| CATEGORII DOCUMENTE |
I).Probleme fundamentale ale unitatii de curs
1). Introducere in problematica informaticii
2). Notiuni de baza ale programului SPSS 11.0
3). Calcularea principalelor valori statistice
4). Grafice in SPSS
5). Corelatie si asociere
II). Scopul unitatii de curs
a). Asumarea de catre studenti a cadrelor generale de studiu propuse de informatica aplicata
b). Formarea unor abilitati de discernere a principalelor metode folosite in cadrul pachetului SPSS 11.0
c). Familiarizarea cu tehnicile fundamentale de lucru
d). Formarea unei imagini generale asupra rolului pe care il are informatica statistica aplicata in cadrul mai general al stiintelor sociale
III). Obiective operationale
a). Studentii trebuie sa distinga situatiile in care pot folosi oportunitatile oferite de programul SPSS 11.0
b). Studentii trebuie sa delimiteze exact principalele metode si tehnici pe care le utilizeaza informatica statistica aplicata
c). Studentii trebuie sa posede cunostintele de baza in ce priveste utilizarea computerului
d). Studentii trebuie sa stie sa utilizeze in mod practic tehnicile de lucru pe computer
e). Studentii trebuie sa aiba capacitatea sa utilizeze notiunile predate pentru scopurilor cercetarii sociale
IV). Modalitati de evaluare vor urmari:
a). Determinarea capacitatii studentului de a opera cu principalele concepte prin lucrari practice aplicative efectuate direct pe computer.
1. Introducere in SPSS
Necesitatea prelucrarii unui volum din ce in ce mai mare de date, a unor cercetari de teren cat mai rapide etc., a impus dezvoltarea unor pachete statistice performante. Au aparut astfel de-a lungul timpului diverse programe : SAS, SPSS, SPAD, STATA etc., majoritatea oferind alternative de calcul pentru aceleasi proceduri statistice de baza. In acest curs vom trece in revista o serie de proceduri pe care le utilizeaza programul SPSS for Windows, varianta 11.5., program care a fost lansat de catre SPSS Inc. Chicago (alte informatii puteti afla pe situl www.spss.com). Traducerea libera a acestor initiale este Statistical Package for Social Sciences . Odata lansat programul Windows, daca SPSS 11.5 este instalat se poate deschide apeland la pictograma specifica sau cautand fisierul executabil dupa comenzile Start Programs SPSS for Windows SPSS 11.5 for Windows
Dupa executarea acestor comenzi va apare fereastra generala a programului SPSS:
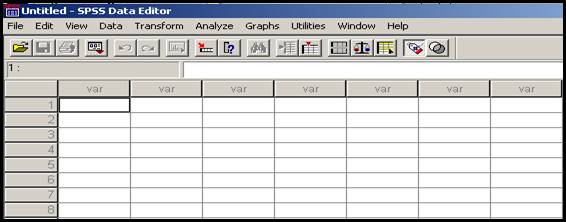
In imaginea de mai inainte, in partea superioara se pot observa, ca si in programele Word sau Excel trei bare:
-Bara de titlu care poate include numele fisierului dupa ce va fi salvat
-Bara de meniuri (File, Edit, View, Data etc.)
-Bara cu instrumente (anumite pictograme care sunt de fapt "scurtaturi" ale unor comenzi care se gasesc de fapt si in meniuri).
Mai jos putem identifica un tablou format din linii si din coloane, tablou numit editor de date (Data Editor). Pe ecran apare doar o mica parte din acest tablou foarte mare. In acest tabel identificam:
-coloanele (care reprezinta variabile statistice)
-liniile (care reprezinta cazuri, persoane supuse cercetarii, observatii)
In partea inferioara de pe ecran apar doua etichete care au functii apropiate de nominalizarea foilor de lucru din programul Excel:
Data View- compartimentul rezervat datelor introduse in Data Editor
Variable view-compartimentul rezervat variabilelor introduse.
In continuare vom explicita pe scurt bara de meniuri:
File- contine comenzi pentru citirea, scrierea sau imprimarea tuturor tipurilor de fisiere cu care opereaza programul.
Edit- contine comenzile pentru editarea, modificarea, copierea, cautarea textelor
Data- contine comenzi pentru definirea variabilelor, inserarea de noi variabile sau cazuri, sortarea, alipirea, inversarea, agregarea, selectarea bazelor de date
Transform- contine comenzi pentru transformari ale variabilelor si ale valorilor lor.
Statistics- meniu cu procedurile statistice disponibile in program
Graphs- contine procedurile pentru reprezentari grafice diverse
Utilities- contine comenzi care pot da informatii despre variabile, pot desemna un set redus de variabile, organizarea meniurilor.
Window- contine comenzi care permit lucrul cu ferestrele SPSS
Help- contine informatii despre program si despre procedurile statistice folosite.
2. Lucrul cu programul SPSS. Elemente introductive
Obiectul de studiu il reprezinta bazele de date, fie ca ele sunt create de catre utilizator fie ca sunt utilizate cele existente deja in cadrul programului. Daca intentionam sa deschidem o astfel de baza de date este necesar sa urmam pasii urmatori: File Open Data dupa care apar toate bazele de date din program:
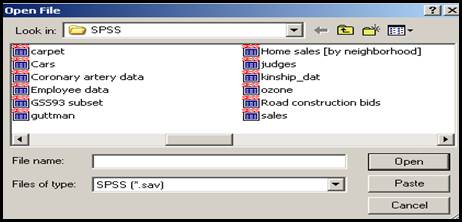
Obs: inafara de fisierele de tip *.sav care desemneaza bazele de date, SPSS utilizeaza si fisiere de tip *.sps (care contin varianta scriptica a comenzilor sau fisiere sintaxa) precum si fisiere de tip *.spo in care sunt incluse rezultatele cercetarii statistice).
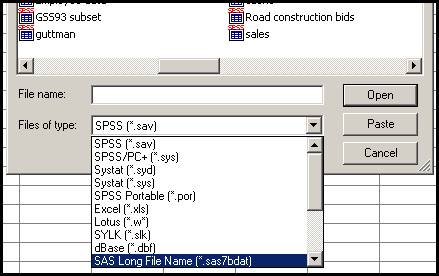
Daca deschidem insa rubrica Files of type apar urmatoarele specificatii:
Deducem de aici ca
SPSS poate citi si multe alte tipuri de fisiere. De exemplu se
pot citi fisiere de tip Spreadsheet (Excel, Lotus), de tip dBase, Ascii sau fisiere din diverse
alte programe statistice. Pentru precizari suplimentare se poate consulta Help-ul programului sau Tutorialul acestuia!
Daca vom alege una din bazele incluse in program si vom executa dublu clic pe numele acesteia atunci va apare pe ecran o imagine de tipul urmator:
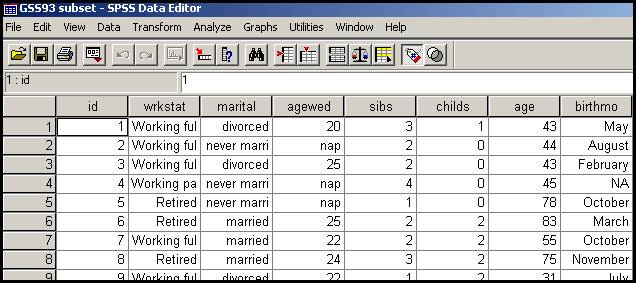
Se observa mai intai ca este afisat numele bazei respective GSS93 subset apoi putem observa dispunerea pe coloana a unor variabile cum ar fi: id (numar de identificare a individului care intra in baza de date), wrkstat (statusul ocupational), marital (situatia maritala), agewed (varsta la prima casatorie) etc. Dupa cum se vede fiecare variabila are un nume prescurtat care poate include maximum 8 caractere (fara spatii si fara anumite semne speciale) iar daca vom opri cursorul mausului pe numele unei variabile va apare instantaneu numele pe lung al acesteia (care se poate extinde pana la 256 de caractere). Pentru a obtine informatii amanuntite despre variabile putem alege optiunea Variable view din partea de jos a ferestrei Data Editor. Pentru aceste informatii sau pentru construirea de noi baze de date trebuie cunoscuta in amanunt problematica variabilelor statistice.
3. Variabile. Elemente de statistica descriptiva
Reluam aici unele consideratii facute intr-un curs anterior de statistica descriptiva datorita utilitatii acestora in cazul de fata. Aminteam cu acel prilej ca in orice cercetare statistica se obtin date asupra unor caracteristici bine precizate ale unitatilor statistice. Daca aceste unitati au unele caracteristici considerate in cadrul cercetarii ca fiind fixe altele sunt considerate ca variind de la o unitate la alta de unde si denumirea de variabila. De exemplu daca unitatile statistice sunt reprezentate de cetatenii romani cu drept de vot, intre acestia apar diferentieri dupa sex, venit, apartenenta religioasa, profesie, nivelul de educatie, numar de copii, optiunea politica etc. Toate acestea din urma sunt caracteristici sau variabile statistice. Fiecare din variabile se distinge prin multimea valorilor pe care le ia. Dupa cum se vede si din enumerarea de mai sus aceste variabile se exprima prin marimi total diferite ceea ce a impus clasificarea lor de o maniera precisa. Astfel, pentru Michle Colin et alii [1995; 32] variabilele sunt de doua feluri:
-calitative (desemneaza feluri de a fi: sex, culoarea ochilor, opiniile etc. )
-cantitative (provin dintr-o masurare: talia, greutatea, varsta etc. )
In ce priveste variabilele calitative, acestea pot fi ordonate atunci cand iau anumite valori pe doua tipuri de scale:
1). Scala nominala (ex. Sexul poate fi masculin/ feminin; starea civila poate fi doar intr-una din situatiile: necasatorit, casatorit, vaduv, divortat)
2). Scala ordinala (ex. Raspunsul la intrebarea " Cat de multumit sunteti de seful dv. direct?", raspuns: a). absolut de loc; b). putin ; c) asa si asa; d). mult e).foarte mult ).
Diferenta dintre cele doua scale este evidenta. Astfel, in cazul primului tip nu exista o relatie de ordine iar valorile variabilei sunt exprimate prin cuvinte (de unde si denumirea de scala nominala!), cuvinte care nu fac decat sa imparta colectivitatea statistica in mai multe grupe sau categorii. In cel de al doilea caz subiectul care raspunde este rugat sa se plaseze singur pe o treapta a unei scale care poate fi ascendenta sau descendenta, dar in orice caz este presupusa aici o relatie de ordine (fiecare din variantele a, b, c, .e este plasata pe un continuum crescator, din care trebuie aleasa una). Din moment ce ele semnifica o ordine atunci ele pot fi notate si cu numere naturale ca in exemplul urmator:
Intrebare: "De cate ori mergeti la biserica din confesiunea dumneavoastra?" Raspuns: 1). Cel putin o data pe saptamana ; 2). Cel putin o data pe luna; 3). Destul de rar ; 4). Practic niciodata. Acest exemplu l-am dat pentru a aminti, odata cu T. Rotariu [1999; 28] ca scala utilizata se distinge prin folosirea variantelor 1,2,3. dar numai in sens ordinal si nu pur numeric, cantitativ. Variantele 1,2,3. genereaza de fapt tot clase sau categorii de raspunsuri! Precizarile acestea sunt foarte importante pentru a nu se confunda acest tip de variabile cu cele cantitative!
In concluzie se poate face distinctia intre variabile calitative nominale si variabile calitative ordinale.
Cat priveste variabilele cantitative, acestea provin dintr-o masurare efectiva, exprimata printr-un numar cardinal si se impart si ele in doua categorii:
-variabile cantitative continui (ex. Inltimea unei persoane poate fi orice valoare din intervalul [140, 220] cm.)
-variabile cantitative discrete (ex: o familie poate avea 0, 1, 2, 3, 4,..copii, dar nu si un numar exprimat printr-o valoare intermediara ex. 1,5 ; 2,3 etc.)
Obs: intuitiv diferenta dintre cele doua tipuri ar putea fi data de modul cum parcurgem, in matematica multimea R, a numerelor reale si multimea N, a numerelor naturale!
Variabilele cantitative uzeaza de doua tipuri de scale:
1). Scala de intervale (ex. gradatia unui termometru, anul nasterii etc. )
2). Scala de rapoarte (ex. greutatea, salariile, varsta etc. )
Obs : in literatura de specialitate le intalnim uneori cu nume in limba engleza (interval scale respectiv ratio scale).
Diferenta dintre cele doua scale este importanta. Astfel, in cazul scalei de intervale gradatia de inceput (ex. 00 Celsius) este conventionala pe cand in cazul scalei de raporturi gradatia de inceput este reala (ex. venitul de 0 lei desemneaza lipsa oricarei surse financiare). O alta diferenta provine din faptul ca scala de intervale nu ne permite sa stabilim raporturi intre valorile unei variabile (de ex. nu putem spune ca la temperatura de 40 0 Celsius este de 40 de ori mai cald decat la temperatura de 10 Celsius). In cazul celei de-a doua scale se pot stabili aceste raporturi (de ex. un individ de 100 de Kg. este ce doua ori mai greu decat unul de 50 Kg.). Avand in vedere ca diferentele dintre aceste scale sunt imediat percepute rareori pot apare anumite confuzii. Se impune totusi precizarea ca unii indicatori statistici nu au sens prin folosirea de scale de intervale.
Incercand o recapitulare iata cum arata o tabelare a variabilelor dupa Michle Colin [1995;34]:
Clasificarea variabilelor dupa tip |
||
|
Tip de varibila |
Scala |
Exemple |
|
Calitativa |
Nominala Ordinala |
Sex, profesiune Opinie |
|
Cantitativa (discreta sau continua) |
De intervale De rapoarte |
Discreta: anul de nastere Continua: temperatura Discreta: nr. de copii, varsta Continua: inaltime, greutate |
Sa precizam in final ca diferentierea dintre variabile (caracteristici) duce in fapt la distingerea a doua directii in analiza statistica: statistica non-parametrica (pentru variabilele calitative) si cea parametrica (pentru variabilele cantitative). Sa mai amintim ca in literatura de specialitate se intalneste notiunea de variabila categoriala uneori cu sens calitativ alteori cu sens cantitativ.
Generalizand, variabilele pot fi de doua feluri : cantitative sau calitative iar dintr-un alt punct de vedere pot fi continue sau discrete (categoriale). Aceste precizari sunt importante pentru ca procedurile statistice alese din cadrul programului SPSS depind de tipul de variabile si de tipul scalelor. De exemplu pentru scale nominale sau ordinale sunt obligatorii proceduri sau teste non-parametrice in timp ce pentru scalele de interval sau de raport se vor folosi proceduri sau teste parametrice. De asemenea este important de precizat ca variabilele trebuie sa indeplineasca anumite conditii inainte de a fi supuse cercetarii. De exemplu se cere ca o variabila cantitativa sa respecte conditiile : distribuirea normala a valorilor in esantionul prelevat si apropierea acestei distributii de distributia din populatia mare din care a fost extras esantionul.
Obs. : Exista uneori tendinta de a trata scalele ordinale ca si scale de intervale. Din cauza ca distantele intre valorile acestor tipuri de scale sunt diferite pot apare insa confuzii. De exemplu daca ne referim la o scala ordinala data de intrebarea Sunteti multumit de seful direct ? cu raspunsurile posibile : 1. Foarte multumit 2. Multumit 3. Deloc multumit 4. Nu am o parere formata, se pune problema daca este legitim sa calculam media aritmetica a valorilor 1-4 ca si pe o scala de intervale. Se pune deci problema daca o medie de 1,75 ne poate indreptati sa declaram ca suntem aproape multumiti de seful direct ? Fara doar si poate ca o astfel de valoare are o reprezentare intuitiva insa in sens strict statistic ea poate fi imprecisa. Sa presupunem ca avem alta scala ordinala atasata intrebarii Cite carti de literatura cititi pe luna ? : 0. Niciuna 1. O carte 2. Doua carti 3. Trei carti 4. Patru sau mai multe carti. In acest caz o astfel de scala poate fi tratata ca si o scala de interval si deci o medie de, sa spunem, 1,5 carti ni se pare plauzibila. Diferenta de interpretare apare din faptul ca cea de a doua scala ordinala are intervale egale. In fiecare caz ramane la latitudinea cercetatorului de a decide interpretarea corecta a datelor.
O distinctie importanta este si aceea dintre variabile independente si variabile dependente. Iata cateva exemple :
|
Variabila independenta |
Variabila dependenta |
|
Stilul managerului Sexul respondentilor Virsta |
Productivitatea muncii Optiuni electorale Preferinte muzicale |
Dupa cum se observa sensul legaturii dintre aceste variabile este univoc relatia inversa neputind fi impusa (de exemplu optiunile electorale nu pot influenta sexul subiectilor). Modul cum sunt desemnate aceste tipuri de variabile difera de la o cercetare la alta. Prin definitie variabilele independente sunt cele care influenteaza pe cele dependente, fiind stabilite sau introduse de catre cercetator. In cercetarile prin chestionar de obicei se introduce un set de astfel de variabile cu caracter demografic sau economic in functie de care se vor face analize privind celelalte variabile (intrebari). Legaturile dintre astfel de variabile sunt fundamentale in experimentele sociologice.
4. Definirea variabilelor in SPSS
Sa presupunem ca dorim sa construim o noua baza de date. Pentru aceasta vom urma comenzile File New Data dupa care apare tabloul gol Data Editor. Vom da apoi dublu clic pe numele sav care apare in capul primei coloane. Automat se va deschide cel de-al doile registru numit Variable view in care putem defini variabilele :
In prima coloana incepand din coltul din stanga sus putem introduce numele variabilelor. Este vorba de numele pe scurt al acestora cu pana la opt caractere. Apoi vom caracteriza respectivele variabile conform indicatiilor care urmeaza : Type, Width, Decimals, Label etc.
De data aceasta tabelul contine pe fiecare linie orizontala cate o variabila iar pe fiecare coloana putem caracteriza in amanunt fiecare variabila. Vom identifica rolul fiecarei coloane :
t Name- include numele pe scurt al variabilei de maximum 8 caractere (nu se folosesc spatiile goale sau anumite semne speciale : !, ?, *, ' ).
Dupa ce am introdus numele in prima casuta vom da clic in partea dreapta a celulei corespunzatoare unei variabile si care este in coloana cu titulatura Type. Va apare urmatoarea fereastra :
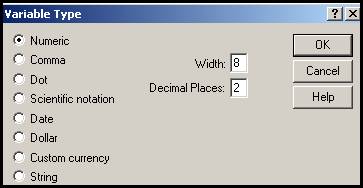
Aceasta ferestra contine tipurile de variabile posibile mai precis tipurile de variabile dupa valorile pe care le pot lua acestea :
Numeric-optiunea pentru valori numerice ; se pot stabili cate cifre au aceste numere, maximum 40 (Width) dar si cifrele pentru partea zecimala, maximum 16 (Decimal Places). Optiunile alese vor apare in urmatoarele doua coloane ale tabloului !
Comma- sau virgula folosita uneori la separarea cifrelor de ordinul miilor, milioanelor etc. ; in acest caz separatorul zecimal este un punct
Dot- sau punct folosit uneori la separarea cifrelor de ordinul miilor, milioanelor etc. ; in acest caz separatorul zecimal este un virgula
Scientific notation notatii speciale de tipul 1,2E3 ceea ce inseamna 1,2*103
Date-notatii pentru date calendaristice (conform unui format care poate fi ales).
Dollar-simbolul monedei americane
Custom currency- variabila numerica cu date dispuse dupa formatul din Edit→Options→Currency
String configureaza variabile alfanumerice care pot contine siruri de caractere (litere sau numere). Odata aleasa aceasta optiune poate fi indicat numarul de caractere ales.
Obs : cele mai des folosite tipuri sunt Numeric si String !
t Label- putem desemna numele pe lung al variabilei cu pana la 256 caractere
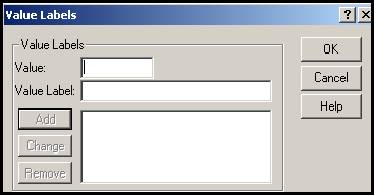
t Values- pot fi numite valorile si etichetele atasate acestor valori pentru cazul variabilelor ordinale sau categoriale. Dupa un clic in partea dreapta a celulei corespunzatoare din coloana cu acest titlu va apare fereastra de dialog urmatoare :
 da valoarea numerica a unei etichete iar Value Label va da numele etichetei
respective. Dupa aceste operatii se apasa pe butonul Add . Optiunile pot fi apoi
schimbate (Change) sau chiar
sterse (Remove). Iata cum
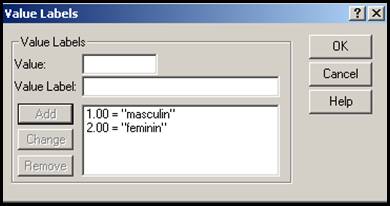
va arata dupa aceste operatii variabila sex cu cele doua alternative
1. masculin, 2. feminin:
da valoarea numerica a unei etichete iar Value Label va da numele etichetei
respective. Dupa aceste operatii se apasa pe butonul Add . Optiunile pot fi apoi
schimbate (Change) sau chiar
sterse (Remove). Iata cum
va arata dupa aceste operatii variabila sex cu cele doua alternative
1. masculin, 2. feminin:
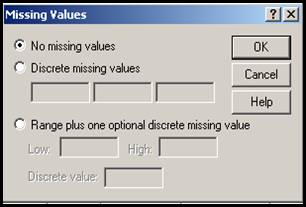
t Missing - poate permite operatorului de a desemna valorile lipsa (Missing Values) din cadrul unei variabile. Pentru inceput, programul are setata optiunea fara valori lipsa dupa cum apare in fereastra urmatoare :
Se poate opta totusi pentru dverse variante:

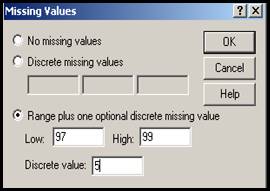
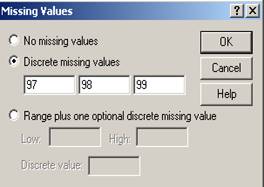
In aceste cazuri operatorul poate decide ca in analizele ulterioare valorile de tipul 97 (Nu stiu), 98 (Nu raspund) 99 (Nu s-a aplicat) sa fie considerate lipsa (missing). De asemenea se poate decide ca pe langa valorile cuprinse intre 97-99 sa mai fie adaugata o valoare din baza de date. Necesitatea unor astfel de operatii este imediata : se pot face analize eliminand pe moment anumite valori spaciale iar apoi se pot analiza separat chiar valorile considerate lipsa. In cazul variabilelor alfanumerice trebuie consemnat un spatiu liber in casuta Discrete missing values deoarece programul considera valide chiar si celulele goale !
t Columns- se poate decide asupra formatului coloanelor in functie de marimea datelor variabilei
t Align- se poate decide asupra modului cum vor fi aliniate valorile variabilei pe coloane
t Measure- optiune deosebit de importanta in urma careia decidem asupra modalitatii de masurare a variabilei. Astfel exista trei optiuni :
Scale- optiune pentru variabile numerice fie ele masurate pe scale de interval sau de rapoarte (ratio)
Ordinal- de obicei este o optiune pentru variabile ordinale care au categorii bine precizate prin etichete numerice si care pot fi ordonate.
Nominal- optiune pentru variabile alfanumerice in care nu exista nici o relatie de ordine intre valori (care pot fi cuvinte dar si numere).
Obs : precizarea corecta a optiunii measurement este importanta deoarece o serie de proceduri statistice se refera doar la anumite tipuru de variabile sau valori. Astfel pentru variabile nominale dintre marimile tendintei centrale (media, mediana, modul) nu are sens sa calculam media !
5. Introducerea variabilelor si a datelor in SPSS
Odata facute precizarile de pana acum putem introduce datele in Data Editor stiind ca fiecare coloana reprezinta o variabila iar fiecare rind reprezinta un caz sau o persoana. Sa presupunem ca intr-un chestionar avem in ordine urmatorii itemi :
Q1. Cum traiti in prezent fata de acum 3 ani?
Mult mai bine 2. Mai bine 3. La fel 4. Mai rau 5. Mult mai rau 9. NS/NR
Q2. Care este principala problema din localitate pe care fostul primar nu a rezolvat-o?
..
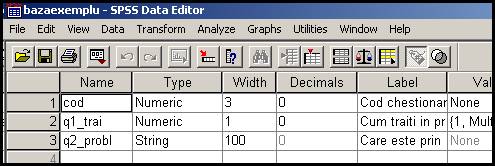
Vom incerca sa introducem itemii de mai inainte ca si variabile in baza de date apoi vom insera valorile pentru primii zece subiecti interogati. Se observa ca primul item reprezinta o variabila cantitativa, Q1 reprezinta o variabila ordinala iar cea de a treia este o variabila nominala. Inainte de a introduce valorile in baza vom intra in optiunea Variable View si vom defini variabilele cod, q1_trai, q2_probl. Pentru prima variabila putem face urmatoarele optiuni:

Se observa ca am optat pentru tipul numeric variabila avand drept valori numere cu pana la trei cifre (Width=3) considerand ca au fost interogate de exemplu 800 de persoane. Codul chestionarului este un numar intreg fara zecimale (Decimals=0), numele pe lung al variabilei este "Cod chestionar", masurarea este de tip Scale.
Definirea variabilei q1_trai trebuie sa tina cont de specificul acesteia prin precizarea etichetelor respective (se scrie Value: 1, apoi Value Label : "Mult mai bine" apoi Add etc.).
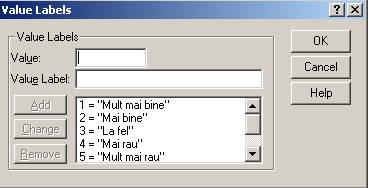
La final noua variabila din randul al doilea va avea urmatorii parametri :

Se observa ca valorile raman numerice dar cu precizarea ca acele numere se refera la valorile etichetelor : 1,2,3,4,5,9. Aceste numere sunt compuse dintr-o singura cifra (Width=1). Numele pe lung al variabilei este chiar intrebarea din chestionar : "Cum traiti in prezent fata de acum 3 ani?".Modalitatea de masurare este Ordinal.
Cea de a treia variabila q2_probl este una nominala raspunsurile fiind consemnate ca variante pentru o intrebare deschisa. Daca in cazul anterior se vor introduce in baza de date doar numerele valori ale etichetelor in acest caz trebuie introduse raspunsurile subiectilor ca atare. Referitor la valorile variabilei tipul acesteia este String:
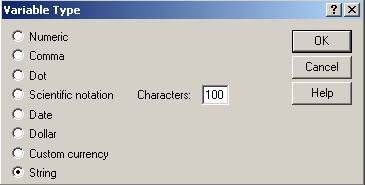
Odata cu alegerea optiunii String se impune precizarea numarului de caractere pe care il poate avea raspunsul subiectilor (in acest caz 100 de caractere). In final aceasta variabila va avea caracteristicile de pe pozitia a treia :

Cea de a treia variabila este de tip String cu variante de pana la 100 de caractere nominale sau numerice. Modalitatea de masurare este Nominal.
Dupa aceste operatii putem salva baza de date cu comenzile File Save As si noua baza o putem numi bazaexemplu. Numele bazei va apare in bara de titlu :
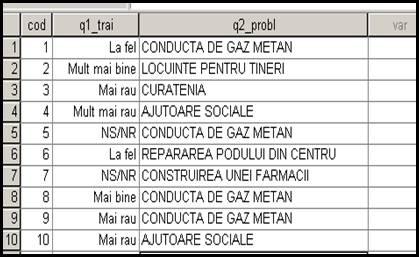
In acest moment putem reveni in fereastra Data View pentru a introduce datele culese din chestionare. Valorile se introduc in tabel acolo unde celula este activa (apare un chenar in jurul celulei) apoi se apasa tasta Enter. Sa presupunem ca am introdus primii zece subiecti chestionati.
Se observa ca in cea
de a doua coloana apar doar valorile numerice ale etichetelor (fapt ce ne
arata ca introducerea datelor in acest caz este mult facilitata). In stanga
sus se poate vedea si pozitionarea celulei active : coloana
2, randul 11. Pentru a vedea
si care sunt etichetele atasate valorilor din coloana a doua putem urma comenzile View Value Label sau putem da clic pe butonul ![]()
![]()
![]() de pe bara cu instrumente. Dupa o astfel de operatie vor apare in baza
si etichetele respective :
de pe bara cu instrumente. Dupa o astfel de operatie vor apare in baza
si etichetele respective :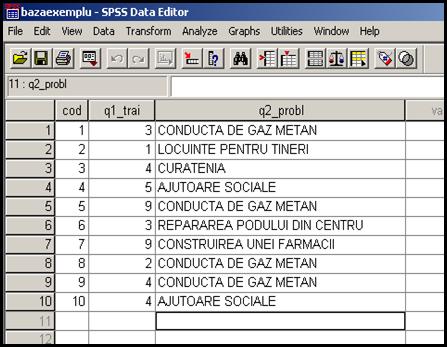
t din moment ce bazele de date au fost constituite putem incepe analizele statistice necesare !
t Toate comenzile de pina acum pot fi executate si intr-un editor de texte sau fisier sintaxa. Acest fisier care are termninatia .sps este foarte util cand se lucreaza frecvent cu baze mari de date pentru ca respectivele instructiuni (comenzi) pot fi salvate si apoi reiterate de cate ori este nevoie. Ceea ce am intreprins pana acum de exemplu putem sa regasim intr-un jurnal al aplicatiilor care poate fi gasit in fisierul spss.jnl din Windows Temp, fisier care poate fi deschis si ca document Word.
Accesand acest document gasim urmatoarele specificatii care rezuma de fapt constructia bazei de date anterioare:
Thu Dec 25 13:42:07
2003 :journaling started GET FILE='C:Documents and SettingsAdrianMy
Documentsspss curs'+ ' Idbazaexemplu.sav'. SAVE
OUTFILE='C:Documents and SettingsAdrianMy Documentsspss curs
Idbazaexemplu.sav' /COMPRESSED.
Un fisier sintaxa poate fi initiat dupa comenzile File New Syntax.
Chiar daca nu lucram in limbaj sintaxa atunci putem salva comenzile folosite fie alegand comanda Paste in loc de OK in diverse aplicatii pe care le efectuam sau putem sa le salvam in outputul aplicatiilor efectuand comenzile Edit→Option→Viewer→Display Commands in the log. Sa dam un exemplu de astfel de comenzi salvate in Output (fisier de rezutate) de exemplu pentru calcularea mediei varstei respondentilor din baya de date GSS93 Subset:
FREQUENCIES
VARIABLES=age
/STATISTICS=MEAN
/ORDER= ANALYSIS
In acest curs nu vom insista pe aspecte legate de limbajul sintaxa insa recomandam pentru cei interesati de exemplu volumul M. Norusis, SPSSx Advanced Statistics Guide, McGraw Hill, 1995. De asemenea se poate apela la site-ul creatorilor si proprietarilor programului www.spss.com sau la Help-ul programului.
6. Elemente de statistica univariata in SPSS
Vom analiza in acest capitol cateva din procedurile statistice elementare pe care le putem aplica datelor statistice. Sa deschidem una din bazele programului anume GSS93 subset (obtinuta in urma unei anchete pe un esantion de 1500 de subiecti):
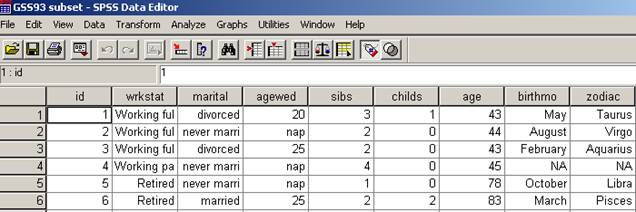
Ne oprim atentia asupra variabilei educ (Highest year of school completed) ale carei caracteristici de baza le putem identifica in fereastra Variable View:
![]()
![]()
![]()

![]()
Variabila este considerata avand valori numerice cu maximum doua cifre, sunt consemnate trei valori speciale: 97 (NAP, neaplicat) 98 (DK, "don't know "; "nu stiu") si 99 (NA, "no answer", "non-raspuns"). In cazul valorilor lipsa (missing values) sunt consemnate valorile 97, 98, 99. Variabila este considerata ordinala dar din considerentele spuse mai inainte ea poate fi la fel de bine considerate variabila cantitativa discreta.
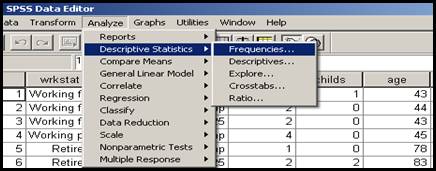
Pentru aceasta variabila vom incerca sa calculam principalele valori statistice. Pentru aceasta vom apela comenzile urmatoare: Analyse Descriptive Statistics Frequencies:
sagetii din mijloc (sau dublu clic) dupa selectare. Sageata se poate actiona si invers!
![]()
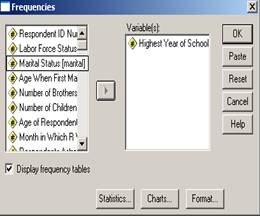
Se observa in aceasta fereastra si alte elemente:
t Display frequency tables- optiune pentru afisarea tabelului frecventelor variabilei; uneori putem renunta la acest tabel (prin deselectarea optiunii)
OK-comanda finala dupa ce am ales toate optiunile de calcul
Paste- comanda pentru salvarea comenzilor in modul sintaxa
Reset- comanda pentru anularea setarilor in curs
Statistics- comanda pentru calculul principalelor valori statistice
Charts-comanda pentru reprezentari grafice
Format- optiuni privind modalitati de afisare ale rezultatelor
Help- comanda de ajutor
Prin actionarea butonului Statistics se va deschide o noua fereastra de dialog :
Se obseva
impartirea acestei ferestre pe o serie de blocuri distincte
referitoare la percentile, dispersie, marimile tendintei centrale
si marimi legate de forma distributiei statistice. Pentru calcularea
acestor valori este necesar sa selectam procedurile care ne intereseaza cu
un clic al mausului in patratelele din fata lor. Pentru
deselectare vom da un clic in aceleasi patratele! Vom discuta pe
larg optiunile acestei ferestre in cele ce urmeaza.
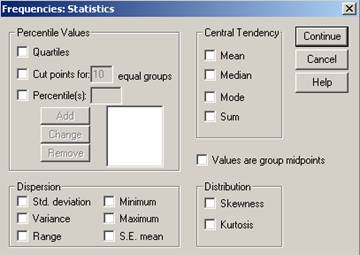
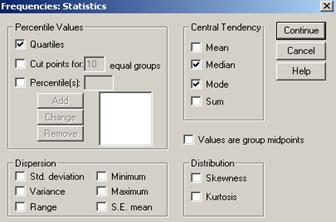
I. Percentile Values- comanda care imparte multimea valorilor statistice in mai multe grupe de date.
Exista mai multe variante:
Quartiles (impartim multimea valorilor in patru parti egale fiecare cate 25% )
Cut points for 10 equal groups (impatire in 10 parti dar pot fi alese marimi intre 2 si 100)
Percntile(s)-se poate specifica o centila anume.
II. Dispersion- include comenzi pentru calcule privind analiza variatiei
Se poate opta pentru Standard Deviation, sau "deviatia standard" sau "abaterea medie patratica", marime care ne arata cu cit se abat in medie valorile seriei de la media lor. Formula de calcul pentru serii cu frecvente este cea cunoscuta din statistica descriptiva deja parcursa:
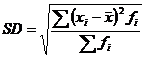
Obs: in cazul unei serii cu distributie normala
sau care se apropie de o astfel de distributie valorile seriei sunt
cuprinse in proportie de 99% in intervalul ![]()
Variance-o notam SD2 este marimea din care am obtinut deviatia standard prin extragerea radicalului. Formula de calcul este sugerata de ridicarea la patrat a formulei anterioare:
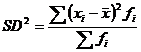
Range- sau "amplitudinea absoluta" se calculeaza cu formula:
![]() , valori notate Minimum,
Maximum.
, valori notate Minimum,
Maximum.
S.E. Mean-sau "standard error of mean" (eroarea standard a
mediei) ne poate arata limitele intre
care variza media esantionului ( ) in cadrul unei populatii de esantioane. Se
stie ca un astfel de interval este foarte util atunci cand aproximam
valoarea mediei dintr-o populatie. Aceasta valoare nu este cunoscuta decit
in urma unor cercetari exhaustive care sunt deosebit de complexe si
costisitoare. In practica majoritatea estimarilor statistice se fac pe
esantioane iar rezultatele, sub conditia reprezentativitatii,
sunt apoi inferate (extinse) la populatia mare din care a fost extras
esantionul. Daca notam media din populatia mare cu μ, S.E.Mean cu SE si eroarea limita admisa cu Δx (Δx=t.SE) putem conchide ca, cu o
anumita probabilitate, ![]() , interval in care
, interval in care ![]() este media din esantion. Atragem atentia ca in majoritatea tratatelor de statistica
valorile care se refera la o populatie statistica sunt notate cu litere
grecesti iar cele referitoare la esantioane se vor nota cu litere
latine.
este media din esantion. Atragem atentia ca in majoritatea tratatelor de statistica
valorile care se refera la o populatie statistica sunt notate cu litere
grecesti iar cele referitoare la esantioane se vor nota cu litere
latine.
III. Central Tendency-grup de valori care poarta denumirea de marimile tendintei centrale (acele marimi care caracterizeaza im medie intreaga multime a valorilor statistice). Se calculeaza de obicei urmatoarele valori:
Mean- media aritmetica (![]() ); este calculate cu formulele:
); este calculate cu formulele:
![]() , pentru serii simple si
, pentru serii simple si 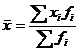 , pentru serii cu frecvente
, pentru serii cu frecvente
Median-sau mediana (Me) reprezinta valoarea atasata individului sau cazului care imparte miltimea statistica in doua parti egale. Se citeste astfel: 50% din valorile seriei sunt mai mici decat Me, iar restul de 50% au valori care depasesc Me. Dupa cum se stie aceasta marime se identifica usor intr-o serie simpla, la mijlocul acesteia, dupa ce am ordonat valorile respective. Pentru o serie cu intervale se foloseste formula:
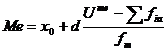 , formula in care
x0 este limita inferioara a intervalului median, d
marimea acelui interval,
, formula in care
x0 este limita inferioara a intervalului median, d
marimea acelui interval, ![]() este frecventa cumulata
anterioara intervalului median, iar fm este frecventa
corespunzatoare acelui interval.
este frecventa cumulata
anterioara intervalului median, iar fm este frecventa
corespunzatoare acelui interval.
Mode-sau modul (dominanta), notat Mo, reprezinta cea mai des intalnita valoare dintr-o serie statistica sau valoarea care are cea mai mare frecventa. Pentru o serie simpla este usor de identificat iar pentru serii cu frecvente se foloseste formula:
![]() , formula in care x0
este limita inferioara a intervalului modal (corespunzator celei mai mari
frecvente), d este marimea respectivului interval, Δ1
si Δ2 sunt diferentele obtinute prin scaderea
din frecventa intervalului modal a frecventelor anterioara si
posterioara acesteia.
, formula in care x0
este limita inferioara a intervalului modal (corespunzator celei mai mari
frecvente), d este marimea respectivului interval, Δ1
si Δ2 sunt diferentele obtinute prin scaderea
din frecventa intervalului modal a frecventelor anterioara si
posterioara acesteia.
Sum-reprezinta suma valorilor seriei
IV. Distribution- valori care se refera la forma distributiei statistice. Cuprinde dua tipuri de valori: skewness (asimetria) si kurtosis (aplatizarea).
Asimetria se refera la masura in care graficul (distributia) valorilor este asimetric spre stinga sau spre dreapta fata de valoarea medie. Pentru un coefficient, sa il notam sk (de fapt coeficientul Pearson de oblicitate) putem avea valorile:
![]()
Sk>0, asimetrie la dreapta (graphic alungit spre dreapta)
Sk<0, asimetrie la stinga (graphic alungit spre stanga)
Sk≈0, distributie simetrica
Aplatizarea sau boltirea se refera la compararea distributiei cu o curba normala. Se poate calcula un coeficient de aplatizare (il notam cu k) iar valorile acestuia pot fi interpretate astfel:
![]()
k>0, distributie leptocurtica (peste o curba normala)
Sk<0, distributie platicurtica (sub o curba normala)
Sk≈0, distributie mezocurtica (tinde la o curbanormala)
Obs1. Valorile sk si k sunt considerate normale daca se incadreaza in intervalul [-1,96; 1,96].
Obs2. Precizam ca o curba normala este binecunoscuta distributie gaussiana, in forma de clopot, perfect simetrica si care se bucura de o serie de proprietati fundamentale pentru cercetarea statistica. Recomanda si parcurgerea bibliografiei de la sfarsitul cursului pentru alte informatii.
V. Values are group midpoints-optiune utilizata cand valorile seriei sunt grupate simetric in jurul unei valori anumite.
7. Calcule statistice in SPSS
Toate marimile precizate pot fi calculate in cazul unei variabile cantitative numerice. Vom seta toate variantele repective vom da OK si vom obtine rezultatele intr-o alta fereastra Output1 (specifica afisarii rezultatelor si care poate fi salvata ca si un fisier de tip *.spo):
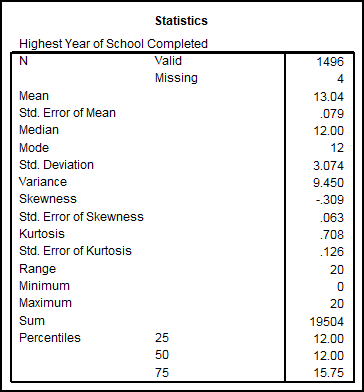
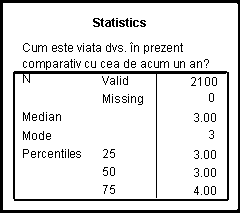
Din aceste date
deducem ca sunt valide 1496 de cazuri iar 4 sunt considerate lipsa (acele
valori 97,98 si 99). Media anilor de studii-scoala incheiata din
esantion este de 13,04 ani iar SE of Mean= 0,079. Jumatate dintre
subiecti au media anilor de studiu de pana in 12 ani, restul de peste
12. Modul este unic si este
Mo=12, cea mai des intalnita valoare. Abaterea standard este de 3,074 ani.
Coeficientul de asimetrie este de -0,309 deci distributia este
alungita usor spre stanga iar coeficientul boltirii este de 0,708 deci
distributia este leptocurtica. Amplitudinea este de 20 ca rezultat din
diferenta Maximum-Minimum. Suma tuturor valorilor este de 19504 ani.
Primii 255 dintre respondenti au pana in 123 ani de scoala,
primii 50% au tot pana in 12 ani, primii 75% au pana in 15,75 ani de
scoala.
Daca apelam la butonul Charts din aceeasi fereastra putem reprezenta graphic seria dupa ce am ales setarile care se potrivesc seriei noastre, din fereastra urmatoare:
Se observa ca am ales
Graficul de tip Histograma care
este specific variabilelor cantitative. Am ales si varianta With normal curve deoarece prin
comparatie se poate stabili si tendinta distributiei
spre o curba normala. Se pot alege
si alte tipuri de grafice: Bar
Charts (grafic cu bare) sau Pie
charts (grafic de tip placinta). Ultimele doua tipuri de grafice sunt
recomandate atunci cand variabilele sunt categoriale pentru o mai buna
vizualizare a acestora (se recomanda ca numarul categoriilor sa nu fie
foarte mare pentru a se pastra lizibilitatea). Pentru aceste grafice exista
si doua optiuni: Frequencies
si Percentages.
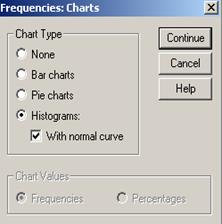
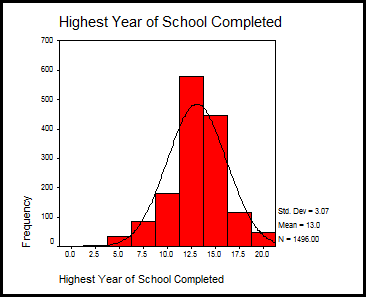
Dupa apelarea butonului Continue graficul va apare tot in fereastra de rezultate Output1:
Se observa in acest
grafic constatarile din primul tabel: distributia se apropie de o
curba normala avand o usoara alungire spre stanga (sk<0) iar din punctul de vedere al boltirii existand o tendinta
leptocurtica (k>0) adica daca am
uni mijloacele dreptunghiurilor histogramei tendinta este de a depasi o curba normala.
In aceeasi fereastra Output1 vom gasi si tabelul frecventelor dupa cum urmeaza:
Prima coloana contine valorile
seriei respectiv anii de studii cu
cifre cuprinse intre 0 si 20 de ani de studiu. Cea de a doua coloana
cuprinde frecventele absolute la final adaugandu-se si numarul
celor care au raspuns "don't know" (DK). Cea de a treia coloana contine frecventele
relative (procentuale). Cea de a patra coloana contine
frecventele procentuale valide adica acele frecvente recalculate
in conditiile in care valorile speciale de tip 97, 98, 99 sau altele
sunt declarate "missing" sau "lipsa". Diferentele dintre coloanele a
treia si a patra nu exista datorita numarului foarte mic de valori
missing. Daca numarul lor era mai mare diferenta era vizibila. Ultima coloana contine
frecventele cumulate calculate dupa coloana din stanga. Algoritmul de
calcul este simplu: se scrie prima frecventa 0,1 si se aduna cu
urmatoarea 0,3, rezulta 0,4 s.a.m.d.
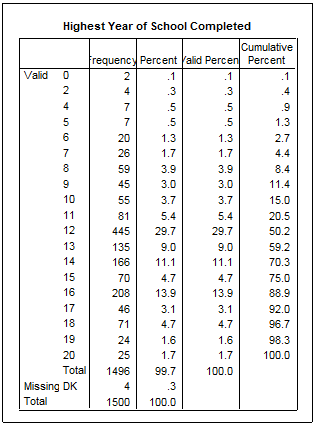
Ultima coloana ajuta la lectura mai rapida a datelor statistice. De exemplu putem citi ca 70% dintre respondentii cu raspunsuri valide au pana in 14 ani de scoala.
Vom cauta sa calculam principalele valori statistice si pentru o variabila categoriala (fie ea ordinala sau nominala). Pentru acest exercitiu vom apela la o alta baza de date BOP_mai-2003_Gallup FINAL.sav baza constituita in urma anchetei la nivel national intitulata Barometru de opinie. Aceasta baza poate fi descarcata de pe site-ul www.osf.ro. Iata cum arata o portiune din acasta baza:
Variabila a12 este o variabila ordinala si reprezinta intrebarea "Cum este viata dvs. in prezent comparativ cu cea de acum un an?". Aceasta intrebare avea variantele de raspuns: 1. Mult mai buna 2. Mai buna 3. Aproximativ la fel 4. Mai proasta 5. Mult mai proasta 8. NS 9. NR. Sa calculam principalele valori statistice si sa reprezentam grafic seria. Vom urma comenzile Analyze→Descriptive statistics→Frequencies:

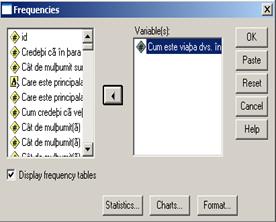
De data aceasta valorile statistice care ne intereseaza sunt mult mai putine datorita variabilei care este calitativa. Foarte util in acest caz este si tabelul frecventelor care este setat in prima fereastra. Graficul va fi de tipul Pie charts. Rezultatele le obtinem tot in Output1:
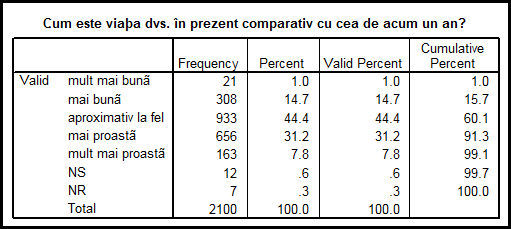
Observam in acest tabel semnificatiile coloanelor dupa observatiile facute anterior. Procentele pentru NS, NR sunt indentice in coloanele a treia si a patra pentru ca respectivele valori nu au fost considerate ca valori lipsa. Graficul de tip Pie Charts va apare in Output, apoi putem da dublu clic pe acest grafic si se va deschide o noua fereatra intitulata Chart1:
Din bara cu meniuri a
ferestrei Chart1 se pot selecta
multe alte facilitati pentru reprezentarile grafice. De exemplu pot fi
eliminate ponderile foarte mici cum ar fi NS, NR pentru o mai buna
vizualizare a categoriilor variabilei! De asemenea pot fi
adaugate/eliminate texte, pot fi facute diverse modificari etc.Dupa
inchiderea ferestrei rezultatul este salvat in Output. Meniul Help poate fi de ajutor in acest
sens
Fereastra
Chart1 este special constituita
pentru a face diverse modificari in graficul respectiv. Aici nu vom aplica
decat comenzile Chart Options→Percent iar dupa eliminarea
titlului din fereastra anterioara graficul final va fi urmatorul:
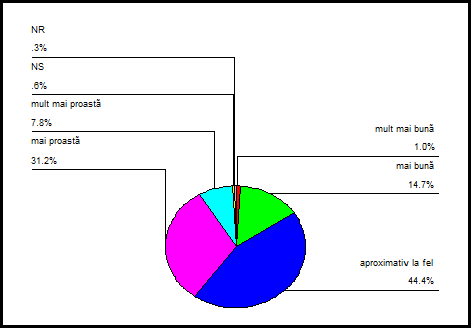
Obs: o buna parte dn valorile statistice calculate pentru o variabila sau mai multe se pot obtine si daca apelam la comenzile Analyze Descriptive Statistics→Descriptives iar valorile respective le putem alege din meniul Options.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 4022
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2024 . All rights reserved