| CATEGORII DOCUMENTE |
Descrierea arhitecturilor MIMD
Arhitecturile MIMD de obicei constau dintr-un numar relativ mic de procesoare independente, care sunt capabile sa execute fluxuri individuale de instructiuni (in principiu, fiecare procesor executand un program diferit).
Avantajele pe care le detin sunt ca pe de o parte, sunt mult mai flexibile decat arhitecturile specializate (ele functioneaza fie ca un intreg, fie ca o masina multiprogramata / multiprogramabila), si pe de alta parte, sunt foarte ieftine (sunt in principiu "off-the-shelf").
In aceasta clasa de arhitecturi, o metoda formala de a le clasifica se aplica pentru criteriul relatiei dintre procesoare si memorie. Aceasta divizare duce la 3 tipuri principale de arhitecturi MIMD:
Masini MIMD cu memorie partajata
Masini MIMD cu memorie distribuita
Masini MIMD organizate in clustere
Masini MIMD cu memorie partajata (shared memory machines)
Aceste masini utilizeaza o memorie globala pe care o pot accesa toate
procesoarele.
Exemple :
masinile multiprocesor Cray Y-MP si C90,
SGI Power Challenge,
masinile secventiale (Sequent Balance),
masinile Convex.
Procesoarele ce utilizeaza acest model comunica folosind locatii de memorie comune, si anume o unitate de prelucrare (UP) scrie intr-o locatie si alta citeste de acolo. Probleme de acces la memorie ce apar:
- Conflicte de acces la memorie
- Retele de interconectare
- Sincronizare (cum te asiguri de faptul ca un consumator are
accesul la memorie dupa un producator).
Intrand mai in detaliu cu clasificarea noastra, vedem ca sunt 3 tipuri de masini MIMD cu memorie partajata:
masini cu memorie partajata cu magistrala
masini cu memorie partajata extinsa
masini cu memorie partajata ierarhica
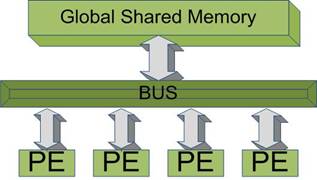 Masinile cu memorie partajata cu magistrala
Masinile cu memorie partajata cu magistrala
Masinile MIMD cu memorie partajata au procesoare care partajeaza o
memorie centrala comuna. In cea mai simpla forma, toate procesoarele sunt atasate la o magistrala care le face conexiunea la memorie. Acest tip de masini pot avea inca o magistrala care sa le permita sa comunice direct intre ele. Magistrala aditionala este folosita la sincronizarea procesoarelor. MIMD-urile cu magistrala suporta un numar mic de procesoare.
Limitare: exista un conflict intre procesoare la accesul memoriei partajate.
2 Masinile cu memorie partajata extinsa
Masinile MIMD cu memorie partajata extinsa incearca sa evite sau sa
reduca conflictul dintre procesoare la accesul la memorie prin impartirea
memoriei in mai multe unitati de memorie independente. Unitatile de
memorie sunt conectate la procesoare printr-o retea de interconectare.
Unitatile de memorie sunt vazute ca o memorie centrala unita. Un tip de
retea de interconectare pentru acest tip de arhitectura este o retea cu
comutator crossbar. In aceasta varianta N procesoare sunt legate la M
unitati de memorie, ceea ce presupune N*M comutatoare simple.
Limitare: aceasta varianta nu este economica pentru un numar mare de procesoare
3 Masinile cu memorie partajata ierarhica
Masinile MIMD cu memorie partajata ierarhica folosesc o ierarhie de magistrale pentru a da accesul procesoarelor la propriile unitati de memorie. Procesoarele de pe placi diferite pot comunica prin magistrale internodale. Magistralele permit comunicatia intre placi. Cu acest tip de arhitectura, masina poate suporta peste 1000 procesoare.
Problema demna de luat in calcul la MIMD cu memorie partajata:
--> Concurenta la citire si scriere
La sistemele cu memorie partajata fiecare procesor are acces la orice variabila din memoria partajata. Daca procesorul x vrea sa trimita un numar procesorului y, acest lucru trebuie facut in doi pasi:
procesorul x scrie numarul in memoria partajata la o anumita locatie accesibila lui y
- 2) procesorul y citeste numarul de la acea locatie
In timpul executiei unui algoritm paralel, cele N procesoare pot accesa memoria pentu citire/scriere de date si/sau rezultate. Toate procesoarele pot primi acces simultan daca locatiile de memorie de unde incearca sa citeasca sau in care incearca sa scrie sunt diferite. Dar pot aparea probleme cand doua sau mai multe procesoare vor acces simultan la aceasi locatie de memorie.
Masini MIMD cu memorie distribuita
(Distributed Memory Machines)
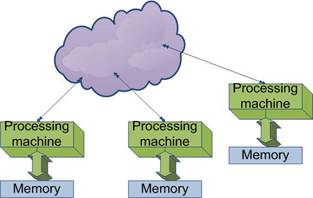 In aceste structuri,
procesoarele au memoria lor locala si comunica informatia cu celelalte
utilizand mesaje (aceste masini se numesc Message Passing Machines). Fiindca nu mai exista memorie partajata, aglomerarea nu mai este o problema
asa de mare. O
unitate de prelucrare va crea si va trimite (va face 'send') un
mesaj, iar alta UP va primi (va face 'receive') si va utiliza mesajul.
Exemple de astfel de masini : nCUBE , transputerele.
In aceste structuri,
procesoarele au memoria lor locala si comunica informatia cu celelalte
utilizand mesaje (aceste masini se numesc Message Passing Machines). Fiindca nu mai exista memorie partajata, aglomerarea nu mai este o problema
asa de mare. O
unitate de prelucrare va crea si va trimite (va face 'send') un
mesaj, iar alta UP va primi (va face 'receive') si va utiliza mesajul.
Exemple de astfel de masini : nCUBE , transputerele.
Probleme de acces la memorie :
- dimensiunea mesajelor
- Routarea mesajelor
- Operatii globale, de genul broadcast
- Retelele de comutare
- Primitevele de tip blocant / non-blocant
Nu este eficienta conectarea directa a unui numar mare de procesoare. O modalitate de evitare a unui numar mare de conexiuni directe ar fi conectarea fiecarui procesor doar la cateva procesoare. Dar si asa sistemul poate fi ineficient datorita cresterii timpului necesar transmiterii unui mesaj intre doua procesoare pe ruta de comunicare. Timpul necesar pentru rutarea mesajelor simple poate fi substantial. S-au proietat sisteme pentru a reduce acest timp de rutare, mesh si hipercub fiind cele mai populare.
Tipuri de MIMD cu memorie distribuita
MIMD in mod de interconectare hypercub
MIMD in mod de interconectare mesh
Alte tipuri de MIMD interconectate: star, ring, tree, bus
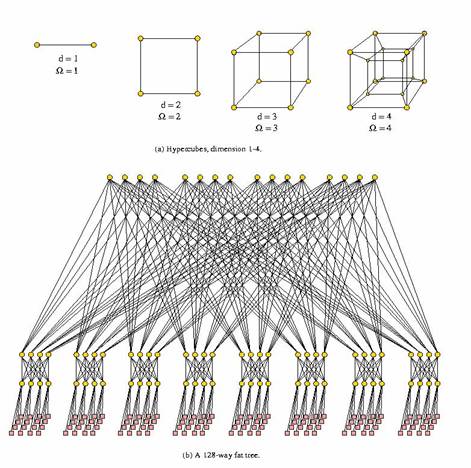 Iata
aici o idee despre ceea ce inseamna conexiuni intre noduri dintr-o topologie.
Figura din partea de jos este un "fat tree" cu 128 de cai. In notatia de aici,
omega este diametrul sistemului.
Iata
aici o idee despre ceea ce inseamna conexiuni intre noduri dintr-o topologie.
Figura din partea de jos este un "fat tree" cu 128 de cai. In notatia de aici,
omega este diametrul sistemului.
1 MIMD cu interconectare hypercub
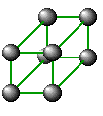 Pentru un MIMD cu
memorie distribuita si cu o retea de
Pentru un MIMD cu
memorie distribuita si cu o retea de
interconectare de tip hypercub sunt 8 procesoare, cu
un modul de memorie , plasate la fiecare varf al patratului. Diametrul sistemului este dat de numarul minim de pasi necesari unui procesor pentru a trimite un mesaj celui mai indepartat procesor. Deci, de exemplu, diametrul unui cub bidimensional este 2. Intr-un sistem hipercub cu 8 procesoare si cu fiecare procesor si memoria lui asezate in varful unui cub, diametrul este 3. In general un sistem cu 2^N cu fiecare procesor conectat direct la N procesoare, diametrul sistemului este N.
Un dezavantaj al sistemelor hipercub este ca trebuiesc configurare in puteri ale lui doi, deci e posibil ca o masina sa fie construita cu mai multe procesoare decat are nevoie.
Un avantaj, pe de alta parte, este ca dimensiunea reteli creste doar logaritmic in comparatie cu numarul de noduri. In plus, teoretic, se poate simula orice alta topologie pe hypercub.
Practic insa, topologia exacta pentru hypercub nu mai conteaza, mai nou; sisteme din ziua de azi folosesc ceea ce se numeste "wormhole routing"; mai precis, un mesaj trimis de la un nod I catre un nod j, creeaza o conexiune directa intre aceste 2 noduri, fara a mai deranja operarea nodurilor vecine.
2. 2 MIMD cu interconectare mesh
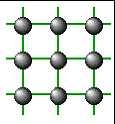 Procesoarele sunt
plasate intr-o grila bidimensionala.
Procesoarele sunt
plasate intr-o grila bidimensionala.
Fiecare procesor este conectat la cei patru vecini adiacenti
lui. Un avantaj fata de reteaua hipercub este ca sistemul nu trebuie proiectat in puteri ale lui 2, un dezavantaj e ca diametrul retelei e mai mare pentru sisteme cu mai mult de 4 procesoare.
2. 3 MIMD in alte variante de interconectare
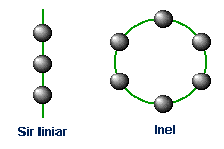 Sirul liniar este cel
mai simplu, dar nu este scalabil datorita cresterii timpului de comunicare
pentru numar mare de procesoare. Mai mult, exista riscul pierderii unui numar
mare de procesoare daca se strica o legatura spre centrul sirului. Reteaua de
tip inel rezolva ultima problema, punand la dispozitie o cale inversa in caz ca
se strica o legatura.
Sirul liniar este cel
mai simplu, dar nu este scalabil datorita cresterii timpului de comunicare
pentru numar mare de procesoare. Mai mult, exista riscul pierderii unui numar
mare de procesoare daca se strica o legatura spre centrul sirului. Reteaua de
tip inel rezolva ultima problema, punand la dispozitie o cale inversa in caz ca
se strica o legatura.
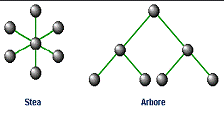
Scheme hibride pot fi construite; la reteaua de tip stea, daca se strica procesorul central, toata comunicatia se opreste.Arborii permit comunicatii punct la punct rapide, desi, ruperea unei legaturi duce
la izolarea unui intreg subarbore.
Masini MIMD organizate in Clustere
Adoptarea clusterelor, care sunt in fapt reuniuni de statii / PC-uri care
sunt conectate printr-o retea locala, a explodat, literalmente, odata cu
introducerea primului cluster in 1994 (Beowulf). Avantajele acestui nou tip  de organizare MIMD consta in costul scazut atat pentru hardware cat si
pentru software, si in controlul pe care si userii si administratorii de sistem
il au asupra acestuia.
de organizare MIMD consta in costul scazut atat pentru hardware cat si
pentru software, si in controlul pe care si userii si administratorii de sistem
il au asupra acestuia.
Diferenta principala dintre clustere si omoloagele lor integrate, este ca atata timp cat primele se folosesc pentru "capability computing", masinile integrate se folosesc pentru "capacity computing". Prima paradigma se refera la faptul ca sistemul este angajat in ducerea la bun sfarsit a unuia sau mai multor programe pentru care nu exista nici o alternativa in termeni de capabilitati de calcul. A doua paradigma: angajarea sistemului cu toate capabilitatile lui, folosindu-i maximul de cicli disponibili pentru aplicatii care au nevoie de calcul intens.
Cateva categorii de clustere:
High-availability (HA) clusters
o Scopul lor este de a asigura disponibilitatea serviciilor pe care le ofera; ele opereaza avand si noduri redundante, folosite in cazul in care sistemul pica (deci invariabil sunt minim 2 noduri). Implementarile de clustere de acest gen incearca sa asigure un echilibru intre redundanta si eliminarea situatiilor "single point of failure".
Load-balancing clusters
o Acestea opereaza in asa fel incat toate sarcinile de lucru parvin sistemului prin unul sau mai multe centre de load-balancing, care la randul lor transmit taskurile unor backend servers. Scopul implementarii: performanta crescuta, dar si disponibilitate crescuta (ex. Sun Grid Engine, Linux Virtual Server)
High-performance (HPC) clusters
o Sunt implementate in principal pentru a asigura performante crescute impartind taskuri de calcul unor diferite noduri din cluster (ex. Beowulf cluster). De asemenea, acest tip de clustere este optimizat pentru a lucra cu taskuri care au nevoie de comunicatie intre procese care ruleaza pe noduri diferite.
Clustere tip Grid
o Difereta de baza fata de clusterele traditionale este ca gridurile conecteaza computere care nu "au incredere" totala unul in celalalt - si de aici faptul ca nu opereaza ca un tot unitar, ci mai degraba ca un serviciu. In plus, gridurile suporta colectii de statii de tip eterogen, iar realizarea joburilor nu presupune comunicatie intre procesele de calcul de pe statii diferite.
Alte tipuri de clasificari pentru MIMD
Pornind de la descrierea lui von Neumann a calculatorului secvential (un CPU ce acceseaza instructiuni si date dintr-omemorie si executa instructiuni unele dupa altele) avem niste caracteristici ce le dorim si in modelele masinilor paralele si anume:
1. simplitate - modelele trebuie sa fie usor de inteles
2. realism - modelele trebuie sa se preteze dezvoltarii realiste de
aplicatii si programe
Cum rezista cele doua modele de MIMD acestor criterii? O extensie
directa a modelului von Neumann este modelul PRAM (Parallel Random Access Machine) (RAM - Random Access Machine este o varianta a modelului von Neumann). PRAM-ul este o abstractizare in care un numar de UP pot accesa orice element din memoria globala partajata. Acesta este un model bun pentru a scrie algoritmi paraleli pentru masini paralele de tip memorie partajata (Shared Memory MIMD). O implementare a unui PRAM este numita de asemenea si Multiprocesor.
Def. Un sistem multicalculator este descris de cele mai multe ori ca un numar de noduri de tip von Neumann conectate impreuna printr-o retea de
interconectare. Dupa cum este evident din discutia de pana acum, acest tip de sistem este caracteristic masinilor cu memorie distribuita si anume Message Passing MIMD sau Distributed Memory MIMD. Totusi, de vreme ce aceasta este o abstractizare, se presupune ca o comunicatie intre oricare doua noduri ia exact aceeasi perioada de timp - acest lucru nefiind, evident, cazul in situatii reale.
Sistemele distribuite, unde masinile sunt conectate printr-o retea de un anume tip,fie ea LAN sau WAN, pot fi modelate de modelul multicalculator.
Sa privim acum un pic si la modelele de programare utilizate pentru aceste masini. Taskul si modelul utilizarii canalelor sunt cele mai potrivite pentru
modelul multicalculator, sau pentru transputere. Un calcul paralel este impartita in taskuri ce se executa in mod concurent. Taskurile se conecteaza intre ele prin canale, iar aceste taskuri trimit si primesc mesaje pe aceste canale. Aceste taskuri pot fi foarte usor modelate peste o masina reala.
Alte modele de programare paralela includ:
Transferul de mesaje (Message Passing)
Paralelismul de date (Data Parallelism)
Memoria partajata (Shared Memory)
Factori importanti care apar in rezolvarea problemelor paralele sunt:
- Concurenta: realizarea mai multor lucruri in acelasi timp;
- Scalabilitatea: cum se schimba solutia cand se modifica numarul de UP angataje in proces;
- Localitatea: incercarea de a minimiza accesele la memorie ale nivelelor ierarhice indepartate;
- Modularitatea: rezolvarea problemelor complexe prin alaturarea solutiilor la probleme mai mici.
- Granularitatea: sau granularitatea paralelismului intr-un task este definita prin cat de multa munca trebuie sa faca fiecare sub-task in momentul in care intreg task-ul initial este impartit in sub-probleme (sub-taskuri). Daca impartirea unei probleme duce la obtinerea multor mini-probleme ce necesita o putere computationala redusa fiecare, avem de a face cu o granularitate scazuta. Pe de alta parte, daca impartirea se face intr-un numar redus de probleme ce necesita fiecare o putere mare de calcul si ce pot sa fie rezolvate in mod concurent, avem de a face cu o granularitate crescuta a problemei. Fiecare masina paralela in parte este pregatita sa rezolve mai bine anume granularitati ale problemelor. Mai simplu spus, masinile SIMD sunt mai bine echpate pentru a rezolva problemele cu o granularitate scazuta in vreme ce masinile MIMD se preteaza mai bine la probleme cu o granularitate crescuta.
Astfel, inainte de orice trebuie sa puteti stabili in ce categorie se afla atat
problema pe care o aveti de rezolvat cat si tipurile de masini paralele ce le aveti la indemana, pentru a va usura in munca de proietare si de programare si pentru a fi siguri ca puteti rezolva problema pe care v-ati pus-o realizand chiar un castig de performanta si nu (un caz deloc dorit) o pierdere de performanta.
Hands-on !
Incercati sa implementati peste modelul arhitecturii MIMD, problema sumelor prefix (Python). Mai precis, dandu-se un vector a[1:n], calculati elementele vectorului sum[1:n], unde sum[i] reprezinta suma numerelor de la 1 la i. Problema are 2 variante:
Cu variabile partajate
Fara variabile partajate ( incercati aici sa gasiti un algoritm corespunzator).
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 1203
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved