| CATEGORII DOCUMENTE |
Acest capitol prezinta trei dintre cele mai simple si fundamentale structuri de date. Practic, orice program mai semnificativ utilizeaza cel putin una din aceste structuri.
Definitie: O lista lineara este o multime de n>=0 elemente X[1],X[2],.,X[n] (numite noduri) ale caror proprietati structurale implica doar pozitionarea relativa liniara a nodurilor.
Pentru oricare lista exceptand lista vida vom spune ca nodul X[i] este succesorul lui X[i-1] si predecesorul lui X[i+1]. Primul element al listei este X[1], iar ultimul element este X[n]. Predecesorul lui X[1] si succesorul lui X[n] sunt nedefinite. Pozitia elementului X[i] in lista este i.
Pentru a defini complet tipul abstract de date (TAD) lista trebuie ca alaturi de structura listei sa definim si care sunt operatiile permise asupra ei. Cele mai uzuale operatii care se fac asupra unei liste sunt:
aflarea lungimii n a listei
parcurgerea listei de la stanga la dreapta sau invers
vidarea (golirea) listei
cautarea, care returneaza pozitia primei aparitii a unui element
inserarea si stergerea, care insereaza sau elimina un element aflat pe o pozitie anume
accesarea (aflarea) celui de-al k-lea element
combinarea uneia sau mai multor liste intr-o singura lista
impartirea unei liste in doua sau mai multe liste
sortarea nodurilor listei in ordine crescatoare conform anumitor informatii din nodurile listei
Daca lista este formata din elementele 34, 12, 52, 16, 12, atunci cauta(52) ar returna valoarea 3; insereaza(x,3) ar transforma lista in 34, 12, 52, x, 16, 12 (daca inserarea se face dupa pozitia data); sterge(3) ar transforma lista in 34, 12, x, 16, 12.
Interpretarea precisa a operatiilor ramane desigur la latitudinea programatorului impreuna cu tratarea cazurilor speciale (de exemplu, ce returneaza cauta(1) in lista de mai sus?).
Exista multe metode de reprezentare a listelor liniare functie de clasa de operatii care se realizeaza mai frecvent. Se pare ca este imposibil sa se gaseasca o reprezentare simpla a listelor pentru care toate operatiile de mai sus sa se poata realiza eficient.
Foarte des intalnite in practica sunt listele lineare pentru care inserarile, stergerile si accesul se fac aproape intotdeauna asupra primului sau a ultimului element; acestor liste le dam nume speciale:
stiva este o lista lineara in care toate inserarile si stergerile (si, de obicei, toate accesarile) se fac la un singur capat. Stivele mai sunt numite si liste last-in-first-out (LIFO), liste push-down etc.
coada este o lista lineara pentru care toate inserarile se fac la un capat, iar toate stergerile se fac la celalalt capat. Cozile au mai fost numite si liste first-in-first-out (FIFO).
|
varf |
cap | ||
|
coada |
Stiva Coada
Cea mai simpla metoda de a retine elementele listei in memoria calculatorului este sa ii asezam elementele nod cu nod, in locatii consecutive (secvential):
LOC(X[k+1]) = LOC(X[k]) + dim
|
Continut |
X[1] |
X[2] |
X[i] |
X[n-1] |
X[n] |
||
|
Adresa |
b |
b+dim |
b+(i-1)*dim |
b+(n-2)*dim |
b+(n-1)*dim |
Toate cele 9 operatii descrise mai sus pot fi cu usurinta implementate utilizand acest mod de alocare.
Accesul la al i-lea element al listei se realizeaza in timp constant, adunand la adresa primului element (notata cu b, si numita adresa de baza) (i-1)*dim octeti, unde dim este dimensiunea unui element al listei.
Operatia de cautare a unui element se face (daca nu utilizam cautare binara) prin parcurgerea elementelor listei, deci in O(n).
Operatiile de stergere, respectiv inserare a unui element pe o anumita pozitie sunt deosebit de costisitoare. Spre exemplu, inserarea unui element pe prima pozitie implica deplasarea tuturor celorlalte spre dreapta. Analog, stergerea elementului de pe prima pozitie implica si ea un numar de n-1 deplasari catre stanga. Ambele operatii au deci o complexitate in cazul cel mai nefavorabil de O(n). Vom vedea ca in cazul alocarii inlantuite (dinamice) stergerea si inserarea se pot face in timp constant ( O(1) ).
Dezavantajul major al acestui mod de alocare consta in faptul ca dimensiunea tabloului odata ce a fost precizata nu mai poate fi modificata. Aceasta implica o supraestimare a numarului posibil de elemente ale listei, care determina risipirea de spatiu in memorie, ceea ce ar putea constitui o limitare serioasa, mai ales in situatia in care exista mai multe liste de dimensiuni necunoscute.
Alocarea secventiala este cea mai adecvata pentru lucrul cu stive, ale caror operatii de inserare si stergere se fac la un singur capat, deci se pot implementa in timp constant.
In cazul stivei, alaturi de tabloul X, mai gestionam o variabila T, numita varful stivei (sau pointer de stiva - SP). Cand stiva este vida, T are valoarea 0.
Operatiile de inserare (PUSH) si stergere (POP) pot fi implementate cu usurinta:
PUSH(Y) //inserare in stiva
T T + 1
daca T > M atunci DEPASIRE (overflow)
X[T] Y
END (PUSH)
POP(Y) //stergere din stiva
daca T = 0 atunci DEPASIRE (underflow)
Y X[T]
T T-1
END (POP)
Am presupus ca X[1].X[M] este spatiul maxim disponibil pentru stiva.
DEPASIRE inseamna ca s-a depasit capacitatea de memorare si programul se termina.
Exercitiu: Sa se defineasca operatiile TOP, VOID, PRINT care returneaza varful stivei, videaza stiva, respectiv afiseaza continutul stivei respectiv.
Tema de laborator: Sa se defineasca un modul Pascal sau C++ care implementeaza o stiva cu elemente numere intregi alocata secvential.
Pentru a reprezenta secvential o coada vom utiliza doua indicatoare, CP si CD (CaP si CoaDa). Daca CP=CD, atunci coada este vida. Putem privi cele M noduri ca fiind asezate circular, cu X[1] succedandu-l de X[M]. Initial coada este vida, si CP=CD=M.

Figura 2.1‑ Reprezentarea unei cozi intr-un tablou circular
Definim variabila auxiliara c (care ne informeaza asupra starii cozii) astfel:

Cu aceste precizari, operatiile de inserare si stergere se realizeaza astfel:
INSERT(Y)
daca c = 1 atunci DEPASIRE (overflow)
daca CD = M atunci CD 1 altfel CD CD+1
X[CD] Y
daca CD = CP atunci c 1 altfel c
END (INSERT)
DELETE(Y)
daca c = 0 atunci DEPASIRE (underflow)
daca CP = M atunci CP 1 altfel CP CP+1
Y X[CP]
daca CP = CD atunci c 0 altfel c
END (INSERT)
Exercitiu: Sa se gaseasca o metoda de reprezentare a doua stive intr-un singur tablou, astfel incat DEPASIREA sa apara numai atunci cand numarul total de elemente al celor doua stive depaseste spatiul total disponibil (M). Sugestie: cele doua stive vor avea baza la cate un capat al tabloului si vor creste una catre cealalta:
|
Lista1 |
Spatiu disponibil |
Lista2 |
|||||
|
Baza |
Varf |
Varf |
Baza |
||||
Putem renunta la restrictia de a mentine o lista liniara in locatii succesive de memorie, utilizand o schema mult mai flexibila, in care fiecare nod contine o legatura la urmatorul nod al listei.
|
Alocare secventiala |
Alocare inlantuita |
|||
|
Adresa |
Continut |
Adresa |
Continut |
|
|
b |
Element1 |
A: |
Element1 |
B |
|
b + dim |
Element2 |
B: |
Element2 |
C |
|
b + 2*dim |
Element3 |
C: |
Element3 |
D |
|
b + 3*dim |
Element4 |
D: |
Element4 |
E |
|
b + 4*dim |
Element5 |
E: |
Element5 |
NIL |
Aici A,B,C,D si E sunt locatii arbitrare de memorie, iar NIL reprezinta legatura vida si este utilizata pentru a indica faptul ca respectivul element nu are succesor. Astfel, din figura de mai sus deducem ca, in cazul alocarii inlantuite, primul element se gaseste la adresa A, iar succesorul sau (Element2) se afla la adresa B,., Element5 se afla la adresa E si el nu are succesor, deci este ultimul element al listei.
Legaturile sunt adeseori reprezentate mai simplu prin sageti, deoarece pentru programator pozitia pe care o ocupa elementele in memorie este cel mai adesea nesemnificativa; lista din exemplul de mai sus ar putea fi reprezentata astfel:
|
|
Element1 |
Element2 |
Element3 |
Element4 |
Element5 |
NIL |
In figura de mai sus A este o variabila de tip pointer (referinta) care indica primul nod al listei.
Vom imparti simbolic un nod al listei in doua componente: INFO (informatia utila) si LEG (informatia de legatura):
|
INFO |
LEG |
Utilizarea alocarii inlantuite presupune existenta unei liste DISPON (de la disponibil) cu spatiul de memorie disponibil si a unui sistem care gestioneaza aceasta lista. Sistemul de gestiune a acestei liste admite urmatoarele operatii:
alocarea de spatiu din DISPON pentru un nou element P al listei. Vom scrie P DISPON. Aceasta operatie isi are echivalentul in procedura new in Pascal, in functiile malloc si calloc din C, si in operatorul new din C++
eliberarea spatiului de memorie ocupat de un element P al listei. Vom scrie DISPON P. Aceasta operatie isi are echivalentul in procedura dispose din Pascal, functia free din C, si cu operatorul delete in C++
Iata cum se definesc operatiile de inserare respectiv stergere in cazul alocarii inlantuite a unei stive (variabila T reprezinta, ca si in paragraful anterior, varful stivei).
PUSH(T, Y)
P DISPON
P.INFO Y
P.LEG T
T P
END (PUSH)
POP(T, Y)
daca T = NIL atunci DEPASIRE (underflow)
P T
T P.LEG
Y P.INFO
DISPON P
END (POP)
Se observa ca, spre deosebire de paragraful precedent, variabila T a fost introdusa ca parametru al procedurilor. Acest lucru aduce un plus de genericitate operatiilor PUSH si POP, in sensul ca ele pot acum opera asupra oricarei stive a carei adresa este transmisa in parametrul T (lucru de care ne-am folosit de altfel in paragraful 2.4).
Sa presupunem ca avem o stiva care contine elementele 10, -5, 0, 4 ca in figura de mai jos:

Figura 2.2‑ .O stiva care contine elementele 10, -5, 0 si 4
In acest caz, efectul realizarii asupra acestei stive a doua operatii POP si a unei operatii PUSH(2) este urmatorul:
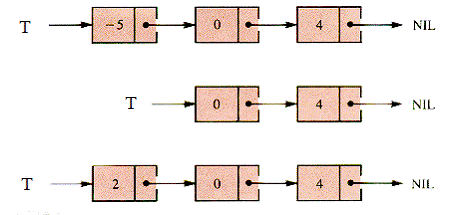
Figura 2.2‑ Efectul realizarii asupra stivei a doua operatii POP(T) si a unei operatii PUSH(T, 2)
Iata cum se definesc operatiile de inserare respectiv stergere in cazul alocarii inlantuite a unei cozi (variabilele CP si CD au aceeasi semnificatie ca si in paragraful anterior):
INSERT (CP, CD, Y)
P DISPON // se aloca memorie pentru noul nod
P.INFO Y //se completeaza informatia utila
P.LEG NIL //se completeaza informatia de legatura
daca CP = NIL atunci CP CD P //o coada este vida pentru CP = NIL
altfel CD.LEG P, CD P
END (INSERT)
DELETE(CD, CD, Y)
daca CP = NIL atunci DEPASIRE (underflow)
P CP
CP P.LEG
Y P.INFO
DISPON P
END (DELETE)
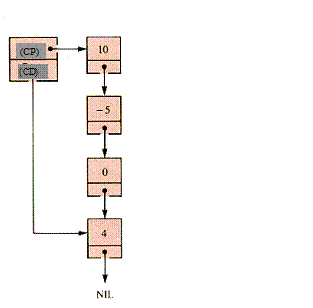
Figura 2.2‑ Reprezentarea inlantuita a unei cozi, utilizand o variabila CP pentru capul cozii si o variabila CD pentru coada ei
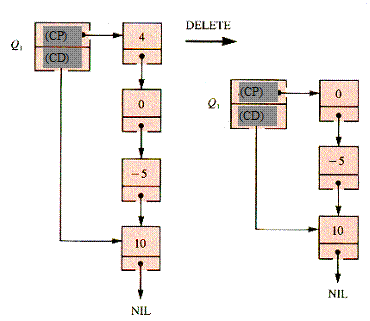
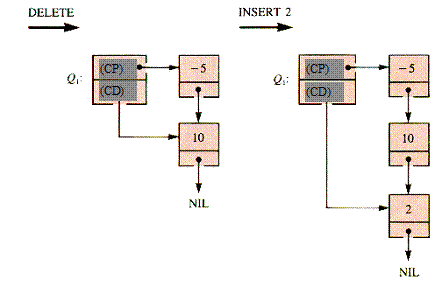
Figura 2.2‑ Efectul realizarii asupra cozii a doua operatii de stergere si a unei operatii de inserare a valorii 2.
Alocarea inlantuita necesita spatiu suplimentar pentru legaturi.
Stergerea si inserarea unui element se face usor in cazul alocarii inlantuite, fara a fi nevoie de deplasarea elementelor ca in cazul alocarii secventiale
In cazul alocarii secventiale, trebuie alocata a priori o anumita zona de locatii continue de memorie; se risca astfel neutilizarea de spatii largi de memorie. In cazul alocarii inlantuite (dinamice) se utilizeaza exact atata memorie cat este necesar.
Accesul la un element oarecare al listei este mult mai rapida in cazul alocarii secventiale (O(1) la alocarea secventiala si O(n) la alocarea inlantuita).
Schema inlantuita permite concatenarea cu usurinta a doua liste, sau ruperea unei liste in doua
O lista circulara este o lista liniara care are proprietatea ca ultimul sau nod este legat de primul nod, in loc sa fie legat la NIL. Avem astfel acces la toate elementele listei indiferent din ce punct pornim; obtinem astfel un grad mai mare de simetrie si, daca dorim, putem considera ca nu mai avem un prim sau ultim nod.
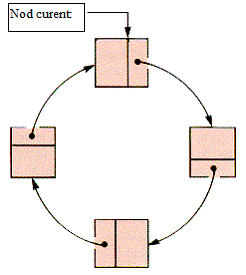
Figura 2.3‑ Reprezentarea unei liste circulare. Avem acces la toate elementele listei, indiferent din care nod pornim
Principalele operatii pe care am dori sa le realizam asupra unei liste circulare sunt:
inserarea unui nod in lista dupa un nod specificat
stergerea unui nod aflat dupa un nod specificat
cautarea unui nod cu anumite proprietati (parcurgerea listei)
In cei trei algoritmi de mai jos presupunem ca exista o variabila CRT, care indica nodul curent al listei. Toate operatiile se vor face relativ la acest nod curent.
Algoritmul Insert de mai jos realizeaza inserarea valorii Y in dreapta nodului curent, CRT. Daca CRT este NIL, atunci se considera ca lista este vida, deci Y este primul nod al listei:
INSERT (Y)
aux DISPON // se aloca memorie pentru noul nod
aux.INFO Y //se completeaza informatia utila din noul nod
daca CRT = NIL atunci // lista a fost vida pentru P = NIL
aux.LEG aux // urmatorul nod este chiar el insusi
altfel
aux.LEG CRT.LEG ; CRT.LEG aux
END (INSERT)
Algoritmul Delete de mai jos realizeaza stergerea nodului aflat in dreapta nodului curent, CRT, si incarca in variabila Y valoarea nodului sters. Daca lista a avut un singur nod (cel indicat de CRT), atunci CRT devine NIL.
DELETE(Y)
daca CRT = NIL atunci DEPASIRE (underflow) //lista este vida, nu avem ce sterge
aux CRT.LEG //aux este nodul care va fi sters
Y aux.INFO //se copiaza in Y informatia din nodul care se sterge
daca CRT.LEG <> CRT atunci //in lista mai avem cel putin un element
CRT.LEG aux.LEG
altfel
CRT NIL
DISPON aux
END (DELETE)
Functia Find de mai jos cauta in lista circulara si returneaza primul nod care contine in campul INFO valoarea Y. In cazul in care nodul nu este gasit, Find va intoarce valoarea NIL:
FIND(Y)
daca CRT = NIL atunci return NIL //lista este vida, nu avem ce cauta
aux CRT //aux este variabila cu care vom parcurge lista
repeta
daca aux.INFO = Y atunci return aux //am gasit nodul cautat
aux = aux.LEG //trecem la urmatorul nod al listei
pana cand aux = CRT //ne-am intors de unde am plecat
return NIL
END (FIND)
Ca o aplicatie la listele liniare simplu inlantuite, vom vedea cum se construieste un tip abstract de date care incapsuleaza principalele operatii asupra polinoamelor.
Se pune problema gasirii unei reprezentari eficiente a unui polinom cu coeficienti reali de forma:
P(X) = anXn + an-1Xn-1 + . + a1X + a0
O idee simpla, care ne vine imediat in minte, este sa reprezentam coeficientii polinomului intr-un tablou A cu n+1 elemente. Aceasta reprezentare are insa doua inconveniente majore: orice tablou are o limita superioara in ceea ce priveste numarul de elemente, ori gradul unui polinom poate atinge, mai ales in cazul unor operatii de inmultire, dimensiuni imprevizibile; pe de alta parte, putem avea polinoame de genul X100 + 1, pentru reprezentarea caruia se folosesc 101 locatii de memorie, din care 99 sunt 0!
Ambele dezavantaje pot fi surmontate utilizand o reprezentare mai convenabila a polinoamelor, sub forma de perechi (coeficient, exponent).
Polinoamele cum sunt cele de mai jos sunt exemple concludente de obiecte care trebuie retinute utilizand alocarea dinamica a memoriei:
P1(X) = 31X17 - X11 + 5X4 + 10X3 -3
P2(X) = 7X17 + 4X6 -2X2 + 8
P3(X) = 3X11 - 5X4 + X2 + 3
Polinomul P1 are gradul 17, deci in prima varianta de reprezentare ar fi necesare 18 locatii de memorie pentru a retine coeficientii sai. Utilizand a doua metoda de reprezentare, trebuie sa retinem doar urmatoarele 5 perechi de forma (coeficient, exponent): (31, 17), (-1, 11), (5, 4), (10, 3), (-3, 0).
Polinoamele de genul lui P1, P2 si P3 se numesc polinoame rare. Un polinom de grad 17 ar putea necesita pana la 18 perechi pentru a fi descris, dar exemplele noastre in mod cert nu necesita acest lucru.
O lista liniara simplu inlantuita, organizata ca o coada (vezi paragraful 2.2.1) este o structura de date naturala pentru reprezentarea polinoamelor. Pentru polinomul P3, o astfel de lista are forma din Figura 2.4‑1
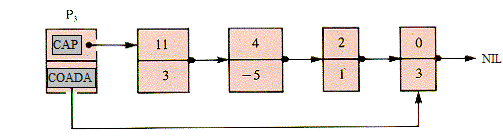
Figura 2.4‑ Reprezentarea polinomului P3 intr-o lista liniara simplu inlantuita, organizata ca o coada. Variabilele CAP si COADA indica inceputul, respectiv sfarsitul listei
Se observa ca in aceasta situatie, un nod al listei va contine trei informatii: coeficientul (COEF), exponentul (EXP) si adresa nodului din dreapta (LEG) (putem privi campul generic INFO ca fiind impartit in doua subcampuri, COEF si EXP).
O prima operatie care este necesar sa o definim pentru tipul nostru abstract de data este operatia de creare a listei inlantuite care contine coeficientii polinomului.
Rutina CITIRE_POL(CAP, COADA)[1] de mai jos realizeaza citirea rand pe rand a coeficientilor polinomului si introducerea lor intr-o coada, ale carei extremitati vor fi indicate de variabilele CAP si COADA, utilizand procedura INSERT din paragraful (adaptata usor pentru a permite retinerea a doua informatii, COEF si EXP):
CITIRE_POL(CAP, COADA)
CAP = COADA = NIL //la inceput coada este vida
repeta //se citesc perechi coeficient-exponent pana cand se introduce
//exponentul -1
citeste COEF, EXP
daca EXP <> -1 atunci
INSERT(CAP, COADA, COEF, EXP) //se adauga in stiva perechea coef-exp
pana cand EXP = -1
END (CITIRE_POL)
Dupa ce polinoamele au fost citite si introduse in stiva, putem defini diferite operatii asupra lor. Vom exemplifica aici cum se realizeaza operatia de adunare a doua polinoame, urmand ca cei ambitiosi sa incerce sa realizeze si alte operatii aritmetice asupra lor.
Rutina AddPol(CP1, CP2, CP3, CD3,) de mai jos, realizeaza adunarea a doua polinoame retinute in doua cozi al caror inceput este indicat de variabilele CP1 respectiv CP2 si depune rezultatul intr-o noua coada indicata de variabilele CP3, CD3. Toate cele trei polinoame au nodurile in ordinea descrescatoare a exponentilor ca in Figura 2.4‑1:
ADD_POL(CP1, CD1, CP2, CD2, CP3, CD3)
CP3 = CD3 = NIL //la inceput rezultatul este polinomul nul
P1 = CP1 ; P2 = CP2 //P1 si P2 sunt variabile care vor parcurge cele doua cozi
cat timp P1<>NIL si P2 <> NIL //mai avem coeficienti neparcursi
daca P1.EXP > P2.EXP atunci
INSERT(CP3, CD3, P1.COEF, P1.EXP)
P1 = P1.LEG //se trece la urmatorul nod in primul
altfel daca P1.EXP > P2.EXP atunci
INSERT(CP3, CD3, P2.COEF, P2.EXP)
P2 = P2.LEG //se trece la urmatorul nod in al doilea
altfel daca P1.EXP = P2.EXP atunci
P1 = P1.LEG; P2 = P2.LEG //avansam in ambele polinoame
daca P1.COEF + P2.COEF <> 0 atunci
INSERT(CP3, CD3, P1.COEF+P2.COEF, P2.EXP)
sfarsit cat timp
daca P1 = NIL atunci Rest = P2 altfel Rest = P1 // se stabileste care dintre
//polinoame mai are coeficienti neadunati
cat timp Rest <> NIL //se trec nodurile ramase in rezultat
INSERT(CP3, CD3, Rest.COEF, Rest.EXP)
END (ADD_POL)
Desi la prima vedere poate sa para complicat, ideea algoritmului de mai sus este simpla: se parcurg in paralel nodurile ambelor polinoame si se trec in polinomul rezultat nodurile in ordinea descrescatoare a exponentului. Daca in cele doua polinoame avem noduri cu acelasi exponent, atunci se trece in rezultat suma coeficientilor cu acelasi exponent. Daca suma lor este 0, atunci nodul nu mai este trecut in rezultat. Primul ciclu cat timp se incheie atunci cand s-au parcurs toate nodurile unuia dintre polinoame. Al doilea ciclu cat timp are rolul de a trece coeficientii ramasi din primul polinom in polinomul suma.
Exercitiu: Rescrieti rutina de adunare a polinoamelor fara a utiliza procedura INSERT!
Posibila tema proiect de diploma: Definiti un tip abstract de date POLINOM care sa incapsuleze urmatoarele operatii asupra polinoamelor rare: CITIRE, SCRIERE, ADUNARE, SCADERE, INMULTIRE, IMPARTIRE, SCHEMA LUI HORNER etc.
In cazul listelor simplu inlantuite, fiecare nod contine un camp LEG care contine adresa urmatorului element al listei. Pentru o mai mare flexibilitate in manipularea listelor liniare, putem sa adaugam in fiecare nod un nou camp, care sa contina adresa nodului anterior nodului curent. O lista liniara dublu inlantuita necesita mai multa memorie decat o lista liniara simplu inlantuita (pentru a retine legatura catre nodul anterior), dar operatiile care se pot realiza astfel constituie o compensare mai mult decat satisfacatoare a acestui dezavantaj.

Figura 2.5‑ Reprezentarea unei liste dublu inlantuite fara nod cap
In Figura 2.5‑1, STANGA si DREAPTA sunt variabile pointer care indica stanga si dreapta listei. Fiecare nod contine doua legaturi, pe care le vom numi LEGS (legatura spre stinga) si LEGD (legatura spre dreapta).
Lucrul cu listele dublu inlantuite devine mult mai comod daca in lista includem si un nod cap al listei, care nu contine informatie utila:

Figura 2.5‑ Reprezentarea unei liste dublu inlantuite, utilizand un nod cap
Campurile LEGD si LEGS ale nodului cap, inlocuiesc variabilele STANGA si DREAPTA din Figura 2.5‑1. Avem in plus si o perfecta simetrie intre stanga si dreapta (In Figura 2.5‑2 capul listei putea fi foarte bine infatisat in dreapta).
Reprezentarea din Figura 2.5‑2 satisface evident relatia:
P.LEGS.LEGD = P.LEGD.LEGS = P
unde P este un nod oarecare al listei. In reprezentarea din Figura 2.5‑1 relatia de mai sus nu este valabila pentru nodul din stanga, respectiv din dreapta listei.
In cazul in care lista este vida, ambele legaturi ale nodului cap indica spre el insusi:
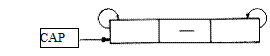
Figura 2.5‑ Reprezentarea unei liste vide. Ambele legaturi ale nodului cap indica spre el insusi.
Evident ca in cazul in care renuntam la statutul special al nodului cap, si acesta va contine informatie ca si celelalte noduri, atunci vom avea de a face cu o lista circulara dublu inlantuita.
Listele dublu inlantuite au doua mari avantaje in raport cu listele simplu inlantuite. Primul este, evident, posibilitatea parcurgerii listei in ambele sensuri. Al doilea este faptul ca putem sterge un nod P al listei, cunoscand doar valoarea lui P!!! Sa ne reamintim ca in cazul unei liste liniare simplu inlantuite nu putem sterge un nod, P, decat daca cunoastem nodul aflat inaintea sa (putem sterge doar nodul aflat in dreapta nodului cunoscut), deoarece nodul anterior trebuie sa isi modifice legatura dupa stergerea lui P. Rutina Delete de mai jos realizeaza stergerea din lista a nodului P pe care il primeste ca parametru:
DELETE(P)
P.LEGS.LEGD = P.LEGD
P.LEGD.LEGS = P.LEGS
DISPON P
END (DELETE)
unde am presupus ca nodul P nu este chiar nodul cap al listei, care nu poate fi sters. Pentru un plus de robustete, se poate insera ca prima linie a algoritmului de mai sus instructiunea:
daca P = CAP atunci EROARE //aici se trateaza eroarea, functie de necesitati.
Figura 2.5‑4 prezinta efectul algoritmului Delete asupra unei liste cu un singur nod:
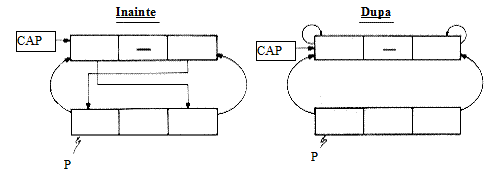
Figura 2.5‑ Efectul algoritmului DELETE pentru o lista cu un singur nod
Chiar daca nodul P mai are inca legaturile intacte catre nodul cap, el a fost efectiv eliminat din lista, si nu mai poate fi nicicum accesat prin nodul cap.
Similar, o lista dublu inlantuita permite cu usurinta inserarea unui nou nod imediat la dreapta sau la stanga unui nod P:
INSERT_RIGHT(P, Y) //inserare la dreapta nodului P a unui nod cu informatia Y
aux DISPON // se aloca memorie pentru noul nod
aux.INFO Y //se completeaza informatia utila din noul nod
aux.LEGS = P
aux.LEGD = P.LEGD
P.LEGD.LEGS = aux
P.LEGD = aux
END (INSERT_RIGHT)
Inserarea la stanga este perfect simetrica in raport cu inserarea la dreapta, in sensul ca se obtine prin interschimbarea stangii cu dreapta:
INSERT_LEFT(P, Y) //inserare la stanga nodului P a unui nod cu informatia Y
aux DISPON // se aloca memorie pentru noul nod
aux.INFO Y //se completeaza informatia utila din noul nod
aux.LEGD = P
aux.LEGS = P.LEGS
P.LEGS.LEGD = aux
P.LEGS = aux
END (INSERT_LEFT)
Este important de observat ca algoritmii de inserare de mai sus functioneaza chiar si in cazul in care se insereaza un nod intr-o lista vida (care contine numai nodul cap).
Exercitiu: Definiti operatiile de stergere si inserare pentru reprezentarea din Figura 2.5‑1. Atentie la cazurile extreme cand lista este vida, sau ne aflam la o extrema a listei. Nu-i asa ca este mult mai anevoios? J
Pe langa operatiile de inserare si stergere dintr-o lista dublu inlantuita, o alta operatie foarte frecvent realizata este parcurgerea elementelor listei. Parcurgerea elementelor unei liste poate fi facuta fie pentru a cauta un element cu anumite proprietati, fie pentru a prelucra succesiv toate elementele listei. Algoritmul de mai jos realizeaza parcurgerea (de la stanga la dreapta a) tuturor elementelor listei pornind de la nodul cap, pe care il desemnam cu variabila CAP:
PARCURGERE(Y)
aux = CAP // aux este variabila cu care vom parcurge lista
repeta
PARCURGE(aux) //se parcurge nodul curent
aux = aux.LEG //trecem la urmatorul nod al listei
pana cand aux = CAP //ne-am intors de unde am plecat
END (PARCURGERE)
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 5069
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved