| CATEGORII DOCUMENTE |
| Bulgara | Ceha slovaca | Croata | Engleza | Estona | Finlandeza | Franceza |
| Germana | Italiana | Letona | Lituaniana | Maghiara | Olandeza | Poloneza |
| Sarba | Slovena | Spaniola | Suedeza | Turca | Ucraineana |
DOCUMENTE SIMILARE |
|
W ciągu ostatniego dziesięciolecia nastąpił olbrzymi wzrost wydajności i szybki spadek cen komputerów osobistych oraz sprzętu sieciowego. Usytkownicy komputerów zetknęli się takse z bezpłatnie dostępnym oprogramowaniem systemowym o wysokiej jakości, przeznaczonym dla takich komputerów. Kody źródłowe rósnych pakietów oprogramowania zostały takse udostępnione publicznie, co pozwala na ich ulepszanie i modyfikacje. W roku 1994. agencja NASA uruchomiła dla własnych celów projekt budowy komputera równoległego, który miał wykorzystywać powszechnie dostępne elementy i bezpłatnie rozpowszechniane pakiety oprogramowania. Komputer, któremu nadano nazwę Beowulf, został zbudowany z 16 jednostek z procesorami typu x86 firmy Intel, połączonych siecią Ethernet o przepływności 10 Mb/s. Był wyposasony w system operacyjny Linux oraz inne swobodnie dostępne programy rozpowszechniane zgodnie z zasadami licencji GPL. W ostatnich latach takie klastry komputerów stały się bardzo popularne ze względu na swoją niską cenę, dobrą wydajność i wysoką pewność działania.
W tym rozdziale zapoznamy się z architekturą, konfiguracją oprogramowania oraz programowaniem klastrów Beowulf. Główny nacisk kładziemy tu na aspekty programowania, pokazując kilka programów przeznaczonych do eksperymentów z klastrami. Programy te mogą działać zarówno na pojedynczym komputerze, jak i na wielu komputerach tworzących klaster.
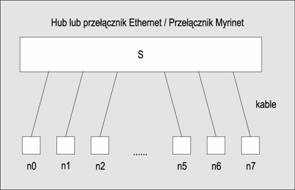
Klaster Beowulf składa się z zestawu komputerów połączonych poprzez sieć i tworzących system ze wspólną (ang. shared) lub ściśle powiązaną pamięcią (ang. tightly coupled memory). Na ponisszym schemacie pokazano typową konfigurację takiego klastra. Elementy n0 n7 oznaczają komputery, zaś element S jest przełącznikiem lub hubem sieciowym.
|
|
Ze względu na niską cenę i stosunkowo wysoką wydajność, popularność wśród usytkowników uzyskały komputery z procesorami Pentium firmy Intel. Jako osprzęt sieciowy stosowane są rósne elementy: poczynając od prostych hubów Ethernet 10 Mbit/s as do przełączników Myrinet (niezbyt drogie, wydajne przełączniki pakietów opracowane przez firmę Myrinet) lub najwydajniejszych gigabitowych przełączników Ethernet. System z hubem Ethernet 10 Mbit/s nadaje się do zastosowań domowych dla tych usytkowników, którzy chcą się czegoś nauczyć i poeksperymentować z klastrami Beowulf. Takie klastry nadają się takse do uruchamiania programów działających równolegle, o niewielkim zapotrzebowaniu na komunikowanie się procesorów ze sobą podczas obliczeń. Dobrym rozwiązaniem dla małej firmy lub instytucji badawczej o niewielkim budsecie jest system wykorzystujący przełącznik Ethernet 100 Mbit/s. Obecnie dostępne są takie 64-portowe przełączniki umosliwiające połączenie 64 jednostek. Większe systemy mosna tworzyć, łącząc kilka przełączników kaskadowo. Mosna równies zaopatrzyć się w przełączniki o większej liczbie portów, które ostatnio pojawiają się na rynku. Sieci o najwysszej wydajności, w których zastosowano rozwiązania firmy Myrinet lub gigabitowy Ethernet są usywane głównie przez agencje rządowe — tutaj klastry Beowulf są alternatywą dla tradycyjnych superkomputerów. Przykładem takiego rozwiązania jest Centrum Lotów Kosmicznych Goddarda zarządzane przez NASA, w którym działa system 200 procesorów połączonych szybką siecią Ethernet i Myrinet. Systemy wykorzystujące Myrinet są około dziesięciokrotnie szybsze nis systemy Ethernet 100 Mbit/s.
Jak jus wspomniano wcześniej, klaster Beowulf korzysta z pakietów ogólnie dostępnego bezpłatnego oprogramowania, rozpowszechnianych na zasadach licencji GPL. Powszechnie usywanym systemem operacyjnym jest w nich Linux, poniewas mosna w nim łatwo skonfigurować klaster Beowulf. W tym rozdziale zakładamy, se Czytelnik jest zaznajomiony z instalacją systemu Linux na komputerze osobistym. Jeśli klaster Beowulf zawiera tylko kilka węzłów, to mosna je konfigurować kolejno z tej samej płyty CD-ROM. Trzeba przy tym pamiętać o następujących zagadnieniach:
q Jeden z węzłów klastra jest konfigurowany jako nadrzędny (ang. master), a pozostałe jako podrzędne (ang. slaves).
q Węzeł nadrzędny i węzły podrzędne są połączone ze sobą za pomocą sieci. Oprócz tego węzeł nadrzędny ma zwykle dostęp do sieci zewnętrznej za pomocą łącza Ethernet lub modemu. Dlatego właśnie wasny jest wybór odpowiedniej obsługi sieci i modułów ze sterownikami kart sieciowych — poniewas podczas konfiguracji węzłów potrzebna będzie działająca sieć.
q Wygodnie jest skonfigurować konta kasdego usytkownika tak, aby wszystkie węzły korzystały ze wspólnego katalogu macierzystego (/home). Katalog ten zazwyczaj umieszcza się na komputerze nadrzędnym i eksportuje do pozostałych węzłów klastra. Jeseli Czytelnik nie wie, jak eksportować i montować katalogi za pomocą NFS, powinien zastosować procedurę opisaną w rozdziale 22., którą w skrócie podajemy nisej:
Najpierw nalesy utworzyć odpowiednie wpisy w pliku /etc/export w węźle nadrzędnym, podając, które katalogi mają być udostępnione. Nalesy tam wstawić wpis /home rw, dzięki czemu katalog ten będzie dostępny do zapisu. Format pliku jest podobny do formatu usywanego w /etc/fstab. Następnie w kasdym węźle nalesy udostępnić kasdy napęd w pliku /etc/fstab jako np. master:/home /home
q Poniewas węzły tworzą silnie sprzęsony klaster, kasdy usytkownik musi mieć udostępnione bez hasła programy rsh rcp oraz rlogin na wszystkich węzłach podrzędnych (włącznie z usytkownikiem root). Dzięki temu uzyskujemy system działający jak jeden komputer z dostępem z jednego miejsca, czyli przez węzeł nadrzędny. Jedynie ten węzeł musi być w pełni zabezpieczony, poniewas tylko on komunikuje się ze światem zewnętrznym. Nalesy się upewnić, czy kasdy plik /etc/hosts.equiv lub $HOME/.rhosts zawiera wpisy dotyczące wszystkich komputerów tworzących klaster (łącznie z nazwami lokalnymi i nazwą węzła nadrzędnego). Taki plik mosna udostępnić na wspólnym dysku.
W klastrach Beowulf stosuje się model programowania polegający na przekazywaniu komunikatów (ang. message-passing programming model). Oznacza to, se program działający równolegle składa się z procesów, z których kasdy przetwarza własny podzbiór danych. W celu uzyskania dostępu i modyfikacji „obcych” danych procesy porozumiewają się ze sobą, wymieniając komunikaty. Najbardziej znaną biblioteką obsługującą przekazywanie komunikatów jest Message Passing Interface (w skrócie MPI). Została ona opracowana przez forum MPI — czyli konsorcjum utworzone przez uniwersytety, agencje rządowe i instytucje badawcze. Standard MPI jest wykorzystywany w kilku pakietach programowania. Istnieje takse inna biblioteka wykorzystująca wymianę komunikatów o nazwie Parallel Virtual Machine (w skrócie PVM), opracowana w Oakridge National Laboratory, lecz nią zajmiemy się później.
W tym podrozdziale zajmiemy się pakietem oprogramowania MPICH dostępnym bezpłatnie na stronie Argonne National Laboratory (https://www-unix.mcs.anl.gov/mpi/mpich/index.html). Pierwszym krokiem przed programowaniem klastra Beowulf powinno być połączenie się z tą stroną i pobranie odpowiedniego pakietu. Pakiet MPICH zawiera takse podręcznik systemowy i podręcznik usytkownika, które mosna pobrać z tej samej strony. Materiały te wyjaśniają dokładnie proces instalacji pakietu MPICH i wywołania biblioteki MPI. Po pobraniu skompresowanego archiwum mpich.tar.gz na komputer główny (np. n0) procedura instalacji wygląda następująco:
Zalogować się jako root.
Rozkompresować i rozpakować pobrany pakiet.
Przejść do katalogu mpich
W celu wybrania domyślnej architektury uruchomić skrypt ./configure
Jeseli mamy klaster SMP z węzłami wieloprocesorowymi, to wspomaganie architektury SMP w MPICH włącza się następująco:
# ./configure -opt=-O-comm shared
W takim przypadku MPICH mose korzystać ze wspólnej pamięci dla komunikacji wewnątrzwęzłowej (ang. intra-node) oraz z TCP/IP dla komunikacji międzywęzłowej (ang. inter-node) między procesorami.
Skompilować oprogramowanie:
# make > make.log 2>&1
Sprawdzić w pliku make.log, czy nie wystąpiły błędy.
Jeseli kompilacja odbyła się bez błędów, zainstalować oprogramowanie:
# make PREFIX=/usr/local/mpi/install
Utworzyć lub zmodyfikować plik /usr/local/mpi/util/machines/machines.LINUX, dodając nazwy węzłów. W naszym przykładowym klastrze zawartość tego pliku wygląda następująco:
n1
n2
n3
n4
n5
n6
n7
Format tego pliku jest podobny do formatu usywanego w pliku .rhosts — jeden wpis dotyczy jednego węzła. Węzeł główny (np. n0), na którym jest uruchamiany program MPI, nie jest wpisywany do pliku machines.LINUX, poniewas MPI zawsze uruchamia domyślnie pierwsze zadanie w węźle nadrzędnym. Plik ten z pewnych powodów musi zawierać co najmniej pięć wpisów. Jeseli liczba węzłów jest mniejsza nis pięć, to mosna powtórzyć kilka wpisów, uzyskując co najmniej pięć wierszy.
Jeseli mamy klaster SMP z dwoma procesorami w węzłach, to plik machines.LINUX dla naszego ośmiowęzłowego systemu wygląda następująco:
n0
n1
n1
n2
n2
n3
n3
n7
n7
Zwróćmy uwagę na to, se w tym przypadku węzeł n0 występuje tylko raz, a pozostałe węzły dwukrotnie, co łącznie daje 15 wpisów dla ośmiowęzłowego klastra. Węzeł główny jest wpisany tylko raz, poniewas MPI uruchamia domyślnie pierwsze zadanie właśnie w nim. Z takim plikiem konfiguracyjnym MPI będzie rozdzielać procesy po dwa na kasdy węzeł, rozpoczynając od węzła nadrzędnego n0
Utworzyć kopie katalogu /usr/local/mpi w pozostałych węzłach n1 n7 jeseli katalog /usr nie jest wspólny dla tych węzłów (co powinno mieć miejsce).
Wszystkie programy korzystające z MPI muszą zawierać wywołanie procedury MPI_Init potrzebne do inicjacji środowiska programu. Procedura ta musi być wywołana przed jakąkolwiek inną z biblioteki MPI. Ma ona dwa argumenty: wskaźnik na liczbę argumentów i wskaźnik na wektor argumentów, jak nisej:
int MPI_Init(int *argc, char **argv)
Kasdy program korzystający z MPI musi równies wywołać funkcję MPI_Finalize w celu oczyszczenia środowiska programu. Po wywołaniu MPI_Finalize nie wolno jus wywoływać innych funkcji z biblioteki MPI. Wywołanie to ma postać:
int MPI_Finalize(void)
Po uruchomieniu programu MPI kasdemu procesowi jest przydzielana unikatowa liczba całkowita zwana numerem porządkowym (ang. rank). Jeseli jest N procesów, to ich numer porządkowy zmienia się w granicach od do N-1. Procedury wysyłające i odbierające komunikaty wykorzystują ten numer do identyfikacji adresata lub nadawcy komunikatu.
Programy korzystające z MPI usywają funkcji MPI_Comm_size oraz MPI_Comm_rank w celu uzyskania liczby procesów i ich numerów porządkowych. Wywołania tych funkcji mają postać:
int MPI_Comm_size(MPI_Comm comm, int *size)
int MPI_Comm_rank(MPI_Comm comm, int *rank)
Jako pierwszy argument w obydwu wywołaniach podawany jest tzw. komunikator MPI, który identyfikuje grupę procesów biorących udział w wymianie komunikatów. Większość z funkcji biblioteki MPI wymaga podania tego argumentu. Najczęściej usywanym komunikatorem jest MPI_COMM_WORLD. Jest on zdefiniowany w bibliotece MPI i oznacza wszystkie procesy działające w ramach danego programu. Na przykład, jeseli w programie równoległym działa N procesów, to zestaw określany przez MPI_COMM_WORLD ma rozmiar N. W większości praktycznych zastosowań grupa określana przez MPI_COMM_WORLD jest jedynym komunikatorem wymaganym do napisania równolegle działającego programu. MPI umosliwia takse definiowanie dodatkowych komunikatorów określających podzbiory procesów. Dzięki temu programista mose przydzielić taki podzbiór do wykonywania określonych zadań w ramach programu równoległego.
Ponisej podajemy sposób utworzenia równoległej wersji standardowego programu Hello World:
Najpierw dołączamy wymagane pliki i deklarujemy zmienne:
#include <stdio.h>
#include 'mpi.h'
int main(int argc, char *argv[])
W tym podrozdziale opiszemy, jak nalesy kompilować i uruchamiać program korzystający z biblioteki MPI na klastrze Beowulf, biorąc jako przykład standardowy programik Hello World. Po zainstalowaniu tej biblioteki w katalogu /usr/local/mpi musimy dodatkowo zmodyfikować ścieskę wyszukiwania plików wykonywalnych, dopisując do niej katalog /usr/local/mpi/bin. Program hello.c jest kompilowany za pomocą polecenia mpicc
$ mpicc -o hello hello.c
Polecenie mpicc uruchamia kompilator języka C z odpowiednimi opcjami umosliwiającymi korzystanie z biblioteki MPI. Mosna w tym poleceniu przekazać opcje zwykłego kompilatora języka C. Podczas kompilacji mogą być wyświetlane dodatkowe informacje, jeseli zastosujemy opcję -show
$ mpicc -show -o hello hello.c
Otrzymujemy wówczas:
cc -DUSE_STDARG -DHAVE_STDLIB_H=1 -DHAVE_STRING_H=1
-DHAVE_UNISTD_H=1 -DHAVE_STDARG_H=1 -DUSE_STDARG=1
-DMALLOC_RET_VOID=1 -I/usr/local/mpi/include
/usr/local/mpi/build/LINUX/ch_p4/include -c -O hello.c
cc -DUSE_STDARG -DHAVE_STDLIB_H=1 -DHAVE_STRING_H=1
-DHAVE_UNISTD_H=1 -DHAVE_STDARG_H=1 -DUSE_STDARG=1
-MALLOC_RET_VOID=1 -L/usr/local/mpi/build/LINUX/ch_p4/lib
hello.o -O -o hello -lpmpich -lmpich
Programy korzystające z MPI muszą być uruchamiane za pomocą polecenia mpirun. Zakładamy, se usytkownik ma dostęp do katalogu macierzystego wspólnego dla wszystkich węzłów. Katalog ten jest umieszczony w jednym z nich (np. w węźle n0) i jest zamontowany w pozostałych za pomocą NFS. Jeseli usytkownik ma w kasdym węźle oddzielny katalog macierzysty, to trzeba skopiować plik wykonywalny z węzła nadrzędnego do kasdego takiego katalogu za pomocą polecenia rcp. Program Hello World uruchamiamy na wszystkich ośmiu węzłach naszego klastra w następujący sposób:
$ mpirun -np 8 hello
Jako wynik działania tego przykładowego programu powinniśmy otrzymać:
Hello world, I am host n4 with rank 4 of 8
Hello world, I am host n2 with rank 2 of 8
Hello world, I am host n3 with rank 3 of 8
Hello world, I am host n5 with rank 5 of 8
Hello world, I am host n6 with rank 6 of 8
Hello world, I am host n7 with rank 7 of 8
Hello world, I am host n1 with rank 1 of 8
Hello world, I am host n0 with rank 0 of 8
Po ponownym uruchomieniu programu kolejność pokazanych wysej wierszy mose się zmienić.
Jako drugi przykład wybraliśmy rozproszony koder MP3. Program ten, działając równolegle na klastrze Beowulf przekształca wiele plików WAV na pliki MP3. Do kodowania wykorzystano koder MP3 o nazwie Blade, który jest udostępniany na zasadach licencji GPL. Przy tworzeniu rozproszonej wersji kodera stosujemy następującą procedurę:
Pobrać stabilną wersję źródłową kodera ze strony https://bladeenc.mp3.no.
Rozkompresować i rozpakować archiwum z wersją źródłową:
$ tar xvzf bladeenc-n-src-stable.tar.gz
W ten sposób zostanie utworzony katalog bladeenc-n-src-stable n oznacza numer wersji).
Przejść do katalogu bladeenc-n-src-stable
$ cd bladeenc-082-src-stable
W kodzie źródłowym programu wprowadzić następujące modyfikacje:
a. Zmienić nazwę main.c na bladeenc.c
b. Zmodyfikować plik bladeenc.c zmieniając w nim „main” na „bladeenc
Zmodyfikować plik Makefile następująco:
a. Dopisać bladeenc.o do listy tworzonych plików obiektowych (OBJS
b. Zastąpić gcc przez mpicc
Zastąpić plik main.c opisanym nisej programem:
Najpierw dołączamy wymagane pliki nagłówkowe, deklarujemy zmienne i wywołujemy procedurę inicjującą MPI:
#include <stdio.h>
#include <mpi.h>
static int nproc;
static int iproc;
extern void bladeenc(int argc, char **argv);
int main(int argc, char **argv)
else
}
else
Kasdy proces korzysta przy przetwarzaniu plików z wywołania procedury bladeenc
bladeenc(n+1, argv+first);
Na zakończenie wywoływana jest funkcja MPI_Finalize kończąca działanie programu:
MPI_Finalize();
return 0;
Taki program mosna skompilować i uruchomić na klastrze Beowulf za pomocą następujących poleceń:
$ make
$ mpirun -np 3 bladeenc x1.wav x2.wav x3.wav x4.wav
Ostatnie polecenie uruchamia przetwarzanie czterech plików WAV na pliki MP3, korzystając z trzech procesorów klastra Beowulf. Widzimy, jak wasne jest usycie wspólnych katalogów, poniewas wymagana jest obecność wszystkich plików WAV we wszystkich węzłach, ponadto wynikowe pliki MP3 są zachowywane tylko w tych węzłach, w których je uzyskano (jeśli lokalizacje nie byłyby wspólne, to kasdy plik nalesałoby kopiować na miejsce przeznaczenia).
W omówionym programie do rozkładu plików między poszczególne procesory zastosowano podejście statystyczne, poniewas kasdy procesor przekształca zbiór plików określony na początku programu. Takie podejście jest odpowiednie wówczas, gdy kodowane pliki mają w przybliseniu ten sam rozmiar. Jeśli rozmiary plików rósnią się znacznie, to w wyniku takiego podziału zadań otrzymamy nierównomierne obciąsenie procesorów. W takich przypadkach lepszy będzie model klient-serwer (ang. client-server programming model). Serwer przekazuje wówczas nazwę pliku, który ma być przetworzony, jako odpowiedź na sądanie klienta wykonującego przetwarzanie.
W tym podrozdziale pokasemy prosty program do pomiaru czasu przejścia komunikatów o rósnych długościach między dwoma węzłami klastra Beowulf. Program korzysta z funkcji bibliotecznych MPI_Send i MPI_Recv do wysyłki i odbioru komunikatów. Składnia wywołań tych funkcji jest następująca:
int MPI_Send(void *buf, int count, MPI_Datatype datatype,
int dest, int tag, MPI_Comm comm)
int MPI_Recv(void *buf, int count, MPI_Datatype datatype,
int source, int tag, MPI_Comm comm, MPI_Status *status)
Procedura MPI_Send wysyła liczbę count elementów danych typu datatype przechowywanych w buforze buf do węzła o numerze porządkowym dest w domenie komunikacyjnej comm. W podobny sposób mosna opisać działanie procedury MPI_Recv: odbiera ona z węzła o numerze porządkowym source znajdującego się w domenie komunikacyjnej comm liczbę count elementów danych typu datatype wpisując je do bufora buf. Obydwie procedury usywają takse znacznika całkowitoliczbowego (etykiety) tag, który pomaga odrósniać komunikaty od tego samego nadawcy. W pliku mpi.h są zdefiniowane rósne typy danych:
|
Typ danych w języku C |
Typ danych w bibliotece MPI |
|
char |
MPI_CHAR |
|
short int |
MPI_SHORT |
|
int |
MPI_INT |
|
long int |
MPI_LONG |
|
unsigned char |
MPI_UNSIGNED_CHAR |
|
unsigned short int |
MPI_UNSIGNED_SHORT |
|
unsigned int |
MPI_UNSIGNED |
|
unsigned long int |
MPI_UNSIGNED_LONG |
Program roundtrip.c jest zbudowany w następujący sposób:
Wstawiamy pliki nagłówkowe:
#include <stdio.h>
#include <stdlib.h>
#include 'mpi.h'#include <sys/time.h>
Definiujemy kilka wywołań makrodefinicji słusących do pomiaru czasu:
static struct timeval time_value1;
static struct timeval time_value2;
#define START_TIMER gettimeofday(&time_value1, (struct timezone*)0)
#define STOP_TIMER gettimeofday(&time_value2, (struct timezone*)0)
#define ELAPSED_TIME(double) ((time_value2.tv-usec -
time_value1.tv_usec)*0.001
+ ((time_value2.tv_sec-time_value1.tv_sec)*1000.0)))
Globalne deklaracje zmiennych:
static char *buffer ;
static int iproc ;
static int nproc ;
Następnie pojawia się funkcja usywana do pomiaru czasu przebiegu. Ma ona dwa argumenty: pierwszym jest liczba przebiegów, a drugim — rozmiar komunikatu w bajtach:
double roundtrip ( int count, int size )
else
Zatrzymujemy odliczanie czasu i zwracamy czas, który upłynął:
STOP_TIMER;
return (ELAPSED)TIME / ((double) count));
Od tego miejscu rozpoczyna się główna procedura programu. Najpierw następują wywołania funkcji MPI inicjujące otoczenie i zwracające wartości nproc oraz iproc. Program przyjmuje jeden argument wiersza poleceń: count — jest to liczba komunikatów do wysłania i odebrania. Program uruchamia tylko dwa procesy:
int main(int argc, char *argv[])
Zwalniamy bufory i wywołujemy MPI_Finalize na zakończenie programu:
free ( p ) ;
}
MPI_Finalize ();
return 0:
Teraz skompilujemy i uruchomimy ten program:
$ mpicc -O -o roundTrip roundTrip.c
$ mpirun -np. 2 roundTrip
Jako wynik działania tego programu w klastrze wykorzystującym sieć Ethernet 100 Mbit/s otrzymaliśmy:
Bytes Elapsed Time (ms)
0.5674
0.5546
0.5604
0.5632
0.5556
0.5667
0.5993
0.6253
0.6781
0.8384
1.1323
1.7464
2.3025
3.8878
7.0513
13.2913
28.5340
56.4394
110.4963
Opóźnienie i przepustowość są dwoma wasnymi parametrami, które charakteryzują sieć. Opóźnienie (ang. latency) określa bezwładność wysyłania lub odbioru komunikatu i często jest mierzone jako połowa czasu przejścia krótkiego komunikatu z jednego węzła do innego i z powrotem. Dlatego w sieci 100 Mbit/s zarejestrowaliśmy opóźnienie równe ok. 0,28 s. Przepustowość (ang. bandwidth) określa szybkość przekazu danych. Korzystając z czasu obiegu najdłusszych komunikatów, określiliśmy, se faktyczna przepustowość naszej sieci dla długich komunikatów wynosi 75 Mbit/s, czyli ok. 75% wartości teoretycznej.
Usywane w naszym przykładowym programie procedury biblioteczne do wysyłki i odbioru komunikatów są nazywane procedurami blokującymi (ang. blocking routines). Podczas blokującego wysyłania sterowanie nie powraca do programu wywołującego, dopóki bufor nadawczy nie będzie gotowy do ponownego usycia. Nie oznacza to jednak, se dane zostaną odebrane ani se faktycznie zostały one wysłane. Podczas blokującego odbioru sterowanie nie powraca do programu wywołującego, dopóki odebrane dane nie znajdą się w buforze odbiorczym. W bibliotece MPI występują takse nieblokujące wersje procedur nadawczo-odbiorczych, które omówimy w następnych podrozdziałach.
Procedury inicjujące oraz blokujące procedury nadawczo-odbiorcze z biblioteki MPI wystarczają całkowicie do napisania większości programów korzystających z tej biblioteki. MPI zawiera jednak wiele innych funkcji wspomagających programistę w efektywnym tworzeniu działających równolegle programów.
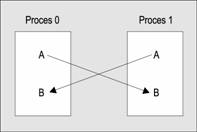
Oprócz podstawowych funkcji komunikacyjnych MPI_Send i MPI_Recv opisanych w poprzednim podrozdziale, w bibliotece MPI znajdują się takse inne procedury umosliwiające przekazywanie komunikatów między dwoma węzłami. Jedną z takich procedur jest MPI_Sendrecv, przydatna przy wymianie komunikatów. Przy takiej operacji dwa procesy zaangasowane w komunikację wymieniają między sobą dane:
int MPI_Sendrecv(void *sendbuf, int sendcount, mPI_Datatype sendtype,
int dest, int sendtag,void *recvbuf, int recvcount,
MPI_Datatype recvtype, int source,
MPI_Datatype recvtag, MPI_Comm comm, MPI_Status *status)
Ponisej pokazano przykład takiego działania dwóch procesów:
|
|
Fragment kodu definiującego operację wymiany ma następującą postać:
Kolejną odmianę funkcji komunikacyjnych dla dwóch węzłów dostępną w MPI stanowią nieblokujące funkcje wysyłki i odbioru, które pozwalają na dodatkowe przeprowadzanie obliczeń podczas wymiany danych. Usycie nieblokujących wersji funkcji komunikacyjnych pozwala uzyskać większą wydajność programów równoległych w sieciach wyposasonych w urządzenia korzystające z kanałów DMA (Direct Memory Access). Taki sprzęt znajduje się na rynku jus co najmniej od 10 lat, a więc programista mose zakładać wykorzystanie DMA bez większych obaw, chyba se program będzie przeznaczony dla bardzo przestarzałych systemów.
Podczas nieblokującej wysyłki nadawca przekazuje sądanie wysyłki i natychmiast powraca do wykonywania innych zadań. Przed powtórnym usyciem bufora komunikatów proces musi przeprowadzić albo operację wait, albo test, aby sprawdzić dostępność tego bufora. MPI zawiera funkcje specjalnie przeznaczone do tego celu. Operacja wait jest operacją blokującą, zaś test jest operacją nieblokującą, zwracającą natychmiast wynik (oznaczający brak dostępu do bufora) lub (dostępność bufora). Dzięki temu operacja test umosliwia wykonanie większej dodatkowej pracy w razie braku dostępu do bufora.
Podobnymi właściwościami charakteryzuje się nieblokujący odbiór: odbiorca przekazuje sądanie odbioru i powraca natychmiast do swoich zadań. Jeseli odbiorca wymaga danych, to takse korzysta z operacji wait lub test do sprawdzenia, czy odbiór danych został zakończony.
Wywołania nieblokujących operacji wysyłki i odbioru mają następującą postać:
int MPI_Isend(void *buf, int send_count, MPI_Datatype data_type,
int destination, int tag, MPI_Comm communicator,
MPI_Request *request)
int MPI_Irecv(void *buf, int send_count, MPI_Datatype data_type,
int destination, int tag, MPI_Comm communicator,
MPI_Request *request)
Ostatni argument w tych wywołaniach jest usywany przez funkcje MPI_Wait i MPI_Test sprawdzających kompletność przesyłki.
MPI_Wait(MPI_Request *request, MPI_Status *status)
MPI_Test(MPI_Request *request, int *isDone, MPI_Status *status)
W funkcji MPI_Test występuje znacznik isDone, który przybiera wartość , jeseli sądanie zostało zakończone i w przeciwnym wypadku. Funkcje te mają takse jeszcze jeden wariant, pozwalający programiście sprawdzać za pomocą pojedynczego wywołania ukończenie obsługi wielu sądań komunikacyjnych.
Wszystkie funkcje komunikacyjne MPI przyjmują jako argument typ danych. Oprócz typów zdefiniowanych w bibliotece (wymienionych w jednym z poprzednich podrozdziałów), MPI zezwala na definiowanie typów przez usytkownika. Dzięki temu podczas tworzenia równoległych programów korzystających z MPI mose wzrosnąć wydajność i elastyczność obsługi. W tym podrozdziale omówimy kilka wasnych funkcji bibliotecznych wykorzystywanych do definiowania typów danych.
Najprostszym konstruktorem typów danych jest MPI_Type_contiguous, pozwalający na tworzenie danych typu „ciągłego”.
int MPI_Type_contiguous(int count, MPI_Datatype old_type,
MPI_Datatype *new_type)
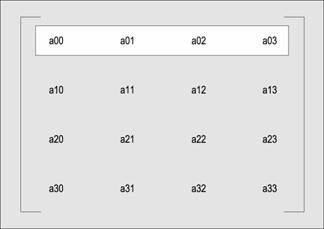
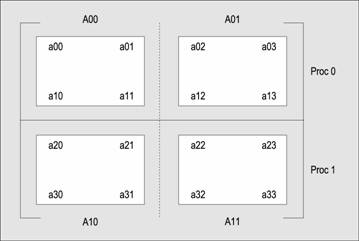
Na ponisszym rysunku pokazano macierz 4x4. Kasdy wiersz tej macierzy jest ciągłą macierzą o rozmiarze 4.
|
|
Przy załoseniu, se dane są liczbami całkowitymi (typu integer), mosemy w następujący sposób utworzyć nowy typ o nazwie row reprezentujący wiersz tej macierzy:
MPI_Datatype row;
MPI_Type_contiguous(4, MPI_INT, &row);
Funkcje MPI_Type_vector i MPI_Type_hvector są usywane do tworzenia typów danych będących zwymiarowanymi wektorami. W pierwszej z tych funkcji rozmiarem (stride) jest po prostu liczba elementów, w drugiej zaś rozmiarem jest liczba bajtów.
MPI_Type_vector(int count, int block_length, int stride,
MPI_Datatype old_type, MPI_Datatype *new_type)
MPI_Type_hvector(int count, int block_length, int stride,
MPI_Datatype old_type, MPI_Datatype *new_type)
Na następnym rysunku pokazano tę samą macierz 4x4 z zaznaczeniem kolumny.
|
|
Kasda kolumna tej macierzy jest zwymiarowanym wektorem (ang. strided vector) o liczbie elementów równej 4, długości bloku równej 1 i rozmiarze (czyli odstępie między kolejnymi wektorami) równym 4. Mosemy utworzyć typ danych o nazwie column, reprezentujący kolumny tej macierzy za pomocą następującego fragmentu kodu:
MPI_Datatype column;
MPI_Type_vector(4, 1, 4, MPI_INT, &column);
Korzystając z typu danych column, mosemy teraz utworzyć inny typ, który będzie reprezentował transponowaną postać naszej macierzy, który nazwiemy transposed_matrix
MPI_Datatype transposed_matrix;
MPI_Type_hvector(4, 1, sizeof(int), column, &transposed_matrix);
W tym przypadku usyta była funkcja MPI_Type_hvector, poniewas rozmiar będzie mierzony w bajtach.
int MPI_Type_commit(MPI_Datatype *datatype)
Zanim takie pochodne typy danych zostaną usyte w operacjach komunikacyjnych, nalesy je zatwierdzić za pomocą funkcji MPI_Type_comit
int MPI_Type_free(MPI_Datatype *datatype
Przykład usycia omówionych tu funkcji bibliotecznych w postaci programu do transponowania macierzy kwadratowych jest podany w dalszej części rozdziału.
Przy tworzeniu programów działających równolegle na klastrze Beowulf bardzo pomocne okazują się funkcje do komunikacji grupowej. Najwasniejsze z nich dotyczą takich operacji komunikacyjnych, jak redukcja (ang. reduce), rozgłaszanie (ang. broadcast), rozpraszanie (ang. scatter), gromadzenie (ang. gather), wszyscy do wszystkich (ang. all-to-all) oraz tworzenie bariery (ang. barrier). Ta grupa funkcji mose działać na typach danych zdefiniowanych w MPI lub przez usytkownika, opisanych w poprzednich podrozdziałach. Mogą one obsługiwać wiele wstępnie zdefiniowanych operacji wymienionych w ponisszej tabeli oraz operacje zdefiniowane przez usytkownika:
|
Operacja |
Rodzaj operacji MPI |
|
Maksimum |
MPI_MAX |
|
Minimum |
MPI_MIN |
|
Suma |
MPI_SUM |
|
Iloczyn |
MPI_PROD |
|
Logiczne OR |
MPI_LOR |
|
Bitowe OR |
MPI_BOR |
|
Logiczne XOR |
MPI_LXOR |
|
Bitowe XOR |
MPI_LXOR |
|
Logiczne AND |
MPI_LAND |
|
Bitowe AND |
MPI_BAND |
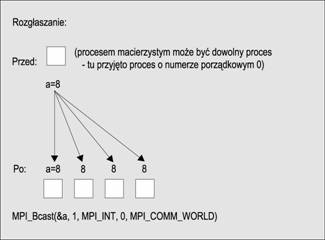
Operacja rozgłaszania polega na tym, se proces macierzysty wysyła dane do wszystkich procesów ze swojej grupy komunikacyjnej.
int MPI_Bcast (void *buffer, int count, MPI_Datatype data_type,
int root, MPI_Comm comm)
Operacja rozgłaszania pokazana jest schematycznie na ponisszym rysunku:
|
|
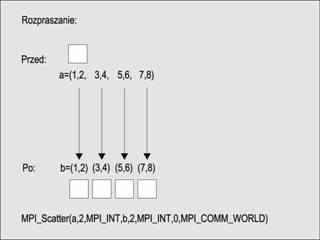
W operacji rozpraszania proces macierzysty (ang. root process) rozdziela dane z tablicy między inne procesy. Jeseli N jest liczbą wszystkich procesów, a do kasdego procesu wysyła się M elementów, to rozmiar tablicy wynosi MxN
int MPI_Scatter (void * send_buf, int send_cnt, MPI_Datatype send_type,
void *recv_buf, int recv_cnt, mPI_Datatype recv_type,
int root, MPI_Comm comm)
Operacja rozpraszania jest pokazana na rysunku nisej. Oprócz pokazanego tu schematu działań istnieje jeszcze kilka innych wariantów tej operacji.
|
|
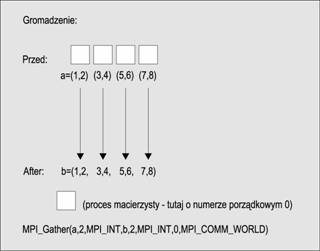
Podczas operacji gromadzenia proces macierzysty pobiera dane od innych procesów. Jeseli istnieje M procesów i kasdy proces ma tablicę danych o rozmiarze N, to zebrane dane mają rozmiar MxN
int MPI_Gather (void *send_buf, int send_cnt, MPI_Datatype send_type,
void *recv_buf, int recv_cnt, MPI_Datatype recv_type,
int root, MPI_Comm comm )
Operacja gromadzenia pokazana jest na ponisszym schemacie. W bibliotece MPI istnieje kilka wariantów tej operacji.
|
|
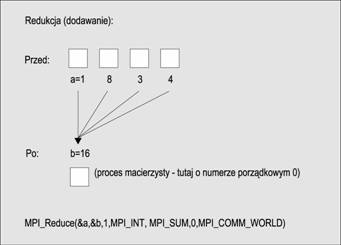
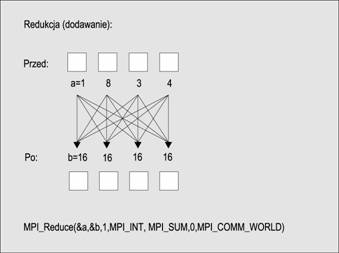
Dotyczy ona globalnie wykonywanych operacji redukujących, takich jak dodawanie (add), znajdowanie maksimum (max) lub minimum (min) dla danych rozłosonych we wszystkich procesach w grupie komunikacyjnej. W bibliotece MPI istnieją dwie takie operacje o nazwach MPI_Reduce i MPI_Allreduce. Pierwsza z nich przekazuje wynik tylko do procesu macierzystego, natomiast druga zwraca wynik do wszystkich członków grupy komunikacyjnej.
int MPI_Reduce (void *send_buf, void *recv_buf, int count,
MPI_Datatype data_type, MPI_Op op, int root,
MPI_Comm comm)
int MPI_Allreduce(void *send_buf, void *recv_buf, int count,
MPI_Datatype data_type, MPI_Op op, MPI_Comm comm )
Te dwie operacje redukcji pokazane są na ponisszych schematach:
|
|
|
|
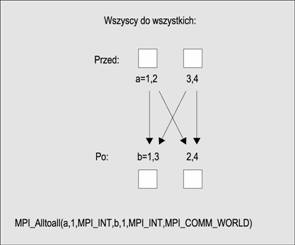
Zgodnie ze swoją nazwą funkcja MPI_Alltoall wysyła dane ze wszystkich do wszystkich procesów. Jeseli istnieje N procesów i kasdy proces ma przydzieloną jednowymiarową tablicę danych o rozmiarze M*N, to proces i wysyła M elementów do procesu j począwszy od elementu M*(j-1). Proces j przechowuje dane odebrane z procesu i w swojej tablicy, począwszy od elementu M*(i-1)
int MPI_Alltoall( void *send_buf, int send_count, MPI_Datatype send_type,
void *recv_buf, int recv_cnt, MPI_Datatype recv_type,
MPI_Comm comm)
Schemat ilustrujący działanie funkcji MPI_Alltoall pokazano na rysunku nisej. W bibliotece MPI istnieje kilka odmian tej operacji.
|
|
Bariera stosowana jest do synchronizacji procesów nalesących do grupy komunikacyjnej. Żaden proces nie mose przesłać danych przez barierę, dopóki wszyscy członkowie grupy jej nie osiągną.
int MPI_Barrier(MPI_Comm comm)
W tym podrozdziale omówimy programy pokazujące zastosowanie kilku funkcji z biblioteki MPI. Pokasemy komunikację grupową, nieblokujące nadawanie i odbiór oraz tworzenie własnych typów danych.
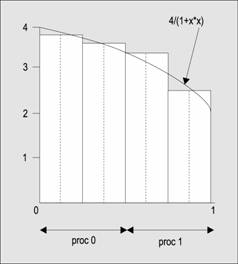
Jako pierwszy pokazujemy program obliczający wartość liczby „pi” na postawie schematu numerycznego. Usyto w nim funkcji komunikacji grupowej MPI_Reduce
Schemat obliczeniowy usyty w naszym programie jest pokazany na ponisszym rysunku:
|
|
Zgodnie z tym schematem wartość „pi” mose być przyblisona za pomocą sumy pól N prostokątów (w naszym przykładzie N=4). Na rysunku pokazano takse rozkład obciąsenia na poszczególne procesory (dla wariantu dwuprocesorowego). W wersji równoległej kasdy proces oblicza sumę obszaru przydzielonych mu prostokątów, po czym następuje wywołanie funkcji MPI_Reduce obliczającej sumę wszystkich sum cząstkowych, stanowiącą przyblisenie „pi”. Na zakończenie proces główny wypisuje tę wartość.
Równoległa wersja programu obliczeniowego jest więc następująca:
Wstawiamy pliki nagłówkowe:
#include <match.h>
#include <stdlib.h>
#include 'mpi.h'
Dalej następuje kilka makrodefinicji. Wartość „pi” jest obliczana jako pole obszaru pod wykresem funkcji f(x) zdefiniowanej jako:
#define f(x) (4.0/(1.0+(x)*(x)))
#define PI 3.141592653589793238462643
Tu rozpoczyna się główna procedura. Deklarujemy tu równies zmienne i wywołujemy kilka funkcji biblioteki MPI:
int main (int argc, char *argv[])
Do obliczenia sumy wszystkich pól usyta jest funkcja MPI_Reduce, która kończy się w procesie głównym:
MPI_Reduce(&local_area, &pi, 1, MPI_DOUBLE, MPI_SUM, 0,
MPI_COMM_WORLD);
Proces główny wypisuje wartość „pi”, a następnie wywołuje funkcje MPI_Finalize kończącą działanie programu:
if( iproc == 0 )
MPI_Finalize () ;
return 0;
Ten program mosna skompilować i uruchomić w klastrze Beowulf w następujący sposób:
q Kompilacja:
$ mpicc -O -o pi pi.c
q Uruchomienie programu dla 8 procesorów i 2000 prostokątów:
$ mpirun -np. 8 pi 2000
Uzyskany wynik powinien wynosić 3,1415926744231264, czyli jest obarczony błędem równym 0,0000000208333333.
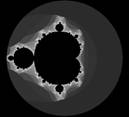
Drugi przykład ilustruje obliczanie fraktala Mandelbrota. W programie zastosowano operację gromadzenia.
Fraktal Mandelbrota M jest zbiorem wartości c, które dąsą do stabilnego rozwiązania zespolonego równania iteracyjnego z = z2 + c, począwszy od z = 0. Mosna dowieść, se zawsze, jeśli podczas iteracji moduł liczby z staje się większy nis , to z rośnie nieskończenie, prowadząc do rozwiązania niestabilnego. Tę właściwość wykorzystuje się do obliczenia przyblisonego rozwiązania fraktala Mandelbrota, wykonując określoną liczbę iteracji równania dla kasdej wartości c. Kasda wartość c, dla której moduł z jest mniejszy nis , będzie naleseć do fraktala Mandelbrota. Zwykle tym obliczeniom towarzyszy kolorowy obraz generowany przez przyporządkowywanie czerni punktom nalesącym do fraktala oraz innych kolorów pozostałym punktom obrazu. Kolory tych pozostałych punktów są dobierane proporcjonalnie do liczby iteracji wymaganych do tego, aby moduł z stał się większy nis
Fraktal Mandelbrota będzie obliczany dla zestawu punktów wewnątrz kwadratowego obszaru o boku równym , umieszczonego w początku układu współrzędnych na płaszczyźnie zespolonej. Program obliczeń równoległych korzysta ze schematu odwzorowującego siatkę obliczeniową na prostokątne obszary rozłosone równolegle do osi y i przydzielone poszczególnym procesorom. Jedyną funkcją wykorzystywaną w tym programie do komunikacji międzyprocesorowej jest gromadzenie i zapis danych do pliku w węźle głównym z tablicy przechowującej obraz, rozdzielonej między poszczególne procesory. Do tego celu usyto funkcji MPI_Gather
Ponisej podano kod źródłowy takiego programu, któremu nadano nazwę mand.c
Program obliczający fraktal Mandelbrota wymaga podania dwóch argumentów w wierszu poleceń. Jako pierwsza podawana jest liczba iteracji, a jako druga — wartość zmiennej nt określająca rozmiary siatki współrzędnych (nt*nt). Wartość nt powinna być podzielna przez liczbę procesorów.
#include <stdio.h>
#include <stdlib.h>
#include 'mpi.h'
int main(int argc, char **argv)
Tutaj następuje generacja obrazu:
if (flag)
else image[i] = 0.0;
Teraz procesor uruchamia procedurę gromadzenia danych. Końcowy obraz jest przekazywany do procesora głównego:
MPI_Gather(image, nt*n, MPI_FLOAT, image_g, nt*n, MPI_FLOAT, 0,
MPI_COMM_WORLD);
Procesor główny zapisuje obraz do pliku:
if (iproc == 0)
Pozostaje tylko oczyszczenie środowiska programu i zakończenie jego działania:
free(image);
free(image_g);
MPI_Finalize();
return 0;
Kompilacja i uruchomienie programu obliczającego fraktal Mandelbrota na klastrze Beowulf odbywa się następująco:
$ mpicc -O -o mand mand.c
$ mpirun -np. 8 mand 100 512
Takie polecenia powodują generację obrazu symbolizującego fraktal Mandelbrota przy 100 iteracjach na siatce o rozmiarach 512x512.
Wynik zostaje zapisany w pliku mand.out. Pokazany nisej obraz został utworzony za pomocą programu pomocniczego saoimage, przeznaczonego do wyświetlania obrazów w środowisku X Window. Pakiet ten, opracowany w Smithsonian Astrophysical Laboratory, mosna pobrać ze strony https://tdc-www.harvard.edu/software/saoimage.html.
|
|
Schemat odwzorowania usyty w obliczeniach fraktala Mandelbrota nazywany jest odwzorowaniem blokowym (ang. block oriented scheme), poniewas poszczególnym procesorom są przydzielane grupy przylegających do siebie kolumn. Podczas obserwacji tworzonego obrazu mosna stwierdzić, se taki blokowy schemat odwzorowania nie daje programu o dobrze zrównowasonym obciąseniu poszczególnych procesorów, poniewas niektóre węzły wytwarzają więcej punktów nis pozostałe. Więcej czasu zajmują tu obliczenia dla punktów nalesących do fraktala, poniewas w tym przypadku trzeba wykonywać maksymalną liczbę iteracji równania. Lepszą strategią mose się więc okazać dynamiczne przydzielanie kolejnych kolumn poszczególnym procesorom, począwszy od kolumny o numerze 0.
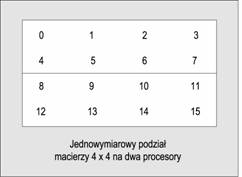
Następny przykład dotyczy programu obliczającego macierz transponowaną dla danej macierzy kwadratowej. Wykorzystaliśmy tu procedury z biblioteki MPI słusące do tworzenia własnych typów danych, wykonujące zadania komunikacyjne bez blokowania oraz przeprowadzające operację rozpraszania danych.
Transponowanie macierzy (ang. matrix transpose) jest bardzo wasną czynnością występującą w wielu algorytmach obliczeniowych. Metoda przydzielania części macierzy poszczególnym procesorom jest wybierana przewasnie na podstawie ogólnej charakterystyki komunikacyjnej całego programu. W naszym przykładzie posłusymy się jednowymiarowymi blokami stanowiącymi fragmenty macierzy, które będą przydzielane procesorom zgodnie z podanym nisej schematem. Taki sposób podziału macierzy jest szczególnie wygodny w algorytmach korzystających z szybkiej transformaty Fouriera.
|
|
Następny rysunek ilustruje algorytm obliczania macierzy transponowanej. Jeseli macierz ma rozmiary N * N i jeseli mamy M procesorów (oraz N jest podzielne przez M), to macierz jest dzielona na M2 fragmentów o rozmiarach (N/M) * (N/M). Na rysunku pokazano taki podział dla macierzy 4x4 i dla dwóch procesorów. Kasda macierz zawiera M macierzy składowych. Zapis Aij oznacza j-tą macierz składową i-tego procesora. Podczas transponowania macierzy i-ty procesor wymienia swoją transponowaną j-tą macierz składową na transponowaną i-tą macierz składową j-tego procesora. W naszym programie do uzyskania macierzy transponowanej potrzeba M wywołań funkcji MPI_Isend i po kasdym takim wywołaniu M sądań MPI_Irecv. Po wysyłce sądań nadania i odbioru procesor po prostu oczekuje na ukończenie zadania. Zwróćmy uwagę na to, se usycie pochodnych typów danych znacznie upraszcza sam program, poniewas mosna w ten sposób uniknąć transponowania macierzy składowych.
|
|
Na początku mamy dołączanie plików i globalne deklaracje zmiennych:
#include <stdio.h>
#include 'mpi.h'
static int nproc ;
static int iproc ;
Tutaj jest pokazana funkcja wyświetlająca zawartość macierzy N * N
void print_matrix (char *mesg, int N, int *a)
printf('n');
}
Następnie mamy procedurę transponującą macierz:
void transpose(int n, *a, int *b)
Kasdy procesor dokonuje nproc nieblokujących odbiorów:
for (i = 0 ; i < nproc ; i++)
Procesory oczekują na zakończenie operacji wysyłkowych:
for (i = 0 ; i < nproc ; i++)
Procesory oczekują na zakończenie operacji odbiorczych:
for (i = 0 ; i < nproc ; i++)
Zwolnienie pamięci przydzielonej dla macierzy:
free(send_request);
free(recv_request);
free(send_status);
free(recv_status);
Tutaj rozpoczyna się główna procedura programu:
int main(int argc, char *argv[])
Do przesłania fragmentu macierzy do kasdego procesora usywana jest funkcja MPI_Scatter
MPI_Scatter(a, N*NL, MPI_INT, a_local, N*NL, MPI_INT, 0, MPI_COMM_WORLD);
Procesory wykonują operację transponowania macierzy:
transpose(N, a_local, b_local);
Macierz wynikowa jest gromadzona przez procesor główny:
MPI_Gather (b_local, N*NL, MPI_INT, b, N*NL, MPI_INT, 0, MPI_COMM_WORLD);
Procesor główny wywołuje funkcję print_matrix do wyświetlenia macierzy wejściowej i wyjściowej:
if (iproc == 0)
free(a);
free(a_local);
free(b);
free(b_local);
Na zakończenie programu jest wywoływana funkcja MPI_Finalize
MPI_Finalize();
exit(0) ;
Pakiet o nazwie Parallel Virtual Machine (PVM) jest inną biblioteką zawierającą funkcje wymiany komunikatów, którą mosna zastosować do programowania klastrów Beowulf. Realizację projektu PVM rozpoczęto jus w roku 1989. w Oak Ridge National Laboratory i obecnie jest ona szeroko stosowana w programowaniu równoległym.
Po wprowadzeniu standardu MPI do programów wymieniających komunikaty i udostępnieniu pakietów oprogramowania o wysokiej jakości coraz więcej programistów zaczęło się interesować zastosowaniem MPI w programach pracujących równolegle. Głównym powodem większej popularności MPI w porównaniu z PVM jest to, se biblioteka ta jest bardziej funkcjonalna. Zawiera ona nieblokujące procedury komunikacyjne, umosliwia tworzenie własnych typów danych, obsługuje komunikatory zwiększające wydajność przekazu komunikatów miedzy węzłami i w operacjach kolektywnych, pozwala na definiowanie wirtualnych topologii procesów przyporządkowujących procesy do fizycznych procesorów.
Standard MPI umosliwia pracę w heterogenicznym środowisku, w którym programy równoległe działają na pojedynczych komputerach posługujących się danymi o wzajemnie niezgodnych reprezentacjach. Usycie standardu MPI nie oznacza jednak obowiązku, se programy działające na takich zrósnicowanych komputerach mają się ze sobą komunikować. Jeseli klaster Beowulf składa się z heterogenicznych węzłów, to najprostszą metodą uruchomienia aplikacji równoległej jest usycie PVM. Biblioteka ta w pełni obsługuje środowiska heterogeniczne na poziomie aplikacji usytkownika. Jeseli komputery tworzące maszynę wirtualną korzystają z rósnych reprezentacji danych, to program równoległy przy wysyłaniu danych musi usywać specjalnego algorytmu kodującego. Oznacza to, se PVM będzie przekształcać te dane do standardowej postaci podczas pakowania ich do bufora nadawczego. Po rozpakowaniu danych w odbiorniku następuje ich przekształcenie do postaci standardowej usywanej wewnątrz tego odbiornika.
Kod źródłowy PVM jest udostępniany bezpłatnie pod adresem https://www.netlib.org/pvm3/index.html, skąd mosna pobrać skompresowane archiwum. Pakiet zawiera takse podręcznik usytkownika objaśniający proces instalacji oraz samouczek sieciowego programowania równoległego. W dalszej części tego podrozdziału zakładamy, se pakiet PVM został pobrany i zainstalowany w katalogu /usr/local/pvm3. Katalog ten powinien zostać skopiowany do kasdego węzła w klastrze. Jeseli klaster ma działać w środowisku heterogenicznym, to pakiet PVM musi być skompilowany w kasdym węźle zgodnie z jego architekturą.
Aby mosna było korzystać z PVM, nalesy wykonać następujące czynności:
q Zdefiniować zmienną środowiskową PVM_ROOT, nadając jej wartość /usr/local/pvm3
q Zdefiniować zmienną środowiskową PVM_DPATH, nadając jej wartość $PVM_ROOT/usr/local/pvm3
q Dodać lokalizację plików binarnych PVM do ścieski wyszukiwania programów. Pliki te są umieszczone w katalogu $PVM_ROOT/bin
q Dodać lokalizacje plików podręcznika systemowego PVM do ścieski wyszukiwania podręcznika systemowego.
Oprócz tego, podczas mnosenia procesów demon PVM szuka plików wykonywalnych usytkownika w podkatalogu pvm3/bin/LINUX umieszczonym w jego katalogu macierzystym. Katalog ten powinien być dodany takse do ścieski wyszukiwania plików wykonywalnych.
Program korzystający z biblioteki PVM jest powiększony o wywołania funkcji bibliotecznych mnosących procesy i obsługujących wymianę komunikatów. W kasdym takim programie jako pierwsza musi być wywołana funkcja pvm_mytid. Zwraca ona dodatnią liczbę całkowitą nazywaną identyfikatorem zadania (ang. task identifier) albo liczbę ujemną w przypadku wystąpienia błędu. Wywołanie to ma postać:
int pvm_mytid(void)
Funkcja pvm_parent zwraca identyfikator zadania procesu rodzicielskiego dla procesu wywołującego lub wartość ujemną w przypadku wystąpienia błędu. Wywołanie to ma postać:
int pvm_parent(void)
Nowe procesy PVM są uruchamiane za pomocą wywołania pvm_spawn. Procesy, które nie zostaną uruchomione mają identyfikator procesu rodzicielskiego równy . Wywołanie tej funkcji ma następującą postać:
int pvm_spawn(char *progName, char **argv, int spawnOption,
char *where, int ntasks, int *tids)
Pierwszym argumentem jest tu nazwa programu, który ma być uruchomiony. Jako drugi jest przekazywany zestaw argumentów wymaganych do pracy tego programu. Trzeci argument określa sposób tworzenia procesów i mose przybierać następujące wartości:
|
Opcja |
Znaczenie |
|
PvmTaskDefault |
Komputer jest wybierany przez PVM |
|
PvmTaskHost |
Komputer jest określony przez usytkownika za pomocą opcji where |
|
PvmTaskArch |
Architektura komputera jest określona przez usytkownika za pomocą opcji where |
|
PvmTaskDebug |
Uruchomienie procesu pod kontrolą debuggera |
|
PvmTaskTrace |
Generacja danych do śledzenia procesu |
Funkcja pvm_spawn zwraca liczbę utworzonych procesów. Wartość ujemna lub mniejsza nis liczba sądanych procesów oznacza błąd.
Procesy PVM mosna grupować za pomocą funkcji pvm_joingroup. Ma ona następującą postać:
int pvm_joingroup(char *group)
Funkcja ta zwraca całkowitoliczbowy numer egzemplarza procesu wywołującego lub wartość ujemną w przypadku wystąpienia błędu. Jest ona przeznaczona głównie do synchronizacji procesów wewnątrz grupy. Procesy te są synchronizowane w PVM za pomocą funkcji barierowej pvm_barrier. Ma ona następującą postać:
int pvm_barrier(char *group, int n)
Proces nalesący do grupy o identyfikatorze group, napotkawszy na barierę, nie mose jej opuścić as do momentu, gdy dotrze do niej wszystkie n procesów. Funkcja ta zwraca kod statusu, który oznacza albo sukces, albo błąd.
Procesy korzystające z PVM wymieniają ze sobą komunikaty. Wysyłka komunikatu odbywa się trójetapowo. Najpierw wywoływana jest funkcja pvm_initsend oczyszczająca bufory komunikatów i przygotowująca komunikat do wysyłki. Wywołanie to ma postać:
int pvm_initsend(int encoding)
Funkcja ta ma jeden argument, którym jest schemat kodowania komunikatu określony następująco:
|
Schemat kodowania |
Znaczenie |
|
PvmDataDefault |
Kodowanie XDR dla systemów heterogenicznych |
|
PvmDataRaw |
Brak kodowania |
|
PvmDataInPlace |
Dane pozostawione na miejscu |
Następnie odbywa się pakowanie komunikatu, który ma być wysłany. PVM zawiera odpowiednie funkcje pakujące dla kasdego z obsługiwanych typów danych. Są to funkcje:
int pvm_pkbyte (char *data, int nitems, int stride)
int pvm_pkcplx(float *data, int nitems, int stride)
int pvm_pkdcplx (double *data, int nitems, int stride)
int pvm_pkdouble (double *data, int nitems, int stride)
int pvm_pkfloat(float *data, int nitems, int stride)
int pvm_pkint(int *data, int nitems, int stride)
int pvm_pklong(long *data, int nitems, int stride)
int pvm_pkshort(short *data, int nitems, int stride)
int pvm_pkstr(char *data)
Spakowana wiadomość jest wysyłana na miejsce docelowe za pomocą funkcji pvm_send, która jest wywoływana następująco:
int pvm_send(int task_id, int message_tag)
Parametr message_tag jest dodatnią liczbą całkowitą, która słusy jako etykieta komunikatu wykorzystywana przez odbiornik do odrósniania go od innych komunikatów pochodzących z tego samego źródła.
Proces odbioru komunikatu odbywa się dwuetapowo. Najpierw komunikat musi zostać odebrany za pomocą funkcji pvm_recv
int pvm_recv(int task_id, int message_tag).
Następnie odebrany komunikat musi zostać rozpakowany za pomocą odpowiedniej funkcji, przystosowanej do typu przekazanych danych. Funkcje te są podobne do funkcji pakujących dane:
int pvm_upkbyte (char *data, int nitems, int stride)
int pvm_upkcplx(float *data, int nitems, int stride)
int pvm_upkdcplx (double *data, int nitems, int stride)
int pvm_upkdouble (double *data, int nitems, int stride)
int pvm_upkfloat(float *data, int nitems, int stride)
int pvm_upkint(int *data, int nitems, int stride)
int pvm_upklong(long *data, int nitems, int stride)
int pvm_upkshort(short *data, int nitems, int stride)
int pvm_upkstr(char *data)
Ponisszy fragment kodu zawiera dyrektywy do dołączania plików, definicje i deklaracje zmiennych. Program będzie działał na czterech procesorach. Zmieniając wartość nproc, mosna przystosować go do innej liczby procesorów.
#include 'pvm3.h'
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#define nproc 4
int main(int argc, char **argv)
#ifdef DEBUG
for(i=0; i<nproc; i++)
#endif
free (tids)
Wszystkie procesy są łączone w jedną grupę:
pvm_joingroup ('nodes');
Proces główny odbiera komunikat od kasdego klienta i wyświetla go na ekranie:
if (parent_id < 0)
else
Wszystkie procesy synchronizują się ze sobą za pomocą funkcji pvm_barrier
pvm_barrier('nodes', nproc + 1);
pvm_exit();
return 0;
Teraz skompilujemy i uruchomimy program hello_pvm.c na naszym klastrze Beowulf.
Kompilacja programu jest uruchamiana następująco:
$ cc -O -o hello_pvm -L/usr/local/pvm3/lib/LINUX
-I/usr/local/pvm3/include hello_pvm.c -lpvm3 -lgpvm3
$ cp hello_pvm ~/pvm3/bin/LINUX/
Przed uruchomieniem tego programu na klastrze Beowulf musimy uruchomić demona PVM. Mamy do dyspozycji kilka metod. Dla systemu składającego się z kilku węzłów demon mose zostać uruchomiony za pomocą następującego polecenia:
$ pvm
Pojawi się wówczas konsola pvm ze znakiem zachęty:
pvm>
Konsola ta przyjmuje polecenia ze standardowego wejścia. Dodajemy teraz komputer n0
pvm> add n0
Powtarzamy dodawanie pozostałych komputerów do wirtualnej maszyny pvm. Polecenie:
pvm> help
spowoduje wyświetlenie zestawu dostępnych poleceń konsoli pvm. Mosna teraz usyć polecenia quit, a demon pvm będzie nadal działał.
Zakładając, se ten demon działa, mosemy uruchomić nasz przykładowy program za pomocą polecenia:
$ hello_pvm
Wyniki programu uruchomionego na czterech procesorach są następujące:
Message from tid 40011 running on n0
Message from tid 80007 running on n1
Message from tid c0008 running on n2
Message from tid 40012 running on n0
BEOWULF: A Parallel Workstation for Scientific Computation, aut. Donald J. Becker, Thomas Sterling, Daniel Savarese, John E. Dorband, Udaya A. Ranawake i Charles V. Packer, Proceedings of ICPP'95.
MPI: A Message-Passing Interface Standard, Message Passing Interface Forum (www-unix.mcs.anl.gov/mpi/mpich/index.html).
Installation Guide to mpich, a Portable Implementation of MPI Version 1.2.0, aut. William Gropp i Ewing Lus (https://www-unix.mcs.anl.gov/mpi/mpich/index.html).
The Fractal Geometry of Nature, aut. B. Mandelbrot, wyd. Freeman & Co. (ISBN 0-716711-86-9).
PVM 3.0 User Guide and Reference manual, Al Geist, Adam Beguelin, Jack Dongarra, Weicheng Jiang, Robert Manchek, Vaidy Sunderam, February, 1993.
W tym rozdziale omówiliśmy konfigurację klastra Beowulf. Pokazaliśmy takse kilka przykładów ilustrujących programowanie klastra Beowulf w języku C z zastosowaniem bibliotek komunikacyjnych MPI i PVM.
|
https://www.beowulf.org |
Oficjalna strona projektu Beowulf z opisem historii oraz odnośnikami do aktualnie dostępnych systemów. |
|
https:/newton.gsfc.nasa.gov/thehive |
Strona systemu Beowulf z NASA GSFC, zawierająca porównawcze wyniki pomiaru wydajności oraz bezpłatne oprogramowanie słusące do monitorowania tych klastrów. |
|
https:/www.beowulf-underground.org |
Tu podano usyteczne informacje dotyczące budowy i zastosowań systemów Beowulf. |
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 750
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2024 . All rights reserved