,
ordinala x- orice fel de variabila
termen rezidual y- o variabila de ratie, de interval,
ordinala x- orice fel de variabila
Regresia liniara simpla
y= ax+b x,y = variabile continue de ratie sau de interval
obiectiv important in biologie, se foloseste pentru a face predictii fara sa fie distrus acel individ.
variabila y trebuie sa fie aleatoare, se obtin diferite valori ale lui y in functie de valoarea lui x
variabila x trebuie sa aibe valori fixe, prestabilite de cercetator sau masurate fara eroare
cu cat e "a" mai mare, efectul variabilei x asupra variabilei y este mai puternic
Prezumtii:
Toate modelele lineare sunt analize parametrice, se pleaca de la prezumtia ca x,y au distributii normale.
Variantele lui y pentru diverse valori a lui x sunt egale.
Valorile lui y sunt independente (au fost obtinute in urma unui esantion aleator, valoarea lui y nu prezinta autocorelatie spatiala/temporala. Ex: temperatura aerului)
Intensitatea relatiei lineare (magnitudinea efectului) dintre x, y poate fi judecata prin intermediul coeficientului de regresie standardizat a lui x. ( a,b- coeficient de regresie) Se variaza x cu o unitate (x-a) si se observa cum influenteaza y.
In analiza regresiei liniare obtinem coeficientul
de determinare (out put) r![]() , in cazul regresiei liniare simple este egal cu coeficientul Pearson
la patrat
, in cazul regresiei liniare simple este egal cu coeficientul Pearson
la patrat ![]()
r![]() spune cat la suta din varianta lui y poate fi
explicata pe baza variabilitatii variabilei x
spune cat la suta din varianta lui y poate fi
explicata pe baza variabilitatii variabilei x
in out-put se
interpreteaza coeficientul de determinare ajustat
![]() = r
= r![]() ajustat cu gradele de libertate
ajustat cu gradele de libertate
nr. gradelor de libertate: n-1 cu cat e mai mare cu atat scade ![]() in raport cu r
in raport cu r![]() pentru intregul model liniar
pentru intregul model liniar
Pentru testul F ipoteza nula este: nu exista nici o relatie liniara intre y si x. Daca probabilitatea este mica (< 0,005, < 0,001) se accepta alternativa, exista o relatie intre y si x.
Daca x=y ipoteza nula este: valoarea lui "a" nu este semnificativa daca e diferita sau egala cu 0.
Daca testul F e semnificativ si "a" este semnificativ.
In output apare:
tabelul "Lock-of-fit" (lipsa ajustarii) care include un test statistic pentru obtinerea
unei ajustari mai bune printr-un model mai complex, care nu e
linear ![]()
Ipoteza nula: modelul linear este suficient de complex, bun
pentru a nu obtine o crestere semnificativa a coeficientul de
determinare ajustat ![]() (prin folosirea unui model mai complex)
(prin folosirea unui model mai complex)
In general ipotezele nule nu sunt adevarate.
- tabelul de estimare a parametrilor (coeficientul de regresie) apar valorile estimate a lui a,b si testul t/student
La testul t "a" are aceasi valoare ca la testul F daca e nesemnificativ (a=0, nesemnificativ) nu se trece la
testul urmator; daca o ecuatie trece prin origine putem
spune ca b=0 ![]() se obtine doar estimarea lui "a"
se obtine doar estimarea lui "a"
Diagnoza regresiei:
Influenta unor factori extremi, din partea lui x sau y, poate determina o estimare slaba a coeficientul de regresie.
Metode pentru diagnosticarea regresiei:
1.
Coeficientul lui COOK-D: daca
![]() avem valori extreme care au o influenta
semnificativa asupra coeficientului de regresie estimat.
avem valori extreme care au o influenta
semnificativa asupra coeficientului de regresie estimat.
2. Puterea (analiza puterii): Puterea analizei regresiei liniare simple se poate calcula pentru fiecare coeficient de regresie estimat
Daca valorile
puterii (![]() ) sunt peste 95% sunt semnificative.
) sunt peste 95% sunt semnificative.
Un bun indicator al puterii este valoarea minima semnificativa (LSN) care se
refera la nr. minim de probe sau
esantioane care ar trebuii sa fie in matricea de Input pentru a
detecta o valoare a parametrilor regresiei la un nivel prestabilit al
probabilitatii de transgresiune ![]() .
.
Puterea poate analiza regresia, estima
coeficientii a,b pentru un nivel prestabilit al probabilitatii ![]() .
.
Daca valoarea a,b e nesemnificativa ![]() 0 se liniarizeaza relatia dintre a,b.
0 se liniarizeaza relatia dintre a,b.
Modalitati de transformare:
O regresie semnificativa nu inseamna ca intre variabilele x,y exista o relatie cauza-efect.
independent de cauza efectul
Variabila x poate influenta indirect variabila y (printr-o forta variabila) sau cele doua variabile covariaza
fiind controlate de forte variabile.
Regresia liniara multipla:
sunt mai multe variabile x (![]() )
)
din punct de vedere geometric ecuatia (tridimensional) reprezinta
coeficientul a,b= pantele pentru y cand cealalta variabila este
constanta (![]() )
)
ipoteza nula: toti coeficientii de regresie = 0
Prezumtii suplimentare fata de regresia liniara simpla:
Factorul de interactiune (![]() ) induce, daca e semnificativ (prin prisma
valorii lui c), un efect de coliniaritate (violarea primei prezumtii
anterioare) incat termenul de interactiune este implicit bine corelat cu
variabilele
) induce, daca e semnificativ (prin prisma
valorii lui c), un efect de coliniaritate (violarea primei prezumtii
anterioare) incat termenul de interactiune este implicit bine corelat cu
variabilele ![]() .
.
Prezenta coliniaritatii poate fi evidentiata prin inflatia variantei (VIF) (daca valorile sunt peste 10 indica
existenta coliniaritatii nu putem avea incredere in valorile, rezultatele obtinute.
Reducerea coliniaritati:
Daca cele doua variabile![]() sunt foarte bine corelate
intre ele atunci includ o informatie
redundanta (repetitiva); una dintre cele 2 variabile e eliminata din model, aceasta duce la regresia multipla
si apoi la regresia simpla
sunt foarte bine corelate
intre ele atunci includ o informatie
redundanta (repetitiva); una dintre cele 2 variabile e eliminata din model, aceasta duce la regresia multipla
si apoi la regresia simpla
Daca variabilele sunt slab/ deloc corelate, se impune centrarea celor doua variabile care se realizeaza prin scaderea mediei din fiecare valoare a lui x.
Transferul nu afecteaza coeficientul de regresie si nici ipoteza nula.
Curs IV
Regresia polinomiala
y= ![]() Ipoteza nula:
toti coeficientii,
Ipoteza nula:
toti coeficientii, ![]()
se manifesta coliniaritatea, nu e bine daca e prea mare
se face centrarea
variabilei x: x= (x-![]() )
)
indicatorul coliniaritatii este inflatia variantei (VIF)
![]()
Variabile indicatoare in regresie
Intr-un model de regresie se pot introduce variabile continue (obligatorii y) si discontinue (variabile independente x) sub forma variabilelor indicatoare (dummy).
Pentru o variabila nominala (x) se creaza c-1 variabile binare, c= nr. starilor, nivelelor (variabilei originale)
O variabila nominala (folosinta pajistilor) are 4 stari posibile (pasune, faneata, folosinta mixta, neexplorat) se creaza 3 variabile indicatoare (dummy), care sunt binare:
|
|
|
|
![]() 1- explorat ca pasune 0-
orice mod de folosire
1- explorat ca pasune 0-
orice mod de folosire
![]() 1- explorat ca
faneata
1- explorat ca
faneata
![]() 1- explorat in
regim mixt
1- explorat in
regim mixt
Coeficientul de regresie ai variabilelor indicatoare masoara efectul diferential al fiecarui nivel in
comparatie cu nivelul de referinta (neexploatat).
Selectarea celui mai bun model de regresie
- se face un compromis intre maximizarea variantei explicate a lui y si obtinerea unui model cat mai simplu
Ex: ![]() (2 variabile)- mai bun
(2 variabile)- mai bun
![]() (5
variabile)
(5
variabile)
O modalitate obiectiva de a selecta modelul potrivit este compararea coeficientiilor de determinare ajustati
(cu cat e mai mare cu atat e mai bine) sau a indicelui Akoiche (cu cat e mai mic e mai bun).
Regresia logistica simpla:
- permite ajustarea probabilitatiilor unei variabile de raspuns discontinue in functie de o variabila independenta continua
y= variabila nominala sau de interval discontinua
x= variabila continua
daca y este variabila ordinala se estimeaza probabilitatea de a obtine o valoare (stare) a lui y mai mica sau egala cu un nivel (stare) dat al variabilei y
daca e variabila nominala se partitioneaza probabilitatea intre diferite raspunsuri
In ambele cazuri se estimeaza un set de curbe (nr. lor este c-1, c- nr. nivelelor sau starilor variabilei y) cu pante egale dar intercept diferit.
Ecuatia: ![]()
y este 1 y nu este 0
PH= 5,2 PH= 4,5
Analiza univariata a variantei
- exista un singur x Ecuatie:
![]()
Diferenta dintre analiza variantei si regresiei x- variabila discontinua (nominala, ordinala)
y- variabila continua (de ratie, de interval)
Trebuie sa existe suficiente replicatii (valorile lui y pentru fiecare nivel/stare al variabilei x) si preferabil nr. replicatiilor sa fie egal.
Ipoteza nula: nu exista diferente semnificative intre mediile lui y calculate pentru diverse grupe determinate de x
Ex: y= fitomasa uscata (kg/ha)
y mediu
x= - pajiste- faneata (f) 30
parcele
![]() ? y mediu
? y mediu![]()
![]()
- pasune- pasunat (p) 30 pasuni ![]()
Analiza univariata a variantei intre grupe
- "intre grupe" inseamna ca grupurile de subiecti (tratamentele aplicate) definite de variabila x sunt independente
Fiecare subiect este tratat (masurat) o singura data, nu este implicata variabila temporala!
Prin transformarea lui y relatia devine liniara. Cel mai frecvent in biologie:
y este o variabila binara (prezent, absent, viu, mort) are 2 stari, rezulta o curba
ipoteza nula: daca b=0 nu exista o relatie intre x, y
probabilitatiile sunt masurate pe verticala, intre curbe; totalul lor este 1 (100%)
daca x nu are efect asupra lui y, curbele sunt paralele cu abscisa
toate testele din output compara modelul cu altele mai simple sau mai complexe
Testul modelului per ansamblu
este analog testului ANOVA de la regresia liniara(analyses of variance)
daca testul e semnificativ ne spune
daca modelul este semnificativ mai bun decat un model care
contine doar interceptul (a) fara nici un efect
(b=0) ![]()
Testul de lipsa ajustarii (Lock of fit)
trebuie sa fie semnificativ ca sa ne spune daca un model mai complex (polinominal) este semnificativ mai bun decat cel specificat
Testul Wald si raportul de probabilitate
ne spune in ce masura modelul este mai bun decat un model fara efectul in cauza (x), daca e semnificativ y poate lua diferite stari
Analiza variantei e o metoda prin care varianta
totala a variabilei de raspuns y este descompusa
intre varianta datorata variabilei independente x
si cea indusa de factori necunoscuti ![]()
![]() varianta=
dispersia valorii
varianta=
dispersia valorii
Varianta mare intre grupe: - F mare- masa e influentata de modul de folosinta
- F mic![]() - masa nu e influentata
- masa nu e influentata
Analiza variantei univariata intre grupe este echivalenta cu testul t- student pentru esantioane independente.
ANOVA superioara testului t-student, aplicat pentru 2 nivele punctului x
Ipoteza nula: in populatia studiata nu exista diferente semnificative intre diversele grupuri (tratamente) in ce priveste media variabilei de raspuns y din fiecare grupa. Grupurile sunt definite de variabila x.
ANOVA foloseste indicele F, daca F e suficient de mare, se respinge ipoteza nula si se alege alternativa
In afara de semnificatia diferentei dintre medii, rezultatele se pot determina prin coeficientul de determinare![]()
![]() indica magnitudinea efectului
(x) (modul de folosinta a pajistilor asupra fitomasei, y)
indica magnitudinea efectului
(x) (modul de folosinta a pajistilor asupra fitomasei, y)
In output avem un test pentru intregul model, daca e semnificativ se trece la compararea mediilor, daca nu e semnificativ nu exista relatie intre x, y.
Spre deosebire de regresia liniara simpla in output din ANOVA nu ne intereseaza in mod special valorile coeficientiilor a,b ci testul efectului x asupra lui y (in ce masura efectul diverselor tratamente/stari ale lui x au o influenta semnificativa asupra variabilei de raspuns y).
Diferenta dintre replicatii (grupuri) sa nu fie mai mare de 20%
In cazul unui design neechilibrat (inegal) mediile sunt ajustate in mod automat, cu nr. de probe din acel grup.
Ideal este ~30 probabilitate pentru fiecare grupa.
O prezumtie care trebuie indeplinita este omogenitatea, egalitatea variantei intre grupe.
Ca sa verificam daca variantele sunt sau nu diferite se face un alt test:
O'Brn
Brown-Forsythe teste de
Levene ajustare a
Bartlett variantelor
Ipoteza nula: variantele sunt egale. (nu e bine daca e respinsa)
Welch ANOVA daca cele 4 teste sunt semnificative se aplica testul F
Prezumtii:
y- distributie normala
valorile lui y sa fie independente, din esantionaj obligatoriu
daca varianta x are 2 stari ANOVA t student
nr. comparatiilor = ![]() c= nr. starilor
variabilei x
c= nr. starilor
variabilei x
Curs V
Anova compararea mediilor
![]()
![]()
![]() ipotezele nule sunt egale
ipotezele nule sunt egale
![]()
Datorita analizei variantei
intre grupe probabilitatea de a gresi (a respinge o
ipoteza nula, care de fapt e adevarata sau invers)
creste odata cu numarul de comparatii de efectuat; se
opereaza ajustari ale nivelului critic de trangresiune: nr. maxim al
comparatiilor: ![]() c - nr. nivelelor
(starilor) factorului x
c - nr. nivelelor
(starilor) factorului x
Aceste ajustari se obtin automat prin softuri, 2 procedee cons cele mai robuste:
REGW= Ryan-Einot-Gabriel-Welsch cel mai bun
Tukey
Daca unul dintre nivele/ grupe este cons ca referinta (martor) si celelalte grupe sunt comparate doar cu acesta atunci cea mai robusta ajustare a probabilitatii se face prin Dunnett.
Puterea de detectie are acelasi valoare cu cel de la regresie.
Nr. minim de replicatii si pragul critic de transgresiune indica credibilitatea rezultatelor obtinute.
A(necesar pt. fiecare grup pt. detectarea diferentelor intre grupe data fiind varianta estimata a lui y)
Analiza simpla a variantei in interiorul grupelor
ONE WAY ANOVA within groups
ONE WAY repeted measures ANOVA
Fiecare subiect este expus fiecarui tratament, se efectueaza masuratori repetate a variabilei y de raspuns.
Se foloseste pentru a studia procese dinamice (in timp) si dependenta cauza- efect prin compararea raspunsurilor subiectiilor inainte si dupa tratament. Daca factorul temporal are 2 nivele, momente de masurare atunci analiza este echivalenta cu testul t- Student pentru esantioane dependente, date perechi(paired data).
Pentru mai mult de 2 moment testul t nu poate fi aplicat.
Interpretarea rezultatelor are 2 etape:
Semnificatia efectului produs de tratament asupra aceluiasi subiectului.
Daca modelul e semnificativ se trece la compararea mediilor obtinute in diferite momente ale tratamentului.
Are avantajul eliminarii variantei reziduale (rckstndig) a diferentei dintre subiecti si al eficientei obtinute folosirii unui nr. redus de subiecti.
Dezavantaj: lipsa unor subiecti de control
Prezumtia de
omogenitate a covariantei (=sfericitate) este foarte importanta
pentru veridicitatea rezultatelor. De aceea se impune aplicarea testului Mauchly bazat pe distributia ![]() , fiind un test de sfericitate. Deviatii
semnificative de la sfericitate sunt evidentiate de valori mici ale
probabilitatii asociate. Daca:
, fiind un test de sfericitate. Deviatii
semnificative de la sfericitate sunt evidentiate de valori mici ale
probabilitatii asociate. Daca:
deviatiile sunt mici pot fi compensate prin aplicarea testului f modificat (ajustari Greenhouse-Geisser)
deviatiile sunt mari (p sub 0,01) se utilizeaza teste multivariate, tratamentul este aplicat la intervale diverse de timp ca niste variabile dependente de raspuns separate, dar corelate intre ele.
y= x+a+![]()
![]()
![]() a=
intercept
a=
intercept
Daca nr. subiectilor este mic, mai putin de 20 ori nr. tratamentelor testul de sfericitate nu are putere de detectie.
trebuie folosita abordarea multivariata
Raspunsul subiectiilor poate fi viciat de ordinea aplicarii tratamentelor, se recomanda foosirea unui design de contrabalansare ce consta in aplicarea tuturor combinatiilor de ordine a tratamentului unui numar egal de subiecti.
Efectul tratamentelor anterioare care poate persista si vicia raspunsul subiectiilor la tratamentele ulterioare se poate evita partial prin marea separare in timp a tratamentelor. (Efectul Placebo)
A-B-C A-C-B
B-A-C B-C-A
C-A-B C-B-A
Curs VI
Teste neparametrice corespunzatoare ANOVA
Daca prezumtia de normalitate a variabilei de raspuns y nu este respectata si sau exista valori extreme in distributia lui y apelam la teste neparametrice. Prezumtia de egalitate a variantelor trebuie luata in considerare si la testele neparametrice. Ipoteza nula nu se mai refera la medii ci la distributii de localizare a distributiei.
daca datele provin din
grupuri independente corespunde lui ANOVA intre grupe se poate aplica testul Mann-Whitney sau
Wilcoxon atunci cand n= 2 (testul se
bazeaza pe aproximarea normala z sau ![]()
ce corespunde indicilor statistici)
daca avem mai multe
grupe se foloseste testul Kruskal-Wallis n>2 (se
bazeaza numai pe aproximarea ![]() )
)
daca se impune
efectuarea de comparatii multiple unui
model Kruskal-Wallis atunci se pot nula mai multe teste Wilcoxon pentru toate
perechile pe care vrem sa le comparam. A-B B-C A-C ![]()
Ulterior probabilitatile de transgresiune trebuie ajustate (ca la ANOVA) fie automat, fie manual pentru ca majoritatea programelor de calcul nu au implementata aceasta procedura.
Se recomanda ajustarea Bon Ferroli secventiala propusa de Hochberg; se incepe cu valoarea p cea mai mare si se continua pana la cea mai mica.
Prima valoare este comparata cu ![]() (5%, 1%):
(5%, 1%):
- daca testul e semnificativ atunci toate pot fi considerate semnificative
- daca nu, valoarea urmatoare a lui p este comparata cu ![]() , a treia cu
, a treia cu ![]()
- daca datele provin din grupuri dependente (corespunzator lui ANOVA in interiorul grupelor) se poate aplica testul rangurilor semnate a lui Wilcoxon (cand sunt 2 grupe) sau testul Friedman cand n>2
![]()
![]()
Calculeaza indicele z (pentru aproximarea normala) calculeaza indicele ![]() a lui Friedman
a lui Friedman
indiciile au asociati o probabilitate de transgresiune se poate pune probabilitatea
comparatiilor multiple
Teste de asociere intre variabile discontinue
y= ![]() - regresie
- regresie ![]() regresie logistica
regresie logistica![]() = x ANOVA
= x ANOVA
In cazul a 2 variabile discontinue se poate
construi un tabel de contingenta al carui nr. de randuri si
coloane corespunde cu nr. nivelelor celor 2 variabile. In interiorul
fiecarei casute din tabel se indica ![]() nr. de cazuri corespunzatoare starilor celor 2
variabile.
nr. de cazuri corespunzatoare starilor celor 2
variabile.
Ipoteza nula: cele 2 variabile sunt independente, nu exista nici o asociere intre ele;
Testul Pearson: - cel mai cunoscut care se poate aplica tabelelor de contingenta
de diverse dimensiuni (lxc) ![]()
|
a |
b |
|
|
c |
d |
Indicele statistic se
calculeaza in functie de ![]() observate (a,b,c,d)
si cele teoretice (asteptate) in cazul unei distributii
intamplatoare frecventa teoretica pentru o anumita
casuta din tabelul de contingenta este egala cu
observate (a,b,c,d)
si cele teoretice (asteptate) in cazul unei distributii
intamplatoare frecventa teoretica pentru o anumita
casuta din tabelul de contingenta este egala cu ![]() totala pe acel
rand.
totala pe acel
rand. ![]() totala pe coloane
reprezinta impartita cu nr. total de observatii.
totala pe coloane
reprezinta impartita cu nr. total de observatii.
a= ![]() a
>> a a
<< a
a
>> a a
<< a
Ca orice indice statistic, ![]() este insotit de o
probabilitate de transgresiune pe baza careia se poate aprecia
semnificatia ei statistica.
este insotit de o
probabilitate de transgresiune pe baza careia se poate aprecia
semnificatia ei statistica.
Acest test nu poate fi validat daca cel mult
20% din casute au ![]() teoretice < 5.
teoretice < 5.
Testul lui Fischer sau G se putea aplica pentru tabele de contingente de 2x2, apoi a fost generalizat.
O alta alternativa la testul ![]() care se poate aplica ori de cate ori una din variabile poate
fi considerata de raspuns si alta de predictie
(independenta) este regresia logistica nominala. Deosebita
fata de regresia logica clasica este ca foloseste
o variabila indicatoare in locul celei discontinue, de predictie.
care se poate aplica ori de cate ori una din variabile poate
fi considerata de raspuns si alta de predictie
(independenta) este regresia logistica nominala. Deosebita
fata de regresia logica clasica este ca foloseste
o variabila indicatoare in locul celei discontinue, de predictie.
Curs VII
Analiza supravietuirii
Scopul: estimarea ratei de supravietuire/ mortalitatii si modul in care variaza in timp.
Se fac observatii repetate, la intervale de timp egale asupra indivizilor unei populatii.
Nu raman aceasi indivizi, unii pot murii sau se pot pierde, iar indivizi noi pot fi adaugati in esantionaj.
In momentul fiecarui observatii se inregistreaza starea fiecarui individ, viu sau mort. Un astfel de studiu impune si manipularea unor factori (la plante: lumina, toxine) care pot determina moartea. Se intampla frecvent ca datele inregistrate sa fie truncate (censored) deoarece nu se cunoaste exact timpul de vietuire pentru indivizii ramasi vii pana la sfarsitul studiului ci doar k e mai mare decat o anumita valoare. Acest lucru se intampla din 2 motive:
Timpul de supravietuire reprezinta distributii asimetrice de tip exponential, log-normal sau Weibull.
Un model matematic pentru supravietuirea indiviziilor trebuie sa fie compus din 2 variabile:
Metoda statistica KAPLAN-MEIER
Se urmareste:
In output este si tipul median de supravietuire care reprezinta intervalul de timp in care jumatea din subiecti au murit.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 1587
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2024 . All rights reserved