| CATEGORII DOCUMENTE |
| Aeronautica | Comunicatii | Electronica electricitate | Merceologie | Tehnica mecanica |
Sistemele actuale de recunoastere a vorbirii se situeaza deocamdata in limite restranse ale parametrilor caracteristici si dedicate unor aplicatii specifice. Din punct de vedere a dimensiunii vocabularului si al modului de vorbire, sistemele de recunoastere cu performante acceptabile, se impart in trei categorii principale.
. sisteme cu vocabular mic (10 - 100 cuvinte) ;
. sisteme cu vocabular mediu si mare si vorbire izolata (10 000 - 20 000 cuvinte) ;
. sisteme cu vocabular mediu si vorbire conectata sau continua, restrictiva la un domeniu de aplicabilitate (1 000 - 5 000 cuvinte) .
Cele mai multe sisteme realizate, apartin claselor sistemelor mici si mijlocii cu recunoasterea vorbirii izolate. Sistemele de recunoastere a vorbirii continue, in marea lor majoritate, exista doar in forma experimentala, in conditii de laborator. Chiar si sistemele utilizate in practica, cele pentru vorbirea izolata sau conectata, nu sunt destul de robuste la zgomotul mediului in care functioneaza si la variabilitatea vorbirii. Toate sistemele dau performante mai bune, daca numarul de utilizatori este mai redus si daca cei care folosesc sistemul sunt cei cu a caror voce s-a folosit pentru invatarea sistemului. Performantele se degradeaza semnificativ, daca vorbitorii se schimba sau daca sistemul este folosit cu alte cuvinte decat cu cele pentru care a fost antrenat.
Caracteristicile principale ale uni sistem de recunoastere automate a vorbirii, fara a aminti parametrii si metodele specifice prin care s-a implementat, sunt urmatoarele:
. dimensiunea vocabularului, adica numarul de cuvinte capabil sa le recunoasca;
. monolocutor sau multilocutor (aici se poate preciza si sexul vorbitorilor) ;
. vorbirea izolata sau continua;
. conditi de zgomot si robustetea sistemului;
. domeniul de aplicabilitate ;
. timpul de operare, care poate fi in timp real, cu intirziere sau off-line ;
. procentajul de recunoastere;
. costul .
Pentru o mai buna intelegere a procesului de recunoastere a vorbirii, voi exemplifica fiecare din componentele acestui proces, astfel:
- analiza acustica este metoda prin care se extrag parametrii auditivi;
- analiza fonetica este metoda prin care ies in evidenta caracteristicile sunetelor;
- analiza sintactica este metoda prin care se analizeaza continutul sintactic al unui cuvant pe baza cuvintelor exprimate in prealabil;
- analiza semantica este metoda prin care se verifica intelesul cuvantului ales;
- analiza pragmatica este metoda prin care se face o estimare a cuvintelor care ar putea fi rostite.
Analiza vocii si a vorbirii
Vocea este rezultatul energiei respiratorii folosita pentru a misca corzile vocale, care genereaza sunetele, aceasta manifestare fiind principala metoda a comunicarii prin coduri comune, respectiv prin limbaj.
Producerea vorbirii este compusa din doua functii mecanice de baza: fonetica si articulatie. Fonetica reprezinta producerea unui semnal acustic. Articulatia include modularea semnalului acustic, in special de catre buze, limba si de palatul moale, precum si de rezonanta in cavitatea supraglotica, oral si/ sau nazal.
Perceptia vocii este general descrisa ca o transformare in cinci etape a semnalului audio in mesaj: analiza auditiva periferica, analiza auditiva centrala, analiza fonetico- acustica, analiza fonologica si analiza de ordin inalt (lexicala, sintactica si semantica). Urechea umana este special adaptata sa perceapa vocea umana, spectrul de perceptie fiind intre 16-20000 Hz, cu o sensibilitate ridicata intre 500-4000 Hz.
Printre primii specialisti care au dezvoltat o reprezentare vizuala a unui cuvant rostit s-a aflat Melville Bell, acesta dezvoltand un sistem de simboluri scrise. In anul 1940 Potter, Kropp si Green, care lucrau pentru "Bell Laboratories", au dezvoltat un proiect ce implica reprezentarea vizuala a vocii cu ajutorul unui spectrograf de sunet, acesta analizand trei parametri: frecventa, intensitate si timp.
Astfel, au fost trasate liniile de baza pentru admisibilitatea identificarii vocii ca proba, sustinatorii pretinzand existenta unui proces valid si pertinent de identificare, iar oponentii cerand efectuarea mai multor cercetari stiintifice care sa sustina admisibilitatea acestei probe in instanta.
De-a lungul timpului au existat trei metode de identificare:
- recunoasterea vorbitorului prin ascultare;
- recunoasterea vorbitorului prin compararea vizuala a spectrogramelor;
- recunoasterea automata a vorbitorului.
1. Recunoasterea vorbitorului prin ascultare are ca fundament principiul conform caruia procesul de perceptie auditiva si procesul de identificare sunt esentialmente subiective, in sensul ca o voce particulara este asociata unui individ sau grup.
2. Recunoasterea vorbitorului prin compararea vizuala a spectrogramelor are in vedere capacitatea de a decide asupra identitatii sau nonidentitatii unei voci, bazata pe examinarea vizuala a spectrogramelor. O spectrograma este reprezentarea vizuala a unui set de sunete, in parametrii timpului, frecventei si amplitudinii.
3. Recunoasterea automata a vorbitorului foloseste metode computerizate bazate pe teorii informatice, pe recunoasterea dupa modele si pe sisteme de inteligenta artificiala. Pana in prezent, metoda nu a cunoscut decat o aplicatie limitata.
Tendinta curenta este de a integra rezultatele recunoasterii vorbitorului prin ascultare cu cele ale recunoasterii automate a vorbitorului si folosirea rezultatelor spectrogramelor doar pentru vizualizare.
1.3 Modelarea mecanismului de producere a vorbirii
Prelucrarea semnalului vocal este unul dintre domeniile in care tehnicile de prelucrare numerica sunt foarte eficiente. Aplicarea algoritmilor de prelucrare a semnalelor digitale s-a dovedit a fi deosebit de utila in problemele de baza ale prelucrarii vorbirii : analiza si sinteza vorbirii, codarea vorbirii, recunoasterea vorbirii, s.a.
Primele modele de producere a vorbirii sintetice au fost cele mecanice realizate inca din anii1779.Ulterior au fost realizate ai modele electrice (1876-Graham Bell, 1939-Dudley, Riesz, Watkins). Un model electric liniar a fost propus de Fant in 1960.
Sunetele generate in timpul vorbirii sunt sonore sau nesonore, de trei tipuri:
Sunetele sonore( vocalizate) cum sunt a,e, i, o,u, a, i care sunt constituite din impulsuri cvasi-periodice
Sunetele fricative (v, z, f, s, s, ..), echivalente cu un zgomot de banda larga uniform distribuit
Sunetele plozive sonore (b, d, g) si sunetele plozive nesonore (p, t, k).
Sunetele sunt caracterizate prin intensitate, inaltime si timbru. Inaltimea intensitatii sunetului este fixata de frecventa fundamentala. Inversul acesteia, T0 = 1/F0 se numeste perioada fundamentala (pitch-P). Frecventa fundamentala poate varia intre limitele:
80-100 Hz pentru o voce masculina
150-450 Hz pentru o voce feminina
200-600 Hz pentru o voce de copil
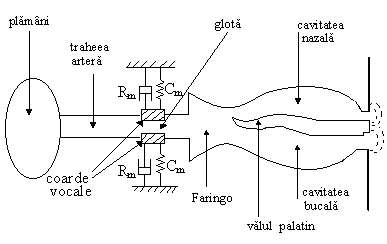
Fig.1. Modelul mecano-acustic de producere a vorbirii.
Timbrul unui sunet sonor este determinat de amplitudinile relative ale armonicelor fundamentalei.
S-au realizat diferite modelari ale procesului de generare a semnalului vocal, acusto-mecanice, electrice analogice sau digitale. In fig.1. este prezentat modelul acusto-mecanic pentru producerea vorbirii.
In cadrul modelarii acusto-mecanice este necesar sa se tina seama de urmatoarele aspecte:
variatia temporala a parametrilor traseului vocal ;
pierderile prin viscozitate si conductie termica;
cuplarea cu traseul nazal;
modul de excitare.
In privinta modului de excitare a traseului vocal, procesul poate avea loc in doua moduri esentiale:
a. Pentru fonemele sonore impulsul glotal are forma unei succesiuni de impulsuri periodice cu perioadaa T0, asa cum se arata in fig.2. O aproximare analitica a expresiei presiunii emisa de glota este de forma:

b. Pentru fonemele insonore, presiunea generala este de tip zgomot alb.
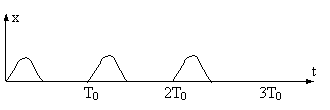
Fig 2. Forma semnalului echivalent fonemelor sonore.
Relativ la traseul vocal, o abordare posibila consta in reprezentarea acestuia ca o inlantuire (concatenare) de tuburi sonore de sectiuni diferite, adica un tub sonor global neunuform, dar pe sectiuni (local) uniform. In fig. 3.a. este aratata o asemenea structura, iar in fig.3.b. este reprezentata schema electrica echivalenta, indicandu-se localizarea elementelor specifice.
Astfel:
masa acustica a aerului;
elasticitatea aerului ;
rezistenta de vascozitate;
conductanta asociata pierderilor calorice;
admitanta acustica transversala.
Linia electrica echivalenta din fig.3.b este terminata pe impedanta acustuca echivalenta a gurii.
Zat = Zc/ (1+1/jβr)
In care Zc este impedanta caracteristica a aerului , iar β constanta de faza in aer la frecventa considerata. Presiunea creata in aer se poate calcula utilizand relatia:
P( r ) = (j β Zc / 4πr ) Qvt. exp.( - jβr)
unde Qvt reprezinta debitul aerului care parcurge impedanta terminala.
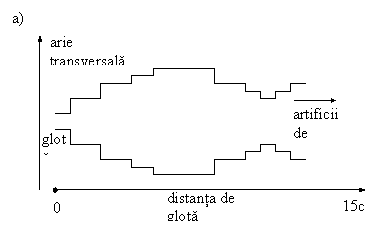
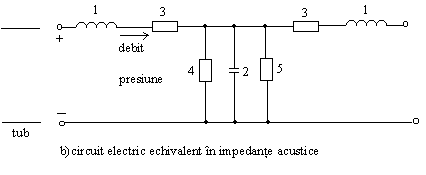
Fig.3 Schema echivalenta a traseului vocal
a. Structura cu tuburi sonore
b. Schema electrica echivalenta a unui tub sonor
Procesarea numerica a semnalelor permite realizarea modelului discret de generare a sunetelor.
Pentru foneme sonore semnalul primar de excitatie este δTo , semnalul delta discret periodic cu perioada T0 corespunzand inaltimii F0 = 1/ T0. Pentru generarea semnalului glotal discretizat, semnalul periodic este trecut printr-un sistem cu functia de pondere care rezulta din urmatoarele considerente.
Frecventa F0 este impusa de fonemul care trebuie sintetizat, valoarea fiind de ordinul sutelor de Hz. Frecventa de esantionare este de ordinul 8-10 KHz, astfel ca intre doua esantioane de T0 secunde se gasesc circa 50-100 de esantioane. Lungimea impulsului glotal trebuie sa fie de ordinul zecilor de intervale de esantionare. Perioada de esantionare s-a notat cu Te. Functia de pondere a sistemului care furnizeaza impulsul glotal se exprima in unitatide Te.
Notam : T0 = N0 Te

Este evident ca are loc inegalitatea : N1 + N2 << N0.
Semnalul g fiind marginit , imaginea sa este de forma unui polinom in z -1.
![]()
Trebuie facute cateva precizari privind functiile de transfer in z utilizate la modelarea discreta a semnalului vocal.
Filtrul numeric este descris de o ecuatie recurenta de forma:
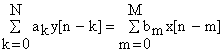
In care: a0 = 1, y reprezinta semnalul de iesire iar x este semnalul de la intrare.
Functia de transfer operationala H asociata ecuatiei anterioare este: Z[y] = Y, Z[x] = X, Y = H. X.
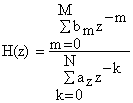
Daca procesul descris de relatia are tactul Te ( echivalent frecventei de esantionare ) sau frecventa de tact fe = 1/Te , atunci el realizeaza o functie de transfer frecventiala Hp (ω ), a carei expresie este:
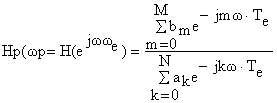
Domeniul util de filtrare este :
0≤ ω ≤ π/ Te sau 0≤ f ≤ fe/2
De regula se scrie :
ωTe = 2 πλ , λ = f/ fe
astfel ca domeniul de filtrare devine: λ є [ 0, 1/2].
Daca se considera un filtru trece jos cu λ ( frecventa digitala de taiere ) egala cu 0,1, atunci lucrand cu tactul fe se realizeaza un filtru trece jos cu frecventa de taiere fc = 0,1 fe.
Un al doilea aspect particular care trebuie mentionat se refera la o anumita clasificare.
Daca in relatia anterioara are loc:
b0 ≠0 ; bm = 0, m є [1,m]
atunci devine :
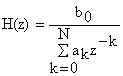
Operatia realizata este de tipul AR ( Auto Regresiv) sau all- poles ( numai cu poli).Daca in relatie se face inlocuirea:
a0 = 1 ; ak = 0, k є [ 1, N ]..
atunci relatia devine:
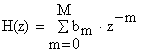
Operatia astfel realizata este de tip MA ( Moving Average- medie alunecatoare). Deci, cu aceste denumiri forma generala este de tip ARMA. De regula, se prefera forma AR.
Relatia descrie o structura MA. In aplicatii si pentru aceasta structura se prefera o realizare AR cu doi poli :
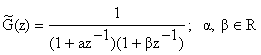
La o frecventa de tact de 10 KHz, G(z) reprezinta un filtru trece jos cu o frecventa de taiere de aproximativ 100 Hz.
Pentru foneme insonore, semnalul primar de excitatie este de tip zgomot ( semnal discret) alb cu densitatea spectrala de putere constanta egala cu 1. Legea de repartitie nu este importanta in acest caz si se poate considera un zgomot cu repartitie gaussiana.
In ceea ce priveste tractul vocal, modelul acusto- mecanic , indica prezenta unor rezonante care genereaza formantii. Modelarea tractului vocal se face cu o structura AR de forma:
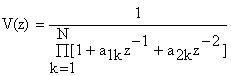
Data fiind caracteristica de tip trece banda a filtrului real, polii apar in perechi complex conjugate.
In privinta functiei de transfer care este asociata orificiului bucal, caracteristica sa de tip trece sus poate fi modelata intr-o prima aproximatie printr-o sectiune MA de forma:
![]()
valorile de la capetele domeniului spectral considerat (λ = 0, si λ = 0,5) sunt respectiv:
B(1) = 0; B(-1) = 1
Pentru a inlocui structura MA printr-una AR ( avantajoasa ca algoritmi de calcul), se considera urmatoarea forma:
![]()
cu 0 < a < l, apropiat de unitate. Valorile la capete sunt:
![]()
ceea ce arata ca daca a≈l atunci structura este apropiata de , dezvoltarea ei in serie :
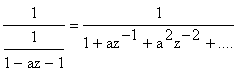
arata ca structura,
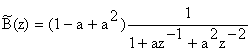
cu valorile de la capete.
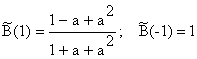
reprezinta un filtru trece sus.
In concluzie se poate spune ca :
pentru foneme sonore functia de transfer operationala este:
![]()
cu semnalul de la intrare δTo iar
pentru foneme insonore:
![]()
Este necesar sa se introduca si un factor multiplicativ ( de scalare), Av pentru foneme sonore si Ac pentru foneme insonore.
Din cele analizate mai sus, rezulta un model discret de producere a vorbirii, cu un singur tract (oral) , prezentat in fig. 4.
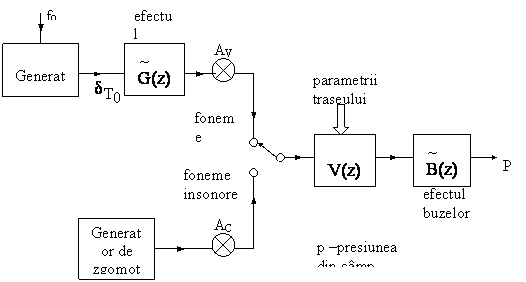
Fig..4.Modelul electric de producere a vorbirii.
Modelarea prezentata in fig.4. este de tip AR, functia de transfer asociata fiind de forma:
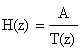
in care A este o constanta ( diferita la cazul sonor si la cel insonor), iar T(z) este un polinom in z-1 , ( diferit la cazul sonor sau insonor). Structura MA de forma:
![]()
se numeste filtrul invers sau " filtrul de albire", deoarece filtrul in cascada cu filtrul formeaza un sistem global cu functia de transfer operationala egala cu o constanta.
Prin schema din fig.4. insa nu pot fi modelate fonemele nazale , schema trebuind completata si cu elementele corespunzatoare tactului nazal.
Astfel relatia se va completa:
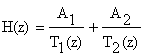
indicele 1 referindu-se la tractul oral iar indicele 2 la tractul nazal.Relatia nu poate fi redusa la o structura AR si deci pentru fonemele nazale se foloseste o structura ARMA. In procesarea semnalului vocal se folosesc valorile tipice prezentate in continuare.
Frecventa de esantionare se alege intre 8 sau 10 KHz, rezultand o banda utila de 4 sau de 5 KHz.
Pentru recunoasterea sau sinteza fonemelor fricative frecventa de esantionare se mareste la 20 KHz., considerand fs =10KHz, Ts = 0,1 ms.
Pe durata a 20-30ms, parametrii tractului vocal se pot considera ca fiind constanti (proces stationar). Alegand o secventa de 30ms, rezulta ca intervalul de consatanta cuprinde N= 300 esantioane.
Pentru a nu se produce efecte de margine , ferestrele de 30ms se preleveaza din 10 in 10ms.
Se constata ca pentru decelarea sau constituirea formantilor, tractul vocal trebuie sa fie reprezentat cu cel putin doi poli pe 1 KHz , ceea ce conduce la 10 poli. Pentru impulsul glotic si pentru radiatia orala mai sunt necesari 2-3 poli. In final deci functia de transfer trebuie sa aiba T(z) de gradul13-14.
Pentru determinarea lui T(z) de gradul p , sunt necesare p esantioane pentru care se evalueaza functia de autocorelatie.
Aceasta prelucrare numerica a semnalului vocal se face in urmatoarele scopuri:
codarea eficienta a semnalului vocal;
sinteza semnalului vocal;
recunoasterea vocii;
studii de fonetica;
anatomia normala si patologica a organului formator.
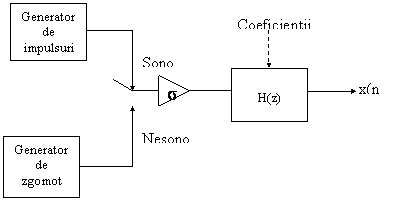
Fig.5.Modelul in timp discret pentru producerea semnalului vocal.
1.4 Reprezentarea digitala a semnalelor vorbirii
Pentru procesarea semnalului vocal, fie ca vorbim despre stocare, sau despre prelucrare este necesara captarea si transformarea semnalului sonor intr-o reprezentare intr-un alt domeniu, in domeniul electric. Reprezentarea electrica a unui semnal vocal se poate face fie in modalitate pur electrica, in care semnalul elextric este analogul semnalului vocal, fie o reprezentare codata sau digitala in care informatia digitala stocheaza semnalul vocal intr-o maniera independenta.
Din aceste doua metode cea mai utilizata in ultima vreme este reprezentarea digitala, la baza acestei alegeri stau o multime de avantaje pe care aceasta le ofera: multitudinea de operatii care se pot efectua si usurinta mare cu care acestea se aplica fata de cazul reprezentarii electrice.
Prin urmare in continuare ma voi ocupa doar de reprezentarea digitala a semnalului vocal. In cadrul acestei reprezentari semnalul vocal este caracterizat de niste parametrii care sunt extrasi din acest semnal. Modelul simplificat al extragerii acestor parametrii este reprezentat in figura urmatoare :
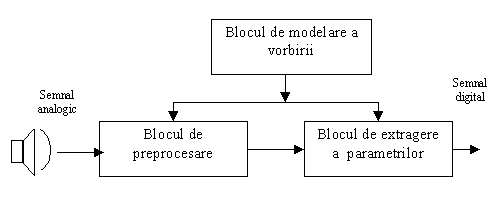
Fig 6. Modelul extragerii parametrilor numerici
Dupa cum se poate vedea din figura precedenta semnalul analogic este preluat de blocul de prepocesare. Semnalul analogic este apoi pregatit pentru a fi supus procesului de extragere a parametrilor. Aceste blocuri pot fi analogice, de exemplu filtre, amplificatoare, sau numerice. Majoritatea operatiilor de acest gen se fac in numeric, in analogic ramanand doar amplificatoarele si convertorul analogic-numeric. Iesirea din acest bloc este un semnal digital.
Dupa ce are loc transformarea semnalului analogic in digital, si aplicarea catorva operatii asupra semnalului, acesta este preluat de blocul de extragere a parametrilor. In cadrul acestui bloc se extrag tipurile de parametrii necesare in continuare. Putem avea parametrii temporali, spectrali etc.
Activitatea acestor doua blocuri este supervizata de catre blocul de Modelare a vorbirii care realizeaza o analogie intre componente fiziologice si componente matematice. Asadar se realizeaza o emulare a componentelor reale prin elemente matematice ce tin de domeniul digital. Parametrii elementelor matematice sunt determinati in blocul de extragere a parametrilor.
Iata in continuare o detaliere a acestor blocuri.
Blocul de preprocesare realizeaza legatura intre semnalul audio real si blocul de extragere a parametrilor, in cadrul acestui bloc avand loc pregatirea semnalului pentru intrarea blocului de extragere a parametrilor. In lumea reala din momentul emiterii sunetului pana cand acesta este captat de blocul de preprocesare, asupra undei sonore intervin o serie de factori datorati canalului/mediului de transmisie, factori ce induc o deformare care poate perturba partial sau total o prelucrare corecta a undei sonore.
Exista o serie de operatii tipice ce se efectueaza aspura undei sonore in cadrul blocului de preprocesare. Aceste operatii sunt urmatoarele :
a)Digitizarea semnalului vocal.
Cea mai mare parte a energiei semnalului vocal este
continuta in banda de frecvente 50-60Hz si 4-5kHz, ceea ce impune folosirea
unor filtre trece jos sau a unor filtre trece banda care vor selecta din unda

Fig 7. Procesul de digitizare.
b) Preaccentuarea semnalului vocal.
Dupa cum aminteam la punctul anterior este necesara o anumita filtrare aplicata asupra semnalului audio. Aceste filtre se pot aplica atat asupra semnalului analog, despre acestea discutand anterior, cat si asupra semnalului digital, in acest caz avand de-a face cu filtre numerice. Un astfel de filtru este si urmatorul , rolul sau fiind acela de a anula efectul atenuarii exercitate de canalul de transmisie asupra undei sonore.
![]()
Dupa cum demonstreaza practica, aplicarea unui asemenea filtru este benefica doar in cazul sunetelor vocalice, nefiind utila in cazul sunetelor nesonore, consoane. O valoare de compromis pentru care aplicarea filtrului este utila in ambele cazuri este valoarea de 0.95 pentru .
c) Segmentarea semnalului vocal.
Una din problemele prelucrarii unui semnal vocal
este modificarea tractului vocal in timp, element ce influenteaza negativ orice
operatiune. Aceasta implica necesitatea analizarii semnalului vocal pe perioade
scurte de timp, perioade in care unda
![]()
k reprezinta in aceasta formula numarul de ordine al segmentului in timp ce n reprezinta numarul de ordine al esantionului in cadrul segmentului, unde fiecare segment contine N esantioane. In literatura de specialitate termenul de esantion este intalnit si ca sample .
Fereastra ce se aplica asupra semnalului poate fi de mai multe tipuri. Cel mai utilizat tip de fereastra este cea dreptughiulara avand forma:
![]()
Desi foarte frecvent utilizata aceasta fereastra are o mare problema determinata de limitarea brusca la capatul segmentului a esantioanelor. Aceasta problema se rezolva printr-o atenuare treptata a esantioanelor la capetele segmentului, prin aplicarea ferestrei Hamming. Aceasta fereastra este de forma:
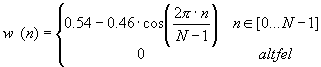
Fereastra Hamming se aplica de obicei aspura unui numar de esantioane putere a lui 2: 128, 256, 512. Pentru obtinerea unor rezultate si mai relevante, printr-o urmarire mai fina a variatiei parametrilor semnalului vocal, in cadrul prelucrarii de multe ori se alege o ferestruire prin acoperire, overlapping in literatura de specialitate. Aceasta acoperire inseamna o suprapunere a doua segmente, suprapunere ce poate varia intre 40% si 80%.
Folosirea acestei ferestre duce la cresterea importantei esantioanelor din centrul ferestrei, iar aplicarea si a unei suprapuneri a ferestrelor asigura calcurearea netezita a parametrilor semnalului vocal. Parametrii se vor calcula cadru cu cadru in intreg semnalul vocal de analizat.
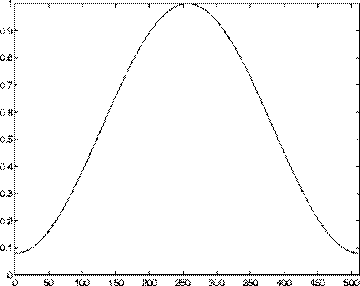
Fig. 8. Fereastra Hamming
Alte ferestre folosite adesea in domeniul prelucrarii semnalelor vocale sunt :
Fereastra Hamming:
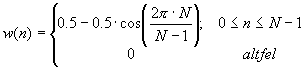
Fereastra Barlett:
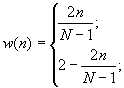
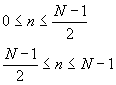
Fereastra Blackman:
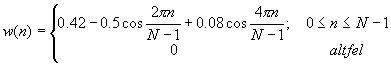
Durata unui cadru, adica lungimea in sample-uri a acestuia este direct proportionala cu viteza de articulare a sistemului de producere a vorbirii. Astfel lungimea cadrelor trebuie sa indeplineasca urmatoarele doua cerinte: sa nu aiba o lungime mai mica decat cea necesara cuprinderii unei perioade de semnal dar nici una prea mare incat sa compromita caracteristica de cvasistationaritate a semnalului. De aici dimensiunea de care vobeam anterior, anume de 10ms-40ms pentru fiecare cadru in parte.
d)Eliminarea componentei de curent continuu
Numarul de treceri prin zero este afectat de componenta continua a semnalului, adica de media aritmetica a celor N esantioane ale cadrului de analiza. Datorita acestui fapt, eliminarea componentei de curent continuu este unul din primii pasi efectuati la procesarea unui semnal vocal.
Se defineste:
![]()
Primul pas este calcularea inceputului cadrului curent dupa care din valoarea fiecarui esantion se scade valoarea lui DC. Operatia se repeta pentru fiecare cadru in parte.
O alta metoda este prin calcularea mediei aritmetice in tot semnalul si apoi aceasta valoare sa se scada din fiecare esantion in parte. In acest caz valoare lui DC este exprimata sub forma:
![]()
unde L reprezinta lungimea intregului semnal.
O optimizare a celor doua metode, in vederea reducerii timpului de executie, este aceea prin care DC se calculeaza doar la al n-lea cadru si aceasta valoare se mentine valabila pe o perioada de n cadre pana la calcularea unei noi valori.
O alta alternativa mai usor de aplicat este folosirea unui filtru trece sus, util prin faptul ca pe langa eliminarea componentei continue, va elimina si variatiile lente datorate tot lantului de prelucrare si mai ales canalului de transmisie. Un astfel de filtru poate fi urmatorul:
![]()
1.5 Perceptia semnalelor vorbirii
Dimensiunea vocabularului . In mod normal, dificultatea recunoasterii vorbirii continue creste cu dimensiunea vocabularului. Cercetarile in domeniu au estimat, ca dificultatea de recunoastere creste logaritmic cu dimensiunea vocabularului. Memoria necesara si timpul de calcul, cresc si ele de obicei dupa aceasi regula. Cresterea memoriei necesare este cauzata si de complexitatea sistemului, care creste si ea, fiind necesara si memorarea mai multor parametri. Sistemele de recunoastere a vorbiri, din punct de vedere al dimensiunii vocabularului, se impart in trei categorii: sisteme cu vocabular mic, mediu si mare . Astfel sistemele cu vocabular mic se incadreaza in intervalul 10-99 cuvinte, cele de dimensiune medie in 100-999 cuvinte, iar cele mari cu dimensiune peste 1000 de cuvinte. Insa, aceste limite pot varia in functie de alte caracteristici ale sistemului, crescand in cazul vorbirii izolate. In cazul unui vocabular mic, sistemul poate fi foarte simplu, cu metode de recunoastere bazate numai pe informatie acustica, compararea rostirii putindu-se face cu fiecare cuvint din baza de date. Cu cit dimensiunea creste, sunt necesare metode mai complexe care sa tina caracteristicile sistemului in limite rezonabile. Aceste metode includ informatii si cunostinte lingvistice, constringeri ce elimina o parte a cuvintelor posibile candidate, nefiind necesara analiza acestora. Totodata, eficientizarea sitemului se poate face si la nivel acustic, prin trecerea la unitati de recunoastere mai mici, de la cuvinte la silabe sau la foneme.
Monolocutor sau multilocutor . In cazul sistemelor monolocutor, o singura persoana este folosita pentru a antrena, testa si utiliza sistemul. Daca acelasi sistem insa, este antrenat de catre mai multi vorbitori, plaja de variabilitate a vocii se extinde, insa numarul de unitati de referinta raminind constant, performantele de recunoastere se degradeaza fata de cazul monolocutor. De asemenea performantele sistemului vor scadea daca utilizatorii sistemului nu fac parte din cei ce au fost folositi la antrenarea sistemului. Important este si sexul persoanelor care au antreneaza respectiv utilizeaza sistemul datorita diferentelor de caracteristici intre cele doua sexe in ce priveste vorbirea.
Vorbire izolata sau continua . Sistemele de recunoastere a vorbirii izolate (RVI) recunosc rostiri discrete ale cuvintelor, adica cu pauze semnificative dintre cuvinte, dupa fiecare rostire avind loc o determinare a extremitatilor cuvantului, dupa care are loc procesul de recunoastere. Precizia determinarii limitelelor cuvintului are o influenta importanta asupra reusitei de recunoastere. Daca dimensiunea vocabularului creste, pentru eficientizarea sistemului, se poate trece la recunoasterea unitatilor sub-cuvinte, introducind in structura sistemului nivele de recunoastere suplimentare, bazate pe lexica limbajului. In cazul sistemelor de recunoastere a vorbirii continue (RVC), acesta trebuie sa recunoasca cuvintele rostite in mod natural, fluent, fara nici o constringere. Sistemul trebuie sa fie capabil sa treaca peste problema necunoasterii frontierelor cuvintelor, a coarticulatiilor si a intrepatrunderii cuvintelor, fara pauze intre ele. In acest caz, este aproape inevitabila folosirea unitatilor sub-cuvint ca si unitati primare de recunoscut, si introducerea de cunostinte lingvistice in structura sistemului de recunoastere. Un astfel de sistem depinde de limba in care se utilizeaza, deoarece constringerile lingvistice difera de la o limba la alta, pe cind la sisteme de recunoastere a cuvintelor izolate, fara nivele lingvistice, limba nu are nici o influenta asupra structurii si regulilor sistemului.
Exista o alta metoda de recunoastere a vorbirii, numita recunoasterea vorbirii conectate . Aceasta este o metoda intre cele doua metode amintite, cea izolata si cea continua, din punctul de vedere a metodelor de recunoastere necesare a fi implementate. Si in acest caz, cuvintele sunt rostite in mod fluent, insa este nevoie de o cooperare mai buna din partea vorbitorului. Cuvintele sunt recunoscute ca unitati de baza, dupa care se folosesc reguli de succesiune a cuvintelor, pentru a discerne intre succesiuni valide sau invalide de cuvinte recunoscute, asemanator unui sistem de RVC.
Conditii de mediu si zgomot . Robustetea sistemului de recunoastere depinde si de capaciatea de a recunoaste cuvintele in conditii mai severe. Prezenta zgomotului in semnalul achizitionat degradeaza performantele sistemului, introducind perturbatii nedorite in caracteristica spectrala a semnalului vocal. Protectia sistemului la zgomot se face prin filtrare sau alte metode mai complexe. Cind se prezinta performantele unui sistem de recunoastere a vorbirii, se precizeaza si conditiile de mediu in care s-au determinat performantele prezentate, care de obicei sunt: conditii de laborator, conditii de oficiu cu zgomot de fond uman sau de alta natura, conditii de semnal telefonic sau zgomot de trafic urban.
Recunoasterea vorbirii este un proces foarte complex, continand diverse blocuri constructive complexe.
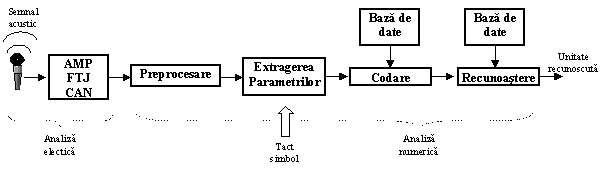
Fig. 9. Structura generala a unui sistem de recunoastere a vorbirii
Sistemul este compus din doua parti componente principale. Prima componenta este una fizica, echipament electronic, care are rolul de a transforma sunetul (vibratiile acustice) in semnal electric si adaptarea acestuia la intrarea blocului urmator. Traductorul acustico-electric reprezinta microfonul, a carei iesire este conectata la intrarea unui amplificator cu o caracteristica spectrala de tip filtru trece jos. Aceasta caracteristica are rolul de a elimina perturbatiilor de inalta frecventa si a efectului de alyazing ce ar putea aparea la conversia analog-numerica. Cerintele esentiale ale acestui bloc sunt: microfon de calitate mediu-buna, amplificare cu zgomot redus si la nivel optim pentru intrarea in convertorul analog-numeric, amplificare liniara, fara deformarea formei de semnal original, caracteristica cit mai uniforma in banda de trecere. Limitarea spectrului semnalului vocal se poate face la 4-8 kHz. Conversia analog-numerica poate fi intre 8-16 biti, frecventa de esantionare putand varia intre 8-16 kHz, codare PCM.
A doua componenta principala a sistemului este o componenta logica, reprezentata de un sistem numeric de calcul. Un exemplu de un astfel de sistem este un calculator personal, echipat cu o placa de sunet. Placa de sunet reprezinta prima componenta, care este fixa si nemodificabila. A doua componenta reprezinta un program care se executa pe calculator, implementand toate prelucrarile necesare.
La iesirea blocului de conversie analog-numerica, exista un flux de date constant, reprezentand semnalul vocal codat digital, prin esantioanele sale, exprimate ca si numere binare. Daca consideram frecventa de esantionare de 10 kHz, si rezolutia de 16 biti, atunci avem un flux de date de 20 000 de octeti/secunda, secvential. Recunoasterea vorbirii nu se poate face pe baza formei de unda a semnalului vocal, deoarece aceasta este o combinatie liniara si neliniara de diverse efecte, utile si redundante, inseparabile in domeniul temporal, cum ar fi zgomotul, variatia amplitudini, a fazei, componente armonice nedorite, etc. Parametrii ce reprezinta mai bine vorbirea sunt cei spectrali, deoarece ei contin informatii relative la sistemul fonator al vorbitorului si dinamica acestuia si sunt separabili. Din acest motiv, majoritatea metodelor de extragere a parametrilor, analizeaza semnalul vocal din punct de vedere a spectrului de amplitudine al acestuia.
Pentru atenuarea componentelor spectrale de frecventa inalta de origine vocalica, datorita mediului de propagare a semnalului acustic, in primul rind, semnalul vocal se trece printr-un filtru cu caracteristica trece-sus implementat digital, proces numit preaccentuare .
Cadrul de semnal vocal se prezinta la intrarea blocului de extragere a parametrilor. In acest bloc se determina parametrii cat mai reprezentativi ai semnalului vocal, pe baza esantioanelor. Astfel de parametrii sunt:
Energia - da informatii asupra amplitudinii medii a semnalului vocal. Poate fi utilizata pentru determinarea originii vocalice sau nevocalice ale sunetelor, determinarea extremitatilor unitatilor acustice, variatia energiei da informatii relative la momentul variatiilor fonetice.
Numarul trecerilor prin zero - se utilizeaza pentru masurarea grosiera a continutului in frecventa a semnalului vocal. Da informatii suplimentare, langa energie despre extremitatile unitatilor acustice.
Frecventa fundamentala -
reprezinta frecventa de rezonanta a corzilor vocale. Din punct de vedere a
recunoasterii vorbirii, se poate neglija acest parametru, deoarece ea varieaza
de la o persoana la alta, dar ramane
Spectrul de energie sau de amplitudine - reprezinta imaginea in frecventa a semnalului vocal. Forma spectrului este rezultatul combinarii efectului semnalului vocal excitatie si a functiei de transfer a semnalului vocal. Ea prezinta maxime ale anvelopei spectrale in jurul componentelor formantilor, si o variatie rapida, datorita semnalului de excitatie. Deoarece memorarea fiecarei componente de frecventa, in numar de N/2 , este ineficienta, se pot determina niste benzi reprezentative repartizate pe domeniul spectral si calcularea amplitudinii medii pe banda respectiva. Numarul de P benzi se poate alege intre 10-16, ele fiind mai aglomerate si de latime mai mica la frecvente joase si mai rasfirate si mai largi, la frecvente inalte. Metoda utilizata de determinare a spectrului de amplitudine este Transformata Fourier Rapida (FFT).
Analiza liniar predictiva - urmareste determinarea parametrilor unui filtru care modeleaza efectul de atenuare selectiva si dinamica de catre tractul vocal al semnalului excitatie. Prin aceasta metoda se face abstractie de semnalul excitatie, astfel spectrul filtrului rezultat va fi fara variatii bruste prezente in spectrul de amplitudine a semnalului vocal. Parametrii determinati, in numar de P , pot fi furnizati direct la iesire, sau se pot determina amplitudinea sau energia spectrala medie din P benzi reprezentative.
Analiza cepstrala - este o analiza speciala, prin care efectul compus al excitatiei si al functiei de transfer a tractului vocal se separa cu o eficienta mai buna, ca in cazul analizei spectrale sau liniar predictive.
Blocul final al sistemului este blocul de recunoastere. Structura acestuia variaza foarte mult, in functie de metoda de recunoastere utilizata. Exista doua categorii principale de metode de recunoastere: recunoasterea bazata pe referinte si recunoasterea bazata pe modele .
a) Prima metoda este folosita exclusiv la recunoasterea cuvintelor pronuntate izolat sau conectate. In acest caz, pentru fiecare cuvint ce se doreste a fi recunoscut, se alege un sir de vectori reprezentanti rezultati dintr-o rostire de referinta a cuvintelor respective, si se memoreaza in dictionar sub aceasta forma. Pentru a nu include in aceste reprezentari, vectori rezultati din semnal vocal din afara cuvintului, extremitatile cuvintelor referinta trebuiesc determinate cu precizie, care se poate face manual sau automat, prin determinarea primului si a ultimului cadru a fiecarui cuvint. Recunoasterea se face prin achizitionarea cuvintului de recunoscut, aplicarea acelorasi prelucrari ca la cuvintele referinta, rezultand sirul de vectori reprezentanti. In continuare, se ia fiecare referinta din biblioteca, si se calculeaza distanta dintre acestea si cuvintul de intrare. Distanta se obtine prin acumularea distantei dintre vectorii celor doua cuvinte de-a lungul axei temporale, comparatia facandu-se intre vectorii corespunzatori acelorasi foneme presupuse ale cuvintelor. Aceasta metoda de comparatie se numeste metoda de aliniere temporala sau Dinamic Time Wrapping ( DTW ). Distanta de cautare a cadrelor asemanatoare se limiteaza, pentru ca alinierea sa nu poata fi deviata pe o cale gresita. Daca cuvantul de referinta si cel de intrare reprezinta acelasi cuvant, avand o variatie de lungime rezonabila, alinierea temporala se face cu succes. Decizia de recunoastere se face pe baza distantei minime dintre cuvantul de intrare si toate cuvintele referinta. Daca distanta minima este mai mare decat o valoare limita, se ia decizia de cuvant necunoscut. Deoarece parametrii cuvintelor sunt memorate sub forma "cruda", astfel de sisteme de obicei sunt monolocutor. Daca se doreste recunoasterea mai multor locutori, este necesara introducerea in dictionar a unei referinte pentru fiecare cuvant de la fiecare locutor.
b) O alta metoda de recunoastere, mai evoluata si cu performante superioare, este recunoasterea pe baza de modele. In aceasta abordare, fenomenul de producere a vorbirii este asociat cu evolutia in timp a unui automat cu stari finite, care trece in stari succesive, sincronizat de tactul de simbol, si la fiecare tranzitie emitand un simbol, care se observa si se inregistreaza. O astfel de modelare a vorbirii se poate face la fiecare nivel de recunoastere, prin stabilirea corespondentei starilor, a tranzitiilor si a simbolurilor corespunzatoare procesului modelat. Astfel de modele pot fi definite pentru foneme, cuvinte sau propozitii. Un model de acest tip este Modelul Markov Ascuns (MMA) sau Hidden Markov Model (HMM) . Numarul de stari si a simbolurilor unui astfel de model sunt limitate. Numarul de stari ai modelului se determina prin corespondenta dintre numarul de "evenimente stationare" din fenomenul modelat. Astfel, daca se modeleaza un cuvant, numarul de stari al modelului va fi identic cu numarul de foneme si al pauzelor dintre acestea. Numarul de simboluri se alege in functie de numarul de simboluri posibile a fi observate la fiecare tact de simbol. In cazul fonemelor, se alege cel putin numarul fonemelor existente in limba respectiva.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 2900
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved