| CATEGORII DOCUMENTE |
| Aeronautica | Comunicatii | Electronica electricitate | Merceologie | Tehnica mecanica |
Algoritmi de codare rapida utilizati in cuantizarea vectoriala
Cuantizarea vectoriala reprezinta o tehnica eficienta de compresie a semnalelor video. Un factor important pentru reusita utilizarii cuantizarii vectoriale in aplicatiile in timp real o reprezinta timpul necesar algoritmului de codare de a gasi cel mai apropiat vector de cod pentru un vector de intrare dat.
Avand
un vector de cod ![]() si un vector de test
si un vector de test ![]() , distanta
euclidiana se calculeaza cu relatia:
, distanta
euclidiana se calculeaza cu relatia:
![]() (3.1)
(3.1)
Din relatia anterioara, fiecare distanta
dintre vectorul ![]() si un vector de cod
si un vector de cod ![]() necesita
necesita ![]() multiplicari (M) si
multiplicari (M) si ![]() adunari (A). Pentru intreg setul de vectori de
cod este necesar a se calcula
adunari (A). Pentru intreg setul de vectori de
cod este necesar a se calcula ![]() distorsiuni si
distorsiuni si ![]() comparatii (C). Astfel, pentru un algoritm de
cautare exhaustiv sunt necesare
comparatii (C). Astfel, pentru un algoritm de
cautare exhaustiv sunt necesare ![]() multiplicari,
multiplicari, ![]() adunari si
adunari si ![]() comparatii. De exemplu, pentru
comparatii. De exemplu, pentru ![]() si
si ![]() , fiecare
vector de intrare necesita 16384 (M), 31744 (A) si 1023 (C). Acest lucru
inseamna ca, pentru performante bune ale cuantizarii vectoriale, ceea ce
inseamna dimensiuni mari ale vectorilor si seturi mari de vectori de cod,
algoritmul de codare necesita un efort computational consistent. In literatura
exista metode care pot accelera procesul de codare. Aceste metode pot fi
clasificate in cateva categorii.
, fiecare
vector de intrare necesita 16384 (M), 31744 (A) si 1023 (C). Acest lucru
inseamna ca, pentru performante bune ale cuantizarii vectoriale, ceea ce
inseamna dimensiuni mari ale vectorilor si seturi mari de vectori de cod,
algoritmul de codare necesita un efort computational consistent. In literatura
exista metode care pot accelera procesul de codare. Aceste metode pot fi
clasificate in cateva categorii.
O
prima strategie consta in proiectarea unui cuantizor
vectorial sub forma de arbore in spatiul ![]() .
Cuantizorul vectorial este compus dintr-un set de hyper-plane in spatiul
.
Cuantizorul vectorial este compus dintr-un set de hyper-plane in spatiul ![]() ortogonale pe una din axele de coordonate.
Procesul de cautare este simplificat, deoarece in fiecare nod din arbore se ia
decizia daca un vector de intrare se afla de o parte sau alta a hyper-planului.
Cautarea poate fi eficienta, dar necesita o procedura complexa de determinare a
hyper-planelor, astfel incat distorsiunea medie sa fie minimizata. Dezavantajul
major al acestei metode este acela ca se ajunge la o solutie suboptimala din
perspectiva raportului rata/distorsiune, comparativ cu algoritmul LBG. Din
aceeasi categorie mai face parte si metoda proiectiilor. De mentionat ca
secventa de cautare este dependenta de setul de vectori de cod.
ortogonale pe una din axele de coordonate.
Procesul de cautare este simplificat, deoarece in fiecare nod din arbore se ia
decizia daca un vector de intrare se afla de o parte sau alta a hyper-planului.
Cautarea poate fi eficienta, dar necesita o procedura complexa de determinare a
hyper-planelor, astfel incat distorsiunea medie sa fie minimizata. Dezavantajul
major al acestei metode este acela ca se ajunge la o solutie suboptimala din
perspectiva raportului rata/distorsiune, comparativ cu algoritmul LBG. Din
aceeasi categorie mai face parte si metoda proiectiilor. De mentionat ca
secventa de cautare este dependenta de setul de vectori de cod.
O
a doua categorie de algoritmi este independenta de
setul de vectori si foloseste inegalitatea triunghiului pentru a rejecta acei
vectori de cod care nu pot fi cei mai apropiati de vectorul de test.
Dezavantajul major al acestei metode este memoria de date necesara stocarii a ![]() distante, intre oricare doi vectori de cod.
distante, intre oricare doi vectori de cod.
O
a treia categorie, ce face obiectul proiectarii din
sectiunea aceasta, este independenta de setul de vectori de cod si se bazeaza
pe rejectarea, dupa un anumit criteriu, a vectorilor de cod care nu pot fi cei
mai apropiati vecini ai unui vector de test. Necesarul de memorie pentru
aceasta clasa de algoritmi este redus (![]() unde
unde ![]() ).
).
O a patra categorie are in vedere gasirea unui vector de cod care este statistic cel mai apropiat de vectorul de test. Astfel vectorul de cod prin care va fi codat vectorul de intrare nu va fi cel mai apropiat, ceea ce inseamna ca algoritmul de cautare va introduce un nou factor de distorsiune in distorsiunea finala a sistemului de compresie. Avantajul metodei este acela ca timpul de cautare poate fi substantial imbunatatit fata de algoritmii rapizi care gasesc, cu probabilitate unu, cel mai apropiat vector de cod.
Un algoritm eficient de gasire a celui mai
apropiat vecin este cel de cautare cu distanta partiala. Algoritmul se bazeaza
pe monotonia distantei euclidiene (distanta creste cu dimensiunea), ceea ce
inseamna ca daca distanta partiala ![]() este mai mare decat cea mai mica distanta
este mai mare decat cea mai mica distanta ![]() atunci vectorul
atunci vectorul ![]() nu poate fi cel mai apropiat vector de cod si,
evident, va fi eliminat. Performantele algoritmului pot fi imbunatatite daca se
utilizeaza in prealabil o proiectie pe componente principale si daca vectorii
de cod sunt aranjati in ordinea descrescatoare a probabilitatii lor de
aparitie. De mentionat ca algoritmul prezentat mai sus nu necesita stocarea
unor date precalculate si poate oferi o scadere de pana la un sfert din volumul
de calcule necesar cautarii exhaustive.
nu poate fi cel mai apropiat vector de cod si,
evident, va fi eliminat. Performantele algoritmului pot fi imbunatatite daca se
utilizeaza in prealabil o proiectie pe componente principale si daca vectorii
de cod sunt aranjati in ordinea descrescatoare a probabilitatii lor de
aparitie. De mentionat ca algoritmul prezentat mai sus nu necesita stocarea
unor date precalculate si poate oferi o scadere de pana la un sfert din volumul
de calcule necesar cautarii exhaustive.
Rutina pentru algoritmul de cautare cu distanta partiala este urmatoarea
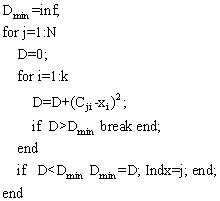
Pentru a gasi o secventa de cautare care
necesita un volum minim de calcule, ideal ar fi sa existe o functie ![]() (mapare), astfel incat:
(mapare), astfel incat:
![]() (3.2)
(3.2)
O
astfel de functie ar trebui sa fie bijectiva, lucru ce nu poate fi realizat,
deoarece functia ![]() nu este bijectiva. In schimb, se pot defini
mai multe functii:
nu este bijectiva. In schimb, se pot defini
mai multe functii:
![]() . (3.3)
. (3.3)
in
scopul gasirii unei secvente de cautare care sa reduca domeniul de cautare din ![]() la un volum cat mai mic, iar vectorul de cod
la un volum cat mai mic, iar vectorul de cod ![]() care este cel mai apropiat de vectorul de test
care este cel mai apropiat de vectorul de test
![]() sa apartina acelui domeniu. Matematic:
sa apartina acelui domeniu. Matematic:
![]() daca
daca ![]() . (3.4)
. (3.4)
![]() este definit ca:
este definit ca:
![]() ,
,
unde ![]() sunt astfel alese incat
sunt astfel alese incat ![]() .
.
Functiile ![]() trebuie sa respecte urmatoarele proprietati:
trebuie sa respecte urmatoarele proprietati:
(i)
corelatia dintre ele sa fie cat mai mica. Ideal ![]() ,
daca
,
daca ![]() ;
;
(ii)
![]() sa fie cat mai mare;
sa fie cat mai mare;
(iii)
![]() sa se poata calcula usor.
sa se poata calcula usor.
O prima
functie care poate fi utilizata in acest sens este media vectorului ![]() :
:
![]() . (3.5)
. (3.5)
Se stie ca pentru orice vector de intrare ![]() si orice vector de cod
si orice vector de cod ![]() are loc urmatoarea inegalitate
are loc urmatoarea inegalitate
![]() (3.6)
(3.6)
Daca la
un moment dat ![]() , unde
, unde ![]() , este
distorsiunea minima curenta, algoritmul ENNS (. Equal average Nearest Neighbor
encoding Search; . cautarea celui mai apropiat vecin prin cea mai apropiata
medie) poate fi formulat astfel:
, este
distorsiunea minima curenta, algoritmul ENNS (. Equal average Nearest Neighbor
encoding Search; . cautarea celui mai apropiat vecin prin cea mai apropiata
medie) poate fi formulat astfel:
Daca ![]() ,
atunci
,
atunci ![]() si vectorul de cod
si vectorul de cod ![]() va fi eliminat deoarece nu poate fi cel mai
apropiat vector de cod pentru vectorul de intrare
va fi eliminat deoarece nu poate fi cel mai
apropiat vector de cod pentru vectorul de intrare ![]() .
.
Rutina care descrie algoritmul este prezentata mai jos:
Pas 0: Pentru
fiecare vector de cod ![]() ,
,
![]() , se calculeaza
, se calculeaza ![]() .Vectorii de
cod sunt aranjati in ordine crescatoare a mediei. Acest pas este operat
off-line. Pentru pasii urmatori memoria pentru
.Vectorii de
cod sunt aranjati in ordine crescatoare a mediei. Acest pas este operat
off-line. Pentru pasii urmatori memoria pentru ![]() ,
, ![]() este disponibila; se trece la Pas 1.
este disponibila; se trece la Pas 1.
Pentru fiecare vector de intrare ![]() se parcurg pasii urmatori:
se parcurg pasii urmatori:
Pas 1: Se
calculeaza ![]() ; se trece
la Pas 2;
; se trece
la Pas 2;
Pas 2: Se cauta
vectorul de cod ![]() a carui index
a carui index ![]() Se
calculeaza distanta euclidiana
Se
calculeaza distanta euclidiana 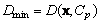 si se initializeaza
si se initializeaza ![]() ; se trece
la Pas 3;
; se trece
la Pas 3;
Pas 3: Daca
![]() sau vectorii de cod
sau vectorii de cod ![]() pana la
pana la ![]() au fost eliminati se trece la Pas 4; Altfel
se trece la Pas 3.1;
au fost eliminati se trece la Pas 4; Altfel
se trece la Pas 3.1;
Pas 3.1:
Daca
![]() se
elimina vectorii de cod de la
se
elimina vectorii de cod de la ![]() la
la ![]() si se trece la Pas 4; Altfel se trece la Pas 3.2;
si se trece la Pas 4; Altfel se trece la Pas 3.2;
Pas 3.2:
Se recalculeaza ![]() ; Se trece la Pas 4;
; Se trece la Pas 4;
Pas 4: Daca
![]() sau vectorii de cod
sau vectorii de cod ![]() pana la
pana la ![]() au fost eliminati se trece la Pas 5; Altfel
se trece la Pas 5.1;
au fost eliminati se trece la Pas 5; Altfel
se trece la Pas 5.1;
Pas 4.1:
Daca
![]() se
elimina vectorii de cod de la
se
elimina vectorii de cod de la ![]() la
la ![]() si se trece la Pas 4; Altfel se trece la Pas
4.2;
si se trece la Pas 4; Altfel se trece la Pas
4.2;
Pas 4.2:
Se recalculeaza ![]() ; Se trece la Pas 5;
; Se trece la Pas 5;
Pas 5: ![]() ; Daca
; Daca
![]() si
si ![]() sau toti vectorii de cod au fost eliminati se
termina cautarea si se returneaza cel mai apropiat vector de cod; Altfel
se trece la Pas 3.
sau toti vectorii de cod au fost eliminati se
termina cautarea si se returneaza cel mai apropiat vector de cod; Altfel
se trece la Pas 3.
Daca ![]() este o transformata ortonormata de forma:
este o transformata ortonormata de forma:
 , (3.7)
, (3.7)
se poate deriva o a doua inegalitate:
![]() (3.8)
(3.8)
Algoritmul prezentat anterior poate fi reformulat astfel:
Daca ![]() ,
atunci
,
atunci ![]() si vectorul de cod
si vectorul de cod ![]() va fi eliminat.
va fi eliminat.
In
cazul in care ![]() este transformata Walsh-Hadamard,
este transformata Walsh-Hadamard, ![]() si pentru
si pentru ![]() se obtine inegalitatea din (3.6).
se obtine inegalitatea din (3.6).
In
scopul eliminarii a cat mai multi vectori de cod care nu pot fi cei mai
apropiati de vectorul de test ![]() , se
utilizeaza a doua functie:
, se
utilizeaza a doua functie:
![]() , unde
, unde ![]() , (3.9)
, (3.9)
iar
urmatoarea inegalitate are loc pentru orice vectori ![]() si
si ![]() :
:
![]() . (3.10)
. (3.10)
Algoritmul poate fi formulat astfel:
Daca ![]() , atunci
, atunci ![]() si
si ![]() va fi eliminat.
va fi eliminat.
Algoritmul care include si inegalitatea (3.10) pe langa (3.6) poarta numele de EENNS (Equal average Equal variance Nearest Neighbor Search; cautarea celui mai apropiat vecin prin cea mai apropiata medie si cea mai apropiata varianta).
O varianta imbunatatita a algoritmului EENNS consta in gasirea unei noi inegalitati de forma:
![]() (3.11)
(3.11)
Algoritmul
poarta numele de IEENNS. Daca la ENNS necesarul de memorie este de ![]() locatii, la EENNS si IEENNS este nevoie de
locatii, la EENNS si IEENNS este nevoie de ![]() locatii de memorie pentru stocarea valorilor
precalculate ale lui
locatii de memorie pentru stocarea valorilor
precalculate ale lui ![]() si
si ![]() .
.
In
figura 3.1a si 3.1b se reprezinta regiunile de cautare ramase, dat fiind un ![]() , la fiecare
din metodele expuse anterior. In 3.1b vectorii de cod sunt bidimensionali si
sunt uniform distribuiti in
, la fiecare
din metodele expuse anterior. In 3.1b vectorii de cod sunt bidimensionali si
sunt uniform distribuiti in ![]() . In cazul
algoritmului IEENNS numarul vectorilor de cod eliminati este cel mai mare, ceea
ce inseamna ca aceasta metoda va da cele mai bune rezultate.
. In cazul
algoritmului IEENNS numarul vectorilor de cod eliminati este cel mai mare, ceea
ce inseamna ca aceasta metoda va da cele mai bune rezultate.
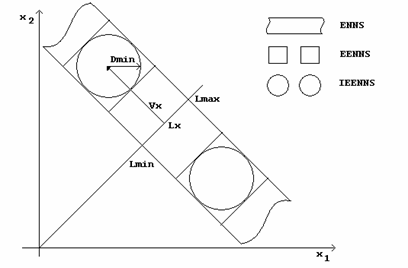
(a)

(b)
Figura 3.1 Regiunile de cautare pentru fiecare metoda
Algoritmii expusi anterior pot reduce volumul de calcule pana la 10-25 % din volumul de calcul necesar cautarii exhaustive. De mentionat ca performantele acestor algoritmi depind, de asemenea, de statistica vectorilor de cod si de statistica vectorilor din intrare.
In scopul gasirii unei secvente ce poate reduce si mai mult timpul de cautare, ceea ce inseamna a gasi o noua inegalitate care poate elimina vectori de cod care nu pot fi eliminati cu ajutorul inegalitatilor anterioare, se defineste functionala:
![]() , (3.12)
, (3.12)
unde ![]() ,
iar
,
iar ![]() este transformata liniara din (3.7). Evident
este transformata liniara din (3.7). Evident ![]() .
.
O noua inegalitate este de forma:
![]() . (3.13)
. (3.13)
In acest caz algoritmul poate fi formulat astfel:
Daca ![]() atunci
atunci ![]() si vectorul
si vectorul ![]() va fi eliminat.
va fi eliminat.
Algoritmul prezentat a fost imbunatatit
prin folosirea ca functii ![]() a momentelor spatiale ale imaginilor-bloc. In
acest fel se poate dispune si de o informatie ce tine cont de repartitia
spatiala a pixelilor in blocurile-imagine.
a momentelor spatiale ale imaginilor-bloc. In
acest fel se poate dispune si de o informatie ce tine cont de repartitia
spatiala a pixelilor in blocurile-imagine.
Rutina
care descrie algoritmul de cautare este prezentata in cele ce urmeaza pentru
cazul in care ![]() , ceea ce
inseamna ca nu pot fi eliminati vectorii de cod dupa medie.
, ceea ce
inseamna ca nu pot fi eliminati vectorii de cod dupa medie.
Pas
0: Pentru fiecare
vector de cod ![]() ,
,
![]() , se calculeaza
, se calculeaza ![]() . Vectorii de cod sunt sortati in ordine
crescatoare dupa
. Vectorii de cod sunt sortati in ordine
crescatoare dupa ![]() . Acest pas
se realizeaza off-line. In pasii urmatori memoria pentru
. Acest pas
se realizeaza off-line. In pasii urmatori memoria pentru ![]() ,
,
![]() , este disponibila; se trece la Pas 1;
, este disponibila; se trece la Pas 1;
Pentru fiecare vector de intrare ![]() se parcurg urmatorii pasi:
se parcurg urmatorii pasi:
Pas 1: Se
calculeaza ![]() ; se trece
la Pas 2;
; se trece
la Pas 2;
Pas 2: Se cauta
vectorul de cod ![]() a carui index
a carui index![]() Se
calculeaza distanta euclidiana si se initializeaza
Se
calculeaza distanta euclidiana si se initializeaza ![]() ; se trece
la Pas 3;
; se trece
la Pas 3;
Pas 3: Daca
![]() sau vectorii de cod
sau vectorii de cod ![]() pana la
pana la ![]() au fost eliminati se trece la Pas 4; Altfel
se trece la Pas 3.1;
au fost eliminati se trece la Pas 4; Altfel
se trece la Pas 3.1;
Pas 3.1:
Daca
![]() se elimina vectorii de cod de la
se elimina vectorii de cod de la ![]() pana la
pana la ![]() si se trece la Pas 4; Altfel se trece la pas 3.2;
si se trece la Pas 4; Altfel se trece la pas 3.2;
Pas 3.2:
Daca
![]() se elimina vectorul de cod
se elimina vectorul de cod ![]() si se trece la Pas 4; Altfel se trece la Pas 3.3;
si se trece la Pas 4; Altfel se trece la Pas 3.3;
Pas 3.3:
Daca
![]() se elimina vectorul de cod
se elimina vectorul de cod ![]() si se trece la Pas 4; Altfel se trece la Pas 3.4;
si se trece la Pas 4; Altfel se trece la Pas 3.4;
Pas 3.4:
Daca
![]() se elimina vectorul de cod
se elimina vectorul de cod ![]() si se trece la Pas 4; Altfel se trece la Pas 3.5;
si se trece la Pas 4; Altfel se trece la Pas 3.5;
Pas 3.5:
Daca
![]() se elimina vectorul de cod
se elimina vectorul de cod ![]() si se trece la Pas 4; Altfel se utilizeaza PDS
pentru a gasi distanta minima
si se trece la Pas 4; Altfel se utilizeaza PDS
pentru a gasi distanta minima ![]() si se trece la Pas 4;
si se trece la Pas 4;
Pas 4: Daca
![]() sau vectorii de cod
sau vectorii de cod ![]() pana la
pana la ![]() au fost eliminati se trece la Pas 5; Altfel
se trece la Pas 4.1;
au fost eliminati se trece la Pas 5; Altfel
se trece la Pas 4.1;
Pas 4.1:
Daca
![]() se elimina vectorii de cod de la
se elimina vectorii de cod de la ![]() pana la
pana la ![]() si se trece la Pas 5; Altfel se trece la Pas 4.2;
si se trece la Pas 5; Altfel se trece la Pas 4.2;
Pas 4.2:
Daca
![]() se elimina vectorul de cod
se elimina vectorul de cod ![]() si se trece la Pas 5; Altfel se trece la Pas 4.3;
si se trece la Pas 5; Altfel se trece la Pas 4.3;
Pas 4.3:
Daca
![]() se elimina vectorul de cod
se elimina vectorul de cod ![]() si se trece la Pas 5; Altfel se trece la Pas 4.4;
si se trece la Pas 5; Altfel se trece la Pas 4.4;
Pas 4.4:
Daca
![]() se elimina vectorul de cod
se elimina vectorul de cod ![]() si se trece la Pas 5; Altfel se trece la Pas 4.5;
si se trece la Pas 5; Altfel se trece la Pas 4.5;
Pas 4.5:
Daca
![]() se elimina vectorul de cod
se elimina vectorul de cod ![]() si se trece la Pas 5; Altfel se utilizeaza PDS
pentru a gasi distanta minima
si se trece la Pas 5; Altfel se utilizeaza PDS
pentru a gasi distanta minima ![]() si se trece la Pas 5;
si se trece la Pas 5;
Pas 5: ![]() ; Daca
; Daca
![]() si
si ![]() sau toti vectorii de cod au fost rejectati se
termina cautarea si se returneaza cel mai apropiat vector de cod; Altfel
se trece la Pas 3.
sau toti vectorii de cod au fost rejectati se
termina cautarea si se returneaza cel mai apropiat vector de cod; Altfel
se trece la Pas 3.
Performantele algoritmilor propusi au fost
testate prin experimente pe un set de imagini cu niveluri de gri si rezolutie
de 512512 pixeli. Trei imagini standard "boat", "goldhill" si "lena" au fost
utilizate ca imagini de antrenare pentru obtinerea setului de vectori de cod.
Imaginile au fost impartite in blocuri de 44 pixeli iar vectorii de antrenare
au fost obtinuti prin extragerea mediei din blocurile respective. Deoarece, in
multe aplicatii de compresie a imaginilor, media unui bloc-imagine se extrage
din pixelii acelui bloc, tehnica denumita MRVQ (Mean Removal Vector
Quantization), vectorii de antrenare si vectorii de cod vor avea medie nula,
iar algoritmul ENNS nu va putea fi folosit. ![]() este transformata Walsh-Hadamard, transformata
separabila, unitara, care exista doar pentru
este transformata Walsh-Hadamard, transformata
separabila, unitara, care exista doar pentru ![]() , unde
, unde ![]() este intreg.
este intreg.
Primii 5 vectori de baza ai transformatei Hadamard in ordine descrescatoare a variantei proiectiilor imaginilor-bloc sunt dati in matricea urmatoare:

Matricea ![]() are elementele +1 si -1, ceea ce inseamna ca
proiectiile pe primii doi vectori vor fi usor de calculat.
are elementele +1 si -1, ceea ce inseamna ca
proiectiile pe primii doi vectori vor fi usor de calculat.
In Tabelul 3.1 se prezinta numarul de multiplicari, adunari si comparatii pe pixel necesare pentru a coda un bloc-imagine pentru doua imagini "peppers" si "baboon". Se observa ca metoda ce utilizeaza inegalitatea (3.13) foloseste cele mai putine operatii. De asemenea, pentru "peppers" numarul de operatii este de aproximativ trei ori mai mic decat numarul de operatii pentru codarea imaginii "baboon". Acest lucru se explica prin statistica diferita a vectorilor din intrare. Cu cat dispersia vectorilor din intrare este mai mare, cu atat timpul de codare a unei imagini creste.
|
Tabel 3.1 |
Numarul mediu de operatii necesare codarii unui pixel |
||||||
|
N |
Metoda |
Imagine codata |
|||||
|
Peppers |
Baboon |
||||||
|
Mult. |
Add. |
Comp. |
Mult. |
Add. |
Comp. |
||
|
Cautare exhaustiva | |||||||
|
PDS | |||||||
|
IEENNS | |||||||
|
| |||||||
|
Cautare exhaustiva |
| ||||||
|
PDS | |||||||
|
IEENNS | |||||||
|
| |||||||
In tabelul 3.2 se prezinta numarul mediu de distante calculate pentru a coda o imagine.
|
Tabel 3.2 |
Numarul mediu de distante calculate pentru a coda un bloc-imagine |
||
|
N |
Metoda |
Imagine codata |
|
|
Peppers |
Baboon |
||
|
Cautare exhaustiva | |||
|
PDS | |||
|
IEENNS | |||
|
| |||
|
Cautare exhaustiva | |||
|
PDS | |||
|
IEENNS | |||
|
| |||
Concluzii
Au fost testate diverse metode de cautare
rapida a celui mai apropiat vector de cod prin introducerea unor inegalitati
care permit ca dupa un numar redus de operatii sa elimine cat mai multi vectori
de cod. In relatia (3.13) s-a prezentat o noua inegalitate in scopul eliminarii
a cat mai multi vectori de cod ce nu pot avea statutul de cel mai apropiat vector de cod fata de vectorul din intrare si care
nu pot fi eliminati cu ajutorul algoritmilor prezentati. Rezultatele
experimentale confirma faptul ca metoda propusa este superioara algoritmului
IEENNS. In comparatie cu IEENNS numarul mediu de operatii matematice si numarul
mediu de distorsiuni evaluate scade cu 9-13 %. Algoritmul prezentat a fost
imbunatatit prin folosirea ca functii ![]() a momentelor spatiale ale imaginilor-bloc.
a momentelor spatiale ale imaginilor-bloc.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 1541
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved