| CATEGORII DOCUMENTE |
Vectori
Structura de vector ("array") este foarte folosita datorita avantajelor sale:
- Nu trebuie memorate decat datele necesare aplicatiei (nu si adrese de legatura);
- Este posibil accesul direct (aleator) la orice element dintr-un vector prin indici;
- Programarea operatiilor cu vectori este foarte simpla.
- Cautarea intr-un vector ordonat este foarte eficienta, prin cautare binara.
Dezavantajul unui vector cu dimensiune constanta rezulta din necesitatea unei estimari a dimensiunii sale la scrierea programului. Pentru un vector alocat si realocat dinamic poate apare o fragmentare a memoriei dinamice rezultate din realocari repetate pentru extinderea vectorului. De asemenea, eliminarea de elemente dintr-un vector compact poate necesita deplasarea elementelor din vector.
Prin vectori se reprezinta si anumite cazuri particulare de liste inlantuite sau de arbori pentru reducerea memoriei ocupate si timpului de prelucrare.
Ca tipuri de vectori putem mentiona:
- Vectori cu dimensiune fixa (constanta);
- Vectori extensibili ( realocabili dinamic);
- Vectori de biti (la care un element ocupa un bit);
- Vectori "heap (care reprezinta compact un arbore binar particular);
- Vectori ca tabele de dispersie.
De obicei un vector este completat in ordinea crescatoare a indicilor, fie prin adaugare la sfarsit a noilor elemente, fie prin insertie intre alte elemente existente, pentru a mentine ordinea in vector.
Exista si exceptii de la cazul uzual al vectorilor cu elemente consecutive : vectori cu interval ("buffer gap") si tabele de dispersie ("hash tables").
Un "buffer gap" este folosit in procesoarele de texte; textul din memorie este impartit in doua siruri pastrate intr-un vector ("buffer" cu text) dar separate intre ele printr-un interval plasat in pozitia curenta de editare a textului. In felul acesta se evita mutarea unor siruri lungi de caractere in memorie la modificarea textului; insertia de noi caractere in pozitia curenta mareste secventa de la inceputul vectorului si reduce intervalul, iar stergerea de caractere din pozitia curenta mareste intervalul dintre caracterele aflate inainte si respectiv dupa pozitia curenta.
Mutarea cursorului necesita mutarea unor caractere dintr-un sir in celalalt, dar numai ca urmare a unei operatii de modificare in noua pozitie a cursorului.
Caracterele sterse sau inserate sunt de fapt memorate intr-un alt vector, pentru a se putea reconstitui un text modificat din greseala (operatia "undo" de anulare a unor operatii si de revenire la o stare anterioara).
Vectorii cu dimensiune constanta, fixata la scrierea programului, se folosesc in unele situatii particulare cand limita colectiei este cunoscuta si relativ mica sau cand se doreste simplificarea programelor, pentru a facilita intelegerea lor. Alte situatii pot fi cea a unui vector de constante sau de cuvinte cheie, cu numar cunoscut de valori.
Vectori cu dimensiune fixa se folosesc si ca zone tampon la citirea sau scrierea in fisiere text sau in alte fluxuri de date.
Vectorul folosit intr-un tabel de dispersie are o dimensiune constanta (preferabil, un numar prim) din cauza modului in care este folosit (se va vedea ulterior).
Un fisier binar cu articole de lungime fixa poate fi privit ca un vector, deoarece are aceleasi avantaje si dezavantaje, iar operatiile sunt similare: adaugare la sfarsit de fisier, cautare secventiala in fisier, acces direct la un articol prin indice (pozitie relativa in fisier), sortare fisier atunci cand este nevoie, s.a. La fel ca intr-un vector, operatiile de insertie si de stergere de articole consuma timp si trebuie evitate sau amanate pe cat posibil.
Vectori ordonati
Un vector ordonat reduce timpul anumitor operatii, cum ar fi: cautarea unei valori date, verificarea unicitatii elementelor, gasirea perechii celei mai apropiate, calculul frecventei de aparitie a fiecarei valori distincte s.a.
Un vector ordonat poate fi folosit si drept coada cu prioritati, daca nu se mai fac adaugari de elemente la coada, pentru ca valoarea minima (sau maxima) se afla la una din extremitatile vectorului, de unde se poate scoate fara alte operatii auxiliare.
Mentinerea unui vector in ordine dupa fiecare operatie de adaugare sau de stergere nu este eficienta si nici nu este necesara de multe ori; atunci cand avem nevoie de o colectie dinamica permanent ordonata vom folosi un arbore binar sau o lista inlantuita ordonata. Ordonarea vectorilor se face atunci cand este necesar, de exemplu pentru afisarea elementelor sortate dupa o anumita cheie.
Pe de alta parte, operatia de sortare este eficienta numai pe vectori; nu se sorteaza liste inlantuite sau arbori neordonati sau tabele de dispersie.
Sunt cunoscuti mai multi algoritmi de sortare, care difera atat prin modul de lucru cat si prin performantele lor. Cei mai simpli si ineficienti algoritmi de sortare au o complexitate de ordinul O(n*n), iar cei mai buni algoritmi de sortare necesita pentru cazul mediu un timp de ordinul O(n*log2n), unde "n" este dimensiunea vectorului.
Uneori ne intereseaza un algoritm de sortare "stabila", care patreaza ordinea initiala a valorilor egale din vectorul sortat. Mai multi algoritmi nu sunt "stabili".
De obicei ne intereseaza algoritmii de sortare "pe loc", care nu necesita memorie suplimentara, desi exista cativa algoritmi foarte buni care nu sunt de acest tip: sortare prin interclasare si sortare prin distributie pe compartimente.
Algoritmii de sortare "pe loc" a unui vector se bazeaza pe compararea de elemente din vector, urmata eventual de schimbarea intre ele a elementelor comparate pentru a respecta conditia ca orice element sa fie mai mare ca cele precedente si mai mic ca cele care-i urmeaza.
Vom nota cu T tipul elementelor din vector, tip care suporta comparatia prin operatori ai limbajului (deci un tip numeric). In cazul altor tipuri (structuri, siruri) se vor inlocui operatorii de comparatie (si de atribuire) cu functii pentru aceste operatii.
Vom defini mai intai o functie care schimba intre ele elementele din doua pozitii date ale unui vector:
void swap (T a[ ], int i, int j)
Vom prezenta aici cativa algoritmi usor de programat, chiar daca nu au cele mai bune performante.
Sortarea prin metoda bulelor ("Bubble Sort") compara mereu elemente vecine; dupa ce se compara toate perechile vecine (de la prima catre ultima) se coboara valoarea maxima la sfarsitul vectorului. La urmatoarele parcurgeri se reduce treptat dimensiunea vectorului, prin eliminarea valorilor finale (deja sortate). Daca se compara perechile de elemente vecine de la ultima catre prima, atunci se aduce in prima pozitie valoarea minima, si apoi se modifica indicele de inceput. Una din variantele posibile de implementare a acestei metode este functia urmatoare:
void bubbleSort(T a[ ], int n)
}
Timpul de sortare prin metoda bulelor este proportional cu patratul dimensiunii vectorului (complexitatea algoritmului este de ordinul n*n).
Sortarea prin selectie determina in mod repetat elementul minim dintre toate care urmeaza unui element a[i] si il aduce in pozitia i, dupa care creste pe i.
void selSort( T a[ ], int n)
}
Sortarea
prin selectie are si ea complexitatea O(n*n), dar in
medie este mai rapida decat sortarea prin metoda bulelor (
Sortarea prin insertie considera vectorul format dintr-o partitie sortata (la inceput de exemplu) si o partitie nesortata; la fiecare pas se alege un element din partitia nesortata si se insereaza in locul corespunzator din partitia sortata, dupa deplasarea in jos a unor elemente pentru a crea loc de insertie.
void insSort (T a[ ], int n)
a[j+1]=x; // muta pe x in pozitia j+1
}
}
Nici sortarea prin insertie nu este mai buna de O(n*n) pentru cazul mediu si cel mai nefavorabil, dar poate fi imbunatatita prin modificarea distantei dintre elementele comparate. Metoda cu increment variabil (ShellSort) se bazeaza pe ideea (folosita si in sortarea rapida QuickSort) ca sunt preferabile schimbari intre elemente aflate la distanta mai mare in loc de schimbari intre elemente vecine; in felul acesta valori mari aflate initial la inceputul vectorului ajung mai repede in pozitiile finale, de la sfarsitul vectorului.
Algoritmul lui Shell are in cazul mediu complexitatea de ordinul n1.25 si in cazul cel mai rau O(n1.5), fata de O(n2) pentru sortare prin insertie cu pas 1.
In functia urmatoare se folosesc rezultatele unor studii pentru determinarea valorii initiale a pasului h, care scade apoi prin impartire succesiva la De exemplu, pentru n > 100 pasii folositi vor fi 13,4 si 1.
void shellSort(T a[ ], int n)
// sortare prin insertie cu increment h variabil
while (h > 0)
h /= 3; // urmatorul increment
}
}
Vectori alocati dinamic
Putem distinge doua situatii de alocare dinamica pentru vectori:
- Dimensiunea vectorului este cunoscuta de program inaintea valorilor ce trebuie memorate in vector si nu se mai modifica pe durata executiei programului; in acest caz este suficienta o alocare initiala de memorie pentru vector ("malloc").
- Dimensiunea vectorului nu este cunoscuta de la inceput sau numarul de elemente poate creste pe masura ce programul evolueaza; in acest caz este necesara extinderea dinamica a tabloului (se apeleaza repetat 'realloc').
In limbajul C nu exista nici o diferenta intre utilizarea unui vector alocat dinamic si utilizarea unui vector cu dimensiune constanta, iar functia 'realloc' simplifica extinderea (realocarea) unui vector dinamic cu pastrarea datelor memorate. Exemplu de ordonare a unui vector de numere folosind un vector alocat dinamic.
// comparatie de intregi - pentru qsort
int intcmp (const void * p1, const void * p2)
// citire - sortare - afisare
void main ()
In aplicatiile care prelucreaza cuvintele distincte dintr-un text, numarul acestor cuvinte nu este cunoscut si nu poate fi estimat, dar putem folosi un vector realocat dinamic care se extinde atunci cand este necesar. Exemplu:
// cauta cuvant in vector
int find ( char ** tab, int n, char * p)
#define INC 100
void main ()
tab[n++]=pc; // adauga la vector adresa cuvant
}
}
}
Functia 'realloc' primeste ca argumente adresa vectorului ce trebuie extins si noua sa dimensiune si are ca rezultat o alta adresa pentru vector, unde s-au copiat automat si datele de la vechea adresa. Aceasta functie este apelata atunci cand se cere adaugarea de noi elemente la un vector plin (in care nu mai exista pozitii libere).
Utilizarea functiei 'realloc' necesita memorarea urmatoarelor informatii despre vectorul ce va fi extins: adresa vector, dimensiunea alocata (maxima) si dimensiunea efectiva. Cand dimensiunea efectiva ajunge egala cu dimensiunea maxima, atunci devine necesara extinderea vectorului. Extinderea se poate face cu o valoare constanta sau prin dublarea dimensiunii curente sau dupa alta metoda.
Exemplul urmator arata cum se pot incapsula in cateva functii operatiile cu un vector alocat si apoi extins dinamic, fara ca alocarea si realocarea sa fie vizibile pentru programul care foloseste aceste subprograme.
#define INC 100 // increment de exindere vector
typedef int T; // tip componente vector
typedef struct Vector;
// initializare vector v
void initV (Vector & v)
// adaugare obiect x la vectorul v
void addV ( Vector & v, T x)
v.vec[v.dim]=x; v.dim ++;
}
Exemplu de program care genereaza si afiseaza un vector de numere:
void main()
Timpul necesar pentru cautarea intr-un vector neordonat este de ordinul O(n), deci proportional cu dimensiunea vectorului. Intr-un vector ordonat timpul de cautare este de ordinul O(lg n). Adaugarea la sfarsitul unui vector este imediata ( are ordinul O(1)) iar eliminarea dintr-un vector compact necesita mutarea in medie a n/2 elemente, deci este de ordinul O(n).
Aplicatie : Componente conexe
Aplicatia poate fi formulata cel putin in doua moduri si a condus la aparitia unui tip abstract de date, numit colectie de multimi disjuncte ("Disjoint Sets").
Fiind data o multime de valori (de orice tip) si o serie de relatii de echivalenta intre perechi de valori din multime, se cere sa se afiseze clasele de echivalenta formate cu ele. Daca sunt n valori, atunci numarul claselor de echivalenta poate fi intre 1 si n, inclusiv.
Exemplu de date initiale (relatii de echivalenta):
~ 80 / 10 ~ 60 /
Rezultatul (clasele de echivalenta , ,
O alta formulare a problemei cere afisarea componentelor conexe dintr-un graf neorientat definit printr-o lista de muchii. Fiecare muchie corespunde unei relatii de echivalenta intre varfurile unite de muchie, iar o componenta conexa este un subgraf (o clasa de noduri ) in care exista o cale intre oricare doua varfuri. Exemplu:
1
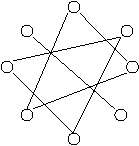
2
6 4
5
In cazul particular al componentelor conexe dintr-un graf, este suficient un singur vector "cls", unde cls[k] este componenta in care se afla varful k.
In cazul mai general al claselor de echivalenta ce pot contine elemente de orice tip (numere oarecare sau siruri ce reprezinta nume), mai este necesar si un vector cu valorile elementelor. Pentru exemplul anterior cei doi vectori pot arata in final astfel (numerele de clase pot fi diferite):
val 10 20 30 40 50 60 70 80
cls 1 2 1 3 2 1 2 3
Vectorii val, cls si dimensiunea lor se reunesc intr-un tip de date numit "colectie de multimi disjuncte", pentru ca fiecare clasa de echivalenta este o multime, iar aceste multimi sunt disjuncte intre ele.
typedef struct ds;
Pentru memorarea unor date agregate intr-un vector avem doua posibilitati:
- Mai multi vectori paraleli, cu aceeasi dimensiune; cate un vector pentru fiecare camp din structura (ca in exemplul anterior).
- Un singur vector de structuri:
typedef struct entry;
typedef struct ds;
S-au stabilit urmatoarele operatii specifice tipului abstract "Disjoint Sets":
- Initializare colectie (initDS)
- Gasirea multimii (clasei) care contine o valoare data (findDS)
- Reunire multimi (clase) ce contin doua valori date (unifDS)
- Afisare colectie de multimi (printDS)
La citirea unei perechi de valori (unei relatii de echivalenta) se stabileste pentru cele doua valori echivalente acelasi numar de clasa, egal cu cel mai mic dintre cele doua (pentru a mentine ordinea in fiecare clasa).
Daca valorile sunt chiar numerele 1 ,..8 atunci evolutia vectorului de clase dupa fiecare pereche de valori citita va fi
clase
initial 1 2 3 4 5 6 7 8
dupa 1 2 3 4 5 3 7 8
dupa 1 2 3 4 5 3 5 8
dupa 1 2 1 4 5 1 5 8
dupa 1 2 1 4 2 1 2 8
dupa 1 2 1 4 2 1 2 4
dupa 1 2 1 4 2 1 2 4 (nu se mai modifica nimic)
Urmeaza un exemplu de implementare cu un singur vector a tipului "Colectie de multimi disjuncte" si utilizarea sa in problema afisarii componentelor conexe.
typedef struct ds;
// determina multimea in care se afla x
int find ( ds c, int x)
// reunire multimi ce contin valorile x si y
void unif ( ds & c,int x,int y)
// afisare multimi din colectie
void printDS (ds c)
if (m) // daca exista valori in multimea i
printf('n'); // se trece pe alta linie
}
}
// initializare multimi din colectie
void initDS (ds & c, int n)
// afisare componente conexe
void main ()
In aceasta implementare operatia "find" are un timp constant O(1), dar operatia de reuniune este de ordinul O(n).
Cea mai buna implementare pentru "Disjoint Sets" foloseste tot un singur vector de intregi, dar acest vector reprezinta o padure de arbori. Elementele vectorului sunt indici (adrese) din acelasi vector cu semnificatia de pointeri catre nodul parinte. Fiecare multime este un arbore in care fiecare nod (element) contine o legatura la parintele sau, dar nu si legaturi catre fii sai. Radacina fiecarui arbore poate contine ca legatura la parinte fie chiar adresa sa, fie o valoare nefolosita ca indice (- .
Pentru datele folosite anterior (8 varfuri in 3 componente conexe), starea finala a vectorului ce reprezinta colectia si arborii corespunzatori pot arata astfel:
valoare
legatura
1 2 4
| | |
3 5 8
| |
6 7
In functie de codul folosit sunt posibile si alte variante, dar tot cu trei arbori si cu aceleasi noduri (se modifica doar radacina si structura arborilor).
Daca se mai adauga o muchie 3-7 atunci se reunesc arborii cu radacinile in 1 si 2 intr-un singur arbore, iar in vectorul ce reprezinta cei doi arbori ramasi se modifica legatura lui 2 (p[2]=1).
/ |
3 2 8
6 5
7
Gasirea multimii care contine o valoare data x se reduce la aflarea radacinii arborelui in care se afla x, mergand in sus de la x catre radacina. Reunirea arborilor ce contin un x si un y se face prin legarea radacinii arborelui y ca fiu al radacinii arborelui x (sau al arborelui lui x la arborele lui y).
Urmeaza functiile ce realizeaza operatiile specifice tipului "Disjoint Sets":
typedef struct ds;
// initializare colectie
void init (ds & c, int n)
// determina multimea care contine pe x
int find ( ds c, int x)
// reunire clase ce contin valorile x si y
void unif ( ds & c,int x,int y)
In aceasta varianta operatia de cautare are un timp proportional cu adancimea arborelui, iar durata operatiei de reuniune este practic aceeasi cu durata lui "find". Pentru reducerea in continuare a duratei operatiei "find" s-au propus metode pentru reducerea adancimii arborilor. Modificarile au loc in algoritm, dar structura de date ramane practic neschimbata (tot un vector de indici catre noduri parinte).
5 Aplicatie: compresia LZW
Metoda de compresie LZW (Lempel-Ziv-Welch), in diferite variante, este cea mai folosita metoda de compresie a datelor deoarece nu necesita informatii prealabile despre datele comprimate (este o metoda adaptiva) si este cu atat mai eficace cu cat fisierul initial este mai mare si contine mai multa redundanta.
Pentru texte scrise in engleza sau in romana rezultatele sunt foarte bune doarece ele folosesc in mod repetat anumite cuvinte uzuale, care vor fi inlocuite printr-un cod asociat fiecarui cuvant.
Metoda LZW este folosita de multe programe comerciale (gzip, unzip, s.a.) precum si in formatul GIF de reprezentare (compacta) a unor imagini grafice.
Metoda foloseste un dictionar prin care asociaza unor siruri de caractere de diferite lungimi coduri numerice intregi si inlocuieste secvente de caractere din fisierul initial prin aceste numere. Acest dictionar este cercetat la fiecare nou caracter extras din fisierul initial si este extins de fiecare data cand se gaseste o secventa de caractere care nu exista anterior in dictionar.
Pentru decompresie se reface dictionarul construit in etapa de compresie; deci dictionarul nu trebuie transmis impreuna cu fisierul comprimat.
Dimensiunea uzuala a dictionarului este 4096, dintre care primele 256 de pozitii contin toate caracterele individuale ce pot apare in fisierele de comprimat.
Din motive de eficienta pot exista diferente importante intre descrierea principiala a metodei LZW si implementarea ei in practica; astfel, sirurile de caractere se reprezinta tot prin numere, iar codurile asociate pot avea lungimi diferite.
Se poate folosi un dictionar format dintr-un singur vector de siruri (pointeri la siruri), iar codul asociat unui sir este chiar pozitia in vector unde este memorat sirul.
Sirul initial (de comprimat) este analizat si codificat intr-o singura trecere, fara revenire. La stanga pozitiei curente sunt subsiruri deja codificate, iar la dreapta cursorului se cauta cea mai lunga secventa care exista deja in dictionar. Odata gasita aceasta secventa, ea este inlocuita prin codul asociat deja si se adauga la dictionar o secventa cu un caracter mai lunga.
Pentru exemplificare vom considera ca textul de codificat contine numai doua caractere ('a' si 'b') si arata astfel (sub text sunt trecute codurile asociate secventelor respective):
a b b a a b b a a b a b b a a a a b a a b b a
0 | 1| 1| 0 | 4 | 2 | 6 | 5 | 5 | 7 | 3 | 0
Dictionarul folosit in acest exemplu va avea in final urmatorul continut:
0=a / 1=b / 2=0b (ab) / 3=1b (bb) / 4=1a (ba) / 5=0a (aa) / 6=2b (abb) / 7=4a (baa)
8=2a (aba) / 9=6a (abba) / 10=5a (aaa) / 11=5b (aab) / 12=7b (baab) / 13=3a (bba)
Intr-o varianta putin modificata se asociaza codul 0 cu sirul nul, dupa care toate secventele de unul sau mai multe caractere sunt codificate printr-un numar intreg si un caracter:
1=0a / 2=0b / 3=1b (ab) / 4=2b (bb) / 5=2a (ba) /
Urmeaza o descriere posibila pentru algoritmul de compresie LZW:
initializare dictionar cu n coduri de caractere individuale
w = NIL; k=n // w este un cuvant (o secventa de caractere)
repeta cat timp mai exista caractere neprelucrate
citeste un caracter c
daca w+c exista in dictionar // '+' pentru concatenare de siruri
w = w+c // prelungeste secventa w cu caracterul c
altfel
adauga wc la dictionar cu codul k=k+1
scrie codul lui w
w = c
Este posibila si urmatoarea formulare a algoritmului de compresie LZW:
initializare dictionar cu toate secventele de lungime 1
repeta cat timp mai sunt caractere
cauta cea mai lunga secventa de car. w care apare in dictionar
scrie pozitia lui w in dictionar
adauga w plus caracterul urmator la dictionar
Aplicarea acestui algoritm pe sirul "abbaabbaababbaaaabaabba" conduce la secventa de pasi rezumata in tabelul urmator:
w c w+c k scrie (cod w)
nul a a
a b ab 2=ab 0 (=a)
b b bb 3=bb 1 (=b)
b a ba 4=ba 1 (=b)
a a aa 5=aa 0 (=a)
a b ab
ab b abb 6=abb 2 (=ab)
b a ba
ba a baa 7=baa 4 (=ba)
a b ab
ab a aba 8=aba 2 (=ab)
a b ab
ab b abb
abb a abba 9=abba 6 (=abb)
a a aa
aa a aaa 10=aaa 5 (=aa)
a a aa
aa b aab 11=aab 5 (=aa)
b a ba
ba a baa
baa b baab 12=baab 7 (=baa)
b b bb
bb a bba 13=bba 3 (=bb)
a - a 0 (=a)
In exemplul urmator codurile generate sunt afisate pe ecran:
// cauta un sir in vector de siruri
int find (char w[], char d[][8], int n)
// functie de codificare a unui sir dat
void compress (char * in) ;
char * p=in; // adresa caracter in sirul de codificat
int k;
// initializare dictionar
strcpy(dic[0],'a');
strcpy(dic[1],'b');
// ciclul de cautare-adaugare in dictionar
k=2; // dimensiune dictionar (si prima pozitie libera)
while (*p)
p++; // avans la caracterul urmator din sir
Dimensiunea dictionarului se poate reduce daca folosim drept chei 'w' intregi mici ("short") obtinuti din codul k si caracterul 'c' adaugat la secventa cu codul k.
Timpul de cautare in dictionar se poate reduce folosind un tabel "hash" sau un arbore in locul unui singur vector, dar cu un consum suplimentar de memorie.
Rezultatul codificarii este un sir de coduri numerice, cu mai putine elemente decat caractere in sirul initial, dar castigul obtinut depinde de marimea acestor coduri; daca toate codurile au aceeasi lungime (de ex 12 biti pentru 4096 de coduri diferite) atunci pentru un numar mic de caractere in sirul initial nu se obtine nici o compresie (poate chiar un sir mai lung de biti). Compresia efectiva incepe numai dupa ce s-au prelucrat cateva zeci de caractere din sirul analizat.
La decompresie se analizeaza un sir de coduri numerice, care pot reprezenta caractere individuale sau secvente de caractere. Cu ajutorul dictionarului se decodifica fiecare cod intalnit. Urmeaza o descriere posibila pentru algoritmul de decompresie LZW:
initializare dictionar cu codurile de caractere individuale
citeste primul cod k;
w = sirul din pozitia k a dictionarului;
repeta cat timp mai sunt coduri
citeste urmatorul cod k
cauta pe k in dictionar si extrage valoarea asociata c
scrie c in fisierul de iesire
adauga w + c[0] la dictionar
w = c
Dictionarul are aceeasi evolutie ca si in procesul de compresie (de codificare).
void decompress (int cod[], int n) ,c[2]=;
int i,k;
// initializare dictionar
strcpy(dic[0],'a');
strcpy(dic[1],'b');
k=2;
printf('%s|',dic[0]); // caracterul cu primul cod
strcpy(w,dic[0]); // w=dic[k]
for (i=1;i<n;i++)
}
Codurile generate de algoritmul LZW pot avea un numar variabil de biti, iar la decompresie se poate determina numarul de biti in functia de dimensiunea curenta a dictionarului. Dictionarul creat poate fi privit ca un arbore binar completat nivel cu nivel, de la stanga la dreapta:
![]()
0 1
a b
![]()
![]() 10 11
10 11
![]()
![]()
![]()
![]() ab bb
ab bb
100 101 110 111
![]()
![]()
![]()
![]()
![]()
![]() ba aa abb baa
ba aa abb baa
aba abba aaa aab baab bba
Notand cu k nivelul din arbore, acelasi cu dimensiunea curenta a dictionarului, se observa ca numarul de biti pe acest nivel este log2(k) +1
6 Vectori multidimensionali (Matrice)
O matrice bidimensionala poate fi memorata in cateva moduri:
- Ca un vector de vectori. Exemplu :
char a[20][20]; // a[i] este un vector
- Ca un vector de pointeri la vectori. Exemplu:
char* a[20]; // sau char ** a;
- Ca un singur vector ce contine elementele matricei, fie in ordinea liniilor, fie in ordinea coloanelor.
Matricele alocate dinamic sunt vectori de pointeri la liniile matricei.
Pentru comparatie vom folosi o functie care ordoneaza un vector de nume (de siruri) si functii de citire si afisare a numelor memorate si ordonate.
Prima forma (vector de vectori) este cea clasica, posibila in toate limbajele de programare, si are avantajul simplitatii si claritatii operatiilor de prelucrare.
De remarcat ca numarul de coloane al matricei transmise ca argument trebuie sa fie o constanta, aceeasi pentru toate functiile care lucreaza cu matricea.
#define M 30 // nr maxim de caractere intr-un sir
// ordonare siruri
void sort ( char vs[][M], int n)
// citire siruri in matrice
int citmat ( char vs[][M] )
// afisare matrice cu siruri
void scrmat (char vs[][M],int n)
O matrice alocata dinamic este de fapt un vector alocat dinamic ce contine pointeri la vectori alocati dinamic (liniile matricei). Liniile matricei pot avea toate aceeasi lungime sau pot avea lungimi diferite. Exemplu cu linii de lungimi diferite :
// ordonare vector de pointeri la siruri
void sort ( char * vp[],int n)
// citire siruri si creare vector de pointeri
int readstr (char * vp[])
return n;
// afisare siruri reunite in vector de pointeri
void printstr ( char * vp[], int n)
In exemplul anterior am presupus ca vectorul de pointeri are o dimensiune fixa si este alocat in functia "main".
Daca se cunoaste de la inceput numarul de linii si de coloane, atunci putem folosi o functie care aloca dinamic memorie pentru matrice. Exemplu:
// alocare memorie pentru o matrice de intregi
// rezultat adresa matrice sau NULL
int * * intmat ( int nl, int nc)
Utilizarea unui singur vector pentru a memora toate liniile unei matrice face mai dificila selectarea de elemente din matrice (prin indici de linie si coloana) si chiar sortarea liniilor (de lungime fixa).
7 Vectori de biti
Atunci cand elementele unui vector sau unei matrice au valori binare este posibila o memorare mai compacta, folosind cate un singur bit pentru fiecare element din vector. Exemplul clasic este al matricelor de adiacente prin care se reprezinta grafuri de relatii (fara costuri asociate muchiilor); elementul a[i j] arata prezenta (1) sau absenta (0) unei muchii intre varfurile i si j.
In exemplul urmator matricea de adiacenta este un vector de biti, obtinut prin memorarea succesiva a liniilor din matrice. Functia "getbit" arata prezenta sau absenta unui arc de la nodul i la nodul j (graful este orientat). Functia "setbit" permite adaugarea sau eliminarea de arce la/din graf. Nodurile sunt numerotate de la 1.
typedef struct graf;
// elementul [i j] din matrice graf primeste valoarea val (0 sau 1)
void setbit (graf & g, int i, int j, int val)
// valoare element [i j] din matrice graf
int getbit (graf g, int i, int j )
// citire date si creare matrice graf
void citgraf (graf & g ) while (1);
// afisare matr de adiacente graf
void scrgraf (graf g)
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 1635
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2026 . All rights reserved