| CATEGORII DOCUMENTE |
DOCUMENTE SIMILARE |
|
TERMENI importanti pentru acest document |
|
Structura de tip coada
Definitie:
O coada (queue) este o lista liniara pentru care toate inserarile sunt facute la unul din capetele listei, iar toate stergerile (si de obicei orice acces) sunt facute la celalalt capat.
O coada completa ('dequeue') sau coada cu doua capete este o lista liniara in care toate inserarile si stergerile sint facute la ambele capete ale listei.
O coada completa (perfecta) este mai generala decit o coada sau o stiva, ea are citeva proprietati comune cu un pachet de carti de joc. O imagine corespunzatoare pentru intelegerea mecanismului unei cozi complete (sugerata de F. J. Dijkstra) este prezentata in figura urmatoare (prin analogie cu linia ferata).
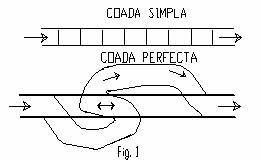
Mai distingem cozi complete cu restrictii la iesire sau la intrare, in care stergerile sau respectiv inserarile se fac numai la unul din capete si in acest caz din figura 1 lipseste unul din tronsoane.
Cozile sunt uneori denumite liste tip 'primul sosit - primul iesit' ('last in - first - out', sau LIFO).
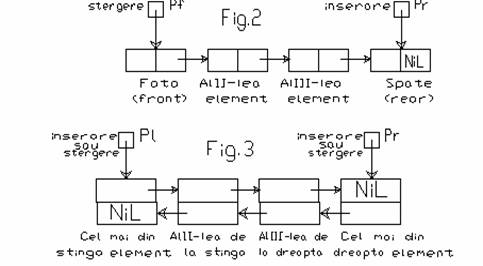
Reprezentarea grafica a unei cozi, respectiv a unei cozi complete este prezentata in figurile 2 si 3.
Se observa ca o coada simpla se poate implementa prin analogie cu o lista liniara simplu inlantuita. Este nevoie insa de doua variabile referinta pentru a specifica elementul din fata (front) numit 'pf', respectiv elementul din spate (rear), numit 'pr'.
O coada completa se poate implementa prin inlantuire dintr-o lista dublu inlantuita, avind nevoie tot de doua variabile referinta pentru specificarea elementului cel mai din stinga (numit 'pl') si a celui mai din dreapta (numit 'pr').
In continuare vom discuta doar cazul cozilor simple, toate operatiile asupra cozilor complete facindu-se prin analogie cu cele de la cazul simplu.
Si in cazul de fata vom renunta la camplul 'key' de la listele liniare simplu inlantuite, rezultind urmatoarea structura pentru elementele unei cozi:
typedef struct queue
pqueue;
pqueue *p, *pf, *pr;
Spatele cozii, specificat de pointerul 'pr' va avea cimpul 'next' incarcat cu valoarea NIL, respectiv NULL.
Operatii efectuate asupra cozilor.
a) Crearea unei cozi vide.
Cel mai simplu mod de a crea o coada vida se face initializind la valoarea NULL pointerii 'pf' si 'pr':
pr:=NULL;
pf:=NULL;
b) Introducerea unui element in coada (dupa elementul din spate).
In cazul in care coada nu este vida (pr<>NIL), se fac urmatoarele operatii:
p=(pqueue *)malloc(sizeof(pqueue));
p->inf=.;
pr->next=p;
pr=p;
In cazul in care coada este vida (pr=NIL):
p=(pqueue *)malloc(sizeof(pqueue));
p->inf:=;
p->next:=NULL;
pf=p;
pr=p;
Deci in general:
p=(pqueue *)malloc(sizeof(pqueue));
p->inf=;
p->next=NULL;
if (pr==NULL) pf=p;
else pr->next:=p;
pr=p;
c) Extragerea unui element (a elementului din fata al cozii).
In acest caz, trebuie analizat inainte daca respectiva coada este vida (pf=NULL), caz in care nu se mai poate extrage nici un element.
if (pf==NULL) printf('Coada vida')
else
Ca si in cazul stivelor, daca se impune ca urmatorul element dintr-o coada sa nu depaseasca o valoare maxima, se poate modifica algoritmul pentru introducerea unui element in coada.
Problema rezolvata
Vom folosi structura de date de tip coada simpla pentru a rezolva o categorie de probleme numita sortare topologica.
Aceasta categorie intervine in rezolvarea unor probleme de tip retele (asa numitele retele Perth) si chiar in probleme de lingvistica. Ea poate fi utilizata in oricare problema in care intervine ordonarea partiala a unei submultimi S finite de elemente.
Relatia de ordonare partiala, reprezentata prin simbolul '<=', satisface urmatoarele proprieteti:
1) Daca x<=y si y<=z ==> x<=z
2) Daca x<=y si y<=x ==> x=y
3) x<=x
pentru oricare elemente x,y si z din S.
Dandu-se o multime finita de elemente S=, relatia de ordonare partiala se poate da sub forma cuplurilor de elemente intre intre care exista asemenea relatie:
ai1<=ai2 ; ai3<=ai4 ; . ; aik<=aip
Problema sortarii topologice inseamna a ordona liniar elementele multimii S:
ak1, ak2, , akn,
astfel ca in stanga unui element 'ak' sa nu existe elemente mai mari ca el (ap>ak, p<k) si in dreapta lui sa nu fie elemente mai mici ca el (as<ak, pentru s>k).
Pentru determinarea structurii de ordine partiale pe o multime S, trebuie specificate numarul de elemente ale multimii S (notat 'ne'), numarul de perechi de elemente ordonate (notat 'np'), precum si efectiv valorile perechilor respective.
Intru-cat intre elementele ale multimii S si multimea indicilor acestora se poate stabili o corespondenta biunivoca, algoritmul de sortare topologica va lucra doar cu acesti indici, elementele corespunzatoare multimii gasindu-se prin indiciere intr-un vector a[i].
Spre exemplu, sa consideram multimea de indici si perechile de ordonare astfel: 1<=2, 3<=7, 5<=8, 8<=6, 4<=6,1<=3, 7<=4, 9<=5, 2<=8 aceasta insemnind ca a1<=a2, a3<=a7, etc.).
Sortarea topologica presupune o ordonare a acestor indici astfel: 1, 3, 7, 4, 9, 2, 5, 8, 6.
Pentru realizarea acestui lucru se folosesc notiunile de succesor si predecesor pentru a specifica un element mai mic, respectiv mai mare ca elementul considerat.
Algoritmul presupune doua parti distincte: - prima, in care se genereaza o anumita structura cu elementele multimii considerate si a doua, in care se extrag efectiv in ordine topologica elementele, folosind structura generata inainte.
Structura contine un vector (notat X), care are atitea componente cite elemente are multimea considerata.
Fiecare element al vectorului are doua componente (cimpuri):
- cimpul 'count', care specifica numarul de predecesori pentru fiecare element;
- cimpul 'prim', care este un pointer catre inceputul listei succesorilor fiecarui element. Lista succesorilor unui element va avea structura:
typedef struct lista
pilst;
in care cimpul 'succ' reprezinta efectiv numarul elementului care este succesor respectivului element, iar cimpul 'urm' este un pointer spre urmatorul element din lista.
Elementele vectorului X vor avea acum urmatoarea structura:
typedef struct elem
Pentru exemplul considerat anterior, structura generata este:
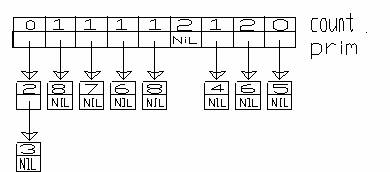
Aceasta structura odata generata, ea poate fi folosita in felul urmator, pentru a extrage elementele in ordinea sortarii:
- se alege un element din X care are cimpul 'count' egal cu 0 (nu are predecesor);
- se extrage elementul respectiv si se decrementeaza toate cimpurile 'count' ale succesorilor sai;
- procesul se repeta pina se epuizeaza toate elementele cu cimpul 'count' =0.
Pentru a realiza alegerea elementelor cu cimpul 'count' =0, se foloseste o structura de tip coada.
Algoritmul de generare contine in principal urmatoarele actiuni:
A1) - Se genereaza coada inserind pentru inceput toate elementele cu cimpul 'count' egal cu 0;
A2) - Se extrage un element din coada;
A3) - Se parcurge lista succesorului elementului respectiv si se decrementeaza cu 1 cimpul 'count' al respectivelor elemente;
A4) - Daca prin decrementare, un element va ajunge sa aiba cimpul 'count' egal cu 0, el se va insera in coada;
A5) - Procesul se repeta incepind cu pasul 2, pina cind coada devine vida.
Daca structura de ordine partiala a fost corect definita, se pot extrage toate elementele; in caz contrar, se va semnala o eroare. Pentru detectarea acestui lucru, se foloseste variabila "n", care la inceput se va initializa cu numarul de elemente al multimii considerate (ne) si la fiecare extragere din coada se va decrementa cu unu. Daca la sfirsit "ne" a ajuns la zero, structura
a fost corect definita; altfel se va semnala eroare.
Elementele din coada vor avea structura :
typedef struct queue
Campul '
Variabilele ce indica primul element al cozii si ultimul element (pf si pr) vor fi variabile globale ale programului principal.
Se vor folosi procedurile 'pop' si 'push' pentru extragerea si introducerea unui element din /in coada.
Programul de sortare topologica va citi in afara de numarul de elemente si numarul de perechi, adica toate perechile (j, k) , pentru care j <= k.
#include <stdio.h>
#include <stdlib.h>
#include <alloc.h>
typedef struct lista
plist;
typedef struct elem
elem;
typedef struct queue
pqueue;
elem x[100];
pqueue *pr, *pf;
plist *p;
int i, err, n, ne, np;
void push(int a)
int pop(void)
void structura(void)
printf('Dati perechile, cite una pe linie:n');
for (i = 1; i <= np; i++)
void extragere(void)
else
while ((!term) && (!ciclu))
if (p == NULL)
ciclu = 1;
else
} while (!(term));
void main()
Probleme propuse
1. Sa se imagineze un numar de cuvinte care pot face parte dintr-un dictionar tehnic. Relatia de ordine partiala intre doua cuvinte se considera urmatoarea: cuvintul 1 <= cuvintul 2 daca in definirea cuvintului 2 intra cuvintul 1.
2. Sa se ordoneze cuvintele alese astfel incit in definirea oricarui cuvint sa intre doar cuvinte anterior descrise.
3. Sa se implementeze o coada cu ajutorul unui masiv unidimensional. Sa se scrie procedurile de inserare in coada, stergere din coada, testare daca coada este vida, determinarea virfului cozii.
4. Scrieti proceduri pentru:
a) Eliminarea celui de-al k-lea element din structura de tip coada de la problema nr 3.
b) Inserarea unui element j imediat dupa cel de-al k-lea element al structurii de tip coada de la problema nr 3.
5. Sa se scrie o colectie de proceduri pentru gestiunea a N cozi intr-un masiv unidimensional V[1..m]. Se presupune ca zonele alocate celor N cozi au lungimi egale cu M/N (unde M/N reprezinta partea intreaga minorata). Se vor scrie proceduri pentru:
a) Depunerea unui termen intr-una din cozi;
b) Extragerea unui termen dintr-o coada;
c) Testarea faptului ca coada I este vida;
d) Testarea faptului ca coada I este plina.
6. Sa se scrie o colectie de proceduri pentru gestiunea a 2 stive si a unei cozi intr-un masiv unidimensional V[1..m].
7. Sa se scrie o colectie de proceduri pentru gestiunea a N cozi intr-un masiv unidimensional V[1..m] in conditiile mentionate din problema 5.
8. Sa se scrie o colectie de proceduri pentru gestiunea a N obiecte de tip stiva sau coada dintre care N1 stive si N2=N-N1 cozi intr-un masiv unidimensional V[1..m]. Se va considera ca un obiect de tip coada cu "r" locatii poate memora doar (r-1) elemente.
9. Sa se implementeze o structura de tip coada utilizind o lista circulara simplu legata. Se vor implementa operatiile mentionate la problema 5.
10. Se numeste coada dubla ('deque') o structura de date de tip lista liniara la care inserarile si stergerile pot avea loc la ambele capete.
a) Implementati acesta structura cu ajutorul unui masiv unidimensional si scrieti proceduri pentru: intializarea structurii, inserarea de elemente la ambele capete, stergerea de elemente din ambele capete si testarea daca structura este vida;
b) Implementati aceasta structura utilizind liste inlantuite.
11. Intr-un sistem de operare joburile gata pentru executie sint depuse intr-un sistem de cozi de unde sint preluate si executate, conform schemei urmatoare:
-utilizatorii sistemului au prioritati in functie de numarul asociat lor, astfel utilizatorii 100-199 au prioritatea cea mai mare, 200-299 au prioritatea imediat inferioara, s.a.m.d, utilizatorii 900-999 avind prioritatea cea mai mica;
-in cadrul fiecarui grup de utilizatori lucrarile se executa in ordinea sosirii lor;
-lucrarile utilizatorilor cu proritate mai mare se executa inaintea lucrarilor utilizatorilor cu prioritate mai mica;
-sistemul gestioneaza 9 cozi, fiecare coada pentru joburile utilizatorilor din fiecare grup de utilizatori;
Sa se scrie proceduri pentru:
a)Adaugarea unui job la sistemul de cozi. Procedura primeste numarul identificatorului utilizatorului caruia ii apartine jobul si un atom pentru identificarea jobului;
b) Prelucrarea unui job din sistemul de cozi;
c) Afisarea tuturor joburilor inca neexecutate pina la momentul apelului sau.
12. Sa se scrie un program care transforma o expresie corecta sintactic dintr-un limbaj L1 intr-un limbaj L2. Expresia este compusa in ambele limbaje din operanzi exprimati prin identificatori, operatori binari si paranteze rotunde inchise si deschise. Programul primeste numarul de operatori, operatorii (aceeasi in ambele limbaje) si prioritatile fiecarui operator in fiecare din cele doua limbaje precum si expresia in L1. Se cere sa se tipareasca expresia corespunzatoare din L2, fara paranteze redundante.
Observatii :
- cele 2 limbaje difera exclusiv prin prioritatile asociate operatorilor;
- expresiile din L1 si L2 sint echivalente daca dupa evaluare produc acelasi rezultat;
- identificatorul este o succesiune de litere si cifre care incepe cu o litera;
- expresia nu contine blancuri si se termina cu primul blanc intilnit;
- operatorii sint reprezentati prin caractere diferite de litere, cifre si paranteze. Prioritatile lor in cele doua limbaje sint date ca numere naturale in ordine crescatoare;
- operatiile au aceeasi asociativitate in ambele limbaje.
Exemplu:
Setul operatorilor: + , * , / ;
Prioritatile operatorilor :
- in L1: 1, 2, 3;
- in L2: 2, 1, 3;
(prioritatile sint asociate in ordinea operatorilor);
Expresia in L1: (A + X53)* RAZA2/ALFA;
in L2: A + X53 * RAZA2/ALFA;
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 1867
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved