| CATEGORII DOCUMENTE |
| Bulgara | Ceha slovaca | Croata | Engleza | Estona | Finlandeza | Franceza |
| Germana | Italiana | Letona | Lituaniana | Maghiara | Olandeza | Poloneza |
| Sarba | Slovena | Spaniola | Suedeza | Turca | Ucraineana |
DOCUMENTE SIMILARE |
|
TERMENI importanti pentru acest document |
|
S.M.A.R.T.
Jak pracuje pevný disk, to asi všichni víme. Na
otáčejícím se kotouči (plotně) se nachází magnetizovatelná
látka, nad plotnou v mikroskopické výšce 'poletuje' čtecí /
zapisovací hlava a pomocí elektromagnetu mění 'nastavení' látky
na hodnoty

Seagate Barracuda 7200.8 se 133 GB na plotnu
Běžný dnešní pevný disk do stolního počítače má hustotu záznamu
80 GB na plotnu, tj. 40 GB z jedné strany (na plotnu se zapisuje z obou stran
pomocí dvou hlav). Jsou ale již i disky se 100 GB či 133 GB na plotnu.
Samotná plotna je z důvodu ochrany obvykle potažena ochranným
'nátěrem', který však někdy může činit problémy -
to byl známý případ katastrofální úmrtnosti disků IBM Deskstar 75GXP
a 60GXP, kdy při delší nečinnosti hlava nabourala do ochranného gelu
a následoval kolaps.
Budeme-li se bavit o spolehlivosti, je jasné, že čím vyšší hustota záznamu, tím hůř. Jednoduše proto, že nový disk používá k záznamu jednoho bitu méně atomů než disk starší. Vyžaduje se tak lepší kvalita plotny (magnetizovatelné látky), přesnější navigace čtecí / zapisovací hlavy, přesnější teplotní rekalibrace no prostě od nového disku nelze čekat stabilitu disků poloviny devadesátých let, ke kdysi běžné spolehlivosti je mu nutné trochu pomoct.
Proč disky odchází? - typy poškození
Jednoduše proto, že jsou to příliš citlivá zařízení. Mechanika je velmi precizní, v důsledku tedy i zranitelná. Čtecí / zapisovací hlava se pohybuje ve velmi malé vzdálenosti nad plotnou, jakékoliv smítko prachu dokáže hlavu zničit či poškodit (disk se vyrábí, podobně jako mikroprocesory, v extrémně čistém prostředí). Plotna se otáčí vcelku vysokou rychlostí, což také na spolehlivosti nepřidává. A disk takto pracuje několik hodin denně, někdy i nepřetržitě.
Přesto však, disk je na takovou zátěž konstruován (snad s výjimkou nepřetržitého provozu, na který jsou připraveny pouze některé série disků). Co jsou tedy skutečné příčiny smrti pevných disků a proč často umírají? Příčin může být několik:
Poškození při převozu - Většina disků je převážena pouze v antistatickém sáčku, tj. bez mechanické ochrany. A přestože disk má ve vypnutém stavu vydržet přetížení 300 až 350G, nemusí to vždy stačit. Jednak tato hodnota je mezní a pak také nemusí platit pro všechny směry vibrací a zcela jistě neplatí pro všechny typy vibrací. Výrobci často garantují pouze omezený čas, po který mohou vibrace působit. Tak například IBM Deskstar 180GXP vydrží půlsinovou vlnu o síle 350G a délce 2ms. Ale náhodné vibrace snese už pouze o síle 1.04G. To vše ve vypnutém stavu, za chodu je odolnost mnohem nižší. Pokud je disk nešetrně převážen, může být vystaven nepříznivějším podmínkám než jsou tyto. Je tak poškozen ještě před vlastním použitím.
Typický důsledek: kompletní selhání disku
Projev selhání: ihned po koupi či během několika prvních dní
provozu
Elektřina - Stabilita napájení je velmi důležitý faktor. Pevné disky se většinou drží specifikace ATX12V, místy mají dokonce tvrdší požadavky, především pak na +12V napětí. Dodržení specifikací a stabilita napětí jsou klíčové faktory. Pevný disk je poháněn napětím +12V (motory), +5V (napěťový regulátor pro elektroniku) a u Serial ATA disků v budoucnu také +3.3V (přímé napájení elektroniky - dnes není využito, protože jen málo zdrojů má SATA napájecí konektor).
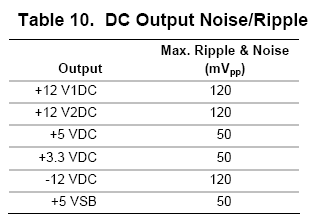
Maximální možné zvlnění dle specifikace ATX12V v2.01
Zdroj by měl splnit požadavky na zvlnění dané specifikací. S tím však
může mít dost problémy, především při rušení v síti. Toto rušení
je běžně způsobováno silnějšími motory jako jsou ty ve
vrtačkách, vysavačích či mixérech - jistě se každý z nás setkal
se situací, kdy se po zapnutí vysavače objevovaly na obrazovce televize
ruchy.
Někteří lidé tvrdí, že tyto rušení v síti jsou přenášena do celého počítače, a narušují tak stabilitu počítače jakožto celku. Je například známé, že chyby v testu Prime95 (testuje stabilitu procesoru) nastávající po delších časových úsecích (např. několika hodinách) jsou způsobovány nestabilitou napájení - v elektrické síti dojde k rušení, to způsobí téměř nepostřehnutelný pokles napětí a procesor špatně vypočte úlohu. Již mnoho lidí nezávisle na sobě potvrdilo, že připojením počítače přes online záložní zdroj napájení (UPSku, která generuje proud pro zdroj z baterií, což je 'krásný' proud bez rušení) bylo možné snížit při stejné frekvenci napětí procesoru a dosáhnout tak lepšího přetaktování.
Co se týče pevných disků, je téměř faktem, že některým lidem odchází pevné disky jak na běžícím pásu, zatímco jiným drží dobře. Důvod? Patrně elektřina. Plotna pevného disku je již z továrny naformátována značkami, které slouží k navigaci čtecí / zapisovací hlavy (tzv. low level formát). Tyto značky se v průběhu používání nemění, slouží jen elektronice disku k zjišťování pozice hlavy. Někteří zastávají názor, že zvýšené rušení v síti způsobuje poškození těchto značek náhodným aktivováním hlavy (náhodným zápisem na nesprávná místa). V dlouhodobém horizontu to vede k nečitelnosti některých sektorů na disku, protože hlavička není schopná nalézt značku, a tedy i přečíst data.
Typický důsledek: vznik chybných sektorů
Projev selhání: dlouhodobý v řádu měsíců
Audio: 'Click of Death' z disku IBM Deskstar 60GXP (přezdívaný Deathstar) zaznamenaný kýmsi z Internetu

Náraz hlavičky do plotny - Čtecí / zapisovací hlava na mnoha
discích po vypnutí dosedá na povrch plotny (tzv. parkuje). To nevadí, protože
na povrch dosedá v okamžiku, kdy se plotna netočí, takže nehrozí
zničení hlavy. Avšak může se stát, že z nějakého důvodu
při opětovném nastartování se začne plotna točit
dříve, než se hlavička vznese (než se odlepí od plotny), či že
se hlava vlivem selhání mechaniky / elektroniky dotkne plotny za provozu. V
takovém případě dochází k poškození plotny a často i samotné
hlavy.
Typický důsledek: vznik chybných sektorů s rychlým
přibýváním dalších chybných sektorů, popř. kompletní selhání
disku
Projev selhání: nepředvídatelné
Výkyvy počasí - Jedná se o poměrně atypický problém v běžných podmínkách. V podstatě jde o to, že různá vlhkost, tlak a teplota vzduchu mohou negativně působit na magnetizovatelnou látku plotny (či na plotnu samotnou), což při častém střídání prostředí (např. klimatizovaná kancelář vs. horko v autě v létě) může vést k degradaci stability magnetizovatelné látky a poruše disku. Protože stolní pevné disky běžně takto nepřenášíme, týká se to především disků pro notebooky.
Typický důsledek: problémy se čtením / zápisem dat
Projev selhání: nepředvídatelné
Selhání elektroniky - Elektronika disku ovládá veškerou činnost mechaniky. Poškození elektroniky tak vede k nefunkčnosti disku jakožto celku. V horším případě můžou chybné povely z řídícího čipu způsobit poškození čtecí / zapisovací hlavy či náhodné přepisování dat. Naštěstí při selhání elektroniky je možné tuto vyměnit za stejnou z jiného disku a alespoň zachránit data.
Typický důsledek: dlouhá či zcela nefunkční
detekce disku systémem, nefunkční DMA režim přenosu, chybné
čtení / zápis dat, poškození čtecí / zapisovací hlavy
Projev selhání: nepředvídatelné
Poškození ložisek motoru - Motorky otáčející plotny sice dnes používají kapalinová ložiska, která mají delší životnost a mnohem menší hlukový projev než jinak běžně používaná kuličková ložiska
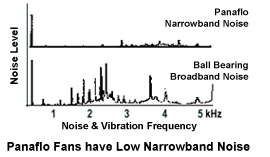
Kapalinová ložiska ventilátorů Panaflo mají nižší úroveň
hlučnosti.
avšak i ta po delší době provozu začínají více
'pískat', než když je disk nový. Časem se prostě
oběhají. Občas se ale stane, že ložiska začnou hlučet
výrazně víc a disk takto začne pískat tak, že je například
slyšet i
Typický důsledek: růst hlučnosti disku v
oblasti vyšších frekvencí až na nesnesitelnou úroveň, selhání motorku
otáčejícího plotnami
Projev selhání: obvykle dlouhodobý proces stárnutí, ale může nastat i
náhodně
Teplota - Vysoká teplota degraduje materiál. Magnetizovatelná látka plotny se může vlivem vysoké teploty poškodit a s tím zmizí i data. Vyšší teplota fyzicky zvětšuje pevný disk (látky se s růstem teploty roztahují), takže je nutná rekalibrace. S vyšší teplotou se zvyšuje riziko chybně zapsaných či chybně přečtených dat. Vysoká teplota je jednou z nejčastějších příčin selhávání pevných disků.
pod 40 stupňů - vhodná teplota, ale málokdy dosažitelná bez aktivního chlazení
nad 40 stupňů - snesitelné, pokud disk není používán nepřetržitě nebo na ukládání cenných dat
nad 45 stupňů - již znatelné riziko
nad 50 stupňů - velké riziko poškození disku
nad 60 stupňů - často nastává chyba čtení / zápisu, selhává elektronika, neodpovídá provozním specifikacím drtivé většiny disků
Typický důsledek: zmizení disku ze systému, problémy s
detekcí disku, poruchy čtení a zápisu
Projev selhání: od určité teploty okamžité následky, jinak urychlený
proces stárnutí.
Samozřejmě mohou nastat i jiné scénáře. Naštěstí je možné řadu z nich předvídat
S.M.A.R.T. je zkratka pro Self-Monitoring Analysis and Reporting Technology. Do češtiny bychom to mohli velmi volně přeložit jako samokontrolní mechanismus. Ten je integrován ve všech moderních pevných discích, přičemž 'moderní' zde znamená cca. od druhé poloviny devadesátých let. Nečekejte S.M.A.R.T. na discích kapacit v řádu stovek MB či prvních 'gigových' discích. Ale již třeba některé 4GB disky ho mají.
Úkolem S.M.A.R.T. je nezávisle na operačním systému či jiném hardware monitorovat stav pevného disku. Hlídají se některé základní ukazatele, jejichž pravidelným sledováním lze předpovědět problémy pevného disku. I některé těžko předvídatelné problémy se mohou projevit změnou některých vlastností - S.M.A.R.T. je dobré cca. jednou týdně zběžně prohlédnout, zda se něco nezměnilo a pokud ano, problém vyhodnotit.
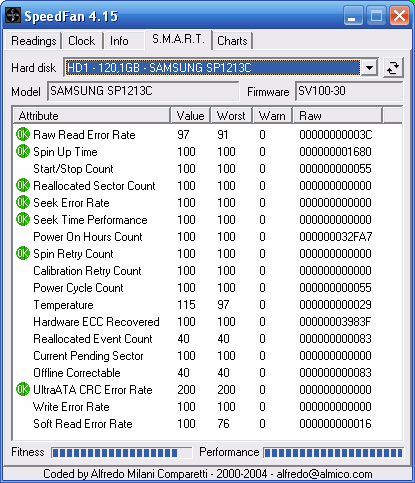
Obecně novější disky hlídají více ukazatelů než disky starší - zatímco můj starý Seagate Medalist obsahoval asi deset položek, nový Maxtor DiamondMax 10 jich má hned třicet.
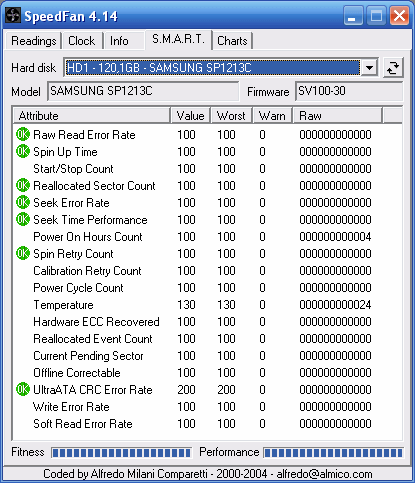
Takto vypadají hodnoty S.M.A.R.T. u nového pevného disku.
Hodnoty S.M.A.R.T. umí zjistit mnoho programů, dle mě jedním z
nejlepších v tomto ohledu je SpeedFan - a to hlavně proto, že má dobrou
podporu ze strany výrobců čipsetů, takže si poradí i s
některými specifickými řadiči jako je Serial ATA na VIA VT8237
či jiné (a patrně ho už tak nebo tak máte nainstalovaný). Bohužel
bez podpory řadiče program není schopen přistupovat k disku, tj.
ani přečíst si z něj hodnoty S.M.A.R.T. V tomto má přeci
jenom výhodu klasické IDE rozhraní oproti Serial ATA, neb IDE funguje na všech
základních deskách stejně (např. má vždy IRQ14 pro první kanál a
IRQ15 pro druhý kanál), čili je vždy kompatibilní s programy - avšak
pozor, toto neplatí, pokud je disk připojen přes přídavný
řadič, tam je situace stejná jako u Serial ATA.
S.M.A.R.T. ukazuje mnoho údajů, z nichž u některých si nikdy nebudete jistí, co přesně znamenají. Navíc u každého typu se mohou různé ukazatele chovat různým způsobem. Je proto dobré sledovat ihned po koupi, co se mění. Nový disk má hodnoty vynulovány a je zcela běžné, že při prvních dnech používání se tyto hodně mění - ustalují se. Pokud to nejsou klíčové položky (viz. níže), není se čeho obávat.
Čtyři položky značí stav:
Value - aktuální výsledná hodnota (obecně čím menší hodnota, tím hůře)
Worst - nejhorší výsledná hodnota
Warn - výsledná hodnota, při jejímž dosažení či překročení (překročení znamená, že Value je menší než Warn) již není doporučeno disk používat, protože některé jeho parametry dosáhly kritických mezí spolehlivosti
Raw - aktuální či kumulovaná hodnota sledovaného parametru (obecně čím více, tím hůře)
Rozdíl mezi Value a Raw lze snadno demonstrovat například na počtu provozních hodin. Pokud bude Value ukazovat 90, znamená to, že 10 procent z předpokládané životnosti disku v hodinách bylo již vypotřebováno. Raw v takovém případě bude ukazovat počet uběhnutých hodin v hexa formátu. Pro uživatele je nejdůležitější parametrem právě Raw, na němž je možné vysledovat přicházející problémy.
Význam položek
Co je důležité sledovat? Některé položky jsou více méně informativní, jiné klíčové.
|
Raw Read Error Rate |
Počet chybných čtení dat z plotny. Disk běžně má problémy se čtením dat, což koriguje pomocí ECC a opakovaného čtení. U některých disků (typicky Seagate) se počítá celkový počet chybných čtení (tedy hodnota rychle roste), u jiných disků pouze počet čtení, které nebylo možné opravit (v takovém případě by měla být Raw hodnota rovna nule, v opačném případě rychle zálohujte). |
|
Spin Up Time |
Čas potřebný k roztočení ploten. S časem se zhoršuje, avšak poměrně pomalu. Náhlá změna značí poškození motorku otáčejícího plotny. |
|
Start/Stop Count |
Počet startů plotny, hodnota v Raw udává kumulovaný součet. Motorek by měl vydržet cca. 50 tisíc startů. |
|
Reallocated Sector Count |
Počet přemapovaných sektorů z původní do záložní oblasti disku. Ideální hodnota je nula. Při rychlých nárůstech či vysokých hodnotách zálohujte. |
|
Seek Error Rate |
Počet chybných seeků (přemísťování hlavy nad stopu plotny). U většiny disků by mělo být rovno nule, jinak potřeba zálohovat. |
|
Seek Time Performance |
Rychlost seekování. Neobvyklé změny hodnoty značí problémy se čtecí / zapisovací hlavou. |
|
Power On Hours Count |
Počet odpracovaných provozních hodin. V Raw je počet uběhnutých časových jednotek, což u některých disků bývá počet hodin (v hex), u jiných to ale mohou být např. pětiminutové intervaly. |
|
Spin Retry Count |
Počet opakovaných pokusů o roztočení ploten. Pokud není rovno nule, zálohujte. |
|
Calibration Retry Count |
Počet opakovaných pokusů o rekalibraci. Mělo by být rovno nule. |
|
Power Cycle Count |
Obdoba Start/Stop Count. U některých disků stejná hodnota, u jiných rozdílná v závislosti na různých faktorech (např. odlišováno vypnutí a Suspend-to-RAM). |
|
Temperature |
Teplota disku (ve Value). Raw má někdy stejnou hodnotu jako Value, jindy neidentifikovatelné číslo. Worst udává nejvyšší kdy dosaženou teplotu. |
|
Hardware ECC Recovered |
Počet opravených chybných čtení (viz. Raw Read Error Rate). Obvykle rychle roste, což ale není na škodu. |
|
Reallocated Event Count |
Počet sektorů k přealokování (1 sektor = 512 byte). Jakákoliv hodnota vyšší než nula značí problémy. |
|
Current Pending Sector |
Počet sektorů, jejichž stav je podezřelý. Po spuštění diagnostických utilit bývá obvykle použití sektoru zakázáno a tento nahrazen jiným sektorem ze záložní oblasti. Current Pending Sector se proto vynuluje a o stejnou hodnotu vzroste Reallocated Sector Count. |
|
Offline Correctable |
Počet problémových sektorů, které je možné nahradit ze záložní oblasti. Pokud hodnota není stejná jako Reallocated Event Count, značí to závažné problémy disku, které nelze ošetřit ani diagnostickými utilitami. V takovém případě je třeba disk reklamovat. |
|
UltraATA CRC Error Rate |
Počet chyb v komunikaci s řadičem. V Raw je kumulováno počet těchto chyb. Pokud není nula, značí to problémy s kabelem (poškození vodičů, přílišné rušení atp.) či problémy řadiče samotného - například při přetaktování. |
|
Soft Read Error Rate |
???. Hodnota rozdílná od nuly značí problémy. |
V případě problémů se sektory (Reallocated Event Count a Current
Pending Sector není rovno nule) je možné spuštěním diagnostických utilit
výrobce tyto přealokovat do záložní oblasti. Obvykle se tomuto postupu
říká Low Level Format, i když to není zcela přesné, protože zde
nedochází k nahrazování značek. Co program provede, je, že prozkoumá
čitelnost všech sektorů a problémové přealokuje. Mimo to program
provede tzv. Zero Write (či Zero Fill), což, jak název napovídá, není nic
jiného než zapsání nul na celý povrch disku. Tím se magnetizovatelná látka
pročistí do výchozí podoby a připraví se pro nové zmagnetizování.
Přirozeně při tom přijdete o všechna data na disku uložená.
Osobně doporučuji zero write preventivně spouštět jednou za
rok, pokud k tomu máte možnosti (tedy především čas a místo na zálohu
dat - ideální je to například pro RAID 1). Zabráníte tím náhodné
změně dat sektoru v důsledku nepoužívání.
Jedním z nejznámějších diagnostických programů je Drive Fitness Test
Odkazy na diagnostické utility:
IBM / Hitachi - Drive Fitness Test
Seagate - SeaTools
Maxtor - PowerMax
Western Digital - Data Lifeguard
Samsung - H-Util
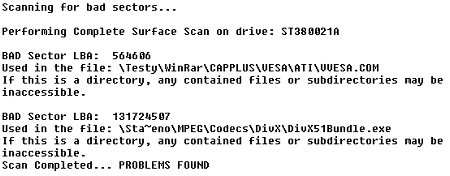
SeaTools našly na disku problémové sektory ve dvou souborech. Disk tyto sektory
sice dokázal po asi minutě snahy přečíst, elektronika je však
preventivně přealokovala.
Co dělat, když už disk nefunguje?
Když už se disk porouchal, je třeba si ujasnit, co se mu stalo (viz. část 'typy poškození'). V případě poškození elektroniky stačí tuto vyměnit za elektroniku ze zcela stejného disku (stejná modelová řada, stejná kapacita a pokud možno i stejný firmware), nastartovat, zazálohovat data, namontovat zpět původní elektroniku a disk odnést na reklamaci. Horší je situace, kdy se disk porouchal mechanicky. V případě vzniku prvního chybného sektoru je nutné ihned zálohovat, protože se může snadno stát, že chyby budou přibývat rapidním tempem a během pár hodin provozu již data zachránit nepůjdou. Někdy se ale může ukázat, že disk po vytvoření asi deseti až dvaceti chybných sektorů (tzv. BBček - Bad Blocks) již pracuje zcela v pořádku několik let - v případě reklamace disku se tak vystavujete potenciálně většímu riziku ztráty dat při chybě nového disku. Osobně takto mám dva disky Seagate a musím přiznat, že jim i přes nějaké ty BBčka věřím.
Takto dopadl disk zmíněný výše po třech měsících provozu - Týden
poté, co Raw Read Error Rate přestal být nulový, se na disku objevily
chybné sektory, které začaly rychle přibývat. Na snímku je 131 (83h)
sektorů k přemapování.
V případě katastrofálního selhání (např. poškození čtecí /
zapisovací hlavy, porucha motoru točícího plotnami) je nutné disk odnést
do specializované firmy provádějící záchranu dat. Taková záchrana ovšem
vyjde dost draho, v řádu tisíců až desetitisíců Kč.
Pořízení RAIDu 1 (zrcadlení dvou disků) je v konečném
důsledku mnohem levnější. Mimo to při fatálním selhání téměř
nikdy nelze obnovit z disku všechna data.
Z uvedeného je vidět, že jakožto uživatel můžete zachraňovat data pouze při vzniku chybných sektorů a případně i při poruše elektroniky (pokud ovšem máte náhradní). Plyne z toho jediné - zálohovat se vyplatí, vždyť data jsou na počítači to nejcennější.
Co udělá prodejce / výrobce při reklamaci (RMA)?

Maxtor tvrdí, že počet ročně vrácených disků je méně
než 1 procento. Je to ale pravda?
V době tvrdých cenových tlaků a klesajícího zájmu o výnosné velké
kapacity se výrobci musí snažit minimalizovat množství vrácených pevných
disků. Řešení v takovém případě je vcelku jednoduché -
výrobce disk opravuje jeho přeformátováním. V továrně při
výrobě disk formátují (vytváří na něm navigační
značky), přičemž vždy narazí na nějaké chyby. Tyto chyby
jsou přealokovány do jiných oblastí, jinými slovy místo s chybou je
nahrazeno volným místem v jiné části disku (vyrobit celou plotnu bez
jediné chyby je prakticky nemožné - stejně se dnes postupuje i při
výrobě např. procesorů, které také obsahují záložní bloky).
Elektronika disku je na toto nastavena, takže pro uživatele to nemá žádný
negativní dopad.
Při opravě chybného disku po vzniku chybných sektorů pak stačí tento znovu low level naformátovat. Výrobce pak nemusí disk vyhodit do koše a ušetří. Jenže pokud už plotna selhávala z důvodu nějakého skrytého defektu, může se snadno stát, že disk z reklamace bude mít větší riziko havárie než průměrný nový disk. Toto se hojně stávalo u disků IBM Deskstar 75GXP, kde si uživatelé velmi stěžovali, že disky přijaté z reklamace selhávají stejně rychle nebo dokonce rychleji než jejich původní kus. Proto pozor, obecně se spíše nevyplatí reklamovat disk, na kterém vzniklo několik málo chybných sektorů, ale jinak již běží bez problémů. Samozřejmě že při rapidně narůstajícím množství BBček či při chybném čtení je nutné se disku co nejrychleji zbavit.
Které disky jsou spolehlivé?
V zásadě platí, že všechny značky se porouchávají. Neexistuje jediná značka, která by byla absolutně spolehlivá. A to bohužel platí i o drahých SCSI discích pro servery. Emocionální diskuze na různých fórech pouze potvrzují, že jistotu o data nemůžete mít nikdy. Problémem při hodnocení spolehlivosti je především to, že příslušná statistická data je možné získat až po dlouhé době, tedy v okamžiku, kdy se disk téměř neprodává.

Který selže příště?
Přesto existuje databáze zkušeností s pevnými disky. Najdete jí na serveru
StorageReview po zaregistrování se a vyplnění vlastních zkušeností (link -
https://www.storagereview.com/map/lm.cgi/survey_login).
Údaje v této databázi se netýkají jen porouchaných, ale také plně
funkčních pevných disků, takže můžete snadno získat
představu, jak jsou které generace na tom. Musím říct, že údaje z
této databáze vcelku odpovídají 'drbům', které se ke mně
dostanou z jiných zdrojů - například od kamarádů, kteří
mají kamarády v nějakém tom větším obchodě (statistiky o
poruchovosti jsou samozřejmě velmi pečlivě střeženy).
Závěr - zásady pro zlepšení spolehlivosti disku
Na závěr shrnutí, co je možné udělat, aby měl disk co nejoptimálnější podmínky, tj. co nejdelší životnost:
Pokud k tomu budete průběžně sledovat hodnoty ze S.M.A.R.T.,
riziko ztráty dat tím výrazně zredukujete. Ještě větší jistotu
lze získat použítím RAID1, o tom si ale povíme až příště.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 846
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2024 . All rights reserved