| CATEGORII DOCUMENTE |
| Bulgara | Ceha slovaca | Croata | Engleza | Estona | Finlandeza | Franceza |
| Germana | Italiana | Letona | Lituaniana | Maghiara | Olandeza | Poloneza |
| Sarba | Slovena | Spaniola | Suedeza | Turca | Ucraineana |
DOCUMENTE SIMILARE |
|
TERMENI importanti pentru acest document |
|
Databázové systémy
Obsah
Teoretický základ relačních databází
Úvod
Kartézský součin
Zavedení pojmu
Komentář
Relace
Zavedení pojmu
Komentář
Vlastnosti binárních relací
Zavedení pojmu
Komentář
Relační databáze
Databázové názvosloví
Organizace dat, báze dat
Úvod
Koncepce báze dat
Klasické metody
Báze dat
Soubor - záznam - pole
Popis a výskyt
Vztah mezi logickými a fyzickými záznamy
Lineární a nelineární záznamy
Uložení dat a přístup k nim
Klíčová pole
Klíče
Metody uložení dat
Úvod
Postupné uložení dat
Sekvenční uložení
Sériové uložení dat
Ostatní postupná uložení dat
Rozptýlené uložení dat
Kombinované uložení
Uložení s oblastí přeplnění
Uložení s indexy
Indexová tabulka
Uložení s odkazy
Odkaz NIL
Odkaz na předchůdce
Odkaz na souseda
Hledání v datech
Úvod
Sekvenční hledání
Sériové hledání
Sériové hledání s pravidelnými skoky
Sériové hledání půlením intervalu
Přímý přístup k datům
Přímé adresování
Nepřímé adresování
Hledání v datech s indexy
Logická organizace báze dat
Úvod
Hierarchicko - síťový model
Relační model
Matematický základ relačního modelu
První normální forma
Operace s relacemi
Normální formy
Návrh logické struktury
Zpracování báze dat
Úvod
Zpracování na úrovni programu
Jazyk pro popis dat
Jazyk pro zpracování dat
Zpracování na úrovni uživatele
Dotazovací jazyk SQL
Úvod
Vymezení dat
Numerická data - N
Znaková (textová) data - C
Datumová data - D
Logická data - L
Organizační příkazy
Vytvoření nové tabulky
Úprava struktury tabulky
Naplnění (doplnění) tabulky daty
Oprava údajů v tabulce
Vypuštění řádků tabulky
Čerpání údajů z databází
Údaje z jedné tabulky
Údaje ze dvou tabulek
Údaje z více tabulek
Údaje podmíněné údaji v jiných tabulkách
Realizace obecného datového modelu v xBase
Úvod
Příkazový soubor
Příkazy xBase
Modelová data
Základní činnosti s tabulkou dat
Vytvoření a přidávání
Otevírání tabulek
Uzavírání tabulek
Aktuální oblast
Aktuální řádek
Zpřístupnění datového pole
Indexové tabulky
Připojení indexové tabulky
Odpojení indexové tabulky
Vazby mezi tabulkami
Dvě tabulky
Více tabulek
Zpřístupnění dat
Tabulkové datové okno
Výpis informací
Agregování informací
Realizace hierarchického modelu prostředky xBase
Datové typy při provozu databází v prostředí Microsoft
Úvod
Obecné typy
Bajt
Celé číslo
Dlouhé celé číslo
Desetinné číslo v jednoduché přesnosti
Desetinné číslo ve dvojnásobné přesnosti
Text
Memo
Date
Logical
Další typy prostředí Windows
Objekt OLE
Binární
Automatické číslo
Měna
Identifikační číslo
Databázové systémy I - témata k procvičování
Úvod
1. Železářství
2. Salon
3. Knihy
4. Modelka
5. Splašky
Teoretický základ relačních databází
Tato kapitola se snaží o pokud možno jednoduché přiblížení teoretického základu toho, co je běžně označováno jako 'tabulka dat relační databáze'. Protože jde o kapitolu publikace pojednávající o databázích v počítačovém prostředí, soustřeďuje se na konečné množiny a rovněž definice některých pojmů přizpůsobuje praktickým databázovým aplikacím. Používá sice běžný matematický aparát známý z teorie množin, autor však doufá, že připojené komentáře vysvětlí dostatečně podstatu problému i těm, kteří matematiku nemají moc rádi - což je vlastně celý národ.
Definice: Kartézský součin množin A, B (značení: A B) je množina všech uspořádaných dvojic takových, že první prvek dvojice je prvkem množiny A a druhý prvek dvojice prvkem množiny B:
A B =
Obdobně kartézský součin množin A, B, C (značení: A B C) je množina všech uspořádaných trojic takových, že první prvek trojice je prvkem množiny A, druhý prvek trojice prvkem množiny B a třetí prvek trojice prvkem množiny C:
A B C =
atd. Je-li jedna z množin prázdná, je i kartézský součin prázdná množina.
Označení: Součin A A označujeme také A2, M M M M M označujeme také M5 atd.
Jsou-li množiny A a B konečné s počty prvků nA a nB, je i jejich kartézský součin A B konečná množina; počet jejich prvků (=počet uspořádaných dvojic) je roven nA nB.
Kartézský součin množin A a B je tedy množina dvojic obsahující kombinace “každý z A s každým z B”. Je-li například množina A tříprvková množina obsahující tři barvy:
A
a množina B dvouprvková množina obsahující dva kusy ovoce:
B
pak kartézským součinem A x B je množina šesti dvojic - každá barva s každým ovocem:
A B =
Tento zápis je však poněkud nepřehledný, pro přehlednější zobrazení kartézského součinu se pro množiny s malým počtem prvků může použít tabulka; např.
|
jablko |
hruška |
|
|
červené |
červené jablko |
červená hruška |
|
zelené |
zelené jablko |
zelená hruška |
|
žluté |
žluté jablko |
žlutá hruška |
I v některých případech nekonečných množin lze s výhodou kartézský součin dvou množin znázornit graficky. Jsou-li např. A a B uzavřené intervaly reálných čísel, A=<2,6> a B=<1,4>, pak znázornění kartézského součinu A B může být např. následující:
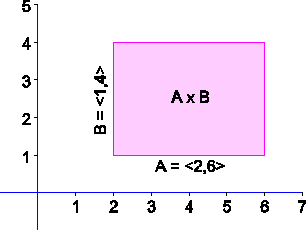
Problematičtější je znázornění kartézského součinu tří nebo více množin - zde by se jednalo o tří- a vícerozměrné útvary znázorňované v rovině papíru obtížně. Proto lze u konečných množin použít i tabulkového znázornění tohoto typu:
|
barva I A |
ovoce I B |
|
červené |
jablko |
|
červená |
hruška |
|
zelené |
jablko |
|
zelená |
hruška |
|
žluté |
jablko |
|
žlutá |
hruška |
Kartézský součin tří množin je pak tabulka se třemi sloupci, čtyř množin se čtyřmi sloupci atd. Důležité je, že 1) v každém sloupci jsou prvky jen jedné konkrétní množiny, 2) první sloupec obsahuje prvky první množiny, druhý druhé atd.
Definice: Binární relace R v množinách A a B je libovolná podmnožina kartézského součinu A B:
R A B
Označení: Je-li [a,b] I R, píšeme: aRb a čteme: prvku a je v relaci R přiřazen
prvek b, nebo: prvek a je v relaci R s prvkem b.
Je-li naopak [a,b] Ï R, píšeme a![]() b
a čteme: prvek a není v relaci R s prvkem b.
b
a čteme: prvek a není v relaci R s prvkem b.
Označení: Je-li R A A, pak R nazýváme relací v množině A.
Definice: Ternární relace R v množinách A, B a C je libovolná podmnožina kartézského součinu A B C:
R A B C
Definice: Obecně pak n-ární relace R v množinách A, B, , Z je libovolná podmnožina kartézského součinu A B Z:
R A B Z
Definice říká: je-li kartézský součin např. A B tvořen všemi kombinacemi prvků z A a B, pak relace je tvořena jen některými kombinacemi prvků z A a B, např.
|
barva I A |
ovoce I B |
|
červené |
jablko |
|
zelené |
jablko |
|
zelená |
hruška |
nebo
|
barva I A |
ovoce I B |
|
červené |
jablko |
|
žlutá |
hruška |
Omezme se nyní jen na binární relaci R a na jedinou množinu A. V množině
A =
je dána relace
R =
Je tedy např.
3R7, 7R9, ale 9![]() 3.
3.
Jsou-li množiny A a B konečné, lze pro znázornění relací použít několika způsobů. Nejčastěji používané jsou dva: maticový a tabulkový. Maticovým zápisem relace R z předchozího příkladu je následující matice 4x4 (nad matici resp. před matici byly pro přehlednost přidány nadpisy sloupců resp. řádků); v ní hodnota 0 značí, že prvky v relaci nejsou, hodnota 1 značí, že prvky v relaci jsou:
|
(a¯) R (b | ||||
Tabulkovým zápisem relace R z předchozího příkladu je následující tabulka:
|
a I A |
b I B |
Poznámka: Tento odstavec je vložen jen pro úplnost, zájemce jen o databáze ho může přeskočit. Nicméně je dobré si ho přečíst proto, že ukazuje teoretický základ některých zcela běžně používaných symbolů.
Definice: V následující tabulce jsou definovány některé základní typy relací podle svých vlastností; relace R je vždy v těchto případech relací v množině A:
|
Relace R je |
právě když platí: |
|
reflexivní |
x I A : xRx |
|
symetrická |
x,y I A : xRy yRx |
|
tranzitivní |
x,y,z I A : xRy Ù yRz xRz |
|
areflexivní |
x,y I A : xRy x ¹ y |
|
antisymetrická |
x,y I A : xRy Ù yRx x=y |
|
ekvivalence |
R je reflexivní, symetrická, tranzitivní |
|
(neostré) uspořádání |
R je reflexivní, antisymetrická, tranzitivní |
|
ostré uspořádání |
R je areflexivní, tranzitivní |
Kartézský součin A x A je množina kombinací každého prvku z A se všemi ostatními prvky A, ale i sám se sebou. Binární relace R v A je pak množina jen některých takových kombinací. Komentujme jen některé vlastnosti.
Relace R je reflexivní, jestliže v množině některých takových kombinací jsou určitě všechny kombinace všech prvků A samy se sebou (a třeba ještě některé jiné kombinace).
Naopak relace R je areflexivní, jestliže v množině některých takových kombinací určitě není žádná kombinace nějakého prvku A sama se sebou. Definice to říká takto: je-li v relaci nějaká kombinace [a,b], pak je určitě a různé od b (protože kdyby b bylo stejné jako a, je tam kombinace [a,a] a to bylo vyloučeno).
Relace R je symetrická, jestliže v množině některých takových kombinací platí toto: je-li tam [a,b], určitě je tam taky [b,a].
Naopak relace R je antisymetrická, jestliže v množině některých takových kombinací platí toto: je-li tam [a,b], určitě tam není [b,a] a naopak. Definice to říká takto: Je-li tam [a,b] i [b,a], pak určitě a i b jsou stejné prvky.
Zjišťování, zda nějaká daná relace má nějakou konkrétní vlastnost, znamená ověření podle definice v hořejší tabulce.
Důležitý příklad: Nechť je dána relace - viz příklad A x A shora. Tato relace je areflexivní (pro všechna [x,y] I R je x ¹ y) a tranzitivní (3R5 Ù 5R7 3R7; 3R7 Ù 7R9 3R9; 5R7 Ù 7R9 5R9). Relace je tedy ostré uspořádání; tato relace se často místo obecného R značí “<”. Je tedy 3<5, 3<7, 3<9, 5<7, 5<9, 7<9.
Na shora zavedeném pojmu relace jsou konstruovány tzv. relační databáze. Nechť například množiny D, C a N značí po řadě množinu všech datumů, množinu všech řetězců (řetězec = posloupnost jednoho nebo více písmen, cifer a jiných znaků) a množinu všech racionálních čísel. Mějme relaci R definovanou jako podmnožinu kartézského součinu K = D N C C. Množina K je (teoreticky nekonečná) množina všech uspořádaných čtveřic, kde první prvek čtveřice je datum, druhý racionální číslo, třetí je řetěz a čtvrtý je rovněž řetěz. Množinu R vytvořme tak, že vybereme jen některé čtveřice. Z hlediska praktického použití jakékoliv náhodná čtveřice, např.
[12/04/1543, 0, blabla, gaga]
asi nebude příliš zajímavá. Ovšem čtveřice
[01/01/1992, 9200, Novák, řidič]
už může vypovídat o jisté reálné situaci: prvního ledna 92 byl přijat Novák jako řidič s platem 9200 Kč. Tabulkový zápis relace R pak může vypadat např. takto:
|
Datum I D |
Plat I N |
Jméno I C |
Profese I C |
|
Novák |
řidič |
||
|
Novotný |
vedoucí |
||
|
Nováček |
vrátný |
||
|
Bratka |
analytik |
Každá čtveřice v tabulce podává jisté informace o jednom konkrétním pracovníkovi. Všechny čtveřice tvořící tuto tabulku pak podávají informace o všech pracovnících nějaké organizační jednotky.
Relační databáze tedy může být chápána jako obdélníkové schéma tvořené řádky a sloupci řídící se následujícími pravidly:
Řádků je libovolný počet (i třebas nula - relace jako množina může být prázdná). Pro praktické databázové aplikace je však oproti definici relace vhodné, aby byla připuštěna možnost násobného výskytu stejných řádků.
Sloupců je libovolný počet (nejméně však jeden - kartézský součin v 'minimálním' případě je alespoň A1).
Sloupce mají 'nadpisy' identifikující množiny, ze kterých pochází prvky daného sloupce. Podle definice nic nebrání tomu, aby se v kartézském součinu nevyskytovala jedna množina vícekrát (viz v příkladu shora množina C). Pak však musí být 'nadpisem' rozlišeno, na jakém místě v kartézském součinu se množina vyskytuje - je totiž nepraktické označení 'množina C třetího sloupce' apod. V příkladě shora nadpis 'Jméno' identifikuje množinu C na třetí a nadpis 'Profese' na čtvrté pozici kartézského součinu D x N x C x C.
Poznámka: Důsledkem teoretického základu relační databáze je to, že v jednom sloupci se nemohou vyskytovat dva prvky z různých množin.
Příklad shora demonstrující pojem relační databáze je jedním z nejjednodušších. Obecně jsou totiž množiny tvořící kartézský součin skutečně libovolné množiny - množina obrázků, množina psychických stavů, množina vůní apod. Nic tedy nebrání např. tomu, aby jedna z nich byla množina uspořádaných n-tic (tedy nějaká relace). Může to být např. relace z kartézského součinu L x S x P, kde L je množina všech kalendářních let, S množina všech škol a P množina všech prospěchů. Označme tuto relaci (=množinu uspořádaných trojic) písmenem A. Konkrétně může být A rovno
|
Rok I L |
Škola I S |
Prospěch I P |
|
ZŠ Dlouhá |
Vyznamenání |
|
|
SVVŠ Příčná |
Uspěl |
|
|
ZŠ Dubí |
Vyhověl |
|
|
VUML |
Výtečný |
Tabulka zaměstnanců pak může být obrazem následující relace:
|
Datum I D |
Plat I N |
Jméno I C |
Absolvent I A |
Profese I C |
||||||||||||
|
Novák |
|
řidič |
||||||||||||||
|
Novotný |
|
vedoucí |
||||||||||||||
|
Bratka |
|
analytik |
V počítačových databázových aplikacích se většinou používá uživatelsky zaměřená terminologie na rozdíl od matematické terminologie podané shora. V následujícím textu jsou tučně označeny termíny používané v databázových aplikacích.
Tabulka relační databáze - konkrétní relace v konkrétním kartézském součinu.
Záznam - konkrétní prvek relace, tj. uspořádaná n-tice, také řádek tabulky relační databáze.
Hodnota - konkrétní prvek uspořádané n-tice, tj. konkrétní prvek záznamu, řádku.
Datový typ - hovorové označení některých konkrétních (reálných i abstraktních) množin figurujících v kartézském součinu (např. datumový pro množinu všech kalendářních datumů, textový pro množinu všech znakových řetězců apod.). Z hlediska uživatele databází klíčové místo. Databázové systémy poskytují totiž velmi omezený počet množin (většinou hardwarově determinovaných), ze kterých může uživatel umísťovat hodnoty ve svých tabulkách.
Typ hodnoty - stejné jako datový typ; používá se pro zdůraznění toho, že hodnota pochází z určité konkrétní množiny.
Organizace dat, báze dat
Organizace dat je jisté uspořádání dat, které má za účel umožnit efektivní zpracování data potřebných pro aplikace. Zahrnuje postupy a metody, jak data na médiích ukládat a jak je hledat. Tyto postupy a metody jsou soustředěny v programech, které požadované akce provádí. Programy mají tři úrovně:
Základní systémová úroveň, kterou realizují komponenty operačního systému pro všechny uživatelské programy jednotně. Záznam a hledání dat podléhá fyzickým charakteristikám jednotlivých médií a proto se tato úroveň nazývá fyzická úroveň (dat, záznamu, organizace apod).
Úroveň báze dat. Jde o maximálně obecné, avšak většinou na jediný typ databázové struktury zaměřené programové systémy. Poskytují především možnost definice struktury záznamu (z jakých polí se záznam skládá, označení, zda jde o pole klíčové nebo hodnotové ap), aktualizace dat (co do množství, kvality i struktury), a získávání informací na základě zadaných specifikací. Základní funkcí bází dat je záznam a čtení takto nadefinovaných struktur na fyzické úrovni (tj. komunikace s programy systémové úrovně). Dále poskytují možnost provádění vazeb mezi jednotlivými soubory a výběr dílčích datových polí z takto provázaných souborů. Tato úroveň se nazývá logická úroveň.
Uživatelská úroveň. Báze dat jsou zcela postačující systémy pro veškeré požadavky uživatelů na zpracování dat. Pro svou obecnost však kladou na běžné uživatele značné nároky na zvládnutí formalizovaného způsobu jejich ovládání. Proto báze dat poskytují prostředky, jak vytvořit rozhraní mezi obecnou bází dat a specializovanou potřebou toho kterého uživatele. Těmito prostředky jsou většinou programovací jazyky různých syntaxí, ale vždy se zajištěnou možností použít kteroukoliv z funkcí báze dat. Databázoví specialisté ve spolupráci s odborníky různých oblastí pak pomocí daného programovacího jazyka vytváří uživatelské, účelově orientované programy, které sice neposkytují možnost kdykoliv použít jakoukoliv funkci báze dat, ale zato uživatel pracuje v prostředí své odbornosti, ve kterém se dobře orientuje především terminologicky.
Tato práce je zaměřena na úroveň báze dat a případné vztahy k úrovni systémové tak, aby byly jasně vidět aspekty zvláště bází nejrůznějších geo-dat v moderních systémech. K vytváření bází dat vedly potřeby nesmírně dynamického rozvoje nových technologií umožňujících koncentraci a zpracování dat kvantity a kvality dříve nevídané (viz např. už jen družicové informace z nejrůznějších oblastí: geografie, geofyzika, strukturní geologie, environmentální inženýrství ap).
Klasické metody zpracování dat většinou nelze na data takového rozsahu a provázanosti aplikovat. Především mají principielní nevýhody a s růstem množství dat jsou stále méně efektivní. Jsou založeny na následujících principech:
Data jsou uložena v souborech. Soubor se skládá ze záznamů.
Záznam se skládá z jednotlivých datových polí. Často má jedno nebo více polí identifikační význam a tvoří pak klíč záznamu. V takovém případě bývají soubory uspořádány ve vzrůstající posloupnosti hodnot klíčů a při každé změně klíčového pole a přidání nebo vypuštění záznamu je nutno soubor fyzicky přeorganizovat.
Organizace souborů (jejich struktura) je dána potřebou konkrétních programů, které je používají. Programátor takových programů nejprve zjistí, jaká data jsou k disposici, jaká data na jejich základě je nutno odvodit, a podle toho navrhne strukturu souborů, která je z jeho subjektivního hlediska optimální.
V každém takto vytvořeném programu je tedy přesně udáno, které soubory se mají pro zpracování použít, jaká je jejich přesná interní struktura, a jaké informace z nich mají tvořit požadované výsledné informace. Takový klasický způsob zpracování dat má mnoho nevýhod; mezi nejvýraznější patří:
Během jednotlivých kroků při zpracování dat vzniká množství různých souborů. Je obtížné udržet přehled o jejich jménech, obsahu, formě, době platnosti ap. všech existujících souborů.
Velké množství souborů vede k tzv. redundanci dat: tatáž data jsou uložena na několika různých místech. Při aktualizaci takového údaje je nutno provést aktualizaci na všech místech jeho výskytu, což je náročné jednak časově a jednak organizačně.
Velké obtíže nastávají při potřebě použít soubory se strukturou definovanou na míru dané aplikaci v jiných programech, které vyžadují strukturu jinou. Programy pro přeorganizování dat (zvláště pro změnu logické struktury) se svou složitostí mohou blížit samotným zpracovávajícím aplikacím.
Jestliže je pro nějaký soubor opodstatněné vést dva nebo více nezávislých klíčů, je zapotřebí při přechodu od zpracování podle jednoho ke zpracování podle druhého provést jeho fyzické přeorganizování.
Právě při fyzickém přeorganizovávání objemných souborů může vznikat několik dočasných souborů, které zahltí kapacitu médií.
Koncepce bází dat se snaží tyto nevýhody odstraňovat. Používají přitom následující metody:
Sdružují a provazují data souborů.
Oddělují popis struktury dat od dat samotných a od zpracovávajících programů.
Přistupují k jednotlivým údajům zvláštní programovou vrstvou, nikoliv přímo jednotlivými uživatelskými programy.
Poskytují možnost vyhodnotit uložená data jakýmkoliv způsobem. K uloženým datům umožňují současný přístup více uživatelů s jejich plnou vzájemnou ochrannou.
ad 1): Sdružování a provazování dat souborů znamená odstranění redundantních dat. Umožňuje spojování logicky navazujících souborů, ve kterých místo násobného přímého výskytu nějaké datové hodnoty udržuje ukazovátka (pointery) na jedinečné místo uložení této hodnoty.
ad 2): Oddělení popisu struktury od vlastních dat znamená, že kromě vlastních uložených dat jsou ukládány také informace o místě a způsobu jejich uložení. Tento popis může být fyzicky přítomen ve stejném souboru jako data, nebo v souboru samostatném. Jestliže se zpracovávající programy opírají o tyto popisy struktury, není zapotřebí programy měnit při reorganizaci vlastních dat.
ad 3): K vlastním datům nepřistupují aplikace přímo, ale žádají o jejich dodání obecně přístupné programové komponenty systému řízení báze dat. Provádí to většinou voláním podprogramů s parametry, kterými jsou popisy požadovaných dat získané z (od dat odděleného) popisu struktury.
ad 4): Zvláště v síťovém prostředí a při práci s citlivými informacemi je zapotřebí zajistit bezpečnost informací. Báze dat k tomu používají na jedné straně prověřování oprávněnosti přístupu pomocí seznamu uživatelů a jejich přístupových hesel a práv, na druhé straně mechanismus zamykání souborů, záznamů a polí dat.
Pro umožnění shora uvedeného musí být zajištěna
fyzická nezávislost dat: fyzické uložení (např. délka bloku) může být změněno, aniž by bylo nutno přepisovat uživatelské aplikace
logická nezávislost dat: může být přidána položka nebo rozšířena logická struktura, aniž by to mělo vliv na existující aplikace
programová komunikace: musí být k disposici vhodné programové moduly systémů řízení báze dat pro dodávání dat do aplikací
uživatelská komunikace: musí být k disposici vhodný komunikační prostředek pro uživatele - nepočítačové odborníky; tím může být uživatelská aplikace, ale preferuje se obecný dotazovací jazyk nezávislý na použitém systému báze dat.
Z uživatelského hlediska je základní logickou jednotkou pole. Obsahuje hodnotu některého typu elementární informace (viz příslušná kapitola shora), fyzicky proto bývá uloženo na jednom nebo více bytech. Pole je charakterizováno atributy (typ pole, jeho délka, poloha desetinné tečky nebo čárky atd).
Jestliže více polí tvoří logický celek, tvoří tato pole segment. Segment sám nemusí být tvořen pouze poli, ale libovolnou posloupností polí a segmentů, je-li to potřebné nebo vhodné z hlediska logické struktury.
Segmenty, které k sobě logicky patří, tvoří záznam. Záznamy, které k sobě logicky patří, tvoří soubor. Soubory tvoří bázi dat.
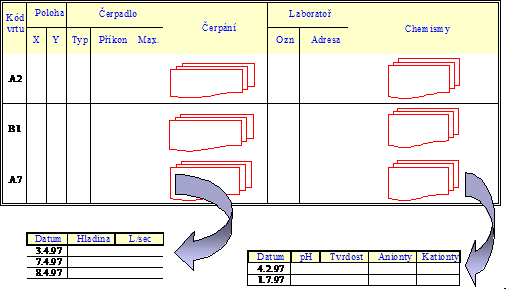
Obrázek 1: Segmentovaný soubor
Předchozí obrázek znázorňuje soubor s informacemi o podzemních vodách. Záznam je tvořen informacemi o jednom vrtu. Má šest segmentů: Kód vrtu, Poloha, Čerpadlo, , Chemismy. První segment je tvořen jediným polem. Segmenty Čerpání a Chemismy mají charakter násobného, opakujícího se segmentu, tj. mohou být přítomny vícekrát. Je samozřejmé, že - až na řídké výjimky - je počet záznamů v souboru vždy proměnný, stejně jako počet násobných segmentů v záznamu. Omezení shora je dáno především kapacitou média.
Některé typy organizace dat na systémové úrovni kladou další omezení na maximální počet záznamů v souboru (např. v systémech s pevným přidělením místa pro soubor) - musí být definován před vytvořením souboru. Některé systémy báze dat kladou další omezení na počet opakování segmentů - rovněž musí být definováno před vytvořením souboru.
Příklad z předchozího odstavce uvádí pohled na 'naplněný' soubor. Z tohoto pohledu je zřejmá nejen logická struktura souboru, ale i jeho obsah (kdyby bylo hodně místa na papíře). Pro potřeby vytváření a zpracování bází dat je však zapotřebí od sebe oddělit popis struktury (typy polí, segmentů ) a výskyt dat (záznamu, segmentu ).
Popis struktury stanovuje počet polí, jejich typ a pojmenování, komposici segmentů ap. Popis každého segmentu se tedy vyskytuje jen jednou. Avšak segment, který je popsán ve struktuře, se - zvláště u násobných segmentů - nemusí ve skutečném datovém záznamu vyskytnout ani jednou, nebo naopak se může vyskytnout několikrát, přitom u různých záznamů v různém počtu. To se týká např. segmentu Čerpání: po založení záznamu tento segment asi ještě zápis o čerpání mít nebude; ale čas od času přibude další záznam o čerpání tak, jak to stanoví provozní podmínky.
Je zřejmé, že popis struktury je zapotřebí formalizovat, a to jak na úrovni uživatele (=člověka), tak na úrovni aplikace (=programu). Různé systémy báze dat přijímají popisy struktur v různé syntaxi. Např. v hierarchickém modelu bývá používán popis, obdobný popisu souboru v jazyku Cobol. Zjednodušený příklad zápisu je následující:
01 Vrt.
02 Kód-vrtu pic X(5).
02 Poloha.
03 X pic N(8).
03 Y pic N(8).
02 Čerpadlo.
03 Typ pic X(10).
03 Příkon pic N(4).
03 Maximum pic N(6).
02 Čerpání occurs (=opakuje se).
03 Datum pic D(8).
03 Hladina pic N(8,2).
03 L-Sec pic N(6,1).
V předchozím odstavci je podána ukázka logického záznamu. Tak uživatel požaduje, aby se mu záznam jevil. Při klasickém způsobu zpracování (a pohříchu mnohde ještě přetrvávajícímu klasickému myšlení) je od logického k fyzickému záznamu velmi blízko - třebas až na úroveň totožnosti. V bázi dat je ovšem logický záznam budován až na požadavek uživatele.
Takové požadavky mohou být v různých situacích velmi rozmanité a v době vytváření databází ani nemusí být známy. Protože je požadováno jen jedno fyzické uložení jednoho údaje, nemusí být jednotlivá pole logického záznamu dokonce ani v jednom jediném fyzickém souboru: např. shora uvedený logický záznam může být komponován z údajů geologa (vrty a jejich poloha), údajů odběratele (čerpadla a čerpání) a údajů chemika (výsledky chemických analýz).
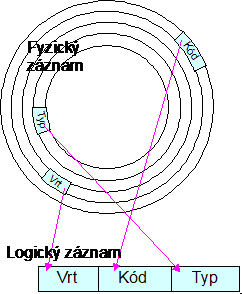
Obrázek 2: Koincidence záznamů
Logické záznamy vytváří na přání uživatele aplikační programy (dotazovací jazyky) výběrem a organizací z fyzického záznamu. Logický záznam tedy může obsahovat
části fyzického záznamu
celý fyzický záznam
více fyzických záznamů nebo jejich částí, přičemž tyto fyzické záznamy mohou a nemusí být součástí jednoho nebo více souborů.
Rozlišuje se tedy struktura organizace dat (vnější, uživatelský popis dat sloužící k vytváření logických záznamů), a struktura uložení dat (vnitřní, systémový popis dat fyzických záznamů).
Organizace dat v bázi dat musí umožňovat právě spolupráci mezi uložením a organizací.
Lineární záznam je takový, jehož pole nejsou vzájemně podřízena. Například záznamy o čerpání vod z vrtů obsahující kód vrtu, datum, hladinu a sekundové množství jsou klasickým příkladem lineárních záznamů. Jednou z jejich charakteristik je např. to, že při návrhu struktury nezáleží na pořadí polí v záznamu.
Nelineární záznam je takový záznam, v němž může existovat vztah nadřazenosti a podřízenosti polím. K nejvýznamnějším a nejpoužívanějším nelineárním strukturám patří shora zmíněná hierarchická struktura. Příklad tamtéž uvedený lze graficky znázornit např. schématem obvyklým v teorii grafů, kde z hlediska této teorie jde o strom.
Obecně lze říci, že u nelineárních záznamů záleží na pořadí polí v záznamu. Konkrétně u hierarchické struktury lze zavést zřejmý pojem úroveň pole jako počet nadřízených polí. Pak při návrhu struktury nezáleží na pořadí polí stejné úrovně podřízené stejnému poli. Všechna ostatní pořadí jsou pak evidentně významná.
Možnost vytvářet nelineární záznamy je důležitou vlastností bází dat. Ukazuje se tak opět význam rozlišení fyzických a logických záznamů.
Uložení dat a přístup k nim
Při zpracování záznamů je nutno se v nich orientovat. Základní způsob orientace nabízí úplná množina hodnot všech polí záznamu. Ten je však pro většinu zpracování prakticky nepoužitelný - už jen pro množství hodnot.
Z logiky databází vyplývá, že k orientaci nemusí sloužit hodnoty všech polí, ale jen některých. Např. jednotlivé záznamy o geochemických vlastnostech prvků jsou jednoznačně identifikovatelné názvem prvku. Bývá však zvykem, že při běžné práci se stejně často jako plného názvu prvků používá také jeho chemické značky, která je (dokonce mezinárodně) běžně známa. Z hlediska datových záznamů a jejich identifikace je název prvku a jeho chemická značka zcela ekvivalentní. Navíc chemická značka je podstatně kratší. Proto nic nebrání použít místo názvu prvku jeho chemickou značku.
Taková a podobná pole se nazývají klíčová pole. Klíčová pole mají v souborech jednu nebo více z následujících funkcí:
identifikační
klasifikační
informační
třídící (řadící)
kontrolní.
Informační funkce je zřejmá. Třídící funkce umožňuje řadit záznamy při zpracování podle požadovaných kriterií. Kontrolní funkce umožňuje ověřovat správnost dat, zpravidla při vytváření záznamů.
Z uvedených funkcí je pro probíranou problematiku nejdůležitější funkce identifikační. Identifikační klíčové pole obsahuje hodnoty mající přímo informační význam, nebo nějaký jednoznačný kód nahrazující původní informaci (např. ve smyslu číselníků). Takový jednoznačný nahrazující kód vždy existuje - např. pořadové číslo v množině původních informací nějakým způsobem uspořádané.
Klasifikační funkce poskytuje možnost z hodnoty klíčového pole získat i některé vlastnosti záznamu. Je-li klíčovým polem např. státní poznávací značka automobilu, pak z něj lze vyjmout kód okresu, kde je daný automobil registrován. Klasifikační klíče mají některé nevýhody. Především je to potřeba daleko většího počtu znaků, než by bylo teoreticky zapotřebí. Např. rodné číslo jednoznačně identifikující občana naší republiky má 10 cifer, ačkoliv je nás deset milionů a stačilo by tedy cifer pouze 7.
Klíčová pole popsaná shora mají velmi často kromě identifikační funkce i funkci informační (a naopak: informační pole mohou být často použita jako pole klíčová). Např. pole obsahující chemickou značku jednak identifikuje záznam, jednak informuje, o jaký prvek jde.
Složitější aplikace však mnohdy identifikují záznam podle několika informačních polí. Např. záznam v souboru čerpání vody z vrtů je identifikován označením vrtu a kalendářním datem měření.
Do takové datové struktury lze přidat klíčové pole, jehož obsah se zkonstruuje připojením obsahu datumového pole za obsah pole s označením vrtu. To je však velmi nepraktické ze dvou důvodů:
Přidáním dalšího pole nabývá soubor dat na objemu, a to celkem zbytečně, protože toto pole obsahuje údaje, které už jednou v záznamu jsou.
Nějakým mechanismem se musí zajistit, aby při změně obsahu některého informačního pole, které je částí klíčového pole, byla provedena příslušná změna klíčového pole.
Proto se při práci s daty používá obecnější konstrukce nazývaná klíč.
Především je zřejmé, že nic nebrání tomu, aby klíč byl konstruován nejen pouhým spojováním obsahů některých polí 'za sebe', ale vytvořen jakýmkoliv (i třeba velmi složitým) výpočtem.
Dále: protože záznam sám nese informace (v některých svých polích), které jsou schopny ho identifikovat, lze je vyhodnotit jako klíč až při zpracování záznamu.
Obou možností, případně jejich kombinace, se výrazným způsobem využívá v kvalitních moderních databázových systémech.
Metody uložení dat
Problematika uložení dat je problematikou proto, že se data ukládají na lineárním fyzickém mediu. Paměť počítače je lineární posloupnost paměťových prvků adresovaných od nuly. Magnetická páska je lineárním mediem už z fyzikální podstaty. Disky a diskety z různou technickou konstrukcí jsou jednotným vzorcem linearizovány na shodnou (nanejvýš různě dlouhou) posloupnost paměťových elementů. Data z klávesnice jsou linearizována reálným časem (jak postupně v čase přichází 'do počítače') apod. Datové struktury však lineární zdaleka být nemusí.
V celé této kapitole se nadále pod pojmem paměť bude rozumět jakékoliv shora naznačené linearizované medium schopné 'zapamatovat si' data.
Toto uložení je charakteristické tím, že při uložení záznamů využívá paměť od počátku (= od adresy nula) a bez mezer. Volná zůstávají paměťová místa s nejvyššími adresami v případě, že objem dat je menší než kapacita paměti.
Další rozlišovací úrovní postupného uložení dat je jejich uspořádání v paměti.
Sekvenční uložení je takové, při němž se záznamy ukládají v pořadí, jak v čase přicházejí - tvoří vstupní sekvenci. Pokud je zapotřebí nějaký záznam najít, je nutno projít všechny záznamy od počátku.
Při sériovém uložení řídí pořadí záznamů hodnota nějakého klíče - posloupnost klíčů tvoří uspořádanou sérii. Záznam s nejmenší (největší) hodnotou je prvním záznamem, záznam s největší (nejmenší) hodnotou je poslední. Řazení dat je vzestupné (sestupné).
Vyhledávání záznamů se v sériovém uložení velmi zjednoduší. Největší nevýhodou je nutnost fyzicky reorganizovat záznamy, když dojde požadavek na přidání nebo vypuštění záznamů (nebo ke změně hodnoty klíče záznamu).
Z ostatních typů se občas používá řazení podle četnosti vyhledávání. Vyhledávání je pak celkově rychlejší než při sekvenčním uložení. Je však podmíněno jednak znalostí této četnosti (nutnost experimentů), jednak stálosti této četnosti v čase.
Zásadní rozdíl oproti postupnému uložení je v tom, že mezi jednotlivými záznamy mohou být mezery a že jsou uloženy bez ohledu na nějaké uspořádání.
Při zápisu dat rozptýleného uložení se používají dvě metody:
Je jedno, kam bude zapisovaný záznam uložen. Proto se uloží do kteréhokoliv volného, délkově vyhovujícího místa v paměti. Tato metoda - má-li být rozumně rychlá a efektivně využívat paměť - používá pomocnou evidenci volného místa v paměti; z této evidence lze kdykoliv zjistit adresy a velikosti volných míst. Při zápisu se pak pomocí této evidence volí optimální strategie ukládání - např. se nejprve hledá přesně stejně veliké volné místo, jako má zapisovaný záznam.
Místo, kam bude záznam zapsán, se určí na základě obsahu záznamu. V naprosté většině se k tomu používá hodnot klíčů. Existuje tedy zobrazení množiny hodnot klíčů do množiny adres. Toto zobrazení nemusí být prosté. Funkce taková zobrazení definující se nazývají Hash - funkce.
Příklad: Nechť každý z 13 vrtů v terénu má číselný kód od 1 do 13 (vrty jsou tedy 'očíslovány'). Nechť délka záznamu obsahující údaje o každém vrtu je 67. (První závěr: pro uložení těchto dat je zapotřebí minimálně 871 elementů paměti, tzn. např. adresový prostor <0,870>). Funkce A
A = A (v) = (v-1) * 67kde v je kód vrtu, je hash - funkce, která každému záznamu s daným číslem vrtu přiřadí adresu uložení, která je z intervalu <0,804>. Tato funkce je prostá (dva různé vrty jsou umístěny na dvě různá místa). Funkce není zobrazením množiny kódů <1,13> na interval <0,804>, ale jen do tohoto intervalu (obrazy jsou jen počáteční adresy záznamů).
Tato metoda kombinuje sériové a rozptýlené uložení. Při primárním vytvoření je soubor vytvářen sériově (tj. ve vzrůstajícím nebo klesajícím pořadí klíčů) s ohledem na Hash - funkci. Nově přidávané záznamy jsou - většinou rozptýleným způsobem - zapisovány do tzv. zóny přeplnění (overflow area).
V případě, že v souboru může existovat větší či menší počet záznamů se stejnou hodnotou klíče, modifikuje se metoda tak, že jsou vytvářeny tzv. skupiny záznamů (záznamy se stejným klíčem), přičemž se předpokládá stejnoměrné rozdělení četnosti výskytu. Proto se každé skupině vyhradí stejné místo. Záznamy se stejným klíčem jsou zapisovány sekvenčně v prostoru paměti vyhrazené skupině a jednotlivé skupiny jsou zapisovány sériově v prostoru paměti vyhrazené skupinám. Dojde-li během zápisu záznamu do skupiny k vyčerpání místa určeného skupině, zapisují se tyto záznamy do zóny přeplnění.
Viz rovněž metody nepřímé adresace pro hledání v datech.
V moderních databázových (zvláště relačních) systémech jde o jedno z nejužívanějších uložení. Zásadně se týká záznamů, pro něž je definován alespoň jeden klíč.
Jde v podstatě o tzv. uložení s odkazy. Kromě záznamů jsou ukládány také odkazy na ně. Tyto odkazy však nejsou většinou ukládány přímo v datovém souboru, ale v samostatných souborech.
Při tomto způsobu uložení jsou data záznamy ukládány sekvenčně do souboru dat. Zároveň je pro každý záznam dat vytvořen záznam indexu. Záznam indexu má dvě pole: prvním je hodnota klíče daného záznamu, druhým je adresa v souboru dat, počínaje kterou byl tento záznam uložen. Takto vytvořený záznam indexu je zapsán do souboru indexů. Záznamy týkající se jednoho klíče jsou souhrnně označovány jako indexová tabulka. Každá indexová tabulka může být uložena v samostatném souboru, nebo mohou být všechny indexové tabulky uloženy v jediném souboru (nebo některé tabulky v jednom, některé v jiném souboru apod). Tyto soubory se nazývají indexové soubory.
Soubor indexů mívá nejrůznější organizaci (snad kromě sekvenční). Nejčastěji to bývá struktura s odkazy nebo jiné rozptýlené uložení, méně často uložení sériové.
Zvláště pro velké objemy dat je tento způsob uložení jedním z nejefektivnějších z hlediska využitého paměťového prostoru i (při vhodně zvolené metodě hledání v indexových souborech) při zpracování přímým způsobem.
Efektivita při ukládání spočívá jak v časovém hledisku (data jsou ukládána bez jakékoliv další reorganizace souboru vždy přímo na konec souboru), tak v hledisku hospodárnosti (v datovém souboru nejsou nevyužitá místa). Nutnost zpracovat současně i indexové soubory však je daleko menším zatížením, protože jednak jsou záznamy indexového souboru krátké (pouze dvě pole oproti např. desítkám polí vlastního datového souboru), jednak mohou být organizována zcela odlišně od vlastního souboru dat. Navíc, protože jsou poměrně málo objemné, mohou být celé umístěny v operační paměti, čímž se jak vytváření, tak zpracování dále nesmírně urychlí.
I když to není vždy pevným pravidlem, jde nejčastěji o sekvenční uložení záznamů, přičemž se při ukládání provádí dodatečné akce.
Odkazem se rozumí takový údaj v záznamu, který popisuje, kde se nachází jiný záznam; pro jednoduchost bude nejprve popsána situace, kdy tímto jiným záznamem je (logicky) další záznam. Odkaz je tedy datové pole, které však na rozdíl od běžných polí nenaplňuje uživatel, ale obslužný program.
Poznámka: Protože vztah před - za je binární operací porovnávání, musí být pro záznamy takovým způsobem ukládané definován výraz, nad jehož hodnotami se porovnávání provádí. Takový výraz je (viz výše) klíčem záznamu.
Odkazem může být např.
adresa v paměti (např. disková adresa)
pořadové číslo záznamu (program si pořadové číslo převede na adresu v paměti)
symbolický odkaz (program musí mít k disposici prostou hash-funkci)
Při popisované organizaci uložení existuje jedna hodnota odkazu (většinou označovaná NIL), která 'neukazuje nikam'. Tato hodnota je volena tak, že jí nemůže nabýt žádná reálná adresa, pořadové číslo nebo odkaz. Touto hodnotou musí být např. obsazen odkaz logicky posledního záznamu, protože za ním 'už nic není'.
Při popisu struktury s odkazy se používá pro vyznačení vztahu mezi dvěma bezprostředně souvisejícími záznamy zřejmá terminologie: předchůdce - následovník, nadřízený - podřízený, rodič - dítě. Poslední termíny (angl. parent record - child record) se používá snad nejčastěji.
Záznamy se zapisují tak, jak přichází; z tohoto hlediska jde o sekvenční organizaci. Při ukládání záznamů se při této organizaci postupuje následovně:
První příchozí záznam se zapíše jako první, přičemž pole odkazu na další se naplní hodnotou NIL. V tomto okamžiku je totiž první záznam také záznamem logicky posledním, za ním 'už není nic'.
Druhý příchozí záznam se zapíše jako druhý. Nyní však mohou nastat dvě situace:
Klíč druhého záznamu je větší nebo roven klíči prvního záznamu. Jinak řečeno, druhý záznam je logicky za prvním záznamem. Proto je nutno pole odkazu na následníka v prvním záznamu (doposud NIL) přepsat odkazem na druhý záznam, a pole odkazu na následníka ve druhém záznamu obsadit hodnotou NIL (druhý záznam se stává záznamem posledním).
Klíč druhého záznamu je menší než klíč prvního záznamu. V tom případě první záznam zůstává logicky posledním záznamem (v poli odkazu na následníka zůstává NIL), kdežto druhý záznam je prvním logickým záznamem, je před prvním záznamem, proto pole odkazu na následníka druhého záznamu se obsadí odkazem na první záznam.
Třetí příchozí záznam se zapíše jako třetí. Teď nastane jedna ze třech situací: třetí záznam je před prvním, mezi prvním a druhým, nebo za druhým. Upraví se tedy pole odkazů na následníka jen ve třetím záznamu, v prvním a třetím, nebo ve druhém a třetím.
Takovým způsobem se postupuje dále. Je zřejmé, že při zápisu každého dalšího záznamu se musí najít v již zapsaných záznamech dva klíče, mezi které klíč nově příchozího záznamu patří, tam stávající řetěz odkazů 'rozpojit' a (pomocí odkazů) tam vložit nově příchozí záznam.
Velmi jednoduché je však logické vypuštění záznamu. Obsah pole odkazu na následníka vypouštěného záznamu se prostě přepíše do pole odkazu předchůdce.
Výše byl popsán způsob vytváření odkazu na následovníky. Zcela stejně se může vytvořit druhé pole odkazu v záznamu, odkaz na předchůdce. V tomto případě je hodnota NIL hodnotou odkazu na předchůdce logicky prvního záznamu.
Sousedem záznamu A je takový záznam B, který má stejný klíč jako záznam A. Stejně jako odkazy na předchůdce a následovníku mohou být v záznamech pole odkazů na sousedy. Z hlediska popisované metody je dále možno rozdělit sousedy na levé a pravé. Levý soused je ten, který je zapsán dříve, pravý soused je zapsán později. Tedy 'nejlevější' soused má odkaz na levého souseda obsazený hodnotou NIL, 'nejpravější' soused má hodnotou NIL obsazený odkaz na pravého souseda.
Tato metoda již ve fázi ukládání používá metod pro hledání; vlastní ukládání tedy probíhá daleko pomaleji než např. prostý sekvenční zápis. Je to však na podporu pozdějšího zpracování souboru, které se stává daleko efektivnějším. Protože se soubor vytváří jen jednou, ale zpracovává násobně, je tato metoda často využívána.
Poznámka: Soubory s indexy jsou takovým případem souboru s odkazy, kdy odkazy spolu s hodnotami klíčů jsou uloženy v samostatném souboru.
Hledání v datech
Geo - data se vyznačují značným množstvím, klíč logického záznamu se může konstruovat z datových polí více souborů ap. Hledání v takových datech je kritickým momentem zpracování. Proto efektivita zpracování dat přímo závisí na efektivitě hledání v datech.
Hledáním rozumíme dodání takového záznamu ze souboru (souborů) dat, který splňuje dané kriterium. Tímto kriteriem může být jakýkoliv logický výraz, vyhodnotitelný pro každý záznam. Záznam, pro nějž po vyhodnocení odevzdá tento logický výraz hodnotu logické 1, dané kriterium splňuje.
Jako kriterium efektivity různých metod hledání se používá průměrný počet vyhodnocení kriteria, jehož splnění je vyžadováno. Toto vyhodnocení vždy pracuje s hodnotami polí záznamu, proto jedno vyhodnocení je přímo spojeno s jedním vyzdvižením dat záznamu (všech nebo jen některých; velmi často jsou rychlosti v obou případech stejné!). Protože vyzdvižení dat záznamu je spojeno s přístupem k mediu - a to je časově velmi náročná operace - potvrzuje to jen tvrzení o hledání v datech jako o kritickém místě procesu zpracování dat.
V dalším bude symbolem N označován počet všech záznamů, symbolem Zi počet kroků nutný pro vyhledání a vyhodnocení i-tého záznamu, symbolem Zp průměrný počet nutných vyhodnocení, Z (= Zp . N) počet všech vyhodnocení.
Při sekvenčním hledání se probírají záznamy postupně od začátku jeden za druhým tak dlouho, dokud není nalezen záznam vyhovující vyhledávacímu kriteriu.
Nechť pi je pravděpodobnost, že i-tý záznam bude nalezen v jednom kroku. Sekvenční hledání se používá tam, kde nejsou známy bližší podrobnosti o způsobu uložení; proto musíme předpokládat rovnoměrné rozložení, kde ovšem je pi = 1/N. Je tedy
Zp = zp1 + + zN.pNPři sekvenčním hledání je zi = i, tedy
Zp = 1/N . (1 + + N) = (N + 1)/2Při sekvenčním hledání je tedy k nalezení požadovaného záznamu nutno prohlédnout průměrně polovinu souboru.
Sériové hledání se uplatňuje v souborech se sériovým způsobem uložení. Záznamy jsou tedy řazeny v uspořádané posloupnosti (sérii) hodnot klíčů. V metodách sériového hledání je vždy vyhledávacím kriteriem hodnota klíče, podle kterého je soubor řazen.
Tato metoda (myšleně) rozděluje soubor na bloky o shodném počtu záznamů. Nejprve je (sekvenčně) nalezen blok, ve kterém se záznam nachází, a poté (sekvenčně) hledaný záznam.
Nechť je tedy počet bloků m, počet záznamů v každém bloku s. Je tedy N = m . s. Nechť j označuje číslo bloku, j je z <1,m>; dále označme h číslo záznamu v bloku, h je z <1,s>. Pro dosažení j-tého bloku je zapotřebí j kroků, pro dosažení h-tého záznamu je zapotřebí 0 až s-1 kroků (nula proto, že hledaný záznam může být prvním v bloku a už tedy netřeba hledat dále; s-1 proto, že s-tý už je první v dalším bloku). Je pak
Z = s . (1 + + m) + m . (1 + + s-1)Protože je s = N/m, je
Z = N . (N + m2) / (m)a tedy
Zp = Z/N = (N + m2) / (m) = f (m)Pro kontrolu: je zřejmé, že uvedená metoda je pro jednozáznamový blok totožná se shora popsaným sekvenčním hledáním: prohledávají se postupně všechny záznamy počínaje prvním, a to po jednom. Je-li m = 1, je
Zp = (N + 12) / (1) = (N + 1) / 2což je shoda s výsledkem odvozeným pro sekvenční hledání.
Dále pro všechna m>1 je
(N + m2) / (m) < (N + 1) / 2z čehož plyne, že průměrný počet kroků při sériovém hledání s pravidelnými kroky je vždy lepší než sekvenční hledání. Už např. pro m=2 je průměrný počet kroků zhruba poloviční.
Protože průměrný počet kroků je funkcí m, lze zjistit, pro jaké m0 má tato funkce minimum (tj. pro jaké velikosti bloků je hledání optimální). Musí být
df / dm = 0a protože
Zp = f (m) = (N + m2) / (m)je po provedení derivace a zjištění m0
m0 = (N)a tedy po dosazení rovněž
Zp = (N)Např. pro
soubor o 10 000 záznamech je optimální délka bloku
Metoda je někdy označována také jako binární hledání, je logicky totožná se stejně označovanou metodou numerické matematiky. Protože jde o sériové hledání, lze aplikovat pouze na soubory se sériovým uložením, tedy seřazené podle hodnot klíče. Metoda je popsána pro vzestupné řazení, pro sestupné postačí zaměnit relace.
Princip metody je následující:
Existuje záznam, který rozděluje soubor na dvě, co do počtu prvků (až na jeden) stejné části. Všechny záznamy před tímto záznamem mají hodnoty klíče menší nebo rovnu, za tímto záznamem větší nebo rovnu. Vybere se tedy tento 'prostřední' záznam a jeho klíč se porovná s hledaným klíčem. Jsou-li totožné, je záznam nalezen. Je-li prostřední klíč větší než hledaný, hledá se stejným způsobem v první polovině souboru. Je-li prostřední klíč menší než hledaný, hledá se stejným způsobem ve druhé polovině souboru.
Metoda končí ve dvou případech: hledaný záznam je nalezen, nebo není co půlit - v tom případě hledaný klíč nemá žádný záznam souboru.
Pro odvození průměrného počtu kroků uvažme toto: existuje jediný záznam dosažitelný právě jedním krokem (prostřední); existují dva záznamy, dosažitelné právě dvěma kroky (prostřední v dolní a hodní polovině souboru); čtyři dosažitelné třemi kroky obecně 2(j-1) dosažitelné j kroky.
Počet kroků, kterými je každý prvek dosažitelný, determinuje rozklad množiny záznamů na třídy. Do třídy j patří 2(j-1) záznamů. Součet kroků pro každou třídu je tedy
Zj = j . 2(j-1)Uvažujme nejprve, že ideální počet záznamů souboru je
N = 2k - 1(tj. pro každé půlení existuje přesně prostřední prvek) a označme
a = log2 (N-1)Pak pro celkový počet kroků je (matematické odvození je vynecháno)
Z = 2a . (a-1) + 1a tedy - protože Zp = Z/N -
Zp = (N+1)/N . log2 (N+1) - 1tj. přibližně
Zp = log2 (N)Tento vztah byl odvozen pro ideální binární hledání (N = 2k - 1), což je v praxi málokdy splněno. Porušení této podmínky však - zvláště pro větší počet záznamů - nevede k podstatnému zhoršení rychlosti vyhledávání.
Tato metoda je tedy ze všech zatím uvedených nejrychlejší.
Pod přímým přístupem k datům se rozumí přímé čtení záznamu ze známé adresy. V těchto metodách je tedy Zp=1, každý požadovaný záznam se přečte hned napoprvé.
Metody přímého přístupu k datům evidentně vyžadují znalost adresy pro každý záznam. To neznamená, že v každém okamžiku jsou známy adresy všech záznamů najednou. Znamená to, že v okamžiku potřeby daného záznamu existuje možnost adresu zjistit.
U těchto metod se obdobně jako u metod sériového hledání předpokládá existence klíče a vzestupné nebo sestupné uspořádání jeho hodnot.
Při této metodě je adresou přímo klíč nebo jeho lineární transformace.
Příklad: Nechť každý z 13 vrtů v terénu má číselný kód od 1 do 13 (vrty jsou tedy 'očíslovány'). Nechť délka záznamu obsahující údaje o každém vrtu je 67. Klíčem vrtu je jeho číslo -v- a z něj lze odvodit adresu záznamu výrazem A = (v-1) * 67.
Metoda přímého adresování je vhodná v případě, že
klíč je numerický
ke každé hodnotě klíče z nějakého uzavřeného intervalu existuje záznam
délka záznamu je u všech záznamů stejná
Nejčastěji však data v souborech nesplňují ani přibližně požadavky odůvodňující přímé adresování. Je to např. tehdy, když
posloupnost klíčů ani teoreticky neobsahuje všechny hodnoty jediného uzavřeného intervalu, ale mezi hodnotami jsou 'velké mezery'.
klíč je koncipován tak, že teoreticky umožňuje použít všechny hodnoty z nějakého uzavřeného intervalu, ale je známo, že všech skutečných záznamů bude mnohem méně.
klíčem je výraz jiného typu než numerického a nemůže tedy být přímo použit k adresování.
V uvedených a podobných případech je nutno mít k disposici funkci, která transformuje hodnotu klíče na adresu. Adresa není tedy určena přímo, ale zprostředkovaně klíčem; proto se tyto metody nazývají metody nepřímého adresování, a protože používají (již při výkladu metod zápisu zmíněnou) Hash - funkci, nazývají se také Hash - metodami.
Zpravidla není možno sestrojit funkci A = A (k) tak, aby to bylo prosté zobrazení (celé) množiny klíčů na rovnoměrně rozložené adresy v množině použitelných adres. Na druhé straně by funkce A neměla být (z časových důvodů při jejím vyhodnocování) příliš složitá. Proto se užívají takové funkce, které některé adresy ponechávají neobsazené a jiné adresy jsou obrazem většího počtu klíčů.
Nechť funkce A (k) zobrazuje množinu klíčů na M různých adres. Pro uložení celého je však zapotřebí N různých adres. Paměť může být tím rovnoměrněji rozdělena, čím větší je poměr M/N. Ve skutečnosti se však pro uložení všech N záznamů nevyužije všech M adres. Některé zůstávají nevyužité, některé jsou použity vícekrát. Je-li počet adres použitých alespoň jednou označen L, pak se hodnota l = L/M označuje jako koeficient zaplnění (loading factor).
Použijme termín skupina záznamů pro ty záznamy, jejichž klíč je transformován na stejnou adresu. Rozměr skupiny záznamů je počet záznamů skupiny (ideální je samozřejmě rozměr všech skupin rovný jedné). Zvolí-li se při vytváření souboru velký rozměr skupiny, zmenší se pravděpodobnost nutnosti zápisu do zóny přeplnění (a tím zkrátí čas hledání v této oblasti), ale zvětší se čas při hledání ve skupině. Zvolí-li se naopak při vytváření souboru malý rozměr skupiny, zvýší se pravděpodobnost nutnosti zápisu do zóny přeplnění a tím se zvětší doba hledání v této zóně.
Je zřejmé, že základem optimální volby rozměru skupiny záznamů je kvalifikovaný odhad množiny skutečných klíčů, které budou do souboru skutečně zapisovány. Protože tento odhad se liší od aplikace k aplikaci, bývá u obecných systémů rozměr skupiny i velikost oblasti přeplnění volitelným parametrem souboru.
Funkcí A = A (k) existuje celá řada a z hlediska zaměření tohoto článku nemá smysl je zde uvádět. Účinnost vyhledávacích metod na nich založených ovlivňují následující parametry:
rozměr skupiny záznamů
hustota zaplnění skupin záznamů
vlastní algoritmus transformace klíče záznamu na adresu počátku skupiny záznamů
způsob zpracování oblasti přeplnění.
Tyto metody hledání mohou být aplikovány pouze na soubory dat, ke kterým byly vytvořeny indexové tabulky (viz odstavec o metodách uložení s indexy). Protože indexové tabulky jsou vytvářeny na základě hodnot klíčů, je možno hledat záznam pouze podle kriteria, kterým je hodnota klíče.
Poznámka: Protože vlastní data jsou uložena sekvenčně, je principielně možno ke každému stávajícímu sekvenčnímu souboru vybudovat indexovou tabulku založenou na nějakém klíči, popř. vybudovat více indexových tabulek s různými přístupovými klíči postupně v čase.
Při této metodě se hledání ve vlastním souboru dat převádí na hledání dané hodnoty klíče v indexové tabulce. Po nalezení záznamu indexové tabulky je z pole adresy získána adresa datového záznamu v souboru dat, a tento záznam se pak přímo získá jediným čtením.
Pro hodnocení metod hledání v datech s indexy platí vše, co bylo uvedeno dříve, ovšem aplikováno na soubor indexů. Organizace uložení v souboru indexů tedy určuje efektivitu používání souborů s indexy. Protože z dosud hodnocených metod hledání je nejméně efektivní sekvenční metoda, téměř nikdy se nepoužívá ani sekvenční organizace uložení, ani sekvenční hledání.
Velmi často se pro indexová tabulky používá uložení s odkazy. Záznam pak má 6 polí: čtyři pole s odkazy (na předchůdce, následovníka, a na levého a pravého souseda), jedno pole pro hodnotu klíče a jedno pro hodnotu adresy záznamu. Indexová tabulka pak má tvar stromu (z teorie grafů). Každý záznam je pak jedním uzlem v tomto grafu, hrany grafu jsou obrazem odkazů. Výhodou je možnost ukládat v každém uzlu ne kompletní hodnoty klíče, ale jen část hodnoty klíče náležející dané úrovni uzlu v grafu.
Poznámka: Právě takovým způsobem jsou organizovány indexové soubory v relačním databázovém systému Microsoft Fox, jednom z nejvýkonnějších databázových systémů v prostředí počítačů třídy IBM/PC.
Logická organizace báze dat
Historický vývoj směřoval od prvotního zpracování dat na úrovni fyzických záznamů přes datové záznamy bez vzájemných vazeb (na úrovni dat) až po báze dat obsahující v sobě popis dat včetně vazeb.
V současné době má smysl rozebírat dva dominantní modely logické organizace bází dat: hierarchický (také hierarchicko - síťový) model a relační model.
Model vychází z použité hierarchické struktury dat tak, jak byla kdysi zavedena pro potřeby jazyka Cobol pro zobrazení hodnot dat a jejich vzájemných vztahů (nadřízenosti a podřízenosti). Tento model se neopírá o matematickou teorii, i když přejímá část terminologie z teorie grafů. Přesto nalezl v praxi široké uplatnění.
Na hierarchickém modelu je založena řada systémů řízení báze dat, např. IMS firmy IBM, český DBS používaný v řadě EC apod.
Hierarchická struktura je taková, kde záznamy jsou v hierarchickém vztahu nadřazenosti a podřízenosti. Přitom se používá 'rodinná' terminologie rodič a potomek ve zřejmém významu.
V hierarchické struktuře má každý potomek jediného rodiče, existuje jediný rodič, který není potomkem a potomek v jednom vztahu může být rodičem v jiném vztahu.
Pokud je zapotřebí popsat, na kterém místě hierarchické struktury se nějaký záznam nalézá, používá se k tomu tzv. přístupová cesta. To je možno díky popsaným vlastnostem hierarchické struktury, které zaručují, že od kořene lze dojít k danému záznamu jediným způsobem.
Často se vyžaduje (většinou z ryze praktických důvodů např. sběru dat), aby v každém záznamu existoval klíč. V takovém případě lze přístupovou cestu popsat jednoduše jako posloupnost klíčů počínaje klíčem kořenového záznamu přes klíče všech nadřízených až po klíč daného záznamu včetně.
Zmíněné pojmy z teorie grafů se při popisu hierarchických struktur využívají v tomto smyslu:
záznam = uzel grafu
vztah rodič - potomek = hrana grafu
rodič a potomek = incidenční uzly hrany
hierarchická struktura = souvislý graf, který je stromem
báze dat hierarchického modelu = graf, který je les (tj. množina disjunktních stromů)
přístupová cesta k záznamu = cesta v grafu od kořene k danému uzlu.

Obrázek 1: Stromová struktura
Nevýhodou hierarchických systémů je velmi obtížná implementace odkazů. V takových případech se sice rozšiřují možnosti, snižuje redundance dat, ale současně dochází k nutnosti promíchávat otázky uložení na médiu s otázkami struktury modelu, ke znepřehlednění a zvláště ke snížení abstrakce při práci s daty.
Jedním z nejjednodušších zápisů dat je zápis do klasické tabulky. Takto převážně vznikají zápisy dat v terénu, obecně v neautomatizovaných částech systému. Charakteristický pro tento zápis je její členění do sloupců, z nich každý má nadpis. To je velmi podstatné, protože nadpis ve smyslu identifikace údajů automaticky indukuje také typ údajů v daném sloupci. Sloupce jsou tedy 'homogenní co do typu'. Klasickým příkladem je výňatek z komplexní petrologické databáze (Global Data Base in Sedimentary Petrology, Géodiffusion, Paris 1991):

Obrázek 2: Relační model
Pevným počtem n sloupců tvoří data v řádcích uspořádané n-tice. Každý prvek n-tice, nazývaný pole, je toho typu, jaký odpovídá typu sloupce. Je tedy prvkem (konečné nebo nekonečné) jednoznačně určené množiny Di (např. množiny všech datumů, množiny všech racionálních čísel, množiny apod).
Množina všech uspořádaných n-tic <a1, a2, , an>, kde Ai jsou libovolné množiny, ai je z Ai a n je přirozené číslo, je z teorie množin známa jako kartézský součin K = A1 x A2 x x An a každá podmnožina R z K je známa jako n-ární relace v K. Je tedy možno pohlížet na každou tabulku, která je vytvořena obdobně jako tabulka shora, jako na n-ární relaci.
Pro určení relace R pro potřeby modelu báze dat je zapotřebí zadat
konečnou množinu atributů F - což jsou jména polí s případnými dalšími specifikacemi (šířka sloupce, počet desetinných míst ap) využitelných pro uživatelskou i programovou identifikaci
domény Ai, tj. množiny možných hodnot každého pole
podmnožinu kartézského součinu domén, tj. vlastní relaci (z hlediska tabulky je tím určen počet polí a pořadí sloupců).
Relaci je tedy možno definovat jako trojici R = <F, D, T>, kde
F je konečná množina jmen atributů
D je zobrazení, přiřazující každému f z F doménu D(f) atributu f. Domény jsou libovolné neprázdné množiny (konečné nebo nekonečné); je-li f, g z F, f různé od g, nemusí být D(f) různé od D(g).
T je konečná podmnožina kartézského součinu X [D(f)] všech domén atributů, f je z F.
Tabulky dat, které reprezentují relace, mají - jak již bylo uvedeno - následující vlastnosti:
Každému prvku relace odpovídá jeden řádek tabulky
Žádné dva řádky nejsou identické
Sloupec s atributem f z F v záhlaví obsahuje jen hodnoty z domény D(f).
Okolnost, že v praxi často nebývá splněna vlastnost ad 2), se řeší 'očíslováním řádků'; přidá se jeden sloupec, jehož doména je podmnožina přirozených čísel.
Přestože domény mohou být libovolné množiny, používá se z čistě praktických důvodů většinou jen množin, jejichž prvky jsou
číselné hodnoty (vzhledem ke zpracování v počítačovém prostředí výhradně racionální)
datumové hodnoty (uspořádané trojice <d,m,r> přirozených čísel s příslušně definovaným oborem a operacemi)
textové hodnoty (posloupnosti prvků z ze Z, kde Z je konečná neprázdná množina)
binární hodnoty (prvky dvouprvkové množiny )
relace.
Domény obsahující jen prvky analogické prvním čtyřem vyjmenovaným se nazývají jednoduché. Jestliže relace obsahuje pouze jednoduché domény, nazývá se relace v první normální formě. Proces převedení relace do první normální formy se nazývá normalizace.
Relace, která není v první normální formě, je dána např. následující tabulkou:

Obrázek 3: Nenormalizovaná relace
Normalizace této relace může vést k jediné relaci, která již v první normální formě je:

Obrázek 4: Normalizovaná relace
Jde o poměrně jednoduchý příklad; je však nutno upozornit na to, že procesem normalizace zvláště u složitě logicky strukturovaných relací mohou často vznikat redundantní údaje. I v tomto příkladu se redundanci dat nevyhneme: souřadnice jednoho vrtu jsou uloženy na několika různých místech. Pokud např. se posléze zjistí, že souřadnice X vrtu A12 byla zaznamenána chybně, je nutno hodnotu opravit ne na jediném, ale na několika různých místech. To je přesně ta situace, kterých by v reálné praxi mělo být co nejméně.
Některé atributy nebo jejich spojení lze v případě potřeby použít jako klíče. Označme je jako možné klíče. Klíče se používají jednak pro vyhledávání, jednak pro uspořádání. Jestliže se některý možný klíč skutečně pro daný účel použije, stává se po dobu použití primárním klíčem. Je-li klíč tvořen jediným atributem, označuje se jako jednoduchý klíč; je-li tvořen spojením dvou a více atributů, nazývá se spojený klíč. Je-li klíč vytvořen pomocí operací definovaných na hodnotách polí a na konstantách, nazývá se obecný klíč.
Pomocí klíčů lze nahradit jednu nenormalizovanou relaci více normalizovanými relacemi se stejným datovým obsahem, jak to ukazuje následující obrázek. Klíčem (a to jednoduchým) je v tomto případě atribut Vrt.

Obrázek 5: Rozklady relace
Pro formalizaci zápisu struktury se často používá notace, která je základem některých dotazovacích jazyků. V této notaci se zapíše struktura relací následovně:
VRTY (^VRT, X, Y, LABORATOŘ)Identifikátor relace je uveden před kulatými závorkami; uvnitř nich jsou uvedeny jednotlivé atributy. Je-li před některým z nich uveden znak ^, je tím označen klíč.
Nenormalizovaná relace se pak v této notaci zapíše následovně:
VRTY (^VRT, X, Y, ČERPÁNÍ (^DATUM, HLADINA, L/SEC), LABORATOŘ)Porovnáním zápisů obou struktur lze odhalit jeden z možných postupů tvorby klíčů při procesu normalizace, kterým vzniká více relací: každá hierarchicky vnořená relace předřadí svému vlastnímu klíči (klíčům) klíč (klíče) relace bezprostředně hierarchicky nadřazené.
V relačním modelu je báze dat definována jako n-ární relace; takových bází dat se tedy týkají všechny vlastnosti, které lze odvodit matematickým aparátem pro relace. Tento aparát jako obecný aparát matematický je pro účely počítačového zpracování velmi dobře algoritmicky propracován. S relacemi jako takovými se pracuje poměrně jednoduše; výhoda relačních modelů databází spočívají právě v jednoduchosti práce s relacemi.
Pro relace se zavádí především operace; ze základních operací uveďme projekci a spojení jako nejčastěji vyžadované operace.
Nechť P a Q jsou relace. Operaci x nazýváme projekcí tehdy, je-li P x Q relace, která vznikne z P vynecháním atributů P, které nejsou současně atributy Q, a následným vynecháním shodných řádků. Tato operace se používá pro zbavení se nepodstatných nebo v danou chvíli nedůležitých informací.
Příklad:
VRTY x (^VRT, LABORATOŘ) = (^VRT, LABORATOŘ)Nechť P a Q jsou relace, které mají alespoň jeden shodný atribut. Operaci + nazýváme spojením tehdy, je-li P + Q relací, která vznikne z P přidáním atributů Q, které nejsou současně atributy P, a následným vynecháním shodných řádků. Spojení vytvoří relaci z hodnot atributů obou relací, které odpovídají hodnotám shodného (shodných) atributů.
Příklad:
VRTY + (^VRT, ^DATUM, L/SEC) = (^VRT, X, Y, LABORATOŘ, ^DATUM, L/SEC)Tyto a další operace vytváří algebru relací. Kromě operací lze vytvářet další relace také relačním kalkulem. Přitom se využívá symboliky používané obdobně v jiných partiích matematiky:

Obrázek 6: Relační symbolika
Pomocí zavedené symboliky a relačního kalkulu můžeme zavést např. relaci U, která popisuje množinu takových čerpacích měření všech vrtů, kde vydatnost přesahuje 0.5:
U (^VRTY.VRT, ^ČERPÁNÍ.DATUM, ČERPÁNÍ.L/SEC) : ČERPÁNÍ.L/SEC > 0.5V předchozích odstavcích byl zaveden termín první normální forma. Příklady osvětlily způsob převodu relace na normalizovaný tvar. Při porovnání výsledků dvou různých normalizací téže relace (do jedné a do dvou relací) a ve smyslu zavedených operací nad relacemi je vidět, že druhý způsob spočívá ve vytvoření dvou projekcí na podmnožiny atributů se stejným informačním významem a ekvivalentním datovým obsahem. Stanovení vhodné (logické) reprezentace dané relace bude cílem následujících odstavců.
Další výklad je dokreslen následujícím příkladem. Nechť je dáno několik vrtů v několika lokalitách; vzorky vod byly podrobeny chemické analýze a výsledky byly shrnuty do relace
ANALÝZA (VRT, LOKALITA,LÁTKA, MNOŽSTVÍ)Je-li tedy
<V12, Poruba, pH, 7>z relace ANALÝZA, pak to znamená, že z vrtu V12, který je v Porubě, byl analyzován vzorek na pH a byla zjištěna jeho hodnota rovna 7.
Z příkladu je vidět, že
kódem vrtu je jednoznačně určeno jeho umístění, jinak řečeno, ze zadaného kódu vrtu lze odvodit jeho umístění: VRT -> LOKALITA
analyzované množství je jednoznačně určeno kódem vrtu a kódem látky, jinak řečeno, ze zadaných kódů vrtů a látky lze odvodit hodnotu: VRT, LÁTKA -> MNOŽSTVÍ
naproti tomu ze samotné lokality nelze jednoznačně odvodit žádný jiný údaj, není tedy např. LOKALITA -> MNOŽSTVÍ.
Rozborem dalších možností lze odvodit, že jediným klíčem relace je ; pouze tento klíč jednoznačně zpřístupňuje všechny údaje v řádku.
Mezi atributy relace se tedy mohou vyskytovat vazby, které jsou dány významem těchto atributů v reálném světě, jejich sémantikou. Formálně jsou tyto vazby označovány jako závislost.
Závislost lze definovat takto:
|
Nechť je dána relace R = <A, D, T>, nechť je B z A, C z A. Množinu atributů C v R nazveme závislou na množině atributů B v R, jestliže pro libovolné n z T, v z T platí: je-li n[b] z B pro všechna b z B, je n[c] = v[c] pro všechna c z C. Skutečnost, že C je závislá na B, je symbolicky označena B -> C. |
Pomocí závislostí atributů je možno zachytit a formalizovat část sémantického významu atributů. O tom, zda v relaci platí závislost mezi atributy, se rozhodne podle tabulky relace. Často je však možné vyjít ze vztahů mezi atributy v popisovaném reálném světě. Takovým způsobem lze definovat např. klíč v relaci.
|
Nechť K je podmnožina A. K je pro R[A] klíčem relace R, jestliže (a) K -> A a dále (b) žádná vlastní podmnožina K nemá předchozí vlastnost. |
Některé problémy mohou nastat při aktualizaci dat. Jestliže se v předchozím příkladě přestane provádět analýza pH ve vrtu V13, odstraní se z relace řádek pro V1 Tím se ovšem ztratí informace o existenci a umístění vrtu V13 (který ovšem reálně existuje dál). Pokud někde vznikne další vrt, nemůže se do relace přidat, dokud není známo, co a v jakém množství bylo analyzováno. Přejmenuje-li se lokalita, je třeba zaměnit starý údaj za nový na mnoha řádcích.
Tyto problémy jsou důsledkem toho, že LOKALITA závisí nejen na celém klíči , ale i na jeho části . Základní myšlenkou, která z toho vyplývá, je vytvoření různých projekcí této relace a uchovávat je samostatně.
V uvedeném příkladě to znamená vytvořit projekce P1 a P2 relace ANALÝZA na množiny a .
Použitá metoda rozkladu se opírá o pojem závislosti. Každý krok rozkladového algoritmu záleží v nahrazení jedné relace dvěma jejími projekcemi, přičemž nesmí dojít ke ztrátě informace.
Lze dokázat, že z platnosti závislosti B -> C v relaci R plyne rozložitelnost (bez ztráty informace) R na své projekce R [BČC] a R [BČC'], kde C' je doplněk množiny C do A-B.
Definujme nejprve úplnou závislost takto:
|
Nechť R [A] je relace, nechť je B z A, C z A. C úplně závisí na B v R, jestliže C -> B a pro žádnou vlastní podmnožinu B1 z B není B1 -> C. |
Nyní lze definovat druhou normální formu:
|
Relace R [A] je relace ve druhé normální formě, jestliže (a) R [A] je v první normální formě a dále (b) každý atribut a z A, jenž nepatří žádnému klíči R, úplně závisí na každém klíči K v R. |
Shora uvedená relace ANALÝZA není ve druhé normální formě, protože má atribut LOKALITA, který nepatří žádnému klíči, funkčně závisí na jediném klíči , ale nezávisí na něm úplně (závisí totiž jen na jeho části VRT). Ovšem obě projekce P1 a P2 relace ANALÝZA už ve druhé normální formě jsou.
Nicméně i s relacemi ve druhé normální formě mohou nastat problémy. Uvažujme relaci VRTY (VRT, LOKALITA, SPAD), kde SPAD je jednotkový spad v dané lokalitě:
Jediným klíčem je . Jestliže se však uzavře poslední vrt v Nové Vsi, ztratí se informace o spadu v dané lokalitě. Problém je zřejmě v existující závislostí LOKALITA -> SPAD; žádný z těchto atributů nepatří ke klíči relace. Tyto a obdobné obtíže se je možno odstranit přechodem k projekcím (zde na ) a relacím ve třetí normální formě:
|
Řekneme, že relace R je ve třetí normální formě, jestliže (a) R je ve druhé normální formě a dále (b) množina všech atributů, které nepatří žádnému klíči (tj. množina neprimárních atributů) je nezávislá: žádný neprimární atribut nezávisí na některém z ostatních neprimárních atributů. |
Uvedenou relaci VRTY lze projekcí převést na dvě relace UMÍSTĚNÍ (VRT, LOKALITA) a ZNEČIŠTĚNÍ (LOKALITA, SPAD). Toto rozdělení je konec konců i logické, protože spad závisí spíše na lokalitě jako takové než na samotném vrtu.
Elementy relace, která je ve třetí normální formě, mají následující strukturu: existují pro ně hodnoty klíčů (zpravidla klíče jediného), které tento element plně identifikují, a dále hodnoty atributů, které jistým způsobem elementy popisují. Tyto 'popisné' hodnoty neprimárních (= neklíčových) atributů jsou na sobě nezávislé v tom smyslu, že žádná z nich není funkčně určena kombinací některých ostatních.
Shora uvedené normální formy mají nesmírný praktický význam.
Především na úrovni řízení báze dat (= úroveň programů) je evidentně zpracování relací ve vyšší normální formě daleko jednodušší a tedy rychlejší než relací v nižší normální formě (popř. zcela nenormalizované). Přestože pro koncového uživatele je to irelevantní, je na místě připomenout, že jednodušší zpracování vyžaduje i jednodušší programování a je známo, že čím jednodušší je program, tím méně potenciálních chyb obsahuje.
Daleko důležitější je však otázka praktického zpracování dat uživatelem počínaje aktualizací a konče čerpáním informací. Údržba koncovým uživatelem dat, která jsou nenormalizovaná, je bez rizika porušení integrity dat nemožná bez obslužných programových nadstaveb, specificky programovaných pouze na tuto datovou strukturu. Toto riziko se - byť v menší míře - vyskytuje i v relacích ve druhé normální formě: přidání dalšího vrtu do relace VRTY předchozího odstavce znamená, že uživatel musí zadat s kódem vrtu a lokality také přesně stejnou hodnotu spadu jako u předchozích řádků téhož vrtu! Teprve relace ve třetí normální formě plně odstraňují (až na zřejmé klíče) redundanci dat.
Protože dnes mají koncoví uživatelé obecných systémů řízení báze dat možnost plně definovat, plnit a aktualizovat své vlastní báze dat, je vhodné závěrem uvést obecný postup normalizace již ve fázi návrhu logické struktury:
Nenormalizovaný tvar -> první normální forma (rozložení všech datových struktur, které nejsou dvourozměrné, na dvourozměrné)
První normální forma -> druhá normální forma (odstranění neúplných závislostí neprimárních atributů na potenciálních klíčích)
Druhá normální forma -> třetí normální forma (odstranění závislostí neprimárních atributů na sobě)
Návrh logické struktury báze dat založené na relačním modelu tedy spočívá v identifikaci všech atributů postihujících existující objekty, a vzájemných vztahů mezi těmito atributy. Na základě této identifikace je třeba - s jistou dávkou opatrnosti - rozhodnout o klíčích relací.
Relační systémy jsou založeny na formalizovaných pojmech používajících matematický aparát. Lze vytvořit analytické nástroje pro automatizaci shora popsaných identifikačních činností a návrhu výsledných relací ve třetí normální formě. Ukázalo se však, že tyto nástroje jsou - zvláště díky moderním propracovaným systémům řízení bází dat - pro koncové uživatele vcelku zbytečné.
Zpracování báze dat
Detailní popisy postupů, metod a nástrojů podaný v předchozích kapitolách stojí v popředí zájmu těch, kdo své databáze sami budují a udržují. Pro uživatele, které již vytvořené báze dat používají jako zdroj informací, mají význam ilustrační, upřesňující pohled uživatelů na konstrukci bází dat, a významným způsobem ulehčují jejich komunikaci s bází dat při formulaci svých požadavků.
Tato kapitola je úvodní kapitolou do rozsáhlé problematiky práce s bázemi dat 'výstupním' směrem. Z hlediska takového způsobu zpracování existujících dat lze uživatele rozdělit na dvě skupiny:
Programátoři; mají k disposici programovací jazyk umožňující přístup do bází dat. Výsledkem jejich činnosti je program, který - po spuštění - podá požadované informace. Data se tedy zpracovávají na úrovni programu.
Laici (přesněji ti, kteří nejsou programátoři, kteří pro získání informací neumí, nechtějí nebo nemohou vytvářet programy); mají k disposici dotazovací jazyk, pomocí něhož formulují své požadavky. Výsledkem jsou - po provedení požadovaného dotazu - přímo požadované informace. Data se tedy zpracovávají na úrovni uživatele.
V současné době je zřetelně vidět tendence implementovat dotazovací jazyky (které jsou nutně formalizované, se svou syntaxí a sémantikou) do programovacích jazyků. Tak je tomu např. v novějších systémech s programováním v xBase, které jako rovnocenné syntaktické kategorie používají (alespoň nejdůležitější) příkazy SQL. Podrobněji právě toto rozebírají dvě následující kapitoly.
Tato práce se nezabývá programováním jako takovým, proto jsou informace k této problematice podány pouze schematicky.
Programovací jazyk obsahuje dvě základní třídy nástrojů: popisy a příkazy. Pomocí popisů (také deklarací) programátor popisuje objekty, nad kterými budou pracovat příkazy. Každá z těchto tříd má relativně samostatný popis syntaxe a sémantiky v daném jazyce. Proto se často vytýká zvlášť jazyk pro popis dat a jazyk pro práci s daty.
Za nejjednodušší 'jazyk' by mohla být považována pouhá tabulka popisu dat, informující tabelární formou o souborech, jejich polích, atributech polí, indexech a vazbách.
Komplexní jazyk pro popis (logické struktury) dat musí plnit následující funkce:
identifikace jmen a typů souborů, záznamů, segmentů a polí
určení klíče
popis struktury segmentu resp. záznamu
pojmenování vztahů mezi segmenty a záznamy
popis přípustných hodnot polí
počet opakování položky v poli (matice, )
popis kontrolních algoritmů
popis přístupových práv a hesel.
Jako příklad může být uveden jazyk DL/1 firmy IBM. Byl používán i na počítačích řady EC, u nás jako součást systému DOS počítače EC-1026.
Základní konstrukcí tohoto jazyka je strom. Mezi stromy mohou být logické vazby, listy stromů jsou zpravidla segmenty. Odkazy mohou být vertikální (rodič - dítě) nebo horizontální (sourozenci). Tento jazyk dovoluje popsat logické i fyzické uložení. Jsou k disposici hierarchické přístupové metody, a to sekvenční, indexový i přímý.
Jednoduchý příklad popisu dat v DL/1:
DBD NAME=VRSTVY, ACCESS=LOGICALPomocí něj aplikační programátor určuje, co se má s daty, popsanými pomocí jazyku pro popis dat, při zpracování stát. Jazyk musí umožňovat
přímé čtení záznamu podle adresy
přímé čtení záznamu podle klíče
čtení záznamu splňujícího zadaná kriteria
čtení následujícího záznamu
čtení následujícího záznamu v mezích stejného rodiče
čtení záznamu následujícího sourozence aktuálního rodiče
označení záznamu za neplatný
přidání nového záznamu.
Ve shora uvedeném jazyce DL/1 tvoří tento jazyk např. následující příkazy:
GU VRSTVY, TEKTONIKA, PORUCHA (TYP='POKLES')dodá první segment vrstvy, tektoniky a poruchy, která jest poklesem,
GN PORUCHAdodá následující poruchu (jakoukoliv),
INSRT VRSTVA (Q1=, Q2=, )vloží za právě přečtenou vrstvu další vrstvu.
Přestože zvláště ve starších systémech existují dotazovací jazyky na úrovni uživatele s oddělenými částmi popisu dat a popisu zpracování obdobně jako v případě programátorském, v novějších preferovaných dotazovacích jazycích jsou obě části obsaženy v jediné konstrukci.
Tak tomu je např. v systému IMS, který firma IBM začleňovala do 'velkých' systémů OS a který nazvala IQF (Interactive Query Facility). Tento jazyk má dvě charakteristické vlastnosti:
je samostatný, tj. netvoří např. procedury v nějakém hostitelském jazyce
je pouze pro čtení (read only), tj. uživatel nemůže měnit obsah polí ani přidávat nové záznamy
Příkladem dotazu uživatele pomocí IQF je např. tento dotaz:
QUERY VRSTVA, TEKTONIKA, PORUCHAkterý zajistí výpis informací o souřadnicích a směru prvních pěti poklesů.
V současné době je jedním z nejrozšířenějších jazyků pro zpracování na úrovni uživatele jazyk označovaný SQL. Protože se stal poměrně obecným (z hlediska implementace v různých operačních systémech) a kombinuje programátorské i uživatelské možnosti, je mu věnována samostatná kapitola.
Dotazovací jazyk SQL
Problematika zpracování dat - jak je možno vidět z celého předchozího textu - je nesmírně rozsáhlá: od fyzického uložení dat po logické struktury, od sekvenčního přístupu po přístup přímý atd.
U koncového uživatele - nepočítačového odborníka však není možno očekávat, že se nejprve stane odborníkem přes data. Proto je pochopitelná snaha vytvářet pro tyto uživatele jednak formalizované, jednak pokud možno normalizované nástroje pro zpracování dat v počítačovém prostředí jednotným způsobem s tím, že uživatel není zatěžován otázkami uložení, organizace apod.
Pokusů o vytvoření jednotného alespoň dotazovacího prostředí bylo učiněno několik. Faktem zůstává, že - zvláště při velkých objemech dat - jistý stupeň přehledu uživatele o datové problematice je vyžadován u všech. Čím vyšší stupeň přehledu o datech uživatel má, tím optimálněji je schopen zajistit zpracování dat a tím mohutnějším nástrojem se pak takový prostředek pro něj stává.
Jedním z poměrně zdařilých a v mnoha různých (operačních) systémech implementovaným nástrojem pro zpracování dat je SQL (z plného anglického označení Structured Query Language; toto označení se nepřekládá a používá se jen SQL).
Oproti jiným podobným obecným nástrojům má SQL nejen funkce dotazovací (tj. pro čerpání dat z existujících databází), ale i funkce pro plné zpracování dat: vytváření nových databází o definované struktuře, plnění daty, opravy dat ap.
V současné době většina implementací SQL pracuje nad relačními databázemi (tj. mající podobu tabulky - viz příslušná kapitola shora). Odtud také zástupná klíčová slova typu 'table'. Protože však existuje poměrně snadná (protože mechanická) konverze hierarchické (ne síťové) struktury na relační, některé SQL mají možnost pracovat i na hierarchických organizacích datových bází.
V této kapitole je popsána logika a nástin použití základních příkazů SQL. Protože jde o poměrně širokou problematiku, u které je předpoklad plného využití, je nutno odkázat na příslušné referenční manuály. Proto také jsou v této kapitole jednotlivé příkazy uváděny již na konkrétních příkladech a nejsou popisovány ani syntakticky úplně. Všechny příklady jsou předkládány na části datového modelu uvedeného v kapitole Jde o data, jejichž strukturu a počátečními řádky i částečně obsah ukazují následující schémata:
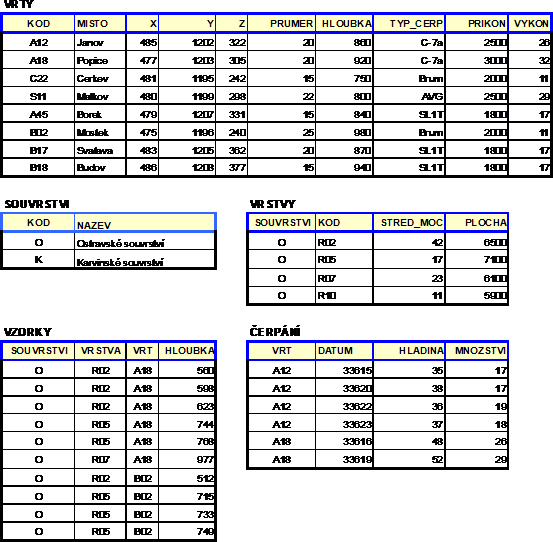
Obrázek 1: Demonstrační relace
Poznámka: z technických důvodů nejsou ve shora uvedených tabulkách šířky sloupců opticky ekvivalentní jejich skutečným hodnotám používaným v příkladech.
Protože uspořádání dat je chápáno 'tabulkově', jsou zavedeny ve zřejmém smyslu tyto pojmy: jméno sloupce, šířka sloupce, typ sloupce. Konkrétně typ sloupce je typem každého z jednotlivých údajů, které sloupec tvoří (viz doména a její atributy v kapitole o relačních databázích). Obecně v celém SQL jsou pojmy 'databáze' a 'tabulka' používány jako označení téhož.
SQL pracuje obecně s následujícími typy dat a jejich kódováním:
Jde o číselná data v běžném pojetí. Charakterizují je celková šířka (v počtu cifer včetně event. desetinné tečky a znaménka), a počet desetinných míst. Celá čísla mají počet desetinných míst nulový a tedy neobsahují ani desetinnou tečku.
Jakékoliv texty, obsahující jakékoliv znaky většinou podle kódových tabulek znaků. Charakteristikou je jejich šířka, tj. maximální počet znaků.
Kalendářní datum bývá zavedeno jako samostatný typ proto, že jsou na něm definovány přirozeným způsobem operace přičítání a odečítání celého čísla, avšak tyto operace nejsou běžné aritmetické operace (např. přechod přes konec měsíce nebo roku). Jejich šířka je vždy konstantní, nejčastěji 8.
Dvouhodnotová data: ANO a NE. Používají se jako indikativní ukazatele apod. Jejich šířka je vždy konstantní, nejčastěji
Různé implementace mohou zavádět další typy údajů; shora uvedené čtyři typy však postačují pro většinu aplikací běžných aplikací.
Vytvořením nové tabulky se ve většině systémů rozumí založení nového souboru s daným jménem, který obsahuje dvě části: jednak popis jednotlivých sloupců tabulky, jednak vlastní data tabulky organizovaná do řádků. Bezprostředně po vytvoření nové tabulky je druhá část prázdná (zatím nejsou vložena žádná data).
Vytvoření tabulky ČERPÁNÍ provede následující příkaz:
create table ČERPÁNÍ (VRT C(5), DATUM D, HLADINA N(3), MNOŽSTVÍ N(8,2))Po klíčových slovech CREATE TABLE se tedy uvede jméno tabulky a za ním, uzavřený v kulatých závorkách, seznam popisů jednotlivých sloupců tabulky (=polí řádků). Každý popis obsahuje jméno sloupce následované znakem ve smyslu typu s uvedením celkové šířky event. počtu desetinných míst.
Příkaz
create table ČERPÁNÍ (VRT C(5) primary key, )provede totéž, ale navíc nadefinuje indexovou tabulku (se jménem stejným jako jméno pole VRT) obsahující přístupový klíč, jehož hodnotami budou kódy vrtů zařazovaných řádků dat.
Úpravou struktury se rozumí přidání nebo vypuštění sloupce tabulky. Bez bližších komentářů jsou uvedeny příklady charakteristického tvaru:
alter table ČERPÁNÍ add VYDATNOST N(10,3)přidá do tabulky ČERPÁNÍ nový sloupec VYDADNOST.
alter table ČERPÁNÍ drop VYDATNOSTvypustí sloupec VYDATNOST z tabulky ČERPÁNÍ.
alter table ČERPÁNÍ add key 100*MNOŽSTVÍ tag KLÍČ3vytvoří k tabulce ČERPÁNÍ další indexovou tabulku; klíčem je stonásobek hodnoty MNOŽSTVÍ a indexová tabulka je nazvána KLÍČ
Do existující tabulky (např. právě vytvořené) je možno přidávat data. Do shora vytvořené tabulky ČERPÁNÍ se přidají nové řádky příkazem např.
insert into ČERPÁNÍ values ('V12', , -122, 78)Příkaz přidá na konec tabulky nový řádek dat a naplní ho hodnotami uvedenými jako seznam v kulatých závorkách. Data musí být uvedena v takovém množství, kolik je polí, a musí následovat v tom pořadí, jak byla pole uvedena při vytvoření tabulky.
Aktualizaci existujících dat v existující tabulce provádí příkaz UPDATE. Např. zvýšení množství čerpání o 0.1 u všech řádků s hladinou pod 100 provede příkaz
update ČERPÁNÍ set MNOŽSTVÍ = MNOŽSTVÍ+0.1 where HLADINA < 100Vynulování hladiny a množství u řádku provede příkaz
update ČERPÁNÍ set MNOŽSTVÍ = 0, HLADINA = 0 where recno () = 4Výrazem za klíčovým slovem WHERE se určuje množina řádků, pro které se má náhrada (=aktualizace) provést.
Otázka vypouštění řádků je poněkud složitější. Příkaz
delete from ČERPÁNÍ where HLADINA < 100 and MNOŽSTVÍ > 1doslova
přeložen vypustí z tabulky ČERPÁNÍ řádky, kde je hladina pod
Proto většina SQL provedou nikoliv fyzické vypuštění, ale pouze označení řádků za neplatné. Toto označení lze především příkazem RECALL odstranit, takže se žádné řádky neztratí. Dále: při jakémkoliv dalším zpracování se takto označené řádky nebudou vůbec brát v úvahu. Při výběrech dat, při aktualizaci atd. to bude vypadat tak, jako by tam tyto řádky skutečně nebyly.
Fyzické zrušení (vypuštění, odstranění) řádků z databáze pak provede specielní, k tomu určený příkaz, který většinou závisí na implementaci. Je-li např. SQL implementováno v prostředí xBase, je tímto příkazem PACK.
Tento odstavec je stěžejním odstavcem celé kapitoly. Zatímco organizaci databází (jejich zakládání a aktualizaci) - zvláště informačních systémů větších rozsahů - provádí většinou specializovaní nebo alespoň zvlášť určení pracovníci, čerpat z databází by měli mít potřebu všichni.
Ke získávání informací z existujících bází dat slouží v SQL jediný příkaz - SELECT. Jde o velmi silný, poměrně obecný a tedy poněkud složitější příkaz. Proto bude vysvětlen v jednotlivých krocích.
Jako příklad budeme uvažovat uvedenou část modelové databáze geologických souvrství. Konkrétně půjde o tabulky VZORKY, VRSTVY, SOUVRSTVÍ.
Obecně lze říci, že příkaz SELECT vybere určené údaje z určených databází (tabulek) a vytvoří tabulku novou. Může jít o tabulku fyzickou (tj. soubor na médiu), tabulku dočasnou (soubor, který se po ukončení zpracování automaticky z média vymaže) nebo o textový výstup, většinou formou výpisu 've sloupečcích' ať na obrazovku, nebo na tiskárnu nebo do textového souboru.
Mějme tedy tabulku VZORKY, která má pole SOUVRSTVI, VRSTVY, VRT, HLOUBKA. Následně jsou uvedeny nejjednodušší tvary příkazu SELECT.
select * from VZORKYVybere všechny sloupce ze všech řádků tabulky VZORKY, a tyto údaje zašle na standardní výstup, kterým je většinou obrazovka terminálu nebo počítače.
select VRT, HLOUBKA from VZORKYVybere sloupce VRT a HLOUBKA ze všech řádků tabulky VZORKY, a tyto údaje zašle na standardní výstup, kterým je většinou obrazovka terminálu nebo počítače.
select distinct VRT, HLOUBKA from VZORKYVybere sloupce VRT a HLOUBKA z tabulky VZORKY, a tyto údaje zašle na standardní výstup, kterým je většinou obrazovka terminálu nebo počítače. Klíčové slovo DISTINCT zajišťuje, že ve vytvořené tabulce nebudou žádné dva řádky stejné - řádků tedy bude nanejvýš stejný počet jako ve zdrojové tabulce VZORKY.
select VRT, HLOUBKA*100/54 as PALCE from VZORKYVybere sloupce VRT a HLOUBKA ze všech řádků tabulky VZORKY, a tyto údaje zpracuje pro standardní výstup, kterým je většinou obrazovka terminálu nebo počítače. Na výstupu však druhý sloupec nebude obsahovat původní údaje o hloubce, ale údaje přepočtené podle uvedeného výrazu (přepočet na palce). Tento druhý sloupec výstupu také nebude mít název HLOUBKA, ale PALCE.
Poznámka: Konstrukci <výraz> AS <jméno> je možno použít kdykoliv kdekoliv při určování, jaké hodnoty mají tvořit sloupec výstupní tabulky, a jak se tento sloupec má jmenovat. Tato skutečnost již nebude dále zdůrazňována a většinou bude používáno pouze jméno sloupce zdrojové tabulky.
select VRT, HLOUBKA from VZORKY into table VÝBĚRVybere sloupce VRT a HLOUBKA ze všech řádků tabulky VZORKY, a z těchto údajů vytvoří novou tabulku VÝBĚR. Tabulka VÝBĚR bude mít dva sloupce VRT a HLOUBKA (v tomto pořadí) s atributy i hodnotami dat přejatými z tabulky VZORKY. Počet řádků obou tabulek bude shodný.
Poznámka: Konstrukci INTO TABLE <výstup> je možno použít, kdykoliv je zapotřebí vytvořit novou tabulku na základě dat v tabulkách již existujících. Tato skutečnost již nebude dále zdůrazňována a klauzule INTO bude většinou vynechána (tj. výstup bude směrován na standardní výstup, kterým je většinou obrazovka terminálu nebo počítače).
select VRT, HLOUBKA from VZORKY into table VÝBĚR where HLOUBKA > 100Vybere sloupce VRT a HLOUBKA ze všech řádků tabulky VZORKY, a z těchto údajů vytvoří novou tabulku VÝBĚR. Tabulka VÝBĚR bude mít dva sloupce VRT a HLOUBKA (v tomto pořadí) s atributy i hodnotami dat přejatými z tabulky VZORKY. V tabulce VÝBĚR však budou zařazeny jen údaje z těch řádků tabulky VZORKY, ve kterých je HLOUBKA větší než 100.
Poznámka: Konstrukci WHERE <podmínka> je možno použít kdykoliv kdekoliv při určování, jaké řádky zdrojové tabulky se mají zpracovávat při vytváření řádků výstupní tabulky. Tato skutečnost již nebude dále zdůrazňována a většinou bude používáno všech řádků zdrojové tabulky.
select VRT, HLOUBKAVybere sloupce VRT a HLOUBKA ze všech řádků tabulky VZORKY, a z těchto údajů vytvoří novou tabulku VÝBĚR. Tabulka VÝBĚR bude mít dva sloupce VRT a HLOUBKA (v tomto pořadí) s atributy i hodnotami dat přejatými z tabulky VZORKY. Řádky v tabulce VÝBĚR budou seřazeny (ascending - vzestupně) podle kódů vrtů (A18 bude před B11). Pokud dva řádky budou mít shodný kód vrtu, bude rozhodovat hloubka: [V18,140] bude před [V18,120], protože u jména HLOUBKA je uvedeno klíčové slovo descending - sestupně.
Poznámka: klíčové slovo ascending se nemusí uvádět. Není-li uvedeno ani ascending, ani descending, platí ascending.
select VRT, min (HLOUBKA) as DOLE, max (HLOUBKA) as NAHORE from VZORKY group by VRTJedna z velmi silných možností příkazu SELECT. Příkaz v tomto tvaru provádí nejprve myšlené seskupování ('grupování') řádků zdrojové tabulky VZORKY podle údajů ze sloupce VRT - v každé takové skupině jsou ty řádky tabulky VZORKY, které mají stejnou hodnotu ve sloupci VRT. Na výstupu se pak vytvoří tolik řádků, kolik je skupin (tj. kolik různých kódů vrtů je ve vstupní tabulce).
Výstupní tabulka bude mít tři sloupce. První (se jménem VRT) bude obsahovat kód vrtu společný všem řádkům skupiny. Druhý (se jménem DOLE) bude obsahovat nejmenší z hodnot HLOUBKA v této skupině. Analogicky třetí sloupec (se jménem NAHORE) bude obsahovat největší z hodnot HLOUBKA v této skupině.
Poznámka: Kromě funkcí MIN a MAX je možno při seskupování používat funkce AVG (average = průměr), COUNT (count = počet) a SUM (suma = počet).
Je možno použít seskupování podle více kriterií. Například klauzule
group by SOUVRSTVI, VRTvytvoří tolik skupin, kolik je ve vstupní tabulce různých dvojic [SOUVRSTVI,VRT].
Poznámka: Konstrukci GROUP BY <sloupec> je možno použít, kdykoliv nastane potřeba na výstup zařadit ne jednoduché údaje ze vstupní tabulky, ale údaje nějakým způsobem agregované. Tato skutečnost již nebude dále zdůrazňována a většinou bude používáno neseskupených dat.
Výstupní tabulku lze vytvořit na základě údajů ze dvou a více zdrojových tabulek. Nejjednodušší je případ dvou tabulek.
select VZORKY.VRT, VZORKY.HLOUBKA, SOUVRSTVI.NAZEV from VZORKY, SOUVRSTVITento základní tvar příkazu SELECT obsahující dva zdrojové soubory pracuje následovně: především je vytvořena kombinace všech řádků (se všemi sloupcovými údaji) jedné zdrojové tabulky a všech řádků (se všemi sloupcovými údaji) druhé zdrojové tabulky.
Poznámka: mají-li obě vstupní tabulky po pouhém tisící řádků, má tato kombinovaná tabulka řádků milion!
Dále: výstupní tabulka je vytvořena ze všech těchto zkombinovaných řádků s tím, že bude mít tři sloupce; v prvním budou data ze sloupce VRT té části, která vznikla z tabulky VZORKY; ve druhém budou data ze sloupce HLOUBKA té části, která rovněž vznikla z tabulky VZORKY; konečně ve třetím budou data ze sloupce NAZEV té části, která vznikla z tabulky SOUVRSTVI.
Toto je přesný popis vzniku tabulky. Je zřejmé, že právě v uvedeném příkladě se většinou ve výstupní tabulce ocitnou nesmyslné kombinace údajů. Jestliže např. vrt A18 zasahuje jen do ostravského souvrství (tj. logická je jen kombinace [O,A18]), přesto se ve výstupní tabulce objeví i kombinace [K,A18] a případné další.
Je proto zapotřebí vybrat jen ty kombinace, které vyplývají z dat vzorků. To provede tvar příkazu SELECT s již dříve uvedenou klauzulí WHERE:
select VZORKY.VRT, VZORKY.HLOUBKA, SOUVRSTVI.NAZEVNyní jsou do výstupní tabulky ze všech možných kombinací zařazeny jen ty, kde kód SOUVRSTVÍ ve VZORKU je rovno KÓDU v SOUVRSTVÍ. Tento mechanismus je možno považovat za vytvoření 'filtru' mezi VZORKY a SOUVRSTVÍmi. 'Odfiltrují' se všechny řádky, které nesplňují podmínku uvedenou za WHERE, jinak zde: ke každému řádku ze VZORKŮ se připojí ten řádek ze SOUVRSTVÍ, který má shodný kód s kódem souvrství ve VZORCÍCH.
Klauzuli WHERE je možno dále rozšířit o běžné podmínky výběru, např.
select VZORKY.VRT, VZORKY.HLOUBKA, SOUVRSTVI.NAZEVFunkce je zcela totožná jako shora až na to, že ve výstupní tabulce budou zahrnuty jen ty řádky, kde je větší hloubka než 100.
Poznámka: zcela podle potřeby je možno použít klauzulí GROUP BY, ORDER BY a INTO TABLE ve smyslu popsaném shora.
Pro tři a více tabulek platí zřejmá analogie se dvěma tabulkami. Nejprve se vytvoří mezi-tabulka tvořená ze všech možných kombinací všech řádků všech zdrojových tabulek. Výstupní tabulka bude mít tolik sloupců, kolik je určeno výčtem za klíčovým slovem SELECT. Na výstup se dostanou jen ty řádky, které splní podmínku uvedenou za WHERE.
Tedy např. pro čtyři tabulky příkaz
selectponechá ve výstupní tabulce jen ty řádky, které mají shodné 'vazební' prvky uvedené na každé straně rovnítek.
Poznámka: i u tohoto tvaru příkazu SELECT je možno zcela podle potřeby použít klauzulí GROUP BY, ORDER BY a INTO TABLE ve smyslu popsaném shora.
Síla příkazu SELECT se násobí možností použít jeden příkaz SELECT uvnitř jiného příkazu SELECT. Především je možno 'na konec' jednoho příkazu SELECT připojit klauzulí UNION další příkaz SELECT, který tabulku vytvořenou prvním příkazem doplňuje o data vytvořená druhým příkazem (a za druhým SELECT lze po UNION psát třetí atd). To zhruba odpovídá postupnému vytvoření dvou a více samostatných tabulek a jejich následným spojením příkazem APPEND.
Zde však popíšeme druhé, daleko důležitější umístění druhého příkazu SELECT: při definování podmínek, za kterých se řádek ve výstupní tabulce vytvoří.
select VRT, HLOUBKATento příkaz SELECT obsahuje druhý příkaz SELECT použitý v klauzuli WHERE; 'vnitřní' příkaz se provede nejdříve a vytvoří (dočasný) seznam kódů vrtů, kde se čerpalo (alespoň jednou) větší množství než 10. Následuje tvorba výsledné tabulky obsahující sloupce VRT a HLOUBKA z tabulky VZORKY již popsaným způsobem. Do výsledné tabulky se však umístí jen ty řádky, které vyhovují podmínce uvedené v klauzuli WHERE - zde ty, kde se kód VRT vyskytuje v (in) seznamu vytvořeném oním 'vnitřním' příkazem SELECT (tedy v seznamu vrtů, v nichž bylo alespoň jednou čerpáno větší množství než 10).
Poznámka: kromě IN lze použít i negaci NOT IN.
select VRT, HLOUBKAPři vytváření výsledné tabulky obsahující sloupce VRT a HLOUBKA z tabulky VZORKY se pro každý řádek nejprve zjistí, zda je splněna podmínka daná klauzulí WHERE; tj. zda existuje (exists) alespoň jeden řádek tabulky vytvořené 'vnitřním' příkazem SELECT. Ten vybere z tabulky ČERPÁNÍ všechny řádky mající kód vrtu shodný s kódem právě zařazovaného řádku z tabulky VZORKY. Pokud existuje, řádek se zařadí; pokud neexistuje, řádek se nezařadí. Výsledná tabulka tedy bude obsahovat údaje jen o těch vrtech, ze kterých bylo čerpáno.
Poznámka: kromě EXISTS lze použít i negaci NOT EXISTS.
select VRT, HLOUBKAPři vytváření výsledné tabulky obsahující sloupce VRT a HLOUBKA z tabulky VZORKY se pro každý řádek nejprve zjistí, zda je splněna podmínka daná klauzulí WHERE; tj. hloubka vrtu je alespoň o 10 větší než všechny hladiny při čerpáních počínaje rokem 1997.
select VRT, HLOUBKAPři vytváření výsledné tabulky obsahující sloupce VRT a HLOUBKA z tabulky VZORKY se pro každý řádek nejprve zjistí, zda je splněna podmínka daná klauzulí WHERE; tj. hloubka vrtu je alespoň o 10 větší než alespoň jedna hladina při čerpáních počínaje rokem 1997.
Realizace obecného datového modelu v xBase
Jako xBase je označován další rozšířený jazyk používaný pro vytváření, údržbu a čerpání informací z bází dat. xBase stejně jako SQL pracuje ve všech známých implementacích na relačních databázích, tj. na datech 'tabulkově' uspořádaných (viz kapitola shora).
Oproti popsanému jazyku SQL má xBase daleko silnější možnosti zvláště při vytváření virtuálních datových struktur a jejich používání pro aktualizaci dat; to SQL neumožňuje vůbec. Na druhé straně většina realizovaných systémů xBase mají zabudovány alespoň základní příkazy SQL jako své vlastní interní příkazy, čímž umožňuje své využití i těmi uživateli, kteří SQL pro své potřeby dobře zvládli.
Většina systémů založených na xBase používá svých příkazů jak v interaktivním, tak v dávkovém režimu. Při prvním z nich se střídá zadání příkazu uživatele s jeho okamžitým provedením systémem.
V dávkovém režimu zapíše nejprve uživatel své příkazy do běžného textového souboru a ten pak předá systému k provedení 'najednou'. Jelikož tento textový soubor obsahuje příkazy, je běžně označován jako příkazový soubor. Textový soubor s příkazy je trvalý, příkazy v něm lze tedy provádět opakovaně; dále je možno jejich provádění parametrizovat. Protože provedení příkazů v souboru se vyžádá od systému jeho příkazem DO (a DO může být jedním z příkazů v souboru), je možno vytvářet zřetězené (až do úrovně rekurze) provádění akcí. Možnost popsat příkazy v textovém souboru algoritmy pro výpočet hodnoty vlastní funkce a zařazení několika příkazů řídících způsob provádění ostatních příkazů tvoří z xBase kompletní, velmi silný jazyk nejen dotazovací a organizační, ale také programovací.
xBase zpřístupňuje uživateli data buď ve tvaru formuláře, nebo ve tvaru tabulky. Datový obsah formuláře i tabulky určuje plně uživatel. Formát tabulky může uživatel částečně určovat sám - na rozdíl od formátu formuláře, který uživatel určuje zcela.
Pokud uživatel neurčí jinak, lze všechna data jak v tabulce, tak ve formuláři měnit. Při jakékoliv změně kteréhokoliv údaje je možno nadefinovat kontrolní funkce. Kromě interních funkcí xBase (kterých je asi 200) lze ke kontrolním účelům nadefinovat jakékoliv vlastní algoritmy.
Pro tiskový výstup obsahuje xBase mechanismus pro definici tvaru výstupní sestavy včetně typů písma, seskupování údajů, základních statistických operací nad skupinami údajů apod.
Příkazů xBase je asi 400. Tato práce není referenční příručka jazyka; výklad je zaměřen na pochopení základní linie, a tou je vytváření datových struktur z více zdrojů. Proto je dále popsána jen velmi omezená podmnožina příkazů, která však plně postačuje k uvedenému účelu.
Příkazy budou vysvětlovány na stejných modelových datech jako v předchozí kapitole příkazy SQL, tj. na datovém modelu uvedeném v kapitole
Vytvoření (=definice) nové tabulky a přidávání řádků dat provádí xBase příkazy CREATE a APPEND, které jsou v tomto tvaru interaktivními příkazy: po jejich zadání je uživatel dotazován na další specifikace resp. data. Protože většina systémů s xBase mají implementovány základní příkazy SQL, lze k těmto dvěma akcím použít také příkaze CREATE TABLE a APPEND INTO kategorie SQL.
Pokud je zapotřebí čerpat data z tabulek nebo je zpřístupnit, je nutno nejprve tyto tabulky 'otevřít' - sdělit systému, že je má 'použít'. Systém má pro zpracovávané tabulky vyhrazeny tzv. oblasti: v každé z nich může být použita (otevřena) jedna tabulka. Počet oblastí bývá minimálně 20. Uvedenou akci provede příkaz ve tvaru např.
use VRTY in 3který v oblasti č. 3 zpřístupní (otevře, použije) tabulku VRTY.
Systémy s xBase mají možnost jednak otevřít již otevřenou tabulku ještě jednou, jednak otevřené tabulce dočasně - po dobu otevření - přidělit jiné jméno:
use VRTY in 7 again alias SONDYUvedený tvar příkazu klíčovým slovem AGAIN sděluje, že se mají VRTY otevřít ještě jednou, a klauzulí ALIAS přidělují souboru v oblasti 7 dočasně jméno SONDY.
Poznámka: jakmile je v oblasti otevřena tabulka, je oblast identifikovatelná nejen číslem, ale také (dočasným) jménem tabulky, která je v oblasti otevřena písmeny A pro oblast č. 1, B pro oblast č. 2 atd.
Příkaz USE bez udání souboru, tj.
use in 7uzavírá tabulku dat v dané oblasti. Kromě jiného bezpečně zaznamená do fyzické tabulky všechny případně provedené změny.
Poznámka 1: Tabulka dat je většinou uložena jako trvalý záznam na nějakém médiu: disku, disketě ap. Pro urychlení práce většina systémů vytváří obraz tabulky (po jejím otevření) ve vnitřní paměti. Tedy všechny případné změny provádí uživatel v paměti a to nastoluje otázku existence změn např. při výpadku napájení počítače. Jednu odpověď podává shora uvedené vysvětlení činnosti při uzavírání tabulky.
Poznámka 2: Tabulka otevřená v nějaké oblasti se uzavře také tehdy, když je vydán příkaz pro otevření jiné tabulky v téže oblasti.
Při práci s tabulkami je vždy jedna oblast tzv. aktuální. Pro ni se nemusí v příkazech zadávat specifikace oblasti klauzulí IN. Po spuštění systému je aktuální oblastí oblast č. 1.
Nastavení se do konkrétní oblasti (učinění oblasti aktuální) provede příkaz SELECT (nikoliv SQL!) tvaru
select 6který v tomto případě učiní aktuální oblastí oblast č. 6.
Každá otevřená tabulka má přiřazeno 'ukazovátko' (=pointer) na tzv. aktuální řádek. Data jsou přístupná pouze z toho řádku, který je aktuálním, na který ukazuje ukazovátko. Pohyb ukazovátka ovládají příkazy GOTO a SKIP. Dále zajišťuje pohyb ukazovátka sám uživatel pomocí (většinou kurzorových) kláves při pohybu ve formuláři nebo zobrazené tabulce.
První ze zmíněných příkazů má tvar např.
gotonebo
gotokterý nastaví ukazovátko do tabulky VRTY, která je otevřena v oblasti č. 7 pod dočasným názvem SONDY, na dvanáctý řádek tabulky. Řádky se přitom počítají podle skutečného, fyzického uložení v tabulce.
Druhý z uvedených příkazů má tvar např.
skipnebo
skipkterý nastaví ukazovátko o tři řádky směrem ke konci tabulky SONDY (v tabulce dolu). Záporné číslo posunuje ukazovátko směrem k začátku tabulky. Pohyb v tabulce přitom podléhá případné připojené indexové tabulce (viz níže). Je-li aktuálním řádkem řádek s fyzickým pořadovým číslem 12, pak po provedení SKIP 3 nemusí být novým aktuálním řádkem řádek s fyzickým pořadovým číslem 15!
Datová pole, se kterými si uživatel právě teď přeje pracovat, jsou určena v mnoha příkazech pro práci s daty. Datové pole má tvar např.
SONDY.MÍSTOtedy (dočasné) jméno tabulky, za kterým bezprostředně po tečce následuje jméno sloupce databáze. Výsledkem je v tomto případě hodnota ve sloupci MÍSTO tabulky SONDY (=VRTY v oblasti č. 7), a to v tom řádku, na který právě teď ukazuje ukazovátko.
Poznámka: Srovnej seznam v příkazu SELECT SQL výše.
Indexové tabulky slouží v relačních databázových systémech ke dvěma účelům:
zpřístupňují řádky tabulky dat v pořadí dle velikosti hodnoty klíče, a to jak vzestupně, tak sestupně
zprostředkovávají vazby mezi tabulkami dat a tím dovolují vytvářet tzv. virtuální (myšlené) datové struktury.
Pro každou tabulky dat je možno (trvale) vytvořit jednu nebo více indexových tabulek s tímto souborem spojených. Spojení je většinou logické; např. v systémech na PC je tabulka dat jako taková uložena v souboru např. VRTY.DBF, a všechny její indexové tabulky v souboru VRTY.CDX - pokud je alespoň jedna tabulka vytvořena. Takový soubor je nazýván indexovým souborem.
Indexové tabulky jsou ukládány pod zadaným jménem. Klíčem je libovolný výraz toho typu, jaký databázový systém připouští pro operace porovnávání (tj. vždy nejméně numerické, textové, datumové a logické).
Poznámka: společně se samotnou indexovou tabulkou se v indexovém souboru ukládá nejen její jméno, ale i výraz, podle kterého je vytvořen její klíč.
Vytvoření indexové tabulky pro tabulku dat v aktuální oblasti provádí příkaz tvaru např.
index on MÍSTO tag INÁZkterý vytvoří k datové tabulce otevřené v aktuální oblasti indexovou tabulku s názvem INÁZ, jejímž klíčem je MÍSTO (tabulka je tedy 'podle abecedy').
Tvar příkazu v předchozím příkladě vytváří indexovou tabulku ve vzestupném pořadí. Připojí-li se na konec příkazu klíčové slovo DESCENDING, vytvoří se tabulka v opačném pořadí (sestupně).
Poznámka: Systém uchovávání a označování indexových tabulek má jeden zásadní pozitivní efekt: kdykoliv je vytvořena alespoň jedna indexová tabulka, při otevírání souboru je databázový systém schopen to zjistit. To dále znamená, že je schopen zjistit i všechny klíčové výrazy. Konečně tedy je schopen automaticky aktualizovat všechny indexové tabulky, které závisí na údaji v tabulce dat, který se právě teď změnil. Uživateli tedy stačí jednou jedinkrát kdykoliv vytvořit indexovou tabulku (např. po založení databáze a ještě před jejím plněním řádky dat!), a dále se o její údržbu nestará.
Sama existence indexových tabulek ještě neznamená jejich využití. Po otevření tabulky dat se pohyb ukazovátka po řádcích řídí fyzickým pořadím řádků (tedy v pořadí jejich záznamů příkazem APPEND). Příkaz ve tvaru např.
set order to INÁZ in SONDYpřipojí pro následné zpracování tabulky dat SONDY indexovou tabulku INÁZ. To znamená, že pohyb ukazovátka na řádky tabulky dat bude zprostředkovávat indexová tabulka. Jako první řádek bude zpřístupněn ne fyzicky první řádek dat, ale řádek dat, který je podle hodnoty klíče (zde MÍSTO) první v indexové tabulce. Jako druhý řádek bude zpřístupněn řádek s hodnotou klíče, která je druhá v indexové tabulce atd.
Poznámka: Je-li indexová tabulka vytvořena vzestupně, je prvním zpřístupněným řádkem řádek s nejmenším klíčem; je-li vytvořena sestupně, je prvním zpřístupněným řádkem řádek s největším klíčem.
Příkaz pro připojení indexové tabulky může obsahovat klíčové slovo DESCENDING:
set order to INÁZ in SONDY descendingTento příkaz připojí pro následné zpracování tabulky dat SONDY rovněž indexovou tabulku INÁZ. Jako první řádek však bude zpřístupněn ne fyzicky první řádek dat, ale řádek dat, který je podle hodnoty klíče (zde MÍSTO) poslední v indexové tabulce. Jako druhý řádek bude zpřístupněn řádek s hodnotou klíče, která je předposlední v indexové tabulce atd.
Poznámka: Je-li v tomto případě indexová tabulka vytvořena vzestupně, je prvním zpřístupněným řádkem řádek s největším klíčem; je-li vytvořena sestupně, je prvním zpřístupněným řádkem řádek s nejmenším klíčem.
Připojit indexovou tabulku lze také již při otevření tabulky dat:
use VRTY in 7 again alias SONDY order INÁZVýše uvedený příkaz SKIP podléhá připojení nebo nepřipojení indexové tabulky. Je-li nějaká indexová tabulka připojena, pak příkaz SKIP 1 posune ukazovátko na řádek tabulky, který má klíč s nejbližší vyšší (nižší v případě sestupného pořadí) hodnotou než řádek aktuální. Není-li žádná tabulka připojena, pak je jako následující řádek zpřístupněn řádek následující podle fyzického pořadí řádků v tabulce.
Poznámka: V daném okamžiku může být připojena nanejvýš jedna indexová tabulka. Kombinace typu 'nejprve podle datumu, potom podle abecedy' se řeší výrazem v (jediném) indexovém klíči.
Příkaz tvaru např.
set index to in SONDYodpojuje (pro další zpracování) připojenou indexovou tabulku k datové tabulce SONDY. Další zpracování tedy bude probíhat podle fyzického pořadí řádků datové tabulky.
Mezi (otevřenými) tabulkami je možno vytvářet logické vazby. Jedna z tabulek je vždy 'řídící': po ní jest pohybováno ukazovátkem a z ní vychází vazby první úrovně. Vazby směřují do jedné nebo více ostatních tabulek; tyto tabulky jsou cílem vazby. Na druhé straně z těchto tabulek mohou vycházet vazby druhé úrovně atd.
Jedna konkrétní vazba je zprostředkována jedním konkrétním klíčem. Tímto klíčem je hodnota jakéhokoliv výrazu toho typu, který může být klíčem při vytváření indexové tabulky (viz nahoře).
Na straně tabulky dat, ze které vychází vazba, musí být hodnota klíče kdykoliv opakovatelně zjistitelná. Na straně tabulky, do které směřuje vazba, musí být podle tohoto klíče vytvořena a připojena indexová tabulka.
Vytvoření vazby z tabulky VZORKY (která obsahuje kódy vrtů) do tabulky VRTY (která obsahuje např. souřadnice vrtu a tedy souřadnice vzorku) vyžaduje především vytvořenou indexovou tabulku podle klíče, pomocí něhož bude vazba zprostředkována, tj. podle kódu vrtu. To provede příkaz tvaru např.
index on KÓD tag IKÓD(viz výše). Celá sekvence příkazů pro vytvoření uvedené vazby je následující:
use VRTY in 2 order IKÓDuse VZORKY in 1
set relation to VRT into VRTYTabulkou, ze které vychází vazba, je tabulka VZORKY. Tabulkou, do které směřuje vazba, je tabulka VRTY. Výrazem, který zprostředkovává vazbu, je kód vrtu, který je v tabulce VZORKY umístěn ve sloupci VRT a v tabulce VRTY ve sloupci KÓD (a podle něhož je pro VRTY vytvořena indexová tabulka IKÓD).
Po vytvoření vazby je 'řídící' tabulkou tabulka VZORKY. Pohyb ukazovátka v tomto souboru řídí uživatel ať přímo příkazy GOTO nebo SKIP nebo pohybem ve zobrazovací tabulce dat, nebo nepřímo příkazy pro hromadné zpracování.
Pohyb ukazovátka v tabulce, do které směřuje vazba, je však řízeno vytvořenou vazbou. Ukazovátko v tomto cílovém souboru ukazuje vždy na ten řádek, který má shodný klíč (v indexové tabulce) s hodnotou klíče, který na straně zdrojové tabulky vazbu zprostředkovává.
Konkrétně tedy ukazovátkem v tabulce VZORKY pohybuje nějakým způsobem uživatel. Ukazovátko v tabulce VRTY ukazuje vždy na ten vrt, který má stejný kód jako je hodnota položky VRT v tom řádku tabulky VZORKY, na který právě ukazuje ukazovátko.
Je nutno řešit dvě situace:
V cílové tabulce neexistuje řádek s požadovaným klíčem. V takovém případě se předává tzv. EMPTY hodnota, kterou je nula pro numerický typ, prázdný text pro textovový typ, pro datumový typ a hodnota NEPRAVDA pro logické hodnoty. Dále je možno logickou funkcí EOF tento stav zjistit.
V cílové tabulce naopak existuje více řádků se stejným požadovaným klíčem. Jde o velmi důležitý případ tzv. vazby 1:n, kterou povoluje nebo zakazuje uživatel.
Je-li vazba 1:n povolena, pak při pokusu o pohyb ukazovátka v řídícím souboru se nejprve pohne ukazovátko v podřízeném souboru na následující řádek, má-li stejný klíč. Teprve až by se tímto způsobem mělo nastavit ukazovátko na řádek s jinou hodnotou klíče, dojde k pohybu ukazovátka v řídícím souboru.
Není-li vazba 1:n povolena, je v podřízeném souboru nastaveno ukazovátko vždy na první řádek skupiny řádků s touto hodnotou klíče.
Stejným mechanismem, tj. indexovými tabulkami a příkazem SET RELATION, se realizují vazby mezi více tabulkami dat. Nic nebrání tomu, aby tabulka, která byla jedním příkazem SET RELATION nastavena do řídící posice, byla dalším příkazem SET RELATION nastavena do pozice řízené. Tím se ovšem původní řízená tabulka na druhé úrovni přesune na úroveň třetí atd.
Dále je možno klauzuli <výraz> INTO <tabulka> v příkaze SET RELATION uvést vícekrát; v tom případě se z jednoho řídícího souboru vytváří vazby do více tabulek řízených na stejné (např. druhé) úrovni.
V tomto postupu lze pokračovat a vytvářet libovolně složité datové vazby, omezené jen technickými parametry použitého databázového systému.
Jako příklad uvažujme 'řídící' tabulku VZORKY. Nechť je zapotřebí při zpracování každého řádku tabulky mít k disposici údaje o vrstvě, ze které byl vzorek odebrán, dále o vrtu, ze kterého vzorek pochází, a nakonec informace o souvrství, kam patří vrstva příslušná vzorku. Jest tedy čerpat další informace z tabulek VRSTVY, VRTY a SOUVRSTVÍ.
K vytvoření těchto vazeb lze použít např. následující sekvenci příkazů (předpokládá se existence příslušných indexových tabulek vytvořených dříve):
use SOUVRSTVÍ in 4 order IKÓDVytvoří se 'propojení' ze VZORKŮ do VRTŮ a VRSTEV, a z VRSTEV do SOUVRSTVÍ. Z hlediska čerpání dat lze situaci znázornit např. takto:

Obrázek 1: Vazby relací
Tento příklad především ukazuje oba dva typy logické hierarchické podřízenosti v případě tří (!) zdrojů dat. Jeden typ je možno nazvat 'paralelní' - v této podřízenosti jsou tabulky VRTY a VRSTVY vzhledem k tabulce VZORKY. Druhý typ je možno nazvat 'sériový'; v ní jsou tabulky VZORKY - VRSTVY - SOUVRSTVÍ.
Dále příklad ilustruje vytvoření invertované hierarchické struktury. Zatímco se v celé předchozí kapitole o hierarchických strukturách uvažovala jako nejvyšší úroveň SOUVRSTVÍ, jíž byla podřízena úroveň VRSTVY a té zase VZORKY, je nyní situace právě opačná (invertovaná): nejvyšší úrovní je VZORKY, jí podřízenou je VRSTVY a té zase SOUVRSTVÍ.
Popis možností, jaké má uživatel pro zpřístupnění resp. zpracování dat, bude podán na shora uvedeném příkladu tabulky VZORKY, z níž vychází vazba do tabulky VRTY.
Zpřístupnění dat uživateli ve formě tabulky provede příkaz tvaru např.
browse fields VZORKY.MÍSTO, VRTY.X, VRTY.YVětšina systémů otevře zobrazovací tabulku v samostatném okně. Tato tabulka bude mít tolik řádků (potenciálně v okně prohlédnutelných), kolik je - v obecném případě - řádků tabulky v aktuální oblasti, popř. tabulky 'řídící' vazbu.
Tabulka v okně bude mít v tomto konkrétním případě tři sloupce. První bude obsahově i kvantitativně totožný se sloupcem MÍSTO tabulky VZORKY. Každý řádek okna bude mít ve druhém sloupci hodnotu sloupce X toho řádku tabulky VRTY, na který právě ukazuje ukazovátko tabulky VRTY. Toto ukazovátko je řízeno vytvořenou vazbou; ukazuje na ten řádek VRTŮ, který má stejný kód vrtu jako daný řádek tabulky VZORKY. Je tedy pravděpodobné, že stejná hodnota souřadnice X se bude vyskytovat ve více řádcích okna (z jednoho vrtu je běžně odebráno více vzorků). Stejná situace je s třetím sloupcem okna Y.
Poznámka: Příkaz BROWSE je nesmírně silným příkazem. V definici xBase má dalších 34 volitelných klauzulí. Jako jednu z nejčastěji používaných klauzulí lze uvést klauzuli FOR <podmínka>, která zpřístupní pouze ty řádky, které splňují zadanou podmínku.
Tento mechanismus je zásadně odlišný od (zdánlivě obdobného) příkazu SELECT kategorie SQL. Příkaz SELECT sice vytvoří obdobnou tabulku se stejným obsahem, jde však o novou tabulku dat bez jakékoliv vazby na původní datové tabulky, ze kterých tato nová tabulka vznikla. Na rozdíl od toho příkaz BROWSE vytvoří pro dobu svého provádění novou logickou datovou strukturu s vazbou do míst zdroje dat. Tato struktura - protože reálně neexistuje - se nazývá virtuální datová struktura. Protože však její pole jsou reálně existující pole, změna hodnot v nich se promítne do místa, kde reálně existují.
To je nejzřetelněji patrné v této situaci: shora uvedený příklad (většinou v okně) ve sloupci X obsahuje několik stejných hodnot, protože přísluší různým vzorkům ze stejného vrtu. Nechť nyní uživatel změní v okně 'jednu ze stejných' hodnot. Okamžitě se změní všechny! Je to právě proto, že nejde o 'několik stejných' hodnot, ale jen o několik zobrazení téže hodnoty, čerpané z jediného místa tabulky VRTY.
Předchozí příkaz BROWSE slouží jednak k prohlížení, jednak k opravám údajů v jedné nebo více tabulkách. Pro rychlý a jednoduchý výpis informací lze použít příkaz
list VZORKY.MÍSTO, VRTY.X, VRTY.Ykterý vypíše stejné informace, jaké zobrazí shora uvedené okno BROWSE. V tomto tvaru zasílá příkaz LIST výstup na standardní zobrazovací zařízení, kterým je většinou obrazovka. Příkaz ve tvaru
list VZORKY.MÍSTO, VRTY.X, VRTY.Y to printprovede totéž, ale na standardní tiskárnu. Kromě klauzule TO PRINT lze uvést klauzuli TO FILE <soubor>, pomocí které lze výpisem vytvořit textový soubor se zadaným názvem.
I velmi složité výstupní sestavy plně (předem) definované uživatelem (např. pod názvem SESTVRTŮ) zajistí příkaz např.
report form SESTVRTŮ to printProblematika výstupních sestav však přesahuje rozsah i cíl této práce.
xBase obsahuje příkazy pro zjišťování hodnot vzniklých zpracováním skupin dat z tabulek (agregované informace). Existující, ale málo používané příkazy COUNT, SUM ap. nahrazuje jediný, silnější příkaz CALCULATE. Popsán bude opět na shora uvedeném příkladu propojených tabulek VZORKY a VRTY.
calculate cnt (), avg (HLOUBKA)spočte počet řádků (cnt = count = počet) a průměrnou hloubku (avg = average = průměr) aktuální popř. 'řídící' tabulky. Výsledek zašle na standardní výstupní zařízení, kterým je většinou obrazovka.
calculate cnt (), avg (HLOUBKA) to POČŘÁD, PRŮMHLprovede totéž, ale výsledek navíc umístí to dvou tzv. paměťových proměnných nazvaných uživatelem POČŘÁD a PRŮMHL; hodnoty umístěné do těchto proměnných je možno dále používat pod jejich názvy.
Poznámka: Kromě uvedených funkcí CNT a AVG je možno použít funkce SUM (součet), MIN (minimum), MAX (maximum) a STD (směrodatná odchylka).
calculate avg (VRTY.X) for HLOUBKA < PRŮMHLspočte průměrnou X-ovou souřadnici těch vzorků, které byly odebrány z menší než průměrné hloubky.
Z doposud uvedeného výkladu je možno odvodit mechanický způsob transformace hierarchického modelu na soustavu relačních databází, které navíc budou v jedné z normálních forem.
Popis každého záznamu na každé úrovni hierarchické struktury se doplní o položku NADŘAZENÝ KLÍČ a - pokud již logicky neexistuje - o položku KLÍČ. Spojená položka NADŘAZENÝ KLÍČ + KLÍČ je položkou NADŘAZENÝ KLÍČ všech záznamů hierarchicky podřízených danému záznamu. NADŘAZENÝ KLÍČ záznamů první úrovně je prázdná položka. Oba uvedené klíče lze zkonstruovat vždy; nejméně to může být znakový klíč bázovaný numerickou hodnotou pořadí záznamu mezi svými 'sourozenci'.
Logická struktura dat každého typu segmentu doplněná o oba uvedené klíče tvoří definici samostatné tabulky dat = relační databáze. Takových databází tedy bude tolik, kolik je různých typů segmentů.
Obsahem každé relační databáze jsou datové obsahy jednotlivých segmentů hierarchické databáze doplněné o hodnoty obou klíčových polí.
Vytvořením vazeb (set relation) mezi jednotlivými tabulkami způsobem popsaným shora, kdy vazebními výrazy jsou spojené klíče dané úrovně, je k disposici datová struktura ekvivalentní původní hierarchické struktuře.
Poznámka 1: Takto vzniklý systém relačních databází je ovšem daleko mohutnějším prostředkem pro zpracování dat. Pouhou záměnou vazeb lze bez jakýchkoliv dalších pomocných konstrukcí a předzpracování dat zřídit invertované datové struktury (ve smyslu hierarchického modelu), které se právě v hierarchických databázových systémech realizují velmi obtížně.
Poznámka 2: Další předností takto transformovaných hierarchických modelů je to, že veškeré struktury jsou virtuální. Jednotlivé relační databáze existují nezávisle na sobě a složité struktury vytváří jen v případě potřeby a na dobu trvání této potřeby.
Datové typy při provozu databází v prostředí Microsoft
Zcela zásadní je v konkrétním databázovém systému přesné určení množiny množin, které poskytují své prvky (= hodnoty) do n-tic (=záznamů) libovolné relace (=tabulky), kterou lze v systému vytvořit a udržovat.
Firma Microsoft se významně podílela na budování databázových prostředí jak obecně, tak konkrétních implementací. Ve své řadě systémů známých jako nejrůznější 'Wokna', provozovaných nejčastěji na strojích řady PC bázovaných procesorem (a matematickým koprocesorem) Intel, staví na hardwarových typech s pochopitelných důvodů: instrukce procesoru zpracovávající hardwarové typy dat jsou evidentně nejrychlejším a nejoptimálnějším nástrojem pro použití v databázových programech.
Na druhé straně se stejná firma musela zabývat přístupem k datům jiných systémů. Jejich autoři však stáli před stejným problémem, a to naštěstí vedlo k jisté unifikaci v realizacích datových modelů a tedy i datových typů.
Obecným nástrojem pro správu databází a čerpání informací se postupem času stal dotazovací jazyk SQL (Structured Query Language). Pomocí příkazů jazyka lze tabulky databází vytvořit a upravit. Příkazy tedy musí mít možnost označit typ dat konkrétního sloupce případně jeho další atributy. Tak např. příkaz
create table VYDAJE (DATUM date, CENA numeric, NAKOUPENO text(30))
vytváří tabulku VYDAJE se třemi sloupci (DATUM, CENA, NAKOUPENO), přičemž ve sloupci DATUM se budou uchovávat datumové, ve sloupci CENA číselné a ve sloupci NAKOUPENO textové údaje. Typy dat jsou označeny klíčovými slovy date, numeric, text.
V jednom (operačním) systému se běžně může uchovávat několik databází (=zdrojů dat) různých formátů. Je to dáno historicky (např. dBase - formát .DBF), požadavky na maximální zabezpečení (servery na úrovni operačního systému) apod. Příkazy jsou vydávány jádru konkrétního databázového systému, který je interpretuje, pomocí driverů - řadičů příslušných ovladačů dat (viz obrázek vlevo níže). Na obrázku vpravo je pak znázorněn případ, kdy je možno požadovat data i od běžících serverů, ne nutně téhož (operačního) systému.
Pro obecné použití jazyka a pro přenositelnost je žádoucí, aby pokud možno všichni poskytovatelé dat přijímali tentýž tvar příkazů včetně klíčových slov. Při použití klíčových slov ve významu typů hodnot je naopak nežádoucí, aby stejná klíčová slova označovala jinou přijímanou množinu hodnot nebo jiná omezení na ni kladenou.

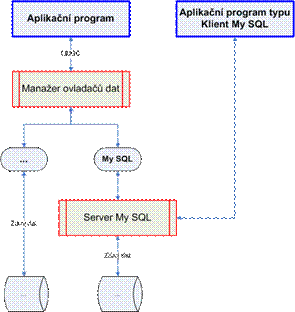
Přístup
k datům v systémech s databázovým jádrem Přístup
k datům v systémech i se servery SQL - příklad pro MySQL
V současné době - z pohledu uživatelů systémů Microsoftu - lze pozorovat několik jemně se odlišujících verzí jazyka SQL.
Především je to ta verze, která by měla být závazná pro všechny interprety - verze popsaná americkou ANSI normou a označovaná jako ANSI SQL. Dále bude označována jako A-SQL.
Dále je to verze, kterou Microsoft používá pro své vlastní specielní databáze, obhospodařované 'databázovým tryskovým strojem' - Database Jet Engine, a kterou nazývá Jet SQL. Dále bude označována jako J-SQL.
Konečně je to verze, kterou - opět Microsoft - používá pro zpracování dat v rámci svého SQL serveru a kterou nazývá MS Server SQL. Dále bude označována jako S-SQL.
Z jiných serverů než Microsoftu uveďme server MySQL hojně v Česku používaný, protože jeho základní verze je zadarmo. Verze jeho SQL bude označována jako M-SQL.
Poznámka: Databázový program Access z Microsoft Office používá J-SQL.
Do databází různých systémů lze čerpat hodnoty z následujících - většinou instrukcemi (ko)procesoru zpracovatelných - množin [v hranatých závorkách jsou tučně uvedena klíčová slova typu použitelná v dané verzi SQL; je-li jich více, jsou to synonyma].
Poznámka: Verze M-SQL má hodnoty některých typů mírně odlišné od ostatních (např. minimální datum je 1.1.1000 místo jinak uváděného 1.1.100).
Množina 256 hodnot celých čísel z intervalu <0,255>. Každá hodnota obsazuje 1 byte. [A-SQL: nemá. J-SQL: byte. S-SQL: tinyint. M-SQL: tinyint unsigned - dvě klíčová slova.]
Množina 65 536 hodnot celých čísel z intervalu <-32 768, +32 767>. Každá hodnota obsazuje 2 byty. [A-SQL: smallint. J-SQL: smallint, short. S-SQL: smallint. M-SQL: smallint.]
Množina 4 294 967 296 hodnot celých čísel z intervalu <-2 147 483 648, +2 147 483 647>. Každá hodnota obsazuje 4 byty. [A-SQL: integer. J-SQL: integer, long. S-SQL: integer. M-SQL: integer, int.]
Množina 4 294 967 296 hodnot racionálních čísel z intervalu <-3.402823 x 1038, +3.402823 x 1038>. Každá hodnota obsazuje 4 byty. Nejmenší kladné číslo různé od nuly je 1.401298 x 10-45. [A-SQL: real. J-SQL: real, single. S-SQL: real. M-SQL: float.]
Množina zhruba 1.845 x 1019 hodnot racionálních čísel z intervalu <-1.79769313486231 x 10308, +1.79769313486232 x 10308>. Každá hodnota obsazuje 8 bytů. Nejmenší kladné číslo různé od nuly je 4.94065645841247 x 10-324. [A-SQL: float. J-SQL: float, double. S-SQL: float. M-SQL: double, real.]
Množina zhruba 10618 textových řetězců, z nichž každý obsahuje žádný, jeden až 256 znaků. Jeden znak je přitom uložen pod svým jednobytových kódem dle zvolené kódové tabulky znaků. [A-SQL: nemá. J-SQL: text. S-SQL: text. M-SQL: tinytext.]
Množina zhruba 10157 713 textových řetězců, z nichž každý obsahuje žádný, jeden až 65 534 znaků. Jeden znak je přitom uložen pod svým jednobytových kódem dle zvolené kódové tabulky znaků. Na rozdíl od předchozího typu Text může Memo obsahovat i znaky pro odřádkování. [A-SQL: nemá. J-SQL: memo. S-SQL: nemá. M-SQL: text.]
Množina 3 615
900 kalendářních datumů počínaje 1.1. roku
Raritou je ve firmě Microsoft tento fakt: počátek datumů v programu Access této firmy je skutečně 30.12.1899. Ovšem počátkem datumů v programu Excel téže firmu je 31.12.1899 (tj. o jeden den víc), přičemž konverze dat mezi oběma programy probíhá v pořádku - prostě odečtou nebo přičtou jedničku. Proč si raději nedali tu práci se sjednocením, to snad neví ani kolega Gates.
Množina dvou hodnot obvykle označovaných , , , apod. Teoreticky stačí pro uchování jedné hodnoty této množiny jeden bit, z praktických důvodů se často používá jeden byte s tím, že nulový byte reprezentuje hodnotu Ne, všechny ostatní hodnoty Ano. [A-SQL: nemá. J-SQL: bit, logical, yesno. S-SQL: bit. M-SQL: bit.]
Do databází lze čerpat hodnoty i z dalších množin. Ty však už mohou být systémově závislé: zatímco hodnota některé množiny je v jednom (zde operačním) systému podporována, ve druhém ne - nebo je podporována jinak. Níže jsou uvedeny ty množiny, které podporují systémy řady Windows firmy Microsoft.
Množina objektů OLE (Object Linking and Embedding), každý o velikosti žádný, jeden až zhruba 2 mld. bytů. Pod pojmem OLE se rozumí unifikované prostředí poskytující objektově orientované služby. OLE objekt je tedy objekt využívající služeb tohoto prostředí. Je zřejmé, že služby jsou vázané na konkrétní operační systém a databáze s OLE objekty nejsou obecně mezi systémy přenositelné. [A-SQL: nemá. J-SQL: image, longbinary, oleobject. S-SQL: image.]
Množina zhruba 101230 (binárních) hodnot na žádném, jednom až 510 bytech. [A-SQL: bit. J-SQL: binary. S-SQL: binary. M-SQL: nemá.]
Množina 2 147 483 647 celých čísel počínaje 1. Z této množiny databázový systém přiděluje hodnoty do databáze jednak automaticky, jednak jedinečně. [A-SQL: nemá. J-SQL: counter. S-SQL: nemá. M-SQL: nemá.]
Množina zhruba 1018 hodnot z intervalu <-922 337 203 685 477.5808, +922 337 203 685 477.5807>. Jde tedy o desetinná čísla vždy se čtyřmi desetinnými místy. [A-SQL: nemá. J-SQL: money, currency. S-SQL: money. M-SQL: do jisté míry lze použít bigint.]
Množina zhruba 3.4 x 1038 celých kladných čísel s binárním vyjádřením na 16 bytech. Jedná se o jedinečný identifikátor každého objektu, který se registruje do prostředí Windows firmy Microsoft, známé GUID (Globally Unique IDentifier). Je generován algoritmem zaručujícím jeho jedinečnost. [A-SQL: nemá. J-SQL: guid. S-SQL: nemá. M-SQL: nemá.]
Databázové systémy I - témata k procvičování
Z důvodů vládou prosazované pozitivní diskriminace žen jsou následující úlohy psány pro ně. Negativně se tvářící pánové nechť si text překonvertují do mužského rodu.
Poznámka 1: Za některými tématy je uvedeno možné řešení ve formě odkazu na MDB soubor zpracovávaný např. Accessem 2000. Pro úplné vyzkoušení je lépe si soubory stáhnout na vlastní počítač a otevírat je až tam.
Poznámka 2: Pro procvičování základních vlastností databázového programu Access je zde možno stáhnout cvičnou databázi ÚTRATA, která je naplněna větším množstvím cvičných dat, než je možno zvládnout ťukáním v úvodním cvičení. Tabulky této databáze jsou zde k disposici také v sešitě Excelu jako pojmenované oblasti.
Jste majitelkou obrovského železářství. V prodejně prodáváte spoustu zboží (asi deset druhů), které máte vedle v místnosti na skladě, a které nakupujete od různých dodavatelů z celého světa (asi od pěti) - vždy jeden druh zboží od jediného dodavatele. Vytvořte databázi, která bude sledovat, kdy jste prodali kolik kusů kterého zboží. Sestavte dotazy, které odpoví na otázky:
Které zboží jsem prodala v únoru 2001?
Kolik jsem si vydělala v únoru 2001, jestliže k ceně dodavatele připočítávám 10% jako svůj zisk?
Kolik kusů zboží jsem celkem dovezla od dodavatelů z Plzně?
Které zboží musím objednat (počet kusů na skladě je menší než 5)?
Možné řešení - zde.
Jste majitelkou světově proslulého módního saloonu. Šijete tisíce modelů (asi pět), každý o různé pracnosti (vyjádřené počtem hodin) a různé průměrné spotřebě látky (vyjádřené metry). Stejné modely šijete i z různých látek (asi třech), každá o jiné ceně. Při šití účtujete 300 Kč za hodinu práce. Vytvořte databázi, která bude sledovat, kdy jste dodali kterým zákazníkům (asi třem) které modely. Sestavte dotazy, které odpoví na otázky:
Které modely jsem dodala v únoru 2001?
Kolik jsem si vydělala v únoru 2001?
Kolik jsem celkem spotřebovala té které látky?
Který můj model je nejžádanější?
Který model jsem ještě vůbec neudala?
Možné řešení - zde.
Jste vášnivou čtenářkou. Doma máte nepřeberné množství knih (asi patnáct) od všech možných autorů (asi od třech), které jste nakoupila v různých dnech v různých knihkupectvích na celém světě (asi třech) za různou cenu. Vytvořte databázi, která bude informovat o vašich knihách. Sestavte dotazy, které odpoví na otázky:
Kolik jsem utratila za všechny knihy?
Kolik jsem utratila za knihy z knihkupectví, mající sídlo v Plzni?
Které knihy mám od nejstaršího žijícího autora?
V kterých městech jsem nakupovala knihy autorů píšících anglicky?
Možné řešení - zde.
Jste světovou topmodelkou. Všechny agentury (asi čtyři) se o vás derou a angažují vás pro různé módní návrháře (asi pro tři) z různých zemí. Za zprostředkování každé akce trvající i několik dnů platíte každé agentuře jednorázově jí požadovaný poplatek, naopak od každého návrháře dostáváte za každý den jím nabízenou odměnu. Vytvořte databázi, která bude informovat o vašich akcích a jejich termínech. Sestavte dotazy, které odpoví na otázky:
Kolik akcí ještě mám nasmlouváno do konce roku?
Kolik akcí ještě mám nasmlouváno do konce roku ve Francii?
Kolik jsem si vydělala v únoru 2001?
Od kterého návrháře jsem dostala nejvíce?
Byla nějaká akce pro mně ztrátová?
Možné řešení - zde.
Jste zazobaná uhlobaronka, ovšem s lidskou tváří. Protože jste uhlobaronka, vlastníte nejméně čtvrtinu všech důlních podniků v republice (nejméně tři; abyste se v nich vyznala, kódujete si je '01', '02' atd.), a to v různých okresech (nejméně třech). Protože jste ovšem s lidskou tváří, s láskou dbáte na ochranu životního prostředí, ve kterém žijí spolu s vámi i ti méně zazobaní. Zvláště pečlivě dohlížíte na kvalitu vody, kterou používáte ve svých provozech a nakonec vypouštíte do řek a potoků. Proto často (nejméně šestkrát ročně) odebíráte ve vytipovaných místech vodohospodářské sítě vašich podniků (minimálně v těch, kde znečištěnou vodu vypouštíte do vodních toků) vzorky a analyzujete je na koncentraci znečišťujících látek (nejméně třech). Vytvořte databázi, která bude informovat o kvalitě vašich vod. Sestavte dotazy, které odpoví na otázky:
Kolik analýz jsem provedla v prvním čtvrtletí?
Kolik analýz jsem provedla v prvním čtvrtletí v podniku '01'?
Kolikrát jsem překročila limit rtuti v okrese FM?
V kterém okrese jsem překročila limit rtuti nejvíc?
Na kterou látku jsem vůbec neprováděla analýzu?
Možné řešení - zde.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 1064
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2024 . All rights reserved