| CATEGORII DOCUMENTE |
| Asp | Autocad | C | Dot net | Excel | Fox pro | Html | Java |
| Linux | Mathcad | Photoshop | Php | Sql | Visual studio | Windows | Xml |
Threading
is the ability of a development framework to spin off parts of an application
into 'threads', which run out of step with the rest of the program.
In most programming languages, you have the equivalent of a
Another concept is that of free threading, which is not new to most C++ or Java developers; we will define this term and further explain the support provided in C#. We will briefly compare this free-threading model to other models, such as Visual Basic 6.0's apartment-threading model. We won't dwell on the differences for too long since this isn't a history lesson and this book certainly isn't about Visual Basic 6.0. However, understanding what sets these models apart will help you to understand why free threading is so wonderful. This chapter's concepts are essential to your understanding of the remainder of this book, as you will learn:
What a thread is, conceptually
Some comparisons between various multitasking and threading models
Where threads exist and how they are allocated processor time
How threads are controlled and managed using interrupts and priorities
The concept of application domains, and how they provide finer grained control on the security of your application than that provided in a simple process environment
By understanding many of the concepts of threading and how they are structured in .NET, you will be better placed to make programming decisions on how to implement these features in your applications, before learning the details of implementation as provided in the rest of the book.
By the end of this section, you will understand the following:
What multitasking is and what the different types of multitasking are
What a process is
What a thread is
What a primary thread is
What a secondary thread is
As you probably know, the term multitasking refers to an operating system's ability to run more than one application at a time. For instance, while this chapter is being written, Microsoft Outlook is open as well as two Microsoft Word windows, with the system tray showing further applications running in the background. When clicking back and forth between applications, it would appear that all of them are executing at the same time. The word 'application' is a little vague here, though; what we really are referring to are processes. We will define the word 'process' a little more clearly later in this chapter.
Classically speaking, multitasking actually exists in two different flavors. These days Windows uses only one style in threading, which we will discuss at length in this book. However, we will also look at the previous type of multitasking so we can understand the differences and advantages of the current method.
In earlier versions of Windows - such as Windows 3.x - and in some other operating systems, a program is allowed to execute until it cooperates by releasing its use of the processor to the other applications that are running. Because it is up to the application to cooperate with all other running programs, this type of multitasking is called cooperative multitasking. The downside to this type of multitasking is that if one program does not release execution, the other applications will be locked up. What is actually happening is that the running application hangs and the other applications are waiting in line. This is quite like a line at a bank. A teller takes one customer at a time. The customer more than likely will not move from the teller window until all their transactions are complete. Once finished, the teller can take the next person in line. It doesn't really matter how much time each person is going to spend at the window. Even if one person only wants to deposit a check, they must wait until the person in front of them who has five transactions has finished.
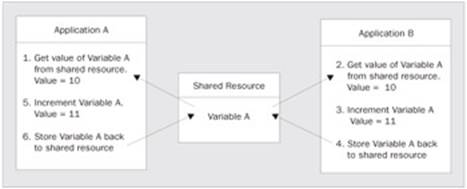
Thankfully, we shouldn't encounter this problem with current versions of Windows (2000 and XP) as the method of multitasking used is very different. An application is now allowed to execute for a short period before it is involuntarily interrupted by the operating system and another application is allowed to execute. This interrupted style of multitasking is called pre-emptive multitasking. Pre-emption is simply defined as interrupting an application to allow another application to execute. It's important to note that an application may not have finished its task, but the operating system is going to allow another application to have its time on the processor. The bank teller example above does not fit here. In the real world, this would be like the bank teller pausing one customer in the middle of their transaction to allow another customer to start working on their business. This doesn't mean that the next customer would finish their transaction either. The teller could continue to interrupt one customer after another - eventually resuming with the first customer. This is very much like how the human brain deals with social interaction and various other tasks. While pre-emption solves the problem of the processor becoming locked, it does have its own share of problems as well. As you know, some applications may share resources such as database connections and files. What happens if two applications are accessing the same resource at the same time? One program may change the data, then be interrupted, allowing another program to again change the data. Now two applications have changed the same data. Both applications assumed that they had exclusive access to the data. Let's look at the simple scenario illustrated in Figure 1.
In Step 1, Application A obtains an integer value from a data store and places it in memory. That integer variable is set to . Application A is then pre-empted and forced to wait on Application B. Step 2 begins and Application B then obtains that same integer value of . In Step 3, Application B increments the value to . The variable is then stored to memory by Application B in Step 4. In Step 5, Application A increments this value as well. However, because they both obtained a reference to this value at , this value will still be after Application A completes its increment routine. The desired result was for the value to be set to 12. Both applications had no idea that another application was accessing this resource, and now the value they were both attempting to increment has an incorrect value. What would happen if this were a reference counter or a ticket agency booking plane tickets?
The problems associated with pre-emptive multitasking are solved by synchronization, which is covered in Chapter 3.
When an application is launched, memory and any other resource for that application are allocated. The physical separation of this memory and resources is called a process. Of course, the application may launch more than one process. It's important to note that the words 'application' and 'process' are not synonymous. The memory allocated to the process is isolated from that of other processes and only that process is allowed to access it.
In Windows, you can see the currently running processes by accessing the Windows Task Manager. Right-clicking in an empty space in the taskbar and selecting Task Manager will load it up, and it will contain three tabs: Applications, Processes, and Performance. The Processes tab shows the name of the process, the process ID (PID), CPU usage, the processor time used by the process so far, and the amount of memory it is using. Applications and the processes appear on separate tabs, for a good reason. Applications may have one or more processes involved. Each process has its own separation of data, execution code, and system resources.
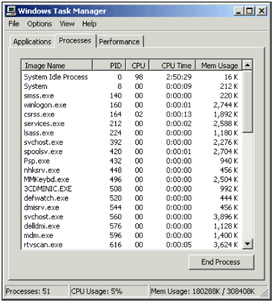
You will also notice that the Task Manager has summary information about process CPU utilization. This is because the process also has an execution sequence that is used by the computer's processor. This execution sequence is known as a thread. This thread is defined by the registers in use on the CPU, the stack used by the thread, and a container that keeps track of the thread's current state. The container mentioned in the last sentence is known as Thread Local Storage. The concepts of registers and stacks should be familiar to any of you used to dealing with low-level issues like memory allocation; however, all you need to know here is that a stack in the .NET Framework is an area of memory that can be used for fast access and either stores value types, or pointers to objects, method arguments, and other data that is local to each method call.
As noted above, each process has
at least one of these sequential execution orders, or threads. Creating a
process includes starting the process running at a point in the instructions.
This initial thread is known as the primary or main thread. The
thread's actual execution sequence is determined by what you code in your
application's methods. For instance, in a simple .NET Windows Forms
application, the primary thread is started in the static
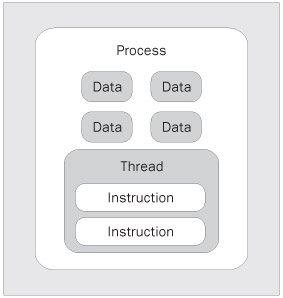
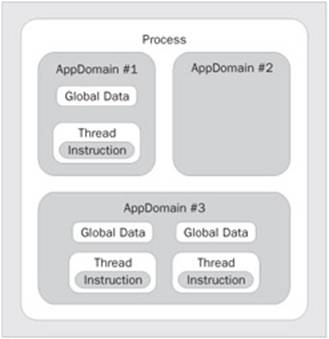
Now that we have an idea of what a process is and that it has at least one thread, let's look at a visual model of this relationship in Figure 2:
Looking at the diagram above, you'll notice that the thread is in the same isolation as the data. This is to demonstrate that the data you declare in this process can be accessed by the thread. The thread executes on the processor and uses the data within the process, as required. This all seems simple; we have a physically separated process that is isolated so no other process can modify the data. As far as this process is concerned, it is the only process running on the system. We don't need to know the details of other processes and their associated threads to make our process work.
To be more precise, the thread is really a pointer into the instruction stream portion of a process. The thread does not actually contain the instructions, but rather it indicates the current and future possible paths through the instructions determined by data and branching decisions.
When we discussed multitasking, we stated that the operating system grants each application a period to execute before interrupting that application and allowing another one to execute. This is not entirely accurate. The processor actually grants time to the process. The period that the process can execute is known as a time slice or a quantum. The period of this time slice is unknown to the programmer and unpredictable to anything besides the operating system. Programmers should not consider this time slice as a constant in their applications. Each operating system and each processor may have a different time allocated.
Nevertheless, we did mention a potential problem with concurrency earlier, and we should consider how that would come into play if each process were physically isolated. This is where the challenge starts, and is really the focus of the remainder of this book. We mentioned that a process has to have at least one thread of execution - at least one. Our process may have more than one task that it needs to be doing at any one point in time. For instance, it may need to access a SQL Server database over a network, while also drawing the user interface.
As you probably already know, we can split up our process to share the time slice allotted to it. This happens by spawning additional threads of execution within the process. You may spawn an additional thread in order to do some background work, such as accessing a network or querying a database. Because these secondary threads are usually created to do some work, they are commonly known as worker threads. These threads share the process's memory space that is isolated from all the other processes on the system. The concept of spawning new threads within the same process is known as free threading.
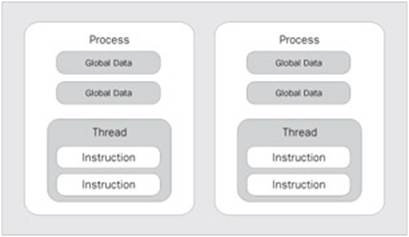
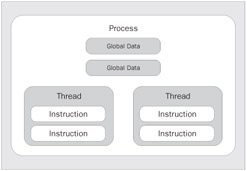
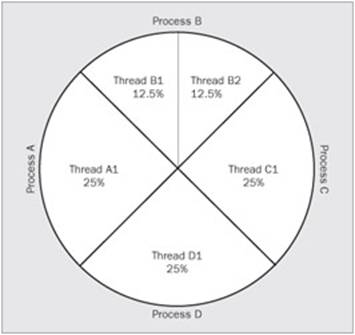
The concept of free threading gives a significant advantage over the apartment-threading model - the threading model used in Visual Basic 6.0. With apartment threading, each process was granted its own copy of the global data needed to execute. Each thread spawned was spawned within its own process, so that threads could not share data in the process's memory. Let's look at these models side by side for comparison. Figure 3 demonstrates the apartment-threading concept, while Figure 4 demonstrates the free-threading concept. We won't spend a much time on this because we are not here to learn about Visual Basic 6.0, but it's important to describe these differences:
As you can see, each time you want to do some background work, it happens in its own process. This is therefore called running out-of-process. This model is vastly different from the free-threading model shown in Figure 4.
You can see that we can get the CPU to execute an additional thread using the same process's data. This is a significant advantage over single threaded apartments. We get the benefits of an additional thread as well as the ability to share the same data. It is very important to note, however, that only one thread is executing on the processor at a time. Each thread within that process is then granted a portion of that execution time to do its work. Let's go one more time to a diagram (Figure 5) to help illustrate how this works.
For the sake of this book, the examples and diagrams assume a single processor. However, there is an even greater benefit to multi-threading your applications if the computer has more than one processor. The operating system now has two places to send execution of the thread. In the bank example that we spoke of earlier, this would be similar to opening up another line with another teller. The operating system is responsible for determining which threads are executed on which processor. However, the .NET platform does provide the ability to control which CPU a process uses if the programmer so chooses. This is made possible with the ProcessorAffinity property of the Process class in the System. Diagnostics namespace. Bear in mind, however, that this is set at the process level and so all threads in that particular process will execute on the same processor.
The scheduling of these threads is vastly more complicated than demonstrated in the last diagram, but for our purposes, this model is sufficient for now. Since each thread is taking its turn to execute, we might be reminded of that frustrating wait in line at the bank teller. However, remember that these threads are interrupted after a brief period. At that point, another thread, perhaps one in the same process, or perhaps a thread in another process, is granted execution. Before we move on, let's look at the Task Manager again.
Launch the Task Manager and return to the Processes tab. Once open, go to the View | Select Columns menu. You will see a list of columns that you can display in the Task Manager. We are only concerned with one additional column at this point - the Thread Count option. Select this checkbox. You should see something like this:
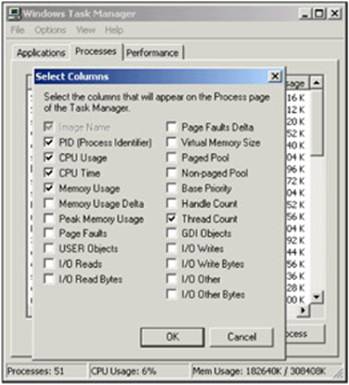
Once you click OK you will notice that several of your processes have more than one thread listed in the Thread Count column. This reinforces the idea that your program may have many threads for one just one process.
When one thread runs out of time in its allocated time slice, it doesn't just stop and wait its turn again. Each processor can only handle one task at a time, so the current thread has to get out of the way. However, before it jumps out of line again, it has to store the state information that will allow its execution to start again from the point it left earlier. If you remember, this is a function of Thread Local Storage (TLS). The TLS for this thread, as you may remember, contains the registers, stack pointers, scheduling information, address spaces in memory, and information about other resources in use. One of the registers stored in the TLS is a program counter that tells the thread which instruction to execute next.
Remember that we said that processes don't necessarily need to know about other processes on the same computer. If that were the case, how would the thread know that it's supposed to give way to anther process? This scheduling decision nightmare is handled by the operating system for the most part. Windows itself (which after all is just another program running on the processor) has a main thread, known as the system thread, which is responsible for the scheduling of all other threads.
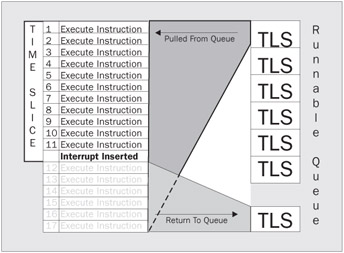
Windows knows when it needs to make a decision about thread scheduling by using interrupts. We've used this word already, but now we are going to define exactly what an interrupt is. An interrupt is a mechanism that causes the normally sequential execution of CPU instructions to branch elsewhere in the computer memory without the knowledge of the execution program. Windows determines how long a thread has to execute and places an instruction in the current thread's execution sequence. This period can differ from system to system and even from thread to thread on the same system. Since this interrupt is obviously placed in the instruction set, it is known as a software interrupt. This should not be confused with hardware interrupts, which occur outside the specific instructions being executed. Once the interrupt is placed, Windows then allows the thread to execute. When the thread comes to the interrupt, Windows uses a special function known as an interrupt handler to store the thread's state in the TLS. The current program counter for that thread, which was stored before the interrupt was received, is then stored in that TLS. As you may remember, this program counter is simply the address of the currently executing instruction. Once the thread's execution has timed out, it is moved to the end of the thread queue for its given priority to wait its turn again. Look at Figure 6 for a diagram of this interruption process:
The TLS is not actually saved to the queue; it is stored in the memory of the process that contains the thread. A pointer to that memory is what is actually saved to the queue.
This is, of course, fine if the thread isn't done yet or if the thread needs to continue executing. However, what happens if the thread decides that it doesn't need to use all of its execution time? The process in context switching (that is switching from the context of one thread to another) is slightly different initially, but the results are the same. A thread may decide that it needs to wait on a resource before it can execute again. Therefore, it may yield its execution time to another thread. This is the responsibility of the programmer as well as the operating system. The programmer signals the thread to yield. The thread then clears any interrupts that Windows may have already placed in its stack. A software interrupt is then simulated. The thread is stored in TLS and moved to the end of the queue just as before. We will not diagram this concept as it's quite easy to understand and very similar to the diagram opposite. The only thing to remember is that Windows may have already placed an interrupt on the thread's stack. This must be cleared before the thread is packed up; otherwise, when the thread is again executed, it may be interrupted prematurely. Of course, the details of this are abstracted from us. Programmers do not have to worry about clearing these interrupts themselves.
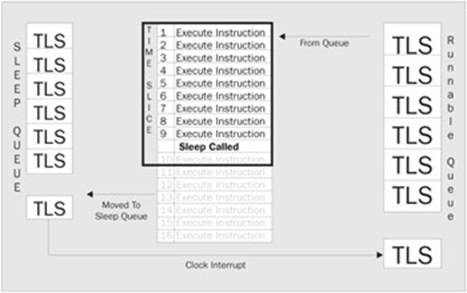
As we stated, the program may have yielded execution to another thread so it can wait on some outside resource. However, the resources may not be available the next time the thread is brought back to execute. In fact, it may not be available the next 10 or 20 times a thread is executed. The programmer may wish to take this thread out of the execution queue for a long period so that the processor doesn't waste time switching from one thread to another just to realize it has to yield execution again. When a thread voluntarily takes itself out of the execution queue for a period, it is said to sleep. When a thread is put to sleep, it is again packed up into TLS, but this time, the TLS is not placed at the end of the running queue; it is placed on a separate sleep queue. In order for threads on a sleep queue to run again, they are marked to do so with a different kind of interrupt called a clock interrupt. When a thread is put into the sleep queue, a clock interrupt is scheduled for the time when this thread should be awakened. When a clock interrupt occurs that matches the time for a thread on the sleep queue, it is moved back to the runnable queue where it will again be scheduled for execution. Figure 7 illustrates this:
We've seen a thread interrupted, and we've seen a thread sleep. However, like all other good things in life, threads must end. Threads can be stopped explicitly as a request during the execution of another thread. When a thread is ended in this way, it is called an abort. Threads also stop when they come to the end of their execution sequence. In any case, when a thread is ended, the TLS for that thread is de-allocated. The data in the process used by that thread does not go away, however, unless the process also ends. This is important because the process may have more than one thread accessing that data. Threads cannot be aborted from within themselves; a thread abort must be called from another thread.
We've seen how a thread can be interrupted so that another thread can execute. We have also seen how a thread may yield its execution time by either yielding that execution once, or by putting itself to sleep. We have also seen how a thread can end. The last thing we need to cover for the basic concept of threading is how threads prioritize themselves. Using the analogy of our own lives, we understand that some tasks we need to do take priority over other tasks. For instance, while there is a grueling deadline to meet with this book, the author also needs to eat. Eating may take priority over writing this book because of the need to eat. In addition, if this author stays up too late working on this book, rest deprivation may elevate the body's priority to sleep. Additional tasks may also be given by other people. However, those people cannot make that task the highest priority. Someone can emphasize that a task may be important, but it's ultimately up to the recipient of the task to determine what should be of extremely high importance, and what can wait.
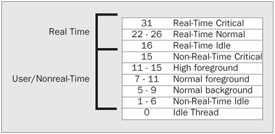
The information above contains much theory and analogy; however, this very closely relates to our threading concept. Some threads just need to have a higher priority. Just as eating and sleeping are high priorities because they allow us to function, system tasks may have higher priorities because the computer needs them to function. Windows prioritizes threads on a scale of 0 to 31, with larger numbers meaning higher priorities.
A priority of 0 can only be set by the system and means the thread is idle. Priorities between 1 and 15 can be set by users of a Windows system. If a priority needs to be set higher than 15, it must be done by the administrator. We will discuss how an administrator does this later. Threads running in a priority between 16 and 31 are considered to be running real-time. When we refer to the term real-time, we mean that the priority is so high that they pre-empt threads in lower priorities. This pre-emption has the effect of making their execution more immediate. The types of items that might need to run in real-time mode are processes like device drivers, file systems, and input devices. Imagine what would happen if your keyboard and mouse input were not high priorities to the system! The default priority for user-level threads is 8.
One last thing to remember is that threads inherit the priority of the processes in which they reside. Let's diagram this for your future reference in Figure 8. We'll also use this diagram to break these numbers down even further.
In some operating systems, such as Windows, as long as threads of a higher priority exist, threads in lower priority are not scheduled for execution. The processor will schedule all threads at the highest priority first. Each thread of that same priority level will take turns executing in a round-robin fashion. After all threads in the highest priority have completed, then the threads in the next highest level will be scheduled for execution. If a thread of a higher priority is available again, all threads in a lower priority are pre-empted and use of the processor is given to the higher priority thread.
Based on what we know about priorities, it may be desirable to set certain process priorities higher so that any threads spawned from those processes will have a higher likelihood of being scheduled for execution. Windows provides several ways to set priorities of tasks administratively and programmatically. Right now, we will focus on setting priorities administratively. This can be done with tools such as the task manager, and two other tools called pview (installed with Visual Studio) and pviewer (installed with either a resource kit for Windows NT or directly with Windows XP Professional). You can also view the current priorities using the Windows Performance Monitor. We won't concentrate on all of these tools right now. We will briefly look at how to set the general priority of processes. If you remember, back when we first introduced processes, we launched the Task Manager to view all of the processes currently running on the system. What we didn't cover is the fact that we can elevate the priority of a particular process in that very same window.
Let's try changing a process's priority. First, open up an instance of an application such as Microsoft Excel. Now launch the Task Manager and go to the Processes tab again. Look at an instance of Excel running as a process. Right-click on EXCEL.EXE in the list and choose Set Priority from the menu. As you can see, you can change the priority class as you wish. It wouldn't make much sense to set the priority of Excel high, but the point is you could if you wanted to. Every process has a priority and the operating system isn't going to tell you what priorities you should and should not have. However, it will warn you that you may be about to do something with undesirable consequences; but the choice is still left up to you.
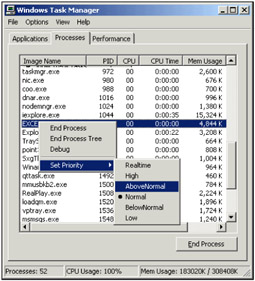
In the previous screenshot, you can see that one of the priorities has a mark next to it. This mark represents the current priority of the process. It should be noted that when you set a priority for one process, you are setting it for that one instance only. This means that all other currently running instances of that same application will retain their default process levels. Additionally, any future instances of the process that are launched will also have the default process level.
Free threading is supported in the .NET Framework and is therefore available in all .NET languages, including C# and VB.NET. In this next section, we will look at how that support is provided and more of how threading is done as opposed to what it is. We will also cover some of the additional support provided to help further separate processes
By the end of this section, you will understand:
What the System.AppDomain class is and what it can do for you
How the .NET runtime monitors threads
When we explained processes earlier in this chapter, we established that they are a physical isolation of the memory and resources needed to maintain themselves. We later mentioned that a process has at least one thread. When Microsoft designed the .NET Framework, it added one more layer of isolation called an application domain or AppDomain. This application domain is not a physical isolation as a process is; it is a further logical isolation within the process. Since more than one application domain can exist within a single process, we receive some major advantages. In general, it is impossible for standard processes to access each other's data without using a proxy. Using a proxy incurs major overheads and coding can be complex. However, with the introduction of the application domain concept, we can now launch several applications within the same process. The same isolation provided by a process is also available with the application domain. Threads can execute across application domains without the overhead associated with inter-process communication. Another benefit of these additional in-process boundaries is that they provide type checking of the data they contain.
Microsoft encapsulated all of the functionality for these application domains into a class called System.AppDomain. Microsoft .NET assemblies have a very tight relationship with these application domains. Any time that an assembly is loaded in an application, it is loaded into an AppDomain. Unless otherwise specified, the assembly is loaded into the calling code's AppDomain. Application domains also have a direct relationship with threads; they can hold one or many threads, just like a process. However, the difference is that an application domain may be created within the process and without a new thread. This relationship could be modeled as shown in Figure 9.
In .NET, the AppDomain and Thread classes cannot be inherited for security reasons.
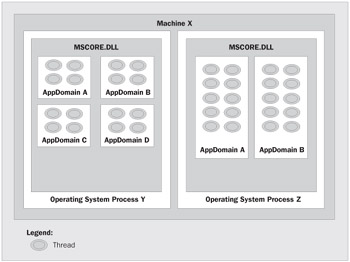
Each application contains one or more AppDomains. Each AppDomain can create and execute multiple threads. If you look at Figure 10, in Machine X there are two OS processes Y and Z running. The OS process Y has four running AppDomains: A, B, C, and D. The OS process Z has two AppDomains: A and B.
You've heard the theory and seen the models; now let's get our hands on some real code. In the example below, we will be using the AppDomain to set data, retrieve data, and identify the thread that the AppDomain is executing. Create a new class file called appdomain.cs and enter the following code:
using System;Your output should look something like this:
Retrieving current domainThis is straightforward for even unseasoned C# developers. However, let's look at the code and determine exactly what is happening here. This is the first important piece of this class:
This method takes parameters for the name of the data to be set, and the value. You'll notice that the SetData () method has done something a little different when it passes the parameters in. Here we cast the string value to an Object data type as the SetData () method takes an object as its second parameter. Since we are only using a string, and a string inherits from System.Object, we could just use the variable without casting it to an object. However, other data that you might want to store would not be as easily handled as this. We have done this conversion as a simple reminder of this fact. In the last part of this method, you will notice that we can obtain the currently executing ThreadId with a simple call to the GetCurrentThreadId property of our AppDomain object.
Let's move on to the next method:
public string GetDomainData(string name)This method is very basic as well. We use the GetData () method of the AppDomain class to obtain data based on a key value. In this case, we are just passing the parameter from our GetDomainData() method to the GetData () method. We return the result of that method to the calling method.
Finally, let's look at the
We start by initializing the name and
value pairs we want to store in our AppDomain and
writing a line to the console to indicate our method has started execution.
Next, we set the Domain field of our class with a
reference to the currently executing AppDomain object
(the one in which your
Moving on, we pass one parameter into GetDomainData() method to get the data we just set and insert it into our console output stream. We also output the ThreadId property of our class to see what our executing ThreadId was in the method we called.
Now let's look at how to create a new application domain and make some important observations about the behavior when creating threads within the newly created AppDomain. The following code is contained within create_appdomains.cs:
using System;The output of this compiled class should look similar to this:
The Value ' was found in create_appdomains.exe running on thread id: 1372You'll notice in this example we have created two application domains. To do this, we call the CreateDomain() static method of the AppDomain class. The parameter that the constructor takes is a friendly name for the AppDomain instance that we are creating. We will see that we can access the friendly name later by way of a read-only property. Here is the code that creates the AppDomain instance:
AppDomain DomainA;Next we call the SetData () method that we saw in the previous example. We won't redisplay the code here because we explained its use earlier. However, what we need to explain next is how we get code to execute in a given AppDomain. We do this with the DoCallBack() method of the AppDomain class. This method takes a CrossAppDomainDelegate as its parameter. In this case, we have created an instance of a CrossAppDomainDelegate passing the name of the method we wish to execute into the constructor:
CommonCallBack();You'll notice that we call CommonCallBack() first. This is to execute our CommonCallBack () method within the context of the main AppDomain. You'll also notice from the output that the FriendlyName property of the main AppDomain is the executable's name.
Lastly, let's look at the CommonCallBack() method itself:
public static void CommonCallBack()You'll notice that this is rather generic so it will work in no matter what instance we run it. We use the CurrentDomain property once again to obtain a reference to the domain that is executing the code. Then we use the FriendlyName property again to identify the AppDomain we are using.
Lastly, we call the GetCurrentThreadId() method again here. When you look at the output, you can see that we get the same thread ID no matter what AppDomain we are executing in. This is important to note because this not only means that an AppDomain can have zero or many threads, but also that a thread can execute across different domains.
The .NET Framework provides more than just the ability for free-threaded processes and logical application domains. In fact, the .NET Framework supplies an object representation of processor threads. These object representations are instances of the System.Threading.Thread class. We will go into this in more depth in the next chapter. However, before we move on to the next chapter, we must understand how unmanaged threads work in relation to managed threads. That is to say, how unmanaged threads (threads created outside of the .NET world) relate to instances of the managed Thread class, which represent threads running inside the .NET CLR.
The .NET runtime monitors all threads that are created by .NET code. It also monitors all unmanaged threads that may execute managed code. Since managed code can be exposed by COM-callable wrappers, it is possible for unmanaged threads to wander into the .NET runtime.
When unmanaged code does execute in a managed thread, the runtime will check the TLS for the existence of a managed Thread object. If a managed thread is found, the runtime will use that thread. If a managed thread isn't found, it will create one and use it. It's very simple, but is necessary to note. We would still want to get an object representation of our thread no matter where it came from. If the runtime didn't manage and create the threads for these types of inbound calls, we wouldn't be able to identify the thread, or even control it, within the managed environment.
The last important note to make about thread management is that once an unmanaged call returns back to unmanaged code, the thread is no longer monitored by the runtime.
We have covered a wide range of topics in this chapter. We covered the basics of what multitasking is and how it is accomplished by the use of threads. We established that multitasking and free threading are not the same thing. We described processes and how they isolate data from other applications. We also described the function of threads in an operating system like Windows. You now know that Windows interrupts threads to grant execution time to other threads for a brief period. That brief period is called a time slice or quantum. We described the function of thread priorities and the different levels of these priorities, and that threads will inherit their parent process's priority by default.
We also described how the .NET runtime monitors threads created in the .NET environment and additionally any unmanaged threads that execute managed code. We described the support for threading in the .NET Framework. The System.AppDomain class provides an additional layer of logical data isolation on top of the physical process data isolation. We described how threads could cross easily from one AppDomain to another. Additionally, we saw how an AppDomain doesn't necessarily have its own thread as all processes do.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 3485
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved