| CATEGORII DOCUMENTE |
| Bulgara | Ceha slovaca | Croata | Engleza | Estona | Finlandeza | Franceza |
| Germana | Italiana | Letona | Lituaniana | Maghiara | Olandeza | Poloneza |
| Sarba | Slovena | Spaniola | Suedeza | Turca | Ucraineana |
DOCUMENTE SIMILARE |
|
Jednym z najwasniejszych aspektów pracy profesjonalnego programisty jest gotowoœæ do podjêcia odpowiedzialnoœci za tworzenie aplikacji wyposasonych we wszelkie funkcje wymagane przez usytkowników. W dzisiejszej globalnej gospodarce ta pe³na funkcjonalnoœæ czêsto oznacza, se trzeba bêdzie zaoferowaæ obs³ugê wejœcia i wyjœcia w wielu jêzykach ³¹cznie z odpowiednim, specyficznym formatowaniem danych.
Na przyk³ad zarówno Amerykanie, jak i Europejczycy rozpoznaj¹ napis „1/2/99” jako datê, jednak Amerykanie odczytuj¹ to jako 2. stycznia 1999, zaœ Europejczycy jako 1. lutego 1999. Takiego problemu mosna unikn¹æ, stosuj¹c format nie pozwalaj¹cy na dowolnoœæ interpretacji, czyli usywaj¹c np. pe³nych nazw miesiêcy i czterocyfrowego zapisu roku.
Wymagania mog¹ jednak dotyczyæ usycia alternatywnego formatu, który mose pozwalaæ na dowolnoœæ interpretacji (np. w celu zachowania „wstecznej zgodnoœci”). Mosna np. zezwoliæ, aby usytkownik wprowadza³ daty rêcznie lub pos³ugiwa³ siê zapisem liczbowym w postaci skróconej. Przyjaznoœæ obs³ugi mose byæ rozszerzona jeszcze bardziej po wprowadzeniu potwierdzania dowolnego formatu, dziêki czemu usytkownik mose usyæ zapisu najlepiej przystosowanego do lokalnych zwyczajów.
Za³ósmy, se chcemy wprowadziæ elastyczne formatowanie dat w aplikacji przeznaczonej dla miêdzynarodowej korporacji. Prawdopodobnie spotkamy siê wówczas z wymaganiem, aby aplikacja obs³ugiwa³a daty w formatach spotykanych we wszystkich krajach przewidzianych przez klienta i to bez koniecznoœci powtórnej kompilacji.
Firmy w operacjach wewnêtrznych prawdopodobnie pos³uguj¹ siê tzw. „formatem miêdzynarodowym” (YYYY-MM-DD) ze wzglêdu na jego czytelnoœæ, odpornoœæ na problemy roku 2000 i mosliwoœæ poprawnego sortowania. Najwasniejszym obszarem dzia³alnoœci firmy na rynku miêdzynarodowym jest jednak kontakt z klientem. Pracownicy mog¹ zostaæ stosunkowo szybko przeszkoleni w zakresie stosowania odpowiednich firmowych konwencji, ale klientów prawdopodobnie nie uda siê przystosowaæ. Jest to szczególnie wasne poza Ameryk¹ Pó³nocn¹ i pó³nocn¹ Europ¹ (nawet w takich krajach jak Japonia), gdzie klienci podczas przekszta³cania wprowadzanych danych na format usywany wewn¹trz firmy wymagaj¹ pomocy osoby znaj¹cej zagadnienie.
Istotnie, maj¹c wielk¹ liczbê usywanych powszechnie formatów dat, nie ma mosliwoœci poprawnej obs³ugi ich wszystkich. Utworzenie prostej aplikacji staje siê wiêc kosztowne, zarówno z punktu widzenia nak³adu pracy programisty, jak i czasu jej powstawania. Oprócz tego zawodowy programista jest zobowi¹zany dostarczyæ produkt w okreœlonym terminie i za okreœlone wynagrodzenie, a zatem powstaje dodatkowy konflikt interesów.
Na szczêœcie te problemy nie s¹ tak straszne, na jakie wygl¹daj¹, przynajmniej dla programisty tworz¹cego aplikacje. Istnieje ca³y zestaw norm, które opisuj¹ problemy powszechnie spotykane w miêdzynarodowym œrodowisku klientów. Standardy te obejmuj¹ nastêpuj¹ce zagadnienia:
q w³aœciwoœci techniczne, takie jak zestawy znaków i ich kodowanie,
q parametry interfejsu usytkownika, takie jak formaty dat i walut,
q wprowadzanie znaków, które nie s¹ bezpoœrednio dostêpne na klawiaturze,
q jêzyk stosowany przy wyœwietlaniu komunikatów.
Standardy te zosta³y wdrosone w bibliotekach dostêpnych w systemie Linux. Dostêpnoœæ Linuksa dla miêdzynarodowych zastosowañ jest jednym z zagadnieñ, w którym projekt GNU wyraŸnie przoduje. Biblioteka GNU libc zawiera wszystkie zaawansowane w³aœciwoœci wymagane przez miêdzynarodowe standardy, takie jak POSIX i UNIX98, wykraczaj¹c dalej nis powszechna praktyka œrodowiska programistów usywaj¹cych tego systemu. Takie domyœlne w³aœciwoœci istniej¹ce w libc zachêci³y œrodowisko programistów Linuksa do przejœcia na wersje miêdzynarodowe zgodne ze standardami i zainspirowa³y powstanie licznych projektów, np. GNU Translation Project
Projekt o nazwie Li18nux (czyli Linux Internationalization Initiative, opisany pod adresem https://www.li18nux.net) jest wspierany przez takie licz¹ce siê firmy, jak IBM i Sun Microsystems, nie wspominaj¹c o oczywistej obecnoœci RedHat, SuSE itd. Ma on na celu doprowadzenie do stanu, w którym miêdzynarodowe w³aœciwoœci Linuksa bêd¹ konkurencyjne dla komercyjnych produktów jak Solaris, Windows i Macintosh. Wstêpny projekt normy Li18nux 2000 (dostêpny pod adresem https://www.linux.net/root/LI18NUX2000/li18nux2k_draft.html) zawiera odnoœniki do wszystkich standardów wi¹s¹cych siê z tymi zagadnieniami oraz liczne przyk³ady ich usycia. Tekst tego dokumentu jest bardzo lakoniczny, a wiêc nie polecamy jego studiowania. Nalesy go traktowaæ jako zbiór pomocnych odnoœników, poniewas zawiera adresy sieciowe wszystkich zwi¹zanych z nim dokumentów.
Wiêkszoœæ ze standardowych w³aœciwoœci opisanych w tym rozdziale jest dostêpna w wersji 2.1 libc, zaœ jeszcze wiêcej planuje siê dla wersji 2.2. Inne mosna znaleŸæ w Xlib lub w zestawach narzêdzi, takich jak Motif lub GTK+. Biblioteki specjalnego przeznaczenia oraz funkcje do³¹czane do bibliotek zwi¹zanych ze specyficznymi aplikacjami mosna znaleŸæ w zestawach narzêdzi przeznaczonych dla programistów zajmuj¹cych siê wprowadzaniem wersji miêdzynarodowych. Celem tego rozdzia³u jest dostarczenie zawodowym programistom pracuj¹cym w œrodowisku GNU i Linux podstaw dla rozpoznawania tych ogólnych wymagañ i niezbêdnej wiedzy o tych bibliotekach i ich funkcjonalnoœci.
G³ówn¹ trudnoœæ przy tworzeniu programów, które maj¹ byæ wystarczaj¹co elastyczne, aby by³y czytelne w wielu œrodowiskach jêzykowych, stanowi to, se standardowe w³aœciwoœci pojawi³y siê ca³kiem niedawno. Ich zastosowania nie s¹ jeszcze wystarczaj¹co stabilne (co mosna sprawdziæ, obserwuj¹c prace nad libc w projekcie GNU oraz stan GTK+ i innych zestawów narzêdziowych). Istnieje kilka przyk³adów stanowi¹cych „najlepszy wzór” dla programistów pracuj¹cych w systemie Linux, mimo se wiêkszoœæ z programów pomocniczych GNU zapewnia przynajmniej obs³ugê komunikatów w jêzyku narodowym. Nowe standardy dla bardziej zaawansowanych w³aœciwoœci s¹ modyfikowane i poprawiane co tydzieñ (przyk³adem mose byæ ustawianie widsetów w graficznym interfejsie usytkownika umosliwiaj¹ce obs³ugê odmiennego kierunku czytania w jêzykach takich jak hebrajski lub arabski). Nalesy mieæ nadziejê, se ten rozdzia³ zachêci Czytelników do pionierskich prac w tej dziedzinie i do tworzenia wzorców dla zwyk³ych programistów, a takse bêdzie stanowi³ podstawowe Ÿród³o informacji wspomagaj¹cych te prace.
Podstawowym procesem w adaptacji oprogramowania w danym œrodowisku kulturowym jest jego dostosowanie do jêzyka lokalnego (czyli tzw. lokalizacja). Mosna to osi¹gn¹æ, zmieniaj¹c Ÿród³owy kod programu w sposób przypominaj¹cy jego przenoszenie na now¹ platformê sprzêtow¹, czyli zmieniaj¹c definicje funkcji i kolejnoœæ argumentów, t³umacz¹c napisy itd. Sugeruje to mosliwoœæ bardziej efektywnej adaptacji, jeœli o tych sprawach bêdzie siê pamiêtaæ jus od pierwszej wersji programu.
Mosna tes postêpowaæ inaczej, stosuj¹c coœ, co jest nazywane internacjonalizacj¹ (ang. internationalization). Internacjonalizacja programu oznacza usycie standardowych zestawów zmiennych i wywo³añ zwrotnych w tym programie. Te zmienne i wywo³ania zwrotne redukuj¹ proces przekszta³cania programu na wersjê zlokalizowan¹ do odpowiedniej inicjacji zmiennych, skonsolidowania go z wywo³aniami zwrotnymi ze standardowej biblioteki i przet³umaczenia komunikatów. Oznacza to, se przy lokalizacji programu mose byæ konieczne wprowadzenie dusych zmian w kodzie, ale przy odpowiedniej internacjonalizacji obs³uga wszystkich rósnic jêzykowych bêdzie zapewniona dziêki za³adowaniu odpowiednich plików danych. Zmniejsza to nie tylko nak³ad pracy programisty, ale takse ze znacznie wiêkszym prawdopodobieñstwem da poprawny wynik. Wynika to np. z faktu, se t³umaczeniami zajmuj¹ siê specjaliœci znaj¹cy dany jêzyk, a nie programiœci.
Warto pamiêtaæ, se prawie we wszystkich aplikacjach program obs³uguje w danym momencie tylko jedn¹ konfiguracjê narodow¹. Dane wejœciowe, dane wyjœciowe oraz komunikaty o b³êdach bêd¹ podawane w tym samym jêzyku. Kilka rodzajów aplikacji wymaga jednak obs³ugi wielu jêzyków równoczeœnie (oczywistym przyk³adem jest edytor usywany przy t³umaczeniach, ale takse dowolna aplikacja obs³uguj¹ca wymianê wiadomoœci, jak np. program pocztowy lub program obs³uguj¹cy grupy dyskusyjne). Mówimy wtedy o tzw. wielojêzycznoœci (ang. multilingualization). Interesuj¹ce jest, se dzia³aj¹ca w architekturze klient-serwer aplikacja dla wyposyczalni p³yt DVD mose dzia³aæ w œrodowisku wielojêzycznym (tzn. usytkownicy mog¹ równoczeœnie korzystaæ z wielu jêzyków), nawet jeœli ani serwer, ani klient osobno nie obs³uguj¹ równoczeœnie wielu jêzyków.
Istnieje kilka skrótów oznaczaj¹cych te terminy: L10N oznacza lokalizacjê, I18N oznacza internacjonalizacjê, zaœ M17N oznacza wielojêzycznoœæ. Skróty te s¹ tworzone od angielskich s³ów przez pozostawienie pierwszej i ostatniej litery oraz zast¹pienie liter znajduj¹cych siê miêdzy nimi przez ich liczbê. Np. w s³owie „localization” sk³adaj¹cym siê z 12 liter miêdzy „L” i „N” jest 10 liter — st¹d skrót „L10N”.
W pozosta³ych czêœciach rozdzia³u opisano modele internacjonalizacji dostêpne dla programistów tworz¹cych aplikacje, interfejsy programowe tych modeli dostêpne w systemie Linux oraz przyk³ady zastosowañ niektórych modeli w przyk³adowej aplikacji do obs³ugi wyposyczalni p³yt DVD.
Tak, Unicode pozwala rozwi¹zaæ wiele problemów pojawiaj¹cych siê przy I18N dziêki temu, se skutecznie przyporz¹dkowuje unikatowy kod kasdemu znakowi usytemu w tekœcie pisanym w dowolnym jêzyku — nie rozwi¹zuje jednak wszystkich problemów.
Unicode jest uniwersalnym zestawem znaków utworzonym na podstawie projektu „Universal Multiple-Octet Coded Character Set” (w skrócie UCS) prowadzonym przez Unicode Consortium oraz International Standards Organization (ISO), który zosta³ opisany w normie ISO-10646. Zestaw ten ma na celu umosliwienie reprezentacji wszelkich tekstów we wszystkich jêzykach œwiata. Jest to takse standard opisuj¹cy kodowanie znaków w postaci odwzorowania zestawu znaków na zbiór liczb ca³kowitych. Bies¹ca wersja standardu opisuje kilka sposobów reprezentacji wycinka tego odwzorowania w pamiêci komputera. Reprezentacje te nosz¹ nazwê Unicode Transformation Formats (w skrócie UTF). Standard zawiera takse opis niektórych w³aœciwoœci znaków, np. wartoœci liczbowe cyfr oraz opis standardowych algorytmów usywanych przy przetwarzaniu znaków (np. przy sortowaniu).
Zestaw znaków jest zbiorem uporz¹dkowanym. Znaki maj¹ rósne w³aœciwoœci, np. glify usywane do prezentacji i klasyfikacjê syntaktyczn¹ (np. zaliczenie znaku do odstêpów lub znaków interpunkcyjnych). Kodowanie jest odwzorowaniem typu „jeden do jednego” znaków z zestawu na zbiór obiektów, które mog¹ byæ przetwarzane komputerowo — zazwyczaj s¹ to ci¹gi bitów lub bajtów (zauwasmy, se w Unicode unika siê mówienia o liczbach ca³kowitych).
Przewasnie d³ugoœæ ci¹gu kodu bitowego przyporz¹dkowanego znakowi jest wielokrotnoœci¹ liczby 8. We wspó³czesnych komputerach pokrywa siê to z bajtem. Poniewas mose siê kiedyœ zdarzyæ, se bajt bêdzie mia³ rósn¹ d³ugoœæ w komputerach rósnego typu, to dla oznaczenia ci¹gu oœmiu bitów wprowadzono okreœlenie „oktet”. Jeseli ci¹gi bitowe reprezentuj¹ce wszystkie znaki w danym kodowaniu maj¹ tê sam¹ liczbê bitów, to mówimy o „kodowaniu znakowym”. Zestaw ASCII jest kodowaniem (zdegenerowanym), w którym dla reprezentacji znaku usywa siê 7 (lub 8) bitów. Unicode (jak pocz¹tkowo zak³adano) jest kodowaniem 16-bitowym (dwa oktety). W przeciwnym wypadku mówimy o „kodowaniu wielobajtowym”. UTF-8 jest przyk³adem kodowania wielobajtowego. Kodowanie o „sta³ym” rozmiarze i kodowanie o „zmiennym” rozmiarze by³yby zapewne lepszymi okreœleniami, ale powszechnie usywane s¹ jednak nazwy „znakowe” i „wielobajtowe”.
Unicode Consortium zosta³o zorganizowane w celu opracowania dostêpnego, praktycznie ujednoliconego zestawu znaków. Badania doprowadzi³y do powstania pocz¹tkowego 16-bitowego formatu, który ogranicza³ dostêpn¹ przestrzeñ do 65536 znaków. W praktyce przestrzeñ ta jest nieco mniejsza, poniewas znaki s¹ przewasnie porz¹dkowane w bloki wyrównane w „wierszach” licz¹cych 256 pozycji kodu kasdy. Kasdy blok odpowiada jednemu alfabetowi (np. alfabetowi greckiemu), zestawowi alfabetów tworz¹cych jedn¹ rodzinê (jak np. alfabet ³aciñski) lub grupie znaków mniej znanych programistom zachodnim (np. sylabiczny alfabet Irokezów z Ameryki Pó³nocnej albo zestaw chiñskich ideogramów Han).
Z drugiej strony, UCS by³ tworzony z myœl¹ o zapewnieniu zwartych podstaw dla unormowanych zestawów znaków, aby kasdy tekst mosna by³o przet³umaczyæ bez zniekszta³ceñ, usywaj¹c jednego uniwersalnego kodowania. Poniewas s³owniki jêzyka japoñskiego i chiñskiego zawieraj¹ po oko³o 50 tysiêcy znaków, a jêzyk koreañski pos³uguje siê oko³o 12 tysi¹cami oznaczeñ sylabicznych, nie wspominaj¹c jus o hieroglifach, to w 16-bitowej przestrzeni kodowej nie ma jus miejsca na 26 liter alfabetu ³aciñskiego, na alfabet grecki, cyrylicê i symbole matematyczne. Projektanci UCS zdawali sobie sprawê, se trzeba bêdzie wiêcej nis 16 bitów do zakodowania wszystkich potrzebnych znaków (nawet przy za³oseniu unifikacji alfabetu Han, który obejmuje wiele znaków japoñskich wywodz¹cych siê z alfabetu chiñskiego). Bior¹c pod uwagê architekturê nowoczesnych komputerów, zdecydowano, se przestrzeñ kodowa bêdzie reprezentowana przez 31 bitów (rezerwuj¹c ostatni bit 32-bitowego s³owa do wykorzystania w zestawach znaków nie wchodz¹cych do UCS i unikniêcia pomy³ek z reprezentacjami liczb ujemnych i dodatnich).
Grupa robocza ISO zajmuj¹ca siê tymi zagadnieniami uwzglêdni³a potrzebê utworzenia niewielkiego podzbioru daj¹cego siê przedstawiæ za pomoc¹ 16 bitów. Podzbiór ten, któremu nadano nazwê Basic Multilingual Plane (w skrócie BMP), jest bardzo zblisony do zestawu znaków Unicode, poniewas wykorzystuje te same podstawy. W dodatku jego autorzy s¹ czêsto cz³onkami obydwu komitetów, a wiêc szybko zdecydowano o po³¹czeniu wysi³ków i dostosowaniu BMP do standardu Unicode.
Podobnie wygl¹da sprawa z kontrowersjami wokó³ unifikacji zestawu Han (patrz dalsze podrozdzia³y), gdzie nawet unifikacja zestawu nie umosliwi uzyskania przestrzeni pozwalaj¹cej na w³¹czenie wszystkich zestawów znaków spe³niaj¹cych wymagania standardu okreœlonego przez Unicode Consortium. Sytuacja ta spowodowa³a, se opracowano powiêkszon¹ przestrzeñ znaków w postaci formatu UTF-16, w którym pominiêto niektóre pary16-bitowych „zastêpczych” znaków, aby zakodowaæ wszystko w przestrzeni o rozmiarze 1024x1024.
Niezgodnoœci w 16-bitowych znakach zastêpczych (oznaczaj¹ce, se liczba znaków w tabeli nie jest taka sama jak liczba znaków Unicode wyrasona w reprezentuj¹cych j¹ ci¹gach bitowych) doprowadzi³y do zdefiniowania „p³askiego” formatu UTF-32. Usyto w nim znaków o kodach 32-bitowych, lecz ich liczba jest dok³adnie taka, jak w formacie UTF-16, poniewas ograniczono liczbê znaków tylko do pocz¹tkowych 1114112 pozycji z licz¹cej 4294967296 miejsc przestrzeni dostêpnej dla 32-bitowych liczb ca³kowitych bez znaku. Niewykorzystane miejsca s¹ niedozwolone w myœl standardu Unicode.
Ujednolicanie standardów Unicode i ISO-10646 zosta³o zakoñczone wówczas, gdy ISO zgodzi³a siê, aby nie przypisywaæ sadnych znaków kodom wiêkszym od 1114112.
Wszystko dosz³o wiêc do etapu, gdy istnieje jeden niepodwasalny i uniwersalny zestaw znaków, z jednym odwzorowaniem znaków na liczby ca³kowite oraz kilkoma dobrze zdefiniowanymi transformacjami formatu Unicode (UTF) reprezentuj¹cymi te kody liczbowe. Oprócz wysej wymienionych formatów istnieje znany format 8-bitowy UTF-8, charakteryzuj¹cy siê tym, se wszystkie znaki ASCII s¹ w nim przedstawiane jako kody jednobajtowe, zaœ pozosta³e s¹ kodowane za pomoc¹ wiêcej nis jednego bajtu (kasdy z tych bajtów ma wartoœæ z zakresu od 0x80 do 0xFF). Oznacza to, se czysto 8-bitowy mechanizm wykorzystuj¹cy zestaw ASCII (np. w uniksowych systemach plików, pow³okach systemu operacyjnego i wielu jêzykach programowania) nie pozwoli na przypadkowe traktowanie napisów w kodzie UTF-8 jako zawieraj¹cych s³owa kluczowe lub konstrukcje sk³adniowe. Istniej¹ takse inne przekszta³cenia formatu, ale obecnie mosna je traktowaæ jako przestarza³e.
|
Format |
Definicja |
Typowe zastosowanie |
|
Unicode, UCS |
Odwracalne odwzorowanie znormalizowanych znaków na nieujemne liczby ca³kowite. |
Abstrakcyjne (reprezentacja ca³kowitoliczbowa nie jest zdefiniowana) i nieokreœlone (zalesnie od kontekstu „Unicode” mose oznaczaæ ca³y zestaw znaków, dwubajtow¹ reprezentacjê UCS-2 bez znaków zastêpczych lub reprezentacjê UTF-16 ze znakami zastêpczymi). |
|
UCS-4 |
Pozycje kodowe Unicode s¹ reprezentowane jako 31-bitowe liczby ca³kowite bez znaku. |
Nadzbiór UTF-32 niezupe³nie zgodny ze standardem. Jest to format wewnêtrzny stosowany przez glibc. |
|
UTF-32 |
Pozycje kodowe Unicode s¹ reprezentowane jako 31-bitowe liczby ca³kowite bez znaku, ale wartoœci kodów s¹ ograniczone do przedzia³u od 0x0 do 0x1FFFF. |
Reprezentacja wykorzystuj¹ca standardowe kodowanie bitowe pozwalaj¹ca zakodowaæ wszystkie znaki zestawu Unicode. |
|
UTF-16 |
Znaki zestawu Unicode z podzbioru BMP (o kodach od 0x0 do 0xFFFF) s¹ reprezentowane jako 16-bitowe liczby ca³kowite bez znaku. Znaki o pozycjach wiêkszych nis s¹ reprezentowane jako pary znaków zastêpczych (pierwszy o kodzie od 0xD800 do 0xDBFF, a drugi o kodzie od 0xDC00 do 0xDFFF). |
Pos¹dany, ale nie wymagany bezwzglêdnie w aplikacjach korzystaj¹cych z semantyki „napis jest tablic¹ znakow¹”, w których musi byæ dostêpna mosliwoœæ przesy³ania ca³ego zakresu znaków Unicode, wymaga siê wiêkszej zwartoœci nis daje UTF-32. |
|
UCS-2 BMP |
Ograniczony do znaków Unicode z zestawu BMP o kodach od 0x0 do 0xFFFF. |
Wymagany bezwzglêdnie w aplikacjach korzystaj¹cych z semantyki „napis jest tablic¹ znakow¹”, w których nie musi byæ dostêpna mosliwoœæ przesy³ania ca³ego zakresu znaków Unicode, wymaga siê wiêkszej zwartoœci nis daje UTF-32. |
|
UTF-8 |
Format o zmiennej d³ugoœci kodu, w którym znaki z zestawu ASCII s¹ reprezentowane przez 8-bitowe liczby ca³kowite bez znaku, a znaki pozosta³e s¹ reprezentowane przez zmienn¹ liczbê bajtów z ustawionym najstarszym bitem. |
Normalnie stosowany jako format zewnêtrzny, szczególnie w programach przyjmuj¹cych dane wejœciowe w postaci bajtów (np. pow³oki i systemy plików), które traktuj¹ niektóre bajty ASCII jako maj¹ce znaczenie syntaktyczne, ale jednoczeœnie s¹ „przezroczyste” dla kodów oœmiobitowych (tzn. traktuj¹ znaki o kodach z ustawionym najstarszym bitem jako nie maj¹ce znaczenia syntaktycznego i przekazuj¹ce je bez przekszta³cania). Format ten stanowi takse efektywny sposób kodowania dla aplikacji, w których oczekuje siê dusej czêœci danych tekstowych typu ASCII, jak np. Ÿród³owe programy komputerowe lub dane SGML. |
Trzeba tu wspomnieæ jeszcze o innym aspekcie Unicode, a mianowicie o tym, se jest on standardem dla przetwarzania tekstów, a nie dla kodowania znaków. Wykracza on znacznie poza standard ISO-10646. Faktycznie Unicode Consortium zobowi¹za³o siê do akceptowania w przysz³oœci zaleceñ ISO dotycz¹cych nowych standaryzacji znaków, a pracuj¹cy tam programiœci bêd¹ musieli skoncentrowaæ siê na algorytmicznych aspektach przetwarzania tekstów. Nie jest prawdopodobne, aby pewnego dnia standard Unicode sta³ siê wszechstronny i stosowany w sposób uniwersalny, ale definiuje on wiele w³aœciwoœci i algorytmów. Nalesy do nich zaliczyæ:
q Alternatywne reprezentacje z³osonych znaków: wiele rozszerzonych liter ³aciñskich mosna rozbiæ na dwa elementy, czyli literê g³ówn¹ i akcent diakrytyczny — obydwie reprezentacje s¹ mosliwe w zestawie Unicode,
q Algorytmy stosowane przy porównywaniu z³osonych znaków (poniewas ten sam tekst mose reprezentowaæ takie same znaki w rósny sposób w rósnych miejscach),
q Przyporz¹dkowanie w³aœciwoœci takich jak np. wartoœci liczbowe dla cyfr lub ograniczaj¹ce jednostki tekstowe dla s³ów i zdañ,
q Algorytmy sortowania i przeszukiwania,
q Algorytmy prezentacji zagniesdsonego tekstu czytanego w rósnych kierunkach.
Pozosta³o jeszcze kilka nieunormowanych obszarów. Niektóre z nich mosna zaliczyæ do podstawowych braków (np. zestaw znaków cyrylicy w³¹czony do specyfikacji Unicode w wersji 1. i 2. by³ charakterystyczny tylko dla jêzyka rosyjskiego — pominiêto w nim niektóre znaki charakterystyczne dla jêzyka ukraiñskiego ze wzglêdu na to, se w owym czasie Ukraina stanowi³a czêœæ Zwi¹zku Radzieckiego). Nalesy oczekiwaæ, se braki te zostan¹ uzupe³nione w przysz³ych wydaniach standardu.
Inne problemy stwarzaj¹ zasadnicze rósnice, jak np. problem unifikacji znaków Han. Punktem wyjœcia jest fakt, se system zapisu stosowany przez Japoñczyków, Koreañczyków i tradycyjnych Wietnamczyków wywodzi siê z chiñskiego zestawu ideogramów i wszyscy zgodzili siê co do kszta³tu kasdego znaku. Znaki, które s¹ „takie same” w kasdym z tych systemów, mosna wiêc okreœliæ jako uzgodnione. Na tej podstawie powyssze zestawy znaków obejmuj¹ce przynajmniej po jednym zestawie narodowym okreœlono jednym terminem „zunifikowany zestaw znaków Han”.
Pojawi³y siê jednak g³osy krytyczne (g³ównie z Japonii), se kasdy wariant narodowy dotyczy w istocie innych znaków i w zwi¹zku z tym w standardzie Unicode powinny one mieæ przypisane inne kody. Argumenty za takim rozwi¹zaniem by³y nastêpuj¹ce:
q Wygodnie jest w tekœcie wielojêzycznym mieæ mosliwoœæ okreœlenia jêzyka na podstawie usytych znaków,
q Wielu Japoñczyków odczuwa coœ szczególnego, mówi¹c o swoim jêzyku, a niektórzy myœl¹, se dzielenie siê kodami znaków z innymi jêzykami os³abi „ducha japoñskiego”,
q Trudniej jest zmieniaæ standardy narodowe, poniewas mog³oby to zaburzaæ sposób przyporz¹dkowania zunifikowanego zestawu Han do zestawów narodowych. Jest to wasne szczególnie w Japonii, poniewas w kilku oficjalnie zarejestrowanych imionach i nazwach miejscowoœci usywane s¹ tam znaki nieobecne w standardach JIS X 0208 i JIS X 0212 stosowanych pomocniczo w BMP.
Jasne jest wiêc, se nie znajdzie siê rozwi¹zanie satysfakcjonuj¹ce wszystkich dyskutantów. Unifikacja pozostanie, ale trzeba zapewniæ rósne œrodki umosliwiaj¹ce w razie potrzeby rozrósnianie rósnych wariantów zestawu Han (zarówno w ramach samego standardu Unicode — tzw. „znaczniki 14. p³aszczyzny”, jak i poza nim — jak np. atrybuty jêzykowe w znacznikach XML).
Na zakoñczenie nalesy wspomnieæ o znacznie powasniejszym problemie stwarzanym przez znaki, które z rósnych powodów nie mog¹ byæ w³¹czone do standardu Unicode. Niektóre z tych znaków, jak zapis nutowy lub oznaczenia na schematach uk³adów elektronicznych, trudno zakwalifikowaæ do znaków pisma, które powinny byæ usywane w postaci zestawu stylizowanych glifów daj¹cych siê uporz¹dkowaæ w okreœlony sposób w strumieniu wyjœciowym. Standard Unicode jawnie odrzuca je na tej podstawie, se ma on s³usyæ do obs³ugi tekstu reprezentowanego jako strumienie u³osone w postaci wierszy, a nie struktur dwuwymiarowych. Ta zasada zosta³a jednak z³amana przez Unicode Consortium, poniewas w³¹czono do standardu pod pozycj¹ 0x2500 blok elementów s³us¹cych do tworzenia ramek. By³o to usprawiedliwiane powszechnym stosowaniem takich znaków w terminalach i w zestawie znaków stosowanym w IBM PC, ale mimo wszystko jest to oczywista niezgodnoœæ.
Inne znaki, jak np. wspomniane jus znaki w jêzyku ukraiñskim lub rzadziej spotykane imiona i nazwy miejscowoœci w jêzyku japoñskim, nie mog¹ byæ w³¹czone do Unicode, poniewas nie zosta³y znormalizowane przez w³aœciwe komitety narodowe. Niektórych znaków jeszcze nie wymyœlono, chocias nie mosna tego powiedzieæ o ostatnio wprowadzonym oznaczeniu waluty euro. Poniewas zestaw Unicode ogranicza siê tylko do oficjalnie unormowanych znaków, to nie s¹ w³¹czane do niego znaki specjalnego przeznaczenia (np. znaki firmowe) i specjalne zestawy znaków (np. „uœmieszki” stosowane w korespondencji elektronicznej).
Wszystkie wymienione tu problemy da siê do pewnego stopnia rozwi¹zaæ w ramach standardu Unicode. Do³¹czenie niewielkiej liczby znaków mosna zrealizowaæ we w³asnym zakresie, wykorzystuj¹c tzw. „przestrzeñ prywatn¹” umieszczon¹ na pozycjach kodu od 0xE000 do 0xF8FF (czyli 6400 pozycji w BMP) oraz od 0xF0000 do 0x10FFFF (czyli 131072 pozycji na koñcu przestrzeni kodowej Unicode). Microsoft i Apple pomog³y sobie same (przyjmuj¹c wzajemnie sprzeczne rozwi¹zania), usywaj¹c czêœci prywatnej przestrzeni w BMP. Problemy z zestawem Han mosna takse rozwi¹zaæ zgodnie ze standardem Unicode wprowadzaj¹c znaczniki jêzykowe zdefiniowane w samym standardzie lub na wysszym poziomie w jêzykach znaczników, takich jak SGML lub XML.
Jeseli wiadomo, se dana aplikacja bêdzie usywana tylko we w³asnym œrodowisku, to mosna w niej na sta³e zakodowaæ prywatny zestaw znaków w prywatnej przestrzeni BMP. Jako przyk³ad takiego rozwi¹zania mosna podaæ Klingon w j¹drze Linuksa. Jeœli jednak mosna siê spodziewaæ, se usytkownicy zechc¹ dodawaæ w³asne znaki (tak jak Japoñczycy) do usytku firmowego lub prywatnego albo se aplikacja ma byæ przenoszona do innych œrodowisk, w których dostawcy tacy jak Microsoft jus zaw³aszczyli znaczn¹ czêœæ prywatnej przestrzeni standardu, to nalesy zapewniæ dynamiczny przydzia³ tej przestrzeni i przekazywanie prywatnego zestawu znaków miêdzy egzemplarzami aplikacji.
Poniewas kasdy znak ma przyporz¹dkowany jednoznaczny kod w standardzie Unicode, wybór tego standardu jest oczywisty dla wewnêtrznej reprezentacji znaków. Dopóki tekst w reprezentacji zewnêtrznej dostarczanej na wejœciu aplikacji jest po prostu t³umaczony na Unicode i odwrotnie przy dostarczaniu go do wyjœcia, to nie trzeba siê obawiaæ o zak³ócenia danych. Takie dzia³anie wynika z podstawowych za³oseñ przyjêtych dla zastosowañ zestawu znaków w standardzie Unicode.
U³atwia to równies sprawdzanie, czy znaki s¹ obs³ugiwane przez dany krój pisma lub inne w³aœciwoœci funkcjonalne. Poniewas kodowanie jest standardowe, krój pisma wymaga tylko podania listy dostêpnych w nim znaków.
Standard Unicode umosliwia takse zdefiniowanie standardowych bibliotek obs³uguj¹cych w³aœciwoœci znaków, czyli ich typ (litera, cyfra itp.) oraz kierunek czytania (np. znaki alfabetu hebrajskiego s¹ czytane od prawej do lewej). Wynika to z tego, se kasdy znak ma unikatowy kod identyfikuj¹cy. Nawet wówczas, gdy podstawowych algorytmów standardu nie mosna traktowaæ jako optymalnych, to umosliwiaj¹ one wyjœcie z sytuacji awaryjnych i z dusym prawdopodobieñstwem mosna je znaleŸæ w bibliotekach i zestawach programów pomocniczych. Przyk³adami mog¹ byæ strumienie w jêzyku Java i klasy Unicode dla jêzyka C++ opracowane przez IBM.
Unicode umosliwia wiêc przede wszystkim rozszerzenie standardowych w³aœciwoœci napisów w jêzyku C o obs³ugê wszystkich narodowych skryptów, a takse rozszerzenie rodzajów napisów i sposobów manipulacji znakami dziêki mosliwoœci przeniesienia tych w³aœciwoœci do standardowych bibliotek. Jest to znaczny postêp w stosunku do stanu istniej¹cego dotychczas.
Przede wszystkim, co podkreœli³ Hideki Hiura (g³ówny twórca protoko³ów XIM i IIIMF obs³uguj¹cych wprowadzanie danych typu I18N przez usytkownika), Unicode rozwi¹zuje problemy wystêpuj¹ce w skryptach (czyli zbiorach znaków), ale te i tak nales¹ do grupy problemów jêzykowych, które naj³atwiej mosna rozwi¹zaæ. Istnieje jeszcze wiele innych problemów:
Oto kilka przyk³adów:
q T³umaczenie
Nawet wówczas, gdy usytkownik dysponuje systemem umosliwiaj¹cym wyœwietlanie komunikatów o b³êdach aplikacji w jêzyku japoñskim, nie oznacza to, se takie komunikaty bêd¹ wyœwietlane! Oryginalne komunikaty o b³êdach trzeba przet³umaczyæ.
q Formatowanie tekstu
Standard Unicode nie gwarantuje poprawnego formatowania tekstu i dlatego np. Amerykanie i Brytyjczycy usywaj¹cy tego samego zestawu znaków ASCII, ale innego formatowania, bêd¹ rósnie interpretowali niektóre powszechnie stosowane skróty. Unicode w pewnym sensie utrudnia nawet formatowanie, poniewas w aplikacjach nie mosna odnosiæ siê do zestawu znaków jako wskazówki na temat formatowania.
q Wybór rodzaju pisma
Chiñskie, japoñskie i koreañskie skrypty licz¹ tysi¹ce znaków, ale rósni¹ siê nie tylko preferowanymi stylami. Faktyczne graficzne kszta³ty znaków mog¹ siê istotnie rósniæ dla danego znaku w tych jêzykach. Oznacza to, se kieruj¹c siê danymi historycznymi, mosna przeœledziæ ewolucjê kszta³tów znaków w kasdej z tych kultur, pokazuj¹c niezalesne nurty standaryzacji i upraszczania. Wszystkie znaki z tych alfabetów wywodz¹ siê jednak z Chin i powsta³y setki lat temu. Istniej¹ wiêc obiektywne kryteria okreœlania, czy dane glify reprezentuj¹ ten sam znak, niezalesnie od rósnic w jego kszta³tach. Poniewas znak jest ten sam, to i jego kod w standardzie Unicode bêdzie ten sam.
q Uk³ad elementów interfejsu graficznego
Wiêkszoœæ usywanych w Japonii interfejsów graficznych prezentuje teksty w kierunku od lewej do prawej, ale pozostawia siê tes mosliwoœæ usywania historycznego zapisu z góry na dó³, oddaj¹c w ten sposób przywi¹zanie Japoñczyków do formy. Oprócz tego wielu japoñskich projektantów interfejsów graficznych bêdzie umieszczaæ elementy interfejsu odmiennie nis projektanci amerykañscy. ¯adne urz¹dzenie obs³uguj¹ce czysty tekst nie bêdzie w stanie obs³usyæ takich wymagañ.
Niezalesnie od wprowadzenia standardu Unicode jednym z problemów spotykanych przez programistów staraj¹cych siê udostêpniæ swoje oprogramowanie na rynku miêdzynarodowym jest wielka liczba usywanych zestawów kodowych. Nie jest tak, se w jednym jêzyku usywa siê jednego kodowania znaków — wiêkszoœæ dopuszcza kilka takich kodowañ. Japoñscy usytkownicy Linuksa musz¹ siê borykaæ z trzema rósnymi systemami kodowania. Kodowanie EUC-JP jest standardem stosowanym w systemie UNIX ze wzglêdu na zwartoœæ i oszczêdnoœæ miejsca w systemie plików. Na platformach firm Microsoft i Apple stosowane jest kodowanie JIS z modyfikacj¹. Kodowanie ISO-2022-JP jest nieco bardziej rozwlek³e, ale obowi¹zkowo musi byæ stosowane w internetowej poczcie i grupach dyskusyjnych. Do tych trzech tradycyjnie stosowanych kodów zostanie wkrótce dodany standard Unicode. Nie zast¹pi on ich, poniewas tradycyjne kodowanie pozostanie w otrzymanych w spadku bazach danych i bêdzie usywane przez dotychczas stosowane oprogramowanie. Prawd¹ jest, se usytkownik mose czêsto rozrósniæ poszczególne kody dziêki znajomoœci ich pochodzenia, ale programy raczej nie potrafi¹ tego robiæ.
Inny problem stwarza to, se rósne kodowania usywaj¹ jako kodów tego samego ci¹gu bitów. Zarówno EBCDIC, jak i ASCII usywaj¹ kodów z zakresu od 0x00 do 0x7F do kodowania jêzyka angielskiego, ale te obydwa rodzaje kodów jednak siê rósni¹. Kodowania dla innych jêzyków, np. kodowania ISO dla greki i cyrylicy takse siê pokrywaj¹. W obydwóch usywa siê oktetów z zakresu od 0x00 do 0x7F do zakodowania znaków z zestawu ASCII, w kodowaniu ISO dla greki stosuje siê zakres od 0xA0 do 0xFF do zakodowania znaków alfabetu greckiego, a w kodowaniu dla cyrylicy ten sam zakres usywany jest do zakodowania znaków cyrylicy. Automatyczne okreœlanie kodowania odniesione do strumienia znaków mose wiêc byæ ryzykowne i nawet najlepsze rozwi¹zanie bêdzie zaleseæ od usytkownika i procesów generuj¹cych strumieñ danych. To, czy takie heurystyczne podejœcie bêdzie mosna bezpiecznie stosowaæ, zalesy od rodzaju aplikacji.
Standard Unicode jest oczywistym rozwi¹zaniem jako uniwersalny zestaw znaków. W latach szeœædziesi¹tych i siedemdziesi¹tych, gdy pojawi³y siê te problemy, bardzo wasne by³o stosowanie rozwi¹zañ oszczêdzaj¹cych miejsce, zaœ wielojêzyczne kana³y komunikacyjne stanowi³y rzadkoœæ. Istnia³o takse utrudnienie o charakterze politycznym: jasne by³o, se podstawowy alfabet ³aciñski zawieraj¹cy 52 litery i 10 cyfr, odpowiedni¹ liczbê znaków interpunkcyjnych i dodatkowo kilkanaœcie akcentowanych liter ³aciñskich nie móg³ wspó³istnieæ z alfabetem greckim, cyrylic¹ oraz hebrajskim i arabskim w ramach dostêpnych 256 znaków. Któs chcia³by siê wówczas zgodziæ na wielobajtow¹ reprezentacjê swojego alfabetu?
Wprowadzono wówczas rozwi¹zanie problemu pokrywania siê przestrzeni kodowych polegaj¹ce na w³¹czeniu do strumienia danych sygna³ów oznaczaj¹cych zmianê kodowania. Rozwi¹zanie to zyska³o swoj¹ normê ISO 2022. Usywa siê tutaj tzw. sekwencji prze³¹czaj¹cych dla oznaczania zestawów znaków, które pojawi¹ siê póŸniej w strumieniu danych, i ich przesuwania do bies¹cego „rejestru”. ISO 2022 definiuje wiêc systemy modalne: proces komunikacyjny powinien pamiêtaæ bies¹cy tryb pracy (czyli kodowanie znaków), aby poprawnie interpretowaæ strumieñ kodów tych znaków. Zestaw Unicode nie jest modalny, poniewas kody znaków z tego zestawu zawsze reprezentuj¹ te same znaki.
Norma ISO 2022 pozostaje wasna z dwóch powodów. Po pierwsze, stanowi ona podstawê dzia³ania wielu istniej¹cych do dziœ aplikacji. Jako przyk³ad mosna podaæ Mule (Multilingual Extension) dla systemu GNU Emacs, gdzie usywane jest kodowanie zgodne z ISO 2022. Po drugie, koniecznoœæ utrzymywania zgodnoœci z t¹ norm¹ silnie wp³ynê³a na projektowanie standardów zestawów znaków. Przyk³adem mose byæ to, se mimo mosliwoœci przedstawienia 256 znaków w kodzie 8-bitowym, aplikacje zgodne z ISO 2022 mog¹ usywaæ tylko 192 z nich do reprezentacji znaków drukowalnych.
Standard ISO 2022 ma jednak wiele wad:
q koniecznoœæ utrzymywania wewnêtrznego rejestru przechowuj¹cego znane kodowania znaków oraz sekwencji prze³¹czaj¹cych te zestawy,
q brak odpornoœci kana³ów komunikacyjnych na zaburzenia w sekwencjach prze³¹czaj¹cych,
q mosliwoœæ powasnej awarii kana³u komunikacyjnego w przypadku napotkania na nieznan¹ sekwencjê prze³¹czaj¹c¹.
Np. program pocztowy VM (wykorzystuj¹cy GNU Emacs) w swojej domyœlnej konfiguracji nie zechce wyœwietlaæ wiadomoœci z kodowaniem Windows-1252. Argumentem przemawiaj¹cym za takim zachowaniem programu jest to, se nieznane kodowanie mose zawieraæ dowolne znaki, które mog¹ byæ potraktowane przez terminal jako sekwencje steruj¹ce. Autorowi wielokrotnie zdarzy³o siê zablokowaæ okno DOS w Windows lub nawet xterm podczas próby wyœwietlenia japoñskiego tekstu. Wiadomoœci zakodowane za pomoc¹ Windows-1252 przesy³ane w poczcie elektronicznej zawieraj¹ jednak przewasnie kody znaków z zestawu US-ASCII, co jest zupe³nie bezpieczne. Z drugiej strony, w œrodowisku wykorzystuj¹cym Unicode rzadko spotykane kody nie wystêpuj¹ce w zestawie ASCII po prostu nie zostan¹ wyœwietlone ze wzglêdu na brak odpowiednich glifów w danym kroju pisma. W pozosta³ych przypadkach wygl¹d ekranu bêdzie prawie idealny.
Pamiêtajmy o tym, se VM jest aplikacj¹ bardzo sprawn¹, która umosliwia usytkownikowi zarówno wyœwietlenie surowych kodów znaków, jak i utworzenie aliasów dla kodowania. Autor programu VM po prostu chcia³, aby sta³o siê jasne, se zastrzesone standardy tworzone wy³¹cznie po to, aby utrudniæ osi¹gniêcie zgodnoœci z programami firmy Microsoft, nie s¹ jego problemem — to usytkownik musi zadbaæ o to, aby wyœwietliæ poprawnie tekst zakodowany w taki sposób.
Pomimo tego, se ISO 2022 ma nadal swoich zwolenników, szczególnie wœród potêpiaj¹cych Unicode, to wiêkszoœæ ekspertów zaprzesta³a usywania tego standardu. Mia³ on jednak przez 30 lat przemosny wp³yw na prace wdroseniowe z dziedziny I18N. Pierwsz¹ konsekwencj¹ tego faktu jest to, se standard X11 opisuj¹cy komunikacjê miêdzy klientami zawiera X Compound Text, czyli wersjê ISO 2022, jako kodowanie dla œrodowiska miêdzynarodowego. Pakiet narzêdziowy Motif korzysta z podobnej techniki sk³adanych napisów, wykorzystuj¹c te same podstawy. Jeseli wyst¹pi potrzeba komunikowania siê ze starymi klientami korzystaj¹cymi z Xlib lub Motif, to zapewne trzeba bêdzie zapoznaæ siê z takimi zagadnieniami, jak Compound Text i ISO 2022.
Oprócz tego, standard ISO 2022 usankcjonowa³ dwuznacznoœæ kodów i rozszerzanie kodowañ oraz bardzo pomóg³ w unormowaniu kodowañ narodowych, dlatego kroje pisma w X11 s¹ indeksowane ogólnie przez takie same zestawy znaków. Dziêki temu mosna uzyskaæ zwartoœæ reprezentacji danego kroju pisma (czyli tabeli odwzorowuj¹cej kody znaków na ich rastrowe obrazy). Usytkownicy chc¹ jednak wyœwietlaæ znaki z jednego kroju pisma ³¹cznie ze znakami z innego kroju. Na przyk³ad istnieje wiele krojów pisma typu Times Roman o bardzo wysokiej jakoœci dla zestawu znaków ISO-8859-1 (czyli ASCII z do³¹czonymi kodami Latin-1), ale bardzo ma³o dla zestawu ISO-8859-2 (czyli ASCII z do³¹czonymi kodami Latin-2). Tylko zestaw znaków ASCII i kilka znaków akcentowanych s¹ wspólne dla obydwu kodowañ. Usytkownik móg³by wiêc korzystaæ z ISO-8859-1 tam, gdzie jest to mosliwe i przechodziæ do krojów pisma o nisszej jakoœci tam, gdzie jest to konieczne.
Jasne jest, se taki wieloetapowy proces odwzorowania by³by prostszy, gdyby istnia³ jakiœ standardowy kod poœredni. Faktycznie jest nim w³aœnie Unicode. Obecnie standardowym rozwi¹zaniem usywanym przy odwzorowaniach krojów pisma o wysokiej jakoœci jest tworzenie tych krojów ze zwartymi tabelami glifów (krzywych lub obrazów rastrowych, które mog¹ byæ wyœwietlone na ekranie) i powi¹zanie ich z tabel¹ odwzorowuj¹c¹ Unicode na ograniczony zakres indeksów faktycznie wymaganych w znakach danego kroju. Mówi siê, se takie kroje maj¹ odwzorowanie CID (CID jest skrótem od „character ID”). Aplikacje nie musz¹ wówczas mieæ sadnej informacji o faktycznym kodowaniu wewnêtrznym pisma danego kroju. Dziêki utworzeniu tabel odwzorowuj¹cych wszystkie inne kodowania na Unicode dany krój pisma mose byæ usywany dla znaków o dowolnym kodowaniu, byle tylko w tym kroju znalaz³y siê odpowiednie glify. Ten system nie jest jednak uniwersalny. Jest on obecnie dostêpny jedynie dla X11 w ostatnio opracowanych serwerach zgodnych z TrueType, serwerach krojów pisma („fontów”) oraz w rozszerzeniach Display Postscript.
Wiêkszoœæ podstawowych funkcji dotyczy konwersji kodów.
Jeœli mosna kontrolowaæ format plików usywanych przez aplikacjê, to mosna takse zastosowaæ w nich standard Unicode. Jeseli jakieœ odziedziczone dane maj¹ postaæ plików tekstowych, do ich konwersji na standard Unicode lub UTF-8 mosna usyæ programu pomocniczego iconv(1). W wersji GNU tego programu dostêpna jest opcja --list umosliwiaj¹ca uzyskanie listy bies¹co stosowanych kodowañ. Poniewas iconv w wersji GNU korzysta z konwersji przejœciowej z kodu Ÿród³owego na UCS-4, a potem z UCS-4 na kod docelowy, nie ma potrzeby podawania zestawieñ par kodów Ÿród³owych i kodów docelowych. Jeseli dla danego kodowania s¹ dostêpne jakieœ przekszta³cenia, oznacza to, se bêd¹ dostêpne wszystkie. Niektóre przekszta³cenia s¹ „dostêpne” jako prowizorka, w tym sensie, se funkcja iconv(3) zwraca kod b³êdu, koñcz¹c swoje dzia³anie, jeœli przekszta³cany znak nie ma odpowiednika w kodowaniu docelowym.
Niestety, wydaje siê prawdopodobne, se w pewnym momencie dane wprowadzane przez usytkownika i dane wyjœciowe bêd¹ wymaga³y konwersji znaków. Oprócz tego wiêkszoœæ odziedziczonych baz danych nie usywa formatu nadaj¹cego siê do przetworzenia bezpoœrednio za pomoc¹ iconv(1). Oznacza to, se programista bêdzie musia³ dokonywaæ wewnêtrznej konwersji na standard Unicode. Na szczêœcie daje siê to prosto wykonaæ za pomoc¹ funkcji icnov(3) z biblioteki libc w wersji GNU. Sposób usycia tej funkcji jest w normalnych zastosowaniach rutynowy:
Przydzielenie deskryptora konwersji za pomoc¹ iconv_open(3)
Sprawdzenie, czy przydzielenie deskryptora powiod³o siê. Jest to wasne, poniewas próba usycia w konwersji wartoœci zwracanej w wypadku b³êdu spowoduje w niektórych systemach zak³ócenie segmentacji pamiêci.
Usycie deskryptora w wywo³aniu iconv(3) dla przekszta³cenia tekstu z bufora wejœciowego i zachowania go w buforze wyjœciowym. Deskryptor pozwala na wype³nianie bufora i przekszta³canie go w sposób asynchroniczny, poniewas zapamiêtuje stan konwersji.
Testowanie stanu konwersji.
Zwolnienie deskryptora konwersji za pomoc¹ wywo³ania iconv_close(3)
Ponisej podano klasyczny przyk³ad programu „hello, world”, zmienionego tak, aby komunikat korzysta³ ze standardu Unicode, ale by³ wyœwietlany jako strumieñ znaków ASCII. Trzeba pamiêtaæ, se funkcja iconv nie mose korzystaæ z w¹tków w tym sensie, se deskryptor konwersji zwracany przez iconv_open(3) mose byæ usywany w sposób bezpieczny tylko w jednym w¹tku, poniewas zawiera w sobie stan zalesny od kontekstu. Znak mose byæ np. czêœciowo pobrany ze strumienia zewnêtrznego, zaœ aplikacja mose mieæ wiele otwartych deskryptorów konwersji. Powyssze ograniczenie pozwala jednemu w¹tkowi odczytywaæ dane ze strumienia zewnêtrznego i przekszta³caæ je na postaæ wewnêtrzn¹, korzystaj¹c z jednego deskryptora konwersji, zaœ inny w¹tek mose przekszta³caæ przetworzony strumieñ wewnêtrzny na docelow¹ postaæ zewnêtrzn¹ i wpisywaæ go na wyjœcie, korzystaj¹c z innego deskryptora. Takie dzia³anie strumieni jest w zupe³noœci wystarczaj¹ce w wiêkszoœci aplikacji.
Na pocz¹tku zajmiemy siê nag³ówkiem. Typy danych i prototypy funkcji iconv(3) s¹ zdefiniowane w <iconv.h>. Prototypy funkcji pomocniczych s¹ podane nisej:
hello_iconv.c
Pokazuje usycie funkcji iconv zgodnej z UNIX98
#include <iconv.h>
#include <stdio.h>
#include <errno.h>
#include <stdlib.h>
/* Prototypy zdefiniowanych funkcji */
void u2a (char *a_string, const unsigned short *u_string);
char *dotted (char *s, int n);
void usage ();
Bufor wejœciowy jest inicjowany w³aœnie w tym miejscu. Dane wygl¹daj¹ znajomo, chocias s¹ nieco dziwnie sformatowane.
W standardzie Unicode stwierdza siê, se zalecany jest format danych z bajtem bardziej znacz¹cym umieszczanym na pocz¹tku (tzw. big-endian), chocias dozwolony jest takse porz¹dek odwrotny (czyli tzw. little-endian). Standard Unicode jest w rzeczywistoœci odwzorowaniem znaków na liczby ca³kowite, a wiêc porz¹dek bajtów ma znaczenie tylko w zewnêtrznych strumieniach danych. Standard definiuje takse formaty przekszta³ceñ (UTF), które w istocie oznaczaj¹ rósne sposoby kodowania liczb ca³kowitych z przedzia³u od 0 do 17*216-1.
Nie usywamy tu typu wchar_t, poniewas nie wiemy, czy opisuje on dane 16-bitowe. Faktycznie w systemach GNU jest to typ 32-bitowy. Mose on jednak byæ nawet 8-bitowy, bowiem przypuszczenie, se typ short jest 16-bitowy, wynika jedynie z tradycji. Bardziej poprawne by³oby usycie typu uint16_t zdefiniowanego przez ISO C 9X.
Inicjacja bufora wyjœciowego jest zbêdna, ale usyto jej tutaj dla podkreœlenia, se ostatni element tablicy jest faktycznie strasnikiem dbaj¹cym o to, aby poprawnie dzia³a³y funkcje napisów z jêzyka C.
unsigned short unicode_string[15] =
/* bufor wyjœciowy */
char c_string[15] =
Funkcja u2a realizuje interesuj¹ce zadanie. Sprawdzanie stanu zawsze jest dobrym pomys³em, ale dla I18N trzeba obs³usyæ nie tylko wiele na ogó³ niepewnych Ÿróde³ — czyli usytkowników i strumienie przychodz¹ce z sieci — tu o formacie strumienia wejœciowego mosna powiedzieæ tylko to, se jest to surowy strumieñ bajtów. Tekst w standardzie Unicode bêd¹cy strumieniem bajtów bêdzie wiêc zawiera³ znaki ASCII, takie jak NUL LF ESC czy DEL
Zwróæmy uwagê na to, se skoro funkcja iconv(3) pos³uguje siê znakami, których kody maj¹ d³ugoœæ 1, 2 lub 4 bajty albo s¹ kodami wielobajtowymi (o zmiennym rozmiarze), to bufory nalesy obs³ugiwaæ jak tablice bajtowe.
void u2a (char *to_c, const unsigned short *from_unicode)
Wykonujemy konwersjê, sprawdzamy status i sygnalizujemy b³êdy:
switch (status = iconv (cd, &unicode_buffer, &u_count, &to_c, &c_count))
printf ('n');
/*
W zalesnoœci od przydzia³u pamiêci i reprezentacji napisu
mose byæ potrzebny ogranicznik tego napisu.
B³êdy E2BIG i EINVAL zazwyczaj nie s¹ b³êdami krytycznymi; status CD
umosliwiaj¹cy wznowienie konwersji po ostatnim udanym przekszta³ceniu
znaku nie daje oczywistej odpowiedzi jak tu go usyæ, oszukamy go.
*to_c = '0';
break;
default:
/*
W zalesnoœci od przydzia³u pamiêci i reprezentacji napisu
mose byæ potrzebny ogranicznik tego napisu.
Najprawdopodobniej jest to najlepsza rzecz, jak¹ mosemy tu zrobiæ.
*to_c = '0';
printf ('%d characters irreveribly convertedn', status);
/*
i z³ota gwiazda za oczyszczenie: struktura danych cd mose
zawieraæ ca³kiem duse tabele, wiêc to mose prowadziæ do istotnych
wycieków pamiêci
*/
iconv_close (cd);
Teraz nastêpuje prosty sterownik, czyli program pomocniczy powoduj¹cy uwidocznienie bajtów o wartoœciach NULL w postaci kropek, oraz funkcja usage
/*
Program sterownika, który obs³uguje wiele wariantów wyœwietlania
unikodowych napisów na terminalu; aby usyæ - patrz usage().
int main (int argc, char *argv[])
switch (argv[1][0])
exit (EXIT_SUCCESS);
Niewielka procedura zastêpuj¹ca kropkami wszystkie bajty NULL w napisie.
char 8dotted (char *s, int n)
Z czystego przymusu
void usage (char *s)
n', s);
printf ('1 - printf converted C stringn');
printf ('2 - printf Unicode string with dots replacing null bytesn');
printf ('3 - printf raw Unicode stringn');
printf ('4 - printf converted C string with dots replacing null
bytesn');
/* end hello_iconv.c */
Oto krótka sesja tego programu w okienku xterm
$ gcc -Wall -g -o test hello_iconv.c
$ ./test
usage: ./test
1 - printf converted C string
2 - printf Unicode string with dots replacing null bytes
3 - printf raw Unicode string
4 - printf converted C string with dots replacing null bytes
$ ./test 1
hello, world
$ ./test 2
h.e.l.l.o.,. .w.o.r.l.d.
.$ ./test 3
h$ ./test 4
hello, world
Po porównaniu wyników wywo³añ ./test 2 i ./test 3 staje siê jasne, se nie mosna stosowaæ zwyk³ych funkcji do przetwarzania napisów zawieraj¹cych kody wielobajtowe. Poniewas znaki ASCII maj¹ takie same ca³kowitoliczbowe wartoœci kodów w Unicode, lecz s¹ reprezentowane przez liczby typu short, to na maszynie pos³uguj¹cej siê porz¹dkiem bajtów „little-endian” na wyjœciu pojawia siê tylko „h”, po czym funkcja printf napotyka na starszy bajt o wartoœci NUL i koñczy dzia³anie. Na maszynie pos³uguj¹cej siê porz¹dkiem bajtów „big-endian” bajt o wartoœci NUL wystêpuje jako pierwszy i na wyjœciu przy wywo³aniu ./test 3 nic siê nie pojawi.
Gdyby zosta³a dodana dodatkowa funkcja wyœwietlaj¹ca napisy Unicode, to na wyjœciu móg³by siê pojawiæ ca³y napis w postaci ci¹gu 16-bitowych znaków. Funkcja ta nie jest w³¹czona do tego przyk³adowego kodu, poniewas wynik jej dzia³ania zalesy od konkretnej konfiguracji emulatora terminala i móg³by powodowaæ jego zawieszanie.
Pomimo tego, se omawiany program wytwarza tylko dane wyjœciowe, to pobieranie danych z wejœcia i wewnêtrzna konwersja na standard Unicode s¹ równie proste. Wasn¹ rzecz¹ do zapamiêtania jest to, se interfejs iconv_open(3) korzysta z nazw kodów w postaci napisów ASCII. Wprowadzono to z dwóch powodów. Po pierwsze, mosna wówczas zdefiniowaæ modu³ obs³uguj¹cy nowy rodzaj konwersji i ³adowaæ go dynamicznie. Zastosowanie makrodefinicji (lub typów wyliczeniowych) w definicjach identyfikatorów kodów mog³oby utrudniæ praktyczne zastosowanie modu³ów tego rodzaju. Po drugie, oznacza to, se nazwa kodu mose byæ przekazana bezpoœrednio przez usytkownika do funkcji iconv_open. Bardzo zabawna mog³aby byæ taka modyfikacja programu hello_iconv.c, aby pobiera³ on rodzaj kodowania z wiersza poleceñ. Poniewas nazwy s¹ zgodne z ASCII, to konwersja na EUC-* i UTF-8 jest bezpieczna, chocias doœæ k³opotliwa. Kodowanie EBCDIC-US na maszynie autora nie powoduje szkód w programie xterm, ale trzeba pamiêtaæ o mosliwoœci zmiany trybu pracy terminala lub mosliwoœci jego zawieszenia.
Uwaga koñcowa: program nie korzysta z sadnej funkcji umiejscawiaj¹cej (ang. locale function). Nie jest to wcale pomy³ka, poniewas nawet dla zmodyfikowanej wersji przyk³adowego programu, zaleconej dla æwiczeñ (czyli programie pobieraj¹cym kodowanie docelowe z wiersza poleceñ) usycie takich funkcji mog³oby daæ niepewne wyniki i byæ skomplikowane. Nie istnieje bowiem saden standardowy sposób okreœlania zestawu znaków na podstawie napisu w danym jêzyku, który zazwyczaj jest aliasem. Mosna zapoznaæ siê z niektórymi informacjami pomocniczymi na temat plików korzystaj¹cych z aliasów dostêpnych w bibliotece GNU libc oraz X11R6. S¹ one zawarte odpowiednio w plikach /usr/share/locale/locale.alias oraz /usr/X11R6/lib/locale/locale.alias. Pliki te nie s¹ jednak unormowane i brak jest standardowych funkcji, które mog³yby byæ zastosowane do ich przetwarzania. Aplikacja po prostu musi dysponowaæ w³asnym sposobem wykrywania (mosliwe, se na podstawie plików locale.alias) i jeœli wydaje siê to ryzykowne z powodu mosliwoœci pope³nienia pomy³ki w kodowaniu, to trzeba usytkownikowi udokumentowaæ potrzebê zastosowania napisów w pe³ni zdefiniowanych w jêzyku lokalnym. W niezbyt odleg³ej przysz³oœci ten najtrudniejszy problem (okreœlanie kodowania w danych wprowadzanych i odbieranych przez usytkownika) powinien znikn¹æ dziêki uniwersalnemu stosowaniu formatu UTF-8 w strumieniach tekstowych. Pozosta³e zastosowania funkcji usywanych do konwersji ogranicz¹ siê do przekszta³ceñ formatów Unicode zalesnych od wymagañ aplikacji oraz przekszta³ceñ odziedziczonych baz danych. To ostatnie zastosowanie powinno jednak prawie siê nie zmieniaæ!
Modele I18N zasadniczo polegaj¹ na ustawieniu standardów w definicjach bibliotek usywanych przy tworzeniu programów, które s¹ przeznaczone na rynek miêdzynarodowy, oraz funkcjonalnoœci kasdego modu³u w takich bibliotekach. Wasne jest, aby programista tworz¹cy aplikacjê by³ zaznajomiony z rósnymi modelami i zakresem ich zastosowañ. Dziêki temu okreœlenie rodzaju internacjonalizacji staje siê stosunkowo prostym zadaniem. Programiœci tworz¹cy aplikacje powinni takse ostrosnie podchodziæ do tych modeli, poniewas pomagaj¹ one wybraæ nie tylko zasoby dostêpne dla programisty i wymagane dla osi¹gniêcia rósnego rodzaju funkcjonalnoœci, ale takse np. zasoby potrzebne przy t³umaczeniach oraz oprogramowanie stowarzyszone, jak serwery obs³uguj¹ce wprowadzanie danych wejœciowych.
Techniczny opis tego, co rozumiemy jako œrodowisko kulturowe, nazywany jest umiejscowieniem (ang. locale). Umiejscowienie jest zbiorem wartoœci takich parametrów jak jêzyk, region, zestaw znaków, kodowanie, format daty, format waluty itd. Mosna dyskutowaæ, co naprawdê jest potrzebne, aby w sposób zwarty opisaæ umiejscowienie, ale standard POSIX podaje podstawowe definicje, czyli model umiejscowienia POSIX (ang. POSIX locale model Podstawowe za³osenia tego modelu s¹ nastêpuj¹ce:
Najwasniejsze charakterystyki tekstu s¹ okreœlane na podstawie rodzimego jêzyka, którym pos³uguje siê usytkownik. Dozwolone s¹ odmiany regionalne (np. rósnice w pisowni amerykañskiej okreœlanej skrótem „en_US” i brytyjskiej „en_GB”). Z powodów historycznych kodowanie zestawu znaków (np. ASCII odniesione do Unicode) stanowi czêœæ opisu jêzyka i regionu. Zauwasmy jednak, se sama znajomoœæ jêzyka nie wystarcza do okreœlenia kodowania. W wiêkszoœci jêzyków europejskich usywa siê co najmniej trzech rodzajów kodowania: 7-bitowej odmiany ASCII, 8-bitowego wariantu ISO-8859 i Unicode. Dozwolone jest stosowanie niezalesnego od aplikacji modyfikatora, ale nie jest on zupe³nie opisany w modelu.
Usytkownicy pos³uguj¹ siê aplikacjami, dla których standardowe umiejscowienia s¹ po czêœci nieodpowiednie, czyli wymagana jest mosliwoœæ ponownego zdefiniowania niektórych kategorii w tych umiejscowieniach.
Ponowne definicje mosna uzyskaæ, stosuj¹c mieszaninê kilku umiejscowieñ.
Pe³na specyfikacja modelu umiejscowienia POSIX jest okreœlana za pomoc¹ nazwy, np. en_US.iso646-irv@unused, w której poszczególne cz³ony maj¹ nastêpuj¹ce znaczenie:
q Cz³on „en” oznacza jêzyk angielski. S¹ tu stosowane dwuliterowe oznaczenia wziête ze standardu ISO 639.
q Cz³on „US” oznacza Stany Zjednoczone, czyli region. Kod regionu jest takse kodem dwuliterowym wziêtym ze standardu ISO 3166.
q Cz³on „iso646-irv” oznacza wersjê ISO standardu ASCII i rósni siê od US ASCII tylko nazw¹. W czasach systemów 7-bitowych zdefiniowano wiele narodowych wariantów ASCII, zaœ ISO 646 próbuje je unormowaæ. Oznaczenie „irv” jest skrótem s³ów „international reference version”.
q Cz³on „unused” oznacza tylko miejsce do wykorzystania i faktycznie nalesa³oby go pomin¹æ. Jego funkcja ca³kowicie zalesy od aplikacji. W bibliotece glibc oraz w ca³ym systemie Linux cz³on ten nie jest usywany.
Jedynym wymaganym cz³onem przy okreœlaniu umiejscowienia jest definicja jêzyka. Pozosta³e trzy czêœci mosna pomin¹æ, ³¹cznie z prefiksem. System powinien wybieraæ odpowiedni¹ wartoœæ domyœln¹, a wiêc w USA wartoœæ „en” powinna oznaczaæ to samo, co „en_US.iso646-irv”, zaœ w Wielkiej Brytanii powinna byæ interpretowana jako „en_GB.iso8859-15”. Oprócz tego w wiêkszoœci systemów zgodnych ze standardem POSIX istniej¹ aliasy dla umiejscowienia. W systemie Linux lista tych aliasów znajduje siê w pliku /usr/share/locale/locale.alias. Po³osenie i nazwa tego pliku zalesy w znacznym stopniu od usywanego systemu.
Pierwsze za³osenie — se rodzimy jêzyk usytkownika okreœla wiêkszoœæ w³aœciwoœci umiejscowienia — powoduje faktycznie problemy, szczególnie w programach wielojêzycznych, poniewas doprowadzi³o do zdefiniowania umiejscowienia jako globalnej w³aœciwoœci procesu. Oznacza to, se obs³uga wielu jêzyków wymaga zmian umiejscowienia, co jest operacj¹ wyj¹tkowo kosztown¹. W szczególnoœci wielojêzyczna aplikacja musi prawdopodobnie obs³ugiwaæ jednoczeœnie rósne kodowania. Takie dzia³anie nie zachowuje w¹tku. Za³osenie to bêdzie z³agodzone w przysz³ych wersjach biblioteki glibc dziêki temu, se zostanie wprowadzony niestandardowy parametr kontekstowy dla rozszerzonego zestawu funkcji umiejscawiaj¹cych. Nie ma jednak pewnoœci, czy takie rozwi¹zane planowane w glibc (mimo swojej logiki) zostanie zaakceptowane jako standard miêdzynarodowy. Programiœci martwi¹cy siê o przenoœnoœæ kodów na platformy nie korzystaj¹ce z glibc musz¹ o tym pamiêtaæ.
Trzecie za³osenie dotyczy konwencji nazewniczej, a wiêc u³atwia tworzenie nowych umiejscowieñ i wyprowadzanie ich z umiejscowieñ zdefiniowanych wczeœniej.
Jedn¹ z prób rozwi¹zañ problemów zwi¹zanych z I18N jest czêœciowe ich obejœcie za pomoc¹ architektury klient-serwer. Pomys³ polega na tym, se serwer bêdzie obs³ugiwa³ teksty przechowywane w bazie danych w postaci obiektów binarnych, a klient mose je formatowaæ. Internacjonalizacja serwera bêdzie wiêc wp³ywaæ na wspó³pracê z operatorem. Oddzia³ywanie na bazê danych i klienty bêdzie „internacjonalizowane” za pomoc¹ prze³¹czania danych zwracanych przez zapytanie, w którym wykorzystuje siê umiejscowienie klienta. Czêsto musi to byæ zrobione w jakiœ sposób: jeseli np. oddzia³ firmy zlokalizowany w San Diego bêdzie wprowadza³ ceny w dolarach, a oddzia³ zlokalizowany w Tijuana bêdzie usywa³ cen w pesos. Obejœcie to mosna wiêc stosowaæ g³ównie do tekstów.
Przy takim rozwi¹zaniu pojawia siê problem, gdy porz¹dek zwracanych wpisów tekstowych ma znaczenie. Poniewas sposób tworzenia zestawieñ zalesy od umiejscowienia, to serwer bazy danych powinien umosliwiaæ prze³¹czanie umiejscowieñ. Istniej¹ dwa sposoby obejœcia tego problemu: uruchomienie egzemplarza bazy danych oddzielnie dla kasdego umiejscowienia albo sortowanie danych przez klienta. Pierwszy sposób mose byæ zbyt kosztowny w sensie zasobów serwera, zaœ drugi w sensie wymaganej przepustowoœci kana³u komunikacyjnego. Takie podejœcie uniemosliwia zastosowanie rósnych w³aœciwoœci bazy danych, np. kursorów. Okazuje siê wiêc, se I18N mose mieæ wp³yw na wybór architektury systemu.
Umiejscowienie POSIX jest, jak jus wspomniano, zmienn¹ wewnêtrzn¹ o zasiêgu globalnym dla procesu. W bibliotece glibc zosta³o to wprowadzone w postaci dynamicznych zmian funkcji wewnêtrznych wywo³ywanych przez standardowe procedury sortowania, funkcje klasyfikuj¹ce i funkcje obs³uguj¹ce wejœciowe i wyjœciowe strumienie danych. Z tego powodu zmiana umiejscowienia jest operacj¹ bardzo kosztown¹.
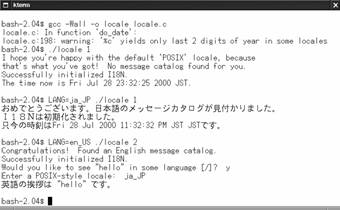
Kategorie dzia³añ modyfikowane przez umiejscowienie s¹ nazywane „atomami”. Kasdy taki atom jest wprowadzany jako zmienna œrodowiskowa oraz jako makrodefinicja (lub, jeœli jest to mosliwe, jako sta³a wyliczeniowa) w programach pisanych w jêzyku C (patrz <locale.h>). Atom zawieraj¹cy format daty i czasu nazywa siê LC_TIME. Usytkownik chc¹cy usyæ konwencji formatowania daty i czasu stosowanej w amerykañskiej odmianie jêzyka angielskiego powinien ustawiæ dla swojego œrodowiska wartoœæ zmiennej LC_TIME=en_US. Programista chc¹cy na sta³e zakodowaæ tê konwencjê w programie powinien wywo³aæ setlocale(LC_TIME,'en_US')
W standardzie POSIX istniej¹ dwie zmienne, które nie okreœlaj¹ specyficznego dzia³ania. S¹ to LANG i LC_ALL. Wartoœæ zmiennej LANG jest usywana jako wartoœæ domyœlna dla kasdej kategorii, jeœli ani nie zosta³a okreœlona jedna specyficzna zmienna, ani nie zdefiniowano zmiennej LC_ALL. Wartoœæ LANG jest przewasnie definiowana w skrypcie konfiguracyjnym pow³oki (np. ~/.bash_login). Zmienna LC_ALL zastêpuje wszystkie wartoœci ustawione dla wszystkich specyficznych kategorii i zazwyczaj usywa siê jej do wymuszenia ustalonej wartoœci umiejscowienia.
W standardzie POSIX zdefiniowano podane nisej kategorie, ale nie zabrania siê wprowadzania dodatkowych kategorii (dlatego w³aœnie wynik dzia³ania LC_ALL nie mose byæ osi¹gniêty przez ustawienia zmiennych osobno dla poszczególnych kategorii, chyba se znany jest z góry system, w którym bêdzie uruchamiany dany program).
Kategoria ta okreœla porz¹dek znaków w danym kodowaniu. Mose ona takse obs³ugiwaæ znaki sk³adane, takie jak np. ligatury Ch oraz Ll w tradycyjnym jêzyku hiszpañskim (we wspó³czesnym jêzyku hiszpañskim zabroniono wprawdzie specjalnego traktowania tych par znaków, ale w jêzyku tajskim i hindi sk³adanie znaków jest obowi¹zkowe). S¹ jêzyki, w których trzeba dzieliæ jeden znak na kilka innych, jak np. „ostre S” w jêzyku niemieckim traktowane jako „SS”. Rósne jêzyki traktuj¹ takse w rósny sposób akcenty. W niektórych litera akcentowana jest przy sortowaniu równowasna literze podstawowej, chyba se akcent jest jedynym sposobem przerwania powi¹zania. W innych jêzykach znaki akcentowane s¹ traktowane jako znaki autonomiczne, a nie jako warianty znaków podstawowych. Wszystko to wp³ywa na wyniki sortowania i algorytmy przeszukiwania, a takse okreœla sposób interpretacji wyraseñ podaj¹cych zakres oraz klasy znaków w bibliotece obs³uguj¹cej wyrasenia regularne. Ta kategoria jest reprezentowana przez LC_COLLATE
Kategoria dotycz¹ca typów znaków okreœla definicje klas tych znaków (np. wielkie i ma³e litery, cyfry dziesiêtne i szesnastkowe, znaki interpunkcyjne itp.). Wp³ywa ona na klasy znaków w bibliotece obs³uguj¹cej wyrasenia regularne, standardowe funkcje klasyfikacyjne i makropolecenia, przekszta³cenia wielkoœci liter oraz obs³ugê kodowañ o szerokoœci znakowej. Ta kategoria jest reprezentowana przez atom LC_CTYPE
Kategoria komunikatów okreœla jêzyk usywany w daj¹cych siê umiejscowiæ komunikatach w jêzyku naturalnym. Okreœlenie „daj¹cy siê umiejscowiæ” nie jest w standardzie POSIX precyzyjnie wyt³umaczone, z wyj¹tkiem tego, se musz¹ byæ okreœlone równowasniki dla „yes” i „no” (istniej¹ bowiem jêzyki, w których „y” jest pierwsz¹ liter¹ s³owa oznaczaj¹cego zaprzeczenie, a „n” jest pierwsz¹ liter¹ s³owa oznaczaj¹cego potwierdzenie). Komunikaty stanowi¹ faktycznie doœæ k³opotliwy problem. W tych sytuacjach, gdy komunikat jest parametryzowany, porz¹dek argumentów dla funkcji podobnych do printf mose siê zmieniaæ w zalesnoœci od jêzyka. Ta kategoria jest reprezentowana przez LC_MESSAGES
Kategoria ta wp³ywa na formatowanie wyjœciowe wartoœci pieniêsnych. Obejmuje ona odpowiedni symbol waluty i czasem wariant formatowania liczb. Jest reprezentowana przez atom LC_MONETARY
Kategoria ta dotyczy wyjœciowego formatowania liczb, ³¹cznie ze znakiem usywanym jako separator u³amka dziesiêtnego (typowo jest to kropka lub przecinek) i znakiem usywanym przy grupowaniu cyfr (jeœli jest stosowane). Reprezentuje j¹ atom LC_NUMERIC
Ta kategoria wp³ywa na wyjœciowe formatowanie daty i czasu. Reprezentuje j¹ atom LC_TIME
Zauwasmy, se model POSIX nie pomaga w obs³udze wejœcia. Wszystkie kategorie umiejscowienia dotycz¹ przetwarzania danych na wyjœcia lub przetwarzania wewnêtrznego, z wyj¹tkiem kategorii LC_MESSAGES. Jednak nawet dla tej kategorii zdefiniowano tylko odpowiedzi „tak” lub „nie”.
Model POSIX jest bardzo przydatny dla programistów, poniewas zgodna z nim implementacja zawiera:
q funkcje inicjuj¹ce, które ustawiaj¹ bibliotekê zapewniaj¹c¹ odpowiednie dzia³anie programu zgodne ze specyfikacj¹ wymagan¹ przez usytkownika oraz dostarczaj¹ w standardowy sposób informacje na temat preferencji usytkownika,
q charakterystyczne elementy o okreœlonych w³aœciwoœciach funkcjonalnych (sortowanie, klasyfikowanie i formatowanie strumienia wyjœciowego),
q bibliotekê wstêpnie zdefiniowanych ustawieñ umiejscawiaj¹cych,
q sposoby definiowania nowych umiejscowieñ bez potrzeby przebudowywania biblioteki funkcji.
W przypadku funkcji zdefiniowanych w modelu POSIX (zestawienia, wyœwietlanie znaków, formatowanie liczb, wartoœci walutowych i czasowych oraz formatowanie dialogów „tak/nie”) programista nie musi robiæ niczego wiêcej oprócz wywo³ania odpowiedniej funkcji z biblioteki. W niektórych okolicznoœciach standardowe funkcje jêzyka C s¹ „umiêdzynarodowione” w sposób niezauwasalny przez programistê, zaœ w innych musi on usyæ specjalizowanej funkcji obs³uguj¹cej ustawienia miêdzynarodowe. Definicje wiêkszoœci umiejscowieñ s¹ jus dostêpne w bibliotece. W sytuacjach, gdy takich wstêpnych definicji jeszcze tam nie ma lub nie s¹ one poprawne, mosliwoœæ tworzenia nowych umiejscowieñ bez przebudowy biblioteki oznacza, se praca ta mose byæ przydzielona specjalistom jêzykowym. Wymagane tu jest tylko niewielkie przeszkolenie w zakresie pos³ugiwania siê jêzykiem programowania usywanym w definicjach. Definicje umiejscowieñ nie musz¹ byæ tworzone przez programistów, którzy nawet nie zawsze potrafi¹ bardzo dobrze mówiæ w danym jêzyku (czego nalesa³oby oczekiwaæ podczas tworzenia aplikacji przeznaczonych na rynek miêdzynarodowy dla rósnych œrodowisk kulturowych).
Oprócz tego, w sytuacjach, gdy mosna usyæ „globalnego umiejscowienia” w us³ugach bardziej zaawansowanych (np. takich jak metody wprowadzania danych lub opisane nisej zarz¹dzanie rozmieszczeniem elementów interfejsu) konfiguracja umiejscowienia zgodna ze standardem POSIX czêsto bywa usywana do okreœlania preferencji usytkownika.
Organizacja X/Open Group tworzy standardy przenoœnoœci dla wielu dziedzin w systemach UNIX, a wiêc internacjonalizacja nie stanowi tu wyj¹tku. Unormowano w ten sposób trzy wasne rozszerzenia standardu umiejscawiania POSIX: funkcje obs³uguj¹ce znaki o kodach wielobajtowych (kody o zmiennej d³ugoœci, np. UTF-8) i o kodach sta³ej d³ugoœci (np. Unicode), ogólny system tworzenia t³umaczeñ komunikatów wykorzystuj¹cy funkcjê biblioteczn¹ catgets(3) oraz podsystem iconv(3) s³us¹cy do konwersji kodowañ znaków.
Funkcje obs³uguj¹ce znaki z kodami o zmiennej i o sta³ej d³ugoœci dotycz¹ bardzo zaawansowanych zagadnieñ, które s¹ spotykane w specjalistycznych zastosowaniach (w szczególnoœci dotyczy to aplikacji w pe³ni wielojêzycznych). S¹ one dobrze wyjaœnione (chocias w bardzo skrócony sposób) na stronach podrêcznika systemowego dotycz¹cych biblioteki libc w wersji GNU. Ich listê mosna uzyskaæ w sposób nastêpuj¹cy:
$ man - k multibyte
oraz:
$ man -k 'wide character'
Ponissza tabela takse zawiera krótki opis tych funkcji. Widaæ, se funkcje obs³uguj¹ce kody wielobajtowe s¹ przeznaczone g³ównie do konwersji zewnêtrznych strumieni danych, które zawieraj¹ kody o zmiennej d³ugoœci na ich wewnêtrzny format o sta³ej d³ugoœci kodu usywany przy przetwarzaniu. Funkcje obs³uguj¹ce znaki o kodach o ustalonej d³ugoœci nie tylko wykonuj¹ operacje odwrotne, ale s¹ takse odpowiednikami wiêkszoœci standardowych funkcji z bibliotek obs³uguj¹cych wejœcia i wyjœcia oraz napisy.
|
Mbstowcs(3) |
Przekszta³ca napis ze znakami o kodach wielobajtowych na napis z kodami o ustalonej d³ugoœci |
|
mbtowc(3) |
Przekszta³ca znak o kodzie wielobajtowym na znak o kodzie z ustalon¹ d³ugoœci¹ |
|
utf-8(7) |
Wielobajtowe kodowanie Unicode zgodne z ASCII |
|
Wcstombs(3) |
Przekszta³ca napis ze znakami o kodach z ustalon¹ d³ugoœci¹ na napis z kodami wielobajtowymi |
|
wctomb(3) |
Przekszta³ca znak o kodzie z ustalon¹ d³ugoœci¹ na znak o kodzie wielobajtowym |
|
Mbstowcs(3) |
Przekszta³ca napis ze znakami o kodach wielobajtowych na napis z kodami o ustalonej d³ugoœci |
|
mbtowc(3) |
Przekszta³ca znak o kodzie wielobajtowym na znak o kodzie z ustalon¹ d³ugoœci¹ |
|
wcstombs(3) |
Przekszta³ca napis ze znakami o kodach z ustalon¹ d³ugoœci¹ na napis z kodami wielobajtowymi |
|
wtcomb(3) |
Przekszta³ca znak o kodzie z ustalon¹ d³ugoœci¹ na znak o kodzie wielobajtowym |
Modu³ catgets(3) jest dostêpny w bibliotece GNU libc, ale przy programowaniu w Linuksie jest on w zasadzie zastêpowany przez opisany nisej modu³ gettext(3). Modu³ catgets(3) móg³by byæ przydatny przy przenoszeniu programu do alternatywnego œrodowiska, albo gdy projekt nie mose zawieraæ dodatków stosuj¹cych siê do licencji GPL.
Sam modu³ gettext jest prawdopodobnie dostêpny w wersji Ÿród³owej biblioteki libc w wersji GNU i dlatego dotyczy go licencja LGPL. Pomocnicze programy i autonomiczna biblioteka libintl wytworzona na podstawie wersji Ÿród³owej gettext s¹ jednak objête licencj¹ GPL. Zgodnie z ustaleniami Free Software Foundation oznacza to, se kasdy program skonsolidowany z libintl musi byæ rozpowszechniany zgodnie z zasadami licencji GPL. Sposób usycia catgets(3) jest bardzo podobny do usycia gettext(3), z wyj¹tkiem tego, se API jest mniej klarowny. Jest to dobrze udokumentowane na stronach podrêcznika systemowego GNU libc
W sk³ad podsystemu iconv(3) wchodz¹ funkcje usywane przy konwersji kodów w ramach tego samego zestawu znaków. Jest to nowoczeœnie zaprojektowany modu³ wykorzystuj¹cy powtórne wejœcia i z dobr¹ obs³ug¹ wyj¹tków. Oznacza to, se zestawy znaków zgodne ze sob¹ nawet w niewielkim stopniu (np. ASCII i EBCDIC) mog¹ byæ przekszta³cane na siebie nawzajem. Podsystem iconv(3) u³atwia takse tworzenie aplikacji, w których wymagana jest np. transliteracja (np. liter cyrylicy na kombinacje liter ³aciñskich). Funkcje tego podsystemu zapewniaj¹ mosliwoœæ efektywnej konwersji zarówno na zestaw Unicode, jak i z tego zestawu na inny (a wiêc np. miêdzy Unicode i UTF-8). S¹ one stosowane g³ównie w celu zapewnienia zgodnoœci z archiwalnymi plikami i przekszta³cania danych wprowadzanych przez usytkowników. Obecnie zaleca siê, aby pliki danych i dane tworzone przez usytkownika by³y przechowywane w kodowaniu Unicode lub UTF-8 (jeœli rozmiary plików s¹ istotne, to mosna sprawdziæ, se plik zawieraj¹cy dane w formacie Unicode i skompresowany za pomoc¹ ogólnie znanego algorytmu, np. gzip, bêdzie mia³ taki sam rozmiar, jak ten sam plik w formacie ASCII skompresowany za pomoc¹ takiego samego programu). Modu³ iconv u³atwia wykorzystanie Unicode lub UTF-8 do zewnêtrznej reprezentacji tekstu, niezalesnie do umiejscowienia.
Biblioteka GNU libc w wersji 2. i nowszych w pe³ni korzysta z modeli POSIX i X/Open. W wersji 2.1 tej biblioteki by³y wprawdzie jakieœ problemy z funkcjami obs³uguj¹cymi znaki o kodach z ustalon¹ d³ugoœci¹ w jêzykach azjatyckich, ale powinno to byæ poprawione jus w wersji 2.2. Najwasniejsz¹ dodatkow¹ w³aœciwoœci¹ tej biblioteki jest dostarczenie API dla katalogów komunikatów. Interfejs ten ma nazwê „GNU gettext” i zosta³ utworzony przez Ulricha Dreppera. Problem w zastosowaniu interfejsu catget(3) polega na tym, se wymaga on utrzymywania uporz¹dkowanego odwzorowania wszystkich komunikatów ³¹cznie z numerem indeksu. Funkcja catget(3) korzysta z tego indeksu w celu uzyskania dostêpu do katalogu. Bardzo utrudnia to zarz¹dzanie katalogiem, poniewas jeœli nowy komunikat ma byæ umieszczony miêdzy komunikatami o numerach 1 i 2, to trzeba by³oby nadaæ mu numer 3. Dlatego w³aœnie programista jest zmuszony do utrzymywania rejestru numerów komunikatów, co prowadzi do wielu konfliktów, szczególnie w rozproszonych œrodowiskach programowania, takich jak np. CVS. Dwaj programiœci przegl¹daj¹cy ten sam katalog powinni widzieæ taki sam „nastêpny” indeks, a wiêc potrzebny jest jakiœ mechanizm przydzielania indeksów. Oprócz tego, jeœli jakiœ katalog dla danego umiejscowienia nie zostanie zaktualizowany lub nie istnieje, to nalesy usyæ w programie zakodowanego na sta³e napisu awaryjnego, który wcale nie musi byæ taki sam, jak napis w odpowiednim katalogu obs³uguj¹cym rodzimy jêzyk programu (zazwyczaj angielski).
Modu³ gettext w wersji GNU (wywodz¹cy siê z prac grupy Uniforum kierowanych przez Sun Microsystems) grupuje awaryjne napisy i numery indeksów do postaci pojedynczych obiektów. Zastosowano tu prost¹ metodê polegaj¹c¹ na usyciu tabeli asocjacyjnej indeksowanej przez napisy awaryjne. Zoptymalizowano tu takse spotykany powszechnie w aplikacjach przypadek stosowania oddzielnego katalogu komunikatów dla kasdego jêzyka, zezwalaj¹c na globalne usycie katalogu. Oznacza to, se wywo³anie catgets(3) wymaga podania czterech argumentów (katalog, numer zestawu w katalogu, numer komunikatu i komunikat domyœlny), zaœ gettext(3) wymaga zwykle podania tylko jednego argumentu — komunikatu domyœlnego.
Powasn¹ zalet¹ modu³u gettext jest to, se przeróbka programu polegaj¹ca na przystosowaniu go do korzystania z tego modu³u jest stosunkowo ³atwa. Mosna do tego usyæ skryptu programu sed(1) wyszukuj¹cego napisy w cudzys³owach i pakuj¹cego je w wywo³ania funkcji gettext(3). Oprócz tego, powszechnie jest usywana definicja makropolecenia przyjmuj¹cego jeden argument o nazwie „ ” (po prostu zwyk³e podkreœlenie). Wówczas napis, do którego siê odwo³ujemy, np. maj¹cy postaæ:
'Please gettext-ize me!'
staje siê wywo³aniem makrodefinicji:
_('Please gettext-ize me!')
Taka metoda szybko staje siê czymœ tak oczywistym, jak oznaczanie komentarzy w jêzyku C. W module catgets(3) podobne podejœcie wykorzystuj¹ce proste makropolecenie nie jest mosliwe, poniewas wymagana jest obecnoœæ dodatkowego argumentu, czyli indeksu. W rzeczywistoœci catgets(3) wymaga podania jeszcze dwóch innych argumentów, czyli katalogu i numeru zestawu znaków, ale dla prostszych zastosowañ mosna utworzyæ makropolecenie lub funkcjê pakuj¹c¹, która obs³usy te argumenty. Nadal jednak wymagany bêdzie numer indeksu i komunikat awaryjny.
Modu³ gettext w wersji GNU (i biblioteka libc zawieraj¹ca ten modu³) definiuje dwie dodatkowe zmienne umiejscawiaj¹ce. Zamienna LANGUAGE jest uogólnieniem zmiennej LANG z dodan¹ œciesk¹ przeszukiwania definicji jêzykowych. Wp³ywa ona tylko na kategoriê umiejscawiaj¹c¹ LC_MESSAGES, umosliwiaj¹c usytkownikowi okreœlenie katalogów komunikatów dla kilku jêzyków, które maj¹ byæ przeszukiwane przed ostatecznym usyciem komunikatu domyœlnego zakodowanego na sta³e w programie. Zmienna LINGUAS jest usywana specyficznie przez modu³ gettext i okreœla, które kategorie umiejscawiaj¹ce dostêpne w aplikacji maj¹ byæ zainstalowane w systemie. Zmienna LINGUAS rósni siê istotnie od innych opisanych wczeœniej kategorii umiejscawiaj¹cych. Korzystaj¹ z niej g³ównie administratorzy systemu i osoby pakuj¹ce dystrybucje, a nie programiœci tworz¹cy aplikacje. Wspomniano o niej w tym miejscu tylko dlatego, aby wskazaæ na jej istnienie i mosliwoœæ odwo³ania siê do niej.
Modu³ gettext w wersji GNU jest rozprowadzany w dwóch postaciach: jako pomocnicza biblioteka libintl.a oraz jako czêœæ biblioteki libc w wersji GNU. W obydwu usywany jest wspólny interfejs libintl.h, natomiast rósnice dotycz¹ ograniczeñ licencyjnych. Biblioteka libintl.a stosuje siê do licencji GPL, zaœ druga postaæ objêta jest licencj¹ LGPL. Dodatkowe programy wspomagaj¹ce programowanie gettextize(1) msgfmt(1) msgmerge(1) i xgettext(1) takse s¹ rozprowadzane tylko z autonomiczn¹ bibliotek¹, poniewas na ogó³ nie s¹ one potrzebne do uruchamiania programów w wersjach miêdzynarodowych. Oznacza to, se tam, gdzie wspomina siê o dokumentacji gettext, nalesy sprawdzaæ zarówno dokumentacjê rozprowadzan¹ z autonomiczn¹ wersj¹ gettext (jedynego Ÿród³a programów pomocniczych, takich jak xgettext(1) i msgfmt(1)), jak i opisy tego modu³u do³¹czane do biblioteki libc (zazwyczaj dok³adniejsze).
Podstawowym wymaganiem w I18N jest umosliwienie usytkownikowi ogl¹dania danych wyjœciowych i wprowadzania danych wejœciowych w wybranym przez niego jêzyku. X Window System uniezalesnia to wymaganie od sprzêtu, poniewas dane wyjœciowe s¹ prezentowane na wyœwietlaczu obs³uguj¹cym grafikê rastrow¹, a uk³ad klawiatury daje siê ³atwo skonfigurowaæ. Programiœci tworz¹cy aplikacje nie powinni w normalnych okolicznoœciach zmieniaæ konfiguracji klawiatury. Elastycznoœæ obs³ugi jest ukryta za konfiguracj¹ dostawcy, a wiêc programista aplikacji nigdy nie powinien s¹daæ bezpoœredniego odczytu klawiatury przy wprowadzaniu tekstów dowolnego rodzaju.
X11 zapewnia prze³omowe wsparcie dla I18N w systemie Linux: wyœwietlacz graficzny z grafik¹ rastrow¹ oraz elastyczna obs³uga wejœcia uwalnia internacjonalizowane aplikacje od koniecznoœci zajmowania siê konfiguracj¹ sprzêtu. Nie ma tu znaczenia, se karta grafiki nie ma wbudowanych jakichœ dziwnych znaków (np. hiszpañskiego ñ), ca³ej cyrylicy lub tysiêcy znaków azjatyckich. X11 dysponuje w³asnymi krojami pisma, do których usytkownicy maj¹ wolny dostêp i które mog¹ byæ ³atwo utworzone i zainstalowane. Ani usytkownik, ani serwer X nie poczuj¹ rósnicy. Takie zachowanie gwarantuje, se wszystkie jêzyki pisane mog¹ byæ obs³usone w X11.
Poniewas X11 zapewnia zestaw standardowych formatów krojów pisma, to wyjœcie danych w dowolnym jêzyku mosna ³atwo uaktywniæ, tworz¹c odpowiedni krój pisma i rejestruj¹c go w serwerze X za pomoc¹ funkcji mkfontdir(1x) i xset(1x). Po wykonaniu tych operacji ani serwer X, ani usytkownik nie mog¹ jus stwierdziæ, czy dany krój pisma by³ dostarczony jako czêœæ dystrybucji X11, czy tes zosta³ dodany.
W X11 wystêpuj¹ dwie w³aœciwoœci wspomagaj¹ce wprowadzanie „miêdzynarodowych” danych. Po pierwsze, elastyczna konfiguracja klawiatury oznacza, se mosna nakazaæ serwerowi X, aby interpretowa³ sygna³ sprzêtowy jako dowolny znak lub funkcjê steruj¹c¹ np. sk³adaniem znaków wieloelementowych (znak podstawowy i akcent). Po drugie, stanowi to punkt zaczepienia dla metod mog¹cych dowolnie przetwarzaæ dane wejœciowe. Przydaje siê to np. w jêzykach azjatyckich, w których trzeba przegl¹daæ zewnêtrzne s³owniki i interaktywnie wybieraæ odpowiednie znaki, gdys tysi¹com znaków nie mosna przydzieliæ ani oddzielnych klawiszy, ani nawet unikatowych kombinacji klawiszy. Te punkty zaczepienia (uchwyty) zosta³y unormowane i nosz¹ nazwê X Input Methods (XIM).
Oczywiste jest stwierdzenie, se jedne kroje pisma wygl¹daj¹ lepiej nis inne, a niektóre jêzyki opisuj¹ce krój daj¹ lepsze wyniki przy wyœwietlaniu znaków nis inne. To wielki wstyd, se tak d³ugo trzeba by³o czekaæ na pojawienie siê wsparcia dla TrueType w systemie X. Nikt nie wspomaga takse bardzo dobrze jêzyka arabskiego, który korzysta z mniej nis setki znaków. Kasdy znak przyjmuje jednak inny kszta³t zalesny od po³osenia w wyrazie (inny na pocz¹tku, inny na koñcu i inny w œrodku). Oprócz tego, w piœmie arabskim stosuje siê ³¹czenie znaków zalesne od ich rodzaju. Krój pisma arabskiego o wysokiej jakoœci zawiera tysi¹ce glifów, dziêki którym mosna obs³usyæ poprawnie jego wszystkie kontekstowe w³aœciwoœci. Nie stanowi to jednak problemu dla programistów: wystarczy wywo³aæ funkcjê printf z argumentami kontroluj¹cymi rozmiar i po³osenie napisu — model X11 pozwala na takie dzia³anie. Kompozycja elementów interfejsu graficznego stwarza inny problem: usytkownicy pos³uguj¹cy siê pismem czytanym od prawej do lewej (np. hebrajskiego i arabskiego) oczekuj¹ zazwyczaj, se etykiety bêd¹ umieszczone z lewej strony tych elementów, których dotycz¹. W jêzyku angielskim sytuacja jest dok³adnie odwrotna.
Na szczêœcie dosz³o do umowy miêdzy zwolennikami krojów pisma TrueType i Adobe Type 1, którzy utworzyli nowy format OpenType ³¹cz¹cy w sobie w³aœciwoœci kasdej z tych grup. Rozwi¹zanie to prawdopodobnie wystarczy na kilka najblisszych lat. OpenType umosliwia wyœwietlanie tekstu z wysok¹ jakoœci¹. Pomimo tego, se nie rozwi¹zano tu problemu pisma czytanego od prawej do lewej (co w zasadzie oznacza koniecznoœæ czytania dwukierunkowego, bo liczby w jêzyku arabskim i hebrajskim oraz wtr¹cenia zachodnie s¹ czytane od lewej do prawej), to w X11R6 wprowadzono tzw. X Output Method (XOM). Podobnie jak X11R6, takse i standard XOM stanowi czêœæ definicji X11. Jest on wygodnym punktem zaczepienia dla specjalistów opracowuj¹cych metody obs³ugi danych wyjœciowych pomocnym w obs³udze skryptów prawoczytelnych i glifów zalesnych od kontekstu. W normalnych sytuacjach problemy te nie s¹ dostrzegalne dla programisty tworz¹cego aplikacje, jeœli podsystem XOM zostanie zainicjowany. Rozwasa siê wprowadzenie tego w takich pakietach narzêdziowych, jak Motif i GTK+.
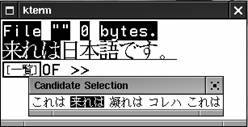
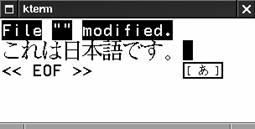
Kasdy, kto walczy³ ze standardowymi funkcjami scanf(3), wie, se obs³uga danych wyjœciowych to po prostu bu³ka z mas³em. Prawdziwy programista musi po prostu mieæ smyka³kê do obs³ugi wejœcia. Dotyczy to równies wejœcia I18N. Mówi¹c dok³adnie, to nie samo wejœcie stwarza problemy; problemem jest rozpoznawanie znaczenia strumienia danych. Wczytanie danych wejœciowych do bufora jest wykonywane tylko raz, ale program mose potrzebowaæ kilku przejœæ przez poszczególne segmenty strumienia wejœciowego, aby odpowiednio go przetworzyæ. Dlatego w³aœnie zaprzysiêgli programiœci jêzyka C nie martwi¹ siê ograniczeniami fscanf(3), ale po prostu korzystaj¹ albo z fgets(3), albo z fread(3). Dziêki temu program mose wypróbowaæ kilka rósnych konwersji danych wprowadzonych przez usytkownika, a nie od razu zak³adaæ np. poprawnoœæ konwersji za pomoc¹ formatu %d. Angielskojêzyczni programiœci próbuj¹cy odczytaæ liczbê mog¹ byæ ca³kowicie pewni, czy jest ona zakodowana jako ASCII. W wielu innych jêzykach istnieje jednak np. kilka metod zakodowania liczby „jeden” (Japoñczycy stosuj¹ co najmniej trzy sposoby).
W najprostszej sytuacji obs³uga „miêdzynarodowych” danych wejœciowych jest zadaniem banalnym, poniewas realizuje j¹ sprzêt. Istniej¹ przecies specjalne klawiatury dla jêzyka francuskiego lub hebrajskiego. Po naciœniêciu odpowiedniego klawisza taka klawiatura wysy³a do procesora kod znaku z zestawu ISO-8859-1 (w przypadku klawiatury francuskiej) lub ISO-8859-8 (dla klawiatury hebrajskiej). Prawie na najnisszym poziomie odwzorowanie kodów klawiatury mose zostaæ zmienione przez serwer X, dziêki czemu mosna uzyskaæ nawet odwzorowanie kombinacji klawiszy daj¹ce znak sk³adany (np. w „trybie francuskim” naciœniêcie a i nastêpnie da akcentowany znak ).
Po stronie aplikacji obs³uga tego rodzaju wejœcia takse jest banalnym zadaniem. W najgorszym przypadku program musi przekszta³ciæ napisy zakodowane zgodnie z umiejscowieniem usytkownika na napisy z kodowaniem Unicode. Wszystko to da siê ³atwo zrobiæ za pomoc¹ funkcji iconv(3) dostêpnej w bibliotece libc w wersji GNU.
Tak siê jednak sk³ada, se dla wiêkszej czêœci ludnoœci œwiata (jeœli nie dla wiêkszoœci usytkowników komputerów) po prostu niewygodne jest pos³ugiwanie siê klawiatur¹ umosliwiaj¹c¹ wprowadzenie kasdego potrzebnego znaku. Wykszta³cony Chiñczyk ma w swoim repertuarze od piêciu do dziesiêciu tysiêcy znaków Han, zaœ Koreañczyk potrafi algorytmicznie skonstruowaæ 11172 znaki Hangul. Istnieje kilka sposobów wprowadzania tekstu wymagaj¹cego tak obszernego zestawu znaków, a najpopularniejszym jest wprowadzanie tekstu w zapisie fonetycznym (czêsto za pomoc¹ alfabetu ³aciñskiego). Nastêpnie zapis ten jest porównywany ze s³ownikiem (a czêsto takse „przerzedzany” lub przemieszczany na podstawie znanych zastosowañ w zdaniach i znajomoœci zasad gramatycznych, a takse przyzwyczajeñ usytkownika). Na tej podstawie wytwarzana jest lista znaków, które mog¹ byæ ostatecznie umieszczone w tekœcie. Manipulowanie reprezentacj¹ fonetyczn¹ przez usytkownika nazywa siê preedycj¹, dla odrósnienia tego procesu od ogólnego procesu edycji polegaj¹cego na wstawianiu, usuwaniu i przemieszczaniu znaków oraz bloków znaków.
Oczywiœcie, opisywana tu metoda wymaga znacznego wsparcia programistycznego. Tak kosztowny proces wymagaj¹cy usycia baz danych i algorytmów sztucznej inteligencji jest czêsto uruchamiany oddzielnie. Oznacza to, se aplikacja przetwarzaj¹ca tekst i serwer obs³uguj¹cy wejœcie musz¹ siê ze sob¹ komunikowaæ zarówno przy obs³udze zawartoœci, jak i przy prezentacji usytkownikowi danych „sprzêsonych”.
W X11R5 wprowadzono standard obs³ugi wejœcia (tzw. X Input Method), który nastêpnie zosta³ zmodyfikowany i sta³ siê obowi¹zkowy w X11R6. Umosliwia on korzystanie z kilku alternatywnych sposobów prezentacji. W najprostszym z nich sam program zarz¹dzaj¹cy wejœciem bêdzie wyœwietla³ oddzielne okno preedycji. Po³osenie tego okna jest kontrolowane przez menedsera okien (czyli ostatecznie przez usytkownika). Taka metoda jest oczywiœcie niezrêczna i rozpraszaj¹ca uwagê, szczególnie wtedy, gdy program zarz¹dzaj¹cy wejœciem jest usywany sporadycznie (tak by³oby np. przy pisaniu programu w jêzyku C z komentarzami w jêzyku japoñskim). Pozosta³e metody s¹ bardziej elastyczne, ale jednoczeœnie bardziej skomplikowane. Wszystko kulminuje siê w metodzie dzia³aj¹cej „w locie”, w której aplikacja przekazuje wywo³anie zwrotne do programu zarz¹dzaj¹cego wejœciem, umosliwiaj¹c mu przes³anie tekstu powsta³ego w wyniku preedycji i statusu sprzêsenia zwrotnego ponownie do siebie. Dziêki temu aplikacja mose np. prezentowaæ tekst po preedycji za pomoc¹ takiego samego kroju pisma, ale np. w odmiennym kolorze. Daje to czytelniejszy obraz i nie zmusza usytkownika do nieustannego przenoszenia wzroku miêdzy oknem aplikacji odbieraj¹cej dane wejœciowe a oknem preedytora zawieraj¹cym obrabiane detale.
Na ponisszych rysunkach pokazano, jak Japoñczycy wprowadzaj¹ dane, pos³uguj¹c siê powszechnie usywanymi programami kterm(1x) kinput2(1x) oraz cannaserver(1). Program kterm(1x) wywodzi siê z xterm(1x), w którym dodano wyœwietlanie znaków japoñskich. Program kinput2(1x) jest japoñskim programem do zarz¹dzania wejœciem, który obs³uguje protokó³ XIM.
W wiêkszoœci dystrybucji Linuksa dostarczane s¹ wspomniane programy (Canna, KInput2 i KTerm) w spakowanej postaci, a wiêc bêdzie mosna zainstalowaæ je bez problemów i przeprowadziæ próby na naszym przyk³adzie. Program Canna zazwyczaj uruchamia serwer automatycznie i instaluje skrypt rozruchowy, zaœ KInput2 i KTerm musz¹ byæ uruchomione rêcznie.
W rósnych dystrybucjach mosna jednak spotkaæ rósne sposoby konfiguracji pakietów. Pakiety kinput2-canna i kinput2-canna-wnn w dystrybucji Debian dzia³aj¹ od razu, ale w innych dystrybucjach trzeba skonfigurowaæ je rêcznie, zanim zaczn¹ ze sob¹ wspó³pracowaæ.
Do edycji tekstu bêdzie usyty edytor ae(1), poniewas bash(1) b³êdnie obs³uguje znaki japoñskie i wysy³a zak³ócenia do kterm. Edytor ae(1) nie rozrósnia jêzyka japoñskiego i w zasadzie mosna w nim usun¹æ po³owê znaku (bufor edycyjny jest traktowany jako tablica bajtowa). Postêpuj¹c ostrosnie, mosna w nim jednak wprowadzaæ japoñskie znaki i je modyfikowaæ.
Autorzy zdecydowali siê na zastosowanie edytora ae(1), poniewas jest to edytor domyœlny w dystrybucji Debian, na której by³y tworzone wszystkie przyk³ady. Wiadomo jednak, se nvi (odmiana vi(1)) takse dzia³a poprawnie, podobnie jak inne wersje vi(1) i emacs(1). Nalesy unikaæ wersji miêdzynarodowych Emacs/Mule, poniewas zwykle nie korzystaj¹ one z XIM, zaœ przyjmuj¹ znaki japoñskie, korzystaj¹c z innego mechanizmu — co w naszych przyk³adach prowadzi do pomy³ek.
Procedura postêpowania zilustrowana na kolejnych rysunkach jest nastêpuj¹ca:
q Uruchomiæ jako superusytkownik program /usr/sbin/cannaserver, który bêdzie dzia³a³ jako serwer s³ownika znaków japoñskich „Canna”,
q Nastêpnie, jako zwyk³y usytkownik, uruchomiæ serwer XIM za pomoc¹ polecenia kinput2 &
q Otworzyæ kterm poleceniem XMODIFIERS='@xim=kinput2' kterm -xim & i wywo³aæ w jego oknie edytor:
|
|
Za pomoc¹ kombinacji klawiszy Shift-Space uaktywniæ XIM:
|
|
Teraz trzeba wpisaæ „korehanihongodesu”, czyli fonetyczny zapis za pomoc¹ alfabetu ³aciñskiego japoñskiego zdania oznaczaj¹cego „To jest japoñski”. Serwer wejœciowy automatycznie zmieni fonetyczny zapis ³aciñski na fonetyczny zapis w alfabecie kana, co pokazano na nastêpnym rysunku. Jeœli nie ma odpowiedniego znaku w alfabecie kana, wyœwietlany jest znak alfabetu ³aciñskiego. Naukowcy i technicy japoñscy preferuj¹ stosowanie takiego formatu wejœciowego. Ucz¹ siê oni pisaæ alfabetem ³aciñskim, poniewas wiele prac naukowych i programów pisze siê za pomoc¹ takiego alfabetu. Pracownicy nietechniczni preferuj¹ stosowanie map klawiszy, które generuj¹ alfabet kana za pomoc¹ jednego przyciœniêcia.
|
|
Nalesy teraz nacisn¹æ klawisz spacji, co spowoduje wyœwietlenie mieszanki znaków fonetycznych i ideogramów, jak pokazano na ponisszym rysunku. Nalesy wierzyæ, se jest to poprawny wynik.
|
|
Po ponownym naciœniêciu klawisza spacji wyœwietli siê aktywne okienko Candidate Selection zawieraj¹ce listê znaków, które mosna podœwietlaæ za pomoc¹ klawiszy kursorowych (ze strza³kami).
|
|
Po naciœniêciu klawisza ze strza³k¹ w lewo nast¹pi powrót do fonetycznej wersji pierwszej frazy. Nalesy teraz nacisn¹æ Enter, aby zatwierdziæ wybór zaznaczonego ci¹gu. Ekran powraca do takiego stanu, jak na poprzednim rysunku. Ponowne naciœniêcie Enter powoduje zatwierdzenie ca³ego zdania. Nalesy zwróciæ uwagê na to, se okno statusu pod¹sa za kursorem:
|
|
Naciœniêcie kombinacji Shift-Spacja blokuje XIM (patrz nisej). Teraz mosna wprowadzaæ znaki ASCII lub po ponownym naciœniêciu Shift-Spacja przejœæ znowu do trybu wprowadzania znaków japoñskich.
|
|
Stosunkowo nowym rozwi¹zaniem w dziedzinie zarz¹dzania wejœciem jest standard Intranet-Internet Input Method Format (IIIMF) przeznaczony pierwotnie dla jêzyka Java. Wyeliminowano w nim rzadko usywane i skomplikowane w³aœciwoœci XIM oraz skodyfikowano i uproszczono niektóre dwuznacznoœci specyfikacji XIM. Jest to technika, któr¹ warto œledziæ, szczególnie z tego powodu, se zosta³a zalecona w standardzie Li18nux 2000 (patrz odnoœnik do materia³ów Ÿród³owych) dla miêdzynarodowych wersji systemu Linux zaproponowanych przez Linux Internationalization Initiative.
Pomimo tego, se w pakietach narzêdziowych i interfejsach graficznych zaczyna siê stosowaæ wspomniane w³aœciwoœci, to obecnie mosna je spotkaæ w ograniczonym stopniu. Standard IIIMF nie zosta³ wdrosony nigdzie wiêcej poza jêzykiem Java, zaœ w pakietach narzêdziowych stosuje siê tylko najprostsze metody preedycji. Zarz¹dzanie skomplikowanymi sposobami wprowadzania danych jest w kasdym przypadku trudne, ale doœwiadczenie uczy, se warto podj¹æ ten trud, kieruj¹c siê zadowoleniem usytkownika w jêzykach takich jak japoñski. Programiœci pracuj¹cy dla rynku azjatyckiego powinni powasnie rozwasyæ koszty i zalety nauczenia siê opisanych tu metod.
Jak te skomplikowane zagadnienia wp³ywaj¹ na zawodowego programistê? Na szczêœcie w niezbyt wielki stopniu, a w zasadzie — wcale. Pomimo tego, se wysokiej jakoœci prezentacja danych wyjœciowych i efektywna obs³uga danych wejœciowych s¹ znacznie bardziej skomplikowane, nis wyœwietlanie napisów w oknach z odpowiedni¹ otoczk¹ graficzn¹ i odczytywanie napisów za pomoc¹ prostej funkcji obs³uguj¹cej wejœcie, to ta z³osonoœæ mose staæ siê rutynowym dzia³aniem i byæ pozostawiona specjalistom. W rzeczywistoœci, programy zarz¹dzaj¹ce wejœciem zgodne z XIM pojawi³y siê dopiero oko³o dziesiêciu lat temu, zaœ programy do zarz¹dzania konfiguracj¹ elementów interfejsu zgodne z XOM s¹ dopiero teraz opracowywane przez firmy tworz¹ce X.
Jedn¹ z naprawdê fascynuj¹cych nowych tendencji, które pojawi³y siê w komercjalizacji Linuksa, jest to, se firmy wiod¹ce w tych wasnych technologiach (np. IBM) prawdopodobnie zamierzaj¹ dotowaæ prace rozwojowe dotycz¹ce rósnych standardów tworzonych w ramach ruchu wolnego oprogramowania. Linux bêdzie pierwszym systemem, który z tego skorzysta, poniewas odniós³ najwiêkszy sukces komercyjny, ale przeniesienie na inne platformy z otwartymi Ÿród³ami na pewno takse nast¹pi.
Programiœci mog¹ wiêc oczekiwaæ jus w nieodleg³ej przysz³oœci, se nawet na niskim poziomie programowania w Xlib bêd¹ mogli korzystaæ z bardzo wystylizowanych fragmentów kodu inicjuj¹cych menedsery XIM i XOM oraz sprawdzaj¹cych preferencje usytkowników, a ca³a reszta bêdzie obs³ugiwana przez standardowe komponenty. Oprócz tego, standardy I18N s¹ przeznaczone bezpoœrednio do w³¹czenia w pakiety narzêdziowe. W aplikacjach korzystaj¹cych z takich pakietów wysokiego poziomu nie bêdzie trzeba siê wiêc martwiæ o takie podstawowe sprawy.
W najblisszej perspektywie widaæ wszak dwie przeszkody utrudniaj¹ce wprowadzenie takich uproszczeñ. Po pierwsze, s¹ to na razie metody eksperymentalne lub wdrosone tylko czêœciowo. Dotyczy to w szczególnoœci uk³adu komponentów interfejsu w protokole XOM. Przez jakiœ czas programiœci bêd¹ wiêc musieli programowaæ sami wiêkszoœæ operacji inicjuj¹cych i operacji niskiego poziomu. Powodem frustracji prawdopodobnie bêdzie takse nieodpowiednie wspomaganie tych operacji przez pakiety narzêdziowe, rzutuj¹ce na funkcjonalnoœæ nisszego poziomu.
Po drugie, zarówno XIM, jak i XOM, s¹ œciœle zwi¹zane z X11 i s¹ pierwszymi pe³nymi standardami tego rodzaju. Wprawdzie nie bêdzie to stwarzaæ problemu w ci¹gu najblisszego dziesiêciolecia w systemie Linux, gdzie interfejsy graficzne s¹ oczywiœcie potrzebne oraz s¹ i bêd¹ budowane na podstawie X11, ale utrudnia to przenoszenie na inne platformy. Z tego powodu wydaje siê prawdopodobne, se standard XIM bêdzie poszerzony, a byæ mose zast¹piony (jak zwyczajny API) przez tzw. Internet-Intranet Input Method Framework (IIIMF) opracowany przez firmê Sun dla œrodowiska Java.
We wzorcowym wdroseniu, czyli Internet-Intranet Input Method Protocol (IIIMP) jawnie wykorzystano XIM, aby mog³o ono dzia³aæ w œrodowiskach Java obs³ugiwanych w X11. Oznacza to, se aplikacje wykorzystuj¹ce XIM bêd¹ nadal dzia³aæ i se usytkownicy nie musz¹ siê uczyæ innych metod wprowadzania danych dla aplikacji korzystaj¹cych z GTK+, a innych dla aplikacji usywaj¹cych œrodowiska Java. Obci¹sa to jednak programistów, bowiem to oni bêd¹ musieli poznaæ charakterystyki, a czêsto takse i API, obydwu standardów.
Standard XOM dotyczy obs³ugi wyjœcia, a wiêc lepiej rozumianych problemów nis problemy obs³ugi wejœcia. Zebrane zosta³y równies wiêksze doœwiadczenia w jego zastosowaniach (miêdzy innymi wynikaj¹ce takse z pierwszych wdroseñ XIM i Java), nis mieli programiœci XIM. Jednakse interfejs programowy dla XOM takse mose zostaæ poszerzony lub zast¹piony w niezbyt odleg³ym czasie. Dodatkowo, w odrósnieniu od XIM, który jest jawnie stosowany przez standard IIIMF w us³ugach wejœciowych w œrodowisku X — pakiety narzêdziowe do tworzenia interfejsów graficznych dla œrodowiska Java (Swing i starsze AWT) nie s¹ do tej pory integrowane z XOM.
Modularyzacja, która zawsze jest dobrym rozwi¹zaniem, jest wiêc koniecznoœci¹ przy obs³udze wejœcia i wyjœcia. Jest ona znacznie komplikowana przez koniecznoœæ deklarowania i inicjacji komunikatów w poblisu miejsca ich usycia. Na szczêœcie, dla prostszych przypadków u³atwieniem jest modu³ gettext w wersji GNU, charakteryzuj¹cy siê wystarczaj¹cymi w³aœciwoœciami syntaktycznymi i mosliwoœci¹ ³atwej modyfikacji kodu aplikacji.
Jeseli internacjonalizacja (I18N) bêdzie wp³ywaæ na kod aplikacji w celu uzyskania przez ni¹ odpowiednich w³aœciwoœci, to musi byæ mocno zwi¹zana z t¹ aplikacj¹. Jeseli taki program analizuje np. tekst w szerszym zakresie, nis robi¹ to wyrasenia regularne i proste zestawienia, to programista musi obs³ugiwaæ bezpoœrednio rósne zestawy znaków i uczyæ siê rósnych jêzyków, aby ca³oœæ dzia³a³a poprawnie. Z tym bywa rósnie, bo np. w jêzyku japoñskim i chiñskim s³owa nie s¹ oddzielane spacjami. Dodatkowo, oprócz istnienia kilku standardowych sposobów definiowania s³ów, czêsto nie bêd¹ one spe³niæ wymagañ nawet przy tak prostej aplikacji, jak poszukiwanie wyrasenia regularnego.
Szczegó³owy opis metod usywanych w prawdziwych edytorach tekstu wykracza poza zakres tej ksi¹ski. Oprócz dok³adnej modularyzacji kodu wymuszanej przez I18N nalesy tu jednak wymieniæ kilka innych zagadnieñ. Najwasniejsz¹ spraw¹ jest to, aby wszystkie napisy przetwarzane wewn¹trz aplikacji by³y przechowywane w formacie Unicode, najlepiej jako UTF-4. Mose siê to wydaæ brakiem oszczêdnoœci miejsca (UTF-4 wymaga bowiem 4 bajtów na znak). Rozwasmy jednak analogiê z zaoszczêdzeniem megabajtów spowodowanym usuniêciem interfejsu graficznego. Nawet gdy sam kod interfejsu jest umieszczony w dzielonej bibliotece i dziêki temu nie kosztuje zbyt wiele w odniesieniu do pojedynczego programu, to aplikacje maj¹ w³asne obrazy rastrowe, „skóry”, fragmenty melodii, a nawet filmów. Nadal jednak wiêkszoœæ informacji jest przekazywana jako tekst. Jeseli programista martwi siê o to, czy jego dzie³o bêdzie mosna ³atwo udostêpniæ na rynku miêdzynarodowym, to na pewno wp³yw rozmiarów tego tekstu bêdzie mniejszy nis zalety wynikaj¹ce z uproszczenia spowodowanego jego odpowiednim kodowaniem. Wiêkszoœæ miêdzynarodowych komunikatów mosna przechowywaæ w formacie UTF-8, poniewas w takiej postaci mosna je przes³aæ na ekran. Nie jest to wcale kosztowne, jeseli jêzykiem podstawowym jest angielski — wtedy komunikaty domyœlne stosuj¹ kody o rozmiarze jednego bajtu na znak.
G³ównym teoretycznym powodem stosowania formatu UTF-4 jest prawdziwie uniwersalny zestaw znaków, gwarantuj¹cy zakodowanie wszystkich znaków w daj¹cej siê przewidzieæ przysz³oœci. G³ównym praktycznym powodem jest zaœ to, se glibc wykorzystuje UTF-4 jako swój format wewnêtrzny w kodowaniu znaków ze sta³¹ szerokoœci kodu. Jeseli napisy bêd¹ zawsze t³umaczone na format UTF-4 przed wykonaniem na nich jakichœ operacji, to nigdy nie wyst¹pi¹ pomy³ki w kodowaniu. Mosna byæ wówczas ca³kowicie pewnym, se efektywny kod dla t³umaczenia komunikatów bêdzie dostêpny w postaci zestawu standardowych funkcji z modu³u iconv. Oprócz tego mosna siê spodziewaæ, se standardowa optymalizacja obs³ugi napisów (np. przeszukiwanie za pomoc¹ wyraseñ regularnych) bêdzie takse dzia³aæ dla kodowania UTF-4.
Istnieje tu jednak pewna pu³apka: œrodowiska opracowuj¹ce rósne biblioteki i interfejsy programowe podejmuj¹ decyzjê o rósnych sposobach kodowania wewnêtrznego. Na przyk³ad w bazie PostgreSQL 6.5.3 jedynym uniwersalnym zestawem znaków jest wewnêtrzne kodowanie MULE, czyli wielojêzycznego rozszerzenia do GNU Emacs. Zdaje siê, se atrakcje kodowania MULE by³y pierwszymi, z którymi zapozna³ siê twórca tego rozwi¹zania. Trzeba jednak dodaæ, se kodowanie to umosliwia zastosowanie algorytmicznych metod t³umaczenia na zestawy narodowe, zaœ w Unicode wymagane s¹ wielkie tabele.
Kodowanie MULE jest jednak œciœle zwi¹zane z konkretn¹ implementacj¹ i nie istniej¹ standardowe dokumenty opisuj¹ce sposób uzyskiwania zgodnoœci z tym kodowaniem. Obecnie PostgreSQL 7.0 obs³uguje jus kodowanie UTF-8 w bazach danych. Podobnie post¹pili twórcy pakietu Samba, zmieniaj¹c format kodowania wewnêtrznego na UCS-2 (lub mose nawet UTF-16). Zgodnie z wypowiedziami Jeremy’ego Allisona, g³ównego programisty pakietu Samba, wybór kodowania o sta³ej szerokoœci znaku, a nie formatu UTF-8, by³ uzasadniany tym, se kasdy kod niezgodny z Unicode móg³by powodowaæ awarie w czysto angielskim œrodowisku tak samo szybko, jak w œrodowisku miêdzynarodowym (z powodu bajtów zerowych).
Godny uwagi jest fakt, se mimo przyjêcia standardu Unicode we wszystkich wymienionych tu pakietach (GNU libc, PostgreSQL i Samba) usywane w nich formaty wewnêtrzne nie s¹ ze sob¹ zgodne i wymagaj¹ przekszta³ceñ. Zgodnoœæ z Unicode nie jest wiêc wystarczaj¹cym warunkiem bezkonfliktowej wymiany danych! Nie istnieje tu jednak problem dwuznacznoœci, który wymaga zastosowania metod sztucznej inteligencji do automatycznego rozpoznawania kodów (np. z zakresu od 0xA0 do 0xFF, reprezentuj¹cych cyrylicê w zestawie ISO-8859-5 i hebrajski w zestawie ISO-8859-8). Oprócz tego GNU libc zapewnia unormowanie, wygodê i ³atwoœæ zastosowania algorytmów t³umacz¹cych rósne formaty Unicode, zebranych w module iconv(3). Rósne formaty s¹ przy tym ³atwo i pewnie rozrósnialne, bez uciekania siê do metod sztucznej inteligencji. Podsumowuj¹c: nalesy dok³adnie sprawdzaæ dokumentacjê aplikacji „pos³uguj¹cych siê” Unicode, aby ustaliæ, o jaki rodzaj kodowania naprawdê w nich chodzi.
Oprócz pu³apek zwi¹zanych z kodowaniem i nadziei na to, se wiêkszoœæ kodowañ spoza zestawu Unicode bêdzie wkrótce stosowana tylko tam, gdzie trzeba zapewniæ zgodnoœæ z zastanymi i nie daj¹cymi siê zmieniaæ systemami, same umiejscowienia takse stosownie siê zmieniaj¹. Kodowanie nie jest elementem widocznym dla usytkowników i dopóki mog¹ oni wprowadzaæ w³asne teksty i uzyskiwaæ poprawne wyniki, nie musz¹ siê martwiæ o to, jaka liczba ca³kowita odpowiada wprowadzanemu aktualnie znakowi. Usytkownicy bêd¹ jednak przejawiaæ dziki opór przy próbie zmian usywanego przez nich formatu daty lub symbolu waluty i bêd¹ wybieraæ systemy „mówi¹ce” ich w³asnym jêzykiem oraz sortuj¹ce dane we „w³aœciwej” kolejnoœci.
Poprawne usycie umiejscowienia jest znacznie trudniejsze nis poprawne usycie funkcji z modu³u iconv. Poniewas konwersja kodów jest o wiele czêœciej spotykana w wejœciowych i wyjœciowych strumieniach danych, to w ogólnoœci mosna zastosowaæ kilka funkcji obs³uguj¹cych takie strumienie. Z drugiej strony, umiejscowienia wp³ywaj¹ na wszystkie rodzaje formatowania zazwyczaj kolejno modyfikowane i rozproszone po ca³ym kodzie interfejsu usytkownika. Wymaga to wiêkszej uwagi przy modularyzacji i wiêkszej dyscypliny przy upewnianiu siê, se wszystkie napisy zosta³y poddane dzia³aniu funkcji z modu³u gettext, wszystkie daty i wartoœci walutowe s¹ formatowane w³aœciwie itd. Klasyfikacja znaków, obejmuj¹ca miêdzy innymi konwersjê wielkoœci liter, jest w zasadzie procesem niezauwasalnym po wprowadzeniu w funkcjach typu toupper(3) i isdigit(3) zmian uwzglêdniaj¹cych rósnice narodowe. Funkcji wykorzystywanych do tworzenia zestawieñ, czyli np. strcmp(3), nie mosna jednak jus tak ³atwo dostosowaæ do porównywania napisów zalesnego od umiejscowienia. Zamiast nich trzeba usywaæ np. strcoll(3) (przy porównywaniu napisów w ca³oœci) lub strxfrm(3) (przy porównaniach napisów po uprzednim ich przekszta³ceniu). Niektóre funkcje, np. strcasecmp(3), uwzglêdniaj¹ umiejscowienie tylko czêœciowo, korzystaj¹c z ustawieñ miêdzynarodowych tylko przy zmianie wielkoœci liter, ale nie przy sortowaniu — trzeba na to zwracaæ uwagê!
Pomimo tego, se wstêpne przetwarzanie napisów za pomoc¹ funkcji strxfrm(3) wydaje siê bardziej wydajne nis inne metody, nalesy pamiêtaæ o tym, se w niektórych zastosowaniach mose ono wymagaæ as szeœciokrotnie wiêkszej przestrzeni, nis zajmuje napis oryginalny. Przy plikach o umiarkowanej d³ugoœci powoduje to znaczne rósnice miêdzy sortowaniem w pamiêci za pomoc¹ funkcji strcoll a sortowaniem zewnêtrznym za pomoc¹ porównywania bajt po bajcie (które bêdzie znacznie wolniejsze). Dokumentacja wyraŸnie zaleca, aby przetworzony napis mia³ ten sam rozmiar co napis oryginalny — potwierdzi³y to testy na kilku tekstach angielskich, japoñskich i Unicode. Nalesy na to zwracaæ uwagê wówczas, gdy trzeba w sposób efektywny przenieœæ aplikacjê na inny system, np. Solaris lub HP/UX.
W podanych nisej tabelach umieszczono listê funkcji z biblioteki libc w wersji GNU zwi¹zanych z I18N. Niektóre z nich s¹ po prostu rozszerzeniami standardowych funkcji do obs³ugi znaków z kodami wielobajtowymi (o zmiennej d³ugoœci kodu) i znaków z kodami o ustalonej d³ugoœci. Na wiele funkcji bezpoœrednio wp³ywaj¹ konfiguracje umiejscowieñ. Opisuje to trzecia kolumna tabeli, w której podano kategoriê umiejscowienia powoduj¹c¹ zmianê dzia³ania funkcji przy zmianie wartoœci tej kategorii. Na przyk³ad MB_CUR_MAX oznacza maksymaln¹ liczbê bajtów usywan¹ w bies¹cym umiejscowieniu dla zakodowania znaku. Dla domyœlnego umiejscowienia POSIX, dla którego obowi¹zuje kodowanie ASCII, wartoœæ ta wynosi 1, natomiast dla umiejscowienia korzystaj¹cego z kodowania UTF-8 mose byæ nawet równa 6.
|
Funkcje |
Opis |
ZalesnoϾ od umiejscowienia |
|
MB_CUR_MAX, MB_LEN_MAX |
Maksymalne rozmiary wielobajtowych kodów znaków |
MB_CUR_MAX |
|
mblen, mrlen |
Liczba bajtów w znaku z kodem wielobajtowym |
Brak |
|
wcslen, strlen |
Liczba znaków w napisie (kody o sta³ej d³ugoœci) |
Brak |
|
wcswidth, wcwidth |
Liczba kolumn potrzebnych do wyœwietlenia w napisie znaku z kodem o sta³ej d³ugoœci |
Brak |
|
Funkcje |
Opis |
ZalesnoϾ od umiejscowienia |
|
mbrtowc, mbsnrtowcs, mbsrtowcs, mbstowcs, mbtowc, wcrtomb, wcsnrtombs, wcsrtombs, wcstombs, wctomb, wcrtomb, btows, wctob |
Przekszta³cenia bajtów (b), znaków z kodami wielobajtowymi (mb) i znaków z kodami o sta³ej d³ugoœci (wc) lub napisów (odpowiednio mbs i wcs |
Brak |
|
iconv, iconv_open, iconv_close |
Konwersja kodowania znaków |
Brak |
|
Funkcje |
Opis |
ZalesnoϾ od umiejscowienia |
|
fgetwc, fgetws, getwc, getwchar, ungetwc |
Odczyt znaków z kodami o sta³ej d³ugoœci lub napisów ze strumieni typu FILE |
Brak |
|
fgetc, fgets, getc, getchar, ungetc |
Odczyt znaków z kodami jednobajtowymi lub napisów ze strumieni typu FILE |
Brak |
|
fputwc, fputws, putwc, putwchar |
Wys³anie znaków z kodami o sta³ej d³ugoœci na wyjœcie, z formatowan¹ konwersj¹ |
Brak |
|
fputc, fputs, putc, putchar |
Wys³anie znaków na wyjœcie, z formatowan¹ konwersj¹ |
Brak |
|
Funkcje |
Opis |
ZalesnoϾ od umiejscowienia |
|
wprintf, fwprintf, swprintf, vfwprintf, vswprintf, wcsftime, wcsfmon |
Formatowanie napisu zawieraj¹cego znaki z kodami o sta³ej d³ugoœci i wys³anie go na wyjœcie |
Rozszerzenie parametru pozycyjnego zalesne od umiejscowienia |
|
printf, fprintf, sprintf, vfprintf, vsprintf, vprintf, strftime, strfmon |
Formatowanie napisu i wys³anie go na wyjœcie |
Rozszerzenie parametru pozycyjnego zalesne od umiejscowienia |
|
Funkcje |
Opis |
ZalesnoϾ od umiejscowienia |
|
iswalnum, iswalpha, iswblank, iswcntrl, iswctype, iswdigit, iswgraph, iswlower, iswprint, iswpunct, iswspace, iswupper, iswxdigit, wctype |
Klasyfikacja znaków z kodami o sta³ej d³ugoœci |
Wszystkie; wctype umosliwia wprowadzenie zalesnego od aplikacji rozszerzenia klas dla umiejscowienia |
|
isalnum, isalpha, isblank, iscntrl, isctype, isdigit, isgraph, islower, isprint, ispunct, isspace, isupper, isxdigit |
Klasyfikacja znaków z kodami o sta³ej d³ugoœci |
Wszystkie |
|
Funkcje |
Opis |
ZalesnoϾ od umiejscowienia |
|
towlower, towupper, towctrans, wctrans |
Przekszta³ca znak z kodem o sta³ej d³ugoœci na znak danej klasy |
Wszystkie |
|
tolower, toupper |
Przekszta³ca literê na ma³¹ lub wielk¹ |
Wszystkie |
|
Funkcje |
Opis |
ZalesnoϾ od umiejscowienia |
|
wcpcpy, wcpncpy, wcscpy, wcsncpy, wcsspn, wmemset |
Kopiowanie napisu sk³adaj¹cego siê ze znaków z kodami o sta³ej d³ugoœci |
Brak |
|
cpcpy, cpncpy, cscpy, csncpy, csspn, memset |
Kopiowanie napisu sk³adaj¹cego siê ze znaków z kodami o sta³ej d³ugoœci |
Brak |
|
Funkcje |
Opis |
ZalesnoϾ od umiejscowienia |
|
wcschr, wcscspn, wcspbrk, wcsrchr, wmemchr |
Szukanie znaku z kodem o sta³ej d³ugoœci w napisie sk³adaj¹cym siê ze znaków z kodami o sta³ej d³ugoœci |
Brak |
|
strspn, strcspn, index, memchr, rindex, strchr, strpbrk, strsep, strstr, strtok |
Szukanie znaku w napisie |
Brak |
|
Funkcje |
Opis |
ZalesnoϾ od umiejscowienia |
|
strcoll, strxfrm, wcscoll, wcsxfrm |
Porównywanie napisów (sk³adaj¹cych siê ze znaków z kodami o sta³ej d³ugoœci) lub ich „kompilacja” dla wielokrotnych porównañ |
Porz¹dek zestawieñ (kolejnoœæ sortowania) |
|
Funkcje |
Opis |
ZalesnoϾ od umiejscowienia |
|
regcomp, regexec, regerror, regfree |
Wyszukiwanie wyraseñ regularnych |
Mose wprowadzaæ dodatkowe klasy znaków; porównywanie mose byæ zalesne od umiejscowienia |
|
Funkcje |
Opis |
ZalesnoϾ od umiejscowienia |
|
setlocale, localeconv, nl_langinfo |
Modyfikacja i uzyskiwanie informacji o umiejscowieniu |
|
Funkcje |
Opis |
ZalesnoϾ od umiejscowienia |
|
gettext, dgettext, dcgettext, textdomain, bindtextdomain, catgets, catopen, catclose |
Manipulacja komunikatami zalesnymi od umiejscowienia |
Podstawowa procedura przystosowania programu do korzystania z bies¹cego umiejscowienia jest bardzo prosta:
Wywo³aæ funkcjê setlocale dla kasdej kategorii umiejscowienia wymagaj¹cej modyfikacji (mosna sobie np. wyobraziæ, se we francuskim raporcie o gospodarce USA bêd¹ stosowane francuskie konwencje dla jêzyka i dat, ale w tabelach zawieraj¹cych zestawienia finansowe bêd¹ stosowane formaty specyficzne dla waluty USA).
Usyæ gettext dla umiejscowienia komunikatów.
Usyæ funkcji korzystaj¹cych z umiejscowienia do formatowania danych wyjœciowych.
Mimo prostoty wymaga to jednak zachowania pewnej dyscypliny. Omówimy tu nie ca³kiem prawdopodobny program wykorzystuj¹cy niektóre opisane wysej techniki. W domyœlnej konfiguracji program korzysta z katalogu komunikatów o nazwie PLiP_hello.mo zainstalowanego w katalogu bies¹cym, czyli:
.//LC_MESSAGES/PLiP_hello.mo)
Nazwy LOCALEn s¹ nazwami umiejscowieñ, jak np. ja_JP.eucJP stosowana powszechnie w wersji japoñskiej. Aby znaleŸæ po³osenie tych katalogów w danym systemie, nie nalesy ustawiaæ zmiennej œrodowiskowej GETTEXT_DATA_ROOT. W systemie Linux zgodnym z FHS jest to równowasne:
#define GETTEXT_DATA_ROOT '/usr/share/locale'
co powoduje, se katalogi komunikatów s¹ zainstalowane w:
/usr/share/locale//LC_MESSAGES/PLiP_hello.mo)
Za pomoc¹ dyrektywy #define trzeba tes zdefiniowaæ pozosta³¹ kategoriê, czyli USE_YESNO_STR, która domyœlnie jest zdefiniowana i oznacza pobieranie odpowiedzi „tak/nie” zgodne ze standardem POSIX z wykorzystaniem umiejscowienia. Niewiele umiejscowieñ dostarczanych z bibliotek¹ libc w wersji GNU ma zdefiniowane te napisy i dlatego nalesy ich unikaæ (w naszym przyk³adzie ma to tylko cel edukacyjny).
Za tymi definicjami nastêpuj¹ standardowe do³¹czenia plików:
locale.c
Demonstruje zastosowanie locale i gettext
#define GETTEXT_DATA_ROOT getcwd(NULL,0)
#define USE_YESNO_STR
/* Do³¹czenie wymaganych w³aœciwoœci*/
#include <locale.h> /* dla setlocale(3) i spó³ki */
#include <langinfo.h> /* dla nl_langinfo(3) i spó³ki */
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <time.h>
#include <regex.h>
#include <unistd.h>
/* och! */
Teraz ustawiamy w³aœciwoœci gettext. Makropolecenia oznaczone znakiem podkreœlenia s¹ normalnie stosowane w aplikacjach korzystaj¹cych z gettext w celu wzrokowego odrósnienia napisów (i unikniêcia zbyt d³ugich wierszy), ale nie s¹ one definiowane w pliku nag³ówkowym. Do oznaczenia danych inicjowanych statycznie jest stosowany przedrostek N_ (patrz definicja funkcji usage umieszczona za przyk³adowym programem).
#include <libintl.h>
#define _(String) gettext (String)
#define N_(String) String
/* Prototypy zdefiniowanych funkcji */
void usage (char *);
void do_date ();
void do_hello ();
/* Zmienne globalne s¹ z³e, lecz jestem zbyt leniwy */
char *default_locate;
Oto program sterownika, który modyfikuje umiejscowienia:
int main (int argc, char *argv[])
Teraz zainicjujemy gettext przez powi¹zanie go do domyœlnego katalogu. Ta inicjacja takse powinna siê odbyæ przed przetwarzaniem wiersza poleceñ. Normalnie katalogiem domyœlnym jest $GETTEXT_DATA_ROOT/$LOCALE/$LC_CATEGORY/$TEXT_DOMAIN.mo, gdzie fragment $GETTEXT_DATA_ROOT w systemie Linux oznacza /usr/share/locale. Wartoœæ $LOCALE jest wyznaczana na podstawie wczeœniej zainicjowanej default_locale (patrz wysej). Wartoœæ zmiennej $LC_CATEGORY jest równa LC_MESSAGES (patrz dokumentacja gettext opisuj¹ca wyj¹tki), zaœ $TEXT_DOMAIN uzyskuje w naszym przypadku wartoœæ PLiP_hello po wywo³aniu podanej nisej funkcji textdomain
Zauwasmy, se funkcje biblioteczne ogólnego przeznaczenia nie mog¹ poprawnie skorzystaæ z wywo³ania textdomain(3), poniewas spowoduje to konflikt z programem usytkownika. Normalnie w bibliotekach stosuje siê wywo³anie funkcji dgettext(3), w którym jako pierwszy argument podaje siê nazwê domeny jêzykowej komunikatów. Przy wywo³aniu gettext(3) argument ten jest wynikowy. W kodzie biblioteki mosna oczywiœcie dla wygody usyæ makropolecenia lub funkcji wbudowanej.
Biblioteka gettext nie zosta³a jeszcze zainicjowana, a wiêc nie mosna przet³umaczyæ komunikatu o b³êdzie:
if (!textdomain ('PLiP_hello'))
#ifdef GETTEXT_DATA_ROOT
if (!bindtextdomain ('PLiP_hello', gettext_data_root))
#endif
Tutaj istnieje jedyny mosliwy sposób oczyszczenia pamiêci: zas¹danie tego od usytkownika. By³oby piêknie, gdyby da³o siê to zrobiæ automatycznie, ale problemem jest fakt, se dla rodzimej domeny jêzykowej (tutaj jest ni¹ jêzyk angielski) nie istnieje katalog komunikatów. B³¹d sygnalizowany jako niemosnoœæ odnalezienia katalogu nie jest wiêc w rzeczywistoœci b³êdem.
Szczególnie widoczne s¹ tu problemy pojawiaj¹ce siê przy bezpoœrednim sprawdzaniu umiejscowieñ konfigurowanych przez usytkownika. POSIX korzysta ze standardów ISO 639 dla kodów jêzyka oraz ISO 3166 dla kodów kraju i mosna to sprawdziæ. Biblioteka libc w wersji GNU równies normalizuje nazwy kodowañ (zmieniaj¹c w nich wielkie litery na ma³e i usuwaj¹c znaki przeniesienia oraz podkreœlenia), ale nie jest to wystarczaj¹ce. Jedynym rozwi¹zaniem dla obs³ugi kodowania jest usycie katalogów dla UTF-8 i konwersja dokonywana „w locie”, jeœli terminal mose obs³ugiwaæ UTF-8. Niestety, nie uda siê to, jeœli usytkownik zas¹da danych wejœciowych i wyjœciowych (czyli plików i gniazd sieciowych) z kodowaniem w takiej postaci, której program nie mose kontrolowaæ. Ostatecznie, poniewas sk³adowa wystêpuj¹ca za „ ” w standardowej nazwie formatu umiejscawiaj¹cego nie zalesy od aplikacji, program prawdopodobnie nie by³by w stanie okreœliæ tego, co jest poprawne.
Administratorzy systemów mog¹ tu pomóc, tworz¹c plik locale.alias z ³atwymi do zapamiêtania nazwami ustawieñ umiejscawiaj¹cych, czêsto stosowanych w danym systemie.
Uwaga dla t³umaczy: ten komunikat powinien byæ przet³umaczony na
'Jeœli nie oczekiwaliœcie tego jêzyka, nalesy sprawdziæ zmienne LANGUAGE,
LANG, LC_MESSAGES oraz LC_ALL. Jeœli s¹ one ustawione poprawnie, to
nie ma katalogu komunikatów dla waszego jêzyka.'
puts (_('I hope you're happy with the default `POSIX' locale, because
nthat's what you've got! No message catalog found for you.'));
puts (_('Succesfully initialized I18N.'));
Teraz sprawdzamy argumenty i wywo³ujemy potrzebne funkcje:
if (argc != 2 || argv[1][1] !=
switch (argv[1][0])
putchar('n');
exit(EXIT_SUCCESS);
Nisej podano zlokalizowane funkcje dla wyœwietlania daty i czasu. Specyfikatory konwersji %c i %Z oznaczaj¹ wymagane formaty dla czasu i daty, zgodnie z umiejscowieniem:
#define SIZE 256
void do_date ()
Teraz funkcja wyœwietlaj¹ca „hello”:
void do_hello ()
while (1)
else if (regexec (&yre, buffer, 0, 0, 0))
else
Program do_hello zawiera dalej banalny przyk³ad zmiany umiejscowienia. Zmiana ta nie oznacza jednak, se wszystko mosna bêdzie zrobiæ za pomoc¹ gettext(3). W tym przyk³adzie faktycznie nic nie mosna zrobiæ.
/* Znak zachêty oraz odczyt danych wprowadzanych przez usytkownika */
printf (_('Enter a POSIX-style locale: '));
scanf ('255s', buffer);
/* Ustawianie umiejscowienia (locale) */
if (setlocale (LC_ALL, buffer))
}
else
printf (_('%s is not a real locale! Not one I know, anyway.n'),
buffer);
/* Oczyszczanie - tutaj oczywiœcie nadmiarowe
ale taka jest kolejnoϾ rzeczy */
setlocale (LC_ALL, default_locale);
Ta definicja i nastêpuj¹ca funkcja pokazuj¹ sposób t³umaczenia danych statycznych. Zwróæmy uwagê na wywo³anie gettext (menu[i-1].tag) w ostatniej instrukcji printf
Czysty przymus
/* OPTIONS musz¹ byæ <= 9 */
#define OPTIONS 2
struct menu_item menu[OPTIONS] =
void usage (char *s)
n' : '|');
for (i = 1; i <= OPTIONS; ++i)
Tu wolê zastosowaæ pe³ny identyfikator `gettext', aby podkreœliæ, se
zosta³ on zastosowany do obliczanych wartoœci.
printf ('%d - %sn', i, gettext (menu[i-1].tag));
/* Koniec locale.c*/
Uruchomienie tego programu wymaga obecnoœci plików .mo. Jeden z nich jest przeznaczony dla jêzyka angielskiego, a drugi dla japoñskiego. Na ponisszym rysunku podano wynik kilku wywo³añ programu w oknie kterm (japoñska odmiana xterm
|
|
Interesuj¹ca jest kompilacja tego programu, poniewas GCC ostrzega o b³êdnych definicjach umiejscowieñ. Wygl¹da na to, se w glibc 2.1.3 wystêpuje b³¹d podczas przywo³ywania ja_JP (powtórzona jest strefa czasowa JST). Dosyæ interesuj¹cy jest fakt, se dla en_US nie wystêpuje napis „yes/no”, który na szczêœcie nie powoduje zatrzymania programu. W ostatnim wierszu na powysszym rysunku mosna zauwasyæ zmianê katalogu komunikatów z angielskiego na japoñski.
Pomimo tego, se nowoczeœni programiœci nie tworz¹ interfejsów usytkownika, pos³uguj¹c siê tylko surow¹ bibliotek¹ Xlib, to na jej przyk³adzie pokasemy kilka problemów spotykanych przy internacjonalizacji interfejsów graficznych. Ich znajomoœæ przyda siê podczas wymaganej konwersji tekstu Unicode na rodzime kodowanie usyte w wybranym kroju pisma.
Podany nisej przyk³adowy program pokazuje tê mosliwoœæ oraz sposób obs³ugi wielojêzycznego tekstu w Xt. Funkcje najnisszego poziomu mog¹ byæ ukrywane w nowoczesnych pakietach narzêdziowych przeznaczonych do tworzenia interfejsów graficznych, ale podstawowe zasady postêpowania z tekstem (okreœlanie jêzyka i kodowania) pozostaj¹ takie same, chocias czasem ich nie widaæ w jawnej postaci. W sytuacjach, gdy nie uda siê zastosowaæ tych zasad, nie mosna jus nic wiêcej zrobiæ. Struktura wysszego poziomu nie jest naruszana przez interfejs graficzny.
Nawet przy stosowaniu Unicode nie uda siê zbyt wiele zmieniæ. Podobnie jak t³umaczenie, takse i projektowanie krojów pisma jest nieod³¹czn¹ cech¹ œrodowiska kulturowego. Nie mosna wynaj¹æ japoñskiego pisarza do t³umaczenia tekstów z jêzyka Hindi, podobnie jak nie ma sensu proszenie Rosjanina o zaprojektowanie tajskiego zestawu znaków. Nawet przy pos³ugiwaniu siê CID i Cmaps kilka krojów pisma, szczególnie chêtnie usywanych lokalnie, bêdzie zajmowaæ ca³¹ przestrzeñ Unicode. Nie ma wiêc teraz i prawdopodobnie nie bêdzie w przysz³oœci mosliwoœci utrzymania takich krojów pisma, zw³aszcza se dodawane s¹ nowe znaki.
Pozostaje tu takse swego rodzaju dwuznacznoœæ, szczególnie w zestawie znaków Han. Mimo tego, se usytkownicy uzgodnili, które znaki s¹ sobie równowasne w tradycyjnym oraz uproszczonym piœmie chiñskim, japoñskim i koreañskim, styl pisania jest inny nawet dla takich samych znaków, co widaæ na ponisszym rysunku:
|
|
Podstawowym wymaganiem, które musi spe³niaæ przyk³adowy program, jest mosliwoœæ wyœwietlenia okna, którego g³ówn¹ zawartoœæ stanowi tabela zawieraj¹ca nazwy jêzyków (po angielsku), nazwy rodzime tych jêzyków (jeseli s¹ znane) i t³umaczenie angielskiego s³owa „hello”.
Projekt ogólny takiego programu nie jest skomplikowany. Podstawow¹ struktur¹ danych jest tablica, której elementami s¹ struktury. Kasda taka elementarna struktura ma szeœæ elementów, które s¹ napisami: nazwa jêzyka, t³umaczenie nazwy, t³umaczenie s³owa „hello”, nazwa kodowania rozpoznawanego przez iconv, nazwa rejestrowa kroju pisma i nazwa preferowanego kroju. We wszystkich napisach usywane jest kodowanie UTF-8. Konstrukcja okna jest umieszczona w tablicy zawieraj¹cej widsety Xt typu Label. Fragmenty X s¹ bardzo dziwne — tak widzi je autor nie maj¹cy w sobie nic z programisty X. Czysto geometryczne rozwasania s¹ nudne, wiêc pominiêto je w przyk³adzie.
Najpierw, jak zwykle, umieszczony jest materia³ nag³ówkowy. Sam program nie jest zinternacjonalizowany (nie korzysta z gettext), a wiêc jedynym nag³ówkiem powi¹zanym z I18N jest iconv.h
m17n.c
Pokazuje niektóre aspekty wielojêzycznego wyœwietlania tekstów
powi¹zanego z I18N.
#include <iconv.h>
/* Ogólnie wymagane */
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
/* Wymagany materia³ X */
#include <X11/Intrinsic.h> /* Definicje wewnêtrzne */
#include <X11/StringDefs.h> /* Standardowe definicje nazw */
#include <X11/Xaw/Label.h> /* Etykiety z pakietu widsetów Athena */
#include <X11/Xaw/Form.h> /* Elementy formularzy z widsetów Athena */
Teraz definiujemy typy danych aplikacji zwi¹zane z I18N:
/*
Wpis o jêzyku
Dane tekstowe
Przechowuje informacje o kasdym jêzyku
typedef struct _LangRec LangRec;
Deklaracje metody LangRec
int langRecValidP (LangRec*); /* prawda, gdy ograniczenia kodowania OK */
char* englishName (LangRec*); /* 'przekszta³ca' nazwê UTF-8 na ASCII */
/* Te funkcje przydzielaj¹ pamiêæ; wywo³uj¹cy musi j¹ zwolniæ */
char* nativeName (LangRec*); /* zmienia UTF-8 na kodowanie rodzime */
char* nativeHello (Langrec*); /* zmienia hello UTF-8 na kod rodzimy */
Dalej nastêpuj¹ informacje usywane w tabeli jêzykowej. Trzy pocz¹tkowe napisy w kasdym wpisie s¹ faktycznie zakodowane w UTF-8. Zwróæmy uwagê na to, se znaki ASCII wystêpuj¹ bez zmian, rozszerzone znaki alfabetu ³aciñskiego stosowane w jêzyku hiszpañskim (np. ma³e „n” z tyld¹ i odwrócony wykrzyknik) s¹ zakodowane za pomoc¹ dwóch bajtów (dla bezpieczeñstwa z modyfikatorem szesnastkowym), zaœ znaki japoñskie, chiñskie i koreañskie maj¹ kody trzybajtowe:
#define NUMLANGS 6
LangRec languages[NUMLANGS] = ,
/* Jêzyki */
,
,
/* Japoñski krój pisma usyty w tym miejscu jest zawarty w X11 */
,
/* Koreañskie i chiñskie kroje pisma s¹ rzadziej spotykane */
*/
'EUC-KR', 'ksc5601.1987-0', 'mincho' },
*/
'GB2312', 'gb2312.1980-0', 'song ti' }
Nastêpny fragment programu zawiera deklaracje struktur danych i definicje funkcji tworz¹cych tabelê. Nie s¹ one interesuj¹ce z punktu widzenia I18N i dlatego tutaj je pominiêto.
Angielski krój pisma jest stosowany w kilku podprogramach. Dla wygody programisty zakodowano go na sta³e i zadeklarowano jako globalny. Zadeklarowano tu równies program pomocniczy tworz¹cy XLFD na podstawie rejestru kodowañ i rodziny krojów pisma:
NUDNY FRAGMENT GLOBALNY
Globalne zmienne s¹ z³em, ale jestem leniwy.
char *englishXLFD = '-*-Helvetica-medium-r-*-*-24-*-100-100-*-*-iso8859-1';
XFontStruct *englishFont = NULL;
Deklaracje funkcji pomocniczej
char *makeXLFD (char*, char*);
Nastêpnie pojawiaj¹ siê funkcje zwi¹zane z I18N. Funkcja utfToNative korzysta z iconv(3), jak to widzieliœmy wczeœniej. Wystêpuje tu jednak pewne wypaczenie spowodowane tym, se funkcja iconv(3) jest przeznaczona do obs³ugi strumieni zewnêtrznych:
/* Implementacje metody LangRec */
utfToNative()
wiêcej podstawowych manipulacji za pomoc¹ iconv
#define UTNBUFSZ 256
char* utfToNative (const char *source, const char *iconv_charset)
fprintf (stderr, 'iconv failed for %sn', iconv_charset);
iconv_close (cd);
return (char *) NULL;
Teraz nastêpuje kod obs³uguj¹cy kroje pisma. Mosna zostawiæ obs³ugê odwzorowania jêzyków na kroje pisma bibliotece Xlib, usywaj¹c krojów dostêpnych w tej bibliotece. Korzystaj¹ one jednak przewasnie z kodowania ISO-2022, co nie jest polecane dla aplikacji wymagaj¹cych dynamicznych zmian. Kroje te niezbyt dobrze siê sprawuj¹ w œrodowisku Unicode ze wzglêdu na braki niektórych zestawów. Ich obs³uga jest takse niezbyt przyjazna, pomimo istnienia aplikacji pomocniczych zarówno w samym X11, jak i w pakiecie GNOME.
Nie mosna wiêc usyæ Unicode i mieæ nadziei na wybór ³adnych krojów pisma, poniewas niektóre jêzyki korzystaj¹ wprawdzie z takich samych znaków, ale pojêcie „³adnego wygl¹du” bywa w nich odmiennie rozumiane. W wypadku wspólnych znaków jêzyka chiñskiego, japoñskiego oraz koreañskiego glify s¹ zazwyczaj odmiennie ukszta³towane i osoba nie znaj¹ca uproszczeñ usywanych przez Chiñczyków i Japoñczyków nie potraktuje ich jako znaków o tym samym znaczeniu. W typowych zastosowaniach internacjonalizacyjnych nie ma z tym zbyt wielkiego problemu, ale w aplikacjach wielojêzycznych problem staje siê jus powasny.
/* Implementacja metody LabelRow */
init()
Zwraca 1 przy powodzeniu, 0 przy b³êdzie (w szukaniu nativeFont).
Przerwanie przy b³êdzie w szukaniu englishFont.
int init (LabelRow *labelRow, LangRec *lr, Widget parent)
}
if (!(nativeFont = XLoadQueryFont (XtDisplay(parent),
makeXLFD (lr->font, lr->x_registry))))
snprintf (widgetname, 128, 'english%d', rownum);
labelRow->english =
XtVaCreateManagedWidget (widgetname, labelWidgetClass, parent,
XtNlabel, englishName (lr),
/* fragment I18N */
XtNfont, englishFont,
XtNinternational, FALSE,
XtNecoding, englishFont->min_byte1 == englishFont->max_byte1
? XawTextEncoding8bit
: XawTextEncodingChar2b,
NULL);
snprintf (widgetname, 128, 'native%d', rownum);
labelRow->native =
XtVaCreateManagedWidget (widgetname, labelWidgetClass, parent,
XtNlabel, nativeName (lr),
XtNborderWidth, 0,
/* fragment I18N */
XtNfont, nativeFont,
XtNinternational, FALSE,
XtNecoding, nativeFont->min_byte1 == nativeFont->max_byte1
? XawTextEncoding8bit
: XawTextEncodingChar2b,
NULL);
snprintf (widgetname, 128, 'hello%d', rownum);
labelRow->hello =
XtVaCreateManagedWidget (widgetname, labelWidgetClass, parent,
XtNlabel, nativeHello (lr),
XtNborderWidth, 0,
/* fragment I18N */
XtNfont, nativeFont,
XtNinternational, FALSE,
XtNencoding, nativeFont->min_byte_1 == nativeFont->max_byte1
? XawTextEncoding8bit
: XawTextEncodingChar2b,
NULL);
++rownum;
return 1;
G³ówna funkcja programu po prostu ustawia pêtlê aplikacji w Xt i wywo³uje j¹. Jest to nudne, mosna to pomin¹æ i dlatego zosta³o to pominiête.
Manipulacje krojem pisma i struktur¹ LangRec nie s¹ trudne. Jedynym wyj¹tkiem jest tu funkcja langRecValidP. Ma ona sprawdzaæ, czy kasdy element LangRec sk³ada siê z trzech napisów w kodzie UTF-8 i dwóch napisów w kodzie ASCII. W przypadku ASCII wystarczy sprawdzenie, czy kasdy znak ma kod mieszcz¹cy siê w przedziale w zakresie od 0x20 do 0x7E. Kod UTF-8 wnosi wiêcej komplikacji, poniewas zalesy od kontekstu. Jego sygnatura jest jednak ca³kiem ³atwo rozpoznawalna. Jeœli pierwszy bajt kodu jest kodem znaku ASCII (zerowy ósmy bit), to ca³y znak ma kod jednobajtowy (faktycznie jest wiêc to znak ASCII). W przeciwnym wypadku liczba najstarszych bitów równych 1 odpowiada liczbie bajtów kodu znaku, maj¹cych postaæ 10xxxxxx. Kod tej funkcji nie zosta³ napisany ze wzglêdu na krótki termin przygotowania tekstu do ksi¹ski.
/* Manipulacje XLFD i XFont */
char *makeXLFD (char *font, char *registry)
/* Implementacja metody LangRec */
int langRecValidP (LangRec *lr)
char *englishName (LangRec *lr)
char *nativeName (LangRec *lr)
char *nativeHello (LangRec *lr)
/* koniec m17n.c */
Nieco nudne szczegó³owe zastosowania geometrii wystêpuj¹ce w programie nie zosta³y tu pokazane. Koñcz¹c opis programu, chcemy dla przypomnienia pokazaæ, czego nalesy oczekiwaæ po kompilacji pe³nego kodu Ÿród³owego pobranego z serwera ftp wydawnictwa Helion (ftp://ftp.helion.pl/przyk³ady/zaprli.zip):
|
|
Na szczêœcie, niezalesnie od tego, se przetwarzanie danych wejœciowych jest znacznie trudniejsze nis wytwarzanie danych wyjœciowych, to w wielu wasniejszych pakietach do tworzenia interfejsów graficznych (np. Qt i GTK+) pojawi³y siê jus widsety tekstowe zgodne z XIM (w niektórych pakietach stosuje siê takse przekszta³canie na Unicode). Poniewas zaleca siê, aby kodowanie wewnêtrzne by³o odmian¹ Unicode, w przypadku t³umaczenia danych wejœciowych z kodu rodzimego na Unicode nalesy zastosowaæ metodê dzia³aj¹c¹ odwrotnie nis opisana w przyk³adowym programie.
Linux na poziomie podstawowej biblioteki systemowej (libc) znacznie rozwin¹³ siê w ci¹gu ostatnich kilku lat. Dotyczy to zarówno unormowania w³aœciwoœci, interfejsów programowych i sk³adni, jak i zastosowañ — szczególnie w bibliotece libc w wersji GNU. Obs³uga tekstu jest na pewno ³atwiejsza nis prezentacja interfejsu graficznego, poniewas ma on na ogó³ strukturê liniow¹ (chocias wystêpuje w nim ³amanie wierszy), zaœ GUI ma strukturê dwu- lub wiêcej wymiarow¹. Dlatego w³aœnie na wysszych poziomach, a w szczególnoœci w pakietach do tworzenia GUI, nie nast¹pi³ tak znaczny postêp ani w normalizacji, ani w zastosowaniach. W pracach maj¹cych na celu opracowanie norm I18N dla Linuksa przewodzi Linux Internationalization Initiative. Opracowana tam szkicowa propozycja standardu Li18nux (dostêpna pod adresem https://www.li18nux.net/ i przewidziana do zatwierdzenia w czasie druku tej ksi¹ski) wskazuje szczególnie na GUI jako obszar wymagaj¹cy unormowania, ale nie gotowy jeszcze do przyjêcia jakichkolwiek rozwi¹zañ ostatecznych.
Zawodowy programista pracuj¹cy w systemie Linux powinien dobrze zdawaæ sobie sprawê z trudnoœci, aby móc podj¹æ decyzjê o zastosowaniu najnowszych rozwi¹zañ (które czêsto jeszcze nie uzyska³y postaci bibliotek) daj¹cych dodatkowe w³aœciwoœci funkcjonalne i przenoœnoœæ aplikacji.
Na przyk³ad, korzystaj¹c z czystego tekstu, zwykle tworzy siê listê wypunktowan¹ nastêpuj¹co:
o pozycja 1
o pozycja 2
Jeœli tak¹ listê zapiszemy po hebrajsku, to naturalnie wiersze bêd¹ siê rozpoczynaæ od prawej strony, zaœ znaki wypunktowania zostan¹ „automatycznie” wyrównane do prawego marginesu. W interfejsie graficznym sprawa wygl¹da nieco inaczej. Obrazki bêd¹ce znakami wypunktowania s¹ umieszczane prawdopodobnie w sposób nie zwi¹zany z konkretnym œrodowiskiem kulturowym (np. od lewego górnego rogu okna w dó³), a nastêpnie s¹ formatowane napisy tworz¹ce etykiety widsetów. W etykietach mosna wiêc uwzglêdniæ hebrajskie formatowanie napisów od prawej do lewej, ale znaki wypunktowania pozostan¹ w takim przypadku na nieprawid³owych pozycjach.
Oczywiste jest, se takie rozwi¹zania, które s¹ prawid³owe w tekœcie liniowo u³osonym (nawet ³amanym), bêd¹ wymaga³y wiêcej zachodu w wielowymiarowym interfejsie graficznym. Prawdopodobnie stanie siê to jeszcze trudniejsze, gdy do prezentacji interfejsu graficznego zostan¹ dodane pliki dŸwiêkowe i animacje. Pomimo tego, se wymiary obrazu, dŸwiêku i animacji wydaj¹ siê lepiej okreœlone nis wymiary tekstu pisanego, to na pewno istniej¹ tu pu³apki wi¹s¹ce siê z normalizacj¹ i zastosowaniami w tych dziedzinach.
Niespodziewanie, ze wzglêdu na swój komercyjny charakter, zarówno dokumentacja, jak i wdrosenia biblioteki Qt s¹ znacznie bardziej zaawansowane nis GTK+. Biblioteka Qt wykorzystuje wewnêtrznie tylko Unicode i obs³uguje wiêkszoœæ kodowañ zewnêtrznych (brak jeszcze obs³ugi jêzyków „dwukierunkowych”, jak arabski i hebrajski oraz skomplikowanych jêzyków „sk³adanych”, jak hindi lub jêzyk tajski). Qt zawiera katalogi komunikatów i korzysta z gettext PO do ich t³umaczeñ, ale kompiluje je do w³asnego formatu (wynika to z tego, se w Qt nie mosna usyæ gettext w wersji GNU na wielu platformach, tam gdzie libc w wersji GNU nie jest bibliotek¹ systemow¹).
Podobnie jak w duecie GTK+/GNOME, w Qt/KDE takse wyraŸnie brak dokumentacji dla internacjonalizacji zarz¹dzania uk³adem interfejsu i komunikacji miêdzy klientami. Nie mosna tego jednak traktowaæ jako braku w porównaniu do braków w samym wdroseniu. Wiêkszoœæ z zagadnieñ jest umieszczona na liœcie pos¹danych w³aœciwoœci. Najpowasniejszym brakiem w bibliotece Qt jest to, se nie nalesy ona do wolnego oprogramowania. Jeseli takie wymaganie dotyczy tworzonych programów (wynikaj¹ce czy to z powodu pewnej filozofii, czy tes z zobowi¹zañ wobec licencji GPL), to nie mosna jej usyæ. Z drugiej strony, Qt powinna byæ silnym rywalem w przysz³oœci, szczególnie w sensie przenoœnoœci rozwi¹zañ I18N na rósne platformy. Dokumentacja I18N jest dostêpna w sieci pod adresem https://doc.trolltech.com/i18n.html. Z drugiej strony, jeœli planuje siê d³ugookresowo, to k³opoty w standardach i wdroseniach I18N na pewno powiêkszaj¹ ryzyko zwi¹zane z przyjêciem „zablokowanych” platform w rodzaju Qt, poniewas nie bêdzie mosna ich poprawiaæ.
Wy³om w bies¹cym rozumieniu I18N stanowi¹ ostatnio opracowania z dziedziny „obiektów sieciowych”, uosabiane przez DCOM firmy Microsoft, otwarty standard CORBA i wdrosenia w GNOME „przyjaznych sieciowo” pulpitach przeznaczonych dla wolnych klonów systemu UNIX, a w szczególnoœci dla Linuksa. Oczywiœcie, zestaw typów danych usywanych w architekturze CORBA jest wystarczaj¹co obszerny, aby zastosowaæ w nim umiejscowienia zgodne ze standardem POSIX. Jedynym zmartwieniem jest to, se te typy danych s¹ zbyt ekspresyjne, aby pozwoli³y na wprowadzenie wielu wzajemnie niezgodnych koncepcji I18N. Zalecamy wiêc programistom ostrosnoœæ i przestrzeganie zgodnoœci ze standardami w tych obszarach. Trochê wysi³ku w³osonego w dostosowanie do standardów, rozpoczynaj¹cego siê jus na pocz¹tku projektu zaprocentuje w przysz³oœci bardzo dobrymi wynikami, jeœli standaryzacja zostanie doprowadzona do koñca.
As do tego miejsca w tym rozdziale zajmowaliœmy siê tylko internacjonalizacj¹ g³ównych bibliotek systemowych (libc Xlib i bibliotek zwi¹zanych z GUI). Trwaj¹ takse prace nad wprowadzeniem I18N do innych bibliotek, lecz nie s¹ one ujednolicone, poniewas nie ma zasad ogólnych, które mosna by wszêdzie przyj¹æ. Jako przyk³ad mosna podaæ bazê danych PostgreSQL usywan¹ w aplikacji obs³uguj¹cej wyposyczalniê p³yt DVD. Baza ta w wersji 6.5.3 obs³ugiwa³a kilka kodowañ danych, a w wersji 7.0.x dodano do niej obs³ugê Unicode (UTF-8). Ogólna obs³uga umiejscowieñ jest jednak doœæ s³aba, co potwierdzaj¹ nawet autorzy, wspominaj¹c o powolnoœci tych funkcji. Biblioteka obs³uguj¹ca wyœwietlanie na ekranie, czyli ncurses, jest umiejscowiona w systemie na wystarczaj¹co niskim poziomie, aby umiejscowienia nie wp³ywa³y na ni¹ bezpoœrednio. Jednak z drugiej strony, nie wprowadzono w niej jeszcze funkcji obs³uguj¹cych znaki o kodach wielobajtowych i znaki o sta³ej d³ugoœci kodu, które s¹ wymienione w standardzie XSI. Nie ma wiêc wspomagania znaków o takich kodach nawet w emulatorach terminali posiadaj¹cych takie mosliwoœci (wirtualna konsola Linuksa wcale nie obs³uguje takich znaków).
Podobnie jak biblioteki, takse i programy pomocnicze powstaj¹ce w ramach GNU s¹ najlepiej zinternacjonalizowane. Wiele z takich programów pomocniczych do obs³ugi plików, tekstów i pow³ok systemowych zawiera kompletne katalogi komunikatów dla rósnych wersji jêzykowych. Inne programy, do których mosna zaliczyæ podstawowe programy sieciowe jak telnet i ftp, próbuj¹ tworzyæ „czyste” 8-bitowe kana³y komunikacyjne i nikt jeszcze nie rozwasa³ zastosowania w nich modu³u gettext. Wiêkszoœæ z nich ma zlokalizowane wersje japoñskie, ale znajduj¹ one niewielkie zastosowanie przy próbie uzyskania z nich np. wersji chiñskiej lub francuskiej.
Jednym z najwasniejszych zagadnieñ s¹ jêzyki skryptowe. Spoœród wasniejszych pow³ok systemowych tylko tcsh doczeka³a siê ostatnio internacjonalizacji. S¹ w niej katalogi komunikatów w jêzyku niemieckim, jêzykach romañskich, greckim i japoñskim. Na szczêœcie Perl w wersji 5.6, bêd¹cy najwasniejszym jêzykiem skryptowym zosta³ zmieniony w taki sposób, aby wewnêtrznie korzystaæ z Unicode. Oprócz tego zawiera on pe³ny zestaw funkcji internacjonalizuj¹cych, które dzia³aj¹ tak samo, jak funkcje z biblioteki libc w wersji GNU. Python pozostaje nieco w tyle za jêzykiem Perl, ale w jego nastêpnym wydaniu bêdzie wprowadzona wewnêtrzna obs³uga Unicode, zatem modu³y wspomagaj¹ce I18N w jêzyku Python stan¹ siê wkrótce dostêpne.
Doœwiadczeni programiœci, którzy nie mieli jeszcze do czynienia z zagadnieniami I18N, dotar³szy to tego miejsca w ksi¹sce s¹ prawdopodobnie nieco oszo³omieni zakresem tematów i ich bardzo lakonicznym omówieniem. Mog¹ siê wówczas zastanawiaæ, czy warto podejmowaæ dodatkowy wysi³ek maj¹cy na celu poznanie tych zagadnieñ.
Celem tego rozdzia³u by³o przedstawienie krótkiego wprowadzenia do terminologii, metod i warsztatu usywanego przy I18N. Jeœli Czytelnik czuje siê przekonany, se potêga I18N wymaga bolesnego wysi³ku i se mosna wiele zyskaæ, podejmuj¹c ten wysi³ek, to czêœæ celów tego rozdzia³u zosta³a zrealizowana.
Rozdzia³ ten ma takse wykazaæ, se zagadnienie I18N jest wartoœciowym przedsiêwziêciem. Patrz¹c na to ze strony zysków, trzeba np. pomyœleæ o mosliwoœci przedstawienia swojego dzie³a na rynku licz¹cym miliard Chiñczyków i drugi miliard Hindusów za stosunkowo niewielk¹ cenê lokalizacji (t³umacze w Tokio pobieraj¹ zwykle nie wiêcej nis jedn¹ trzeci¹ wynagrodzenia programisty, a zakres pracy da siê ³atwo oszacowaæ). Nalesy tes pamiêtaæ, se polepszanie podstawowego interfejsu usytkownika daje znikome zyski, poniewas usytkownicy naprawdê doceniaj¹cy aplikacjê prawdopodobnie bêd¹ sobie syczyli stosunkowo prostego interfejsu. I18N i wynikaj¹ca z tego lokalizacja da jednak ca³kowicie now¹ grupê cennych usytkowników, którzy nie usywali jeszcze przedstawionego im programu, bez wzglêdu na jego interfejs.
To rozumowanie, oczywiœcie, nie musi dotyczyæ kasdej aplikacji. Warto jednak to przemyœleæ!
W praktyce podstawowe funkcje I18N bêd¹ kosztowaæ prawdopodobnie mniej nis to siê wydaje na pierwszy rzut oka. Przede wszystkim, kasdy interfejs usytkownika mose byæ ulepszony, a w wielu wypadkach proste podejœcie ca³kowicie wystarcza do realizacji jakiegoœ zadania. Jest wiêc prawdopodobne, se takie uproszczone potraktowanie sprawy I18N takse wystarczy dla potrzeb aplikacji. Oprócz tego, metody programowania obiektowego i narzêdzia automatycznie dodaj¹ce w³aœciwoœci I18N do programów umosliwiaj¹ odskok od nudnych zadañ zarz¹dzania funkcjami niskiego poziomu i oznaczania komunikatów.
Jeden z recenzentów tego rozdzia³u z wielkim bólem usi³owa³ wykazaæ, se wiêkszoœæ metod I18N jest powtarzalna. Jest to naturalny obszar zastosowania metod programowania obiektowego. Mia³ on oczywiœcie racjê. Trzeba jednak podkreœliæ, se na dzieñ dzisiejszy wsparcie ze strony programowania obiektowego nie mose byæ tak duse, jakiego siê oczekuje.
Najpierw rozwasmy zalety programowania obiektowego. Interfejsy w I18N (np. iconv(3)) s¹ bardzo ogólne, ale usywa siê w nich trudnych do odczytu konstrukcji (jak podwójne poœrednie odniesienie) i kilku obiektów po³¹czonych w bardzo ³adny sposób. W iconv(3) mamy dwa poœrednie bufory, dwa poœrednie wskaŸniki oraz kontekst konwersji, który trzeba przywo³aæ w kasdym wywo³aniu. Naturalne jest wiêc po³¹czenie tego wszystkiego i dodanie metod wype³niania, konwersji i oprósniania buforów.
G³ównym powodem trudnoœci w zastosowaniu metod obiektowych w I18N jest to, se w³aœciwoœci I18N s¹ s³abo przystosowane do zamykania w kontenerach (ang. encapsulation). Umiejscowienia ze standardu POSIX s¹ tego najlepszym przyk³adem, poniewas s¹ zmiennymi globalnymi dla procesu. Oznacza to, se nie mosna w prosty sposób zbudowaæ obiektu zawieraj¹cego umiejscowienia i korzystaæ z niego do zmiany tych umiejscowieñ.
Mosna potraktowaæ konfiguracjê umiejscowieñ jako inicjacjê obiektu umiejscowienia, ale bardzo trudno to zrobiæ za pomoc¹ programowania obiektowego — s¹ to zwyk³e czynnoœci w programowaniu strukturalnym, które mosna zrealizowaæ za pomoc¹ funkcji lub makropolecenia.
Problem polega na tym, se aby zmieniæ umiejscowienie lokalnie, trzeba zatrzymaæ inne dzia³aj¹ce w¹tki i wznowiæ je w sposób jawny po wyjœciu z podprogramu. Automatyczne usuniêcie lokalnie przydzielonego obiektu mose pomóc przy zachowaniu pewnej dyscypliny w odtwarzaniu umiejscowienia. Jednak zmiana umiejscowienia jest operacj¹ kosztown¹, której nie mosna zbyt ³atwo wprowadziæ.
Deskryptor konwersji usywany przez iconv(3) równies nie mose byæ usywany przez rósne w¹tki. Tutaj takse mosna usyæ metod programowania obiektowego, aby zapobiec operacjom, które nie mog¹ byæ wykonywane poprzez publiczny interfejs. Polega to np. na utworzeniu klasy IconvThread, która bêdzie przydzielaæ nowy prywatny deskryptor dla kasdego strumienia danych. Wydaje siê to nieefektywne i znacznie utrudnia projektowanie klasy ortogonalnej, która mog³aby byæ usywana w kasdym kontekœcie.
Drugim powodem os³abienia wydajnoœci metod programowania obiektowego jest stopieñ komplikacji zadañ. Przede wszystkim dotyczy to interfejsów usytkownika, które zawsze s¹ bardzo skomplikowane. Usytkownik mose pope³niaæ bardzo wiele b³êdów przy wprowadzaniu danych, zaœ programista musi pewnie obs³usyæ jak najwiêcej takich mosliwych sytuacji. To zadanie jus ze swej natury wymaga wiele wysi³ku programisty. Spójrzmy teraz na ten problem w I18N: programista tworzy aplikacjê dla jêzyków, o których czêsto nawet nie s³ysza³, a wiêc nie ma pojêcia, jakiego rodzaju b³êdy trzeba bêdzie obs³usyæ. B³êdy, które siê nie pojawiaj¹ lub które mosna zignorowaæ dla danych wejœciowych typu ASCII, mog¹ byæ powszechnie pope³niane i byæ niebezpieczne w jêzyku japoñskim i odwrotnie. I18N ma siê wiêc tak do projektu zwyk³ego interfejsu jak „Kreigspiel” do szachów.
„Kreigspiel” jest odmian¹ gry w szachy, w której kasdy zawodnik ma oddzieln¹ szachownicê. Jedyn¹ informacj¹ o aktywnoœci przeciwnika jest fakt pobicia (ale bez podawania rodzaju figury) oraz zabronienie ruchu przez sêdziego na skutek blokady miejsca przez figurê przeciwnika.
Programowanie obiektowe mose wiêc nadaæ czytelnoœæ i u³atwiæ zachowanie porz¹dku dziêki mosliwoœci zamykania w kontenerach. Wykorzystuj¹ce te zalety metody programowania obiektowego s¹ godne polecenia. Kasda aplikacja ma jednak rósne wymagania w stosunku do sk³adników I18N, wiêc obecnie mosna tylko pomarzyæ o obszernej bibliotece zawieraj¹cej elementy wielokrotnego usytku.
Pakiety do tworzenia aplikacji bêd¹ z pewnoœci¹ bardzo wspomaga³y I18N. Jedn¹ z najbardziej interesuj¹cych w³aœciwoœci, któr¹ dostrzeg³ autor tego rozdzia³u w kodzie interfejsu usytkownika przyk³adowej aplikacji do obs³ugi wyposyczalni DVD, by³o pojawienie siê w nim wiêkszoœci wyników prac nad I18N. Autorzy ksi¹ski zastanawiali siê nad wprowadzeniem I18N, a programiœci po prostu to zrobili. Umosliwi³ to pakiet Glade.
Zastanówmy siê wiêc, co robi Glade (i czego nie robi) w dziedzinie I18N. Zauwasmy najpierw, se aplikacja nie zosta³a wcale lokalizowana. Nie wymaga ona niczego szczególnego w innych umiejscowieniach nis domyœlne umiejscowienie zgodne ze standardem POSIX. Przede wszystkim nie ma tu t³umaczeñ. Pojawi³y siê w niej jednak nastêpuj¹ce w³aœciwoœci:
q Inicjacja funkcji umiejscawiaj¹cych w libc w wersji GNU (poœrednio poprzez GTK+),
q Inicjacja katalogu komunikatów (jawnie poprzez wywo³anie textdomain oraz bindtextdomain dodane przez Glade w pliku ./src/main.c
q Inicjacja metod obs³ugi wejœcia (poœrednio poprzez GTK+),
q Deklaracja w³aœciwoœci gettext (dodana jawnie przez Glade w pliku ./src/support.h
q Pakowanie napisów w wywo³ania gettext (dodane jawnie przez Glade w postaci konwencjonalnego makropolecenia „
q Generacja szablonu katalogu komunikatów w pliku ./po/dvdstore.pot
Z punktu widzenia programisty to wszystko sta³o siê ca³kowicie automatyczne. W pakiecie Glade w wersji 0.5.7 wszystkie powyssze w³aœciwoœci — oprócz generacji szablonu katalogu komunikatów — dodawane s¹ domyœlnie. Proces ten jest uaktywniany po wyborze w Glade pozycji menu Options | LibGlade Options i uaktywnieniu Save Translatable Strings z plikiem po/dvdstore.pot. Katalog komunikatów nie jest kompletny, poniewas jest generowany w czasie tworzenia plików Ÿród³owych. Wszystkie komunikaty dodane póŸniej w wywo³aniach zwrotnych i w g³ównym programie trzeba wiêc do³¹czaæ rêcznie. Prawdopodobnie pakiet Glade mose to zrobiæ sam automatycznie po przebudowaniu projektu, ale wydaje siê, se do tego celu nie bêd¹ wywo³ywane funkcje pomocnicze gettext. Mosna takse skorzystaæ z msgmerge(1) xgettext(1) lub pakietu Emacs pracuj¹cego w trybie po (dostêpnego jako po-mode.el w module gettext
W aplikacji niewiele pozosta³o do zrobienia, aby osi¹gn¹æ podstawow¹ funkcjonalnoœæ I18N. Po pierwsze, trzeba uzupe³niæ szablon dla textdomain, zamieniaj¹c PACKAGE na dvdstore. Taka zamiana powinna byæ wykonana takse w pliku src/support.h. Mosna siê spodziewaæ, se w nastêpnych wersjach Glade bêdzie wykonywaæ te czynnoœci automatycznie, obecnie jednak tego nie robi.
Wywo³anie bindtextdomain jest zbêdne w naszej aplikacji i mosna je usun¹æ. Jest ono przydatne g³ównie tam, gdzie z jakichœ powodów dochodzi od konfliktów nazw z rósnych pakietów.
Wszystko to wystarcza do uzyskania podstawowej obs³ugi rósnojêzycznych komunikatów i trzeba jedynie znaleŸæ t³umaczy, którzy utworz¹ pliki dvdstore.po dla kasdego obs³ugiwanego jêzyka, skompilowaæ te pliki za pomoc¹ msgfmt(1) uzyskuj¹c pliki .mo nadaj¹ce siê do instalowania.
Do rozwi¹zania pozosta³y jeszcze trzy zagadnienia. Pierwsze z nich to brak obs³ugi rósnych walut. Jest to dosyæ trudne, poniewas wymaga zmian projektu samej bazy danych polegaj¹cych na powi¹zaniu cen z rósnymi wersjami jêzykowymi. Powi¹zanie z umiejscowieniem mose jednak okazaæ siê niewystarczaj¹ce, bowiem byæ mose warto zrósnicowaæ ceny w zalesnoœci od wielkoœci i po³osenia miejscowoœci. Prawdopodobnie usycie do tego sk³adowej modyfikuj¹cej „ ” w umiejscowieniu s³us¹cej jako poœrednik do przechowywania adresu nie jest wystarczaj¹co elastyczne. Przygotowuj¹c siê jednak do takich modyfikacji, warto zmieniæ nastêpuj¹cy fragment kodu w pliku ./src/title_dialog.c
strncpy((new_title.rental_cost), g_strdup_printf('%f', cost), COST_LEN);
na nastêpuj¹cy:
char *buffer = g_malloc (COST_LEN);
/* Zauwasmy, se koszt jest zmiennoprzecinkowy takse w strfmon */
strfmon (buffer, COST_LEN, '%n, cost);
strncpy((new_title.rental_cost), buffer, COST_LEN);
Drugi problem polega na tym, se podobne zmiany musz¹ dotyczyæ takse dat. Trzeba tu usyæ funkcji strftime do formatowania dat widocznych dla usytkownika. G³ównym powodem tych zmian jest za³osenie o „humanizacji” dat i uzyskanie zgodnoœci ze stylem zalecanym przez normê ISO 8601 (YYYY-MM-DD), tak aby w przysz³oœci programista modyfikuj¹cy aplikacjê mia³ u³atwione zadanie (aby daty usywane wewn¹trz bazy danych i daty pokazywane usytkownikowi da³o siê ³atwo odrósniæ).
Trzecim zagadnieniem jest usycie parametru opisuj¹cego pozycjê t³umaczonych napisów, gdy wystêpuje wiêcej nis jedna specyfikacja formatu. Na przyk³ad w pliku ./src/disk_dialog.c znajduje siê nastêpuj¹cy fragment kodu:
msg = g_strdup_printf(_('Created Disk ID %d for Title ID %d'),
new_disk.disk_id,
new_disk.title_id);
Wygl¹da to zupe³nie niewinnie, ale w niektórych jêzykach (np. w niemieckim i japoñskim) usywany jest odmienny szyk nis w jêzyku angielskim (podobnie jak „odwrotna notacja polska”). Naturalnie jest w nich powiedzenie równowasne angielskiemu „For Title ID %d, Disk ID %d was created”. W jêzyku angielskim jest wiêc to mosliwe, chocias brzmi nieco dziwnie. Problem stanowi to, se programista mose nic nie wiedzieæ o takich sprawach. Jest to zadanie, którym zajmuj¹ siê eksperci od t³umaczeñ. W innych jêzykach mose byæ wymagany jeszcze inny szyk.
Jedynym rozwi¹zaniem, które mose zastosowaæ programista, s¹ zatem parametry pozycyjne. Jest to obecnie standardowa w³aœciwoœæ w bibliotece jêzyka C i na pewno s¹ one obs³ugiwane przez libc w wersji GNU. W kodzie Ÿród³owym nalesy wiêc dokonaæ nastêpuj¹cej zmiany:
/* Uwaga na ci¹gi formatuj¹ce '%' INTEGER '$d' */
msg = g_strdup_printf(_('Created Disk ID %1$d for Title ID %2$d'),
new_disk.disk_id,
new_disk.title_id);
W pliku .po dla wersji japoñskiej, czyli w /po/ja/dvdstore.po, nalesy dodaæ
#: src/disk_dialog.c:30
msgid 'Created Disk ID %1$d for Title ID %2$d'
msgstr 'For Title ID %2$d, Disk ID %1$d was created'
Zwróæmy uwagê na to, jak parametry pozycyjne wskazuj¹ poprawne powi¹zania „Disk ID” z new_disk.disk_id oraz „Title ID” z new_disk.title_id. Nie powinno byæ to zbyt k³opotliwe, poniewas umieszczanie parametrów pozycyjnych w kodzie Ÿród³owym mosna w prosty sposób zautomatyzowaæ za pomoc¹ skryptów jêzyka Perl lub Python. W rzeczywistoœci jedynie 5% zlokalizowanych napisów w naszej aplikacji korzysta z wiêcej nis jednego konwertera formatu. Nie jest to rzecz niespotykana, poniewas takie napisy spotyka siê stosunkowo rzadko.
Podsumowuj¹c wszystko, wydaje siê, se nie w³osono zbyt wiele wysi³ku w internacjonalizacjê przyk³adowej aplikacji. Jest to usprawiedliwione faktem, se programiœci tworz¹cy aplikacjê nie specjalizuj¹ siê w dziedzinie I18N, ale mimo to wykonali ok. 95% zadañ.
Organizacja o nazwie The Linux Internationalization Initiative (https://www.li18nux.net/) przoduje we wdrasaniu w³aœciwoœci I18N w systemie Linux, a ogólnie mówi¹c — w wolnych odmianach systemu UNIX. W³¹czenie tych w³aœciwoœci do w³asnego programu zalesy tylko od jego twórcy, a wiêc nie nalesy zwlekaæ!
Internacjonalizacja obejmuje szeroki zakres problemów, g³ównie o charakterze technicznym. Wspomnieliœmy jus w tym rozdziale o kilku materia³ach Ÿród³owych, ale dla przypomnienia wymienimy je ponownie. Rozpoczynaj¹c od tej lektury, mosna bêdzie znaleŸæ opis wszystkich zagadnieñ, którymi zajmuje siê I18N.
Jest to konsorcjum utworzone przez dystrybutorów systemu Linux, firmy i osoby zainteresowane tworzeniem standardów i najlepszych wzorców dla internacjonalizacji Linuksa. Wstêpn¹ wersjê standardu Li18nux 2000 (z maja 2000 r.) mosna znaleŸæ pod adresem https://www.linux.net/root/LI18NUX2000/li18nux2k_draft.html.
Li18nux powo³uje siê na wiele standardów. Niestety, ich drukowane wersje s¹ zazwyczaj bardzo drogie. Wiêkszoœæ z nich ma swoje tañsze alternatywy, czêsto nawet lepszej jakoœci. Kasdy z programistów podchodz¹cy powasnie do zagadnieñ I18N powinien mieæ dostêp do standardu ISO 10646 (zawieraj¹cego definicje uniwersalnego zestawu znaków), ale kosztuje on oko³o 500 dolarów! Unicode Standard w wersji 3.0 kosztuje tylko oko³o 50 dolarów i zawiera nie tylko definicje zestawu znaków, ale takse wiele dodatkowych informacji o przetwarzaniu tekstu. Wiele tabel, przyk³adów i narzêdzi mosna takse znaleŸæ w Internecie pod adresem https://www.unicode.org/.
Seria dokumentów RFC publikowana przez Internet Engineering Task Force stanowi g³ówny obszar zainteresowania dla specjalistów wdrasaj¹cych poszczególne protoko³y i dla samych twórców standardów. Jednak wiele dokumentów RFC wzoruje siê na I18N, zaœ grupa poœwiêcona standardowi MIME (RFC o numerach od 2045 do 2049) jest tu szczególnie wasna ze wzglêdu na zastosowanie MIME w poczcie elektronicznej i wiadomoœciach z grup dyskusyjnych. Oprócz tego wiele zasad stosowanych w MIME przyjêto bezpoœrednio w innych protoko³ach (np. w HTTP). Warto wiêc przejrzeæ dokument rfc-index.txt, dostêpny na wielu serwerach przechowuj¹cych kopie dokumentów RFC.
Autorem tej ksi¹ski jest Ken Lunde, a wyda³o j¹ wydawnictwo O’Reilly and Associates w roku 1999. Jest to biblia dla osób zajmuj¹cych siê przetwarzaniem jêzyków azjatyckich i punkt wyjœcia dla rozpoczynaj¹cych zaawansowane studia w tej dziedzinie. Wiele przyk³adów i narzêdzi mosna znaleŸæ pod adresem: ftp://ftp.uu.net/vendor/oreilly/nutshell/cjkv/.
Oczywiœcie, to jest Linux. Wiele narzêdzi i aplikacji jest jus napisanych w wersjach miêdzynarodowych. Niektóre z nich nie s¹ mose doskona³e — lecz mosna spróbowaæ polepszyæ je samemu, nieprawdas? „Use the Source, Luke”.
q Biblioteki systemowe: j¹dro Linuksa, GNU libc, X11R6
q GUI i menedsery wygl¹du pulpitu: GTK+, GNOME, Qt, KDE
q Polecenia systemowe: programy pomocnicze GNU dla plików, pow³oki i tekstów
q Edytory: GNU Emacs/Mule, XEmacs/Mule, yudit
q Przegl¹darki: Lynx, Mozilla
q Jêzyki: C/C++, Perl, Python
q Biblioteki zwi¹zane z aplikacjami: bazy danych itp.
Nie ma jeszcze automatycznego oczyszczania pamiêci dla I18N, ale prawdopodobnie nied³ugo jus siê ono pojawi. I18N zapewni wiêc pracê dla wielu programistów w daj¹cym siê przewidzieæ okresie. W sytuacji gwa³townie postêpuj¹cej globalizacji WWW i rynku oprogramowania (czyli ogólnie rzecz bior¹c — rozwoju oprogramowania) odpowiedzialni za opracowania dobrych projektów i ich wdrosenie na tym polu mog¹ siê spodziewaæ wielkiej nagrody.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 742
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2024 . All rights reserved