| CATEGORII DOCUMENTE |
| Asp | Autocad | C | Dot net | Excel | Fox pro | Html | Java |
| Linux | Mathcad | Photoshop | Php | Sql | Visual studio | Windows | Xml |
DOCUMENTE SIMILARE |
||
|
||
When we developers work on a Web application, we focus mostly on the server side, the N-tier layering in its architecture, Model View Controller in its presentation layer, Data Transfer Objects across layers, various design patterns, database organization, etc. Then we focus on client or browser side where the presentation layer is rendered - CSS, HTML, JavaScript, etc. Here in this Web application development process, the thrust is primarily on the server side and occasionally we do some tweaking in JavaScript or CSS and achieve some presentation behavior on the browser screen. Now a days Microsoft has helped us in doing most of the development on the server side itself and within Visual Studio IDE and this is especially true if use server controls in an ASP.NET page.
But sometimes, it takes pretty long to detect some issues, as it requires an insight on overall programming model in the context of Web application; this includes the World Wide Web infrastructure, I call it infrastructure as the Web application always assumes this WWW backbone. So what is this overall programming model in the context of modern Web application? We will find an answer in this article.
Once I started thinking on this issue in the
past, I came across some wonderful articles on Web development series by Sean
Ewington (Beginner's Walk - Web Development in Code Project) and clearly in
this series I find there is a concerted approach to demystify what is going on
inside a Web application by studying its several ingredients for development
for example, JavaScript, HTML, CSS, ASP.NET with its associated state
management techniques. Now when we are talking about this Web application
development, things are getting little more complicated as user expectation is
increasing and technology landscape is not being stationary. It is also
evolving based on demand. For example, today
In order to understand a Web application better, we need to differentiate it from a Desktop application. This differentiation will help us in understanding the constraints in a Web application.
Desktop application is a stand alone application, say for example Microsoft Word. We need to install it on our computer. Occasionally we might use the internet to download for updates, but the code that runs these applications resides entirely on our Desktop PC.
Web application on the other hand runs on a Web server somewhere and we access the application with our Web browser on the internet. It is always updated on the server and when we use it on client browser we always get the updated version, say for example as in Google mail.
In Web application, there are waits (although things are changing with the power of internet bandwidth and asynchronous request made through AJAX which is described later) waiting for the server to respond, waiting for a request to come back with response through internet and waiting for screen to refresh with this page data on the browser. This wait is called latency between a request and a response.
Desktop applications do not have to depend on something like HTTP (described later), so the application states can easily be managed. Additionally, the stand alone Desktop application usually maintains connection on the database server which can be on the same Desktop PC or to a database server connected through LAN (Local Area Network).
On the other hand, in a Web application, the users fill out form fields and click a 'Submit' button. Then, the entire form is sent to the Web server, the server delegates processing to an engine based on the extension of the page, and when the processing is done, it sends back a completely new page. The new page might be HTML with a new form with some data filled in or it might be verification with its results or possibly a page with certain options selected based on data entered in the original form. Of course, while the script or program on the server is processing and returning a new form, the users have to wait. Our screen will go blank and then be redrawn as data comes back from the server. Here lies the difference in experience. Here, the users don't get instant feedback as is usually observed in a Desktop application.
Another distinct difference we should note from the security standpoint. In this context a Web application running on a browser should not get direct hardware access or direct OS access without required permissions and specific plug-ins like Adobe Flash player. This is called Sandbox security in a browser, it keeps HTML rendering and JavaScript execution within the browser in isolation from the client OS. Sandboxing is a generic security term referring to a limited-privilege application execution environment. Additionally, again due to security reasons browsers do not allow scripted calls to URLs located outside the domain of the current page, so there are some restrictions.
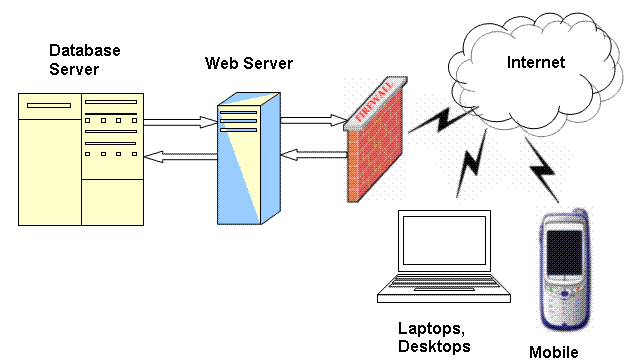
The following deployment diagram shows a Web application is deployed on a Web server and database in a separate server connected through LAN. Clients which could be accessing this Web applications through browsers on laptops, desktops, mobile, etc. In this simplistic diagram, note the differences on technologies on the client platform as well as within WWW including communication media. Here WWW is not just the components outside the client and server; it also standardizes what will flow through the wire at least with the application level protocol (in this case HTTP) between client and server.
Now let us have a look at the WWW infrastructure. When we talk about the World Wide Web (WWW) infrastructure for a Web application, the interesting model that comes on top is REST. This is explained in detail in his great PHD thesis by no other than Roy T. Fielding (dissertation) where he gave an architectural model for the World Wide Web.
In his thesis, he has mentioned that World Wide
Web is really vast and its scale is beyond imagination. It has pervaded and
penetrated all round the world and in every corner (I think it is only next to
Ether in Physics "the imponderable elastic media" of radio communication). This
full potential has been achieved only because of universal method of electronic
communication and a standard naming system. WWW also has several constraints to
ensure scalability.
In REST, the most important element is Resource. Resource in REST is identified by URL (he referred to as URI) which can be an application like bookcrossing. A Resource can be a Word Document, a PDF Document, an HTML document, an ASP.NET page, an image, etc.
The key characteristic of REST model is loose
coupling between its member components. REST defines stateless collaboration
among its member components.
So as per this standardization, each request in REST model is expected to be self-contained. Thus, the servers do not need to know where it came from, who is the client and what was his/her previous request. All they do is respond to requests as they come without keeping any continuity of state.
Another feature of World Wide Web (as it is consisting of large electronic networks for example, wireless communication, fiber optics and the old dial-ups to name a few) is that technology changes rapidly so it is important that the WWW is able to work independent of the underlying details.
REST is layered. In a layered system, each component layer behavior is such that each layer component cannot 'see' beyond the immediate layer with which it is interacting. In REST, layering promotes independence through encapsulation.
In terms of REST, a well-designed Web application running on WWW should behave as a network of web pages (a virtual state-machine), where the user progresses through the application by selecting links (state transitions), resulting in the next page (representing the next state of the application) being transferred to the user and rendered for their use.
As explained in REST in World Wide Web, the component interface has been designed to be efficient for large-grain hypermedia data transfer that is simple but necessarily not optimal especially when we apply them for an interactive Web application.
In REST, an architect uses the option by sending raw data to the recipient along with metadata that describes the data type, so that the recipient (in Web application usually the browser) can choose her/his own rendering engine.
Another constraint as set in REST model comes from the style Code-on-Demand. REST allows client functionality to be extended by downloading and executing code in the form of scripts. Since the script (JavaScript) is in text form, the visibility is not impaired (think of different client platforms for example, Windows, Linux, Mac, etc., think of firewalls for security). Also note that this part, i.e. text/HTML/JavaScript is interpreted and not compiled before executing on the browser environment.
In REST architecture, the primary connector types are client and server. The essential difference between the two is that a client initiates communication by making a request, whereas a server listens for connection requests and responds by opening its port in order to supply access to its services.
A user agent uses a client connector to initiate a request and becomes the ultimate recipient of the response. The most common example is a Web browser, which provides access to information services provided by servers and renders service responses according to the application needs.
Web server uses a server connector to service a requested resource.
The following figure (taken from the PHD Thesis) demonstrates process view architecture of a REST-based WWW when a Web application is running on top.
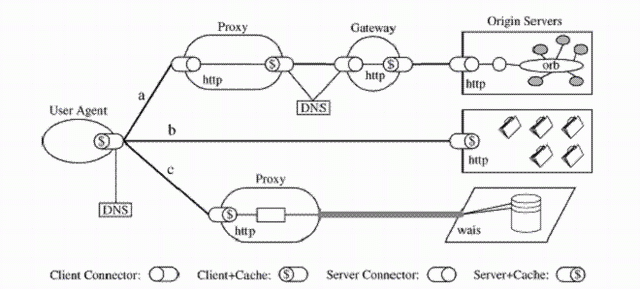
There are three different scenarios: a, b, and c.
In all of them, client requests were not satisfied by the user agent's client connector cache, so each request has been routed to the resource origin according to the properties of each resource identifier and the configuration of the client connector.
Request (a) has been sent to a local proxy, which in turn accesses a caching gateway found by DNS lookup, which forwards the request on to be satisfied by an origin Server.
Request (b) is sent directly to an origin server, which is able to satisfy the request from its own cache.
Request (c) is sent to a proxy that is capable of directly accessing WAIS, an information service that is separate from the Web architecture, and translating the WAIS response into a format recognized by the generic connector interface.
For network-based applications, system performance is dominated by network communication. For a distributed hypermedia system (which was the original target application on WWW), component interactions consist of large-grain data transfers rather than computation-intensive tasks. The REST model of WWW is developed in response to those needs. Its focus upon the generic connector interface of resources and representations has enabled intermediate processing, caching, and substitutability of components. This in turn has allowed Web-based applications on WWW to scale from 100,000 requests per day in 1994 to 600,000,000 requests per day in 1999 and still growing (can anyone say where it stands today?).
Now take a take a look at ASP.NET in the context of Web application just discussed above. With Microsoft ASP.NET technology, ASP.NET files are just text files and placed in the Web server (Microsoft IIS) and request URL (resource link entered or keyed on browser) points to those files. They are like any other Resource file as has been depicted in REST. When a request comes for an ASP.NET page, the server will locate the requested file and ask the ASP.NET engine to serve the request. The ASP.NET engine will process the server tags and generate HTML for it and return back to the client.
Now take a look at what
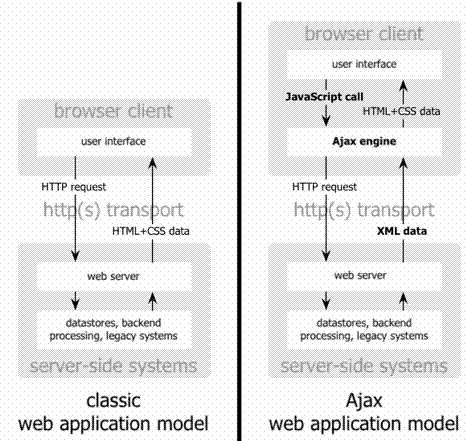
(Note - This diagram is taken
from 'Making Dizzy shine with
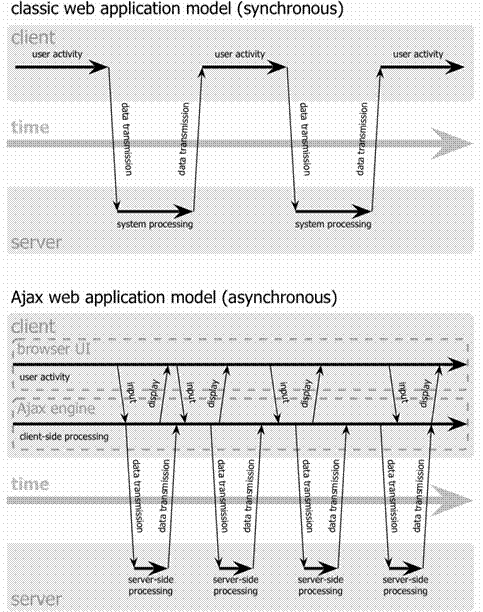
(Note - This diagram is taken
from 'Making Dizzy shine with
As shown in the diagram, theoretically there can be any number of connections between client and server working asynchronously which may be overlapped but there are limitations imposed by browsers. For example, Internet Explorer allows up to 2 connections to work simultaneously with any server.
As per Microsoft, Internet Explorer follows RFC2616 which states: "Clients that use persistent connections SHOULD limit the number of simultaneous connections that they maintain to a given server. A single-user client SHOULD NOT maintain more than 2 connections with any server or proxy."
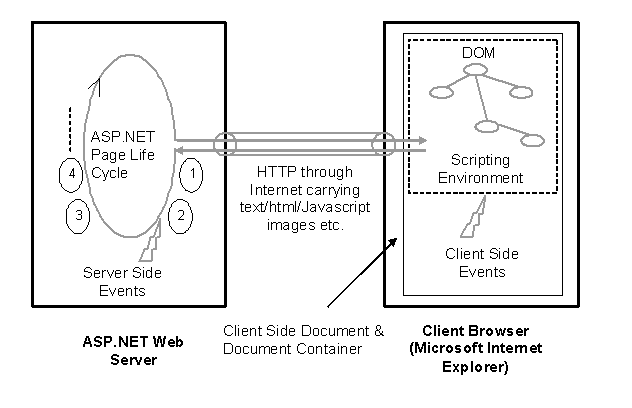

In this simplistic view (without going into
details like IIS architecture, Internet Explorer (browser) architecture, TCP
communication stack, etc.), the left side world is the server world and right
side world is the client world and they are connected through internet governed
by WWW infrastructure standards, so HTTP is the application protocol between
this client and server. The figure above illustrates both classic ASP.NET as
well as ASP.NET
Here both client and server provide event driven programming environment. Developer needs to intercept server side and/or client side events to do custom coding for custom behaviors or actions.
Let us have a look at the client side first. When we consider a Web application on a browser, we come across two types of object models:
Browser Object Model (BOM) - for example Windows - Frames etc. These are the objects supplied by the browser application running on top of client operating system. The important thing to understand here is that they are container of DOM elements of HTML document.
Document Object Model (DOM) - It models the document and its elements in the HTML document. This is what is returned as a response by server as per the URL requested from the client. Note it is this document which flows through internet (of course after serialization as text streams).
As a result, the DOM which represents the HTML document is dynamic in nature; it keeps changing during web page round trips between client and server. There are content changes, color changes; other attribute changes like selection changes - some controls may disappear and some new controls get added, etc. based on user interactions with the page. When we combine these behavior changes with server trips say during post-backs (the request and response are happening on the same page), we can imagine as if DOM objects are being serialized as text streams and passing through Internet pipe between client and server in both directions. On receiving response, the client browser de-serializes again and reconstructs the DOM for new presentation and further actions.
Browser programming environment is JavaScript for historical reasons started with Netscape browser and then as standard all browsers have built-in JavaScript interpreter.
JavaScript is primarily used to embed functions in HTML pages that glue together a user's actions with DOM elements in the page. We need to be careful when using the client side events while accessing DOM elements because of the dynamic nature of DOM. Unless we are careful, we may come across 'Object expected' error in JavaScript on some event handler say 'onload' whereas the same DOM element works fine and is valid for 'onclick' event handler. Because of the top down nature of interpretation, it is also important during load where we are placing the JavaScript method, at the beginning of the form (when DOM is not yet built) or at the end of the form (when DOM is already built).
There is no direct interface like remote procedure call (RPC) between server and client side applications as per the constraints imposed by WWW requirements and defined in REST model - the only common thing here is a stream of text which flows through Internet. This text stream contains both data (in the form of HTML) and program (i.e. JavaScript).
Using JavaScript, we can programmatically
rename, edit, add, or delete elements in the displayed document and handle any events
fired by such elements essentially using Document Object Model (DOM). In
addition, we can perform any browser-specific actions, such as opening or
popping up a new window or-what makes AJAX so special-invoke the popular XMLHttpRequest object and place
asynchronous calls to a remote URL on Web server.
While JavaScript is a powerful language,
putting complex application logic on the client can take a lot of time and
effort. ASP.NET
When a request arrives to the web server for an
ASP.NET page, the runtime creates an instance of the page's code-behind class
and invokes its ProcessRequest method,
which starts the server side ASP.NET page lifecycle and, ultimately, generates
the page's content, which is returned to the client in text/HTML/JavaScript
form.
When we combine
Partial rendering with
Remote services, on the other hand, involve a
service-oriented approach where the backend service is invoked by an
From an architectural viewpoint, partial
rendering doesn't add anything new. It enhances existing ASP.NET applications
with some
A partial rendering request is often referred
to as an
Once on the server, the request goes through
the typical lifecycle of post-back requests and raises such events as Init,
Load, and Pre-Render. On the server, an
Please note that origin of flickering is latency between request and response. The human eye can detect changes if this delay is more than 20 msec. AJAX eliminates this latency by using asynchronous request and response without the user being aware of this. Additionally since only a portion of the document is being changed each time, even the local processing involved during each interaction on client is significantly reduced and it results in smoother screen transition and rich user experience.
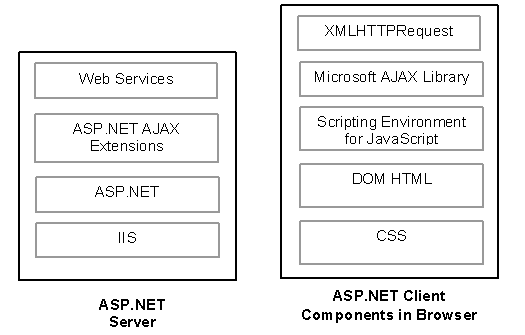
ASP.NET takes a set of files that contain code
and markup and generates a Page
class that is then compiled and cached.
For each request to the page, the class is instantiated and a complete page lifecycle is followed and a set of events are executed on the server. Some of these events are usually overridden by us in the generated page class through our coding to have customized set of actions and behaviors. Controls in the page also participate in the lifecycle, data-binding to backend databases, reacting to user input, and dealing with changes to their state from the user's previous view.
For example, the button control exposes a click
event. When using it, we don't need to write code to examine all form variables
on a page to know if the button was clicked. Instead, we just provide code for
this 'button_Click' event
handler. The event handler code can then update the HTML for the page or the
properties and data of other controls on the page.
An ASP.NET ScriptManager control. This control is
the real nerve center of ASP.NET ScriptManager control checks an HTTP
header in the request to determine whether the request is an
MicrosoftAjax.js defines language extensions supported by the Microsoft AJAX Library including namespaces, interfaces, enums, and inheritance. MicrosoftAjaxWebForms.js defines the partial rendering engine and the whole communication network stack.
In an ASP.NET ScriptManager which manages the download
of proper JavaScript files and client-side data, including the
Hyper Text Transfer Protocol (HTTP) is an application level protocol which is used in the 'World Wide Web (WWW)'. It is a request/response style protocol. Clients (Browsers) will request to a Server (Web Server) and the Server responds to these requests. HTTP uses TCP/IP protocol for communication. It connects to a specific port (default is 80) to the Server and communicates via that port. Once the response is received completely, client programs will be disconnected from the server. For each request, client programs have to acquire a connection with servers and do all the request cycles again.
In the response message HTTP contains status codes 100-199 indicating that the message contains a provisional information response, 200-299 indicating that the request succeeded, 300-399 indicating that the request needs to be redirected to another resource, 400-499 indicating that the client made an error that should not be repeated, and 500-599 indicating that the server encountered an error, but that the client may get a better response later (or via some other server), etc.
In HTTP, requests are directed to resources using a generic interface with standard semantics that can be interpreted by intermediaries in WWW as well as by the machines that originate services. The result is an infrastructure that allows for layers of transformation and indirection that are independent of the information origin and this helps an Internet-scale, multi-vendor, scalable information system. To understand HTTP, let us try to translate into HTTP a real life scenario. Consider the following (taken from 'An Overview of REST' by Alan Trick):
Request: Get milk from grocery store. I want 1%, but 2% is acceptable too.
Response: Ok, here is 1% milk:
[Milk contents]
In the language of HTTP headers, the request might look something like this:
![]() Collapse
Collapse
And the response:
![]() Collapse
Collapse
Resources in HTTP are nouns; the verb in HTTP
is a method. Two common methods are GET and
POST.
There were two pieces of meta-data in the example above. The first was in the request: the request asked for either 1 percent milk or 2 percent, although 1 percent is preferred twice as much. Note that these values correspond to media types (or MIME types); the particular values here are not real media types, but rather ones which are reserved to be used as examples. The response contains a statement that it is sending back 1 percent milk.
The 'content' on the web is often an HTML page or another electronic format like a GIF image. It may also contain links to other resources on the Web.
Although early HTTP based single request/response per connection behavior made for simple implementations, it resulted in inefficient use of the underlying TCP transport due to the overhead of per-interaction set-up costs.
To handle this, the Web architects adopted a form of persistent connections, which uses length-delimited messages in order to send multiple HTTP messages on a single connection. For HTTP/1.0, this was done using the 'keep-alive' directive within the connection header field. HTTP/1.1 eventually settled on making persistent connections the default, thus signaling its presence via the HTTP-version value, and only using the connection-directive 'close' to change the default.
As shown in the REST diagram, proxy lies between client and server. A client connects to the proxy, requesting some service, such as a file, connection, web page, or other resource, available from a different server. The proxy evaluates the request according to its filtering rules. If the request is validated by the filter, the proxy provides the resource by connecting to the relevant server and requesting the service on behalf of the client. Caching proxies keep local copies of frequently requested resources, allowing large organizations to significantly reduce their upstream bandwidth usage and cost, while significantly increasing performance.
A gateway is a network point that acts as an entrance to another network. On the Internet, a node or stopping point can be either a gateway node or a host (end-point) node. Both the computers of Internet users and the computers that serve pages to users are host nodes, while the nodes that connect the networks in between are gateways. For example, the computers that control traffic between company networks or the computers used by internet service providers (ISPs) to connect users to the internet are gateway nodes.
On an IP network, clients should automatically send IP packets with a destination outside a given subnet mask to a network gateway. A subnet mask defines the IP range of a network. For example, if a network has a base IP address of 192.168.0.0 and has a subnet mask of 255.255.255.0, then any data going to an IP address outside of 192.168.0.X will be sent to that network's gateway. On a Windows computer, this gateway feature is achieved by sharing the internet connection on that desktop.
The Domain Name System (DNS) is a hierarchical naming system for computers, services, or any resource participating in the Internet. It associates various information with the domain names assigned to each of the participants. Most importantly, it translates domain names meaningful to humans into the numerical (binary) identifiers associated with networking equipment for the purpose of locating and addressing these devices world-wide. An often used analogy to explain the Domain Name System is that it serves as the 'phone book' for the Internet by translating human-friendly computer hostnames into IP addresses. For example, www.example.com translates to 208.77.188.166.
JavaScript Object Notation (JSON) in its simplest form allows us to transform a set of data represented in a JavaScript object into a string. It is more compact in notation than XML.
Postback is a mechanism of communication between client-side (browser) and server-side (IIS) of a Web application. Through postback, all contents of page/form(s) sent to the server from client for processing and after following page life cycle all server side contents get rendered and client (browser) displays that content. It is also termed as round-trips for the page.
Understanding architectural principles of
underlying WWW infrastructure using REST model helps us in understanding the
constraints on ASP.NET Web application with or without
Based on your feedback for this article I am planning to write a sequel where I would demonstrate with an example ASP.NET project, how the changes on the server side code based on some event goes through wire and affects changes in the behavior on the client side. There I will use a helper tool named 'Fiddler' which is available free to download from Microsoft. Thank you for reading this article. Please send your feedback.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 2571
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2026 . All rights reserved