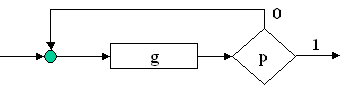| CATEGORII DOCUMENTE |
Din cursul anterior am aflat cum s-a ajuns de la limbajul vorbit la limbajele de programare
Sa vedem cum se pot transpune problemele pe care dorim sa le rezolvam cu ajutorul calculatorului, in aplicatii cu ajutorul carora sa rezolvam problemele propuse.
Realizarea unui program pentru o anumita aplicatie presupune parcurgerea mai multor etape. Aceste etape sunt independente de limbajul de programare utilizat si implica existenta catorva restrictii cu privire la computerul utilizat. Etapele realizarii aplicatiilor sunt urmatoarele
Analiza-proiectare
specificarea problemelor - descrierea clara si precisa a problemelor indiferent din ce domeniu provin acestea ;
proiectarea solutiilor - includerea problemelor in clasa de probleme corespunzatoare si alegerea modului de reprezentare a problemelor prin formularea etapelor si procedeelor corespunzatoare pentru procesele de rezolvare;
Programare-executie
implementarea solutiilor - elaborarea algoritmilor si codificarea acestora intr-un limbaj de programare modern;
analiza solutiilor - eficienta solutiilor raportata la resursele utilizate: memorie, timp, utilizarea dispozitivelor I/O, etc.;
testarea si depanarea - verificarea executiei programului cu diverse seturi de date de intrare pentru a putea raspunde rezolvarii oricarei probleme pentru care aplicatia a fost elaborata;
actualizarea si intretinerea - adaptarea solutiilor implementate pentru eliminarea erorilor in rezolvarea unei anumite probleme si compatibilitatea cu sistemul de calcul si sistemul de operare folosite.
Pentru inceput, sa intelegem prin algoritm, pasii facuti pentru rezolvarea unei probleme.
Noul concept, de gandire algoritmica a facut posibila aparitia si dezvoltarea Tehnologiei Informatiei (IT), ce reprezinta de fapt implementarea filosofiei procesarii, gestionarii si comunicarii informatiilor.
Complexitatea problemelor care necesita descrierea mai multor procese de calcul complexe a determinat folosirea notiunii de algoritm in activitatea de rezolvare a problemelor. Multe procese naturale, multe activitati umane, pot fi descrise intr-o forma algoritmica prin definirea unor informatii si actiuni clare si precise, eliminandu-se ambiguitatile in interpretare si in operatii. Algoritmizarea este o cerinta fundamentala in rezolvarea oricarei probleme cu ajutorul calculatorului. Experienta a demonstrat ca nu orice problema poate fi rezolvata prin algoritmizarea rezolvarii, adica prin descrierea unui algoritm de rezolvare. Un algoritm implementeaza diverse metode si tehnici de rezolvare care au fost descoperite sau definitivate intr-un anumit moment in evolutia stiintifica a domeniului respectiv. Exista algoritmi ce urmeaza metode dezvoltate inainte de aparitia calculatoarelor, dar cele mai multe probleme cer abordari noi.
Problemele se impart in :
Probleme rezolvabile cu calculatorul (probleme decidabile) :
clasa problemelor rezolvate prin metode imperative(procedurale) ;
clasa problemelor rezolvate prin metode declarative ;
problemelor nedecidabile
Prin algoritm vom intelege o secventa finita de comenzi explicite si neambigue care executate pentru o multime de date (ce satisfac anumite conditii initiale I), conduce in timp finit la rezultatul corespunzator
Solutia unei probleme, din punct de vedere informatic, este descrisa printr-o multime de comenzi (instructiuni) explicite si neambigue, exprimate intr-un limbaj de programare. Aceasta multime de instructiuni prezentata conform anumitor reguli sintactice formeaza un program.
Un program poate fi privit si ca un algoritm exprimat intr-un limbaj de programare.
Un algoritm descrie solutia problemei independent de limbajul de programare in care este redactat programul
Practic, intereseaza daca exista solutia ce poate fi descrisa algoritmic, deci daca solutia problemei poate fi construita efectiv. De asemenea, pentru rezolvarea anumitor probleme pot exista mai multi algoritmi (de exemplu problemele de sortare).
Stabilirea celui mai bun dintre acestia se realizeaza in urma unui proces de analiza prin care se determina performanta fiecaruia.
Principalele caracteristici ale unui algoritm trebuie sa fie :
generalitate - algoritmul trebuie sa fie cat mai general astfel ca sa rezolve o clasa cat mai larga de probleme;
claritate/determinare - actiunile algoritmului trebuie sa fie clare, simple si riguros specificate;
finitudine - actiunile algoritmului trebuie sa se termine dupa un numar finit de operatii, aceasta pentru orice orice set de date valide;
corectitudine - algoritmul trebuie sa produca un rezultat corect (date de iesire) pentru orice set de date de intrare valide;
performanta - algoritmul trebuie sa fie eficient privind resursele utilizate, si anume sa utilizeze memorie minima si sa se termine intr-un timp minim.
Intreaga activitate de cercetare si elaborare de software din domeniul Tehnologiei Informatiei este determinata de inventarea, conceperea, elaborarea, testarea, si implementarea de algoritmi performanti si utili. Marea diversitate a algoritmilor si marea aplicabilitate a acestora in toate domeniile, face ca aceasta tema sa fie mereu actuala si intr-o continua schimbare si perfectionare.
Practica si experienta elaborarii programelor pentru rezolvarea problemelor scot in evidenta urmatoarele aspecte foarte importante:
Modelul fizic- modelul dat se sistemul de calcul si sistemul de operare, model de care trebuie sa se tina seama atunci cand se proiecteaza si se elaboreaza o aplicatie; acest aspect reclama competenta in domeniul sistemelor de calcul si perfectionare continua pentru cel care proiecteaza si elaboreaza aplicatia;
Modelul virtual - modelul dat de gandirea obiectuala si algoritmica, de modul de reprezentare a algoritmilor, de masina virtuala pe care trebuie sa se execute algoritmul elaborat; in timp, acest model a suferit schimbari majore deoarece a fost tot timpul influentat de modelul fizic si de clasa problemelor ce urmau sa fie rezolvate;
Modelul program - model reprezentat de o imbinare intre modelul fizic(SC/SO) si modelul virtual (Algoritmul); intotdeauna un program se elaboreaza intr-un limbaj de programare care trebuie sa respecte restrictiile modelului fizic (sistemul de calcul si sistemul de operare) si restrictiile modelului virtual (algoritmul)
Conform acestor aspecte trebuie sa existe o echivalenta/congruenta intre Algoritm si Program indiferent de restrictiile particulare ale modelelor. In esenta,
Program = codificare intr-un limbaj de programare a unui Algoritm
Algoritm = codificare intr-un limbaj de reprezentare a unui Rationament
Definitie. Un algoritm este sistemul virtual
A = (M, V, P, R, Di, De, Mi, Me)
caracterizat de urmatoarele aspecte
elaborare;
reprezentare;
executie ;
corectitudine si analiza;
sistemul A este constituit din urmatoarele elemente:
M - memorie virtuala(interna) utilizata pentru stocarea temporara a informatiilor destinate variabilelor din multimea de variabile V; asupra variabilelor actioneaza procesul de calcul P ce are acces la memorie prin rezervarea de memorie pentru variabilele din multimea V; initial memoria virtuala este folosita pentru rezervare de memorie pentru variabilele din multimea V, dupa care este utilizata pentru scrierea si citirea de informatii in locatiile corespunzatoare variabilelor utilizate in procesul de calcul P;
V - multime de variabile/structuri de date definite conform rationamentului R corespunzator rezolvarii unei probleme si care utilizeaza memoria M prin locatii de memorie pentru fiecare tip de variabila din V; locatiile de memorie rezervate variabilelor din V sunt utilizate de procesul de calcul P care prin executia instructiunilor ce constituie P, schimba valorile(starea) locatiilor de memorie corespunzatoare variabilelor in conformitate cu implementarea rationamentului R;
P - proces de calcul ce este reprezentat de o colectie de instructiuni/comenzi exprimate intr-un limbaj de reprezentare(cel mai utilizat fiind pseudocod-ul); folosind memoria virtuala M si multimea de variabile V, colectia de instructiuni implementeaza/codifica tehnicile si metodele ce constituie rationamentul R conceput special pentru rezolvarea unei clase de probleme; executia instructiunilor din P determina o dinamica a valorilor locatiilor de memorie corespunzatoare din V; dupa executia tuturor instructiunilor din P, solutia/solutiile problemei se afla in anumite locatii de memorie ce constituie datele de iesire De;
R - rationament de rezolvare exprimat prin diverse tehnici si metode specifice domeniului din care face parte clasa de probleme supuse rezolvarii (matematica/fizica/chimie, etc.), care imbinate cu tehnici de programare corespunzatoare realizeaza actiuni/procese logice prin utilizarea memoriei virtuale M si a multimii de variabile V;
Di - date de intrare/input ce repezinta valori ale unor parametri ce caracterizeaza ipoteze de lucru/stari initiale; valorile datelor de intrare sunt stocate in memoria M prin intermediul instructiunilor de citire/intrare ce utilizeaza mediul de intrare Mi; acesta este un dispozitiv virtual pentru citirea datelor de intrare;
De - date de iesire/output ce repezinta valori ale unor parametri ce caracterizeaza solutia/solutiile problemei invocate de cerintele problemei/starile finale; valorile datelor de iesire sunt obtinute din valorile intermediare ale unor variabile generate de executia instructiunilor din procesul de calcul P si care in final sunt stocate in memoria M in vederea transmiterii/scrierii lor catre mediul de iesire Me; acesta este un dispozitiv virtual pentru reprezentarea/scrierea datelor de iesire sub forma grafica sau alfanumerica;
Mi - mediu de intrare/input ce este un dispozitiv virtual de intrare/citire pentru citiri virtuale ale valorilor datelor de intrare pentru a fi stocate in memoria virtuala M;
Me - mediu de iesire/output ce este un dispozitiv de iesire/scriere pentru preluarea datelor de iesire din memoria virtuala M si care au fost obtinute prin executia procesului de calcul P; datele de iesire sunt transmise/scrise sub forma grafica sau alfanumerica pe un suport virtual(ecran virtual, hartie virtuala, disk magnetic virtual, etc.).
2. elaborare - elaborarea/conceperea algoritmului inseamna elaborarea unui proces demonstrativ/computational ce va constitui rationamentul de rezolvare R si care va ingloba metode si tehnici eficiente pentru gasirea solutiei/solutiilor problemelor pentru care se elaboreaza algoritmul; elaborarea rationamentului de rezolvare R consta din urmatoarele:
- definirea datelor de intrare/input(Di) si a datelor de iesire/output(De)
- aplicarea metodelor si tehnicilor utilizate pentru rezolvare
- definirea multimii variabilelor V utilizate in rezolvare;
codificarea rationamentului de rezolvare R intr-un limbaj de reprezentare(de tip pseudocod) va constitui procesul de calcul P
3. reprezentare - prin reprezentarea algoritmului se intelege exprimarea formalizata
intr-un limbaj de reprezentare(in general, de tip pseudocod) a legaturii intre memoria M, multimea de variabile V si procesul de calcul P ;
Forma generala a unui algoritm
algorithm <nume_algoritm>
<declarare_variabile>
begin
<procesul_de_calcul_P>
end
4. executie - algoritmii se considera executati pe masini abstracte/virtuale (ale caror caracteristici le 'abstractizeaza' pe cele ale masinilor de calcul/sistemelor de calcul existente la un moment dat).
5. corectitudine si analiza -
a) corectitudinea algoritmului este exprimata de corectitudinea partiala (procesul de calcul se termina-timpul de executie este finit- pentru orice data de intrare dintr-un anumit domeniu de valori) si corectitudinea totala (pentru orice data de intrare dintr-un domeniu de valori, procesul de calcul realizeaza valori corecte conform scopului/functiei algoritmului); exista diverse metode pentru verificarea celor doua componente ale corectitudinii (de exemplu, pentru algoritmul lui Euclid reprezentat corect in pseudocod, corectitudinea partiala este verificata de faptul ca sirul valorilor resturilor obtinute din impartirile succesive este un sir convergent catre 0, iar corectitudinea totala este verificata de metoda lui Euclid printr-o simpla demonstratie matematica); elaborarea aplicatiilor informatice necesita testarea programelor care implementeaza diversi algoritmi pentru ca programatorul sa se convinga de corectitudinea algoritmilor conceputi;
b) analiza algoritmului se refera la spatiul de memorie utilizat si la timpul necesar executiei algoritmului(timpul de executie); aceasta analiza inseamna masurarea si descrierea(cantitativa) a performantelor algoritmului ce permite compararea diverselor solutii algoritmice pentru aceeasi problema; de regula resursa timp este mai critica decat resursa spatiu de memorie, dar sunt situatii in activitatea de proiectare si implementare a unor noi algoritmi, cand se stabileste un compromis intre cerintele de spatiu de memorie si cele referitoare la timpul de executie; analiza unui algoritm cuprinde urmatoarele abordari:
stabilirea unui model de calcul ce va specifica operatiile fundamentale(elementare) pe care le utilizeaza algoritmul si costul- in unitati de timp- asociat fiecarei operatii elementare; de exemplu, algoritmii numerici sunt analizati prin numararea operatiilor aritmetice mai costisitoare(costul unei inmultiri/impartiri este mult mai mare decat al unei adunari/scaderi), algoritmii de sortare/cautare sunt analizati prin numararea operatiilor de comparatie, iar algoritmii din geometria computationala care realizeaza operatii asupra poligoanelor, sunt analizati prin numararea varfurilor/muchiilor prelucrate;
stabilirea timpului de calcul/executie in functie de volumul setului de date de intrare; exista asa-numite masuri de complexitate care descriu aspectul de performanta ce trebuie masurat: timpul de executie in cazul cel mai defavorabil, in cazul mediu si in cazul amortizat(marginea superioara in cazul cel mai defavorabil);
stabilirea ratei de crestere(analiza asimptotica) a timpului de executie in functie de volumul setului de date de intrare; analiza asimptotica exprima cresterea timpului de executie al unui algoritm in cazul cresterii-spre infinit- a volumului setului de date de intrare; daca timpul de executie este exprimat de functia f(n), n fiind numarul de elemente de intrare, atunci rata de crestere a lui f(n) este data de functia T(n); de exemplu, daca f(n) = an2 + bn + c, unde a,b,c sunt constante, atunci cand n creste spre infinit, termenii de ordin 1 si 0 sunt nesemnificativi si astfel in acest caz rata de crestere a lui f(n) este functia T(n) = n2; in functie de variatia functiei T(n) exista urmatoarele categorii de algoritmi: lineari, patratici, cubici, exponentiali, logaritmici, Divide et Impera(n * log2 n ); notatiile utilizate in analiza asimptotica a algoritmilor sunt urmatoarele: O(f(n)) ce repezinta clasa functiilor care cresc mai putin decat f(n) cand n tinde catre infinit, o(f(n)) ce exprima clasa functiilor care cresc strict mai lent decat f(n), W(f(n)) ce exprima clasa functiilor care nu cresc mai incet decat f(n), Q(f(n)) ce exprima clasa functiilor care cresc cu aceeasi rata ca si f(n).
Intr-un algoritm fiecare regula trebuie sa precizeze foarte clar operatiile ce se executa asupra datelor, lucru nu tocmai simplu de realizat in contextul limbajului natural. De aceea pentru operatiile ce pot sa apara in descrierea unui algoritm au fost introduse si consacrate notatii simple, care sa nu genereze ambiguitati. Aceste notatii se vor prezenta in continuare.
Operatii de calcul
Prin operatii de calcul se inteleg operatiile elementare de adunare, scadere, inmultire, impartire si ridicare la putere.
Alte operatii algebrice (extragerea radacinii, logaritmarea, etc) sunt considerate neelementare si ele pot fi executate numai prin reducere la operatii elementare.
Reprezentarea operatiilor in cadrul unui algoritm se poate face fie prin simbolurile consacrate in aritmetica fie prin simbolurile consacrate in limbajele de programare:
+ adunare
- scadere
* inmultire
/ pentru impartire
** pentru ridicare la putere
Aceste operatii intervin in cadrul expresiilor. Expresia este o succesiune de variabile si constante legate intre ele prin semne de operatii si eventual paranteze, dupa reguli bine definite.
Intr-un algoritm o expresie apare in cadrul unei operatii de atribuire.
Operatii de atribuire
Printr-o asemenea operatie se atribuie o valoare unei variabile, valoare ce poate fi a unei constante, a unei alte variabile sau a unei expresii.
Operatii de test
Scopul acestor operatii este de a verifica relatiile existente intre datele asupra carora opereaza algoritmul pentru a decide transmiterea controlului executiei. Aceste operatii sunt cunoscute deja din algebra si se reprezinta prin semnele: <, >, =, ≠, ≤, ≥.
In urma executarii unei operatii de test rezultatul obtinut este una din asa numitele valori logice: adevarat sau fals.
Operatii de intrare/iesire
Aceste operatii au o semnificatie bine definita in cadrul prelucrarii automate a datelor si se refera la introducerea datelor initiale, respectiv furnizarea rezultatelor.
Operatia de intrare se mai numeste si operatie de citire si reprezinta practic operatia de atribuire a unor valori din afara algoritmului, inregistrate pe diferite suporturi de stocare a datelor, unor variabile utilizate de acesta.
Operatia de iesire se mai numeste si operatia de scriere sau operatia de afisare si din punct de vedere practic consta in furnizarea de la algoritmi catre utilizator a valorilor unor variabile, valori ce constituie rezultate si care pot fi scrise pe diferite suporturi de stocare a datelor.
Descrierea algoritmilor intr-un limbaj natural prezinta serie de inconveniente care se reflecta negativ asupra caracteristicilor acestora. De aceea a fost necesara introducerea unor limbaje pentru descrierea algoritmilor, care sa permita o prezentare simpla, intr-o forma apropiata de limbajul natural, dar in acelasi timp avand o structura apropriata de cea a limbajelor de programare.
Schemele logice constituie un asemenea limbaj de descriere a algoritmilor, usor de invatat, usor de transpus intr-un limbaj de programare.
In continuare vor fi prezentate simbolurile si structurile elementare care stau la baza elaborarii schemelor logice.
Simbolurile utilizate sunt de fapt figuri geometrice compuse din arce (sageti) si noduri. Un nod se reprezinta printr-o figura geometrica simpla (dreptunghi, romb, etc). In cele ce urmeaza vor fi prezentate patru tipuri de simboluri.
|
Figura 1 |
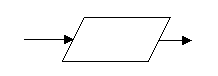
In figura 1 este reprezentat simbolul pentru o instructiune de prelucrare. S-a utilizat simbolul f pentru reprezentarea functiei care opereaza modificarea asupra datelor ce intra in acest nod si care poate fi o operatie elementara sau o operatie complexa. |
Printr-un astfel de simbol se reprezinta regulile de tip prelucrare. In practica sunt folosite urmatoarele variante ale acestui simbol:
|
Figura 2 |
. Figura 3 |
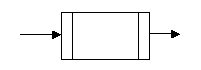
In figura 2 este prezentat simbolul utilizat pentru operatiile de intrare/iesire. In figura 3 este prezentat simbolul utilizat pentru reprezentarea unor prelucrari complexe care urmeaza sa fie detaliate ulterior
|
Figura 4 |
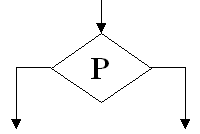
In figura 4 este reprezentat simbolul pentru o instructiune predicat. S-a utilizat simbolul P pentru reprezentarea unei conditii, unui test, sau o expresie booleana. In functie de valorile datelor, cand se ajunge la acest nod, p poate lua valoarea adevarat sau fals, alegandu-se o iesire sau cealalta, conform unei conventii facute anterior. Prin acest simbol se reprezinta regulile de tip predicat. |
|
Figura 5 |
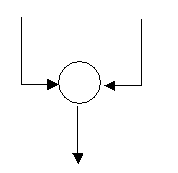
Acest simbol nu joaca nici un rol in prelucrarea efectiva a datelor. El permite regruparea a doua iesiri intr-o singura intrare in modul urmator, precum si etichetarea acestui nod prin inscrierea in cerculet a unui cod de identificare. |
|
Figura 6 |
Aceste doua simboluri nu au nici un rol in prelucrarea efectiva a datelor ele fiind utilizate numai ca semnificatie a inceperii respectiv terminarii unor prelucrari. |
Reprezentarea algoritmilor prin scheme logice reprezinta una din cele mai utilizate tehnici pentru exprimarea clara si completa a modului de rezolvare a unei probleme.
Prin schema logica se intelege forma grafica de reprezentare a unui algoritm utilizand simbolurile prezentate anterior.
Pentru a obtine schema logica a unui algoritm se procedeaza astfel:
v se inlocuiesc regulile algoritmului prin simboluri adecvate reprezentand in noduri operatiile ce trebuie executate.
v se unesc simbolurile in sensul indicat de succesiunea regulilor algoritmului
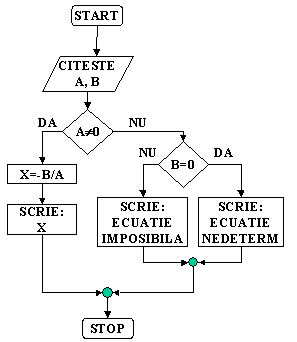
Pentru exemplificare in continuare se vor prezenta schemele logice ale algoritmilor celor doua exemple prezentate la cursul anterior.
v Sa se precizeze algoritmul de rezolvare a ecuatiei de gradul I AX +B = 0, valorile coeficientilor A si B fiind cunoscute. (Figura 7);
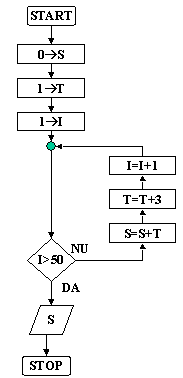
v Sa se precizeze algoritmul pentru calculul sumei primilor 50 de termeni ai sirului: 1, 4, 7, 10, 13, 16, . (Figura 8)
Notatii
Ø T pentru valoarea unui termen al sirului;
Ø I pentru rangul unui termen al sirului;
Ø S pentru suma primilor 50 de termeni.
|
Figura 7 |
Figura 8 |
O schema logica se numeste normalizata daca indeplineste urmatoarele reguli:
v Are un singur arc de intrare (bloc terminal de inceput) si un singur arc de iesire (bloc terminal de sfarsit);
v Exista un traseu de la intrare catre orice nod si de la orice nod catre iesire.
Schemele logice normalizate prezinta interes prin faptul ca pot fi inlocuite in intregime prin noduri de tip prelucrare. Aceasta si pentru ca intr-o acceptiune mai larga nodurile de tip prelucrare pot prezenta un anumit stadiu de analiza a problemei, de prelucrari foarte complexe ce pot fi detaliate ulterior. Uneori o asemenea schema logica se mai numeste si schema functionala sau program normalizat.
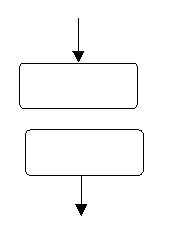
Unele structuri intalnite in schemele logice normalizate se remarca prin generalitatea functionarii lor. Este vorba de acele structuri care se refera la prelucrari in serie, alternative si repetitive. In continuare se vor prezenta tipurile de structuri de baza pentru fiecare precizandu-se notatia si reprezentarea lor sub forma de schema logica normalizata.
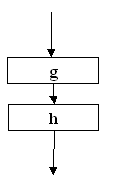
|
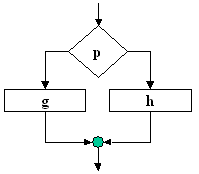
Figura 9 |
Se refera la inlantuirea (tratarea succesiva) a doua prelucrari g si h care pot fi instructiuni simple sau orice prelucrare admisa, conform cu cele prezentate pana la acest moment, precum si orice parte de schema logica, daca aceasta parte are ea insasi o structura se schema normalizata. |
|
Figura 10 |
In aceasta structura p este un predicat iar g si h sunt doua prelucrari. In functie de variabilele datelor controlul va fi transmis catre una din instructiunile g si h. Cu conventia ca g se executa in cazul in care predicatul ia valoarea "adevarat", iar h se executa in cazul in care p ia valoarea "fals", aceasta structura IF-THEN-ELSE (p, g, h) admite urmatoarea exprimare: "DACA p, ATUNCI executa g, ALTFEL executa h". |
Structurile de tip alternativ admit doua variante:
|
v Tipul pseudo-alternativ: este o structura de tip alternativ in care prelucrarea h este vida. Se citeste: "DACA p, ATUNCI executa g". |
Figura 11 |
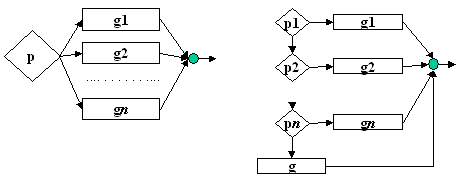
v Tipul multialternativ. Reprezinta o generalizarea tipului alternativ propriu zis, in care apare si o regrupare automata a iesirilor.
|
Figura 12 |
|
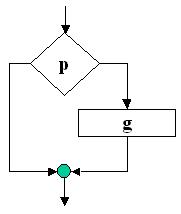
Figura 13 |
In aceasta structura p reprezinta un predicat iar g o prelucrare. Aceasta structura se numeste ciclu, si admite exprimarea: "CAT TIMP p este adevarat, EXECUTA g" |
Trebuie remarcat ca daca p este de la inceput fals g nu se executa nici macar o data.
Tipul repetitiv admite la randul sau doua variante:
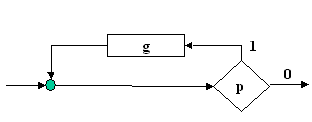
|
v Structura DO-UNTIL: unde g se executa cel putin o data. Admite exprimarea "EXCUTA g PANA CAND p". |
Figura 14 |
|
v
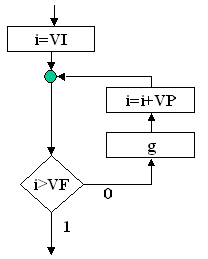
Structura DO-FOR: este o varianta a structurii
WHILE-DO in care predicatul p nu da numai conditia de iesire din ciclu, dar precizeaza si numarul de
executii ale corpului ciclului. Acest control se realizeaza cu variabila de
control (aici notata cu I) careia I se precizeaza valoarea initiala VI,
valoarea finala VF si pasul VP. Variabila de control poate fi utilizata in
calculele din prelucrarea g daca prin aceasta nu I se modifica valoarea.
Prelucrarea g se mai noteaza in aceasta varianta si prin g(I), pentru a
sugera faptul ca executia lui g se face sub controlul |
Figura 15 |
Orice algoritm se poate transpune folosind numai structurile secventiala, selectia simpla si repetitiva conditionata anterior.
Pentru usurinta scrierii se admit si selectia multipla, structura repetitiva conditionata posterior si structura repetitiva cu un numar cunodascut de pasi.
Limbajul pseudo-cod are o sintaxa si semantica asemanatoare limbajelor de programare moderne, avand o anumita flexibilitate in ceea ce priveste sintaxa, in ideea ca prin codificarea unui algoritm intr-un limbaj de programare, operatia sa fie cat mai comoda. De aici, iese in evidenta influentarea reciproca intre algoritmica si programare, iar ambele fiind influentate de sistemele de calcul si sistemele de operare actuale.
Un algoritm reprezentat in limbajul pseudo-cod este constituit dintr-o sectiune in care se declara variabilele si tipul de date asociat acestora, precum si definirea procedurilor sau functiilor apelate de algoritm, si corpul algoritmului ce este o succesiune finita de instructiuni executabile:
algorithm <nume_algoritm>
<declarare_variabile>
<declarare_proceduri>
begin
<procesul_de_calcul_P>
end
Din definitia unui algoritm rezulta ca structura unui algoritm este constituita din urmatoarele elemente de baza:
Elementele lexicale ale limbajului sunt urmatoarele:
Identificatori - secvente de caractere pentru definirea numelor de variabile si a numelor de proceduri si functii;
Expresii - forme lexicale asemanatoare expresiilor matematice ce se construiesc folosind operanzi(constante, nume de variabile, apel de functii), operatori(operatii) corespunzatoare tipului de expresie si eventual paranteze pentru definirea prioritatilor operatiilor.
Cuvinte-cheie - cuvinte din limba engleza care identifica un tip de date sau descriu o instructiune.
Eficienta unui algoritm depinde atat de metodele si tehnicile implementate in procesul de calcul , cat si de tipurile de date utilizate. Complexitatea algoritmilor implica o complexitate atat a metodelor utilizate , cat si a organizarii datelor in vederea prelucrarii lor. De modul in care sunt structurate datele , depinde eficienta algoritmilor. O structura de date este o colectie de date inzestrata cu o structura care precizeaza componentele si procedeele de reprezentare, identificare si inregistrare a componentelor. De aceea, limbajele de programare moderne ofera o mare varietate de tipuri de date, inceputul l-a realizat limbajul Pascal care ulterior a implementat si tehnica OOP. Un tip de date este sistemul T = (D, O), unde D este domeniul de valori, iar O este multimea operatorilor/operatiilor care actioneaza asupra valorilor din D.
Tipurile de date -ce utilizeaza static memoria unui SC- sunt clasificate in :
Tipurile de date prezentate mai sus utilizeaza memoria sistemului de calcul in mod static, nu totdeauna eficient pentru algoritmul in cauza. Pentru utilizarea dinamica a memoriei sistemului de calcul, in scopul utilizarii ei eficiente, este definita o organizare speciala a datelor: liste liniare si liste circulare. In acelasi scop, limbajele de programare moderne ofera tipul referinta (pointer). Evident, in spiritul celor de pana acum, conceperea si elaborarea unui algoritm trebuie sa tina seama de limbajul de programare utilizat in final pentru codificarea algoritmului.
O lista liniara este o structura de date omogena, secventiala, formata din elemente ale unei multimi de date. O lista poate fi vida(nu contine nici un element), sau plina(nu mai poate stoca alte elemente). Orice lista liniara are doua elemente speciale, unul de inceput(baza listei) si altul de sfarsit(varful listei).
Operatiile asupra elementelor unei liste sunt exprimate de extragerea/accesarea unui element din lista, inserarea/adaugarea unui element in lista, precum si eliminarea/stergerea unui element din lista. Aceste operatii vor fi implementate de utilizatori prin proceduri/functii particulare elaborate special pentru un anumit limbaj de programare(Pascal, C++, etc).
Stocarea listelor in memoria unui sistem de calcul se poate realiza in doua moduri :
secvential - stocarea elementelor listei se face in locatii succesive de memorie conform ordinii elementelor din lista ; se retine primul element al listei(adresa de baza) ce este baza listei; structura elementara adecvata reprezentarii secventiale a listelor este tabloul unidimensional ;
inlantuit(simplu sau dublu inlantuit) - lista inlantuita este organizata secvential, elementele fiind dispersate in memorie; fiecare element este inlocuit cu o celula(nod) formata dintr-o parte de informatie(corespunzatoare elementului listei) si o parte de legatura ; in cazul listei simplu inlantuite partea de legatura contine adresa celulei urmatorului element din lista si se va retine adresa de baza a listei, iar ultima celula va indica o valoare speciala(NIL) ce nu poate desemna o legatura; in cazul listei dublu inlantuite, partea de legatura are o componenta ce indica elementul succesor si o componenta ce indica predecesorul elementului.
Tipurile de date care utilizeaza dinamic memoria unui SC sunt urmatoarele :
stack(stiva) - lista liniara la care inserarea si extragerea elementelor se face prin varful listei(de exemplu, stiva se utilizeaza pentru parcurgerea in adancime(DF-Depth First) a arborilor/grafurilor, pentru generarea solutiilor unei probleme folosind metoda Backtracking, etc.);
queue(coada) - lista liniara la care inserarile se fac la baza listei, iar extragerile se fac prin varful listei(de exemplu, coada se utilizeaza pentru parcurgerea pe latime(nivele)(BF-Breath First) a arborilor/grafurilor);
Listele liniare pot fi transformate in liste circulare daca se considera ca legatura ultimului element indica adresa bazei listei. Utilizarea inlantuirii permite o usoara manipulare a listelor circulare prin considerarea unui singur nod fictiv, numit baza.
Definitie.
O declarare este constituita dintr-o parte in care se indica tipul de date- prin cuvintele cheie corespunzatoare-, si o parte ce reprezinta o lista de nume de variabile- prin identificatori corespunzatori:
<tip_date> <lista_identificatori>
Definitie.
Un identificator(nume) de variabila reprezinta o secventa de caractere ASCII(maxim 256 caractere) primul caracter fiind litera(pentru unele limbaje de programare poate fi si caracterul underline '_'), iar celelalte fiind litere, cifre sau caracterul '_'. Evident, lungimea secventei de caractere trebuie sa fie rezonabila, suficient de mica pentru ca semantic sa sugereze un aspect privind functii, operatii, metode, etc. implementate in procesul de calcul.
Exista libertate si flexibilitate in definirea identificatorilor pentru variabilele utilizate in conceperea si reprezentarea unui algoritm.
Exemple.
integer a,b,c,max_X, x(100);
real x,y,z, m_produs(20,20);
boolean ind_1,ind_2;
char ch1,ch2; string s1,s2,s3;
stack S ; queue Q1,Q2;
record(integer cod;string nume;real media) x, y, z, t;
Din punct de vedere sintactic, instructiunile sunt delimitate prin caracterul ';' si pot fi scrise pe randuri separate sau pot fi scrise pe acelasi rand. Ca o conventie, in continuare o constructie de forma [<expresie>] reprezinta cazul optional pentru 'lipsa'.
Rezolvarea multor probleme complexe necesita executarea repetata a acelorasi calcule/operatii pentru date de intrare diferite. Procedurile si functiile(in domeniul limbajelor de programarese numesc subprograme) ofera posibilitatea definirii si descrierii acestor calcule o singura data. Prin intermediul subprogramului aceste calcule se executa prin apelarea lor ori de cate ori este necesar. Orice subprogram este identificat printr-un nume/identificator de procedura/functie si o lista de parametri(argumente).
Declararea unei proceduri:
Procedure <nume>[(<lista_parametrii_formali>)]
[<declarare_variabile>]
[<declarare_proceduri>]
begin
<procesul_de_calcul>
end
Declararea unei functii:
Function <nume>[(<lista_parametrii_formali>)]:<tip_rezultat>
[<declarare_variabile>]
[<declarare_proceduri>]
begin
<procesul_de_calcul>
end
Un algoritm este complet elaborat daca este descrisa si definitia procedurilor si functiilor folosite. Definitia presupune descrierea instructiunilor pentru efectuarea calculelor proprii si modul cum se transmit rezultatele intre programul principal(programul apelant) si subprogramul apelat. In cazul unei proceduri, <lista_parametrii_formali> contine atat parametrii de intrare, cat si paramentrii de iesire(in urma apelarii procedurii, vor stoca rezultatele calculate de instructiunile procedurii). In cazul unei functii, <lista_parametrii_formali> contine doar parametrii de intrare, in urma apelarii functiei, rezultatul va fi stocat in identificatorul(numele) functiei. De aceea este obligatoriu ca printre instructiunile functiei sa existe o instructiune de atribuire in care membrul stang sa fie chiar identificatorul functiei. Aceasta deosebire dintre procedura si functie face ca modul de apelare a acestora sa fie diferit:
Limbajul pseudo-cod ofera urmatoarele categorii de instructiuni executabile :
Ø simple :
de intrare/iesire(READ, WRITE) ;
de atribuire/memorare
de transfer(RETURN, EXIT);
de operare liste(inserare,extragere)
Ø structurate :
secventiale/Secventa(BEGIN . END);
decizionale/Decizia
selectia simpla(IF_THEN_ELSE) ;
selectia multipla(CASE) ;
repetitive/Repetitia
ciclu cu test initial(WHILE_DO);
ciclu cu test final(REPEAT_UNTIL) ;
ciclu cu contor(FOR_DO);
apel de procedura/functie
In continuare, fiecare instructiune va fi descrisa si prezentata prin sintaxa si semantica sa.
Instructiuni de intrare/iesire
Sintaxa
read <lista_variabile>
write <lista_variabile>
unde <lista_variabile> este o lista de nume de variabile de tip elementar.
Semantica
Se presupune ca citirea valorilor(datelor) se va face de la un mediu de intrare (de exemplu: tastatura, suport magnetic, etc.), iar scrierea rezultatelor(valori de iesire) se va face la un mediu de iesire(de exemplu: display, imprimanta, plotter, suport magnetic, etc.). Executia instructiunii read determina citirea de pe mediul de intrare a valorilor corespunzatoare tipului de variabile ale caror nume sunt indicate in <lista_variabile>. Ordinea citirii valorilor este data de ordinea numelor de variabile din <lista_variabile>. Executia instructiunii write determina scrierea pe mediul de iesire a valorilor corespunzatoare tipului de variabile ale caror nume sunt indicate in <lista_variabile>. Ordinea scrierii valorilor este data de ordinea numelor de variabile din <lista_variabile>.
Instructiunea de atribuire/memorare
Sintaxa
<var> <expresie>
sau
(<var1>, <var2>,. ,<varn>) (<e1>,<e2>, . ,<en>)
unde <var> si <var1>, <var2>,. ,<varn> sunt nume de variabile, iar <expresie> si <e1>,<e2>, . ,<en> sunt expresii de acelasi tip(aritmetic, logic, caracter, etc.) cu tipul variabilelor corespunzatoare. Simbolul " " reprezinta operatorul(operatia) de atribuire/memorare. O expresie se construieste folosind oparanzi (constante, nume de variabile, apel de functii), operatori adecvati si eventual paranteze.
Semantica
Executia instructiunii in prima varianta are ca efect evaluarea valorii expresiei din membrul drept, dupa care in locatia corespunzatoare variabilei <var> se memoreaza valoarea obtinuta in urma evaluarii expresiei <expresie>. In cazul celei de-a doua variante, executia instructiunii este echivalenta cu executia secventiala/paralela a instructiunilor de atribuire/memorare
<vari> <ei> , unde ![]()
Instructiuni de transfer
Sintaxa
Return [<expresie>]
Exit
Semantica :
Instructiunea Return poate fi utilizata in cadrul subprogramelor(proceduri si functii) avand rolul in executie sa provoace parasirea corpului(procesului de calcul) unui subprogram si revenirea in unitatea de program din care a avut loc apelul, si anume la instructiunea ce urmeaza imediat dupa acest apel, in cazul unei proceduri. In cazul in care cuvantul Return este urmat de o expresie, valoarea expresiei obtinuta prin evaluare este folosita ca valoare de retur a subprogramului. Instructiunea Exit este utilizata in cazul iesirii fortate din corpul unei instructiuni si anume controlul este preluat de instructiunea ce urmeaza dupa instructiunea respectiva.
Instructiuni de operare liste (stive,cozi)
Sintaxa
<var> Þ <lista>
<var> <lista>
unde <var> este un nume de variabila de acelasi tip cu tipul elementelor listei <lista>, iar <lista> este un nume de lista.
Semantica
Prima instructiune reprezinta instructiunea de inserare a elementului <var> in lista <lista> , iar a doua instructiune reprezinta instructiunea de extragere a elementului curent din lista <lista> si memorarea lui in variabila <var>.
Sintaxa
Begin
<instructiune1>
. . .
<instructiunen>
End
unde <instructiunei>, ![]() este o instructiune executabila oferita de limbajul
pseudo-cod.
este o instructiune executabila oferita de limbajul
pseudo-cod.
Semantica
Executia acestei constructii (modul de instructiuni) inseamna executia secventiala ('step by step') a celor n instructiuni in ordinea in care sunt scrise, dupa care controlul procesului de calcul este dat urmatoarei instructiuni de dupa cuvantul cheie End.
Instructiuni decizionale(DECIZIA)
Selectia simpla(IF-THEN-ELSE)
Sintaxa
if <expresie_bool> then <corp_1>
[else <corp_2>]
unde <expresie_bool> este o expresie booleana(logica), iar <corp_1> si <corp_2> sunt module de instructiuni executabile, inclusiv decizionale.
Semantica
Se evalueaza valoarea logica a expresiei booleene (logice) <expresie_bool>. In cazul in care valoarea obtinuta este True, atunci (then) se trece controlul pentru executia instructiunilor din <corp_1>, altfel(else) se trece controlul pentru executia instructiunilor din <corp_2>, in situatia cand acest modul este prezent. In cazul in care valoarea expresiei booleene este False si modulul de instructiuni <corp_2> nu apare, controlul este trecut la urmatoarea instructiune de dupa if , actiune realizata si dupa executia instructiunilor din <corp_1>, respectiv <corp_2>.
Sintaxa
Case <selector> of
C11[,C12, . , C1m] : <modul1>
[Cn1[,Cn2, . , Cnm]: <moduln>
[else <moduln+1>]
End
unde <selector> este o variabila sau o expresie simpla de tip diferit de tipul real, ce va putea avea
valori constantele distincte Cij, unde ![]()
![]() , iar <moduli>,
, iar <moduli>, ![]() este un modul de instructiuni executabile.
este un modul de instructiuni executabile.
Semantica
Prin executia acestei instructiuni,
daca <selector> este o expresie simpla, aceasta va fi
evaluata obtinundu-se o valoare ce va
fi comparata cu constantele Cij, ![]()
![]() . In cazul in care <selector> este o variabila se
va considera valoarea variabilei.
Daca valoarea este identica cu o
constanta Cij , atunci se trece controlul pentru executia
instructiunilor din <moduli> dupa care se trece la executarea primei instructiuni de dupa End. In
cazul in care valoarea nu este
identica cu nici una din constantele Cij,
. In cazul in care <selector> este o variabila se
va considera valoarea variabilei.
Daca valoarea este identica cu o
constanta Cij , atunci se trece controlul pentru executia
instructiunilor din <moduli> dupa care se trece la executarea primei instructiuni de dupa End. In
cazul in care valoarea nu este
identica cu nici una din constantele Cij,![]()
![]() , atunci se trece controlul pentru executia
instructiunilor din <moduln+1> , dupa care se trece la
executarea primei instructiuni de dupa End.
, atunci se trece controlul pentru executia
instructiunilor din <moduln+1> , dupa care se trece la
executarea primei instructiuni de dupa End.
Sintaxa
While <expresie_bool> DO
<corp>
unde <expresie_bool> este o expresie booleana (logica), iar <corp> este un modul de instructiuni executabile, inclusiv repetitive.
Semantica
Executia acestei instructiuni determina evaluarea repetitiva (in cadrul unui proces dinamic) a valorii logice a expresiei <expresie_bool>. La prima evaluare, daca valoarea obtinuta este True, se trece la executarea instructiunilor din modulul <corp> si se continua cu reevaluarea valorii de adevar(instructiunile din modulul <corp> pot schimba starea unor variabile care apar in <expresie_bool>), altfel daca valoarea de adevar este False, nu se mai executa instructiunile din modulul <corp>. In cazul in care instructiunile din modulul <corp> s-au executat o data, se repeta executia atata timp cat (while) valoarea de adevar a expresiei <expresie_bool> ramane True. Procesul repetarii executarii instructiunilor din modulul <corp> se incheie in momentul in care valoarea de adevar a expresiei <expresie_bool> devine False.
In concluzie, este posibil ca instructiunile din modulul <corp> sa nu se execute niciodata in cazul in care la prima evaluare(test initial) valoarea de adevar a expresiei <expresie_bool> este False. De asemenea, se poate face observatia ca executia instructiunilor din modulul <corp> este precedata intotdeauna de testul privind valoarea de adevar a expresiei <expresie_bool>.
Sintaxa
repeat
<corp>
until <expresie_bool>
unde <expresie_bool> este o expresie booleana (logica), iar <corp> este un modul de instructiuni executabile, inclusiv repetitive.
Semantica
Executia acestei instructiuni determina executia repetitiva (in cadrul unui proces dinamic) a instructiunilor din modulul <corp> si evaluarea repetitiva a valorii logice a expresiei <expresie_bool>. La inceput, neconditionat se trece la executarea instructiunilor din modulul <corp> si apoi se continua cu evaluarea valorii de adevar(instructiunile din modulul <corp> pot schimba starea unor variabile care apar in <expresie_bool>). Daca valoarea de adevar a <expresie_bool> este True, nu se mai executa instructiunile din modulul <corp>, altfel se repeta executia instructiunilor din modulul <corp> pana cand (until) valoarea de adevar a expresiei <expresie_bool> devine True. Procesul repetarii executarii instructiunilor din modulul <corp> se incheie in momentul in care valoarea de adevar a expresiei <expresie_bool> devine True.
In concluzie, totdeauna instructiunile din modulul <corp> se executa cel putin o data si fiecare executie a instructiunilor din modulul <corp> este urmata de evaluarea (test final) valorii de adevar a expresiei <expresie_bool> . De asemenea, se poate face observatia ca executia instructiunilor din modulul <corp> este urmata totdeauna de testul privind valoarea de adevar a expresiei <expresie_bool>.
Sintaxa
For <var> = <exp_inf>, <exp_sup>[, <pas>] do
<corp>
unde <var> este o variabila (numita contorul ciclului) de acelasi tip (exceptie tipul real) cu tipul expresiile simple <exp_inf>, <exp_sup> ce reprezinta valori (marginea inferioara, respectiv marginea superioara) dintr-o multime de valori ordonate ce pot fi generate prin intermediul valorii <pas> (numit pasul de generare- pasul ciclului), iar <corp> este un modul de instructiuni executabile, inclusiv for.
Semantica
Executia acestei instructiuni determina executia repetitiva (in cadrul unui proces dinamic) a instructiunilor din modulul <corp> prin modificarea automata a valorii contorului, initial avand valoarea data de marginea inferioara <exp_inf>,iar apoi valori generate prin actiunea pasului (prin incrementare sau decrementare) <pas> pana cand in final va lua valoarea data de marginea superioara <exp_sup>. In momentul cand valoarea contorului <var> va fi valoarea data de marginea superioara <exp_sup>, instructiunile din modulul <corp> vor fi executate pentru ultima oara, iar controlul se va transfera la urmatoarea instructiune de dupa instructiunea for.
Problema 1. (Suma de
valori). Daca x1, x2,
., xn sunt componentele reale ale vectorului X=(x1, x2,
., xn), sa se calculeze suma valorilor sale, adica ![]() .
.
INPUT(Di) : n - numarul componentelor ; X=(x1, x2, ., xn)
OUTPUT(De) : ![]()
Rezolvare.
a) R - rationamentul de rezolvare
Vom defini urmatorul sir de valori :
S0 = 0
Si = Si-1 + xi , unde i > 0.
Evident, prin inductie matematica se poate demonstra ca ![]() .
Prin urmare, este necesar sa se elaboreze procesul de calcul P care sa calculeze succesiv valorile S0, S1, ., Sn,
valori care genereaza valoarea S = Sn.
.
Prin urmare, este necesar sa se elaboreze procesul de calcul P care sa calculeze succesiv valorile S0, S1, ., Sn,
valori care genereaza valoarea S = Sn.
b) V- definirea variabilelor
X - vector cu componente reale pentru stocarea valorilor de intrare
n- numarul componentelor
S - variabila pentru stocarea valorilor intermediare si a valorii finale
c) P - procesul de calcul
Dupa citirea(read) unei valori pentru variabila n si citirea (read) a n valori pentru componentele vectorului X, in memoria interna sunt stocate(prin intermediul mediului de intrare Mi) aceste valori, in locatii de memorie la care se poate avea acces prin intermediul instructiunilor(executate de un robot virtual /masina virtuala).
Conform relatiei de recurenta de mai sus, initial trebuie ca in locatia lui S sa fie valoarea 0.
Evident, pentru calculul valorilor intermediare se va utiliza intructiunea repetitiva cu contor FOR.
Dupa incheierea executiei acestei instructiuni, in locatia variabilei S se va afla valoarea ceruta de problema (conform rationamentului conceput), valoare ce se va transfera din memorie pe mediul de iesire Me.
Prin urmare, vom avea urmatorul proces de calcul :
begin
read n
read x1, x2, ., xn
S
For i = 1, n do
S S + xi ;
write S
end
d) ALGORITMUL - reprezentare
Reprezentarea completa a algoritmului este urmatoarea :
Algorithm Suma_valori ;
Integer n
Real s, x(500)
begin
read n
read x1, x2, ., xn
S
For i = 1, n do
S S + xi ;
write S
end
Problema
2 (Algoritmul lui
INPUT(Di) : a, b - numere intregi
OUTPUT(De) : c.m.m.d.c. (a,b)
Rezolvare.
a) R - rationamentul de rezolvare
Se executa sirul de impartiri succesive tinand seama de teorema impartirii cu rest :
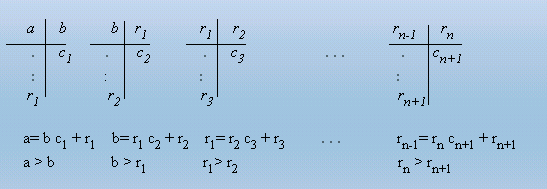
Se poate observa ca
sirul resturilor (ri)i
> 0 este marginit, descrescator si convergent catre 0. Daca rn+1= 0,
In concluzie, trebuie realizat un proces de calcul care sa execute operatiile din sirul de impartiri succesive, procesul se va termina atunci cand la un moment dat restul impartirii va fi 0.
b) V- definirea variabilelor
a, b - deimpartitul, respectiv impartitorul (variabile simple)
r - restul impartirii (variabila simpla)
c) P - procesul de calcul si reprezentarea algoritmului
Tinand seama ca nu este necesara stocarea valorilor intermediare ale resturilor, rolul variabilelor a si b se va schimba la executarea urmatoarei impartiri. Se repeta procesul de impartire pana cand r=0. Se poate observa ca valoarea catului nu intervine in dinamica procesului de calcul.
Algorithm EUCLID_1;
Integer a,b,r
begin
write 'Alg. Euclid: metoda impartirilor succesive'
read a,b
repeat
r a mod b;
a b;
b r;
until r = 0;
write 'c.m.m.d.c.=', a
end
Folosind doar doua variabile a si b (initial vor stoca datele de intrare), se poate concepe un altfel de proces de calcul prin inlocuirea impartirilor succesice cu scaderi repetate (o operatie de impartire fiind de fapt un sir de operatii de scadere). Se va obtine asa-numitul algoritm Nicomachus.
Algorithm EUCLID_2;
Integer a,b
begin
write 'Algoritmul lui Euclid: metoda lui Nicomachus'
read a,b
repeat
if a > b then
a a-b
else
b b-a
until a = b;
write 'c.m.m.d.c.=', a
end
Problema 3. (Algoritm de sortare). Daca x1, x2, ., xn sunt componentele reale ale vectorului X=(x1, x2, ., xn), sa se gaseasca s o permutare (aranjzare) a componentelor vectorului astfel ca acestea sa fie sortate(crescator sau descrescator), adica
X=(xs , xs , ., xs(n)) si xs £ xs £ £ xs(n)
INPUT(Di) : n - numarul componentelor ; X=(x1, x2, ., xn)
OUTPUT(De) : X=(xs , xs , ., xs(n)) si xs £ xs £ £ xs(n)
Rezolvare.
a) R - rationamentul de rezolvare
Exista foarte multi algoritmi de sortare, unii foarte performanti, altii mai putin performanti[23]. Vom aplica un algoritm foarte cunoscut bazat pe metoda interschimbarilor sau metoda bulelor . Metoda consta dintr-un proces de calcul principal de parcurgere de mai multe ori a componentelor vectorului(numarul de pasi ai procesului fiind nedefinit, terminarea procesului fiind data de obtinerea sortarii dorite). Prin parcurgerea componentelor vectorului X se intelege un subproces de clacul ce se executa in (n-1) pasi si consta din analiza cuplurilor (xi, xi+1), iI ce inseamna compararea valorilor celor doua componente si efectuarea sau nu a interschimbarii acestor componente in functie de tipul sortarii (crescatoare sau descrescatoare).
Efectuarea interschimbarii componentelor xi, xi+1 se poate realiza prin utilizarea unei variabile intermediare (de lucru), notata de exemplu prin K ce poate sa aiba valorile 0 sau 1, daca nu se realizeaza interschimbarea, respectiv, daca se realizeaza interschimbarea. Aceasta variabila cu rol de indicator (semafor) se va utiliza pentru a controla terminarea procesului de calcul principal, si anume pentru a incheia parcurgerea componentelor vectorului X. Pentru acest scop, inainte de fiecare parcurgere valoarea lui K se seteaza cu 0. In cazul in care in timpul parcurgerii componentelor vectorului (executarii subprocesului de calcul pentru analiza celor n-1 cupluri; se va utiliza instructiunea for), se va efectua cel putin o interschimbare, indicatorul K se va seta cu valoarea 1. In cazul in care nu s-a efectuat nici o interschimbare, valoarea lui K ramane neschimbata, adica 0, ceea ce este echivalent cu faptul ca valorile vectorului X sunt sortate. Prin urmare, la sfarsitul fiecarei parcurgeri se va verifica daca valoarea indicatorului K este 0, caz in care procesul de calcul principal se va termina (se va utiliza instructiunea repeat). Evident, metoda utilizeaza structura vectorului X ca suport de stocarea a componentelor sortate. Din acest motiv, pentru ca operatia de interschimbare sa se realizeze corect, se va utiliza o variabila intermediara (de lucru) notata save, variabila care va stoca temporar valoarea xi si care ulterior se va stoca in locul valorii xi+1 . Secventa corecta de instructiuni (metoda celor trei scaune) este urmatoarea (executia secventiala a instructiunilor):
![]()
![]() 1. save x(i); xi 2 xi+1
1. save x(i); xi 2 xi+1
![]() 2. x(i) x(i+1); 1 3
2. x(i) x(i+1); 1 3
3. x(i+1) save; save
Observatie.Este incorecta operatia de interschimbare prin simplele operatii de atribuire x(i) x(i+1) ; x(i+1) x(i) deoarece s-ar pierde valoarea x(i) si in final vectorul X ar contine alte valori si nu cele initiale (citite).
b) V- definirea variabilelor
X - vector cu componente reale
n- numarul componentelor
K - indicator pentru interschimbare (variabila simpla)
save - variabila de salvare (variabila simpla)
c) P - procesul de calcul si reprezentarea algoritmului
Algorithm sortare_crescatoare;
Integer n,k
Real save,X(500)
begin
read n
read x1, x2, ., xn
repeat
k
for i=1,n-1 do
begin
if xi > xi+1 then
begin
k
save xi
xi xi+1
xi+1 save;
end
end
until k=0;
write 'Vectorul sortat: ', x1, x2, ., xn
end
VLADA Software Educational pentru Invatarea Utilizarii Calculatorului, Univ. Bucuresti
G. D. MATEESCU, P. F. MORARU , INFORMATICA pentru LICEU si BACALAUREAT , Ed. NICULESCU, 2000
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 4463
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved