| CATEGORII DOCUMENTE |
| Aeronautica | Comunicatii | Electronica electricitate | Merceologie | Tehnica mecanica |
Metode de sinteza ( recunoasterea vorbirii )
1 Arhitectura sistemelor de recunoastere a vorbirii
Sistemele de recunoastere a vorbirii realizate pana in momentul de fata, din punct de vedere al recunoasterii sunt relativ modeste situandu-se in urmatoarele categorii:
Sisteme cu vocabular redus (10-100 cuvinte)
Sisteme in care cuvintele sunt pronuntate izolat ( 10.000 cuvinte)
Sisteme care accepta vorbire naturala (continua) dar in domenii specializate (1.000- 5.000 cuvinte)
De cele mai multe ori recunoasterea vorbirii este tratata ca o problema de recunoastere a formelor, comparandu-se "formele vocale" cu anumite modele. Structura unui sistem de recunoastere a vorbirii pe baza recunoasterii formelor este prezentat in fig. 20, iar procesul de recunoastere a vorbirii in fig. 21.
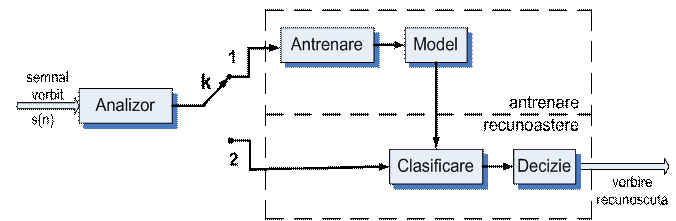
Fig.20. Structura unui sistem de recunoastere a vorbirii
k-1 antrenare ; k-2 recunoastere.
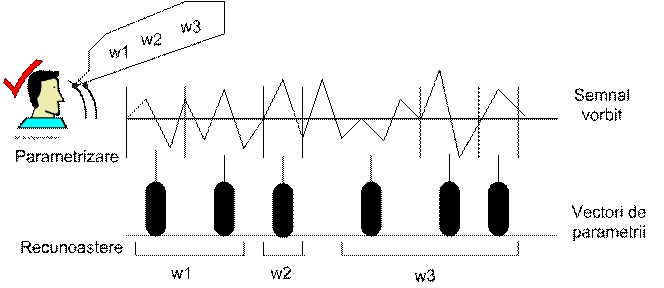
Fig.21. Procesul de recunoastere automata a vorbirii.
Sistemul poate fi folosit pentru recunoasterea vorbirii fie prin metoda globala, in care vorbirea este tratata ca un semnal global wi facandu-se abstractie de aspectele fonetice, sau prin metoda analitica in care vorbirea este tratata ca o succesiune de unitati fonetice de baza wi, din care se compune secventa rostita. Aceste unitati pot fi : cuvant, silaba sau fonema.
Sistemul realizeaza urmatoarele prelucrari esentiale :
1. In prima etapa se face "parametrizarea semnalului" prin masurarea trasaturilor esentiale ale semnalului vocal, respectiv prin determinarea parametrilor spectrali, fonetici, LPC relevanti pentru diferite cadre ale semnalului. Aceasta operatie este urmata de o segmentare a semnalului care urmareste despartirea fluxului vorbit in " unitati fonetice" ca foneme, semisilabe, silabe. Prin etichetare acestor unitati se realizeaza de fapt decodarea acusto-fonetica, primul pas in procesul de recunoastere a vorbirii prin metode analitice. In sistemele globale de recunoastere operatia de decodare acusto-fonetica nu exista, recunoasterea facandu-se la nivel de cuvinte sau chiar fraze.
2. In a doua etapa se face antrenarea sistemului in vederea formarii modelului fiecareia din clase. Daca pentru sistemele fonetice modelul corespunde unei unitati 'fonetice', pentru sistemele globale modelul se constitute pentru intreaga rostire. In aceasta etapa formele de recunoscut suficient de variate sunt folosite pentru crearea modelelor fie utilizand o tehnica de mediere a trasaturilor esentiale fie o caracterizare acustica a acestora; in ultimul timp tehnici de clustering realizate prin cuantizare vectoriala sau 'mapare'cu ajutorul unor retele neuronale incep sa joace un rol din ce in ce mai important.
3. Etapa de antrenare se efectueaza cu un lot de antrenare,in scopul obtinerii modelelor
A treia etapa este cea de clasificare a formelor. In aceasta etapa forma necunoscuta este comparata cu toate modelele elaborate in decursul antrenarii si sunt evaluate distantele dintre formele necunoscute si modelele disponibile fie chiar in forma unor distante in diferite metrici, fie in forma unor scoruri de 'potrivire',
5. In ultima etapa se ia o decizie fie pe baza unui criteriu de distanta minima, fie pe baza unui criteriu de plauzibilitate maxima (sau probabilitate maxima); forma necunoscuta se atribuie modelului cu care se aseamana, se potriveste cel mai bine.
Etapele de clasificare si decizie constituie procesul propriu-zis de recunoastere, care se face on- line si in urma caruia se stabileste succesiunea wi de clase recunoscute.
Exista o mare varietate de sisteme pentru recunoasterea formelor vocale, care se pot deosebi in raport cu alegerea modurilor de reprezentare a tipului de model de referinta, a parametrilor pentru formarea modelului, a metodei de clasificare pentru formele necunoscute.
Chiar cu aceste criterii de diferentiere a sistemelor de recunoastere a formelor, o clasificare riguroasa nu este posibila din cauza diversitatii abordarilor practice.
Performantele sistemului depind de cantitatea de date disponibile pentru faza de antrenare, in vederea formarii modelului; in general loturi mari de antrenament imbunatatesc performantele recunoasterii.
1.Modelele formate sunt sensibile la mediul in care se vorbeste si la caracteristicile de transmisie ale acestui mediu, caci aceste elemente afecteaza caracterizarea spectrala a vorbirii, efectele lor regasindu-se in diversificarea trasaturilor esentiale ale modelului.
2. Complcxitatea de calcul atat pentru antrenarea modelelor cat si pentru recunoasterea formelor necunoscute este practic proportionala cu numarul modelelor.
3 Sistemul nu inglobeaza explicit cunostinte despre vorbire, fiind insensibil la clasele de sunete de recunoscut ca si la alegerea vocabularului.
Sistemul fiind insensibil la clasele de sunete de recunoscut, aceleasi tehnici sunt aplcaibile unei largi categorii de secvente vorbite, cu alte cuvinte un sistem care recunoaste cuvinte poate fi adaptat sa recunoasca fraze dar si unitati fonetice mai mici decat cuvantul, ca silabele, semisilabele, fonemele. Astfel de sisteme isi pot gasi deci cu usurinta locul in structurile ierarhice.
5. Este avantajoasa inglobarea unor constrangeri sintactice si semantice pentru imbunatatirea performantelor de recunoastere.
Caracteristicile enumerate mai sus se pot oricand constitui in criterii dupa care sa se aleaga un sistem de recunoastere potrivit unei anumite aplicatii.
Daca sistemul lucreaza dupa metoda globala, in urma deciziei se stabileste care este rostirea cea mai probabila din cele posibile si eventual sunt intreprinse actiuni in sensul secventei recunoscute.
Daca sistemul lucreaza dupa metoda analitica, decizia se ia in favoarea unei anumite 'unitati fonetice' si trebuie vazut cum pot fi obtinute prin concatenarea acestor unitati cuvinte si cum se pot forma din cuvinte fraze cu sens pentru aplicatia respectiva.. Daca pentru vocabulare limitate aceste probleme se pot solutiona cu constrangeri interne, pentru vocabulare mari se apelaza la o serie de surse de cunostinte care sa contina regulile de urmat pentru ca sistemul sa depaseasca simplul stadiu al recunoasterii 'unitatilor fonetice'. Vor trebui inglobate cunostinte de lexic, eventual intr-un model al limbii pentru a forma cuvinte valide, reguli de sintaxa cuprinse intr-o gramatica pentru a forma constructii gramatical corecte, cunostinte de semantica pentru a gasi succesiuni de cuvinte care sa aiba un sens , pentru a alege din formularile corecte gramatical si cu sens pe cele potrivite aplicatiei respective. Rezulta in felul acesta un sistem capabil sa 'inteleaga' vorbirea bazat pe cunostinte, numit si sistem expert.
2 Modele computationale pentru recunoasterea vorbirii
Exista un numar mare de modele pentru sisteme de recunoastere a vorbirii, fiecare cu diferite perspective de abordare. Cele mai multe modele pot fi, in general, clasificate in doua categorii:
bazate pe segment - extragerea trasaturilor se face pe segmente de rostire mai mari de 20msec;
bazate pe cadru - extragerea trasaturilor se face pe segmente de rostire mai mici de 20msec.
In continuare vom face referiri la cele mai importante dintre aceste sisteme.
Sisteme de recunoastere a vorbirii bazate pe
segment.Sistemul
Sistemul SUMMIT a fost dezvoltat de Victor Zue de la MIT in 1980 iar in variante ulterioare imbunatatite, de catre Jim Glass. Caracteristic acestui sistem este faptul ca mai intai imparte semnalul in segmente si apoi clasifica din punt de vedere fonetic fiecare segment. Procedura
generala
de recunoastere in sistemul
1.
Granitele acustice sunt determinate pe baza unei multimi de modificari
spectrale. Intr-o implementare mai particulara a sistemului
2. O retea de segmente (dendrograma) este creata prin una din urmatoarele metode:
Unind segmentele mici in segmente mai mari in acord cu similaritatile lor spectrale.
Aceasta
este o metoda traditionala folosita in
Segmentarea prin recunoastere, folosind o procedura de recunoastere prin care sunt clasificate fiecare segment sau zona, marcate fie ca foneme, fie ca portiuni tranzitorii (co-articultii). Dupa aceasta clasificare, este facuta o cautare Viterbi "forword-pass", care este urmata de o cautare inapoi de tip A*. Cautarea A* produce un numar de alternative de segmentare fonetica care reprezinta rezultatul intr-o dendograma.
Aceasta metoda are un cost computational mai mare dar are performante de recunoastere mai bune.
3. Pe baza dendogramelor create in pasul 2, se efectueaza clasificarea fonetica a tuturor segmentelor, folosind urmatoarele doua metode:
Prima metoda efectueaza recunoasterea independent de context a fiecarui segment din dendodrama. In aceasta metoda sunt intre N+1 si 2*N categorii, dintre care un numar de N categorii corespund celor N foneme posibile, iar restul de N categorii sunt folosite pentru a modela segmentele neincluse in segmentarea cu ipoteze numite "ne-modelabile" sau "aproape de a fi modelate" .
A doua metoda efectueaza recunoasterea dependenta de context a fiecarei granite de segment din dendograma . Categoriile dependente de context pot fi granite fonetice sau granite interne unui fonem, si ar putea fi in numar de (N + N2). In practica, numai 750 de categorii sunt folosite.
Aceste clasificatoare sunt antrenate cu aceleasi trasaturi spectrale care sunt comune si sistemelor bazate pe HMM-uri, iar clasificarea este facuta folosind o combinatie de gaussiene.
Cautarea continua cu un "bigram" Viterbi forward si, pentru cele mai bune N ipoteze, o cautare de tip n-gram A* cu trecere inapoi. Daca ambele recunoasteri (cea independenta de context si cea a zonelor de granita) sunt efectuate in pasul 3, atunci probabilitatea finala a secventei de cuvinte este calculata prin inmultirea probabilitatilor fiecarui segment si a
zonelor de granita dintre acestea.
Performantele celor mai recente
sisteme
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 1987
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved