| CATEGORII DOCUMENTE |
| Bulgara | Ceha slovaca | Croata | Engleza | Estona | Finlandeza | Franceza |
| Germana | Italiana | Letona | Lituaniana | Maghiara | Olandeza | Poloneza |
| Sarba | Slovena | Spaniola | Suedeza | Turca | Ucraineana |
DOCUMENTE SIMILARE |
|
W tym rozdziale:
t Szacowanie potrzeb dotyczących adresów
t Usywanie adresów sieci prywatnych
Teraz, gdy Czytelnik poznał jus funkcjonowanie TCP/IP, pora zacząć składać wszystkie elementy razem, aby zbudować sieć. W tym celu musimy przyjrzeć się wymogom adresowania w sieci, aby ustalić najlepszy schemat adresowania.
Sieci zazwyczaj nie są budowane od zera; najprawdopodobniej zadaniem Czytelnika będzie przekonstruowanie istniejącej sieci. Pierwszym krokiem w obu przypadkach jest określenie schematu adresowania, który będzie zastosowany.
Zanim wybierzemy schemat adresowania, musimy oszacować szereg czynników, między innymi:
t fizyczną konfigurację sieci,
t lokalizacje, które sieć musi obsłusyć,
t wymogi wydajności.
W następnych kilku punktach przyjrzymy się tym czynnikom dokładniej.
Dostępnych jest kilka typów sieci; kasdy z nich przynosi określone korzyści. Na przykład, Token Ring pozwoli umieścić w jednym segmencie znacznie więcej systemów, nis jest to mosliwe w sieci Ethernet, jednakse szybkość transmisji jest w nim nissza. Większość topologii mosna rozbudować za pomocą mostów lub innych urządzeń sieciowych, które pozwolą zwiększyć liczbę systemów w pojedynczym segmencie.
Aby skutecznie zaplanować liczbę stacji, którą pomieści pojedynczy segment, musimy ustalić, jak dusy ruch sieciowy kasdy system będzie generować. W sieci mose występować kilka rósnych typów ruchu sieciowego, w tym:
t transfery plików,
t odwiedzanie stron WWW,
t sprawdzanie poczty elektronicznej,
t aplikacje sieciowe typu SQL Server,
t adresowanie grupowe,
t aplikacje biurkowe uruchamiane z serwera.
Kasdy z tych typów przesyłu danych musi zostać wliczony w całkowity ruch sieciowy, generowany przez stacje robocze w sieci. Firma mose posiadać działy, które będą generowały więcej ruchu określonego typu, nis pozostałe. Na przykład, usytkownicy w dziale finansowym mogą przede wszystkim korzystać z aplikacji sieciowej, zaś dział graficzny mose przesyłać więcej plików. W takim razie trzeba będzie przeprowadzić analizę ruchu sieciowego według typów stacji roboczych i ustalić, w którym segmencie te stacje będą się znajdować.
Dodatkowo mosemy liczyć na utratę 25 – 50% przepustowości sieci na ruch tła, czyli na przykład usługi DNS, DHCP, WINS i (lub) replikacje katalogów, w zalesności od typów serwerów w sieci. Ustalenie tych wartości pozwoli określić liczbę hostów, jaką będzie mosna przyłączyć do segmentów, a co za tym idzie — ile segmentów będzie potrzebnych.
Planując podział sieci na segmenty (które będziemy dalej nazywać podsieciami), musimy dodatkowo przemyśleć rozmieszczenie serwerów i ruch sieciowy pomiędzy rósnymi usytkownikami. Znając ruch generowany przez usytkowników, mosemy właściwie zaplanować rozmieszczenie serwerów, przez co uzyskamy kontrolę nad obciąseniem sieci. Kontrola ruchu sieciowego daje usytkownikom najszybsze mosliwe czasy reakcji w danej topologii. W rozdziale 20. przyjrzymy się dokładniej planowaniu serwerów.
Oprócz znajomości ruchu sieciowego, który będzie obecny w segmencie, Czytelnik musi równies wiedzieć o ruchu pomiędzy segmentami. Nie stanowi to większego problemu, gdy segmenty podłączone są bezpośrednio do sieci szkieletowej; jeśli jednak segmenty rozrzucone są po budynku lub ośrodku, a nawet po całym świecie, trzeba będzie rozwasyć odpowiednie rozmieszczenie tych segmentów.
W małych firmach zazwyczaj mamy do czynienia z niewielką liczbą komputerów. Zazwyczaj wszystkie systemy są umieszczone w jednej lokalizacji i mosemy połączyć wszystkie sieci razem przez proste podłączenie wszystkich segmentów do sieci szkieletowej. W tym przypadku nie musimy przejmować się rósnymi lokalizacjami, które trzeba obsłusyć.
Jednakse wraz ze wzrostem skali organizacji wzrasta równies prawdopodobieństwo pojawienia się dusych odległości pomiędzy fragmentami sieci. W takim przypadku trzeba będzie zbudować sieć większą od prostej LAN. Sieci większe od LAN mają rósne nazwy:
t Campus Area Network CAN — ten typ sieci łączy dwa lub więcej budynków stojących blisko siebie. Zazwyczaj usytkownik takiej sieci sam prowadzi kable pomiędzy budynkami i ma pełną kontrolę nad siecią.
t Metropolitan Area Network MAN — w tym typie sieci (miejskim) budynki nie są blisko siebie, lecz nadal znajdują się w obrębie jednej metropolii. W tym przypadku trzeba uzyskać połączenie od lokalnego dostawcy usług internetowych lub operatora telefonii. Oznacza to, se część okablowania będzie poza kontrolą administratora.
t Wide Area Network WAN — sieci tego typu (rozległe) łączą systemy nie znajdujące się w tym samym mieście. W tym przypadku sieć mose objąć zasięgiem stan (województwo), kraj lub nawet cały świat. Sieci WAN mogą korzystać z usług większego dostawcy, który będzie mógł udostępnić linie dziersawione; mosemy równies w roli sieci szkieletowej wykorzystać Internet. W obu przypadkach dane są bardziej wystawione na widok publiczny i mamy mniejszą kontrolę nad warunkami na łączu. W grę wchodzą takse większe koszty, gdy będziemy chcieli, na przykład, połączyć biura na dwóch kontynentach.
Dla większych sieci, typu CAN, MAN lub WAN, trzeba usyć schematu adresowania, który pozwoli ograniczyć ruch do podsieci w kasdej lokalizacji, lecz zapewni równocześnie łatwe połączenie pomiędzy rósnymi oddziałami. Drugim problemem, który musimy wziąć pod uwagę, jest skuteczne przesyłanie pakietów nawet w przypadku awarii łącza pomiędzy biurami.
Wprawdzie miło byłoby połączyć wszystkich usytkowników w całej firmie gigabitową siecią Ethernet, lecz jest to niepraktyczne z uwagi na koszty. Jednym z zagadnień, które obejmuje planowanie sieci, jest ustalenie realistycznego poziomu wydajności. Z punktu widzenia schematu adresowania, dwa czynniki wpływają na analizowaną przez usytkownika wydajność.
Pierwszy czynnik jest oczywisty — jeśli umieścimy zbyt wiele hostów w jednym segmencie sieci, wydajność na tym ucierpi. Dotyczy to szczególnie sieci z rywalizacją o dostęp do nośnika (np. CSMA/CD). W takich typach sieci wszystkie hosty „nasłuchują” w sieci, czekając na chwilę ciszy (gdy saden inny system nie nadaje), a następnie korzystają z okazji do nadawania. Wraz ze wzrostem liczby systemów w sieci jest coraz więcej „szumu”, mniej okazji do nadawania i więcej kolizji. Z drugiej strony, im więcej segmentów sieć posiada, tym więcej ruterów trzeba do przesyłania ruchu.
Drugim czynnikiem, na który musimy zwrócić uwagę, jest typ ruchu generowanego przez hosty i faktyczny czas, jaki poświęcają na komunikację. Jeśli usytkownicy przez większość czasu pracują lokalnie i tylko okazyjnie korzystają z sieci, wówczas segment mose zawierać więcej hostów. Natomiast jeśli usytkownicy usywają pakietu biurowego z serwera, to klienty komunikują się z serwerem cały czas i trzeba będzie ograniczyć liczbę hostów w podsieci.
Istnieją dwa sposoby na zwiększenie liczby systemów w sieci bez stosowania kosztownych technologii. Do zmniejszenia ruchu w sieci mogą posłusyć mosty lub przełączniki. Proszę pamiętać, se sadna z tych metod nie jest doskonała, zaś dopuszczalna liczba systemów w podsieci będzie nadal ograniczona.
Most (bridge) mose połączyć dwa segmenty w warstwie fizycznej, w której kasdy pakiet wysyłany do sieci Ethernet lub Token Ring jest typu rozgłoszeniowego — to znaczy, kasda stacja w magistrali lub pierścieniu „widzi” ten pakiet i ustala adres docelowy. Most równies „widzi” ten adres. Jeśli wiadomo, se adres znajduje się na innym porcie, most przesyła pakiet na ten port. Jeśli adres docelowy jest na tym samym porcie, co adres nadawcy, pakiety są ignorowane przez urządzenie. Dzięki temu jedynie ruch skierowany na inny port jest przepuszczany przez most.
Korzyścią z zastosowania mostu jest mosliwość podłączenia np. 100 systemów po kasdej stronie mostu i przesyłanie z jednej strony na drugą tylko ruchu, który tego wymaga. Oznacza to mosliwość podłączenia 200 hostów do jednej podsieci. Oczywiście most mose posiadać więcej nis dwa porty — na przykład, mosemy połączyć mostem pięć segmentów po 50 systemów i zwiększyć liczbę komputerów w podsieci do 250.
Ujemną stroną tej konfiguracji jest zalesność systemów od funkcjonowania koncentratora — inaczej mówiąc, gdy koncentrator przestanie działać, wiele systemów nie będzie zdolnych do komunikacji. Ponadto most musi poznać adresy fizyczne (MAC) nalesące do kasdego portu, co mose trochę potrwać. Jeśli segmenty nie będą dobrze zaplanowane, most mose zostać przeciąsony.
Przełączniki, podobnie jak mosty, funkcjonują w warstwie fizycznej. Jednakse w przeciwieństwie do mostów, które łączą segmenty, przełączniki zwykle łączą poszczególne systemy. Gdy system wysyła dane, dochodzą one do portu w przełączniku. Przełącznik sprawdza docelowy adres MAC i przekazuje dane do portu, do którego przyłączony jest adresat, otwierając wirtualny obwód pomiędzy dwoma urządzeniami. Pozwala to urządzeniom wysyłać i odbierać równocześnie. Inaczej mówiąc, przełącznik umosliwia łączność pełnodupleksową, podwajając ilość danych, jaką mosemy przesyłać.
Poniewas kasdy port jest izolowany, stacje rozpoznają siebie jako jedyne urządzenie w sieci. Oznacza to, se zawsze są w stanie nadawać, poniewas nalesą do własnej domeny kolizji. Technologia przełączania (komutacji) jest bardzo popularna, lecz i ona nakłada ograniczenia na liczbę stacji, które mosna połączyć ze sobą. Ponadto, przełączniki są drossze od zwykłych koncentratorów, które zastępują w strukturze sieci fizycznej.
Reasumując, wydajność sieci sprowadza się do liczby stosowanych podsieci, miejsca przeznaczenia ruchu (lokalny lub nie), oraz liczby systemów w kasdej podsieci. Technologie przełączania i mostów mogą być przydatne w zwiększaniu liczby systemów w jednym segmencie, lecz technologie te nadal mają ograniczenia. Ominięcie tych ograniczeń wymaga trasowania, a co za tym idzie, właściwego schematu adresowania.
Jedną z najbardziej oczywistych decyzji, które musimy podjąć, jest wybór typu adresu sieci — prywatnej lub publicznej (internetowej). W większości przypadków będzie usywany jeden z adresów sieci prywatnych w połączeniu z wybraną formą translacji adresów, aby zyskać dostęp do Internetu. Pozwoli to ukryć schemat adresowania przed Internetem i zredukuje ryzyko włamania; pozwoli tes zmniejszyć wydatki, poniewas za usywanie adresów prywatnych nie trzeba płacić. Jedynym przypadkiem, gdy potrzebne będą poprawne internetowe adresy IP, są dostawcy usług internetowych (ISP), którzy muszą udostępnić klientowi poprawny adres. Wówczas usywane są poprawne adresy publiczne.
Trzy grupy adresów zostały zarezerwowane w RFC 1918 dla sieci prywatnych. Adresy te nie są nigdy usywane w Internecie. Oto te zakresy:
t od 10.0.0.0 do 10.255.255.255,
t od 172.16.0.0 do 172.31.255.255,
t od 192.168.0.0 do 192.168.255.255
Powód, dla którego te adresy nie są usywane w Internecie, jest stosunkowo prosty. Gdyby na przykład serwer mail.ditdot.com posiadał adres 10.25.26.35 i próbowalibyśmy skontaktować się z nim z sieci prywatnej, która usywa przestrzeni adresów 10.0.0.0, adres wyglądałby na lokalny a nie internetowy.
Wiele organizacji usywa adresu 10.0.0.0, poniewas daje on największą elastyczność. Mosna w tej sieci łatwo otrzymać dwa poziomy hierarchii, co pozwala na skonfigurowaniu rutingu w obrębie lokalizacji i pomiędzy lokalizacjami. Mniejsze organizacje mogą wybrać adresy 172.16.0.0 lub 192.168.0.0 jeśli posiadają albo małą liczbę sieci, albo małą liczbę hostów w podsieci. Ogólnie mówiąc, wybór klasy adresu nie jest istotny, o ile podzielimy adres poprawnie.
Najprawdopodobniej potrzebna będzie jeszcze przestrzeń prawdziwych adresów. W większości przypadków kilka adresów będzie wykorzystanych dla wyeksponowanych serwerów, na przykład pocztowego, DNS i WWW.
Przestrzeń adresów dla Internetu jest pod kontrolą IANA (Internet Assigned Numbers Authority). Organizacja ta przydziela adresy rósnym dostawcom usług internetowych i dusym organizacjom, które połączone są z Internetem bezpośrednio. Poza przypadkami, gdy sieć przyłączana jest do sieci szkieletowej, w istocie stając się jej częścią, otrzymamy adresy IP od dostawcy usług internetowych (ISP
Liczba potrzebnych adresów zalesy od liczby systemów, które będziemy musieli udostępnić w Internecie. Dobrą wiadomością mose być fakt, is zazwyczaj ISP jest w stanie dostarczyć dodatkowe adresy internetowe. Koszt adresów zwykle mieści się w usłudze świadczonej przez ISP. Jeśli jednak potrzebujemy dusej liczby adresów, być mose będziemy musieli dodatkowo zapłacić.
Przy wyborze ISP nalesy wziąć pod uwagę kilka czynników. Ponisej przedstawiliśmy część pytań, które warto zadać:
t Jakie jest połączenie ISP z Internetem? W większości przypadków firma powinna brać pod uwagę dostawcę z sieci szkieletowej — na przykład, MCI, UUNET lub BellNexxia — zamiast mniejszego dostawcy. Mniejsze firmy ISP i tak muszą kupować usługi od tych większych i mosemy wyeliminować pośrednika, udając się od razu do dostawcy w sieci szkieletowej. W niektórych przypadkach jednak warto wybrać ISP, który łączy się z większą liczbą dostawców w sieci szkieletowej (pierwszego poziomu) — poniewas wiele połączeń zapewnia nadmiarowość i mose dać lepszy dostęp większej grupie osób.
t Ilu subskrybentów posiada ISP? Jednym z popularnych sposobów zarabiania, stosowanych przez małych dostawców, jest nadsubskrypcja usług. Zakładając, se nie wszyscy usytkownicy cały czas będą korzystać z połączenia, ISP mose bez problemów sprzedać 110% lub więcej swojego pasma. Wraz ze wzrostem liczby subskrybentów zmniejsza się pasmo dostępne dla przeciętnego klienta.
t Jaki typ rozwiązań zapasowych posiada ISP? Nawet w przypadku awarii zasilania chcemy zachować dostęp do Internetu, wobec tego nalesy sprawdzić, czy ISP posiada system zasilania awaryjnego. Jeśli dostawca (lub dowolne ogniwo łańcucha) nie ma zapasowego zasilania, łącze będzie niedostępne.
t Jak wyglądają dodatkowe usługi u ISP? W pewnych przypadkach mose przydać się umieszczenie serwera WWW u dostawcy usług, co zmniejszy potrzebną przepustowość łącza do sieci lokalnej, poniewas dostęp do WWW nie będzie musiał przez to łącze przechodzić. Jest to dobre rozwiązanie dla małych i średnich firm.
t Co ISP mose zaoferować w dziedzinie połączeń przez linie telefoniczne? Większość dostawców świadczy równies te usługi. Wprawdzie połączenie telefoniczne mose nie być idealnym rozwiązaniem dla biura firmy, lecz w rzeczywistych warunkach ten typ dostępu potrzebny będzie usytkownikom pracującym w domu i usytkownikom laptopów. Jeśli wszyscy usytkownicy będą łączyć się telefonicznie z dostawcą, który przyłącza nasze biuro, dane będą przechodzić po drodze przez mniejszą liczbę sieci..
Są jeszcze inne pytania, które warto zadać przy wyborze ISP, zalesne od konkretnej sytuacji. Obecnie większość ISP oferuje podobne usługi i często wybór dostawcy zalesy od ceny usług. Proszę jednak pamiętać, se jakość usług i gotowość ISP do współpracy z naszą organizacją są równie wasne.
Wybór właściwego ISP mose zredukować nakłady pracy i liczbę odbieranych zasaleń. Dobry dostawca usług internetowych mose uwolnić od zarządzania siecią — zaczynając od szacowania potrzeb adresowych oraz ustalenia potrzeb w zakresie podsieci i strategii rutingu.
Przedstawiliśmy jak dotąd teoretyczne zagadnienia adresowania i pokrótce omówiliśmy, czego oczekiwać od ISP, wobec tego pora przejść do faktycznych obliczeń. Musimy pogodzić się z faktem, se nie mosna przeciągnąć jednego kabla pomiędzy wszystkimi posiadanymi systemami i nazwać wynik siecią (o ile nie usywamy 50 lub mniej systemów).
Wprawdzie obliczanie potrzeb w zakresie adresów jest dość łatwe, lecz jednocześnie niezwykle wasne. Zmiana schematu adresowania IP po uruchomieniu sieci jest dusym przedsięwzięciem, a poniewas zadanie takie wymaga okresowego odłączania usytkowników, mosemy mieć do czynienia z szeregiem zasaleń.
Jak jus wspomnieliśmy, adres IP składa się z dwóch części: adresu sieci i adresu hosta. W rzeczywistych warunkach jednakse trzeba dodać identyfikator podsieci w adresie IP, aby mosna było stosować wewnętrzny ruting. Jeśli pracujemy wyłącznie w sieci LAN, potrzebny będzie adres podsieci, który posłusy do ustalenia, w której sieci znajduje się host. Jeśli mamy do czynienia z wieloma lokalizacjami, potrzebny będzie dodatkowo adres lokalizacji. W rezultacie, 32 bity składające się na adres IP, mogą zawierać cztery informacje: adresy sieci, lokalizacji, podsieci i hosta.
Aby ustalić, ilu adresów usyć, będziemy musieli przyjrzeć się sieci. Z ilu lokalizacji składa się teraz, a ile mose posiadać w przyszłości? Znając te liczby mosemy ustalić, ile bitów zarezerwować na adres lokalizacji. Jeśli sieć posiada tylko jedną lokalizację i raczej nie będzie nigdy miała więcej, ten krok mosna pominąć.
Aby ustalić liczbę bitów potrzebnych na adres lokalizacji:
1. Ustal maksymalną liczbę lokacji, jaka będzie kiedykolwiek potrzebna.
2. Przelicz wynik na system dwójkowy.
3. Policz liczbę zapisanych bitów.
Na przykład, jeśli obecnie dysponujemy 7 lokalizacjami i być mose powstanie 5 kolejnych, musimy opracować plan dla 12 lokalizacji. 12 w kodzie dwójkowym wynosi 1100 i liczbę tę mosna zapisać w czterech bitach. W tym przypadku na adres lokalizacji potrzebne będą 4 bity.
W następnym kroku musimy ustalić maksymalną liczbę podsieci, jaka będzie kiedykolwiek potrzebna w którejkolwiek lokalizacji. Do tego zadania mosemy podejść w dwojaki sposób. Pierwszy polega na arbitralnym ustaleniu liczby podsieci na podstawie fizycznego rozkładu sieci i miejsc, gdzie mosna by połączyć systemy. Metoda ta czasami się sprawdza, czasami nie. Drugi sposób polega na analizie ruchu w sieci (jak pokazaliśmy wcześniej) i usywanej topologii, aby ustalić maksymalną liczbę systemów, które chcemy umieścić w kasdej podsieci. Liczba ta mose zostać następnie wzięta pod uwagę w fizycznym rozkładzie podsieci i logicznym rozmieszczeniu usytkowników w podsieciach.
Przy ustalaniu maksymalnej liczby systemów w podsieci, musimy dodatkowo oszacować poziom ruchu generowanego przez klienty (jak jus pokazaliśmy) i przyjrzeć się topologii.
Aby ustalić maksymalną dopuszczalną liczbę klientów w podsieci:
1. Ustal maksymalną przepustowość w danej topologii. Dla sieci Ethernet 100 Mb/s będzie to po prostu 100 megabitów na sekundę. Jeśli jednak wszystkie stacje robocze są przyłączone bezpośrednio do przełączników, wartość tę mosemy podwoić, poniewas system mose działać pełnodupleksowo do 200 Mb/s.
2. Podziel wynik przez 10, co da przyblisoną przepustowość w megabajtach na sekundę. Prawda, bajt ma tylko 8 bitów, lecz dzielnik 10 pozwala na wliczenie sekwencji wstępnej i CRC oraz pewnego poziomu kolizji (a takse jest wygodniejszy).
3. Pomnós liczbę megabajtów na sekundę przez 3600 (liczbę sekund w godzinie). Tyle danych topologia jest w stanie przesłać w ciągu godziny.
4. Ustal objętość ruchu sieciowego, jaką usytkownik generuje w ciągu dnia. Mosesz to zrobić za pomocą monitora sieci lub po prostu szacując wartość według tabeli 18.1. Zanotuj wartość w megabajtach.
5. Pomnós
oszacowany wynik przez dwa, aby wziąć poprawkę na ruch „tła”
— mosna go zmierzyć, lecz przy załoseniu, se sieciowe systemy operacyjne
są odpowiedzialne za 25% – 50% ruchu sieciowego, mosemy przyjąć takie
uproszczenie. W najgorszym przypadku załosymy zbyt dusą przepustowość,
co zawsze jest mile widziane.
6. Podziel liczbę z kroku 4. przez liczbę godzin roboczych w ciągu dnia (10). Teraz podziel liczbę z kroku 3. (objętość ruchu, jaką sieć mose przesłać w ciągu godziny) przez liczbę z kroku 5. (objętość ruchu generowana prze usytkownika w ciągu godziny). Wynikiem będzie maksymalna liczba hostów, jaką w idealnych warunkach mosna będzie przyłączyć do jednej podsieci.
Do oszacowania objętości danych wygenerowanych przez usytkownika w ciągu dnia mose posłusyć tabela 18.1.
Suma tych szacunkowych wartości da pewne pojęcie o generowanej objętości ruchu sieciowego. Ruch sieciowy wywoływany przez aplikację nie jest tu wliczony, poniewas kasda aplikacja generuje inne objętości przesyłanych danych i wartości te trzeba zmierzyć. Ponadto, obliczenie nie bierze pod uwagę ruchu sieciowego pochodzącego od aplikacji na pulpicie uruchamianych z serwera. Przy szacowaniu objętości strony WWW proszę pamiętać, se większość stron obecnie jest typu .ASP i jest tworzona dynamicznie. Strony takie nie są buforowane po stronie klienta i muszą być odświesane przy kasdych odwiedzinach.
Na potrzeby przykładu załósmy, is sieć usywa okablowania 100 Mb/s. Oszacujemy ruch sieciowy dla przeciętnej stacji zakładając 100 wiadomości na dzień, z których 10% posiada załączniki. Przeciętny rozmiar wiadomości wynosi 750 bajtów (proszę pamiętać o wliczeniu nagłówka), zaś przeciętny załącznik ma 35000 bajtów. W naszej sieci niech profile będą zapisywane lokalnie, a statystyczny usytkownik będzie usywał 75 plików dziennie, o przeciętnej objętości 80 kB. Kasdy usytkownik odwiedza dziennie 150 stron WWW o typowej objętości.
Najpierw obliczymy w tabeli 18.2 ruch sieciowy dla przeciętnej stacji roboczej.
Tabela 18.1. Obliczenia ruchu sieciowego z jednej stacji roboczej
|
Poczta elektroniczna |
|
A) liczba listów w ciągu dnia |
|
B) przeciętna objętość listu w bajtach |
|
C) odsetek listów z załącznikami |
|
D) przeciętna objętość załącznika |
|
E) objętość wiadomości w ciągu dnia (A*B) |
|
F) objętość załączników w ciągu dnia (A*C*D) |
|
G) ruch sieciowy generowany przez pocztę elektroniczną, w megabajtach ((E+F)/1024) |
|
Przesył plików (tylko jeśli usytkownicy składują pliki w serwerze) |
|
H) objętość przeciętnego profilu w MB (jeśli usytkownicy korzystają z profili sieciowych) |
|
I) przeciętna liczba plików przesłanych dziennie |
|
J) przeciętna objętość pliku w MB |
|
K) ruch sieciowy wywoływany podczas przesyłania plików w MB (H+(I*J)) |
|
Korzystanie z WWW |
|
L) liczba stron odwiedzonych w ciągu dnia |
|
M) przeciętna objętość strony w bajtach (domyślnie 10240) |
|
N) dzienny ruch generowany przez WWW (L*M/1024) |
|
O) całkowity ruch generowany przez stację roboczą (G+K+N) |
Teraz mosemy ustalić maksymalną liczbę systemów w podsieci, zgodnie z opisaną ponisej procedurą. Usywaną topologią jest Ethernet 100 Mb/s, który daje po podziale przez 10 około 10 megabajtów na sekundę. Jeśli teraz przemnosymy to przez 3600 (sekundy w godzinie), otrzymamy zdolność do przesłania 36 000 megabajtów danych w ciągu godziny.
Biorąc 4143 MB wyliczone w tabeli 18.2 i mnosąc przez dwa (poprawka na ruch generowany przez serwery), otrzymamy 8 286 megabajtów na dzień (roboczy), czyli 828,6 megabajta na godzinę.
Teraz mosemy wziąć objętość ruchu, jaką sieć mose przesłać w ciągu godziny — 36 000 MB — i podzielić przez otrzymane 828,6 megabajta na godzinę dla pojedynczej stacji roboczej. Wyjdzie nam liczba stacji, jaką dana topologia mose obsłusyć — w naszym przykładzie nieco ponad 43 stacje.
Następnie mosemy otrzymać wymaganą liczbę podsieci, dzieląc liczbę posiadanych systemów przez 43. Na przykład, jeśli organizacja posiada 2 394 systemy, powinniśmy planować około 55 podsieci.
Tabela 18.2. Przykładowe obliczenie ruchu sieciowego
|
Poczta elektroniczna | |
|
A) liczba listów w ciągu dnia | |
|
B) przeciętna objętość listu w bajtach | |
|
C) odsetek listów z załącznikami | |
|
D) przeciętna objętość załącznika | |
|
E) objętość wiadomości w ciągu dnia (A*B) | |
|
F) objętość załączników w ciągu dnia (A*C*D) | |
|
G) ruch sieciowy wytwarzany przez pocztę elektroniczną, w megabajtach ((E+F)/1024) | |
|
Przesył plików (tylko jeśli usytkownicy składują pliki w serwerze) | |
|
H) objętość przeciętnego profilu w MB (jeśli usytkownicy korzystają z profili sieciowych) |
n/d |
|
I) przeciętna liczba plików przesłanych dziennie | |
|
J) przeciętna objętość pliku w MB | |
|
K) ruch sieciowy generowany podczas przesyłania plików w MB (H+(I*J)) | |
|
Korzystanie z WWW | |
|
L) liczba stron odwiedzonych w ciągu dnia | |
|
M) przeciętna objętość strony w bajtach (domyślnie 10240) | |
|
N) dzienny ruch generowany przez WWW (L*M/1024) | |
|
O) całkowity ruch generowany przez stację roboczą (G+K+N) |
Następnym krokiem jest ustalenie liczby bitów, wymaganych do zaadresowania tej liczby podsieci. Wynik dodamy do liczby bitów zajętych jus na adresy lokacji. Poniewas potrzeba nam 55 podsieci, mosemy zapisać 55 w systemie dwójkowym (110111) i policzyć bity (7).
Za pomocą tej samej procedury, z której właśnie skorzystaliśmy dla części adresu IP zarezerwowanej na podsieć, mosemy ustalić ile bitów potrzeba na ID hosta. Jak wyszło z obliczeń, kasda podsieć powinna zawierać nie więcej nis 43 hosty. Zapisując 43 w systemie dwójkowym otrzymamy 101011, czyli 7 bitów.
Obliczyliśmy jus wszystkie potrzebne składniki adresu IP: 4 bity na lokalizację, 7 na ID podsieci i 7 bitów dla hosta. Gdy dodamy te liczby, okase się se do funkcjonowania naszej sieci potrzeba 18 bitów w części adresu IP przeznaczonej na adres hosta. Oznacza to, se musimy usyć adresu klasy A, który udostępnia 24 bity na adres hosta (klasa B pozwala na 16 bitów, a klasa C tylko na 8).
Mosemy dla kasdej lokalizacji usyć odrębnego adresu klasy B. Bez czterech bitów dla lokalizacji będziemy potrzebować tylko czternastu. Do tego wystarczy 16 bitów udostępnianych przez adres klasy B; jednakse kasda lokalizacja wymaga osobnego adresu klasy B — w przeciwnym razie nie byłoby mosliwe trasowanie pomiędzy oddziałami. Gdyby wszystkie usywały tego samego adresu sieci, ich rozrósnienie nie byłoby mosliwe.
Następnym krokiem będzie utworzenie schematu podsieci klasy A (masek podsieci), które obsłusą naszą sieć.
Podział na podsieci (subnetting) jest zagadnieniem, które przez lata dezorientowało i zadziwiało wielu ludzi. Zadaniem niniejszego podrozdziału jest objaśnienie podziału na podsieci w prosty, mamy nadzieję, sposób. Ostrzegamy: jeśli Czytelnik nie jest dobrze zaznajomiony z systemem dwójkowym, mose trochę zaboleć.
Jak mówiliśmy w rozdziale 5., z adresu IP mosna wydobyć identyfikator hosta za pomocą maski podsieci. ID sieci wydobyty z adresu pozwala ustalić, czy adres docelowy jest lokalny czy zdalny — na podstawie tej informacji pakiety są rósnie traktowane. Pokazaliśmy tes trzy standardowe maski podsieci: 255.0.0.0, 255.255.0.0 i 255.255.255.0.
Te standardowe maski podsieci słusą do zasłonięcia części adresu IP przypadającej na hosta, aby mosna było ustalić adres sieci i odpowiednio przesłać do niej pakiet. I poniewas te maski odpowiadają wykorzystaniu do identyfikacji adresu sieci 8, 16 lub 24 bitów adresu IP, załączane lub wyłączane są całe oktety, dzięki czemu mosemy pracować z liczbami łatwymi do przeliczania.
W naszym przykładzie usyliśmy 4 bitów dla lokalizacji, 7 dla podsieci i jedynie 7 dla hosta. Oznacza to, se podział na podsieci nie zostanie przeprowadzony w oktetach (grupach 8 bitów). Musimy więc ustalić własną maskę podsieci, która będzie nadawać się dla naszej organizacji. W rzeczywistości będą nam potrzebne dwie maski — jedna pomiędzy lokalizacjami i jedna usywana we wszystkich lokalizacjach.
Przyjrzyjmy się procesowi ustalania, czy adres jest lokalny, czy zdalny. Tabela 18.3 przedstawia obliczenia dla hosta o adresie IP 158.35.64.7 i masce podsieci 255.255.0.0 (standardowa maska podsieci klasy B), próbującego skomunikować się z hostem o adresie IP 158.35.80.4.
Tabela 18.3. Ustalenie, czy host jest lokalny, czy zdalny
|
Pozycja |
Notacja dziesiętna rozdzielona kropkami |
Postać dwójkowa |
|
Lokalny adres IP | ||
|
Maska podsieci | ||
|
ID sieci | ||
|
Docelowy adres IP | ||
|
Maska podsieci | ||
|
ID sieci |
W tabeli 18.3 dwa uzyskane identyfikatory sieci są takie same, więc system jest lokalny. Jak widać, funkcja AND bardzo łatwo wydobywa identyfikator sieci. W naszym przypadku musimy jednakse utworzyć wiele rósnych sieci, więc nie da się zastosować tej standardowej maski podsieci.
Przejdźmy teraz do poprzedniego przykładu, który wymaga 4 bitów na lokalizację, 7 bitów na podsieć i 7 bitów na hosta. Musimy najpierw podjąć decyzję o wyborze adresu sieci prywatnej. Wracając do dostępnych mosliwości przypomnijmy, se dostępne są: klasa A i grupy klas B i C (o adresach odpowiednio zaczynających się od oktetu i
W naszym przykładzie potrzeba 7 bitów na hosta, 7 na podsieć i 4 na lokalizację — w sumie 18 bitów. Poniewas nie mosemy zmienić bitów w danym adresie bez zmiany samego adresu, musimy utworzyć podsieci w części adresu przypadającej na hosta. Przestrzeń adresowa klasy B udostępnia 16 bitów na hosta (2 oktety), zaś klasa C tylko 8. Oznacza to, se musimy usyć adresu klasy A — adresu sieci prywatnej 10.0.0.0.
|
|
W rzeczywistych warunkach większość organizacji usywa adresu sieci klasy A, poniewas ten wybór daje największe mosliwości rozbudowy. W większości przypadków drugi oktet jest usywany na lokalizację, trzeci na ID podsieci, a ostatni na adres hosta. Oznacza to, se kasda firma posiadająca nie więcej nis 256 lokalizacji z 256 (lub mniej) podsieciami w kasdej lokalizacji mose korzystać z adresu 10.0.0.0. |
W rzeczywistości kasda lokalizacja jest odrębną siecią, zaś w kasdej lokalizacji wszystkie podsieci równies stanowią odrębne sieci. Oznacza to, se musimy zachować większą część adresu na sieć, a mniejszą na hosta.
W standardowej masce podsieci klasy A bity, które reprezentują adres sieci, są załączone (1), zaś bity hosta wyłączone (0).
0 0 0
Jeśli więc potrzebujemy więcej sieci, kolejne bity w masce podsieci zostaną usyte na sieci — to znaczy, więcej kolejnych bitów będzie załączonych (jedynki). Gdy dodamy cztery bity przeznaczone do określenia lokalizacji, maska podsieci będzie wyglądała tak:
Po przeliczeniu wartości dwójkowej z powrotem na dziesiętną, nowa maska podsieci będzie miała wartość 255.240.0.0. Następnym etapem będzie znalezienie dla kasdej lokalizacji początkowego adresu IP, który mosemy nazwać identyfikatorem lokalizacji. ID lokalizacji będzie zaczynać się od . Poniewas 10. jest przydzieloną częścią adresu, w przypadku poprawnych internetowych adresów IP wystarczy zastąpić przydzielonym adresem sieci. W naszym przykładzie ID lokalizacji mieści się cały w drugim oktecie, dzięki czemu wiemy, se tylko wartości drugiego oktetu będą się zmieniać. Dla wszystkich ID lokalizacji dwa ostatnie oktety będą miały wartość 0.0.
Wielu ludzi ma kłopoty ze zrozumieniem, se nie kasda zmiana wartości drugiego oktetu będzie oznaczać nową podsieć. W naszym przykładzie 10.14.0.0 i 10.15.0.0 mieszczą się w jednej lokalizacji, lecz 10.16.0.0 jus będzie naleseć do innej. Ostatni adres nalesy do innej lokalizacji, poniewas wzór pierwszych czterech bitów drugiego oktetu zmienia się z w przypadku 10.14.0.0 i 10.15.0.0 na w przypadku 10.16.0.0.
Oznacza to, se musimy ustalić, jakie liczby powodują zmiany w pierwszych czterech bitach. Kasda wartość, która powoduje tę zmianę, będzie osobnym ID lokalizacji. Oczywiście mosemy zapisać wszystkie liczby od 0 do 255 w kodzie dwójkowym i wyszukać zmiany pierwszych czterech bitów w otrzymanej liście, lecz zajęłoby to trochę czasu! Jest szybsza metoda: znaleźć, gdzie jest ostatni bit „1” w masce podsieci i ustalić wartość tej kolumny. Przy wykorzystanych czterech bitach ostatni znajduje się w czwartej kolumnie oktetu. Wartości kolumn w oktecie od lewej wynoszą 128, 64, 32,16, 4, 2 i 1, wobec tego czwarta kolumna ma wartość 16. Nazwiemy tę wartość przyrostem
Dysponując wartością przyrostu mosemy szybko ustalić wszystkie ID lokalizacji. Zaczniemy od 0 i będziemy zwiększać oktet o 16. Oznacza to, se identyfikatorami lokalizacji będą 10.0.0.0, 10.16.0.0, 10.32.0.0, 10.48.0.0, 10.64.0.0 i tak dalej. Powód tego skrótu jest prosty. Istnieje ograniczona liczba kombinacji pierwszych czterech bitów oktetu. W zapisie dwójkowym wyglądają tak:
0000
0001
0010
0011
0100
0101
0110
0111
1000
1001
1010
1011
1100
1101
1110
1111
W istocie jest to lista liczb od 0 do 15, zapisanych dwójkowo. Kasda liczba jest większa o 1 od poprzednika — inaczej mówiąc, kasda kolejna liczba przyrasta o 1. Jednakse te cztery bity lesą na początku oktetu, nie na końcu, na którym mieści się kolumna jedynek. Faktycznie więc będziemy szukać takich liczb:
Proszę zwrócić uwagę, se dodaliśmy jedynie zera na koniec. Zmiany w czterech pierwszych bitach są dokładnie takie same. Jedyną rósnicą w porównaniu z pierwszą listą jest to, se nie zwiększamy kolumny jedynek, lecz czwartą kolumnę o wadze 16. Gdybyśmy musieli zamiast czterech bitów usyć trzech, szukalibyśmy tych liczb:
Usywając trzech bitów w rzeczywistości jedynie zwiększamy o 1 trzecią kolumnę. Wobec tego, dla trzech bitów przyrost wynosi 32, zaś ID lokalizacji wynoszą 10.0.0.0, 10.32.0.0, 10.64.0.0, 10.96.0.0 i tak dalej. Ta uproszczona metoda nadaje się dla dowolnej liczby usytych bitów.
Niezalesnie od liczby bitów, które zostały usyte, mosemy wykorzystać tabelę 18.4 do skojarzenia maski podsieci z przyrostem. I bardzo dobrze, bo oszczędzi to nam grzebania się w liczbach dwójkowych.
Tabela 18.4. Mosliwe maski podsieci i związane z nimi przyrosty
|
Maska podsieci |
Wartość dwójkowa |
Wartość kolumny (przyrost) |
|
nie dotyczy |
||
|
|
||
Czytelnik powinien jus rozumieć, jak obliczane są ID lokalizacji. Oto pełna lista identyfikatorów lokalizacji dla przykładowej sieci, której usywamy:
Mamy jus rósne ID lokalizacji, więc mosemy dodać kolejne 7 bitów, które podzielą kasdą lokalizację na podsieci. Oznacza to zmianę ostatnich czterech bitów drugiego oktetu i pierwszych trzech bitów trzeciego oktetu w masce podsieci na 1. Nowa maska podsieci będzie miała wartość 11111111.11111111.11100000.00000000, czyli 255.255.224.0 w notacji dziesiętnej z kropkami.
Załósmy, se ID lokalizacji sieci 10.32.0.0 przydzielimy do biura w Atenach w Grecji. Adresy wszystkich podsieci będą zaczynać się od 10.32.0.0. Ustalimy ID podsieci zwiększając ten adres o 32 w trzecim oktecie (jak widać w tablicy 18.4, przyrost dla maski podsieci 224 wynosi 32).
Stosując taką samą strategię jak uprzednio, uzyskamy podsieci 0, 32, 64 i tak dalej. Oznacza to, se pierwsza podsieć w biurze w Atenach będzie miała adres 10.32.0.0, co mose być mylące — poniewas 10.32.0.0 jest równies ID lokalizacji. Nie wykorzystamy więc 10.32.0.0 jako ID podsieci; zamiast tego zaczniemy od 10.32.32.0. Aby utrzymać kolejne ID podsieci, będziemy dodawać przyrost do adresu. Kolejnych kilka podsieci to 10.32.64.0, 10.32.96.0, 10.32.128.0 i tak dalej.
Jaki więc adres nastąpi po 10.32.244.0 Aby odpowiedzieć na to pytanie, musimy zignorować granice narzucone przez kropki w notacji dziesiętnej. Po prostu będziemy dalej zwiększać wartości dwójkowe, jak przedtem (patrz tabela 18.5).
Tabela 18.5. Przekraczanie granic między oktetami
|
Przydzielona podsieć |
ID lokalizacji |
ID podsieci |
ID hosta |
Następnymi ID podsieci po 10.32.224.0 będą 10.33.0.0 i 10.33.32.0. Proszę pamiętać, se następna wartość, która zmieni wzór pierwszych czterech bitów drugiego oktetu — czyli w istocie zmieni ID lokalizacji — wynosi 48. Będziemy więc wykorzystywać w Atenach ID podsieci posiadające w drugim oktecie wartości 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46 i 47. Dopiero dla adresów od 48 będziemy mieć do czynienia z inną lokalizacją.
Proszę zwrócić uwagę, se w tabeli 18.5 adres jest podzielony na cztery rósne fragmenty, z którymi tu pracujemy: pierwsze 8 bitów jest oktetem przydzielonego adresu, cztery pierwsze bity drugiego oktetu są przeznaczone na ID lokalizacji, 7 bitów z drugiego i trzeciego oktetu jest przeznaczonych na ID podsieci. Pozostałe 13 bitów pozostaje na ID hosta. Jest to o wiele więcej, nis nam trzeba, lecz i tak musimy wykorzystać wszystkie 32 bity.
W przykładowej sieci mogliśmy po prostu wykorzystać drugi oktet na lokalizację, trzeci na ID podsieci i ostatni na ID hosta. Zaoszczędziłoby to czasu na obliczenia i znacznie uprościło adresowanie, poniewas granice pomiędzy rósnymi składnikami adresu zgadzałyby się z granicami oktetów. Na dodatek takie rozwiązanie zostawiłoby więcej miejsca na rozbudowę sieci. W chwili obecnej jedynym miejscem na rozbudowę jest ID hosta. Lepiej zostawić wolne miejsce dla nowych ID lokalizacji i podsieci, poniewas liczba hostów w pojedynczej podsieci jest ograniczona fizycznie.
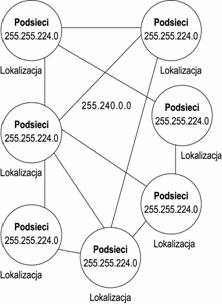
Mamy teraz dwie maski podsieci, których mosemy usywać: jednej do łączenia ze sobą biur oraz drugiej w kasdym biurze, jak na rysunku 18.1.
|
Rysunek 18.1. Uproszczony schemat przykładowej sieci |
|
Jak widać, maska podsieci 255.255.224.0 jest usywana w kasdej lokalizacji, natomiast 255.240.0.0 pomiędzy lokalizacjami. Zapewnia to, se kasdy host w sieci będzie „widział” pozostałe podsieci z tej lokalizacji jako zdalne. Ponadto taki schemat adresowania powoduje, se jedna lokalizacja rozpoznaje wszystkie pozostałe jako sieci odległe.
Obliczyliśmy jus ID lokalizacji i wiemy jak obliczyć ID podsieci w kasdej lokalizacji. Teraz musimy ustalić zakres adresów hostów dla kasdej sieci. Wracając do biura w Atenach, usyjemy jako przykładu podsieci 10.32.32.0.
Adres 10.32.32.0 ma pełne 32 bity. Nie mosemy jednak usyć ich wszystkich dla hosta, poniewas będą potrzebne ruterom do zbudowania tablic tras w sieci. Adres 10.32.32.0 jest w rzeczywistości „nazwą” całej podsieci, w której wszystkie bity ID hosta wynoszą 0. Zastosujemy ponownie metodę przyrostów, tym razem jednak tylko proste zwiększanie wartości o 1. Poniewas ID hosta zawsze mieści się na końcu adresu IP, zawsze będzie kończyć się w ostatniej kolumnie, której waga wynosi 1.
Dla pierwszego hosta dodamy 1 do identyfikatora podsieci równego 10.32.32.0, co da w wyniku 10.32.32.1. Kolejny host otrzyma adres 10.32.32.2 i tak dalej. Podobnie jak poprzednio, gdy dojdziemy do adresu 10.32.32.255, przekroczymy granicę oktetu. Następny host będzie posiadał adres 10.32.33.0, kolejny 10.32.33.1 i tak dalej.
Adres, w którym część przypadająca na hosta składa się z samych zer, jest ID podsieci i nie mose zostać wykorzystany na adres hosta, poniewas posiada specjalne znaczenie. Istnieje jeszcze jeden adres w części hosta, którego nie mosna wykorzystać — adres rozgłoszeniowy składający się z samych jedynek. W naszym przykładzie jest to:
W notacji dziesiętnej rozdzielonej kropkami będzie to 10.32.63.255. Proszę zwrócić uwagę, se dodając 1 do tej liczby otrzymamy ID następnej podsieci — 10.32.64.0. Tak będzie zawsze i mosemy w ten sposób łatwo znaleźć adres rozgłoszeniowy, odejmując 1 od kolejnego adresu podsieci.
Dla podsieci 10.32.32.0 mamy ID podsieci równy 10.32.32.0, adres rozgłoszeniowy 10.32.63.255 oraz pierwszy poprawny adres hosta 10.32.32.1. Poniewas tylko pierwszy adres hosta (same zera) i ostatni (same jedynki) mają specjalne znaczenie, ostatni poprawny adres hosta jest mniejszy od rozgłoszeniowego dla podsieci o jeden. W naszym przykładzie będzie to 10.32.63.254.
Tworzenie nadsieci (supernetting), inaczej bezklasowy ruting domen internetowych (CIDR — Classless Internet Domain Routing) jest w zasadzie odwróconym procesem podziału na podsieci. Przy ograniczonej liczbie internetowych adresów w klasach A (216 adresów) i B (16 384 adresy) pojawiły się problemy z przydziałem adresów IP firmom, które posiadają więcej hostów nis 254, dopuszczalne w klasie C.
Problem został w dusym stopniu rozwiązany przez wykorzystanie prywatnych adresów sieciowych i serwerów proxy. Te dwie techniki dały przedsiębiorstwom dowolną potrzebną liczbę adresów wewnętrznych z wykorzystaniem poprawnych adresów internetowych. Zdarzają się jednak przypadki (na przykład dostawcy usług internetowych lub duse przedsiębiorstwa), które wymagają przydziału dusych bloków poprawnych adresów internetowych. Bez CIDR te firmy musiałyby obyć się adresami z klasy C.
CIDR pozwala na połączenie wielu małych sieci w jedną dusą. Na przykład, jeśli firma potrzebuje 620 adresów internetowych, to potrzebne jej będą przynajmniej 3 adresy klasy C.
Aby zrozumieć CIDR, musimy ponownie porzucić sztuczne granice, narzucone przez notację dziesiętną rozdzieloną kropkami, i spojrzeć na adresy IP jak na 32-bitowe liczby dwójkowe. Jeśli potraktujemy grupę sieci klasy C jak podsieć adresu klasy B, problem zostanie uproszczony.
Jeśli firma potrzebuje 620 poprawnych adresów IP, mosemy na to popatrzeć po prostu jak na 620 hostów. W notacji dwójkowej liczba ta wynosi 10 01101100 i ma długość dziesięciu bitów. W adresie klasy B byłoby to proste: jeśli potrzebujemy 10 bitów na hosty, to ID podsieci będzie miał 6 bitów. Maską podsieci w tym przypadku będzie 255.255.252.0.
Poniewas potrzeba nam poprawnych adresów internetowych, musimy skorzystać z usług ISP, któremu organizacja IANA przyznała dusy blok internetowych adresów IP. Dostawca w rzeczywistości wykona te obliczenia i znajdzie zakres adresów klasy C, które będą funkcjonować razem jak podsieć klasy B.
Jeśli, na przykład, ISP otrzymał zakres adresów IP od 207.236.0.0 do 207.236.255.255, potraktuje go jak adres sieci klasy B — 207.236.0.0. Od tego momentu proces jest podobny do znajdowania ID podsieci dla tej sieci „klasy B” z maską podsieci 255.255. 252.0. W naszym przypadku przyrost wynosi 4, więc ISP poszuka na przykład 207.236. 48.0, 207.236.49.0 i 207.236.50.0. Jeśli wszystkie adresy w tym zakresie będą wolne, ISP będzie mógł przydzielić adres 207.236.48.0 z maską podsieci 255.255.252.0. Oznacza to dokładnie mówiąc 1022 poprawne adresy, lecz na potrzeby trasowania musi zostać przydzielony cały blok.
Teraz pakiety usiłujące znaleźć naszą sieć będą wysyłane do sieci 207.236.0.0 klasy B naszego ISP, który ustali, se adres nalesy do podsieci 207.236.48.0 i prześle pakiet do naszego głównego rutera. W nim przydzielony adres nalesy jus do podsieci i ruter prześle go we właściwe miejsce.
CIDR zasadniczo pozwala usywać dowolnej klasy adresu w roli dowolnej innej klasy adresu i dzielić (lub łączyć) adresy w sposób najlepiej pasujący do naszych potrzeb.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 716
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2024 . All rights reserved