| CATEGORII DOCUMENTE |
Alte proceduri pentru reprezentari grafice in SPSS
Comenzile pentru diverse alte grafice
le putem gasi in meniul Graphs.
Din acest meniu vom detalia cateva optiuni care sunt mai uzuale. Vom
gasi si aici de exemplu optiunea Histogram dar cu o fereastra usor diferita:
![]()
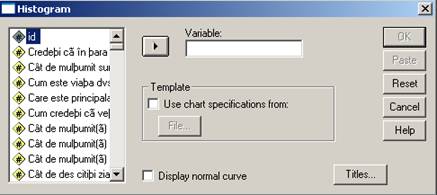
Sa presupunem ca vrem sa facem histograma variabilei loc4 [Care este suprafata totala (in metri patrati) a
camerelor (fara baie, bucatarie, hol) pe
care le ocupa gospodaria dumneavoastra?].
Vom trece variabila din stanga in dreapta, putem seta optiunea Display normal curve, deasemenea putem sa cautam un titlu adecvat graficului:
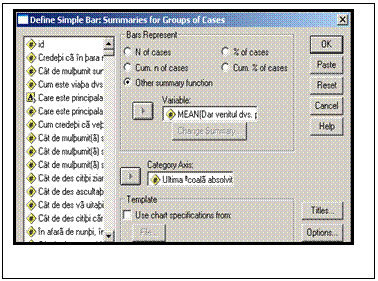
Bar. Din aceasta fereastra vom pastra optiunea Simple care este potrivita situatiei noastre deoarece exista o singura variabila independenta scoala0. Din partea de jos vom lasa setarea Summaries for groups of cases (barele reprezinta grupuri de cazuri). Clic pe butonul Define:
![]()
Se observa in aceasta
fereastra ca am deplasat variabila scoala0
in rubrica Category Axis (este
variabila independenta care va defini axa OX) iar in rubrica Variable am trecut variabila vensub iar pentru aceasta in grafic
vor apare pe axa OY mediile veniturilor. De altfel aceasta optiune a
fost aleasa de program in mod automat dar ea poate fi schimbata din butonul
Change Sumary. Pentru exemplul
nostru vom lasa aceste setari si vom continua cu OK! Obs: Daca variabila
independenta are "valori lipsa" atunci din butonul Options se va dezactiva comanda Display groups defined by missing values!

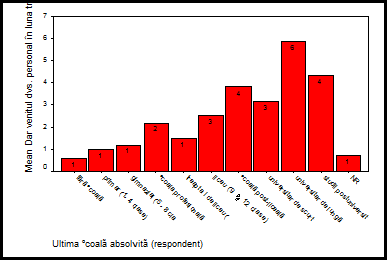
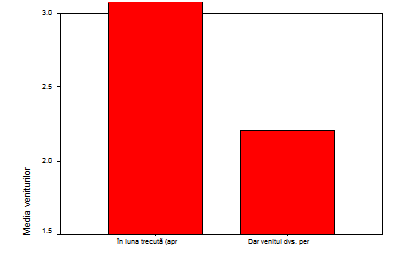
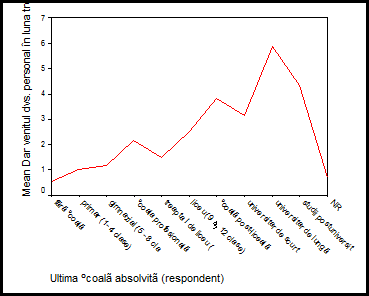
Valorile de pe axa OY
reprezinta mediile veniturilor in milioane lei in luna aprilie 2003. Se
observa din grafic modul cum influenteaza variabila independenta
"studii" variabila dependenta "venit". Pentru studii postuniversitare se
manifesta o scadere a mediei veniturilor!
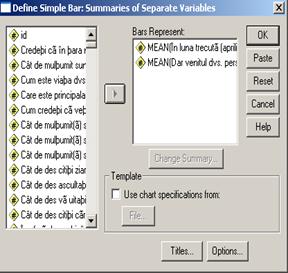
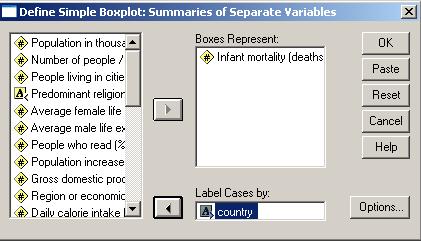
Sa presupunem ca dorim sa reprezentam grafic variabila ven (venitul familiei) si variabila vensub (venitul respondentului la chestionar). Reprezentarea se alege de data aceasta dupa optiunea Summarise of separate variables. Dupa actionarea butonului Define va apare fereastra urmatoare apoi graficul:
![]()
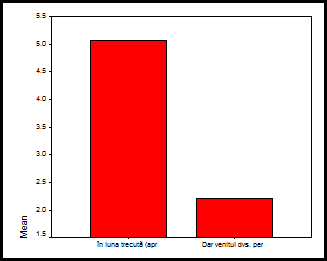
Obs: scala folosita pe axa OY poate crea impresia unei disproportii prea mari intre mediile celor doua variabile. Respectiva scala poate fi modificata dupa ce am dat dublu clic pe grafic si am intrat in fereastra Graph1 vom urma comenzile Chart→Axis→Scale dupa care vom modifica in optiunea Range limitele axei OY. Iata cum arata dupa o astfel de modificare acelasi grafic:
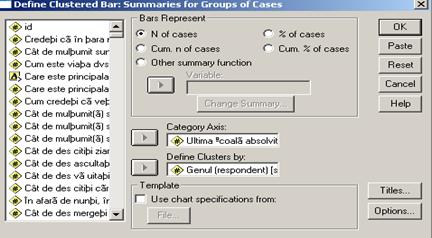
O alta varianta de reprezentare grafica si care este foarte des uzitata este data de optiunea reprezentarii de tip cluster (apar grupuri de bare care se pot compara mai usor). De exemplu ne-ar interesa repartitia din esantionul folosit in aceeasi cercetare dupa variabila scoala0 dar in functie de sexul respondentilor. Vom alege de data aceasta comenzile Charts→Bar Charts→Clustered iar optiunea Summaries for groups of cases ramane neschimbata. Dupa Define apare fereastra:
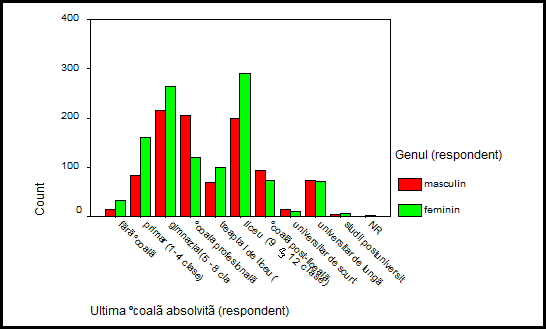
Observam ca pentru axa OX am ales
aceeasi variabila iar variabila care dicteaza dispunerea cluster este
varibila sex. Frecventele vor reprezenta efectiv numarul de
subiecti (N of cases). Din Option am deselectat optiunea Display groups defined by missing values! Graficul este urmatorul:
Revenind la primul exemplu care se referea la variabilele scoala0 si vensub le vom reprezenta un nou grafic cu linii dupa ce vom urma comenzile Graphs→Line.
Procedurile sun asemanatoare cu cele dinainte si vom obtine urmatorul grafic(in fapt un poligon al frecventelor!):
Un alt tip de graphic este cel numit box-plot" si care este foarte util in a depista distributia valorilor seriei dar si dispunerea valorilor (scorurilor) extreme ale variabilei. Acest tip de graphic se mai numeste cutia cu mustati si are urmatoarea conformatie:
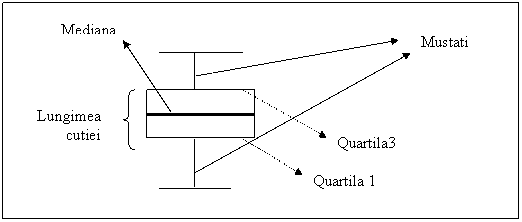
In cazul acestui grafic 50% din date sunt in interiorul cutiei (care are bazele la 25% si la 75% din date adica la quartilele 1 si 3). Mustatile pot avea o lungime de pana la 1,5 latimi ale cutiei. Valorile care cad inafara limitelor (desemnate prin drepte orizontale la capatul "mustatilor" si numite uneori valori adiacente) se numesc valori extreme. Valorile adiacente se obtin scazand din Q1 lungimea cutiei inmultita cu 1,5 si adunind la Q3 aceeasi distanta. Daca o valoare extrema este mai indepartata de trei lungimi de cutie atunci este reprezentata printr-o steluta marcata si cu numarul cazului respectiv. Daca mustatile sunt egale distributia tinde la una normala. Daca mustata superioara este mai mica distribusia este alungita spre stanga.
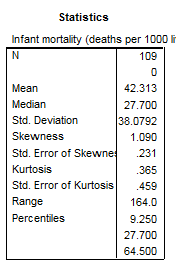
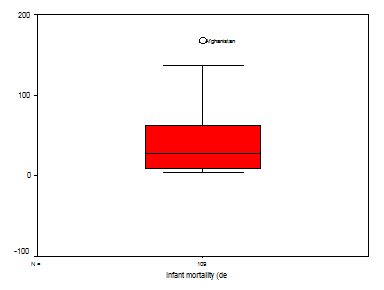
Sa reprezentam grafic variabila babymort din baza de date word95. Vom urma comenzile Graphs→Boxplot:
In cazul graficului
obtinut se observa o singura valoare extrema: mortalitatea infantila
cea mai ridicata este in Afganistan.
De altfel se pot compara reperele grafice cu principalele valori statistice
obtinute din Analyze→Descriptive
Statistics→Frequencies
Obs1: daca cutia este situata mai jos distributia este alungita spre dreapta si exista o concentrare a valorilor mici in partea stanga.
Obs2: daca linia medianei este exact in mijlocul cutiei atunci distributia este normala
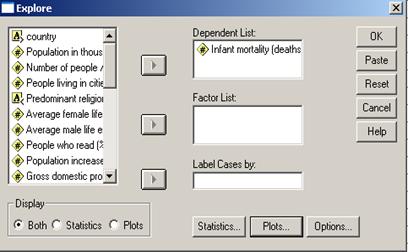
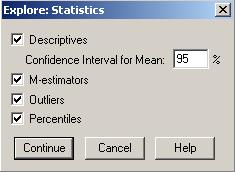
O alta analiza grafica importanta se poate face cu ajutorul comenzilor Analyze→Descriptive Statistics→Explore
Am trecut variabila
de interes in sectorul Dependent
List si apoi vom alege anumite optiuni din cele doua butoane Statistics si Plots. Se pot seta elemente de
statistica descriptiva, intervalul de incredere pentru medie, lista cu
primele/ultimele valori din serie, percentilele 5, 10, 25, 50, 75, 90, 95. De
asemenea se pot alege graficele histograma
si graficul de tip stem-and-leaf.
Acest graphic este expus mai jos:
 Am trecut variabila de inters
Am trecut variabila de inters
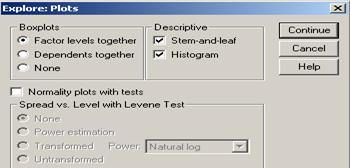
Optiunea
Factor levels together ajuta la
compararea categoriilor variabilei independente iar optiunea Dependent together ajuta la comparari
intre mai multe variabile sau intre mai multe situatii in timp ale
aceleeasi variabile.
Infant mortality (deaths per 1000 live births) Stem-and-Leaf Plot
Frequency Stem & Leaf
200 4455555666666666777778888899
13.00 0122223467799
16.00 0001123555577788
Acest tip de grafic ca si box
plotul a fost propus de catre Kohn W. Tukey si este asemanator
histogramei. In primul rind sunt 28 de tari care au babymort egal cu 4,4,5,5.Pe al
doilea rind sunt valorile 10, 12, 12, 12.Similitudinea cu histograma
este vizibila. Dispunerea se face dupa trunchi (stem) cu valorile 0,1,2,3.si frunzele (leaf) dispuse in partea dreapta a
graficului.
6.00 135679
1.00 Extremes (>=168)
Stem width: 10.0
Each leaf: 1 case(s)
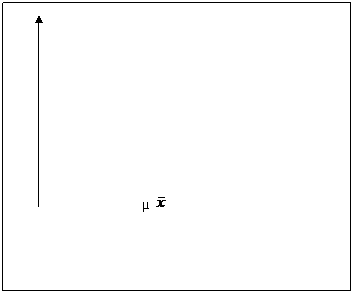
Un alt grafic deosebit de util in cercetarea statistica este cel denumit Error Bar Chart si care e destinat variabilelor numerice. Cu ajutorul acestuia putem reprezenta intervalul de incredere pe care il putem estima pentru media dintr-o populatie. Dupa cum se stie atunci cand extindem rezultatele de la un esantion la o populatie intreaga suntem intr-o situatie de tipul urmator:
Am definit anterior intervalul de
incredere ca fiind tocmai [ SD si n-deviatia standard
si marimea esantionului.
![]() unde
unde ![]() este eroarea standard (adica eroarea data de
pozitia esantionului in populatia de esantioane).
este eroarea standard (adica eroarea data de
pozitia esantionului in populatia de esantioane). ![]()
![]() unde t=1,96 pentru
un nivel de incredere de 95%.
unde t=1,96 pentru
un nivel de incredere de 95%.
Media din esantion Media din populatie Interval de incredere


![]()
![]()
![]()
![]()
![]()
![]()
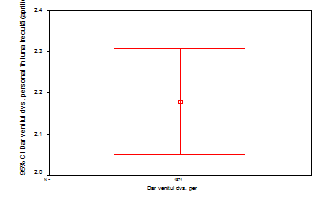
Sa facem graficul pentru variabila vensub (venitul subiectului) din baza de date BOP_mai-2003_Gallup. Alegem comenzile Graphs→Error Bar:
![]()
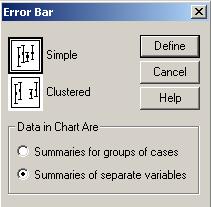
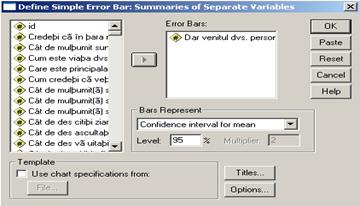
Putem observa
limitele intervalului de incredere pentru o probabilitate de 95% (sau un
prag de semnificatie de 0.05). Spunem ca sunt 5% sanse sa ne
inselam atunci cind facem predictia ca media veniturilor din
populatie este cuprinsa in intervalul respectiv.
Obs: Alte variante de reprezentari grafice se pot executa cu optiunea Graphs→Interactive din care putem alege tipul de grafic necesar .
9. Notele (cotele) Z
Am vorbit si in alte ocazii despre cotele z. Reluam aici unele precizari si le vom aplica apoi in cadrul programului SPSS. Cotele Z ne dau o imagine directa asupra pozitiei pe care o are un subiect fata de media colectivitatii respective cat si fata de dispersia datelor. Acest indicator se numeste masura standard sau cota Z si ne arata cu cate deviatii standard se abate o valoare de la medie. Nota Z are formula urmatoare:
z=![]() sau il gasim cu
notatia z=
sau il gasim cu
notatia z=![]()
Pentru a intelege importanta acestei marimi sa preluam un exemplu din A. Novak [1995]. Astfel fie cazul unui student care a luat la statistica calificativul 7 iar in grupa media
m =5 si s=1. La obiectul psihologie acelasi student a obtinut nota 9 iar in grupa m = 6 si s =2. Se pune intrebarea la care dintre discipline nota a fost mai buna? Initial putem crede ca nota a doua este mai buna. Sa calculam si cotele Z ale respectivelor calificative:
7 - 5 9 - 6
![]()
![]()
Z1
= = 2 Z2= = 1,5
1 2
Din aceste valori deducem ca la prima materie studentul se abate de la media grupei cu doua abateri standard iar la cea de a doua materie se abate de la media grupei cu 1,5 abateri standard. Inseamna ca el se abate in primul caz cu 2 puncte iar in al doilea cu 3 puncte, de unde rezulta ca la prima materie studentul este mai bine plasat. Deoarece datele provin de la aceeasi colectivitate atunci cele doua note Z pot fi cumulate: (2+1,5)/2=1,75 care poate da o pozitie in ansamblu. O aplicatie importanta a variabilei Z o gasim in diverse probleme care impun totusi utilizarea tablei legii normale (afisata in orice carte de statistica).
Pentru a intelege astfel de aplicatii sa dam un alt exemplu, dupa M. Colin et alii [1995] :intr-o universitate rezultatele obtinute la un test se distribuie dupa o lege normala cu m=75 si s= Daca luam un student la intamplare care sunt sansele ca el sa aiba un rezultat cuprins intre 75 si 95 ?
Daca am reprezenta grafic aceasta serie atunci ea ar fi de forma urmatoare:
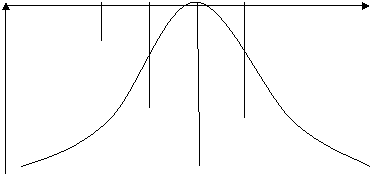
m-3s m-2s m-s m m+s m+2s m+3s
![]()
51 59 67 75 83 91 99
Fiind o distributie normala putem spune ca 68,26% din rezultatele la examen se gasesc intre [59; 91] etc. Acest grafic poate fi reprezentat si in cote Z.
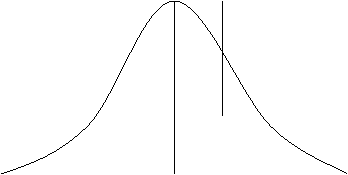
Daca
am reprezenta grafic aceasta serie atunci ea ar fi de forma
urmatoare:
-3 -2 -1 0 1 2 3
Vom calcula cotele Z pentru principalele valori din problema:
Zm 75-75)/8 = 0 Z1 = (X - 75) / 8 Z2= (95 -75)/ 8= 2,50
Daca rezumam pe scurt problema noastra cu enuntul P < X < 95) [a se citi probabilitatea .] atunci in limbajul notelor Z acest enunt devine P ( 0< Z < 2,50) .
Cautand in tabelul legii normale [vezi tabelul de pe pagina urmatoare ; in acest tabel sunt date doar valorile pozitive, cele negative find simetrice vor fi considerate cu semnul minus] se gaseste valoarea 0,4938 care reprezinta proportia din suprafata delimitata de catre curba normala, axa OX si perpendicularele ridicate in punctele 0 si 2,5. Aceasta valoare se poate scrie si 49,38 % si reprezinta chiar probabilitatea cautata: sunt 49,38 % sanse ca studentul respectiv sa aiba calificativul cuprins intre 75 si 95. Practic s-a facut urmatorul transfer:
facut urmatorul transfer:

95 0 2,5

Obs1 : din tabelul urmator atragem atentia si asupra valorii corespunzatoare lui z=1.96 care este de 0,4750 valoare pe care daca o multiplicam cu doi rezulta 0.95. Citim ca la un nivel de 95% incredere z=1 . La fel rationam si pentru o alta valoare importanta z=2 !
Obs2. in general se considera ca scorurile
z trebuie sa se inscrie in intervalul [-3,+3]. Daca z <-1
sau z.>+1 se considera ca valorile respective sunt mici (respectiv mari)
pentru o serie statistica data. Daca z![]() 1] marimea respectiva este considerata medie.
1] marimea respectiva este considerata medie.
X 0.00 0.03 0.04 0.05 0.06 0.07 0.08 0.09
0.49865 0.49869 0.49874 0.49878 0.49882 0.49886 0.49889 0.49893 0.49896 0.49900
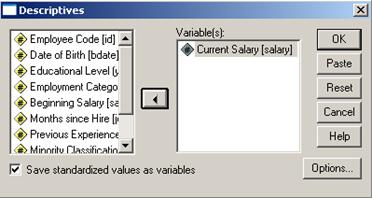
Ne propunem sa calculam cotele z pentru variabila salary din baza de date Employee Data. Pentru aceasta vom urmari comenzile Analyze→ Descriptiv Statistics→Descriptives:
Vom trece in dreapta variabila de
interes si vom seta optiunea Save
standardized values as variables. Din butonul Options se pot alege diverse valori generale da statistica
descriptiva. In baza va apare o noua variabila:![]()
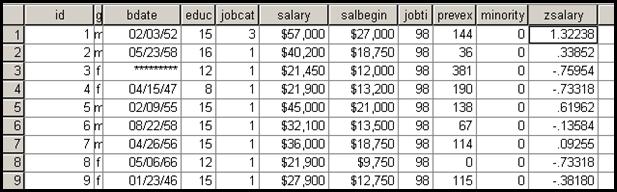
In cazul variabilei zsalary vom putea sa comentam in ce masura anumite valori sunt mici, mari sau medii. De exemplu subiectul nr.1 cu un salar mediu anual de 57.000$ are un scor z de 1,32 ceea ce semnifica o valoare mare printre valorile seriei. Valoare salariului se abate 1,32 abateri standard de la media salariala.
Observatie : in general metodele grafice sunt foarte utile pentru analiza prealabila a datelor. Astfel, inainte de a se trece la analiza propriu-zisa a datelor pe care le-am inserat in Data Editor trebuie sa avem mai intai o imagine generala asupra variabilelor. Dupa cum am vazut in submeniul Explore putem sa obtinem o imagine de ansamblu a variabilelor si reprezentarea grafica a acestora. Prin aceste proceduri putem evita greselile inerente : greseli de inregistrare, greseli date de necunoasterea distributiei variabilei, greseli generate de cazurile lipsa (exista diverse optiuni cum ar fi Exclude cases pairwise-cind un caz nu are o valoare pentru o anumita variabila este exclus din analiza ) etc. Informatii la fel de importante pot fi obtinute si din submeniul Descriptive.
10. Testarea ipotezelor statistice; praguri de semnificatie
In general majoritatea rationamentelor umane sunt alcatuite din combinatii de doua sau mai multe variabile. Este si cazul ipotezelor statistice care nu sunt altceva decat asertiuni privind diverse fenomene naturale sau sociale, asertiuni pe care la facem in vederea testarii lor ulterioare. O ipoteza statistica este de obicei compusa dintr-un cuplu de doua enunturi:
-H0 (ipoteza de nul) si
-H1 ( ipoteza de lucru).
Primul enunt H0 descrie, de obicei (dar nu e obligatoriu!) situatia cand o anumita variabila sau fenomen nu este prezenta sau nu actioneaza (sau ca, de exemplu, nu exista o diferenta semnificativa intre doua conditii). Este ca si cum am spune ca un anumit lucru daca se intampla este doar rodul intamplarii. Ipoteza de nul este tocmai cea care este testata.
Al doilea enunt H1 descrie situatia contrara enuntului H0 cand o variabila sau fenomen actioneaza si are o influenta semnificativa:
Exemple: H1: sexul respondentilor influenteaza parerea acestora despre impozite.
H0: opinia despre impozite nu este influentata de sexul respondentilor.
H1: autoturismul
H0: autoturismul
Din astfel de exemple deducem ca in analiza statistica suntem nevoiti fie sa acceptam H0 fie pe H1, deoarece ambele sunt disjunctive. Un astfel de rationament se va face intotdeauna in termeni de prag de semnificatie (sau interval de incredere) pentru ca in realitate orice presupozitie statistica se face cu o anumita marja de eroare, cu o anumita sansa de a ne insela. De exemplu cand vorbim de un prag de semnificatie (notat p) de 0.05 spunem de fapt ca sunt 5% sanse sa ne inselam atunci cind facem o anumita asertiune statistica (iar in "oglinda" spunem ca sunt 95% sanse sa nu ne inselam cand facem respectivul rationament). La fel, cand vorbim de un prag de semnificatie de 0,01 spunem ca sunt 1% sanse sa ne inselam (sau 99% sanse sa nu ne inselam). Evident ca in cel de al doilea caz gradul de siguranta este mai mare.
Si in cazul
testarii ipotezelor intervin astfel de precizari. Astfel ca vorbim de un prag de semnificatie de 0.05 in sensul ca "sunt 5%
sanse de a ne insela atunci cind acceptam ipoteza de lucru H1 (sau
respingem ipoteza de nul H0)". In majoritatea cercetarilor este acceptat un prag maxim de 0.05 sau p![]() 0.05 dar se intalnesc si praguri mai mari decat 0.05 (intotdeauna aceste
praguri trebuie amintite pentru a se clarifica gradul de precizie dorit de
cercetator).
0.05 dar se intalnesc si praguri mai mari decat 0.05 (intotdeauna aceste
praguri trebuie amintite pentru a se clarifica gradul de precizie dorit de
cercetator).
Trebuie sa precizam ca exista posibilitatea sa ne inselam chiar si in aceste conditii. Adica de exemplu sa acceptam o ipoteza de lucru pentru ca toate datele statistice o confirma dar, in esenta, acea ipoteza sa fie totusi falsa. In general se pot comite doua feluri de erori:
Eroare de gradul I: respingem ipoteza nula desi este adevarata
Eroare de gradul II: ipoteza nula este acceptata desi este falsa.
Aceste
doua tipuri de erori sunt complet diferite: eroarea de gradul I este considerata mai grava si tocmai de aceea se cere
sa micsoram pe cat posibil pragul de semnificatie. Unii cercetatori
recomanda aici un prag p![]() 0.01
cu atat mai mult cu cat influenta cercetatorului poate fi importanta. In cel de-al doilea caz
gradul de influenta al cercetatorului este redusa si se recomanda un
prag p
0.01
cu atat mai mult cu cat influenta cercetatorului poate fi importanta. In cel de-al doilea caz
gradul de influenta al cercetatorului este redusa si se recomanda un
prag p![]() 0.05.
Legat de aceste erori sunt folosite in statistica notiunile de putere
(sau probabilitatea de a respinge ipoteza nula cand de fapt ea este
adevarata). [pentru o analiza pe larg a acestei problematici a
se vedea C.Coman, N. Medianu, 2002 ;144 si
urm.]
0.05.
Legat de aceste erori sunt folosite in statistica notiunile de putere
(sau probabilitatea de a respinge ipoteza nula cand de fapt ea este
adevarata). [pentru o analiza pe larg a acestei problematici a
se vedea C.Coman, N. Medianu, 2002 ;144 si
urm.]
Ipotezele statistice sunt testate prin teste statistice. De obicei testul statistic desemneaza o comparatie intre o situatie presupusa si una rezultata in urma cercetarii de teren efective. Comparatiile in statistica sociala sunt foarte diverse: fie se fac observatii pe o singura variabila, fie se compara valori din doua esantioane, fie se compara valorile dintr-un esantion cu valorile unei populatii mai extinse, fie se analizeaza diverse situatii experimentale etc. In general in testarea ipotezelor se urmareste o anumita directie, un anumit sens al legaturilor.Din acest punct de vedere sunt doua tipuri de rationamente: one-tailed (unilateral) si two-tailed (bilateral)! One-tailed este utilizat atunci cand se cunoaste dinainte sensul predictiei statistice iar varianta two- tailed este preferata atunci cand nu se cunoaste "in avans" sensul predictiei.
O alta precizare importanta este aceea ca sunt doua tipuri fundamentale de teste statistice: parametrice si non-parametrice. Testele parametrice sunt considerate mai puternice dar pentru aceasta trebuie sa fie indeplinite mai multe conditii importante:
- populatia din care a fost extras esantionul sa aiba o distributie normala (distributia normala trebuie sa se regaseasca si in esantion altfel se pot face anumite transformari pentru a se ajunge la o distributie normala)
-regula omogenitatii variantei (dintre cea din esantion si cea din populatie)
-in majoritatea cazurilor variabilele trebuie sa fie masurate pe scale de interval.
-nu trebuie sa existe scoruri extreme (metodele parametrice sunt sensibile in astfel de situatii).
Daca testele parametrice folosesc metode numerice cele ne-parametrice folosesc pozitiile pe care valorile le au in cadrul variabilelor. Nefiind vulnerabile la valori extreme unii statisticieni vorbesc de o mai mare stabilitate a acestor teste.
In functie de aceste precizari se recomanda folosirea unor teste diverse in functie de necesitati. Din multele tipuri de clasificari redam una dintre ele consemnata de Christine P. Dancey si J. Reidy (1999) [vezi tabelul urmator]. Spatiul limitat al acestui curs nu permite insa decat parcurgerea a catorva proceduri din acest tabel.
Obs: 1.Testele incluse in tabelul respectiv reprezinta modalitati de analiza a legaturii dintre variabile. Se disting astfel metode parametrice dar si neparametrice de studiu a acestor legaturi.
2. Testarea diferentei intre doua conditii reprezinta o modalitate foarte raspindita de analiza. De exemplu putem analiza care este influenta unei sesiuni de comunicari pentru studentii la sociologie. Probabil ca cei ce parcurg sesiunea respectiva vor avea cunostinte mai bune. Pentru a testa acest lucru putem dispune de doua tehnici principale:
A. Se compara doua grupuri diferite de studenti (alocati aleator) unul care parcurge respectiva sesiune si unul care nu urmeaza acea sesiune, apoi se compara rezultatele unei examinari. Acest tip de analiza se numeste between participants design (rezultatele vin de la doua grupuri).
B. Se compara un singur grup care trece prin cele doua conditii, odata fara sa parcurga sesiunea respectiva iar a doua oara dupa parcurgerea acesteia. Rezultatele unor examinari succesive vor decide care este influenta urmarii sesiunii. Acest tip de analiza se numeste within participant design (rezultatele vin de la acelasi grup).
In fapt compararea intre conditii inseamna compararea unor medii si daca diferenta dintre aceste medii este semnificativa. Testele folosite in aceste cazuri trebuie sa raspunda la o intrebare importanta: este diferenta data de erori de esantionare sau cu adevarat se manifesta influenta unei variabile independente cu efecte importante in variatia variabilei dependente?
|
Nivel al masurarii |
Tip de statistica descriptiva |
Tipuri de statistica inferentiala |
||||||||||||||||||||||||
|
Teste de corelatie/asociere |
Teste ale diferentei intre doua conditii asupra unei var. Independ. |
Teste ale diferentei mai mult de doua conditii asupra unei var. independente |
Teste referitoare la doua sau mai multe var. Independ. Sau var. depend |
|||||||||||||||||||||||
|
|
|
Testul
|
| |||||||||||||||||||||||
|
Ordinal |
Scala poate fi de interval? Mediana
/modul
DA DA |
Spearman (
|
Within-participants TestWilcoxon Between-participants Mann Whitney U Test |
Within-participants Friedman ANOVA Between-participants Kruskal-Wallace one way ANOVA | ||||||||||||||||||||||
|
Interval/ratio |
Aveti
valori extreme? NU
Media |
Coeficientul lui Pearson DA |
Within-participants Related t-test Between-participants Independent t-test |
One way ANOVA |
Factorial ANOVA Multivariate ANOVA |
|||||||||||||||||||||
11. Testarea normalitatii unei distributii
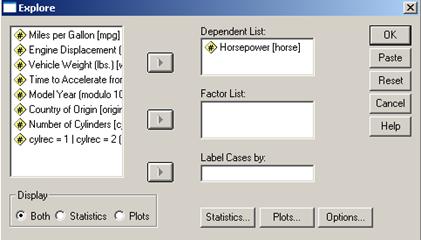
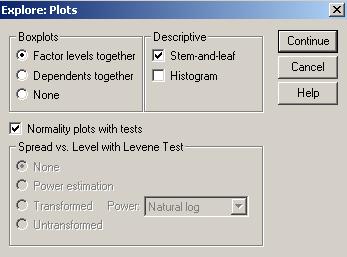
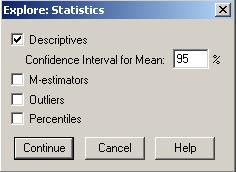
Nu de putine ori asumtia ca un esantion sau o populatie sa aiba o distributie normala dupa o variabila cantitativa este necesara pentru a executa anumite analize statistice. O prima impresie poate fi data de histograma seriei dar nu este suficient acest lucru. Un test care poate sustine aceasta analiza este testul Kolmogorov-Smirnov si care de fapt compara distributia din esantion cu o alta distributie (normala) care are aceeasi medie si abatere standard. Sa presupunem ca dorim sa verificam normalitatea variabilei horsepower (puterea motorului) din baza de date Cars din programul SPSS. Vom urma comenzile Analyze→Descrtiptive Statistics→Explore:
In rubrica Dependent list am trecut variabila
care urmeaza sa fie analizata. Din butonul Statistics putem selecta principalele valori de statistica
descriptiva iar din butonul Plots
nu trebuie uitata setarea Normality
plots with tests.
Interpretarea
testului este urmatoarea: daca pragul de semnificatie este p<0.05 atunci testul este semnificativ in
sensul ca distributia din esantion este semnificativ diferita de
o distributie normala. Este si
aici cazul pt. Sig.=0.000. Rezultatul
testului este urmatorul:


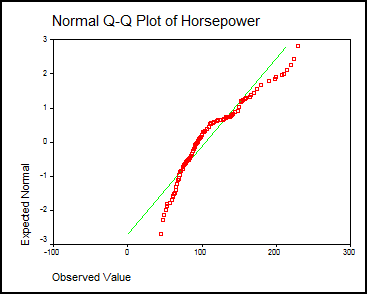
Obs: In aplicarea testului de mai sus am tinut seama si de marimea esantionului. Astfel se considera ca testul K.-Smirnov este valabil cand esantionul>50 de subiecti. Daca esantionul este mai mic atunci se aplica testul W al lui Shapiro-Wilks. Programul SPSS calculeaza oricum automat ambele teste. Formularea in sensul ipotezelor statistice ar fi urmatoarea: Ho: "intre distributia variabilei si cea teoretica nu este o diferenta semnificativa" iar H1: "intre cele doua distributii exista o diferenta semnificativa". Daca p<0.05 atunci respingem ipoteza de nul si o admitem pe cea de lucru.
12. Corelatia dintre doua variabile cantitative
Se pune deseori problema de a analiza legatura dintre doua variabile cantitative in sensul de a vedea in ce masura valorile respective co-variaza (de exemplu valorile mari dintr-o variabila coreleaza cu valorile mari din cealalta variabila). Corelatia masoara relatia liniara dintre variabile si se masoara cu coeficientul de corelatie Pearson (r). Acest coeficient are o formula simpla si care sugereaza modul cum este calculat:
![]()
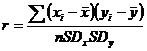 .
.
Din formula se vede ca la numitor avem suma tuturor produselor distantelor valorilor din cele doua serii de la mediile respective iar la numitor produsul dintre numarul de cazuri (n) si cele doua abateri standard din cele doua serii. Fiind asadar un test parametric (luand in calcul in mod direct toate valorile seriilor) calcularea acestui coeficient trebuie sa tina seama de conditiile din acest caz [A. Field, 2000; 37]:
1.Asumtia distributiei normale [datele trebuie sa provina din populatii normal distribuite (se poate verifica acest lucru cu testul K.-Smirnov)],
2. Asumtia omogenitatii variantei [variantele din cele doua variabile trebuie sa fie stabile la orice nivel],
3. Asumtia scalei de masurare (scala de masurare trebuie sa fie cea de interval)
4. Asumtia independentei (subiectii de la care s-au obtinut valorile respective sa fie independenti unul de altul).
Coeficientul de corelatie este intotdeauna cuprins in intervalul [-1, +1] intelegand prin aceasta toate valorile reale din acest interval. Interpretarea valorilor este urmatoarea:
1. r tinde sau este foarte
aproape de ![]() 1 atunci corelatia este puternica (de acelasi
sens sau de sens contrar)
1 atunci corelatia este puternica (de acelasi
sens sau de sens contrar)
2. r tinde la 0 atunci corelatia nu exista
3. r tinde la ![]() 0,5 corelatia este de intensitate medie.
0,5 corelatia este de intensitate medie.
Se impun aici o serie de observatii:
1. Relatia de corelatie nu trebuie privita ca si o relatie cauza- efect, de la o variabila independenta la una dependenta, desi de multe ori se face un astfel de rationament. Interpretarea nu priveste decat faptul ca valorile ambelor variabile co-variaza intr-un anume sens!
2. In general daca variabilele sunt independente atunci coeficientul r se anuleaza. Dar reciproca nu este adevarata: nu este sigur ca daca r se anuleaza atunci si variabilele sunt independente [a se vedea T. Rotariu, 1999; 173]. Aici se impune o observatie importanta: cand r=0 suntem siguri doar ca nu exista o corelatie liniara a celor doua variabile dar poate exista o corelatie de alt fel (curbilinie). Cand vorbim de corelatie liniara intelegem faptul ca daca reprezentam grafic corelatia cu ambele variabile axe de coordonate vom obtine un "nor de puncte" care se poate alinia dupa o dreapta (intotdeauna este recomandat sa verificam si grafic corelatia deoarece ea este valabila doar ca si corelatie liniara). Situatiile pot fi urmatoarele:
![]()
![]()
![]()
 | |||||||
 |
|||||||
r r→ -1 r→0
3. Coeficientul de corelatie da doua
rezultate importante: puterea asocierii dintre variabile si sensul acestei
asocieri. In general valorile din jurul valorilor ![]() 1 sugereaza o
corelatie foarte puternica, aproape perfecta. Valorile intre
1 sugereaza o
corelatie foarte puternica, aproape perfecta. Valorile intre ![]() 0,6 si
0,6 si ![]() 0,8 denota o corelatie puternica, valorile din jurul
valorilor de
0,8 denota o corelatie puternica, valorile din jurul
valorilor de ![]() 0,5 dau o corelatie de intensitate medie iar cele
marimea
0,5 dau o corelatie de intensitate medie iar cele
marimea ![]() 0,1
0,1![]() 0,4 sugereaza corelatii slabe. Sensul corelatiilor
este dat de semnul acestora: semnul +sugereaza ca variabilele cresc sau scad in
acelasi timp iar semnul - sugereaza faptul ca valorile unei variabile
cresc in acelasi timp ce valorile celeilalte variabile scad.
0,4 sugereaza corelatii slabe. Sensul corelatiilor
este dat de semnul acestora: semnul +sugereaza ca variabilele cresc sau scad in
acelasi timp iar semnul - sugereaza faptul ca valorile unei variabile
cresc in acelasi timp ce valorile celeilalte variabile scad.
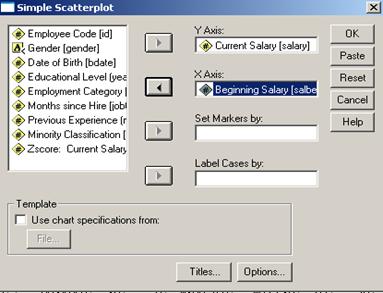
Sa da un exemplu clasic din literatura de specialitate: corelatia dintre variabilele salbegin si salary din baza de date Employee Data. Mai intai vom face analiza asumtiilor destinate metodelor parametrice. Apoi este recomandata vizualizarea grafica a corelatiei urmand comenzile Graphs Scatter si vom alege varianta Simple apoi Define
Cele doua variabile
vor defini chiar axele de coordonate. Optiunea Set Markers by ajuta la analiza corelatiei dupa diferite
categorii de subiecti. Label
Cases by ajuta la identificarea cazurilor dupa o anumita variabila (din
care putem atasa etichete sau
numere de ordine). Graficul este urmatorul:
![]()
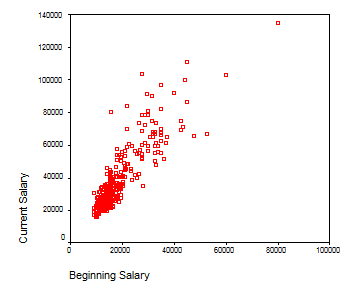
Se observa gruparea punctelor din plan
dupa o dreapta inclinata la aproximativ 450 fata de axa OX.
Putem fi deci siguri privind linearitatea legaturii iar ca si
intensitate se prefigureaza o legatura puternica de acelasi sens.
Acestea fiind spuse putem calcula coeficientul de corelatie dupa alegerea comenzilor: Analyze→Correlate→Bivariate
Exclude cases pairwise- elimina perechile de rezultate pentru care una din valori lipseste. Aceasta optiune este mai des intalnita.
Exclude cases listwise- elimina din analiza un rand intreg daca lipseste doar una dintre valori. Dupa Continue obtinem rezultatul urmator:
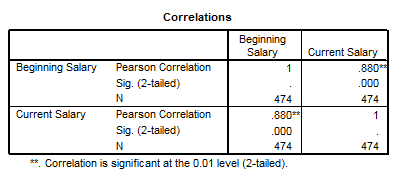
In partea dreapta a tabelului se intersecteaza cele doua variabile. Vedem ca corelatia dintre Beginning Salary si ea insasi este perfecta (r=1). Corelatia dintre Beginning Salary si Current Salary se dovedeste a fi foarte puternica si de acelasi sens (r=0.880). Pragul de semnificatie Sig. (2-tailed) este de 0.000 valoare care nu este un zero absolute ci in realitate doar o valoare foarte mica. Corelatia cuprinde in studiu un numar de 474 perechi de valori sau 474 cazuri. Pe diagonala observam in matrice aceleasi rezultate. Sub tabel este specificat faptul ca corelatia calculate este semnificativa la un prag de p= 0.01. In primul rand se observa ca acest prag p<0.05 ceea ce ne arata ca legatura dintre variabile este semnificativa. In termeni de probabilitate putem spune ca sunt 1% sanse sa ne inselam atunci cand predictionam legatura dintre cele doua variabile (sau marimea si sensul corelatiei). In termenii testarii statistice spunem ca daca H0 este enuntul "variabilele nu sunt corelate" iar H1 este enuntul "exista corelatie intre cele doua variabile" atunci sunt 1% sanse sa ne inselam atunci cand respingem ipoteza de nul.
Obs. Se pot obtine si matrici de corelatie. De exemplu adaugand o a treia variabila educ (nivel educational in ani de zile):
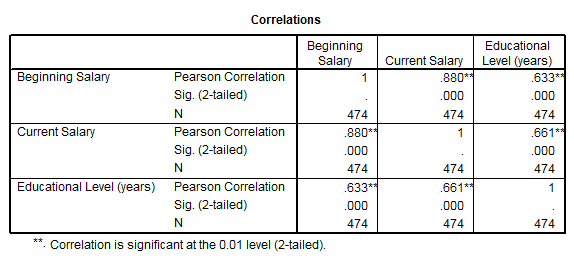
Rezultatele se interpreteaza doua cate doua excluzand prima diagonala unde corelatiile sunt perfecte! In unele analize nu este prezentata decat partea de deasupra sau de dedesuptul acestei diagonale!
12.1 Coeficientul de variatie
Dupa cum am spus mai inainte corelatia nu se interpreteaza ca si o relatie cauzala deoarece nu se poate dovedi statistic care dintre variabile o influenteaza pe alta chiar daca uneori noi rationam in acest sens. Pe de alta parte in evolutia unei variabile pot interveni si alte variabile decat cele considerate in calculul corelatiei. Imaginea dependentei dintre doua variabile putem sa o avem dupa ce am analizat varianta comun impartasita de acestea. Daca am avea doua variabile si am reprezenta grafic variantele lor prin doua diagrame circulare putem spune ca partea din intersectia comuna este varianta comun impartasita:
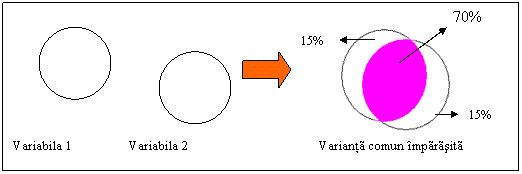
Cu cat suprafata intersectiei este mai mare cu atat varianta comun impartasita este mai mare. In cazul nostru daca am nota suprafata intersectiei cu 100% putem deduce ca aproximativ 70% este varianta comuna restul de 30% nefiind comuna. Varianta comuna ne da o informatie despre dependenta dintre variabile: putem spune ca 70% din varianta unei variabile depinde de varianta celeilalte (altfel spus cat las suta din variatia unei variabile se explica prin variatia celeilalte) iar 15% nu este varianta impartasita sau este datorata influentei altor variabile. In general varianta comuna este calculata prin ridicarea la patrat a coeficientului de corelatie dar se interpreteaza procentual. Se obtin astfel valorile urmatoare [adaptat dupa Ch. P. Dancey si J. Reidy (1999)]:
|
Coeficientul de corelatie r |
Patratul coeficientului r2 |
Se
observa ca de exemplu o corelatie care este foarte puternica de 0,8
desemneaza doar 64% din varianta comuna. De asemenea se observa ca o
corelatie de 0.8 este in realitate de patru ori mai puternica decat
o corelatie de 0.4 (varianta comuna creste de la 16% la
64%). Aceste interpretari nu trebuie insa vazute ca relatii de tip
cauza-efect! |
||
12.2 Corelatie partiala
Din consideratiile de pana acum se deduce faptul ca atunci cand studiem corelatia dintre doua variabile poate exista si influenta altor variabile care vor explica evolutia, variatia unei variabile. De exemplu o buna parte din marimea salariului actual se poate explica prin marimea salariului de debut dar pot exista si alte variabile care sa influenteze remuneratia: nivel de motivatie, performanta in munca, numarul de inovatii aduse procesului muncii etc. Se pune insa si problema relatiilor false dintre doua variabile cand o corelatie puternica dintre doua variabile sa depinda in primul rand de evolutia unei a treia variabile. De exemplu P. Lazarsfeld amintea de legatura care se facea candva intre numarul mare de berze aparute undeva in nordul Frantei si numarul de nasteri in crestere. Cu alte cuvinte se putea obtine o corelatie puternica intre cele doua variabile, ceea ce ar fi explicat mitul berzelor aducatoare de copii! Numai ca relatia dintre variabile controlata de o a treia (denumita mediu) a aratat ca daca rata natalitatii se pastra relativ ridicata in mediul rural, ea scadea semnificatif in mediul urban. Un alt exemplu, cunoscut in literatura de specialitate se referea la corelatia dintre aparitia unui numar crescut de furnici in cautare de hrana si numarul turistilor care au venit la mare pe plaja. Corelatia dintre fenomene se dovedeste falsa din moment ce ele sunt controlate de oa treia variabila caldura care va explica in final co-evolutia primelor doua.
Vom calcula o corelatie partiala plecand de la baza de date World95 [pe larg si in SPSS Base 9.0 Application guide]. Vom analiza mai intai variabilele urban (People living in cities %) si birth_rt (Birth rate per 1000 people). Pentru inceput vom calcula corelatia simpla intre cele doua variabile:
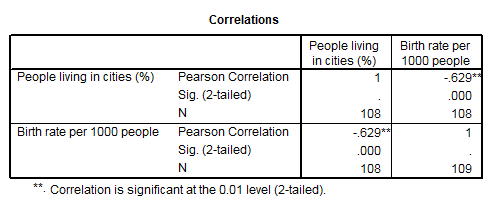
Rezultatul ne arata o corelatie puternica de sens contrar (r = - 0.629) la un prag de semnificatie de 0.01. Ceea ce insemna ca cifrele inalte ale urbanizarii sunt insotite de cifre scazute ale ratei natalitatii. Se pune problema daca aceasta corelatie ramane valida daca o controlam cu o a treia variabila. Am ales pentru control variabila log_gdp (logaritm zecimal din produsul intern brut /locuitor). Aceasta variabila a fost obtinuta prin logaritmare din variabila gdp_cap dar sensul acesteia este acelasi: gradul de prosperitate al unei tari oarecare. Aceasta operatie a fost necesara pentru a normaliza distributia variabilei si astfel pentru a putea intra in calculele de tip parametric!
Pentru a genera o corelatie partiala vom urma comenzile urmatoare: Analyze→ Correlate→Partial dupa care a va apare fereastra urmatoare:
In aceasta fereastra
am trecut in dreapta variabilele de corelat iar in rubrica Controlling for am trecut variabila
de control. Din butonul Option
pot fi selectate si alte elemente de statistica descriptiva si
chiar matricea corelatiilor dintre toate cel trei variabile. Rezultatul corelatiei partiale
este vizibil in urmatoarea situatia de mai jos. Se observa ca
corelatia dintre variabilele urban si birth_rt scade semnificativ la -0.11 aproape de zero
ceea ce face ca relatia dintre
variabile sa se anuleze. Daca se intampla acest lucru spunem ca
influenta variabilei de control este semnificativa si ca fosta
corelatie nu se mai pastreaza. Este ca si cum am spune ca rata
natalitatii se va mentine ridicata in zonele cu o populatie
urbana mai putin prospera. Daca coeficientul de corelatie ramanea
aproximativ la fel atunci se considera ca influenta variabilei de control
este neglijabila.

Obs: situatia de pana acum descrie corelatia partiala de prim ordin. Se pot face insa si corelatii partiale de al doilea ordin atunci cand introducem doua variabile de control. Pot urma chiar mai multe variabile de control.
12.3 Corelatia ca metoda neparametrica
Dupa cum am observat corelatia se leaga de variabile exprimate cantitativ (prin numere). Aceste variabile pentru a putea fi tratate prin metode parametrice trebuie sa indeplineasca o serie de conditii (asumtii). Daca aceste conditii nu sunt indeplinite se recomanda folosirea metodelor neparametrice deoarece in acest caz se va lucra cu pozitiile valorilor respective si nu cu valorile in sine. Apelam la astfel de tehnici atunci cind, de exemplu, variabilele de interes nu provin dintr-o populatie normal distribuita sau cand anumite valori extreme (outliers) pot vicia rezultatele statistice. Practic se produce o trasnsformare a unor date numerice oarecare intr-o variabila ordinala dar in care distantele dintre valori sunt egale. De exemplu daca intr-o serie avem 5 subiecti cu salariile de 1,5; 2,3; 4,8; 3,9 si 25,4 milioane de lei, avand in vedere distributia seriei putem sa le dam pozitii acestora dupa salariul respectiv: 5, 4, 2,3, 1. Aceste valori nu sunt cantitative dar genereaza o ordine exact ca si pe o scara de interval cu intervale egale.
Pentru exemplificare sa alegem variabilele age si educ din baza de date GSS93 subset.
Vom observa ca cele
doua variabile sunt definite ca ordinale si vor imparti
populatia in mai multe categorii. De exemplu cand un subiect primeste
eticheta 10 pentru variabila educ asta inseamna ca el intra in clasa celor cu
10 ani de studii. La fel se procedeaza si in variabila age. In acest caz este mai recomandat
coeficientul Spearman (![]() ) care are aceleasi valori ca si coeficientul Pearson. Dupa aceleasi etape
si dupa setarea coeficientului Spearman obtinem rezultatul urmator:
) care are aceleasi valori ca si coeficientul Pearson. Dupa aceleasi etape
si dupa setarea coeficientului Spearman obtinem rezultatul urmator:
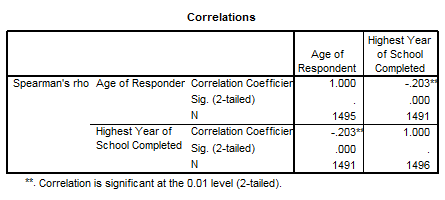
Se observa ca corelatia
este ![]() = -0.203 si este semnificativa (p=0.01). Corelatia
este slaba si de sens contrar.
= -0.203 si este semnificativa (p=0.01). Corelatia
este slaba si de sens contrar.
In astfel de cazuri se recomanda chiar folosirea unui al treilea coeficient
Kendall (![]() ). El este util mai ales cand exista foarte multe valori
care ca aiba acelasi rang. In cazul nostru de exemplu 55 de subiecti
au pozitia 10 (ani de studiu) in timp ce pozitia 12 (12 ani de studiu) este destinata la 445 de
subiecti dintr-un esantion de 1500. Se poate deci calcula si acest
coeficient:
). El este util mai ales cand exista foarte multe valori
care ca aiba acelasi rang. In cazul nostru de exemplu 55 de subiecti
au pozitia 10 (ani de studiu) in timp ce pozitia 12 (12 ani de studiu) este destinata la 445 de
subiecti dintr-un esantion de 1500. Se poate deci calcula si acest
coeficient:
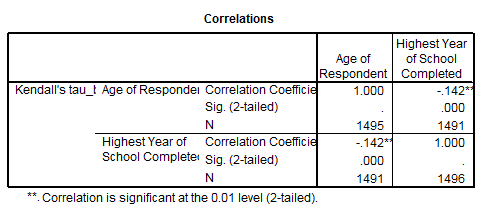
Se observa ca
corelatia este ![]() = -0.142 si este semnificativa (p=0.01). Corelatia
este slaba de sens contrar. Avand in vedere conditiile de aplicare se
poate spune ca acest coeficient este mai fidel in a reflecta corelatia
dintre variabile. Este deci important de a analiza atent variabilele pentru a
aplica mai apoi testarea corelatiei.
= -0.142 si este semnificativa (p=0.01). Corelatia
este slaba de sens contrar. Avand in vedere conditiile de aplicare se
poate spune ca acest coeficient este mai fidel in a reflecta corelatia
dintre variabile. Este deci important de a analiza atent variabilele pentru a
aplica mai apoi testarea corelatiei.
13. Asocierea variabilelor calitative (nominale)
Daca pentru variabilele cantitative vorbim de corelatie atunci pentru variabile categoriale (calitative) vorbim de asociere. Exemple de astfel de variabie sunt foarte frecvente in analizele sociale: sexul respondentilor, religia respondentilor, statut marital, aprecierea despre seful direct (1. foarte buna, 2. buna, 3.proasta, 4. foarte proasta, 5. ns/nr), etc. In toate aceste variabile subiectii sunt impartiti in mai multe categorii dupa o caracteristica sau raspuns dat cu precizarea ca fiecare subiect va intra intr-o singura categorie. Se pune deci problema de a vedea in ce masura doua variabile de acest fel sunt asociate. De exemplu daca sexul respondentilor influenteaza opinia despre seful direct. Datele obtinute in urma anchetelor sau cercetarilor se introduc in ceea ce se numeste tabel de contingenta asemanator cu o matrice in care pe linie intra categoriile unei variabile iar pe coloana categoriile celeilalte variabile. In aceste conditii fiecare celula este la intersectia a doua variante de raspuns din cele doua variabile. In general se disting mai multe cai de a studia asocierea:
-cind ne referim doar la o singura variabila
-cind ne referim la doua variabile dihotomice
-cand ne referim la asocierea dintre variabile cu mai mult de doua categorii.
Ne propunem in continuare sa ne ocupam de problematica asocierii dar numai pentru variabile categoriale nominale cei interesati putand urmari tematica pentru variabile ordinale si din bibliografia anexata cursului.
Cand ne referim doar la o singura variabila analizam practic o grupare de subiecti dupa diverse valori nominale sau ordinale ale unei variabile. Ideea este de a compara frecventele observate cu o serie de valori impuse de cercetator si care sunt considerate valori teoretice. Sa analizam un exemplu din baza de date GSS 93 subset. Una din variabile este opera si reprezinta raspunsurile subiectilor privitoare la acest gen muzical. Se pune intrebarea daca respondentii au o parere formata despre acest gen muzical. Se va apela la comenzile Analyze→Nonparametric Tests→ Chi-Square Test:
Dupa ce am trecut variabila de interes
in dreapta putem alege variante privind valorile teoretice. Astfel vom alege
optiunea All categories equal care
ar fi situatia teoretica in care toate variantele de raspuns sunt
egale cantitativ. Pot fi alese si alte cofiguratii teoretice prin
optiunea Values Add sau date de
anumute ranguri (Use specified ranges).
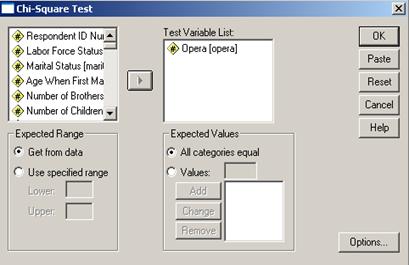
Facem precizarea ca situatia teoretica descrie in fapt situatia de independenta cind toate variantele de raspuns ar fi indicate de acelasi numar de subiecti. Faptul ca frecventele observate (cele din teren) nu coincid cu cele teoretice ne poate da o sugestie privind preferinta pentru acest gen muzical. Rezultatele sunt urmatoarele:
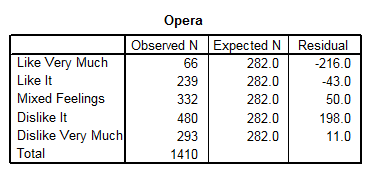

Dupa ce trecem cele
doua variabile in dreapta ca definind liniile (rows) si colooanele
(columns) vom apela la butonul Cells
pentru o serie de optiuni suplimentare:
Cazul a doua variabile dihotomice (ambele cu cate doua valori) este tratat
pe larg in T. Rotariu (1999; 121-133) si de aceea vom face doar cateva
precizari sumare. Sa construim un tabel de contingenta plecand de la
variabilele a1 (Credeti
ca in tara noastra lucrurile merg intr-o directie buna sau intr-o
directie gresita?) si sex0
(sexul respondentilor) din baza de date BOP_mai-2003_Gallup. sav. Tabelul respectiv se obtine dupa
comenzile Analyze Descriptive
Statistics Crosstabs dupa ce in
prealabil am considerat valorile care nu sunt principalele doua variante de
raspuns ca fiind valori lipsa:
Se observa ca am selectat apoi optiunile Observed, Expected precum si procentajele pe linii (Percentages Rows). Se mai pot alege optiuni privind reziduurile care nu sunt altceva decat diferentele intre frecventele observate si cel asteptate. Dupa Continue OK tabelul este urmatorul:
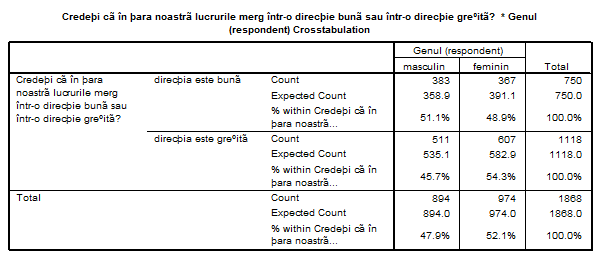
Datele din astfel de tablouri sunt relativ simplu de interpretat. Astfel 389 (51%) dintre respondentii care cred ca directia este buna sunt de gen masculin si la fel 511 (45,7%) dintre cei ce cred ca directia este gresita. Se observa ca totalul cazurilor valide este de 1868 persoane din care 894 barbati si 974 femei. In fiecare celula se gasesc si valorile numite Expected, valori teoretice care corespund situatiei cand cele doua variabile sunt independente.
Atunci cand analizam problematica asocierii de fapt urmam rationamentul unei ipoteze statistice:
H0: variabilele calitative nu sunt asociate
H1: variabilele sunt asociate.
Pentru masurarea asocierii dintre cele doua variabile se foloseste
testul ![]() . Acest test se bazeaza pe diferentele calculate dintre
doua tipuri de date: cele asteptate (teoretice) care reprezinta situatia
de independenta dintre variabile si cele observate (obtinute in
urma cercetarii efective). Conform formulei de calcul
. Acest test se bazeaza pe diferentele calculate dintre
doua tipuri de date: cele asteptate (teoretice) care reprezinta situatia
de independenta dintre variabile si cele observate (obtinute in
urma cercetarii efective). Conform formulei de calcul ![]() este o marime care se obtine din suma patratelor
diferentelor dintre frecventele observate (fo) si si cele teoretice (ft)
impartite la frecventele teoretice:
este o marime care se obtine din suma patratelor
diferentelor dintre frecventele observate (fo) si si cele teoretice (ft)
impartite la frecventele teoretice: ![]() . Se pleaca de la ideea ca cu cat acest coeficient este mai
mic cu atat cresc sansele ca variabilele sa fie independente si cu
cat coeficientul este mai mare cu atat mai sigur variabilele sunt asociate.
Pentru ca aceste aprecieri au nevoie de intervale precise de fapt se impune
compararea valorilor coeficientului cu alte valori, considerate teoretice
si care se gasesc in tabele statistice speciale. De fapt se ajunge la reformularea
ipotezei statistice de care vorbeam:
. Se pleaca de la ideea ca cu cat acest coeficient este mai
mic cu atat cresc sansele ca variabilele sa fie independente si cu
cat coeficientul este mai mare cu atat mai sigur variabilele sunt asociate.
Pentru ca aceste aprecieri au nevoie de intervale precise de fapt se impune
compararea valorilor coeficientului cu alte valori, considerate teoretice
si care se gasesc in tabele statistice speciale. De fapt se ajunge la reformularea
ipotezei statistice de care vorbeam:
1. Daca ![]() atunci resping H0 si admit H1
atunci resping H0 si admit H1
2. Daca ![]() atunci resping H1
si admit H0.
atunci resping H1
si admit H0.
Aceste rationamente trebuie sa tina seama de urmatoarele conditii:
a. relatiile de mai sus se specifica pentru un anumit prag de semnificatie
b. trebuie avute in vedere gradele de libertate ale tabelului de contingenta. Se noteaza cu df (degree of freedom) si se calculeaza cu formula: df= (n-1)(m-1), unde n este numarul de linii ale tabloului iar m numarul de coloane.
c. In tabloul de
contingenta trebuie sa nu existe celule in care valoarea frecventelor
asteptate (Expected Count) sa fie mai mici de 5. In unele calcule se cere
ca numarul acestor cazuri sa fie mai mic de 20%. Reducerea numarului de cazuri
este insa foarte importanta: daca creste marimea tabelului de
contingenta si invariabil creste si coeficientul ![]() !
!
d. valorile teoretice (sau critice) ale coeficientului sunt cele din urmatoarea lista:
|
Df Praguri semnif |
.10 |
.05 |
.02 |
.01 |
.001 |
|
1 |
2.71 |
3.84 |
5.41 |
6.64 |
10.83 |
|
2 |
4.60 |
5.99 |
7.82 |
9.21 |
13.82 |
|
3 |
6.25 |
7.82 |
9.84 |
11.34 |
16.27 |
|
4 |
7.78 |
9.49 |
11.67 |
13.28 |
146 |
|
5 |
9.24 |
11.07 |
13.39 |
15.09 |
20.52 |
|
6 |
10.64 |
12.59 |
15.03 |
16.81 |
22.46 |
|
7 |
12.02 |
14.07 |
16.62 |
148 |
24.32 |
|
8 |
13.36 |
15.51 |
117 |
20.09 |
26.12 |
|
9 |
14.68 |
16.92 |
19.68 |
21.67 |
27.88 |
|
10 |
15.99 |
131 |
21.16 |
23.21 |
29.59 |
|
11 |
17.28 |
19.68 |
22.62 |
24.72 |
31.26 |
|
12 |
155 |
21.03 |
24.05 |
26.22 |
32.91 |
|
13 |
19.81 |
22.36 |
25.47 |
27.69 |
34.53 |
|
14 |
21.06 |
23.68 |
26.87 |
29.14 |
36.12 |
|
15 |
22.31 |
25.00 |
226 |
30.58 |
37.70 |
|
16 |
23.54 |
26.30 |
29.63 |
32.00 |
39.25 |
|
17 |
24.77 |
27.59 |
31.00 |
33.41 |
40.79 |
|
18 |
25.99 |
287 |
32.35 |
34.80 |
42.31 |
|
19 |
27.20 |
30.14 |
33.69 |
36.19 |
43.82 |
|
20 |
241 |
31.41 |
35.02 |
37.57 |
45.32 |
|
21 |
29.62 |
32.67 |
36.34 |
393 |
46.80 |
|
22 |
30.81 |
33.92 |
37.66 |
40.29 |
427 |
|
23 |
32.01 |
35.17 |
397 |
41.64 |
49.73 |
|
24 |
33.20 |
36.42 |
40.27 |
42.98 |
51.18 |
|
25 |
34.38 |
37.65 |
41.57 |
44.31 |
52.62 |
|
26 |
35.56 |
388 |
42.86 |
45.64 |
54.05 |
|
27 |
36.74 |
40.11 |
44.14 |
46.96 |
55.48 |
|
28 |
37.92 |
41.34 |
45.42 |
428 |
.56.89 |
|
29 |
39.09 |
42.56 |
46.69 |
49.59 |
530 |
|
30 |
40.26 |
43.77 |
47.96 |
50.89 |
59.70 |
Se obseva in acest
tabel pe prima linie orizontala pragurile de semnificatie de las 0.1
la 0.001. Pe prima coloana se gasesc gradele de libertate. Valoarea critica
a lui Pentru a calcula
coeficientul
![]() se citeste la intersectia unui prag de
semnificatie si a unui anumit numar de grade de libertate. Se
compara apoi valoarea coeficientului cu valoarea calculata (de catre
computer) si se urmareste rationamentul de mai sus.
se citeste la intersectia unui prag de
semnificatie si a unui anumit numar de grade de libertate. Se
compara apoi valoarea coeficientului cu valoarea calculata (de catre
computer) si se urmareste rationamentul de mai sus. ![]() vom apela in fereastra de mai sus la butonul Statistics si vom alege doar varianta
Chi-Square din coltul din
stanga sus apoi Continue OK
vom apela in fereastra de mai sus la butonul Statistics si vom alege doar varianta
Chi-Square din coltul din
stanga sus apoi Continue OK
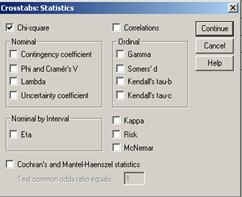
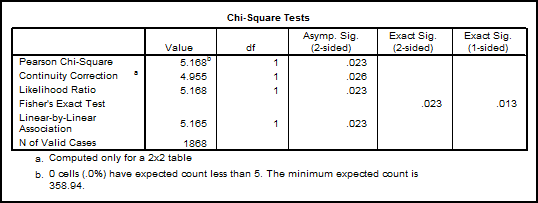
Rezultatul se
interpreteaza din acest tabel. Coeficientul ![]() =5,168 pentru 1 grad de libertate si un prag de
semnificatie de 0.023 (Asymp. Sig).
Programul mai calculeaza un coeficient de corectie care se aplica de
obicei cand exista celule cu valori teoretice mai mici decat 5; un coeficient
echivalent cu primul Likelihood
Ratio) apoi un gen de corelatie care nu este semnificativa aici
(Linear-by-Linear Association). Distingem valorile testului Fisher
=5,168 pentru 1 grad de libertate si un prag de
semnificatie de 0.023 (Asymp. Sig).
Programul mai calculeaza un coeficient de corectie care se aplica de
obicei cand exista celule cu valori teoretice mai mici decat 5; un coeficient
echivalent cu primul Likelihood
Ratio) apoi un gen de corelatie care nu este semnificativa aici
(Linear-by-Linear Association). Distingem valorile testului Fisher ![]() (ale carui valori le
vom detalia in continuare) care confirma lipsa asocierii. Sunt precizate numarul de cazuri valide (aici 1868) iar la final se
precizeaza cate celule au valori asteptate in numar mai mic decat 5.
Valoarea lui
(ale carui valori le
vom detalia in continuare) care confirma lipsa asocierii. Sunt precizate numarul de cazuri valide (aici 1868) iar la final se
precizeaza cate celule au valori asteptate in numar mai mic decat 5.
Valoarea lui ![]() =5,168 se compara cu cea din tabelul de mai inainte si
anume cu valoarea 5,41 (pentru df=1 si p=0.02). Deducem
urmatoarele:
=5,168 se compara cu cea din tabelul de mai inainte si
anume cu valoarea 5,41 (pentru df=1 si p=0.02). Deducem
urmatoarele:
![]() calculat=5,168<
calculat=5,168<![]() teoretic=5,41 din care cauza vom respinge H1
si admitem H0.
teoretic=5,41 din care cauza vom respinge H1
si admitem H0.
In concluzie nu exista o asociere intre sexul respondentilor si aprecierea privind directia de dezvoltare a tarii sau altfel spus nu avem diferente majore in raspunsurile respondentilor diferentiate dupa sexul acestora.
13.1. Sensul si intensitatea asocierii
Coeficientul ![]() poate atesta prezenta asocierii dar nu si
intensitatea sau sensul acesteia. Tocmai de aceea se folosesc si alti
coeficienti pentru o astfel de analiza. Iata pentru inceput unii
coeficienti utili pentru cazul a doua variabile dihotomice nominale:
poate atesta prezenta asocierii dar nu si
intensitatea sau sensul acesteia. Tocmai de aceea se folosesc si alti
coeficienti pentru o astfel de analiza. Iata pentru inceput unii
coeficienti utili pentru cazul a doua variabile dihotomice nominale:
1. Coeficientul ![]() =
=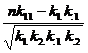 in care k11 este frecventa observata din celula 11 iar celelalte sunt frecvente
marginale (cele ce sunt sumele pe linii si pe coloane ale
frecventelor din tabel). Acelasi coeficient se mai calculeaza cu
formula
in care k11 este frecventa observata din celula 11 iar celelalte sunt frecvente
marginale (cele ce sunt sumele pe linii si pe coloane ale
frecventelor din tabel). Acelasi coeficient se mai calculeaza cu
formula ![]() . In aceasta ultima formula
. In aceasta ultima formula ![]() este o marime care se obtine din suma patratelor
diferentelor dintre frecventele observate (fo) si si cele teoretice (ft)
impartite la frecventele teoretice:
este o marime care se obtine din suma patratelor
diferentelor dintre frecventele observate (fo) si si cele teoretice (ft)
impartite la frecventele teoretice: ![]() .
.
Daca ![]() >0 tendinta datelor este sa se grupeze pe diagonala
principala caz in care exista o asociere pozitiva intre variabile. Asocierea este negativa daca
>0 tendinta datelor este sa se grupeze pe diagonala
principala caz in care exista o asociere pozitiva intre variabile. Asocierea este negativa daca ![]() <
<
2. Coeficientul Q al lui Yule are formula urmatoare: Q= ![]() si ia valori in intervalul [-1, +1]. Interpretarea este
asemanatoare cu aceea de la corelatie (pentru Q=0 situatia este de independenta).
si ia valori in intervalul [-1, +1]. Interpretarea este
asemanatoare cu aceea de la corelatie (pentru Q=0 situatia este de independenta).
3. Coeficientul Y al lui Yule, pe care nu il mai detaliem aici si care are valori tot intre
Pentru variabile categoriale cu mai mult de doua variante se impun si alti coeficienti:
1. Coeficientul de contingenta (C) ia valori in intervalul [0 ] si are formula:
C=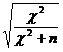 , formula in care n este volumul esantionului.
, formula in care n este volumul esantionului.
Acest coeficient daca e aplicat in cazul a doua variabile dihotomice are valoarea maxima de 0,707. Aceasta valoare creste apoi odata cu cresterea tabelului de contingenta darn u va atinge niciodata valoare 1 deoarece fractia de sub radical este subunitara. T. Rotariu [1999 ] recomanda folosirea acestui coefficient pentru tabele mari. Oricum daca C 1 atunci asocierea dintre variabile este puternica iar daca C 0 asocierea este slaba.
2. Coeficientul V (Cramer) ia valori tot in intervalul [0 ] interpretarea fiind aceeasi. Formula de calcul este urmatoarea:
V=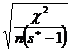 , formula in care s*=min (n,m)
adica minimul din nr. de linii/coloane.
, formula in care s*=min (n,m)
adica minimul din nr. de linii/coloane.
3. Coeficientul
![]() (Goodman si Kruskal) ia valori in intervalul [0,1] dar interpretarea lui este
diferita: el urmareste proportia cu care se reduc erorile prin
introducerea variabilei independente. Daca
(Goodman si Kruskal) ia valori in intervalul [0,1] dar interpretarea lui este
diferita: el urmareste proportia cu care se reduc erorile prin
introducerea variabilei independente. Daca ![]() tinde la 0
atunci variabila independenta nu are un aport in predictia variabilei
dependente. Daca
tinde la 0
atunci variabila independenta nu are un aport in predictia variabilei
dependente. Daca ![]() tinde la 1 atunci aportul in predictie este mare. O varianta este
coeficientul
tinde la 1 atunci aportul in predictie este mare. O varianta este
coeficientul ![]() cu interpretari
apropiate.
cu interpretari
apropiate.
4. Coeficientul de incertitudine U se mai numeste coeficientul de entropie si ia valori in intervalul [0,1]. El reprezinta procentul de reducere a a erorilor de interpretare a variatiei variabilei dependente cand actioneaza variabila independenta (varianta este definita in termeni de entropie sau grad de nedeterminare dat de plasarea subiectilor in categoriile din tabelul de contingenta) . daca U 0 variabila independenta nu explica varianta celei dependente situatia fiind opusa daca U
Vom incerca sa aplicam si acesti din urma coeficienti la o analiza pentru variabile nominale cu mai mult de doua categorii. Din baza de date GSS93 subset vom analiza asocierea dintre variabilele marital status si life: ne intereseaza daca rasa respondentilor influenteaza opinia despre viata in general. Prima variabila are categorii principale: married, widowed etc. iar variabila life ["Is life exciting or dull?"] are si ea trei variante principale (exciting, routine si dull). Vom urma aceleasi comenzi: Analyze Descriptive Statistics Crosstabs si vom opta si pentru cei patru coeficienti din fereastra Statistics: Contingency Coefficient, Phi and Cramer's V, Lambda si Uncertainty coefficient. Rezultatele sunt urmatoarele:
Se observa ca au fost procesate un numar de 995 cazuri valide iar 504 au fost considerate lipsa.

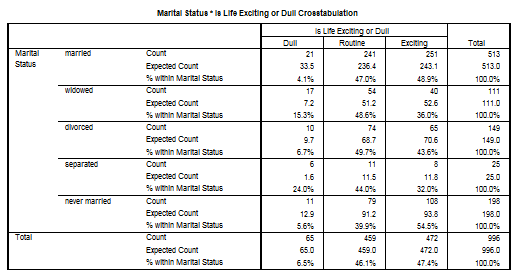

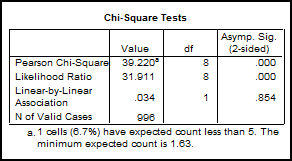
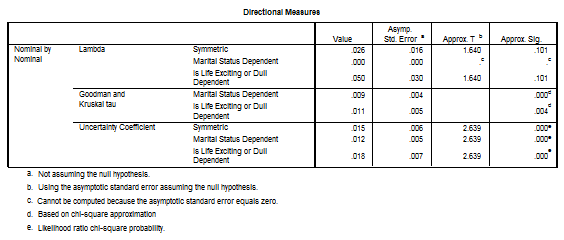
Observam
![]() calculat=32,2>
calculat=32,2>![]() teoretic=26,1 pentru 8 grade de libertate
si p=0.000. Acceptam ipoteza H1 deci variabilele sunt asociate.
Intensitatea asocierii este totusi slaba (C=0.190;V=0.140) iar
directia presupusa de var independenta marital status explicand var. dependenta life este
mai plauzibila (
teoretic=26,1 pentru 8 grade de libertate
si p=0.000. Acceptam ipoteza H1 deci variabilele sunt asociate.
Intensitatea asocierii este totusi slaba (C=0.190;V=0.140) iar
directia presupusa de var independenta marital status explicand var. dependenta life este
mai plauzibila (![]() =0.05>
=0.05> ![]() =0.00 sau
=0.00 sau ![]() =0.011>
=0.011>![]() =0.009). Se observa de asemenea valorile mici pentru
coeficientul U.
=0.009). Se observa de asemenea valorile mici pentru
coeficientul U.

13.2 Asocierea si raporturile de sanse (odds ratio)
Cu ajutorul tabelului de contingenta se poate analiza sansa (probabilitatea) ca un anumit fenomen sa se petreaca. Daca un fenomen, sa spunem, are o probabilitate p de aparitie atunci prin sansa se intelege raportul p/ (1-p). Dintr-un exemplu anterior vom spune ca exista probabilitatea de 0.511 ca subiectii care cred ca "directia este buna" sa fie barbati. Altfel sansa ca un intervievat sa fie barbat a fost 511/(1-0.511)= 1.04.
Sa analizam aceasta problematica plecand de la baza de date GSS93 subset si de la doua variabile sex si gunlaw (acordul sau dezacordul portului armei). Dupa ce am transferat variabilele pe linie si coloana din fereastra statistics alegem doar Chi-square si Risk:
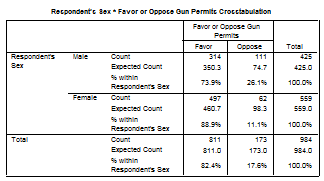
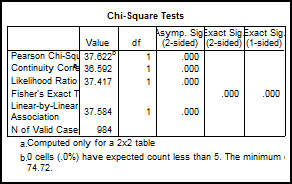
Din rezultatele obtinute se
observa ca cele doua variabile sunt asociate [deoarece![]() calculat=37,6>
calculat=37,6>![]() teoretic=10,83 pentru 1 grad de libertate si
p=0.000 deci vom accepta H1]. Cu alte cuvinte sexul respondentilor
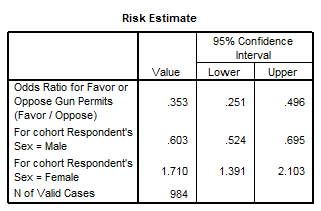
influenteaza opinia despre portul armei. Sansa ca un respondent sa
fie de acord este diferita pentru barbati si pentru femei. Pentru
barbati este de 314/111=2,82 iar pentru femei este de 497/62= 01 valoare
semnificativ mai mare. Raportul de sanse dintre femei si barbati
este de 01/2.82= 2,84 cu alte cuvinte sunt 2,8 sanse ca o femeie sa fie de
acord fata de un barbat. Aceasta valoare cu cat este mai mare decat 1 cu
atat sunt mai pronuntate diferentele dintre grupuri. Pentru cei ce
sunt de acord coeficientul de risc este
de 1.20 iar pentru cei ce nu sunt de acord 0,42.
teoretic=10,83 pentru 1 grad de libertate si
p=0.000 deci vom accepta H1]. Cu alte cuvinte sexul respondentilor
influenteaza opinia despre portul armei. Sansa ca un respondent sa
fie de acord este diferita pentru barbati si pentru femei. Pentru
barbati este de 314/111=2,82 iar pentru femei este de 497/62= 01 valoare
semnificativ mai mare. Raportul de sanse dintre femei si barbati
este de 01/2.82= 2,84 cu alte cuvinte sunt 2,8 sanse ca o femeie sa fie de
acord fata de un barbat. Aceasta valoare cu cat este mai mare decat 1 cu
atat sunt mai pronuntate diferentele dintre grupuri. Pentru cei ce
sunt de acord coeficientul de risc este
de 1.20 iar pentru cei ce nu sunt de acord 0,42.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 3474
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2024 . All rights reserved

