| CATEGORII DOCUMENTE |
| Astronomie | Biofizica | Biologie | Botanica | Carti | Chimie | Copii |
| Educatie civica | Fabule ghicitori | Fizica | Gramatica | Joc | Literatura romana | Logica |
| Matematica | Poezii | Psihologie psihiatrie | Sociologie |
|
|
ECOLE SUPERIEURE D'ELECTRICITE |
UNIVERSITATEA POLITEHNICA BUCURESTI |
|
Studiul de fata se ocupa de cautarea unei metode de determinare a oportunitatilor de transmisie pe connexiuni multiple simultane si de planificarea pachetelor pe slot-uri temporale oportune. Aceste conexiuni permit scurgerea fluxurilor de date caracterizate de anumiti parametri de QoS si stocate in cozi adaptate. Metoda propusa tine seama de nevoile catorva clase mari de flux aplicativ, dar neglijeaza in principal un anumit numar de puncte cum ar fi nivelul fizic al sistemului sau economisirea energiei folosite.
|
Multumiri | |
|
Rezumat | |
|
Cuprins | |
|
1. Introducere | |
|
2. Sinteza bibliografica relativa la optimizarea unei interfete OFDMA | |
|
3. Modelarea simplificata a a mecanismelor de acces pe legatura descendenta intr-un sistem radio de banda larga OFDMA 3.1. Problema ce trebuie rezolvata. Ipoteze si parametri utilizati 3.2. Constructia unui banc de simulare cu ajutorul OPNET 3.3. Elaborarea si integrarea generatorului de flux video sintetic | |
|
4. Propunerea si evaluarea performantelor unui algoritm de alocare a resurselor si de planificarea transmisiei pachetelor 4.1. De la algoritmul optimal la algoritmul practic 4.2. Simularile si interpretarea rezultatelor | |
|
5. Concluzii si perspective | |
|
Anexa 1 - Modelul statiei mobile | |
|
Anexa 2 - Coada de asteptare, starea de initializare a procesorului statiei de baza si sursa sintetica de semnal video | |
|
Anexa 3 - Optimizarea temporala | |
|
Anexa 4 - Optimizarea instantanee | |
|
Anexa 5 - Implementarea Algoritmului A | |
|
Anexa 6 - Implementarea Algoritmilor B1 si B2 | |
|
Bibliografie |
1. Introducere
Accesul la Internet si la serviciile multimedia ocupa deja un loc important in viata noastra cotidiana si acesta nu este decat inceputul. Posta electronica (e-mail) a inlocuit deja in numeroase cazuri scrisoarea clasica. Informatia a devenit mai accesibla si aproape orice poate fi gasit pe site-urile de Internet, de la retete culinare la programe.
Accesul wireless de banda larga la Internet reprezinta o miza majora. Apar insa problemele suplementare, legate de caracteristicile restrictive ale accesului radio si de posibilitatile terminalului mobil, comparativ cu cele ale omoloagelor fixe.
Aplicatiile cu mare potential de dezvoltare sunt cele care vor permite utilizatorilor mobili sa aiba acces la diverse servicii multimedia, mai ales audio si video, in conditii de confort si de calitate, daca nu comparabile cu cele obtinute prin intermediul unui acces fix, macar de o calitate acceptabila. Aceste servicii pot interesa utilizatori individuali, grupuri sau un public larg. Tehnicilor utilizate pentru accesul fix la Internet vor trebui adaptate posibilitatilor transmisiei radio. Se vor utiliza in continuare download-ul, de streaming-ul si broadcast-ul. Download-ul este o solutie comuna, usoara din punct de vedere tehnic. Broadcast-ul este in faza de dezvoltare cu ajutorul tehnicii DVB-H. In cadrul acestui studiu ne vom interesa mai ales de o tehnica recenta, adresata utilizatorilor individuali: streaming-ul pe o statie mobila. Acesta se bazeaza pe transmisia continua a unui flux video si/sau audio intre server si terminalul client.
Desi mai dificil de pus in aplicare, streaming-ul prezinta un mare potential. Contrar mijloacelor media traditionale, cum sunt televiziunea sau radioul, care au o acoperire limitata, Internetul ofera posibilitatea de a stabili millioane de sesiuni simultane. Este astfel posibil pentru utilizatori sa aiba acces la mult mai multe programe de televiziune sau de radio, la filmele preferate dar care nu au mai fost difuzate de mult, etc. Streaming-ul are nevoie de o banda suficienta pentru a transmite in bune conditii si deci aplicatia si nu reteaua limiteaza accesul. Fluxul unidirectional scurs intre server si client trebuie sa fie receptionat in mod continuu, dar tolereaza o anumita intarziere a pachetelor. Dupa umplerea initiala a memoriei tampon a receptorului, aceasta trebuie sa fie suficient alimentata in continuare, ceea cea implica o variatie limitata a intarzierii pachetelor (jitter). Daca datele nu ajung la timp, antrenand golirea tamponului, sesiunea se intrerupe temporar, lucru foarte dezagreabil atunci cand se vizioneaza un film sau se asculta o piesa muzicala.
Aceste restrictii au limitat dezvoltarea streaming-ului, dar tehnologia progreseaza, permitandu-ne sa ne imaginam exemplul unui utilizator aflat in calatorie si care acceseaza posturile radio favorite pe PDA sau pe telefonul mobil, la mii de kilometri de domiciliul sau.
Evolutia retelelor mobile merge in sensul definirii unor interfete radio din ce in ce mai performante (in termeni de eficienta in utilizarea benzilor de frecventa disponibile, de crestere a ratei de transmisie etc) si a constituirii de retele de acces radio la servicii multimedia bazate pe IP, in cadrul eforturilor de standardizare si de dezvoltare a interoperabilitatii intre diversi producatori de echipamente.
In acest context al accesului wireless de banda larga la Internet, atat pentru terminale fixe cat si pentru terminale mobile, a aparut standardul IEEE 802.16 sustinut de Forumul WiMAX (Worldwide interoperability for Microwave Acess). Cu rate de rtansfer de pana la 70 Mbit/s [1], sau si mai mult, el a fost conceput pentru a oferi unui numar mare de utilizatori radio posibilitatea unor servicii multiple simultane, atat timp real (Real Time - RT), cum sunt telefonia si videotelefonia, sau timp cvasi real, cum este streaming-ul, cat si non-timp real (Non Real Time - NRT), interactive cum sunt navigatia pe Internet (Web browsing) si transferul de fisiere (FTP), sau de fond (background) cum este posta electronica (e-mail).
Pentru aceasta, la baza, interfata radio a IEEE 802.16 suporta mai multe tehnici de transmisie si de acces multiplu, monopurtatoare (Single Carrier - SC) sau cu diviziune in frecventa (Orthogonal Frequency Division Multiplexing - OFDM, Orthogonal Frequency Division Multiple Access - OFDMA). Aceasta da posibilitatea, dupa nevoi, de a constitui legaturi simple cu vizibilitate directa (Line of Sight - LoS) sau retele de metropolitane cu vizibilitate directa sau fara (NLoS), in medii de propagare cu reflexii multiple. Mai nou insa s-a ajuns cu standardul 802.16e chiar la adevarate retele de comunicatii mobile. WiMAX foloseste astfel o interfata radio multicanal de tipul OFDMA care pare sa fie solutia privilegiata pentru viitoarea generatie de sisteme celulare 4G [2].
In figura 1.1 am reprezentat in frecventa mai multe subpurtatoare ortogonale, caracteristice OFDMA, in scopul de a facilita intelegerea conceptului.
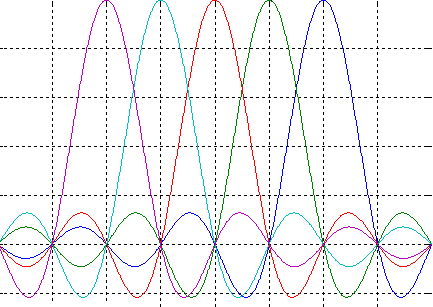
Fig. 1.1 - Subpurtatoare OFDM
Pentru a depasi problemele de transmisie radio banda larga, tehnica OFDM (Orthogonal Frequency Division Multiplexing) ofera numeroase avantaje. Transmisia este repartizata pe mai multe canale (subchannel) sau subpurtatoare (sub-carriers) paralele. Se utilizeaza, in domeniul temporal, un impuls rectangular care ia forma unui sinus cardinal in domeniul frecventa. Subpurtatoarele nu sunt separate, ci suprapuse. Ele se intersecteaza in puncte unde numai una dintre ele are valoare maxima, iar celelalte sunt nule. Este de notat faptul ca sincronizarea perfecta intre emitator si receptor este foarte importanta, dar si foarte dificil de realizat.
Avantajele OFDM sunt numeroase. In principiu ofera cea mai buna utilizare a spectrului disponibil, datorita ortogonalitatii subpurtatoarelor. Aceasta proprietate permite eliminarea intervalelor de garda intre canalele vecine. In acest mod este posibl sa se aglomereze in banda alocata mai multe subpurtatoare decat ar fi posibl cu tehnica clasica FDMA, si aceasta fara sa se creeze interferente intre ele la demodulare. OFDM este adesea utilizat cu o metoda de acces multiplu de tipul TDMA (Time Division Multiple Access), ansamblul de subpurtatoare constitue atunci un canal unic pe care diferitii utilizatori si-l impart succesiv in timp.
Sistemul de acces radio devine mai flexibil atunci cand ansamblul de subpurtatoare se poate imparti in mai multe canale utilizabile pentru transmisii simultane (channelisation) si cand aceste canale paralele servesc pentru a suporta accesul concomitent al diferitilor utilizatori. Este principiul OFDMA care ofera posibilitatea de a aloca mai multe canale cu rate de transmisie variabile unuia sau mai multor utilizatori, conform nevoilor fiecaruia. Aceasta flexibilitate a resurselor face ca cererile de acces la retea sa poata fi mai bine diferentiate si tratate, in functie de caracteristicile datelor de transmis si de criteriile de calitate asociate.
Datorita acestei impartiri a benzii, fading-ul selectiv al canalului de banda larga (selective fading) lasa locul unui fading plat (flat fading) pe fiecare din diferitele canale de banda ingusta.
Conditiile de propagare dovedindu-se diferite pentru diversii utilizatori, rezulta de aici o posibilitate de optimizare a transmisiei folosind aceasta proprietate, alocand fiecaruia dintre ei numai subpurtatoarele care ofera cel mai bun castig de canal si cele mai mici pierderi.
Concomitent cu alocarea adaptiva a canalelor, OFDMA foloseste si controlul puterii alocate subpurtatoarelor si bit loading-ul adaptiv [3] al acestora din urma, prin intermediul schemelor de modulare-codare, pe durata slot-urilor temporale ulizate.
Lipsa de sensibilitate a communicatiei la Interferenta Intersimbol (IIS) este si ea un avantaj asociat cu OFDMA. Factorul IIS pentru un singur canal este impartit la numarul de subpourtatoare K. Efectul de propagare pe mai multe cai poate fi eliminat fara sa fie nevoie de effectuarea calculelor complicate de egalizare a canalului in receptor. [4] Acest resultat este obtinut adaugand un prefix ciclic la fiecare simbol OFDM.

Fig. 1.2 - Emitator/receptor OFDM
Figura 1.2 reprezinta un emitor si un receptor OFDM simplificate.
Dupa codare si intretesere, datele DE sunt supuse unei modulari QAM pentru a putea fi transportate pe subpurtatoarele alocate transmiterii lor. Modularea OFDM se efectueaza cu ajutorul unei Transformari Inverse Fourier Rapide (Inverse Fast Fourier Transform - IFFT).
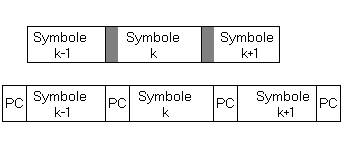
Fig. 1.3 - Prefixul ciclic
Apoi, pentru eliminarea interferentei produse de canal se adauga un prefix ciclic (PC) fiecarui simbol OFDM. Este de fapt o copie a ultimei parti a simbolului care serveste ca interval de garda. Prefixul trebuie sa fie dimensionat in asa fel incat sa fie mai lung decat dispersia temporala a intarzierilor datorate propagarii pe cai multiple, permitand astfel sa se elimine interferenta intersimbol. [4] De asemenea, prefixul poate servi si la sincronizarea comunicatiei. Dupa adaugarea prefixului ciclic, semnalul intra in etajul analogic de radiofrecventa care asigura transmisia sa efectiva.
In receptor, semnalul iesit din etajul RF este transformat in semnal digital, apoi este eliminat prefixul ciclic. Demodularea OFDM este realizata prin intermediul unei Transformari Fourier Rapide (FFT), urmata de o demodulare QAM pentru obtinerea datelor DR.
Ramane totusi un anumit numar de probleme de implementare a aceastei tehnici. Ea este foarte sensibila la desincronizari si necesita circuite analogice de buna calitate. Dar aceste ultime puncte nu fac obiectul prezentului proiect.
Al doilea capitol schiteaza succinct starea actuala in domeniul cercetarii in domeniul considerat si se refera la alte studii care au tratat aceasta tema.
Al treilea capitol prezinta modelul sistemului considerat si al patrulea algoritmul de ordonare a pachetelor si alocare a resurselor propus, precum si rezultatele simularilor.
In capitolul al cincilea sunt subliniate concluziile la care s-a ajuns.
Bibliografie:
[1] P. Piggin, WiMAX in-depth, IEE Communications Engineer, October/November 2004, pages 36 - 39
J. Gross, H. F. Geerdes, H. Karl, A. Wolisz, Performance Analysis of Dynamic OFDMA Systems with Inband Signaling, IEEE Journal on Selected Areas in Communications (JSAC) - Special Issue on 4G Wireless Systems, March 2006
[3] G. Kulkarni, S. Adlakha, M. Srivastava, Subcarrier Allocation and Bit Loading Algorithms for OFDMA Based Wireless Networks, IEEE Transactions on Mobile computing, November/December 2005
[4] M. Glesner, L. D. Kabulepa, VLSI Design for Wireless Communications, Darmstadt University of Technology, Department of Electrical Engineering and Information Technology, Institute of Microelectronic Systems, 2005
Sinteza bibliografica relativa la optimizarea unei interfete OFDMA
Alocarea de resurse radio este o problema pe care incercam sa o rezolvam cat mai bine posibil la nivelul statiei de baza. A fost deja subliniat interesul de a utiliza un algoritm adaptiv pentru exploatarea avantajelor oferite de OFDMA. [1] Aceasta trebuie sa rezolve doua probleme principale: cate si care canale sunt alocate fiecarui terminal care se gaseste in celula. In acest domeniu sunt urmate actualmente doua directii principale de cercetare.
Prima este axata pe minimizarea puterii de emisie utilizata de statia de baza, tinand cont de constrangerile asupra ratei de transmisie. De exemplu, in lucrarea [2], Pietryzik si Janssen propun un algoritm de alocare a subpurtatoarelor nu numai in functie de exigentele de rata de transmisie a fiecarui utilizator, dar si in functie de conditiile particulare de propagare pe canale. In [3] Shen et al. trateaza separat alocarea canalelor si alocarea de putere, cu scopul de a reduce complexitatea calculelor. Studiul lor a fost prelungit [4] de Wong et al. care au linearizat ecuatiile algoritmului de alocare a puterii si au simplificat astfel problema. Este de notat ca posibilitatile practice de executie in timp real pe procesorul statiei de baza motiveaza si cautarea unei solutii cu mai putine calcule.
A doua directie de cercetare este orientata in special catre o maximizare a debitului global, luand in considerare cateva constrangeri majore relative la aplicatiile solicitate de utilizatori, ca de exemplu transmisia de flux audio sau video, care necesita multe resurse radio.
Plecand de la aceasta idee, Kittipiyakul si Javidi propun [5] un algoritm de alocare de subpurtatoare care incearca sa maximizeze performanta medie a sistemului pe termen lung. Ei realizeaza pentru aceasta un amestec intre un algoritm de umplere (water-filling), care maximizeaza rata de transmisie instantanee, si o echilibrare de sarcina (load balancing) pe termen lung, care asigura o ocupare echitabila a cozilor de asteptare pentru diferitele subpurtatoare si minimizeaza astfel timpul de asteptare al pachetelor in coada inaintea emiterii lor. Ei arata ca ocuparea cozilor de asteptare joaca un rol important si ca algoritmii conventionali de water-filling prezinta performante inferioare, deoarece nu iau in considerare lungimea cozii. Din acest motiv ei cred ca echilibrarea sarcinii este un element esential pentru optimizarea intarzierii pachetelor.
Trebuie realizat un echilibru intre dorinta de a obtine o rata de transmisie maxima in prezent si a obtine o rata de transmisie maxima in viitor. Algoritmul propus de ei se numeste Rata Maxima si Echilibru de Sarcina (Maximum Throughput and Load Balancing - MTLB). Simularea a fost facuta pentru patru situatii :
Algo-I, care utilizeaza informatii complete asupra dimensiunii cozilor si informatii minime asupra starii canalelor (ON/OFF - daca se poate emite sau nu, fara detalii asupra ratei) si care folosesc apoi MTLB pentru alocarea resurselor
Algo-II, care utilizeaza informatii complete asupra starii canalelor si informatii minime asupra dimensiunii cozilor (ON/OFF - daca contin pachete sau nu) si care folosesc water-filling pentru alocarea resurselor pentru a goli cozile care sunt ON
Algo-III si IV, care utilizeaza informatii complete asupra starii canalelor si asupra dimensiunii cozilor si care aloca banda utilizand MTLB; diferenta este ca Algo-III poate aloca mai multe resurse decat este necesar, dar Algo-IV, chiar daca el nu are aceasta problema, este sensibil la ordinea in car ese aloca subpurtatoarele
Resultatele simularii au aratat ca Algo-III si IV sunt mai bune decat I si II din punct de vedere a timpului mediu de raspuns. Dintre primele doua, IV este mai eficace, dar el este si mai complex si are nevoie de mai multe resurse de calcul. Algo-I este superior fata de Algo-II in conditiile unui trafic mai lejer, dar cand acesta se intensifica, Algo-II se comporta mai bine. Aceasta demonstreaza avantajele si dezavantajele algoritmului water-filling pe care trebuie sa le luam in consideratie.
Un alt studiu este cel al lui Yanhui et al. [6] care, pentru a maximiza debitul conform puterii disponibile la nivelul statiei de baza, au combinat un algoritm de alocare a resurselor radio (Radio Resource Allocation - RRA) cu un criteriu de echitate a atribuirii subpurtatoarelor (Multi-carrier Proportional Fair) vizand satisfacerea utilizatorilor proportional cu nevoile lor.
Intr-un prim pas, RRA aloca subpurtatoarele, incercand sa maximizeze rata de transmisie totala in fiecare slot temporal. Singura constrangere este de a nu depasi puterea disponibila la nivelul statiei de baza. Este o problema non-lineara si necesita multe calcule pentrua fi rezolvata, fapt pe care dorim sa il evitam. Yanhui et al. au ales sa emita cu o putere egala pe fiecare subpurtatoare, deoarece alocarea adaptiva de putere nu mareste mult performantele daca se utilizeaza deja o alocare adaptiva de debit. Astfel, avem numai o variabila pentru determinarea ratei de transmisie: rata de eroare de bit sau castigul de canal. RRA va aloca fiecarui utilizator subpurtatoarele care prezinta cele mai bune conditii de transmisie si va maximiza rata de transmisie instantanee. Dar nu este echitabil si va favoriza o parte a terminalelor mobile care se gasesc in celula.
In al doilea timp, MPF redistribue
resursele pentru a garanta fiecarui utilizator debitul minim necesar. El
calculeaza rata de transmisie medie destinata fiecarui terminal
pe mai multe slot-uri temporale si determina daca nevoile sale
de transmisie in slot-ul curent sunt satisfacute. El face aceasta
vazand daca diferenta relativa intre debitul alocat de RRA
si debitul mediu este mai mic decat o limita prestabilita
δ: 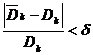 . Daca conditia nu este satisfacuta,
algoritmul ia subpurtatoare utilizatorilor care au un debit mai mare decat
cel mediu si le aloca utilizatorilor care au un debit mai mic decat
au nevoie. El face aceasta pana ce ajunge la echilibru intre toti
utilizatorii.
. Daca conditia nu este satisfacuta,
algoritmul ia subpurtatoare utilizatorilor care au un debit mai mare decat
cel mediu si le aloca utilizatorilor care au un debit mai mic decat
au nevoie. El face aceasta pana ce ajunge la echilibru intre toti
utilizatorii.
Simularile demonstreaza ca din punctul de vedere al debitului, RRA este cel mai eficace, dar nu este echitabil, asa cum este MPF. Algoritmul combinat ofera o rata de transmisie superioara comparativ cu MPF si pastreaza impartialitatea alocarii. El este mai eficace prin flexibilitate comparativ cu fiecare dintre cele doua luate separat, dar este si putin mai complicat.
In [7] Li si Liu constata ca nu este suficient sa se tina seama numai de caracteristicile canalelor radio, ci este necesar sa se ia in considerare si caracteristicile traficului. Una dintre cele mai importante cauze aflate in spatele problemelor de transmisie este umplerea memoriei tampon (buffer overflow) si trebuie sa ne concentram si asupra managementului buffer-erelor statiei de baza.
Astfel ei propun o solutie simpla si introduc un nou parametru pentru a ilustra constrangerile de calitate a serviciului: probabilitatea de incapacitate de transmisie (outage probability). Daca se utilizeaza un algoritm Adaptive-OFDMA (AOFDMA), similar cu water-filling sau RRA din punct de vedere al maximizarii ratei de transmisie instantanee, care tine cont numai de raportul semnal zgomot si care aloca subpurtatoarele terminalelor mobile care au cele mai bune rapoarte, probabilitatea de incapacitate de transmisie va fi aproape 1 pentru utilizatorii care nu au suficiente canale pentru a transmite si aproape 0 pentru utilizatorii care au mai multe canale decat au nevoie.
Algoritmul lor, denumit Alocare de Banda si Distributie de Canale (Bandwidth allocation-Channel assignment OFDMA - BCOFDMA) presupune doua etape. In prima, numarul de canale necesare fiecarui utilizator este calculat tinand cont de probabilitatea de incapacitate de transmisie asigurand o calitate de serviciu suficienta. Probabilitea depinde de rata de sosire a pachetelor, de dimensiunea tamponului si de rata de transmisie in fiecare slot temporal. Se cunosc primele doua si se poate determina si a treia daca se impune o valoare limita pe care probabilitatea nu trebuie sa o depaseasca. Se gaseste numarul de subpurtatoare necesare impartind banda totala cu media geometrica a benzii necesare utilizatorului curent, calculata pe toate canalele. Desigur ca, numarul de subpurtatoare alocat trebuie sa fie numar intreg si se rotunjeste rezultatul fractionar.
In a doua etapa, un algoritm Greedy aloca fiecarui utilizator subpurtatoarele care prezinta pentru el cele mai bune rapoarte semnal zgomot, cu scopul de a maximiza rata de transmisie. Numarul de canale alocate unui singur terminal mobil nu trebuie sa depaseasca numarul calculat la primul pas si numarul tuturor canalelor alocate nu poate depasi numarul total de canale disponibile. Daca se ajunge la aceasta situatie, utilizatorul care necesita mai multe subpurtatoare nu mai transmite, iar celelalte ar trebui sa aiba suficienta banda disponibla.
Simularile au fost facute pentru patru algoritmi:
algoritmul propus de autori
algoritmul AOFDMA
algoritmul IAOFDMA, care este un AOFDMA modificat sa aloce un numar de canale fiecarui utilizator corespunzator cu rata de sosire a pachetelor
algoritml ROFDMA, care aloca subpurtatoarele in mod aleator, dar tinand seama de aceleasi constrangeri ca si IAOFDMA
Rezultatele demonstreaza faptul ca algoritmul propus este superior tutoror celorlalte din punct de vedere al ratei de transmisie si al echitatii intre terminalele mobile, dar el nu atinge valorile optime. IAOFDMA se apropie de el ca performante si pana si ROFDMA este superior algoritmului AOFDMA. Aceasta subliniaza inca o data miopia abordarii care presupune maximizarea ratei de transmisie numai pentru fiecare slot temporal, in loc de a avea o viziune mai larga, pe o scara de timp mai indelungata.
In [8], Ryu et al. constata ca multi algoritmi existenti au fost creati in primul rand pentru planificarea traficului non-timp real (NRT). Sunt de asemenea cateva idei de algoritmi care pot sa suporte trafic de tip timp real (RT), dar este dificil sa se faca distinctie intre cele doua tipuri de pachete.
Ei propun un algoritm pentru OFDMA care suporta in acelasi timp atat trafic RT cat si NRT si le trateaza in mod diferit. Planificarea pachetelor pentru transmisia pe subpurtatoare este realizata dupa doua criterii: urgenta de emisie si eficacitatea utilizarii spectrului. Pentru a formaliza si cuantifica acestea din urma ei folosesc respectiv o functie 'timp - utilitate' si notiunea de 'stare a canalului'. Autorii considera patru mari clase de trafic (voce, video, WWW, e-mail) si realizeaza o clasificare a pachetelor corespunzatoare in cozi separate. Primele doua clase de trafic sunt timp real si ultimele doua sunt non-timp real.
Algoritmul propus (Urgency- and Efficiency-based Packet Scheduling - UEPS) urmareste sa realizeze planificarea traficului cu rezultate diferentiate. El maximizeaza banda traficului non-timp real si satisface constrangerile de calitate de serviciu ale traficului de timp real (din punct de vedere al intarzierii, ratei de pierdere a pachetelor). In ceea ce priveste pachetele de flux timp real, algoritmul vegheaza mai ales sa le plaseze in intervale temporale care preceda termenele limita respective (deadlines) dincolo de care constrangerile de intarziere/jitter nu vor mai putea fi satisfacute. Pentru aceasta, ei introduc un nou termen: interval de timp de planificare marginala (Marginal Scheduling Time Interval - MSTI), care este perioada egala cu jitter-ul, pozitionata inaintea termenului limita. Numai in acest interval se transmit pachetele de timp real.
In simulari, autorii au ales sa compare UEPS cu alti doi algoritmi utilizati in WCDMA:
Intai cea mai mare intarziere mediata - modificat (Modified - Largest Weighted Delay First - M-LWDF), care incearca sa mentina intarzierea intregului trafic sub o limita impusa cu o anumita probabilitate
Proportiuonal echitabil (Proportionally Fair - PF), care maximizeaza pe termen lung rata de transmisie catre terminalele mobile care necesita o banda mai mare decat media
Criteriile pentru evaluarea performantelor algoritmilor simulati sunt rata de pierdere a pachetelor, intarzierea medie a pachetelor si rata de transmisie medie. Pentru traficul timp real, exista constrangeri stabilite de calitatea serviciului pe care criteriile trebuie sa le respecte. Vocea este mai sensibila la intarzieri, care nu pot sa depaseasca 40 ms pentru ca sa se efectueze o comunicare in bune conditii. Limita pentru rata de pierdere a pachetelor nu este asa de stricta si se pot tolera des valori pana la 3%. Pe de alta parte, transmisia video permite o intarziere mai lunga (150 ms), dar o rata de pierdere a pachetelor de maximum 1%. Caracteristicile tipurilor de trafic sunt diferite si trebuie sa fie tratate differit.
Simularile au fost realizate tinand cont de aceasta idee. Pentru traficul de voce, algoritmul a surclasat M-LWDF din punct de vedere al ratei de pierdere a pachetelor care este situata sub limita de 3%. Cand MSTI are valoarea de 10 ms, UEPS se apropie mult de M-LWDF, insa pentru 20 si 30 ms, performantele sunt cele mai bune. Din punct de vedere al intarzierii medii situatia este complet diferita. Algoritmul M-LWDF are o intarziere medie mai mica decat cea realizata de UEPS cu MSTI de 10 sau 20 ms. Numai pentru o valoare de 30 ms si in conditii de trafic intens, UEPS depaseste performanta M-LWDF. In acelasi timp, intarzierea medie nu depaseste limita de 40 ms decat atunci cand multe terminale mobile utilizeaza reteaua in acelasi slot temporal. S-a observat ca, in cazul traficului de voce, cu cat este mai lung intervalul MSTI cu atat este mai scazuta este rata de pierdere a pachetelor si mai putin scurta este intarzierea medie.
Pentru traficul video, cele mai bune performante din punct de vedere al ratei de pierdere a pachetelor sunt obtinute prin algoritmul UEPS cu MSTI de 10 sau 20 ms. Cand intervalul este de 30 ms, UEPS este comparabil cu M-LWDF. Valoarea maxima a ratei de 1% este respectata daca exista un numar limita de terminale mobile care utilizeaza reteaua in acelasi slot temporal. Deoarece constrangerile de intarziere in cazul transmisiilor video sunt mai permisive, nu este foarte important ca algoritmul M-LWDF sa fie mai performant decat UEPS, ci este suficient ca intarzierea medie obtinuta de ultimul sa fie mai mica de 150 ms.
Banda medie este de asemenea evaluata pentru fiecare tip de trafic. UEPS surclaseaza M-LWDF si PF in cazul navigatiei pe Internet (WWW) si cu cat este mai intens traficul, cu atat este mai mare rata de transmisie medie. Cand se simuleaza comportamentul algoritmilor considerati pentru traficul de posta electronica, performantele UEPS sunt similare cu cele ale PF si superioare celor ale M-LWDF. Este bine de notat ca algoritmii PF si M-LWDF au fost proiectate pentru traficul non timp real. Cand simularea se complica si exista toate clasele de trafic, UEPS obtine din nou cele mai bune rezultate.
Pentru a realiza planificarea la nivelul statiei de baza transmisiile catre mobile in sensul descendent pe canale multiple, si considerand nevoile unui trafic non timp real, Bechetti et al. abordeaza problema intr-un alt mod [9]. Ei considera pachetele ce trebuie transmise catre utilizatori ca sarcini ce trebuiesc indeplinite si cauta sa minimizeze timpul maxim de raspuns (max-flow) utilizand cele doua resurse : puterea si numarul de canale. Sunt luate in consideratie doua abordari. Prima, denumita offline, consta in a considera cunoscute in avans toate sarcinile. Aceasta abordare, care permite sa se gaseasca planificarea cea mai buna, prezinta un interes pur teoretic si serveste in principal pentru a determina beneficiile unuia sau altuia dintre algoritmii practici de planificare fata de solutia optima teoretica. A doua abordare, care prezinta interes in practica, denumita online considera ca pachetele sosesc in timp real si ca deciziile de planificare trebuie sa fie luate pe parcurs fara sa se cunoastca sosirile viitoare. Pentru a-si atinge scopul, autorii fac apel la teoria de planificare a sarcinilor pe procesoare facand substitutia 'procesor' 'subpurtatoare'. Ei se intereseaza mai ales de strategia de planificare utilizand simple cozi FIFO (First In First Out), amintind de performantele lor pe sisteme mono sau multiprocesor, si propun algoritmi FIFO modificati pentru sisteme de transmisie radio CDMA sau OFDM. De notat ca ei considera nivele discrete de rate de transmisie in functie de puterea alocata fiecarei subpurtatoare si de conditiile particulare de propagare pe fiecare canal radio. Este posibil sa se intalneasca situatii in care nu toata puterea disponibla si nu toate subpurtatoarele sunt utilizate in fiecare slot temporal. Cei trei algoritmi online care folosesc valori discrete pentru rata de transmisie sunt : FIFO, 2D-FIFO (coada FIFO modificata ca in cazul in care volumul de date ce trebuie transmise nu ar utiliza toata resursa putere-canale in slotul curent, inceapa transmisia urmatorului pachet in ordinea sosirii) si 2D-PIKI (planificare prioritara a volumelor de date cu cea mai mare putere pe canal, iar, in cazul in care mai raman resurse disponibile in slotul curent, sunt planificate altele care necesita mai putina putere pe canal). Ultimii doi algoritmi pot suporta mai multi utilizatori pe acelasi slot temporal in limita resurselor disponibile. Ei raman destul de simpli si dau rezultate bune, in special 2D-FIFO, care poate fi optimizat prin cresterea puterii statiei de baza.
Ca urmare a acestei treceri in revista a articolelor publicate, se pot trage mai multe concluzii utile. Posibilitatile limitate de executie in timp real ale procesorul statiei de baza pledeaza pentru adoptarea unui algoritm destul de simplu. Maximizarea ratei de transmisie fara a tine cont de constrangerile de calitate a serviciilor, mai ales din punct de vedere al intarzierii/jitter-ului nu poate fi suficient de satisfacatoare in cazul traficului de tip timp real sau quasi timp real. Caracteristicile traficului trebuie sa fie luate in considerare. Iata de ce este oportun ca acesta sa fie clasificat si sa se simuleze algoritmul tinand cont de fiecare clasa. Printre diferitele metode prezentate, ultima pare sa merite o investigatie mai apropiata pentru a-i judeca eficacitatea.
Dintre toate criteriile mentionate, intarzierea este unul dinte cele mai importante cand se trateaza diferitele clase de trafic deoarece valoarea sa maxima difera mult, de exemplu intre un email si un flux de streaming video. Acest studiu are ca obiectiv sa se concentreze asupra acestei probleme, cu scopul de a incerca sa gaseasca o solutie simpla pentru planificarea simultana a transmisiei pachetelor a caror urgenta de emisie nu este aceeasi. Algoritmul FIFO modificat va putea cu siguranta sa serveasca ca punct de plecare, putand sa fie complicat ulterior la nevoie.
Bibliographie:
[1] M. M. Saleh, Adaptive Resource Allocation in Multiuser OFDM Systems, Literature Survey, University of Texas at Austin, Spring 2005
[2] S. Pietrzyk, G. Janssen, Multiuser Subcarrier Allocation for QoS Provision in the OFDMA Systems, IEEE Vehicular Technology Conference Fall, 24-28 September 2002, Vancouver
[3] Z. Shen, J. Andrews, B. Evans, Optimal Power Allocation in Multiuser OFDM Systems, University of Texas at Austin, August 2003
[4] I. Wong, Z. Shen, B. Evans, J. Andrews, A Low Complexity Algorithm for Proportional Resource Allocation in OFDMA Systems, IEEE International Signal Processing Systems Workshop, pp. 1-6, October 2004
[5] S. Kittipiyakul, T. Javidi, Resource Allocation in OFDMA Wireless Networks with Time-Varying Arrivals, VTC Journal, November 2005
[6] L. Yanhui, W. Chunming, Y. Changchuan, Y. Guangxin, Downlink Scheduling and Radio Resource Allocation in Adaptive OFDMA Wireless Communication Systems for User-Individual QoS, Transactions on Engineering, Computing and Technology V12 March 2006
[7] G. Li, H. Liu, Dynamic Resource Allocation with Finite Buffer Constraint in Broadband OFDMA Networks, Department of Electrical Engineering, University of Washington, May 2003
[8] S. Ryu, B. H. Ryu, H. Seo, M. Shin, S. Park, Wireless Packet Scheduling Algorithm for OFDMA System Based on Time-Utility and Channel State, ETRI Journal, Volume 27, Number 6, December 2005
[9] L. Bechetti, S. Diggavi, S. Leonardi, A. Marchetti-Spaccamela, S. Muthukrishnan, T. Nandagopal, A. Vitaletti, Parallel Scheduling Problems in Next Generation Wireless Networks, DIMACS Technical Report 2002 - 29, July 2002
3. Modelarea simplificata a a mecanismelor de acces pe legatura descendenta intr-un sistem radio de banda larga OFDMA
3.1. Problema ce trebuie rezolvata. Ipoteze si parametri utilizati.
Consideram o retea radio celulara care foloseste tehnologia OFDMA. Fiecare statie de baza este conectata la Internet prin intermediul unei conexiuni care suporta rate de transmisie foarte mari. Ea faciliteaza mobilelor legaturi (radio) pe ultimul tronson al retelei (last mile) si controleaza cererile de acces pe sensurile descendent si ascendent. Pentru a simplifica analiza noastra, vom alege sa ne concentram numai asupra legaturii descendente; in cazul 4G serviciile multimedia vor fi de fapt cele mai solicitate (si generatoare de trafic video sau audio) [1] si datele vor fi transmise cu preponderenta pe acest sens.
Simularea va fi limitata la o singura celula. Statia de baza trebuie sa rezolve cererile de trafic venit de la N utilizatori ui situati in zona sa de responsabilitate. Problema propusa este una de optimizare dubla dificila. Pe de o parte, statia de baza trebuie sa faca sa 'curga' in cea mai buna ordine posibila (algoritmul de planificare) pachetele care se gasesc in cele N cozi de asteptare corespunzatoare celor N statii mobile considerate. Pe cealalta parte, ea trebuie sa aloce, in limita resurselor disponibile, o putere si un numar de canale suficiente pentru a transmite pachetele catre mobilele destinatare, utilizand interfata radio si tinand cont de criteriile de calitate a serviciului.
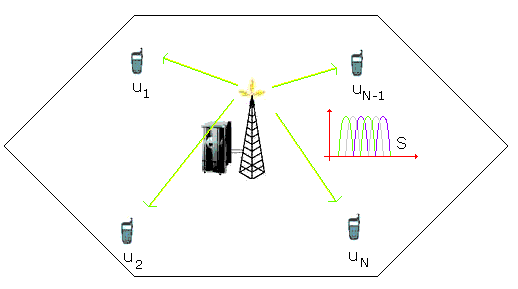
Fig. 3.1 - Celula considerata
Statia de baza distribuie puterea disponila P pe cele S subpurtatoare paralele, in timpul fiecarui slot temporal. Merita notat faptul ca aceasta durata a slotului temporal a fost diminuata o data cu evolutia sistemelor radiomobile, ajungand de la 20 ms la 2G (GSM) la 2 ms la 3G (UMTS HSPA). Din aceasta cauza am considerat un slot temporal cu durata de o milisecunda pentru sistemul nostru.
Tinand cont de aceasta durata scurta, prin simplificare, am considerat ca statia de baza nu poate sa utilizeze aceeasi subpurtatoare pentru transmisia de date catre mai multe terminale mobile in timpul unui slot temporal, ci numai catre unul singur. De la un slot temporal la urmatorul alocarea resurselor si mobilele deservite pot sa evolueze. Conectivitatea canalelor radio este consemnata intr-o matrice c cu N linii si S coloane. Cand subpurtatoarea j este alocata utilizatorului i, elementul cij devine egal cu 1. Toate celelalte elemente ale coloanei j trebuie sa ramana nule, deoarece nu este posibil sa se foloseasca aceeasi subpurtatoare pentru comunicatia cu alte terminale mobile in timpul aceluiasi slot temporal. Acest lucru este exprimat prin conditia:
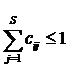
Bineinteles, numarul total de canale alocate in timpul unui slot temporal nu poate depasi numarul total de canale disponibile la nivelul statiei de baza:
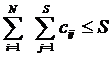 (2)
(2)
Cum a fost deja mentionat, exista o putere totala de emisie maxima P care poate fi distribuita de statia de baza intre canalele existente. Aceasta introduce o constrangere suplimentara: suma puterilor utilizate pentru emisie pe canalele alocate in timpul slotului curent nu poate depasi puterea totala disponibila:
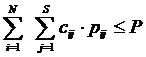 (
(
unde pij este puterea alocata pentru emisia pe subpurtatoarea j catre utilizatorul i.
Rata de transmisie ce poate fi atinsa pe canalul j alocat utilizatorului i este data de expresia urmatoare [3] :
![]()
unde B reprezinta largimea de banda a canalului, τ este durata slotului temporal si gij castigul canalului j cand e alocat utilizatorului i. B si τ sunt constante de sistem.
Debitul total al sistemului catre totalitatea mobilelor se obtine insumand debitele inregistrate pe fiecare subpurtatoare in parte.
Nu vom detalia in acest studiu de bugetul de putere pe legatura radio si am ales sa reprezentam efectele canalului printr-un singur parametru: castigul de canal g. Acest castig tine cont de pierderile de propagare L pe care semnalul le sufera in timpul transmisiei de la statia de baza la terminalul mobil, de puterea totala a zgomotului σ2 in banda canalului, precum si de un castig Γ rezultat din schema de modulare-codare din nivelul fizic al sistemului:
![]()
Se presupune ca valorile castigurilor de canal pentru fiecare utilizator in parte sunt cunoscute de catre statia de baza in fiecare slot temporal, pe baza informatiilor primite periodic de la terminalele mobile. Aceste valori sunt centralizate intr-o matrice g cu N linii si S coloane. Pentru simplificare, vom considera ca toate terminalele mobile nu se deplaseaza mult, deci conditiile de propagare nu evolueaza in timp. Astfel, matricea g va ramane neschimbata pe parcursul simularii. In continuare vom putea complica situatia variind valorile castigului de canal.
Vom detalia in continuare cele trei componente adoptate pentru evaluarea castigului de canal.
Pentru a modela pierderile am ales o lege de propagare simpla, insa adaptata la conditiile sistemului. WiMax, singurul sistem implementat actual, utilizeaza OFDMA ca tehnica de acces multiplu in banda de 3,5 GHz. De aceea am ales un model statistic pentru aceasta banda de frecventa. Acest model a fost propus in [2] de catre Walden si Roswell. A fost elaborat plecand de la masuri efectuate in Londra, Birmingham, Liverpool si Manchester si 100 m si 2 km.
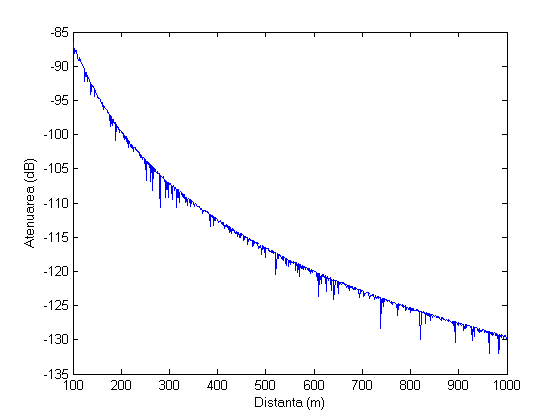
Fig. 3.2 - Dependenta intre atenuare si distanta in cazul propagarii unui semnal in banda de 3,5 GHz
Pierderile, exprimate in dB, sunt date de expresia urmatoare:
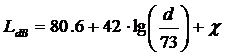
unde d este distanta in metri intre statia de baza si statia mobila si unde χ reprezinta contributia fading-ului (distribuit log-normal cu varianta de 7,5 dB).
Pentru a evalua nivelul global al zgomotolui la iesirea receptorului de pe terminalul mobil, am tinut cont de nivelul zgomotului termic in banda canalului, precum si de zgomotul intern al receptorului. Expresia este compusa deci din zgomotul termic din banda canalului de receptie (K fiind constanta lui Boltzmann, T temperatura absoluta in Kelvin, B largimea de banda), din factorul de zgomot al receptorului F si din castigul in putere al receptorului Grec:
![]() (
(
Vom preciza valoarea numerica adoptata pentru simularile ulterioare. Constanta lui Boltzmann este 1,38 10-23 J/K. Am considerat o temperatura ambianta de 27C, adica o temperatura absoluta de 300 K, si un receptor cu factorul de zgomot de 4 (6 dB) si un castig in putere disponibila de 100 (10 dB). Am ales largimea de banda a canalului de 62,5 KHz, compatibila cu un numar maxim de canale S de 64, presupunand de exemplu un spectru global de 7 MHz si o frecventa de esantionaj de 8 MHz pentru a respecta conditia lui Nyquist. Din aplicatia numerica va rezulta astfel un nivel global al zgomotului σ de -110 dBm (10-14 W).
Pentru ultima componenta a castigului de canal, castigul generat de nivelul fizic, am utilizat o expresie derivata dintr-o aproximare a ratei de roare de bit (Bit Error Rate - BER) :
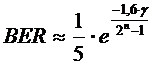
unde γ este raportul semnal zgomot si n este numarul de biti utilizati de modulatia numerica pentru a coda un simbol. Aceasta aproximatie este valabila de obiocei pentru BER ≤ 10-4 si n ≥ 4.
WiMax foloseste patru tipuri de modulatie cu performante diferite:
Modulatiile care ofera mai multe simboluri pentru transmisie si deci si o rata de transmisie mai mare sunt, de asemeanea, mai exigente din punct de vedere al conditiilor de recptie. Cum se poate observa in expresia (8), BER depinde de raportul semnal zgomot. Daca nu este suficient de mare, decodarea corecta a simbolurilor generate de modulatiile mai performante (ca 64QAM de exemplu) nu se va putea efectua si va trebui sa utilizam modulatii mai putin exigente din punct de vedere a raportului semnal zgomot, dar si mai putin eficiente din punct de vedere al ratei de transmisie.
Considerand expresia urmatoare a numarului de biti pe simbol al unei modulatii numerice:
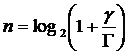
si introducand-o in (8), obtinem expresia urmatoare a castigului nivelului fizic:

Valoarea numerica pe care am adoptat-o pentru simulare este Γ = 4,75, adica 6,77 dB, corespunzand unei rate de eropare de bit de
Rata de transmisie fizica maxima ce poate fi atinsa pe o subpurtatoare cu ajutorul acestor modulatii este data de expresia urmatoare:
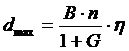
unde η este rendamentul codajului canalului si G este un factor de garda (reprezentand o fractiune din durata simbolului OFDM, intervalul de garda adaptat unei dispersii mai mari sau mai mici in functie de intarziere datorata propagarii pe cai multiple: 1/32, 1/16, 1/8, 1/4). Am ales η = 0,67 si G = 0,0625 si astfel am obtinut valorile urmatoare pentru ratele de transmisie maxime:
Trebuie sa amintim ca aceste rate nu pot fi obtinute decat daca se asigura un raport semnal zgomot suficient la receptie, permitand demodularea corecta a datelor transmise. Acesta este calculat cu ajutorul formulei (12):
![]()
Se obtin valorile urmatoare:
BPSK - γmin1 = 4,7506
QPSK - γmin2 = 14,2518
16QAM - γmin3 = 71,2590
64QAM - γmin4 = 299,2728
3.2. Constructia unui banc de simulare cu ajutorul OPNET
Pentru a modela sistemul, am utilizat software-ul OPNET spcializat in simularea de retele de telecomunicatii. OPNET abordeaza problemele cu ajutorul unei structuri ierarhizate pe mai multe nivele, si anume:
Retea
o Nod
Modul
Proces
Nivelul cel mai inalt este cel al retelei. El este compus din mai multe noduri interconectate intre ele. In cazul nostru, au fost create doua tipuri de noduri:
statia de baza (BS), situata in centrul celulei
statiile mobile (MS), la periferia unei zone de patru kilometri patrati
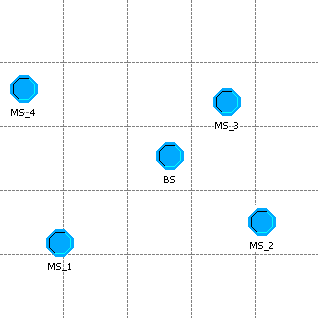
Fig. 3.3 - Exemplu de retea radio realizata in OPNET
Pentru exemplul ilustrat in figura 3.3, am considerat configuratia unei retele cu patru statii mobile. Cum se poate observa MS sunt plasate la distante variate de BS. Am ales inaltimea de 20 m pentru statia de baza, pentru a a asigura o buna acoperire a celulei. Inaltimea terminalelor mobile este de 2 m.
Legaturile radio nu sunt reprezentate grafic in OPNET, spre deosebire de cele cablate. Ele sunt stabilite automat de software in timpul simularii, tinand cont de caracteristicile emitatorului si receptorului utilizati. Pentru a realiza conexiunea intre doua noduri prin intermediul unei interfete radio, trebuie sa avem grija sa comunicam in aceeasi banda de frecventa, sa se poata suporta aceleasi rate de transmisie maxime si sa se dispuna de un raport semnal zgomot care permite o buna receptie. OPNET ofera de asemenea posibilitatea de a utiliza coduri pentru canale, lucru care va fi detaliat mai tarziu.
Nodul este la randul sau compus din mai multe module. Acestea din urma sunt caracterizate printr-un anumit numar de atribute si printr-un proces care ii descrie comporetamentul cu ajutorul unui automat cu stari finite.
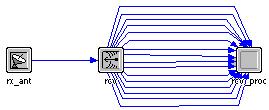
Fig. 3.4 - Le modulul statiei mobile
Figura 3.4 ilustreaza structura nodului statiei mobile. Semnalele iesite din statia de baza sunt captate de antena omnidirectionala (rx_ant) a MS si transmisa receptorului sau (rcv). Doar pachetele sosite pe subpurtatoarele alocate de sistem statiei mobile respective vor fi selectionate; toate celelalte vor fi ignorate. Procesorul terminalului mobil (rcv_proc) este legat de receptor prin 16 conexiuni care corespund celor 16 canale considerate in acest exemplu. Acesta din urma colecteaza satatisticile asupra volumului de date receptionate si a intarzierilor de transmisie, iar apoi distruge pachetele primite.
Datorita utilizarii atributului de cod de dispersie (spreading code) a canalelor am reusit sa configuram receptorul in asa fel incat sa selecteze numai pachetele care vin pe subpurtatoarele alocate pentru comunicarea intre BS si MS. Acest atribut a fost conceput in OPNET pentru a putea implementa tehnica CDMA, dar este posibil sa-l folosim si in cazul OFDMA. Pentru simplificarea sistemului am ales sa nu reprezentam sincronizarea dintre emitator si receptor, deoarece era prea complicata si nu intra direct in subiectul studiului nostru; am cosniderat-o perfecta. Tot pentru simplificarea modelarii, nu am reprezentat cu adevarat canalele suprapuse ale OFDMA-ului, dar le-am transformat in canale separate prin intervale de garda (ca in cazul FDMA) si am folosit codurile de dispersie mentionate anterior pentru a modela ortogonalitatea subpurtatoarelor. Codul canalului i al emitatorului statiei de baza trebuie sa fie identic cu codul canalului i din receptorul statiei mobile vizate, toate canalele i din receptoarele tuturor celorlalte terminale mobile avand coduri diferite pentru a le impiedica sa capteze pachete care nu le sunt adresate.
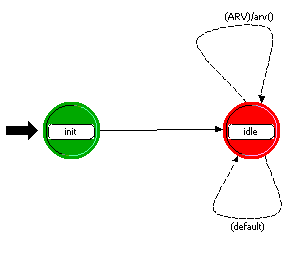
Fig. 3.5 - Automatul procesorului statiei mobile (vn_video_rcv)
Logica procesorului statiei mobile este ilustrata in figura 3.5. Automatul este compus din doua stari. Prima stare, numita init si colorata in verde, este o stare de initializare. Este vorba de o stare fortata, care dupa executarea liniilor de cod pe care le contine, trece controlul celei de-a doua stari botezata idle.
Identitatile canalelor sunt determinate in timpul fazei de initializare. Structura ierarhica utilizata de OPNET induce trecerea prin mai multe obiecte pana sa se ajunga la canalele propriu-zise. Se incepe cu nodul statiei mobile si se continua cu receptorul si grupul de canale. In continuare vom configura codul de dispersie, compus din numarul care identifica statia mobila si numarul care identifica canalul. De exemplu, daca e vorba de canalul 7 al statiei mobile MS_4, codul va fi 3 100 + 7 = 307 (terminalul mobil MS_1 are numarul de ordine 0 si le-am numarat pe toate celelalte pornind de la acesta). Codul va ramane fix la nivelul statiei mobile pe tot parcursul simularii. Doar codurile canalelor emitatorului statiei de baza se vor schimba de la un slot temporal la altul.
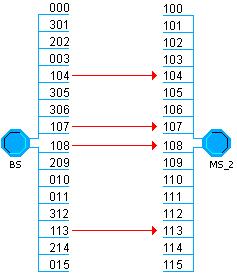
Fig. 3.6 - Exemplu de conexiuni radio in OPNET
In figura 3.6 am ilustrat un exemplu de conexiuni intre statia de baza si terminalul mobil 2. Cele 16 canale sunt desemnatee prin codurile 100, 101, . 115. In exemplul de mai sus, procesorul statiei de baza a alocat canalele 4, 7, 8 si 13 pentru transmisia catre MS_2 si codurile au fost configurate in consecinta.
Starea idle este o stare normala, nefortata (de aceea este si colorata in rosu), care raspunde evenimentului ARV cu functia arv().
Noi am definit ARV ca sosirea unui pachet pe subpurtatoarele alocate de sistem:
#define ARV (op_intrpt_type () == OPC_INTRPT_STRM)
Functia arv() nu face decat sa calculeze mai multe statistici care ne intereseaza: dimensiunea pachetului receptionat, intarzierea sa si numarul de pachete. Aceste sarcini sunt realizate de functii specifice OPNET-ului ca op_pk_total_size_get pentru dimensiune, si in ceea ce priveste intarzierea, calculand diferenta intre momentul in care pachetul a fost emis de emitator, determinat cu ajutorul op_ pk_stamp_time_get, si momentul crearii pachetului, determinat cu op_pk_creation_time_get. Anexa 1 contine codul sursa al starii init si al functiei arv().
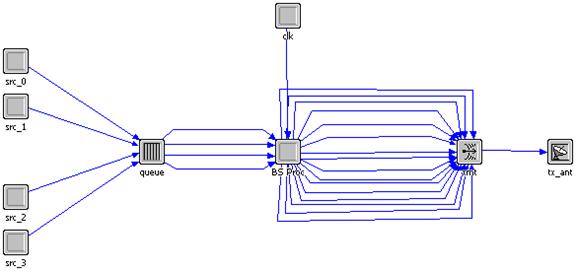
Fig. 3.7 - Le modelul statiei de baza
Statia de baza este creierul sitemului. Ea controleaza toate comunicatiile statiilor mobile din celula sa. Ea utilizeaza o antena omnidirectionala (tx_ant) pentru a trimite pachetele spre statiile mobile. Emitatorul (xmt) utilizeaza acelasi numar de canale ca fiecare receptor al statiei mobile, adica 16 in exemplul considerat. Emitatorul de pe BS este configurat in fiecare slot temporal pentru a stabili conexiunile comandate de procesor.
Sistemul evolueaza conform unei structuri temporale bine definite, impartite in sloturi temporale cu durata de o milisecunda. In OPNET timpul nu este insa o notiune continua, ci discreta. Software-ul foloseste evenimentele ca referinte pentru calculul timpului curent. Practic timpul nu exista decat asociat cu un eveniment. De aceea am folosit ca 'ceas al sistemului' o simple_source (clk) carer genereaza pachete de dimensiuni constante la intervale de o milisecunda.
Datele care transmise de catre statia de baza catre terminalele mobile sunt generate local, de catre patru, in exemplul nostru, surse sintetice de semnal video (src), corespunzatoare celor patru utilizatori considerati.
Inainitea emisiei lor, pachetele unei surse video sunt retinute in BS intr-o coada (queue) de tipul primul venit, primul servit (First In, First Out - FIFO). Acest lucru este realizat pentru a nu supraincarca procesorul statiei de baza (BS_proc) si pentru a face posibil un multiplexaj temporal pe interfata radio. Aceasta coada are N intrari si N iesiri si contine N subcozi, una pentru fiecare utilizator in parte (patru in cazul nostru). Ea a fost realizata plecand de la modelul pf_fifo deja existent in OPNET. Acesta este o coada pasiva de tipul primul venit, primul servit. Pachetele intra in subcozi corespunzatoare intrarilor si ies numai daca procesorul face o cerere de acces a unei subcozi. Procesorul reuseste astfel sa extraga, dupa o logica preprogramata, pachetele destinate diferitelor terminale mobile.
Figura 3.8 reprezinta automatul cozii de asteptare vn_fifo, denumirea data de noi acestui model. Automatul are trei stari. Starea fortata plasata la mijloc (BRANCH) indeplineste numai rolul de interpret al evenimentelor. Celelalte doua stari sunt dedicate principalelor doua decizii pe care le ia coada: intrarea sau iesirea unui pachet.
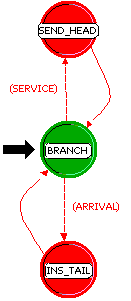
Fig. 3.8 - Automatul cozii FIFO (vn_fifo)
Starea INS_TAIL desemneaza operatia de adaugire a unui pachet la la sfarsitul unei cozi. La sosirea acestui pachet are loc o determinare a dimensiunii sale si crearea unuia sau mai multor pachete noi daca acesta are mai mult de 352 biti. Pentru a permite la receptie o determinare mai precisa a intarzierii de transmisie, recuperam timpul initial al crearii pachetului cu ajutorul functiei OPNET op_pk_creation_time_get si impunem aceasta valoare ca timpul de creatie a noilor pachete cu ajutorul functiei op_pk_creation_time_set. Acestea din urma inlocuiesc astfel vechiul pachet care va fi distrus.
Dupa insertie vom determina doua valori care vor ajuta procesorul sa ia decizia de planificare. Daca subcoada era goala inainte de sosirea acestui pachet (aceasta se traduce printr-o valoare nula a elementului vectorului start corespunzatoare indexului subcozii), este vorba de un pachet care se va gasi in capul cozii din acel moment incolo. Dimensiunea sa va fi deci memorata in vectorul first_pk_size, pe pozitia corespunzatoare indexului subcozii.
A doua valoare pe care o determinam este dimensiunea totala a subcozii, exprimate in biti. Aceasta, realizata cu ajutorul functiei OPNET op_subq_stat, este retinuta in vectorul subq_size. Ca si in cazul lui first_pk_size este vorba de variabile globale care pot sa fie citite si de module ale nodului, cum ar fi procesorul. Aceste variabile sunt definite in header-ul procesului.
Automatul trece in starea SEND_HEAD cand coada receptioneaza o cerere de acces din partea procesorului care vrea sa extraga un pachet dintr-una din subcozi. Daca ea nu este goala, pachetul este trimis la iesirea corespunzatoare si in continuare este determinata dimensiunea pachetului care se gaseste in acel moment in capul cozii. Anexa 2 detaliaza codul celor doua stari explicate mai sus.
Procesorul statiei de baza (BS_proc) tine cont de traficul iesit din diferite surse si si aloca resursele pentru a transfera pachetele catre statiile mobile inainte de expirarea termenului limita.
Pentru a realiza acest lucru, el este prevazut cu N+1 porturi de intrare si S porturi de iesire. Aceste porturi sunt definite in header-ul procesului:
/* Definitii ale fluxurilor de pachete iesite din surse */
#define CLOCK 0
#define SRC_IN_STRM1 1
#define SRC_IN_STRM2 2
#define SRC_IN_STRM3 3
/* Definitii ale fluxurilor de pachete catre emitator */
#define XMT_OUT_STRM00 0
#define XMT_OUT_STRM01 1
#define XMT_OUT_STRM02 2
Porturile de intrare sunt de doua tipuri: portul CLOCK desemnat ca intrarea 0 legata de 'ceasul de sistem' clk, si de porturile SRC_IN_STRMx (x = 1.N) prin care intra pachetele iesite din cele N surse de semnal video.
Pe porturile de iesire XMT_OUT_STRMx (x = 0.S - 1) curg fluxurile de pachete catre cele S canale ale emitatorului.
In header sunt declarate de asemenea variabilele globale subq_size si first_pk_size, generate de coada de asteptare si destinate unei exploatari ulterioare in procesul de alocare a resurselor.

Fig. 3.9 - Automatul procesorului statiei de baza (vn_BS_proc)
Automatul procesului vn_BS_proc, care descrie functionarea procesorului, este alcatuit din doua stari numite init si arv, sensibile la doua evenimente: ARV si CLK.
#define CLK (op_intrpt_type () == OPC_INTRPT_STRM && op_intrpt_strm () == CLOCK)
#define ARV (op_intrpt_type () == OPC_INTRPT_STRM && op_intrpt_strm () != CLOCK)
Evenimentul CLK este generat de aparitia unui pachet pe intrarea CLOCK. ARV este generat de aparitia unui pachet pe una dintre portile de intrare, in afara de CLOCK. Separam astfel pachetele utile de pachetele sursei clk care serveste numai pentru a semnala inceputul unui nou slot temporal.
La fel ca in cazul statiei mobile, starea init este o stare fortata care preda controlul asupra simularii dupa initializarea parametrilor de sistem (numarul de utilizatori si resursele disponibile), calculul castigului de canal pentru fiecare terminal mobil si determinarea identitatii de obiect a canalelor pentru a permite schimbarea dinamica a codurilor lor de dispersie.
Initializarile presupujn declararea parametrilor urmatori:
puterea si numarul de canale disponibile
numarul de statii mobile
nivelul total al zgomotului
castigul schemei de modulare-codare a nivelului fizic
ratele de transmisie discrete care vor fi utilizate pentru emisie
rapoartele semnal zgomot necesare pentru a atinge aceste rate de transmisie
In continuare, determinarea identitatii de obiect a canalelor este efectuata intr-o maniera similara celei descrise pentru canalele statiilor mobile si identitatile de obiect ale nodurilor terminalelor mobile, care sunt necesare pentru a putea determina pozitiile lor.
In OPNET, fiecare nod are doua atribute, denumite x position si y position, care reprezinta distanta intre nod si extremitatea stanga si, respectiv, extremitatea superioara a zonei considerate pentru simulare. Cunoasterea valorii acestor atribute, pentru statia de baza si pentru statia mobila, permite calculul distantei intre ele cu ajutorul teoremei lui Pitagora. In cazul sistemului prezentat, distanta este exprimata in kilometro si este mai convenabil sa inmultim rezultatul cu 1000 pentru a obtine distanta in metri. (necesara in expresia 6).
Aceasta distanta permite sa se determine valoarea pierderilor de propagare care afecetaza receptia semnalului de catre fiecare statie mobila in parte. Cum a fost deja mentionat, pentru a simplifica calculele, am considerat castigul de canal ca fiind acelasi pentru toate subpurtatoarele pentru un utilizator dat. Aceasta reduce complexitatea calculelor, deoarece vom retine numai N valori in vectorul g. Mai multe etape prealabile sunt totusi necesare pentru a obtine acest vector.
Mai intai am construit o distributie log-normala cu o varianta de 7,5 pentru a tine cont de eroarea fading-ului care este adaugata pierderilor de propagare. Aceasta distributie este determinata prin formula urmatoare:
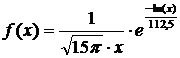
x ia valori intre 0,05 si 5, si variaza cu un pas de 0,01. Vectorul pdf_lognorm corespunde functiei de distributie de probabilitate. Pentru calculul pierderilor de propagare (path_loss), generam un numar aleator distribuit uniform intre 0 si 1, apoi cautam in pdf_lognorm valoarea cea mai apropiata. Aceasta corespunde unei erori a fading-ului x pe care o vom utiliza in formula (6). Dupa ce am determionat vectorul path_loss, ultima etapa consta in a calcula componentele vectorul g cu expresia (5).
Deoarece g nu se schimba in timpul simularii, este mai bine sa se calculeze de la inceput puterea minima necesara pentru a satisface rapoartele semnal zgomot cerute pentru fiecare utilizator in parte. Valorile date de formula (14) sunt memorate in matricea p_min cu N linii si 4 coloane corespunzand celor 4 rate de transmisie discrete.
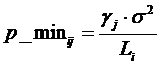 (
(
O data terminate initializarile, starea init preda controlul starii arv, care este o stare normala, activata de fiecare data cand soseste un pachet. Exista doua evenimente posibile: CLK - sosirea unui pachet de la sursa clk semnaland inceputul unui nou slot temporal - , si ARV - sosirea unui pachet extras din coada de asteptare.
Cele doua evenimente apeleaza doua functii distincte: ck() si arv(), care rezolva sarcini diferite, functie de algoritmul implementat. Oricare ar fi acest algortim, cele doua functii trebuie sa aleaga pachetele ce trebuiesc transmise, sa aloce resursele, sa extraga pachetele din cozile de asteptare si apoi sa le transfere emitatorului. Felul in care ele realizeaza toate aceste operatii va fi prezentat in capitolul urmator, dupa prezentarea algoritmilor practici adoptati. Anexa 3 listeaza codul sursa al starii init si header-ul procesului.
3.3. Elaborarea si integrarea generatorului de flux video sintetic
Am ales traficul video pentru simulare deoarece solicita foarte puternic resursele statiei de baza, prin variatia dimensiunii pachetelor si a intervalelor dintre acestea.
Semnalul video corespunde unei secvente de grupuri de imagini care sunt codate tinand cont de corelatia lor foarte puternica. Fiecare grup este alcatuit din mai multe tipuri de cadre, avand dimensiuni diferite.
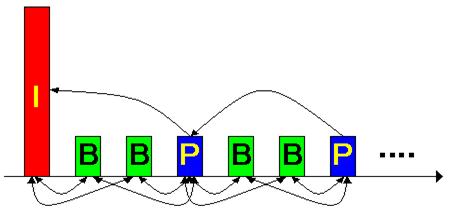
Fig. 3.10 - Cadre ale semnalului video
Cadrele I sunt cele mai voluminoase, deoarece contin majoritatea informatiei. Ele sunt urmate de mai multe cadre de dimensiuni mai mici, B et P, codate intr-o prima etapa relativ la cadrele de referinta de tip I si la cele de tip P intr-o a doua. Diferenta dintre cadrele B si P provine din faptul ca cele de tip B tin cont de doua cadre de referinta, pe cand cadrele P nu au nevoie decat de una: aceea care le precede, cum se poate observa si in figura 3.10.
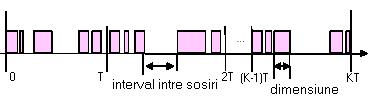
Fig 3.11 - Flux video
Figura 3.11 de mai sus reprezinta o sesiune de flux video in care se observa ca pachetele au dimensiuni foarte diferite si sunt separate de intervale care variaza mult. Dimensiunea medie a pachetelor este in jur de 270 de biti si intervalul intre sosiri mediu este de 10 ms.
Pentru a modela aceste caracteristici, am utilizat o distributie Pareto truncata [5], descrisa de functia de distributie de probabilitate urmatoare:
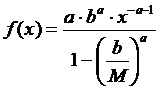
unde b este parametrul de pozitie (valoarea minima) si a parametrul de forma. Diferenta intre aceasta distributie si distributia Pareto clasica consta in existenta unei limite superioare M. In cazul nostru, aceste limite sunt de 1000 de biti pentru dimensiunea pachetelor si de 12,5 ms pentru intervalul intre sosiri.
|
Dimensiunea pachetelor (biti) |
Minim (b) | |
|
Maxim (M) | ||
|
Forma (a) | ||
|
Intervalle inter arrives (ms) |
Minim(b) | |
|
Maxim (M) | ||
|
Forma (a) |
Tabel 1 - Valorile utilizate pentru implementarea unei surse video sintetice
Pentru a construi un generator video sintetic, am modificat nodul simple_source existent in OPNET. Acesta ne dadea posibilitatea de a crea rapid pachete care respecta diferite distributii pentru dimensiunea si intervalul intre sosiri (exponentiala, constanta, .), dar distributia de Pareto truncata nu figura printre ele si a trebuit s-o implementam direct.
Automatului mostenit de la simple_source (figura 3.12) i-am adaugat o functie care genereaza o distributie Pareto truncata plecand de la parametrii de intrare (pozitie, valoare maxima si forma). Am efectuat de asemenea si modificarile necesare pentru a atribui rezultatele returnate de functie pentru dimensiune si intervalul intre sosiri.
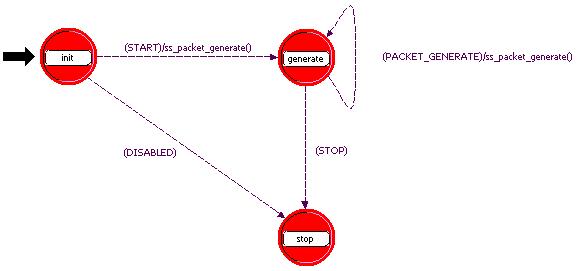
Fig. 3.12 - Automatul sursei de pachete video
Sursa de pachete video creeaza cadre cu o perioada de de 50 ms, ceea ce corespunde unei frecvente de aproape 20 de cadre pe secunda. Acest semnal videodecalitate modesta este destinat posibilitatilor limitate de afisaj ale terminalelor mobile.
Functia truncated_pareto care genereaza distributia Pareto truncata este detaliata in Anexa 4. Parametrii sai initiali sunt: location (valoarea minima), max (valoarea maxima) si shape (forma). Valorile lor sunt utilizate pentru a determina limitele intre care poate varia valoarea distributiei de probabilitate si pentr ua calcula rezultatul distributiei.
Din (15) obtinem expresia urmatoare:
![]()
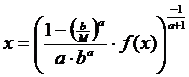
care reprezinta dimensiunea pachetului sau durata intervalului intre sosiri, calculate utilizand o densitate de probabilitate data de o distributie uniforma.
Bornele corespunzatoare minimului si maximului dimensiunii pachetului/intervalului intre sosiri permit generarea de pachete care respecta conditiile definite.
Acestea sunt determinate cu ajutorul formulelor:
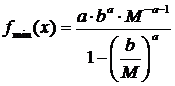
si
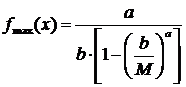 (18)
(18)
Ele se traduc in limbajul proto-C utilizat de OPNET :
min_pdf = shape * pow(location,shape) * pow(max,-shape-1)/(1 - pow(location/max,shape));
max_pdf = shape/(location * (1 - pow(location/max,shape)));
Valoarea lui x este determinata folosind functia op_dist_uniform (max_pdf) care genereaza un rezultat distribuit uniform intre 0 si fmax, dar care trebuie sa fie mai mare decat fmin. Aceasta valoare, desemnata in cod de variabila uniform_outcome, va fi introdusa in calculul distributiei Pareto truncata returnata de expresia (16) :
truncated_pareto_outcome = pow((1 - pow(location/max,shape)) * uniform_outcome/(shape * pow(location, shape)), -1.0/(shape + 1));
Modificarile in starea de initializare a automatului (init) au constat in a inlocui atributele vechii simple_source cu sase noi atribute care reflecta caracteristicile distributiei Pareto truncate: pozitia, valoarea maxima si forma distributiei dimensiunii pachetelor, si pozitia, valoarea maxima si forma distributiei intervalului intre sosiri. Configuratia standard corespunde valorilor din Tabelul 1. Automatul foloseste aceste atribute ca parametri cand apeleaza functia truncated_pareto
Acest lucru se produce de mai multe ori in cursul rularii programului. In primul rand pentru calculul dimensiunii pachetului in cadrul executiei functiei ss_packet_generate
pksize = truncated_pareto (pk_size_loc, max_pk_size, pk_size_shape);
Pentru calculul intervalului intre sosiri, truncated_pareto este utilizata in timpul starii de initializare si apoi in cadrul starii de generare (generate) :
next_intarr_time = truncated_pareto (interarrv_time_loc, max_interarrv_time, interarrv_time_shape);
Variabila next_intarr_time desemneaza durata dupa care se va apela din nou functia ss_packet_generate. Ea poate lua doua valori distincte. Prima a fost deja explicitata mai sus. A doua este egala cu intervalul care separa doua cadre: 50 ms. Folosim un contor frame_counter, incrementat dupa crearea unui pachet, pentru a decide daca trecem sau nu la un nou cadru. Acest contor este testat in starea generate. Daca este egal cu 8, este resetat la 0 pentru a programa trecerea la un alt cadru..
Datele generate de sursa video sintetica implementata in OPNET au fost comparate cu cele furnizate de un program realizat in MATLAB pentru calculul unei distributii Pareto truncate. Comparatia a fost facuta numai pentru dimensiunea pachetelor, deoarece dupa introducerea intarzierii datorate cadrelor intervalele intre sosiri nu mai respecta distributia originala.
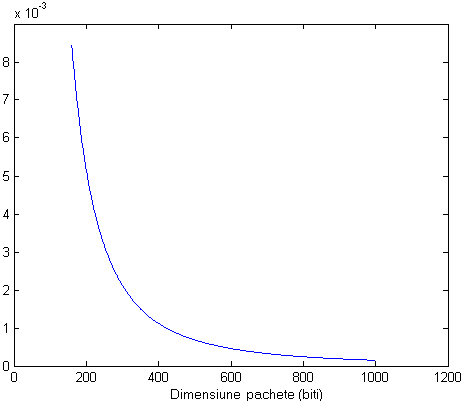
Fig. 3.13 - Distributia dimensiunii pachetelor calculata in MATLAB
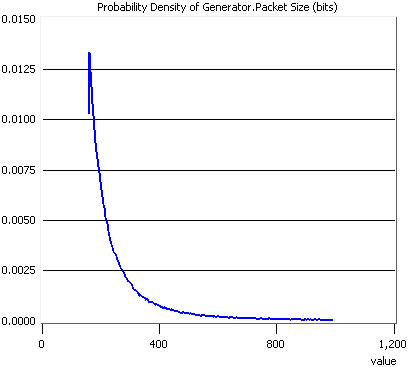
Fig 3.14 - Distributia dimensiunii pachetelor generate de OPNET
Se observa ca cele doua distributii au o alura similara. Diferentele sunt datorate faptului ca in OPNET este nevoie de o perioada de stabilizare inainte ca sursa sa inceapa sa functioneze la parametri normali.
Bibliographie:
[1] I. Akyildiz, D. Goodman, L. Kleinrock, C. T. Lea, Mobility and Resource Management in Next Generation Wireless Systems, IEEE Journal on Selected Areas in Communications, Vol. 19, No. 10, October 2001, pp. 1825-1829
[2] M. Walden, F. Roswell, Urban Propagation Measurements and Statistical Path Loss Model at 3.5 GHz, Antennas and Propagation Society International Symposium, 3-8 July 2005
[3] L. Bechetti, S. Diggavi, S. Leonardi, A. Marchetti-Spaccamela, S. Muthukrishnan, T. Nandagopal, A. Vitaletti, Parallel Scheduling Problems in Next Generation Wireless Networks, DIMACS Technical Report 2002 - 29, July 2002
[4] L. Yanhui, W. Chunming, Y. Changchuan, Y. Guangxin, Downlink Scheduling and Radio Resource Allocation in Adaptive OFDMA Wireless Communication Systems for User-Individual QoS, Transactions on Engineering, Computing and Technology V12 March 2006
[5] S. Ryu, B. H. Ryu, H. Seo, M. Shin, S. Park, Wireless Packet Scheduling Algorithm for OFDMA System Based on Time-Utility and Channel State, ETRI Journal, Volume 27, Number 6, December 2005
Propunerea si evaluarea performantelor unui algoritm de alocare a resurselor si de planificarea transmisiei pachetelor
4.1. De la algoritmul optimal la algoritmul practic
Algoritmul de alocare a resurselor si planificare a pachetelor trebuie sa aloce o putere mai mica sau egala cu puterea disponibila P si un numar de canale mai mic sau egal cu numarul total disponibil S, pentru a efectua in bune conditii transmisia datelor catre statiile mobile. Acestea sunt cele doua variabile care vor fi determinate in fiecare slot temporal. Dificultatea rezulta din faptul ca amandoua vor varia in acelasi timp.
Am considerat doua situatii diferite:
in cazul online toate detaliile legate de pachete (momentul sosirii, dimensiunea) si utile in alocarea resurselor si planificarea transmisiei sunt cunoscute in avans; acesta este asimilabil cazului optimal
in cazul offline pachetele sosesc la momente necunoscute si algortimul trebuie sa aloce resursele in timp real
A). In primul caz am incercat sa realizam o alocare a resurselor si o planificare optimale, folosind ecuatiile si inecuatiile date in [1]. Scopul este de a maximiza rata de transmisie catre utilizatorul i in slotul temporal k, tinand cont de constrangerile de resurse finite (S numarul de canale, P puterea de emisie maxima a statiei de baza) si de intarziere a pachetelor (transmisia inaintea unui termen limita). Aceste constrangeri sunt formalizate de inecuatiile urmatoare:
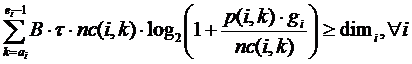
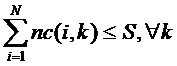
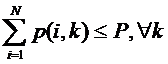
unde dimi desemneaza dimensiunea pachetului transmis de statia de baza utilizatorului i. Vom aloca puterea p(i,k) si numarul de canale nc(i,k), tinand cont de castigul de canal gi corespunzator utilizatorului i. Astfel vom genera o rata de transmisie suficienta pentru a face sa treaca pachetul in decursul a mai multor sloturi temporale, daca este necesar, incepand cu momentul sosirii ai, dar intotdeauna inainte ca termenul limita ei sa expire.
Pentru a incerca sa implementam optimizarea, am folosit Optimization Toolbox din MATLAB. Insa datorita limitarilor sale, nu am putut implementa optimizarea asa cum este ea exprimata in relatiile (1), ci facand mai multe compromisuri, explicate mai jos.
Functia pe care am folosit-o pentru a realiza optimizarea a fost fgoalattain. Aceasta incearca sa atinga un scop (o valoare pentru o functie cu mai multe variabile) tinand cont de mai multe constrangeri impuse de inegalitati liniare sau neliniare. Am ales ca scop dimensiunea pachetului pe care trebuie sa-l transmitem si ca functie rata de transmisie sau suma ratelor pe mai multe slot-uri temporale. Puterea si numarul de canale alocate constituie variabilele functiei. Inegalitatile pe care optimizarea trebuie sa le respecte reprezinta constrangeri de putere totala si de numar total de subpurtatoare disponibile.
Intr-o prima etapa am facut o optimizare temporala, pentru a vedea cum se aloca resursele disponibile, in anumite cazuri simple.
Am considerat situatia a doi utilizatori situati la 250 (prima statie mobila notata cu SM1), respective la 500 m (a doua notata cu SM2) distanta de statia de baza. Aceasta emite catre ei doua pachete de dimensiuni comparabile in decursul mai multor slot-uri temporale. Transmisia catre SM1 se face in timpul a doua slot-uri, incepand din momentul t = 4 ms, si transmisia catre SM2 se face pe parcursul a patru slot-uri temporale, incepand cu momentul t = 3 ms.
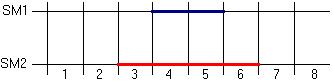
Fig. 4.1 - Structure des tranches temporelles
Programul in MATLAB este continu de Anexa 3. Simularea are o durata de 8 slot-uri temporale, fiecaruia corespunzandu-i patru variabile: o putere si un numar decanale pentru cei doi utilizatori. Deci vom avea 32 de variabile reprezentate prin vectorul x in modul urmator
unde k = 1.8
Matricea care contine functia ce trebuie optimizata are doua linii, corespunzand celor doi utilizatori si este definita in alt fisier, denumit objfun_2. Functia este de fapt suma ratelor de transmisie pe slot-urile temporale considerate pentru emisie. Rata este data de expresia urmatoare:
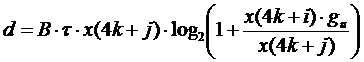 (
(
unde i = 1 si j = 2 pentru u = SM1 si i = 3 si j = 4 pentru u = SM2. Deoarece suntem intr-un caz teoretic, rata de transmisie nu va fi discreta si va putea varia intr-o maniera continua.
Castigul de canal gu a fost considerat acelasi pentru toate subpurtatoarele pentru a simplifica calculele. Posibilitatile lui fgoalattain nu ne permit sa ne imaginam facil o transmisie pe o interfata radio avand canale cu proprietati diferite.
Vectorii lb si ub reprezinta limitele intre care elementele vectorului x pot sa varieze. Pentru putere ele sunt sont 0 si P = 50 W, iar pentru numarul de canale ele sunt 1 si S = 64. Valoarea minima a x(4k+j) este 1 si nu zero deoarece trebuie sa evitam impartirea la zero in timpul simularii. Bineinteles, puterea poate sa ia orice valoare reala in acest interval, dar numarul de canale trebuie sa fie intotdeauna intreg.
Cele doua inegalitati sunt traduse prin intermediul altor parametri ai functiei fgoalattain. Aceasta ofera posibilitatea exprimarii unor inegalitati liniare pentru elementele vectorului x cu ajutorul matrricii A si a vectorului b, in maniera urmatoare:
![]()
Folosim aceasta expresie pentru traduce existenta unor limite pentru resursele totale alocabile in decursul unui slot temporal la valorile maxime posibile P si S.
Parametrul goal, scopul pe care functia trebuie sa-l atinga, este, cum am mentionat deja, dimensiunea pachetului si care in acest caz va fi de 1000 de biti. Pentru ca fgoalattain sa depaseasca scopul, trebuie sa introducem de asemenea si parametrul weight egal cu - | goal |.
Simularea a returnat rezultatele urmatoare.
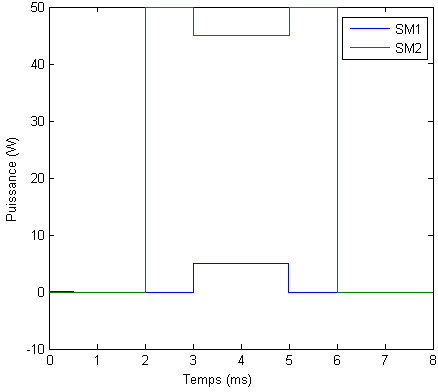
Fig. 4.2 - Puterea alocata

Fig. 4.3 - Numarul de canale alocate
Plecand de la analiza rezultatelor simularii, se pot face mai multe observatii. Mai intai se constata ca algoritmul de optimizare utilizat imparte pachetele in parti egale in timpul fiecarui slot temporal in care se emite. Statia de baza aloca o putere care poate varia de la un slot temporal la altul, dar numarul de canale va ramane fix pe toata durata transmisiunii. In primul slot temporal, transmisia catre SM2, care este mai departe, va primi aproape toata puterea disponibila. Cand incepem sa emitem si spre SM1, puterea se va imparti intre ei, astfel incat transmisia catre SM1 sa se efectueze in bune conditii in cele doua slot-uri temporale.
Aceasta demonstreaza ca e de preferat ca, atat cat este posibil, la nivelul statiei de baza sa se favorizeze cresterea puterii in comparatie cu cresterea numarului de canale alocate, rezultat care este conform cu relatia de calcul a ratei de transfer (2).
A doua etapa a constat in implementarea unui algoritm care face maximizarea ratei de transfer in timpul fiecarui slot temporal, ca in cazul algoritmului water-filling. Pachetele pe care trebuie sa le transmita sunt generate utilizand o distributie Pareto truncata similara celei implementate in OPNET.
Pentru a reduce numarul de variabile (si timpul de simulare) am adaptat implementarea functiei fgoalattain la aceasta noua situatie multi-utilizator, considerand succesiv fiecare slot temporal cand realizam optimizarea. Numarul de variabile va fi astfel proportional cu numarul de utilizatori considerati. Vectorul x va avea dimensiunea 2N, unde x(2k va fi puterea alocata terminalului mobil k si x(2k) numarul de subpurtatoare alocate, k = 1.N.
Functia care trebuie optimizata este definita printr-o matrice cu N linii corespunzatoare celor N utilizatori si contine ratele de transmisie catre fiecare dintre ei. Ea este construita intr-un fisier separat, denumit objfun_4
Constrangerile impuse valorilor puterii si numarului de canale in timpul fiecarui slot temporal sunt aceleasi din cazul precendet, singura noutate fiind faptul ca toti parametrii functiei fgoalattain vor fi generati dinamic.
Scopul pe care functia trebuie sa-l atinga este dimensiunea pachetrului destinat utilizatorului i. Daca pachetul nu trece in timpul slot-ului curent, noul scop va fi cantitatea de biti corespunzatoare partii netransmise a pachetului. In cazul cand nu exista pachet in coada (ne aflam de exemplu inaintea unei sosiri), scopul este configurat la o valoare foarte scazuta, de 10 biti, pentru a consuma resurse neglijabile. Programul in MATLAB se gaseste in Anexa 4.
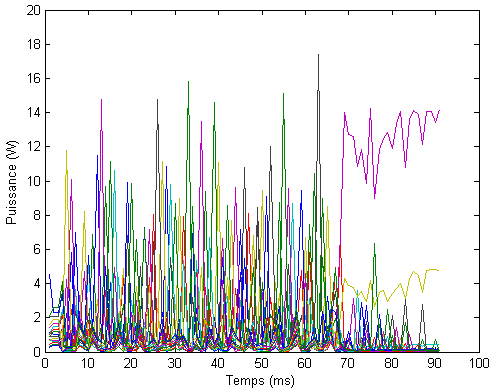
Fig. 4.4 - Puterea alocata
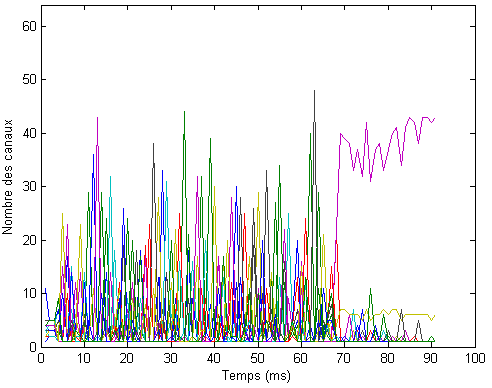
Fig. 4.5 - Numarul de canale alocate
Am simulat situatia unei statii de baza care trebuie sa serveasca transmisiile catre un numar de N = 32 statii mobile, care se gasesc la distante cuprinse intre 500 si 1000 m, utilizand o putere totala P = 50 W si un numar de subpurtatoare S = 64, si am obtinut rezultatele ilustrate in figurile 4.4 si 4.5. Am generat numai 20 de pachete pe utilizator, pentru a ajunge mai rapid la rezultate. Resursele alocate fiecarui terminal mobil variaza mult de la un slot temporal la altul, cum se poate usor observa in cele doua figuri. Este interesant sa notam faptul ca algoritmul privilegiaza alocarea de putere in comparatie cu alocarea de canale. Valorile maxime alocate unui singur utilizator in timpul unui slot temporar sunt de 75% din canale si de mai mult de 85% din puterea disponibila.
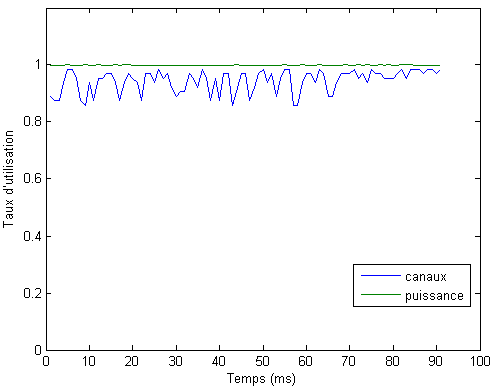
Fig. 4.6 - Rata de utilziare a resurselor
In figura 4.6 am reprezentat ratele de utilizare a resurselor (puterea si numarul de canale), care sunt calculate ca rapoarte intre valorile alocate in total pe parcursul unui slot si valorile total disponibile. Se observa ca puterea este intotdeauna utilziata la maximum, in timp ce nu toate subpurtatoarele au fost alocate in timpul unui slot temporal. Aceasta ne conduce din nou la concluzia ca e mai bine sa se mareasca puterea utilizata decat numarul de canale.
B). A doua abordare, desemnata ca online, a fost implementata pe bancul de simulare realizat in OPNET. Pachetele sosesc in timp real si algoritmul trebuie sa faca planificarea si alocarea resurselor pentru a le face sa treaca cu cea mai mica intarziere posibila.
Au fost considerati doi algoritmi. Amandoi aloca resursele pentru transmisie intr-o maniera similara, dar ele sunt diferite din punctul de vedere al planificarii pachetelor. Vom incepe prin a prezenta alocarea resurselor, care este comuna.
Cea mai mare rata de transmisie care poate fi atinsa pe o singura subpurtatoare este de 352 Kbps, deci, in timpul unui slot temporal cu o durata de o milisecunda, vom putea transmite maximum 352 de biti. De aceea am ales sa limitam la aceasta valoare dimensiunea pachetelor care intra in coada de asteptare. Toate pachetele mari (adica cu o dimensiune de peste 352 de biti) vor fi impartite in mai multe pachete mai mici. De exemplu, daca dimensiunea unui pachet care intra in coada este de 878 de biti, el va fi divizat in trei pachete : doua cu o dimensiune de 352 de biti si unul cu o dimensiune de 174 de biti.
Astfel nu vor exista pachete mai mari de 352 de biti. In aceste conditii, alocarea resurselor este simplificata. Nu am utilizat un algoritm foarte performant, ci unul care seamana mai mult cu un algortim de tip Greedy.
Cum a fost deja mentionat in capitolul precedent, vom utiliza patru rate de transmisie discrete: 62 Kbps, 118 Kbps, 246 Kbps si 352 Kbps. Pentru a atinge aceste valori, patru puteri diferite vor fi necesare si de asemenea patru numere de canale. Ele sunt complementare astfel incat puterii celei mai mari ii corespunde un singur canal, iar puterii celei mai reduse ii corespunde cel mai mare numar de canale (6 in cel mai rau caz). Puterea este calculata tinand cont de raportul semnal zgomot necesar fiecarui tip de modulatie si numarul de canale este obtinut impartind dimensiunea pachetului curent la fiecare rata de transmisie discreta (inmultita cu 1 ms).
S-au considerat separat cele doua situatii pe care le putem intalni: cand exista mai multa putere disponibila si, respectiv, cand exista mai multe canale disponibile. Se ia decizia comparand rata de utilizare a celor doua resurse si se va aloca mai mult din aceea care are rata mai mica. Incepem prin a testa daca puterea/numarul de canale maxim este disponibil. Puterea maxima corespunde ratei de transmisie de 352 Kbps si numarul maxim de canale celei de 62 Kbps. Aceste valori necesita un numar minim de canale, respectiv, o putere minima. Vom testa de asemenea daca exista destule canale/putere complementara disponibila. De abia dupa aceea se aloca resursele. Cand una din cele doua conditii nu este satisfacuta, se trece la urmatoarea rata de transmisie discreta si incercam din nou.
Nu este cel mai bun algoritm de alocare, dar este mai putin complicat si atat de rapid cat este necesar si este superior unei simple alocari de putere.
Prima idee de planificare a pachetelor prezentata este bazata pe o scara temporala mult mai lunga decat durata unui slot temporal. Ea va fi desemnata in paginile urmatoare drept "Algoritmul A".
Vom considera Nt slot-uri temporale modelate cu ajutorul mai multor matrici si vectori:
vectorul pu, care are Nt elemente si care contine informatia despre alocarea de putere
vectorul su, care are Nt elemente si care contine informatia despre alocarea numarului de subpurtatoare
matricea c, care are S linii si Nt coloane si care contine informatia despre alocarea nominala a canalelor
matricea pk, care are S linii si Nt coloane si care contine pachetele programate pentru a fi transmise
vectorul chan, care are Nt elemente si care contine contorul de canal
Procesorul statiei de baza va extrage un pachet dintr-una din cozile de asteptare si va aloca resursele necesare pentru a-l emite spre destinatar. Daca nu este posibil sa fie programat pentru transmisie in cel mai apropiat slot temporar, algoritmul va incerca sa faca acest lucru in slot-urile urmatoare, pana cand reuseste sau depaseste al Nt-lea slot.
Informatia asupra consumarii resurselor in slot-ul temporal k este continuta in vectorii pu si su. Cand se aloca puterea si canalele pentru transmisia unui pachet, se privesc intotdeauna mai intai valorile elementelor acestor vectori care indica daca este posibil sa se planifice o alta transmisie. Dupa ce s-a luat decizia de a se emite pachetul in slot-ul temporal k, intervin matricile c si pk. Ele contin informatia asupra programarii propriu-zise a transmisiilor. Un element al cjk reprezinta terminalul mobil spre care se va emite pachetul pkjk utilizand subpurtatoarea j in timpul slot-ului temporal k.
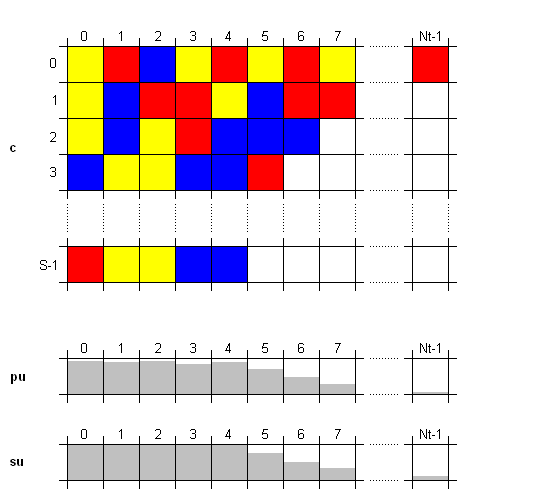
Fig. 4.7 - Exemplu de umplere a matricilor Algoritmului A
In figura 4.7 am ilustrat un exemplu de umplerea a matricilor si vectorilor utilizati pentru a modela Algortimul A. Acesta va incerca intotdeauna sa umple primele slot-uri temporale si numai in conditii de sarcina foarte mare se va ajunge la situatii cand si ultimile slot-uri vor fi de asemenea ocupate.
Algoritmul a fost implementat cu ajutorul celor doua functii mentionate in capitolul precedent: ck() si arv(). Codul sursa se gaseste in Anexa 5. In continuare, vom detalia aceasta implementare.
ck() este apelata in fiecare milisecunda, cand soseste un pachet de la ceasul sistemului, modelat cu ajutorul sursei clk. Ea trebuie sa realizeze operatiunile urmatoare:
configurarea conexiunilor radio necesare pentru a efectua transmisiile programate in timpul slot-ului curent (k = 0)
transmisia efectiva a pachetelor programate
actualizarea matricilor si vectorilor
alegerea unei cozi de asteptare din care se va extrage urmatorul pachet.
Configurarea conexiunilor se face intr-o maniera similara celei utilizate la nivelul statiei mobile. Pentru canalul j (j = 0.S-1), numarul care desemneaza terminalul mobil (u = 0.N-1) este inmultit cu 100 si apoi este adunat cu j. Astfel se obtine un code de dispersie, care este incarcat in atributele canalului j al emitatorului statiei de baza. Acest cod este unic la receptie si reusim sa realizam legatura radio dorita. Terminalul mobil cu care se va comunica este continut in elementul cj0. Daca canalul j nu este alocat, valoarea lui cj0 si a codului de dispersie va fi -1.
Dupa ce am terminat de configurat interfata radio, este posibil sa se transmita pachetele programate. Acestea se gasesc in prima coloana a matricii pk. Pentru transmisie folosim procedura OPNET op_pk_send, dar, inainte de a face acesta, 'stampilam' temporar pachetul (cu op_pk_stamp) pentru a putea determina la receptie timpul care a trecut de la intrarea sa in coada de asteptare pana la plecarea spre terminalul mobil.
Nu mai avem nevoie de informatii asupra pachetelor pe care le-am trimis deja catre terminalele mobile si, deci, urmatoarea etapa va fi actualizarea matricilor si vectorilor. Realizam aceasta mutand coloanele spre stanga. Noul slot temporal k va fi vechiul k+1 si valorile ultimelor elemente vor fi initializate.
Aceasta operatie termina starea de transmisie si pana la urmatorul inceput de slot temporal vom aloca resurse si vom programa mai multe alte pachete. Acestea sunt rolurile functiei arv(), care este activata de sosirea unui pachet pe porturile de intrare ale procesorului. Deci este necesar sa generam acest eveniment la sfarsitul functiei ck(), extragand un pachet dintr-una din cele N cozi de asteptare. Pentru a alege o coada, s-a considerat dimensiunea sa in biti drept criteriu de selectie. Aceasta este continuta in vectorul subq_size, care este o variabila globala accesibila de asemenea procesorului statiei de baza. Vom gasi cea mai incarcata coada si vom extrage un pachet cu ajutorul procedurii OPNET op_strm_acces, apelata pentru portul de intrare corespunzator.
In acest fel trecem la functia arv(). Aceasta trebuie sa indeplineasca mai multe sarcini:
receptia unui pachet iesit din coada si determinarea parametrilor sai
calculul numarului de canale necesare pentru transmisia sa
alocarea resurselor si programarea transmisiei pachetului
cererea unui nou pachet
Pachetul este extras din fluxul de intrare cu ajutorul functiei OPNET op_pk_get. Apoi se determina dimensiunea si timpul de creare al acestuia cu op_pk_total_size_get si op_pk_creation_time_get
Dimensiunea pachetului ne va servi la calculul numarului de canale necesare pentru a-l transmite cu fiecare din cele patru rate discrete, numar care va fi utilziat in alocarea de resurse.
Dupa acesti pasi initiali, se ajunge la bucla principala. Aici se iau cele mai importante decizii. Atat timp cat avem inca biti din pachetul original de programat pentru transmisie, vom ramane in aceasta bucla. Algoritmul testeaza daca resursele slot-ului curent sunt consumate si daca sunt, va trece la urmatorul slot, pana va gasi resurse disponibile. Apoi le va aloca dupa algoritmul explicat mai sus, adica alegand resursa cea mai putin utilizata, si va actualiza valorile corespunzatoare vectorilor pu si su. Urmatoarea etapa va fi sa configureze matricile c si pk, ca sa putem efectiv transmite pachetul. Vom avea din nou doua cazuri. Cel mai simplu este cand utilizam numai un canal pentru transmisie. Din cauza faptului ca am considerat toate subpurtatoarele cu proprietati identice, este posibil sa simplificam alocarea nominala a canalelor. Vom folosi vectorul chan drept contor de canale pentru fiecare slot temporal si, de fiecare data cand programam un pachet, incrementam elementul chank si alocam canalul corespondent valorii sale. De exemplu, daca pachetul provenit de la sursa i trebuie sa fie transmis in timpul slot-ului temporal k pe canalul j (unde j = chank), elementul cjk ia valoarea i si elementul pkjk va contine pointerul de pachet.
Situatia este mai complicata cand am alocat mai multe canale si va trebui mai intai sa impartim pachetul intr-un numar corespunzator de pachete mai mici. Acestea vor avea o dimensiune fixa stabilita prin rata de transmisie aleasa si vom configura timpul de creare identic cu cel al pachetului original.
La sfarsit decrementam dimensiunea pachetului curent cu cantitatea programata pentru o viitoare transmisie pentru a putea iesi din bucla.
In continuare vom extrage un pachet dintr-una din cozile de asteptare folosind acelasi criteriu ca in functia ck(). Avem o limitare impusa prin numarul de slot-uri temporale considerate. Daca matricea de pachete este deja plina nu vom mai extrage pachete si vom astepta urmatoarea transmisie pentru ca aceasta sa se goleasca putin.
Algoritmul A se aseamana cu algortimul de tipul water-filling, deoarece incearca sa gaseasca cea mai buna maniera de a 'umple' subpurtatoarele in decursul celor Nt slot-uri temporale. Nu este insa o maximizare a ratei de transmisie instantanee, datorita scarii temporale mult mai lungi, dar este totusi in spiritul water-filling. Chiar daca cautam coada cea mai incarcata pentru a extrage un pachet, ea nu va fi cea mai incarcata la momentul respectiv, ci probabil candva in viitor, deoarece mai exista inca pachete netransmise in memoria tampon a procesorului. Structura evenimentelor din OPNET ne impune aceasta limitare pentru criteriul folosit. Extragem cate un pachet pe rand si, cand realizam acest lucru, el va parasi coada si dimensiunea acesteia se va diminua, chiar daca el nu este programat pentru transmisie decat cateva milisecunde mai tarziu. Din acest motiv, nu stim daca extragem din coada cea mai potrivita sau nu.
Al doilea algoritm propus, denumit "Algoritmul B1", incearca sa elimine aceasta problema. Nu mai gandim pe o scara temporala lunga, ci de la un slot temporal la altul, supraveghiind starea de ocupare a cozilor de asteptare.
O alta metoda de extragere a pachetelor a fost aleasa. Ea presupune notiunea de prioritate a cozilor. La debutul fiecarui slot temporal, determinam prioritatea fiecarei cozi in parte si apoi incepem alocarea pentru transmisia pachetelor in ordinea stabilita. De abia dupa ce am terminat alocarea pentru slot-ul curent vom extrage pachetele programate pentru transmisie si le vom trimite catre statiile mobile. In acest fel controlam mai bine ocuparea cozilor de asteptare si eliminam memoria tampon interna a procesorului.
Fig. 4.8 - Exemplu de functionare a Algoritmului B1
In figura 4.8 am reprezentat un exemplu de functionare al Algortimului B1. Cele N cozi de asteptare au dimensiuni diferite. Vom determina prioritatea lor tinand cont de acest criteriu simplu si natural. Coada u1, care este cea mai incarcata, are mai mare nevoie de a fi golita decat celelalte. Dupa ce prioritatile au fost stabilite, se aloca resurse pentru transmisia pachetului care se gaseste in capul cozii u1. Apoi se trece la urmatoarea coada din punct de vedere al prioritatii, care este u0, si se repeta operatiile. Este posibil sa nu se ajunga sa se satisfaca nevoile de transmisie a tuturor utilizatorilor in timpul aceluiasi slot temporal, dar in urmatorul vor avea probabil cele mai incarcate cozi si, deci, cea mai mare prioritate.
Algoritmul a fost implementat de asemenea folosind cele doua functii ck() si arv(). Datorita faptului ca realizam alocarea resurselor inainte de extragerea pachetelor, de aceasta data functia ck() va fi cea mai importanta. Ea trebuie:
sa faca initializarile parametrilor de sistem
sa stabileasca prioritatea cozilor
sa aloce resursele necesare pentru a transmite pachetele cele mai prioritare
sa inceapa sa extraga pachetele din cozile de asteptare
La inceputul fiecarui slot temporal, semnalat de sosirea unui pachet provenit de la sursa clk, se initializeaza parametri de sistem si apoi se evalueaza vectorul subq_size, care contine deimensiunea cozilor de asteptare in acel moment. Pentru aceasta copiem informatia in vectorul size si initializam elementele vectorului prior. Indexul sau reprezinta prioritatea, iar valoarea elementului reprezinta utilizatorul care are aceasta prioritate. Intr-o etapa initiala, indexul va fi egal cu elementul.
Pentru a determina prioritatea, vom sorta cozile in ordinea crescatoare a dimensiunii lor, simultan in vectorii size si prior. Realizam aceasta cu ajutorul unui agoritm de tipul Bubble Sort. Astfel, coada cea mai ocupata se vagasi pe pozitia N-1 in cei doi vectori si va fi cea mai prioritara.
Pentru alocarea resurselor, care urmeaza in continuare, vectorii sunt parcursi incepand cu ultima pozitie. Dimensiunea pachetului care se gaseste in capul cozii este continuta in vectorul first_pk_size. Aceasta valoare este utilizata pentru a calcula numarul de subpurtatoare necesare pentru atingerea fiecarei rate de transmisie discrete. In continuare sunt alocate resursele necesare transferului acestei cantitati de informatie, folosind algoritmul de alocare prezentat la inceputul acestui capitol. Dar, acum, pu si su nu mai sunt vectori, ci scalari. Ei vor servi la contabilizarea utilizarii puterii si canalelor in timpul slot-ului curent.
Pachetul nefiind inca extras din coada, transmisia sa este programata cu ajutorul unui vector auxiliar dim. Acest vector de S elemente contine valoarea ratei discrete aleasa pentru transmisia pe fiecare canal. Aceasta informatie va permite mai tarziu sa se construiasca pachete care vor fi transmise. Un contor de canale chan este din nou utilizat si subpurtatoarele sunt alocate una dupa alta. De exemplu, pentru a transmite cu rata de 352 Kbps pe canalul j (unde j = chan), un pachet provenit de la sursa i, elementul cj ia valoarea i si elementul dimj ia valoarea 352. Contorul chan este incrementat de fiecare data cand un canal este alocat pe parcursul unui slot temporal.
Pentru a obtine la sfarsit o imagine realista a starii de ocupare a cozii curente, decrementam dimensiunea sa (mai precis indicele ocuparii sale) cu cea a pachetului programat. Aceasta imagine este importanta, in etapele urmatoare, pentru a determina daca alocarea a fost deja facuta sau nu. In caz afirmativ, contorul pachetelor programate packi este incrementat si un compromis este realizat asupra dimensiunii urmatorului pachet din coada. Deoarece nu am reusit sa gasim o metoda de determinare corecta, am considerat cazul cel mai defavorabil, adica atunci cand pachetul are dimensiunea maxima (352 de biti). Acesta nu este pregatit pentru transmisie decat daca ocuparea cozii este inca superioara celei cu prioritate direct inferioara. Daca aceasta conditie nu este satisacuta, se va trece la coada cu prioritate inferioara. Idem in cazul in care alocarea n-a fost facuta.
Cand algoritmul iese din bucla, alocarea resurselor disponibile si programarea transmisiilor sunt terminate. Ramane de efectuat extractia pachetelor alese si trimiterea lor pe subpurtatoarele desemnate. Functia ck() initializeaza acest proces, iar arv() il va termina.
Vectorul pack este utilizat drept contor de pachete programate pentru transmisie. Acest vector contine N elemente, fiecare corespunzand unei statii mobile, precum si informatia asupra numarului de pachete ce trebuiesc extrase din fiecare coada in timpul slot-ului curent. Acest vector este parcurs in sensul prioritatilor descrescatoare ale terminalelor mobile, pana cand se intalneste primul element nenul si extragem un pachet.
Functia arv(), activata la sosirea unui pachet provenit dintr-una din cozile de asteptare, realizeaza doua sarcini principale:
extragerea din cozi a tuturor pachetelor programate pentru transmisie
expedierea acestor pachete pe subpurtatoarele alocate
Intr-o prima etapa, pachetul curent este segmentat daca este necesar si apoi este prgramat pentru transmisie cu ajutorul vectorului pk. Acesta din urma contine pointerii catre pachetele care vor fi trimise pe fiecare subpurtatoare. Noile pachete sunt create cu dimensiunea continuta in vectorul dim si momentul de creare este configurat la o valoare egala celei a pachetului initial (pentru a se putea colecta statistici corecte la receptie, cum a fost deja explicat mai sus). Baleierea canalelor este efectuata cu ajutorul contorului chan. Dimensiunea pachetului initial trebuie neaparat actualizata, pentru a nu transmite mai mult decat este necesar.
De exemplu, dupa sosirea unui pachet, algoritmul incrementeaza pe chan, creeaza un nou pachet cu dimensiunea dimchan, configureaza timpul de creare adevarat si memoreaza pointerul sau in pkchan.
O data tratat pachetul curent, algoritmul decrementeaza contorul pack si determina coada din care trebuie extras urmatorul.
Programarea transmisiilor este terminata atunci cand toate elementele vectorului pack sunt nule. Expedierea pachetelor catre destinatari poate incepe. Aceasta parte este identica cu cea a Algoritmului A: legaturile radio sunt configurate calculand codurile de dispersie, apoi procedurile op_pk_stamp si op_pk_send sunt utilizate pentru stampilarea temporala si pentru transmisia elementelor vectorului pk.
Algoritmul B1 reuseste sa obtina o imagine mai fidela a starii cozilor de asteptare, dar nu foloseste o scara temporala mai lunga. De aceea am incercat sa-l modificam din acest punct de vedere. Aceasta tentativa se numeste Algoritmul B2.
Vom introduce o memorie a ocuparii cozilor pentru a putea evalua tendinta de crestere sau scadere a ocuparii fiecarei cozi. In mod logic, cand coada este pe o curba ascendenta, golirea sa devine mai prioritara decat a unei cozi care se gaseste pe o curba descendenta, chiar si daca nivelul de umplere al acesteia din urma este important. In conseciinta, am adaugat un coeficient (egal cu N) la prioritatea fiecarui utilizator pentru care ocuparea unei cozi are tendinta sa creasca si am efectuat pe aceasta baza un clasament inainte de a incepe alocarea resurselor.
Pentru a implementa aceste modificari am transformat vectorul size intr-o matrice cu 3 linii si N coloane. Prima linie are aceeasi utilitate ca si vectorul size in Algoritmul B1. Celelalte doua linii contin ocuparea cozii la inceputul slot-ului temporal curent k si al celui precedent k-1. Aceste doua linii ne permit sa descoperim tendinta de umplere/golire a fiecarei cozi si sa stabilim noile prioritati.
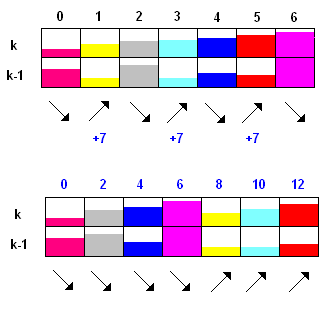
Fig. 4.9 - Exemplu de prioritati stabilite dupa evolutia umplerii cozilor
Daca ocuparea cozii a crescut in raport cu ultimul slot temporal, prioritatea sa initiala este si ea crescuta cu N. Aceasta alegere ne permite sa ne asiguram ca nu va exista alta coada cu un indice de ocupare mai important (si deci mai prioritara) si cu o tendinta descendenta, care sa aiba o prioritate mai mare.
Trecerea de la vechiul algoritm B1 la noul algortim B2 se face cu ajutorul vectorului index, care indeplineste rolul lui prior din B1. Acesta din urma continea numarul care desemna identitatea utilizatorului cu prioritatea egla cu indexul elementului. Pentru noul prior situatia este inversata. Vectorul contine prioritatile si indexul desemneaza utilizatorul. Rolul sau este de a ajuta in cea de-a doua sortare a lui size si index. Aceasta se realizeaza efectuand un aranjament al cozilor in ordinea descrescatoare a noii lor prioritati. Operatiunea va conduce la o situatie similara celei din B1 si la actiuni similare. Codul sursa al functiilor ck() si arv() pentru B1 si modificarile pentru B2 sunt listate in Anexa 6.
4.2. Simularile si interpretarea rezultatelor
Criteriul ales pentru evaluarea performantelor algoritmilor propusi este intarzierea de transmisie suferita intre momentul in care pachetul intra in coada de asteptare a statiei de baza si momentul in care este trimis spre emitator (timpul de transmisie pe interfata radio si de receptie la nivelul mobilului sunt aici neglijate). Noi am observat media precum si functia de repartitie a acestui parametru, in conditiile in care sarcina sistemului creste pana la blocarea completa a acestuia.
Noi am considerat o configuratie celulara unde toate statiile mobile se gasesc la aproximativ 460 metri de statia de baza aflata in centrul celulei. Traficul mediu oferit de fiecare sursa video sintetica este de 27 Kbps. Am inceput cu 4 surse, crescand numarul utilizatorilor pana la 44, situatie corespunzand unui trafic mediu global de 1,118 Mbps.
Mai multe modificari in interfata vizuala si in codul sursa al proceselor vn_BS_proc si vn_fifo trebuie efectuate pentru aceasta. Mai intai adaugam statii mobile in sistem. Fiecareia din ele, denumite MS_x, trebuie sa-i corespunda un numar de identificare (atributul Terminal ID, egal cu x-1) pentru a putea stabili in mod corect legaturile radio. In modelul statiei de baza este convenabil sa adaugam atatea module tpareto_source cate statii mobile avem. Momentul de pornire al acestora (atributul Start Time) trebuie sa fie diferit si continut in intervalul [1,01 ; 1,99]. Sursele sunt legate de coada de asteptare queue al carei numar de subcozi trebuie sa fie egal cu numarul de surse N. Mici modificari sunt de asemenea necesare in header-ul procesului vn_fifo, unde vectorii subq_size, first_pk_size si start trebuie sa fie declarati cu un numar de elemente egal cu N.
Coada este de asemenea legata de procesor prin intermediul a N conexiuni corespunzatoare celor N subcozi. Este deci necesar sa adaugam un numar de conexiuni egal cu numarul de surse noi. Apoi in header-ul lui vn_BS_proc sunt declarate noile intrari SRC_IN_STRMx si dimensiunea vectorilor subq_size si first_pk_size, precum in cazul lui vn_fifo.
In starea init trebuie sa se faca actualizarea valorii lui N, apoi calculul distantei intre BS si noile statii mobile, ca pentru celelalte.
Este de asemenea necesar sa modificam in declaratiile de variabile de stare (Status Variables) dimensiunile vectorilor si matricilor care depind de N. Este vorba de obicei de dist, g, path_loss, p_min si de asemenea de prior, index si size pentru algoritmii B.
Ultima etapa consista in a adauga linii care corespund noilor utilizatori, in instructiunile switch din codul functiilor ck() si arv().
Acest mod de a proceda pentru a mari numarul de utilizatori devine repede destul de dificil si desenarea a mai mult de 40 de linii intre doua module este o operatiune delicata pe interfata vizuala a OPNET. De asemenea am decis sa generam o crestere a sarcinii modificand de asemenea parametrii de trafic ai surselor video. Pentru aceasta am scazut valoarea maxima a intervalului intre sosiri de la 12,5 ms la 5 ms si am crescut dimensiunea minima a pachetului de la 160 la 350 de biti. Astfel am atins sarcini superioare valorii de 2 Mbps.
Resursele de care dispune statia de baza au fost fixate la 5 W si 16 canale, in banda de 3,5 GHz.
Timpul de simulare ales este de 100 de secunde, destul de lung pentru a evalua performantele sistemului nostru. Seed-ul initial este de 64 si numarul de statistici colectate de 100.000. Acesta trebuie sa fie egal cu numarul de slot-uri temporale pentru a oferi o imagine clara asupra posibilitatilor sistemului.
Am efectuat trei serii de simulari, una pentru fiecare algoritm in parte, epntru a evalua in fiecare caz intarzierea medie, functia sa de repartitie, precum si rata de transmisie pe ansamblul celor 16 subpurtatoare.
Figura 4.10 ilustreaza performantele celor trei algoritmi.
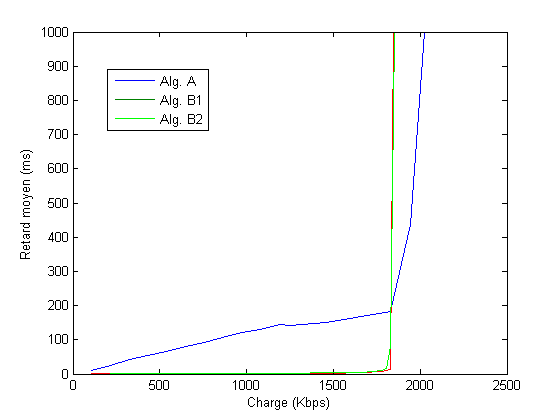
Fig. 4.10 - Intarzierea medie la sarcini variate pentru cei 3 algoritmi
Cum se poate observa, din punct de vedere al intarzierii minime, Algoritmii B1 et B2 sunt net superiori Algoritmului A atat timp cat sarcina maxima nu este atinsa. Pentru B1 si B2 aceasta intarziere nu depaseste 15 ms in conditii normale de functionare, pe cand Algoritmul A ofera o intarziere de pana la 10 ori mai mare. Totusi Algoritmul A continua sa functioneze acolo unde celelalte doua se blocheaza, dincolo de 1,8 Mbps. Rata maxima de transfer obtinuta de algoritmii B este de 1,75 Mbps, pe cand la Algoritmul A este de 2 Mbps.
Curbele Algoritmilor B1 si B2 fiind foarte apropiate pe figura 4.10, le-am reprezentat mai detaliat in figura 4.11.
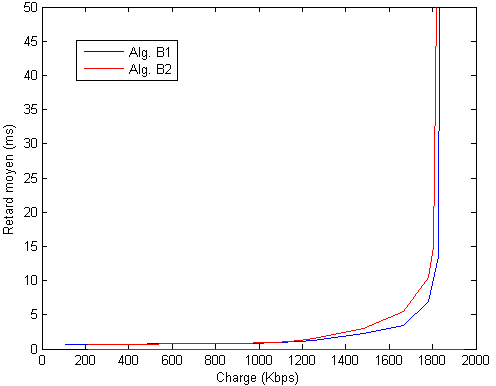
Fig. 4.11 - Intarzierea minima a pachetelor la sarcini variate pentru Algoritmii B1 si B2
Notam ca aparent performantele lui B2 nu sunt superioare lui B1, dar si ca am intampinat dificultati in reprezentarea grafica a rezultatelor graficelor si ca mici erori de masura sunt probabile. Pentru a ameliora judecata asupra rezultatelor, vom efectua in continuare o prezentare mai detaliata a rezultatelor celor doi algoritmi.
Figurile 4.12 si 4.13, generate de OPNET, arata intarzierea medie a pachetelor ordonate si transmise de Algoritmii B1 et B2, cand sistemul este incarcat la 1,806 Mbps (44 utilizatori).
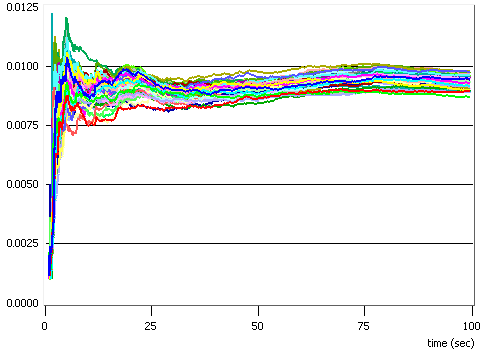
Fig. 4.12 - Intarzierea medie (in sec) a pachetelor ordonate si transmise de Algoritmul B1, pentru o sarcina de 1,806 Mbps
Aceasta figura arata ca intarzierea medie variaza intre 8,67 si 9,95 ms. Pentru reprezentarea de pe graficul 4.10 am ales valoarea de 9,25 ms corespunzatoare unei sarcini de 1,806 Mbps.
Algoritmul B2 furnizeaza rezultate de acelasi ordin de marime, dar cu intarzieri care variaza mai mult de la o statie mobila la alta.
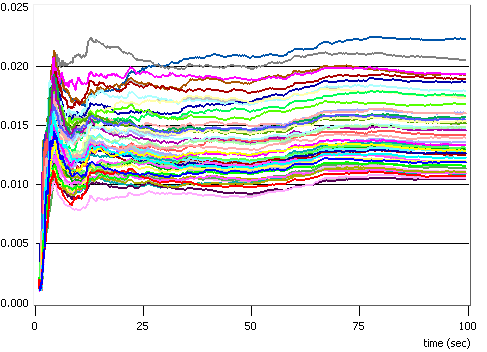
Fig. 4.13 - Intarzierea medie (in sec) a pachetelor ordonate si transmise de Algoritmul B2, pentru o sarcina de 1,806 Mbps
Cum se poate observa, intarzierea ia valori intre 10 si 22 ms. Pe graficul 4.10 am considerat o valoare medie de 15 ms. Algoritmul B1 ofera deci performante mai bune decat B2 in conditii de sarcina puternica. Intarzierea medie este insa inferioara si statiile mobile sunt tratate aproape echitabil. Nu exista statii favorizate, ca in cazul lui B2.
Cand sarcina este destul de joasa rezultatele sunt aproape identice. Figurile 4.14 si 4.15 reprezinta intarzierea medie obtinuta de cei doi algoritmi in cazul unei sarcini de 648 Kbps (24 utilizatori). Intarzierea este la fel de mica, aflandu-se in zona de sub o milisecunda.
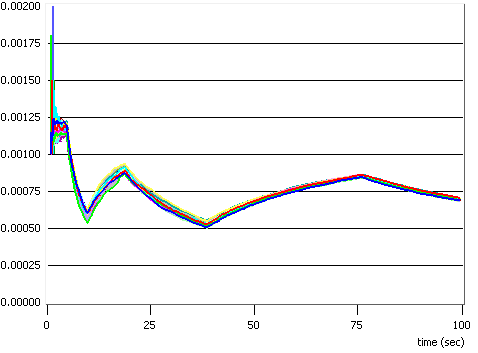
Fig. 4.14 - Intarzierea medie (in sec) a pachetelor ordonate si transmise de Algoritmul B1, pentru o sarcina de 648 Kbit/s
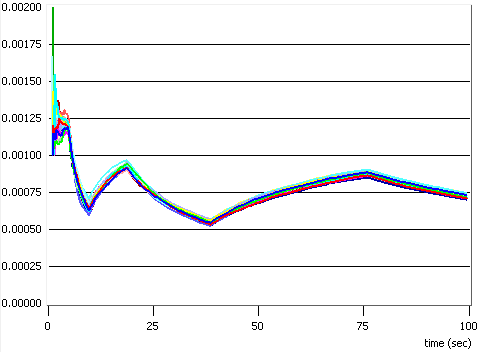
Fig. 4.14 - Intarzierea medie (in sec) a pachetelor ordonate si transmise de Algoritmul B2, pentru o sarcina de 648 Kbit/s
La sarcini joase, algoritmul B2 nu mai favorizeaza anumite terminale mobile. Cei doi algoritmi dau rezultate bune si intarzierea medie se gaseste in limite rationale.
Pentru comparatie, vom nota ca intarzierea indusa de Algoritmul A depaseste de cateva ori durata unui cadru video. Figura 4.16 arata intarzierea medie a pachetelor ordonate si transmise de acest algoritm cand sistemul este incarcat la 1,482 Mbps.
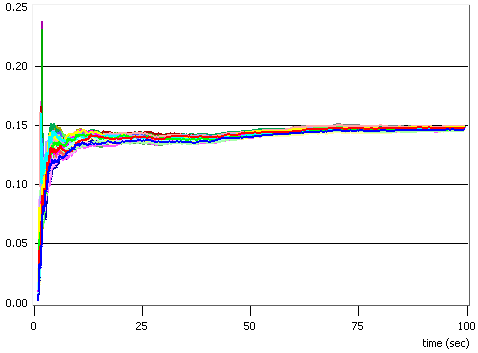
Fig. 4.16 - Intarzierea medie (in sec) a pachetelor ordonate si transmise de Algoritmul A, pentru o sarcina de 1,482 Mbit/s
Intarzierea medie se situeaza intre 140 si 150 ms pentru sarcini cuprinse intre 1 si 1,9 Mbps, ceea ce nu este o valoare prea buna daca o comparam cu performantele celorlalti doi algoritmi. Algoritmul A ofera totusi o rata de transmisie superioara si nu se blocheaza decat la sarcini ceva mai mari (cu intarzieri superioare). Aceasta nu poate constitui un avantaj decat pentru tipurile de trafic care nu solicita o intarziere mai mica decat 150 ms de exemplu.
Trebuie retinut faptul ca performantele Algoritmului A sunt de asemenea influentate de dimensiunea memoriei tampon pe care am utilizat-o pentru programarea transmisiei pachetelor. Exemplul precedent pe care l-am considerat a fost obtinut pentru un Nt de 20 slot-uri temporale. Daca marim acest numar, sarcina pe care sistemul poate s-o suporte se va mari si ea. Pentru a pune acest fapt in evidenta, am ales un nou Nt de 50 de slot-uri temporale. Avantajele sunt de altfel vizibile in figura 4.18, comparativ cu figura 4.17 obtinuta pentru o simulare cu Nt = 20. Sarcina considerata este de 1,945 Mbps; la aceasta sarcina sistemul cu mai putina memorie incepe sa se blocheze si intarzierea medie nu mai este stabila.
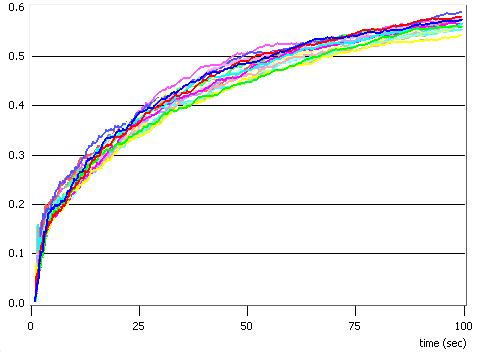
Fig. 4.17 - Intarzierea medie (in sec) a pachetelor ordonate si transmise de Algoritmul A, pentru o sarcina de 1,945 Mbit/s si o memorie tampon de 20 de slot-uri temporale
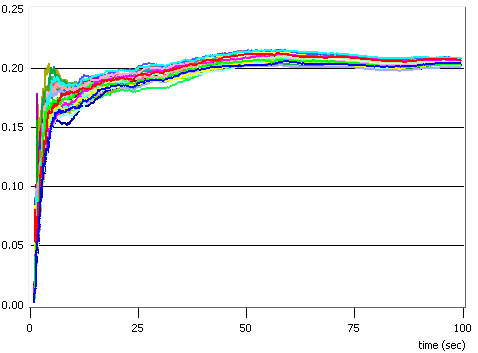
Fig. 4.18 - Intarzierea medie (in sec) a pachetelor ordonate si transmise de Algoritmul A, pentru o sarcina de 1,945 Mbit/s si o memorie tampon de 50 de slot-uri temporale
Sistemul cu mai multa memorie nu se blocheaza, ci functioneaza normal, intarzierea minima situandu-se in jurul valorii de 200 ms.
Pentru a evalua jitter-ul (variatia intarzierii), am evaluat functia de repartitie a intarzierii. Graficele corespondente reprezinta intarzierea maxima pe care o putem intalni in x % din cazuri. Daca curba are o panta foarte accentuata aceasta inseamna ca diferenta intarzierile maxime intalnite in 10 % din cazuri si cele intalnite in 90 % din cazuri nu va fi foarte mare si deci jitter-ul se va afla in limite rezonabile. Daca panata graficului este mai putin inclinata, aceasta corespunde unor diferente mari si deci unui jitter considerabil. Figurile 4.19 si 4.20 reprezinta functiile de repartitie (distributiile cumulate) ale intarzierilor obtinute de algoritmii A si B1, in cazul unei sarcini de 1,118 Mbps.
Fig. 4.19 - Functia de repartitie a intarzierilor pachetelor ordonate si transmise de Algoritmul A, pentru o sarcina de 1,188 Mbit/s
Fig. 4.20 - Functia de repartitie a intarzierilor pachetelor ordonate si transmise de Algoritmul A, pentru o sarcina de 1,188 Mbit/s
Se poate observa ca din punct de vedere al performantelor Algoritmul B1 este superior Algoritmului A. Panta graficului 4.20 este mult mai accentuata decat a celui din 4.19 si deci intarzierea variaza mai putin.
Am simulat de asemenea o configuratie a celor 44 de statii mobile palsate la distante aleatoare in celula, cum este indicat in figura 4.21 de mai jos. Sarcina este tot de 1,188 Mbps.
Fig. 4.21 - Exemplu de distributie aleatoare a 44 de statii mobile in celula considerata
Daca pentru algoritmul A nu exista diferente semnificative intre aceasta configuratie si cea anterioara cand toate statiile mobile se gasesc la aproximativ 460 metri de statia de baza, pentru Algoritmul B1, din contra, rezultatele prezinta diferente.
Figurile 4.22 arata intarzierea medie obtinuta de Algoritmul A. Pentru 4.22a distantele fata de taote mobilele sunt fixate la 460 de metri. Pentru 4.22b distantele sunt aleatoare. Intarzierea medie pastreaza aceeasi valoare de 147 ms pentru cele doua situatii si putem trage concluzia ca Algoritmul A se comporta intr-o maniera aproape similara in conditii diferite. Bineinteles, este necesar sa se faca mai multe simulari pentru a intari aceasta concluzie.
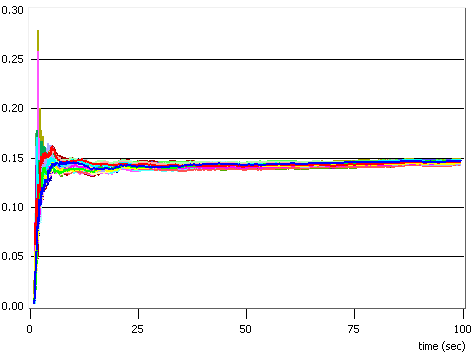
Fig. 4.22a - Intarzierea medie (in sec) a pachetelor ordonate si transmise de Algoritmul A, pentru o sarcina de 1,188 Mbit/s, cand statiile mobile se gasesc la distante de 460 m
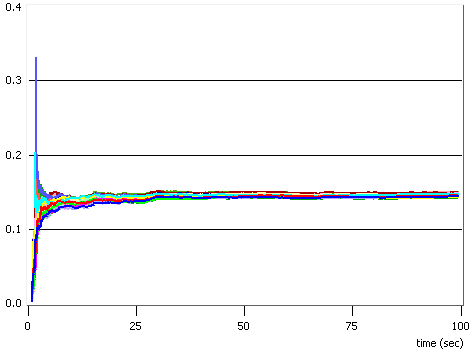
Fig. 4.22b - Intarzierea medie (in sec) a pachetelor ordonate si transmise de Algoritmul A, pentru o sarcina de 1,188 Mbit/s, cand statiile mobile se gasesc la distante aleatoare
Figurile 4.23 arata rezultatele obtinute de Algoritmul B1 pentru aceleasi configuratii ca anterior. 4.23a corespunde distantelor BS-MS fixate la 460 de metri, 4.23b distantelor aleatoare. Intarzierea medie din prima figora este de aproximativ 1 ms, iar in a doua varaiza intre 1,58 si 2,18 ms. Nu mai exista o echitate strcita intre terminalele mobile si performantele sistemului prezinta o tendinta descrescatoare. Este adevarat ca intarzierea obtinuta este inca acceptabila, dar cand sarcina va creste sistemul se va bloca mai repede.
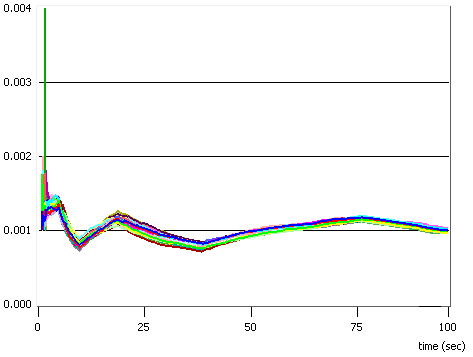
Fig. 4.23a - Intarzierea medie (in sec) a pachetelor transmise de Algoritmul B1, pentru o sarcina de 1,188 Mbit/s, cand statiile mobile se gasesc la distante de 460 m
Fig. 4.23b - Intarzierea medie (in sec) a pachetelor transmise de Algoritmul B1, pentru o sarcina de 1,188 Mbit/s, cand statiile mobile se gasesc la distante aleatoare
Algoritmul B2 folosit intr-o situatie similara, cu 44 de statii mobile pozitionate in mod aleator in celula si o sarcina a sistemului de 1,188 Mbps, ofera performante comparabile celor ale lui B1. In definitiv, B2 se comporta intr-o maniera similara lui B2 in situatiile mai realiste cand terminalele mobile se gasesc la distante diferite de statia de baza.
Bibliografie:
[1] L. Bechetti, S. Diggavi, S. Leonardi, A. Marchetti-Spaccamela, S. Muthukrishnan, T. Nandagopal, A. Vitaletti, Parallel Scheduling Problems in Next Generation Wireless Networks, DIMACS Technical Report 2002 - 29, July 2002
5. Concluzii si perspective
In acest studiu s-a incercat sa se propuna algoritmi de planificare a pachetelor si alocare a resurselor pentru statia de baza a unui sistem de comunicatii radio celulare, care foloseste OFDMA ca tehnica de acces multiplu pentru a transmite trafic video.
Simularile efectuate ne-au condus la mai multe concluzii asupra aspectelor pozitive si negative ale algoritmilor propusi.
Algoritmul A este cel mai rezistent din punct de vedere al sarcinii pe care o poate suporta, care este cu 15% mai mare decat in cazul algoritmilor B, si din punct de vedere a varietatii pozitiilor statiilor mobile. Dar intarzierea medie si jitter-ul pachetelor ordonate si transmise de el sunt mediocre pentru necesitatile traficului video.
Algoritmul B1 este mai sensibil la sarcina sistemului si ajunge sa se blocheze mai repede cand aceasta urca. De asemnea, intarzierea medie variaza mult de la un terminal mobil la altul in functie de distanta intre acesta si statia de baza. Dar intarzierea medie si jitter-ul obtinute sunt foarte mici in raport cu cele ale Algoritmului A si sunt favorabile unei transmisii de trafic video.
S-a incercat sa se amelioreze performantele acestui algoritm adaugand un sistem mai complex de prioritati, dar nu s-a reusit. Algoritmul B2 este inferior lui B1 din toate punctele de vedere considerate cand utilizatorii se gasesc egal distantati de statia de baza, dar cand sunt distribuiti aleator in celula, ei au performante similare.
Ideile prezentate in aceasta lucrare pot fi dezvoltate in mai multe directii.
Tinand cont de complementaritatea calitatilor si defectelor Algoritmilor A si B1, va fi interesanta gasirea unei solutii de a le combina, castigand stabilitatea primului si intarzierea medie a celui de-al doilea.
Ne imaginam ca vom putea realiza aceasta adaugand o memorie tampon Algoeritmului B1. Dar pentru a implementa aceasta idee cu succes, va fi nevoie sa se cunoasca dimensiunile tuturor pachetelor care se gasesc in cozile de asteptare. In acest studiu am simplificat la maxim aceasta problema si am considerat cazul cel mai defavorabil, cand toate pachetele care se gasesc in spatele primului pachet, a carui dimensiune o cunoastem, au 352 de biti. Bineinteles, nu toate pachetele au dimensiunea maxima si daca ajungem sa le determinam corect, vom folosi mai putine resurse pemtru a le transmite.
O alta modificare, care in mod sigur va ameliora performantele algoritmilor nostri, este un algoritm de alocare a resurselor mai eficace. Exista multe cazuri cand algoritmul Greedy pe care il utilizam aloca mai multe resurse decat este necesar si astfel se ajunge sa se transmita mai putin decat este teoretic posibil.
Urmatoarea etapa va fi trecerea la un adevarat sistem OFDMA, care are castiguri de canal diferite pentru toate subpurtatoarele si apoi de a modela un adevarat sistem de comunicatii mobile.
Anexa 1 - Modelul statiei mobile
1. Starea de initializare init
/* Declaration des statistiques locales */
ete_gsh = op_stat_reg ('ETE', OPC_STAT_INDEX_NONE, OPC_STAT_LOCAL);
pk_size = op_stat_reg ('PS', OPC_STAT_INDEX_NONE, OPC_STAT_LOCAL);
pk_count = op_stat_reg ('Pk Count', OPC_STAT_INDEX_NONE, OPC_STAT_LOCAL);
/* Initialisation des paramtres de systme */
S = 16;
/* Initialisation des variables locales */
pk = 1;
n = 0;
/* On obtient l'identification d'objet du noeud */
own_id = op_id_self ();
/* On obtient l'identification du terminal contenue dans l'attribut 'Terminal ID'
op_ima_obj_attr_get (own_id, 'Terminal ID',&id);
/* On obtient l'identification d'objet du rcepteur*/
rcv_id = op_id_from_name (op_topo_parent(own_id), OPC_OBJTYPE_RARX, 'rcv');
/* On obtient l'identification d'objet du group des canaux*/
chan_id = op_id_from_name (rcv_id, OPC_OBJTYPE_COMP, 'channel');
/* On obtient l'identification d'objet du chaque canal radio*/
for (j = 0;j < S; j++)
ch_ids[j] = op_topo_child (chan_id, OPC_OBJTYPE_RARXCH, j);
/* On configure les canaux du rcepteur en concordance avec les dcisions prises par la station de base sur l'allocation des canaux */
for (j = 0;j < S; j++)
2. Starea idle
/* La fonction arv() */
static void arv(void)
Anexa 2 - Coada de asteptare, starea de initializare a procesorului statiei de baza si sursa sintetica de semnal video
1. Starea SEND_HEAD a cozii de asteptare vn_fifo
/* Une demande de transmettre un paquet sur un des flux de sortie est arrive ; le paquet sera tir de la sous-file avec le mme index que le flux de sorite */
/* On dtermine de la quelle sous-file il s'agit */
subq_index = op_intrpt_code ();
/* On verifie si elle est vide */
if (!op_subq_empty (subq_index))
else
}
2. Starea INS_TAIL a cozii de asteptare vn_fifo
/* Un nouveau paquet est arriv ; on dtermine le index du flux d'entre */
strm_index = op_intrpt_strm ();
/* On prend le paquet */
pkptr = op_pk_get (strm_index);
/* On dtermine sa taille */
pk_size = op_pk_total_size_get (pkptr);
/* On le partage en plusieurs petits paquets s'il est ncessaire */
while (pk_size > 0)
/* On dcrmente la taille initiale du paquet */
pk_size -= 352;
/* On introduit le paquet dans la file */
op_subq_pk_insert (strm_index, aux_pkptr, OPC_QPOS_TAIL);
op_pk_destroy (pkptr);
/* On dtermine la nouvelle taille de la file */
subq_size[strm_index] = op_subq_stat (strm_index, OPC_QSTAT_BITSIZE);
3. Starea de initializare a procesorului statiei de baza vn_BS_proc
/* Inititialisation des paramtres de systme */
P = 5; /* W */
S = 16; /* canaux */
N = 4; /* utilisateurs */
Nt = 20; /* tranches temporelles*/
noise = -140; /* -110 dBm */
gamma = 6.77; /* dB */
/* Dbits discrets */
d[0] = 62; /* kbps - BPSK */
d[1] = 118; /* kbps - QPSK */
d[2] = 246; /* kbps - 16QAM */
d[3] = 352; /* kbps - 64QAM */
/* Rapports signal sur bruit */
snr[0] = 4.7506; /* BPSK */
snr[1] = 14.2518; /* QPSK */
snr[2] = 71.2590; /* 16QAM */
snr[3] = 299.2728; /* 64QAM */
/* Initialisation du compteur des canaux */
for (k = 0; k < Nt; k++)
chan[k] = -1;
/* On obtient l'identit d'objet du module */
own_id = op_id_self ();
/* On obtient l'identit d'objet de chaque canal */
xmt_id = op_id_from_name (op_topo_parent(own_id), OPC_OBJTYPE_RATX, 'xmt');
chan_id = op_id_from_name (xmt_id, OPC_OBJTYPE_COMP, 'channel');
for (k = 0; k < S; k++)
ch_ids[k] = op_topo_child (chan_id, OPC_OBJTYPE_RATXCH, k);
/* On obtient les coordonnes de la station de base */
op_ima_obj_attr_get (op_topo_parent(own_id), 'x position',&BS_x);
op_ima_obj_attr_get (op_topo_parent(own_id), 'y position',&BS_y);
/* On calcule les distances entre la station de base et chaque station mobile */
MS_id = op_id_from_name (op_topo_parent(op_topo_parent(own_id)), OPC_OBJMTYPE_NODE, 'MS_1');
op_ima_obj_attr_get (MS_id, 'x position',&MS_x);
op_ima_obj_attr_get (MS_id, 'y position',&MS_y);
dist[0] = 1000 * sqrt((MS_x - BS_x)*(MS_x - BS_x) + (MS_y - BS_y)*(MS_y - BS_y));
MS_id = op_id_from_name (op_topo_parent(op_topo_parent(own_id)), OPC_OBJMTYPE_NODE, 'MS_2');
op_ima_obj_attr_get (MS_id, 'x position',&MS_x);
op_ima_obj_attr_get (MS_id, 'y position',&MS_y);
dist[1] = 1000 * sqrt((MS_x - BS_x)*(MS_x - BS_x) + (MS_y - BS_y)*(MS_y - BS_y));
MS_id = op_id_from_name (op_topo_parent(op_topo_parent(own_id)), OPC_OBJMTYPE_NODE, 'MS_3');
op_ima_obj_attr_get (MS_id, 'x position',&MS_x);
op_ima_obj_attr_get (MS_id, 'y position',&MS_y);
dist[2] = 1000 * sqrt((MS_x - BS_x)*(MS_x - BS_x) + (MS_y - BS_y)*(MS_y - BS_y));
MS_id = op_id_from_name (op_topo_parent(op_topo_parent(own_id)), OPC_OBJMTYPE_NODE, 'MS_4');
op_ima_obj_attr_get (MS_id, 'x position',&MS_x);
op_ima_obj_attr_get (MS_id, 'y position',&MS_y);
dist[3] = 1000 * sqrt((MS_x - BS_x)*(MS_x - BS_x) + (MS_y - BS_y)*(MS_y - BS_y));
/* On calcule la fonction de distribution de probabilit de la distribution log normale */
for (k = 0; k < 495; k++)
/* On calcule le gain de canal pour chaque utilisateur */
for (k = 0; k < N; k++)
for (l = 0; l < 495; l++)
if (abs(pdf_lognorm[l] - unif_dist) <= 0.01)
/* On calcule les pertes de propagation */
path_loss[k] = 80.6 + 43 * log10(dist[k]/73) + x;
/* On calcule le gain effectif du canal */
g[k] = pow(10,(- path_loss[k] - noise - gamma)/10);
/* On calcule la puissance minimale ncesaire pour atteindre les dbits discret */
for (k = 0; k < N; k++)
for (l = 0; l < 4; l++)
p_min[k][l] = snr[l] * pow(10,-14)/pow(10,-path_loss[k]/10);
4. Starea de initializare a sursei sintetice de semnal video tpareto_source
/* On lit les valeurs des paramtres de gnration des paquets, i.e. les valeurs des attributs du noeud */
op_ima_obj_attr_get (own_id, 'Packet Size Location', &pk_size_loc);
op_ima_obj_attr_get (own_id, 'Max Packet Size', &max_pk_size);
op_ima_obj_attr_get (own_id, 'Packet Size Shape', &pk_size_shape);
op_ima_obj_attr_get (own_id, 'Interarrival Time Location', &interarrv_time_loc);
op_ima_obj_attr_get (own_id, 'Max Interarrival Time', &max_interarrv_time);
op_ima_obj_attr_get (own_id, 'Interarrival Time Shape', &interarrv_time_shape);
/* Initialisation de compteur des paquets par trame*/
frame_counter = 0;
next_intarr_time = truncated_pareto (interarrv_time_loc, max_interarrv_time, interarrv_time_shape);
5. Starea generate a sursei sintetice de semnal video tpareto_source
/* Dans l'tat 'generate', on programme l'arrive du prochain paquet */
next_intarr_time = truncated_pareto (interarrv_time_loc, max_interarrv_time, interarrv_time_shape);
/* On verifie si le temps inter arrivges n'est pas negatif et s'il est, on l'annulera */
if (next_intarr_time <0)
/* On verifie si la trame courante est finie et on programmera la prochaine s'il est ncessaire.
if (frame_counter == 8)
/* On appelle le procs aprs le temps calcul pour la prochaine arrive */
next_pk_evh = op_intrpt_schedule_self (op_sim_time () + next_intarr_time, SSC_GENERATE);
6. Functia truncated_pareto
double truncated_pareto (double location, double max, double shape)
/* On calcule le rsultat de la distribution */
truncated_pareto_outcome = pow((1 - pow(location/max,shape)) * uniform_outcome/(shape * pow(location, shape)), -1.0/(shape + 1));
FRET (truncated_pareto_outcome);
Anexa 3 - Optimizarea temporala
1. Functia objfun_2
function f = objfun_2(x)
% Declaration des variables globales
global g;
global B;
global t;
% Declaration de la fonction
f = [B * t * x(14) * log2(1 + x(13) * g(1)/x(14)) + B * t * x(18) * log2(1 + x(17) * g(1)/x(18));
B * t * x(12) * log2(1 + x(11) * g(2)/x(12)) + B * t * x(16) * log2(1 + x(15) * g(2)/x(16)) + B * t * x(20) * log2(1 + x(19) * g(2)/x(20))] + B * t * x(24) * log2(1 + x(23) * g(2)/x(24))];
2. Programul MATLAB
clear
clc
% Declaration des variables globales
global g;
global B
global t;
% Initialisation des paramtres du systme
P = 50; % la puissance totale disponible est 50 W
S = 64; % le nombre des sous-porteuses
N % le nombre d'utilisateurs
B = 62.5 * 10^4; % la largeure de bande du canal est de 62.5 KHz
t = 10^-3; % la dure du tranche temporelle
gamma = 6.77; % le gain de codage est de 6,77 dB
n = -140; % le niveau du bruit est de -110 dBm
dist = [250 500]; % les distances in metrs jusqu' la station de base
% Distribution log-normale pour un vanouissement avec une variation de 7,5 dB
x = 0.05:0.01:5;
for i = 1:495
pdf_lognorm(i) = 1/(x(i)*sqrt(2*pi)*7.5)*exp(-log(x(i))/112.5);
end
% On calcule le gain de canal
for i = 1:N
% On calcule le fading
z = 0;
b = 1;
while b==1
y = abs(randn);
if y >= 1
b = 1;
else
b = 0;
end
end
for k = 1:495
if abs(pdf_lognorm(k)-y)<=0.01
z = x(k);
break;
end
end
% On calcule les pertes de propagation
path_loss(i) = -(80.6 + 43 * log10(dist(i)/73) + z);
% On calcule le gain de canal
g(i) = 10^((path_loss(i) - n - gamma)/10);
end
dim = 8*[125;
125]; % la taille des paquets
r = zeros(N,8); % le dbit instantan
p = zeros(N,8); % la puissance instantane
can = zeros(N,8); % le nombre des canaux instantan
% Initialisation des paramtres de la fonction fgoalattain
x = [0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1];
A = zeros(16,32);
A = [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0;
0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0;
0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0;
0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0;
0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0];
b = [P;
S;
P;
S;
P;
S;
P;
S;
P;
S;
P;
S;
P;
S;
P;
S];
lb = [0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1];
ub = b';
x0 = [0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1];
goal = dim';
weight = -abs(goal);
options = optimset('LargeScale','off','GoalsExactAchieve',4);
% On appelle la fonction fgoalattain
[x, fvalattainfactor] = fgoalattain(@objfun_2,x0,goal,weight,A,b,[],[],lb,ub,[],options);
% On calcule le dbit, la puissance et le nombre des canaux instantans
for i = 1:8
r(1,i) = B * t * floor(x(4*i-2)) * log2(1 + x(4*i-3) * g(1)/floor(x(4*i-2)));
p(1,i) = x(4*i-3);
can(1,i) = floor(x(4*i-2));
r(2,i) = B * t * floor(x(4*i)) * log2(1 + x(4*i-1) * g(2)/floor(x(4*i)));
p(2,i) = x(4*i-1);
can(2,i) = floor(x(4*i));
end
% On reprsente les ressources utilises et les taux d'utilisation
y = 1:1:8;
figure(1)
plot(y,can(1,:),y,can(2,:))
figure(2)
plot(y,p(1,:),y,p(2,:))
tp = sum(p/P,1);
figure(3)
plot(y,tp)
tcan = sum(can/S,1);
figure(4)
plot(y,tcan)
figure(5)
plot(y,tcan+tp)
Anexa 4 - Optimizarea instantanee
1. Functia objfun_4
function f = objfun_4(x)
% Declaration des variables globales
global g;
global B;
global t;
global N
% Declaration de la fonction
f = zeros(N,1);
for i = 1:N
f(i,1) = B * t * x(2*i) * log2(1 + x(2*i-1) * g(i)/x(2*i));
end
2. Programul MATLAB
clear
clc
% Declaration des variables globales
global g;
global B
global t;
% Initialisation des paramtres du systme
P = 50; % la puissance totale disponible est 50 W
S = 64; % le nombre des sous-porteuses
N % le nombre d'utilisateurs
Npk = 20; % le nombre des paquets gnrs
B = 62.5 * 10^4; % la largeure de bande du canal est de 62.5 KHz
t = 10^-3; % la dure du tranche temporelle
gamma = 6.77; % le gain de codage est de 6,77 dB
n = -140; % le niveau du bruit est de -110 dBm
dist = zeros(1,N); % les distances in metrs jusqu' la station de base
for i = 1:N
dist(i) = 490 + 30 * i;
end
% Distribution log-normale pour un vanouissement avec une variation de 7,5 dB
x = 0.05:0.01:5;
for i = 1:495
pdf_lognorm(i) = 1/(x(i)*sqrt(2*pi)*7.5)*exp(-log(x(i))/112.5);
end
% On calcule le gain de canal
for i = 1:N
% On calcule le fading
z = 0;
b = 1;
while b==1
y = abs(randn);
if y >= 1
b = 1;
else
b = 0;
end
end
for k = 1:495
if abs(pdf_lognorm(k)-y)<=0.01
z = x(k);
break;
end
end
% On calcule les pertes de propagation
path_loss(i) = -(80.6 + 43 * log10(dist(i)/73) + z);
% On calcule le gain de canal
g(i) = 10^((path_loss(i) - n - gamma)/10);
end
% On gnre des paquets
% Initialisations des paramtres pour la taille et intervalle inter arrive
% des paquets
location_pk = 160;
max_pk = 1000;
location_t = 2.5;
max_t = 12.5;
shape = 1.2;
% On calcule les limites de la distribution Pareto tronque pour les
max_pdf_pk = shape/(location_pk * (1 - (location_pk/max_pk)^shape));
min_pdf_pk = shape * location_pk^shape * max_pk^(-shape-1)/(1 - (location_pk/max_pk)^shape);
max_pdf_t = shape/(location_t * (1 - (location_t/max_t)^shape));
min_pdf_t = shape * location_t^shape * max_t^(-shape-1)/(1 - (location_t/max_t)^shape);
% On gnre effectivement les tailles des paquets
dim = zeros(N,Npk);
for i = 1:N
rand('seed',i*Npk);
for j = 1:Npk
uniform_outcome = rand;
% On gnre une valeur distribu uniformment entre les deux limites
b = 1;
while b == 1
if uniform_outcome < max_pdf_pk
if uniform_outcome > min_pdf_pk
b = 0;
else
uniform_outcome = rand;
end
else
uniform_outcome = rand;
end
end
% On calcule le rsultat de la distribution Pareto tronque
dim(i,j) = round(((1 - (location_pk/max_pk)^shape) * uniform_outcome/(shape * location_pk^shape))^(-1/(shape + 1)));
end
end
% On gnre les intervalles inter arrives
arv = ones(N,Npk);
for i = 1:N
rand('seed',i*Npk/2+5);
for j = 2:Npk
uniform_outcome = rand;
% On gnre une valeur distribu uniformment entre les deux limites
b = 1;
while b == 1
if uniform_outcome < max_pdf_t
if uniform_outcome > min_pdf_t
b = 0;
else
uniform_outcome = rand;
end
else
uniform_outcome = rand;
end
end
% Si on est arriv la fin de la trame, on la prochaine arrive sera
% dans 50 ms. Si non, on calcule le rsultat de la distribution Pareto
% tronque
frame = j - 8 * floor(j/8);
if frame == 8
arv(i,j) = arv(i,j-1) + 50;
else
arv(i,j) = arv(i,j-1) + round(((1 - (location_t/max_t)^shape) * uniform_outcome/(shape * location_t^shape))^(-1/(shape + 1)));
end
end
end
% On calcule le nombre de tranches temporelles ncessaires, en tenant compte
% de l'instant d'arrive du dernier paquet
Nts = max(arv(:,Npk)) + 1;
ct = zeros(N,Npk); % le moment du fin de transmission du paquet
r = zeros(N,Nts); % le dbit instantan
p = zeros(N,Nts); % la puissance instantane
can = zeros(N,Nts); % le nombre des canaux instantan
pk = ones(1,N); % le paquet courant
x = ones(N*2);
% Initialisations des paramtres de la fonction fgoalattain
b = [P;
S];
lb = zeros(1,N*2);
ub = zeros(1,N*2);
A = zeros(2,N*2);
for i = 2:2:N*2
A(1,i-1) = 1;
A(2,i) = 1;
x0(i-1) = 1;
x0(i) = S/N;
lb(i-1) = 0.001;
lb(i) = 1;
ub(i-1) = P;
ub(i) = S;
end
% On parcourra les tranches temporelles l'aide du compteur st, en faisant
% l'optimisation pendant chacune d'elles
for st = 1:Nts
% On tabli le but de l'optimisation pendant la tranche courrante
for i = 1:N
if pk(i) > Npk
pk(i) = Npk;
end
if st >= arv(i,pk(i))
goal(i) = dim(i,pk(i));
else
goal(i) = 10;
end
end
weight = -abs(goal);
options = optimset('LargeScale','off','Display','off');
% On fait l'optimisation
[x, fvalattainfactor] = fgoalattain(@objfun_4,x0,goal,weight,A,b,[],[],lb,ub,@confun_4,options);
% On calcule le dbit et les ressopurces utilis pendant chaque
% tranche
for i = 1:N
r(i,st) = B * t * floor(x(2*i)) * log2(1 + x(2*i-1) * g(i)/floor(x(2*i)));
p(i,st) = x(2*i-1);
can(i,st) = floor(x(2*i));
dim(i,pk(i)) = dim(i,pk(i)) - r(i,st);
% Si on a russit transmettre un paquet, on doit passer au
% prochain
if goal(i) ~= 10
if dim(i,pk(i)) <= 0
ct(i,pk(i)) = st;
pk(i) = pk(i) + 1;
end
end
end
end
% On reprsente les rsultats
y = 1:1:Nts;
figure(1)
plot(y,can(1,:),y,can(2,:),y,can(3,:),y,can(4,:),y,can(5,:),y,can(6,:),y,can(7,:),y,can(8,:),y,can(9,:),y,can(10,:),y,can(11,:),y,can(12,:),y,can(13,:),y,can(14,:),y,can(15,:),y,can(16,:),y,can(17,:),y,can(18,:),y,can(19,:),y,can(20,:),y,can(21,:),y,can(22,:),y,can(23,:),y,can(24,:),y,can(25,:),y,can(26,:),y,can(27,:),y,can(28,:),y,can(29,:),y,can(30,:),y,can(31,:),y,can(32,:))
figure(2)
plot(y,p(1,:),y,p(2,:),y,p(3,:),y,p(4,:),y,p(5,:),y,p(6,:),y,p(7,:),y,p(8,:),y,p(9,:),y,p(10,:),y,p(11,:),y,p(12,:),y,p(13,:),y,p(14,:),y,p(15,:),y,p(16,:),y,p(17,:),y,p(18,:),y,p(19,:),y,p(20,:),y,p(21,:),y,p(22,:),y,p(23,:),y,p(24,:),y,p(25,:),y,p(26,:),y,p(27,:),y,p(28,:),y,p(29,:),y,p(30,:),y,p(31,:),y,p(32,:))
tp = sum(p/P,1);
tcan = sum(can/S,1);
figure(3)
plot(y,tcan,y,tp)
Anexa 5 - Implementarea Algoritmului A
1. Functia ck()
static void ck(void)
else
/* On transmet les paquets programms pour la tranche temporelle courante */
for (j = 0; j < S; j++)
if (pk[j][0] != 0)
/* Actualisation des vecteurs d'utilisation de puissance et sous-porteuses et des matrices d'allocation des canaux et de transmission des paquets */
for (i = 0; i < Nt-1; i++)
}
pu [Nt-1] = 0;
su [Nt-1] = 0;
chan[Nt-1] = -1;
for (j = 0; j < S; j++)
/* On dtermine la file la plus charge */
for (i = 0; i < N; i++)
if (subq_size[i] > max)
/* On tirera un paquet de la plus charge file s'il y d'space libre dans les matrices d'allocation des canaux et de transmission des paquets */
if (pk[0][Nt-1] == 0)
switch (user)
FOUT;
2. Functia arv()
static void arv(void)
else
/* Dans le cas quand on a allou seulement un canal, on transmettra le paquet sur la prochaine sous-porteuse libre */
/* On dcrmente la taille du paquet */
pk_size -= d[i] * s_min[i];
break;
}
/* Dans le cas quand il n'y a pas assez de ressources dans la tranche courrante, on passe au prochaine */
if (!alloc)
t++;
}
/* On considre le cas avec plus des canaux disponibles pour allocation que de la puissance */
else
else
/* Dans le cas quand on a allou seulement un canal, on transmettra le paquet sur la prochaine sous-porteuse libre */
/* On dcrmente la taille du paquet */
pk_size -= d[i] * s_min[i];
break;
}
/* Dans le cas quand il n'y a pas assez de ressources dans la tranche courrante, on passe au prochaine */
if (!alloc)
t++;
}
/* Dans le cas quand il n'y a pas assez de ressources dans la tranche courrante, on passe au prochaine */
else
t++;
/* On dtermine la file la plus charge */
for (i = 0; i < N; i++)
if (subq_size[i] > max)
/* On tirera un paquet de la plus charge file s'il y d'space libre dans les matrices d'allocation des canaux et de transmission des paquets */
if (pk[0][Nt-1] == 0)
switch (user)
FOUT;
Anexa 6 - Implementarea Algoritmilor B1 si B2
1. Functia ck()
static void ck(void)
/* On cre le vecteur de priorit des files d'attente */
for (j = 0; j < N; j++)
/* On range les vecteurs size et prior dans le sens ascendant */
bubble = 1;
while (bubble)
}
/* Boucle principale */
i = N-1;
while (i >= 0)
/* On dcrmente la taille du paquet */
size[i] -= pk_size;
break;
}
/* On considra le cas quand il y a plus des canaux disponibles que de la puissance */
else
/* On dcrmente la taille du paquet */
size[i] -= pk_size;
break;
}
}
else
alloc = 0;
if (alloc)
/* Dans le cas quand on n'a pas fait l'allocation on passe la file avec la prochaine priorit */
else
i--;
}
chan = -1;
/* On dtermine s'il y a des paquets programs pour la transmission et on tire le premier trouv */
trans = 0;
for (i = N-1; i >= 0; i--)
if (pack[prior[i]])
if (trans)
switch (user)
FOUT;
2. Functia arv()
static void arv(void)
/* On dcrmente le compteur des paquets */
pack[user]--;
/* On dtermine s'il y a des paquets programms pour la transmission et on tire le premier trouv */
trans = 0;
for (i = N-1; i >= 0; i--)
if (pack[prior[i]])
if (trans)
}
/* S'il n'y a plus des paquets programms, on peut commencer la transmission */
else
else
/* On envoye les paquets sur les sous-porteuses */
for (i = 0; i < S; i++)
if (pk[i])
FOUT;
3. Modificarile functiei arv() pentru Algoritmul B2
/* On actualise la matrice de tailles des files */
for (j = 0; j < N; j++)
/* On range la matrice et le vecteur index dans le sens ascendant */
bubble = 1;
while (bubble)
}
/* On calcule les priorits */
for (i = 0; i < N; i++)
if (size[1][i] > size[2][i])
prior[index[i]] = i + N;
else
prior[index[i]] = i;
/* On reconstruit la matrice size et le vecteur index en concordance avec les nouvelles priorits */
for (i = N-1; i > 0; i--)
/* On limine cette priorit pour qu'on ne le trouve pas la prochaine recherche */
prior[max_pos] = -2;
/* On trouve dans le vecteur index l'utilisateur avec la plus grande priorit et on le met sur la position i, qui lui corresponde dans la nouvelle matrice */
for (j = N-1; j >= 0; j--)
if (index[j] == max_pos)
} /* Suivi par boucle principale de l'Algorithme B1, o prior a t remplac par index et size par size[0] */
I. Akyildiz, D. Goodman, L. Kleinrock, C. T. Lea, Mobility and Resource Management in Next Generation Wireless Systems, IEEE Journal on Selected Areas in Communications, Vol. 19, No. 10, October 2001, pp. 1825-1829
L. Bechetti, S. Diggavi, S. Leonardi, A. Marchetti-Spaccamela, S. Muthukrishnan, T. Nandagopal, A. Vitaletti, Parallel Scheduling Problems in Next Generation Wireless Networks, DIMACS Technical Report 2002 - 29, July 2002
M. Glesner, L. D. Kabulepa, VLSI Design for Wireless Communications, Darmstadt University of Technology, Department of Electrical Engineering and Information Technology, Institute of Microelectronic Systems, 2005
J. Gross, H. F. Geerdes, H. Karl, A. Wolisz, Performance Analysis of Dynamic OFDMA Systems with Inband Signaling, IEEE Journal on Selected Areas in Communications (JSAC) - Special Issue on 4G Wireless Systems, March 2006
S. Kittipiyakul, T. Javidi, Resource Allocation in OFDMA Wireless Networks with Time-Varying Arrivals, VTC Journal, November 2005
G. Kulkarni, S. Adlakha, M. Srivastava, Subcarrier Allocation and Bit Loading Algorithms for OFDMA Based Wireless Networks, IEEE Transactions on Mobile computing, November/December 2005
G. Li, H. Liu, Dynamic Resource Allocation with Finite Buffer Constraint in Broadband OFDMA Networks, Department of Electrical Engineering, University of Washington, May 2003
S. Pietrzyk, G. Janssen, Multiuser Subcarrier Allocation for QoS Provision in the OFDMA Systems, IEEE Vehicular Technology Conference Fall, 24-28 September 2002, Vancouver
P. Piggin, WiMAX in-depth, IEE Communications Engineer, October/November 2004, pages 36 - 39
S. Ryu, B. H. Ryu, H. Seo, M. Shin, S. Park, Wireless Packet Scheduling Algorithm for OFDMA System Based on Time-Utility and Channel State, ETRI Journal, Volume 27, Number 6, December 2005
M. M. Saleh, Adaptive Resource Allocation in
Multiuser OFDM Systems, Literature Survey,
Z. Shen, J. Andrews, B. Evans, Optimal Power
Allocation in Multiuser OFDM Systems,
M. Walden, F. Roswell, Urban Propagation Measurements and Statistical Path Loss Model at 3.5 GHz, Antennas and Propagation Society International Symposium, 3-8 July 2005
I. Wong, Z. Shen, B. Evans, J. Andrews, A Low Complexity Algorithm for Proportional Resource Allocation in OFDMA Systems, IEEE International Signal Processing Systems Workshop, pp. 1-6, October 2004
L. Yanhui, W. Chunming, Y. Changchuan, Y. Guangxin, Downlink Scheduling and Radio Resource Allocation in Adaptive OFDMA Wireless Communication Systems for User-Individual QoS, Transactions on Engineering, Computing and Technology V12 March 2006
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 2575
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2024 . All rights reserved

