| CATEGORII DOCUMENTE |
ARHITECTURI SIMD
Arhitecturile SIMD (Single Instruction stream Multiple Data stream, rom: un singur flux de instructiuni, mai multe fluxuri de date) au o singura unitate de control (ce executa cate o singura instructiune la un moment dat) si mai multe unitati aritmetice ce pot executa simultan operatii pe mai multe seturi de date (sub controlul unei singure instructiuni). Sunt simple extensii ale modelul von Neumann in care sunt replicate unitatile aritmetice (ALU - Arithmetic Logic Unit).
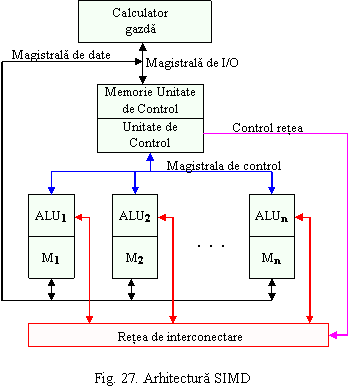
Istoric, sunt primele arhitecturi paralele aparute. Sunt utilizate la rezolvarea problemelor stiintifice si ingineresti cu calculelor intensive pe structuri de date vectoriale si matriciale. O arhitectura SIMD tipica este prezentata in figura 27. Sunt definite doua categorii de arhitecturi SIMD: procesoare vectoriale si procesoare matriciale.
1. Procesoare vectoriale
Procesoarele vectoriale, in special prin linia de masini Cray (Cray-1 in 1976, C90 si T90), sau bucurat de un anumit succes comercial dominand calculul stiintific pentru mai multe decenii.
In principiu operatiile tipic vectoriale vectoriale sunt cele definite in figura 28.
|
Operatie |
Exemple |
|
Ai = f1(Bi) |
f1 = cosinus, sinus, radacina patrata etc |
|
Scalar = f2(A) |
f2 = suma, minim etc |
|
Ai = f3(Bi, Ci) |
f3 = adunare, scadere |
|
Ai = f4(scalar, Bi) |
f4 = inmultire cu un scalar |
Fig. 28. Operatii tipic vectoriale
Avand in vedere ca structuri cu foarte multe ALU foarte putenice si rapide sunt foarte scumpe, in locul replicarii intr-un numar foarte mare a acestor ALU, in practica s-a preferat utilizarea unor ALU specializate, dar care sa lucreze intr-o arhitectura de tip linie de asamblare (pipeline). Calculatorul Cray-1 este tipic din acest puct de vedere. El este de fapt modelul a foarte multe alte arhitecturi paralele si nu numai. Arhitecturile superpipeline si superscalare ale procesoarelor actuale datoreaza foarte mult inovatiilor introduse de calculatorul Cray-1. Insusi setul de instructiuni este unul RISC (operatii simple, orientate pe registre, cu 3 operanzi) precumsi un set bogat de registre interne. De asemeni el permite inlantuirea operatiilor (pipeline).
1. Procesoare matriciale
Istoric au fost primele arhitecturi paralele (prin calculatorul Iliac IV). In general arhitectura tipica a acestor sisteme este cea prezentata in figura 27. Variatiile de la un calculator la altul sunt date de complexitatea ALU si numarul lor, de dimensiunea modulelor de memorie locale, de topologia retelei de interconectare si de complexitatea comutatoarelor.
Astfel, la calculatorul CM-2 ALU sunt foarte simple (pe bit) dar sunt in numar foarte mare (65536). Altele utilizeaza ALU pe 8 /16/32 de biti.
Topologia grila rectangulara este cea mai populara alegere, dar exista si topologii hipercub, retele Omega si altele.
Majoritatea procesoarelor matriciale nu s-au bucurat de prea mult succes comercial. Multe au raamas doar la stadiul de model experimental.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 1120
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved