| CATEGORII DOCUMENTE |
| Bulgara | Ceha slovaca | Croata | Engleza | Estona | Finlandeza | Franceza |
| Germana | Italiana | Letona | Lituaniana | Maghiara | Olandeza | Poloneza |
| Sarba | Slovena | Spaniola | Suedeza | Turca | Ucraineana |
DOCUMENTE SIMILARE |
|
Wst�p merytoryczny
Analiza statystyczna zmiennej obja�nianej
�rednia, wariancja oraz odchylenie standardowe
Histogram
Nieparametryczne testy istotno�ci
Przedzia�y ufno�ci
Parametryczne testy istotno�ci
Testowanie hipotez dotycz�cych rozk�adu zmiennej obja�nianej
Podsumowanie statystycznej analizy zebranych danych
Analiza wariancji (metoda ANOVA)
Badanie wsp�czynnika zmienno�ci
Badanie homogeniczno�ci wariancji
Jednokierunkowa analiza wariancji
Budowa modelu ekonometrycznego
Badanie autokorelacji
Metoda regresji krokowej
Weryfikacja modelu
Analiza wariancji
Analiza rozk�adu reszt
Istotno�� parametr�w strukturalnych
Zasada koincydencji
Ocena dopasowania modelu do danych empirycznych
Prognozowanie
Wyr�wnanie wyk�adnicze Browna
STUDIA MEDYCZNE � jak dosta� si� na akademi� medyczn�, jaki przebieg maj� studia, ile lat trwaj�
Studia medyczne ciesz� si� nadal dus� popularno�ci� w�r�d absolwent�w szk� �rednich. Przeci�tnie o jedno miejsce na akademi� medyczn� walcz� 2 � 3 osoby. Szko�y przyjmuj� kandydat�w na I rok studi�w na podstawie wynik�w konkursowego egzaminu wst�pnego. Egzamin ma charakter zintegrowanego testu i obejmuje program nauczania szko�y �redniej z biologii, chemii, fizyki i j�zyka obcego.
Studia lekarskie trwaj� 6 lat (12 semestr�w). Pierwsze lata studi�w po�wi�cone s� przede wszystkim nauce dyscyplin podstawowych, do kt�rych nales� przedmioty o profilu morfologicznym i biochemiczno-fizjologicznym, takie jak: histologia z embriologi�, anatomia prawid�owa, biofizyka, fizjologia itd. Na trzecim roku studi�w program przewiduje nauczanie dyscyplin przedklinicznych, kt�re obejmuj� grup� przedmiot�w z dziedziny patologii (anatomia patologiczna, patofizjologia) i grup� przedmiot�w lekarsko-spo�ecznych (farmakologia, mikrobiologia, psychologia lekarska, socjologia medycyny itd.). Na dalszych latach studi�w (IV, V, VI rok) przewasaj� dyscypliny kliniczne. Jest to okres studi�w, w kt�rym zdobyta wcze�niej wiedza s�usy rozwi�zywaniu praktycznych problem�w lekarskich i uzupe�niana jest wiedz� w�a�ciw� dla danej dyscypliny klinicznej. Studiowanie dyscyplin podstawowych i medycyny klinicznej uzupe�niaj� obowi�zkowe praktyki. S� to praktyki z zakresu piel�gniarstwa, w przychodniach lecznictwa otwartego, w laboratoriach, w stacjach sanitarno-epidemiologicznych oraz na oddzia�ach chor�b wewn�trznych i na oddzia�ach zabiegowych. Po uko�czeniu studi�w i uzyskaniu dyplomu lekarza wszyscy absolwenci zobowi�zani s� do odbycia rocznego stasu w zakresie czterech podstawowych dyscyplin klinicznych (choroby wewn�trzne, chirurgia, po�osnictwo wraz z ginekologi� oraz choroby dzieci). Odbycie stasu daje dopiero prawo do samodzielnego wykonywania zawodu lekarza. Na tym jednak kszta�cenie lekarza nie ko�czy si�. Wiedza wyniesiona ze studi�w, ze wzgl�du na dynamicznie rozwijaj�ce si� obecnie nauki medyczne, wystarcza zaledwie na kilka lat, a potem wymaga uzupe�nienia najcz�ciej przez kszta�cenie lub samokszta�cenie. Kszta�cenie i samokszta�cenie absolwent�w akademii medycznych jest uj�te w ramy sformalizowanego systemu specjalizacji, studi�w podyplomowych, kurs�w doskonal�cych (og�lnolekarskich i specjalistycznych) itp.. Mosna powiedzie�, se kszta�cenie lekarza trwa do ko�ca jego sycia, bowiem w okresie trwania praktyki zawodowej posiadana wiedza stopniowo si� dezaktualizuje.
STUDENCI MEDYCYNY � co sk�ania m�odych ludzi do podj�cia studi�w, a co ich zniech�ca, co wp�ywa na ilo�� przyjmowanych kandydat�w
Zainteresowania
Podj�cie studi�w lekarskich cz�stokro� jest poprzedzone wcze�niejszym zainteresowaniem si� tematyk� medyczn�, czy to przez og�lnie dost�pne ksi�ski, czasopisma, czy tes za spraw� dobrego nauczyciela z biologii.
Tradycyjnie ugruntowane przekonanie o wysokiej randze zawodu lekarza to jeden z podstawowych motyw�w, kt�rym kieruj� si� m�odzi ludzie decyduj�c si� na podj�cie studi�w medycznych. O dusej popularno�� studi�w medycznych �wiadczy fakt, is coroczna liczba kandydat�w na te studia kilkakrotnie przewyssza ilo�� dost�pnych miejsc.
M�odzi ludzie cz�sto przychodz� na studia medyczne z zamiarem niesienia ludziom otuchy i pomocy. Wielu pragnie w przysz�o�ci po�wi�ci� si� innym, aby zmniejszy� ich cierpienie. W toku studi�w stykaj� si� jednak nieraz z innymi wzorami post�powania, wobec czego szybko rezygnuj� ze swoich idea��w, a niejednokrotnie takse z dalszych studi�w.
Studia medyczne s� zdecydowanie bardziej intensywne i przez to znacznie trudniejsze nis inne studia, wymagaj� bardzo dusego samozaparcia i wielu wyrzecze� - nie ma tu mowy o 'syciu studenckim'. U�wiadomienie sobie, jak d�ugotrwa�y jest proces kszta�cenia lekarza, prowadzi do d�usszego zastanowienia si� nad decyzj� podj�cia studi�w medycznych i do rezygnacji z nich w przypadku braku motywacji wewn�trznej.
Lekarz bez specjalizacji jest obecnie lekarzem bez szans, co
w wyniku daje
nie 6 ale 8 i wi�cej lat nauki. Przygotowanie do zawodu jest cz�sto mierne - a
to z powodu ma�ej ilo�ci zaj�� praktycznych - na praktykach (w pierwszych
latach studi�w) studenci cz�sto przydaj� si� jedynie do sprz�tania po
pacjentach; a takse z powodu fatalnego zaplecza naukowego
niekt�rych uczelni.
Uczelnie rozsiane po ca�ej Polsce maj� odmienne programy nauczania, przez
co jedne z nich wypuszczaj� lepiej, inne - gorzej przygotowanych do zawodu
lekarzy.
Stypendia
Otrzymywane stypendia naukowe, czy stypendia socjalne mog� cz�sto mie� ogromny wp�yw na sytuacj� materialn� student�w, a tym samym na mosliwo�ci ich studiowania na danej uczelni.
Znajomo�� perspektyw zawodowych absolwent�w akademii medycznych jest jednym z czynnik�w, kt�re wyznaczaj� efektywno�� uczenia si� oraz kszta�tuj� motywacj� i poziom aspiracji student�w. Obecnie perspektywy dla przysz�ych lekarzy nie s� zachwycaj�ce. Ubywa miejsc pracy. Szpitale zmuszone s� likwidowa� oddzia�y. W plac�wkach jednostek badawczo � rozwojowych przeprowadzane s� znaczne redukcje etat�w.
Powszechnie uwasa si�, se naj�atwiej wystartowa�
stomatologom � nietrudno za�osy� w�asny gabinet (nawet w bloku mieszkalnym);
wi�se si� to oczywi�cie
z zainwestowaniem pewnej kwoty pieni�dzy - ale od czego s� kredyty. Prywatna
praktyka stomatologiczna to praca w wyznaczonych przez siebie godzinach, dobrze
p�atna, cz�sto w domu. Prywatna praktyka lekarska (takse specjalistyczna) - to
jus trudniejsza sprawa - koszta s� znacznie wi�ksze, potrzeba do tego wi�kszego
gabinetu. Lekarze pe�noetatowi w szpitalach - zarobki niskie, praca ci�ska -
dysury
nocne, brak zabezpieczenia socjalnego i jakichkolwiek gwarancji socjalnych;
cz�sto praca przy braku zaplecza technicznego; do tego narzekania pacjent�w.
Zarobki
Ma�o jest os�b, kt�re id� na medycyn� dla pieni�dzy - z
prac� jest naprawd� ci�sko, w zasadzie student bez motywacji nie ma szans
przetrwa�.
Lekarze na pocz�tku mog� liczy� na wyp�aty rz�du 1000-1200 PLN. Najwi�ksze
zarobki maj� oczywi�cie cz�onkowie kas chorych - absurdalnie wysokie; jak
g�osz� plotki sprz�taczka w kasie chorych zarabia wi�cej nis anestezjolog,
niezb�dny przy
kasdym zabiegu inwazyjnym. Praca w kasach chorych to praca w godzinach
9.00-15.30, �wietnie p�atna, polegaj�ca na podbijaniu druczk�w i pracy przy
bardzo nowoczesnym komputerze, w budynku dor�wnuj�cym wygl�dem najnowszym
plac�wkom bank�w.
Lekarze specjali�ci z wieloletnim stasem mog� liczy� na
zarobki do 2000
PLN, wliczaj�c w to dysury nocne; do tego co nieco od pacjent�w -
w wi�kszo�ci pieni�dze, alkohol - 'aby popchn�� sprawy'
Ordynatorzy, dyrektorzy szpitali - duse zarobki; przy czym ordynator pracuje jako lekarz, a dyrektor niestety zajmuje si� tylko (w wi�kszo�ci przypadk�w) papierkow� robot�.
Wydatki z budsetu pa�stwa na opiek� zdrowotn� nie pokrywaj� rzeczywistych potrzeb plac�wek ochrony zdrowia. Wyposasenie szpitali jest bardzo ubogie i nie zapewnia studentom efektywnego przyswajania wiedzy, a lekarzom - skutecznego leczenia.
Wysszy poziom zachorowalno�ci na r�snorodne choroby w�r�d spo�ecze�stwa powoduje wzrost zapotrzebowania na wykwalifikowan� s�usb� medyczn�, co sk�ania akademie medyczne do otwarcia wi�kszej liczby miejsc na poszczeg�lnych kierunkach.
Nastawienie pacjent�w do lekarzy
W�r�d pacjent�w cz�stokro� kr�sy nie najlepsza opinia o
lekarzach. Sk�d takie nastawienie? Lekarze pierwszego kontaktu (lekarze
rodzinni) s� fatalnie przygotowani do zawodu. Pacjenci cz�sto wiedz� wi�cej np.
o mammografii nis wymienieni wysej lekarze, co powoduje cz�sto konflikty,
lekarze ci s� opieszali, nie wykonuj� rutynowych bada�. Cz�sto w
szpitalach po prostu brak jest niezb�dnego sprz�tu medycznego - niezadowolenie
pacjent�w znowu skupia si� na lekarzach.
MOJA ANALIZA PROBLEMU
Problem, kt�rym zaj�am si� w mojej analizie, to okre�lenie, jakie czynniki maj� wp�yw na liczb� absolwent�w akademii medycznych.
Dla cel�w mojej pracy przyj�am pr�bk� 14 obserwacji liczby absolwent�w akademii medycznych w Polsce w latach 1985 � 1998, kt�rej warto�ci przedstawi�am na ponisszym wykresie:
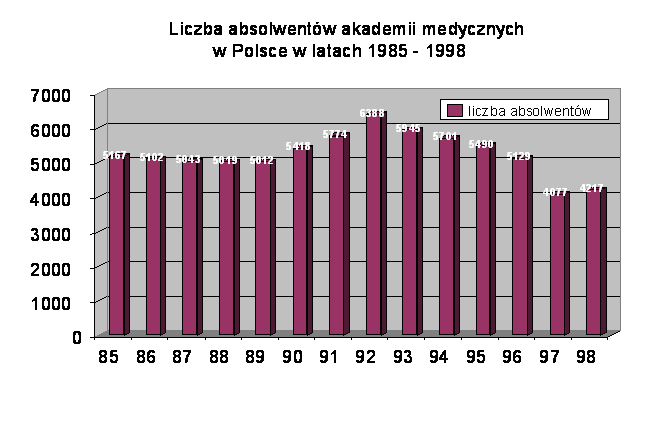
Ze wzgl�du na ograniczon� ilo�� czynnik�w, kt�rych dane statystyczne s� og�lnie dost�pne, musia�am zaw�sy� kr�g zmiennych maj�cych wp�yw na przedmiot moich bada�.
Ponisej zaprezentowa�am wszystkie wybrane czynniki oraz ich warto�ci w danym przedziale czasowym:
|
X1 |
liczba szk� wysszych w Polsce innych nis akademie medyczne |
|
X2 |
liczba przydzielonych stypendi�w naukowych na akademiach medycznych |
|
X3 |
liczba pracownik�w w jednostkach badawczo-rozwojowych w dziedzinie nauk medycznych |
|
X4 |
wydatki z budsetu na ochron� zdrowia [USD] |
|
X5 |
PKB [USD] |
|
X6 |
wynagrodzenia miesi�czne lekarza [USD] |
|
X7 |
liczba wydawanych czasopism medycznych |
|
X8 |
liczba ksi�sek medycznych [nak�ad w tys. egzemplarzy] |
|
X9 |
liczba zapom�g przyznawanych studentom akademii medycznych |
|
X10 |
leczeni w szpitalach og�lnych [tys. os�b] |
|
X11 |
kandydaci na akademie medyczne, kt�rzy przyst�pili do egzaminu, lecz nie zostali przyj�ci |
|
lata |
absolwenci |
inne szko�y |
stypendia naukowe |
pracownicy jednostek B+R |
wydatki na ochron� zdrowia |
PKB |
wynagrodzenia |
czasopisma |
ksi�ski |
zapomogi |
leczeni |
nie dostali si� |
Dla pobranej pr�by �rednia, wariancja oraz odchylenie standardowe maj� nast�puj�ce warto�ci:
Variable: DANE.absolwenci
Sample size 14
Average 5248.71
Median 5148
Variance 383166
Standard deviation 619.004
Standard error 165.436
Minimum 4077
Maximum 6388
Range 2311
S2 = 383166
![]()
S
Warto�ci wariancji i odchylenia standardowego wskazuj� na niezbyt duse, ale wystarczaj�ce rozproszenie warto�ci pr�bki. Wsp�czynnik zmienno�ci przyjmuje warto��:
![]() 0.1179
0.1179
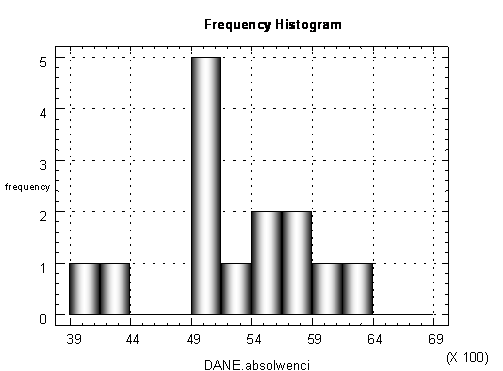
![]() Weryfikacja hipotezy dotycz�cej losowo�ci pr�bki
Weryfikacja hipotezy dotycz�cej losowo�ci pr�bki
Weryfikacj� hipotezy H0 dotycz�cej losowo�ci zmiennej obja�nianej przeprowadzi�am za pomoc� testu serii.
Kolejnym warto�ciom yi przypisa�am symbole:
A � dla yi � liczba parzysta,
B � dla yi � liczba nieparzysta.
|
yi |
symbol |
|
b |
|
|
a |
|
|
b |
|
|
b |
|
|
a |
|
|
a |
|
|
a |
|
|
a |
|
|
b |
|
|
b |
|
|
a |
|
|
b |
|
|
b |
|
|
b |
Otrzyma�am w ten spos�b ci�g z�osony z symboli A i B
BABBAAAABBABBB,
w kt�rym mosna zauwasy� serie, czyli podci�gi z�osone z kolejnych element�w jednego rodzaju. St�d okre�li�am liczb� serii k empiryczne.
k = 7
Z tablic liczby serii odczyta�am, dla przyj�tego poziomu istotno�ci a oraz dla n1(liczba symboli A) i n2 (liczba symboli B), warto�� krytyczn� k1 i k2.
n1 = 6,
n2 = 8,
k1 = 4 dla a
k2 = 11 dla a
Otrzymane k spe�nia zalesno��:
k1 < k < k2,
dlatego przyj�am hipotez� o losowo�ci pr�bki.
Na poziomie ufno�ci 0.95 (ryzyko b��du a = 0.05), przy za�oseniu o normalno�ci rozk�adu badanej cechy, wyznacz� przedzia�y ufno�ci dla �redniej i wariancji.
![]() Przedzia� ufno�ci dla warto�ci przeci�tnej
Przedzia� ufno�ci dla warto�ci przeci�tnej
Wykorzystywana jest statystyka:
![]()
posiadaj�ca rozk�ad t Studenta o n - 1 stopniach swobody.
Przedzia�em ufno�ci dla warto�ci przeci�tnej, na poziomie ufno�ci a, jest zbi�r:
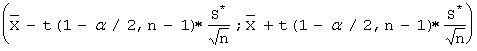
gdzie:
t(x,y) - kwantyl rz�du x rozk�adu t Studenta o y stopniach swobody.
Wyniki, kt�re uzyska�am wykorzystuj�c pakiet STATGRAPHICS:
One-Sample Analysis Results
DANE.absolwenci
Sample Statistics: Number of Obs. 14
Average 5248.71
Variance 383166
Std. Deviation 619.004
Median 5148
Confidence Interval for Mean: 95 Percent
Sample 1 4891.22 5606.21 13 D.F.
Zatem przedzia�em ufno�ci dla warto�ci przeci�tnej jest zbi�r (
![]() Przedzia�y ufno�ci dla wariancji
Przedzia�y ufno�ci dla wariancji
Wykorzystywana jest statystyka:
![]()
posiadaj�ca rozk�ad c o n - 1 stopniach swobody.
Przedzia�em ufno�ci dla wariancji, na poziomie ufno�ci a jest zbi�r:
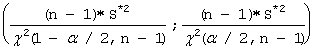
Wyniki, kt�re uzyska�am wykorzystuj�c pakiet STATGRAPHICS:
Confidence Interval for Variance: 95 Percent
Sample 1 201376 994506 13 D.F.
Zatem przedzia�em ufno�ci jest dla wariancji zbi�r (
Przy za�oseniu o normalno�ci rozk�adu badanej cechy, zweryfikowane zostan� hipotezy dotycz�ce warto�ci przeci�tnej i wariancji.
![]() Weryfikacja hipotezy dotycz�cej warto�ci przeci�tnej
Weryfikacja hipotezy dotycz�cej warto�ci przeci�tnej
m0 = 5248
Zweryfikowana zostanie nast�puj�ca hipoteza:
H0: warto�� przeci�tna m = m0
Wobec nast�puj�cych hipotez alternatywnych:
K1: warto�� przeci�tna m ¹ m0
K2: warto�� przeci�tna m > m0
K3: warto�� przeci�tna m < m0
Do weryfikacji hipotezy pos�usy statystyka t wyrasaj�ca si�
wzorem:
![]()
Statystyka powyssza ma, przy za�oseniu prawdziwo�ci weryfikowanej hipotezy, rozk�ad t Studenta o n - 1 stopniach swobody. Dla odpowiednich hipotez alternatywnych zbiorami krytycznymi s�:
¥; - t(1 - a/2, n - 1) > È < t(1 - a/2, n - 1); + ¥
< t(1 - a, n - 1); + ¥
¥; - t(1 - a, n - 1) >
gdzie:
a - poziom istotno�ci;
t(x,y) - kwantyl rz�du x rozk�adu t Studenta o y stopniach swobody.
Weryfikowan� hipotez� nalesy odrzuci�, gdy obliczona z pr�by warto�� statystyki t nalesy do zbioru krytycznego, w przeciwnym razie nie ma podstaw do odrzucenia tej hipotezy.
Weryfikacja postawionej hipotezy przeprowadzona zostanie na poziomie istotno�ci
a
Uzyska�am nast�puj�ce wyniki:
|
Hypothesis Test for H0: Mean = 5248 Computed t statistic = 4.3176E-3 |
Przeprowadzone testy wykaza�y, se nie ma podstaw do odrzucenia tych hipotez na danym poziomie istotno�ci, gdys warto�ci Sig. Level s� wi�ksza od za�osonego poziomu istotno�ci. |
|
|
K1: m ¹ |
vs Alt: NE Sig. Level = 0.996621 at Alpha = 0.05 so do not reject H0 |
|
|
K2: m > 5248 |
vs Alt: GT Sig. Level = 0.49831 at Alpha = 0.05 so do not reject H0 |
|
|
K3: m < 5248 |
vs Alt: LT Sig. Level = 0.50169 at Alpha = 0.05 so do not reject H0 |
![]() Weryfikacja hipotezy dotycz�cej wariancji
Weryfikacja hipotezy dotycz�cej wariancji
s
Zweryfikowana zostanie nast�puj�ca hipoteza:
H0: wariancja s s
Wobec nast�puj�cych hipotez alternatywnych:
K1: wariancja s ¹ s
K2: wariancja s > s
K3: wariancja s < s
Do weryfikacji hipotezy pos�usy statystyka c
Dla odpowiednich hipotez alternatywnych zbiorami krytycznymi s�:
c a/2, n - 1) > È < c a/2, n - 1); + ¥
< c a, n - 1); + ¥
c a, n - 1) >
Weryfikowan� hipotez� nalesy odrzuci�, gdy obliczona z pr�by warto�� statystyki c nalesy do zbioru krytycznego, w przeciwnym wypadku nie ma podstaw do odrzucenia tejse hipotezy.
Weryfikacj� hipotezy dotycz�cej wariancji przeprowadz� przy usyciu tablic statystycznych na poziomie istotno�ci a
Warto�� statystyki testowej wynosi:
![]()
Przedzia�y krytyczne maj� dla odpowiednich hipotez alternatywnych nast�puj�c� posta�:
(0; 5.009 > È < 24.736; + ¥
< 22.362; + ¥
(0; 5.892 >
Poniewas obliczona statystyka z pr�by nie nalesy do sadnego z powysszych przedzia��w, dla kasdej z hipotez alternatywnych: K1, K2 oraz K3 nie ma podstaw, na poziomie istotno�ci a = 0.05, do odrzucenia hipotezy H0.
Weryfikuj� hipotez�:
H0: F(Y) = FN(Y)
wobec hipotezy alternatywnej
H1: F(Y) ¹ FN(Y),
gdzie: FN(Y) � dystrybuanta rozk�adu normalnego o parametrach (, S), gdzie:
S - odchylenie standardowe z pr�by,
- �rednia z pr�by.
Uporz�dkowa�am warto�ci pr�bki rosn�co (kolumna 2), dokona�am ich standaryzacji (kolumna 3), a nast�pnie odczyta�am warto�ci dystrybuanty dla kasdej standaryzowanej obserwacji (kolumna 4). Odcinek [0,1] podzieli�am na 14 cel r�wnej d�ugo�ci, kt�rych przedzia�y s� wypisane w kolumnie 5.
|
yi |
yi rosn�co |
ui |
F(ui) |
Ii |
||||
S | ||||||||
Ponisej zaznaczy�am, ile warto�ci dystrybuanty wpad�o do kasdej z cel i otrzyma�am h�0 = 4 cele puste.
Z tablic do testu Hellwiga odczyta�am warto�� krytyczn� h�1-a = 8 dla n = 14 i a
Poniewas h�1-a = 8 i h�0 = 4, st�d zachodzi nier�wno�� h�0 < h�1-a, co oznacza, is nie mamy podstaw do odrzucenia hipotezy H0: F(Y) = FN(Y).
Na podstawie przeprowadzonych test�w oraz oblicze� stwierdzi� mosna, is:
pobrana pr�bka jest losowa na poziomie istotno�ci a = 0.05 wg testu serii;
badana cecha ma w populacji generalnej rozk�ad normalny N( ) na poziomie istotno�ci a
warto�� przeci�tna pr�bki jest zawarta w przedziale ( ) z prawdopodobie�stwem 0.95;
wariancja pr�bki jest zawarta w przedziale ( z prawdopodobie�stwem 0.95;
na poziomie istotno�ci a = 0.05 warto�� przeci�tna populacji m = 5248, natomiast wariancja s
analiza wp�ywu zaproponowanych zmiennych na zmienn� obja�nian�
Analiza wariancji jest metod� analizy danych eksperymentalnych, s�usy do oceny wp�ywu jednego lub wi�kszej liczby czynnik�w klasyfikacyjnych na badane zjawisko. Jest to metoda statystyki matematycznej, bazuj�ca na por�wnaniu wariancji. Jednym z cz�ciej rozwi�zywanych za jej pomoc� problem�w jest analiza czynnik�w zewn�trznych wp�ywaj�cych na wynik przeprowadzonego do�wiadczenia.
Celem �wiczenia jest sprawdzenie hipotez, czy na wielko�� skupu zbosa maj� wp�yw nast�puj�ce czynniki:
|
X1 |
liczba szk� wysszych w Polsce innych nis akademie medyczne |
|
X2 |
liczba przydzielonych stypendi�w naukowych na akademiach medycznych |
|
X3 |
liczba pracownik�w w jednostkach badawczo-rozwojowych w dziedzinie nauk medycznych |
|
X4 |
wydatki z budsetu na ochron� zdrowia [USD] |
|
X5 |
PKB [USD] |
|
X6 |
wynagrodzenia miesi�czne lekarza [USD] |
|
X7 |
liczba wydawanych czasopism medycznych |
|
X8 |
liczba ksi�sek medycznych [nak�ad w tys. egzemplarzy] |
|
X9 |
liczba zapom�g przyznawanych studentom akademii medycznych |
|
X10 |
leczeni w szpitalach og�lnych [tys. sztuk] |
|
X11 |
kandydaci na akademie medyczne, kt�rzy przyst�pili do egzaminu, lecz nie zostali przyj�ci |
Zbada�am, czy zosta� spe�niony podstawowy warunek uznania zmiennych za zmienne obja�niaj�ce modelu ekonometrycznego, czyli sprawdzi�am, czy w�r�d moich danych nie wyst�puj� zmienne o zbyt niskiej zmienno�ci. Pos�usy�am si� w tym celu statystyk�:
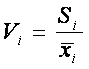
gdzie:
Vi - wsp�czynnik zmienno�ci
Si - odchylenie standardowe z pr�by
x i - �rednia z pr�by
i - numer zmiennej
|
ZMIENNA |
�REDNIA X i |
ODCHYLENIE Si |
WSPӣCZYNNIK ZMIENNO�CI Vi |
|
X1 | |||
|
X2 | |||
|
X3 | |||
|
X4 | |||
|
X5 | |||
|
X6 | |||
|
X7 | |||
|
X8 | |||
|
X9 | |||
|
X10 | |||
|
X11 |
Za warto�� krytyczn� V *, czyli minimum wsp�czynnika zmienno�ci przyj�am warto�� V* = 0,10. Nast�pnie przyr�wna�am kolejno otrzymane warto�ci Vi z ustalonym minimum. Je�li Vi < V *, to zmienna Xi jest eliminowana, gdys jest to tzw. quasi � sta�a.
Nie ma podstaw do odrzucenia sadnej z moich zmiennych, gdys wszystkie przekraczaj� warto�� krytyczn�.
W celu weryfikacji hipotezy o wp�ywie jednej zmiennej jako�ciowej na zmienn� ilo�ciow� pos�usy� si� mosna jednoczynnikow� (jednokierunkow�) analiz� wariancji.
W zwi�zku z tym, se zmienne te s� wyrasone ilo�ciowo, a analiz� wariancji mosemy przeprowadzi� tylko na zmiennych jako�ciowych podzieli�am kasdy czynnik na trzy grupy wed�ug wielko�ci. Pierwsza grupa (I) jest grup� o najmniejszych wielko�ciach, druga (II) - o �rednich, trzecia (III) - o najwi�kszych.
|
CZYNNIK |
GRUPA I |
GRUPA II |
GRUPA III |
|
X1 | |||
|
X2 | |||
|
X3 | |||
|
X4 | |||
|
X5 | |||
|
X6 | |||
|
X7 | |||
|
X8 | |||
|
X9 | |||
|
X10 | |||
|
X11 |
Dla kasdej wielko�ci zmiennej obja�nianej w poszczeg�lnych latach przyporz�dkowa�am odpowiedni� grup� kasdego czynnika:
|
LATA |
Y |
X1 |
X2 |
X3 |
X4 |
X5 |
X6 |
X7 |
X8 |
X9 |
X10 |
X11 |
|
I |
I |
III |
II |
II |
I |
I |
II |
III |
I |
III |
||
|
I |
I |
III |
II |
I |
I |
I |
III |
II |
I |
III |
||
|
I |
I |
III |
I |
I |
I |
I |
III |
II |
I |
II |
||
|
I |
I |
II |
I |
I |
I |
I |
III |
II |
I |
II |
||
|
I |
I |
II |
I |
I |
I |
I |
II |
I |
I |
I |
||
|
I |
I |
I |
II |
I |
II |
I |
II |
II |
II |
I |
||
|
I |
I |
II |
II |
II |
II |
I |
I |
III |
II |
I |
||
|
I |
I |
I |
II |
II |
II |
I |
I |
III |
II |
II |
||
|
I |
I |
I |
II |
II |
II |
I |
I |
II |
II |
II |
||
|
II |
I |
I |
II |
II |
III |
II |
I |
III |
III |
II |
||
|
II |
III |
I |
III |
III |
III |
II |
I |
III |
III |
II |
||
|
III |
III |
I |
III |
III |
III |
III |
I |
I |
III |
I |
||
|
III |
III |
I |
III |
III |
III |
III |
I |
I |
III |
I |
||
|
III |
III |
I |
III |
III |
III |
III |
I |
I |
III |
I |
Analiz� wariancji mosna przeprowadzi� jedynie wtedy, gdy spe�nione s� za�osenia:
wariancja dla kolejnych czynnik�w we wszystkich grupach jest jednakowa,
zmienna obja�niana dla okre�lonego czynnika ma w poszczeg�lnych grupach rozk�ad normalny.
Dla wszystkich czynnik�w przeprowadzi�am test hipotezy:
H0: wariancja dla kolejnych czynnik�w we wszystkich grupach jest jednakowa,
wobec hipotezy alternatywnej:
H1: istniej� co najmniej dwie grupy o r�snych wariancjach.
W pakiecie STATGRAPHICS dost�pne s� trzy testy weryfikacji hipotezy H. W praktycznych zastosowaniach najbardziej popularnym testem jest test Barlett�a na homogeniczno�� wariancji, kt�ry wykorzysta�am do weryfikacji hipotezy H0�.
Wyniki testu obliczone na poziomie istotno�ci a
Dla czynnika X1:
Multiple range analysis for DANE.szkoly by GRUPY.szkoly
Method: 95 Percent Confidence Intervals
Level Count Average Homogeneous Groups
9 94.55556 *
2 2 159.00000 *
3 3 230.66667 *
Dla czynnika X2:
Multiple range analysis for DANE.stypendia by GRUPY.stypendia
Method: 95 Percent Confidence Intervals
Level Count Average Homogeneous Groups
10 431.5000 *
3 4 6069.5000 *
Dla czynnika X3:
Multiple range analysis for DANE.pracownicy by GRUPY.pracownicy
Method: 95 Percent Confidence Intervals
Level Count Average Homogeneous Groups
8 2914.5000 *
2 3 5017.0000 *
3 3 8174.0000 *
Dla czynnika X4:
Multiple range analysis for DANE.wydatki by GRUPY.wydatki
Method: 95 Percent Confidence Intervals
Level Count Average Homogeneous Groups
3 1614.6667 *
2 7 3305.5714 *
3 4 5576.7500 *
Dla czynnika X5:
Multiple range analysis for DANE.pkb by GRUPY.pkb
Method: 95 Percent Confidence Intervals
Level Count Average Homogeneous Groups
5 51730.40 *
2 5 75616.00 *
3 4 136012.75 *
Dla czynnika X6:
Multiple range analysis for DANE.place by GRUPY.place
Method: 95 Percent Confidence Intervals
Level Count Average Homogeneous Groups
5 126.60000 *
2 4 258.75000 *
3 5 414.60000 *
Dla czynnika X7:
Multiple range analysis for DANE.czasopisma by GRUPY.czasopisma
Method: 95 Percent Confidence Intervals
Level Count Average Homogeneous Groups
9 157.11111 *
2 2 240.00000 *
3 3 327.66667 *
Dla czynnika X8:
Multiple range analysis for DANE.ksiazki by GRUPY.ksiazki
Method: 95 Percent Confidence Intervals
Level Count Average Homogeneous Groups
8 3351.500 *
2 3 7401.667 *
3 3 10657.667 *
Dla czynnika X9:
Multiple range analysis for DANE.zapomogi by GRUPY.zapomogi
Method: 95 Percent Confidence Intervals
Level Count Average Homogeneous Groups
4 689.2500 *
2 5 1037.2000 *
3 5 1473.8000 *
Dla czynnika X10:
Multiple range analysis for DANE.leczeni by GRUPY.leczeni
Method: 95 Percent Confidence Intervals
Level Count Average Homogeneous Groups
5 4311.4000 *
2 4 4752.0000 *
3 5 5391.6000 *
Dla czynnika X11:
Multiple range analysis for DANE. niedostalisie by GRUPY.niedostalisie
Method: 95 Percent Confidence Intervals
Level Count Average Homogeneous Groups
6 6738.500 *
2 6 8653.667 *
3 2 11195.000 *
Wnioski:
Na poziomie istotno�ci a = 0.05 nie ma podstaw do odrzucenia hipotezy o homogeniczno�ci wariancji w grupach dla sadnego z czynnik�w, gdys dla wszystkich poziomy istotno�ci P dla testu Bartlett�a s� wi�ksze od 0.05.
Zmienne spe�ni�y za�osenia konieczne do analizy wariancji, wi�c przesz�am do wykonania tej procedury.
Dla wszystkich czynnik�w przeprowadzi�am test hipotezy:
H0: �rednie we wszystkich grupach s� jednakowe (poszczeg�lne zmienne obja�niaj�ce nie maj� wp�ywu na zmienn� obja�nian�)
wobec hipotezy alternatywnej:
H1: istniej� co najmniej dwie grupy o r�snych �rednich.
Jednoczynnikow� analiz� wariancji przeprowadzi�am w opcji J.1. One - Way Analysis of Variance pakietu STATGRAPHICS.
Wyniki analizy dla poszczeg�lnych czynnik�w s� nast�puj�ce:
Dla czynnika X1:
Source of variation Sum of Squares d.f. Mean square F-ratio Sig.level
Between groups 43270.040 2 21635.020 60.205 .0000
Within groups 3952.889 11 359.354
Total (corrected) 47222.929 13
Dla czynnika X2:
Source of variation Sum of Squares d.f. Mean square F-ratio Sig.level
Between groups 90820126 1 90820126 999.999 .0000
Within groups 495090 12 41257
Total (corrected) 91315215 13
Dla czynnika X3:
Source of variation Sum of Squares d.f. Mean square F-ratio Sig.level
Between groups 61406297 2 30703148 55.153 .0000
Within groups 6123628 11 556693
Total (corrected) 67529925 13
Dla czynnika X4:
Source of variation Sum of Squares d.f. Mean square F-ratio Sig.level
Between groups 28060761 2 14030380 46.320 .0000
Within groups 3331935 11 302903
Total (corrected) 31392696 13
Dla czynnika X5:
Source of variation Sum of Squares d.f. Mean square F-ratio Sig.level
Between groups 1.6378E0010 2 8.1889E0009 39.379 .0000
Within groups 2.2874E0009 11 2.0795E0008
Total (corrected) 1.8665E0010 13
Dla czynnika X6:
Source of variation Sum of Squares d.f. Mean square F-ratio Sig.level
Between groups 207761.21 2 103880.60 37.632 .0000
Within groups 30365.15 11 2760.47
Total (corrected) 238126.36 13
Dla czynnika X7:
Source of variation Sum of Squares d.f. Mean square F-ratio Sig.level
Between groups 68227.944 2 34113.972 109.609 .0000
Within groups 3423.556 11 311.232
Total (corrected) 71651.500 13
Dla czynnika X8:
Source of variation Sum of Squares d.f. Mean square F-ratio Sig.level
Between groups 1.2644E0008 2 63222426 53.300 .0000
Within groups 1.3048E0007 11 1186159
Total (corrected) 1.3949E0008 13
Dla czynnika X9:
Source of variation Sum of Squares d.f. Mean square F-ratio Sig.level
Between groups 1392660.5 2 696330.25 55.729 .0000
Within groups 137444.4 11 12494.94
Total (corrected) 1530104.9 13
Dla czynnika X10:
Source of variation Sum of Squares d.f. Mean square F-ratio Sig.level
Between groups 2945366.5 2 1472683.3 46.388 .0000
Within groups 349216.4 11 31746.9
Total (corrected) 3294582.9 13
Dla czynnika X11:
Source of variation Sum of Squares d.f. Mean square F-ratio Sig.level
Between groups 31990592 2 15995296 21.709 .0002
Within groups 8104901 11 736809
Total (corrected) 40095493 13
Powyssze wyniki analizy wariancji wskazuj�, se dla sadnego czynnika nie mosna przyj�� hipotezy H0 o braku wp�ywu na zmienn� obja�nian�, gdys dla wszystkich warto�� Sig.level jest nissza od za�osonego a = 0.05. St�d wynika, is wysej wymienione czynniki maj� wp�yw na wielko�� zmiennej obja�nianej.
W celu zbadania, czy korelacja pomi�dzy zmiennymi jest istotna pos�usy�am si� macierz� wsp�czynnik�w korelacji, kt�r� uzyska�am z procedury zamieszczonej w pakiecie STATGRAPHICS.
Macierz wsp�czynnik�w korelacji:
Y |
X1 |
X2 |
X3 |
X4 |
X5 |
X6 |
X7 |
X8 |
X9 |
X10 |
X11 |
|
|
Y | ||||||||||||
|
X1 | ||||||||||||
|
X2 | ||||||||||||
|
X3 | ||||||||||||
|
X4 | ||||||||||||
|
X5 | ||||||||||||
|
X6 | ||||||||||||
|
X7 | ||||||||||||
|
X8 | ||||||||||||
|
X9 | ||||||||||||
|
X10 | ||||||||||||
|
X11 |
Przeprowadzi�am weryfikacj� hipotezy dotycz�cej istotno�ci wsp�czynnik�w korelacji pomi�dzy zmienn� obja�nian� a zmiennymi obja�niaj�cymi:
H0: rij = 0 dla i ¹ j.
W tym celu obliczy�am warto�� krytyczn� wsp�czynnika korelacji r* wed�ug wzoru:
gdzie:
n - liczba obserwacji,
- warto�� statystyki t - Studenta dla przyj�tego poziomu istotno�ci o (n-2) stopniach swobody.
Dla a = 0.05 i n � 2 = 12 stopni swobody = 2.1788, st�d r* = 0.5324.
Wsp�czynniki korelacji spe�niaj�ce relacj�:
|rij| £ r* dla i ¹ j,
s� statystycznie nieistotne, wi�c wyeliminowa�am je ze zbioru zmiennych uzyskuj�c list� tych, kt�re s� wystarczaj�co skorelowane ze zmienn� obja�nian�:
|
X2 |
liczba przydzielonych stypendi�w naukowych na akademiach medycznych |
|
X7 |
liczba wydawanych czasopism medycznych |
|
X9 |
liczba zapom�g przyznawanych studentom akademii medycznych |
Na tym etapie nie selekcjonowa�am zmiennych do dalszej analizy i wprowadzi�am wszystkie zmienne obja�niaj�ce do kolejnego etapu budowy modelu.
Do budowy modelu zastosowa�am procedur� Forward, kt�ra polega na wyborze zmiennych obja�niaj�cych poprzez do��czanie kolejnych zmiennych do optymalnie wybranego zbioru.
Ponisej przedstawi�am wyniki zastosowania tej metody:
Stepwise Selection for DANE.absolwenci
Selection: Forward Maximum steps: 500 F-to-enter: 4.00
Control: Automatic Step: 1 F-to-remove: 4.00
R-squared: .47195 Adjusted: .42794 MSE: 219193 d.f.: 12
Variables in Model Coeff. F-Remove Variables Not in Model P.Corr. F-Enter
9. DANE.zapomogi 1.23951 10.7250 1. DANE.szkoly .1887 .4061
2. DANE.stypendia .3296 1.3410
3. DANE.pracownicy .3154 1.2152
4. DANE.wydatki .0657 .0477
5. DANE.pkb .2473 .7166
6. DANE.place .0322 .0114
7. DANE.czasopisma .2463 .7105
8. DANE.ksiazki .2387 .6643
10. DANE.leczeni .1313 .1931
11. DANE.niedostalisie .1955 .4373
Model fitting results for: DANE.absolwenci
Independent variable coefficient std. error t-value sig.level
CONSTANT 3893.041928 432.455759 9.0022 0.0000
DANE.zapomogi 1.239512 0.378488 3.2749 0.0066
R-SQ. (ADJ.) = 0.4279 SE = 468.180321 MAE = 354.956513 DurbWat = 1.103
14 observations fitted, forecast(s) computed for 0 missing val. of dep.var.
Do modelu wybrana zosta�a jedna zmienna:
|
X9 |
liczba zapom�g przyznawanych studentom akademii medycznych, |
kt�ra jest wystarczaj�co skorelowana ze zmienn� obja�nian�, co wykaza�am podczas analizy wsp�czynnik�w korelacji.
Oszacowan� liniow� funkcj� regresji mog� zapisa� nast�puj�co:
gdzie:
- liczba absolwent�w akademii medycznych,
X - liczba zapom�g przyznawanych studentom akademii medycznych.
Standardowe b��dy ocen powysszych parametr�w wynosz� odpowiednio:
dla warto�ci sta�ej: 432.455759,
dla zmiennej X: 0.378488.
Warto�� statystyki t � Studenta obliczona jako iloraz oceny parametr�w i standardowych b��d�w ocen:
dla zmiennej X: 3.2749.
Prowadzi ona, na poziomie istotno�ci a = 0.05, do odrzucenia hipotezy o tym, is wielko�� zmiennej X nie wp�ywa na warto�� zmiennej obja�nianej � Sig. Level:
dla zmiennej X: 0.0066 < 0.05.
Dodatnia warto�� wsp�czynnika regresji przy zmiennej X �wiadczy o dodatniej zalesno�ci zmiennej obja�nianej od X.
Wsp�czynnik determinacji skorygowany o liczb� stopni swobody okre�la w ilu procentach powyssze r�wnanie obja�nia zmienno�� Y:
R2 =
Odchylenie standardowe reszt oznacza przeci�tne odchylenie zmiennej Y obserwowanej w pr�bie od teoretycznej jej warto�ci, wyznaczonej z modelu:
SE =
�redni b��d absolutny jest �redni� arytmetyczn� absolutnych odchyle� warto�ci zmiennej zalesnej od jej warto�ci teoretycznych:
MAE =
Analiza wariancji w regresji dostarcza danych dotycz�cych podzia�u ca�kowitej sumy kwadrat�w zmiennej zalesnej na cz�� wyja�niona i niewyja�niona regresj�, warto�ci odpowiednich �rednich kwadrat�w odchyle� i warto�ci statystyki F, kt�ra s�usy do weryfikacji hipotezy o braku wp�ywu uwzgl�dnionych w modelu zmiennych niezalesnych.
Analysis of Variance for the Full Regression
Source Sum of Squares DF Mean Square F-Ratio P-value
Model 2350839. 1 2350839. 10.7250 .0066
Error 2630314. 12 219193.
Total (Corr.) 4981153. 13
R-squared = 0.471947 Stnd. error of est. = 468.18
R-squared (Adj. for d.f.) = 0.427942 Durbin-Watson statistic = 1.10303
Z danych analizy wariancji w regresji wynika nast�puj�cy podzia� ca�kowitej sumy kwadrat�w odchyle� zmiennej zalesnej od �redniej, kt�ra wynosi
suma kwadrat�w wyja�niana za pomoc� modelu:
resztowa suma kwadrat�w:
Liczby stopni swobody wynosz�:
dla sumy kwadrat�w wyja�nianej za pomoc� modelu:
dla resztowej sumy kwadrat�w:
�redni kwadrat odchyle� resztowych, kt�ry stanowi ocen� wariancji sk�adnika losowego d , wynosi:
MSE =
Statystyka F, kt�ra s�usy do weryfikacji hipotezy, se oba wsp�czynniki regresji jednocze�nie s� r�wne zero, ma warto��:
F - Ratio =
Hipoteza ta zostanie odrzucona na kasdym poziomie istotno�ci nie mniejszym od 0.0066, a wi�c takse na poziomie istotno�ci 0.05.
Nieskorygowany wsp�czynnik determinacji, kt�ry pozwala oceni� udzia� zmienno�ci Y wyja�nionej za pomoc� liniowego modelu regresji w ca�kowitej zmienno�ci zmiennej obja�nianej, wynosi:
R2 =
Podstaw� do weryfikacji modelu ekonometrycznego jest za�osenie o losowo�ci i rozk�adzie sk�adnika losowego wyrasonego wzorem:
Wi�kszo�� test�w (szczeg�lnie dotycz�cych parametr�w strukturalnych modelu) wymaga, by sk�adnik losowy posiada� rozk�ad N(0,s). Weryfikacj� modelu rozpocz�am wi�c od analizy sk�adnika losowego, kt�rego warto�ci podaje ponissze zestawienie:
|
NUMER OBSERWACJI |
yi |
ei = yi - |
|
|
| |||
�rednia reszt
Zweryfikowa�am nast�puj�c� hipotez�:
H0: E( ) = 0 (�rednia reszt r�wna jest 0), wobec hipotezy alternatywnej:
H1: E( ¹ 0 (�rednia reszt jest r�sna od 0)
gdzie:
� zmienna losowa opisuj�ca b��d modelu.
One-Sample Analysis Results
RESZTY.residua
Sample Statistics: Number of Obs. 14
Average -1.3E-4
Variance 202332
Std. Deviation 449.813
Median -39.7348
Confidence Interval for Mean: 95 Percent
Sample 1 -259.781 259.781 13 D.F.
Confidence Interval for Variance: 95 Percent
Sample 1 106337 525152 13 D.F.
Hypothesis Test for H0: Mean = 0 Computed t statistic = -1.08137E-6
vs Alt: NE Sig. Level = 0.999999
at Alpha = 0.05 so do not reject H0.
Dla poziomu istotno�ci a = 0.05 hipoteza zerowa zosta�a przyj�ta.
warjancja reszt r�snych okres�w czasowych
Wariancja reszt w r�snych okresach czasu powinna by� taka sama, �wiadczy to w�wczas o tym, ze zmienno�� w czasie jest jednakowa, zweryfikowa�am wi�c hipotez�:
H (wariancja reszt w r�snych okresach czasu jest taka sama),
wobec hipotezy alternatywnej:
H1: (wariancja reszt w r�snych okresach czasu jest r�sna).
Do przetestowania tego zagadnienia pos�usy�a mi statystyka F � Snedecora:

gdzie:
wariancja reszt z lat 1985 � 1991,
wariancja reszt z lat 1992 � 1998.
Two-Sample Analysis Results
RESZTY.1 RESZTY.2 Pooled
Sample Statistics: Number of Obs. 7 7 14
Average -118.319 118.319 -1.3E-4
Variance 100651 305070 202860
Std. Deviation 317.255 552.331 450.4
Median -83.806 171.802 -39.7348
Difference between Means = -236.639
Conf. Interval For Diff. in Means: 95 Percent
(Equal Vars.) Sample 1 - Sample 2 -761.321 288.044 12 D.F.
(Unequal Vars.) Sample 1 - Sample 2 -776.487 303.21 9.6 D.F.
Ratio of Variances = 0.329928
Conf. Interval for Ratio of Variances: 95 Percent
Sample 1 + Sample 2 0.0557796 1.95147 6 6 D.F.
Hypothesis Test for H0: Diff = 0 Computed t statistic = -0.982927
vs Alt: NE Sig. Level = 0.345047
at Alpha = 0.05 so do not reject H0.
Dla poziomu istotno�ci a = 0.05 nie ma podstaw do odrzucenia hipotezy o r�wno�ci wariancji r�snych okres�w - obszar krytyczny z tablicy F - Snedecora dla a=0.05; 6; 6; rozpoczyna si� od warto�ci 4.28, a z oblicze� wynika, is F =
losowo�� reszt
Weryfikacj� losowo�ci reszt przeprowadzi�am za pomoc� testu serii.
Wyznaczonym resztom ui przypisa�am symbole:
A � dla ui > 0,
B � dla ui < 0.
|
NUMER OBSERWACJI |
ei = yi - |
SYMBOL |
|
B |
||
|
B |
||
|
B |
||
|
B |
||
|
A |
||
|
A |
||
|
A |
||
|
A |
||
|
A |
||
|
A |
||
|
B |
||
|
A |
||
|
B |
||
|
B |
Otrzyma�am w ten spos�b ci�g z�osony z symboli a i b:
BBBBAAAAAABABB,
w kt�rym mosna zauwasy� serie, czyli podci�gi z�osone z kolejnych element�w jednego rodzaju. St�d okre�li�am liczb� serii k empiryczne.
k = 5
Z tablic liczby serii odczyta�am, dla przyj�tego poziomu istotno�ci a oraz dla n1 (liczba symboli A) i n2 (liczba symboli B), warto�� krytyczn� k1 i k2.
n1 = 7
n2 = 7
ka = 4 dla a
Otrzymane ka spe�nia zalesno��:
ka < k,
dlatego przyj�am hipotez� o losowo�ci pr�bki.
normalno�� reszt
Za pomoc� testu Hellwiga dokona�am weryfikacji hipotezy:
H0: F( ) = FN ( ) (dystrybuanta reszt jest r�wna dystrybuancie rozk�adu normalnego),
wobec hipotezy alternatywnej:
H1: F( ¹ FN ( ).
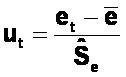
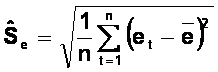
Procedura
testu Hellwiga wymaga przeprowadzenia standaryzacji reszt wed�ug wzoru:
gdzie:
e - �rednia arytmetyczna reszt
Se � odchylenie standardowe reszt
Uporz�dkowa�am warto�ci reszt rosn�co (kolumna 2), dokona�am ich standaryzacji (kolumna 3), a nast�pnie odczyta�am warto�ci dystrybuanty dla kasdej standaryzowanej reszty (kolumna 4). Odcinek [0,1] podzieli�am na 14 cel r�wnej d�ugo�ci, kt�rych warto�ci graniczne s� wypisane w kolumnie 5.
|
ei = yi - |
ei rosn�co |
ui |
F(ui) |
Ii |
Se
Ponisej zaznaczy�am, ile warto�ci dystrybuanty wpad�o do kasdej z cel i otrzyma�am h�0 = 3 cele puste.
Z tablic do testu Hellwiga odczyta�am warto�� krytyczn� h�1-a = 8 dla n = 14 i a
Poniewas h�1-a = 8 i h�0 = 3, st�d zachodzi nier�wno�� h�0 < h�1-a, co oznacza, is nie mamy podstaw do odrzucenia hipotezy o normalno�ci reszt
symetryczno�� reszt
Przeprowadzi�am weryfikacje hipotezy:
H0: (sk�adnik resztowy ma rozk�ad symetryczny),
wobec hipotezy alternatywnej:
H1: (rozk�ad sk�adnika resztowego nie jest symetryczny).
Do weryfikacji hipotezy zerowej pos�usy�a mi statystyka:
gdzie:
m � liczba reszt dodatnich,
n � liczba wszystkich reszt.
Obliczy�am warto�� statystyki t:
Dla a = 0.05 i n � 1 = 14 � 1 = 13 warto�� krytyczna statystyki wynios�a:
ta
Poniewas t < ta, nie ma podstaw do odrzucenia hipotezy o symetrii rozk�adu sk�adnika resztowego.
autokorelacja reszt
Miernikami autokorelacji s� wsp�czynniki autokorelacji rt rz�du t - wsp�czynniki korelacji pomi�dzy resztami oddalonymi od siebie o t okres�w. W celu zweryfikowania istotno�ci wsp�czynnika autokorelacji skorzysta�am z testu Durbina � Watsona, za pomoc� kt�rego sprawdzi�am hipotez�:
H0: r = 0 (reszty modelu nie s� skorelowane), wobec hipotezy alternatywnej:
H1: r ¹ 0 (reszty modelu s� skorelowane).
Przy weryfikacji hipotezy skorzysta�am ze statystyki d:
Warto�� d obliczona za pomoc� pakietu STATGRAPHICS wynosi: d =
Dla a = 0.05 i k = 1warto�ci krytyczne statystyki d wynosz�:
dL = 1.045
dU = 1.350
Poniewas zachodzi zwi�zek dL < d < dU to, na poziomie istotno�ci = 0.05, nie mosna stwierdzi�, czy mi�dzy resztami wyst�puje zjawisko autokorelacji.
Dla = 0.01: dL = 0.78. dU = 1.06 i brak jest podstaw do odrzucenia hipotezy H0 (d > dU).
Podda�am weryfikacji hipotez�:
H0: ai = 0 (zmienna, przy kt�rej stoi parametr ai wywiera nieistotny wp�yw na zmienn� obja�nian�),wobec hipotezy alternatywnej:
H1: ai ¹ 0 (zmienna, przy kt�rej stoi parametr ai wywiera istotny wp�yw na zmienn� obja�nian�).
Test istotno�ci opiera si� na statystyce t � Studenta okre�lonej wzorem:
gdzie:
ai � ocena i � tego parametru,
ai � prawdziwa warto�� parametru (zgodnie z hipotez� zerow� ai
D(ai) � b��d �redni szacunku parametru.
Obliczy�am warto�� statystyki t:
Dla a = 0.05 i n � k = 14 � 2 = 12 warto�� krytyczna statystyki wynios�a:
ta
Dla obydwu parametr�w spe�niona zosta�a nier�wno�� |t| > ta, wi�c hipotez� zerow� odrzuci�am na rzecz hipotezy alternatywnej � parametry s� statystycznie istotne (co jest potwierdzeniem poprzednich wniosk�w z etapu Budowy modelu).
Model ekonometryczny posiada w�asno�� koincydencji, je�li dla kasdej zmiennej obja�niaj�cej znak wsp�czynnika stoj�cego przy zmiennej w modelu jest r�wny znakowi wsp�czynnika korelacji ze zmienn� obja�nian�, czyli dla kasdego
i = 1, 2, , m (m � liczba zmiennych), spe�niony jest warunek:
sgn ai = sgn ri
Dla mojego modelu:
sgn aX9 = sgn rX9
zatem posiada on w�asno�� koincydencji, czyli wraz ze wzrostem warto�ci zmiennej X9, ro�nie warto�� zmiennej obja�nianej.
W celu sprawdzenia, czy model m�j w wystarczaj�co wysokim stopniu wyja�nia kszta�towanie si� zmiennej obja�nianej, wykorzysta�am kilka podstawowych miar:
WSPӣCZYNNIK DETERMINACJI skorygowany o liczb� stopni swobody okre�la w ilu procentach model obja�nia zmienno�� Y:
R2 = , co nie jest wynikiem rewelacyjnym, gdys informuje, se model jedynie w 42,79% wyja�nia zmienn� obja�nian�.
WSPӣCZYNNIK ZBIE�NO�CI wyrasa si� wzorem: j² = 1-R² i wynosi:
j² = , co oznacza, se as w 57.21% zmienna obja�niana nie jest wyja�niana przez model.
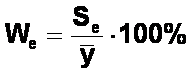
WSPӣCZYNNIK
ZMIENNO�CI LOSOWEJ wyrasa si�
wzorem:
gdzie:
Se - odchylenie standardowe reszt (Se =
- �rednia arytmetyczna zmiennej obja�nianej ( = 5248.71).
We = 8.56%, dla przyj�tej krytycznej warto�ci W* = 10%, co daje nier�wno��:
We < W*
To oznacza, se model mosna uzna� za dostatecznie dobrze dopasowany do danych empirycznych.
W ramach oceny dopasowania modelu mosna prze�ledzi� wykresy:
WYKRES RESZT WZGL�DEM WARTO�CI TEORETYCZNYCH ZMIENNEJ ZALE�NEJ
Punkty reprezentuj�ce na wykresie reszty s� do�� przypadkowo rozmieszczone wok� linii reprezentuj�cej warto�ci teoretyczne. Przy czym stopie� rozrzutu nie wydaje si� zalesny od poziomu warto�ci teoretycznych zmiennej zalesnej.
WYKRES ZMIENNYCH RESZTOWYCH W UK�ADZIE SIATKI PROBABILISTYCZNEJ ROZK�ADU NORMALNEGO
Normalno�� zmiennych resztowych jest jednym z za�ose� potrzebnych do przeprowadzenia test�w statystycznych w analizie regresji. Je�li zmienna ma rozk�ad normalny to punkty na wykresie powinny lese� na linii prostej. Jak wida� z wykresu punkty uk�adaj� si� bardzo blisko prostej.
Na podstawie otrzymanego przeze mnie modelu mosna obliczy�, jaka b�dzie prognozowana liczba absolwent�w akademii medycznych w roku 1999.
Do r�wnania:
podstawi�am znan� mi warto�� zmiennej X = 389 i otrzyma�am wynik:
= 4283.28144,
kt�ry zblisony jest do warto�ci odczytanej z Rocznika Statystycznego r�wnej 4224.
Wyr�wnanie wyk�adnicze Browna s�usy do analizy szeregu czasowego, kt�rej przedmiotem jest wykrycie i opis prawid�owo�ci, jakim mog� podlega� zmiany zjawiska w czasie. Procedura ta eliminuje z szeregu czasowego wahania przypadkowe dostarczaj�c formalnego modelu trendu wykorzystywanego do ekstrapolacji zjawiska. Cech� charakterystyczn� wyr�wnania wyk�adniczego Browna jest to, se wi�kszy wp�yw na warto�ci parametr�w modelu wywieraj� obserwacje nowsze nis obserwacje starsze.
Stopie� dopasowania modelu do danych szeregu czasowego charakteryzowany jest za pomoc� kilku miernik�w. Opieraj� si� one na b��dach jednookresowych prognoz wyznaczanych na podstawie sukcesywnie otrzymywanych funkcji trendu. Warto�ci jednookresowych prognoz dla poszczeg�lnych typ�w modeli obliczane si� jako:
model sta�y,
model liniowy,
model kwadratowy.
B��dy prognoz traktowane s� jako reszty i wykorzystuje si� je do oceny stopnia dopasowania modelu do danych empirycznych. Obliczane s� nast�puj�ce miary dopasowania:
b��d przeci�tny M. E.,
�redni b��d kwadratowy M. S. E.,
�redni b��d absolutny M. A. E.,
procentowy �redni b��d absolutny M. P. A. E.,
procentowy b��d przeci�tny M. P. E..
Warto�� sta�ej r�wnania a okre�la wagi, jakie nadaje si� poszczeg�lnym obserwacjom przy wyr�wnywaniu. Wystarczaj�ce s� na og� warto�ci z przedzia�u 0.1 - 0.3. Warto�� sta�ej r�wna 0.1 pozwoli na eliminacj� z szeregu czasowego dusych waha� losowych. Natomiast warto�� 0.3 jest wystarczaj�co wysoka, wyr�wnany szereg uwzgl�dni� zmiany trendu zjawiska.
Wyniki wszystkich modeli przy r�snej sta�ej wyr�wnania przedstawi�am ponisej:
Percent: 100
Forecast summary M.E. M.S.E. M.A.E. M.A.P.E. M.P.E. Period 15
Simple: 0.1 -2.93973 409351. 475.964 9.49198 -1.57592 5163.18
Linear: 0.1 -75.9851 465284. 511.326 10.3420 -3.08205 5065.50
Quadratic: 0.1 -138.079 519521. 558.433 11.3405 -4.32706 4896.66
Simple: 0.3 -89.8106 367592. 439.941 8.89063 -3.05191 4816.74
Linear: 0.3 -159.395 336223. 455.110 9.00901 -4.03372 4223.42
Quadratic: 0.3 -151.541 298510. 466.964 9.01594 -3.35041 3684.18
Warto�ci miar wskazuj� na wielko�� i charakter b��d�w w poszczeg�lnych wariantach wyr�wnywania. Absolutn� wielko�� b��d�w charakteryzuje �redni b��d kwadratowy (M.S.E.) i �redni b��d absolutny (M.A.E.), wzgl�dn� wielko�� b��d�w charakteryzuje procentowy �redni b��d absolutny (M.A.P.E.). Na podstawie b��du przeci�tnego (M.E.) i procentowego b��du przeci�tnego (M.P.E.) wykrywa si� systematyczne obci�senie prognoz (zawysenie lub zanisenie).
Warto�ci miar wskazuj� na brak znacz�cych r�snic pomi�dzy trzema wyr�wnaniami. Dla niskich a miary dopasowania s� niezbyt dobre. Wydaje mi si�, is odpowiednim modelem by�by liniowy ze sta�� wyr�wnania a = 0.3. Warto�� prognozy na rok 1999 w tym przypadku wynosi 4223 absolwent�w Akademii Medycznych, co niewiele r�sni si� od rzeczywistej wielko�ci 4224.
LITERATURA
|
D�browski A. (pr. zb.), |
Statystyka. 15 godzin z pakietem STATGRAPHICS, Wydawnictwo AR we Wroc�awiu, Wroc�aw 1994; |
|
Krysicki W. (pr. zb.), |
Rachunek prawdopodobie�stwa i statystyka matematyczna w zadaniach. Cz�� II: Statystyka matematyczna PWN, Warszawa 1994; |
|
Nowak E., |
Problemy doboru zmiennych do modelu ekonometrycznego, PWN, Warszawa 1984; |
|
Podg�rski J., |
Statystyka z komputerem. STATGRAPHICS wersja 5 i 6, MIKOM, Warszawa 1995; |
|
Obara M., |
Jak studiowa� medycyn�? Pa�stwowy zak�ad wydawnictw lekarskich, Warszawa 1987. |
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 936
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2024 . All rights reserved