| CATEGORII DOCUMENTE |
1. Introducerea datelor statistice
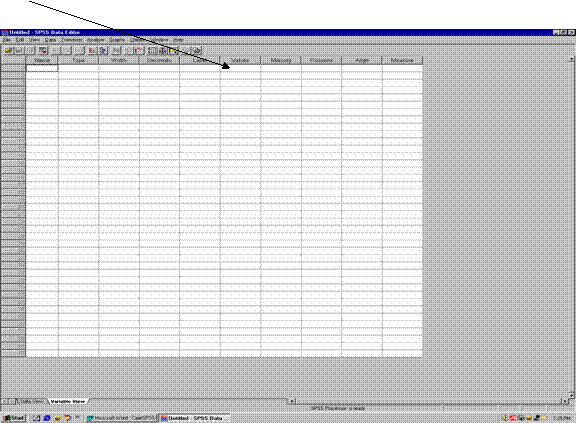
In fereastra "Variable View" se introduc atributele variabilei: nume (name), tip (type), lungimea (width), numar zecimale (decimals), eticheta (label), valorile etichetei (values), valorile lipsa (missing), alinierea (align) si modalitatile de masurare a variabilei (measure) ( scala, ordinal, nominal) (vezi figura 2).
1.1 Numele variabilei
Numele variabilei se editeaza in coloana Name tinand cont de urmatoarele restrictii :
sa fie unic
sa aiba cel mult 8 caractere
primul caracter sa fie o litera
ultimul caracter sa nu fie "_" (underscore)
poate sa contina litere, cifre, si simbolurile @,#, _ , $
sa nu contina spatii sau simboluri speciale folosite in SPSS
De exemplu intrebarii din baza de date 1 (vezi anexa 1) "Consumati produse alimentare certificate ca fiind ecologice ?" i se va atasa variabila "consumat" nume ce va fi trecut in capul de tabel.
1.2 Tipul variabilei
Se realizeaza in coloana Type . La pozitionarea cursorului pe patratul gri din dreapta casutei corespunzatoare caracteristicii Type ( vezi Figura 3 sageata) apare fereastra cu ajutorul careia se poate alege tipul variabilei: Numeric ( cu zecimale separate prin virgula - Comma sau punct Dot ) , Data, insotite de un simbol financiar ( de exemplu Dolar) sau sub forma unui sir de caractere - String (in cazul in care dorim sa introducem un cuvant sau o fraza).
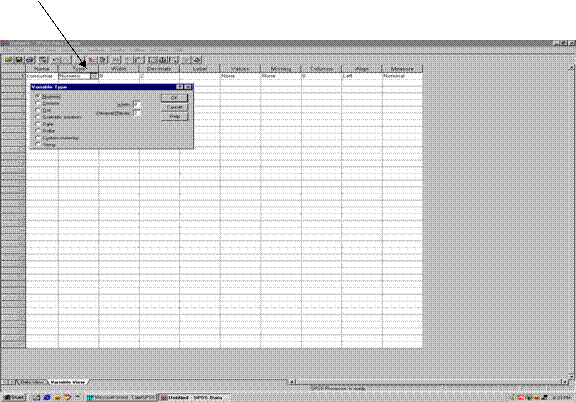 Figura
3: Introducerea atributelor unor variabile
Figura
3: Introducerea atributelor unor variabile
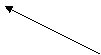
La rubrica Label se introduce eticheta variabilei (Figura 4 Sageata 1) . Aceasta eticheta reprezinta explicatiile care vor aparea langa rapoarte ( grafice sau tabele) atunci cand vor fi realizate.
Atunci cand variabilele sunt nominale (categoriale) acestea vor fi introduse codificat de exemplu raspunsurile la intrebarea 1 vor fi codate astfel:
"1" daca raspunsul a fost "Deseori"
"2" daca raspunsul a fost "Cateodata"
"3" daca raspunsul a fost "Nu"
Acestea vor fi introduse in fereastra ce apare actionand celula corespunzatoare coloanei Values (Figura 4 -sageata 2)
Introducerea valorii se face actionand butonul "Add" , modificarea unor valori se face folosind butonul "Change" iar pentru stergere butonul "Remove" din aceeasi fereastra. Pentru a face efective aceste schimbari e necesar sa se actioneze butonul "OK"
 1 2
1 2
In practica anchetelor de sondaj se folosesc pentru raspunsurile invalide, codurile:
97 - pentru "nonraspuns", 98 - pentru " neaplicabil", 99 - pentru " raspuns ilizibil"
Analog se introduc toate variabilele necesare.
2. Transformarea unei variabile
Pentru a transforma datele unei variabile se va folosi comanda Recode din meniul Transform asa cum se observa in figura de mai jos -sageata:
Figura 5: Transformarea unei variabile
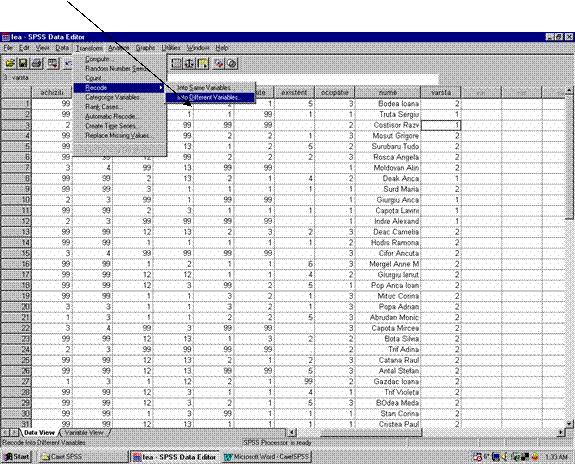
Recodificarea unei variabile se face fie in aceeasi variabila -atunci cand vechea variabila dispare ( optiunea Into Same Variables) sau in alta variabila
( optiunea Into Different Variables).
In cazul in care a fost aleasa optiunea schimbarii variabilei intr-o alta variabila diferita apare fereastra Recode into Different Variables
Figura 6: Recodificarea unei variabile
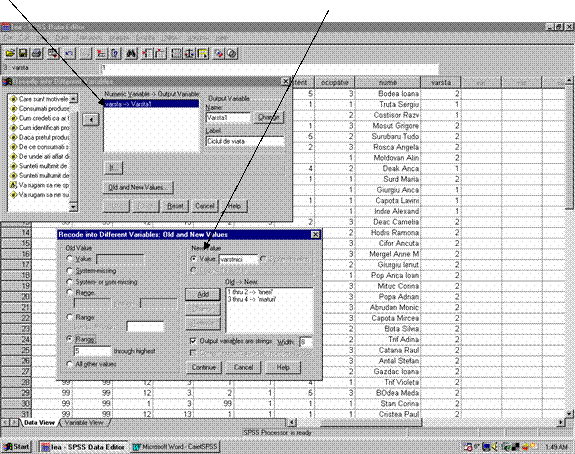 1 2
1 2
De exemplu dorim ca varsta respondentilor sa fie recodificata astfel:
Pentru cei cu varsta sub 35 ani codificat initial cu valorile 1 si 2 sa atribuim cuvantul "tineri"
Pentru varsta mai mare de 65 ani codificat cu 5 atributul "varstnici"
Astfel in fereastra de mai sus (figura 6 sageata 1), in fereastra "Recode into different values" se selecteaza variabila "Varsta", care, cu ajutorul butonului sageata din fereastra se muta in fereastra Numeric Variable ->Output Variable
In caseta Nume se trece numele noii variabile Varsta1 iar mai jos in caseta Label se trece eticheta. Se actioneaza apoi butonul Change pentru a face schimbarile efective. Prin actionarea butonului Old and new values apare apoi fereastra Recode into Different Variables , Old and New Values (figura 6, sageata 2) . In aceasta fereastra se selecteaza optiunea Output Variables are Strings pentru a putea defini noua variabila ca si "string" (sir de caractere). Pentru a schimba valorile 1 si 2 cu valoarea "tineri" se selecteaza butonul Range iar casetele de editare corespunzatoare sunt folosite pentru a stabili limita inferioara si superioara a intervalului dorit (through - de la- pana la). Se scrie 1 in caseta din stanga si 2 in caseta din dreapta. Apoi se selecteaza butonul de optiuni Value si se scrie "tineri" in caseta de editare dupa care se actioneaza butonul Add . Se procedeaza analog pentru toate categoriile. Prin clic pe butonul de comanda Continue se revine in fereastra Recode into Different Variables. Prin butonul de comanda OK se va declansa recodificarea variabilei. Noua foaie de date apare in foaia de date Data View cu datele de cod corespunzatoare fiecarui caz. O comanda asemanatoare comenzii Recode este comanda Compute.
In meniul Data exista comanda Select Cases. Ca urmare se deschide fereastra de dialog Select Cases. Dorim de exemplu sa alegem toate cazurile in care consumatorii consuma "Cateodata " produse agroalimentare ecologice.
Figura 7 . Filtrarea variabilelor statistice
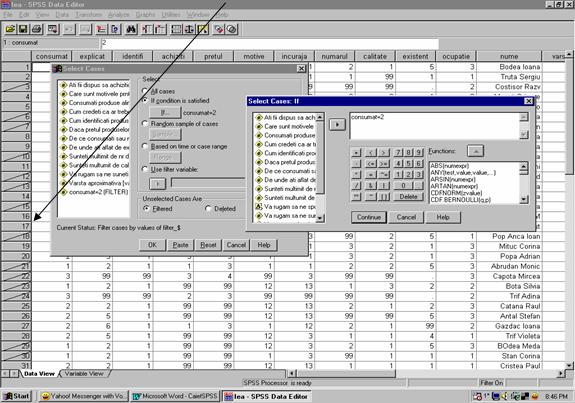
Pentru aceasta se actioneaza butonul de comanda If care va deschide fereastra Select cases in care se introduce conditia de filtrare "consumat" =2, consumat fiind numele variabilei prin care au fost codificate raspunsurile la intrebarea " Consumati produse alimentare certificate ca fiind ecologice"
( vezi anexa ). Butonul de comanda Continue determina revenirea la fereastra Select Cases in care se activeaza butonul de comanda OK pentru a obtine fisierul filtrat. Astfel in foaia Data View din fereastra Data Editor, cazurile anulate sunt taiate printr-un slash (/ -linie oblica) ( vezi sageata din figura de mai sus). Aceste cazuri nu vor fi folosite la nici o raportare.
Sistematizarea datelor in SPSS poate fi realizata prin optiunea Frequencies subordonata comenzii Descriptive Statistics din meniul Analyze (vezi figura 8). Activarea optiunii Frequencies determina deschiderea ferestrei Frequencies.
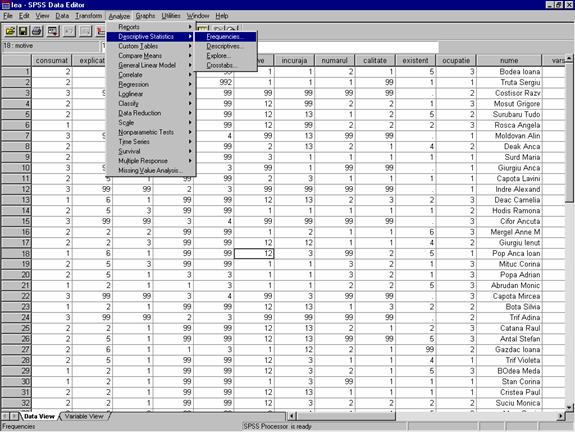
Figura 8: Activarea optiunii Frequencies
Din partea din stanga a ferestrei Frequencies se selecteaza variabila dorita prin click de mouse, apoi este mutata prin actionarea butonului sageata in caseta Variables. Prin butonul de comanda OK se obtine Tabelul de frecventa afisat in fereastra de rezultate Output Viewer
Intr-un tabel de frecventa sunt prezentate pentru fiecare variabila selectata, urmatoarele elemente:
valorile sau clasele de valori ale variabilei, efectivul
procentele
procentele cumulate corespunzatoare ( suma procentelor categoriilor inferioare)
5. Tabelul de asociere (Crosstabs)
Acest tip de tabel este folosit pentru prezentarea relatiilor dintre doua variabile categoriale. In fiecare rubrica (celula) este prezentata frecventa partiala asa cum va fi selectata.
Obtinerea unui tabel de asociere in SPSS presupune alegerea optiunii Crosstabs, subordonata comenzii Descriptive Statistics din meniul Analyze (figura 9).
Figura 9 Obtinerea tabelului de asociere Crosstabs
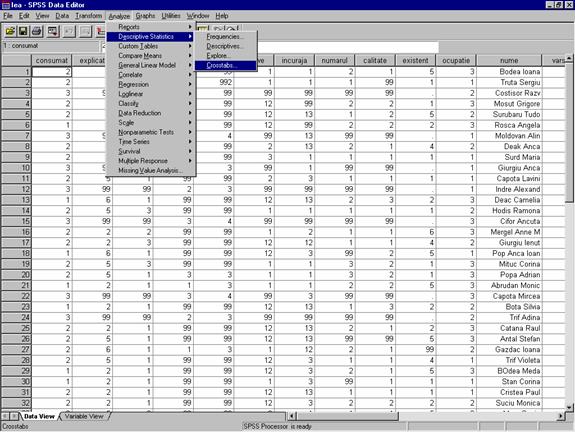
Dupa ce se selecteaza aceasta optiune , apare pe monitor fereastra Crosstabs in cadrul careia selectam variabile pentru randuri si coloane. Se observa in fereastra Crosstabs posibilitatea de a alege mai multe optiuni care apar in fereastra (figura 10):
Numere observate- Observed
Efective sperate - Expected
Percentages: - Pe randuri -Row, pe coloane -Column, pe total - Total
Residuals: se refera la abateri Standardizate , nestandardizate, ajustate.
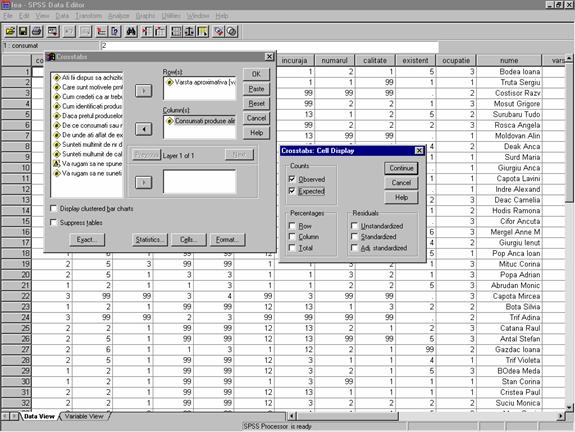
Figura 10: Alegerea optiunilor pentru alcatuirea tabelelor
Se pot executa o multime de aplicatii grafice cu ajutorul programului SPSS. Acestea se pot gasi in meniul Graphs (figura 11)
Figura 11. Alegerea tipurilor de grafic din Meniul Graph
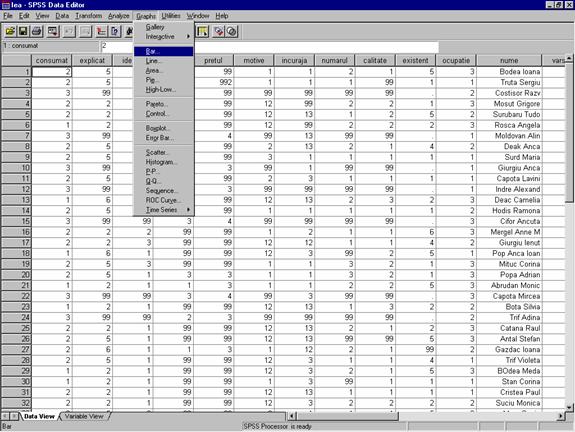
Line- Diagrama liniara
Pie- diagrama pe structura placinta
Boxplot - Diagrama "cutia cu mustati" este folosita pentru a prezenta amplitudinea, intervalul interquartilic si mediana unei distributii
Error Bar - Diagrama "bara erorilor" este folosita pentru a arata media si intervalul de incredere de 95% pentru media respectiva.Scatter - Diagrama "norul de puncte" este folosita pentru a reprezenta relatiile dintre variabile
Histograma - Este folosita pentru a arata forma unei distributii dupa o variabila inregistrata asupra unei colectivitati.
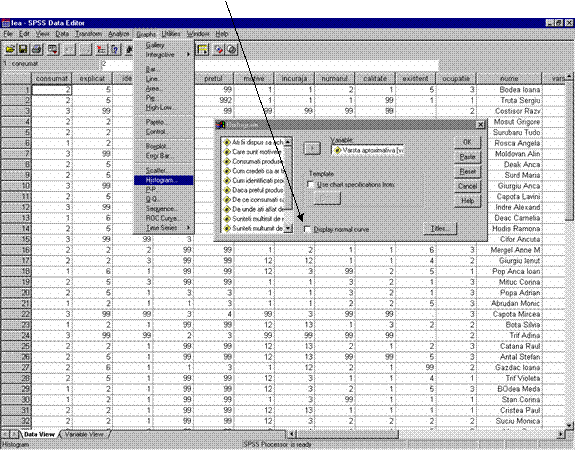
6.1 Histograma - permite vizualizarea formei unei distributii statistice, dupa o variabila cantitativa continua divizata pe intervale egale sau inegale. Constructia histogramei se face intr-un sistem de de doua axe rectangulare: pe abscisa se inscriu valorile variabilei cantitative sub forma de intervale (clase de valori) iar pe ordonata numarul de observatii sau frecventa corespunzatoare fiecarui interval. Pentru variabila cantitativa se ia un numar de intervale (k) egal cu radacina patrata din numarul de observatii (n) sau k= 1+ 3.322lg n. Comanda Histogram se obtine din meniul Graphs. ( vezi figura 12 de mai jos). In fereastra Histogram se poate alege optiunea Display normal curve (vezi sageata) pentru redarea distributiei normale.
Figura 12: Obtinerea histogramei din comanda Graphs
Forma grafica a histogramei este redata in figura de mai jos.
Figura 13: Forma grafica a histogramei
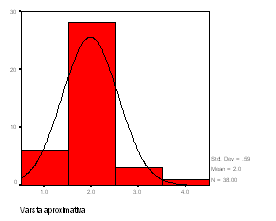
O alta modalitate de obtinere a histogramei este alegerea comenzii Interactive cu optiunea Histogram din meniul Graphs . A treia modalitate consta in accesarea meniului Analyze -> Descriptive Statistics -> Frequencies -> Charts -> Histogram.
6.2 Diagrama Boxplot - Diagrama Boxplot este folosita pentru prezentarea unei distributii dupa o variabila numerica , chiar atunci cand numarul datelor de care dispunem este mic. Constructia sa presupune ordonarea datelor si impartirea lor in patru grupe , fiecare variabila reprezentand 25% din distributie. Sunt marcate astfel cinci valori ale variabilei si anume: valoarea minima si valoarea maxima, fara outlieri , quartila 1, quartila 2 si mediana ( vezi figura)
Figura 14. Diagrama BoxPlot
 Maximum (fara outlieri)
Maximum (fara outlieri)
Percentila 75 ( Quartila 3)
Mediana (Quartila 2)
Percentila 25 (Quartila 1)
Minimum (fara outlieri)
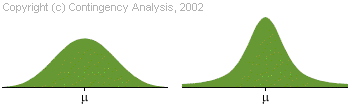
In general, un fenomen pentru a putea fi descris in termeni statistici trebuie sa evalueze dupa o anumita lege- adica sa-i poata fi descrisa evolutia dupa anumite coordonate. Cea mai cunoscuta lege , inclusiv in agricultura este distributia normala. Exemple de distributie normala: productia de grau la hectar la nivelul fermelor, cantitatea de precipitatii cazute in luna iulie din ultimii 100 ani , samd. De exemplu, putem considera productia medie de grau la hectar in ultimii 30 de ani, ca fiind 3000 kg/ha (figura de mai jos)
Aceasta nu inseamna ca in fiecare an s-au obtinut recolte de 3000 kg /ha ci inseamna ca s-au obtinut recolte mai mici sau mai mari in jurul acestei valori. Totusi putem spune ca este mult mai probabil sa intalnim o recolta de 3500 kg/ha decat o recolta de 10.000 de kg/ha. Deci cu cat ne indepartam de valoarea medie cu atat productia respectiva este mai greu de obtinut. Acest aspect este redat de curba de mai jos care reflecta distributia de probablitate intr-un astfel de caz , distributie numita "normala" . O astfel de distributie se numeste normala si se caracterizeaza prin doi parametrii: media si abaterea medie patratica (deviatia standard)
Media se
noteaza cu μ=![]()
![]() unde xi sunt valorile variabilei iar N volumul populatiei
unde xi sunt valorile variabilei iar N volumul populatiei
Abaterea medie patratica (deviatia standard) masoara dispersia in jurul mediei si se calculeaza ca radacina patrata din varianta
σ = ![]() unde
unde 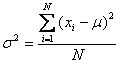
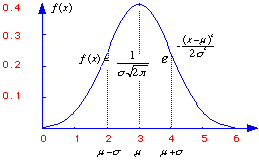
Figura 15: Curba distributiei normale
In Statistica se defineste urmatoarea notiune: Momentul centrat μ de ordinul k e definit ca:
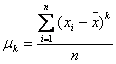
Coeficientul
de asimetrie a unei distributii exprima gradul de dezechilibru al unei
distributii si se calculeaza ca raport dintre momentul centrat de ordin trei ![]()
![]() la
puterea a doua si momentul centrat de ordin doi
la
puterea a doua si momentul centrat de ordin doi ![]() la
puterea a treia dupa relatia:
la
puterea a treia dupa relatia: ![]() adica
adica 

Figura 16: Distributia asimetrica cu abaterea spre stanga respectiv spre dreapta
Acest indicator se numeste Skewness iar atunci cand ia valori intre -1 si 0 indica prezenta unei distributii asimetrice negative cu abatere spre stanga iar cand variaza intre 0 si 1 indica o distributie cu abatere spre dreapta ( vezi figura). Valoarea 0 indica prezenta unei distributii simetrice.
Coeficientul de boltire sau aplatizare (kurtosis) e o masura a raspandirii fiecarei observatii in jurul valorii centrale. Pentru o distributie normala , valoarea kurtosis-ului statistic e 0 si se numeste distributie mezocurtica.
Atunci cand coeficientul este mai mare ca zero indica o grupare mai puternica a valorilor in jurul valorii centrale, curba este mai boltita decat o distributie normala si se numeste distributie leptocurtica. Atunci cand coeficientul este mai mic decat zero, indica o grupare mai slaba in jurul valorii centrale , curba frecventelor este mai aplatizata si se numeste distributie platicurtica ( vezi figura 17) DuD
Kurtosis-ul: 
Figura 17: Distributia leptocurtica / platicurtica
Din meniul Analyze din comanda Descriptive Statistics alegem optiunea de calcul Descriptives . Dupa alegerea variabilei pentru care dorim sa calculam parametrii distributiei se deschide fereastra de dialog Descriptives: Options . Din aceasta fereastra selectam, prin bifare, in caseta/casetele de validare corespunzatoare , indicatorul/indicatorii care urmeaza a fi calculati.
Se pot realiza urmatoarele calcule:
Mean (media)
Sum (suma tuturor observatiilor)
Std. Deviation ( abaterea medie patratica, numita si abaterea standard)
Variance (varianta)
Range ( amplitudinea variatiei)
Minimum si Maximum (valoarea minima si valoarea maxima a variabilei selectate)
S.E. mean standard
Error mean (eroarea medie de selectie: ![]() )
)
Kurtosis (boltirea)
Skewness (asimetria)
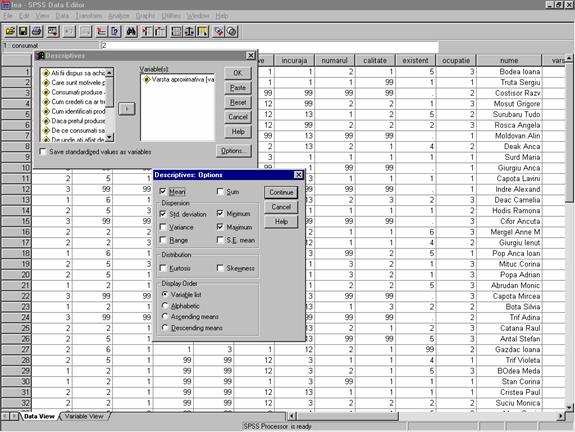
Figura 18: Calculul indicatorilor
statistici utilizand comanda Descriptive Statistics
Mai exista doua modalitati pe care le puteti aborda pentru a obtine calculul indicatorilor statisticii descriptive prin optiunea Frequencies.
Din Meniul Analyze comanda Descriptive Statistics optiunea Frequencies
Din Meniul Analyze comanda Reports optiunea Case Summaries (Tabel 1)
Tabel 1: Raport obtinut prin comanda Case Summaries privind frecventa consumului de produse ecologice

9. Parametrii unei distributii bivariate (bidimensionale)
Distributia de frecventa : "Consumati produse alimentare certificate ca fiind ecologice ?" si "Varsta aproximativa a respondentului" exprima distributia esantionului de persoane observate simultan dupa cele doua variabile considerate , adica arata cate persoane dintr-o anumita categorie de varsta au un anumit nivel al venitului. Distributia bivariata se poate obtine pe mai multe cai:
meniul Analyze à comanda Descriptive Statistics àoptiunea Crosstabs
meniul Analyze à comanda Reports à optiunea Case Summaries
meniul Date à comanda Split File à comanda Analyze àReports à OLAP Cubes
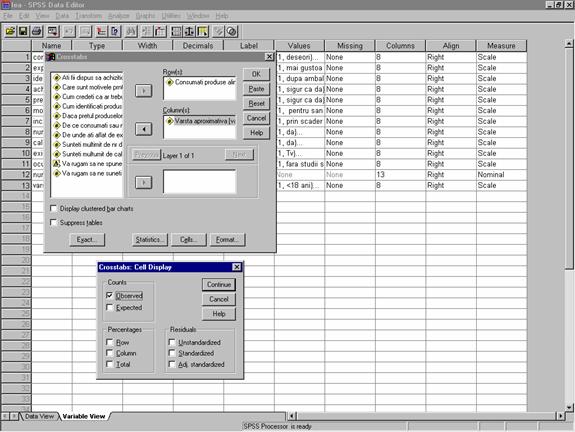
Prin demersul AnalyzeàDescriptive Statisticsà Crosstabs se poate obtine o distributie bivariata parcurgand urmatorii pasi:
se deschide fereastra de dialog Crosstabs , in care selectam variabilele "consumat" si "varsta" , din lista variabilelor si le mutam in zonele Row(s) si Column(s)
din fereastra Crosstabs, activand butonul de comanda Cells, se deschide fereastra Crosstabs: Cell Display, in care bifam modul dorit de afisare a frecventelor in crosstable;
activarea butonului de comanda Continue ne intoarce in fereastra Crosstabs, unde prin OK se comanda SPSS-ului afisarea raportului(vezi figura 19).
Figura 19: Comandarea raportului bivariat- Crosstabs
S-a obtinut urmatorul tabel:
Tabel 2: Tabel privind frecventa consumului in functie de varsta

10. Verificarea normalitatii unei distributii folosind SPSS
Majoritatea testelor statistice si a procedeelor de modelare statistica cer indeplinirea conditiilor de normalitate pentru a putea fi interpretate. Prin urmare e deosebit de important sa se determine daca esantionul observat provine dintr-o populatie normal distribuita.
Vizualizarea grafica a diferentelor dintre o distributie empirica si distributia teoretica folosind histograma, boxplot, PP-plot si QQ-plot sau folosind teste statistice .
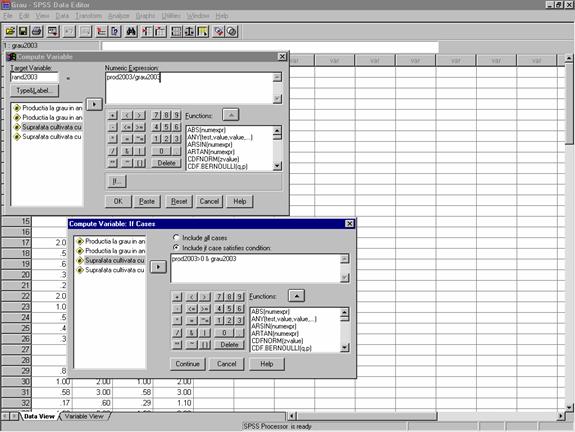
Pentru aceasta vom folosi baza de date grau.sav. Aceasta baza de date are campurile: grau2003, prod2003, grau2004 si prod2004 care reprezinta rezultatele unui sondaj privitoare la suprafetele cultivate cu grau in fiecare ferma (ha) (grau2003 respectiv grau2004 ) si productia obtinuta la aceasta recolta in anii 2003 si 2004 (prod2003 si prod2004 in tone). Acolo unde datele lipsesc fermierii fie nu au cultivat grau fie au omis sa declare productiile obtinute. Asa cum deja s-a aratat, cu ajutorul comenzii Transform à Compute se calculeaza randamentele pe ferma pentru fermele care au cultivat grau obtinand campurile rand2003 si rand2004 astfel:
rand2003= prod2003/supr2003 iar rand2004=prod2004/supr2004.
Nu uitati conditia de filtrare: prod2003&supr2003>0 respectiv prod2004&supr2004>0 pentru a elimina valorile lipsa (figura 20).
Pentru vizualizarea formei grafice a distributiei consideram procedeul histogramei. Reamintim: meniul GraphsàHistogram se bifeaza caseta de validare Display normal curve (vezi figura 21 de mai jos) si alegem de exemplu variabila rand2004.
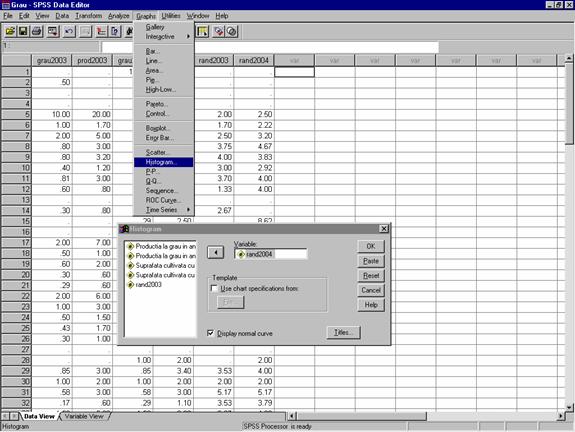
Figura 21: Comenzi pentru vizualizarea distributiei normale prin diagrama Histogram
Se obtine urmatoarea histograma
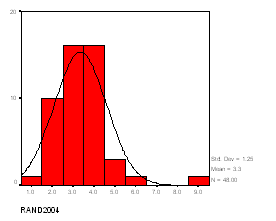
Se poate observa ca distributia corespunde aproximativ distributiei normale
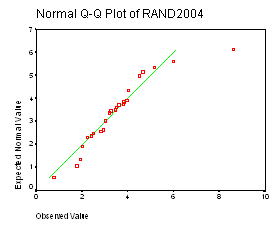
Alte modalitati grafice sunt procedeele Q-Q plot si P-P plot (vezi figurile 22,23 ) Q-Q plot compara valorile ordonate ale variabilei observata cu valorile quantilice ale distributiei teoretice specificate (in cazul nostru distributia normala). Daca distributia variabilei testate este normala , atunci punctele Q-Q contureaza o linie care se suprapune cu dreapta care reprezinta distributia teoretica adica trece prin origine si are panta egala cu unu. In diagrama Q-Q plot se observa ca punctele nu sunt serios deviate de la linia dreapta in cazul randamentelor obtinute in anul 2004 ceea ce arata o distributie normala.
Aceeasi interpretare grafica avem si pentru diagrama PP plot care compara functia de repartitie a distributiei unei variabile empirice cu functia de repartitie a unei distributii teoretice specificate (in cazul nostru, functia distributiei normale standard).
Figura 22: Diagrama Q-Q plot
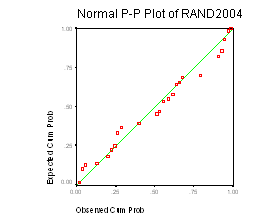
Observatie: Procedeele grafice sunt procedee intuitive, bazate pe impresii vizuale fiind astfel incarcate cu subiectivism. Putem doar sa estimam veridicitatea ipotezei distributiei normale a variabilelor.
O alta modalitate de a verifica normalitatea pentru o anumita variabila -in cazul nostru- randamentele obtinute in anul 2003 respectiv 2004 este urmatoarea ( aplicarea testului Kolmogorov Smirnov-Lilliefors):
Selectarea optiunii: Analyze ->Nonparametric Tests à 1 Sample K-S (figura 24)
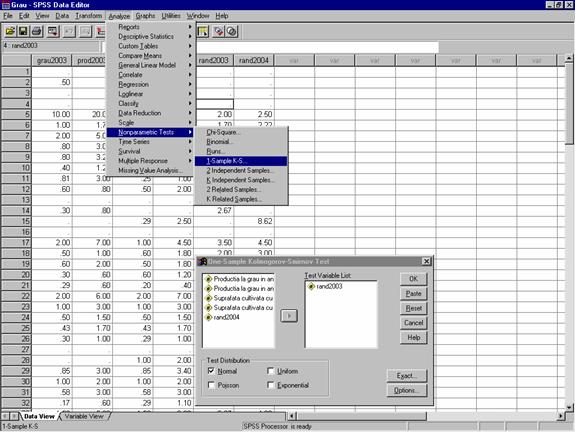
Figura 24: Selectarea testului Kolmogorov-Smirnof pentru verificarea normalitatii
La rubrica Test Variable List se alege variabila de testat: rand2003 obtinandu-se urmatorul tabel:
Tabel 3: Raport privind testul Kolmogorov-Smirnov

Concluzia normalitatii o putem trage din studiul coeficientului sig. (ultimul rand). Acest coeficient ia valori intre 0 si 1. In functie de valoarea acestuia ipoteza de nul
" Distributia nu e normala " se respinge sau se accepta!
Astfel: daca valoarea coeficientului sig<0,05 ipoteza de nul se respinge cu o probabilitate de 95%
- daca valoarea coeficientului sig<0,01 ipoteza de nul se respinge cu o probabilitate de 99%
In cazul de fata valoarea lui Sig de 0,320 este mai mare decat 0,05 in consecinta acceptam ipoteza de normalitate.
Procedam analog si pentru variabila rand2004 si observam ca si in acest caz distributia este normala.
Folosim baza de date "grau" .
Dorim sa examinam indicatorii acestei distributii. Pentru aceasta efectuam selectiile urmatoare: meniul Analyze, comanda Descriptive Statistics , optiunea Frequencies. In fereastra Frequencies se deschide fereastra de dialog cu acelasi nume din care, prin clic pe butonul Statistics se deschide butonul Frequencies: Statistics din care se pot selecta parametrii doriti, prin bifare in casetele de validare corespunzatoare (vezi figura 25)
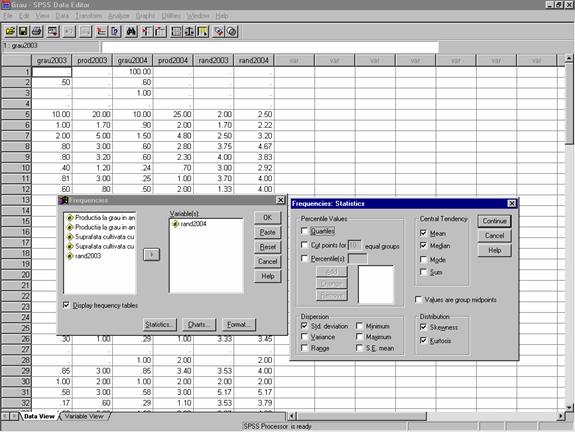
Figura 25: calculul indicatorilor statisticii
descriptive
Obtinem un tabel de forma (tabel 4):
Tabel 4: Raport privind indicatorii statisticii descriptive

O alta modalitate de calcul a acestor indici este:
Meniul Analyze à Reports à Case Summaries. Aceasta optiune deschide fereastra Summary Report: Statistics, de unde se pot selecta parametrii doriti (vezi figura 26):
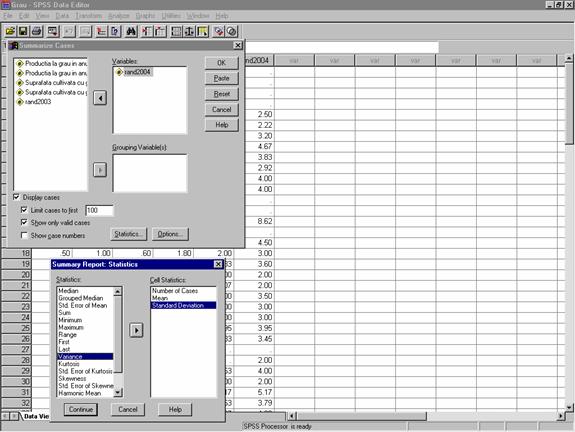
Figura 26: Calculul indicatorilor statisticii
descriptive prin comanda Case Summaries
Dorim sa aflam probabilitatea ca o valoare a unei variabile aleatorii distribuita normal sa apartina unui interval. Dintre functiile disponibile in acest sens sunt functiile CDF.NORMAL si IDF.NORMAL
Pentru functia CDF.NORMAL sintaxa este urmatoarea:
CDF.NORMAL(q,mean,stddev) unde mean- valoarea medie a distributiei iar stddev- deviatia standard calculate asa cum am vazut in precedentul capitol.
Dorim de exemplu sa calculam, data fiind distributia rand2004- (randamentele la hectar pentru grau in anul 2004 asa cum reiese din esantion), care este probabilitatea de a obtine o recolta de sub 3 t/ha. Litera "q" din sintaxa functiei CDF.NORMAL va fi inlocuita cu cifra 3 deoarece reprezinta valoarea in functie de care calculam probabilitatea. Demersul e urmatorul:
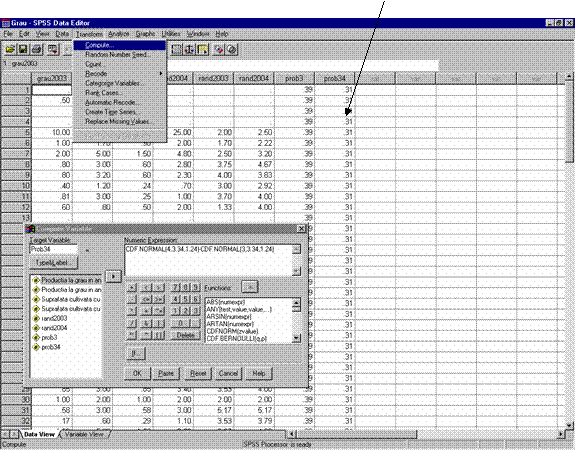
Se alege meniul Transform comanda Compute (figura 27)
- In zona Target Variable din fereastra Compute Variable introucem numele variabilei pentru a carei valoare dorim sa calculam probabilitatea , de exemplu "prob3"
In zona Numeric Expression introducem expresia functiei , selectata din lista Functions , CDF.NORMAL (q,mean,stddev) unde q este o valoare a variabilei X. Pentru exemplul dat, CDF.NORMAL (3,3.34,1.24), 3.34 fiind valoarea medie, iar 1.24 deviatia standard pentru aceasta variabila (rand2004).
Prin butonul OK se comanda calculul propriu-zis al probabilitatii
Figura 27 : Calculul probabilitatilor pentru distributii normale folosind SPSS
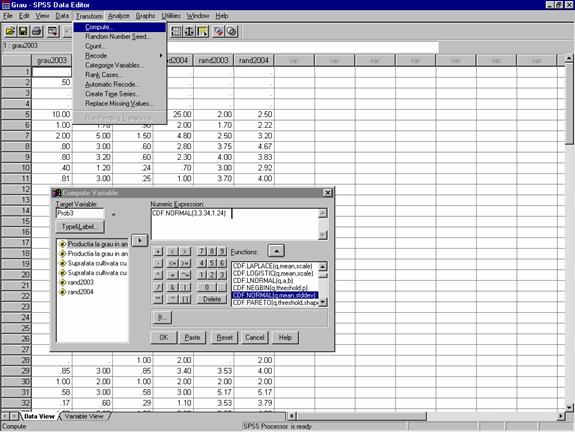
Dupa apasarea butonului OK se va obtine probabilitatea P(rand2004<3)= 0.39 care apare in celula de sub numele variabilei prob3.
Putem spune astfel ca probabilitatea ca un fermier sa obtina la grau o recolta de sub 3t/ha este de 39% , si in acelasi timp, putem spune ca probabilitatea de a obtine o recolta de peste 3t/ha este de 61 % (100%-39%). Daca dorim ca sa aflam probabilitatea ca recolta unui fermier sa fie intre 3 si 4 tone calculam P(rand2004<4) - P(rand2004<3) urmarind acelasi demers.
Se obtine astfel o probabilitate de 0,31% ca un fermier sa aiba o productie de grau, intre 3 si 4 tone/hectar (vezi sageata figura 28)
Figura 28: Calcul al probabilitatilor pentru distributia normala
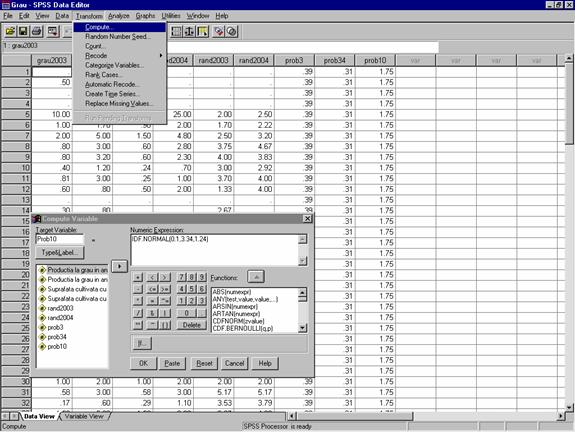
Pentru operatiunea inversa, adica de a afla care este valoare distributiei pentru care probabilitatea este mai mica de o anumita valoare se foloseste functia IDF.NORMAL(prob,mean,stddev). Astfel, daca vrem sa aflam valoarea sub care in anul 2004 au coborat 10% din fermieri vom calcula valoarea functiei IDF.NORMAL(0.1,3.34,1.24) urmarind acelasi demers ca cel descris pentru functia CDF.NORMAL.
Valoarea obtinuta este de 1.75 t/ha. Putem spune deci, ca 10% dintre fermieri au obtinut o recolta de sub 1.75 t/ha la grau in anul 2004.
Figura 28. Calculul probabilitatilor prin functia IDF
Alegerea unui esantion dintr-o anumita populatie are o anumita valoare de reprezentativitate. Asta inseamna ca caracteristicile acelui esantion aproximeaza cu o oarecare probabilitate caracteristicile intregii populatii. De exemplu nu putem spune cu siguranta ca media celor 48 de inregistrari ce fac parte din esantionul rand2004 este exact media inregii populatiei datorita factorilor aleatorii ce au intervenit in formarea acestui esantion. Dar putem estima media printr-un interval "de incredere". Astfel nu putem spune cu siguranta cat e media populatiei dar putem spune cu o anumita probabilitate in ce interval se incadreaza.
Calculam de exemplu, valoarea medie pentru variabila rand2004.
Selectam meniul Analyzeà comanda Descriptive Statistics à optiunea Explore
(figura 29)
In fereastra Explore selectam variabila dorita (rand2004) si o mutam in zona Dependent List
Activam butonul de comanda Statistics care deschide fereastra Explore:Statistics, unde bifam caseta de validare Descriptives si precizam in caseta Confidence Interval for Mean (sageata) nivelul de incredere dorit ( implicit e 95%).
Butonul de comanda Continue determina revenirea in fereastra Explore, din care activam OK pentru a comanda afisarea rezultatelor in fereastra Output
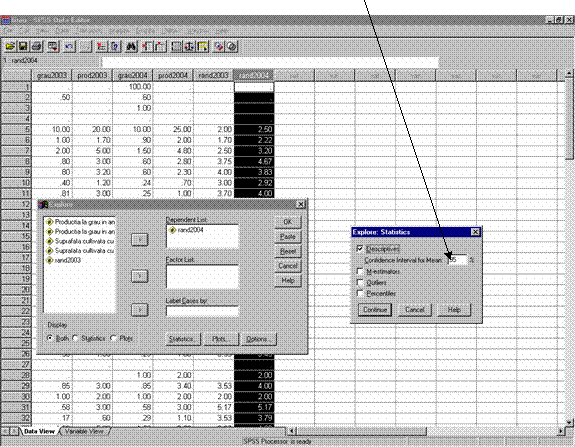 Tabel 29: Estimarea prin interval de incredere
Tabel 29: Estimarea prin interval de incredere
Se obtine raportul de mai jos (Tabel 5):
Tabel 5: Raport privind estimarea prin interval de incredere
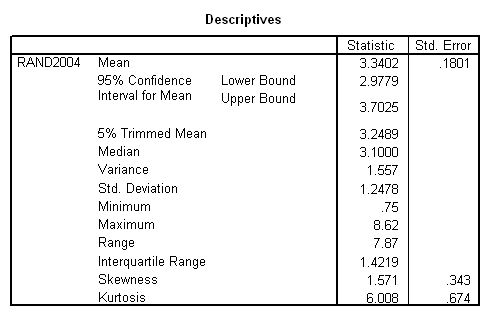
In dreptul mentiunii Mean (media) observam valoarea media a esantionului, 3,3402 t/ha - randament mediu la grau in anul 2004. Limitele intervalului de incredere se gasesc in dreptul mentiunii "95% Confidence Interval for Mean" cu limita inferioara " Lower Bound" = 2.9779 si limita superioara
" Upper Bound" = 3.7025. Putem spune asadar cu o incredere de 95% ca productia medie la hectarul de grau, pentru anul 2004 este intre 2,97 t/ha si 3,7 t/ha. Cu alte cuvinte, daca s-ar repeta studiul de 100 de ori ( adica daca s-ar inregistra 100 de esantioane, independente si identic observate) datele obtinute pentru 95 de esantioane s-ar incadera in acelasi interval de incredere,numai 5 din cele 100 de esantioane fiind susceptibile sa dea valori in afara limitelor intervalului de incredere calculat.
Demersul testarii unei ipoteze presupune parcurgerea unor etape dupa cum urmeaza:
Se formuleaza ipotezele, in functie de problema pusa;
Se alege un test statistic in functie de distributia de selectie a statisticii considerate
Se alege un prag de semnificatie pentru test
Se stabilesc regulile de decizie , definind regiunile de "acceptare" si de "respingere" a ipotezei H0
Se calculeaza valoarea statisticii test, folosind datele inregistrate prin sondaj
Se compara valoarea calculata a statisticii test cu valoarea teoretica
Se ia decizia de a nu respinge sau de a respinge ipoteza admisa
O ipoteza statistica este o presupunere cu privire la un parametru al unei distributii date sau cu privire la legea de probabilitate a populatiei studiate. Exemplu: ipoteza de egalitate a mediilor pentru a verifica daca sunt diferente semnificative intre populatiile din care s-au extras esantioanele observate.
In procesul de testare statistica , se formuleaza ipoteza nula si ipoteza alternativa.
Ipoteza nula (ipoteza de nul). Ipoteza nula pe care dorim sa o testam este notata H0. Prin ipoteza nula H0 se admite , in principal, ca nu exista nici o diferenta intre valorile comparate. Ipoteza nula H0 este ipoteza pe care, de fapt, dorim sa o discreditam.
Ipoteza alternativa Ipoteza alternativa , ipoteza pe care dorim sa o testam in opozitie cu ipoteza nula, se noteaza cu H1. Ipoteza alternativa este cea care va fi acceptata daca, prin regula de decizie, se va respinge ipoteza nula. Ipoteza H1 este cea pe care, de fapt, vrem sa o dovedim ca fiind adevarata.
Din meniul Analyze comanda Compare Means optiunea One- Sample t test
Dorim, de
exemplu sa observam daca fermierii considerati au obtinut in anul 2003 un
randament mai mare la grau decat media pe
Dupa selectarea optiunii One-Sample T Test, se parcurg urmatorii pasi (figura 30):
Selectam in fereastra One-Sample T Test variabila varsta si o mutam in zona Test Variable (s);
Specificam valoarea dorita 1.428 in zona de editare Test Value
Activam butonul de comanda Options care deschide fereastra One-Sample T Test:Options in care, in zona Confidence Interval alegem gradul de incredere 95% dupa care actionam butonul de comanda Continue pentru a reveni in fereastra Sample T Test
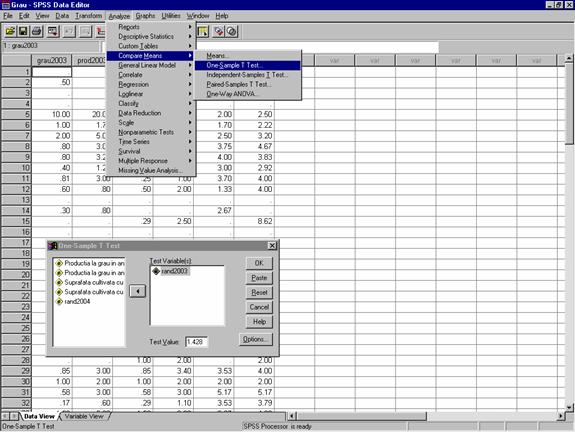
Figura 30: Demersul alegerii testului student pentru
compararea unui esantion cu o valoare
Actionam butonul OK si comandam SPSS obtinerea raportului
Tabelul 6: Raport "One-Sample Statistics"

Tabelul 7: Raport "One-Sample Test"

In raportul "One-Sample Statistics" sunt redate
N- marimea esantionului (numarul de raspunsuri din esantion -48)
Mean - media esantionului
Std. Deviation - deviatia standard
Std. Error Mean - eroarea standard a mediei
In output-ul "One-Sample Test"
Test Value - valoarea cu care s-a comparat media esantionului
T - rezultatul statisticii Student
df- numarul gradelor de libertate ale statisticii ( se calculeaza ca marimea esantionului (48) -1)
Sig. - gradul de siguranta al acceptarii ipotezei de nul. Explicatia acestui coeficient a mai fost oferita pe parcursul acestui caiet ( Vezi verificarea ipotezei de normalitate - testul Kolmogorov-Smirnof-Lillefors)
Mean Difference - diferenta dintre media esantionului si valoarea testata
( Mean - Test Value adica 2.7192 - 1.428 = 1.2912 )
95% Confidence Interval of the difference - Intervalul de incredere al valorii Mean Difference cu limita inferioara (lower) si limita superioara ( upper)
Ipoteza de nul in cazul de fata este H0: media esantionului nu difera foarte mult de productia medie inregistrata in agricultura Romaniei . Pentru acceptarea/respingerea acestei ipoteze studiem valoarea coeficientului Sig.
Se observa din valoarea acestuia: Sig= 0.000 ca ipoteza de nul este respinsa cu o probabilitate de 100 % sau ca este "acceptata" cu o probabilitate de 0%. Concluzia de respingere a ipotezei de nul poate fi respinsa si studiind intervalul de incredere al "Mean Difference" interval ce nu contine valoarea zero. Faptul ca acest interval nu contine valoarea zero inseamna ca diferenta celor 2 medii ( a esantionului si valoarea testata) nu poate fi zero deci mediile nu pot fi egale.
Tragem deci concluzia ca intre
media randamentele inregistrate la grau , pentru esantionul considerat in anul
2003 si media randamentelor inregistrate
pe
16. Testarea egalitatii mediilor a doua esantioane perechi
Paired -Samples T Test este un procedeu care se aplica in cazul esantioanelor dependente. Prin acest procedeu , se compara mediile pentru un singur grup observat in momente diferite. Adesea prin acest test se observa aceiasi subiecti in doua momente diferite, verificandu-se daca diferentele dintre valorile medii sunt semnificative. Se calculeaza diferentele dintre valorile celor doua variabile pentru fiecare caz in parte si se testeaza daca diferentele dintre mediile acestora difera de zero.
Demersul folosit in SPSS este: meniul Analyze à comanda Compare Means à optiunea Paired-Samples T Test
Exemplu: Consideram variabilele rand2003 si rand2004 . Dorim sa verificam daca nivelul mediu al randamentelor la grau in anul 2004 este mai mare sau mai mic decat in anul 2003.
Pentru aceasta selectam in fereastra de dialog Paired Samples T Test prima variabila rand2003 prin clic asupra ei vom vedea ca SPSS o muta in Current Selections (in partea din stanga jos a ferestrei) ca Variable 1;
Mutam perechea de variabile in zona Paired Variables (in partea dreapta a ferestrei dialog) (vezi figura de mai jos).
Figura
30: Demersul alegerii testului student pentru compararea unui esantion cu o 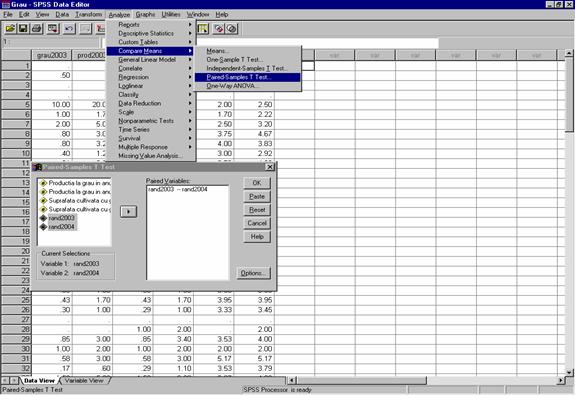
valoare
Intervalul de incredere al ipotezei de nul se poate modifica ( implicit e 95%) apasand butonul Options.
- Prin apasarea butonului de comanda OK se obtine output-ul prezentat mai jos.
Tabelul 8: Raportul "Paired Samples Statistics"
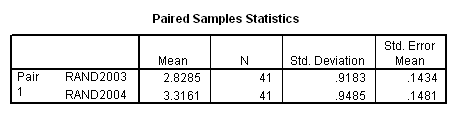
In tabelul "Paired Samples Statistics" la rubrica " Mean" sunt prezentate mediile celor doua esantioane rand2003 respectiv rand2004 .
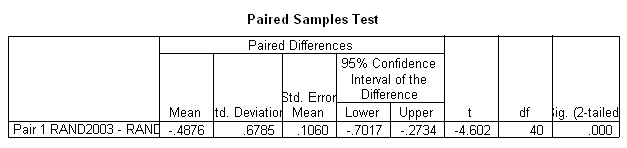
In tabelul "Paired Samples Statistics" studiem valoarea lui Sig., care este 0.000. De asemenea constatam ca intervalul de incredere nu contine valoarea zero. Ipoteza de nul se respinge, adica putem afirma ca intre randamentele inregistrate in anul 2003 respectiv 2004 exista diferente semnificative. Astfel in acelasi tabel la rubrica "Mean" putem constata valoarea acestei diferente : -0.4876. Putem spune deci ca, pe ansamblu , randamentele obtinute la grau in anul 2003 sunt mai mici decat cele obtinute in anul 2004, in medie cu 487,6 kg/ha.
17. Testarea egalitatii mediilor a doua esantioane independente (Independent Samples T Test)
Independent Samples T Test este un procedeu care se aplica in cazul esantioanelor independente. Prin acest procedeu se testeaza daca mediile a doua grupe sunt egale.
Exemplu: (Folosim din nou, baza de date IEA.sav aflata pe CD) Dorim sa aflam daca intre doua categorii de varsta ale consumatorilor exista diferente
semnificative cu privire la frecventa consumului de alimente ecologice.
Demersul testarii folosind SPSS este: meniul Analyze
à comanda Compare Means à optiunea Independent-Samples T Test
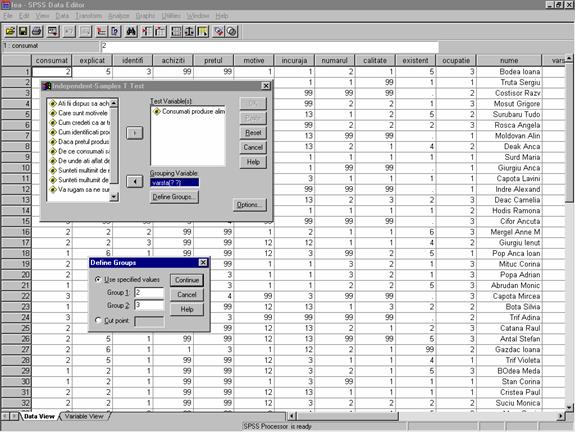
Figura 31: Demersul alegerii testului student pentru
compararea egalitatii mediilor a doua
esantioane independente (Independent-Samples T Test)
In fereastra Test Variable(s) (figura 31 )mutam variabila consumat iar in fereastra Grouping Variable mutam variabila varsta. Actionam apoi butonul Define Groups. si definim cele doua grupuri ce apartin variabilei varsta:
"2" - care descrie categoria de respondentii intre 18-35 ani si "3" care descrie categoria de respondenti intre 35 si 50 ani ( vezi categoriile variabilei varsta asa cum au fost definite). Se obtin tabelele de mai jos (tabelul 10 si tabelul 11):
Tabelul 10: Raport generat de aplicarea testului " Independent Samples Test"
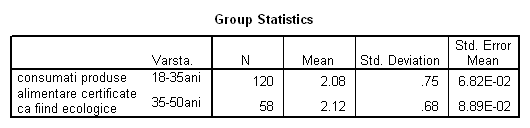
2 3
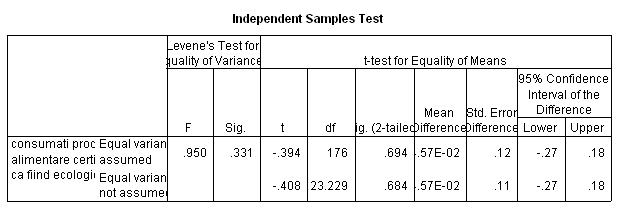
Calculul statisticii test pentru compararea mediilor a doua populatii cere sa se verifice daca deviatiile standard la nivelul celor doua grupe sunt semnificativ diferite, deoarece prin ipoteza de nul se presupune ca cele doua populatii au variante egale. Se foloseste in acest scop testul Levene de egalitate a variantelor ( Levene's test for equality of Variances)
Daca nivelul de semnificatie observat pentru acest test este mic ( de exemplu mai mic de 0,05) atunci se folosesc variante distincte (Equal variance not assumed) pentru testarea mediilor. Daca acest nivel este mare, ca in cazul considerat ( Sig. al testului Levene este egal cu 0,331 -sageata 1 figura ) atunci se folosesc variante comune ( Equal variances assumed). In aceasta ipoteza se observa ca coeficientul Sig. al testului t
( sageata 2 tabelul 11) este de 0.694 (mai mare decat 0,05) si ne arata ca pentru mediile celor doua grupe nu se poate trage concluzia ca difera semnificativ. Aceeasi concluzie o putem trage din studierea intervalului de incredere a diferentelor (sageata 3, tabelul 11),
interval care contine valoarea 0. In concluzie nu se poate trage concluzia ca diferenta dintre valorile medii ale celor doua grupe este semnificativa.
Prin ANOVA se compara medii pentru trei si mai multe subpopulatii definite de variabila de grupare (variabila independenta). Aceasta metoda permite extensia analizei realizate prin testul t aplicabil asupra a doua medii, la situatii in care variabila independenta (variabila de grupare ) prezinta trei si mai multe categorii (niveluri).
De asemenea , ANOVA poate fi folosita in analiza unor situatii in care asupra variabilei numerice ( variabila dependenta) actioneaza simultan mai multe variabile independente. In astfel de cazuri , prin ANOVA se poate prezenta modul in care aceste variabile independente interactioneaza una cu alta si ce efecte au aceste interactiuni asupra variabilei dependente.
One way ANOVA (ANOVA unifactoriala) este unul din procedeele de analiza a variantei pentru o variabila cantitativa dependenta de o singura variabila factor ( de grupare). Variabila factor, numita si variabila independenta , explicativa trebuie sa fie calitativa si trebuie sa aiba un numar redus de categorii (modalitati).
Ipoteza nula , ipoteza de testat , formulata prin acest procedeu , presupune egalitatea a trei si mai multe medii:
H0: m1=m2=.=mk
Unde mk este media grupei mk
Interpretarea rezultatelor ANOVA vizeaza doua teste si anume:
Testul de omogenitate a variantelor. Aceasta problema implica testul de omogenitate a variantelor subpopulatiilor , definite de modalitatile variabilei factor (de grupare). Ipoteza de nul este respinsa daca valoarea Sig. (probabilitatea ) este inferioara valorii 0,05 (5%) semnificand ca nu sunt egale toate variantele.
Testul ANOVA. Ipoteza nula este respinsa daca valoarea Sig. este inferioara valorii 0,05 (5%), semnificand ca cel putin doua medii calculate la nivelul subpopulatiilor , difera intre ele.
In SPSS , pentru compararea a trei si mai multe medii este folosit urmatorul demers: meniul Analyze à comanda Compare Means à optiunea One-Way ANOVA.
De exemplu: Utilizam baza de date IEA.sav Dorim sa vedem daca pentru cele trei categorii de intervievati (cu frecventa definita ca: "deseori", "cateodata" si "niciodata" respectiv variabila "consumat") exita diferente in ceea ce priveste varsta acestora. Adica daca cei care consuma "deseori" sunt mai tineri decat celelalte doua categorii.
Pentru aceasta , din fereastra Variable View vom exclude variabilele lipsa prin excluderea variabilelor ce contin "99" adica non-raspuns. Pentru variabila "Varsta" se da Click pe celula corespunzatoare coloanei Missing ( Figura 32 sageata 1 ) iar in fereastra Missing Values se introduce valoarea "99" (sageata 2).
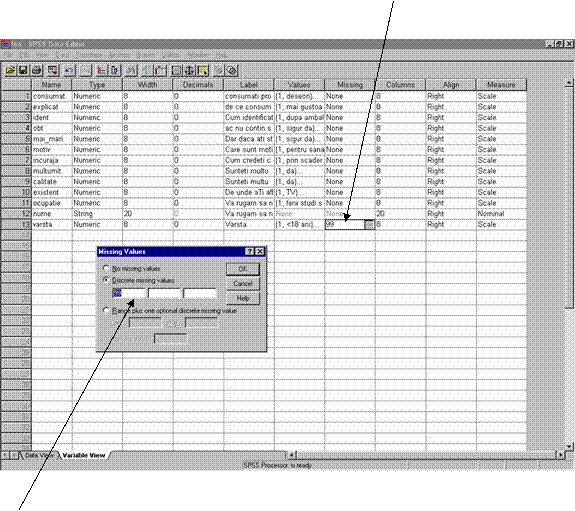 Figura
32: Excluderea valorilor indezirabile prin comanda "Missing Values"
Figura
32: Excluderea valorilor indezirabile prin comanda "Missing Values"
1
Dupa selectarea optiunii One-Way ANOVA , se parcurg urmatorii pasi:
- In fereastra de dialog One-Way ANOVA alegem variabila "consumat" pe care o mutam in zona Dependent List si variabila Varsta pe care o mutam in zona Factor;
Prin butonul de comanda Options (vezi figura si sageata) se deschide fereastra One-Way ANOVA :Options in care se bifeaza casetele de validare Descriptive, Homogenity of variance si Means plot pentru a se verifica indeplinirea restrictiilor de normalitate, homoscedaticitate si independenta impuse unei analize ANOVA (figura 33).
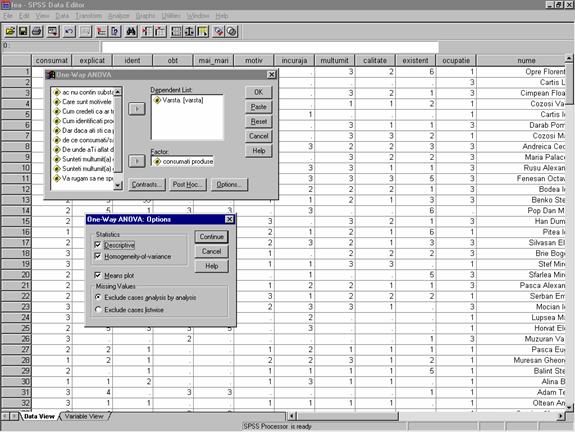
 Figura
33: Alegerea parametrilor analizei ANOVA
Figura
33: Alegerea parametrilor analizei ANOVA
Restrictia de homoscedaticitate. Una din restrictiile aplicarii ANOVA o constituie homoscedasticitatea, adica se presupune ca variantele grupelor sunt egale. Se poate verifica aceasta ipoteza cu ajutorul testului Levene-Test of Homogenity of Variances.
( vezi Tabelul 11 de mai jos)
Tabelul 11: Raport generat de testul Levene
Tabelul 12: Analiza variantelor generata de conditia de homoscedasticitate

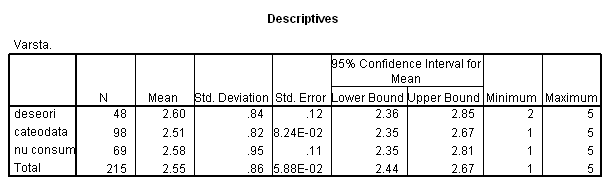
In noile conditii , valoarea Sig. (0.391) pentru testul de omogenitate a variantelor este mai mare ca 0,05 sugerand ca variantele pentru cele trei categorii de consumatori sunt egale, deci restrictia de homoscedasticitate este indeplinita si astfel se poate aplica ANOVA.
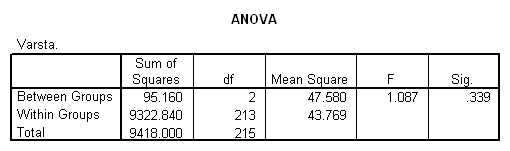
Tabelul ANOVA corespunzator pentru cele trei categorii de varsta selectate sunt prezentate in tabelul 13 .
Tabelul 13: Raportul generat de testul ANOVA pentru trei categorii de varsta
In tabelul ANOVA sunt prezentate statistica test F (vezi testul Fisher din manualul de Statistica) , valoarea Sig. precum si elementele de calcul pentru statistica test F.
Reamintim ,
statistica test F se calculeaza dupa relatia: ![]()
![]()
![]() reprezinta estimatorul variantei intergrupe (Between-Groups)
. Se calculeaza ca medie a patratelor abaterilor mediei fiecarei grupe fata de
media pe ansamblul grupelor si arata varianta datorata influentei factorului de
grupare;
reprezinta estimatorul variantei intergrupe (Between-Groups)
. Se calculeaza ca medie a patratelor abaterilor mediei fiecarei grupe fata de
media pe ansamblul grupelor si arata varianta datorata influentei factorului de
grupare;
![]() reprezinta estimatorul mediei variantelor de
grupa si arata varianta din interiorul
fiecarei grupe (Within Groups) , varianta datorata influentelor aleatorii.
reprezinta estimatorul mediei variantelor de
grupa si arata varianta din interiorul
fiecarei grupe (Within Groups) , varianta datorata influentelor aleatorii.
Cu cat mediile grupelor au valori mai diferite intre ele , cu atat variatia dintre grupe este mai mare; cu cat o variatie , in interiorul grupelor, este relativ mai mica, cu atat statistica test F este mai mare, aratand ca ipoteza nula poate fi respinsa.
In exemplul considerat statistica test F este mica (1.087) cu o probabilitate asociata Sig. ( 0.339) mai mare decat 0,05 -evidentiaza ca ipoteza de egalitate a mediilor pe grupe nu se respinge, deci inclinatiile spre consum a clientilor nu difera semnificativ in raport cu varsta.
19. Testarea egalitatii unei proportii cu o valoare specificata (Binomial Test)
Binomial Test este un procedeu prin care se testeaza ipoteze cu privire la o variabila cu distributie binomiala, variabila care poate lua doar doua valori, de exemplu, sexul persoanelor.
Pentru astfel de variabile , se calculeaza frecventele de aparitie a fiecareia dintre cele doua valori, iar pe baza lor, media, deviatia standard, etc.
Binomial test este similar cu One Sample t-test si este folosit pentru a compara o proportie cu o valoare specificata.
Exemplu: Dorim sa verificam daca proportia persoanelor multumite de calitatea produselor agroalimentare este mai mare decat 75 %
Dupa filtrarea datelor pentru eliminarea non-raspunsurilor efectuam urmatorul demers: meniul Analyze à comanda Nonparametric Tests à optiunea Binomial (Tabel 35)
Pentru aceasta , dupa selectarea optiunii Binomial si deschiderea ferestrei Binomial Test
Selectam variabila "multumit" si o mutam in zona Test variable List
- In zona Define Dichotomy alegem Get from date daca avem o variabila dihotomica sau Cut point in cazul in care dorim sa dihotomizam o anumita variabila. In cazul nostru variabila "multumit" este codificata astfel: 1- pentru raspunsul "DA sunt multumit"
2- pentru raspunsul "partial multumit" si 3 - pentru "nemultumit"
In zona Cut point introducem valoarea "1" pentru a selecta valorile <=1 respectiv valorile >1. Valorile <=1 vor desemna grupa consumatorilor multumiti de calitatea produselor ecologice.
In zona de editare Test Proportion se precizeaza valoarea dorita (0.75).
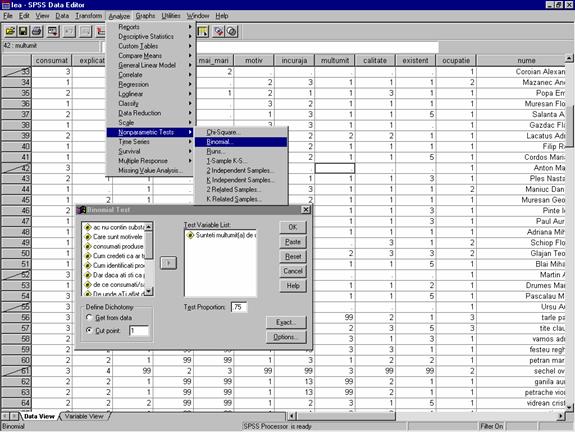
Tabel 35: Demersul testarii egalitatii unei proportii
cu o valoare specificata
Se apasa butonul de comanda OK si se declanseaza obtinerea raportului (vezi Tabelul 14)
Tabelul 14: Raportul generat de "Binomial Test"

Astfel se observa ca proportia observata in esantion pentru grupa consumatorilor multumiti e de 60% . Datorita faptului ca valoarea Sig. asociata testului este mai mica decat 0.01, se poate concluziona cu o incredere de 99% ca proportia celor multumiti de produsele agroalimentare ecologice difera semnificativ de proportia de 75%. Adica , mai putin de trei sferturi dintre consumatori sunt multumiti de calitatea acestor produse.
In cazul unei distributii nominale, testul Hi-patrat este folosit pentru a verifica daca distributia teoretica a frecventelor relative (ipoteza de nul presupune ca toate categoriile au proportii egale), fie cu o distributie de frecventa propusa.
Aplicarea acestui procedeu de testare presupune urmatorul demers: meniul Analyze à comanda Nonparametric Tests à optiunea Chi-Square Test.
Exemplu: Consideram variabila "consumat" din fisierul "iea.sav" Dorim sa verificam daca proportia respondentilor pe cele trei categorii este egala. Adica daca consumatorii se impart in mod egal in -consumatori frecventi, consumatori ocazionali respectiv nonconsumatori.
In fereastra de dialog Chi-Square Test (vezi figura 34) selectam variabila pentru care dorim sa testam proportiile, in cazul nostru variabila "consumat" si o mutam in zona Test Variable List. Se pot selecta mai multe variabile , pentru fiecare variabila obtinandu-se cate un tabel de frecventa separat.
In zona Expected Range definim categoriile pentru care dorim sa testam proportiile . Alegem Get from data, considerand categoriile definite pentru variabila " consumat"
In zona Expected Values alegem ipoteza toate proportiile egale sau proportii specificate (Values). In cazul nostru alegem sa verificam daca exista urmatoarea corespondenta: consumatori frecventi 30%, consumatori ocazionali -40%, respectiv non- consumatori consumatori -30 % , deci specificam proportiile 30,40,30 la rubrica "Values" .
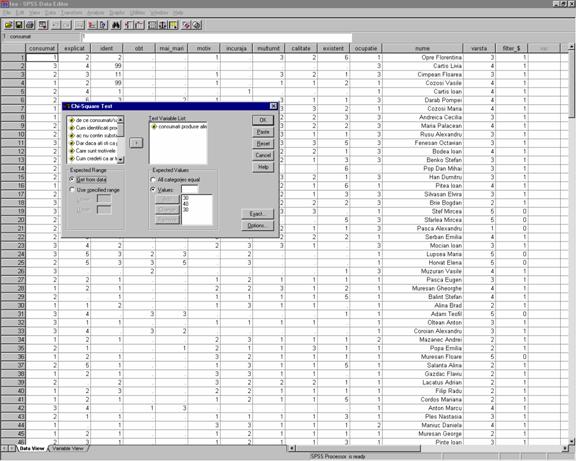
Figura 34: Demersul alegerii
proportiilor de testat prin testul Hi-patrat
Prin clic pe butonul de comanda Continue , se revine in fereastra Chi-Square Test , din care se selecteaza OK, care comanda lansarea procedurii de obtinere a rapoartelor de mai jos (figura )
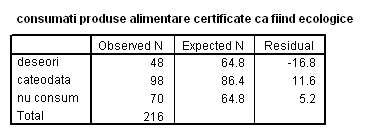
Interpretare In tabelul frecventelor , sunt comparate frecventele observate cu frecventele teoretice ( asteptate conform ipotezei de nul), pentru fiecare categorie i. Diferentele sunt prezentate pe categorii in coloana Residual. Exemplele teoretice asteptate de noi in cazul de fata sunt: (din totalul de 216 respondenti)
216 x 30 % = 64.8 pentru raspuns "deseori"
216 x 40% = 86.4 pentru raspuns "cateodata"
216 x 30 % = 64.8 pentru raspuns "nu consum"
Rezultatele sunt prezentate in tabelul de mai jos (Tabelul 15):
Tabelul 15: Frecventele observate si teoretice privitoare la aplicarea testului Hi-patrat
In tabelul Chi Square Test se prezinta valoarea statisticii Hi-patrat (Chi-Square) gradele de libertate (df) si valoarea semnificatiei (Asymp. Sig).
Tabelul 16: Rezultatul testului Hi-patrat
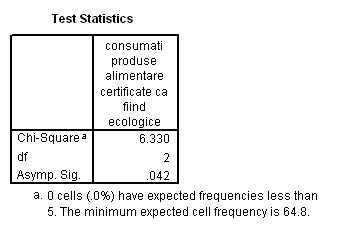
In exemplul dat, valoarea estimata a statisticii Hi-patrat este semnificativa la un nivel de incredere de 95% deoarece valoarea Asimp. Sig< 0,01. Ca urmare ipoteza nula este respinsa. Se poate trage concluzia ca cele trei categorii de consumatori nu au proportia specificata: 30:40:30.
Exemplul 2:
Dorim sa calculam deviatia de la frecventele teoretice pentru o distributie de 2 variabile: presupunem "varsta" si "consumat" . Selectam doar categoriile de varsta intre 18-65 de ani , cele mai numeroase in sondajul nostru. Pentru aceasta filtram doar categoriile de varsta 2, 3,4 ( Vezi Data à Select Cases) conditia (varsta >1 & varsta < 5)
Tabel 35: Demersul aplicarii testului Hi-patrat pentru doua variabile
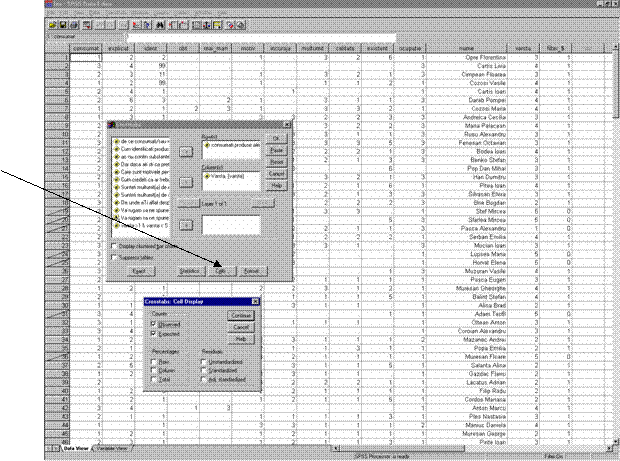
Demersul este urmatorul (Figura 35): Meniul Analyze à Descriptive statistics à Crosstabs
In fereastra Crosstabs la rubrica Row(s) trecem variabila "consumat" iar la rubrica column(s) trecem variabila "varsta" Actionand butonul Cells (sageata) se deschide fereastra Cells Display unde se selecteaza la rubrica "Counts" afisarea valorilor observate " Observed" si a valorilor teoretice asteptate " Expected".
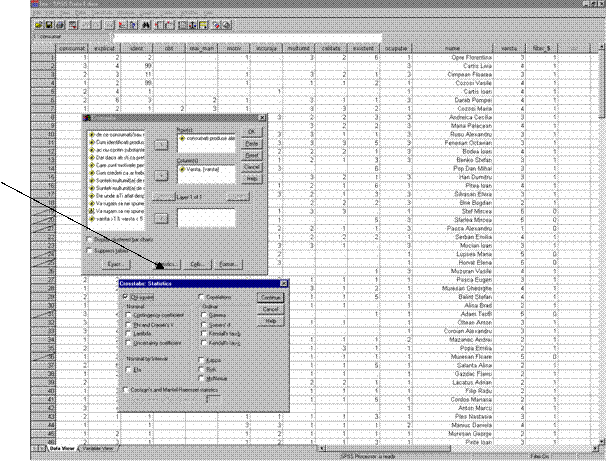
Analog actionand butonul "Statistics" se obtine o noua fereastra din care bifam optiunea Chi-Square ( vezi sageata din figura 36)
Figura 36: Alegerea optiunii Hi-patrat din fereastra "Statistics"
Dupa actionarea butoanelor "Continue" si OK" se obtin rapoartele de mai jos:
Tabel 17: Raport privitor la frecventele observate si teoretice pentru variabilele "consumat" si "varsta"
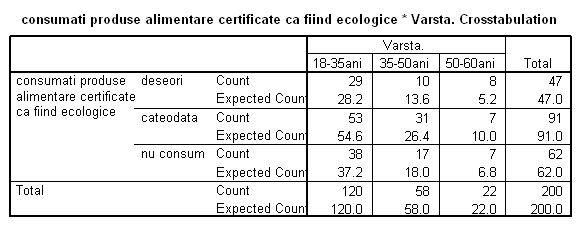
In tabelul sunt afisate atat frecventele observate "count" cat si cele teoretice "expected count".
Astfel au fost primite 29 de raspunsuri pentru consumul frecvent de produse ecologice "deseori" de catre consumatorii cu varste intre 18-35 ani.
Frecventa teoretica " expected count" a fost calculata tinand cont de urmatoarele aspecte:
Numarul total al tinerilor de 18-35 ani din esantion este (vezi tabel Total-Count) de 120 in timp ce numarul respondentilor este de 200. Aceasta inseamna ca proportia tinerilor din esantion este: p= 120/200* 100% = 60%
Numarul total al celor care au raspuns cu "deseori" privind frecventa consumului este
(vezi Tabel 17) de 47. Teoretic ne astepam deci ( in cazul ipotezei de nul) ca 60 % din acestia sa fie tineri intre 18-35 ani. Frecventa teoretica este deci : ft= 47x 60% adica 28,2
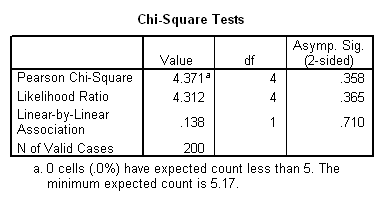
In figura de mai jos avem rezultatele testului Hi-patrat. Se observa coeficientul Sig. >0.05 ceea ce inseamna ca ipoteza de nul nu se respinge. Adica frecventele observate , nu difera de cele teoretice pentru nici una din cele trei categorii de consumatori. Cu alte cuvinte, comportamentul consumatorilor in ceea ce priveste consumul de produse ecologice nu este influentat de varsta.
Analiza de
corelatie este folosita pentru a studia intensitatea legaturii dintre
variabile. In sens strict, corelatia este o masura a intensitatii legaturii
dintre variabile. Pentru stabilirea corelatiei dintre doua marimi in SPSS se
pot calcula trei coeficienti de corelatie: Pearson,
Exemplu: In baza de date Anuarul_statistic.sav gasi date preluate din anuarul statistic privind productivitatea medie la nivel national pentru diferite culturi intre anii 1990 si 2003 .
Astfel am dori sa punem in vedere existenta unei corelatii intre randamentele inregistrate la grau si cele inregistrate la orz.
Consideram urmatorul demers: meniul Analyze àCorrelate à Bivariate prin care se deschide fereastra Bivariate Correlations .
Dupa deschiderea ferestrei Bivariate Correlations se parcurg urmatorii pasi:
-Selectam variabilele dorite si le mutam in zona Variables;
In zona Correlation Coefficients, alegem prin bifare in casetele de validare corespunzatoare , coeficientii de corelatie pe care dorim sa-i calculam.
Casera de validare Flag significant correlations este activata la deschiderea ferestrei dialog si are ca efect semnalizarea corelatiilor semnificative. Astfel coeficientii de corelatie semnificativi la pragul de 0,05 sunt marcati cu un asterisc, iar cei semnificativi la pragul de 0,01 sunt marcati cu doua asteriscuri.
Figura 37: Demersul analizei de corelatie
Activand OK cerem obtinerea raportului ( vezi Tabel 19)
Tabel 19: Raportul de corelatie randamente grau-orz
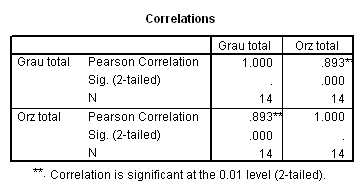
In raport sunt prezentate statisticile pentru fiecare variabila , precum si valoarea coeficientului de corelatie Pearson, cu nivelul de semnificatie (Sig.) corespunzator.
Tabelul Correlations este un tabel cu matricea coeficientilor de corelatie. Valorile sunt distribuite simetric, de o parte si de alta a diagonalei coeficientilor de corelatie egali cu 1, corespunzatori corelatiei fiecarei variabile cu ea insasi. De o parte si de alta a diagonalei tabelului sunt prezentate valorile coeficientilor de corelatie dintre variabile, luate doua cate doua si valorile pragului de semnificatie (Sig.) corespunzator , precum si numarul observatiilor considerate, N.
Reamintim ca valoarea coeficientului de corelatie Pearson este cuprinsa intre - 1 si 1
Daca coeficientul ia valoarea 0, atunci intre variabile nu exista legatura. Valoarea coeficientului indica intensitatea legaturii si anume: cu cat se apropie mai mult de 1, cu atat legatura e mai puternica, respectiv cu cat se apropie mai mult de zero, cu atat legatura este mai slaba. Un coeficient de corelatie egal cu +1 indica o legatura directa perfecta intre variabile. Un coeficient de corelatie egal cu -1 arata o legatura inversa perfecta.
Pentru exemplul considerat s-a obtinut un coeficient de corelatie Pearson egal cu 0,893
ceea ce sugereaza ca intre variabile exista o corelatie directa puternica , valoarea coeficientului fiind foarte apropiata de 1.
Valoarea Sig. corespunzatoare egala cu 0.000 evidentiaza ca s-a obtinut un coeficient de corelatie semnificativ la 0.01 adica sunt sanse mai mici de 1% de a gresi daca afirmam ca intre cele doua variabile exista o corelatie semnificativa. Putem spune deci ca culturile de grau si orz sunt corelate din punct de vedere al randamentelor obtinute annual.
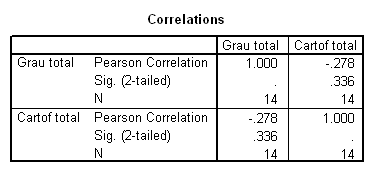
In tabelul urmator se observa ca o astfel de corelatie nu exista intre randamentele obtinute la grau si cartof.
Tabelul 20: Raportul de corelatie randamente grau - cartofi
ANEXA
CHESTIONAR
Universitatea de Stiinte Agricole si Medicina Veterinara a initiat acest studiu care urmareste sa evalueze gradul de cunoastere, in randul consumatorilor a produselor alimentare ecologice , precum si parerile lor in legatura cu acest subiect.
Datele personale, furnizate de dvs., vor fi considerate strict confidentiale
I ) Consumati produse alimentare certificate ca fiind ecologice?
1) Deseori 2) Cateodata 3) Nu
I b) Va rugam explicati de ce ati ales una din aceste optiuni:
Daca raspunsul a fost " Nu cunosc aceste produse" se pun intrebarile III si IV, se iau date le personale, -(intrebarile X, XI, varsta) apoi se incheie interviul.
II) Cum identificati produsele alimentare ecologice intr-un magazin?
1) Dupa ambalaj /sigla 2) Dupa spatiile special amenajate 3) Altele...
Daca in urma intrebarilor I si II observam ca intervievatul nu cunoaste notiunea de produs ecologic se pun intrebarile III si IV, se iau datele personale -(intrebarile X si XI, varsta) apoi se incheie interviul. Daca se cunoaste notiunea de produs alimentar ecologic, se trece direct la intrebarea cu numarul V fara a se mai pune intrebarile III si IV.
III ) Daca ati sti ca produsele ecologice sunt mai sanatoase pentru ca nu contin substante chimice si in plus sunt obtinute prin protejarea mediului, ati fi dispus sa achizitionati aceste produse?
Sigur da 2) Cred ca da 3) Nu stiu 4) Mai degraba nu 5) Sigur nu
IV) Dar daca ati sti ca pretul produselor ecologice ar fi cu 40% mai mare decat cele clasice ati mai cumpara?
1) Sigur da 2) Cred ca da 3) Nu stiu 4) Mai degraba nu 5) Sigur nu
V) Care sunt motivele pentru care achizitionati produsele alimentare ecologice?
1) pentru sanatate 2 ) sunt mai gustoase 3) pentru copii / pentru batrani
4)Altele:......................
VI) Cum credeti ca ar trebui incurajat consumul de produse ecologice?
1) Prin scaderea preturilor 2) Prin publicitate mai intensa
3) Prin informarea consumatorilor asupra avantajelor acestui tip de produs
Altele...........................
VII) Sunteti multumit(a) de numarul de produse ecologice ce se afla pe piata?
1) DA 2) Partial 3 ) NU
VIII) Sunteti multumit (a) de calitatea produselor ecologice ce se afla pe piata ?
1) DA 2) Partial 3) NU
Va rugam sa ne spuneti de ce ati ales una din optiunile "Partial" sau "NU" ?
..............................
IX) De unde ati aflat despre existenta produselor alimentare ecologice?
1 ) De la TV 2 ) Din reviste 3) Din magazine 4) De la un prieten
5) De pe Internet 6) De la mine 7) Altele...........
X) Va rugam sa ne spuneti ce ocupatie aveti
( sau ati avut inainte de pensionare, somaj etc)
XI) Va rugam sa ne spuneti numele si nr. dvs de telefon:
Nume:......................
Nr. telefon...................
Va multumim foarte mult pentru atentia acordata !
1) < 18 ani 2) 18-35 ani 3) 35-50 ani 4) 50- 65 ani 5 ) 65 ani
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 4018
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2024 . All rights reserved