| CATEGORII DOCUMENTE |
In general dispozitivele de retea (rutere, switch-uri, bridge-uri) au o arhitectura mai deosebita fata de calculatoarele personale sau de micro-calculatoare, chiar daca la baza contin aceleasi elemente. Acest lucru este normal, intrucat dispozitivele de retea pot fi considerate ca facand parte din clasa sistemelor embedded systems, echipamente specializate si nu de uz general, care se preteaza la o implementare hardware mult mai specifica, dar in acelasi timp si mai eficienta.
Acest capitol doreste sa familiarizeze cititorul cu structura interna a dispozitivelor de retea, pentru a putea intelege la un nivel satisfacator afirmatii esentiale din domeniul retelelor de calculatoare cum ar fi:
La fel ca un calculator personal, arhitectura unui dispozitiv de retea contine elemente discrete: procesoare de uz general sau embedded, memorie (RAM, ROM, FLASH, NVRAM), magistrale, switch fabrics, procesoare de retea (procesoare specializate pe operatiile de cautare/inlocuire sau inspectie a pachetelor sau cadrelor), controlere pentru diversele medii de comunicatie (Ethernet, wireless, serial, etc.). Aceasta sectiune va face o descriere sumara a acestor elemente discrete intalnite in dispozitivele de retea.
Subsections
Proiectarea circuitelor integrate a evoluat fata de timpul in care aceasta se facea pe hartie, se verifica apoi pe un Printed Circuit Board (PCB) si se stabilea manual pozitia tranzistorilor si a cailor de interconectare pe pastila de siliciu. Astazi exista pachete software grupate sub denumirea generica de Computer Aided Engineering (CAE) care dau posibilitatea proiectantului sa se concentreze asupra partii de proiectare logica, in timp ce programele garanteaza proiectantului ca circuitul integrat generat indeplineste conditiile necesare procesului tehnologic de fabricatie.
Proiectarea unui circuit integrat include mai multe etape pe care le vom descrie in continuare pe scurt:
proiectarea logica
- proiectantul descrie circuitul integrat folosind un limbaj de programare hardware (Verilog sau VHDL)
sinteza logica
- folosind un utilitar de sinteza se genereaza un netlist - o descriere a elementelor folosite impreuna cu modul de interconectare al acestora
partitionarea
- daca este cazul se imparte logica rezultata in mai multe circuite integrate
simulare (prelayout simulation)
- se verifica corectitudinea proiectarii prin simularea circuitelor in software
plasamentul
- se aranjeaza componentele pe suprafata chipului
rutarea
- se interconecteaza elementele
extragerea
- se determina rezistenta capacitatea legaturilor dintre elemente
simulare (postlayout simulation)
- se verifica inca o data corectitudinea simularii luand in calcul informatiile determinate la pasul anterior
Primele patru etape se incadreaza in partea de proiectare logica in tinp ce ultimele patru sunt considerate ca facand parte din partea de proiectare fizica. Este important de mentionat ca exista programe care automatizeaza partial sau total toate etapele descrise in afara de proiectarea logica.
Circuitele integrate sunt fabricate pe suprafete circulare denumite wafers ce contin cateva zeci de pastile de siliciu. Pastilele de siliciu vor fi mai apoi plasate in pachete (packages) de ceramica sau plastic la un loc cu pinii aferenti. Procesul tehnologic construieste circuitele integrate din mai multe straturi (in momentul actual 10-15 straturi), primele straturi definind tranzistorii iar ultimele straturi realizand interconectarea intre acestia. Fiecare strat se construieste pe baza unei masti care defineste daca avem sau nu siliciu/metal pe portiunea descrisa de masca.
Procesul tehnologic de realizare a circuitelor integrate nu este lipsit de erori. Erorile de fabricatie pot fi de doua feluri: globale si locale. Cele globale afecteaza toata suprafata de productie si pot fi detectate usor masurand parametri precum intensitatea curentului si viteza de comutare a tranzistorilor, atat pe circuitele integrate produse cat si pe dispozitive de test incorporate in suprafata de productie.
Cele locale sunt cauzate de impuritati sau de dislocarea cauzata de socuri mecanice a cristalelor de silicon ce alcatuiesc wafer-ul. Din aceasta cauza este afectata o suprafata extrem de redusa, greu de detectat. Detectia unor astfel de erori este ingreunata si de faptul ca la testare nu sunt disponibili decat pinii de iesire ai circuitului integrat. Pentru detectia unor astfel de erori, odata cu proiectarea unui circuit integrat trebuie realizata si strategia de testare a acestuia. Generarea unei strategii de testare necesita un efort considerabil si implica cunostinte din domeniul teoriei sistemelor ca testabilitatea, observabilitatea, controlabilitatea.
|
|
|
Figura: Un circuit integrat in care se observa pastila de siliciu incastrata si un wafer cu cateva zeci de pastile de siliciu |
Toate elementele discrete din care sunt construite dispozitivele de retea sunt in cele din urma circuite integrate, insa datorita faptului ca ele au functii precise ele sunt clasificate in procesoare, controlere, switch fabrics, memorii, etc. Exista insa o clasa aparte de circuite integrate care nu poate fi plasata in nici una din aceste categorii, pentru ca de cele mai multe ori ele contin parti din fiecare dintre categoriile enumerate mai devreme, sau pentru ca sunt atat de specifice incat nu se incadreaza in nici una din categorii.
Aceste circuite integrate sunt denumite Application Specific Integrated Circuits, sau ASICs. Dupa cum se observa si din numele acestora, ASIC-urile sunt circuite integrate dezvoltate pentru o functie specifica ce nu poate fi efectuata cu performante similare de catre circuite integrate standard. Din punct de vedere strict tehnologic ASIC-urile sunt circuite integrate, insa pentru ca sunt proiectate si fabricate intr-un timp relativ scurt, metodologia de proiectare si dezvoltare a ASIC-urilor difera fata de cea a circuitelor integrate standard. Putem considera ca odata cu aparitia ASIC-urilor, circuitele integrate au intrat intr-o noua faza, care le face mai ieftine si mai accesibile pentru o categorie mai vasta de probleme. Pentru a intelege de ce, este necesar sa studiem sumar tipurile de ASIC-uri care exista la ora actuala.
Subsections
Aceste tipuri de ASIC-uri (full-custom ASICs) sunt similare cu circuitele integrate clasice. Cel care proiecteaza astfel de ASIC-uri proiecteaza practic de la zero un nou circuit integrat. Costul de proiectare pentru acest tip de ASIC este mare, astfel incat numai companiile mari folosesc aceasta alternativa. De asemenea, costurile de productie pentru astfel de ASIC-uri sunt cele mai mari pentru ca nici o parte a acestuia nu este fixa, astfel incat trebuie generate masti pentru toate straturile. Timpul de productie este proportional cu numarul de straturi al circuitului integrat ce trebuie generate, si din acest motiv, pentru un ASIC complet customizat, timpul actual de productie este de aproximativ 8 saptamani.
Chiar daca costurile de proiectare si productie sunt mari, avantajele pentru astfel de circuite integrate constau in faptul ca acestea au cea mai mare densitate de porti pe chip, ceea ce inseamna ca pot fi fabricate mai multe ASIC-uri intr-un lot de productie, ceea ce duce la diminuarea costului pe ASIC, daca numarul de ASIC-uri produse este mare.
Pentru majoritatea pietii de ASIC-uri insa, aceasta abordare este mult prea scumpa, astfel incat producatorii de ASIC-uri au cautat metode mai ieftine de fabricare a ASIC-urilor. Aceste tehnologii poarte denumirea de ASIC-uri partial customizabile, pentru ca anumite parti/straturi ale ASIC-urilor sunt deja proiectate/fabricate.
customizabile1
ca o nota istorica, este interesant faptul ca ASIC-urile au fost initial denumite Custom Integrated Circuits; termenul de ASIC s-a impus mai tarziu, cand tot mai multe companii au inceput sa le foloseasca pentru reducerea costurilor in diverse aplicatii
B.2 ASIC-uri bazate pe celule standard
Aceasta tehnologie foloseste elemente electronice de baza grupate predefinit in celule standard, de unde si denumirea acestor tipuri de ASIC-uri, care uneori mai sunt denumite si CBIC-uri (Cell Based Integrated Circuit). In functie de tipul ei, o celula poate cuprinde porti logice SI, porti logice SAU, multiplexoare, flip-flopuri, etc. Astfel, pentru acest tip de ASIC, tipul, plasamentul si interconectarea celulelor sunt stabilite de cel care proiecteaza ASIC-ul. Mai multe celule pot fi legate intre ele formand un bloc flexibil.
In plus, aceste ASIC-uri pot include arii de celule predefinite (microcontrolere, microprocesoare, controlere Ethernet, etc.) denumite megacelule, megafunctii, blocuri complet customizate (full-custom blocks), system-level macros (SLM), blocuri fixe, cores sau blocuri standard functionale (FSB - Functional Standard Blocks).
Avantajele folosirii celulelor standard fata de proiectarea completa a unui ASIC constau in faptul ca celulele standard si megacelulele sunt deja proiectate, testate si au construit un model pentru simulari de catre producator. Proiectarea unui CBIC seamana cu proiectarea clasica, in care se plaseaza si interconecteaza circuite integrate pe un PCB (Printed Circuit Board).
Datorita faptului ca blocurile fixe si blocurile flexibile pot fi plasate oriunde pe suprafata ASIC-ului, productia unui astfel de ASIC necesita ca pentru toate straturile circuitului integrat sa fie generate masti. Din aceasta cauza timpul de productie a CBIC-urilor este de aproximativ 8 saptamani, acelasi ca si pentru ASIC-urile complet customizate. De asemenea, costurile de productie sunt similare (pentru ca trebuie generate toate mastile).
Avantajul CBIC-urilor este acela ca costurile de proiectare sunt reduse. Producatorul de ASIC-uri pune la dispozitia proiectantului librarii in limbaje de programare hardware atat cu celulele standard cat si cu megacelule. Librariile contin modele de simulare, astfel incat, dupa proiectarea ASIC-ului, acesta poate fi verificat prin simulari, inainte de inceperea productiei. Megacelulele cat si celulele standard pot fi definite de variabile care sa specifice diverse caracteristici precum optimizare a tranzistorilor generati pentru viteza sau spatiu.
Pentru ca sarcina proiectantului sa fie si mai usoara, producatorii de ASIC-uri pun la dispozitia clientilor si compilatoare care pot genera blocuri flexibile de DRAM, SRAM, ROM. Exista si compilatoare de cai de date (datapath compilers) care genereaza celule ce lucreaza cu mai multe semnale ale unei magistrale de date: sumatoare, scazatoare, chiar si unitati aritmetico-logice simple. Numarul de biti al caii de date poate fi specificat de proiectant. Celulele rezultate pot fi usor interconectate astfel incat sa formeze cai de date cu performante mai bune, ca viteza si spatiu ocupat, decat daca s-ar fi folosit celule standard (aceste tipuri de celule sunt grupate in datapath libraries).
Aceste tipuri de ASIC-uri folosesc celule de baza care sunt mai apoi replicate in vectori de baza. La randul lor, acestia sunt replicati pe toata suprafata waferului sub forma unei matrice. Primele versiuni (Channeled Gate Arrays) asezau vectorii de baza cu spatii intre ei, pentru a-i putea interconecta. Versiunile mai noi (Channelless Gate Arrays, Channel Free Gate Arrays, Sea of Gate Arrays) nu mai necesita spatii intre vectorii de baza, datorita faptului ca s-a introdus un strat izolator intre ultimul strat ce defineste tranzistorii si primul strat de interconectare.
Celulele de baza contin tranzistori deja formati, astfel incat primele straturi ale waferului sunt deja fabricate. Proiectantul va alege tipul celulei de baza si dimensiunea ASIC-ului dintr-un set pus la dispozitie de producator. Din acesta cauza timpul de productie pentru astfel de ASIC-uri este extrem de redus, de la doua saptamani pana la chiar cateva zile. De asemenea, costul de productie este extrem de mic. Dezavantajele folosirii unui astfel de ASIC sunt date de densitatea mai mica de porti logice pe ASIC si posibilitatea ca unii tranzistori sa nu fie folositi deloc. De asemenea, pentru ca structura este fixa, nu exista posibilitatea integrarii de megacelule.
Aceste ASIC-uri incearca sa combine tehnologiile prezentate mai sus, pentru a obtine un ASIC ieftin si flexibil. O parte din suprafata ASIC-ului este rezervata (embedded area) si contine memorie, controlere sau chiar nuclee de microprocesoare, restul suprafetei fiind ocupate de celule de baza. Timpul si costurile de productie sunt asemanatoare cu cele pentru ASIC-uri bazate pe vectori de porti, insa, in anumite cazuri, aceste ASIC-uri sunt mai usor de proiectat (pot incorpora logica deja existenta) si sunt mai flexibile (proiectantul poate alege dintr-un set de tipuri de ASIC-uri in care dimensiunea acestuia, dimensiunea zonei embedded, tipul zonei embedded si a tipul celulei de baza variaza).
Dispozitivele logice programabile (PLD - Programmable Logic Devices) sunt circuite integrate ce sunt disponibile in configuratii standard ce pot fi programate sau configurate. Cea mai simpla forma de circuit integrat programabil este ROM-ul. Exista mai multe tipuri de ROM-uri programabile: PROM-urile sunt programate permanent, EPROM-urile pot fi programate, iar apoi pentru o noua programare este nevoie de stergerea lor prin aplicarea unei tensiuni (EEPROM) sau prin expunerea la raze ultraviolete (UV-EPROM). Exista si ROM-uri special folosite in ASIC-uri (ca megacelule, sau incluse in ariile rezervate ale ASIC-urilor bazate pe vectori de porti structurate): ROM-uri programabile prin masti (mask-programable ROMs). Un astfel de ROM este creat prin programarea permanenta a tranzistorilor.
O categorie mai flexibila de PLD-uri sunt PLA-urile (Programable Logic Arrays) si PAL-urile (Programmable Array Logic). Ele sunt formate din porti logice SI sau SAU fixe care pot fi interconectate arbitrar la programare. In functie de cum sunt programate, PLD-urile sunt grupate in erasable PLD (EPLD) sau mask-programmed PLD. EPLD-urile folosesc tranzistori care pot fi programati de mai multe ori pentru a crea legaturile intre porti. MPLD-urile folosesc sigurante care pot fi arse definitiv prin aplicarea unei supratensiuni. Din cauza structurii lor, aceste PLD-uri pot fi folosite doar pentru o clasa mica de probleme cum ar fi decodificatoarele de tranzitii pentru automate finite.
O alta clasa de dispozitive logice programabile sunt Field Programmable Gate Arrays (FPGA). Aceste circuite integrate reprezinta urmatorul pas in evolutia PLD-urilor si cu ajutorul lor se pot rezolva o gama mult mai larga de probleme. Intern, FPGA-urile sunt formate din celule logice reprogramabile si logica ce poate fi programata pentru a interconecta celulele. Datorita acestei structuri, spre deosebire de celelalte tipuri de ASIC-uri, FPGA-urile pot fi programate de mai multe ori si au un grad de complexitate asemanator cu ASIC-urile neprogramabile daca le comparam cu PLD-urile clasice.
Dispozitivele de retea folosesc un numar relativ mare de tipuri de memorii in diverse scopuri. Astfel , este comun ca un ruter sau switch sa incorporeze memorie RAM, ROM, FLASH si NVRAM.
De cele mai multe ori, memoria RAM este folosita in doua scopuri: pentru rularea sistemului de operare si pentru a retine pachetele (packet buffers) ce traverseaza dispozitivul. Chiar daca memoria folosita pentru cele doua scopuri poate fi aceeasi, in general se foloseste o memorie mai rapida (SRAM) pentru pachete. Mai poate exista insa si o alta diferenta. Pentru ca dispozitivele interconectare sa fie performante, transferul pachetelor intre interfete si memorie (vezi sectiunile 8.2 si 8.3.1) trebuie facut de catre interfete. Asta inseamna ca memoria folosita pentru retinerea pachetelor trebuie sa fie mapata astfel incat interfetele sa o poata accesa singure, fara a face apel la procesor. Procesorul va programa interfata prin asa numitele inele de transfer (TX/RX rings) care nu sunt decat niste tabele cu pointeri catre zone de memorie alocate de catre sistemul de operare pentru interfata.
Memoriile de tip flash sunt folosite pentru a pastra imaginea sistemului de operare si alte fisiere importante folosite de aceasta. Avantajul folosirii de memoriile flash in locul hard discurilor este nu atat costul mai redus al memoriilor flash, cat fiabilitatea extrem de buna a acestora in comparatie cu hard discurile.
Memoria NVRAM (Non Volatile RAM) este folosita in cadrul dispozitivelor de interconectare pentru a pastra configuratia sistemului. Memoriile NVRAM sunt memorii normale (RAM) alimentate permanent de un acumulator. In unele dispozitive de interconectare acest tip de memorie nu este folosit, configuratia salvandu-se tot in flash. Datorita particularitatii memoriilor flash, aceasta abordare necesita insa implementarea a unui sistem de fisiere special conceput pentru ele.
Pentru ca, in afara de perioada de configurare initiala, un dispozitiv de interconectare nu are nevoie sa fie accesat direct (configurari in-band ulterioare se pot face accesand ruterul cu telnet, ssh sau cu un browser) interfata cu utilizatorul este minimala. In general se foloseste un port serial RS232 (portul de consola) pe care utilizatorul se poate conecta folosind un terminal sau un calculator si un emulator de terminal. Acest lucru restrictioneaza mobilitatea utilizatorului la cativa metri de dispozitivul de interconectare. Din acest motiv unele dispozitive folosesc un port auxiliar care se poate conecta la un modem. Acesta este cauza pentru care practic fiecare dispozitiv de interconectare contine un controler compatibil UART, daca nu ca dispozitiv discret atunci integrat in procesorul embedded.
Multibus este un tip de magistrala dezvoltat de Intel in anii '70 si apoi adoptat ca standard in IEEE 796 si IEEE P959. Chiar daca are o vechime considerabila, el mai este inca folosit astazi mai ales in aplicatii industriale si embedded. Primele generatii de rutere si switch-uri au folosit aceasta magistrala datorita faptului ca era simpla si bine inteleasa. In anii '80 Intel a imbunatatit standardul, creand Multibus II. Aceasta magistrala a fost si ea standardizata in IEEE-STD 1296. Avand 16 linii de date si o frecventa de maxim 10MHz, cu latentele introduse de protocol, Multibus are o largime de banda de 155Mbps, mai mult decat suficient pentru perioada in care a fost conceput. Un aspect important al acestei magistrale este faptul ca suporta facilitati avansate in protocol, cum ar fi blocarea magistralei pentru executie de operatii atomice read-modify-write pe platforme multiprocesor. Ca un punct negativ, Multibus supoarta doar 24 de linii de adresa, ceea ce inseamna ca are un spatiu de adresa de doar 8Mb.
Cbus este o magistrala proprietara Cisco dezvoltata pentru a elimina problemele magistralei Multibus, folosita la inceput de produsele CISCO. Este o magistrala moderna chiar si la standardele de astazi, comparabila cu PCI. Avand 32 de linii de date si adresa si o frecventa de maxim 16.67MHz are o largime de banda de 533Mbps si un spatiu de adresa de 4Gb. Ulterior Cisco a dezvoltat a imbunatatit magistrala creand CyBus-ul dar incercand sa pastreze compatibilitatea cu CxBus-ul (CBus-ul mai este intalnit si sub denumirea de CxBus). Astfel, CyBus are aceleasi specificatii, dar poate transfera doua cuvinte in acelasi ciclu de ceas. Aceasta abordare permite coexistenta ambelor tipuri de interfete (CxBus si CyBus) pe aceeasi magistrala (CyBus bineinteles) si creste largimea de banda pana la 1066Mbps.
Procesul de comutare a pachetelor este operatia de baza a dispozitivelor de interconectare ce lucreaza la nivelele OSI 2 si 3 si devine o operatie necesara atunci cand dispozitivul lucreaza cu pachete si cu mai multe porturi sau interfete pe unde poate receptiona sau transmite un pachet. Operatiile de baza efectuate pentru orice dispozitiv de interconectare sunt:
Arhitecturile acestor dispozitive sunt realizate astfel incat operatiile descrise sa se realizeze cat mai eficient, atat din punctul de vedere al vitezei de transmisie (care trebuie sa fie cat mai mare) cat si a latentei introduse (care trebuie sa fie cat mai mica).
Fiecare tip de dispozitiv de interconectare ce foloseste comutarea de pachete (rutere, switch-uri Ethernet, switch-uri ATM, switch-uri frame-relay) implementeaza si alte operatii, dar cele mentionate sunt prezente intotdeauna. Examinarea adresei destinatie a pachetului precum si comparare acesteia cu intrari din diverse tabele sunt operatii ce sunt implementate diferit de fiecare tip de desipozitiv de interconectarea si va fi discutat in sectiunile ce urmeaza.
Pentru a prezenta probleme teoretice ce apar in cadrul implementarii comutarii de pachete, in cele ce urmeaza vom considera ca lucram cu un dispozitiv cu NxN porturi (cu N porturi de intrare si N porturi de iesire).
Principala problema care apare in cadrul procesului de comutare de pachete este datorat faptului ca exista posibilitatea ca in acelasi timp dispozitivul sa fie nevoit sa trimita doua pachete pe aceeasi interfata. Bineinteles ca acest lucru nu se poate, si din acest motiv se folosesc comutare de pachete in care se memoreaza pachete pana cand ele pot fi transmise. Se poate demonstra ca daca nu se folosesc comutare de pachete, pentru un dispozitiv cu un numar mare de porturi si cu un trafic aleator, se pierd 37% din pachete. De asemenea, daca dorim pentru acelasi tip de dispozitiv sa mentinem procentul de pachete pierdute sub 1%, incarcarea acestuia trebuie sa fie sub 2% .
|
|
|
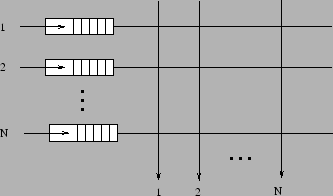
Figura 8.2: Bufere pe intrare |
In functie de modalitatea in care se utilizeaza comutare de pachetele in dispozitiv avem doua categorii de comutare de pachete: comutare de pachete cu bufere pe intrari (input queuing) si comutare de pachete cu bufere pe iesiri (output queuing).` La abordarea cu bufere pe intrari se folosesc N comutare de pachete in care sunt retinute pachetele ce intra in dispozitiv. Daca la un moment dat trebuie ca mai multe pachete sa iasa pe aceeasi iesire, se alege unul dupa o anumita politica dintr-unul din bufere. Problema cu acesta abordare este fenomenul head of queue blocking: daca un pachet dintr-o coada asteapta sa fie trimis la o iesire pe care trebuie sa iasa mai multe pachete, celelalte pachete din comutare de pachete sunt blocate, chiar daca ar putea fi trimise. Se poate demonstra ca incarcarea maxima pe care switch-ul o suporta fara pierderi de pachete este de 68% .
|
|
|
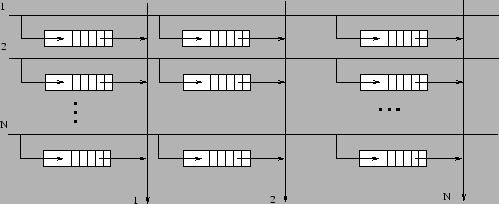
Figura: Bufere pe iesire |
Problema head of queue blocking
se poate rezolva daca se foloseste un dispozitiv cu
bufere pe iesire. In acest caz dispozitivul poate functiona
cu o incarcare de 100% fara a pierde pachete. De asemenea,
implementarea broadcast si multicast nu duce la pierderi de pachete sau
fenomene head of queue blocking asa cum se intampla in cazul precedent. Pretul platit: se folosesc N![]() bufere.
bufere.
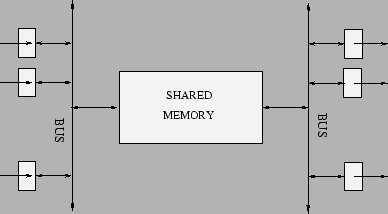
Pentru ca folosirea bufere pe iesire este costisitoare, dar si tehnologic greu de integrat, s-a incercat sa se gaseasca o arhitectura care sa combine cele doua tipuri de arhitecturi prezentate astfel incat sa se obtina un dispozitiv performant si ieftin. O astfel de arhitectura des intalnita foloseste o zona de memorie partajata accesibila tuturor porturilor, in care sunt pastrate pachetele pe perioada tranzitarii acestora prin dispozitiv. Pachetele se copiaza intre porturi si memoria comuna prin intermediul unei magistrale. Avantajul acestei arhitecturi este acela ca este usor de implementat si are performante foarte bune pentru switch-uri mici (12 porturi de 10Mbps Ethernet). Totusi pentru switch-uri medii aceasta arhitectura ajunge foarte repede la limite impuse de tehnologia actuala (pentru un switch ATM 155Mbps cu 32 de porturi si o magistrala pe 16 biti ar trebui sa avem un clock pe magistrala de 310MHz).
|
|
|
Figura: Comutarea de pachete folosind memoria partajata |
Rolul unui ruter este de a directiona pachetele intre diversele retele pe care le interconecteaza. Principalele actiuni pe care le realizeaza ruterul in procesul de comutare a pachetelor sunt:
In afara de aceste operatii de baza, ruterul mai poate efectua si operatii de filtrare de pachete, translatare de adrese, implementarea de politici QoS, precum si operatii dependente de protocolul de nivel trei (pentru IP decrementarea TTL, fragmentarea pachetului daca este necesar).
Vom prezenta in continuare o clasificare a ruterelor Cisco in functie de elementele principale ce definesc arhitecturile lor, precum si dupa scalabilitatea ce o ofera aceste arhitecturi. Diferentele intre primul ruter Cisco, care era o simpla placa ce se insera intr-o masina Sun, si ruterele bazate pe un procesor de uz general nu sunt semnificative, in vreme ce aparitia AGS+ marcheaza o schimbare importanta in modul de gandire a ruterelor, atat prin componentele incluse (ASIC-uri specializate pe switching) cat si prin modul lor de interconectare (magistrala, fabric switch-uri). Unele din conceptele acoperite de prezentarile de mai jos se regasesc acum si in solutiile oferite de alti producatori, dar urmatoarele sectiuni urmaresc evolutia arhitecturilor propuse de Cisco, mai ales datorita faptului ca o buna perioada de timp nu au existat alternative comparabile ca performanta pentru acestea.
Subsections
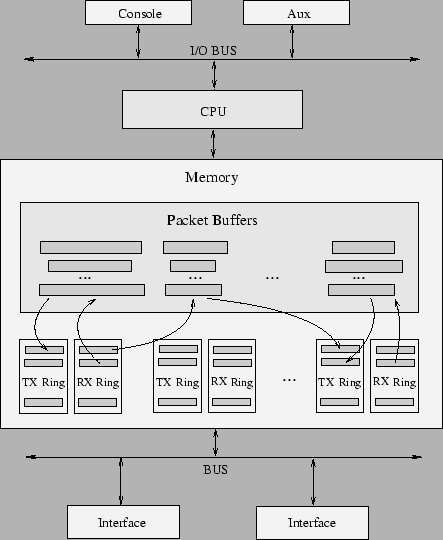
Primele generatii de rutere au avut la baza arhitectura unui calculator de uz general si foloseau pentru comutare de pachete arhitectura cu memorie partajata. Din aceasta cauza aceste tipuri de rutere au fost denumite rutere cu memorie partajata (shared memory routers Componentele principale ale unui ruter din prima generatie nu sunt spectaculoase: procesorul (in general un procesor embedded), memorie si interfete pentru diversele medii de transmisie suportate de ruter.
|
|
|
Figura: Rutere cu memorie partajata |
Rolul principal al procesorului este de a comuta pachetele. Tot procesorul are rolul de a construi tabelele de rutare si de a le mentine consistente atunci cand se folosesc protocoale de rutare. De asemenea, procesorul asigura interfata cu utilizatorul pentru configurarea si examinarea comportarii ruterului. Sistemul de operare al ruterului realizeaza toate aceste operatii doar cu procesorul, inclusiv comutarea pachetelor, fara a utiliza ASIC-uri sau alt tip de hardware specializat. Din acest motiv se spune ca comutarea pachetelor se face prin software. Interfetele ruterului sunt elementele discrete ce asigura receptionarea si transmiterea pachetelor. Interfetele sunt de obicei controlere Ethernet, seriale, ATM, etc. integrate in arhitectura ruterului astfel incat sa receptioneze pachetele din mediu si sa le transfere in memorie, sau invers, sa transfere pachetele din memorie catre mediu. Interfetele pot comunica direct cu memoria prin intermediul magistralei astfel incat procesorul nu trebuie sa intervina in procesul de copiere a datelor intre memorie si interfete. Memoria folosita de interfete este gestionata de catre sistemul de operare. Exemple clasice de rutere din prima generatie sunt ruterele Cisco 1600 si 2500. Arhitectura acestora include procesoarele Motorola 68000 cu frecvente cuprinse intre 20 si 33MHz, magistrala Motorola 68K si o gama variata de tipuri de interfete (Ethernet, Token Ring, seriale sincrone sau asincrone, ISDN).
Ruterele de tip shared memory au o serie de dezavantaje datorita faptului ca exista o singura unitate de prelucrare care realizeaza mai multe operatii in acelasi timp. Totodata raportul pret / performanta adica pret procesor/viteza de switching este destul de mare, si datorita faptului ca procesoarele folosite sunt procesoare de uz general - asta pentru ca ele nu trebuie sa faca numai switching de pachete, ci si alte operatii, dupa cum am vazut. Pentru cresterea performantelor s-a incercat dezvoltarea unor altfel de arhitecturi in care procesul de switching sa se faca in hardware, si nu software. In aceste tipuri de arhitecturi exista doua tipuri de procesoare: un procesor de rutare (route processor) si un procesor de comutare (switch processor). Procesorul de comutare este un procesor specializat pe comutarea de pachete, astfel incat el va prelua aceasta sarcina, procesorul de rutare urmand sa ajute procesorul de comutare prin construirea unei tabele (cache de rute) usor de inspectat de procesorul de comutare. De fapt, procesorul de rutare este un procesor de uz general care, in afara de mentinerea cache-lui de rute, ruleaza procesele ce asigura interfata cu utilizatorul, procesele de mentinere a tabelei de rutare (protocoale de rutare) si celelalte operatii pe care ruterul este capabil sa le faca (filtrare de pachete, translatare de adresa, QoS, etc.).
|
|
|
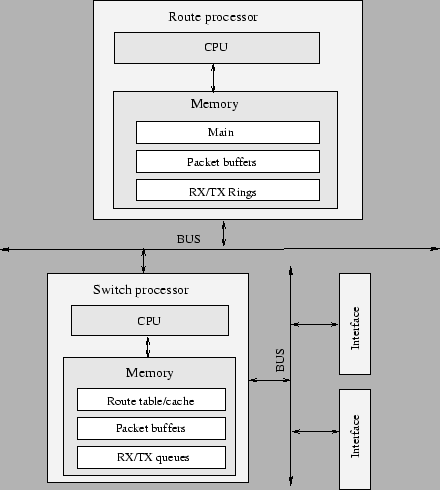
Figura 8.6: Rutere cu procesoare de comutare |
Procesorul de comutare are asociata o memorie, pe care o vom denumi memorie locala. Cele doua procesoare pot accesa oricare dintre cele doua memorii, dar accesul de la procesorul de rutare la memoria locala cat si de la procesorul de comutare la memoria principala se face prin intermediul unei magistrale mai lente. Din acest motiv este de dorit ca procesorul de rutare sa acceseze in mod normal memoria principala iar procesorul de comutare memoria locala. La randul lui, procesorul de comutare este conectat cu mai multe interfete prin intermediul unei magistrale rapide.
Actiunile pe care le efectueaza procesorul de comutare sunt:
Desi ruterele cu procesoare de comutare au ridicat performantele ruterelor destul de mult, pentru un ruter cu multe interfete ce suporta medii cu largimi de banda de ordinul sutelor de Mbps, un sigur procesor de comutare nu mai face fata. In plus, pentru ca procesorul de comutare sa tina pasul cu viteza interfetelor, el trebuia sa contina un numar mic de porti logice, datorita tehnologiei din perioada respectiva. De aici restrictii fata de flexibilitatea acestuia: nu poate sa comute pachete decat pentru un numar mic de protocoale (IP, IPX), filtrarea si translatarea de adrese era imposibil de facut direct de catre procesoarele de comutare, capacitatile de a manipula trafic QoS erau practic inexistente. Astfel incat, toate aceste operatii trebuia efectuate de procesorul de rutare. Odata cu cresterea de cerinte pentru QoS, filtrare si translatare de adrese, a fost evident ca arhitectura nu mai facea fata; chiar daca procesoarele de uz general au crescut in puterea de procesare, un singur procesor nu putea face fata. Proiectarea unor procesoare de comutare mai performante era o optiune, pentru ca tehnologia evoluase. Dar costurile erau prea mari, astfel incat solutia a fost folosirea unor sisteme cu mai multe procesoare de uz general deja proiectate, chiar daca performantele acestora putea fi surclasate de procesoare de comutare speciale.
|
|
|
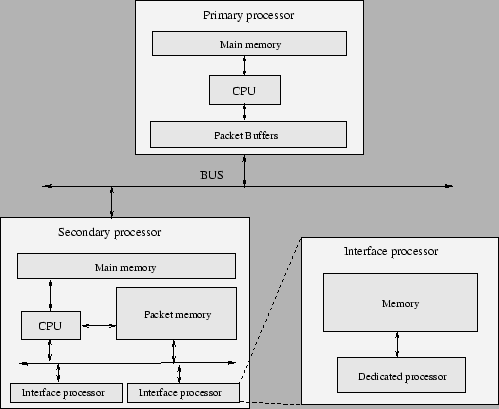
Figura 8.7: Rutere cu procesoare multiple |
Arhitectura ruterelor cu procesoare multiple a fost directionata catre o arhitectura paralela pentru a crea rutere scalabile. A fost introdus conceptul de distribuire a prelucrarii si in comutarea de pachete, conceptul de distributed switching luand locul procesorului de comutare. Arhitectura acestor rutere seamana foarte mult cu arhitectura calculatoarelor de uz general de tip multiprocesor. Pentru ca partea software nu este destul de matura, ruterele folosesc o abordare ASMP (ASymmetric Multi-Processing), in care exista un procesor principal care coordoneaza unul sau mai multe procesoare secundare. In implementarile initiale procesoarele (fie principale, fie secundare) realizau comutarea de pachete, fara ajutorul unui procesor de comutare. Motivul eliminarii procesorului de comutare a fost faptul ca procesoarele folosite erau destul de puternice pentru a face ca magistrala existenta (lenta) dintre un procesor de rutare si unul de comutare sa fie mult prea aglomerata.
Aceasta arhitectura necesita construirea unui cache de rute special, care este mentinut de catre procesorul central atat in memoria asociata lui cat si in memoriile asociate procesoarelor secundare. Procesoarele secundare ruleaza o versiune speciala a sistemului de operare si executa urmatoarele operatii:
Procesorul central are urmatoarele functii:
Datorita faptului ca procesoarele secundare sunt procesoare puternice facilitati de filtrare si QoS pot fi implementate distribuit.
Componentele de baza ale unui switch nu sunt cu mult diferite fata de cele intalnite intr-un ruter: un procesor de uz general, memorie pentru cadre si o magistrala sau switch fabric prin care circula cadrele in procesul de comutare, strans cuplata cu unul sau mai multe procesoare specializate care realizeaza comutarea pachetelor. Performanta switch-ului este data de largimea de banda a backplane-ului (fie el switch sau magistrala), memoria folosita pentru bufere, dar si arhitectura folosita.
In general switch-urile folosesc o arhitectura cu memorie partajata. Procesul de frame forwarding si address learning se realizeaza de catre ASIC-uri iar partea mai complexa - servicii SNMP, RMON, interfata cu utilizatorul - este realizata de catre un procesor de uz general. Backplane-ul are capacitati de ordinul Gbps sau chiar a zecilor de Gbps. In conditii normale (hardware-ul functioneaza corect, iar switch-ul este configurat bine) un switch modern nu pierde pachete decat eventual din cauza unor gatuiri determinate de mediul de transmisie.
Pentru comutarea cadrelor switch-ul analizeaza cadrele primite si decide daca ele trebuie trimise, si daca da, pe ce port. Acest proces, desi aparent simplu, datorita unor facilitati pe care un switch modern trebuie sa le posede (VLAN-uri, mirroring, monitorizare), este destul de complex si nu poate fi realizat eficient decat cu procesoare specializate).
Informatiile folosite pentru comutarea pachetelor sunt tinute intr-o tabela denumita Content Adressable Memory (CAM) care trebuie construita automat de catre switch in cadrul procesului de invatare a adreselor. Procesul este relativ simplu: dupa ce switch-ul efectueaza niste verificari de baza despre integritatea cadrului, se trece la cautarea in CAM a adresei, apoi daca cadrul trece de anumite verificari impuse de utilizator se scrie in tabela o noua intrare, se modifica una deja existenta sau nu se executa nici o actiune.
Subsections
Catalyst 1900 sunt switch-uri ce folosesc arhitectura ClearChannel, o arhitectura cu memorie partajata ce foloseste ca backplane o magistrala. Sunt suportate servicii ca SNMP, RMON, VLAN-uri si diverse moduri de frame switching: store&forward, cut-through (fast forward si fragment free).
|
|
|
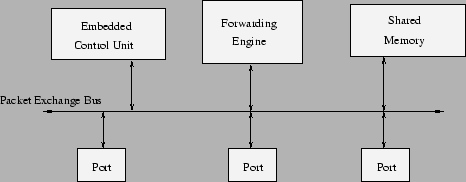
Figura 8.8: Cisco Catalyst 1900 |
Este folosita o magistrala pe 53 de biti la 20MHz (XBus), arbitrata de un scheduler bazat pe prioritati si timpul de sosire al cererii. Capacitatea backplane-ului este deci de 1Gpbs.
Forward engine-ul este implementat intr-un ASIC si se ocupa de:
Pachetele receptionate de catre switch sunt tinute in buffere alocate din memoria comuna (3 MB DRAM). Fiecare port are asociate cozi logice de intrare si iesire, in care se tin pointeri la buffere. Un cadru odata copiat (de la controlerul Ethernet de pe un port) in memorie nu mai este mutat in memorie. Memoria se elibereaza atunci cand cadrul este transmis. Pentru broadcast sau multicast pachetul nu este duplicat in memorie ci se leaga buferul pachetului la mai multe cozi de iesire a interfetelor.
Embedded Control Unit-ul (ECU) este format dintr-un procesor 486DX, 512KB DRAM folositi de procesor si 1 MB flash pentru firmware si configuratie. La ECU ajung pachetele de broadcast, cele destinate switch-ului si alte pachete ale protocoalelor folosite de swich-uri (CDP2, STP3) si sunt procesate de catre acesta. ECU ruleaza serverul de SNMP, RMON, telnet pentru configurare si management in-band. De asemenea gestioneaza traficul out-band - configurarea switch-ului pe portul de consola. Tot ECU controleaza led-urile si butoanele de pe panoul switch-ului si testeaza switch-ul la bootare.
CDP2
Cisco Discovery Protocol, protocol de nivel legatura de date care permite aflarea de informatii despre dispozitive de interconectare de retea CISCO adiacente
STP3
Spanning Tree Protocol, protocol ce elimina problemele ridicate de utilizarea legaturilor redundate intr-o retea de switch-uri
Switch-urile Catalyst 2900 sunt switch-uri ce folosesc o arhitectura cu memorie partajata, dar spre deosebire de Catalyst 1900, accesul intre memoria partajata si interfete se face cu un switch fabric. In plus, comutarea pachetelor se face distribuit.
|
|
|
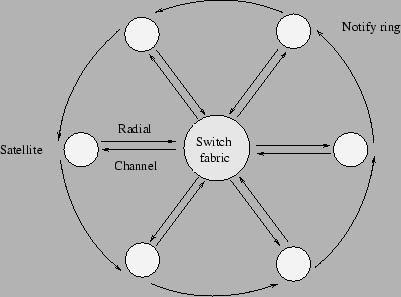
Figura 8.9: Cisco Catalyst 2900 |
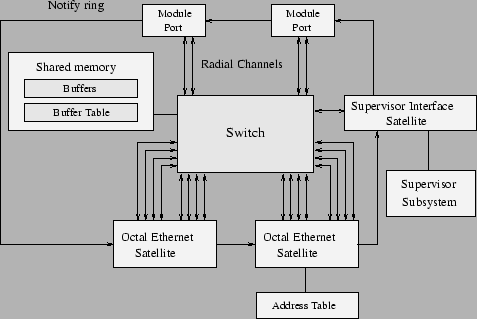
Arhitectura este formata dintr-un switch fabric cu o largime de banda de 3.2Gbps si un ansamblu de ASIC-uri care controleaza transferul intre switch fabric si sateliti si asigura alocarea de bufere pentru frame-uri in memoria partajata. Canalul de transmisie intre switch fabric si sateliti este bidirectional, cu o capacitate de 200 Mbps in fiecare sens - comunicatie cu 2 canale inspre switch fabric si 2 canale dinspre switch fabric. Atunci cand un cadru ajunge intr-unul din sateliti acesta il trimite prin switch fabric in memoria partajata. La fel, cand un frame trebuie transmis de catre un satelit acesta il ia din memoria partajata prin switch fabric. Prin switch fabric nu circula cadre, ci celule de dimensiune fixa. Satelitii sunt responsabili de fragmentarea cadrelor in celule la trimitere si asamblarea celulelor in cadre la primire.
|
|
|
Figura 8.10: Cisco Catalyst 2900 |
Comutarea cadrelor se realizeaza de catre sateliti, care pentru acest scop tin copii ale CAM intr-o tabela locala. Tot satelitii fac si invatare de adrese. Daca tabela de adrese este modificata in urma receptionarii unui cadru de catre unul din sateliti, acesta foloseste inelul de notificare pentru a anunta toti ceilalti sateliti. Satelitii pot fi de trei tipuri: supervizor, retea si special.
Satelitii de retea pot fi direct conectati pe placa de baza sau pot fi prezenti intr-un modul optional. Fiecare suporta pana la 8 porturi 10/100 Mbps, fiecare port avand cate un canal de comunicatie cu switch fabric-ul.
Satelitii speciali sunt folositi pentru VLAN tagging, criptarea frame-urilor si alte servicii speciale. Acesti sateliti pot fi conectati pe placa de baza sau intr-un modul optional.
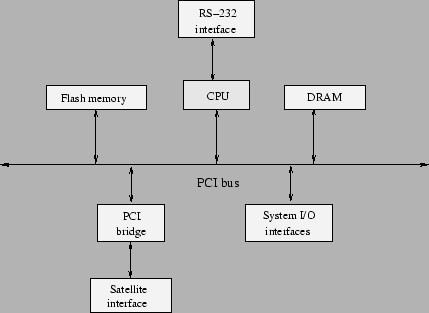
Satelitul supervizor este format dintr-un procesor, o memorie flash, o interfata de satelit si o interfata de sistem. Procesorul (PowerPC) se ocupa de partea de network management (SNMP, RMON), interfata cu utilizatorul out-band (prin portul de consola) si in-band (server de telnet si/sau web), testarea si initializarea componentelor switch-ului. In memoria flash se tin sistemul de operare si informatii despre configuratia switch-ului. Interfata de satelit asigura conectivitatea cu switch fabric-ul si satelitii adiacenti. Prin interfata sistem sunt controlate ledurile, sursa de alimentare si portul de consola.
|
|
|
Figura 8.11: Satelitul supervisor |
Inelul de notificare interconecteaza toti satelitii printr-un inel unidirectional de 8 biti cu o largime de banda de 800 Mbps. Canalele radiante sunt folosite numai pentru transfer de frame-uri intre sateliti si memoria partajata. Pe acest inel circula frame-uri de notificare: update in tabela de adrese, notificare catre un satelit ca un frame din memoria partajata trebuie transmis de catre acesta, etc. Protocolul folosit in acest inel este de tip Token Ring. Memoria partajata (4MB DRAM in configuratia standard) este folosita pentru a tine frame-urile primite de la sateliti. Gestiunea memoriei partajate este facuta de catre ASIC-uri ce mentin cozi (logice) de output pe fiecare port. Cadrele de broadcast si multicast nu sunt copiate in memorie, ci exista mai multe referinte la acelasi bufer din mai multe cozi.
Pentru studiu de caz am ales sa prezentam arhitectura ruterele Cisco din familia 7500. Acestea sunt primele rutere Cisco cu mai multe procesoare. Arhitectura este formata dintr-un procesor central, o magistrala de tip CyBus si mai multe VIP-uri (Versatile Interface Processor) sau IP-uri (Interface Processor). Un VIP este o placa ce contine un procesor, memorie locala si mai multe interfete.
|
|
|
Figura 8.12: Seria de rutere CISCO 7500 |
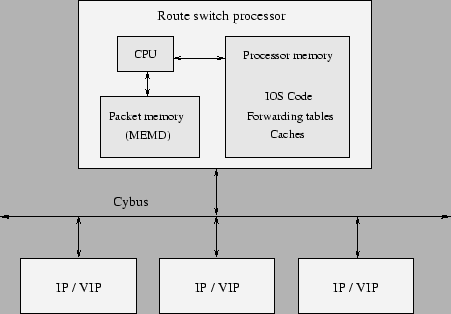
Procesorul si memoria sunt grupate intr-o unitate modulara denumita RSP (Route Switch Processor), tocmai pentru a sublinia faptul ca nu mai exista un procesor de comutare separat. Procesoarele sunt procesoare MIPS cu frecvente cuprinse intre 100 si 250MHz. Este interesant faptul ca RSP poate veni echipat cu doua tipuri de memorie: SRAM pentru bufere le de pachete si DRAM pentru alte utilizari, ceea ce il face extrem de atragator din punctul de vedere al raportului pret/performanta. Unele rutere din familia 7500 suporta o configuratie cu doua RSP-uri. Daca ambele RSP-uri sunt instalate si active in sistem, unul dintre ele va fi principal, iar celalalt secundar. Memoria de pe RSP-ul slave va fi si ea folosita pentru packet buffers. Daca ruterul este configurat cu High System Availability (HSA), atunci procesorul secundar va monitoriza procesorul principal si in cazul unei defectiuni a acestuia ii va prelua rolul. Daca exista posibilitatea de balansare a traficului implementata in sistemul de operare, RSP-ul secundar va putea fi folosit pentru comutare de pachete.
|
|
|
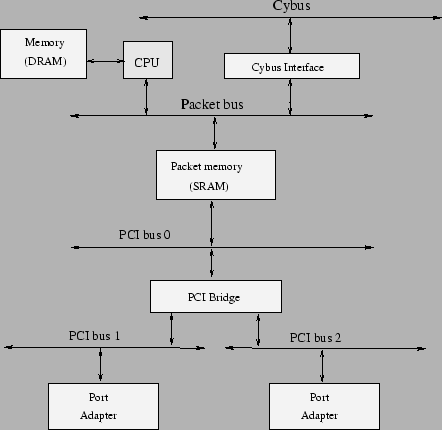
Figura 8.13: VIP CISCO 7500 |
Arhitectura VIP-urilor de pe ruterele 7500 este asemanatoare cu arhitectura ruterelor 7200. Port adaptoarele sunt conectate intre ele si la memorie prin intermediul a trei magistrale PCI (la 25 Mhz -> 800 Mbs fiecare), separate de un bridge. VIP-urile sunt conectate intre ele si cu RSP-ul prin intermediul unei magistrale Cybus si pot efectua doua citiri in aceeasi perioada de ceas. Procesoarele de pe VIP sunt procesoare MIPS. Pentru ca aceste procesoare sunt puternice VIP-ul suporta filtrare de pachete si QoS. VIP-urile au memorie de tip SRAM incorporata pentru pachete iar port adaptoarele suporta transferuri scatter-gather.
a ruta traficul pe interfetele speciale de loopback
a aloca memorie pentru controlere de interfata
a indica controlerelor de interfata locatia din memorie unde un pachet asteapta sa fie transmis
atat (b) cat si (c)
folosesc bufere pe intrare
folosesc bufere pe iesire
folosesc bufere si pe intrare si pe iesire
nu folosesc bufere nici pe intrare nici pe iesire
bufere pe procesoarele de interfata
o memorie partajata de toate procesoarele de interfata
o memorie partajata de toate procesoarele dispozitivului
atat (a) cat si (c)
doua procesoare, unul dedicat rularii protocoalele de rutare si unul dedicat comutarii de pachete
trei procesoare, unul dedicat rularii protocoalelor de rutare, unul dedicat comutarii de pachete si unul dedicat rularii interfetei cu utilizatorul
doua procesoare, din care unul e folosit doar pentru comutarea pachetelor
un procesor specializat pe comutarea in hardware a pachetelor
o memorie partajata de toti satelitii
un inel partajat de toti satelitii
un switch fabric
atat (b) cat si (c)
satelitul supervisor
de catre inelele de transfer
toti satelitii, distribuit
de catre switch fabric
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 1765
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2024 . All rights reserved