| CATEGORII DOCUMENTE |
MULTIPROCESOARE CU MEMORIE PARTAJATA
Multiprocesoarele cu memorie partajata sunt arhitecturi cu mai multe procesoare si un singur spatiu de adrese comun pentru toate procesoarele. Pe un astfel de sistem se executa o singura copie a sistemului de operare, care foloseste un singur set de tabele pentru gestiunea proceselor, a paginilor de memorie si a intrarilor/iesirilor.
1. Modele de consistenta a memoriei
Pentru astfel de sisteme, in care procesoarele detin memorie intermediara (cache) pe mai multe nivele, in care controlerele memoriei cache implementeaza diverse politici legate de citire si in special de scriere, in care se utilizeaza diverse solutii de interconectare (de la magistrala si inel pana la arhitecturi tip grila si hipercub, fiecare cu latente specifice si variabile), in care mai multe procesoare pot incerca sa citeasca sau sa scrie simultan acelasi bloc de memorie, problema asigurarii consistentei memoriei este o problema esentiala.
Vom prezenta in continuare principalele modele de consistenta a memoriei.
In acest model fiecare citire de la o locatie de memorie m intoarce valoarea celei mai recente scrieri la aceasta locatie. Programatorii prefera acest model de consistenta, dar in arhitecturile cu foarte mute procesoare, module de memorie si nivele de memorie cache, el este greu de asigurat pentru ca ar transorma memoria intr-un punct de congestie.
Ideea de baza a acestui model este ca daca sunt mai multe cereri de citire si scriere, hardware-ul alege aleatoriu o succesiune a lor (posibil determinata de timp si sansa), dar toate procesoarele vor vedea scrierile in aceasi ordine, in ordinea adevarata in care ele apar. Deci, scrierile mai multor procesoare sunt vazute de toate procesoarele in exact secvanta adevarata in care ele s-au petrecut.
Este un model de consistenta mai relaxat decat consistenta secventiala si are la baza doua reguli:
Scrierile oricariu procesor in parte sunt vazute de toate procesoarele in aceeasi ordine in care ele au fost emise.
Pentru fiecare cuvant de memorie, toate procesoarele vad toate scrierile in aceeasi ordine.
Primul punct garanteaza ca, daca Proc1 emite catre o locatie de memorie m cererile de scriere a valorilor 1A, 1B si 1C in aceasta secventa, toate celelalte procesoare vor putea citi aceste valori (intr-o bucla rapida) tot in aceasta ordine.
Al doilea punct garanteaza ca dupa ce mai multe procesoare au scris intr-un cuvant de memorie si s-au oprit, el va avea o valoare neambigua, aceea a ultimei scrieri. Toate procesoarele trebuie sa fie de acord care a fost ultima scriere.
Acest model de consistenta nu garanteaza nici macar ca scrierele facute de un singur procesor sunt vazute in aceeasi ordine. Unele procesoare pot vedea 1A dupa 1B. Totusi, pentru a asigura o anumita ordine a scrierilor se folosesc variabile (operatii) de sincronizare. Cand se executa o sincronizare, se bloachaza toate cererile noi de scriere pana la terminarea cererilor vechi (se realizeaza golirea tuturor memoriilor tampon sau canalelor de scriere). Operatiile de sincronizare sunt secvential consistente (sunt vazute de toate procesoarele in aceeasi ordine). Golirea bufferelor periodica este o operatie care totusi dureaza.
Este un model mai apropiat de mediul programarii concurente prin inrudirea sa cu sincronizarile prin regiuni critice. Conform acestui model, un proces cand iese dintr-o zona critica nu forteaza terminarea imediata a tuturor scrierilor, dar este necesar ca ele sa fie terminate inainte ca un alt proces sa intre in acea regiune critica. In principiu, o zona critica este protejata printr-un semafor sau zavor. Un proces, pentru a intra intr-o zona critica, trebuie sa execute mai intai o operatie de acaparare (acquire) a zavorului si numai dupa obtinerea zavorului poate executa codul zonei critice de modificare a variabilelor asociate. La iesirea din zona critica, procesul executa operatia de eliberare (release) a zavorului, dar nu forteaza terminarea tuturor scrierilor. Terminarea tuturor scrierilor anterioare este realizata prin operatia acaparare a zavorului.
2. Arhitecturi SMP UMA bazate pe magistrala
Sunt cele mai simple si mai putin scalabile arhitecturi multiprocesor. Arhitectura tipica a acestor mutiprocesoare este prezentata in Figura 1.
Magistrala unica este principalul impediment al scalabilitatii multiprocesoarelor SMP UMA. Cand un procesor doreste sa citeasca un cuvant din memorie, mai intai verifica daca magistrala e libera. Daca nu, asteapta mai intai eliberarea magistralei si abia dupa aceea poate trimite adresa si citi cuvantul dorit. Timpul de asteptare pentru obtinerea magistralei poate creste foarte mult pentru arhitecturi cu 16, 32 sau 64 de procesoare. Practic largimea de banda a magistralei se imparte la numarul de procesoare.
Solutia acestei probleme este reducerea traficului pe magistrala prin utilizarea memoriilor intermediare (cache) pe mai multe nivele si chiar a unor memorii locale private pentru codul programului, constante, stiva si variabilele locale. Memoria partajata va fi utilizata numai pentru variabilele partajate ce pot fi scrise. Sarcina alocarii datelor si codului la memoria locala si cea partajata revine in primul rand compilatorului.
Utilizarea memoriilor intermediare (cache) genereaza problema asigurarii coerentei.
Mai multe procesoare pot avea in memoria intermediara copii ale unei date comune (partajate). Daca un procesor modifica o copie a unei date partajate din cache-ul propriu, atunci trebuie initiata o procedura pentru:
- actualizarea datei in memoria principala si
- invalidarea sau actualizarea copiilor datei din celelalte cache-uri.
Scopul acestei proceduri este mentinerea coerentei cache-urilor, adica toate cache-urile sa contina copii valide (actuale) ale datelor.
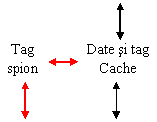
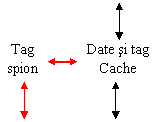
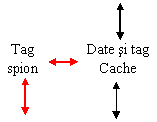
Exista mai multi algoritmi de asigurare a coerentei memoriilor cache care, in cazul arhitecturilor bazate pe magistrala, se bazeaza pe supravegherea (spionarea) magistralei. In toate solutiile, controlorul memoriei cache este proiectat special pentru implementa protocolul de coerenta prin supravegherea magistralei (fig. 29). Rolul principal al acestor protocoale este sa previna aparitia in memoriile cache a unor versiuni diferite ale aceluiasi bloc de memorie.
Protocoalele de asigurare a coerentei prin spionare au devenit populare incepand din anii 1980. Mentinerea coerentei are doua componente: citirile si scrierile. Mai multe copii ale aceluiasi bloc de date nu sunt o problema cand se citeste, dar un procesor trebuie sa aiba acces exclusiv atunci cand scrie un cuvant. Procesoarele trebuie sa aiba cea mai recenta copie atunci cand citesc, deci, dupa o scriere, trebuie sa obtina noua valoare. Consecinta scrierii unei date partajate este fie sa se invalideze toate celelalte copii sau sa se actualizeze toate copiile cu valoarea ce a fost scrisa.
Deoarece spionarea, care inseamna monitorizarea fiecarui transfer pe magistrala prin compararea adreselor datelor transferate cu adresele (tag) memorate in cache, ar putea stanjeni accesul procesorului la mamoria cache, se recurge la duplicarea adreselor (tags) pastrate in cache. Astfel actiunea comparare se face pe o copie a tag-urilor (fig. 29 - tag spion).
![]()
![]()
Procesor Procesor Procesor
. .
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Magistrala
unica
![]()
![]()
![]()
I/O Memorie partajata
![]()
![]()
Multiprocesor cu o singura magistrala ce utilizeaza coerenta cache-urilor prin spionare
Protocoalele de spionare sunt de doua tipuri, in functie de ce se intampla la o scriere:
Scriere-invalidare (Write-invalidate): procesorul care scrie trimite un semnal de invalidare si adresa pe magistrala inainte de a schimba copia sa locala; celelalte cache-uri care spioneaza magistrala, verifica daca au o copie si daca au, o invalideaza. Procesorul care a scris poate modifica in continuare copia sa locala pana cand un alt procesor doreste sa citeasca sau sa scrie in blocul partajat, atunci procesorul care a scris trebuie sa salveze blocul din cache in memoria principala, pentru ca celalalt sa poata incarca o copie valida.
Scriere-actualizare (Write-update): procesorul care scrie intr-un bloc partajat, trimite o copie a noii date pe magistrala (write-broadcast) si atunci toate copiile din celelalte cache-uri sunt actualizate. O noua scriere, in acelasi bloc, va insemna o noua difuzare (broadcast) ceea ce va creste foarte mult traficul pe magistrala.
Protocolul scriere-actualizare este asemenea politicii de scriere directa imediata (write-through) deoarece toate scrierile merg direct pe magistrala pentru actualizarea copiilor datei partajate. Protocolul scriere-invalidare utilizeaza magistrala numai pentru prima scriere, pentru a invalida celelalte copii, astfel ca urmatoarele scrieri nu conduc la activitate pe magistrala. In concluzie, protocolul scriere-invalidare are beneficii similare politicii de scriere intarziate (write-back) in sensul reducerii acceselor la magistrala.
Masuratorile efectuate pe date indica faptul ca datele partajate au o localitate spatiala si temporala mai redusa decat alte tipuri de date. Astfel, esecurile in accesul la date partajate (cache misses) domina comportamentul memoriilor cache, reprezentand 10% la 40% din totalul esecurilor.
O alta problema o reprezinta partajarea falsa: in cazul blocurilor cache mari, mai multe variabile partajate independente se pot gasi in acelasi bloc, dar procesoarele schimba intre ele intregul bloc desi acceseaza variabile diferite. Rezolvarea problemei cade in sarcina compilatoarelor care trebuie sa aloce in acelasi bloc doar variabile puternic corelate.
In cazul in care mai multe procesoare incearca sa scrie simultan intr-un cuvant partajat in acelasi ciclu magistrala, arbitrul de magistrala este cel ce decide care procesor va obtine magistrala si va invalida copiile din cache-urile celorlalte procesoare. Celelalte procesoare cand vor obtine accesul vor avea esec (cache miss) si vor trebui sa reincarce blocul din nou in cache inainte de a scrie. Arbitrul de magistrala este deci cel care forteaza un comportament secvential la scriere (model de consistenta secvential).
Vom prezenta in continuare un exemplu de protocol simplificat de coerenta prin spionare. Figura 30 prezinta diagrama de stari a automatului finit pentru un protocol de scriere-invalidare bazat pe politica de scriere intarziata (write-back).
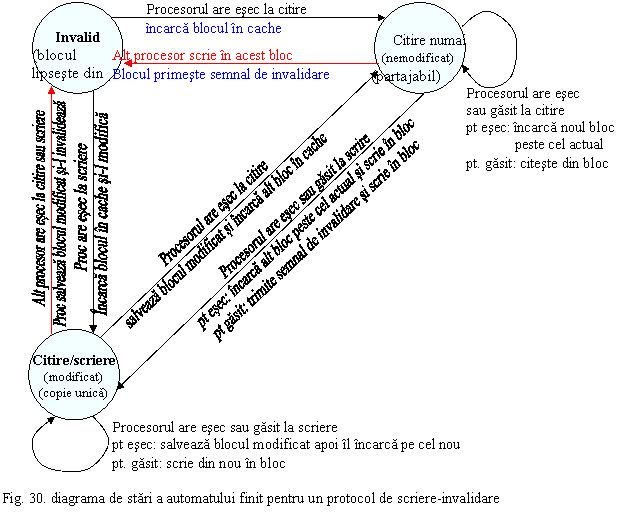
Fiecare bloc din cache se poate afla in una din urmatoarele 3 stari:
Citire numai (read only): acest bloc din cache este curat (nu s-a scris in el) si poate fi partajat.
Citire/Scriere (Read/Write): acest bloc din cache a fost modificat (scris) si nu poate fi partajat (nu se mai poate gasi si in alte memorii cache).
Invalid: acest bloc din cache nu contine date valide.
Schimbarea starii unui bloc de cache are loc numai in urmatoarele cazuri: esec la citire (read miss), esec la scriere (write miss) si gasit la scriere (write hit).
Un esec la citire (read miss) schimba starea blocului in citire-numai (partajabil). Daca anterior blocul se afla in starea invalid, el este mai intai incarcat in cache. Daca anterior se gasea in starea citire/scriere (modificat), se salveaza blocul vechi in memorie (write back) si se incarca apoi noul bloc peste cel vechi. Celelate cache-uri monitorizeaza magistrala si, daca detin o copie a acestui bloc in starea citire/scriere (modificat), atunci salveaza blocul in memorie (write back) pentru ca procesorul care a avut esec sa obtina o copie valida a blocului. Cache-ul care a facut salvarea isi trece blocul in starea invalid, dar ar putea foarte bine sa-l treaca in starea citire numai (ar fi mai eficient).
Pentru a scrie (write) intr-un bloc, procesorul obtine magistrala, trimite un semnal de invalidare cu tag-ul (adresa) blocului la celelate cache-uri si apoi scrie in bloc si-l pune in starea citire/scriere (modificat). Celelalte cache-uri monitorizeaza magistrala si, daca au o copie a blocului, o invalideaza.
Un protocol asemanator, dar cu 4 stari, este protocolul de coerenta cache MESI utilizat de procesoarele Pentium Pro si PowerPC. Denumirea sa reprezinta o abreviere a numelor starilor sale: Modified, Exclusive, Shared, Invalid. Starea modificat (Modified) este identica cu starea citire/scriere a protocolului simplificat prezentat mai sus. Starea citire numai insa este divizata in doua: partajat (Shared), daca mai exista copii ale blocului si in alte cache-uri si starea exclusiv (Exclusive) daca blocul se gaseste numai intr-un cache. Scrierea intr-un bloc in starea exclusiv nu mai necesita trimiterea unui semnal de invalidare.
Vom analiza in continuare modul in care se realizeaza sincronizarea proceselor care lucreaza la o sarcina comuna prin utilizarea variabilelor zavor pentru a obtine accesul exclusiv la o variabila partajata. Pentru aceasta, arhitectii de procesoare vor asigura mecanismul prin care un procesor poate obtine zavorul si inchide o variabila (blocheaza accesul celorlalte procesoare la variabila).
In cazul procesoarelor conectate printr-o singura magistrala acest lucru e mai simplu pentru ca un singur procesor va avea acces la memorie la un moment dat. Procesorul si magistrala trebuie sa asigure o operatie atomica (indivizibila) de modificare (swap) prin care procesorul poate citi si modifica zavorul. Citirea si modificarea trebuie sa fie inseparabile pentru ca procesorul sa nu piarda magistrala imediat dupa ce a citit zavorul, inainte de a-l modifica.
Zavorul este o variabila booleana (2 stari): sa presupunem ca starea 0 semnifica zavor neblocat (liber) si strea 1 zavor blocat (stop).
Un procesor citeste si testeaza starea zavorului pana cand zavorul este deblocat de procesorul care l-a blocat. Numai ca procesorul citeste zavorul nu din memoria principala ci din copia sa aflata in cache. Se reduce astfel considerabil traficul pe magistrala.
Cand procesorul care a detinut zavorul i-l deblocheaza scriind in el valoarea 0, el modifica copia zavorului din cache-ul propriu si invalideaza toate celelate copii. In acest moment, toate celelate procesoare nu mai au in cache o copie valida a zavorului si vor incerca sa obtina magistrala pentru a citi zavorul. Dar magistrala poate fi obtinuta de un singur procesor (decide arbitrul de magistrala cine este castigatorul).
Procesorul care a obtinut magistrala va executa operatia atomica de citire si modificare a zavorului. Dupa care va putea avea acces exclusiv la data partajata pentru modificarea ei.
Celelalte procesoare cand vor obtine magistrala vor gasi zavorul tot in starea blocat, dar de data aceasta de alt procesor. Ele vor incarca in cache o copie a zavorului pe care o vor testa pana la eliberarea lui, cand copia va fi din nou invalidata.
Arhitecturi UMA bazate pe comutatoare tip grila
Utilizarea unei singure magistrale limiteaza drastic scalabilitatea multiprocesoarelor SMP UMA, conectate prin magistrale, la cel mult 16 sau 32 de procesoare. Pentru arhitecturi cu mai mult de 32 de procesoare e necesar un alt tip de retea de interconectare. Retelele cu comutatoare de tip grila (crossbar switch - fig. 19) au ca principala proprietate ca sunt strict neblocante. Dezavantajul lor este ca numarul de comutatoare creste cu patratul numarului de procesoare conectate la memorii. Astfel, pentru 64 de procesoare conectate la 64 de module de memorie numarul de comutatoare este de 4096, iar dimensiunea retelei este de , ceea ce inseamna o latenta considerabila. Totusi, pentru sisteme de marime medie, cum este cazul sistemelor UMA, o schema cu comutatoare de tip grila este o solutie foarte buna.
Exemple de sisteme UMA comerciale care folosesc retele cu comutatoare de tip grila sunt multiple, cele mai semnificative sunt:
HP/Convex Exemplar X-class: maxim 64 procesoare PA-8000, max 64 GB memorie, noduri de tip SMP cu 2 procesoare, comutatoare de tip grila 8x8 plus inel. Largimea de banda pe legatura este de 980 MBps.
Compaq ProLiant ML770: maxim 32 procesoare Pentium Xeon, max 32 GB memorie, noduri de tip SMP cu 4 procesoare, comutatoare de tip grila 4x4. Largimea de banda pe legatura este de 1 GBps.
Sun Enterprise 10000: maxim 64 procesoare UltraSPARC 1, max 64 GB memorie, noduri de tip SMP cu 4 procesoare, comutatoare de tip grila 16x16. Largimea de banda pe legatura este de 1,6 GBps.
Sistemul Sun Enterprise 10000 consta dintr-un singur cabinet cu maxim 16 placi, fiecare placa cu 4 procesoare UltraSPARC II, si maxim 4 GB de memorie pe fiecare placa.
Procesoarele UltraSPARC II sunt procesoare RISC superscalare cu pipiline in 9 etape, ce asigura:
lucru la frecvente de ceas de 400 MHz;
executia a 4 instructiuni pe ciclu de ceas (4 unitati aritmetice pentru intregi, 2 pentru virgula mobila si o unitate de operatii grafice);
magistrale de date si adrese pe 64 de biti;
cache de nivel 1, inclus in procesor, separat pentru date si instructiuni, fiecare de 16 kB, neblocabil;
cache de nivel 2, inclus in procesor de 4 MB;
pana la 666 Mflops pe procesor (42,6 Gflops pe sistem);
transferurile cu memoria la o largime de banda de 1,3 GBps.
Comutatorul de tip grila 16x16 este utilizat pentru transferul intre memoriile principale si memoriile cache. Blocurile de memorie cache au 64 ocetti, iar latimea comutatoarelor este de 16 octeti (128 de biti), deci este nevoie de 4 cicluri de ceas pentru a muta un bloc. Prin proiectarea comutatorului s-a urmarit realizarea unei largimi de banda ridicate (1,24 GBps pe legatura si 19,87 GBps largimea de banda totala) si a unei latente scazute si constante (500 ns), s-a obtinut astfel dezideratul principal al arhitecturilor UMA ca accesarea memoriei din afara placii sa nu fie mai lenta decat accesarea memoriei de pe placa.
Pentru ca, totusi, comutatorul de tip grila asigura numai legaturi punct la punct, el nu poate fi utilizat pentru a mentine consistenta memoriei cache. De aceea, arhitectura Sun utilizeaza patru magistrale de adrese pentru spionare (fig. 31).
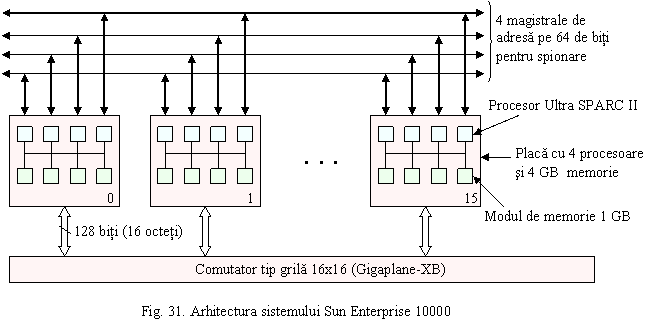
Fiecare magistrala este folosita pentru din spatiul de adrese fizice, deci 2 biti de adrese sunt folositi pentru a selecta magistrala de supravegheat. De fiecare data cand un procesor are esec la citire (cache miss), pune mai intai adresa pe magistrale de adrese potrivita pentru a selecta blocul de memorie ce trebuie transferat. Toate cele 16 placi observa simultan cele 4 magistrale de adrese si daca unul din ele contine o copie modificata a blocului va bloca transferul, va salva mai inai blocul in memorie si apoi va permite efectuarea citirii. Daca blocul nu se mai gaseste in nici-un alt cache sau daca se gaseste este in starea citire numai (curat, partajabil), atunci citirea blocului se face fara intarziere. Transferul datelor se face prin comutatorul de tip grila, punct la punct.
Sun Enterprise 10000 este un exemplu de sistem care forteaza limitele unui modelelor UMA conectate prin magistrala si a celor conectate prin retele pentru a obtine maximul posibil. Dar pentru a trece de limita de 64 de procesoare e nevoie de altceva.
4. Arhitecturi UMA bazate pe retele multietapa
Aceste arhitecturi folosesc pentru conectarea procesoarelor la memorie retele de tipul celor prezentate in figurile 15, 16 si 17. Pentru comutare se folosesc cumutatoare de la cel mai simplu (2 intrari x 2 iesiri) pana la comutatoare 4x4, 8x8 sau 16x16. Functiile de permutare cele mai folosite sunt amestecare perfecta sau hipercub.
Tehnicile de comutare pot fi comutare de circuite, comutare de pachete (cu memorare si retransmitere sau cu cale directa virtuala) sau gaura de vierme. Algoritmii de rutare preferati sunt rutarea la sursa si ruatrea distribuita (statica sau dinamica). In general sunt preferate retelele neblocante, dar sunt utilizate chiar si retele blocante de genul retelei Omega. Blocarea (conflictele) in aceste retele poate avea mai multe cauze: concurenta la un port al comutatorului sau la un modul de memorie. O solutie pentru a impiedica blocarea definitiva este de regula utilizarea mai multor canale virtuale pe un canal fizic, prin utilizarea a mai multor cozi logice la un port de iesire. O alta solutie este un sisteme de memorie intretesut (dispunerea unui bloc de memorie peste mai multe module de memorie fizica). Aceasta solutie poate aduce o crestere a largimii de banda.
Totusi, nici aceste arhitecturi nu pot creste dimensiunile sistemului peste 100 de procesoare. Majoritatea sistemelor din aceasta categorie de arhitecturi nu sau bucurat de un succes comercial deosebit si sunt acum de domeniul istoriei.
Amintim, ca exemple, urmatoarele arhitecturi:
Sistemul Cedar, dezvoltat la Universitatea Illinois (1985). Cedar combina procesarea vectoriala, arhitectura multiprocesor, o memorie ierarhica si retele de mare viteza. Astfel foloseste noduri cu 8 procesoare, un nivel de memorie cache intretesut, 2 retele Omega, unidirectionale, multietapa pentru accesul la memoria partajata. Boxele de comutare sunt grila de comutare 8x8, tehnica de comutare este comutarea de pachete. Memoria partajata este constituita din mai multe module intretesute (maxim 16 MB). Sincronizarea procesoarelor se face prin regiuni critice pentru excluderea mutuala.
Arhitecturile hipercub dezvoltate de Caltech (1983 - Caltech Cosmic Cube), Intel iPCS, AMTEK System 14, NCUBE/ten (1986).
5. Arhitecturi NUMA
Construirea de sisteme cu mai mult de 128 de procesoare presupune deja ca caestea vor ocupa un volum ce poate depasi un cabinet. Modulele de memorie vor trebui sa fie distribuite fizic pe mai multe placi, de regula in vecinatatea unui numar de procesoare. Placile sunt legate intre ele prin retele de dimensiuni scalabile. Toate acestea fac sa se renunte la ideea de timp de acces uniform la memorie, dar in acelasi timp nu se renunta la ideea foarte ademenitoare pentru programatori de memorie partajata (spatiu de adrese comun pentru toate programele). In concluzie, multiprocesoarele NUMA (NonUniform Memory Access, rom: acces neuniform la memorie), la fel ca multiprocesoarele UMA, asigura un singur spatiu de adrese pentru toate procesoarele, dar accesul la modulele de memorie locala este mai rapid decat accesul la cele de la distanta. Rezulta deci ca toate programele ce se executa pe sistemele UMA se pot executa fara modificari si pe sistemele NUMA, dar performantele vor fi mai slabe decat cele obtinute cu un sistem UMA, la aceeasi frecventa a cesului.
Toate arhitecturile NUMA au trei proprietati esentiale, care le separa de toate celelalte arhitecturi:
(1) Au un singur spatiu de adrese accesibil pentru toate procesoarele.
(2) Accesul la memorie (locala sau la distanta) se realizeaza folosind instructiuni LOAD si STORE.
(2) Accesul la memoria la distanta este mai lent deat accesul la memoria locala.
Arhitecturile NUMA se impart in doua categorii:
NC-NUMA (NonCoherent-NUMA, rom: NUMA-necoerent): timpul de acces la memoria la distanta nu este mascat (nu se utilizeaza nivele de memorie cache);
CC-NUMA (Cache Coherent-NUMA, rom: NUMA cu memorii intermediare coerente): timpul de acces la memorie (locala sau la distanta) este ascuns prin utilizarea memoriilor cache. Utilizarea memoriilor cache presupune automat si utilizarea protocoalelor de asigurare a coerentei. Acest tip de arhitectura mai este denumit de programatori sistem de memorie distribuita partajata implementata prin hardware (Hardware Distributed Shared Memory Hardware DSM), pentru analogia cu sistemul de memorie distribuita partajata prin program.
Arhitecturile NC-NUMA (NonCoherent-NUMA) sunt arhitecturi acum de domeniul istoriei. Memoriile cache si-au dovedit de mult timp utilitatea in cresterea performantei si nu mai lipsesc paractic din nici-o arhitectura de calculator. Majoritatea procesorelor actuale includ cache pe unu sau doua nivele. NC-NUMA reprezinta totusi o etapa importanta in evolutia conceptuala a arhitecturilor cu acces neuniform la memorie (NUMA). Una din primele masini NC-NUMA a fost Cm* de la Carnegie Mellon.
5.1. Arhitecturi CC-NUMA
O arhitectura CC-NUMA tipica este prezentata in figura 32. In conditiile in care interconectarea nodurilor nu se mai face prin magistrala ci prin retea, iar memoria e distribuita fizic, nu se mai poate asigura coerenta memoriilor cache prin protocoale bazate pe directoare. Solutia a fost asigurarea coerentei prin protocoale bazate pe directoare. Multiprocesoarele care folosesc aceasta solutie se mai numesc multiprocesoare bazate pe cataloage (directory-based multiprocessor).
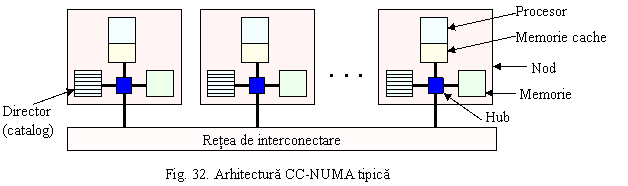
Directoarele sunt baze de date care contin informatii despre locul in care se gaseste fiecare bloc de memorie cache si care este starea lui. Cand este referit un bloc de memorie cache, directorul este interogat pentru a determina unde este localizat blocul si care este starea lui (curat, adica nescris, sau modificat). Deoarece acest director este referit la fiecare acces la memoria cache (practic la fiecare instructiune), el trebuie sa fie realizat cu memorii foarte rapide si sa fie localizat cat mai aproape de procesor.
Copii ale aceluiasi bloc de memorie se pot gasi in mai multe memorii cache (in mai multe noduri) si e necesara o metoda de a le localiza pe toate (ex: pentru a le invalida in cazul scrierii intr-una din copii). Sunt mai multe metode prin care un director poate indica localizarea copiilor:
(1) Rezervarea pentru fiecare intrare in catalog a k campuri in care sa se pastreze adresele nodurilor care contin o copie a blocului. Are dezavantajul ca limiteaza la k numarul copiilor. Are avantajul ca nodurile sunt identificate imediat.
(2) Indicarea nodurilor care pastreaza copii ale blocului printr-o harta de biti, cu un bit pentru fiecare nod. Are avantajul ca nu exista o limita in ce priveste numarul copiilor, dar are dezavantajul unui consum mare de memorie (ex: pentru 256 de noduri vor fi necesari 256 biti pentru un bloc de cache uzual de 64 de octeti, adica 512 biti, reprezinta o crestere de 50%). In plus, e necesara o decodificare a hartii de biti si transformarea in adrese de noduri.
(3) Indicarea nodurilor printr-o lista inlantuita a adreselor lor, in director se pastreaza doar capul acestei liste. Are dezavantajul ca necesita inca o memorie care sa pastreze listele si in plus se pierde mult timp cu parcurgerea listei atunci cand e necesar.
Asigurarea coerentei memoriei cache presupune utilizarea unor biti de stare pentru fiecare bloc care sa indice ca un bloc este curat (nu a fost scris) sau a fost modificat. De asemeni trebuie asigurata posibilitatea partajarii unui bloc si scrierea exclusiva.
Universitatea Stanford (Daniel Lenoski s.s., 1992) a construit primul multiprocesor CC-NUMA ce utilizeaza cataloage, DASH (Directory Architecture for SHared memory, rom: arhitectura cu cataloage pentru memoria partajata). Pentru faptul ca a influientat puternic o serie intreaga de produse comerciale, cum ar fi SGI Origin 2000 (proiectat tot de Lenoski), Sequent NUMA-Q s.a., vom analiza in continuare arhitectura sa (fig. 33).
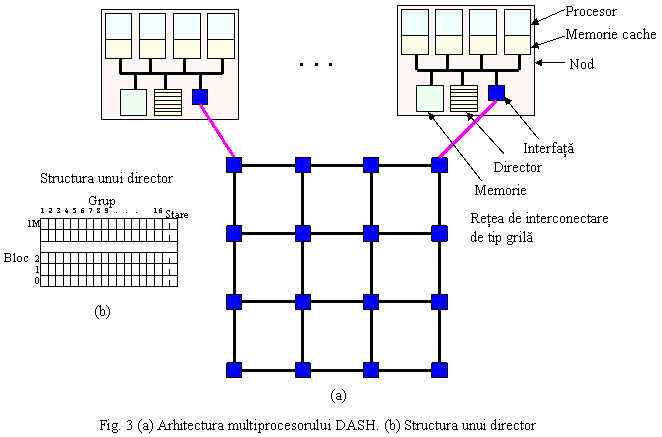
Prototipul a fost realizat cu 64 procesoare MIPS R3000, dispuse in 16 module a 4 procesoare fiecare. Fiecrea modul dispune de 16 MB de memorie RAM. Spatiul total de adrese este de 256 MB. Primul modul detine spatiul de adrese de la 0 la 16 MB, al doile de la 16 MB la 32 MB si asa mai de parte, ultimul avand adresele de la 240 MB la 256 MB.
Fiecare bloc de memorie are 16 octeti, deci in 16 MB memorie se vor gasi 1 M de blocuri. Rezulta deci ca fiecare director va trebui sa aiba 1 M de intrari (una pentru fiecare bloc). Fiecare intrare contine o harta de biti, cu un bit pe grup de 4 procesoare. In plus se mai folosesc 2 biti care indica starea liniei, utilizaii de protocolul de coerenta. Fiecare intrare va avea deci 16+2 18 biti. Obtinem deci ca fiecare director are peste 2 MB. Totalul memoriei utilizate pentru directoare este de 36 MB ceea ce reprezinta aproximativ 14% din 256 MB.
Fiecare grup este conectat printr-o interfata la o retea de tip grila dubla (una pentru pachetele de cereri si alta pentru pachetele de raspuns). O astfel de retea permite scalarea sistemului. Algoritmul de rutare in retea este de tip gaura de vierme reducandu-se astfel latenta destul de ridicata a retelelor de tip grila.
Fiecare bloc al memoriei cache se poate afla intr-una din urmatoarele 3 stari (indicata de cei 2 biti de stare - fig. 33(b)):
(1) Nememorat (Uncached) in memoria cache: unica copie a blocului in memoria principala a nodului.
(2) Partajat (Shared): memoria principala este actualizata, copii ale blocului pot exista in mai multe memorii cache.
(3) Modificata (Modified): exista o singura memorie cache ce detine acest bloc, iar memoria principala nu este actualizata.
Protocolul DASH se bazeaza pe proprietate si scriere-invalidare. Un bloc de memorie se poate gasi intr-o singura memorie principala, cea nodului gazda. Deci, in orice moment, fiecare bloc de cache are un proprietar unic. Pentru blocurile nememorate sau partajate, proprietarul este nodul gazda al blocului. Pentru blocurile modificate proprietarul este nodul care detine copia unica. Scrierea intr-o linie partajata presupune mai intai gasirea si invalidarea tuturor copiilor existente. Gasirea lor se face cu ajutorul directorului nodului gazda.
Vom prezenta mai intai modul in care se desfasoara o citire. Procesorul care doreste sa citeasca un cuvant (data sau instructiune), mai intai face acces la memoria cache proprie. Daca aceasta nu contine cuvantul, atunci este lansata o cerere pe magistrala locala pentru a vedea daca un alt procesor din nod nu detine o copie a blocului. Daca unul din procesoare detine in cache o copie a blocului in starea partajat, atunci se mai poate face o copie. Daca blocul este in starea modificat, atunci este informat mai intai directorul gazda ca blocul va fi salvat in memorie si trecut in starea partajat, dupa care se poate face o copie. Harta de biti din catalog nu se modifica.
Daca blocul nu se gaseste intr-o memorie cache din nod se trimite nodului gazda un pachet de cerere prin reteaua de tip grila. Calea spre nodul gazda este determinata prin bitii mai semnificativi ai adresei. Daca nodul gazda este chiar nodul care a facut cererea, atunci pachetul nu paraseste nodul ci se obtine blocul din memoria principala a nodului. Controlorul directorului nodului gazda (cel care detine blocul) examineaza starea blocului si, daca este in starea nememorat sau partajat, trimite blocul nodului care a facut cererea si modifica harta de biti pentru indica faptul ca o copie a blocului se gaseste si in nodul care a facut cererea.
Daca blocul este in starea modificat, atunci lucrurile sunt mai complicate, pentru ca nodul gazda nu detine o copie valida a blocului si atunci controlorul catalogului nodului gazda determina din harta de biti care nod este proprietarul copiei valide si trimite un pachet de cerere catre acesta (ar putea fi chiar nodul gazda si atunci poate raspunde direct cu o copie a blocului). Nodul care detine copia valida va trimite o copie a blocului catre nodul care a facut cererea si una catre nodul gazda pentru a actualiza memoria principala a acestuia. Toate cele trei noduri implicate isi vor modifica harta de biti pentru a marca starea blocului ca partajata si nodurile care mai detin copii valide.
Rezulta deci ca in cazul cel mai defavorabil o citire inseamna acces la cache-ul local, acces pe magistrala la cache-urile din nod, un pachet catre nodul gazda, apoi un pachet de la nodul gazda catre nodul care detine copia modificata si in sfarsit un pachet de raspuns cu copia blocului. Toate acestea inseamna o latenta enorma.
Scrierea trebuie sa fie exlusiva, deci cel care scrie trebuie sa fie proprietarul unic al blocului. Daca procesorul care face scrierea are blocul in cache si este in starea modificat, atunci scrie fara nici-o alta complicatie. Daca blocul este partajat, trimite mai intai un pachet catre nodul gazda cu cererea ca toate celelalte copii sa fie invalidate.
Daca procesorul care a facut cererea nu are blocul in cache, atunci va face o cerere pe magistrala locala pentru a vedea daca unul din procesoarele vecine detine o copie in cache. Daca da, atunci se transfera blocul la cel care l-a cerut si, daca blocul era partajat se trimite o cerere la nodul gazda pentru a invalida toate celelalte copii.
Daca blocul nu se gaseste in nodul local, este trimis un pachet catre nodul gazda. Sunt trei situatii posibile.
Daca blocul este nememorat, este marcat in director ca modificat si trimisa o copie din memoria principala a nodului gazda catre nodul care a facut cererea.
Daca blocul este partajat, se trimit pachete de invalidare catre toate nodurile care detin copii, se marchaeza blocul ca modificat si se trimite o copie catre nodul care a facut cererea.
Daca blocul este modificat, nodul gazda trimite un pachet de cerere catre nodul care poseda copia unica, acesta satisface cererea si isi invalideaza copia. Nodul gazda isi actualizeaza harta de biti pentru a indica noul posesor al copiei unice.
Din acesata prezentare a protocolui de coerenta DASH bazat pe directoare se observa ca este complex si lent, necesita in cazurile cele mai defavorabile transmiterea a numeroase pachete in retea. mai mult accesul nu este terminat decat cand toate pachetele au fost confirmate. Pentru a rezolva aceste probeleme, protocolul a cunoscut unele imbunatatiri: scrieri inlantuite, utilizarea consistentei la eliberare in loc de consistenta secventiala.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 1427
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2026 . All rights reserved