| CATEGORII DOCUMENTE |
Clusterizare
Cuprins
![]() Notiuni
introductive
Notiuni
introductive
![]() Algoritmi
Algoritmi
n K-means
n Algoritmi statistici
![]() Implementari
in Weka
Implementari
in Weka
n K-means
n EM
Notiuni introductive
n este metoda de invatare a cunostintelor din date ce poate fi folosita cand nu avem un atribut clasa.
n Clasificarea rezultata in urma "clustrizari" este o impartire in grupe, numite "clustere", formate in mod "natural", urmarind corelatiile dintre atributele setului de date.
n Daca clasificarea este corecta atunci ea va reflecta un mecanism real prezent in domeniul din care apartin datele.
![]() Algoritm
de invatare nesupervizata
Algoritm
de invatare nesupervizata
![]() Scopul:
gasirea unei structuri in date
Scopul:
gasirea unei structuri in date
![]() Clusterizarea
are ca obiectiv impartirea datelor in grupe astfel incat
Clusterizarea
are ca obiectiv impartirea datelor in grupe astfel incat
![]() Date
aflate in aceeasi grupa sa fie cat mai similare
Date
aflate in aceeasi grupa sa fie cat mai similare
![]() Date
aflate in grupe diferite sa fie cat mai diferite
Date
aflate in grupe diferite sa fie cat mai diferite
![]() Exista
mai multe moduri de a gasit "structura" din date
Exista
mai multe moduri de a gasit "structura" din date
![]() Cel
mai utilizat este prin calculul unei "distante" dintre vectorii de date
Cel
mai utilizat este prin calculul unei "distante" dintre vectorii de date
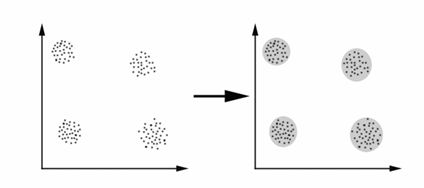
Fig.1: Date grupate in clustere pe baza calculului distantei
Algoritmi
Algoritmul K-means
![]() Este
o metoda de clusterizare iterativa
Este
o metoda de clusterizare iterativa
![]() Metoda
K-means alcatuieste clustere pe atribute cu valori numerice.
Metoda
K-means alcatuieste clustere pe atribute cu valori numerice.
![]() Ea
imparte instantele in grupe disjuncte folosind o marime numita
"distanta".
Ea
imparte instantele in grupe disjuncte folosind o marime numita
"distanta".
![]() In
functie de implementari aceasta "distanta" poate fi
calculata folosind mai multe formule.
In
functie de implementari aceasta "distanta" poate fi
calculata folosind mai multe formule.
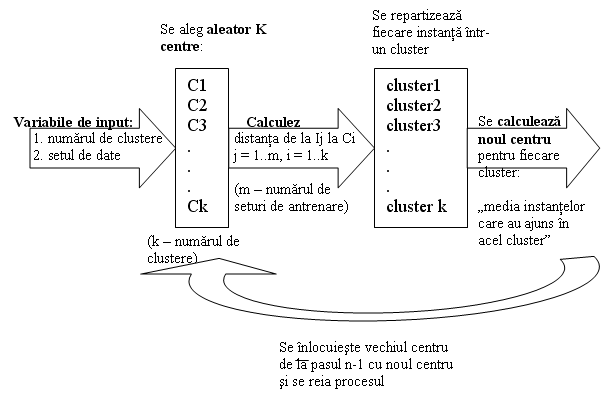
Algoritmul K-means este urmatorul:
Pas1: Se precizeaza cate clustere va avea impartirea:
n acesta este parametrul k
Pas2: Sunt alese aleator k puncte:
n care vor fi desemnate "centrele clusterelor": C1, ,Ck
Pas3: Instantele sunt repartizate in clusterul de a carui centru este cel mai aproape corespunzator distantei folosite.
Pas4: Pentru fiecare cluster format dupa repartizarea tuturor instantelor se va calcula "centroid-ul" care este media instantelor din acel cluster
Pas5: Centru clusterului va fi inlocuit cu "centroid"-ul calculat la pas 4.
Pas6: Algoritmul este reluat de la pasul 2.
Procesul este oprit cand instantele sunt repartizate succesiv in acelasi cluster de mai multe ori. In acest caz se considera ca clusterele s-au "stabilizat".
Etapele algoritmului k-means
![]() In
functie de implementare parametrul k este predefinit sau este introdus de
utilizator.
In
functie de implementare parametrul k este predefinit sau este introdus de
utilizator.
![]() Deoarece
instantele sunt repartizate in clusterul de a carui centru este mai
aproape centrele se vor stabiliza pe un minim. Principala problema
de implementare este ca minimul poate fi unul local si nu global ceea ce poate duce la
o clasificare incorecta a instantelor.
Deoarece
instantele sunt repartizate in clusterul de a carui centru este mai
aproape centrele se vor stabiliza pe un minim. Principala problema
de implementare este ca minimul poate fi unul local si nu global ceea ce poate duce la
o clasificare incorecta a instantelor.
![]() De-a
lungul anilor au existat mai multe implementari si
perfectionari a acestui algoritm. Cea mai des folosita
implementare este cea in care se produce o clusterizare ierarhica astfel:
De-a
lungul anilor au existat mai multe implementari si
perfectionari a acestui algoritm. Cea mai des folosita
implementare este cea in care se produce o clusterizare ierarhica astfel:
n Pas1: Se aplica algoritmul k-means pe intregul set de date pentru k = 2.
n Pas2: Pentru fiecare dintre clusterele formate se aplica algoritmul k-means (k = 2).
n Astfel algoritmul k-means este reluat recursiv formand o clasificare ierarhica.
![]() Una dintre formulele folosite de algoritmul
k-means pentru calculul distantei
este:
Una dintre formulele folosite de algoritmul
k-means pentru calculul distantei
este:
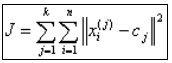 unde
unde 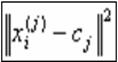 Este distanta aleasa
Este distanta aleasa
Exercitiu
![]() Deschideti
in notepad fisierul cluster1.arff
Deschideti
in notepad fisierul cluster1.arff
n Cate atribute prezinta setul de date? Cate instante?
n Alcatuiti manual o clusterizare folosind k-means pe aceste date
![]() Indicatii:
Indicatii:
n Desenati pe grafic cele 6 date
n Centrele initiale vor fi: K1 = (1,4), K2 = (3,10)
![]() Dupa
ce ati obtinut clasificarea deschideti fisierul in Weka
si rulati algoritmul
Dupa
ce ati obtinut clasificarea deschideti fisierul in Weka
si rulati algoritmul
n Comparati centroidele
n Vizualizati clasificarea
Exercitiu
![]() Deschideti
link-ul de mai jos:
Deschideti
link-ul de mai jos:
![]() https://www.elet.polimi.it/upload/matteucc/Clustering/tutorial_html/AppletKM.html
https://www.elet.polimi.it/upload/matteucc/Clustering/tutorial_html/AppletKM.html
![]() Ex1:
Ex1:
n
Introduceti
n Aveti puse cu patrat 2 centre initiale
n Marcati datele din exemplul anterior cu mouse-ul
n Apasati Start -> Step -> . End
n Bifati / debifati "Show History"
![]() Ex2:
Ex2:
n Reluati exercitiul pentru mai multe date: 100 date / 3 clustere
n 75 date, 10 clustere
n Observati
![]() modul
in care se modifica pozitia centrelor clusterelor
modul
in care se modifica pozitia centrelor clusterelor
![]() modul
in care sunt realocate instantele
modul
in care sunt realocate instantele
![]() Distante
care pot fi folosite in algoritmul k-means
Distante
care pot fi folosite in algoritmul k-means
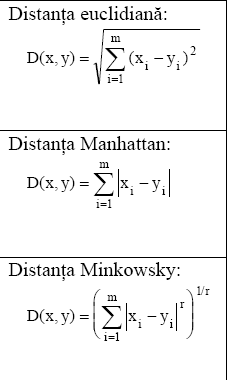
![]() Un dezavantaj
al algoritmului k-means
Un dezavantaj
al algoritmului k-means
n este "greoi"
n la fiecare pas algoritmul trebuie sa efectueze un numar mare de calcule pentru a determina distanta dintre fiecare instanta si fiecare centru.
n algoritmul trebuie sa efectueze un numar mare de iteratii:
![]() dupa
ce au fost alcatuite clusterele, sunt recalculate centrele lor iar
procesul este reluat.
dupa
ce au fost alcatuite clusterele, sunt recalculate centrele lor iar
procesul este reluat.
n > algoritmul este foarte lent.
![]() Pentru
a diminua cat mai mult acest dezavantaj
Pentru
a diminua cat mai mult acest dezavantaj
n au fost gasite diverse metode de a scadea numarul de iteratii necesare si numarul de calcule efectuate, cum ar fi
![]() folosirea
proiectiei setului de date,
folosirea
proiectiei setului de date,
![]() sau divizarea setului dupa anumite axe
pentru a nu mai lucra cu fiecare instanta in parte, ci cu diviziunile
respective,
sau divizarea setului dupa anumite axe
pentru a nu mai lucra cu fiecare instanta in parte, ci cu diviziunile
respective,
![]() toate
aceste "imbunatatiri" in sensul cresterii vitezei au
neajunsul scaderii calitatii clasificarii.
toate
aceste "imbunatatiri" in sensul cresterii vitezei au
neajunsul scaderii calitatii clasificarii.
Algoritmi de clusterizare statistica
![]() impart
instantele in grupe pe principiul probabilitatilor
impart
instantele in grupe pe principiul probabilitatilor
![]() clusterizarea
"statistica" mai este numita si clusterizare "pe baza de
probabilitate".
clusterizarea
"statistica" mai este numita si clusterizare "pe baza de
probabilitate".
![]() La baza
clasificarii statistice sta un model numit "mixturi finite" (finite
mixtures).
La baza
clasificarii statistice sta un model numit "mixturi finite" (finite
mixtures).
![]() O "mixtura"
este:
O "mixtura"
este:
n un set de k distributii de probabilitate
n reprezentand k clustere (in sensul de grupe supuse unor legi distincte si bine definite) care guverneaza valorile atributelor pentru membrii acelui cluster.
![]() Cu
alte cuvinte, fiecare distributie ofera probabilitatea ca o
instanta oarecare are un anume set de atribute daca ar fi
stiut ca apartinand acelui cluster.
Cu
alte cuvinte, fiecare distributie ofera probabilitatea ca o
instanta oarecare are un anume set de atribute daca ar fi
stiut ca apartinand acelui cluster.
Algoritmi de clusterizare statistica
![]() Exemplu:
Exemplu:
n consideram persoanele care sunt clientii unui magazin.
n Cunoastem mai multe gurpe ce au comoprtament similar.
n Una dintre grupe fiind "femei tinere".
n Cunoscand ca o instanta apartine acestui "cluster" de clienti, modelul mixturilor finite ne va oferi informatii de genul:
![]() atributul "achizitii_cosmetice" are
valoarea "da" cu probabilitatea de x%.
atributul "achizitii_cosmetice" are
valoarea "da" cu probabilitatea de x%.
![]() Fiecare
cluster are o distributie distincta, guvernata de legi diferite.
Fiecare
cluster are o distributie distincta, guvernata de legi diferite.
![]() Toate
instantele din setul de date apartin:
Toate
instantele din setul de date apartin:
n unui singur cluster
n si in mod obligatoriu unui dintre clustere
![]() problema
este determinarea carui cluster ii apartine
problema
este determinarea carui cluster ii apartine
![]() dimensiunea
clusterelor va diferi, modelul mixtura oferind si o distributie
de probabilitate care da populatia relativa a clusterelor.
dimensiunea
clusterelor va diferi, modelul mixtura oferind si o distributie
de probabilitate care da populatia relativa a clusterelor.
Notiuni generale: mixturi finite
![]() Cea
mai simpla mixtura finita:
Cea
mai simpla mixtura finita:
n exista un singur atribut numeric,
n care are o distributie Gaussiana sau normala pentru fiecare cluster,
n dar cu medii si deviatii diferite.
![]() Problema de clusterizare poate fi
formulata in felul urmator:
Problema de clusterizare poate fi
formulata in felul urmator:
n se ia un set de intante (in cazul de mai sus fiecare instanta este alcatuita doar dintr-un numar) si un
n numar de clustere cunoscut apriori;
n trebuie sa calculam
![]() media si
media si
![]() Deviatia
standard fiecarui
cluster si
Deviatia
standard fiecarui
cluster si
![]() distributia
populatiei pentru
fiecare clustere.
distributia
populatiei pentru
fiecare clustere.
Notiuni generale: mixturi finite
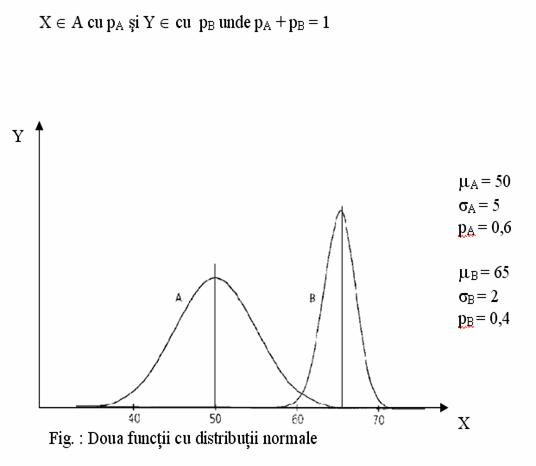
![]() Consideram
doua functii:
Consideram
doua functii:
n A si
n B cu
distributiile normale din figura
![]() Luam
esantioane din ambele functii cu:
Luam
esantioane din ambele functii cu:
n pA probabilitatea de a fi situat in A si
n pB probabilitatea de a apartine clusterului B
![]() Cu
aceste esantioane se formeaza un set de date.
Cu
aceste esantioane se formeaza un set de date.
Notiuni generale: mixturi finite
![]() problema numita mixturi finite
consta calculul celor 5 parametrii daca nu se cunoaste
carei functii apartine
problema numita mixturi finite
consta calculul celor 5 parametrii daca nu se cunoaste
carei functii apartine
![]()
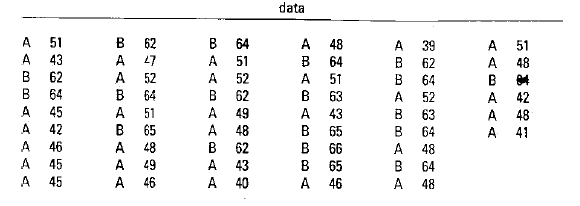 Detinem doar setul de date, ca in
figura de mai jos, fara identificatorul de clasa
Detinem doar setul de date, ca in
figura de mai jos, fara identificatorul de clasa
Clusterizarea statistica rezolva problema gasirii parametrilor
n m A, sA, pA, m B, sB (si din pA, pe pB)
n
fara
a sti care inregistrare apartine
![]() se
estimeaza media respectiv deviatia instantelor din A si B
folosind formulele:
se
estimeaza media respectiv deviatia instantelor din A si B
folosind formulele:
Iar pA se calculeaza considerand proportia instantelor din A in intregul set de date stiind ca x1 + x2 + + xn apartin lui A (sau B).
Notiuni generale: mixturi finite
![]() Daca
se cunosc cei cinci parametrii
Daca
se cunosc cei cinci parametrii
n m A, sA, pA, m B, sB) se poate calcula probabilitatea ca o instanta anume sa apartina lui A sau B folosind formula:
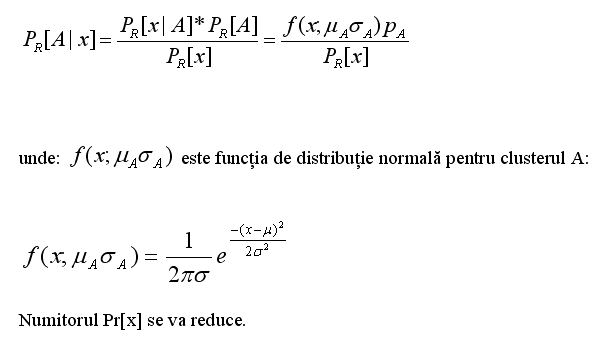
Notiuni generale: mixturi finite
![]() Se calculeaza atat Pr[A|x] si
Pr[B|x] si se normalizeaza impartindu-se la suma lor:
Se calculeaza atat Pr[A|x] si
Pr[B|x] si se normalizeaza impartindu-se la suma lor:
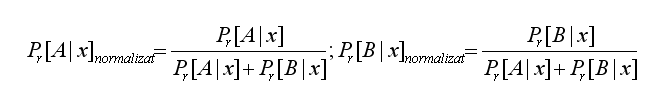
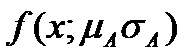 nu reprezinta propriu-zis probabilitatea ca x I A fiind doar un numar real, operatia de normalizare
transformandu-l in probabilitate.
nu reprezinta propriu-zis probabilitatea ca x I A fiind doar un numar real, operatia de normalizare
transformandu-l in probabilitate.
Rezultatul final nu ne va spune daca
x I A sau x I B
ci probabilitatea ca x I A sau x I B.
Problema de implementare:
![]() In
prelucrarile datelor reale algoritmul trebuie sa faca
fata la un set de date cu mai multe functii.
In
prelucrarile datelor reale algoritmul trebuie sa faca
fata la un set de date cu mai multe functii.
n modelul cu doua functii este extins la un model cu n functii.
![]() Pentru
a se realiza aceasta extindere a modelului de la 2 la n functii
trebuie sa cunoastem apriori numarul de distributii prezente
in setul de date.
Pentru
a se realiza aceasta extindere a modelului de la 2 la n functii
trebuie sa cunoastem apriori numarul de distributii prezente
in setul de date.
![]() in
cadrul implementarilor algoritmilor trebuie facuta o mica
ajustare care sa compenseze faptul ca rezultatul nu indica
apartenenta propriu-zisa a unei instante la cluster ci o
probabilitate ca ea sa apartina clusterului respectiv.
in
cadrul implementarilor algoritmilor trebuie facuta o mica
ajustare care sa compenseze faptul ca rezultatul nu indica
apartenenta propriu-zisa a unei instante la cluster ci o
probabilitate ca ea sa apartina clusterului respectiv.
![]() Aceste probabilitati se
comporta ca "greutati" (weights):
Aceste probabilitati se
comporta ca "greutati" (weights):
n daca wi este probabilitatea ca instanta i sa apartina clusterului A, media si deviatia standard a lui A sunt:
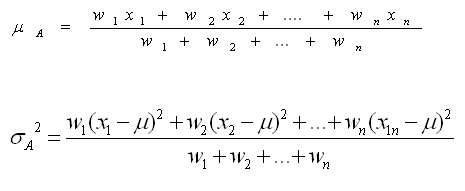
n
unde
xi sunt toate instantele nu doar cele care apartin
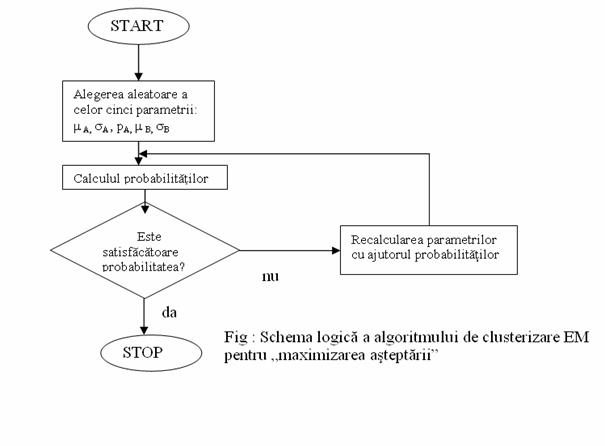
Algoritmul EM: algoritm statistic (Expectation Maximisation)
![]() Pas 1: Se porneste cu alegerea aleatoare a celor 5
paramterii
Pas 1: Se porneste cu alegerea aleatoare a celor 5
paramterii
![]() Pas 2: Se calculeaza probabilitatile
pentru fiecare cluster folosind marimile alese aleator la pasul 1
Pas 2: Se calculeaza probabilitatile
pentru fiecare cluster folosind marimile alese aleator la pasul 1
![]() Pas 3: Se folosesc probabilitatile pentru a se
recalcula cei cinci parametrii
Pas 3: Se folosesc probabilitatile pentru a se
recalcula cei cinci parametrii
![]() Pas 4: Se reia de la pas 1 folosind noile marimi
ale parametrilor.
Pas 4: Se reia de la pas 1 folosind noile marimi
ale parametrilor.
![]() Algoritmul se opreste cand se
stabilizeaza cei cinci parametrii.
Algoritmul se opreste cand se
stabilizeaza cei cinci parametrii.
![]() Se
observa ca algoritmul este identic cu k-means cu diferenta
ca aici nu se aleg centrele clusterelor ci parametrii
distributiei.
Se
observa ca algoritmul este identic cu k-means cu diferenta
ca aici nu se aleg centrele clusterelor ci parametrii
distributiei.
![]() O
alta implementare este prin alegerea aleatoare a clasei la care
apartine instanta, la pasul 1.
O
alta implementare este prin alegerea aleatoare a clasei la care
apartine instanta, la pasul 1.
![]() Algoritmul EM se numeste pentru
"maximizarea asteptarii" doarece cuprinde doua task-uri
esentiale:
Algoritmul EM se numeste pentru
"maximizarea asteptarii" doarece cuprinde doua task-uri
esentiale:
n Task 1: Asteptarea: se calculeaza probabilitatile clusterului, adica vrem sa stim care sunt valorile "asteptate" ale clusterului.
n Task 2: Maximizarea: calcularea parametrilor distributiei cu alte cuvinte "maximizarea" probabilitatilor distributiei avand datele.
![]() Algoritmul
EM converge catre un punct fix, dar nu-l atinge niciodata.
Algoritmul
EM converge catre un punct fix, dar nu-l atinge niciodata.
![]() Ca
si algoritmul k-means, algoritmul EM poate converge spre un maxim local.
Ca
si algoritmul k-means, algoritmul EM poate converge spre un maxim local.
![]() Pentru
a creste sansa obtinerii unui maxim global, algoritmul EM va fi
repetat de mai multe ori plecand de fiecare data de la valori
initiale diferite.
Pentru
a creste sansa obtinerii unui maxim global, algoritmul EM va fi
repetat de mai multe ori plecand de fiecare data de la valori
initiale diferite.
Weka: Implementarea algoritmilor de clusterizare
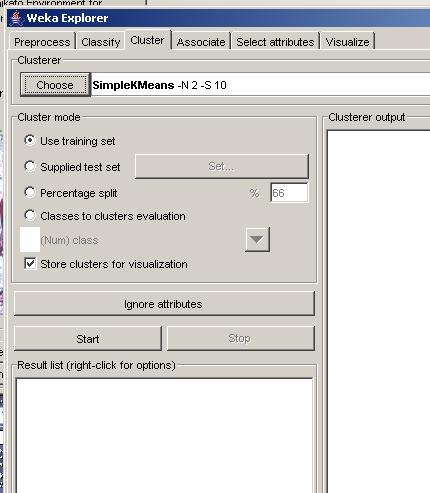
Algoritmul folosit
SimpleKMeans
Optiuni implicite
Optiunea
Store cluster for visualisation sa fie selectata
Clases to cluster evaluation, sa fie deselectata
obs: se poate folosi datele "weather"
Interpretarea rezultatelor obtiunite
![]() Se
face pe baza cetroidelor clusterelor obtinute ca output
Se
face pe baza cetroidelor clusterelor obtinute ca output
![]() Un
cluster va fi caracterizat de "vectorul" centroid
Un
cluster va fi caracterizat de "vectorul" centroid
![]() Exemplu:
Exemplu:
n Rulati algoritmul k-means pe fisierul "weather"
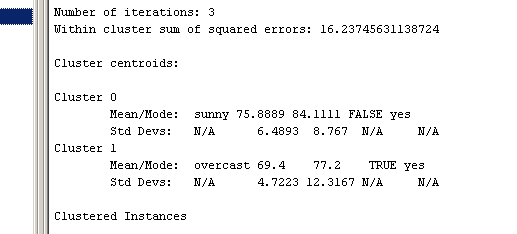
Clusterul 0:
Va avea loc partida de tenis
(atributul clasa = yes)
Daca
Outlok = sunny
Temperatura are media de 75
Umiditatea va fi: 84
Iar windy: false
Vizualizarea clusterelor
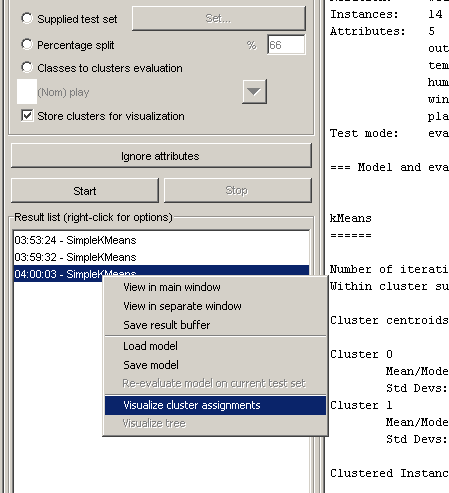
Optiunea de vizualizare a clusterelor - reprezentare grafica
Vizualizarea modului in care au fost repartizate instantele in clustere
Ofera posibilitatea:
reprezentarii oricarui atribut in functie de altul
salvarii clasificarii intr-un fisier nou cu identificatorul clusterului in care a fost repartizat

Bibliografie
[1] Bounsaythip, C., si Runsala, R., E., - Overview of Data Minig of Customer Behavior Modeling, Research Report, VTT Information Technology, 2001.
[2] Lipai, A., - Digital Economy, Ed. Economica, Bucuresti 2003.
[3] Kirkby, R., - WEKA Explorer User Guide, The
[4]
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 8000
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved