| CATEGORII DOCUMENTE |
DOCUMENTE SIMILARE |
|
TERMENI importanti pentru acest document |
|
| : | |
NEORIENTATE
In general prin traversarea unei structuri de date se intelege vizitarea intr-o maniera sistematica a tuturor elementelor sale. Elementele ce vor fi vizitate intr-un graf sunt nodurile sale. Traversarea este utila in situatia in care trebuie realizate un set de operatii de prelucrare asupra tuturor nodurilor sau o inspectare a informatiilor asociate acestora.
In continuare se va face referire la un graf generic cu N noduri. Deoarece intre multimea nodurilor si multimea exista intotdeauna o bijectie, se poate presupune fara a restrange generalitatea ca multimea nodurilor grafului este chiar . Intotdeauna este posibila traversarea unui graf intr-o maniera dependenta de implementare. De exemplu, pentru un graf reprezentat prin matrice de adiacente simpla listare a intregilor de la 1 la N (sau a altor informatii atasate nodurilor) poate fi o 'traversare' a grafului. In mod similar, in cazul structurilor de adiacente, traversarea acestor structuri poate fi considerata o traversare a grafului. Insa este indicat ca un graf sa fie privit ca un obiect, independent de modalitatea de implementare, si deci si traversarea lui trebuie sa fie de asemenea independenta de implementare.
Traversarea unui graf trebuie sa respecte o regula precisa: trecerea de la un nod la altul nu se poate face oricum, ci doar de-a lungul unei muchii directe. Ideea de baza a parcurgerii unui graf este deci urmatoarea: se porneste dintr-un nod si se exploreaza nodurile accesibile din el. Daca raman noduri neexplorate, atunci se alege unul din ele si se executa din nou algoritmul. Procedeul se poate repeta pana la vizitarea tuturor nodurilor grafului.
Din descrierea de mai sus se observa usor ca pornind dintr-un nod se pot vizita doar acele noduri care sunt conectate cu nodul de unde s-a pornit, deci fac parte din componenta conexa a acestuia.
Desi traversarea grafurilor poate fi privita in contextul general al traversarii structurilor de date, deci si a listelor si arborilor, aceasta ridica cateva probleme suplimentare:
In general nu exista 'primul' nod al grafului, de unde sa inceapa traversarea (asa cum au listele un nod header, sau arborii un nod radacina).
Dupa vizitarea unui nod al grafului, toate nodurile adiacente lui convenim a le numi 'succesorii' acestuia. Este natural sa se continue traversarea grafului cu vizitarea acestora. Este insa greu de stabilit o relatie intre succesorii unui nod, deci nu poate fi vorba de o ordine naturala in care sa fie acestia vizitati.
Un nod s-ar putea sa fie succesorul unor noduri diferite. Exista deci posbilitatea de a se ajunge la acest nod pe mai multe cai.
Asadar, un algoritm eficient de traversare a grafurilor trebuie sa ofere solutii problemelor enumerate mai sus.
Trebuie determinat un nod cu care sa inceapa traversarea, nod denumit conventional nod de start. Exista mai multe posibilitati. Astfel, o solutie acceptabila este alegerea ca nod de start a nodului cu indicele cel mai mic din randul nodurilor nevizitate inca. (Aceasta varianta este dependenta de maniera de implementare a nodurilor grafului). Nu intotdeauna insa relatia de ordine a multimii poate fi acceptata si pe multimea nodurilor grafului. O alta solutie este determinarea aleatoare a unui nod de start dintre nodurile candidate.
In general se accepta ca ordinea in care vor fi vizitati succesorii unui nod sa ramana dependenta de implementare. Astfel, in cazul implementarii prin matrice de adiacente ordinea succesorilor unui nod va fi cea din matrice (adica ordinea crescatoare a indicilor). Daca implementarea este prin structuri de adiacente, ordinea succesorilor estre dependenta de ordinea in care au fost inserate muchiile spre acestia in listele de adiacente. (Pentru simplificare se poate adopta si in acest caz ordinea crescatoare a indicilor). Cazul cel mai general insa este acela cand si aceasta alegere este aleatoare.
Daca un nod deja vizitat este succesorul cel putin a unui nod nevizitat, este posibil ca dupa vizitarea acestuia, sa se incerce vizitarea succesorilor lui, deci si a nodului deja vizitat. Ingaduirea unui asemenea fapt ar introduce un grad ridicat de ineficienta. De aceea este nevoie de marcarea intr-un anumit fel a nodurilor deja vizitate, pentru ca pe viitor acestea sa fie evitate. O solutie pentru aceasta problema este pastrarea nodurilor deja vizitate intr-o multime. Inainte de vizitarea unui nou nod se va verifica daca acesta este sau nu in multime. Daca el apare, atunci se trece mai departe, daca nu, se insereaza nodul in multime (dupa sau inainte de efectuarea propriu-zisa a vizitarii). O alta solutie consta in atasarea cate unui marcaj (sau fanion) fiecarui nod, ce va fi (conventional) 'vizitat' (sau setat pe 1/ true) in cazul nodurilor vizitate si 'nevizitat' (sau setat pe 0/ false) pentru nodurile nevizitate.
Se poate observa ca pasul cel mai important al unei tehnici de traversare este cautarea urmatorului nod ce va fi vizitat. In functie de aceasta cautare se pot evidentia doua tehnici de traversare dezvoltate in continuare: Tehnica de traversare bazata pe cautarea prin cuprindere si Tehnica de traversare bazata pe cautarea in adancime.
Pentru a pune in evidenta urma unui algoritm de traversare a grafurilor, si deci implicit si a cautarii nodurilor in graf se construiesc arbori de cautare pentru fiecare tehnica in parte.
De obicei o traversare a grafului presupune vizitarea tuturor nodurilor accesibile (prin drumuri) dintr-un nod oarecare al grafului, numit si nod initial, sau nod de start. Deci, pornind dintr-un anumit nod se va vizita doar acea componenta conexa a grafului care contine nodul de start. Se va initia asadar cate o traversare pentru fiecare componenta conexa a grafului.
Fie k ultimul nod vizitat. Trebuie in continuare sa se ia decizia care va fi urmatorul nod ce va fi vizitat. Una dintre posibilitati este ca urmatoarele noduri vizitate sa fie cele adiacente lui k si nevizitate inca. Se vor vizita pe rand toate aceste noduri, iar pentru fiecare dintre ele se va aplica acelasi procedeu.
Deci, pornind de la un nod de start, cuprindem in aria de vizitare nodurile adiacente lui, apoi cuprindem nodurile adiacente primului nod adiacent cu nodul initial, s.a.m.d.
Aceasta metoda de cautare sta la baza uneia din tehnicile fundamentale de traversare a grafurilor, numita Traversarea bazata pe cautarea prin cuprindere sau Breadth-first search (BFS).
Ideea de baza a algoritmului este aceea de a pastra intr-o coada acele noduri care au fost identificate in procesul de cautare, dar pentru care procesul de vizitare nu s-a incheiat inca. Cozile sunt o categorie speciala de liste in care elementele sunt inserate la un capat (la sfarsitul cozii) si sunt extrase de la celalalt capat (inceputul cozii). Asupra unei cozi se opereaza cu operatori specifici, cum ar fi: initializare coada, test de coada vida, adaugarea unui element la sfarsitul cozii, extragerea unui element din coada.
Schema de principiu a algoritmului de traversare utilizand cautarea prin cuprindere pornind dintr-un nod oarecare k este urmatoarea:
Tehnica BFS(k)
}
}
In timpul vizitarii unui nod, pe masura parcurgerii muchiilor adiacente nodului, se introduc in coada nodurile corespunzatoare care nu au fost vizitate inca si care nu se afla in coada. In momentul in care toate nodurile adiacente nodului curent, care indeplinesc cerintele anterioare, sunt introduse in coada, vizitarea acestuia se considera incheiata si se reia procesul de cautare cu nodul ce se extrage din coada.
Memorand nodurile ce urmeaza a fi vizitate intr-o structura de date coada, cautarea avanseaza radial, acoperind complet zona din jurul nodului curent, memorand in coada de fapt frontiera locurilor deja identificate.
Se observa ca nodurile sunt marcate cu vizitat inainte de a fi introduse in coada, desi vizitarea lor propriu-zisa se face doar la extragere, aceasta pentru a evita plasarea de mai multe ori in coada a unui nod. Deci se poate spune ca in coada avem noduri 'in curs de vizitare', adica noduri a caror vizitare a inceput dar nu s-a terminat inca. O alta posibilitate o constituie folosirea a doua tipuri de marcaje, unul pentru nodurile depuse in coada si nevizitate inca, si altul pentru cele vizitate.
Deoarece algoritmul descris anterior asigura traversarea unei singure componente conexe a grafului, este necesar apelul procedurii BFS pentru fiecare componenta in parte. Este insa greu de determinat componentele conexe ale unui graf, aceasta fiind una din aplicatiile imediate ale traversarii grafurilor. Este important faptul ca pentru a initia o traversare a unei componente conexe a grafului nu este necesara cunoasterea acesteia in intregime, ci este suficient sa se cunoasca un singur nod al componentei respective, care va juca rol de nod de start. Deoarece in urma unui apel al procedurii de traversare exista certitudinea ca vor fi vizitate toate nodurile componentei conexe din care a facut parte nodul de start, existenta in continuare in graf a cel putin unui nod nevizitat conduce la concluzia ca acesta face parte dintr-o alta componenta conexa a grafului, pentru care se poate initia o noua traversare.
Deci o traversare a intregului graf se poate face determinand intotdeauna daca in urma unui apel au mai ramas noduri nevizitate in graf, iar in caz afirmativ se initiaza o noua traversare. Urmatorul mecanism asigura acest lucru:
pentru toate nodurile x ale grafului executa
daca x nevizitat atunci
BFS(x)
In mod normal primul nod gasit este nevizitat. Se apeleaza procedura BFS avand acest nod drept nod de start. La revenirea din apelul procedurii se testeaza urmatoarele noduri daca au fost vizitate sau nu. La gasirea primului nod nevizitat se apeleaza din nou procedura BFS cu acest nou nod de start. Dupa ce s-au parcurs si s-au testat toate nodurile, intregul graf este traversat.
Un arbore de cautare atasat unui graf este un arbore cu urmatoarele proprietati:
este un subgraf maximal al grafului initial (contine deci toate nodurile grafului si multimea maxima de muchii posibile astfel incat sa nu apara cicluri);
are ca radacina nodul de start al grafului.
In cazul in care graful este neconex se obtine o padure de arbori de cautare, cate unul pentru fiecare componenta conexa.
S-a putut constata ca la un moment dat, un nod provoaca introducerea in coada a tuturor vecinilor sai nevizitati. Deci explorand muchiile ce pornesc din nodul curent, se cauta nodurile ce vor deveni noduri in curs de vizitare si apoi vizitate. Astfel de muchii ce conduc la noduri ce vor fi introduse in coada au un rol special, de aceea ele pot fi retinute intr-un fel (in algoritmul de mai sus ele sunt introduse intr-o multime T). Dupa terminarea traversarii, aceste muchii, impreuna cu nodurile grafului formeaza un arbore numit Arbore de Cautare prin Cuprindere. Radacina acestui arbore este primul nod vizitat al grafului.
Astfel, muchiile grafului se impart in doua categorii:
muchiile ce au fost retinute ca avand un rol special si care constituie arcele arborelui, numite muchii (arce) de arbore.
celelalte muchii ale grafului ce se numesc muchii (arce) de retur.
Muchiile (arcele) de arbore evidentiaza clar tehnica de cautare folosita, din fiecare nod pornind astfel de muchii, radial, spre toti vecinii sai nevizitati. De asemenea, se poate usor observa pe un graf peste care se suprapune arborele sau de cautare prin cuprindere, ca o muchie de retur inchide un ciclu al grafului ce cuprinde arcele arborelui care conecteaza extremitatile acestuia prin cel mai apropiat stramos. Deci, este evident ca in cazul in care o componenta conexa a grafului nu are cicluri (adica este un arbore), atunci arborele de cautare corespunzator coincide cu componenta insasi.
|
|
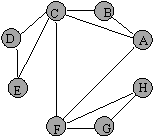
Sa consideram un graf avand 8 noduri ale caror informatii sunt primele 8 litere ale alfabetului, si muchiile dispuse ca in fig. 1. Ne propunem traversarea grafului utilizand tehnica bazata pe cautarea prin cuprindere, descrisa anterior.
|
|
Figura 1 Figura 2
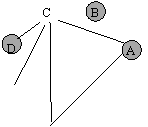
Se va alege in acest scop un nod de start, conventional nodul A. Dupa vizitarea nodului A se vor introduce in coada nodurile adiacente acestuia, adica nodurile B, C si F. (figura 2). In acest moment vizitarea nodului A se considera incheiata si se trece la extragerea unui nod din coada, care va fi nodul B. Deoarece acesta nu are vecini care sa nu fie in coada (singurii sai vecini sunt nodurile A si C) si vizitarea acestuia se considera incheiata, trecandu-se la urmatorul nod din coada, adica la nodul C. Inainte de incheierea vizitarii nodului C se introduc in coada vecinii sai nevizitati, adica nodurile D si E, secventa ce corespunde figurii
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
![]()
![]()
![]()
![]()
![]()

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
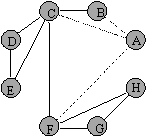
Figura 3 Figura 4
Urmatorul nod ce se va extrage din coada este urmatorul vecin al nodului A, nodul F. Odata cu introducerea in coada a nodurilor adiacente cu el si nevizitate inca: G si H, vizitarea acestuia se considera incheiata (figura 4).
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
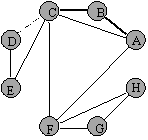
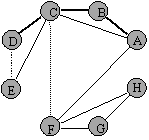
Figura 5 Figura 6
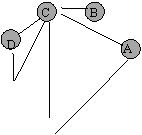
Urmatoarele noduri din coada sunt nodurile D si E, care, neavand la randul lor vecini neplasati in coada, sunt vizitati (figura 5). Ultimele noduri din coada sun nodurile G si H pentru care se va proceda ca mai sus. In acest moment coada este vida, iar graful este cel din figura 6.
Se distinge clar arborele de cautare prin cuprindere (muchiile ingrosate ale grafului), precum si cele doua categorii de noduri care au fost atinse in procesul de cautare: nodurile ce fac deja parte din subarborele de cautare si care sunt noduri deja vizitate, pe de o parte, iar pe de alta parte noduri ce au fost selectionate, adica au fost introduse in coada, urmand a fi vizitate. In figuri aceste noduri au fost unite cu nodurile care au provocat introducerea lor in coada prin muchii desenate cu linie intrerupta.
Evolutia cozii corespunzatoare fiecarei faze surprinse in cate o figura este:
|
|
|
Figura 1a
In prima faza a executiei algoritmului se introduce in coada nodul de start. Sunt marcate (cu sageata de intrare) nodurile ce sunt introduse in coada si nodurile se urmeaza a fi extrase in etapa viitoare (cu sageata de iesire).
![]()
![]()
![]()
|
|
|
|
![]()
![]()
Se observa ca desi nodul A a fost extras din coada, el a fost pastrat, imaginar, pe prima pozitie a cozii. Procedand in aceeasi maniera si in etapele urmatoare se va ajunge in final practic la o coada vida, dar ramanand in ea, imaginar, toate nodurile grafului in ordinea in care au fost ele vizitate. Acest lucru este posibil avand grija ca extragerea unui nod sa se faca din dreptul marcajului de iesire din etapa anterioara. Astfel urmatorul nod ce se va extrage va fi nodul B, apoi C:
|
|
|
|
|
|
|
|
Figura 3a
|
|
|
|
|
|
|
|
Figura 4a
|
A H G E D F C B |
|
H G E D F C B A |
In acest moment coada devine vida, iar ordinea de vizitare a nodurilor este A, B, C, F, D, E, G, H.
Se poate testa acest exemplu cu ajutorul programului ce insoteste prezenta lucrare : GraphSearch.
Se alege din meniul File optiunea Load ;
Selectati si incarcati graful "Ex8_gra";
Apoi alegeti din posibilitatile de la Options traversarea prin cuprindere;
Initiati traversarea grafului actionand StartSearch.
Este cunoscut faptul ca prin analiza unui algoritm se intelege in principal determinarea necesarului de memorie, precum si timpul cerut de executarea lui, adica studiul eficientei sale. Necesitatea acestei analize rezulta pe de o parte din faptul ca multi algoritmi sunt eliminati din practica datorita memoriei mari si/sau timpului mare de executie, iar pe de alta parte nevoii crescande de a elabora algoritmi cat mai performanti in conditiile abordarii cu ajutorul calculatorului a unor probleme din ce in ce mai complexe.
In consecinta, analiza algoritmilor consta in determinarea marimii memoriei necesare, determinarea timpului necesar executiei algoritmului si determinarea optimalitatii algoritmului (care este o consecinta a parametrilor descrisi anterior).
Existenta unor calculatoare cu memorii din ce in ce mai mari fac ca atentia sa se abata de la analiza necesarului de memorie in favoarea timpului de executie. De accea, in general criteriul conform caruia se analizeaza un algoritm este doar timpul de executie. Acesta este direct proportional cu numarul si tipul operatiilor efectuate in cazul cel mai defavorabil.
Eficienta algoritmului de traversare bazat pe cautarea prin cuprindere (in principal timpul de executie) este de cele mai multe ori dependenta de implementarea grafului. Considerand un graf cu N noduri si M muchii, se poate observa ca bucla cat timp din algoritm se executa atata timp cat coada nu este vida. Indiferent de numarul de noduri introduse in coada la un moment dat, la fiecare executie a corpului buclei se extrage un singur nod, deci secventa de instructiuni din corpul buclei se va executa de N ori, deoarece fiecare nod va fi introdus odata in coada. In cadrul fiecarei bucle cat timp se acceseaza fiecare nod adiacent cu nodul curent de-a lungul muchiilor ce pornesc de la el si se testeaza daca nodul de la capatul muchiei este sau nu vizitat. Indiferent de momentul in care este testat un nod, aceste teste sunt in numar de 2M (de-a lungul fiecarei muchii, si intr-un sens si in altul). Astfel, operatiile asupra cozii se fac de 2N ori (N inserari si N extrageri), vizitarile (marcarile) nodurilor se fac de N ori, iar testarile asupra vizitarii sau nevizitarii unui nod se fac de 2M ori.
Tehnica descrisa anterior 'cuprindea' in vederea traversarii toate nodurile adiacente nodului curent k si nevizitate inca. O alta metoda de selectie a nodurilor ce urmeaza a fi vizitate, o constituie inaintarea in graf pe o directie aleasa, atata timp cat acest lucru este posibil. Daca s-a ajuns intr-un nod de unde inaintarea nu mai e posibila, se revine la predecesorul acestui nod si se incearca o noua posibilitate (directie). Mai concret, presupunand ca ultimul nod vizitat este x, se va selecta un nod adiacent acestuia. Presupunem ca acest nod este y. Daca el nu a fost vizitat anterior, atunci el se marcheaza vizitat (eventual se efectueaza anumite operatii asupra nodului) si se initiaza o noua cautare incepand cu acest nod. In momentul in care se epuizeaza cautarea pe toate drumurile pornind din nodul y se revine la nodul x, continuand in aceeasi maniera detectarea unui alt nod adiacent lui. Se aplica acelasi procedeu pana sunt epuizate toate posibilitatile ce deriva din nodul x.
Altfel spus, odata 'ajunsi' intr-un nod, alegem in continuare unul din nodurile nealese inca si continuam parcurgerea. Cand acest lucru nu mai este posibil, 'facem un pas inapoi' spre nodul din care am plecat ultima data si plecam, daca este posibil, spre urmatorul nod neales inca. Ori de cate ori suntem in impas, facem deci un pas inapoi, atata timp cat si acest lucru mai este posibil. Avem deci de-a face cu un algoritm backtracking.
Se observa clar tendinta initiala de adancire, de indepartare fata de sursa, urmata de reveniri, pe masura epuizarii posibilitatilor de avansare. De aceea aceasta metoda de cautare poarta numele cautare in adancime (Depth-First Search), si ea sta la baza celei de-a doua tehnici fundamentale de traversare a grafurilor neorientate. Aceasta tehnica poate fi privita ca o generalizare a traversarii in preordine a arborilor si ea constituie nucleul in jurul caruia pot fi dezvoltati numerosi algoritmi de prelucrare a grafurilor.
Ca si in cazul oricarui algoritm backtracking, pentru a retine traseul 'parcurs' de algoritm este nevoie de o structura de date auxiliara de tip stiva. Este cunoscut faptul ca stiva este o lista in care elementele se pot introduce si extrage de la un singur capat, care se numeste varful stivei. O stiva se exploateaza de regula cu ajutorul unor operatori specifici care se refera, pe langa initializarea stivei, la introducerea unui element in stiva (operatia PUSH), extragerea unui element din stiva (operatia POP), accesarea elementului din varful stivei, sau testul de stiva vida. Se viziteaza primul nod apoi se introduce in stiva. Se cauta un nou nod pentru a fi vizitat printre vecinii primului nod. Odata gasit, acesta este vizitat, apoi este plasat in stiva, astfel ca in varful stivei va fi intotdeauna ultimul nod vizitat. In cazul in care acestuia nu i se gaseste un vecin nevizitat, trebuie revenit cu un pas inapoi, adica se va extrage (elimina) din stiva acest nod. In varful stivei va ramane penultimul nod vizitat, caruia acum trebuie sa i se gaseasca un vecin nevizitat pentru a continua inaintarea, sau dimpotriva, pentru a continua 'retragerea'. In momentul in care se epuizeaza toti vecinii nodului de start traversarea grafului este incheiata, ceea ce conform algoritmului inseamna extragerea acestuia din stiva (intotdeauna nodul de start va fi plasat la baza stivei), aceasta devenind vida, moment ce marcheaza sfarsitul algoritmului.
Schema generala a algoritmului de traversare a grafurilor neorientate bazata pe cautarea in adancime este urmatoarea:
Tehnica DFS(S)
}
}
Se observa ca se inscriu in stiva nodurile grafului, in ordinea in care sunt intalnite: nodul de start S, apoi primul nod adiacent cu S, apoi primul nod adiacent acestuia, s.a.m.d. De fiecare data se exploreaza urmatoarea legatura a nodului din varful stivei, nodul fiind eliminat din stiva cand sunt vizitate toate nodurile adiacente lui.
Deoarece traversarea grafurilor prin cautarea in adancime se bazeaza pe un algoritm backtracking, iar aceasta categorie de algoritmi admit si implementari recursive, se va incerca in continuare o astfel de descriere. Tehnica de traversare ramane aceeasi: se inainteaza in graf atat cat este posibil, in momentul in care inaintarea nu este posibila revenindu-se cu un pas inapoi. Problema vizitarii grafului incepand cu un nod S (nod de start) poate fi insa formulata si altfel:
se viziteaza nodul de start;
se determina urmatorul nod ce ar putea fi vizitat printre vecinii nodului de start;
se viziteaza graful avand drept nod de start nodul determinat anterior
s.a.m.d.
Deoarece se vor folosi si in acest caz marcaje specifice nodurilor vizitate, la o noua cerere de traversare a grafului cu un alt nod de start, practic se cere vizitarea subgrafului format din nodurile nevizitate (adica a acelora care nu au fost noduri de start).
Deci, pe scurt, se marcheaza vizitarea nodului initial, dupa care se parcurge in adancime, recursiv, fiecare nod adiacent cu el; adica se apeleaza procedura pentru fiecare din aceste noduri. In acest caz 'urma' inaintarii in graf este pastrata de sistem prin stiva sa interna. Schema de principiu a algoritmului este urmatoarea:
Tehnica DFS2(x)
}
Avantajul evident al acestei abordari este simplitatea algoritmului si nu mai este necesara gestionarea unei structuri de date auxiliara. De regula insa performanta implementarii iterative a algoritmului este superioara implementarii recursive. De asemenea algoritmul prezentat mai sus este posibil de implementat doar in limbajele de programare care suporta apeluri recursive.
Deoarece trecerea de la un nod la altul se face doar de-a lungul unei muchii directe, algoritmii descrisi anterior asigurau la un apel, traversarea unei singure componente conexe, pentru traversarea intregului graf fiind necesare atatea apeluri cate componente conexe are graful. Similar cu algoritmul de cautare in adancime, acest lucru este asigurat de urmatorul mecanism:
pentru toate nodurile x ale grafului executa
daca x nevizitat atunci
BFS1(x)
respectiv
pentru toate nodurile x ale grafului executa
daca x nevizitat atunci
BFS2(x)
Si in acest caz urma executiei algoritmului poate fi retinuta prin intermediul arborilor de cautare, care datorita specificului metodei, vor purta numele de Arbori de cautare in adancime. Un arbore de cautare in adancime este si el un subgraf maximal al grafului (in sensul ca nu ajunge sa contina cicluri) si are drept radacina nodul de start al grafului. Muchiile ce vor intra in componenta arborelui de cautare sunt muchii de-a lungul carora se inainteaza in graf spre urmatorul nod ce va fi vizitat si poarta numele de muchii (arce) de arbore. Restul muchiilor grafului se vor numi muchii de retur.
Mecanismul de determinare a arborelui de cautare in adancime este acelasi cu cel pentru determinarea arborelui de cautare prin cuprindere. Muchiile de-a lungul carora se
face inaintarea in graf se vor retine intr-o multime T. La final, nodurile grafului impreuna cu aceste muchii vor forma arborele dorit.
Cercetand atent semnificatia si forma unui arbore de cautare prin cuprindere, se observa ca un nod are atatia descendenti cate noduri adiacente cu el exista in graf care nu au fost conectate pe alte cai. Deci un nod al arborelui tinde sa aiba gradul maxim posibil, adica se incearca ca pe acelasi nivel al arborelui sa fie cat mai multe noduri posibile. Astfel inaltimea unui astfel de arbore tinde sa fie minima.
In contrast cu acesta, intr-un arbore de cautare in adancime fiecare nod tinde sa fie conectat doar cu un descendent, iar atunci cand este nevoie (nu mai sunt noduri nevizitate in subarborele descendentului sau, dar mai sunt noduri nevizitate in graf) se mai adauga cate un descendent, numarul lor fiind cel mai mic cu putinta. Astfel numarul nodurilor de pe acelasi nivel tinde sa fie minim, ceea ce duce la cresterea inaltimii arborelui.
Se observa ca la construirea unui arbore de cautare prin cuprindere, descendentii unui nod sunt stabiliti toti deodata, pe cand in cazul arborilor de cautare in adancime acestia sunt adaugati unul cate unul, in functie de necesitati.
Se considera graful din figura 7, un graf cu 8 noduri ale caror informatii sunt primele 8 litere ale alfabetului. Se va supune acest graf traversarii prin tehnica cautarii in adancime, varianta iterativa.Se viziteaza primul nod (acesta fiind nodul A) si se introduce in stiva.Se cauta un nou nod pentru a fi vizitat printre vecinii primului nod (adica nodul B).Dupa ce a fost gasit un nou nod (in cazul nostru nodul B), acesta este vizitat, apoi este plasat in stiva astfel incat in varful stivei va fi intodeauna ultimul nod vizitat (in acest caz nodul B).Se continua in acest fel pana cand se epuizeaza toti vecinii nodului de start (nodul A in acest caz) si in acel moment traversarea grafului se considera incheiata.
|
|

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() Figura 7 Figura 8
Figura 7 Figura 8
In figura 8 este redata inaintarea in graf, dupa vizitarea nodului de start (ales A) spre B, care va fi introdus in stiva. Se cauta un nod adiacent cu B si nevizitat inca. Se detecteaza nodul C care va fi vizitat si introdus in stiva (figura 9). Se continua adancirea in graf, pornind de la nodul C, care este in varful stivei, introducand nodul D in stiva si vizitandu-l, iar apoi in continuare de la acesta, spre nodul E. (figura 10).
|
|
Figura 9 Figura 10
|
|
|
![]() Figura 11 Figura 12
Figura 11 Figura 12
In acest moment inaintarea in graf nu mai este posibila (nodul C fiind deja vizitat), astfel ca se revine la nodul D (prin extragerea nodului E din stiva) de unde, din pacate nu exista o alta ramificatie, asa ca se revine la nodul C (prin aceeasi operatie), de unde exista alternativa unei noi adanciri prin nodul F (asadar se viziteaza nodul F si se introduce in stiva) - figura 11.
Din nodul F va exista o tentativa de a o lua spre A, dar acesta fiind vizitat se porneste spre G. Acesta va fi introdus in stiva, apoi se
va inainta spre nodul H. Dupa vizitarea nodului H, nu se mai poate inainta in graf, asa ca se revine cu cate un pas inapoi (prin extragerea din stiva a nodurilor pentru care s-au epuizat toate cautarile), pana se ajunge la extragerea nodului A, moment in care stiva devine vida, deci algoritmul se incheie (figura 12).
|
|
|
|
Figura 9a
![]() Evolutia
stivei, corespunzator fiecarei etape a algoritmului ilustrata in
cate o figura este redata in figura urmatoare :
Evolutia
stivei, corespunzator fiecarei etape a algoritmului ilustrata in
cate o figura este redata in figura urmatoare :
|
![]()
![]()
Semnificatiile
sagetilor de intrare si iesire din stiva raman
aceleasi ca si in exemplul din capitolul anterior, adica
sageata de intrare marcheaza introducerea unui nod in stiva respectiva
etapa, iar cea de iesire marcheaza extragerea nodului in etapa
viitoare.
![]()
C B A
|
|
|||||||||||||||||
Figura 9a
![]()
![]()
|
|
|
|
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Figura 11a
Figura 12 a
Se poate testa acest exemplu cu ajutorul softului ce insoteste prezenta lucrare: GraphSearch.
Alegeti din meniul File optiunea Load;
Selectati si incarcati graful 'Ex8_gra'
Alegeti din posibilitatile de la Options traversarea in adancime;
Initiati traversarea grafului actionand StartSearch.
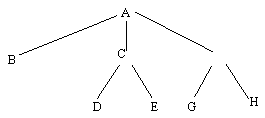
Avand in vedere ca s-a utilizat acelasi graf pentru a fi supus ambelor metode de traversare, se va face in continuare o comparatie intre cei doi arbori de cautare rezultati, pentru a justifica afirmatiile teoretice. Dupa o rearanjare a nodurilor si arcelor, cei doi arbori de cautare pot fi redati ca in figura 13 (arborele de cautare in adancime) si figura 14 (arborele de cautare prin cuprindere).
![]()
![]()
F![]()
![]()
![]()
![]() A
A
![]()
![]()
![]()
F D![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
G E
![]()
![]()
![]()
![]()
Figura 13 Figura 14
In figura 13 este redat arborele de cautare in adancime corespunzator grafului traversat. In figura 14 este redesenat arborele de cautare prin cuprindere, asa cum a rezultat el in figura 6 din capitolul precedent.
Se observa usor diferentele dintre cei doi arbori. Arborele de cautare in adancime din figura 13 se intinde pe sase nivele, toate nodurile, cu exceptia nodului C, avand un singur descendent (adica toate nodurile tind sa aiba numarul minim de descendenti posibil). Daca s-a urmarit constructia arborelui s-a observat ca in prima faza fiecarui nod, inclusiv nodului C, i s-a cautat un singur descendent, iar atunci cand acest lucru nu a mai fost posibil, s-a revenit pana la nodul C, caruia i s-a mai gasit un descendent. Apoi s-a inaintat liniar pana la nodul H.
Arborele de cautare prin cuprindere se intinde doar pe 3 nivele, iar nodurile, cu exceptia celor terminale, au cel putin doi descendenti (nodul A are trei descendenti, adica maximul posibil, el fiind adiacent in graf doar cu aceste trei noduri). Toti descendentii unui nod au fost stabiliti in momentul introducerii lor in coada.
Comparand exemplele de traversare prin cele doua tehnici prezentate, precum si structurile de date auxiliare intrebuintate, se poate usor vedea ca in cazul traversarii prin cuprindere coada memoreaza "frontiera" locurilor identificate, iar in cazul traversarii in adancime, stiva memoreaza drumul parcurs de la nodul de start pana la nodul curent.
Se poate testa acest lucru cu ajutorul softului ce insoteste prezenta lucrare: GraphSearch.
Alegeti din meniul File optiunea Load;
Selectati si incarcati graful 'Ex8_gra'
Alegeti din posibilitatile de la Options traversarea in paralel;
Initiati traversarea grafului actionand StartSearch.
Din punctul de vedere al complexitatii, algoritmul de traversare in adancime nu difera de algoritmul de traversare bazat pe cautare prin cuprindere. Fiecare nod este plasat in stiva si este extras o singura data Corpul buclei cat timp se executa de 2N ori, deoarece la o iteratie fie se adauga un nod la stiva, fie se extrage un nod din stiva, si aceasta pana cand stiva devine vida. Desi bucla cat timp se executa de mai multe ori de cat in cazul traversarii prin cuprindere, numarul operatiilor dintr-o iteratie este mai mic.
Indiferent de momentul in care se fac, testele de adiacenta si de vizitare sunt in numar de cate 2M, unde prin M s-a notat simbolic numarul de muchii ale grafului.,
In cazul algoritmului recursiv operatiile asupra stivei sunt implicite, ramanand valabile numarul testelor de adiacenta si vizitare. Numarul apelurilor recursive ale procedurii de traversare este N (cate o data pentru fiecare nod).
Traversarea unui graf, indiferent de metoda utilizata, are principial un caracter unitar. S-a vazut ca se porneste dint-un anumit nod al grafului (nodul de start) ales dupa una din principiile enuntate in paragraful 1, in functie de gradul de generalitate si abstractizare al problemei ce trebuie rezolvata. Se continua apoi cu vizitarea unui nod adiacent cu nodul de start, care este cautat dupa una din tehnicile de cautare tratate, continuandu-se cautarea pentru a determina vecini ai acestor noduri s.a.m.d.
Tehnicile de traversare se diferentiaza dupa metoda de cautare a nodurilor. A fost constatat faptul ca nodurile grafului, in orice moment al executiei unui algoritm de traversare, se pot partitiona in doua clase: clasa nevizitat si clasa vizitat (sau clasa arbore - deoarece nodurile deja vizitate sunt considerate ca facand parte din subarborele de cautare specific, care se construieste pas cu pas). In acest fel, traversarea unui graf poate fi vazuta ca o metoda de trecere a nodurilor grafului din clasa nevizitat in clasa arbore. Metodele de traversare se diferentiaza deci dupa maniera in care sunt alese nodurile care se trec din clasa nevizitat in clasa arbore. La parcurgerea grafului prin cuprindere se iau in vedere la un moment dat toti vecinii nodului curent ce nu au fost vizitati pe alte cai, construind cu acestia o structura de date coada. Intotdeauna va fi trecut in clasa arbore nodul cel mai vechi in coada, cel mai de demult intalnit. La parcurgerea in adancime se are in vedere, la un moment dat, doar un singur vecin al nodului curent, astfel ca se continua vizitarea cu unul din vecinii celui mai 'proaspat' nod vizitat. In acest scop nodurile sunt pastrate intr-o structura de date stiva.
Contrastul dintre cele doua metode este si mai evident in cazul grafurilor de dimensiuni mari. Cautarea in adancime se 'avanta' in profunzime de-a lungul muchiilor grafului, memorand in stiva posibilele puncte de ramificatie. Cautarea prin cuprindere 'matura' prin extindere radiala graful, memorand in coada frontiera locurilor deja vizitate. La cautarea in adancime graful este explorat cautand noi noduri cat mai departe de punctul de plecare, luand in considerare noduri mai apropiate doar cand nu se mai poate inainta. Cautarea prin cuprindere acopera complet zona din jurul punctului de plecare, mergand mai departe doar cand tot ceea ce a fost in imediata sa apropiere a fost vizitat.
Se observa ca atat alegerea nodului de start, comentata mai sus, precum si ordinea in care sunt selectate si introduse nodurile vecine in coada, in cazul cautarii prin cuprindere, precum si criteriul folosit la alegerea directiei de inaintare in cazul cautarii in adancime, sunt dependente de tehnica de gestionare a nodurilor grafului. Conform definirii grafului ca o structura neliniara de date, este de dorit ca aceasta tehnica de gestionare a nodurilor grafului sa nu introduca nici un fel de prioritati intre acestea. De aceea cea mai abstracta metoda de traversare ce are la baza una din tehnicile de cautare prezentate este cea in care toate nodurile grafului sunt tratate egal: ori de cate ori avem de facut vreo selectie intre doua sau mai multe noduri sa se aleaga aleator unul. Astfel, se introduce o independenta totala de implementare, dar si un grad ridicat de nedeterminare, ordinea de vizitare a nodurilor grafului fiind imprevizibila: in cazul cautarii prin cuprindere ordinea de memorare a nodurilor adiacente unui nod dat in coada este aleatoare, ceea ce duce la o 'cuprindere' nu tocmai regulata a grafului, iar in cazul cautarii in adancime, directia pe care va 'inainta' algoritmul aflat intr-un punct de ramificatie este greu de prevazut.
In multe aplicatii insa, acest factor de nedeterminare a unui algoritm general de traversare a unui graf, il face foarte greu de aplicat. De aceea multe aplicatii accepta o dependenta a algoritmului de tehnica de gestiune a nodurilor grafului si chiar de metoda de reprezentare a grafului in limbajul de programare folosit, in schimbul unui rezultat previzibil al traversarii grafului.
Anii '80 au intrat in istorie ca fiind decada in care calculul paralel a avut un impact deosebit asupra lumii stiintifice. Calculul paralel a dat o noua dimensiune constructiei de algoritmi si programe.
S-a vazut pe parcursul capitolelor anterioare ca timpul de executie al unui algoritm de traversare a unui graf este dependent atat de numarul de noduri cat si de numarul total de muchii. O abordare paralela a unei traversari ar trebui sa conduca la un timp de executie proportional cu cel mai lung lant dintre doua noduri (diametrul grafului).
In cazul tehnicii de traversare bazat pe cautarea prin cuprindere se observa ca nodurile grafului ce au fost introduse in coada raman in asteptare pana cand pentru toate nodurile dinaintea lui se initiaza un proces de cautare radiala. Acest inconvenient poate fi inlaturat prin elaborarea unui algoritm paralel de traversare a grafului bazat pe cautarea prin cuprindere, in care, fiecare nod ce a fost atins in procesul de cautare (noduri corespunzatoare cozii din algoritmul secvential) este vizitat si initiaza cate o cautare radiala independenta si in paralel cu celelalte.
Este cunoscut faptul ca nu toti algoritmii secventiali pot fi paralelizati. Un astfel de caz este si algoritmul de traversare a unui graf neorientat bazat pe cautarea in adancime.
Asadar, daca traversarea in adancime avea avantajul unei posibile implementari recursive ce conducea la simplificarea algoritmului, traversarea bazata pe cautarea prin cuprindere are avantajul de a permite paralelizarea algoritmului.
De cele mai multe ori un criteriu de alegere a unui algoritm pentru o problema data este eficienta acestuia. Deoarece algoritmii de traversare prezentati nu difera in ceea ce priveste eficienta, este necesar un alt criteriu de decizie, criteriu dependent de problema concreta ce trebuie rezolvata. De aceea s-a dorit in acest capitol sa se sublinieze particularitatile fiecareia din tehnicile de traversare prin prezentarea asemanarilor si deosebirilor dintre ele, a calitatilor si lipsurilor fiecareia.
Aplicatiile tehnicilor de traversare a grafurilor neorientate sunt numeroase, regasindu-se in multe domenii de activitate in care teoria grafurilor este aplicata cu succes: chimie, economie, studiul retelelor electrice, politica sau critica textelor.
Dintre aceste aplicatii ale traversarii grafurilor se vor prezenta in continuare unele dintre ele, care isi gasesc utilizarea chiar in teoria grafurilor sau in domeniul calculatoarelor paralele.
Una dintre aceste aplicatii deriva din insasi baza algoritmilor de traversare: cautarea unui nod. Exista tehnici speciale de cautare a unor elemente in structuri de date de tip lista sau arbore si se face des referire la ele. Insa mai putin utilizata este cautarea unui element al unei structuri de date de tip graf (nod al grafului) in vederea efectuarii unei anumite prelucrari a informatiei acestuia. In cazul listelor sau arborilor (in special cei ordonati) exista algoritmi simpli de cautare a unor elemente, efortul fiind indreptat spre ridicarea gradului de eficienta a acestora.
In cazul grafurilor, care sunt structuri neliniare de date in care nodurile nu pot fi partitionate in anumite clase ierarhice (nivelele arborilor), nu se poate vorbi de algoritmi superiori de cautare, ci doar de algoritmi de cautare derivati din algoritmii de traversare. Astfel, corespunzator celor doua metode de traversare, se pot construi doua tehnici de cautare in grafuri: cautarea prin cuprindere si cautarea in adancime. Problemele teoretice legate de aceste metode de cautare au fost expuse pe larg in paragrafele anterioare, in continuare prezentand schema generala a unui algoritm de cautare in grafuri:
Se porneste traversarea grafului cu ajutorul uneia din tehnicile prezentate anterior.
In momentul vizitarii unui nod se compara informatia acestuia cu informatia nodului ce trebuie gasit.
Algoritmul se incheie cand graful a fost in totalitate traversat (ceea ce inseamna ca nodul cautat nu se afla in graf), sau cand a fost gasit nodul cautat (in cazul in care exista certitudinea ca exista un singur nod cu informatia cautata, in caz contrar parcurgand graful in totalitate).
Este cunoscut ca un arbore este un graf conex si fara cicluri. De asemenea faptul ca nodurile unui graf neorientat oarecare, impreuna cu o parte a muchiilor pot forma intotdeauna un arbore.
Un arbore de acoperire al unui graf este un graf partial maximal al grafului dat, in sensul definitiei unui arbore (adica oricum s-ar adauga o noua muchie a grafului la acest graf partial el devine ciclic - nu mai este un arbore). O alta definire a unui arbore de acoperire a unui graf este de a-l considera drept cea mai mica colectie de muchii a grafului, care permite comunicarea intre oricare doua noduri (structura obtinuta ramane conexa), la care se adauga multimea nodurilor grafului.
Una din aplicatiile traversarii grafurilor neorientate o reprezinta determinarea unui arbore de acoperire pentru un graf dat. In prezentarea tehnicilor de traversare a grafurilor s-a facut precizarea ca fiecarei traversari a unui graf i se poate asocia un arbore de cautare. Arborii de cautare in adancime sau prin cuprindere nu sunt altceva decat arbori de acoperire pentru graful supus traversarii. Exista multi arbori de acoperire pentru un graf dat, insa metodele de traversare a grafurilor ofera tehnici riguroase de a determina doua tipuri de astfel de arbori.
Metodele de determinare a arborilor de cautare prin cuprindere, respectiv in adancime, precum si comparatia acestora a fost prezentata in capitolele anterioare, cand, odata cu traversarea grafului, a fost construit si arborele de cautare corespunzator.
Se mai poate face insa precizarea ca unei metode de traversare ii este specifica o clasa de arbori corespunzatori. Un arbore de cautare corespunzator unui graf si unei metode nu este unic, el fiind dependent de tehnica de gestionare a nodurilor sau de implementarea grafului.
In cadrul grafurilor, notiunea de conexiune joaca un rol central si ea este strans legata de notiunea de muchie si de notiunea de lant. Astfel se definesc, pornind de la aceste elemente, notiunile de graf conex, respectiv componenta conexa a unui graf. Se reaminteste ca un graf conex este acela in care pentru fiecare nod al sau exista un lant spre oricare alt nod al grafului, iar un graf neconex este format din componente conexe. Deoarece in anumite situatii, prelucrarea grafurilor este simplificata daca grafurile sunt partajate in componentele lor conexe, in continuare se va prezenta o tehnica simpla de determinare a acestor componente.
S-a vorbit mult in capitolele anterioare despre faptul ca tehnicile de traversare prezentate asigurau vizitarea tuturor nodurilor grafului doar daca graful era conex, in caz contrar vizitandu-se doar nodurile componentei conexe in care se afla nodul de start. De aceea, oricare din metodele de traversare a grafurilor poate fi utilizata pentru determinarea componentelor conexe ale unui graf. O usoara modificare a oricarui algoritm de traversare poate determina numarul si structura componentelor conexe.
O solutie in acest sens este construirea unor multimi de noduri, cate o multime pentru fiecare componenta conexa. In momentul traversarii uneia din ele, odata cu vizitarea unui nod, acesta va fi inserat in multimea corespunzatoare. La revenirea dintr-un apel al unei proceduri de traversare, daca mai exista noduri nevizitate, se initiaza o noua cautare, de data aceasta cu o alta multime de noduri.
Daca intereseaza doar numarul componentelor conexe (in particular, daca graful este conex sau nu) se poate incrementa un contor la fiecare apel al procedurii de traversare, numarul acestor apeluri fiind numarul componentelor conexe ale grafului.
O alta metoda de a determina numarul de componente conexe ale unui graf (consideram un graf de referinta cu N noduri) porneste de la urmatoarea observatie: orice arbore cu N noduri are N-1 arce (fiecare nod este conectat printr-un arc de parintele sau, mai putin nodul radacina). In urma traversarii unui graf se determina arborele de cautare si deci se cunoaste numarul arcelor sale. Daca acesta este un arbore (graful e conex) atunci numarul arcelor sale este N-1. Daca insa este o padure de arbori atunci numarul arcelor sale scazuta din N va da tocmai numarul radacinilor, adica numarul componentelor conexe ale grafului de referinta.
Aplicatiile traversarii unui graf descrise anterior au un caracter general si mai mult teoretic. Exista insa multe alte aplicatii concrete ale algoritmilor descrisi. Pentru exemplificare se poate considera un exemplu din domeniul procesarii paralele (distribuite).
Intr-un calculator paralel (retea de calculatoare) reteaua de procesoare (statiile de lucru) se poate modela cu ajutorul unui graf (de cele mai multe ori neorientat) caruia i se pot aplica diferiti algoritmi specifici. Nodurile grafului vor mapa procesoarele calculatorului paralel (sau statiile retelei), iar muchiile vor reprezenta legaturile dintre acestea.
Cea mai frecventa utilizare a unui algoritm de parcurgere a unui graf este in diferite probleme de comunicare de tip 'broadcasting'. Aceasta implica transmisia unui mesaj de la un nod (procesor / statie de lucru) sursa catre toate celelalte noduri. Acest lucru se rezolva foarte usor utilizand algoritmul de parcurgere a grafului asociat prin metoda cautarii prin cuprindere. Acesta poate fi descris astfel:
nodul initiator S trimite mesaje in paralel pe muchiile de iesire (se convine a se denumi muchii de iesire toate muchiile incidente in acel nod, mai putin cel pe care a fost primit mesajul);
dupa sosirea primului mesaj la un nod, muchia pe care a venit este marcata. Se trimite in paralel mesajul pe muchiile de iesire;
dupa sosirea unui alt mesaj decat primul, mesajul nou este trimis in ecou pe muchia pe care a venit. Daca mai multe mesaje sosesc simultan, se determina unul ca fiind 'primul';
dupa sosirea unui ecou de la un nod, muchia pe care a venit este marcata. Daca au sosit toate ecourile si nodul nu este initiator, atunci se trimite un ecou de-a lungul primei muchii. In caz contrar algoritmul se termina.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 2094
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved