| CATEGORII DOCUMENTE |
| Asp | Autocad | C | Dot net | Excel | Fox pro | Html | Java |
| Linux | Mathcad | Photoshop | Php | Sql | Visual studio | Windows | Xml |
In order to use the numerical integrator, you must supply it with a Butcher Table object derived from the abstract class CButcherTable. This class provides a number of routines that define the method of integration. A Butcher Table is a compact means of supplying the coefficients that make up the equations of integration. Note that there is also a class of integration routines called Linear Multi-step Methods (LMM), which are generally used for stiff differential equations. These methods operate differently from Runge-Kutta methods and cannot be described by the Butcher Table format. LMM methods cannot be used with this numerical integration package.
Section provides a brief discussion of the theory behind Runge-Kutta methods. The following sections describe the various variables and member functions which you must override in order to provide the appropriate behavior for the Butcher Table object.
A Runge-Kutta (RK) method is a means of numerically solving an ordinary differential equation (ODE) of the Initial Value Problem (IVP) type. The IVP is a first order ODE that may be written in the form
![]() (4-1)
(4-1)
where the "prime" indicates differentiation with
respect to t, and y is an n-dimensional vector ![]() . The RK method attempts to solve this equation by starting
with the initial time and state value, (t0,
y0), and an integration
step size,
. The RK method attempts to solve this equation by starting
with the initial time and state value, (t0,
y0), and an integration
step size, ![]() , and computing an estimate of the state value at the time t0+h. This new value is then used to compute the next stage, and so
on. The equations describing this procedure for the nth step are given by
, and computing an estimate of the state value at the time t0+h. This new value is then used to compute the next stage, and so
on. The equations describing this procedure for the nth step are given by
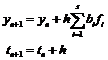 (4-2)
(4-2)
where
![]() (4-3)
(4-3)
s is the number of stages in the RK method, and aij, bi, and ci are appropriately chosen coefficients. The coefficients can be written as matrices and vectors, and placed in the Butcher Table format
![]() (4-4)
(4-4)
Note that, as written, Eq. (4-3) is an implicit equation; the computation of the ith derivative estimate requires knowledge of all of the other estimates. Generally, however, the upper triangle of A is set to zero. This makes Eq. (4-3) explicit, and is a much easier problem to solve. The rest of this discussion will assume that the method is explicit, except for Section , which goes into more details on how this integration package handles implicit methods.
There are a number of relationships between the elements of A, b, and c based on satisfying the error requirements of the method. Two of these relationships can be useful in verifying that the coefficients have been recorded correctly and to differentiate between b and c. These two are
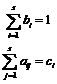 (4-5)
(4-5)
Thus the rows of A will add up to the values of c, and the values of b will add up to one.
As an example of this notation, the first-order Euler method, commonly defined as
![]() (4-6)
(4-6)
has the Butcher Table representation
![]() (4-7)
(4-7)
Similarly, the classic four stage Runge-Kutta method has the Butcher Table representation
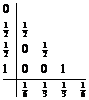 (4-8)
(4-8)
where the upper triangle of A is left blank to indicate all zeros.
Some methods employ the First-Same-As-Last (FSAL) strategy. In this case, the final stage of the nth step is identical to the first stage of the (n+1)th step. This reduces the number of function evaluations by one for each step.
The local truncation error (LTE) is the difference between
the estimated solution given by Eq. (4-2) and the true solution given initial
conditions at yn. The
order of the method comes from consideration of a
![]() (4-9)
(4-9)
which means that if you halve the step size, the local error will be reduced by a factor of 2p.
Quite often, the RK method is integrated using a fixed step size, h. Depending on the behavior of the differential equation, this step size may be too large or too small. If it is too large, errors will accumulate and the method can become unstable. If the step size is too small, the derivative function is computed excessively, resulting in wasted computational effort. What is needed is an estimate of the error which can be used to modify the step size to get the best accuracy without wasted effort.
When the actual solution to the differential equation is not known or cannot be computed (the usual case), the RK method must compute an error estimate on its own. One of the most accurate methods is to use Richardson Extrapolation (RE). RE computes the step normally using Eq. (4-2). It then computes the same step again using two smaller steps of size h/2. The estimate of the local error, e, is given by
![]() (4-10)
(4-10)
where ![]() is the solution
computed in the normal way,
is the solution
computed in the normal way, ![]() is the solution
computed with the two half-steps, and p
is the order of the solution.
is the solution
computed with the two half-steps, and p
is the order of the solution.
It should be noted that while Richardson Extrapolation is very accurate, it is computational expensive. Eq. (4-2) is evaluated three times, which requires triple the number of derivative function evaluations than for a normal step. One solution in common use is to provide an Embedded Formula in the Butcher Table.
An Butcher Table with an embedded formula has an extra set of b coefficients which provide a solution with a different order (typically one order higher than the main solution). The second solution is computed using
![]() (4-11)
(4-11)
where the coefficients are shown in the Butcher Table as
![]() (4-12)
(4-12)
The estimate of the local error, e, is given by
![]() (4-13)
(4-13)
An example of a Butcher Table with an embedded formula is the following three-stage, 2(3) order method
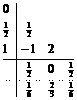 (4-14)
(4-14)
The embedded formula does not provide quite as accurate a step size measure as does Richardson Extrapolation, but it does so with far fewer additional function evaluations. The method typically requires only one or two additional stages to provide the higher order estimate. As both methods use the same set of function evaluations, this is a substantially smaller computational effort. Originally, the lower order solution was kept and used to continue integration. More recent methods have been developed to use Local Extrapolation whereby the higher order solution is kept. In these cases, the methods do not maintain the same stability guarantee that the lower order methods have, but for most well-behaved ODE's, stability is not a problem.
This integration package allows you to use either error estimate. By default, if the method provides an embedded formula then it will be used. In other cases, Richardson Extrapolation will be used. However, you can force the integrator to use the latter method even when there is an embedded formula.
Once the local error estimate is known, the step size may be changed for the next step to get near the accuracy target without wasting too much effort with small step sizes. For either error estimate, the new step size is computed using
![]() (4-15)
(4-15)
where EPS, the error per stage, is the left-hand side of Eq. (2-1). The factor of 0.5 in the numerator keeps the method from trying to maintain the accuracy requirements exactly, as this could lead to too many rejected steps. Also, the step is not allowed to grow to more than double its previous value to avoid stability issues with large changes in step size. Also, should the error estimate fail (i.e., the error is too large), the step size is halved until the step is accepted or the minimum allowed step size is reached.
While variable step size methods are able to reduce the computational effort for a given error tolerance, they suffer from the problem that the resulting solution points, tn, cannot be predicted a priori. Also, the step sizes may be large relative to the desired output spacing. This is a serious disadvantage when trying to produce uniform output, such as for plotting or frequency analysis.
One method for achieving this is to limit the step size such that the current step will not go beyond the next desired output point. While this reduction in step size is acceptable in terms of the error tolerance, it is inefficient because the step size must be arbitrarily shortened. This method is used in this numerical integration code for methods without dense output (see below).
The solution to this dilemma is to employ dense output.
The b coefficients are reformulated
in terms of the parameter ![]() . These new coefficients are called b*, and are related to the original b elements through
. These new coefficients are called b*, and are related to the original b elements through
![]() (4-16)
(4-16)
The elements of b*
satisfy the same order and error conditions as the original b elements. Also, if the method has an
embedded formula, a corresponding ![]() must be formulated.
The elements of b* must
be recomputed for every s.
must be formulated.
The elements of b* must
be recomputed for every s.
The value of the solution at any point in the interval ![]() can be computed from
can be computed from
![]() (4-17)
(4-17)
where
![]() (4-18)
(4-18)
for the desired output time, ![]() . Thus, the integration may proceed with the step size
computed from error consideration and still produce uniformly spaced output.
Also, dense output guarantees that the intermediate solution will have the same
order of accuracy as the original method. This differs significantly from
linear interpolation, which is only first-order accurate. Note, too, that dense
output does not require any additional derivative function evaluations. Thus
there is no additional penalty for using it.
. Thus, the integration may proceed with the step size
computed from error consideration and still produce uniformly spaced output.
Also, dense output guarantees that the intermediate solution will have the same
order of accuracy as the original method. This differs significantly from
linear interpolation, which is only first-order accurate. Note, too, that dense
output does not require any additional derivative function evaluations. Thus
there is no additional penalty for using it.
As an example of a method with dense output, consider the two-stage, second order RK method given by
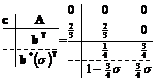 (4-19)
(4-19)
Note that b
= b*(1), as required. For
systems that have an embedded formula as well, there will be a corresponding ![]() formula.
formula.
All of the examples above have assumed that the method is explicit. This numerical integration package does allow you to use implicit methods, although the computational cost is generally not worth the extra accuracy.
Implicit methods generally perform much better against stiff ODE's. Stiff systems are ones in which the solution has several time constants which differ by several orders of magnitude. An example of a stiff ODE is
![]() (4-20)
(4-20)
which has the exact solution
![]() (4-20)
(4-20)
for initial conditions ![]() . In order to maintain the stability of the solution, the
step size must be driven very small because of the e-1000t term,
even though this plays a small part of the final solution.
. In order to maintain the stability of the solution, the
step size must be driven very small because of the e-1000t term,
even though this plays a small part of the final solution.
Implicit methods are better able to maintain a reasonable step size with these types of systems. But because they are implicit, iterative methods are required to solve Eq. (4-3) for the fi. These iterations drive up the cost due to the number of additional function calls required. Some improvements can be made for semi-implicit systems where only diagonal elements of the upper triangle are non-zero. However, this package does not differentiate between implicit and semi-implicit methods.
If you encounter a stiff ODE and the explicit formulas fail, you can try to use an implicit formula. However, the preferred methods for solving these types of problems are Linear Multi-step Methods, which have a completely different formulation, and are beyond the scope of this integration package.
You must create a new object to represent the integration method. This object must be derived from the abstract class CButcherTable, with it as a public base class. You must define a number of member functions and initialize the member variables based on the capabilities of the specific method. This section describes some of the considerations in creating your Butcher Table object. The following sections describe the member functions and variables in more detail.
At a minimum you must provide a constructor and creation functions for the A, b, and c coefficients. The constructor is responsible for setting the order and number of stages, as well as setting the informational flags. The creator functions will be called once by the initialization code, and will populate the coefficient tables. The remaining abstract functions only need to be overridden for when your method has dense output or an embedded formula.
The base method class has a number of virtual member functions to define the various coefficient tables. There are tables to handle normal steps, embedded formula, and dense output.
These functions are grouped according to purpose. Table 26 gives a brief description of the general nature of each group. The actual functions are defined in the sections to follow. For each, the usage is defined, along with any required or optional inputs, and a description of the purpose of the routine and any special considerations in using it. The final sections list the member functions that you cannot override, and also the member variables you may need to set based on your needs.
Table 26. Butcher Table Function Classifications.
|
Class |
Description |
Section |
|
Constructor |
The constructor is called when the Butcher Table object is created. This is generally an empty function; use the Initialization Functions to set up. |
4.4 |
|
Initialization Functions |
These functions are called after the Butcher Table object is created in order to finish preparation for use. |
4.5 |
|
Creation Functions |
These functions are called during creation and initialization to populate the matrices which define the method. |
4.6 |
|
Generation Functions |
The functions in this class are called to generate new coefficient values as integration proceeds. |
4.7 |
|
Functions That Cannot Be Overridden |
These functions are defined by the base class and cannot be overridden. They report the values of some of the variable you set in the constructor. |
4.8 |
|
Internal Variables |
These are the internal variables that are defined in the base class. You must set their values based on the needs of the Butcher Table. |
4.9 |
The constructor is called automatically when the Butcher Table object is instantiated.
CMyBT() ;
CMyBT MyBT;
CMyBT* pMyBT;
pMyBT = new CMyBT;
None.
None.
The constructor can generally be left blank. Initialization of the method should occur in UserInit().
Table 27 lists the initialization functions. Of these, you generally only need to override UserInit(). The other two functions are defined by the base class and should handle all the appropriate behaviors.
Table 27. Butcher Table Initialization Functions.
|
Function |
Description |
|
UserInit |
This is where you do all of the preparation work. |
|
Initialize |
Performs the initialization (You should not need to override this!) |
|
SetErrorPowers |
Sets the error power coefficients (You should not need to override this!) |
virtual void UserInit();
UserInit();
None.
None.
This private member function is where you set the flags, declare the order and number of stages, and size the coefficient tables (A, b, c, etc.). The base class function is a pure virtual function and must be overridden.
virtual void Initialize();
mBT->Initialize();
None.
None.
This public member function is called by the integrator through the helper function InitButcherTable(). This function in turn calls the following functions in this order:
UserInit()
SetErrorPowers()
CreateA()
CreateB()
CreateC()
CreateBHat()
This function is defined in the base class and should not need to be overridden, except under extreme circumstances.
virtual void SetErrorPowers();
SetErrorPowers();
None.
None.
This private member function is defined in the base class and computes the error power coefficients required for variable step size control. Specifically, it computes the multiplicative constant in Eq. (4-10), and the exponent in Eq. (4-15). It requires that you have set the order of the method in UserInit(). This function should not need to be overridden, except in extreme circumstances.
Table 28 lists the functions which you must override to create the elements of the coefficient tables.
Table 28. Butcher Table Creation Functions.
|
Function |
Description |
|
CreateA |
This function populates the A matrix. |
|
CreateB |
This function populates the b vector. |
|
CreateBHat |
This function populates the |
|
CreateC |
This function populates the c vector. |
virtual void CreateA();
CreateA();
None.
None.
You must override this pure virtual function and use it to populate the elements of the A matrix. Note that for explicit functions, you only need to populate the lower triangle of A since the values of the matrix are set to zero by default.
virtual void CreateB();
CreateB();
None.
None.
You must override this pure virtual function and use it to populate the elements of the b vector.
virtual void CreateBHat();
CreateBHat();
None.
None.
You can override this function and use it to populate the ![]() if you have an
embedded formula. Recall that
if you have an
embedded formula. Recall that ![]() should contain the
coefficients of the higher-order method, while b contains those of the lower order method. If you have dense
output, you can use ComputeBStar()
to populate this vector.
should contain the
coefficients of the higher-order method, while b contains those of the lower order method. If you have dense
output, you can use ComputeBStar()
to populate this vector.
virtual void CreateC();
CreateC();
None.
None.
You must override this pure virtual function and use it to populate the elements of the c vector.
There is only one generator function in the Butcher Table object: ComputeBStar(). This function is used to compute the elements of the b* vector for a given s.
virtual void ComputeBStar(double sigma);
pBT->ComputeBStar(sigma);
None.
None.
If your method has dense output, you should override this public function and have it computes the value of b* for a given value of s. Recall that s should be in the range [0,1], and you may wish to check for this (although this is not required). In functions with dense output and an embedded formula, the elements of b* will correspond to whichever order is used to propagate the solution (see Section about Local Extrapolation).
The integrator calls this function just before computing the dense output to make sure it has the proper values.
This section describes the functions defined in the base class which will be inherited by your Butcher Table object. These functions are called by the integrator at various times to provide information about the method and return the coefficients. While you cannot override these functions, they will reference internal variables that you will need to set in the other routines listed above. The functions are listed below grouped according to purpose.
|
Function |
Description |
|
A() |
Returns the Butcher Table A matrix. |
|
b() |
Returns the Butcher Table b vector. |
|
bHat() |
Returns the Butcher Table |
|
bStar() |
Returns the Butcher Table b* vector. |
|
c() |
Returns the Butcher Table c vector. |
|
A(i,j) |
Returns aij. |
|
b(i) |
Returns bi. |
|
bHat(i) |
Returns |
|
bStar(i) |
Returns |
|
c(i) |
Returns ci. |
|
Function |
Description |
|
order |
Returns the order of the method. |
|
stages |
Returns the number of stages (excluding dense output stages). |
|
denseStages |
Returns the number of stages (including dense output stages). |
|
errPow |
Returns the error power coefficient from Eq. (4-15). |
|
RichFactor |
Returns the Richardson Extrapolation coefficient from Eq. (4-10). |
|
Function |
Description |
|
IsEmbedded |
Tells the integrator whether the method has an embedded formula. |
|
UseLocalExtrapolation |
Tells the integrator whether to use Local Extrapolation when taking a step. |
|
HasFSALstage |
Tells the integrator whether the method has an FSAL stage. |
|
HasDenseOutput |
Tells the integrator whether the method has dense output. |
|
IsImplicit |
Tells the integrator whether the method is implicit. |
This section lists the internal variables defined in the base class. These are the variables which you must modify to prepare the Butcher Table to communicate with the integrator. These variables are listed below, grouped by purpose. Recall that Boolean values default to false.
|
Variable |
Type |
Description |
|
m_A |
matrix |
Contains the matrix A. |
|
m_b |
colvec |
Contains the vector b. |
|
m_bHat |
colvec |
Contains the vector |
|
m_bStar |
colvec |
Contains the vector b*. |
|
m_c |
colvec |
Contains the vector c. |
|
Variable |
Type |
Description |
|
mStages |
int |
Supply the number of stages (excluding dense output stages). |
|
mDenseStages |
int |
Supply the number of stages (including dense output stages). |
|
mOrder |
double |
Supply the order of the method (lower order for embedded methods). |
|
mErrPow |
double |
Value of the exponent from Eq. (4-15). Computed by method. |
|
mRichFactor |
double |
Value of the coefficient from Eq. (4-10). Computed by method. |
|
Variable |
Type |
Description |
|
mIsEmbedded |
bool |
Set to true if the method has an embedded formula. |
|
mUseLocalExtrapolation |
bool |
Set to true if the method uses Local Extrapolation. |
|
mHasFSALstage |
bool |
Set to true if the method has an FSAL stage. |
|
mHasDenseOutput |
bool |
Set to true if the method has dense output. |
|
mIsImplicit |
bool |
Set to true if the method is implicit. |
The code below provides an example Butcher Table class derived from CButcherTable. It demonstrates how to provide the proper information values. It is also a part of the ODE test suite (see Section ).
class CBT_Fehlberg45 : public CButcherTable
public:
CBT_Fehlberg45 () // Default constructor
~CBT_Fehlberg45 () // Destructor
protected:
virtual void CreateA (); // Creates the elements of the A matrix
virtual void CreateB (); // Creates the elements of the b vector
virtual void CreateBHat (); // Compute the elements of the bHat vector
virtual void CreateC (); // Creates the elements of the c vector
virtual void UserInit (); // Initialize mStages, mOrder, etc.
void CBT_Fehlberg45::UserInit()
void CBT_Fehlberg45::CreateA()
void CBT_Fehlberg45::CreateB() // 4th order method
void CBT_Fehlberg45::CreateBHat() // 5th order method
void CBT_Fehlberg45::CreateC()
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 882
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved