| CATEGORII DOCUMENTE |
| Bulgara | Ceha slovaca | Croata | Engleza | Estona | Finlandeza | Franceza |
| Germana | Italiana | Letona | Lituaniana | Maghiara | Olandeza | Poloneza |
| Sarba | Slovena | Spaniola | Suedeza | Turca | Ucraineana |
DOCUMENTE SIMILARE |
|
Ostatnio najmodniejszym tematem jest XML, czyli eXtensible Markup Language. Jeseli spojrzymy do którejkolwiek gazety „komputerowej”, to znajdziemy wzmiankę o XML, często w połączeniu ze skrótami SAX, XSLT, DOM, DTD i innymi. Przeglądając katalogi ksiąsek, równies mosna natrafić na bardzo wiele pozycji poświęconych XML i tematom pokrewnym.
Podczas wstępnych rozmów z wydawnictwem Wrox omawialiśmy koncepcję i zawartość tej ksiąski oraz przykładową aplikację, która miała posłusyć jako szkielet pomagający pokazać metody omawiane w kasdym z rozdziałów. Aby ta aplikacja działała, potrzebne były jakieś przykładowe dane do katalogu wyposyczalni płyt DVD. Wydawnictwo natychmiast wysłało nam dane (podziękowania dla DanM!) w formacie XML. Oto początkowy fragment tego pliku pokazany dla oddania atmosfery (przy okazji: ceny nie są poprawne):
<?xml version='1.0' encoding='UTF-8' standalone='yes' ?>
<!DOCTYPE catalog [
<!ELEMENT catalog (dvd+) >
<!ELEMENT dvd (title, price, director, actors, year_made)>
<!ATTLIST dvd
asin CDATA #REQUIRED >
<!ELEMENT title (#PCDATA)>
<!ELEMENT price (#PCDATA)>
<!ELEMENT director (#PCDATA)>
<!ELEMENT actors (actor+)>
<!ELEMENT actor (#PCDATA)>
<!ELEMENT year_made (#PCDATA)>
]>
<catalog>
<dvd asin='0780020707'>
<title>Grand Illusion</title>
<price>29.99</price>
<director>Jean Renoir</director>
<actors>
<actor>Jean Gabin</actor>
</actors>
<year_made>1938</year_made>
</dvd>
<dvd asin='0780020685'>
<title>Seven Samurai</title>
<price>27.99</price>
<director>Akira Kurosawa</director>
<actors>
<actor>Takashi Shimura</actor>
<actor>Toshiro Mifune</actor>
</actors>
<year_made>1954</year_made>
</dvd>
</catalog>
Były to rzeczywiście dobre dane przykładowe i nie byliśmy raczej zdumieni formatem przekazu, ale w jaki sposób mieliśmy je przekształcić na postać usyteczną w naszej bazie danych? Początkowo zakładaliśmy, se dane będą dostarczone w postaci pliku z polami oddzielonymi za pomocą przecinków (tzw. format CSV, ang. comma separated variable) lub w innym formacie łatwo przyswajalnym przez bazę danych.
Oczywiście, mosna było napisać nowy program w języku C (lub w języku Python, Perl itd.), który zmieniałby format zapisu danych. Myśleliśmy takse o zastosowaniu programów flex i bison wspomagających obsługę składni. Zastanawialiśmy się nad napisaniem programu przekształcającego w postaci arkusza stylu (XSL, eXtensible Stylesheet Language), próbując rozgryźć ten plik za pomocą programu awk lub wyraseń regularnych języka Perl
Doszliśmy w końcu do wniosku, se dokonanie „poprawnego” rozbioru XML będzie mosliwe za pomocą parsera XML. Po cós budować własny parser, jeśli istnieje kilka eleganckich i bezpłatnych programów? Ich zastosowaniem zajmiemy się w tym rozdziale.
Opiszemy tutaj następujące zagadnienia:
q Krótki przegląd dokumentów XML i sposoby ich definiowania,
q Przegląd zastosowań niektórych programów wspomagających przetwarzanie dokumentów XML w systemie Linux,
q Omówienie wywołań zwrotnych programu SAX zastosowanych do pobierania danych z dokumentu XML.
Zanim zajmiemy się problemami odzysku danych z naszego dokumentu dvdcatalog.xml, powinniśmy dokładnie poznać, czym jest XML i jak są tworzone dokumenty XML.
Na pierwszy rzut oka dokumenty XML wyglądają bardzo podobnie do dokumentów HTML, poniewas zawierają znaczniki, atrybuty znaczników oraz dane między znacznikami. Takie podobieństwo wynika z tego, se zarówno HTML, jak i XML wywodzą się ze wspólnego źródła, czyli z SGML (Standard Generalized Markup Language). XML jest podzbiorem SGML i — mimo podobieństwa do HTML występują między nimi bardzo wasne rósnice:
q HTML jest usywany głównie dla celów zobrazowania informacji.
Niezalesnie od tego, se pierwotne wersje HTML koncentrowały się wokół opisu elementów dokumentu (np. „to jest nagłówek”), to później zaczęto stosować wiele znaczników (ang. markup tags) niosących informację o sposobie wyświetlania danych, nie rozszerzając jednak ich znaczenia na definicje faktycznej zawartości dokumentu. Znaczniki w XML nie zawierają zaś informacji o sposobie prezentacji dokumentu — mówią natomiast o tym, czym są w istocie przekazywane w nim dane. Oczywiście, mosemy usyć znaczenia danych do określenia sposobu ich prezentacji, ale mimo wszystko jest to bardzo istotne rozrósnienie. Spójrzmy na pierwszy film opisany w naszym przykładowym dokumencie. Na stronie HTML opisującej ten film moglibyśmy widzieć wyrósniony tekst „Jean Renoir” i „Jean Gabin”, oznaczający osoby. Bez informacji kontekstowej nie mosna byłoby jednak powiedzieć, kto jest aktorem, a kto resyserem. W XML mosemy oznaczyć te pola właśnie odpowiednio jako resysera i jako aktora, czyli przekazać informację o ich znaczeniu.
q Dokumenty HTML nie są spełniają wymagań XML.
Odnosi się to nawet do tych dokumentów, które są zgodne z definicjami HTML w wersji 4. Została zdefiniowana nowa wersja HTML oznaczana skrótem XHTML, która zapewnia równoczesną zgodność definicji XHTML i XML.
q W znacznikach XML jest brana pod uwagę wielkość liter.
W HTML znacznik <H1> jest traktowany tak samo jak znacznik <h1>, lecz w XML są to całkowicie rósne znaczniki. W języku angielskim nieco dziwna wydaje się zamiana wielkich liter na małe, ale w innych językach uzalesnienie XML od wielkości liter jest przyjmowane w sposób naturalny i pozwala uniknąć wielu pułapek spotykanych przy automatycznej konwersji. Dane XML nie ograniczają się tylko do zestawu znaków ASCII; mosna w nich stosować pełny zestaw UNICODE jeseli tylko jest to potrzebne. Nie wolno tylko usywać znaczników, których nazwy rozpoczynają się od xml lub xsl, niezalesnie od wielkości usytych liter. Wszystkie nazwy, które tak się rozpoczynają, są zarezerwowane przez World Wide Web Consortium (W3C), czyli przez komitet normujący XML.
Podobnie jak najnowsze wersje standardu HTML, równies i standardy dla dokumentów XML są ściśle określone za pomocą reguł składniowych opracowanych przez World Wide Web Consortium (dalej nazywane W3C). Mosna się z nimi zapoznać w materiałach źródłowych wymienionych na końcu tego rozdziału. Dokument XML musi spełniać te wymagania, aby mosna było go nazwać dokumentem „dobrze sformatowanym”. Jeseli te reguły nie są spełnione, nie jest to dokument XML.
W tym rozdziale omówimy skrótowo reguły składni XML, których nalesy przestrzegać.
Kasdy dokument XML składa się z trzech sekcji (a nie tak jak HTML — z dwóch). Sekcje te zostały nazwane: prolog, treść i epilog (faktycznie w standardzie nie usyto nazwy epilog). Jedynie sekcja treść (ang. body) jest obowiązkowa; pozostałe dwie nie muszą występować w dokumencie.
Pierwsza sekcja dokumentu XML stanowiąca prolog „mose i powinna rozpoczynać się od deklaracji XML” (to cytat wzięty z oficjalnej normy). Pomimo tego, se przed chwilą wspomnieliśmy o braku przymusu usycia tej sekcji, to dokument normatywny zaleca usycie jej przynajmniej w minimalnej postaci we wszystkich dokumentach XML. Deklaracja XML wygląda następująco:
<?xml version='1.0'?>
Jak łatwo odgadnąć, deklaracja ta zawiera nie tylko informację, se dokument jest dokumentem XML, ale takse to, se spełnia określoną wersję specyfikacji XML (w tym przypadku 1.0). Mosna takse podać w tej deklaracji specyfikację języka oraz informacje dodatkowe, mówiące czytelnikowi (człowiekowi lub komputerowi), czy do interpretacji XML wymagane są jakieś dokumenty zewnętrzne. W naszym przykładzie wygląda to następująco:
<?xml version='1.0' encoding='UTF-8' standalone='yes' ?>
Mamy tu informację, se w dokumencie usyto znaków ośmiobitowych zdefiniowanych w zestawie Unicode UTF-8 (czyli ISO-LATIN1) i se nie są wymagane sadne dokumenty zewnętrzne. W prologu mosna takse określić typ dokumentu, rozpoczynając od oznaczenia <!DOCTYPE (tak jak w naszym przykładzie). Poniewas jednak nie omawialiśmy tego oznaczenia, to powrócimy do niego przy okazji skrótowego omawiania definicji typów dokumentu. Prolog mose takse zawierać komentarze.
W treści dokumentu XML znajdują się właściwe dane. Zawiera ona tylko jeden element — objęty parą znaczników w taki sposób, jak dokument HTML jest objęty znacznikami <HTML></HTML>. W XML kasdy element mose zawierać elementy zagniesdsone dowolnego poziomu. W naszym przykładzie pojedynczym elementem jest catalog, w którym są zagniesdsone inne elementy zawierające takse zagniesdsone elementy itd. Dość trudną definicję „elementu” odłosymy do następnego podrozdziału.
W treści mosna wstawiać komentarze.
Epilog jest często pomijany. Mose on zawierać instrukcje dotyczące przetwarzania i opisy zaawansowanych zagadnień, którymi nie musimy się tutaj zajmować.
Definiując treść dokumentu XML dla wygody pominęliśmy definicję samego elementu. Poniewas element jest podstawowym kontenerem do przechowywania danych w dokumencie XML, to jego znaczenie jest bardzo wasne. Musimy więc omówić go oddzielnie w tym podrozdziale.
Elementy są pojemnikami zawierającymi dane, atrybuty, inne elementy lub kombinacje tych wszystkich składników. Elementy są ograniczane za pomocą znaczników w nawiasach trójkątnych, podobnych do znaczników HTML. W odrósnieniu od HTML, w XML nie wolno pominąć znacznika końcowego (w HTML często pomijany jest np. znacznik końcowy </P>). Oprócz tego, o czym jus wspomniano, w znacznikach wasna jest wielkość liter.
Znacznik początkowy składa się z otwierającego nawiasu trójkątnego, nazwy i opcjonalnego zestawu atrybutów oraz z końcowego nawiasu trójkątnego. Znacznik końcowy zawiera dodatkowo ukośnik umieszczony za nawiasem otwierającym. Poprawnie zapisany znacznik XML ma więc następującą postać:
<my_tag_name>The data content goes here</my_tag_name>
W pełni dozwolony jest brak zawartości między parą znaczników. Oznacza to, se zamiast pisać:
<my_tag_name> </my_tag_name>
mosemy usyć skróconego zapisu:
<my_tag_name/>
Taki pusty znacznik mose wyglądać nieco dziwnie, ale tylko dlatego, se nie omówiliśmy jeszcze atrybutów znacznika. Pozwalają one zawrzeć w znaczniku informację ilościową prawie w taki sam sposób, jak w znacznikach HTML. Jako przykład mosna podać specyfikację tabeli, zawierającą szerokości marginesu i wypełnienia:
<TABLE BORDER='2' CELLPADDING='10'>
</TABLE>
W XML dodajemy atrybuty z wartościami w bardzo podobny sposób, na przykład zapis:
<my_tag_name text_type='example'>The data content goes here</my_tag_name>
definiuje znacznik z atrybutem text_type o wartości example
Zasady dodawania atrybutów do znaczników XML są bardziej ścisłe nis przy znacznikach HTML:
q W XML wszystkie wartości atrybutów muszą być ujęte w cudzysłów lub w apostrofy. Nie mosna więc np. usyć znacznika <TABLE BORDER=2>, który w HTML jest poprawny.
q W HTML jest mosliwe, chocias czasami powoduje to błędy, kilkakrotne usycie tej samej nazwy atrybutu w ramach jednego znacznika. W XML takie powtórzenia nie są dozwolone.
q W wartościach atrybutów nie mogą występować dwa znaki specjalne < i &. Zamiast nich trzeba stosować znane takse z HTML skróty < i %amp;
q Jeseli wewnątrz atrybutu muszą występować cudzysłowy tego samego rodzaju, co cudzysłowy ograniczające wartość atrybutu, to zamiast nich nalesy usyć skrótów ' (dla oznaczenia apostrofu) lub " (dla oznaczenia pojedynczego znaku cudzysłowu).
Jasne są kryteria wyboru informacji przekazywanej w części znacznika zawierającej atrybuty oraz w postaci danych zawartych między parą znaczników. Ogólnie mówiąc, jeseli dane nie zmieniają znaczenia, a zwłaszcza nie zmieniają wartości, to nalesy zastosować atrybuty. Jeseli informacja nie zalesy od jakichś czynników, to nalesy ją przekazać jako dane. Jako przykład, mosna podać dokument XML opisujący samochód. Kolor samochodu mose występować jako atrybut, poniewas nie zmienia istoty samego samochodu, stanowiąc tylko szczegół jego wyglądu. Pojemność silnika powinna być jednak przekazywana jako dane, poniewas istotnie wpływa na sam samochód. Jeśli nie mamy pewności, jak rozdzielić taką informację, to zawsze bezpieczniejsze będzie przekazanie jej jako dane, a nie jako atrybut.
Dokument XML nie byłby wiele wart, gdybyśmy usyli w nim tylko jednego znacznika. Znakomita większość usytecznych cech XML wynika z tego, se znaczniki mosna w nim zagniesdsać. W naszym przykładzie pokazanym na początku rozdziału mieliśmy znacznik catalog, wewnątrz którego był umieszczony znacznik dvd, zaś wewnątrz dvd umieszczone były kolejne znaczniki np. title i actors. Poniewas do dokumentu mosna wstawić ten sam znacznik wielokrotnie, to wewnątrz znacznika dvd o atrybucie „Seven Samurai” znajdują się dwa znaczniki opisujące aktorów. Widzimy więc, se dokument XML opisuje pewną strukturę drzewiastą. Jeśli narysujemy schemat tej struktury, to zobaczymy, se catalog zawiera wielokrotne wpisy dvd dvd zawiera elementy title price director actors i year_made, zaś actors zawiera jeden lub więcej elementów actor
|
|
W XML nalesy koniecznie przestrzegać poprawności zagniesdsania sekwencji znaczników. Wszystkie znaczniki muszą być dokładnie uporządkowane. W HTML konstrukcja taka, jak w ponisszym przykładzie jest wprawdzie niedozwolona, poniewas zawiera niepoprawnie zagniesdsone znaczniki, ale przeglądarki interpretują ją zazwyczaj w „rozsądny” sposób:
<B>Hello<I>Word</B></I>
W XML tego rodzaju sekwencja jest traktowana jako powasny błąd i powoduje, se cały dokument staje się niepoprawny.
Komentarze w XML są bardzo podobne do komentarzy stosowanych w HTML. Komentarz rozpoczyna się od znaków <!-- i kończy znakami -->
Wewnątrz komentarza nie wolno wstawić dwóch minusów ( ) ani kończyć treści komentarza minusem (
W odrósnieniu od HTML, parsery XML nie mają obowiązku przeglądać treści komentarza, a więc znana sztuczka z ukrywaniem skryptów wewnątrz komentarza nie mose być tu stosowana. Na szczęście tego rodzaju sztuczki nie są potrzebne, poniewas w XML określono sposób dołączania instrukcji przetwarzania dokumentu.
W poprzednim podrozdziale omówiono reguły składni XML, które zawsze musi spełniać dokument, aby mosna było go nazwać dokumentem XML. Reguły te nic nie mówią o zawartości dokumentu lub sekwencjach znaczników w XML — nakazują tylko zgodność ich składni z XML. Zazwyczaj nie wystarcza to do określenia formatu dokumentu, który ma być przetwarzany. Załósmy, se nasz katalog płyt DVD zawiera następujące dane:
<dvd asin='0780020707'>
<title>Grand Illusion</title>
<price>29.99</price>
<director>Jean Renoir</director>
<actors>
<actor>Jean Gabin</actor>
</actors>
<year_made>1938</year_made>
</dvd>
<director>Jean Renoir</director>
<wibble>Black Adder</wibble>
<year_made>1954</year_made>
<dvd asin='0780020685'>
<title>Seven Samurai</title>
<price>27.99</price>
<director>Akira Kurosawa</director>
<actors>
<actor>Takashi Shimura</actor>
<actor>Toshiro Mifune</actor>
</actors>
<year_made>1954</year_made>
</dvd>
Co oznaczają np. ponissze elementy?
<director>Jean Renoir</director>
<wibble>Black Adder</wibble>
<year_made>1954</year_made>
Poniewas są one umieszczone na zewnątrz jakiegoś znacznika dvd, nie ma mosliwości dokładnego określenia, do którego znacznika dvd nalesy je przypisać. Oprócz tego nie mosna określić, czego dotyczy znacznik wibble. Widzimy więc, se powysszy fragment dokumentu XML jest dobrze sformatowany i ma poprawną składnię, ale jest bezusyteczny ze względu na swoją niepoprawność semantyczną. Musimy więc znaleźć sposób takiego definiowania struktury dokumentu XML, aby oprócz składni mosna było zdefiniować dokładnie znaczniki i ich sekwencje, które mogą występować w danym dokumencie. Ten problem mosna rozwiązać między innymi za pomocą definicji typu dokumentu określanej skrótem DTD (od Document Type Definition).
DTD jest dokładną specyfikacją tego, co mose się pojawić w danym dokumencie XML, a więc narzuca pewnego rodzaju ograniczenia na strukturę dokumentu w postaci określonego zestawu i sekwencji znaczników. Dokumenty XML, z którymi jest związana DTD są klasyfikowane jako „poprawne”. Jest to dodatkowe wymaganie, niezalesne od „dobrego sformatowania”, a więc dokument XML nie mose być „poprawny”, jeśli nie jest takse „dobrze sformatowany”.
Łatwo się przekonać o konieczności stosowania odpowiednio zdefiniowanej struktury dokumentu XML, poniewas będziemy się nim posługiwali głównie do przenoszenia informacji. W XML, w odrósnieniu od HTML, nie występuje coś takiego jak znaczenie wynikające z samego dokumentu ani wstępnie zdefiniowane znaczniki. Bez odpowiedniego „słownika” nie mosna więc określić znaczenia dokumentu XML Zanim rozpocznie się jego rozpowszechnianie, nalesy uzgodnić jego strukturę. Wszystko to mosna osiągnąć, stosując DTD.
Definicja typu dokumentu (DTD) stanowi szkielet XML. W tym rozdziale zbrakłoby miejsca na pełne omówienie wszystkich zagadnień związanych z DTD, a więc pokasemy tylko zagadnienia podstawowe. Czytelnicy chcący uzyskać więcej informacji na ten temat powinni się zapoznać z materiałami źródłowymi wskazanymi na końcu tego rozdziału. Podstawę DTD stanowi deklaracja ELEMENT, która ma następującą postać:
<!ELEMENT mytagname >
Deklaracja ta oznacza, se „mytagname” jest znacznikiem w strukturze dokumentu XML. Za nazwą definiowanego znacznika mosna wymienić zawarte w nim elementy podrzędne. Obowiązują tu pewne reguły dotyczące sposobu dodawania elementów podrzędnych, definiowania listy tych elementów, sposobu ich wyboru oraz ich dopuszczalnej liczby. Reguły te są bardzo proste:
|
Operator |
Znaczenie |
|
Usywany w liście do rozdzielenia elementów podrzędnych, które muszą pojawiać się w wymienionym porządku |
|
|
Wybór spośród elementów podrzędnych |
|
|
Opcjonalny element podrzędny |
|
|
Dowolna liczba wystąpień elementu podrzędnego (zero lub więcej razy) |
|
|
Co najmniej jedno wystąpienie elementu podrzędnego |
|
|
Grupowanie elementów podrzędnych |
Operatory oraz następują za elementem, do którego się odnoszą.
Pokasemy to na przykładzie opisu zwykłej kanapki. Załósmy, se chcemy zdefiniować element sandwich zawierający parę elementów bread, między którymi będzie występował jeden element honey albo jelly. Mosemy to zapisać następująco:
<!ELEMENT sandwich (bread, (honey | jelly), bread) >
Fragment XML spełniający tę specyfikację powinien mieć postać:
<sandwich><bread>/><honey/><bread/></sandwich>
Załósmy teraz, se wypełnienie kanapki ma być opcjonalne. Dodajemy więc odpowiedni kwantyfikator:
<!ELEMENT sandwich (bread, (honey | jelly)?, bread) >
Mamy teraz zapis oznaczający opcjonalność. Jeseli trzeba, mosemy zastosować dowolnie duso nawiasów, powiększając stopień złosoności naszej definicji.
Wróćmy jednak do naszego początkowego przykładu z katalogiem płyt DVD. Wymagamy, aby element catalog składał się z pewnej liczby elementów dvd. Zawsze musi tu występować co najmniej jeden element dvd. To wymaganie zapisujemy w następujący sposób:
<!ELEMENT catalog (dvd+) >
Musimy zapisać, se element dvd zawiera elementy podrzędne (ang. sub-elements), czyli title price director actors i year_made. Deklaracja dvd jest więc następująca:
<!ELEMENT dvd (title, price, director, actors, year_made)>
Na najnisszym poziomie zagniesdsania musimy wskazać, se w elemencie actors musi występować przynajmniej jeden element actor
<!ELEMENT actors (actor+)>
Zdefiniowaliśmy w ten sposób strukturę znaczników, ale nie mamy jeszcze sadnych informacji o dopuszczalnych atrybutach tych znaczników. Wiemy, se nasz element dvd musi mieć numer asin. Definiujemy to, dodając do naszej DTD element ATTLIST
<!ATTLIST dvd
asin CDATA #REQUIRED >
Taki zapis oznacza, se element dvd charakteryzuje się atrybutem asin, który zawiera dane znakowe (napis) i jest atrybutem obowiązkowym. Ogólna postać znacznika ATTLIST jest następująca:
<!ATTLIST nazwa_znacznika nazwa_atrybutu typ_danych_atrybutu kwalifikator>
Ciąg nazwa_znacznika nazwa_atrybutu typ_danych_atrybutu kwalifikator mose być powtarzany wielokrotnie — pod warunkiem, se sadne atrybuty się nie powtórzą. Dozwolone są tu następujące typy danych:
|
Typ danych |
Znaczenie |
|
CDATA |
Napis |
|
ID |
Nazwa unikatowa w dokumencie XML |
|
IDREF |
Odwołanie do innego elementu za pomocą podanego ID |
|
IDREFS |
Odwołanie do listy innych elementów za pomocą podanych ID |
|
ENTITY |
Nazwa zewnętrznej jednostki |
|
ENTITIES |
Lista nazw zewnętrznych jednostek |
|
NMTOKEN |
Nazwa |
|
NMTOKENS |
Lista nazw |
|
NOTATION |
Zdefiniowana na zewnątrz notacja, np. TEX lub PNG |
|
Explicit value |
Ciąg jawnie zdefiniowanych wartości |
Omówienie wszystkich wymienionych tu typów wykracza znacznie poza zakres tego rozdziału.
Kwalifikator występujący w elemencie ATTLIST mose mieć następujące wartości:
|
Wartość |
Znaczenie |
|
#REQUIRED |
Atrybut musi się pojawić |
|
#IMPLIED |
Atrybut jest opcjonalny |
|
#FIXED <wartość> |
Atrybut musi mieć podaną wartość |
|
<wartość domyślna> |
Jeśli atrybutowi nie nadano wartości, to automatycznie przybiera on podaną wartość domyślną |
Poniewas nasz element dvd ma tylko jeden atrybut, to w specyfikacji DTD tego elementu trzeba usyć tylko jednej deklaracji ATTLIST
Musimy takse określić typ danych, które mogą występować w elementach między ich znacznikami początkowymi i końcowymi. Na najnisszym poziomie wszystkich danych znajdują się przetwarzalne dane znakowe (Parseable Character Data), co w XML zapisujemy jako (#PCDATA). Zakończymy więc naszą specyfikację DTD wpisem, który to definiuje:
<!ELEMENT title (#PCDATA)>
<!ELEMENT price (#PCDATA)>
<!ELEMENT director (#PCDATA)>
<!ELEMENT actor (#PCDATA)>
<!ELEMENT year_made (#PCDATA)>
Podsumujmy nasze rozwasania, podając specyfikację DTD w całości:
<!ELEMENT catalog (dvd+) >
<!ELEMENT dvd (title, price, director, actors, year_made)>
<!ATTLIST dvd
asin CDATA #REQUIRED >
<!ELEMENT title (#PCDATA)>
<!ELEMENT price (#PCDATA)>
<1ELEMENT director (#PCDATA)>
<!ELEMENT actors (actor+)>
<!ELEMENT actor (#PCDATA)>
<!ELEMENT year_made (#PCDATA)>
Mosna to wyrazić opisowo: element catalog zawiera jeden lub więcej elementów dvd. Kasdy element dvd musi mieć atrybut asin, który zawiera pewne dane. Element dvd zawiera elementy title price directory actors oraz year_made Element actors zawiera przynajmniej jeden element actor. Wszystkie elementy najnisszego poziomu muszą zawierać dane znakowe.
Musimy się zgodzić, se specyfikację DTD łatwiej zrozumieć nis taki opis (pod warunkiem, se rozumie się podstawy DTD).
Pomimo tego, se DTD zawierają dokładne definicje struktury dokumentu, to dość trudno jest się nimi posługiwać. Z tego właśnie powodu W3C opracowuje bardziej rygorystyczną i zarazem bardziej elastyczną metodę, tzw. schematy (ang. schemas). Będą się one lepiej nadawały do definiowania sposobów przetwarzanie plików XML i ułatwią aplikacjom wymianę danych w tym formacie.
W czasie pisania tej ksiąski rozwasano kilka zgłoszonych propozycji, które stanowią główny przedmiot zainteresowania w światku XML. Obserwuje się konkurencyjną walkę rósnych firm na tym polu i próby wymuszania uznania własnego rozwiązania za standard, powiązane z bezpłatnym udostępnianiem narzędzi i stron w Internecie wspierających takie rozwiązania. Na szczęście zostanie to wkrótce rozwiązane i powstanie uzgodniony oficjalny standard. Poniewas podczas pisania tych słów nie istniał jeszcze ostateczny schemat definiowania XML, to w pozostałych częściach tego rozdziału będziemy omawiać tylko DTD, nie zwasając na to, se prawdopodobnie specyfikacja ta mose być w przyszłości zastąpiona bardziej złosonym dokumentem.
Po zdefiniowaniu specyfikacji DTD musimy powiązać ją z dokumentami XML, których strukturę ona definiuje. Dla potrzeb naszego katalogu płyt DVD wystarczy po prostu wstawienie tej specyfikacji do dokumentu. Pamiętajmy jednak, se w ogólnym przypadku takie rozwiązanie nie jest dobre: jeseli dwie instytucje chcą wymieniać dokumenty w formacie XML, to niezbyt wygodne jest, aby kasda wiadomość zawierała własną specyfikację. Potrzebny jest zatem uzgodniony standard zewnętrzny, z którym będą zgodne wszystkie wymieniane dokumenty XML. Schematy XML zapewniające taką zgodność są dopiero opracowywane.
Specyfikacja DTD w naszym przykładowym dokumencie XML jest włączona w dokument za pomocą znacznika <!DOCTYPE określającego typ dokumentu:
<!DOCTYPE catalog [
<!ELEMENT catalog (dvd+) >
<!ELEMENT dvd (title, price, director, actors, year_made)>
<!ATTLIST dvd
asin CDATA #REQUIRED >
<!ELEMENT title (#PCDATA)>
<!ELEMENT price (#PCDATA)>
<!ELEMENT director (#PCDATA)>
<!ELEMENT actors (actor+)>
<!ELEMENT actor (#PCDATA)>
<!ELEMENT YEAR_MADE (#pcdata)>
]>
Jeśli zrozumieliśmy jus sposób przekazywania danych katalogowych w naszym przykładowym dokumencie XML, to musimy dokonać rozbioru tego dokumentu. Czynność ta musi poprzedzić przetwarzanie danych zawartych w dokumencie. W tym momencie mamy powasny dylemat: jaki parser zastosować? Stosowane są dwa odmienne modele rozbioru dokumentów XML: model obiektowy dokumentu (oznaczany skrótem DOM od słów Document Object Model) oraz model, w którym wykorzystuje się prosty interfejs programowy dla XML (skrótowo nazywany SAX od słów Simple API for XML). Przed dokonaniem wyboru i rozpoczęciem pracy nad kodem omówimy skrótowo obydwa z nich.
Konsorcjum W3C wydało standardową specyfikację dla modelu obiektowego (DOM), która określa dostęp do wewnętrznych elementów dokumentu w sposób unormowany i niezalesny od usytego języka programowania. W modelu DOM dokument jest pobierany i dokonywany jest jego rozbiór. Od tego momentu staje się on dostępny dla programu, który mose go modyfikować. Po zakończeniu modyfikacji modelu obiektowego mosna go ponownie zapisać jako dokument XML.
Istnieje jednak powasna wada modelu obiektowego: cały dokument przed przetworzeniem musi być przetrzymywany w pamięci i mose to sprawiać kłopoty przy dusych plikach XML. Dlatego tes powszechnie usywany jest mniej oficjalny standard, czyli SAX, nie stwarzający takich ograniczeń.
SAX został pierwotnie napisany w języku Java. Ostatnio projektem tej specyfikacji zarządzał David Meggison i na jego stronie internetowej mosna znaleźć najświessze informacje (adres jest podany w wykazie źródeł na końcu rozdziału).
Specyfikacja jest bardzo prosta i została wykorzystana w sposób prawie uniwersalny w parserze XML napisanym w języku Java. Istnieją takse wersje dla języków C i C++ (patrz wykaz materiałów źródłowych).
Według modelu SAX dokument XML nie jest ładowany do pamięci w całości, ale odczytywany częściami. Udostępniane są tu wywołania zwrotne do własnego kodu usytkownika, oznaczające np. początek znacznika, znalezienie komentarza lub wykrycie końca dokumentu. Zmusza to programistę do nieco większego wysiłku, poniewas musi on przyjmować dokument XML w kolejności zgodnej z dokonywanym rozbiorem, a nie w kolejności dowolnej.
Taki sposób działania przypomina nieco wywołania zwrotne (ang. callbacks) usywane w GNOME podczas obsługi zdarzeń. SAX jest interfejsem typu tylko do odczytu, nie generującym dokumentów XML. W wielu praktycznych zastosowaniach jest to jednak rozwiązanie całkowicie wystarczające, a pozbycie się niedogodności związanych z przetrzymywaniem całego dokumentu w pamięci oznacza, se mose to być rozwiązanie jedyne dla bardzo dusych dokumentów XML.
W naszej aplikacji obsługującej wyposyczalnię płyt DVD zdecydowaliśmy się skorzystać z modelu SAX, a w szczególności z biblioteki o nazwie libxml (poprzednio znanej pod nazwą gnome-xml) z następujących powodów:
q Wiedzieliśmy, se biblioteka ta była jus stosowana w Glade i se działała ona pewnie.
q Występuje w niej interfejs do języka C, czyli tego, który jest podstawowym językiem programowania stosowanym w tej ksiąsce.
q Potrzebowaliśmy jedynie odczytywać dokumenty XML, a nie tworzyć je.
q Biblioteka ta jest bardzo szybko rozwijana.
Jeseli na komputerze z systemem Linux jest jus zainstalowany pakiet GNOME, to prawie na pewno mosna znaleźć tam bibliotekę libxml. Jeseli zamiast GNOME jest stosowany inny system interfejsów graficznych, to mose jej nie być. Nie stwarza to problemu, bowiem libxml jest dostępna w postaci pakietu RPM.
Na stronie macierzystej libxml mosna znaleźć adresy serwerów umosliwiających pobranie pakietu. Nalesy pamiętać o pobraniu zarówno pakietu standardowego, jak i wersji -devel potrzebnej do kompilacji programów obsługujących XML (chyba se instalacja odbywa się po własnej kompilacji kodu źródłowego).
Kod korzystający z libxml wydaje się na pierwszy rzut oka nieco dziwny. To wrasenie wynika częściowo z konieczności zastąpienia oryginalnych konstrukcji w języku Java konstrukcjami w języku C. Kolejną przyczyną dziwnego wyglądu jest usycie funkcji wywołań zwrotnych, z czym nie wszyscy programiści są zaznajomieni.
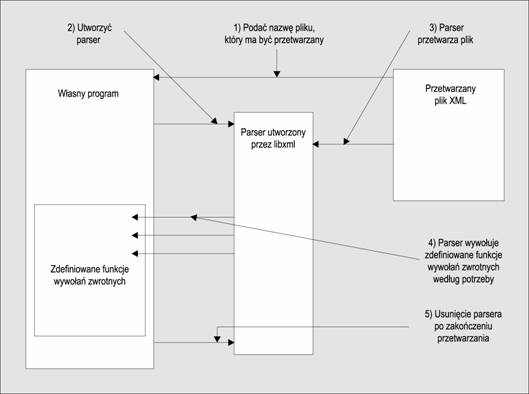
Podstawowy przepis na zastosowanie modelu SAX przy przetwarzaniu dokumentu XML jest bardzo prosty:
q Utworzyć egzemplarz parsera,
q Napisać zestaw funkcji, które będą wywoływane po wykryciu przez parser określonych konstrukcji,
q Poinformować parser o swoich funkcjach,
q Nakazać, aby parser przeprowadził rozbiór pliku,
q Parser wywołuje utworzone funkcje podczas przetwarzania XML, powiadamiając o przetwarzanych przez siebie danych.
W praktyce trzeba jeszcze pokonać kilka dodatkowych kłopotów, ale schemat działań nie odbiega zbytnio od powysszego.
Tę sekwencję działań mosna przedstawić graficznie:
|
|
Chyba wszyscy mają jus dosyć tej teorii — zapoznajmy się więc z niewielkim przykładowym programem, który korzysta z parsera zawartego w libxml. Program nazywa się sax1.c
#include <stdlib.h>
#include <stdio.h>
#include <parser.h>
#include<parserInternals.h>
int main()
xmlParseDocument(ctxt_ptr);
if (!ctxt_ptr->wellFormed)
xmlFreeParserCtxt(ctxt_ptr);
printf('Parsing completen');
exit(EXIT_SUCCESS);
Program ten jest dość krótki, a więc nie dodawaliśmy do niego sadnych funkcji wywołań zwrotnych. Nie nalesy się tym martwić — jus wkrótce będziemy mieli okazję je zobaczyć.
Przy kompilacji tego programu nalesy podać ścieskę do dołączanych plików nagłówkowych parser.h i parserInternals.h. Jeśli na komputerze jest zainstalowana wersja libxml wcześniejsza nis 2, to te pliki są prawdopodobnie umieszczone w katalogu /usr/include/gnome-xml; poczynając od wersji 2 nalesy ich szukać w /usr/include/xml. Program nalesy takse konsolidować z bibliotekami xml i zlib (ta druga bibliotek jest wymagana dlatego, se libxml mose czytać skompresowane pliki XML). Polecenie uruchamiające kompilację przykładowego programu mose mieć postać:
$ gcc -I/usr/include/gnome-xml sax1.c -lxml -lz -o sax1
lub:
$ gcc -I/usr/include/xml sax1.c -lxml -lz -o sax1
Spójrzmy teraz na szczegóły naszego kodu:
xmlParserCtxtPtr ctxt_ptr;
ctxt_ptr = xmlCreateFileParserCtxt('dvdcatalog.xml');
if (!ctxt_ptr)
Powysszy fragment tworzy parser, wskazywany następnie przez ctxt_ptr. Wywołanie:
xmlParseDocument(ctxt_ptr);
uruchamia rozbiór pliku przez parser, zaś instrukcja:
if (!ctxt_ptr->wellFormed)
jest wywoływana po zakończeniu przetwarzania i mose ostrzec o tym, se dokument jest niepoprawnie sformatowany. Końcowe wywołanie:
xmlFreeParserCtxt(ctxt_ptr);
zwalnia parser po zakończeniu pracy.
Po uruchomieniu tego programu zobaczymy na ekranie:
$./sax1
Parsing complete
Jest to komunikat początkowy, lecz niewiele z niego wynika: wiemy tylko, se parser nie potraktował naszego pliku XML jako błędnie sformatowanego. Spróbujmy zaburzyć ten plik, aby sprawdzić, jak zareaguje na to parser.
Umieścimy więc celowo w jednym z wpisów dvd znacznik <B>
<dvd asin='0780020707'>
<title>Grand Illusion</title>
<price>29.99</price>
<director>Jean<B>Renoir</director>
<actors>
<actor>Jean Gabin</actor>
</actors>
<year_made>1938</year_made>
</dvd>
Uruchamiamy parser ponownie:
$./sax1
dvdcatalog.xml:7: error: Opening and ending tag mismatch: B and director
<director>Jean<B>Renoir<director>
^
dvdcatalog.xml:12: error: Opening and ending tag mismatch: director and dvd
</dvd>
^
dvdcatalog.xml:25: error: Opening and ending tag mismatch: dvd and catalog
</catalog>
^
dvdcatalog.xml:26: error: detected an error in element content
dvdcatalog.xml:26: error: Premature end of data in tag <catalog>
<dvd asin='07800
Document not well formed
Parsing complete
Upewniliśmy się jus, se parser rzeczywiście przetwarza nasz dokument i podaje usyteczne komunikaty po wykryciu błędów.
Zanim przejdziemy do omawiania dalszych zagadnień, musimy przywrócić plik XML do pierwotnego stanu. Sposób obsługi błędów zgłaszanych przez parser omówimy nieco później, gdy staną się jasne metody dołączania własnych funkcji wywołań zwrotnych, które mosna będzie usyć, jeśli domyślna obsługa błędów nie będzie wystarczająca.
W naszym pierwszym przykładzie występowało wyrasenie:
ctxt_ptr->wellFormed
Umosliwiało ono sprawdzenie, czy dokument jest poprawnie sformatowany. Biblioteka libxml zawiera takse kilka innych usytecznych elementów w tej kontekstowej strukturze. Przeglądając plik parser.h zobaczymy zdefiniowany typ _xmlParserCtxt, który zwiera kilka elementów, a między innymi informacje o wersji XML i sposobie kodowania znaków. Mosna je wykorzystać do uzyskania pełniejszej informacji o pliku przetwarzanym przez parser. Usyjemy tej właściwości w programie sax2.c, rósniącym się od sax1.c tylko następującym fragmentem:
if (!ctxt_ptr->wellFormed)
printf('XML version %s, encoding %sn', ctxt_ptr->version, ctxt_ptr->encoding);
ctxt_ptr->sax = NULL
Po kompilacji i uruchomieniu tego programu otrzymujemy:
$./sax2
XML version 1.0, encoding UTF-8
Parsing complete
Wiemy jus, se parser przetwarza nasz plik, sprawdza jego poprawność i pobiera podstawowe informacje na jego temat, a więc mosna rozpocząć tworzenie funkcji wywołań zwrotnych. Posłusą one do uzyskiwania danych zawartych w pliku XML.
W pliku parser.h zdefiniowano strukturę xmlSAXHandler, która podaje miejsca dostępne dla wywołań zwrotnych. Strukturę tę omówimy za chwilę.
Zdefiniowano takse prototypy funkcji, których nalesy usyć w wywołaniach zwrotnych:
typedef xmlParserInputPtr (*resolveEntitySAXFunc) (void *ctx,
const CHAR *publicId,
const CHAR *systemId);
typedef void (*internalSubsetSAXFunc) (void *ctx, const CHAR *name,
const CHAR *ExternalID,
const CHAR *SystemID);
typedef xmlEntityPtr (*getEntitySAXFunc) (void *ctx, const CHAR *name);
typedef void (*entityDeclSAXFunc) (void *ctx, const CHAR *name, int type,
const CHAR *publicId,
const CHAR *systemId,
CHAR *content);
typedef void (*attributeDeclSAXFunc) (void *ctx, const CHAR *elem,
const CHAR *name,
int type, int def,
const CHAR *defaultValue,
xmlEnumerationPtr tree);
typedef void (*elementDeclSAXFunc) (void *ctx, const CHAR *name,
int type, xmlElementContentPtr content);
typedef void (*unparsedEntityDeclFunc)(void *ctx,
const CHAR *name,
const CHAR *publicId,
const CHAR *systemId,
const CHAR *notationName);
typedef void (*setDocumentLocatorSAXFunc) (void *ctx,
xmlSAXLocatorPtr loc);
typedef void (*startDocumentSAXFunc) (void *ctx);
typedef void (*endDocumentSAXFunc) (void *ctx);
typedef void (*startElementSAXFunc) (void *ctx, const CHAR *name,
const CHAR **atts);
typedef void (*endElementSAXFunc) (void *ctx, const CHAR *name);
typedef void (*attributeSAXFunc) (void *ctx, const CHAR *name,
const CHAR *value);
typedef void (*referenceSAXFunc) (void *ctx, const CHAR *name);
typedef void (*charactersSAXFunc) (void *ctx, const CHAR *ch, int len)
typedef void (*ignorableWhitespaceSAXFunc) (void *ctx,
const CHAR *ch, int len);
typedef void (*processingInstructionSAXFunc) (void *ctx,
const CHAR *target,
const CHAR *data);
typedef void (*commentSAXFunc) (void *ctx, const CHAR *value);
typedef void (*warningSAXFunc) (void *ctx, const char *msg, );
typedef void (*errorSAXFunc) (void *ctx, const char *msg, );
typedef void (*fatalErrorSAXFunc) (void *ctx, const char *msg, );
typedef int (*isStandaloneSAXFunc) (void *ctx);
typedef int (*hasInternalSubsetSAXFunc) (void *ctx);
typedef int (*hasExternalSubsetSAXFunc) (void *ctx);
Nalesy zwrócić uwagę na to, se usywany jest tu typ CHAR, a nie char. Jest to nowy typ zadeklarowany w nagłówkach i takie oznaczenie nie jest błędem.
Na szczęście, do przetworzenia pliku XML i pobrania z niego usytecznych informacji potrzeba tylko kilku wywołań zwrotnych. Zanim utworzymy wymaganą główną funkcję wywołania zwrotnego, dodajmy do naszego kodu dwie proste funkcje, które będą wykorzystywane w celach szkoleniowych.
Funkcje te będą sygnalizować początek i koniec dokumentu i będą wywoływane w tych właśnie miejscach. Mosna je znaleźć w podanych wysej deklaracjach pod nazwami startDocumentSAXFunc i endDocumentSAXFunc. Wykorzystuje się je często w operacjach inicjujących i oczyszczających pamięć.
Aby usyć wywołania zwrotnego, nalesy wykonać następujące trzy czynności:
q Utworzyć funkcję obsługującą wywołanie zwrotne,
q Ustawić w strukturze wywołań zwrotnych libxml wywoływanie tej funkcji,
q Przekazać do parsera informację o strukturze wywołań zwrotnych.
Pierwszy etap jest prosty, a nasze funkcje wywołań zwrotnych mają następującą postać (nie stosujemy jeszcze parametrów):
static void start_document(void *ctx)
static void end_document(void *ctx)
Teraz następuje niewielka sztuczka z ustawianiem struktury wywołań zwrotnych. Najpierw nalesy we własnym kodzie zadeklarować strukturę typu xmlSAXHandler i przydzielić w odpowiednich miejscach wskaźniki do naszych funkcji.
Struktura xmlSAXHandler opisująca dostępne wywołania zwrotne znajduje się w pliku parse.h
typedef struct xmlSAXHandler xmlSAXHandler;
Jak widzimy, wskaźniki do funkcji wywołań zwrotnych są odpowiednio nazwane, a więc łatwo mosna z nich skorzystać.
Wszystkie lokalizacje nieusywanych funkcji wywołań zwrotnych muszą mieć wskaźnik NULL, dzięki czemu libxml uzyska informację o tym fakcie. Aby zabezpieczyć się przed zmianami struktury, usyjemy funkcji memset oczyszczającej całą jej zawartość i nadającej jej wartości NULL, a następnie jawnie wpiszemy wskaźniki do usywanych funkcji wywołań zwrotnych. Kasdy, kto usywał struktur wywołań zwrotnych, dobrze wie, jaki chaos mose spowodować wpisanie wskaźnika do funkcji w nieprawidłowe miejsce, jeśli lista tych funkcji jest długa
static xmlSAXHandler mySAXParseCallbacks;
memset(&mySAXParseCallbacks, sizeof(mySAXParseCallbacks), 0);
mySAXParseCallbacks.startDocument = start_document;
mySAXParseCallbacks.endDocument = end_document;
Na zakończenie musimy poinformować parser o naszej strukturze wywołań zwrotnych:
if (!ctxt_ptr)
ctx_ptr->sax = &mySAXParseCallbacks;
xmlParseDocument(ctxt_ptr);
ctxt_ptr->sax = NULL;
Zwróćmy uwagę na to, se po zakończeniu rozbioru pliku wskaźnikowi kontekstu ponownie nadano wartość NULL
Po połączeniu tych wszystkich fragmentów w całość nadajemy jej nazwę sax3.c i po uruchomieniu widzimy, se nasze funkcje są wywoływane automatycznie podczas przetwarzania dokumentu:
$./sax3
Document start
Document end
Parsing Complete
W tym przykładzie usunęliśmy informację o wersji XML i kodowaniu znaków, poniewas nie wnosi ona tu nic nowego.
Widzimy więc, se konfiguracja wywołań zwrotnych nie jest trudna. Przejrzyjmy teraz całą listę wywołań zwrotnych i sprawdźmy, które z nich mogą się przydać. W praktyce około 95% wszystkich potrzeb występujących przy rozbiorze dokumentu mosna zaspokoić, korzystając tylko z pięciu wywołań (mosna takse usyć jeszcze trzech dodatkowych, które zajmują się obsługą błędów). Tymi właśnie funkcjami zajmiemy się nisej. Wszystkie z nich wymagają podania wskaźnika void *ctx jako pierwszy parametr. Jego zastosowanie zostanie omówione przy okazji opisywania rósnic występujących miedzy poszczególnymi wywołaniami zwrotnymi.
Wszystkie funkcje obsługi błędów mają ten sam format, lecz korzystają z rósnych wywołań zwrotnych zalesnych od stopnia wasności błędu. Są to następujące trzy funkcje:
typedef void (*warningSAXFunc) (void *ctx, const char *msg, );
typedef void (*errorSAXFunc) (void *ctx, const char *msg, );
typedef void (*fatalErrorSAXFunc) (void *ctx, const char *msg, );
Funkcja warningSAXFunc obsługuje ostrzesenia, errorSAXFunc obsługuje zwykłe błędy, a fatalErrorSAXFunc obsługuje błędy krytyczne, przy których parser nie mose kontynuować działania. W odrósnieniu od poprzednich wywołań tutaj usywany jest zwyczajny typ char, a nie CHAR
Wszystkie wymienione wysej funkcje wymagają rósnej liczby argumentów. Mosna uzyskać do nich dostęp za pomocą wywołania stdarg. Komunikaty o błędach mogą być wówczas wyświetlane (po dołączeniu <stdarg.h>), a więc mamy:
va_list args;
va_start(args, msg);
vprint(msg, args);
va_end(args);
Jeśli wywołujemy nasz parser z wiersza poleceń tak, jak opisywaliśmy, to obsługa błędów działa bez problemów. Gdy usyjemy jakiegoś interfejsu graficznego, to nie będzie jus to takie proste i musimy utworzyć nieco bardziej rozbudowane procedury korzystające z wywołań zwrotnych.
Oto przykład pochodzący z pliku saxp.c, w którym zastosowano wywołania zwrotne do obsługi błędów. Plik ten znajduje się w zestawie programów testowych w pakiecie Glade:
static void gladeError(GladeParseState *state, const char*msg, )
Funkcja startDocumentSAXFunc jest wywoływana jednokrotnie w momencie rozpoczęcia rozbioru dokumentu, zawsze przed jakimkolwiek innym wywołaniem zwrotnym. Jej prototyp wygląda następująco:
typedef void (*startDocumentSAXFunc) (void *ctx);
Funkcja endDocumentSAXFunc jest wywoływana jednokrotnie po zakończeniu rozbioru dokumentu — albo z powodu wykrycia końca dokumentu, albo po wystąpieniu błędu krytycznego. Oto jej prototyp:
typedef void (*endDocumentSAXFunc) (void *ctx);
Funkcja startElementSAXFunc jest wywoływana zawsze po wykryciu nowego elementu:
typedef void (*startElementSAXFunc) (void *ctx, const CHAR *name,
const CHAR **atts);
Parametr name oznacza nazwę elementu, zaś parametr atts ma albo wartość NULL, albo jest listą wskaźników do nazw i wartości atrybutów, zakończoną wartością NULL. W naszym przykładowym katalogu płyt DVD element dvd ma atrybut asin, którego wartością jest napis — a więc tablica parametrów atts będzie zawierać dwa wskaźniki: jeden na napis „asin”, a drugi na faktyczną treść tego napisu (składającego się z cyfr). W następnej wersji parsera pokasemy sposób dostępu do tych atrybutów.
Funkcja endElementSAXFunc jest wywoływana zawsze po wykryciu końca elementu, nawet wtedy, gdy jest to element pusty (np. zapisany jako <fud/>). Dzięki temu kasdemu wywołaniu zwrotnemu związanemu z początkiem elementu towarzyszy odpowiednie wywołanie oznaczające koniec elementu (pod warunkiem, se nie wystąpi błąd krytyczny):
typedef void (*endElementSAXFunc) (void *ctx, const CHAR *name);
Funkcja charactersSAXFunc jest wywoływana zawsze po wykryciu sekwencji znaków nie tworzących jakiegoś specyficznego składnika, np. elementu lub komentarza:
typedef void (*charactersSAXFunc) (void *ctx, const CHAR *ch, int len);
W przypadku długich napisów mosna je dzielić na mniejsze fragmenty, wywołując tę funkcję wielokrotnie. Aplikacja musi wówczas zadbać o odpowiednią obsługę takich wywołań.
Wiemy jus, jak wyglądają wywołania zwrotne i mosemy utworzyć jakiś kod, który będzie realizował bardziej skonkretyzowane zadania, czyli będzie pobierał dane i atrybuty z elementów. Jest to pierwsze realistyczne podejście do rozbioru dokumentu. Oto kod, któremu nadaliśmy nazwę sax4.c
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <parser.h>
#include <parserInternals.h>
static void start_document(void *ctx);
static void end_document(void *ctx);
static voidstart_element(void *ctx, const CHAR *name, const CHAR **attrs);
static void end_element(void *ctx, const CHAR *name);
static void chars_found(void *ctx, const *chars, int len);
static xmlSAXHandler mySAXParseCallbacks;
int main()
ctx_ptr->sax = &mySAXParseCallbacks;
xmlParseDocument(ctxt_ptr);
if (!ctxt_ptr->wellFormed)
ctxt_ptr->sax = NULL;
xmlFreeParserCtxt(ctxt_ptr);
printf('Parsing completen');
exit(EXIT_SUCCESS);
} /* main */
static void start_document(void *ctxt) /* start_document */
static void end_document(void *ctx) /* end_document */
static void start_element(void *ctx, const CHAR *name, const CHAR **attrs)
}
} /* start_element */
static void end_element(void *ctx, const CHAR *name) /* end_element */
#define CHAR_BUFFER 1024
static void chars_found(void *ctx, const CHAR *chars, int len) /* chars_found */
Przykład jest dosyć długi, ale niezbyt skomplikowany — z wyjątkiem dwóch fragmentów, na które warto zwrócić szczególną uwagę:
q funkcja start_element pokazuje sposób wykrywania obecności atrybutów oraz dostępu do ich nazw i wartości,
q funkcja chars_found wyświetla znalezione dane. Zwróćmy uwagę na to, se przekazywany napis nie kończy się wartością NULL (a przynajmniej tak się dzieje w biesącej implementacji) — a więc, chcąc wyświetlać odpowiednią liczbę znaków, trzeba zastosować specjalne środki.
Po uruchomieniu programu sax4 otrzymamy następujące wyniki (podane tu w skróconej postaci):
$ ./sax4
Document start
Element catalog started
Found 5 characters:
Element dvd started
Attribute asin
Attribute 0780020707
Found 8 characters:
Element title started
Found 14 characters: Grand Illusion
Element title ended
Found 8 characters:
Element price started
Found 5 characters: 29.99
Element price ended
Found 8 characters:
Element director started
Found 11 characters: Jean Renoir
Element director ended
Found 8 characters:
Element actors started
Found 11 characters:
Element actor started
Found 10 characters: Jean Gabin
Element actor ended
Found 8 characters:
Element actors ended
Wnikliwi czytelnicy wykryją tu bardzo szybko trudności. Przy wywoływaniu procedury start_element nie jest jeszcze znana zawartość elementu, zaś przy wywołaniu chars_found jus nie wiemy, który element był przetworzony. Oprócz tego, funkcja chars_found jest wywoływana w tych miejscach, w których nie ma potrzeby przetwarzania znaków. Jest to wada parsera posługującego się modelem SAX. Mosna ją ominąć, zachowując informację o stanie parsera.
Potrzeba utrzymywania informacji o stanie przy sekwencyjnym przetwarzaniu strukturalnych danych jest prawie oczywista i biblioteka libxml dysponuje pewnymi właściwościami, które mosna wykorzystać do tego celu.
W kontekstowej strukturze, podobnie jak we wskaźniku do struktury wywołań zwrotnych, istnieje wskaźnik void * do zmiennej userData, którą mosna wykorzystać do przechowywania informacji o stanie. Informacja ta nie ma ściśle określonej postaci, co jest tu zaletą, poniewas mosna wówczas uzyskać coś więcej nis tylko czysty stan. Przy kasdym wywołaniu funkcji wywołania zwrotnego wskaźnik do naszej struktury jest przekazywany jako pierwszy argument (wskaźnik void * ctx do wywołań zwrotnych) i tej właściwości jeszcze nie wykorzystaliśmy.
Aby utrzymywać informację o stanie parsera, musimy najpierw zadeklarować strukturę do jej przechowywania. W przypadku naszego pliku XML, oprócz informacji o stanie parsera, potrzebna jest jeszcze dodatkowa informacja o liczbie aktorów występujących w danym filmie. W poprzednich rozdziałach załosyliśmy, se z jednym tytułem filmu będą związane dokładnie dwie osoby i jeśli brak będzie nazwisk, to na ich miejsce wpisywana będzie wartość NULL
Specyfikacja DTD w naszym pliku XML przewiduje, se z tytułem jest zawiązany zawsze co najmniej jeden aktor (musi wystąpić element actors, który zawiera co najmniej jeden element actor). Mogą więc wystąpić tytuły, dla których podane będą nazwiska więcej nis dwóch aktorów. Musimy więc wychwycić tylko przypadki z jednym aktorem, aby dla drugiego wpisu usyć wartości NULL
Najpierw wyliczymy wszystkie stany, w których mose znaleźć się parser:
typedef enum parse_state;
Następnie zadeklarujemy strukturę do przechowywania stanu parsera i liczby aktorów:
typedef struct catalog_parse_state;
W funkcji głównej deklarujemy egzemplarz tej struktury, a w strukturze kontekstowej parsera przydzielamy jej wskaźnik:
xmlparserCtxtPtr ctxt_ptr;
catalog_parse_state parsing_state;
ctxt_ptr = xmlCreateFileParserCtxt('dvdcatalog.xml');
if (!ctxt_ptr)
ctxt_ptr->sax = &mySAXParseCallbacks;
ctxt_ptr->userData = &parsing_state;
xmlParseDocument(ctxt_ptr);
Dostęp do struktury stanu w kasdym z naszych wywołań zwrotnych mosemy uzyskać poprzez wskaźnik ctx
static void start_element(void *ctx, const char *name, const char **attrs) parse_event;
/* Mapa stanów */
typedef enum parse_state;
Deklarujemy strukturę do przechowywania informacji przekazywanych miedzy wywołaniami zwrotnymi. Tą informacją jest stan parsera i liczba aktorów:
/* Struktura przechowująca między wywołaniami stan i liczbę aktorów */
typedef struct catalog_parse_state;
Deklarujemy teraz prototypy:
/* Prototypy wywołań zwrotnych */
static void start_document(void *ctx);
static void end_document(void *ctx);
static void start_element(void *ctx, const char *name, const char **attrs);
static void end_element(void *ctx, const char *name);
static void chars_found(void *ctx, const char *chars, int len);
/* Funkje pomocnicze */
static parse_event get_event_from_name(const char *name);
static parse_state state_event_machine(parse_state curr_state, parse_event
curr_event);
oraz strukturę wywołania zwrotnego:
static xmlSAXHandler mySAXParseCallbacks;
Główna procedura realizuje kolejno następujące zadania:
q tworzy parser,
q konfiguruje wywołania zwrotne,
q ustawia wskaźnik na dane przechowujące stan między wywołaniami zwrotnymi,
q sąda przetworzenia dokumentu,
q usuwa wywołania zwrotne,
q usuwa parser.
Kod tej procedury zawiera niewiele więcej wierszy nis powysszy opis:
int main()
ctxt_ptr->sax = &mySAXParseCallbacks; /* Set callback map */
ctxt_ptr->usrData = &parsing_state;
xmlparseDocument(ctxt_ptr);
if (!ctxt_ptr->wellFormed)
ctxt_ptr->sax = NULL;
xmlFreeParserCtxt(ctxt_ptr);
printf('Parsing completen');
exit(EXIT_SUCCESS);
} /* main */
To wywołanie zwrotne jest wzywane na początku rozbioru dokumentu. Zeruje ono informację zawartą w maszynie stanu:
static void start_document(void *ctx) /* start_document */
To wywołanie zwrotne jest wzywane na zakończenie rozbioru dokumentu. Zmienia ono informację zawartą w maszynie stanu w taki sposób, aby kasde następne wywołanie zwrotne było traktowane jako niewasne:
static void end_document(void *ctx) /* end_document */
Wywołanie zwrotne start_element jest wzywane po kasdym wykryciu początku elementu w przetwarzanym dokumencie XML. Jego głównym zadaniem jest wywołanie maszyny stanu w celu określenia jego nowej wartości. Dodatkowo zliczani są aktorzy oraz obsługiwane atrybuty elementu dvd
static void start_element(void *ctx, const char *name, const char **attrs)
if (curr_event == parse_actors_e)
if (state_ptr->current-state == parse_dvd_s)
}
}
} /* start_element */
To wywołanie zwrotne jest wzywane po wykryciu końca elementu. Wywołuje ono maszynę stanu do obsługi tego zdarzenia:
static void end_element(void *ctx, const char *name) /* end_element */
Funkcja chars_found jest wywoływana zawsze, gdy wykryty napis nie jest nazwą elementu, komentarzem lub atrybutem. Na podstawie biesącego stanu w maszynie stanu określany jest sposób przetwarzania znaków. Elementy price i year_made są traktowane nieco odmiennie, aby pokazać, jak maszyna stanu mose wykrywać mieszaninę specyficznych i uogólnionych elementów, usywając stanu parse_valid_string_s dla elementów typu rodzimego:
/* W celu uproszczenia załosyliśmy ograniczenie długości nazwy zdarzenia
oraz przekazywanie wszystkich znaków podczas jednego wywołania */
#define CHAR_BUFFER 1024
static void chars_found(void *ctx, const char *chars, int len) /* switch */
} /* chars_found */
Mamy takse funkcję pomocniczą, która słusy do przekształcania nazw elementów na wyliczone zdarzenia:
/* Odwzorowanie nazw elementów na wyliczone zadarzenia */
const struct events[] = ,
,
,
,
,
,
,
static parse_event get_event_from_name(const char *name)
return parse_other_e;
} /* get_event_from_name */
Na zakończenie mamy maszynę stanu, która określa nowy stan na podstawie podanego stanu biesącego i zdarzenia:
/* Przeszukiwanie maszyny stanu */
const struct event_state[] = ,
,
,
,
,
,
,
{parse_director_e, parse_valid_string_s],
,
,
,
,
,
,
static parse_state_event_machine(parse_state curr_state, parse_event
curr_event)
return parse_unknown_s;
} /* state_event_machine */
Po uruchomieniu tego programu (z plikiem wejściowym skróconym z powodu braku miejsca w ksiąsce) uzyskujemy bardzo przejrzysty wynik. Zwróćmy uwagę na to, se kasdy aktor ma przypisany numer, pod którym występuje w elemencie dvd, a zarówno resyser, jak i tytuł filmu mają dodany napis „Other valid”. Pokazaliśmy więc, se mosna uprościć parser, jeśli nie trzeba rozrósniać znaczenia jakichś elementów, obsługując je w jednolity sposób!
Element dvd started
Attribute asin
Attribute 0780020707
Other valid Grand Illusion
Price 29.99
Other valid Jean Renoir
Actor Jean Gabin (1)
Year 1938
Element dvd started
Attribute asin
Attribute 0780020685
Other valid Seven Samurai
Price 27.99
Other valid Akira Kurosawa
Actor Takashi Shimura (1)
Actor Toshiro Mifune (2)
Year 1954
Parsing complete
Głównym miejscem do rozpoczęcia jakichkolwiek prac z XML jest strona ze standardami W3C pod adresem: https://www.w3.org/xml.
Warto równies zajrzeć do wersji standardu XML opatrzonej komentarzami, którą mosna znaleźć pod adresem: https://www.xml.com/pub/a/axml/axmlintro.html[ZW1].[MH2]
Strona macierzysta biblioteki libxml, poprzednio znanej jako gnome-xml, znajduje się pod adresem: https://xmlsoft.org. Oprócz dokumentacji i odnośników do plików, które mosna pobrać, jest to równies dobre źródło odnośników do innych informacji o XML, które warto prześledzić. Alternatywne źródło dokumentacji libxml mosna znaleźć pod adresem https://www.daa.com.au/~james/gnome/xml-sax/xml-sax.html.
Doskonałe źródło prac na temat XML z grupy Open Source mosna znaleźć pod adresem https://xml.apache.org/, dotyczy to zwłaszcza parsera XML o nazwie Xerces, który jest dostępny w wersjach Java i C++, działa w systemie Linux i zastosowano w nim model DOM blisko spokrewniony ze standardem W3C dla schematów XML.
Firma IBM wykonuje duso prac dotyczących XML (i Linuksa), a więc strona https://www.alphaworks.ibm.com/ jest często dobrym miejscem na zapoznanie się z nowymi technologiami.
Dobrym źródłem wiedzy jest takse strona Jamesa Clarka — https://www.jclark.com/.
Inny interfejs DOM o nazwie Gdome zbudowany na podstawie libxml mosna znaleźć pod adresem: https://levien.com/gnome/gdome.html.
Standard interfejsu SAX do rozbioru XML znajduje się pod adresem: https://www.megginson.com/SAX.
Zestaw najczęściej zadawanych pytań na temat XML z odpowiedziami (FAQ) znajduje się pod adresem: https://www.ucc.ie/xml.
Bezpłatny edytor XML (napisany w języku Java) znajduje się pod adresem: https://www.merlotxml.org/.
Napisano takse bardzo wiele ksiąsek o XML, ale trudno jest wskazać tę, od której warto zacząć. Jedną z takich pozycji godnych przeczytania mose być XML. Vademecum profesjonalisty, wyd. Helion (ISBN 83-7197-434-5).
W tym rozdziale omówiliśmy struktury dokumentu XML oraz specyfikacje DTD, definiujące te struktury. Przedyskutowaliśmy takse rósnice między „dobrym sformatowaniem” dokumentu XML oznaczającym poprawność składniową a „poprawnością” dokumentu, potwierdzoną przez związaną z nim specyfikację DTD.
Następnie skrótowo omówiliśmy dwa główne rodzaje parserów stosowanych do dokumentów XML (model DOM i model SAX).
Pokazaliśmy takse szczegółowo bibliotekę libxml stanowiącą pierwotnie część interfejsu graficznego GNOME, ale obecnie przekształconą do postaci samodzielnego narzędzia. Zawiera ona parser działający na zasadzie SAX i wyposasony w interfejs programowy do języka C.
Na zakończenie rozdziału pokazaliśmy parser przetwarzający nasz plik catalog.xml
[ZW1]Aktualny to: https://www.xml.com/pub/a/axml/axmlintro.html
[MH2]nieaktualny!
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 657
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2024 . All rights reserved