| CATEGORII DOCUMENTE |
TEHNICI DE CAUTARE EURISTICE
Multe dintre problemele care cad sub incidenta Inteligentei Artificiale sunt mult prea complexe pentru a fi rezolvate cu tehnici directe si trebuie sa fie atacate cu metode de cautare corespunzatoare impreuna cu tehnicile directe de ghidare a cautarii disponibile. Aceste tehnici pot fi descrise independent de orice domeniu de probleme. Atunci cand sunt aplicate problemelor concrete eficacitatea lor depinde direct de modul in care exploateaza cunostinte specifice domeniului deoarece nu pot sa depaseasca singure explozia combinatoriala. Acesta este motivul pentru care se numesc si tehnici slabe. Aceste tehnici ofera un cadru in care pot fi plasate cunostinte specifice domeniilor, fie manual fie ca rezultat al invatarii automate. Cateva dintre strategiile de baza sunt urmatoarele:
Depth First Search
Breath First Search
Generate And Test
Hill Climbing
Best First Search
Problem Reduction
Constrain Satisfaction
Means-ends analysis
1. Generate and Test
Strategia Generate and Test este cea mai simpla dintre abordari si este formata din urmatorii pasi:
Algoritm Generate-And-Test
1. Genereaza o posibila solutie. Pentru unele probleme inseamna generarea unui anumit punct in spatiul problemei, in timp ce pentru altele inseamna generarea unui drum pornind de la o stare initiala.
2. Testeaza daca este intr-adevar o solutie prin compararea punctului ales sau a punctului final a drumului ales cu un set de stari finale acceptabile.
Daca s-a gasit o solutie renunta. Daca nu, revine la pasul l.
Daca generarea de solutii posibile se face sistematic atunci aceasta procedura va gasi in cele din urma o solutie, daca aceasta exista, insa daca spatiul problemei este foarte vast, timpul necesar gasirii solutiei ar putea fi foarte mare.
Algoritmul Generate-And-Test este o procedura de cautare depth first search deoarece solutiile trebuie sa fie complet generate inainte de testare. In cea mai sistematica abordare este o cautare exhaustiva in spatiul problemei. Generate-And-Test poate lucra si cu solutii generate aleatoriu dar in acest caz nu mai avem nici o garantie ca vom gasi o solutie vreodata, intre cele doua extreme se afla o cale de mijloc in care procesul de cautare este sistematic dar unele cai nu sunt luate in considerare deoarece e putin probabil sa ne conduca la o solutie.
Cea mai simpla modalitate de a implementa Generate-And-Test sistematic este ca depth-first-search cu backtracking. Daca unele stari intermediare pot sa apara des in arbore, este mai bine sa modificam aceasta procedura astfel incat sa traverseze un graf in loc de arbore.
Pentru probleme simple Generate And Test este de cele mai multe ori o tehnica rezonabila. Ca exemplu putem considera un puzzle din patru cuburi in care fiecare fata a cubului este pictata intr-una din patru culori. O solutie a acestui puzzle consta in aranjarea cuburilor intr-o linie astfel incat pe fiecare din cele patru fete ale liniei sa existe toate cele patru culori. Aceasta problema poate fi rezolvata de o persoana in cateva minute incercand sistematic toate posibilitatile, insa poate fi rezolvat chiar mai repede utilizand o procedura euristica Generate And Test. Daca ne uitam cu atentie la cuburi am putea observa de exemplu ca sunt mai multe fete rosii decat din celelalte culori, iar atunci cand vom plasa un cub cu mai multe fete rosii ar trebui sa utilizam cat mai putine dintre ele ca fete exterioare. Utilizand aceasta euristica multe configuratii nu mai trebuie explorate iar o solutie poate fi gasita destul de repede. Pentru probleme mai dificile aceasta tehnica nu este foarte eficienta, dar daca este combinata cu alte tehnici care restrang spatiul de cautare eficienta sa creste.
Prin aceasta combinare a unei metode de rezolvare a unei probleme cu planul unei alte metode de rezolvare se pot depasi limitele pe care le are fiecare dintre ele. Unul dintre punctele slabe ale planificarii este producerea de solutii inexacte datorita lipsei de comunicare cu mediul. Dar, daca este utilizata pentru a produce parti de solutii care vor fi mai apoi exploatate in procesul Generate And Test, acuratetea devine mai putin importanta si in acelasi timp sunt evitate problemele combinatoriale care pot aparea in cazul utilizarii metodei Generate And test simple.
2. Hill Climbing
Hill Climbing este o varianta de Generate And Test in care feedbackul procedurii de test este utilizat pentru a decide directia in care sa se faca mutarile in spatiul de cautare, intr-o procedura Generate And test simpla functia test da doar un raspuns afirmativ sau negativ. Daca aceasta functie este imbunatatita cu o functie euristica ce ofera o exprimare a apropierii starii actuale de cea finala, procedura de cautare poate utiliza aceasta informatie. Este un lucru pozitiv deoarece de cele mai multe roi calculele functiei euristice se pot face aproape fara nici un cost in acelasi timp in care se realizeaza testul pentru o solutie. Hill Climbing se utilizeaza mai ales atunci cand este disponibila o functie euristica buna de evaluare a starilor dar cand nu mai exista alte informatii utile. Sa presupunem de exemplu ca ne aflam intr-un oras necunoscut, fara harta si dorim sa ajungem in centrul sau. in acest caz se pot cauta cladirile inalte iar functia euristica reprezinta distanta dintre locatia curenta si locatiile cladirilor inalte, iar starile dorite sunt acelea in care distanta este minima.
Hill Climbing simplu
Cea mai simpla modalitate de a implementa hill climbing este urmatoarea:
1. Evalueaza starea initiala. Daca este o stare finala, o returneaza si termina, in caz contrar continua cu starea initiala ca stare curenta.
2. Repetam pana gasim o solutie sau nu mai avem operatori pe care sa-i aplicam starii curente :
a) Selecteaza un operator care nu a mai fost aplicat starii curente si il aplica pentru a produce o noua stare.
b) Evaluam noua stare:
i. Daca este o stare finala, o returnam si terminam
ii.Daca nu e o stare finala dar e mai buna decat starea curenta, o vom face stare curenta
iii.Daca nu e mai buna decat starea curenta, vom continua in ciclu.
Diferenta intre acest algoritm si cel de la Generate And Test este utilizarea unei functii de evaluare ca modalitate de a introduce cunostinte specifice sarcinii in procesul de control. Utilizarea acestor cunostinte face ca aceste metode sa fir metode de cautare euristice si tot aceste cunostinte dau metodelor puterea de a rezolva probleme dificile.
in acest algoritm apare o intrebare destul de vaga, si anume daca o stare este mai buna decat o alta. Pentru ca algoritmul sa functioneze, este necesara o definitie precisa, in unele cazuri acest lucru echivaleaza cu o valoare mai mare a functiei euristice, in altele inseamna o valoare mai mica. Nu conteaza care dintre interpretari le alegem, atat timp cat programul Hill Climbing este consecvent in interpretare.
Pentru a vedea cum functioneaza Hill Climbing vom folosi din nou exemplul cu puzzle de patru cuburi. Pentru a rezolva problema, trebuie sa definim o functie euristica care sa descrie cat de anroane este o anumita configuratie de solutie. O astfel de functie noate fi suma culorilor definite de pe fiecare din cele patru fete . o solutie ar avea valoarea 16. Apoi trebuie sa definim un set de reguli care sa descrie modalitati de a transforma o stare in alta. O singura regula va fi suficienta: alegem un cub si il rotim cu 90 in orice directie. Urmeaza generarea unei stari initiale, iar acest lucru se poate face aleatoriu , fie cu ajutorul functiei euristice. Vom genera o noua stare selectand un bloc pe care il vom roti. Daca starea rezultata este mai buna, o retinem, iar daca nu, revenim la starea anterioara si incercam o alta schimbare.
Steepest Ascent Hill Climbing
O varianta utila a Hill Climbing simplu ia in considerare toate miscarile de la starea curenta si o selecteaza pe cea mai buna ca stare urmatoare. Aceasta metoda mai este denumita Steepest Ascent Hill Climbing sau cautarea gradienta. Ea se deosebeste de metoda de baza in care prima stare care este mai buna decat cea curenta este selectata. Algoritmul este urmatorul:
1.Evaluam starea initiala. Daca este o stare finala, o returnam si terminam, in caz contrar continuam cu starea initiala ca stare curenta.
2. Ciclam pana cand gasim o solutie sau pana cand o iteratie completa nu produce nici o schimbare starii curente.
a. SUCC va fi o stare aleasa astfel incat orice succesor posibil al starii curente sa fie mai bun decat SUCC.
b. Pentru fiecare operator care se aplica starii curente vom:
i. Aplica operatorul si vom genera o stare noua.
ii. evalua noua stare. Daca este finala, o returnam si terminam. Daca nu, o comparam cu SUCC: daca e mai buna, vom seta SUCC pe acea stare., daca nu, nu schimbam nimic.
c.Daca SUCC este mai bun decat starea curenta, vom seta starea curenta pe SUCC Pentru a aplica Steepest Ascent Hill Climbing problemei cuburilor colorate, trebuie sa luam in considerare toate modificarile starii initiale si sa o alegem pe cea mai buna. Pentru aceasta problema este dificil deoarece sunt foarte multe miscari posibile. Trebuie sa se faca o alegere intre timpul necesar selectarii unei miscari (de obicei mai lung pentru Steepest Ascent Hill Climbing ) si numarul de miscari necesare pentru a ajunge la o solutie ( de obicei mai lung pentru Steepest Ascent Hill Climbing simplu) , iar aceasta alegere va influenta decizia cu privire la alegerea metodei pentru o problema particulara.
Atat Steepest Ascent Hill Climbing cat si Hill Climbing simplu pot sa esueze in gasirea unei solutii. Oricare dintre acesti algoritmi se pot termina fara a gasi o solutie, ci doar ajungand la o stare din care nu pot fi generate stari mai bune. Acest lucru se intampla atunci cand programul ajunge intr-un punct de maxim local, platou sau o culme (ridge).
Un maxim local este o stare care e mai buna decat oricare dintre vecinii sai dar nu e mai buna decat unele stari mai indepartate, intr-un maxim local toate miscarile par sa inrautateasca lucrurile. Aceste maxime locale sunt adesea foarte apropiate de o solutie.
Un platou este o zona plana a spatiului de cautare in care un set de stari vecine au aceeasi valoare. Pe un platou nu este posibila determinarea celei mai bune directii de urmat prin comparari locale.
O culme este un tip special de maxim local. Este o zona a spatiului de cautare care e mai inalta decat zonele inconjuratoare, care are si ea o panta, insa orientarea regiunii inalte, comparata cu setul de miscari disponibile si directiile in care se fac mutarile, fac imposibila traversarea unei culmi cu miscari unice.
Exista mai multe cai de a rezolva aceste probleme, desi nici una dintre metode mi sunt garantate:
Backtrack spre un nod anterior si incercarea unei alte directii. Este o modalitate rezonabila daca la acel nod se afla o directie la fel sau aproape la fel de promitatoare ca si cea care a fost aleasa anterior. Pentru a implementa aceasta strategie trebuie sa retinem o lista de cai si sa ne intoarcem la una dintre ele atunci cand calea aleasa ajunge intr-un punct mort. Este o metoda potrivita de a rezolva maximele locale.
O saritura mai mare intr-o directie oarecare pentru a incerca sa ajungem la o noua sectiune a spatiului de cautare. Este o metoda eficienta de solutionare a platourilor. Daca regulile disponibile descriu doar pasi mici le vom aplica de mai multe ori in aceeasi directie.
Aplicam doua sau mai multe reguli inainte de a face testul, corespunzatoare miscarii in mai multe directii in acelasi timp. Este o strategie buna pentru solutionarea culmilor.
Chiar si cu aceste masuri de ajutor, Hill Climbing nu este intotdeauna eficient. Este ineficient mai ales in cazurile in care valoarea functiei euristice scade brusc atunci cand ne indepartam de solutie. Acesta este cazul atunci cand este prezent orice efect de prag. Hill Climbing este o metoda locala, adica decide ce va face in continuare uitandu-se doar la consecintele imediate ale alegerii mai degraba decat explorand exhaustiv toate consecintele. Are avantajul ca este mai putin exploziv combinatorial decat alte metode de comparare globale, dar are de asemenea si dezavantajul lipsei de garantie al eficientei sale. Desi este adevarat ca procedura de Hill Climbing priveste doar cu o miscare inainte, examinarea poate exploata o multime arbitrara de informatii globale daca acele informatii sunt inglobate in functia euristica.
Sa consideram problema blocurilor. Avem doi operatori: luam un bloc si il punem pe masa, luam un bloc si il punem pe altul. Vom folosi urmatoarea functie euristica: adunam un punct pentru fiecare bloc care se afla pe ce ar trebui sa se afle si scadem cate un punct pentru fiecare bloc care sta unde nu ar trebui (locala).
Folosind aceasta functie starea tinta are un scor de 8. Starea initiala are scorul 4 (se aduna cate un punct pentru cuburile C,D,E,F,G, si H si se scade cate unul pentru A si B) Din starea initiala se poate face o singura miscare : se muta A pe masa. Aceasta miscare produce o stare cu scorul 6. Procedura de Hill Climbing va accepta aceasta miscare. Pentru noua stare sunt trei miscari posibile, care conduc spre trei stari posibile. Fiecare din cele trei stari are scorul 4 . Hill Climbing se va opri pentru ca toate au un scor mai mic decat starea curenta. Procesul a ajuns intr-un punct de maxim local care nu este maximul global. Problema care a aparut este ca prin examinarea locala a structurilor , starea curenta pare a fi mai buna decat oricare dintre succesorii sai deoarece mai multe blocuri se afla in pozitii corecte. Pentru a rezolva aceasta problema este nevoie sa dezansamblam o structura locala buna deoarece este gresita in contextul global. Pentru acest esec ar putea fi invinovatit Hill Climbing deoarece nu priveste suficient de mult inainte pentru a descoperi o solutie. Dar am putea de asemenea sa acuzam functia euristica si sa incercam sa o modificam. Sa presupunem ca vom folosi urmatoarea functie euristica: pentru fiecare bloc care are structura de suport potrivita (adica intreaga structura de sub el este exact cum ar trebui sa fie), adunam cate un punct pentru fiecare bloc din structura de suport. Pentru fiecare bloc ce are structura de suport incorecta, vom scadea cate un punct pentru fiecare bloc din structura de suport existenta (globala).
Utilizand aceasta functie starea finala are scorul 28. Starea initiala are scorul -28. Daca mutam blocul A pe masa va rezulta o stare cu scorul -21 deoarece A nu mai are 7 blocuri gresite sub el. Cele trei stari care pot rezulta in continuare au urmatoarele scoruri : a) -28, b) -16, si c) -15. de aceasta data Steepest Ascent Hill Climbing va alege varianta c), aceasta functie euristica noua capteaza cele doua aspecte cheie ale problemei: structurile incorecte trebuie inlaturate iar structurile bune trebuie construite. Ca rezultat, aceeasi procedura Hill Climbing care a esuat cu prima functie euristica lucreaza acum perfect.
Din nefericire nu este intotdeauna posibil sa construim o astfel de functie euristica perfecta. Sa reconsideram , de exemplu, problema mersului in centru. O functie euristica perfecta ar trebui sa aiba informatii despre drumurile cu sens unic si fundaturi, ceea ce in cazul unui oras necunoscut nu este intotdeauna posibil. Si chiar daca sunt disponibile informatii perfecte, nu este intotdeauna posibil sa fie prelucrate computational pentru a fi folosite.
Hill Climbing poate fi ineficient intr-un spatiu al problemei mare si dificil. Este insa util atunci cand este combinat cu alte metode care il directioneaza spre o vecinatate corespunzatoare.
Simulated Annealing
Simulated Annealing este o varianta a Hill Climbing in care, la inceputul procesului, se pot face cateva miscari in jos. Ideea este de a explora suficient intreg spatiul din timp astfel incat solutia finala sa fie relativ insensibila la starea de pornire. Astfel ar trebui sa se reduca sansele de a fi prinsi intr-un maxim local, platou sau culme.
Simulated annealing ca si proces computational copiaza procesul fizic de calire , in care substante fizice precum metalele sunt topite ( aduse la nivele ridicate de energie) si apoi racite treptat pana se ajunge intr-o anumita stare solida. Scopul acestui proces este de a produce o stare finala cu energie minima. Substantele fizice de obicei se misca din configuratiile cu energie inalta spre cele cu energie joasa, coborarea facandu-se natural. Exista insa probabilitatea sa se produca si tranzitii spre stari cu energie mai inalta. Aceasta probabilitate este data de functia: p=e'AE/T.
Algoritmul de Simulated Annealing difera foarte putin de procedura simpla de Hill Climbing. Cele trei diferente sunt:
Trebuie sa fie mentinut programul de calire;
Pot fi acceptate mutari spre stari mai proaste;
Este bine sa retinem, pe langa starea curenta, cea mai buna stare gasita pana atunci. Apoi , daca starea finala este mai proasta decat cea anterioara (din cauza acceptarii miscarilor spre stari mai proaste), starea anterioara este inca disponibila.
Algoritm Simulated Annealing
Evalueaza starea initiala. Daca este o stare finala, o returnam si terminam, in caz contrar, continuam cu starea initiala ca stare curenta.
Initializam BEST-SO-FAR cu starea curenta
Initializam pe T conform planului de calire.
repetam pana se gaseste o solutie sau pana nu mai exista operatori noi care sa fie aplicati pentru a produce o noua stare.
a) Selectam un operator care nu a mai fost aplicat starii curente si il aplicam pentru a produce o noua stare.
b) Evaluam noua stare. Calculam
AE=( valoarea starii curente)- (valoarea noii stari)
Daca noua stare este una finala, o returnam si terminam
Daca nu este o stare finala, dar este mai buna decat cea curenta, o vom face stare curenta. Vom seta si BEST-SO-FAR la noua stare.
Daca nu este mai buna decat starea curenta, o vom face stare curenta cu probabilitatea p definita mai sus. Acest pas este implementat de obicei folosind generatorul de numere aleatoare pentru a produce un numar in intervalul [0,1]. Daca acel numar este mai mic decat p, miscarea este acceptata, in caz contrar nu se face nimic,
c) revizuim T conform planului de calire.
returnam BEST-SO.FAR.
Pentru a implementa acest algoritm revizuit, trebuie sa alegem un program de calire care are trei componente. Primul este valoarea initiala a temperaturii. Al doilea este criteriul care va fi utilizat pentru a decide momentul in care temperatura sistemului trebuie redusa. Al treilea este masura in care temperatura va fi redusa de fiecare data cand este schimbata. Ar putea exista si o a patra componenta a programului, momentul terminarii.
Simulated Annealing este adesea utilizat pentru a rezolva probleme in care numarul miscarilor posibile dintr-o anumita stare este foarte mare (precum numarul permutarilor care pot fi facute pentru ruta unui comisionar). Pentru asemenea probleme nu are nici un sens sa incercam numarul de miscari care au fost incercate din momentul gasirii unei imbunatatiri.
Experimentele facute cu Simulated Annealing pe o varietate de probleme au sugerat ca cea mai buna modalitate de a alege un program de calire este prin incercarea mai multora si observarea efectelor asupra calitatii solutiei gasite precum si a ratei in care procesul converge. Primul lucru care ar trebui observat este ca T se apropie de zero, probabilitatea acceptarii unei mutari spre o stare mai proasta tinde spre zero, iar Simulated Annealing devine identic cu Hill Climbing simplu. Trebuie sa observam ca ceea ce are intr-adevar importanta in calculul probabilitatii de acceptare a unei miscari este raportul AE/T. Este deci important ca valoarea lui T sa fie determinata astfel incat acest raport sa aiba sens. De exemplu, t ar putea fi initializat la o valoare astfel incat, pentru AE mediu, p sa aiba valoarea 0,5.
Best-First Search
Metoda Best -First Search combina avantajele Depth-First Search si Breath-First Search intr-o singura metoda.
Grafuri Sau
Depth - First Search este o metoda buna deoarece gasirea unei solutii fara sa fie nevoie de expandarea tuturor ramurilor concurente. Breath -First Search este buna deoarece nu se blocheaza in fundaturi. O modalitate de a le combina este urmarirea unei singure cai la un moment dat, dar sa schimbam caile atunci cand o cale concurenta pare mai promitatoare decat cea curenta.
La fiecare pas al procesului de cautare Best First Search se selecteaza cel mai promitator nod dintre cele generate pana atunci. Acest lucru se face aplicand o functie euristica adecvata fiecaruia dintre ele. Vom expanda apoi nodul utilizand reguli de generare a succesorilor. Daca vreunul din ei este solutie , putem termina. Daca nu, toate nodurile noi sunt adaugate setului de noduri generate pana atunci. Se alege din nou nodul cel mai promitator si procesul continua. Pe masura ce ramura cea mai promitatoare este explorata se utilizeaza Depth First Search. insa, daca nu se gaseste nici o solutie, acea ramura va aparea mai putin promitatoare decat unele din ramurile de pe primul nivel care au fost ignorate, in acel punct va incepe explorarea unei ramuri ignorate anterior dar care acum pare mai promitatoare. Vechea ramura insa nu va fi uitata, ultimele sale noduri ramanand in setul de noduri generate dar neexpandate. Cautarea poate reveni la ea atunci cand va fi din nou cea mai promitatoare cale.
Figura 9 descrie inceputul unei proceduri de Best First Search. Initial exista un singur nod, care va fi expandat. Se genereaza astfel trei noduri. Functia euristica , care in acest exemplu este o estimare a costului de a ajunge la o solutie dintr-un nod dat, este aplicata fiecaruia din noile noduri. Deoarece nodul D este cel mai promitator, el este cel expandat in continuare, producand doi succesori, nodurile E si F. Li se aplica si lor functia euristica. In acest moment, o alta cale, cea care trece prin nodul B pare mai promitatoare. Nodul B este expandat si genereaza nodurile G si H. Dar cand aceste noduri noi sunt si ele evaluate, par mai putin promitatoare decat o alta cale, astfel incat atentia revine spre calea care trece prin D si E . E este expandat generand nodurile I si J. La pasul urmator J va fi cel expandat deoarece pare cel mai promitator. Procesul continua pana la gasirea unei solutii.
Aceasta procedura seamana mult cu procedura Steepest Hill Climbing, existand doar doua diferente, in Hill Climbing se alege o singura miscare, toate celelalte fiind respinse si nemaifiind luate vreodata in considerare, ceea ce produce comportarea liniara, caracteristica pentru Hill Climbing. in Best First Search se selecteaza o miscare dar toate celelalte sunt retinute astfel incat sa poata fi revizitate mai tarziu , daca vor fi mai promitatoare decat calea selectata, in continuare, cea mai buna stare disponibila este selectata de Best First Search, chiar daca acea stare are o valoare mai redusa decat valoarea starii care tocmai a fost explorata. Acest lucru difera de Hill Climbing , care se va opri daca nu exista stari succesoare cu valori mai bune decat cea a starii curente.
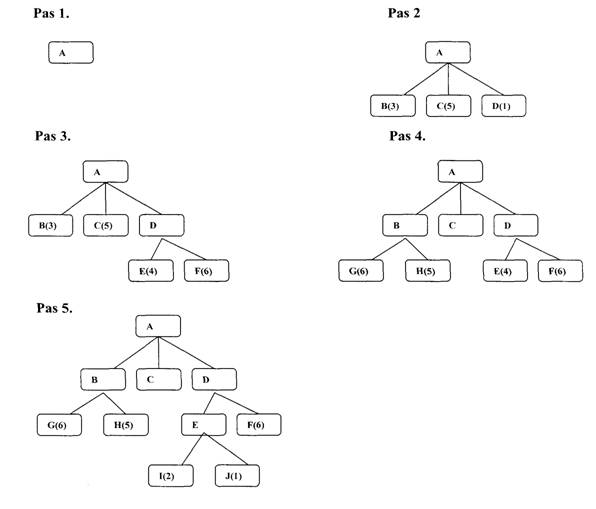 Fig.9. Best
First Search
Fig.9. Best
First Search
Desi exemplul de mai sus ilustreaza o cautare Best First intr-un arbore, uneori este important sa se caute mai degraba intr-un graf astfel incat sa nu fie urmata de mai multe ori aceeasi cale. Un algoritm pentru aceasta problema va cauta intr-un graf orienta, in care fiecare nod reprezinta un punct in spatiul problemei. Aditional descrierii problemei pe care o reprezinta, fiecare nod va contine o indicatie cu privire la cat este de promitatoare, o legatura parinte care pointeaza inapoi spre cel mai bun nod din care provine si o lista a nodurilor care au fost generate din el. legatura parinte va face posibila recuperarea caii spre tinta atunci cand s-a ajuns la aceasta. Lista succesorilor face posibila (atunci cand se descopera o cale mai buna spre un nod deja existent ) propagarea imbunatatirii spre succesori. Un astfel de graf este numit graf SAU, deoarece fiecare din ramurile sale reprezinta o cale alternativa de rezolvare a problemei.
Pentru implementarea acestei proceduri de cautare in graf trebuie sa utilizam doua liste de noduri:
. OPEN - noduri care au fost generate si carora le-a fost aplicata functia euristica dar care nu au fost examinate inca ( adica le-au fost generati succesorii (. OPEN este de fapt o coada de prioritati in care elementele de cea mai mare prioritate sunt cele care au cea mai promitatoare valoare a functiei euristice.
. CLOSED - noduri care au fost deja examinate. Aceste noduri trebuie memorate atunci cand vom cauta mai degraba intr-un graf decat intr-un arbore, deoarece atunci cand un nod nou este generat trebuie sa se verifice daca nu a fost generat anterior.
Vom avea nevoie de asemenea de o functie euristica care sa estimeze valoarea fiecarui nod generat. Acest lucru va permite algoritmului sa urmeze mai intai caile mai promitatoare. Vom numi aceasta functie f (pentru a indica faptul ca este o aproximare a unei functii f care da adevarata evaluare a unui nod). Pentru multe aplicatii este mai convenabil sa definim aceasta functie ca suma a doua componente pe care le vom numi g si h'. Functia g este o masura a costului drumului de la starea initiala la nodul curent. Functia g nu este o estimare ci este suma exacta a costurilor de aplicare a fiecarei reguli utilizate de-a lungul celei mai bune cai spre nod. Functia h' este o estimare a costului suplimentar implicat de drumul de la nodul curent la starea tinta. Acesta este locul in care se utilizeaza cunostintele referitoare la domeniul problemei. Functia combinata f reprezinta o estimare a costului drumului de la starea initiala la starea finala pe calea care a generat nodul curent. Daca nodul a fost generat de mai multe cai, algoritmul o va inregistra pe cea mai buna. Deoarece g si h' trebuie adunate, este important ca h' sa fie o masura a costului parcurgerii drumului dintre nod si o solutie (astfel nodurile bune vor primi valori scazute, in timp ce celelalte vor primi valori mari) mai degraba decat o masura a gradului in care un nod este bun (adica nodurile bune sa primeasca valori mai mari). Acest lucru este usor de rezolvat plasand corect semnul minus. De asemenea este important ca functia g sa nu fie negativa. Daca nu se respecta acest lucru, drumurile care traverseaza cicluri din graf vor aparea ca fiind mai bune pe masura ce devin mai lungi.
Algoritmul este foarte simplu si progreseaza in trepte, expandand cate un nod la fiecare pas pana va genera un nod care sa corespunda unei stari finale. La fiecare pas alege nodul cel mai promitator dintre cele generate anterior si care nu au fost expandate. Genereaza succesorii nodului ales, le aplica functia euristica si ii adauga in lista nodurilor OPEN dupa ce in prealabil a verificat daca vreunul nu a fost generat anterior. Facand aceasta verificare se poate garanta ca fiecare nod apare o singura data in graf, desi mai multe noduri pot sa pointeze spre el ca succesor. Apoi incepe pasul urmator.
Algoritmul Best First Search
Initial OPEN va contine doar starea initiala.
Pana se va ajunge la o stare finala sau atata timp cat mai exista noduri in OPEN:
a) Se va alege cel mai bun nod din OPEN
b) I se genereaza succesorii
c) Pentru fiecare succesor
i. Daca nu a mai fost generat se evalueaza, se adauga in OPEN si i se
inregistreaza parintele
ii. Daca a mai fost generat anterior , i se va schimba parintele daca aceasta noua cale este mai buna decat cea gasita anterior. In acest caz se va actualiza costul ajungerii la acest nod si spre orice succesor pe care il poate avea deja acesta
Ideea de baza a acestui algoritm este simpla. Din nefericire sunt rare cazurile in care algoritmii de traversare a grefurilor sunt simplu de scris corect. Si este si mai rar cazul in care se poate garanta usor corectitudinea unor astfel de algoritmi.
Algoritmul A*
Algoritmul Best First Search prezentat anterior este o simplificare a unui algoritm denumit A* , prezentat pentru prima data de Hart in 1968. Acest algoritm utilizeaza aceleasi functii f, g si h', precum si listele OPEN si CLOSED descrise anterior.
Algoritmul A*
incepe cu OPEN continand doar nodul initial. Se seteaza valoarea g a nodului la O, h' va avea o valoare aleatoare, iar valoarea lui f va fi h' + O sau h'. CLOSED va fi initializat ca lista vida.
Pana la gasirea unui nod final se repeta urmatoarea procedura:
a) Daca nu mai exista noduri in OPEN se va raporta esec.
b) in caz contrar se va alege din OPEN nodul cu cea mai mica valoare a functiei f. Acesta va fi denumit BESTNODE. il scoatem din OPEN. il plasam in CLOSED. Verificam daca BESTNODE nu este o stare finala. Daca este, iesim si raportam solutia ( fie BESTNODE daca ne intereseaza doar nodul, fie calea creata intre starea initiala si BESTNODE). in caz contrar generam succesorii lui BESTNODE dar nu vom seta BESTNODE sa pointeze spre ei inca (va trebui sa verificam mai intai daca vreunul nu a mai fost generat anterior). Pentru fiecare nod SUCCESOR:
i. Setam SUCCESOR sa pointeze inapoi spre BESTNODE. Aceste legaturi inapoi vor face posibila recuperarea caii atunci cand este gasita solutia.
ii. Calculam g(SUCCESOR)=g(BESTNODE) + costul drumului de la BESTNODE la SUCCESOR
iii. Verificam daca SUCCESOR nu exista deja in OPEN ( a fost deja generat dar nu a fost procesat). Daca exista, il vom numi OLD. Deoarece acest nod exista deja in graf, se poate renunta la SUCCESOR si sa adaugam OLD pe lista succesorilor lui BESTNODE. Acum trebuie sa decidem daca legatura spre parinte a lui OLD ar trebui resetata pentru a pointa spre BESTNODE. Ar trebui resetata in cazul in care calea pe care tocmai am descoperit-o spre SUCCESOR este mai ieftina decat cea mai buna cale curenta spre OLD (deoarece SUCCESOR si OLD sunt de fapt acelasi nod). Trebuie deci sa verificam daca este mai ieftin sa ajungem la OLD prin parintele lui actual sau spre SUCCESOR prin BESTNODE comparand valorile lor in g. daca OLD este mai ieftin (sau la fel de ieftin ) nu trebuie sa facem nimic. Daca SUCCESOR este mai ieftin, vom reseta legatura spre parinte a lui OLD astfel incat sa pointeze spre BESTNODE, inregistram noua cale cea mai ieftina in g(OLD) si actualizam f (OLD).
iv. Daca SUCCESOR nu a fost gasit in OPEN , il cautam in CLOSED. Daca il gasim, vom denumi nodul din CLOSED OLD si vom adauga nodul OLD pe lista succesorilor lui BESTNODE. Verificam daca noua cale este mai buna decat cea veche sau nu, precum in pasul anterior iii) si setam legatura spre parinte si valorile lui g si f corespunzator. Daca tocmai am gasit o cale mai buna spre OLD , va trebui sa propagam imbunatatirea spre succesorii lui OLD . Acest lucru este un pic mai dificil deoarece OLD pe lista succesorilor lui BESTNODE. Verificam daca noua cale este mai buna decat cea veche sau nu, precum in pasul anterior si setam legatura spre parinte si valorile lui g si f corespunzator. Daca tocmai am gasit o cale mai buna spre OLD, va trebui sa propagam imbunatatirea spre succesorii lui OLD. Acest lucru este putin mai dificil deoarece OLD pointeaza spre succesorii sai si asa mai departe pana se termina fiecare ramura cu un nod care este inca in OPEN sau care nu are succesori. Pentru a propaga noul cost in jos trebuie sa se faca o traversare depth first a arborelui pornind din OLD, schimband valoarea g a fiecarui nod (deci si valoarea f) si terminand fiecare ramura atunci cand se ajunge la un nod care fie nu are succesori, fie la un nod spre care s-a gasit deja o cale echivalenta sau mai buna. Aceasta conditie se verifica usor deoarece legatura parinte a fiecarui nod pointeaza spre cel mai bun parinte cunoscut si pe masura ce ne propagam in jos spre un nod verificam daca parintele sau pointeaza spre nodul din care venim. Daca da, continuam propagarea, iar daca nu, atunci valoarea sa in g reflecta deja cea mai buna cale din care face parte, propagarea putand sa se opreasca acolo. Este insa posibil ca odata cu propagarea in jos a noii valori a lui, calea pe care o urmam sa devina mai buna decat cea care trece prin parintele curent. Astfel, cele doua cai trebuie comparate, iar daca cea care trece prin parintele curent inca este mai buna, vom opri propagarea, vom reseta parintele si vom continua propagarea.
v. Daca SUCCESOR nu a fost gasit nici in OPEN nici in CLOSED, il vom pune in OPEN si il vom adauga in lista succesorilor lui BESTNODE. Vom calcula f (SUCCESOR) - g(SUCCESOR) + h'(SUCCESOR).
Pe marginea acestui algoritm se pot face mai multe observatii interesante. Prima priveste rolul functiei g. Aceasta ne permite sa alegem nodul pe care il vom expanda in continuare pe baza a nu numai cat este de bun nodul respectiv (asa cum este masurat de h') ci si a cat e de buna a fost calea spre nod. Incorporand pe g in f nu vom alege intotdeauna nodul care parea a fi cel mai apropiat de tinta ca nod urmator de expandat. Acest lucru este util daca are importanta calea pe care o gasim. Daca ne intereseaza doar sa ajungem cumva la o solutie putem sa definim functia g ca fiind intotdeauna O, alegand astfel intotdeauna nodul care pare cel mai apropiat de tinta. Daca vrem sa descoperim o cale cu un numar minim de pasi, vom seta costul drumului de la un nod la altul astfel incat sa reflecte aceste costuri. Algoritmul A* poate fi utilizat atunci cand dorim sa gasim o cale de cost minim sau pur si simplu sa gasim cat mai repede o cale.
A doua observatie priveste functia h', estimatorul lui h, distanta dintre un nod si tinta. Daca h' este un estimator perfect al lui h, atunci A* va converge rapid spre tinta fara cautare. Cu cat este mai bun h', cu atat ne vom apropia mai mult de aceasta abordare directa. Daca insa valoarea lui h' este intotdeauna O, cautarea va fi controlata de g. Daca si valoarea lui g este tot O, strategia de cautare va fi aleatoare. Daca valoarea lui g este intotdeauna l, cautarea va fi una breadth first. Toate nodurile de pe un nivel vor avea valori mai scazute pentru g, ceea ce implica si valori mai scazute pentru f decat a tuturor nodurilor de pe nivelul urmator, in cazul in care h' nu este nici perfect si nici nu are valoarea O, dar daca putem garanta ca h' nu supraestimeaza functia h niciodata, algoritmul A* este garantat sa gaseasca o cale optima spre tinta, daca aceasta exista.
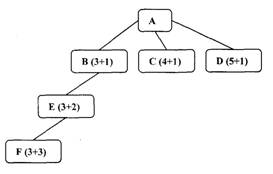
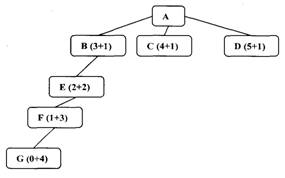
Fig.10. h' subestimeaza h Fig.11. h' supraestimeaza h
Sa consideram situatia din figura 10 Presupunem ca fiecare arc are costul 1. Initial toate nodurile, cu exceptia lui A sunt in OPEN. Pentru fiecare nod f este indicat ca suma a lui h' si g. in acest exemplu nodul B are cel mai mic f, astfel incat este expandat primul. Presupunem ca are un singur succesor, E, care pare si el a fi la trei pasi de tinta. Acum f (E) = 5, la fel ca si f (C). Sa presupunem ca vom urma in continuare aceeasi cale si vom expanda in continuare nodul E. Presupunem ca si el are un singur succesor, F, care se afla si el tot la trei miscari de tinta. Se vede clar ca se fac miscari care nu duc la nici un progres. Doar ca acum f (F) este 6, care este mai mare decat f (C), astfel incat vom expanda in continuare nodul C. Se presupune astfel ca subestimand h(B) s-a risipit putin efort, dar in cele din urma s-a descoperit ca B se afla la o distanta mai mare decat s-a crezut initial si se incearca o alta cale.
In situatia din figura 11 expandam din nou nodul B la primul pas, la al doilea pas nodul E, la al treilea nodul F si in final generam nodul G, cu o cale spre solutie de lungime Este posibil insa sa existe o cale directa din D spre o solutie, cu o cale de lungime 2. Aceasta nu va fi gasita niciodata, deoarece, supraestimand h'(D), nodul D pare atat de rau incat putem gasi o alta solutie, mai slaba, fara a mai ajunge sa expandam si nodul D. in general, daca h' poate sa supraestimeze pe h, nu se poate garanta gasirea celei mai ieftine cai spre o solutie fara o expandare a intregului graf pana in momentul in care toate caile sunt mai lungi decat cea mai buna solutie. Pentru problemele reale, singura cale prin care se poate garanta ca h' nu supraestimeaza h niciodata este sa il setam pe 0. Acesta insa este cazul cautarii Breadth First, care este admisibila dar nu eficienta.
A treia observatie priveste relatia dintre arbori si grafuri. Algoritmul a fost prezentat in forma sa cea mai generala, asa cum se aplica grafurilor, dar poate fi simplificat astfel incat sa poata fi aplicat arborilor renuntand la a mai verifica daca un nod nu face parte deja din OPEN sau CLOSED. Aceasta simplificare va determina o crestere a vitezei de generare a nodurilor dar poate avea ca rezultat repetarea multipla a unei cautari daca un nod este duplicat frecvent.
in unele situatii algoritmul A* poate aparea ca optimal deoarece genereaza cele mai putine noduri in procesul gasirii unei solutii la o problema.
3.3. Agenda Driven
O agenda este o lista de sarcini pe care o poate executa sistemul. De obicei fiecarei sarcini i se asociaza doua lucruri : o lista a motivelor pentru care sarcina este propusa (denumita adesea justificare) si o evaluare reprezentand intreaga cantitate de dovezi care sugereaza ca acea sarcina ar fi utila. Un sistem condus de agenda foloseste urmatoarea procedura:
Algoritm Cautare Agenda Driven
l. Repeta pana se ajunge intr-o stare finala sau pana cand agenda este goala:
a) Se alege sarcina cea mai promitatoare din agenda. Aceasta sarcina poate avea orice reprezentare dorim, putand fi gandita ca o declaratie explicita a ceea ce trebuie facut in continuare sau pur si simplu o indicare a urmatorului nod care trebuie expandat.
b) Se executa sarcina alocandu-i un numar de resurse determinat de importanta sa. Cele mai importante resurse care trebuie avute in vedere sunt timpul si spatiul. Executand sarcina se vor genera probabil alte sarcini (noduri succesor). Pentru fiecare dintre ele se va face:
i. Verificare daca nu este deja in agenda. Daca este, se verifica daca motivul pentru care se executa se afla deja in lista de justificari. Daca se afla, se ignora dovada curenta. Daca justificarea nu era prezenta deja, o adaugam listei. Daca sarcina nu era in agenda, o introducem,
ii. Calcularea noii evaluari a sarcinii, combinand dovezile tuturor justificarile sale. Nu toate justificarile au obligatoriu aceeasi importanta. De obicei este util sa asociem fiecarei justificari o masura a puterii argumentarii acesteia. Aceste masuri sunt apoi combinate pentru a genera o evaluare globala pentru sarcina.
Una din problemele care pot aparea in sistemele conduse de agenda este selectia celei mai promitatoare sarcini in fiecare ciclu. Exista o modalitate simpla de a face acest lucru prin pastrarea agendei sortata dupa evaluari. Cand se creeaza o noua sarcina se insereaza in agenda in locul sau. Atunci cand unei sarcini i se modifica justificarile, i se recalculeaza evaluarea si se muta pe pozitia corespunzatoare in lista. Aceasta metoda consuma insa mult timp pentru pastrarea in ordine a agendei. O mare parte din acest timp este risipit deoarece nu avem nevoie de o ordine perfecta, ci doar sa stim care este primul element corespunzator. Urmatoarea strategie modificata poate uneori cauza executia unei alte sarcini decat cea mai buna, dar este mult mai ieftina decat metoda precedenta. Atunci cand se propune o sarcina sau se adauga o noua justificare unei sarcini existente deja, se calculeaza noua evaluare si se compara cu cea a primelor elemente din agenda. Daca este mai buna, se insereaza nodul in pozitia corespunzatoare intre primele de pe lista, in caz contrar se lasa acolo unde este sau este pur si simplu inserat la sfarsitul listei. La inceputul fiecarui ciclu se alege prima sarcina din agenda, iar din cand in cand agenda va fi reordonata corespunzator.
O structura de control condusa de agenda este utila si in cazul in care unele sarcini (sau noduri) genereaza dovezi negative cu privire la meritele altor sarcini (sau noduri). Acestea pot fi reprezentate prin justificari cu influenta negativa. Daca sunt utilizate astfel de influente negative poate fi important sa verificam nu doar posibilitatea mutarii unei sarcini intre primele din agenda ci si aceea a mutarii unei sarcini dintre primele intre ultimele din agenda daca apar noi justificari negative.
Mecanismul cu agenda ofera o metoda potrivita de concentrare a atentiei unui sistem complex in zonele sugerate de numarul mai mare de indicatori pozitivi, insa efortul pentru executia unei sarcini poate fi destul de ridicat, astfel ca se pune problema marimii adecvate pentru impartirea intregului proces de rezolvare in sarcini individuale. Daca sarcinile sunt foarte mici, nu se va face nici cel mai mic lucru daca nu este intr-adevar cel mai bun care se poate face. in acest caz insa, o mare parte a efortului total va fi utilizat pentru a determina ce urmeaza, insa daca sarcinile sunt de marimi foarte mari se poate pierde efort terminand o sarcina atunci cand exista altele mai promitatoare care ar putea fi executate, dar se va utiliza un procent mai mic din timpul total pentru a determina ce vom face in continuare.
Exista si domenii de probleme pentru care mecanismul condus de agenda nu este potrivit , deoarece acesta presupune ca daca exista un motiv suficient de bun pentru a face ceva acum, atunci va fi acelasi motiv bun sa facem ceva mai tarziu, cu exceptia cazului in care apare ceva mai bun intre timp. Acest lucru nu este adevarat intotdeauna si mai ales in cazul sistemelor care interactioneaza cu oameni.
in ciuda dificultatilor, structurile de control conduse de agenda sunt foarte utile deoarece ofera o modalitate excelenta de integrare a informatiilor dintr-o mare varietate de surse intr-un singur program deoarece fiecare sursa adauga pur si simplu sarcini si justificari in agenda. Pe masura ce programele de IA devin mai complexe si bazele lor de cunostinte cresc, acest lucru devine un avantaj deosebit de important.
Simplificarea problemelor
Pana acum am tratat strategii de cautare pentru grafuri SAU in care dorim sa gasim o singura cale spre o tinta . Aceste structuri reprezinta situatia in care stim sa ajungem de la un nod la o stare finala daca putem descoperi cum sa ajungem din nodul respectiv la o stare finala, prin intermediul oricareia dintre ramurile care pornesc din el.
1. Grafuri SI-SAU
Un alt tip de structura, graful (sau arborele) SI-SAU , este utila pentru reprezentarea solutiei unor probleme care pot fi rezolvate descompunandu-le intr-un set de probleme mai mici, care trebuie apoi rezolvate. Descompunerea sau reducerea genereaza arce pe care le vom numi arce SI. Un arc SI poate pointa spre orice numar de noduri succesoare, toate acestea trebuind rezolvate pentru ca arcul sa pointeze spre o solutie. Ca si in cazul grafurilor SAU, mai multe arce pot sa porneasca dintr-un singur nod, indicand o multitudine de cai prin care problema originala ar putea fi solutionata. Acesta este motivul pentru care structura nu se numeste graf SI ci graf SI-SAU. Un exemplu de graf SI-SAU este cel din figura 12. Arcele SI sunt reprezentate cu o linie care conecteaza toate componentele.
 Fig.12. Un graf
SI-SAU
Fig.12. Un graf
SI-SAU
Pentru a gasi o solutie intr-un graf SI-SAU avem nevoie de un algoritm similar cu Best First dar care sa poata trata arcele SI corespunzator. Acest algoritm ar trebui sa gaseasca o cale de la nodul initial al grafului spre un set de noduri care sa reprezinte starile solutii. De remarcat este faptul ca este posibil sa fie nevoie sa ajungem la mai mult de o stare solutie deoarece fiecare brat al unui arc SI trebuie sa conduca spre propriul nod solutie. Pentru a vedea de ce algoritmul Best First nu este adecvat vom considera exemplul urmator. Nodul din varful A a fost expandat producand doua arce, unul indicand spre nodul B si unul spre C si D. Numerele de pe fiecare nod reprezinta valoarea lui f in acel nod. Presupunand ca fiecare operatie are un cost uniform, astfel incat fiecare arc cu un singur succesor are un cost egal cu l si fiecare arc SI cu mai multi succesori are costul l pentru fiecare dintre componentele sale.
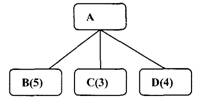
Fig.13.
Daca ne uitam doar la noduri si alegem pentru expandare pe cel cu cea mai mica valoare in f, trebuie sa il alegem pe C. dar folosind toate informatiile de care dispunem acum, ar fi mai bine sa exploram calea care trece prin B deoarece daca il vom utiliza pe C va trebui sa il utilizam si pe D pentru un cost total de 9 (C+D+2) comparat cu costul 6 pe care 1-am obtine trecand prin B. problema este ca alegerea urmatorului nod de expandat depinde nu numai de valoarea in f a acelui nod ci si de apartenenta acelui nod la cea mai buna cale curenta din nodul initial.
Pentru a descrie un algoritm de cautare intr-un graf SI-SAU trebuie sa exploatam o valoare numita PRISOS, in cazul in care costul estimat al unei solutii devine mai mare decat valoarea lui PRISOS, abandonam cautarea. PRISOS ar trebui ales astfel incat sa corespunda unui prag pentru care orice solutie cu un cost superior este prea scumpa pentru a fi practica, chiar daca ar fi gasita vreodata.
Algoritm: Simplificarea problemelor
Initializam graful cu nodul de pornire.
Repetam pana cand nodul de pornire este etichetat SOLVED sau pana cand costul lui ajunge superior lui PRISOS.
a) Traversam graful, incepand cu nodul initial si urmand cea mai buna cale curenta si acumulam setul de noduri care sunt pe acea cale si nu au fost inca expandate sau etichetate ca rezolvate.
b) Alegem unul din nodurile neexpandate si il expandam. Daca nu exista succesori atribuim lui PRISOS valoarea acestui nod. In caz contrar i se adauga succesorii la graf si pentru fiecare dintre ei se calculeaza f (utilizand doar h' si ignorand pe g ). Daca pentru oricare dintre noduri f este O, se marcheaza acel nod ca SOLVED.
c) Se schimba estimarea functiei f a nodului proaspat expandat astfel incat sa reflecte informatiile noi furnizate de succesorii sai. Se propaga aceasta schimbare inapoi in graf. Daca vreun nod contine un arc succesor ai carui descendenti sunt toti rezolvati, se eticheteaza acel nod ca si SOLVED. La fiecare nod pe care il vizitam in timp ce urcam in graf decidem care din arcele lor succesoare este mai promitator si il marcam ca si parte a celei mai bune cai curente. Aceasta propagare a estimarilor de costuri revizuite in sus in arbore nu era necesara in algoritmul de cautare Best First deoarece erau examinate doar nodurile neexpandate. Acum insa, nodurile expandate trebuie reexaminate pentru ca sa poata selecta cea mai buna cale curenta. De aceea este important ca valorile lui f sa fie cele mai bune estimari disponibile.
Acest proces este
ilustrat in figura 1 la primul pas singurul nod este A , astfel incat el se
afla la sfarsitul celei mai bune cai curente. Este expandat
generand nodurile B, C, si D . Arcul spre D este etichetat ca fiind cel
mai promitator dintre cele care pornesc din A deoarece are costul 6,
comparat cu B si C care costa 9 (arcele marcate sunt indicate in
figura prin sageti). La pasul 2 este ales pentru expandare nodul
D. Acesta produce un arc nou, arcul SI spre E si F, cu un cost total
estimat la 10. Se actualizeaza astfel valoarea lui f in D la 10. Urcand
inapoi un nivel, vom observa ca arcul SI B-C este mai bun decat arcul
care porneste din A si descoperim nodurile neexpandate B si C.
daca dorim sa gasim o solutie pe aceasta cale va
trebui sa expandam ambele noduri. Alegem sa exploram mai
intai nodul B. acesta genereaza doua noi arce, spre G si H. propagandu-le
valorile in f inapoi, vom actualiza f in B la 6. Aceasta implica
actualizarea costului arcului SI B-C la 12 (6+4+2). Dupa aceasta
operatie, arcul D este din nou cea mai buna cale care porneste
din A, astfel incat o inregistram a cea mai buna cale si nodul
E, fie F vor fi alese pentru expandare la pasul Acest proces continua fie pana este
gasita o solutie, fie cand toate caile au dus spre
fundaturi, indicand ca nu exista solutie.![]()
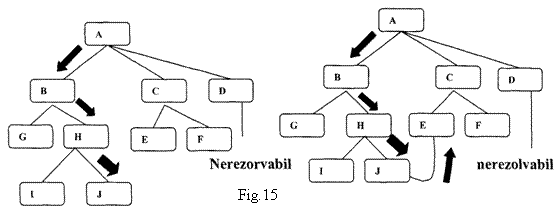
Mai exista o diferenta importanta pentru care algoritmii de cautare in grafuri SI-SAU trebuie sa difere de cei in grafuri SAU. Caile individuale dintre noduri nu pot fi considerate independent de caile spre alte noduri conectate prin arce SI de nodurile initiale. In algoritmul de cautare breath first, calea dorita dintre doua noduri era intotdeauna cea de cost minim, ceea ce nu este adevarat intotdeauna pentru cautarea in grafuri SI-SAU.
In exemplul din figura 15 nodurile au fost generate in ordine alfabetica. Presupunem ca nodul J va fi expandat la pasul urmator si unul din succesorii sai este nodul E. Aceasta noua cale spre E este mai lunga decat cea anterioara care trecea prin C, dar deoarece calea prin C va duce la o solutie numai daca si D va avea o solutie (imposibil), calea prin J este mai buna.
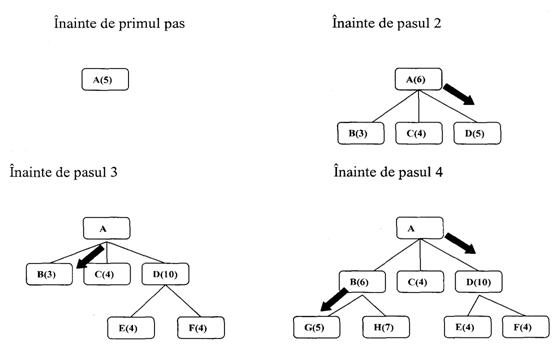 Fig.1
Fig.1
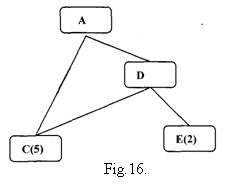
Algoritmul descris anterior are o limitare importanta: nu ia in considerare interactiunile dintre tintele partiale. Un exemplu este in figura 16. Presupunand ca nodurile C si E vor duce in final la o solutie, algoritmul va raporta o solutie completa care le va include pe amandoua. Algoritmul SI - SAU spune ca pentru ca A sa fie rezolvat , atat C si D trebuie sa fie rezolvate. Apoi algoritmul considera solutionarea lui D, E este cea mai buna cale. Dar se dovedeste ca C este oricum necesar, astfel incat ar fi mai bine sa il utilizam pentru a - l satisface pe D. Deoarece algoritmul nu ia in considerare astfel de interactiuni, nu va gasi o cale optimala.
2. Algoritmul AO*
In locul celor doua liste OPEN si CLOSED care au fost utilizate in algoritmul A*, algoritmul AO* utilizeaza o singura structura GRAPH, reprezentand acea parte a grafului de cautare a fost generata explicit pana atunci. Fiecare nod din graf va avea asociata o valoare h', o estimare a costului unei cai de la el spre un set de noduri solutie.
Nu se memoreaza g (costul drumului de la nodul de pornire spre cel curent) asa cum se procedeaza in algoritmul A*. Nu este posibil sa memoram o singura astfel de valoare deoarece pot exista mai multe cai spre aceeasi stare. O astfel de valoare nu este necesara din cauza traversarii de sus in jos a celei mai bune cai cunoscute care garanteaza ca numai nodurile pe care le contine vor fi luate in considerare pentru expandare. Astfel h' va servi si ca estimare a cat de bun este un nod.
Algoritm AO*
GRAPH va contine numai nodul reprezentand starea initiala. Acesta va fi numit INIT. Calculam h'(INIT)
Pana cand INIT nu este etichetat ca SOLVED sau pana cand valoarea lui h'(INIT) devine mai mare decat PRISOS, repetam urmatoarea procedura:
a. Urmam arcele etichetate care pornesc din INIT si selectam pentru expandare unul dintre nodurile care apar pe aceasta cale si inca nu a fost expandat. Vom numi nodul selectat NODE
b. Generam succesorii lui NODE. Daca nu exista succesori, atribuim PRISOS ca valoare a lui h' in NODE, adica NODE nu este solvabil. Daca exista succesori, pentru fiecare dintre ei (numiti SUCCESOR) care nu sunt in acelasi timp si stramosi pentru NODE se executa urmatorii pasi:
i. Se adauga SUCCESOR la GRAPH.
ii. Daca SUCCESOR este un nod terminal se eticheteaza ca SOLVED si i se atribuie valoarea O in h'.
iii. Daca SUCCESOR nu este un nod terminal i se va calcula valoarea in h'. c. Se propaga informatia proaspat descoperita ascendent in graf astfel: fie S un set de noduri care au fost etichetate SOLVED sau care au valoarea in h' schimbata si pentru care trebuie astfel propagata valoarea inapoi spre parinti. Initializam pe NODE cu S. Pana cand S este gol, se repeta urmatoarea procedura:
i. Daca este posibil se selecteaza din S un nod ai carui descendenti in GRAPH nu apar nici unul in S. Daca nu exista un astfel de nod selectam oricare nod din S. II vom numi CURRENT si il vom scoate din S.
ii. Calculam costul pentru fiecare arc care pleaca din CURRENT. Costul pentru fiecare arc este egal cu suma dintre valorile h' a oricaror noduri de la capatularcului plus costul arcului. Se atribuie lui h' corespunzator nodului CURRENT minimul costurilor arcelor care pleaca din acest nod.
iii. Se marcheaza cea mai buna cale care pleaca din CURRENT notand arcul care a avut costul minim,
iv. Marcam CURENT ca SOLVED daca toate nodurile conectate la el prin arcul nou etichetat au fost etichetata ca SOLVED.
v. Daca CURRENT a fost etichetat SOLVED sau daca i s-a schimbat costul, noua situatie trebuie propagata ascendent in graf. Se adauga toti stramosii lui CURRENT in S.
Stramosii unui nod al carui cost s-a schimbat sunt adaugati setului de noduri a caror cost trebuie revazut, ceea ce poate avea drept rezultat propagarea unui cost ascendent in graf intr-un numar mare de cai despre care se stie deja ca nu sunt foarte bune.
Deoarece graful poate sa contina cicluri nu exista nici o garantie ca acest proces se va termina atunci cand ajunge in "varful' grafului.
Constraint Satisfaction
Multe dintre problemele din AI pot fi vazute ca probleme de constraint satisfaction in care scopul este descoperirea unei stari a problemei care satisface un anumit set de conditii. Acest tip de probleme include problemele de puzzle criptaritmetic. Problemele de design pot fi vazute si ele ca probleme de constraint satisfaction in care un design trebuie sa se incadreze in limite de timp, costuri si materiale.
Considerand problema ca una de constraint satisfaction este adesea posibil sa se reduca substantial numarul de cautari necesare, comparativ cu o metoda care incearca sa formeze solutii partiale alegand direct anumite valori pentru componente ale unei eventuale solutii. O abordare constraint satisfaction de rezolvare a unei probleme criptaritmetice evita sa atribuie anumite numere literelor pana cand este absolut necesar. Setul initial de constrangeri, care spune ca un numar poate corespunde unei singure litere si suma numerelor trebuie sa respecte regulile din problema, este marit incluzand restrictii aritmetice. Desi este inca necesar sa ghiceasca, numarul de incercari este redus.
Constraint satisfaction este o procedura de cautare care opereaza intr-un spatiu de seturi de constrangeri. Starea initiala contine constrangerile care sunt date in descrierea problemei. O stare finala poate fi orice stare care indeplineste conditiile.
Constraint satisfaction este un proces cu doi pasi. in primul rand sunt descoperite constrangerile si propagate pe cat posibil in sistem. Apoi, daca nu s-a descoperit inca o solutie, incepe cautarea. Se face o presupunere cu privire la ceva si se adauga ca o noua constrangere, propagarea continuand cu aceasta noua constrangere.
Constraint satisfaction se poate termina din doua motive: fie se ajunge la o contradictie si in acest caz nu exista solutii care sa satisfaca toate conditiile (daca aceasta contradictie e data din constrangerile din descrierea problemei nu exista solutii), fie nu mai exista modificari posibil de facut pe baza cunostintelor detinute si in acest caz este nevoie de cautari pentru a pune procesul in miscare din nou.
In acest punct incepe cel de-al doilea pas si trebuie facuta o ipoteza cu privire la o modalitate de restrangere a constrangerilor, in cazul unei probleme criptaritmetice de exemplu, acest lucru inseamna de obicei ghicirea unei anumite valori pentru o litera. Daca se ajunge la o contradictie se poate utiliza backtrakingul pentru a incerca sa ghicim din nou.
Algoritm Constraint Satisfaction
Se propaga constrangerile disponibile. Pentru aceasta setam OPEN spre setul tuturor obiectelor care trebuie sa aiba valori atribuite pentru ca o solutie sa fie completa. Apoi, pana cand se detecteaza o contradictie sau OPEN este gol, se repeta pasii urmatori:
a. Selectam un obiect OB din OPEN. Se intareste setul de restrictii care se aplica lui OB.
b. Daca acest set difera de setul care i-a fost atribuit ultima data cand a fost examinat OB sau daca este examinat pentru prima data, se adauga in OPEN toate obiectele care au aceleasi constrangeri ca si OB. c. Se scoate OB din OPEN.
Daca setul de constrangeri descoperite mai sus definesc o solutie se paraseste procedura si se raporteaza solutia.
Daca setul de constrangeri descoperite mai sus definesc o contradictie, se returneaza esec.
Daca nu suntem in nici unul din cazurile de mai sus, pentru a continua, trebuie sa ghicim si se repeta urmatorii pasi pana se gaseste o solutie sau se elimina toate solutiile posibile.
a. Selectam un obiect a carui valoare nu a fost determinata inca si o cale de a intari constrangerile asupra acelui obiect,
b. Invocam recursiv constraint satisfaction cu setul curent de constrangeri marit prin intarirea constrangerilor care tocmai a fost selectata.
Acest algoritm a fost prezentat la modul general. Pentru a fi aplicat intr-un anumit domeniu de probleme avem nevoie de doua tipuri de reguli: reguli care definesc modul in care o constrangere poate fi valid propagata si reguli care sa sugereze cum sa ghicim atunci cand este necesar. Faptul ca in unele probleme nu este necesar sa ghicim nu conteaza, in general, cu cat sunt mai puternice regulile de propagare a unei constrangeri, cu atat este mai mica nevoia de a ghici.
Pentru a vedea modul in care lucreaza acest algoritm sa consideram problema criptaritmetica urmatoare:
S E N D Starea initiala - nu exista doua litere cu aceeasi valoare
+ M O R E - suma numerelor trebuie sa fie ca in problema
MONEY
Procesul de gasire a solutiei se desfasoare in cicluri, in cadrul fiecarui ciclu se fac doua lucruri:
se propaga constrangerile utilizand reguli corespunzatoare proprietatilor aritmetice - se ghiceste o valoare pentru unele litere a caror valoare nu a fost inca determinata.
La primul pas de obicei nu conteaza foarte mult ordinea in care se face propagarea, deoarece se vor efectua toate propagarile disponibile. La al doilea pas insa ordinea in care se ghiceste poate avea un impact major asupra cautarilor care vor urma. Cateva euristici pot ajuta selectarea primei valori care trebuie ghicita. De exemplu, daca este o litera care poate avea doar doua valori si o alta cu sase, avem o sansa mai mare sa ghicim corect la prima decat la a doua. O alta euristica poate fi preferarea unei litere care apare de mai multe ori fata de o alta care apare mai putin. Daca vom ghici valoarea unei astfel de litere asupra careia actioneaza mai multe constrangeri avem sanse mai mari sa ajungem fie la o contradictie fie la generarea altor constrangeri. Daca vom incerca sa ghicim valoarea unei litere asupra careia actioneaza mai putine constrangeri, informatia obtinuta va fi mai putina.
Adesea exista doua tipuri de constrangeri: unele care listeaza posibilele valori ale unui obiect si altele, mai complexe, care descriu relatiile dintre sau intre obiecte. Ambele tipuri de constrangeri au acelasi rol in cadrul procesului de constraint satisfaction. Pentru unele probleme este totusi mai utila o reprezentare diferita a celor doua tipuri de constrangeri. Constrangerile simple, care listeaza valorile posibile, sunt mai dinamice si trebuie intotdeauna reprezentate explicit in orice stare a problemei. Constrangerile care exprima relatii, mai complicate, sunt dinamice pentru acest domeniu al problemelor criptaritmetice deoarece difera de la problema la problema, in multe alte domenii de probleme insa sunt statice.
Means - Ends Analysis
Pana acum am prezentat o colectie de strategii de cautare care pot rationa fie spre inainte, fie inapoi, dar pentru o anumita problema trebuie sa fie aleasa una din aceste directii. Adesea un amestec a celor doua directii este cel mai potrivit pentru a rezolva o problema. O astfel de strategie mixta ar face posibila mai intai solutionarea partilor mari ale problemei si apoi intoarcerea la partile mai mici care apar din alipirea pieselor mari. O tehnica numita means - ends analysis ne permite acest lucru.
Procesul means-ends analysis este centrat asupra detectarii diferentelor dintre starea curenta si cea obiectiv. Odata definita aceasta diferenta se gaseste un operator care sa reduca aceasta diferenta. Se poate insa ca acest operator sa nu poata fi aplicat starii curente. Vom forma astfel o subproblema care ne va duce din starea in care am ajuns la cea dorita. Daca diferenta a fost aleasa bine si operatorul este intr-adevar eficient in reducerea acestei diferente, cele doua subprobleme ar trebui sa fie mai usor de rezolvat decat problema initiala. Procesul de means-end analysis poate fi aplicat apoi recursiv. Pentru a concentra atentia sistemului asupra problemelor majore se pot acorda anumite nivele de prioritate diferentelor, cele cu prioritate superioara putand fi tratate inaintea celor cu prioritate mai mica.
Primul program care a exploatat means-ends analyss a fost General Problem Solver (GPS). Proiectarea lui a fost motivata de observatia ca oamenii folosesc adesea aceasta tehnica atunci cand rezolva probleme. GPS ofera insa un exemplu a cat de subtire este granita dintre constructia de programe care simuleaza ce fac oamenii si realizarea de programe care rezolva o problema prin orice mijloace pot.
Means-ends analysis are la baza un set de reguli care pot transforma o stare a problemei in alta. Aceste reguli de obicei nu sunt reprezentate prin descrieri complete ale starii ci si ca descrieri de conditii care trebuie indeplinite pentru ca o regula sa fie aplicabila (numite preconditii de reguli) si descrieri ale acelor aspecte ale starii problemei care vor fi modificate prin aplicarea acestor reguli. O structura separata de date numita tabel de diferente indexeaza regulile in functie de diferentele pe care le pot reduce .
Uneori pot exista mai multi operatori care pot reduce o diferenta si unii operatori pot fi aplicati pentru a reduce mai multe diferente.
Algoritm Means-Ends Analysis:
MEA (CURRENT,GOAL)
l.Se compara CURRENT cu GOAL. Daca nu sunt diferente se returneaza valoarea.
2.In caz contrar se selecteaza cea mai importanta diferenta si se reduce urmand pasii urmatori pana cand se semnaleaza succes sau eroare:
a) Se selecteaza un operatori O care nu a fost inca incercat care poate fi aplicat diferentei curente. Daca nu exista un astfel de operator se va semnaliza eroare.
b) Se incearca aplicarea lui O asupra lui CURRENT. Se genereaza descrieri ale celor doua stari: O-START, o stare in care preconditiile lui O sunt satisfacute si O-RESULT, starea care ar rezulta daca s-ar aplica O lui O-START.
c) daca (FIRST-PART ^-MEA(CURRENT,O-START)) Si
(LAST-PART <- MEA(O-RESULT,GOAL))
sunt corecte, se semnaleaza succes si se returneaza rezultatul concatenarii lui FIRST-PART, O si LAST-PART.
Ordinea in care vor fi tratate diferentele poate avea o importanta majora. Este foarte important ca diferentele majore sa fie reduse inaintea celor mici. Daca nu se face acest lucru se poate pierde mult timp si efort pentru parti ale problemei care se pot rezolva singure odata ce partile mari ale problemei au fost rezolvate.
Acest proces nu este potrivit de obicei pentru rezolvarea de probleme complexe deoarece numarul de permutari ale diferentelor poate ajunge sa fie prea mare, Lucrul asupra unei diferente poate sa interfereze cu planul de reducere a alteia, iar pentru probleme complexe tabelul de diferente ar fi imens.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 2590
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved