| CATEGORII DOCUMENTE |
O colectie de date de acelasi tip poate fi stocata sub forma unui masiv de date, fiind necesara o zona continua de memorie de volum suficient pentru a stoca intreaga colectie. Masivele pot fi alocate static (la compilare) sau dinamic (la executie). In primul caz, dimensiunea alocata este independenta de numarul efectiv de date ale colectiei (cu observatia ca dimensiunea alocata trebuie sa o depaseasca pe cea necesara, efectiva). In cazul alocarii dinamice, modificarea, in timpul executiei, a dimensiunii masivului comporta eliberarea memoriei utilizate si realocarea unei noi zone de memorie, cu dimensiunea cea noua.
Listele sunt o alternativa de stocare a unei colectii de date de acelasi tip, nefiind necesara o zona continua de memorie si nici cunoasterea apriorica a numarului de elemente ale colectiei.
Listele reprezinta o colectie de noduri, fiecare nod continand pe langa informatia propriu-zisa, adresele (pointeri catre) altor noduri. Datorita modului lor de organizare, aceste liste se numesc liste inlantuite. Astfel, nodurile listei sunt implementate ca structuri recursive.
Adaugarea/stergerea de noduri in lista se realizeaza la executie, prin urmare o lista este o multime dinamica de date. Initial, listele sunt vide. Pentru ca, prin definitie, o lista se autorefera, prin nodurile sale, listele sunt de natura recursiva.
Modul de organizare a listelor prezinta si unele dezavantaje, minore insa in comparatie cu beneficiile oferite de alocarea inlantuita, cum ar fi: consum sporit de memorie -datorat prezentei in fiecare nod a unor pointeri- si efort ridicat de calcul in cazul accesului la un nod -aceasta presupune parcurgerea tuturor nodurilor anterioare-.
Intre datele ce alcatuiesc informatia propriu-zisa, se alege una (alegerea fiind dependenta de natura problemei) care sa identifice nodul respectiv, pentru a putea permite astfel cautarile in lista. Aceasta va fi numita cheia nodului. Pentru simplificare, in exemplele care urmeaza vom considera ca nodurile contin o singura informatie si anume cheia nodului.
In functie de modul in care sunt inlantuite nodurile, se disting mai multe categorii de liste: liste liniare simplu inlantuite, circulare, dublu inlantuite samd.
O categorie importanta de liste este constituita de listele liniare simplu inlantuite, in care fiecare nod contine, pe langa informatia propriu-zisa, adresa nodului urmator, cu exceptia ultimului nod din lista care nu pointeaza catre nimic (este nul). Gestiunea nodurilor listei se face cu ajutorul adresei primului nod, numit capul listei.

Fig. I . Lista liniara simplu inlantuita
In figura I-1. este reprezentata grafic o lista liniara simplu inlantuita ce contine numere intregi (13, 17, ., 89). Se observa cum fiecare nod contine un pointer ce reprezinta adresa nodului urmator. Ultimul nod nu mai pointeaza catre nimic (adresa continuta va fi 0). Lista este gestionata prin pointerul cap, care contine adresa primului nod al listei.
Un nod poate fi implementat (in C++) astfel:
struct TNod
Adeseori, in practica, sunt necesare prelucrari la sfarsitul listei. In aceste situatii, pentru a evita parcurgerile repetate (si ineficiente) ale listei, se poate utiliza un pointer suplimentar, care va contine adresa ultimului nod al listei.
Listele circulare sunt similare celor simplu inlantuite, cu particularitatea ca ultimul nod pointeaza catre capul listei (nu este nul). In cazul acestui tip de lista, alegerea capului este arbitrara, intrucat toate nodurile sunt identice: fiecare are un succesor si este, la randul sau, succesorul altui nod.
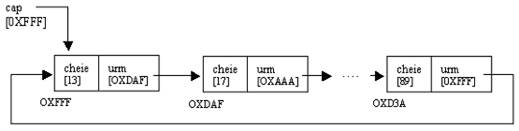
Fig. I . Lista circulara simplu inlantuita
In figura I-2. este reprezentata o lista circulara simplu inlantuita, care difera de cea liniara prin faptul ca nu are un ultim nod (nici un nod nu contine pointerul nul). Listele circulare isi gasesc o utilitate deosebita in probleme de tipul: Un numar de soldati sunt asezati in cerc. Ei trebuie sa aleaga, numarand din p in p, care sunt aceia dintre ei care vor pleca la razboi. De cate ori numaratoarea se opreste la un soldat, acesta iese din formatie (problema lui Josephus).
O alta categorie importanta de liste liniare este constituita de listele dublu inlantuite, in care fiecare nod contine, pe langa informatia propriu-zisa, inca doua adrese: cea a nodului anterior si cea a nodului urmator.

Fig. I . Lista liniara dublu inlantuita
Asa cum se observa in figura I-3., nodurile unei liste liniare dublu inlantuite contin, in plus fata de listele simplu inlantuite, adresa nodului anterior, ceea ce conduce la un consum de memorie suplimentar, dar permite parcurgerea listei si in sens invers, asigurand un acces mai rapid la date.
Nodul unei liste dublu inlantuite poate fi implementat astfel:
struct TNod
Operatiile fundamentale ce se pot efectua pe listele inlantuite sunt:
crearea listei;
acces la un nod (extragere/modificare);
adaugarea unui nod;
stergerea unui nod;
stergerea listei.
O stiva este o lista simplu inlantuita care functioneaza dupa principiul LIFO (Last In, First OUT-ultimul sosit, primul servit). Astfel, in cazul stivelor, operatiile de adaugare/stergere se fac la un singur capat al listei, varful sau. Gestiunea nodurilor se va face printr-un pointer la varful stivei.
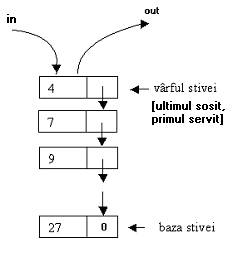
Fig. I . Stiva - lista simplu inlantuita FIFO.
Operatiile fundamentale pe stive sunt:
adaugare in varful stivei - operatie denumita uzual PUSH;
eliminare din varful stivei - operatie denumita uzual POP;
stergere (distrugere) stiva;
verificarea daca stiva este vida;
verificarea daca stiva este plina (daca exista o limita superioara).
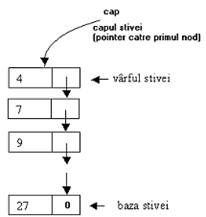
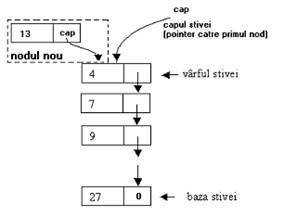
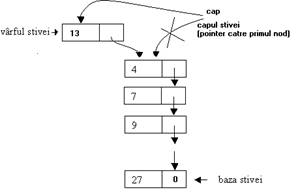
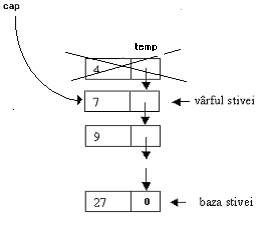
Operatia PUSH, de adaugare a unui nod la inceputul stivei, presupune parcurgerea urmatorilor trei pasi:
se elibereaza memorie pentru noul nod;
se incarca zona alocata cu date -in figura I.5 b) nodul a fost incarcat cu cheia 13- si se "leaga" la actualul prim nod al stivei, prin intermediul pointerului cap;
pointerul cap va pointa acum catre zona de memorie proaspat alocata, aferenta nodului cel nou.
|
a) |
b) |
|
c) |
|
Fig. I . Adaugarea unui nod in stiva - operatia PUSH.
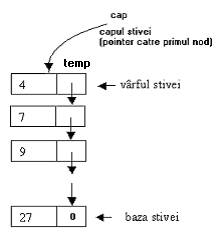
Stergerea primului nod al stivei presupune:
realizarea unui copii a adresei primului nod (cap), pentru a se putea elibera ulterior zona de memorie afectata de acesta;
actualizarea pointerului cap, el va pointa acum catre urmatorul nod din lista;
eliberarea zonei afectate de nodul eliminat, se va folosi aici copia realizata in primul pas.
|
a) |
b) |
Fig. I Stergerea unui din stiva - operatia POP
Prezentam mai jos implementarea in limbajul C/C++ a principalelor operatii ce sunt efectuate pe stive.
Operatii fundamentale pe stiva
#include<iostream.h>
struct TNod;
int isEmpty(TNod* cap)
void Push(TNod* &cap, int nr)
void Pop(TNod* &cap)
void Empty(TNod* &cap)
void List(TNod *cap)
cout<<'-';
TNod* cap=NULL;
main()
Programul produce iesirea:
Stivele isi gasesc o utilitate deosebita in procesele recursive, probleme de inversare samd.
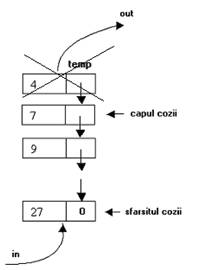
O coada este o lista simplu inlantuita care functioneaza dupa principiul FIFO (First In, First OUT-primul sosit, primul servit). Astfel, in cazul cozilor, operatiile de adaugare se fac la un capat al listei, varful sau, iar operatiile de stergere la celalalt capat.
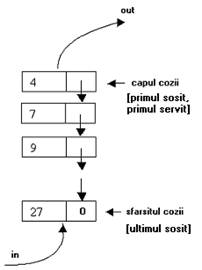
Fig. I Coada - lista simplu inlantuita FIFO
Operatiile fundamentale pe cozi sunt:
adaugare la sfarsitul cozii (in "coada cozii");
eliminare din capul cozii;
stergere (distrugere) coada;
verificarea daca coada este vida;
verificarea daca coada este plina.
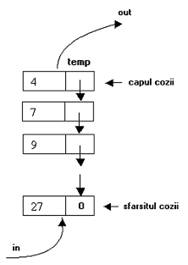
Pentru gestionarea unei cozi se utilizeaza doi pointeri ce contin adresele primului nod (capul cozii) si a ultimului nod (sfarsitul cozii).
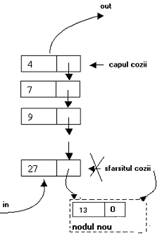
Adaugarea la sfarsitul cozii se face similar adaugarii in stiva, numai ca se lucreaza la nivelul sfarsitului - se foloseste pointerul sfarsit:
se aloca memorie pentru nodul nou;
se incarca datele nodului, iar legatura catre urmatorul nod (inexistent) se initializeaza cu NULL;
se "leaga" sfarsitul cozii la nodul nou (legatura sfarsitului cozii va pointa catre nodul nou), apoi nodul cel nou devine sfarsitul cozii.
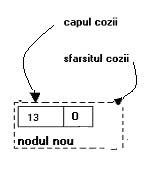
Apare in plus o situatie distincta atunci cand se incearca adaugare in coada vida, caz in care atat sfarsitul, cat si capul cozii vor pointa catre nodul cel nou.
|
a) |
b) |
Fig. I Adaugarea unui nodului cu cheia 13 in coada a) cand coada era nevida; b) cand coada era vida
Stergerea unui nod din coada se realizeaza ca si in cazul stivelor, prin parcurgerea celor trei pasi, la nivelul capului listei:
se realizeaza o copie a capului cozii (adresa primului nod), pentru a putea fi eliberata ulterior memoria alocata;
cap va pointa acum catre urmatorul nod din lista;
se elibereaza memoria pointata de copie.
|
a)
|
b)
|
Fig. I . Operatia POP pentru cozi
Principalele operatii pe cozi pot fi implementate in limbajul C/C++ astfel:
Operatii fundamentale pe cozi
#include<iostream.h>
struct TNod;
int isEmpty(TNod *cap)
void Push(TNod* &cap, TNod* &sfarsit, int nr)
void Pop(TNod* &cap)
void Empty(TNod* &cap)
void List(TNod *cap)
cout<<'-';
TNod *cap, *sfarsit=NULL;
main()
Programul produce iesirea:
Organizarea in coada este frecvent intalnita in situatiile reale, de aceea cozile sunt utilizate in simularea proceselor reale.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 3275
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved