| CATEGORII DOCUMENTE |
Registrii (sau registrele) microprocesorului reprezinta locatii de memorie speciale aflate direct pe cip; din aceasta cauza reprezinta cel mai rapid tip de memorie. Alt lucru deosebit legat de registri este faptul ca fiecare dintre acestia au un scop bine precizat, oferind anumite functionalitati speciale, unice. Exista patru mari categorii de registri: registrii de uz general, registrul indicatorilor de stare (flags), registrii de segment si registrul pointer de instructiune.
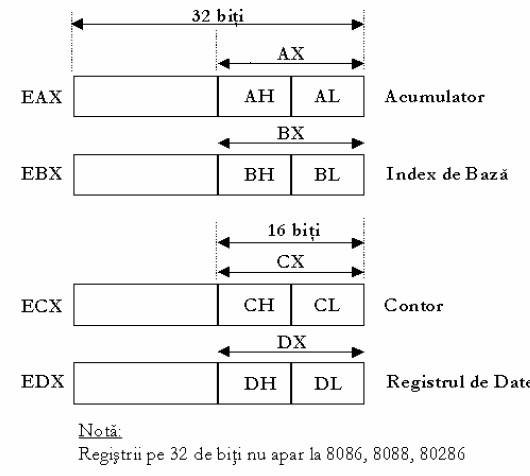
Fig. Registrii de uz general - acumulator, index de baza, contor si de date
contorizare. Fiecare
dintre cei 8 registrii de uz general AX, BX, CX, DX, SP, BP, DI,SI sunt
registrii pe 16 biti pentru microprocesorul 8086, iar de la procesorul 80386
incoace au devenit registrii pe 32 de biti, denumiti, respectiv: EAX, EBX, ECX,
EDX,
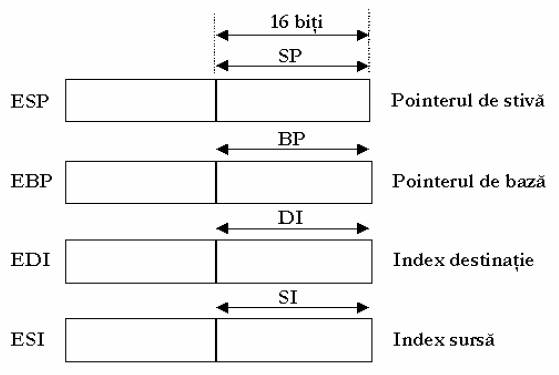
Fig. Registrii de uz general index si pointer
Ne vom concentra in continuare atentia asupra registrilor generali pe 16 biti; fiecare dintre acestia poate stoca o valoare pe 16 biti, poate fi folosit pentru stocarea unei valori din memorie sau poate fi utilizat pentru operatii aritmetice si logice. Spre exemplu, urmatoarele instructiuni:
MOV BX, 2
MOV DX, 3
ADD BX, DX
Incarca valoarea 2 in registrul BX, valoarea 3 in registrul DX, aduna cele doua valori iar rezultatul (5) este memorat in registrul BX. In exemplul anterior putem utiliza oricare dintre registrii de uz general in locul registrilor BX si DX. In afara proprietatii de a stoca valori si de a folosi drept operanzi sursa sau destinatie pentru instructiunile de manipulare a datelor, fiecaredintre cei opt registri de uz general au propria "personalitate". Vom vedea in continuare care sunt caracteristicile specifice fiecaruia dintre registrii de uz general.
Registrul AX (EAX)
Registrul AX (EAX) este denumit si registrul acumulator,
fiind principalul registru de uz general utilizat pentru operatii aritmetice,
logice si de deplasare de date. Totdeauna operatiile de inmultire si impartire
presupun implicarea registrului AX. Unele dintre instructiuni sunt optimizate
pentru a se executa mai rapid atunci cand este folosit AX. In plus, registrul
AX este folosit si pentru toate transferurile de date de la/catre porturile de
Intrare/Iesire. Poate fi accesat pe portiuni de 8, 16 sau 32 de biti, fiind
referit drept
Prezentam in continuare alte cateva exemple de instructiuni ce utilizeaza registrul AX. De remarcat este faptul ca transferurile de date se fac pentru instructiunile (denumite si mnemonice) Intel de la dreapta spre stanga, exact invers decat la Motorola, unde transferul se face de la stanga la dreapta.
Instructiunea: MOV AX, 1234H incarca valoarea
1234H (4660 in zecimal) in registrul acumulator AX. Dupa cum spuneam, cei mai
putini semnificativi 8 biti ai registrului AX sunt identificati de AL (A-Low)
iar cei mai semnificativi 8 biti ai aceluiasi registru sunt identificati ca
fiind AH (A-High). Acest lucru este utilizat pentru a lucra cu date pe un
octet, permitand ca registrul AX sa fie folosit pe postul a doi registri
separati (AH si
MOV AH, 1
INC AH
MOV
Valoarea finala a registrului AX va fi 22 (AH =
Registrul BX (EBX)
Registrul BX (Base), sau registrul de baza poate stoca adrese pentru a face referire la diverse structuri de date, cum ar fi vectorii stocati in memorie. O valoare reprezentata pe 16 biti stocata in registrul BX poate fi utilizata ca fiind o portiune din adresa unei locatii de memorie ce va fi accesata. Spre exemplu, urmatoarele instructiuni incarca registrul AH cu valoarea din memorie de la adresa 21.
MOV AX, 0
MOV DS, AX
MOV BX, 21
MOV AH, [ BX ]
Se observa ca am incarcat valoarea 0 in registrul DS inainte de a accesa locatia de memorie referita de registrul BX. Acest lucru este datorat segmentarii memoriei (segmentare discutata mai in detaliu in sectiunea consacrata registrilor de segment); implicit, atunci cand este folosit ca pointer de memorie, BX face referire relativa la registrul de segment DS
adresa la care face referire este o adresa relativa la adresa de segment continuta in registrul DS).
Registrul CX (ECX)
Specializarea registrului CX (Counter) este numararea; de aceea, el se numeste si registrul contor. De asemenea, registrul CX joaca un rol special atunci cand se foloseste instructiunea LOOP. Rolul de contor al registrului CX se observa imediat din exemplul urmator:
MOV CX, 5
start:
<instructiuni ce se vor executa de 5 ori>
Deoarece valoarea initiala a lui CX este 5,
instructiunile cuprinse intre eticheta start si instructiunea JNZ se vor
executa de 5 ori (pana cand registrul CX devine 0). Instructiunea
In limbajul microprocesorului exista si o instructiune
speciala legata de ciclare. Aceasta este instructiunea
MOV CX, 5
start:
<instructiuni ce se vor executa de 5 ori>
Se observa ca instructiunea LOOP este folosita in
locul celor doua instructiuni
Registrul DX (EDX)
Registrul de uz general DX (Data register), denumit si
registrul de date, poate fi folosit in cazul transferurilor de date
Intrare/Iesire sau atunci cand are loc o operatie de inmultire sau de
impartire. Instructiunea IN
in portul I/O 1002:
MOV AL, 101MOV DX, 1002
OUT
Referitor la operatiile de inmultire si impartire, atunci cand impartim un numar pe 32 de biti la un numar pe 16 biti, cei mai semnificativi 16 biti ai deimpartitului trebuie sa fie in DX. Dupa impartire, restul impartirii se va afla in DX. Cei mai putin semnificativi 16 biti ai deimpartitului trebuie sa fie in AX iar catul impartirii va fi in AX. La inmultire, atunci cand se
inmultesc doua numere pe 16 biti, cei mai semnificativi 16 biti ai produsului vor fi stocati in DX iar cei mai putin semnificativi 16 biti in registrul AX.
Registrul SI
Registrul SI (Source Index) poate fi folosit, ca si BX, pentru a referi adrese de memorie. De exemplu, secventa de instructiuni urmatoare:
MOV AX, 0
MOV DS, AX
MOV SI, 33
MOV AL, [ SI ]
Incarca valoarea (pe 8 biti) din memorie de la adresa 33 in registrul AL. Registrul SI este, de asemenea, foarte folositor atunci cand este utilizat in legatura cu instructiunile dedicate tipului STRING (sir de caractere).
Secventa urmatoare :
CLD
MOV AX, 0
MOV DS, AX
MOV SI, 33
LODSB
nu numai ca incarca registrul AX cu valoarea de la adresa de memorie referita de registrul SI, dar aduna, de asemenea, valoarea 1 la SI. Acest lucru este deosebit de eficient atunci cand se acceseaza secvential o serie de locatii de memorie, cum ar fi sirurile de caractere. Instructiunile de tip STRING se pot repeta de mai multe ori, astfel incat o singura instructiune
poate avea ca efect sute sau mii de operatii.
Registrul DI
Registrul DI (Destination Index) este utilizat in mod asemanator registrului SI. In secventa de instructiuni urmatoare:
MOV AX, 0
MOV DS, AX
MOV DI, 1000
ADD BL, [ DI ]
se aduna la registrul BL valoarea pe 8 biti stocata la adresa 1000. Registrul DI este putin diferit fata de registrul SI in cazul instructiunilor de tip string; daca SI este intotdeauna pe post de pointer sursa de memorie, registrul DI serveste drept pointer destinatie de memorie. Mai mult, in cazul instructiunilor de tip string, registrul SI adreseaza memoria relativ la
registrul de segment DS, in timp ce DI contine referiri la memorie relativ la registrul de segment ES. In cazul in care SI si DI sunt utilizati cu alte instructiuni, ei fac referire la registrul de segment DS.
Registrul BP
Pentru a intelege mai bine rolul registrilor BP si SP, a sosit momentul sa spunem cateva lucruri despre portiunea de memorie denumita stiva (in engleza stack). Stiva reprezinta o portiune speciala de locatii adiacente din memorie. Aceasta este continuta in cadrul unui segment de memorie si identificata de un selector de segment memorat in registrul
SS (cu exceptia cazului in care se foloseste modelul nesegmentat de memorie in care stiva poate fi localizata oriunde in spatiul de adrese liniare al programului). Stiva este o portiune a memoriei unde valorile pot fi stocate si accesate pe principul LIFO (Last In - First Out), drept urmare ultima valoare stocata in stiva este prima ce va fi citita din stiva. De regula, stiva
este utilizata la apelul unei proceduri sau la intoarcerea dintr-un apel de procedura (principalele instructiuni folosite sunt CALL si RET).
Registrul pointer de baza, BP (Base Pointer) poate fi utilizat ca pointer de
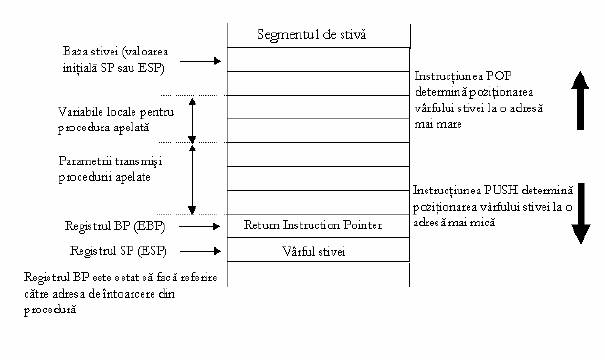 Fig. Structura
stivei
Fig. Structura
stivei
Registrul pointer de baza, BP (Base Pointer) poate fi utilizat ca pointer de memorie precum registrii BX, SI si DI. Diferenta este aceea ca, daca BX, SI si DI sunt utilizati in mod normal ca pointeri de memorie relativ la segmentul DS, registrul BP face referire relativ la segmentul de stiva SS. Principiul este urmatorul: o modalitate de a trece parametrii unei subrutine este aceea de a utiliza stiva (acest lucru se intampla in mod obisnuit in limbajele de nivel inalt, C sau Pascal, spre exemplu). Daca stiva se afla in portiunea de memorie referita de registrul de segment SS (Stack Segment), datele se afla in mod normal in segmentul de memorie referit de
catre DS, registrul segment de date. Deoarece BX, SI si DI se refera la segmentul de date, nu exista o modalitate eficienta de a folosi registrii BX, SI, DI pentru a face referire la parametrii salvati in stiva din cauza ca stiva este localizata intr-un alt segment de memorie. Registrul BP ofera rezolvarea acestei probleme asigurand adresarea in segmentul de stiva. Spre exemplu, instructiunile:
PUSH BP
MOV BP, SP
MOV AX, [ BP+4 ]
fac sa se acceseze segmentul de stiva pentru a incarca registrul AX cu primul parametru trimis de un apel C unei rutine scrise in limbaj de asamblare. In concluzie, registrul BP este conceput astfel incat sa ofere suport pentru accesul la parametri, variabile locale si alte necesitati legate de accesul la portiunea de stiva din memorie.
Registrul SP
Registrul SP (Stack Pointer), sau pointerul de stiva, retine de regula adresa de deplasament a urmatorului element disponibil in cadrul segmentului de stiva. Acest registru este, probabil, cel mai putin "general" dintre registrii de uz general, deoarece este dedicat mai tot timpul
administrarii stivei.
Registrul BP face in fiecare clipa referire la varful
stivei - acest varf al stivei reprezinta adresa locatiei de memorie in care va
fi introdus urmatorul element in stiva. Actiunea de a introduce un nou element
in stiva se numeste "impingere" (in engleza push);
de aceea, instructiunea respectiva poarta numele de PUSH. In mod asemanator,
operatia de scoatere a unui element din varful stivei poarta, in engleza,
numele de pop, iar instructiunea echivalenta operatiei se numeste
Este permisa stocarea valorilor in registrul SP precum si modificarea valorii sale prin adunare sau scadere la fel ca si in cazul celorlalti registri de uz general; totusi, acest lucru nu este recomandat daca nu suntem foarte siguri de ceea ce facem. Prin modificarea registrului SP, vom modifica adresa de memorie a varfului stivei, ceea ce poate avea efecte neprevazute,
aceasta pentru ca
instructiunile PUSH si
Indiferent daca
apelam o subrutina sau ne intoarcem dintr-un astfel de apel de subrutina, fie
procedura sau functie, in acest caz este folosita stiva. Unele resurse de
sistem, precum tastatura sau ceasul de sistem, pot folosi stiva in momentul
trimiterii unei intreruperi la microprocesor. Acest lucru presupune ca stiva
este folosita continuu, deci daca se modifica registrul SP (adica adresa
stivei), datele din noile locatii de memorie nu vor mai fi cele corecte. In
concluzie, registrul SP nu trebuie modificat in mod direct; el este modificat
automat in urma instructiunilor
Registrul pointer de instructiuni este folosit, intotdeauna, pentru a stoca adresa urmatoarei
instructiuni ce va fi executata de catre microprocesor. Pe masura ce o instructiune este executata, pointerul de instructiune este incrementat si se va referi la urmatoarea adresa de memorie (unde este stocata urmatoarea instructiune ce va fi executata). De regula, instructiunea ce urmeaza a fi executata se afla la adresa imediat urmatoare instructiunii ce a fost executata, dar exista si cazuri speciale (rezultate fie din apelul unei subrutine prin instructiunea CALL, fie prin intoarcerea dintr-o subrutina, prin instructiunea RET). Pointerul de instructiuni nu poate fi modificat sau citit in mod direct; doar instructiuni speciale pot incarca acest registru cu o noua valoare. Registrul pointer de instructiune nu specifica pe de-a intregul adresa din memorie a urmatoarei instructiuni ce va fi executata, din aceeasi cauza a segmentarii memoriei. Pentru a aduce o instructiune din memorie, registrul CS ofera o adresa de baza iar registrul pointer de instructiuneindica adresa de deplasament plecand de la aceasta adresa de baza.
Fig. Registrii de segment, pointerul de instructiuni si registrul
indicatorilor de stare
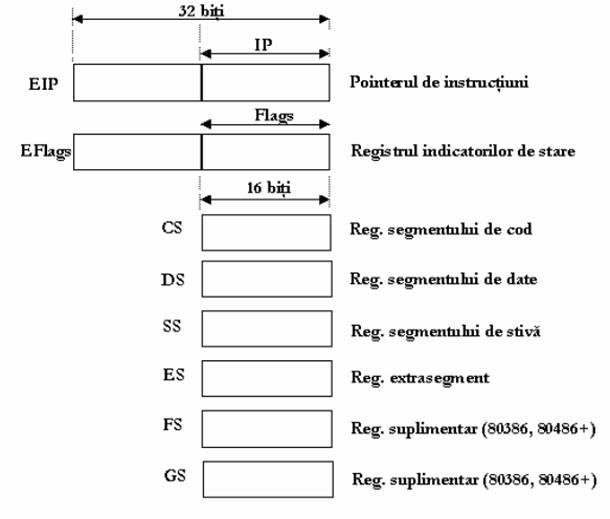
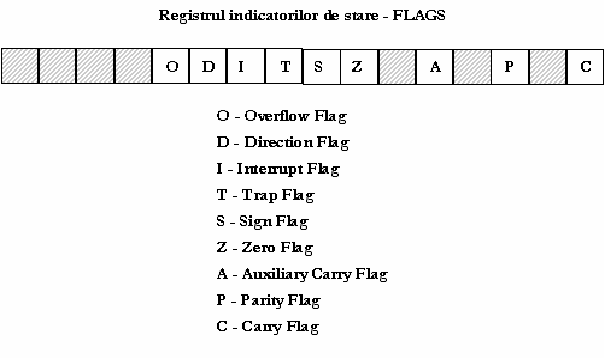
2.3. Registrul indicatorilor de stare (FLAGS) pe 16 biti contine informatii legate de starea microprocesorului precum si de rezultatele ultimilor instructiuni executate. Un indicator de stare (flag) este in sine o locatie de memorie de 1 bit ce indica starea curenta a microprocesorului si modalitatea sa de operare. Un indicator se spune ca "este setat" daca are
valoarea 1 si "nu este setat" in caz contrar. Indicatorii de stare se modifica dupa executia unor instructiuni aritmetice sau logice.
Exemple de indicatori de stare:
- C (Carry) indica aparitia unei cifre binare de transport in cazul unei adunari sau imprumut in cazul unei scaderi;
- O (Overflow) apare in urma unei operatii aritmetice. Daca este setat, inseamna ca rezultatul nu incape in operandul destinatie;
- Z (Zero) indica faptul ca rezultatul unei operatii aritmetice sau logice este zero;
- S (Sign) indica semnul rezultatului unei operatii aritmetice;
- D (Direction) - cand este zero, procesarea elementelor sirului se face de la adresa mai mica la cea mai mare, in caz contrar este invers;
- I (Interrupt) controleaza posibilitatea microprocesorului de a raspunde la evenimente externe (apeluri de intrerupere);
- T (Trap) este folosit de programele de depanare (de
tip debugger), activand sau nu posibilitatea executiei programului pas cu pas.
Daca este setat,
- A (Auxiliary carry) suporta operatii in codul BCD. Majoritatea programelor nu ofera suport pentru reprezentarea numerelor in acest format, de aceea se utilizeaza foarte rar;
- P (Parity) este setat in conformitate cu paritatea bitilor cei mai putin semnificativi ai unei operatii cu date. Astfel, daca rezultatul unei operatii contine un numar par de biti 1, acest indicator este setat. Daca numarul de biti 1 din rezultat este impar, atunci indicatorul PF este zero. Este folosit de regula de programe de comunicatii, dar Intel a introdus acest indicator nu pentru a indeplini o anumita functionalitate, ci pentru a asigura compatibilitatea cu vechile microprocesoare ale familiei x86.
Proprietatile registrilor de segment sunt in stransa legatura cu notiunea de segmentare a memoriei. Premisa de la care se pleaca este urmatoarea: 8086 este capabil sa adreseze 1MB de memorie, astfel ca sunt necesare adrese pe 20 de biti pentru a cuprinde toate locatiile din
spatiul de 1 MB de memorie. Totusi, registrele utilizate sunt registre pe 16 biti, deci a trebuit sa se gaseasca o solutie pentru aceasta problema.
Solutia gasita se numeste segmentarea memoriei in acest caz memoria de
1MB este impartita in 16 segmente de cate 64 KB (16*64 KB = 1024 KB = 1 MB).
Notiunea de segmentare a memoriei presupune utilizarea unor adrese de memorie formate din doua parti. Prima parte reprezinta adresa segmentului iar cea de-a doua portiune reprezinta adresa de deplasament, sau offset-ul.
O linie de cod scrisa in limbaj de asamblare are urmatorul format general:
<nume> <instructiune/directiva> <operanzi> <;comentariu>
unde:
<nume> - reprezinta un nume simbolic optional;
<instructiune/directiva> - reprezinta mnemonica (numele) unei instructiuni sau a unei directive;
<operanzi> - reprezinta o combinatie de unul, doi sau mai multi operanzi (sau chiar nici unul), care pot fi constante, referinte
de memorie, referinte de registri, siruri de caractere, in functie de structura particulara a instructiunii;
<;comentariu> - reprezinta un comentariu optional ce poate fi plasat dupa caracterul ";" pana la sfarsitul liniei respective de cod.
Numele folosite intr-un program scris in limbaj de asamblare pot identifica variabile numerice, variabile sir de caractere, locatii de memorie sau etichete. Spre exemplu, urmatoarea secventa de cod, care calculeaza valoarea lui trei factorial (3! = 1 x 2 x 3 = 6) cuprinde cateva nume de variabile si etichete:
.MODEL small
.STACK 200h
.
Valoare_Factorial DW ?
Factorial DW ?
.CODE
Trei_Factorial PROC
MOV ax, @data
MOV ds, ax
MOV [Valoare_Factorial], 1
MOV [Factorial], 2
MOV cx, 2
Ciclare:
MOV ax, [Valoare_Factorial]
MUL [Factorial]
MOV [Valoare_Factorial], ax
INC [Factorial]
RET
Trei_Factorial ENDP
END
Numele Valoare_Factorial si Factorial sunt
utilizate pentru definirea a doua variabile de tip word (pe 16 biti), Trei_Factorial identifica
numele procedurii (subrutinei) ce contine codul pentru calculul factorialului, permitand
apelul sau din alta parte a programului. Ciclare reprezinta un nume de
eticheta, identificand adresa instructiunii MOV ax, [Valoare_Factorial], astfel
incat instructiunea
De exemplu, in secventa urmatoare:
JMP scadere
scadere:
urmatoarea instructiune care va fi executata dupa
instructiunea JMP scadere va fi instructiunea
JMP scadere
scadere:
Exista unele avantaje atunci cand scriem instructiunile pe linii separate. In primul rand, atunci cand scriem un nume de eticheta pe o
singura linie, este mai usor sa folosim nume lungi de etichete fara a strica "forma" programului scris in limbaj de asamblare. In al doilea rand, este mai usor sa adaugam ulterior o noua instructiune in dreptul etichetei daca aceasta nu este scrisa pe aceeasi linie cu instructiunea.
Numele variabilelor sau etichetelor folosite intr-un program nu trebuie sa se confunde cu numele rezervate de asamblor, cum ar fi numele de directive si instructiuni, numele registrilor, etc. De exemplu, o declaratie de genul:
ax DW 0
BYTE:
nu poate fi acceptata, deoarece AX este numele registrului acumulator, AX, iar BYTE reprezinta un cuvant cheie rezervat.
Orice nume de eticheta ce apare pe o linie fara instructiuni sau apare pe o linie cu instructiuni trebuie sa aiba semnul ":" dupa numele ei.
Tototdata, se incearca sa se dea un nume sugestiv etichetelor din program.
Fie urmatorul exemplu:
CMP
JB Nu_este_litera_mica
CMP AL, 'z'
JA Nu_este_litera_mica
Nu_este_litera_mica:
comparativ cu:
CMP
JB x5
CMP AL, 'z'
JA x5
x5:
Daca in primul caz am folosit un nume sugestiv de eticheta (Nu_este_litera_mica), in cazul al doilea, identic din punct de vedere al functionalitatii cu primul, eticheta a fost denumita x5, absolut nesugestiv!
Observatie:
Limbajul de asamblare nu este case sensitive. Aceasta semnifica faptul ca, intr-un program scris in limbaj de asamblare, numele de variabile, etichete, instructiuni, directive, mnemonice etc., pot fi scrise atat cu litere mari cat si cu litere mici, nefacandu-se diferenta intre ele (Nu _ este _ litera _ mica este acelasi lucru cu nu_este_litera_mica sau Nu_Este_Litera_Mica
etc.).
Datorita faptului ca registrii microprocesorului 8086 sunt registrii pe 16 biti, s-a impus folosirea unor segmente de memorie de cate 64 Ko (maxim cat se poate adresa avand la dispozitie 16 biti - 64 Ko = 2 ^ 16 = 65536). Intr-un program scris in limbaj de asamblare (vom folosi in continuare prescurtarea ASM) exista trei segmente: segmentul de cod, segmentul de date si segmentul de stiva.
Directivele de segment (fie sub forma standard, fie sub forma simplificata) sunt necesare in orice program scris in limbaj de asamblare
pentru a defini si controla utilizarea segmentelor iar directiva END este folosita intotdeauna pentru a incheia codul programului.
Exemple de directive de segment simplificate sunt:
.STACK
.CODE
.
.MODEL
DOSSEG
END
.STACK,.CODE,.
De exemplu, .STACK 200H defineste o stiva de 512 octeti (in ASM valorile ce sunt incheiate cu litera H semnifica faptul ca este vorba despre hexazecimal). O astfel de valoare pentru stiva este suficienta in mod normal; unele programe, insa (indeosebi cele recursive) pot necesita dimensiuni mai mari ale stivei.
Directiva .CODE marcheaza inceputul segmentului de cod.
Directiva .
mov ax, @data
mov ds, ax
(se poate folosi si alt registru general in locul lui AX).
Secventa anterioara semnifica faptul ca DS se va
referi catre segmentul de date ce incepe cu directiva .
Consideram in continuare un exemplu de program ce afiseaza textul memorat in DataString pe ecran:
;Program p01.asm
.MODEL small ;se specifica modelul de memorie
;SMALL
.STACK 200H ;se defineste o stiva de 512 octeti
.
;date
DataString DB 'Hello!$' ;se defineste variabila
;DataString, initializata cu valoarea
;'Hello!'
.CODE ;inceputul segmentului de cod al
;programului
ProgramStart: ;orice program are o eticheta de
;inceput
mov bx,@data ;secventa ce seteaza registrul DS sa
;faca referire la segmentul de date ce
;incepe cu .
mov ds,bx
mov dx, OFFSET DataString ;se incarca in DX adresa
;variabilei DataString
mov ah,09 ;codul functiei DOS de afisare a unui
;string
int 21H ;apelul DOS de afisare a string-ului
mov ah, 4cH ;codul functiei DOS de terminare a
;programului
int 21H ;apelul DOS de terminare
;a programului
END ProgramStart ;directiva de terminare a codului
;programului
Explicatii:
Se pot introduce comentarii intr-un program ASM prin folosirea ';'. Tot ce urmeaza dupa ';' si pana la sfarsitul liniei este considerat comentariu.
Nu are importanta daca programul este scris folosind litere mari sau mici (nu este 'case sensitive').
Fara
cele doua instructiuni care seteaza registrul DS catre segmentul definit de .
Observatii:
Nu trebuie sa incarcam in mod explicit registrul de segment CS deoarece DOS face acest lucru automat in momentul cand rulam un program. Astfel, daca CS nu ar fi deja setat la momentul executiei primei instructiuni din program, procesorul nu ar sti unde sa gaseasca instructiunea si programul nu ar rula niciodata. In mod asemanator, registrul de segment SS este setat de DOS inainte de executia programului si de regula ramane nemodificat pe perioada executiei programului.
Cu registrul de segment DS lucrurile stau altfel. In timp ce registrul CS se refera la intructiuni (cod), SS se refera ('pointeaza') la stiva, DS 'pointeaza' la date. Programele nu manipuleaza direct instructiuni sau stive dar au de-a face in mod direct cu date. De asemenea, programele vor acces la date situate in segmente diferite in orice moment. Se poate dori incarcarea in DS a unui segment, accesarea datelor din acel segment si apoi incarcarea lui DS cu un alt segment pentru a accesa un bloc diferit de date. In programe mici sau medii nu vom avea nevoie de mai mult de un segment de date dar programe mai complexe folosesc deseori segmente de date multiple.
Urmatorul program va afisa un caracter pe ecran, folosind incarcarea registrului ES in locul lui DS.
;Program p02.asm
.MODEL small
.STACK 200H
.
OutputChar DB 'B' ;definirea variabilei OutputChar
;initializata cu valoarea 'B'
.CODE
ProgramStart:
mov dx, @data
mov es, dx ;spre deosebire de programul anterior,
;se foloseste ES pentru specificarea
;segmentului de date
mov bx, offset OutputChar ;se incarca BX cu adresa
;variabilei OutputChar
mov dl, es:[bx] ;se incarca
;adresa explicita es:[bx]
;(adresare indexata)
mov ah,02 ;codul functiei DOS de afisare a unui caracter int 21H
;apelul DOS de executie a afisarii
mov ah, 4cH ;codul functiei DOS de terminare a
;programului
int 21H ;apelul DOS de terminare
;a programului
END ProgramStart ;directiva de terminare a codului
;programului
DOSSEG este directiva ce face ca segmentele dintr-un program sa fie grupate conform conventiilor Microsoft de adresare a segmentelor.
Directiva .MODEL Este directiva ce specifica modelul de memorie pentru un program ASM ce foloseste directive de segment simplificate.
Definitii:
'near' inseamna adresa (offset-ul) pe 16 biti din cadrul aceluiasi segment, in timp ce 'far' inseamna o adresa completa de tip segment:offset, din cadrul altui segment decat cel curent.
Modelele de memorie ce se pot specifica prin intermediul directivei
.MODEL sunt:
tiny - atat codul cat si datele programului incap in acelasi segment de 64 Ko. Atat codul cat si datele sunt de tip near
small - codul programului trebuie sa fie intr-un singur segment de 64 Ko si datele intr-un bloc separat de 64Ko; codul si datele sunt near
medium - codul programului poate fi mai mare decat 64 Ko dar datele trebuie sa fie intr-un singur segment de 64 Ko. Codul este far, datele sunt near
compact - codul programului poate fi intr-un singur segment, datele pot fi mai mari de 64 Ko. Codul este near, datele sunt far
large - atat codul cat si datele pot depasi 64Ko, dar nici un masiv de date nu poate depasi 64 Ko. Atat codul cat si datele sunt far
huge - atat codul cat si datele pot depasi 64 Ko si masivele de date pot depasi 64 Ko. Atat codul cat si datele sunt far. Pointerii la elementele dintr-un masiv sunt far
In continuare sunt prezentate cateva exemple legate de modalitatile
de declarare a variabilelor si de adresare a memoriei:
var1 DW 01234h ;se defineste o variabila word cu
;valoarea 1234h
var2 DW 01234 ;se defineste o variabila word cu valoarea zecimala 1234 (4D2 in hexa)
var3 RESW 1 ;se rezerva spatiu pentru o variabila
;word (de valoare 0)
var4 DW ABCDh ;atribuire ilegala!
; Memoria poate fi adresata folosindu-se patru registri:
; SI -> Implica DS
; DI -> Implica DS
; BX -> Implica DS
; BP -> Implica SS ! (nu este foarte des utilizat)
Exemple:
mov ax,[bx] ; ax <- word in memorie referit de BX
mov al,[bx] ; al <- byte in memorie referit de BX
mov ax,[si] ; ax <- word referit de SI
mov ah,[si] ; ah <- byte referit de SI
mov cx,[di] ; di <- word referit de DI
mov ax,[bp] ; AX <- [SS:BP] Operatie cu stiva!
; In plus, sunt permise BX+SI si BX+DI:
mov ax,[bx+si]
mov ch,[bx+di]
; Deplasamente pe 8 sau 16 biti:
mov ax,[23h] ; ax <- word in memorie DS:0023
mov ah,[bx+5] ; ah <- byte in memorie [DS:BX+5]
mov ax,[bx+si+107] ; ax <- word la adresa [DS:BX+SI+107]
mov ax,[bx+di+47] ; ax <- word la adresa [DS:BX+DI+47]
; ATENTIE: copierea din memorie in memorie este ilegala!
;Totdeauna trebuie sa se treaca valoarea copiata printr-un registru
mov [bx],[si] ;Ilegal
mov [di],[si] ;Ilegal
; Caz special: operatiile cu stiva!
pop word [var] ; var <- [SS:SP]
o MOV - mutare de informatie,
o PUSH - punere de informatii in memoria organizata ca o stiva,
o
instructiuni de intrare/iesire
o IN - depunerea in registrul acumulator a informatiei stocate in registrul de intrare/iesire (portul de date),
o OUT - scrierea in portul de date a informatiei aflate in registrul acumulator;
instructiuni aritmetice
o
adunare (ADD,
o
scadere (
o
inmultire (MUL,
o impartire (DIV, IDIV etc.);
instructiuni de manipulare a sirurilor de biti
o
operatii logice (NOT,
o
deplasare (SHL,
o
rotire (
instructiuni de transfer
o salt neconditionat (CALL, RET, JMP),
o
salt conditionat - prin testarea indicatorilor de conditii (JC,
o cicluri (LOOP etc.),
o
intreruperi (
instructiuni de sincronizare externa:
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 2394
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved