| CATEGORII DOCUMENTE |
Sistemul de adresare URL
1 Definitie, elemente si protocoale
Urmarind descrierea unui mod convenabil de adresare a paginilor Web, aplicatia WWW introduce un sistem ingenios, mai general, prin care se pot referi dupa principii unitare diverse resurse din Internet, nu numai pagini Web. Acest sistem se numeste URL (Uniform Resource Locator) si permite adresarea unei resurse specificand: cum se numeste, unde este localizata si cum se face accesul la resursa respectiva. (Pentru intelegerea sistemului, se poate face o analogie cu regasirea persoanelor care au un anumit nume si o adresa - trebuie sa se poata distinge intre mai multe persoane cu acelasi nume dar cu adrese diferite.)
Astfel, intr-o adresa URL care refera o anumita resursa se introduc trei elemente:
protocolul de acces
serverul (specificat cu numele DNS sau eventual cu adresa IP) pe care se gaseste resursa (fisierul) si
un nume local, care identifica in mod unic resursa (uzual, numele fisierului). Sintactic, dupa numele protocolului apare // iar dupa numele serverului - / .
De exemplu, urmatoarele adrese URL vor referi pagini web:
https://www.yahoo.com,
https://www.netscape.com,
https://www.microsoft.com/,
Daca se omite numele resursei la accesul unei pagini Web, se va incarca implicit fisierul numit index.html sau index.htm. In principal, acest mod de adresare este utilizat pentru regasirea paginilor Web- prin intermediul protocolului HTTP (dupa cum se poate vedea in exemplele anterioare) dar, asa cum se va explica mai jos, se poate aplica unitar si in cazul altor tipuri de protocoale si resurse.
O adresa URL poate fi specificata direct in zona de adresare a navigatorului sau poate fi asociata unui hiperlegaturi, caz in care activarea obiectului respectiv va avea ca efect incarcarea resursei asociate. Pentru crearea unui hiperlegaturi, se va specifica textul / imaginea prin care se va face selectia si adresa URL asociata (uzual, a unei pagini web). Procedura de creare a hiperlegaturilor este detaliata in paragraful 9.4 si capitolul 18. La selectarea acelui obiect, programul de navigare cauta serverul utilizand DNS si, pe baza adresei sale IP, stabileste o conexiune TCP catre acesta; pe aceasta conexiune se va transfera resursa (fisierul), utilizand protocolul specificat (implicit http). Adresele URL pot utiliza mai multe protocoale, cele mai importante fiind:
Exemplu: news://comp.infosystems.www.providers
Se observa ca sistemul URL permite nu numai navigarea prin Web, ci integreaza si alte servicii Internet, cum ar fi: FTP, news, Gopher, e-mail si telnet, care pot fi astfel utilizate din navigatoare. Utilizatorul are in consecinta la dispozitie, intr-o interfata prietenoasa, toate tipurile de acces in Internet.
Principiile care stau la baza sistemului de adresare URL, alaturi de dezvoltarea unor programe de navigare foarte accesibile au dus la o extindere masiva a Web-ului.
2 URL sau generalizarea URI
In ciuda tuturor acestor proprietati, cresterea Web-ului scoate in evidenta si o slabiciune a metodei utilizarii URL-urilor. Pentru o pagina care este foarte des referita, ar fi de preferat sa existe mai multe copii pe servere diferite, pentru a reduce traficul in retea. Problema este ca URL-urile nu ofera nici o posibilitate de indicare a unei pagini fara sa se specifice unde este localizata pagina respectiva. Nu exista nici o metoda pentru a spune ceva de genul: "Vreau pagina xyz, dar nu ma intereseaza de unde o aduci". Pentru a rezolva aceasta problema si a permite multiplicarea paginilor IETF lucreaza la un sistem de URI (Universal Resource Identifiers - identificatori universali de resurse). Un URL poate sa fie privit ca un URI generalizat.
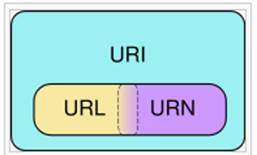
Fig. 2 Diagrama Venn a categoriilor URI
In diagrama de mai sus URN reprezinta un URI care identifica o resursa prin numele sau, intr-un spatiu de nume dat.
Oricine poate crea un URI cu scopuri bine definite pentru a aduce un aport la dezvoltarea tehnologiei de baza ideale in Web. Astfel, din acest punct de vedere, se poate spune ca: orice aplicatie ce contine URI se considera a fi compatibila Web. Ca orice identificator, URI trebuie sa se supuna unor reguli; acest lucru se realizeaza prin controlul sintaxei de catre standardul IETF. Pe de alta parte, datorita faptului ca Web este mult prea mare pentru a fi controlat de vreo organizatie, implica un URI descentralizat; in timp ce unele scheme URI (ex: .https://.) depind de sisteme centralizate ca DNS (Domain Name Service), altele cum ar fi .freenet://. Sunt complet descentralizate. Acest lucru implica faptul ca nu trebuie sa obtii permisiunea cuiva pentru a-ti crea propriul URI, ba chiar mai mult decat atat, iti poti face propriul URI pentru informatii ce nu-ti apartin. Cu toate ca aceasta facilitate face ca URI sa fie flexibil, aduce de la sine si cateva probleme legate de consistenta informatiei. Deoarece oricine poate crea un URI, se vor obtine in consecinta mai multe structuri de link- ri pentru aceeasi resursa, care va fi greu de identifcat. Dar acestea sunt compromisurile ce trebuiesc facute daca dorim sa cream semantic Web.
Pentru a identifica item-urile dintr-un Web se folosesc identificatori iar deoarece sistemul utilizat este unul uniform si fiecare item identificat este considerat o resursa, ii numim identificatori URI. Una din formele specifice acestui tip de identificator se poate spune a fi URL(Uniform Resource Locator), care nu reprezinta altceva decat o adresa ce face posibila accesarea unei pagini Web(ex: https://www.electronica.pub.ro.) de catre calculatorul respectiv. Asemeni multor forme de URI, URL identifica si apoi localizeaza destinatia, abatandu-se de la regula URLul ce incepe cu .mid://. care poate identifica un mesaj de e-mail dar care nu poate obtine o copie a acestuia pentru utilizator.
3 Semantic Web
Semantic Web utilizeaza cu precadere, pentru reprezentarea datelor, sintaxe ce au la baza identificatorul URI; datele sunt de obicei grupate sub forma unor structuri triple. De exemplu, mai multe triplete de date URI pot fi stocate in baze de date, sau se pot interschimba pe Web utilizand un set particular de sintaxe special dezvoltate pentru un anumit task, acestea numindu-se sintaxe RDF (Resource Description Framework). Acest identificator da posibilitatea de a construi declaratii ce pot fi procesate de catre un calculator si astfel acesta poate conversa cu utilizatorul.
Semantic Web reprezinta un set de informatii astfel imbinate pentru a fi usor procesate de catre masinile de lucru, la nivel global. Acest lucru te poate duce cu gandul la o eficienta reprezentare a datelor pe World Wide Web, sau la o baza de date globala
Concepute de catre Tim Berners-Lee, creatorul WWW (World Wide Web), URIs (Uniform Resource Identifier), HTTP (HyperText Transfer Protocol) si HTML (HyperText Markup Language), tehnologiile bazate pe acest concept se afla inca intr-o stare incipienta, iar cu toate ca viitorul proiect, in general vorbind, se arata a fi stralucit iar cu toate acestea se pare ca exista mici retineri legate de directii si caracteristici.
Care este rationamentul fundamental pentru un astfel de sistem? Datele care se afla in general in fisiere HTML sunt folosite in diferite contexte. Problema esentiala legata de majoritatea datelor ce se afla pe Web intr-o astfel de forma se reduce la dificultatea utilizarii la scara ridicata, datorita inexintentei unui sistem global care sa realizeze prezentarea acestora astfel incat sa fie preluate si respectiv procesate de catre oricine.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 1408
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved