| CATEGORII DOCUMENTE |
| Bulgara | Ceha slovaca | Croata | Engleza | Estona | Finlandeza | Franceza |
| Germana | Italiana | Letona | Lituaniana | Maghiara | Olandeza | Poloneza |
| Sarba | Slovena | Spaniola | Suedeza | Turca | Ucraineana |
DOCUMENTE SIMILARE |
|
TERMENI importanti pentru acest document |
|
Implementace netriviálních datových struktur (seznamů, stromů,…)
Datová struktura je množina dat (prvků, složek, datových objektů), pro kterou jsou definovány určité operace a stanoven způsob reprezentace (implementace). Datová struktura je statická, jestliže počet složek datové struktury je neměnný. Statické datové struktury jsou ve vyšších programovacích jazycích přímo podporovány strukturovanými datovými typy (pole, řetězec, třída). Datová struktura je dynamická, jestliže počet jejích složek je proměnný.
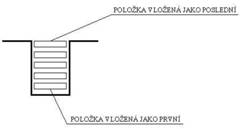
Zásobník
Zásobník je dynamická množina, u které je specificky definována operace vybrání a vložení prvku. Operace vyber ze zásobníku vybere prvek, který je na jeho vrcholu (ten, který jsme vložili jako poslední). Při vkládání prvků do zásobníku se vkládaná položka vloží na jeho vrchol. Zásobník si tedy můžeme představit jako jakousi sklípkovou paměť, nebo zásuvku, do které vkládáme např. listy papíru, a na povrchu máme vždy tu položku, kterou jsme vložili jako poslední.
Strom
Stromy mají široké uplatnění jako datové struktury pro různé algoritmy. Jsou to matematické abstrakce organizace dynamických množin, kterou v běžném životě používáme velice často. Příkladem může být rodokmen, sportovní soutěž založená na vylučovacím principu, kdy dál postupuje jeden ze soupeřů, botanický klíč ap. V počítači může být ve formě stromu organizován systém souborů uložených v adresářích, které definujeme rekurzivně jako množinu souborů a adresářů. Prvky v dynamické množině organizované jako strom nazýváme vrcholy. Některé vrcholy jsou spojeny a toto spojení nazýváme hranou.
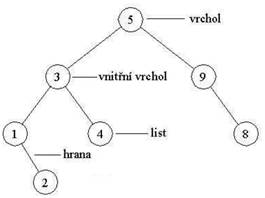 V tomto stromě je x kořenem
stromu a stromy T1, T2, , Tn se nazývají podstromy. Jejich kořeny
jsou přímými následníky vrcholu
x a vrchol x je jejich přímým předchůdcem. Vrchol, který nemá přímé následníky se
nazývá listem. Vrchol, který není listem se nazývá vnitřním
vrcholem.
V tomto stromě je x kořenem
stromu a stromy T1, T2, , Tn se nazývají podstromy. Jejich kořeny
jsou přímými následníky vrcholu
x a vrchol x je jejich přímým předchůdcem. Vrchol, který nemá přímé následníky se
nazývá listem. Vrchol, který není listem se nazývá vnitřním
vrcholem.
Délka cesty je počet hran cesty. Délku cesty z vrcholu k sobě samému potom můžeme definovat jako nulovou. Ke každému vrcholu je z kořene právě jedna cesta.
Hloubka vrcholu ve stromě (úroveň, na které se vrchol nachází) je definována jako délka této cesty. Úroveň (hloubka) kořene stromu je tedy nulová.
Výška stromu je maximální hloubka vrcholu stromu.
Cesta je posloupnost po sobě jdoucích vrcholů, které jsou spojeny hranou.
Binární stromy
V binárním stromu jsou ke každému vrcholu připojeny dva podstromy (jeden nebo oba mohou být prázdné). Jeden z nich označíme jako levý a druhý jako pravý podstrom.
Nejčastěji se setkáme s binárními stromy, ve kterých jsou data uspořádána podle následujícího pravidla:
Pro každý vrchol U platí, že všechny údaje, uložené v levém podstromu, připojeném k U, jsou menší, než je údaj uložený v U, a všechny údaje, uložené v pravém podstromu, připojeném k U, jsou větší, než je údaj uložený v U.
Pokud nezdůrazníme něco jiného, budeme dále pod označením binární strom rozumět takto uspořádaný binární strom. Základem implementace binárního stromu bude záznam vrchol, definovaný takto:
type uVrchol = ^vrchol;
vrchol = record
Dt: data;
Levý, Pravý: uVrchol;
end;
Binární strom je obvykle přístupný pomocí ukazatele na kořen. Vrcholy zpravidla alokujeme dynamicky. Také u stromů se někdy používá zarážka: všechny „prázdné“ ukazatele na následovníky obsahují místo hodnoty nil adresu pevně stanoveného prvku - zarážky. Jde o analogii zvláštních uzlů, kterých jsme použili při definice vnější cesty stromu; zarážka je ale jen jedna, společná pro celý strom (viz obr. 2.7). Data uložená v zarážce jsou samozřejmě bezvýznamná.
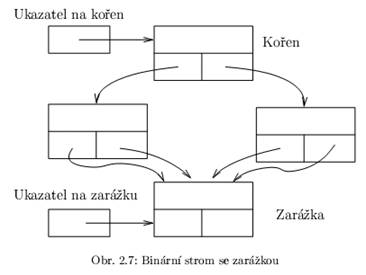
Adresu zarážky, podobně jako adresu kořene, ukládáme do zvláštní proměnné.
Při procházení binárního stromu se obvykle používá některá z metod, označovaných jako přímé zpracování (anglicky preorder), vnitřní zpracování (inorder) a zpětné zpracování (postorder). Při přímém zpracování nejprve zpracujeme data, uložená v kořeni, pak zpracujme levý podstrom a nakonec pravý podstrom. Při vnitřním zpracování nejprve projdeme levý podstrom, pak zpracujeme kořen a nakonec projdeme pravý podstrom; při zpětném zpracování postupujeme v pořadí levý podstrom, pravý podstrom, kořen.
Předpokládejme, že pro zpracování dat v uzlu s adresou t použijeme proceduru P(t). Potom procedura pro zpracování celého stromu přímou metodou bude mít tvar
procedure preorder(kořen: uVrchol);
begin
if t <> nil then begin
P(t);
preorder(t^.Levý);
preorder(t^.Pravý);
end;
end;
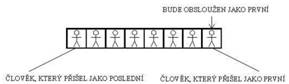
Fronta
Fronta je dynamická množina, u které je specificky definována operace vybrání a vložení prvku. Operace vyber z fronty vybere prvek, který jsme vložili jako první. Při vkládání prvků do fronty se vkládaná položka vloží na jeho konec.
Seznam
Nejjednoduššími ze spojových struktur jsou lineární spojové seznamy. Prvky seznamu jsou dynamické proměnné stejného typu záznam, jehož jedna položka je ukazatelem na následníka uvažovaného prvku v seznamu. Celý seznam je pak referován ukazatelem na první prvek — začátek seznamu. Označení posledního prvku — konce seznamu — může být provedeno tak, že do jeho položky odkazu na následníka je dosazena hodnota nil. V některých aplikacích je však výhodné zavést kromě ukazatele na začátek seznamu rovněž ukazatele na jeho konec, hodnota ukazatele na následníka posledního prvku se pak obvykle ponechává nedefinovaná.
Seznam (anglicky list) je datová struktura, která představuje posloupnost složek. Složky jsou uspořádány podle určitého klíče. Jako klíč může sloužit hodnota dat, uložených ve složkách, nebo hodnota funkce, vypočítané na základě těchto dat. Jiné uspořádání seznamu může být dáno pořadím, ve kterém byly složky do seznamu přidávány. Přestože seznam představuje uspořádanou datovou strukturu, nemusí jednotlivé složky ležet v paměti za sebou. Seznam lze implementovat také tak, že každá složka bude obsahovat odkaz na následující prvek; tento odkaz (ukazatel, označovaný často jako spojka, anglicky link) bude zajišt’ovat návaznost složek. První prvek seznamu označujeme jako hlavu seznamu (head), zbytek seznamu po odtržení hlavy se někdy označuje jako ohon (tail). Seznam může být i prázdný, nemusí obsahovat žádný prvek. Seznamy obvykle používáme jako dynamické datové struktury. To znamená, že v programu deklarujeme pouze ukazatel na hlavu seznamu (na obr. 2. 2 je to proměnná unh); jednotlivé prvky seznamu podle potřeby dynamicky alokujeme nebo rušíme.
Seznamy se (spolu se stromy) označují jako rekurzivní datové struktury, nebot’ každý prvek seznamu obsahuje odkaz na položku stejného typu.
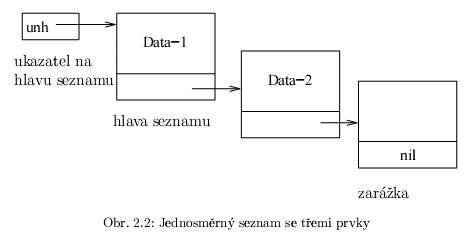
Jednosměrný seznam
Jednosměrný seznam je nejjednodušší variantou seznamu: každý prvek obsahuje pouze odkaz na následující prvek. Prvky jednosměrného seznamu bychom mohli v Pascalu deklarovat následujícím způsobem:
type uPrvek = ^Prvek;
Prvek = record
D: data;
Další: uPrvek;
end;
D je složka typu data, do které budeme ukládat informace. Složka Další bude obsahovat ukazatel na další prvek seznamu nebo v případě posledního prvku nil.
Při práci s jednosměrným seznamem často používáme zarážku: poslední prvek seznamu nenese užitečná data, pouze slouží jako zarážka při prohledávání. Vedle ukazatele na hlavu seznamu si pak uchováváme také ukazatel na tuto zarážku.
Příklad
Odvozené datové struktury je výhodné deklarovat jako objektové typy. Následující deklarace objektového typu seznam navazuje na deklaraci typu prvek a ukazuje procedury pro vytvoření prázdného seznamu, vložení prvku na konec seznamu a funkci, která vyhledá v seznamu prvek se zadanou hodnotou (pokud jej najde, vrátí jeho adresu, jinak vrátí nil).
type seznam = object
hlava, konec: uPrvek;
constructor VytvořSeznam;
procedure VložNaKonec(var dd: data);
function Vyhledej(var dd: data):uPrvek;
end;
Podívejme se na některé běžné operace se seznamem.
Vytvoření prázdného seznamu
Prázdný seznam, složený z prvků typu Prvek, vytvoříme takto:
1. Deklarujeme ukazatel na hlavu seznamu hlava a ukazatel na zarážku konec jako proměnné typu uPrvek
(ukazatel na prvek).
2. Vytvoříme dynamickou proměnnou typu Prvek a její adresu uložíme do proměnných hlava a konec.
3. Do složky hlava^.Další, tj. do složky Další nově vytvořené dynamické proměnné, vložíme hodnotu nil.
Příklad (pokračování)
Metoda seznam.VytvořSeznam, která vytvoří prázdný seznam, může vypadat takto:
constructor seznam.VytvořSeznam;
begin
New(hlava);
konec := hlava;
hlava^.Další := nil;
end;
Halda
Halda vychází z prioritní fronty implementované pomocí stromu. N prvků můžeme, zaplňujeme-li postupně jednotlivé úrovně počínaje kořenem, uložit ve stromě s výškou O(log2N). Takové stromy nazýváme úplné. Navíc potřebujeme, aby uložení prvků ve stromě zohledňovalo velikosti jejich klíčů tak, aby bylo možno efektivně určit prvek s největším (nejmenším) klíčem. Takovou strukturou je halda. Strom má vlastnost haldy, když klíč v každém vrcholu je větší (menší) nebo roven klíčům v jeho následnících, pokud je má. Ekvivalentně, klíč v každém vrcholu je menší (větší) nebo roven klíči v jeho předchůdci, pokud ho má. Z uvedené vlastnosti plyne, že žádný vrchol ve stromě s vlastností haldy nemá klíč větší (menší) než kořen. Halda je úplný binární strom s vlastností haldy reprezentován pomocí pole.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 719
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2024 . All rights reserved