| CATEGORII DOCUMENTE |
Statistica multivariata Inferenta statistica - Testarea ipotezelor statistice (Excel)
A. Notiuni teoretice
Fie un spatiu de probabilitate Ω,A, P). Se numeste variabila aleatoare o functie reala XΩ→ℜ , care satisface conditia:
X ≤ x∈ A, oricare ar fi x ∈ ℜ.
Numim functie de repartitie a v a. X, functia reala de variabila reala,
F ℜ→ℜ, definita prin
F(x) P(X ≤ x), unde prin (X ≤ x) s-a notat evenimentul
ϖ X ≤ x adica reuniunea acelor evenimente elementare pentru care v a. ia valori mai mici sau egale cu x.
Functia de repartitie se zice absolut continua daca exista o functie reala,
f:ℜ→ℜ, astfel încât
x
F( x)
∫ f u) d u,
−∞
Interpretarea geometrica este cea uzuala de marime a ariei de sub graficul functiei f.
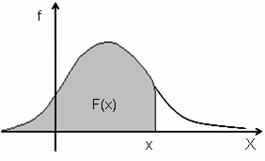
Functia f, daca exista, se numeste densitate de probabilitate a v a. X.
Observatie Functia de repartitie contine toata informatia necesara pentru calcularea probabilitatilor cu care o variabila aleatoare ia valori n anumite intervale si pentru acest lucru va fi utilizata în ceea ce ne intereseaza.
Repartitii teoretice remarcabile
Repartitia normala
Aceasta repartitie are un rol central, atât din considerente teoretice, c t si practice (nu în ultimul rând, usurinta aplicarii). Teoretic, repartitia normala reprezinta o repartitie limita catre care tind, în anumite conditii, celelalte repartitii.
Prin definitie, o variabila continua X are o repartitie normala, sau repartitie
![]() GaussLaplace, daca functia de repartitie este data de:
GaussLaplace, daca functia de repartitie este data de:
x
−∞
![]() 1 e−
1 e−
2
(t − 2
2σ 2
dt
x ∈ ℜ, ∈ ℜ 0,
unde si sunt parametrii functiei de repartitie
Functia de repartitie normala se va nota prin N iar faptul ca v a. X este repartizata normal cu parametrii si se noteaza X ~ N 2
Parametrii repartitiei au semnificatia unor valori tipice si anume
M(X) = Me(X) = Mo(X) = D2(X) = 2
motiv pentru care se poate vorbi de repartitia normala cu media si dispersia 2, ceea ce determina complet repartitia.
Repartitia normala N(0,1) se numeste repartitia normala redusa, repartitia normala normata sau repartitia normala standard. O v.a. repartizata N(0;1) este notata, n mod uzual, cu Z si este referita drept variabila Z, variabila normala redusa etc. Orice variabila repartizata normal poate fi transformata într-o v.a. repartizata N(0;1) prin transformarea (de normare, de standardizare)
![]() Z X−
Z X−
Inferenta statistica
Prin inferenta statistica se ntelege, în sensul precizat anterior, obtinerea de concluzii bazate pe o evidenta statistica, adica pe informatii derivate dintr-un esantion. Concluziile sunt asupra caracteristicilor populatiei din care provine esantionul.
Observatie. Daca este investigata întreaga populatie, atunci rezultatele care se obtin
constituie finalul prelucrarii si nu sunt necesare si nici posibile) prelucrarile introduse în aceasta sectiune.
Prin esantion sau selectie) vom întelege o submultime a populatiei statistice
considerate. Operatiunea de formare a unui esantion se numeste sondaj. Sondajele care au sanse mai mari de a produce esantioane reprezentative sunt cele bazate pe proceduri de selectie aleatoare.
In esantioane diferite, statisticile calculate au valori diferite. În acest fel se poate vorbi despre o distributie a valorilor statisticii n multimea esantioanelor de un acelasi volum; apare astfel distributia de sondaj a statisticii respective.
Inferenta statistica implica trei distributii asociate cu caracteristica studiata:
distributia populatiei;
distributia de sondaj;
distributia esantionului.
Prin distributia populatiei se ntelege distributia pe care o are caracteristica studiata (sau v.a. asociata ei) n populatie. Aceasta distributie nu este, în general, cunoscuta. Interesul unei cercetari este tocmai acela de a studia aceasta distributie.
Prin distributia esantionului se întelege distributia pe care o are caracteristica
studiata în esantionul disponibil n studiu. Aceasta distributie este cunoscuta complet, întrucât toate datele necesare sunt masurate.
Prin distributia de sondaj a unei statistici se întelege distributia pe care o are statistica în multimea tuturor esantioanelor de volum dat. Este nsa remarcabil faptul ca, din considerente teoretice, între distributia populatiei si distributia de sondaj exista legaturi bine precizate sau, datorita unor teoreme de limita centrala, se cunoaste forma acestei distributii atunci când volumul esantionului creste tinde spre infinit).
Inferenta statistica urmeaza, în general, urmatorul algoritm:
se obtine, printr-un procedeu valid, un esantion;
se calculeaza o valoare tipica a esantionului (o statistica de sondaj);
din considerente teoretice, se cunoaste repartitia din care provine aceasta valoare tipica si relatia repartitiei de sondaj a statisticii cu valoarea tipica din populatie;
utilizând repartitia de sondaj a statisticii se pot face evaluari ale erorilor de estimatie.
Repartitia de sondaj a mediei este caracterizata de
![]()
D 2 x)
![]()
![]() D( x) .
D( x) .
n n
Practic, se poate accepta o repartitie N(/n)
pentru n > 10 daca repartitia lui X este aproape simetrica, sau
pentru n > 30 pentru repartitii cu asimetrie pronuntata sau necunoscuta.
2
Estimatii
Se numeste estimator orice entitate a carei valoare poate fi utilizata drept valoare (de regula aproximativa) pentru o alta entitate. Valoarea estimatorului se zice ca este o estimatie.
Valoarea care aproximeaza, pe baza datelor de sondaj, valoarea necunoscuta a
unui parametru al populatiei poarta denumirea de estimatie statistica. Astfel, media aritmetica este estimator pentru media populatiei , abaterea standard s este estimator pentru abaterea standard a populatiei etc.
Dupa natura lor, n statistica se utilizeaza doua tipuri de estimatii:
punctuale
sub forma de interval.
Printr-o estimatie punctuala se întelege valoarea unui estimator calculata într-un esantion. Numim eroare de estimare valoarea absoluta a diferentei dintre estimatia punctuala si valoarea parametrului estimat.
Fie o populatie statistica, caracterizata de o v.a. continua X a carei repartitie
depinde de un parametru , necunoscut. Prin definitie, daca se pot determina 1 si 2 astfel încât pentru o valoare prestabilita (0 < < 1) sa aiba loc P(1 2 1 − atunci intervalul 1, 2) se numeste interval de ncredere pentru parametrul necunoscut cu un coeficient (sau nivel) de încredere egal cu , sau cu o siguranta statistica S 1.
Daca at t 1 c t si 2 sunt finite, atunci intervalul de încredere se zice bilateral.
În cazul c nd 1 este -∞, sau 2 este +∞, ceea ce revine în fapt la determinarea unei singure limite, intervalul se zice unilateral.
Intervale de ncredere pentru valoarea medie
![]() Fie o populatie
statistica
caracterizata
de o v a.
X
repartizata
normal, cu parametrii si 2 Presupunem ca s-au obtinut, dintr-un esantion de volum n, media de sondaj
x si dispersia de sondaj s2 Fixam pragul de semnificatie .
Fie o populatie
statistica
caracterizata
de o v a.
X
repartizata
normal, cu parametrii si 2 Presupunem ca s-au obtinut, dintr-un esantion de volum n, media de sondaj
x si dispersia de sondaj s2 Fixam pragul de semnificatie .
Daca dispersia, 2 este cunoscuta, intervalul de încredere pentru media populatiei:
![]()
![]() x −
z
x −
z
![]() n 1−
n 1−
2
![]() x
x
z
![]()
![]() n 1−
n 1−
2
Daca dispersia, 2, nu este cunoscuta
![]()
![]() x − s
x − s
n
t1− / 2
![]() x
x
s
t1− / 2
![]() n
n
2
Intervale de ncredere pentru dispersie
Fie o populatie normala, sau aproximativ normala, cu parametrii si 2 necunoscuti. Se demonstreaza ca intervalul de ncredere bilateral pentru dispersia populatiei, cu încrederea statistica de 1, este dat de
![]() 2
2
2 n − 1 s
![]()
1− 2
2
unde n este volumul esantionului, 2 este dispersia de sondaj, iar
2
2 si
1− 2
sunt quantilele de ordin 2, respectiv 1- /2, ale repartitiei
cu = n1
grade de libertate.
Testarea ipotezelor statistice
Fara a ncerca o generalizare, se poate accepta ideea ca, n cele mai multe prelucrari statistice, datele sunt obtinute si prelucrate pentru a verifica ipoteze ale cercetatorilor. Deci, ca o prima imagine a subiectului, trebuie retinuta secventa:
1. formularea unei ipoteze;
2. obtinerea de date experimentale;
3. verificarea ipotezei pe baza acestor date.
Vom considera semnificativ un eveniment care contrazice ipoteza de plecare.
Rationamentul general
|
Lumea reala |
Statistica |
|
|
Se formuleaza setul de ipoteze H0 H1 |
|
Are loc un eveniment Rezulta ca probabilitatea de realizare este suficient de mare |
Se calculeaza, dintr-un esantion, o statistica (statistica testului). |
|
Se calculeaza, în ipoteza H0 probabilitatea pc de aparitie a valorii calculate (probabilitatea critica a testului, p value |
|
|
Daca pc este mica, apare o contradictie, |
|
|
|
Pentru a rezolva contradictia se va respinge H0 n favoarea ipotezei H1 deoarece motivul pentru care probabilitatea critica este mica este faptul ca la calculul acesteia s-a acceptat ipoteza H0 |
|
|
Daca pc este mare, nu se respinge H0 nu exista nici un motiv pentru a lua decizia contrara. |
Ram ne o singura întrebare: începând de unde o probabilitate este considerata
drept mica ? Pentru a nu introduce subiectivismul în aceasta decizie, se fixeaza, anterior deciziei în test, un prag sub care o probabilitate este considerata mica Aceasta valoare se numeste prag de semnificatie si se noteaza uzual cu .
Regula de decizie în test poate fi formulata atunci:
daca pc ≤ , atunci se respinge ipoteza nula, H0, în favoarea ipotezei alternative, H1
daca pc , atunci nu se respinge ipoteza nula H0
Se numeste regiune de respingere, pentru un nivel de semnificatie fixat, multimea rezultatelor (valorilor statisticii testului) care conduc la respingerea ipotezei
H0. Daca se pot defini limitele numerice ale regiunii de respingere, acestea se vor numi, uneori, valori critice ale testului.
Testele pot fi
parametrice = ipoteza H0 este strict legata de un parametru al populatiei, iar statistica testului are o repartitie cunoscuta tocmai din aceasta ipoteza.
neparametrice = repartitia statisticii testului se calculeaza si nu rezulta din presupuneri apriorice asupra acestei distributii si a probabilitatilor atasate.
Testele parametrice pot fi ( noteaza un parametru al populatiei):
bilaterale (nedirectionale) H0:
H1: ≠
unilaterale (directionale)
H0:
H1: < (sau >)
Un test statistic are, de multe ori, o denumire data de repartitia statisticii
testului: teste normale (sau Z), teste Student (sau t), teste F etc. Astfel, un test 2 reprezinta un test a carui statistica are o repartitie de sondaj din clasa 2..
Categorii de teste
Testele sunt clasificate în teste pentru variabile continue si teste pentru variabile discrete nominale sau ordinale). Primele sunt, de regula, teste parametrice, celelalte sunt neparametrice.
Teste de concordanta
Aceste teste se refera la potrivirea, concordanta dintre valorile calculate în esantion (statisticile de sondaj) si valorile parametrilor respectivi din populatia statistica (valori cunoscute sau presupuse). Cu alte cuvinte, problema poate fi formulata: cât de mult poate sa se abata o valoare calculata (dintr-un esantion) de la valoarea presupusa pentru întreaga populatie pentru a putea considera ca are loc o nepotrivire între cele doua valori?
Desi formulata astfel problema pare ca se refera la esantion si la populatia de baza, punctul de vedere corect este:
1. exista o populatie statistica de interes, fie ea P1
2. pentru orice esantion se poate considera o populatie de baza din care este
extras esantionul (reprezentativ pentru acea populatie); fie P2aceasta
populatie;
3. problema este daca se poate considera ca P2 este în concordanta cu P1, adica parametrii de interes ai celor doua populatii nu difera semnificativ.
Se observa ca testarea se va efectua pentru ipoteze privind populatii, se va utiliza informatia dintr un esantion, deci ramânem în domeniul inferentei statistice.
Ipoteza nula va afirma, n general, ca populatiile P1 si P2 concorda. Respingerea ipotezei nule poate avea, în practica, doua consecinte:
se va considera ca esantionul nu este reprezentativ pentru populatia de interes, populatie care se considera stabila; se va cauta un alt esantion;
sau
se va considera ca populatia P1si-a modficat ntre timp parametrii; noua populatie de referinta este P2
Alegerea între cele doua afirmatii apartine practicianului din domeniul studiat, fiind, de cele mai multe ori, o alegere ghidata de intuitie, de experienta etc.
Testul erorii standard a mediei
Fie P1 populatia statistica de interes, caracterizata de media 0 (cunoscuta sau presupusa) si de abaterea standard (cunoscuta . Întrebarea este daca valorile tipice de sondaj sustin ipoteza ca esantionul este din populatia P1, accentul fiind pus pe media populatiei.
În testul erorii standard a mediei se presupune ca sunt ndeplinite conditiile care asigura mediei de sondaj o repartitie normala sau aproape normala:
caracteristica studiata este repartizata normal sau
esantionul este mare (n≥30).
In aceste conditii, media de sondaj urmeaza o repartitie normala N(2/n), unde este media populatiei (notata în introducerea sectiunii cu P2) din care provine
esantionul. Pentru P2 se presupune aceeasi abatere standard (se studiaza modificarea mediei unei populatii). Rezulta ca variabila transformata
![]()
![]()
![]()
![]() Z x − x − n
Z x − x − n
![]() x
x
 este
repartizata normal
standard si
poate fi utilizata
pentru calcularea probabilitatilor necesare. Ipotezele testului erorii standard a mediei sunt
este
repartizata normal
standard si
poate fi utilizata
pentru calcularea probabilitatilor necesare. Ipotezele testului erorii standard a mediei sunt
pentru testul bilateral:
pentru testele unilaterale:
H0 0
(A)
H1 ≠ 0
(B)
H0 0
1
H 1
sau
H0 0
(C)
H1 0
devine
În conditiile ipotezei nule, 0, rezulta ca transformata Z a mediei de sondaj
![]()
![]() Z x − 0 n
Z x − 0 n
în care toate valorile sunt cunoscute si prin urmare poate fi localizata pe curba densitatii de probabilitate normala standard.
Pentru a aplica acest test este necesar sa se cunoasca si, prin urmare, situatia practica de referinta este aceea în care se studiaza daca o populatie statistica, constanta ca variabilitate, si-a mentinut, sau nu, valoarea medie. Deoarece, în general, nu se poate sti cu siguranta ca repartitia caracteristicii studiate este riguros normala, acest test se utilizeaza pentru esantioane mari.
Acest test este referit si ca testul Z de concordanta, datorita utilizarii unei statistici repartizate normal standard .
Testul de concordanta Student (t)
Atunci când nu se cunoaste abaterea standard a populatiei, , se va utiliza estimatia s, abaterea standard de sondaj, în locul lui , iar repartitia statisticii testului va fi repartitia Student. Pentru caracteristica studiata se presupune, însa, o repartitie normala cu parametri necunoscuti) sau apropiata de o repartitie normala.
![]() Ipotezele testului sunt aceleasi cu seturile de ipoteze anterioare (A), (B), (C). Statistica testului este similara statisticii din testul erorii standard a mediei, cu
Ipotezele testului sunt aceleasi cu seturile de ipoteze anterioare (A), (B), (C). Statistica testului este similara statisticii din testul erorii standard a mediei, cu
exceptia faptului ca n loc de se utilizeaza estimatia s:
![]() t x − 0 n s
t x − 0 n s
Daca ipoteza nula, H0: 0, este adevarata, atunci variabila t urmeaza o repartitie Student cu = n1 grade de libertate si se poate aplica o regula uzuala de decizie în test.
Teste de comparare
Categoriile de teste prezentate aici se bazeaza, aparent, pe compararea datelor de sondaj care apartin la doua esantioane. Cum sansa de a se obtine doua esantioane identice este extrem de redusa, problema compararii esantioanelor, luata n sensul strict al cuvântului, pare neimportanta.
Un test de comparare trebuie, însa, înscris n inferenta statistica: fie doua esantioane extrase din doua populatii P1 si P2 respectiv. Prin utilizarea esantioanelor se doreste de fapt compararea celor doua populatii.
Dificultatea procedurii consta n aceea ca diferentele dintre cele doua
esantioane, ca si similaritatea lor, se pot datora:
diferentelor dintre populatii, si sau
diferentelor de sondaj dintre esantioane.
Testul F
Compararea mediilor populatiilor normale ia n considerare mprastierea datelor în cele doua populatii. Este important atunci sa se cunoasca daca dispersiile celor doua populatii pot fi considerate egale, sau nu. Acest fapt se decide utilizând testul F, bazat pe repartitia teoretica F FisherSnedecor).
Situatia poate fi recunoscuta prin:
doua populatii, caracterizate de variabilele X1 si X2, respectiv;
variabilele sunt repartizate normal, X
~ N 2 ) X
~ N
2
1 1 1 2 2 2
1
din doua esantioane, unul din fiecare populatie, dispunem de estimatiile s 2
s 2
si 2
ale dispersiilor populatiilor; esantioanele au volume
n1 si
n2
respectiv.
Ipotezele testului F sunt atât de tip bilateral cât si de tip unilateral. Testul bilateral:
H : 2 2
(A) 0 1 2
H : 2 ≠ 2
1 1 2
Teste unilaterale:
H : 2 2
|
|
|
|
2 (C) 0 1 2
1
H :
1
2
H :
1
1
2
Când ipoteza nula este adevarata, atunci statistica
este repartizata F cu
1 n1 − 1
2![]()
F s1
s
2
2
si 2 n2 − 1 grade de libertate, încât se pot utiliza
valorile tabelate pentru F 1 2) pentru determinarea probabilitatilor critice.
Pentru simplificarea deciziei în test, în practica se utilizeaza o statistica usor
modificata prin considerarea ca prima populatie, P1, a populatiei pentru care dispersia de sondaj este mai mare:
max s 2 s 2 ) F 1 2 min s 2 s 2
1 2
în asa fel ncât sunt utilizabile doar testele (A) si (C). În acest caz se noteaza cu max numarul gradelor de libertate pentru numarator si cu min numarul gradelor de libertate pentru numitor.
Decizia, la nivelul de semnificatie pentru testul bilateral (A):
se respinge ipoteza nula H0 în favoarea ipotezei alternative H1 daca
max min
F F1− 2
sau
F F 2
Decizia, la nivelul de semnificatie , pentru testul unilateral (C):
1
se respinge ipoteza nula H0 în favoarea ipotezei alternative H
max min
daca
max min
F F1−
Teste t de comparare
Compararea mediilor a doua populatii se realizeaza prin teste de comparare t. Sunt utilizate frecvent trei asemenea teste, diferentiate de situatia existenta între dispersiile populatiilor si independenta esantioanelor:
esantioane independente, dispersii egale,
esantioane independente, dispersii neegale,
esantioane dependente (perechi, corelate).
B. Instrumente Excel
Procedurile prezentate sunt disponibile prin dialogul Tools - Data Analysis.
RANDOM NUMBER GENERATION
Utilizând aceasta procedura se pot genera serii de numere aleatoare distribuite dupa 7 tipuri diferite de functii de repartitie. Rezultatul consta în una sau mai multe coloane de numere, fiecare coloana reprezent nd valori ale unei variabile repartizate dupa o functie de repartitie precizata.
Pentru fiecare generare se va da numarul de coloane (variabile) generate, numarul de valori acelasi pentru toate variabilele , tipul functiei de repartitie, parametrii functiei si locul unde se vor nscrie rezultatele.
Deoarece parametrii unei functii de repartitie depind de tipul functiei, prezen- tarea procedurii va fi particularizata pentru câteva clase de functii. Dialogul principal al procedurii Random Number Generation este prezentat în figura care urmeaza.
Se observa cele patru componente principale ale dialogului: zona care
precizeaza tipul de generare (numar de variabile, numar de valori, tipul distributiei , zona cu parametrii functiei de repartitie specifica functiei selectate , zona parametrului de initializare a generarii aleatoare si zona de precizare a domeniului rezultat.
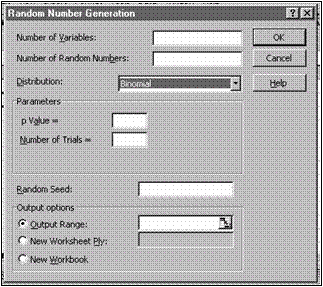
Tipul de g e nerar e
Number of Variables se precizeaza numarul de variabile generate, adica numarul de coloane;
Number of Random Numbers se precizeaza numarul de valori generate, acelasi pentru toate variabilele;
Distribution se alege functia de repartitie a variabilelor generate.
Ini t ia liza r ea gener a rii
Random Seed Procesele de generare aleatoare sunt caracterizate si prin fixarea unei valori initiale functie de care se ncepe procesul de generare. Aceasta valoare, care nu înseamna prima valoare generata, este un numar întreg între 1 si 32000. Daca nu se precizeaza aceasta valoare, atunci se va considera n mod automat un numar aleator (obtinut din data curenta si timpul curent).
Diferenta între cele doua situatii este: la alegerea automata se genereaza de
fiecare data serii diferite; la alegerea de catre utilizator se va genera aceeasi serie de fiecare data când se indica acelasi numar. Prin urmare, se va completa aceasta zona doar daca, pentru a simula o anumita comportare sau prelucrare, este nevoie de generarea aceleeasi serii de numere aleatoare n utilizari succesive.
Outpu t o p tions
Output Range, New Worksheet Ply, New Workbook potrivit descrierii de la Descriptive
Statistics. Precizeaza domeniul din foaia de calcul unde se vor nscrie rezultatele.
Para meters
Structura acestei zone depinde de functia de distributie selectata.
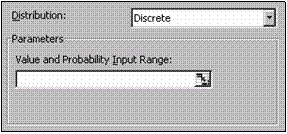 Repartitie discreta (Discrete)
Repartitie discreta (Discrete)
Structura zonei Parameters este prezentata în figura. O distributie discreta este distributia unei variabile care ia un numar finit de valori cu probabilitati fixate. Deoarece valorile trebuie sa fie numerice, acest tip de repartitie
poate fi utilizat pentru probleme care implica variabile nominale atunci c nd categoriile nominale sunt codificate numeric.
1 0,40 2 0,15 3 0,20 4 0,25
Precizarea
distributiei se face enumerând, într o zona continua, valorile posibile si
probabilitatile asociate acestora, de genul
pentru o variabila care ia valoare 1 cu probabilitatea 0,4, valoarea 2 cu probabilitatea 0 15 etc. Acest exemplu poate sa corespunda repartitiei unei variabile nominale pentru care categoriile au fost codificate cu 1, 2, 3, sau 4.
Value and Probability Input
Repartitie normala (
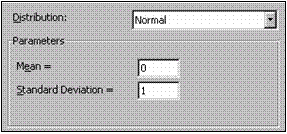 Structura zonei Parameters este prezentata în figura alaturata. Pentru
determinarea
distributiei este
necesar
sa se
precizeze valorile pentru media si abaterea standard
a
populatiei.
Structura zonei Parameters este prezentata în figura alaturata. Pentru
determinarea
distributiei este
necesar
sa se
precizeze valorile pentru media si abaterea standard
a
populatiei.
Mean se precizeaza valoarea pentru media populatiei.
Standard Deviation se precizeaza valoarea pentru abaterea standard a populatiei.
Valorile implicite sunt cele ale
repartitiei normale standard, media 0 si abaterea standard 1.
SAMPLING
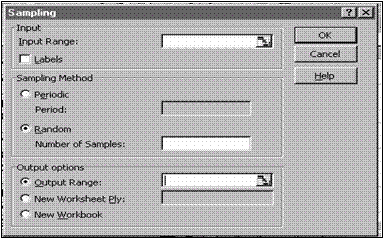 Procedura de sondaj permite obtinerea unei submultimi dintr-o multime de valori existenta. Parametrii prezenti în dialogul procedurii sunt explicati n continuare.
Procedura de sondaj permite obtinerea unei submultimi dintr-o multime de valori existenta. Parametrii prezenti în dialogul procedurii sunt explicati n continuare.
Inp u t
Input Range se specifica domeniul, sau denumirea domeniului, care contine datele din care se va face selectia. Domeniul poate fi selectat si n mod dinamic. Datele care joaca rolul populatiei statistice trebuie sa fie de tip numeric si organizate, de preferinta, sub forma unei coloane sau a unei linii. Prima celula poate contine denumirea setului de date. În cazul în care selectia se face dintre nregistrarile unei baze de date (fiecare înregistrare av nd, uzual, mai multe câmpuri) se va indica drept domeniu doar coloana unui c mp cum ar fi numarul înregistrarii, sau codul (numeric) de identificare etc.
Labels boxa de control va fi marcata daca domeniul indicat contine pe prima pozitie denumirea setului de date.
Sa mplin g Method
n acest grup se precizeaza metoda de selectie.
Periodic selectarea acestui buton radio permite indicarea n c mpul Period a cotei fixe de formare a esantionului. Daca, de exemplu, se completeaza 5, atunci esantionul este format din al 5-lea element si toate cele care urmeaza din 5 în 5 (al 10-lea element, al 15-lea, al
20-lea etc.)
Random selectarea acestui buton radio indica o formare aleatoare a esantionului. Fiecare element are aceeasi probabilitate de a fi ales. Din acest motiv, daca multimea de baza este relativ restrânsa, atunci unele elemente pot sa apara de mai multe ori în esantionul constituit. Volumul esantionului se specifica în câmpul Number of Samples.
Outpu t o p tions
Output Range, New Worksheet Ply, New Workbook potrivit descrierii de la Descriptive Statistics. Precizeaza domeniul din foaia de calcul unde se vor nscrie rezultatele. Rezultatul este o coloana cu valorile selectate.
Verificarea ipotezelor statistice
Sunt disponibile proceduri pentru efectuarea a trei tipuri de teste statistice:
test F pentru compararea dispersiilor;
test t pentru compararea mediilor, în toate variantele principale (esantioane corelate, dispersii egale, dispersii neegale ;
test z pentru compararea mediilor.
Fiecare procedura are ca rezultat at t probabilitatea critica a testului respectiv, c t si valoarea critica pentru un nivel de semnificatie fixat de utilizator. Ipoteza nula este, pentru fiecare test, aceea a egalitatii, deci respingerea ei se va face daca probabilitatea critica este mai mica dec t , sau daca valoarea calculata este mai mare dec t valoarea critica.
Compararea mediilor unor (sub)populatii se realizeaza prin proceduri apelate
din dialogul deschis prin Tools Data Analysis.
Atunci când se compara mediile a doua populatii pe baza unor esantioane necorelate este necesara parcurgerea etapelor:
1. Testarea egalitatii dispersiilor prin procedura F-Test Two-Sample for
Variances
2. În functie de decizia n test se va aplica
t-Test: Two-Sample Assuming Equal Variances în cazul nerespingerii ipotezei nule din testul F
t-Test: Two-Sample Assuming Unequal Variances n cazul respingerii ipotezei nule n testul F.
Daca esantioanele sunt corelate, situatie caracteristica compararii rezultatelor unui grup nainte si dupa efectuarea unui experiment, se aplica procedura t-Test: Paired Two Sample For Means.
FTEST TWO SAMPLE FOR VARIANCES
Dialogul initiat de alegerea optiunii F-Test Two-Sample for Variances este prezentat în figura III 25. În zona Input se vor indica domeniile ocupate de cele doua esantioane si pragul de semnificatie ales. Zona Output va preciza domeniul unde se înscriu rezultatele prelucrarii.
Inp u t
Variable 1 Range se va preciza domeniul primului esantion. Este obligatoriu ca acesta sa fie o coloana sau o linie. Domeniul poate fi ales dinamic sau dat prin denumirea sa.
Variable 2 Range se va preciza domeniul celui de al doilea esantion. Este obligatoriu ca acesta sa fie o coloana sau o linie si sa nu se intersecteze cu domeniul primului esantion. Domeniul poate fi ales dinamic sau dat prin denumirea sa.
Labels se va marca boxa de control daca domeniile esantioanelor contin n prima celula
denumirea eticheta) variabilei.
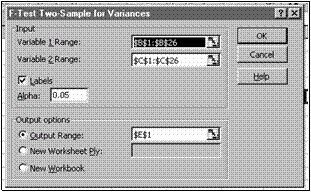 Alpha se precizeaza valoarea nivelului de semnificatie. Implicit se va considera = 0,05.
Alpha se precizeaza valoarea nivelului de semnificatie. Implicit se va considera = 0,05.
Fig. III 25. Dialogul procedurii F Test
Outpu t o p tions
Output Range, New Worksheet Ply, New Workbook potrivit descrierii de la Descriptive Statistics. Precizeaza domeniul din foaia de calcul unde se vor nscrie rezultatele. Rezultatele sunt formatate ca un tabel pentru care se va preciza pozitia coltului din stânga sus. Semnificatia rubricilor din tabel este explicata în exemplul prezentat.
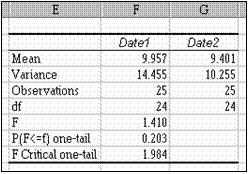
Ex emplu
Un exemplu de aplicare a procedurii F-Test este aratat în figura urmatoare numarul zecimalelor afisate a fost redus).
Mean mediile esantioanelor; Variance dispersiile esantioanelor; Obsevations volumele esantioanelor; df gradele de libertate;
F statistica testului F (câtul dispersiilor); P(F< f) one-tail probabilitatea critica
 unilaterala, adica probabilitatea ca o variabila f, repartizata Fisher-Snedecor, cu
numerele respective de grade de libertate, sa
unilaterala, adica probabilitatea ca o variabila f, repartizata Fisher-Snedecor, cu
numerele respective de grade de libertate, sa
depaseasca valoarea calculata.
Ipoteza nula a egalitatii dispersiilor poate fi respinsa daca valoarea raportata aici este mai mica sau egala cu nivelul de
F-Test structura rezultatelor
semnificatie ales. De exemplu, pentru = 0,25 un prag neuzual) se poate respinge ipoteza nula ntrucât 0,203 < 0,25.
F Critical one-tail valoarea critica a testului. Determina regiunea de respingere a testului, la pragul de semnificatie fixat n dialogul procedurii. Daca valoarea F, din linia a 5-a a rezultatelor, este mai mare sau egala cu valoarea critica, înseamna ca apartine regiunii de respingere si deci se poate respinge ipoteza egalitatii dispersiilor. În tabel avem 1,410 <
1,984 si deci nu se poate respinge ipoteza nula (la pragul fixat).
Concluzia testului este aceea ca ipoteza nula nu poate fi respinsa. Se va tolera prin urmare ipoteza ca dispersiile sunt egale sau, cu alte cuvinte, ca în populatiile din care provin esantioanele variabila urmarita prezinta acelasi grad de mprastiere.
TESTE STUDENT (t)
Sunt disponibile trei teste bazate pe distributia Student. În toate cazurile se verifica
ipoteza nula privind mediile atât într un test unilateral, cât si bilateral.
Ipoteza nula priveste o diferenta fixata a mediilor:
H0: 1 2 d,
unde 1, 2 sunt mediile populatiilor din care provin esantioanele disponibile, iar d este diferenta presupusa sau cunoscuta a mediilor.
Pentru a testa egalitatea mediilor celor doua populatii se va aplica procedura n cazul particular d = 0.
Cele trei teste t sunt cazurile principale din punct de vedere practic:
testul t pentru esantioane corelate;
testul t pentru populatii cu dispersii egale;
testul t pentru populatii cu dispersii neegale.
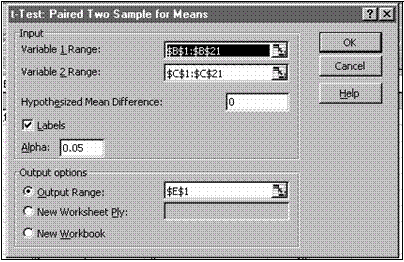
t TEST: PAIRED TWO SAMPLE FOR MEANS
 Sunt considerate
doua esantioane cu date
perechi corelate), provenite eventual
dintr-o cercetare pretest-posttest pe un acelasi esantion, din care un esantion este lotul experimental, celalat fiind lotul martor. Compararea mediilor este efectuata pentru a decide daca experimentul la care este supus
lotul experimental produce o abatere suficient de mare în media variabilei de control.
Sunt considerate
doua esantioane cu date
perechi corelate), provenite eventual
dintr-o cercetare pretest-posttest pe un acelasi esantion, din care un esantion este lotul experimental, celalat fiind lotul martor. Compararea mediilor este efectuata pentru a decide daca experimentul la care este supus
lotul experimental produce o abatere suficient de mare în media variabilei de control.
În figura se prezinta dialogul de fixare a parametrilor procedurii.
Inp u t
Variable 1 Range, Variable 2 Range contin referintele la zonele celor doua esantioane, respectiv. Deoarece testul este pentru esantioane cu date perechi, este necesar ca zonele indicate sa aiba acelasi numar de celule completate cu date numerice, valorile de pe aceleasi pozitii în cele doua serii fiind perechi. Domeniile pot fi selectate dinamic.
Hypothesized Mean Difference contine valoarea testata pentru diferenta mediilor. Daca se indica valoarea 0 zero , atunci se verifica ipoteza egalitatii mediilor.
Labels boxa de control se marcheaza daca zonele de date indicate contin pe primele locuri denumirile zonelor.
Alpha contine valoarea pragului de semnificatie utilizat de procedura pentru a calcula valorile critice ale statisticii (utilizate ca limite ale domeniului de respingere a ipotezei nule).
Outpu t o p tions
Output Range, New Worksheet Ply, New Workbook potrivit descrierii de la Descriptive Statistics. Precizeaza domeniul din foaia de calcul unde se vor nscrie rezultatele. Rezultatele sunt formatate ca un tabel pentru care se va preciza pozitia coltului din stânga sus. Semnificatia rubricilor din tabel este explicata în exemplul prezentat.
Ex emplu
 Un grup
de
20
de persoane
au
fost evaluate înainte si dupa efectuarea unui experiment, care avea scopul de a micsora valoarea unei caracteristici masurate. Deoarece efectul experimentului
trebuie
evaluat
la
nivelul
Un grup
de
20
de persoane
au
fost evaluate înainte si dupa efectuarea unui experiment, care avea scopul de a micsora valoarea unei caracteristici masurate. Deoarece efectul experimentului
trebuie
evaluat
la
nivelul
populatiei de unde s-a selectat esantionul, un
indicator statistic adecvat este media rezultatelor înainte si dupa. Cum datele sunt perechi, situatia descrisa fiind tipica, compararea mediilor s-a efectuat printr-un test t pentru date perechi (corelate). Seriile de date sunt numite Date1 datele pretest , Date2 datele posttest) si s-a indicat n dialogul procedurii, un prag de semnificatie = 0,05.
Rezultatele produse de procedura t Test:
Paired Two Sample for Means sunt descrise n figura alaturata:
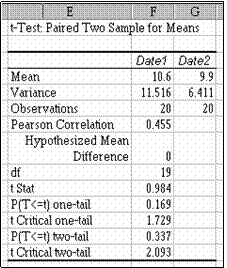
Mean mediile celor doua esantioane. Se observa ca media primului esantion este mai mare (10 6 fata de 9 9), diferenta fiind relativ importanta, 0,7 reprezinta o diminuare a
mediei cu 6,6 . Compararea mediilor vrea sa
arate daca aceasta diferenta poate fi acceptata
pentru ntreaga populatie, sau este efectul
Rezultatele aplicarii testului t
pentru date perechi.
sondajului (întâmplator în primul esantion sunt mai multe valori mari).
Variance dispersiile celor doua esantioane. Se poate emite ipoteza ca dispersiile se modifica semnificativ: se pare ca experimentul are efectul unei concentrari a rezultatelor în jurul mediei.
Observations numarul de observatii (= volumul esantionului).
Pearson Correlation coeficientul de corelatie Pearson. Valoarea obtinuta este relativ mare, apropiata de 0,5. Desi nu este însotita de testul de semnificatie, arata o buna corelatie între seriile de rezultate, cu interpretarea ca scaderea valorilor dupa experiment are loc oarecum uniform: observatiile cu valori mari nainte ramân, n general, cu valori mari si dupa experiment (evident ca observatiile cu valori mici înainte ramân, în general, cu valori mici si dupa experiment).
Hypothesized Mean Difference valoarea cu care se compara diferenta mediilor populatiilor.
Deoarece ne-am propus sa testam egalitatea mediilor, aceasta revine la a compara diferenta mediilor cu zero.
df numarul gradelor de libertate al repartitiei t (a statisticii testului). Este numarul de observatii mai putin unu.
t Stat valoarea calculata a statisticii testului. Provine, teoretic, dintr-o repartitie Student cu df (raportat anterior) grade de libertate.
P(T<=t) one-tail probabilitatea critica unidimensionala, arata care este probabilitatea ca o variabila Student cu df grade de libertate sa depaseasca valoarea calculata. Daca aceasta valoare este mai mica decât pragul de semnificatie fixat, atunci se poate respinge ipoteza nula în favoarea ipotezei alternative. Deoarece, n situatia data, prima medie este mai mare, ipoteze alternativa ntr-un test unilateral este
H1 : 1 2 > 0 sau, echivalent, H1 : 1 > 2
Valoarea 0 169 afisata este mai mare decât toate valorile uzuale, deci nu se poate
respinge ipoteza nula. Prin urmare se pare ca diferenta dintre medii este datorata mai mult întâmplarii, selectiei esantionului.
t Critical one-tail valoarea critica unidimensionala pentru pragul de semnificatie = 0,05
(precizata n dialogul procedurii). Daca valoarea t calculata este mai mare decât aceasta valoare critica, atunci se poate respinge H0 n favoarea ipotezei alternative H1 : 1 > 2. Pentru exemplul prezentat acest fapt nu se înt mpla 0,984 < 1 729 .
P(T<=t) two tail probabilitatea critica bilaterala, arata care este probabilitatea ca o variabila Student cu df grade de libertate sa depaseasca, n valoare absoluta, valoarea calculata. Cu alte cuvinte, probabilitatea ca diferenta dintre mediile populatiilor sa fie mai departata de zero decât diferenta observata.
Daca aceasta valoare este mai mica decât pragul de semnificatie fixat, atunci se
poate respinge ipoteza nula în favoarea ipotezei alternative a unor medii diferite: H1 : 1 ≠
2
Valoarea 0,337 afisata este mai mare decât toate valorile
uzuale, deci nu se poate respinge ipoteza nula.
t Critical two-tail valoarea critica bidimensionala pentru pragul de semnificatie = 0 05 (precizata n dialogul procedurii). Daca valoarea t calculata este mai mare, în valoare absoluta, decât aceasta valoare critica, atunci se poate respinge H0 n favoarea ipotezei alternative H1 : 1 ≠ 2. Pentru exemplul prezentat, | t | = |0 984| = 0 984 < 2 093, deci nu se poate respinge ipoteza nula.
z-TEST: TWO SAMPLE FOR MEANS
 Aceasta procedura serveste pentru compararea mediilor a doua populatii atunci când se cunosc dispersiile acestora. Testul utilizat este bazat pe distributia normala standard.
Aceasta procedura serveste pentru compararea mediilor a doua populatii atunci când se cunosc dispersiile acestora. Testul utilizat este bazat pe distributia normala standard.
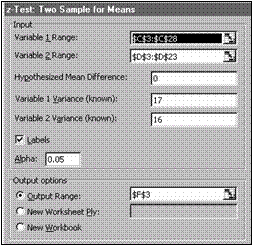
Inp u t
Variable 1 Range, Variable 2 Range contin referintele la zonele celor doua esantioane, respectiv. Domeniile indicate pot sa aiba numere diferite de celule, dar completate cu date
numerice (cel mult prima celula n fiecare zona poate fi un titlu). Domeniile pot fi selectate dinamic.
Hypothesized Mean Difference contine valoarea testata pentru diferenta mediilor. Daca se indica valoarea 0 zero , atunci se verifica ipoteza egalitatii mediilor.
Variable 1 Variance (known), Variable 2 Variance known) dispersiile celor doua populatii.
Acestea se presupun cunoscute. n practica, pentru esantioane mari, se pot lua valorile dispersiilor de sondaj, dar în aceasta situatie este preferabil sa se aplice un test t decât un test z.
Labels boxa de control se marcheaza daca zonele de date indicate contin pe primele locuri denumirile zonelor.
Alpha contine valoarea pragului de semnificatie utilizat de procedura pentru a calcula valorile critice ale statisticii (utilizate ca limite ale domeniului de respingere a ipotezei nule). Implicit se ia = 0,05.
Outpu t o p tions
Output Range, New Worksheet Ply, New Workbook potrivit descrierii de la Descriptive Statistics. Precizeaza domeniul din foaia de calcul unde se vor nscrie rezultatele. Rezultatele sunt formatate ca un tabel pentru care se va preciza pozitia coltului din stânga sus. Semnificatia rubricilor din tabel este explicata în exemplul prezentat.
Ex emplu
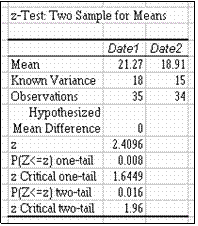 Pentru a compara mediile a doua populatii s-au extras doua esantioane de volume 35,
respectiv
34. Se cunoaste, din alte cercetari, ca dispersiile populatiilor sunt 18 si 15, respectiv.
Dispersiile de sondaj concorda cu aceste valori.
Pentru a compara mediile a doua populatii s-au extras doua esantioane de volume 35,
respectiv
34. Se cunoaste, din alte cercetari, ca dispersiile populatiilor sunt 18 si 15, respectiv.
Dispersiile de sondaj concorda cu aceste valori.
Pentru a compara mediile populatiilor se aplica un
test z. Resultatele sunt explicate în continuare.
Mean mediile de sondaj ale celor doua esantioane. Known Variance dispersiile cunoscute ale celor
doua populatii.
Observations numarul de observatii volumul esantionului).
Hypothesized Mean Difference valoarea cu care se compara diferenta mediilor populatiilor. Testarea egalitatii mediilor revine la a compara diferenta mediilor cu zero.
z valoarea calculata a statisticii testului. Provine,
teoretic, dintr-o repartitie normala standard.
Serveste pentru raportare sau pentru decizia n test la alte grade de semnificatie dec t valoarea
fixata n dialogul procedurii.
Rezultatele procedurii z-Test.
P(Z<=z) one-tail probabilitatea critica unidimensionala, arata care este probabilitatea ca o variabila normala redusa sa depaseasca valoarea calculata. Daca aceasta valoare este mai mica decât pragul de semnificatie fixat, atunci se poate respinge ipoteza nula în favoarea ipotezei alternative. Deoarece, n situatia data, prima medie este mai mare, ipoteza alternativa într-un test unilateral este
H1 : 1 2 > 0 sau, echivalent, H1 : 1 > 2
Valoarea 0 008 afisata este mai mica decât valorile uzuale 0,05 sau 0 01 , deci nu se
poate respinge ipoteza nula la aceste valori ale lui . Prin urmare se poate respinge ipoteza nula si accepta ipoteza alternativa ca prima populatie are o medie mai mare.
z Critical one-tail valoarea critica unidimensionala pentru pragul de semnificatie = 0,05
(precizata n dialogul procedurii). Daca valoarea z calculata este mai mare decât aceasta
valoare critica, atunci se poate respinge H0 n favoarea ipotezei alternative H1 : 1 > 2. Pentru exemplul prezentat acest fapt nu se înt mpla (2,4096 < 1,6449).
P(Z<=z) two tail probabilitatea critica bilaterala, arata care este probabilitatea ca o variabila normala standard sa depaseasca, în valoare absoluta, valoarea calculata. Cu alte cuvinte, probabilitatea ca diferenta dintre mediile populatiilor sa fie mai departata de zero decât diferenta observata.
Daca aceasta valoare este mai mica decât pragul de semnificatie fixat, atunci se
poate respinge ipoteza nula în favoarea ipotezei alternative a unor medii diferite: H1 : 1 ≠
2
Valoarea 0,016 afisata este mai mica dec t = 0 05, deci se poate respinge ipoteza nula.
z Critical two-tail valoarea critica bidimensionala pentru pragul de semnificatie = 0 05 (precizata în dialogul procedurii). Daca valoarea z calculata este mai mare, n valoare absoluta, decât aceasta valoare critica, atunci se poate respinge H0 n favoarea ipotezei alternative H1 : 1 ≠ 2. Pentru exemplul prezentat, | z | = |2,4096| = 2,4096 > 1 96, deci se poate respinge ipoteza nula.
C. Lucrarea practica
1) Un studiu a aratat ca 50% dintre utilizatorii de internet au primit mai mult de 10 mesaje e mail pe zi. Repetând, dupa un timp, studiul, se doreste verificarea ipotezei ca a crescut utilizarea e mail-ului. Sa se precizeze ipoteza nula si ipoteza alternativa a testului statistic adecvat.
2) Într-un test z cu ipotezele H0 : 1 − µ2 5 vs. H1 : µ1 − µ2 > 5 s-a obtinut statistica testului z = 1.69. Care este probabilitatea critica a testului?
3) Se vor genera doua coloane de câte 100 de valori dintr-o repartitie normala cu media 0 si dispersia 1.
i) sa se calculeze mediile si dispersiile celor sirruri de valori; sa se compare cu valorile 0, respectiv 1, si sa se interpreteze rezultatul comparatiilor în termenii populatie esantion.
ii) sa se testeze egalitatea mediilor celor doua seturi de valori cu valoarea
teoretica 0.
iii) sa se testeze daca cele doua seturi de valori au mediile egale.
4) Se vor genera doua coloane de valori din repartitii normale cu medii si dispersii diferite. Presupunând ca media celei de a doua coloane difera de media primei coloane cu , sa se verifice, prin generari repetate ale coloanelor, daca esantioanele pot fi considerate ca apartinând aceleiasi populatii.
i) Se va mari treptat diferenta ca si diferenta dispersiilor, pentru a obtine o imagine intuitiva asupra raspunsului la întrebarea: cât de mare trebuie sa
fie diferenta pentru ca esantioanele sa nu pota fi considerate omogene?
ii) Se va studia si influenta diferentelor dintre dispersii asupra concluziei testului.
5) Se importa n Excel fisierul admitere txt (utilizat la lucrarea nr.1). Sa se verifice statistic daca
i) mediile la bacalaureat pot fi considerate egale pentru cei care opteaza la
analiza, programare C sau programare Pascal
ii) mediile la scris pot fi considerate egale pentru cei care opteaza la analiza, programare C sau programare Pascal
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 95
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2024 . All rights reserved