| CATEGORII DOCUMENTE |
| Bulgara | Ceha slovaca | Croata | Engleza | Estona | Finlandeza | Franceza |
| Germana | Italiana | Letona | Lituaniana | Maghiara | Olandeza | Poloneza |
| Sarba | Slovena | Spaniola | Suedeza | Turca | Ucraineana |
DOCUMENTE SIMILARE |
|
TERMENI importanti pentru acest document |
|
S jazykem SQL (Structured Query Language) se můžeme setkat již v roce 1974. V té době se však jmenoval Sequel. Jako první byl použit v Systému R vyvynutého v kalifornské laboratoři IBM.Od té doby se jazyk rozšířil a byl používán v ostatních systémech. Postupem času však vznikaly další „verze“ jazyka a bylo potřeba, aby byl standardizován. K tomu došlo v roce 1986, kdy jej přijala standardizační skupina ANSI (a v roce 1987 ISO). Standardem byl uznán „dialekt“ firmy IBM. V literatuře se můžeme setkat také s označením SQL86. Později bylo potřeba rozšířit definičního jazyka pro možnost integritního omezení. Výsledná zpráva byla zveřejněna v roce 1989 organisací ISO. Tomuto rozšíření se říká SQL89. Poslední přijatý standard byl v roce 1992 (ANSI) a je označován jako SQL92.
První významější produkty, kde byl jazyk SQL zabudován, byly od IBM: DB2, SQL/DS (oba vycházejí ze Systému R) a QMF. S nástupem počítačů třídy PC začaly i ostatní výrobci více uvažovat o SQL. Asi nejznámější je firma Ashton-Tate se svou dBASE IV (i když implementace SQL nebyla úplná). Jako další jmenujme INFORMIX-SQL, INGRES pro PC, ORACLE, SQLBase, XDB II, XQL. Postupem času ze začal jazyk SQL přenášet i na systém UNIX a od jednouživatelských úloh se přecházelo k serverům založených na SQL. Jmenujme aspoň SŘBD ORACLE, INFORMIX, PROGRESS a INGRES. Dále např. SQL Server od firmy Sybase či Microsoft.
Mezi standardy patří i X/OPEN SQL vycházející z ANSI, ale je přihlédnuto k některým rysům systému UNIX. Ačkoliv jako standard byl uznán dialekt firmy IBM, ustanovila si svůj vlastni standard pod názvem SAA-SQL. SQL je také částí federálního standardu pro zpracování informací (FIPS).
Použitá literatura: Jaroslav Pokorný - Dotazovací jazyky, Science 1994
S jazykem SQL (Structured Query Language) se můžeme setkat již v roce 1974. V té době se však jmenoval Sequel. Jako první byl použit v Systému R vyvynutého v kalifornské laboratoři IBM.Od té doby se jazyk rozšířil a byl používán v ostatních systémech. Postupem času však vznikaly další „verze“ jazyka a bylo potřeba, aby byl standardizován. K tomu došlo v roce 1986, kdy jej přijala standardizační skupina ANSI (a v roce 1987 ISO). Standardem byl uznán „dialekt“ firmy IBM. V literatuře se můžeme setkat také s označením SQL86. Později bylo potřeba rozšířit definičního jazyka pro možnost integritního omezení. Výsledná zpráva byla zveřejněna v roce 1989 organisací ISO. Tomuto rozšíření se říká SQL89. Poslední přijatý standard byl v roce 1992 (ANSI) a je označován jako SQL92.
První významější produkty, kde byl jazyk SQL zabudován, byly od IBM: DB2, SQL/DS (oba vycházejí ze Systému R) a QMF. S nástupem počítačů třídy PC začaly i ostatní výrobci více uvažovat o SQL. Asi nejznámější je firma Ashton-Tate se svou dBASE IV (i když implementace SQL nebyla úplná). Jako další jmenujme INFORMIX-SQL, INGRES pro PC, ORACLE, SQLBase, XDB II, XQL. Postupem času ze začal jazyk SQL přenášet i na systém UNIX a od jednouživatelských úloh se přecházelo k serverům založených na SQL. Jmenujme aspoň SŘBD ORACLE, INFORMIX, PROGRESS a INGRES. Dále např. SQL Server od firmy Sybase či Microsoft.
Mezi standardy patří i X/OPEN SQL vycházející z ANSI, ale je přihlédnuto k některým rysům systému UNIX. Ačkoliv jako standard byl uznán dialekt firmy IBM, ustanovila si svůj vlastni standard pod názvem SAA-SQL. SQL je také částí federálního standardu pro zpracování informací (FIPS).
Použitá literatura: Jaroslav Pokorný - Dotazovací jazyky, Science 1994
Začínáme s SQL
SQL (Structured Query Language) je jedním z mnoha jazyků vyšší úrovně. Přesto má své jedinečné postavení, které je dáno především jeho úzkou orientací na databáze. V tom je jeho síla a koneckonců téměř vše, co umí. Vítejte na procházce ve světě databází SQL.
Běžné aplikace umějí poskytovat řadu databázových funkcí. Pro některá použití jsou vhodné. Pro jiná nikoliv. Pokud jde o bezpečnost, výkon, stabilitu a další vlastnosti, které zejména u databází hrají důležitou úlohu, mohou toho nabídnout málo. Pokud přijde na řadu požadavek na použití současně více uživateli, bývají v úzkých.
Zde je pak vhodné místo pro databázové servery. Takový server pak přijímá veškeré požadavky na databázové operace, zpracovává je a výsledek vrací klienům. Ti nemusí mít tušení o tom, jak jsou data fyzicky umístěna. Zda jsou na disku, nebo někde v síti. Nemusí znát dokonce ani formát, v jakém jsou uložena. To vše je úkol pro databázový server. Ten je nejenom jakýmsi správcem dat a skladníkem součastně, ale i ochráncem a bezpečnostním agentem. S vnějším světem komunikuje jen přes speciální rozhraní, která jsou postavena na nejrůznějších technologiích a protokolech na nižší úrovní, ale v té nejhořejší vrstvě je vždy nějaký jazyk, s jehož pomocí klient popisuje serveru, co by vůbec rád. Jedním z takových jazyků (a dodejme , že tím nejčastějším a nejrozšiřenějším) může být SQL.
SQL vzniklo ve vývojových laboratořích IBM v San Jose v roce 1970. Své dětství tedy má již za sebou pěknou řádku let. Ta léta však rozhodně nepromarnilo a postupně bylo přijato jako standardní jazyk mnoha databázových serverů. Jazyk byl dokonce oficiálně uznán za standard ISO (Internacional Organization for Standardization) a ANSI (American National Standards Institute). Za tu pěknou řádku let se dočkal jazzyk SQL také řady rozšíření (ať již objektových nebo rozšiřujících) jeho funkcionalitu blíže procedurálním jazykům. Zde ovšem již taková jednota jako v čistém SQL nevládne. Odchylky a vylepšení jednotlivých výrobců databázových serverů jdou každá trochu jiným směrem. Bitevní pole ovládá nejspíše hlavně Transact-SQL používaný v serverech firem Sybase a Microsoft spolu s PL/SQL, který používá špička tohoto oboru, tedz databázové servery firmy Oracle.
My se vydáme na procházku nejdříve po více méně standardním SQL, i když se nevyhneme i některým jeho rozšířením. Pak bude následovat Transact-SQL, který bude orientován zejména na uživatele produktů Sybase pod Unixem (ale to by nemělo hrát významnou úlohu) a místy bude jistě zajímavý i pro uživatele MS SQL serveru. Jako bonbónek na závěr se zakousneme do šťavnatého PL/SQL. A pak Ale to je tajemství. Nechte se překvapit.
Jak tvořit databáze a tabulky s pomocí SQL
Již dříve jsme se zmínili o tom, co je to jazyk SQL a jaké datové typy v něm máme k dispozici. Nyní se k SQL vrátíme a podíváme se na zoubek vytváření databáze a tabulek. Pokud nemáme vytvořenu nějakou databázi a v ní tabulku, vlastně ani nemáme kam ukládat data. Veškeré příkazy SQL jsou nám tak prakticky nanic. Přesněji řečeno všechny až na dva: CREATE DATABASE a CREATE TABLE.
Ačkoli s každou implementací SQL serveru mohou mít některé příkazy trochu jinou syntaxi, základ je vždy stejný. Pro vytvoření databáze slouží příkaz CREATE DATABASE a pro vytvoření tabulky CREATE TABLE.
CREATE DATABASE
Některé velice jednoduché SQL servery mohou umožňovat vytvoření pouze databáze bez možnosti definování dalších parametrů. Jiné umožňují určit i kde a na kterém zařízení bude databáze umístěna, kam se budou ukládat logy a jaká bude její velikost okamžitě po vytvoření. Nejjednodušší možností je tedy prosté vytvoření „nějaké“ databáze. Stačí si vybrat vhodné jméno a to uvést jako parametr příkazu CREATE DATABASE. I v tak jednoduchém případě nebude jistě na škodu menší příklad:
CREATE DATABASE moje_dbNásledující příklad bude o něco složitější a použitelný spolu s například Sybase SQL Serverem nebo MS SQL serverem. Pokud vás překvapuje, že tyto dva servery jsou si v mnohém blízké, pak věřte, že není divu. MS SQL vznikal ve spolupráci se Sybase (a řekl bych, že je to stále znát). Ale vraťme se k našemu příkladu:
CREATE DATABASE moje_dbTakto vytvoříme databázi moje_db na zařízení DATADEV. Této databázi současně vyhradíme 30 MB místa. Kromě toho bude na zařízení LOGDEV umístěn transakční log. Tomu bude vyhrazena velikost 10 MB.
CREATE TABLE
Každá databáze může obsahovat řadu tabulek. Jejich množství je implementačně závislé a může být značně různorodé. K vytvoření tabulky nám postačí pouhý jeden příkaz: CREATE TABLE. Počet jeho možných parametrů je výrazně rozsáhlejší než v případě vytváření databáze, což je způsobeno zejména tím, že jím současně také popisujeme strukturu tabulky (tj. i jeden nebo více sloupců, které bude obsahovat). Velice jednoduchá tabulka, která by mohla obsahovat například základní informace o zaměstnancích nějakého podniku, by ve velice zjednodušené podobě mohla vypadat třeba nějak takto:
Jak vidíte, je třeba definovat nejen jméno tabulky, ale i jména všech v ní obsažených sloupců (a dokonce i jejich datové typy). Na jednotlivé sloupce se pak můžeme odvolávat jen prostřednictvím jejich jména nebo prostřednictvím jména ve spojení se jménem tabulky, ve které jsou umístěny. Například takto:
zamestnaci.jmenoTaková tabulka je sice dobře použitelná, ale syntaxe příkazu CREATE TABLE je daleko bohatší. Umožňuje totiž vytvoření primárních klíčů a definování matic, umožňuje mít vliv na fyzické uspořádáni dat na disku, dále umožňuje určit nutnost uložení jednoznačných hodnot v rámci jednoho sloupce i prázdných hodnot a umožní vám i další speciality, o kterých se zmíníme příště.
Datové typy v SQL
Jazyk SQL je orientován velice úzce na databáze. Poskytuje řadu možností, jak s nimi pracovat a jak v nich uchovávat data. Data je ovšem třeba nějak popsat, definovat. Jak na to jít v SQL?
Stejně jako každý jiný jazyk, i SQL vytváří jakýsi abstraktní pohled na data uložená v databázi. Ta jsou uložena v databázi (nebo více databázích), které mohou obsahovat několik tabulek. Každá tabulka má definovaný počet sloupců a předem neznámý počet řádků. Sloupce jsou dány při vytvoření tabulky. To nemusí být pravidlo, ale často tomu tak bývá. Určují vlastně atributy jednotlivých řádů. Vezmeme-li jeden řádek, například z tabulky zaměstnanců podniku, budou v něm veškeré dostupné údaje o zaměstnanci. Jeho jméno, datum narození, výše platu, adresa, konto, zařazení atd. Každý z těchto údajů je jedním sloupcem.
|
Číslo řádku |
Jméno |
Výše platu |
telefon |
|
|
Pavel Novák |
|
|
|
|
Robert Nero |
|
|
|
|
Jaroslav Šedivý |
|
|
|
|
Miroslav Zbořil |
|
|
|
|
Karel Vrána |
|
|
|
|
Josef Dědina |
|
|
|
|
Markéta Dlouhá |
|
|
Každý sloupec tabulky může obsahovat pouze předen definované hodnoty. Ty jsou popsány datovými typy při vytváření tabulky (nemusí to být ovšem pravidlo, ale nejčastěji tomu tak je). Datových typů není mnoho. Tedy alespoň těch základních. Z nich se však odvozuje celá řada dalších. Ne vždy je vhodné použít datový typ, který je schopen obsáhnout několik miliard čísel na zaznamenání věku lidí ve firmě. Přece jen je nepravděpodobné, že by některý z nich měl více než 255 let, nebo byla reálná šance, že takového věku dosáhne. A tak lze použít typ, který pokrývá pouze interval 0 až 255, přičemž zabere jen jeden bajt paměti. Ačkoliv se to nezdá, u rozsáhlých databází to může být hodně poznat. Proto si vždy při definici databázové tabulky dobře rozmyslete, co má obsahovat a jakých hodnot které sloupce mohou nabývat atd.
Základní datové typy můžeme rozdělit do několika skupin.
![]() Exaktní
numerické typy - celá čísla a čísla s desetinnou tečkou, která
musí být naprosto přesná
Exaktní
numerické typy - celá čísla a čísla s desetinnou tečkou, která
musí být naprosto přesná
![]() Přibližné
numerické typy - čísla, často s několika desetinnými místy,
která mají různou míru přesnosti. Mohou vznikat při aritmetických
operacích, mohou vyjadřovat konstanty jako pí apod.
Přibližné
numerické typy - čísla, často s několika desetinnými místy,
která mají různou míru přesnosti. Mohou vznikat při aritmetických
operacích, mohou vyjadřovat konstanty jako pí apod.
![]() Peněžní
typy - uchovávají data, která obsahují peněžní hodnoty, hodnoty v
nějaké měně.
Peněžní
typy - uchovávají data, která obsahují peněžní hodnoty, hodnoty v
nějaké měně.
![]() Časové
a datové typy - uchovávají informace o čase a datumu
Časové
a datové typy - uchovávají informace o čase a datumu
![]() timestamp
- Typ, který uchovává informace o tom, kdy byl řádek vytvořen,
modifikován atd.
timestamp
- Typ, který uchovává informace o tom, kdy byl řádek vytvořen,
modifikován atd.
![]() Znakové
typy - typy, které obsahují znaky,čísla a symboly v podobě znakových
řetězců
Znakové
typy - typy, které obsahují znaky,čísla a symboly v podobě znakových
řetězců
![]() Binární
typy - slouží k uchování binárních dat, obrázků, vide, zvuku atd.
Binární
typy - slouží k uchování binárních dat, obrázků, vide, zvuku atd.
![]() Logické
a bitově orientované typy - uchovávají pouze dvoustavové informace typu
ano - ne, pravda - nepravda apod.
Logické
a bitově orientované typy - uchovávají pouze dvoustavové informace typu
ano - ne, pravda - nepravda apod.
![]() Uživatelem
definované typy - datové typy odvozené od standardních uživatelem.
Uživatelem
definované typy - datové typy odvozené od standardních uživatelem.
Pro orientační přehled je zde tabulka, která popisuje datové typy SQL serveru Sybase, kolik bajtů zabírají a také, jakého rozsahu mohou nabývat.
Exaktní numerické typy
|
Typ |
Synonymum |
Rozsah |
Bajtů |
|
Tinyint |
|
0 až 255 |
|
|
Smallint |
|
-32768 až 32767 |
|
|
Int |
Integer |
-2 147 483 648 až 2 147 483 647 |
|
|
Numeric (p,s) |
|
-10 na 38 až 10 na 38 -1 |
2 až 17 |
|
Decimal |
Dec |
-10 na 38 až 10 na 38 -1 |
2 až 17 |
Přibližné numerické typy
|
Typ |
Bajtů |
|
Float |
4 až 8 |
|
Double |
|
|
Real |
|
Poznámka: rozsah je různý dle platformy
Typy časové a datum
|
Typ |
Rozsah |
Bajtů |
|
Smalldatetime |
1. leden 1900 až 1. červenec 2079 |
|
|
Datetime |
1. ledna 1753 až 31. prosince 9999 |
|
Znakové typy
|
Typ |
Komentář |
|
Char (n) |
Pevná délka řetězce, například rodné číslo |
|
Nchar (a) |
Totéž jako předchozí, ale kódováno v multibyte |
|
Varchar |
Poměrná délka řetězce |
|
Nvarchar |
Poměrná délka řetězce v kódování multibyte |
|
Text |
Jakékoli tisknutelné znaky až do délky 2 147 483 647 znaků |
Binární datové typy
|
Typ |
Komentář |
|
Binary |
Binární data pevné délky až 255 bajtů |
|
Varbinary |
Binární data poměné délky až 255 bajtů |
|
image |
Jakékoli znaky až do délky 2 147 483 647 bajtů |
Logické typy
|
Typ |
Popis |
|
Bit |
Nabývá pouze hodnot 1 nebo 0 |
Jaký datový typ v SQL?
V minulých kapitolách o SQL jsme se věnovali datovým typům a možnostem vytváření databází a tabulek. Každá tabulka může obsahovat řadu sloupců a každý z nich může být úplně jiného typu. Jenže jakého? Jak vybrat ten pravý?
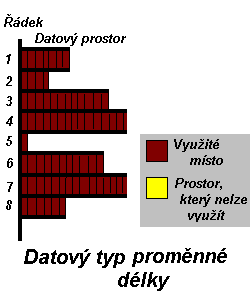
Výčet všech možných datových typů by byl dlouhý a také zbytečný. V zásadě lze všechny rozdělit na datové typy s pevnou a datové typy s proměnlivou délkou. Pevná délka je běžná u číselných hodnot, ale můžete ji najít i u hodnot textových. Zatímco v prvém případě se jedná o určení intervalu čísel, které daný datový typ 'umí', ve druhém případě jde o počet znaků, které řetězec může obsahovat. Typy s proměnnou délkou jsou doménou řetězců, ale nejen jich. Často se objevují u binárních typů určených pro ukládání buď jakýchkoliv dat, nebo jsou přímo učeny pro multimediální data, jakými jsou zvuky, obrázky, video apod.
Při vytváření SQL tabulky velice často narážíme na to, že si musíme mezi těmito dvěma skupinami vybrat. Každá z nich má své výhody, ale i své nevýhody. Datové typy s pevnou
|
|
délkou zabírají zbytečně místo. Pokud budeme chtít datový typ o délce 200 znaků, potom i když do něho uložíme daleko méně, bude na disku místa méně o celou jeho délku. Na druhé straně je pravdou, že pokud budeme potřebovat více než 200 znaků, máme smůlu, jelikož jsme na to měli myslet již při vytváření tabulky. Jednu výhodu pevná délka ale přece jen má. Vyhledávání v takovém sloupci je rychlejší než ve sloupci, který může mít v každém řádku tabulky jinou délku. Důvod je prostý - není třeba zjišťovat délku hodnoty každého řádku v daném sloupci, neboť je pořád stejná.
Z toho všeho lze odvodit i výhody a nevýhody proměnné délky. Na prvním místě bude úspora místa na disku, ale na druhém o něco menší rychlost při procházení tímto sloupcem SQL
|
|
tabulky. I přesto může být volba jednoduchá. Pokud je v daném sloupci délka dat přibližně stejná, postačí datový typ s definovanou pevnou délkou. Pokud se může radikálně měnit, bude výhodnější proměnná délka.
Velký vliv může mít také požadavek na změnu dat na některém řádku sloupce. Toto sice záleží na každém SQL serveru, ale pokud je dána položka pevné délky, postačí jen její obsah zaměnit. Pokud nemá pevnou délku (a nová hodnota je větší než předchozí), je problém ji umístit na stejné místo. Ale to už se skutečně může lišit server od serveru. Jeden může označit původní data za neplatná a pro změněná alokovat místo někde jinde. Může se také snažit veškerá data za měněnou položkou posunout tak, aby se vytvořilo potřebné místo, ale také může využít místo, které by se mohlo za každou položkou nacházet nevyužité, právě pro tyto případy.
To, jak s daty SQL server naloží, ovlivňuje ještě jedna velice důležitá věc, kterou jsou indexy. Pokud by se při každém SELECTu musela procházet celá databáze tak dlouho, dokud se nedosáhne jejího konce nebo se nenarazí na požadovanou hodnotu (pokud by byla požadována jen první nalezená, není třeba projít úplně vše), bylo by to zbytečně pomalé. A tak si lze celou tabulku oindexovat podle vybraných sloupců. Ne každý typ může být použit pro vytvoření indexu, ale ty nejzákladnější v každém případě. Index je jakýmsi rejstříkem, který umožní rychlé vyhledání požadovaných dat bez nutnosti prohledat celou databázi. Samozřejmě to není tak úplně zadarmo. Někdy se musí index také vytvářet, ale jeho použití pak vede k výraznému zrychlení práce s databází. Indexy mohou být dva. Clusterované a neclustrované. Clustrovaný index udržuje data v tabulce seřazena podle definovaného klíče. Přístup k nim pak podle tohoto indexu může být velice rychlý, protože není třeba procházet řadu ukazatelů na samotná data. Ale zase takový index může být v celé tabulce jen jeden. To je cena za fyzické setřídění dat přímo na disku. Samozřejmě se to musí také projevit při vložení nového řádku do tabulky. Vyjma případu, kdy by dle klíče byl zařazen až na konec tabulky, je nutno najít jeho správné místo, umístit ho tam (a před tím veškeré řádky za ním posunout o kousek dál). Zatímco SELECT bude rychlý, INSERT bude velice pomalý (stejně jako UPDATE ve sloupci, podle něhož je INDEX vytvářen).
Neclusterované indexy vytvářejí jen datové struktury popisující rozložení dat na disku, tak aby zajistili rychlý přístup k těm, které hledáte. Výhodou je, že takových indexů může být více. Nevýhodou je, že k jejich vytvoření je třeba další místo na disku (a také to, že jejich procházení bude o něco pomalejší než v případě clusterovaných indexů). Ale rychlost vkládání dat a jejich modifikace v tabulce (příkazy INSERT a UPDATE) bude naopak o něco lepší, protože není třeba jednotlivé řádky třídit na disku i fyzicky.
Vytváření indexů je jednoduché, ale dle databáze může být v detailech rozdílné. V zásadě je však princip vždy stejný:
CREATE INDEX jméno ON tabulka (jméno sloupce)Syntaxe může být i daleko pestřejší:
CREATE [UNIQUE] [CLUSTERED | NONCLUSTERED]Při vytváření indexu můžeme také definovat omezující podmínky (nejen jeho typ). K tomu je určen parametr UNIQUE.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 1000
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved