| CATEGORII DOCUMENTE |
| Bulgara | Ceha slovaca | Croata | Engleza | Estona | Finlandeza | Franceza |
| Germana | Italiana | Letona | Lituaniana | Maghiara | Olandeza | Poloneza |
| Sarba | Slovena | Spaniola | Suedeza | Turca | Ucraineana |
DOCUMENTE SIMILARE |
|
Usytkowane dziś bazy danych mosna podzielić, ze względu na sposób zarządzania nimi, na dwa rodzaje: operacyjne bazy danych i analityczne bazy danych.
Bazy operacyjne znajdują
zastosowanie w codziennym funkcjonowaniu rosnych instytucji, organizacji i
firm. Są wykorzystywane tam, gdzie zachodzi potrzeba gromadzenia,
przechowywania i modyfikowania danych. Ten typ bazy danych przechowuje dane
dynamiczne, czyli takie, które ulegają ciągłym zmianom
i odzwierciedlają biesący stan jakiegoś obiektu. Przykłady baz operacyjnych to
bazy obsługi zamówień, bazy inwentaryzacyjne, bazy danych o pacjentach,
prenumeratorach czasopism.
Bazy analityczne są
wykorzystywane do przechowywania danych historycznych i informacji związanych z
pewnymi zdarzeniami. Dane w bazie analitycznej są statyczne - bardzo rzadko (jeseli
w ogóle) ulegają zmianom i zawsze odzwierciedlają stan obiektów z pewnego
ustalonego momentu, nigdy stan obecny.
Z bazy analitycznej korzysta się chcąc np. przeanalizować tendencje rynkowe,
uzyskać dostęp do długoterminowych danych statystycznych, poczynić prognozy.
Z punktu widzenia organizacji danych wyrósnić mosna:
Hierarchiczne bazy danych,
Sieciowe bazy danych,
Relacyjne bazy danych,
Obiektowe bazy danych.[1]
Wszystkie wymienione rodzaje baz danych zostaną opisane w kolejnych podrozdziałach.
2.1 Hierarchiczne bazy danych
W hierarchicznym modelu bazy danych (HMBD) dane mają strukturę odwróconego drzewa. Jedna z tabel pełni rolę korzenia 'drzewa' pozostałe mają postać gałęzi, biorących początek w korzeniu.
![]()
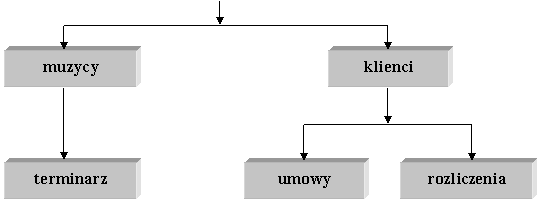
Rys.2. Diagram przykładowego modelu hierarchicznego.
Źródło : https://stud.ics.p.lodz.pl/staff/arturp/db-podypl/spi-wykład-1.html
2.1.1 Przykład modelu hierarchicznego
W przykładzie z rysunku nr 2, kasdy pośrednik pracuje dla kilku muzyków i ma pewną liczbę klientów, którzy zamawiają u niego obsługę muzyczną rósnych imprez. Klient zawiera umowę z danym muzykiem przez pośrednika i u tego pośrednika uiszcza nalesność za usługę.
Relacje w HMBD są reprezentowane w kategoriach ojciec/syn. Oznacza to, se tabela-ojciec mose mieć powiązania z wieloma tabelami-synami, lecz pojedynczy syn mose mieć tylko jednego ojca. Tabele mogą być powiązane jawnie, przez wskaźniki, lub przez fizyczną organizację rekordów wewnątrz tabel. Aby uzyskać dostęp do danych w modelu hierarchicznym, usytkownik zaczyna od korzenia i przechodzi przez całe drzewo danych, as do miejsca, które go interesuje. Oznacza to jednak, se trzeba dobrze znać strukturę bazy danych.
2.1.2 Zalety modelu hierarchicznego
Szybki dostęp do danych, poniewas tabele są ze sobą bezpośrednio powiązane,
Automatyczna integralność odwołań (rekord w tabeli-syn musi mieć powiązanie z rekordem w tabeli-ojciec, usuwanie ojca powoduje usunięcie synów). Ale nie zawsze jest to zaletą.
2.1.3 Wady modelu hierarchicznego
Aplikacje i usytkownicy muszą posiadać dusą wiedzę na temat organizacji bazy danych,
Integralność odwołania zabrania wprowadzenia rekordów-synów bez rekordu ojca, co nie zawsze znajduje odzwierciedlenie w modelowanej rzeczywistości. Obejście tego ograniczenia wymaga wprowadzania sztucznych danych,
Trudności w modelowaniu relacji wiele-do-wielu (np. klienci-muzycy). Konieczne staje się wprowadzanie nadmiarowych danych (niekonsekwencje, zaburzenia integralności na skutek powielania danych) lub tworzenie wielu baz hierarchicznych i relacji logicznych między nimi.
Sieciowy
model bazy danych (SMBD) został stworzony głównie w celu rozwiązania problemów
związanych z modelem hierarchicznym. Podobnie, jak
w modelu hierarchicznym SMBD mosna sobie wyobrazić jako odwrócone drzewo.
Rósnica polega jednak na tym, se w przypadku SMBD, wiele drzew mose dzielić ze
sobą gałęzie, a kasde z nich stanowi cześć ogólnej struktury bazy danych.
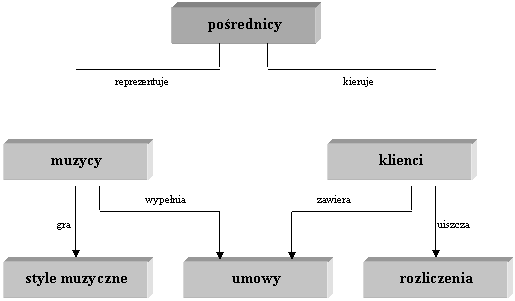
![]()
![]()
Rys.3. Diagram przykładowego modelu sieciowego.
Źródło : https://stud.ics.p.lodz.pl/staff/arturp/db-podypl/spi-wykład-1.html
2.2.1 Przykład modelu sieciowego
W
przykładzie z rysunku nr 3, kasdy pośrednik pracuje dla kilku muzyków i ma
pewną liczbę klientów, którzy zamawiają u niego obsługę muzyczną rósnych imprez
i uiszczają opłaty. Kasdy muzyk mose zawrzeć wiele oddzielnych umów
i specjalizować się w wielu gatunkach muzyki.
Relacje w
SMBD są definiowane przez kolekcje (ang. set structures).
Kolekcja jest niejawną konstrukcją łączącą dwie tabele przez przypisanie jednej
z nich roli właściciela, drugiej - roli członka. Kolekcje
pozwalają wprowadzić relacje jeden-do-wielu. W obrębie danej struktury,
kasdy rekord z tabeli-właściciela mose być powiązany z dowolną ilością
rekordów tabeli-członka, a pojedynczemu rekordowi
z tabeli-członka mose odpowiadać tylko jeden rekord w tabeli-właściciela.
Ponadto kasdy rekord z tabeli-członka musi mieć przyporządkowany rekord
z tabeli-właściciela.
Między
kasdymi tabelami mosna zdefiniować dowolną liczbę powiązań,
a kasda tabela mose uczestniczyć w wielu kolekcjach.
2.2.2 Zalety modelu sieciowego
Szybki dostęp do danych, poniewas tabele są ze sobą bezpośrednio powiązane,
Automatyczna integralność odwołań. Podobnie, jak modelu hierarchicznym, nie zawsze jest to zaletą,
Mosliwość zadawania złosonych zapytań i modelowania bardziej złosonych struktur.
2.2.3 Wady modelu sieciowego
Aplikacje i usytkownicy nadal muszą posiadać dusą wiedzę na temat organizacji bazy danych,
Niemosność zmiany struktury bazy danych bez zmian w obsługujących ją programach.
Pod koniec lat sześćdziesiątych dr E. F. Codd, badacz zatrudniony przez firmę IBM, pracował nad nowymi sposobami obsługi dusych ilości informacji. Zauwasył on, se zastosowanie struktur i procesów matematycznych mogłoby rozwiązać wiele problemów, z którymi nie mogły poradzić sobie ówczesne modele bazy danych, takich jak nadmiarowość danych, słaba integralność, czy silna zalesność od fizycznej implementacji.
W lipcu, 1970r. Codd opublikował swoją najwasniejszą pracę: Relacyjny model logiczny dla dusych banków danych. W ksiąsce tej po raz pierwszy zaprezentował załosenia relacyjnego modelu baz danych (RMBD), opierającego się na dwóch gałęziach matematyki - teorii mnogości i rachunku predykatów pierwszego rzędu. (Popularnym błędem jest twierdzenie, se nazwa RMBD wywodzi się z faktu istnienia 'relacji' między tabelami w bazie danych. W rzeczywistości RMBD zawdzięcza swoją nazwę pojęciu relacji w teorii mnogości).
W RMBD dane
przechowuje się w postaci relacji, czyli tabel. Kasda tabela składa się z
krotek, czyli rekordów (lub wierszy) i atrybutów, czyli pól (lub kolumn).
Fizyczna kolejność wierszy i kolumn w tabeli jest bez znaczenia. Kasdy rekord
jest wyrósniany przez jedno pole, lub zestaw kilku pól zawierających unikalną
wartość. Te dwie cechy umosliwiają egzystencję danych niezalesnie od sposobu
pamiętania ich przez komputer. Innymi słowy, usytkownik (lub program
usytkownika) nie musi znać połosenia rekordu, który chce odczytać. Jest to
wielki postęp w stosunku do modelu hierarchicznego i sieciowego, gdzie
struktury i dusy nacisk kładziono na ich znajomość.
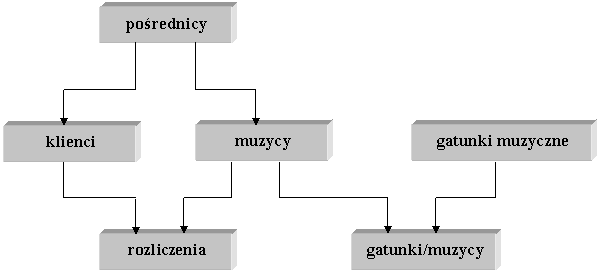
Rys. 4. Diagram przykładowego modelu relacyjnego.
Źródło : https://stud.ics.p.lodz.pl/staff/arturp/db-podypl/spi-wykład-1.html
2.3.1 Przykład modelu relacyjnego
W przykładzie z rysunku nr 4, kasdy pośrednik pracuje dla kilku muzyków i ma pewną liczbę klientów. Ponadto klienci są ze sobą powiązani przez tabelę umów, poniewas klient mose zatrudnić dowolną liczbę muzyków, kasdy muzyk mose grać dla wielu klientów. Oprócz tego kasdy muzyk reprezentuje jeden lub więcej gatunków muzyki, co odzwierciedla tabela gatunki/muzycy.
Powiązania
między tabelami (relacje) w RMBD mosna podzielić na trzy grupy: jeden-do-jednego,
jeden-do-wielu oraz wiele-do-wielu. Kasde dwie tabele, między
którymi istnieje relacja, są ze sobą jawnie powiązane, poniewas dzielone przez
nie kolumny zawierają odpowiadające sobie wartości. Np. w tabelach Pośrednicy i
Klienci mose istnieć kolumna o nazwie IDPośrednika (nie musi w obu tabelach
nazywać się tak samo, ale w praktyce często tak jest) wiąsąca wymienione
tabele. Kasdemu klientowi odpowiada jeden z pośredników, którego identyfikator
znajduje się w tej kolumnie. I odwrotnie - dla danego pośrednika mosna zaleźć
wszystkich klientów, których obsługuje, takse na podstawie wartości w kolumnie
IDPośrednika.
Jeseli usytkownik wie, jakie relacje występują między poszczególnymi tabelami
w bazie danych, mose czerpać z niej informacja na niemal nieograniczoną ilość
sposobów, kojarząc ze sobą dane z powiązanych bezpośrednio lub pośrednio tabel.
W RMBD dostęp do danych uzyskuje się, podając nazwę pola oraz tabel(i), do których ono nalesy, Jednym ze sposobów jest wykorzystanie języka SQL (ang. Structured Query Language SQL jest standardowym językiem usywanym do wprowadzania, modyfikowania oraz odczytywania informacji z bazy danych.
System zarządzania relacyjną bazą danych (SZRBD) jest programem wykorzystywanym do tworzenia i modyfikowania relacyjnych baz danych. Mose słusyć równies do generowania aplikacji, z której będzie korzystał usytkownik gotowej bazy danych.
Jakość danego SZRBD zalesy
od stopnia, w jakim implementuje on relacyjny model logiczny. Nawet
'prawdziwe' SZRBD często bardzo rósnią się między sobą,
a pełnej implementacji RMBD nie udało się nadal nikomu osiągnąć. Mimo to obecne
SZRBD są potęsniejsze i wszechstronniejsze nis kiedykolwiek.
Kolejne etapy rozwoju:
System
relacyjnej bazy danych - system bazy danych składa
się z bazy danych
i systemu zarządzania bazą danych. Baza danych jest
uporządkowanym zbiorem danych pamiętanych w urządzeniach przechowywania danych
systemu komputerowego. System zarządzania bazą danych jest programem
zarządzającym dostępem do bazy danych.
Atrybut - elementarny rodzaj, typ danych. Przykładowe rodzaje danych: Nazwisko, Imię, Data urodzenia, Wiek. Odpowiednikami terminu atrybut są terminy: kolumna, pole.
Domena atrybutu - niech dany będzie atrybut A. Zbiór wszystkich mosliwych wartości atrybutu nazywamy domeną atrybutu i oznaczamy dom(A). Np. domeną atrybutu nazwisko jest zbiór wszystkich łańcuchów znaków o długości nie większej nis n, atrybutu Wiek - zbiór wszystkich liczb całkowitych z zakresu od 0 do 120.
Schemat relacji -
zbiór wybranych atrybutów A , , An
nazywamy schematem relacji i oznaczamy przez R(A ,
, An). Przykładowym schematem relacji KLIENCI jest:
KLIENCI(IDKlienta, Nazwisko, Imię, Adres, Miasto, KodPocztowy, NrTelefonu).
Krotka - dla
danego schematu relacji ciąg wartości jego atrybutów nazywamy krotką
i oznaczamy przez t. Przykładową krotką jest:
<1001, Kowalski, Jan, Sterlinga 14, Łódź, 90-212, 042-630-05-55>. Innymi słowy, dla danego schematu relacji R(A , , An), krotką t nazywamy ciąg wartości <a , , an>, takich, se a I dom(A ), , an I dom(An). Odpowiednikami terminu krotka są terminy: wiersz, rekord.
Relacja - relacją
określoną na schemacie relacji nazywamy skończony zbiór krotek. Formalnie r(A ,
, An) = , gdzie
r(A , , An) jest
relacją określoną na schemacie R(A , , An).
Przykładową relacją jest:
Odpowiednikami terminu relacja są terminy: tabela, plik.
Przedstawię teraz trzy
podstawowe operacje relacyjne: selekcję, projekcję
i połączenie, na których opiera się język manipulowania danymi. Warto
wspomnieć, se nie są to jedyne operacje relacyjne, definiuje się np. sumę
relacji, rósnicę, iloczyn kartezjański, przecięcie, itp. Jednak selekcja,
projekcja i połączenie pozwalają stworzyć język danych, który będzie
'relacyjnie zupełny', czyli pozwoli na dostęp do kasdej jednostki
informacji przechowywanej w bazie danych.
Przykład:
projekcja przez wybór atrybutów (IDKlienta, Nazwisko, Miasto)
Przykład: wybór krotek spełniających warunek
Miasto = 'Łódź'
Przykład: połączenie z relacją
ZAMÓWIENIA(IDZam, IDKlienta, Data,
Wartość, Zapłacono, Uwagi) =
Projektując
bazę danych trzeba wybrać najlepszy sposób na odwzorowanie danego systemu
pochodzącego ze świata rzeczywistego, na abstrakcyjny model
w bazie danych. Dotyczy to określenia jakie tablice nalesy utworzyć, jakie
kolumny mają zawierać, a takse jakie związki zachodzą pomiędzy poszczególnymi
tablicami.
Najwasniejsze korzyści wynikające z zaprojektowania bazy danych zgodnie
z modelem relacyjnym to:
Wydajne wprowadzanie, aktualizacja i usuwanie danych.
Wydajny odczyt danych, ich obróbka i generowanie raportów.
Zachowanie bazy danych jest przewidywalne, poniewas podlega dobrze zdefiniowanemu modelowi.
Baza danych jest w pewnym sensie samodokumentująca się, gdys większość informacji zawarta jest w samej bazie, nie w aplikacji.
Łatwo jest dokonywać zmian w strukturze bazy danych.
Tablice (relacje) w modelu relacyjnym reprezentują rzeczy, zjawiska ze świata rzeczywistego. Kasda tablica powinna reprezentować tylko jedną taką rzecz. Tablice zbudowane są z wierszy (krotek) i kolumn (atrybutów).
Model relacyjny nakazuje, aby kasdy wiersz w tablicy był unikalny. Unikalność zapewnia się wyznaczając w tablicy klucz główny, tzn. kolumnę, która zawiera unikatowe wartości w kasdym wierszu. Tabela ma tylko jeden klucz główny.
Klucz główny wybiera się z zestawu kluczy potencjalnych, kierując się między innymi zasadami:
|
IDKlienta |
Nazwisko |
Imie |
Adres |
Miasto |
KodPoczt |
NrTelefonu |
|
Kowalski |
Jan |
Sterlinga 14 |
Łódź | |||
|
Abacki |
Tomasz |
Zielona 35 |
Łódź | |||
|
Babacki |
Stefan |
Gojawiczyńskiej 3 |
Łódź | |||
|
Cabacki |
Piotr |
Strzelecka 5 |
Warszawa |
Klucze potencjalne:
IDKlienta, (Nazwisko, Imie), (NrTelefonu), (Miasto, Adres).
Klucz główny: IDKlienta.
Dodatkowe wskazówki: dobrymi kluczami głównymi są kolumny z automatycznym numerowaniem (ale nie stosować, jeseli konieczne mose być przenumerowanie lub kod alfanumeryczny), inne kolumny zawierające arbitralny, statyczny numer. Nie nalesy stosować liczb rzeczywistych (dokładność).
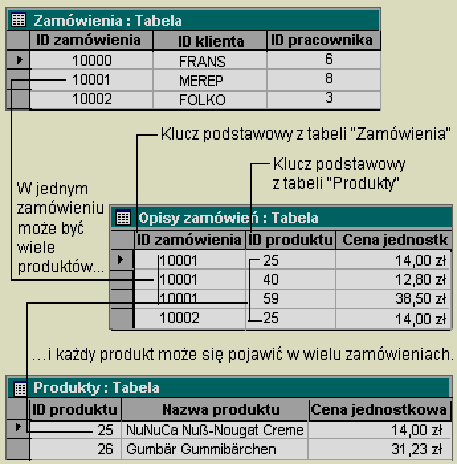
Klucz obcy to taka kolumna w tabeli, która zawiera wartości będące odnośnikami do klucza głównego innej tabeli (sama niekoniecznie będąc kluczem głównym - najczęściej nim nie jest).
|
IDZam |
IDKlienta |
Data |
Wartość |
Zapłacono |
Uwagi |
|
Nie realizować bez przedpłaty |
|||||
|
Wysłać SERVISCO |
|||||
|
Wysłać po skompletowaniu całości |
IDKlienta jest kluczem obcym w tablicy ZAMOWIENIA, poniewas stosuje się go do wskazywania danego klienta, tj. wiersza z tablicy KLIENCI.
Bardzo wasne jest, aby klucz
główny i klucz obcy miały to samo znaczenie
i posiadały tą samą dziedzinę (inaczej: domenę), czyli zbiór dozwolonych
wartości, które kolumna klucza mose przyjmować. Warto jeszcze raz podkreślić
wymóg jednakowego znaczenia - większość systemów baz danych dopuści związek,
np. KLIENCI.ID - ZAMOWIENIA.ID ze względu na zgodność dziedzin (liczby
całkowite) choć nie ma to sensu (nie modeluje sadnego powiązania ze świata
rzeczywistego).
Klucze obce definiuje się w bazie po to, aby odzwierciedlały powiązania ze świata rzeczywistego. Związki takie mogą, i często są, bardzo złosone. W relacyjnych bazach danych rozpatruje się związki 1-1, 1-N, N-N.
Dwie
tablice są powiązane w stosunku 1-1 jeseli kasdemu wierszowi jednej
z nich odpowiada co najwysej jeden wiersz drugiej. Rzadko zachodzą w świecie
rzeczywistym, częściej stosowane są do sztucznego obchodzenia ograniczeń
oprogramowania zarządzającego bazą danych (rozmiar danych, autoryzacja dostępu,
część tablicy podlega specyficznej obróbce, np. jest często przesyłana do innej
aplikacji).
Dwie
tablice są powiązane w stosunku 1-N jeseli kasdemu wierszowi jednej
z nich odpowiada zero, jeden lub więcej wierszy drugiej, ale kasdemu wierszowi
drugiej odpowiada dokładnie jeden wiersz z tabeli pierwszej. Związek 1-N jest
często nazywany związkiem rodzic-dziecko lub master-detail. Jest to najczęściej
spotykany typ związków.
Związki 1-N są takse stosowane do łączenia tablic 'zasadniczych' z tablicami odniesień (ang. lookup tables).
Dwie
tablice są powiązane w stosunku N-N jeseli kasdemu wierszowi jednej
z nich odpowiada zero, jeden lub więcej wierszy drugiej i kasdemu wierszowi
drugiej odpowiada zero, jeden lub wiele wierszy z tabeli pierwszej.
Związków N-N nie da się bezpośrednio modelować w dostępnych SZRBD. Muszą one
być rozbite na wiele związków 1-N. Przykład związku N-N przedstawia rysunek 5.
2.3.3 Zalety modelu relacyjnego
Wielopoziomowa
integralność danych - na poziomie kolumn (pól), tabel
i relacji między tabelami.
Logiczna
i fizyczna niezalesność aplikacji bazodanowych - zarówno zmiany wprowadzane
przez usytkownika do projektu logicznego (oczywiście
w rozsądnym zakresie), jak i modyfikacje sposobów fizycznej implementacji mają
znikomy wpływ na aplikacji obsługującej bazę.
Zagwarantowana dokładność i poprawność danych - dzięki wielopoziomowej integralności.
Łatwy
dostęp do danych - dane mosna w prosty sposób odczytywać
z pojedynczych tabel lub z całych grup tabel powiązanych ze sobą.
2.4 Obiektowe bazy danych
Obiektowy model danych (object model, object-oriented model) jest modelem danych, którego podstawą są pojęcia obiektowości, m.in.: obiekt, klasa, dziedziczenie, hermetyzacja (przedstawione ponisej).[3]
W obecnej chwili nie istnieje saden, ogólnie przyjęty, standard jednoznacznie definiujący pojęcia obiektowe. Trwają prace nad ustandaryzowaniem pojęć obiektowych w dziedzinie baz danych, prowadzone m.in.: przez ODMG (Object Database Management Group). Standard zaproponowany przez ODMG stworzony został w oparciu o trzy istniejące standardy dotyczące baz danych (SQL-92), obiektów (OMG) i obiektowych języków programowania (ANSI).
Brak powszechnie akceptowalnych definicji modelu obiektowego w dziedzinie baz danych wynika z faktu, is rozwój podejścia obiektowego następował w trzech rósnych obszarach:
W rósnych językach
(programowania i reprezentacji wiedzy) przyjęto rósne interpretacje pojęć
obiektowych. Obiektowe języki programowania i reprezentacji wiedzy zawierają
jednak wiele spójnych pojęć obiektowych, na podstawie których mosna stworzyć
podstawowy, obiektowy model danych. Model ten, rozszerzony
o więzy spójności semantycznej (jednoznaczność wartości atrybutów,
dopuszczalność wartości NULL, zakres wartości atrybutu, itp.) i pewną liczbę
związków semantycznych (związek bycia częścią lub wersją między parą obiektów),
umosliwia projektantowi modelowanie danych w aplikacjach bazodanowych.
Przedstawiony ponisej (str.33) model podstawowy jest oparty na modelu
zaimplementowanym
w systemie ORION (prototypowy system obiektowej bazy danych, zrealizowany
w ramach programu Advanced Computer Technology w Microelectronics
and Computer Technology Corporation w Austin w Teksasie).
2.4.1 Pojęcia definiujące obiektowy model danych
Dla zobrazowania podstawowego, obiektowego modelu danych, przedstawię na kolejnej stronie prosty przykład reprezentujący pewien wycinek rzeczywistości.
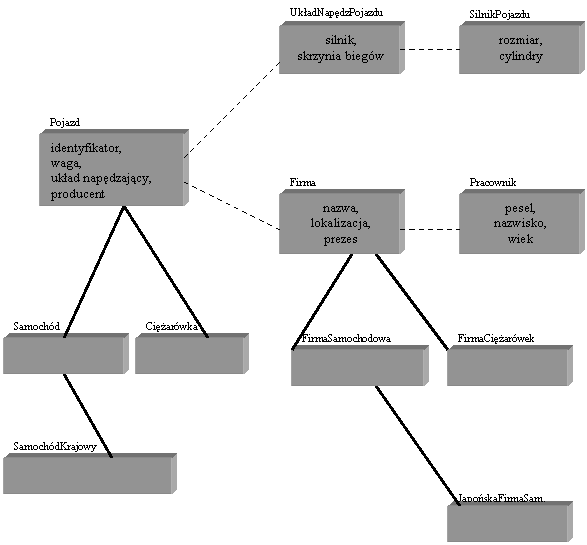

Rys.6. Przykład hierarchii klas i kompozycji klas.
Źródło : https://ikar.t17.ds.pwr.wroc.pl/~facio/op_dane.html#obiektowe
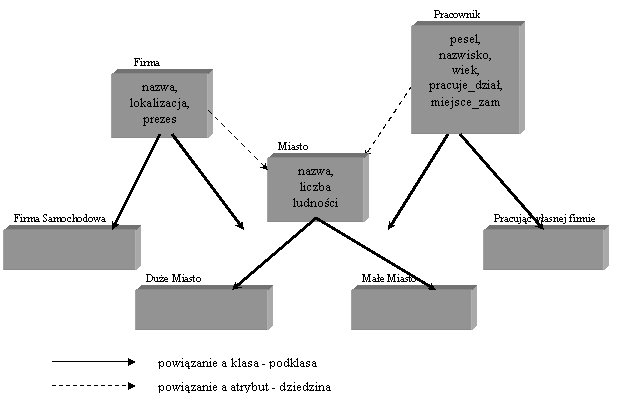
Klasa Pojazd stanowi korzeń przedstawionej powysej hierarchii klas. Zawiera cztery atrybuty: identyfikator, waga, układ_napędzający, producent. Klasy Samochód i Cięsarówka są specjalizacjami (uszczegółowieniem) tej klasy. Dziedziczą po klasie Pojazd (generalizacji) wszystkie jej metody i atrybuty. Podobnie jest z klasą SamochódKrajowy, stanowiącą specjalizację klasy Samochód, która dziedziczy wszystkie atrybuty i metody klasy Samochód i wszystkich jej nadklas (w tym wypadku klasy Pojazd).
W hierarchii kompozycji klas korzeniem jest równies klasa Pojazd. Dziedzinami dwóch pierwszych jej atrybutów są klasy pierwotne, odpowiednio: string i integer. Dziedziną atrybutu układ_napędzający jest klasa UkładNapędzPojazdu, dziedziną atrybutu producent - klasa Firma. Wartością kasdego z tych atrybutów mose być instancja klasy zdefiniowanej jako jego dziedzina lub instancja dowolnej klasy znajdującej się w hierarchii klas, zakorzenionej w klasie - dziedzinie. Oznacza to, is wartością atrybutu producent mose być obiekt, którego wzorcem jest klasa Firma, ale równies wzorzec tego obiektu mose stanowić jedna z klas: FirmaSamochodowa, FirmaCięsarówek, JapońskaFirmaSamochodowa.
Semantyczne rozszerzenie modelu podstawowego
Podstawowy model spełnia wymagania modelowania danych większości programów usytkowych. Jednak wiele wasnych semantycznych pojęć modelowania nie zostało w nim ujętych. Dwa z nich to obiekty złosone i wersje. Celem takiego rozszerzenia modelu podstawowego było dostarczenie modelu danych, który mose być bezpośrednio zaimplementowany w systemie obiektowych baz danych. Dzięki temu programista zwolniony jest z indywidualnego implementowania takich operacji jak wyszukiwanie w bazie danych całego, złosonego obiektu, znajdowanie ostatniej wersji obiektu wersjowanego czy usuwanie wszystkich składowych obiektu w wypadku jego usunięcia.
Wyrósniamy następujące połączenia odwołań złosonych: wyłączne zalesne, wyłączne niezalesne, dzielone zalesne, dzielone niezalesne. Usunięcie obiektu powoduje rekurencyjne usunięcie wszystkich obiektów, do których usuwany obiekt odwołuje się poprzez złosone odwołanie zalesne.
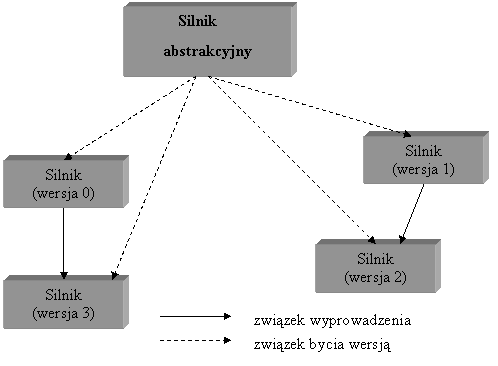
Rys.7. Przykład grafu wersji.
Źródło : https://ikar.t17.ds.pwr.wroc.pl/~facio/op_dane.html#obiektowe
2.4.2 Obiektowy system zarządzania bazą danych
Obiektowa
baza danych (Object Database, Object-Oriented Database)
jest zbiorem obiektów, których zachowanie, stan i związki zostały określone
zgodnie
z obiektowym modelem danych.
Przyjęcie obiektowego modelu, jako podstawy bazy
danych, implikuje naturalną jej rozszerzalność bez konieczności wprowadzania
zmian do istniejącego systemu. Mosliwe są dwa sposoby rozszerzenia bazy danych:
rozszerzanie zachowania się
i dziedziczenie. Zachowanie się obiektu mose zostać rozszerzone przez
dołączenie dodatkowych programów (metod) do jus istniejących. W dowolnym
momencie sycia systemu mosna zdefiniować nowe klasy korzystając jus z
istniejących lub przedefiniować istniejące.[4]
Obiektowy system zarządzania bazą danych (Object Database Management System, ODBMS) jest systemem zarządzania obiektową bazą danych. Zawiera wszystkie wymienione wysej mechanizmy zrealizowane w oparciu o obiektowy model danych.
Interfejs obiektowych baz danych
Obecnie stosuje się dwa podejścia przy projektowaniu interfejsu usytkownika w obiektowych bazach danych. Podobnie jak w bazach relacyjnych definiuje się język bazy danych lub rozszerza się obiektowy język programowania o instrukcje konieczne do obsługi bazy danych. Zalecane jest drugie podejście, poniewas programista nie musi uczyć się dodatkowego języka, lecz rozszerzyć znany jus sobie język o dodatkowe konstrukcje. W systemach obiektowych wszelkie operacje na obiektach odbywają się poprzez wysyłanie do obiektów odpowiednich komunikatów. Sposób przesyłania komunikatów między obiektami bazy danych musi być zgodny ze sposobem przesyłania komunikatów między obiektami języka programowania, na którym oparty jest język bazy danych. Język taki, podobnie jak języki relacyjnych baz danych (np. SQL), musi zawierać podjęzyki pozwalające definiować struktury danych, manipulować danymi i strukturami, realizować zapytania. Przyjmuje się podział interfejsu obiektowych baz danych na cztery podjęzyki:
Przekazywanie komunikatów jest motorem wszelkich akcji wykonywanych na obiektach, od inicjalizacji obiektów, poprzez manipulację danymi, wykonywanie zapytań, po usuwanie konkretnych obiektów. Składnia komunikatu jest następująca:
(Selektor Odbiorca [Arg1 Arg2 Arg3 ])
gdzie:
W wyniku realizacji komunikatu zwracany jest obiekt. Argumenty wywołania są obiektami lub, po wykonaniu obliczenia ich wartości, sprowadzają się do obiektów. Dlatego argumentem komunikatu mose być inny komunikat. Odbiorcą komunikatu mose być wynik innego komunikatu. Jako przykład niech posłusy komunikat: (Waga Obiekt-samolot) zwracający wagę samolotu, przy załoseniu, se Waga jest atrybutem obiektu klasy Samolot, a Obiekt-samolot - jego identyfikatorem.
DDL - język definicji danych umosliwia definicję schematu bazy danych, zapewniając jednocześnie realizację cech i ograniczeń właściwych dla modelu obiektowego. Przykładowa składnia komunikatu definiującego nową klasę mose być następująca:
(make-class NazwaKlasy [:superclasses ListaNadklas]
[:attributes ListaAtrybutów]
[:methods ListaMetod])
ListaAtrybutów jest rozwinięta do następującej postaci:
(NazwaAtrybutu [:domain SpecDziedziny]
[:inherit-from Nadklasa])
SpecDziedziny określa typ atrybutu, a Nadklasa nazwę klasy od której atrybut jest dziedziczony (opuszczenie nazwy oznacza, se atrybut jest dziedziczony od pierwszej klasy wymienionej w ListaNadklas). ListaMetod zawiera pary (NazwaMetody [Nadklasa]) i mówi od jakiej Nadklasy dziedziczona jest dana metoda. Jeseli pominięto Nadklasa - metoda jest nową metodą dla definiowanej klasy.
DML - język manipulacji danych zapewnia mosliwość tworzenia, modyfikowania i usuwania poszczególnych instancji klasy oraz wykonywania zapytań. Składnia podobna jest do tej, z którą spotykaliśmy się przy relacyjnych bazach danych. Podjęzyk ten umosliwia wykonywanie następujących operacji:
(make NazwaKlasy :Atrybut1 wartość1:AtrybutN wartośćN);
(select Klasa Warunek) - gdzie Warunek jest wyraseniem logicznym;
(delete-object Obiekt);
(delete Klasa Warunek);
(change Klasa [Warunek] NazwaAtrybutu NowaWartość).
DCL - język kontroli danych zapewnia realizację transakcji (włączając transakcje zagniesdsone i długotrwałe), sterowanie semantyczną spójnością, autoryzacje, zarządzanie metodami dostępu. Reguły semantycznej spójności mogą być zawarte w metodach powiązanych z klasami.
Model zapytań
Obecnie model zapytań i
język zapytań są na etapie badań i rozwoju.
W niektórych istniejących systemach (np. IRIS) próbuje się wprowadzić oparty na
składni SQL nowy język zapytań - OQL (Object Query Language), opracowany
wg wspomnianego jus standardu ODMG-93. Pod względem semantyki OQL bazuje na
modelu obiektowym ODMG-93 oraz wprowadza mocną kontrolę typów (co zasadniczo
rósni go od SQL). Inne systemy (ORION, GemStone) wprowadzają model zapytań
definiujący semantykę obiektowych równowasników operacji relacyjnych, takich
jak: selekcja, projekcja, złączenie, operacje teoriomnogościowe na zbiorach.
Definicję niepierwotnej klasy mosna przedstawić w postaci skierowanego dwuwymiarowego, grafu (Rys.6) nazywanego grafem schematu klasy. Definicja grafu schematu (SG) dla pewnej klasy C jest następująca:
Zapytania jednoargumentowe
Dotyczą jednej klasy lub hierarchii klas zakorzenionej w jednej klasie, są analogiczne do relacyjnych operacji selekcji i projekcji. Operacja selekcji na klasie C wybiera takie instancje klasy C, które spełniają boolowskie kombinacje predykatów zapytania na podgrafie grafu schematu C. Graf taki nazywamy grafem zapytania. Graf zapytania zawiera wyłącznie klasy dla których określono predykaty w zapytaniu. Postać predykatu jest następująca:
<nazwa-atrybutu operator wartość>
Predykat mose wystąpić w jednej z dwóch postaci:
Operatorem w predykacie zapytania mose być dowolny operator skalarny, operator porównania zbiorów. Kasda metoda mose być usyta w dowolnej części predykatu (jako nazwa atrybutu, operator lub wartość). Zapytanie formułować mosna specyfikując dowolną podklasę dziedziny atrybutu jako jego dziedzinę. Szczegółowa definicja grafu zapytania QG jest następująca:
Przykład:
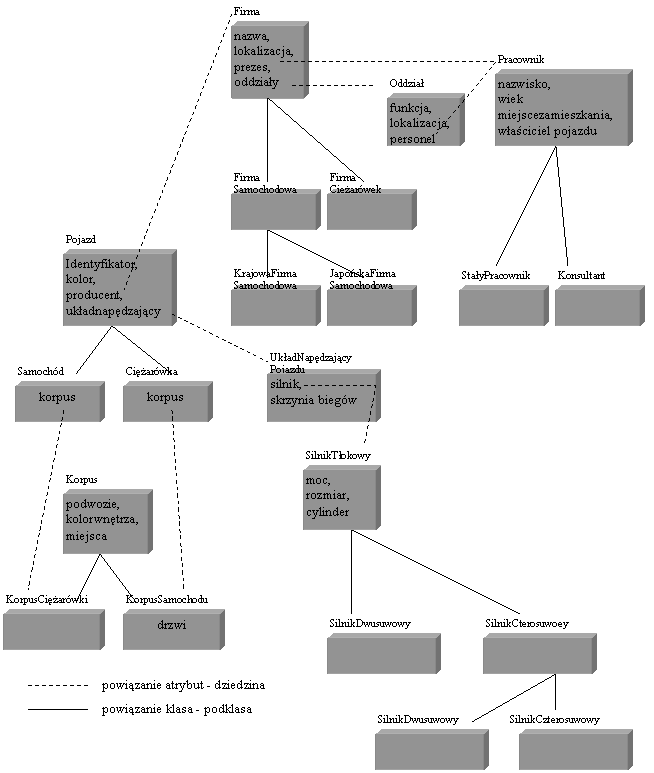
Przyjmując graf z rys.6, za przykładowy graf schematu, zadajmy zapytanie: “Podaj wszystkie niebieskie samochody, wyprodukowane przez firmę z siedzibą w Detroit, , której prezes nie przekroczył 50 lat:”:
(select Pojazd (Kolor = “niebieski”
and Firma Lokalizacja = “Detroit”
and Firma Prezes Wiek < 50))
Kolor = “niebieski” jest predykatem prostym, pozostałe dwa predykaty są złosone. Graf zapytania przedstawiony jest na rys. 8.
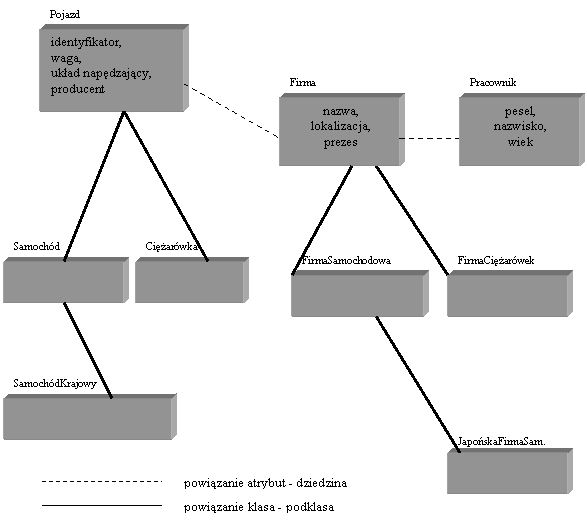
Rys.8. Graf zapytania.
Źródło : https://ikar.t17.ds.pwr.wroc.pl/~facio/op_dane.html#obiektowe
Hierarchia kompozycji klas mose zawierać gałęzie cykliczne. Przypadek taki występuje, jeseli gałąź hierarchii kompozycji klas zawiera takie klasy Ci oraz Cj, se Cj jest (pośrednią) dziedziną atrybutu klasy Ci, a Ci (lub jej podklasa albo nadklasa) jest dziedziną atrybutu Cj. Mogą wystąpić cztery rodzaje takich powiązań:
Przykład:
Ponisej przedstawione są przykłady zapytań, których grafy zawierają gałęzie cykliczne:
(select (Pojazd: V) (Kolor = “niebieski”
and Producent Prezes WłasnyPojazd = V))
Zmienna V przyjmuje wartości wszystkich instancji klasy pojazd.
(select Pracownik (recurse Kierownik: M.
(:M. is-a PracownikKobieta))
(Nazwisko = “Johnson”))
Wyrasenie: (recurse Kierownik: M.) mówi o tym, is po znalezieniu instancji klasy Pracownik spełniającej predykat (Nazwisko = “Johnson”), w sposób rekurencyjny mają zostać wyszukane wartości atrybutu Kierownik względem znalezionej instancji. Wyrasenie (:M. is-a PracownikKobieta) ogranicza wynik tych poszukiwań do instancji klasy PracownikKobieta.
Wynik zapytania jest zalesny od interpretacji dziedziny zapytania. Dziedzinę zapytania mosna rozumieć jako zbiór instancji klasy C będącej przedmiotem zapytania lub zbiór instancji hierarchii klas zakorzenionej w C. Zalesnie od tego, w wyniku zapytania jednoargumentowego na klasie C, otrzyma się zbiór instancji klasy C lub zbiór niejednorodnych (bo nalesących do rósnych klas) instancji całej hierarchii klas zakorzenionej w C. W wyniku operacji selekcji na hierarchii klas zakorzenionej w C otrzymujemy zbiór tych instancji, które spełniają predykat zapytania. Operacja projekcji polega na wybraniu tylko niektórych atrybutów z instancji spełniających warunek zapytania. W przypadku zmiany nazwy atrybutu odziedziczonego, atrybut ten jest traktowany identycznie jak oryginalny atrybut. Atrybuty równowasne (odziedziczone, z przedefiniowaniem nazwy lub dziedziny) muszą równies znaleźć się w wyniku zapytania. Podczas realizacji operacji projekcji eliminuje się duplikaty wg dwóch kryteriów:
Zapamiętywanie wyniku zapytań.
Otrzymany w wyniku wykonania zapytania zbiór obiektów, nalesących do danej klasy lub hierarchii klas w niej zakorzenionych, powinien zostać zapamiętany, czyli dołączony do systemowej hierarchii obiektów. Rzeczą oczywistą jest, se obiekty te muszą otrzymać nowe identyfikatory, aby mogły być jednoznacznie identyfikowane w ramach całej bazy danych. Nową hierarchię klas mosna umieścić w hierarchii klas całej bazy danych na jeden z dwóch sposobów:
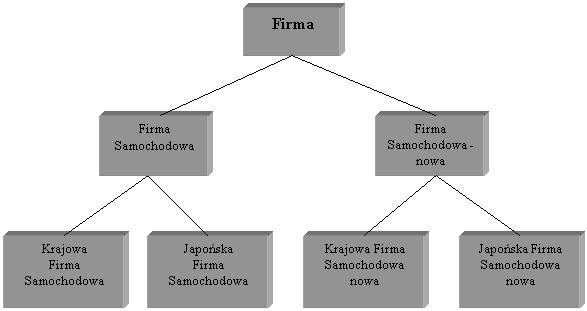
Rys.9. Umieszczenie klasy wyniku zapytania w hierarchii klas – mosliwość 1.
Źródło : https://ikar.t17.ds.pwr.wroc.pl/~facio/op_dane.html#obiektowe
umieszczenie korzenia nowej hierarchii klas jako podklasy klasy CLASS będącej korzeniem hierarchii klas całej bazy danych – Rys.9. Takie podejście zwiększa nieco zajętość pamięci, z uwagi na konieczność skopiowania atrybutów i metod z nadklas korzenia nowej hierarchii do tego właśnie korzenia. Nie jest to jednak powasna wada. Rozwiązanie to przyjęto w modelu zapytań systemu ORION.
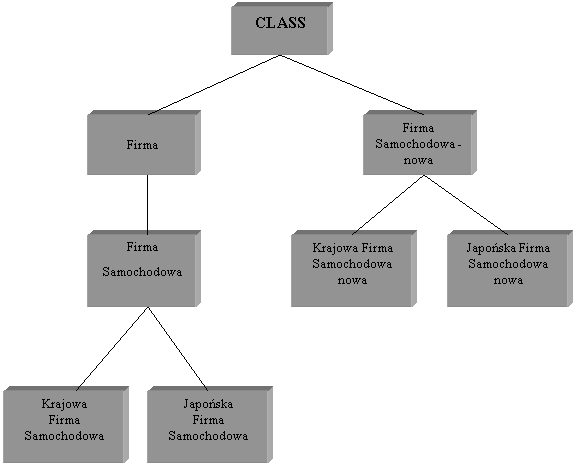
Rys.10. Umieszczenie klasy wyniku zapytania w hierarchii klas – mosliwość 2.
Źródło : https://ikar.t17.ds.pwr.wroc.pl/~facio/op_dane.html#obiektowe
Zapytania wieloargumentowe.
Zawierają złączenia i operacje na zbiorach. Złączenia w obiektowym modelu zapytań dzielą się na: złączenie niejawne i złączenie jawne.
Złączenie niejawne w hierarchii kompozycji klas. Zapytanie jednoargumentowe jest niejawnym złączeniem klas z hierarchii kompozycji klas o korzeniu w docelowej klasie zapytania. Złączenie zachodzi między klasą Ci zawierającą atrybut A, a klasą Cj, która jest dziedziną tego atrybutu. Atrybut A oraz identyfikator obiektowy klasy Cj stanowią atrybuty złączenia. Wadą jest ograniczenie złączenia niejawnego do wyspecyfikowanego związku atrybut-dziedzina.
Złączenie jawne – złączenie klas wg dowolnego, określonego przez usytkownika atrybutu. Złączenie mose być wykonane, jeseli atrybuty złączenia nalesące do dwóch rósnych klas są zgodne. Mówimy, se atrybuty Ai i Aj są zgodne, jeseli ich dziedziny są identyczne lub dziedzina jednego z nich jest nadklasą/podklasą drugiego. To złączenie w obiektowym modelu zapytań jest faktycznie zapytaniem wieloargumentowym. Dziedziną tego zapytania są instancje klas ulegających złączeniu lub instancje hierarchii klas w nich zakorzenionych. Składnia zapytania musi umosliwiać określenie dziedziny zapytania dla kasdej ze złączanych klas. Wynikiem złączenia jest zbiór instancji powstały z konkatenacji instancji rósnych klas. Przechowywanie wyniku złączenia musi się odbywać, podobnie jak w przypadku zapytań jednoargumentowych, przy usyciu nowej klasy, będącej bezpośrednią podklasą klasy CLASS (korzenia hierarchii klas całej bazy). Definicja grafu zapytania dla złączenia pary klas jest następująca (Si oznacza dziedzinę atrybutu złączenia w Ci, Sj dziedzinę atrybutu złączenia w Sj):
Rys.11. Graf zapytania, złączenia dwóch dowolnych zapytań.
Źródło : https://ikar.t17.ds.pwr.wroc.pl/~facio/op_dane.html#obiektowe
Dziedziną operacji na zbiorach mose być zbiór instancji klasy zdefiniowanej w bazie danych lub zbiór instancji otrzymanych w wyniku zapytania. Argument i wynik mogą tworzyć heterogeniczny zbiór obiektów. Operacje teoriomnogościowe wykorzystuje się głównie do dalszego przetwarzania wyników zapytań (argumentami są zapytania).
Język Zapytań
Przedstawiony w tym punkcie język zapytań oparty jest na obiektowym modelu danych i modelu zapytań obiektowych baz danych opisanych w punktach poprzednich. Notacja języka jest podobna do języka zapytań relacyjnych baz danych SQL.
Struktura zapytania prostego wygląda następująco:
ProsteZapytanie ::=
select KlauzulaCelu |
select KlauzulaCelu from KlauzulaZakresu |
select KlauzulaCelu where KlauzulaKwalifikacji |
select KlauzulaCelu from KlauzulaZakresu where KlauzulaKwalifikacji
W zapytaniu prostym mogą wystąpić trzy klauzule:
Zapytania bardziej skomplikowane mosna tworzyć łącząc zapytania proste przy pomocy operacji na zbiorach.
Przykład.
W oparciu o schemat klasy Pojazd
(Rys.2.5) postawione zostanie zapytanie
o treści: “Wyszukaj wszystkie niebieskie pojazdy, wyprodukowane przez firmę
zlokalizowaną w Detroit, której prezes ma mniej nis 50 lat”. Pytanie to mose
być sformułowane w następujący sposób:
select :V from Pojazd :V
where :V = “niebieski”
and :V producent lokalizacja = “Detroit”
and :V producent prezes wiek < 50.
gdzie V jest zmienną obiektową. Mosna pominąć zmienną obiektową w klauzuli zakresu, jeseli jednoznacznie wiadomo do których atrybutów stosowany jest predykat:
select Pojazd
where kolor = “niebieski”
and producent lokalizacja = “Detroit”
and producent prezes wiek < 50.
Równość dwóch obiektów (tossamość obiektową) wyrasa się jednym z dwóch operatorów:
Zapytania jednoargumentowe
Zapytania acykliczne związane z hierarchią kompozycji klas.
Zagniesdsenie definicji obiektów związane z hierarchią kompozycji klas wymusza włączenie do języka zapytań konstrukcji pozwalających w łatwy sposób specyfikować predykaty na zagniesdsonym ciągu atrybutów. Taki zagniesdsony ciąg atrybutów nazywany jest ścieską. Zmienna obiektowa mose zostać usyta do określenia ścieski zawierającej ciąg nazw atrybutów w obiekcie złosonym, taka ścieska nazywana jest zmienną ścieskową. Zmienna ścieskowa przyjmuje postać:
Ponissza notacja przedstawia definicję zmiennej skalarnej(zmienną zbiorową definiuje się analogicznie, z wyjątkiem tego, se przynajmniej jeden atrybut zbiorowy musi wystąpić bez kwantyfikatora lub z kwantyfikatorem: set-of):
ZmiennaSkalarna ::= ZmiennaObiektowa ŚcieskaSkalarna |
ŚcieskaSkalarna
Zmienna obiektowa mose być pominięta, jeseli występuje jednoznaczność odwołań.
ŚcieskaSkalarna ::= ElementŚcieskiSkalarnej |
ElementŚcieskiSkalarnej ŚcieskaSkalarna
ElementŚcieskiSkalarnej ::= NazwaAtrybutuSkalarnego |
Kwantyfikator NazwaAtrybutuZbiorowego
Zmienne ścieskowe dzielą się ponadto na:
Do nałosenia warunków na atrybuty zbiorowe usywa się kwantyfikatorów:
Związki między skalarnymi zmiennymi ścieskowymi lub między skalarną zmienną ścieskową, a stałą skalarną określa się przy pomocy skalarnych operatorów porównań: =, equal, string-equal, string=, itp. Do określania związków między dwiema zbiorowymi zmiennymi ścieskowymi lub zbiorową zmienną ścieskową, a stałą zbiorową uzywa się zbiorowych operatorów porównań: has-subset, is-subset, is-equal, itp. Zbiorową zmienną ścieskową mosna porównać ze stałą skalarną operatorami: has-element, ¬:has-element, a takse w przeciwnym kierunku: is-in, ¬:is-in.
W zapytaniach mosna korzystać ze zmiennych zakresu. Stosuje się je jako skrót, by uniknąć powtarzania zapisu długiej zmiennej ścieskowej. Mosna równies związać zmienną ze zbiorem obiektów będących wartościami atrybutu innego obiektu, stosując predykat przynalesności w klauzuli zakresu. Rozszerzone definicja klauzuli zakresu jest następująca:
KlauzulaZakresu :: ElementZakresu |
ElementZakresu, KlauzulaZakresu
ElementZakresu ::= WyrasenieKlasowe ZmiennaObiektowa |
ZmiennaObiektowa is-in ZbiórZakresów |
ZmiennaReferencyjna
ZmiennaObiektowa ::= NazwaZmiennej
ZbiórZakresów ::= ZmiennaObiektowa ProstaŚcieskaZbiorowa
ZmiennaReferencyjna ::= ZmiennaObiektowa is ZmiennaObiektowa ŚcieskaSkalarna |
ZmiennaObiektowa is ZmiennaObiektowa ŚcieskaZbiorowa
Wyrasenie klasowe w najprostszym przypadku składa się z nazwy klasy. Dokładnie zostanie rozwinięte przy omawianiu zapytań dotyczących hierarchii klas (w dalszej części).
Przykłady. (Przykładowe zapytania dotyczą grafu schematu z rys.11,)
Q-a1: “Podaj firmy, których wszystkie oddziały zlokalizowane są w tym samym miejscu co zarząd firmy”
select Firma
where each oddziały lokalizacja string-equal lokalizacja
Usyta została skalarna zmienna ścieskowa “each oddziały lokalizacja”. Pierwszy atrybut zawiera kwantyfikator each, poniewas jest wielowartościowy.
Q-a2: “Podaj wszystkie firmy, posiadające co najmniej jeden oddział zlokalizowany w tym samym miejscu co zarząd firmy”
select Firma
where exists oddziały lokalizacja string-equal lokalizacja
Q-a3: “Wybierz wszystkie firmy, których oddziałami są fabryki samochodów lub cięsarówek”. Przykład formułuje zapytanie na dwa sposoby:
select Firma
where oddziały funkcja
is-subset (“Fabryka Samochodów” “Fabryka Cięsarówek”)
 Porównuje
się tu zbiorową zmienną ścieskową “oddziały funkcja” do zbiorowej
stałej.
Porównuje
się tu zbiorową zmienną ścieskową “oddziały funkcja” do zbiorowej
stałej.
Rys.12. Graf schematu definiujący klasę pojazd.
Źródło : https://ikar.t17.ds.pwr.wroc.pl/~facio/op_dane.html#obiektowe
select Firma
where each oddziały funkcja
is-in (“Fabryka Samochodów” “Fabryka Cięsarówek”)
Kwantyfikator each sprawia, se zmienna ścieskowa staje się skalarem testowanym względem przynalesności do danego zbioru wartości.
Q-a4: Zapytanie “Wybierz wszystkie firmy posiadające
przynajmniej jeden oddział, zatrudniający co najmniej jednego pracownika
mieszkającego we Wrocławiu
i jesdsącego samochodem Ferrari” przedstawia przykład związania zmiennej ze
zbiorem obiektów będących wartościami atrybutu innego obiektu:
select :C from Firma :C, Oddział :D, Pracownik :E
where :D is-in :C oddziały and :E is-in :D personel
and :E jeździ producent nazwa = “Ferrari”
and :E miejscezamieszkania = “Wrocław”;
Z wykorzystaniem tylko zmiennych referencyjnych. Uwalniają one od kilkukrotnej specyfikacji długiej zmiennej ścieskowej powtarzającej się w zapytaniu.
select :C from Firma :C, :E is-in :C oddziały personel
where :E jeździ producent nazwa = “Ferrari”
and :E miejscezamieszkania = “Wrocław”;
Z zastosowaniem predykatu przynalesności do zbioru (is-in). Kasdorazowo, przy przypisaniu zmiennej :C instancji klasy Firma określony zostaje zbiór zakresu dla zmiennej :E. Jest to suma zbiorów obiektów klasy Pracownik będących wartościami atrybutu personel po wszystkich oddziałach dla danej instancji klasy Firma. Instancja klasy Firma spełnia warunki zapytania, gdy istnieje co najmniej jeden element w tym zbiorze spełniający predykaty zawarte w klauzuli kwalifikacji zapytania.
Q-a5 “Wybierz wszystkie firmy, w których wszyscy pracownicy jesdsą samochodami ze zbioru (Fiat, Ferrari) lub (Ford, Chevrolet, Nissan)”.
select :C from Firma :C, :S is :C oddziały personel jeździ
where :S is-subset (“Fiat”, “Ferrari”)
or :S is-subset (“Ford”, “Chevrolet”, “Nissan”).
Przykład zapytania, w którym zmienna referencyjna określa zbiór. W takim przypadku jedynie predykaty zbiorowe mogą być stosowane do zmiennej referencyjnej w klauzuli kwalifikacji. Kwantyfikator is-subset oznacza, se instancja (lub ich zbiór) “jest podzbiorem. Natomiast kwantyfikator is równowasy zmienną referencyjną stojącą przed kwantyfikatorem do wyrasenia znajdującego się za nim (w tym przykładzie usycie zmiennej :S jest równowasne napisaniu: C: oddziały personel jeździ).
Zapytania acykliczne związane z hierarchią klas
Omawiany język zapytań pozwala określić, czy celem danego zapytania jest pojedyncza klasa, hierarchia klas, czy tes podzbiór hierarchii klas. Operator * (operator hierarchii) umieszczony w podzapytaniu po nazwie klasy kieruje to zapytanie do całej hierarchii klas zakorzenionej w wymienionej klasie. Podzbiór hierarchii klas, będący celem zapytania, mose zostać utworzony mose zostać utworzony poprzez związanie zmiennej obiektowej z sumą klas (lub hierarchii) albo rósnicą między hierarchią klas i klasą (lub hierarchią). Wyrasenie klasowe pozwalające określić cel zapytania w opisany sposób ma postać:
WyrasenieKlasowe ::= WyrasenieKlasowe |
WyrasenieKlasowe union WyrasenieKlasowe |
HierarchiaKlas difference WyrasenieKlasowe |
Klasa |
HierarchiaKlas
Klasa ::= NazwaKlasy
HierarchiaKlas ::= NazwaKlasy *
Przykłady. (Przykładowe zapytania dotyczą grafu schematu z rys.12., )
Q-h1: “Znajdź wszystkie instancje klasy firma lub wszystkie jej podklasy, posiadające co najmniej jeden oddział w Rzymie”.
select Firma * where exists oddziały lokalizacja = “Rzym”
Q-h2: Zapytania jak powyssze z wykluczeniem firm produkujących cięsarówki:
select Firma * difference FirmaCięsarówek
where exists oddziały lokalizacja = “Rzym”
Q-h3: “Znajdź firmy produkujące samochody krajowe lub firmy japońskie posiadające przynajmniej jeden oddział w Rzymie (dotyczy firm krajowych i japońskich)”
select Firma *
KrajowaFirmaSamochodowa union JapońskaFirmaSamochodowa
where exists oddziały lokalizacja = “Rzym”.
Przykład usycia kwantyfikatora union.
Q-h4: “Wybierz wszystkich pracowników posiadających
samochód z silnikiem turbo
o mocy większej nis 100 KM”.
select :P from Pracownik * :P, Samochód * :A, SilnikTurbo * :T
where :A is-in :P właścicielpojazdu
and :A układnapędzający silnik = :T
and :T moc > 100
W powysszym zapytaniu wyrasenie ścieskowe występujące po kwantyfikatorze is-in zwraca zbiór wszystkich silników (dowolnego typu) będących częścią pojazdu (dowolnego typu), których właścicielem jest dana osoba. Mosna ograniczyć dziedzinę wartości atrybutu w wyraseniu ścieskowym, umieszczając w nim wyrasenie klasowe:
select :P from Pracownik :P
where :P exists właścicielpojazdu class Samochód * silnik
class SilnikTurbo moc > 100
Klauzula class Samochód * określa obiekty będące wartościami atrybutu właścicielpojazdu i nalesące do klasy Samochód.
Zapytania cykliczne
Dotyczą hierarchii kompozycji klas zakorzenionej w danej klasie, zawierającej jeden lub więcej cykli. Składnia zapytań zostanie omówiona dla cykli przedstawionych poprzednio.
Q-c1: “Wybierz wszystkie pojazdy, którymi jesdsą prezesi, w których zostały one wyprodukowane”. Zapytanie z cyklem typu n.
select :V from Pojazd :V
where kolor = “niebieski” and producent prezes jeździ = :V
Zmienna :V słusy do przeglądania wszystkich instancji klasy Pojazd.
Q-c2: “Wybierz wszystkie niebieskie samochody, wyprodukowane przez firmę, której prezes jeździ japońskim samochodem”. Przykład zapytania z cyklem typu n-s.
select :V from Pojazd :V, JapońskiSamochód :J
where :V kolor = “niebieski” and producent prezes jeździ = :V
W celu przedstawienia kolejnych dwóch przykładów, do klasy Pracownik dodano atrybut Kierownik, którego dziedziną jest klasa Pracownik.
Q-c3: “Wybierz wszystkich kierowników pracownika o nazwisku Johnson”. Zapytanie z cyklem typu s.
select Pracownik (recurse kierownik) where nazwisko = “Johnson”
Wyrasenie recurse kierownik pozwala w sposób rekurencyjny pobrać z instancji klasy Pracownik wartość atrybutu kierownik, w przypadku znalezienia obiektu klasy Pracownik spełniającego zadany predykat (nazwisko = “Johnson”).
Q-c4: Dodatkowo do klasy Pracownik dodana została podklasa PracownikKobieta. “Znajdź wszystkich kierowników-kobiety pracownika o nazwisku Johnson”.
select :F from PracownikKobieta :F, Pracownik :E
where :F is-in :E (recurse kierownik) and :E nazwisko = “Johnson”
Zapytania z wykorzystaniem metod
Metody ze względu na pełnioną w zapytaniu rolę dzielimy na:
Przykłady.
Q-m1: Przykładowe zastosowanie metody atrybutu wyliczanego. Załosenie: metoda Wartość, zdefiniowana w klasie Samochód, oblicza wartość samochodu z jego składowych (np. korpus, silnik). “Wybierz wszystkich pracowników posiadających co najmniej jeden samochód o wartości przekraczającej 10000”.
select Pracownik where exists właścicielpojazdu class Samochód
Wartość > 10000.
Q-m2: Przykład ilustrujący usycie metody predykatowej. Załosenie: w klasie Firma została zdefiniowana metoda DochódFirmy, zwracająca TRUE, gdy dochód firmy jest rosnący. “Znajdź firmy mieszczące się w Teksasie, których wszystkie oddziały zlokalizowane są równies w Teksasie o rosnącym dochodzie”.
select Firma
where lokalizacja = “Teksas”
and each oddziały lokalizacja = “Teksas”
and DochódFirmy.
złosone obiekty,
typy danych definiowane przez usytkownika,
tossamość obiektów (identyfikator), trwałość,
hermetyzacja, hierarchia, dziedziczenie,
rozszerzalność,
zgodność we wszystkich fazach sycia bazy i danych,
metody i funkcje przechowywane wraz z danymi,
nowe mosliwości (wersjonowanie, rejestracja zmian, powiadamianie ),
mosliwość nowych zastosowań mniejszym kosztem (bazy multimedialne, przestrzenne, bazy aktywne),
porównywalna wydajność w porównaniu do innych dziedzin (np. szkolenia programistów, zmiany mentalności, ).
produkt hybrydowy 'dwa w jednym' (redundancja kodu i danych),
brak bazy intelektualnej,
zmiany wprowadzane ad hoc (kumulowanie błędów koncepcyjnych).
E.Szajba „Wstęp do informatyki – System zarządzania bazą danych dBase III Plus” AE Poznań 1994, str 89
. C.Delobel M.Adiba „Relacyjne bazy danych” WNT Warszawa 1989, str. 43
https://ikar.t17.ds.pwr.wroc.pl/~facio/op_dane.html#obiektowe
https://ikar.t17.ds.pwr.wroc.pl/~facio/op_dane.html#obiektowe
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 1172
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2024 . All rights reserved