| CATEGORII DOCUMENTE |
| Asp | Autocad | C | Dot net | Excel | Fox pro | Html | Java |
| Linux | Mathcad | Photoshop | Php | Sql | Visual studio | Windows | Xml |
DOCUMENTE SIMILARE |
|||
|
|||
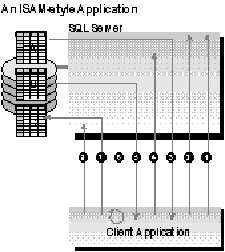
Another key aspect of database application design is how the application code interacts with the database. Some applications treat the database simply as a storage place for records. The application itself performs most of the operations on the data, such as filtering, aggregating, or matching records. Other applications treat the database as a data management engine, performing all of these data operations at the server. The first style of database access is common in programs written to use an indexed sequential access method (ISAM) database. The second style of database access is more appropriate for a program interacting with a relational database like SQL Server. This section compares these two styles of database access.
Many applications are originally developed on an ISAM database and are later moved to a relational database. Usually porting to a relational database supports better data sharing with other applications or fits customer database standards. The first port of such an ISAM‑style application often substitutes a relational database table for the equivalent ISAM file and leaves the bulk of the application code unchanged. SQL Server will work for these ISAM‑style applications, but the application performs much better if it is adapted to take full advantage of relational‑style database access and asks the server to do the jobs it is capable of doing.
An example illustrates why an ISAM‑style application does not perform optimally on SQL Server. This application example involves three tables: a master customer table, a detail orders table, and a summary invoice table. The program task is to extract the appropriate record for customer "Viki Parrott," find the customer's current orders, and then aggregate the order totals for that customer into the invoice summary table. An ISAM-style application to accomplish this task is coded as follows:
The client sends a BEGIN TRANSACTION request to the server.
The client requests that the server open a cursor on the customer table (A) for records with the last name >= 'Parrott'.
The client fetches one or more customer records until the correct record is found.
Having found the customer ID, the client program asks the server to open a cursor on the orders table (B) for orders matching the customer ID.
The client fetches all matching order records for the customer.
The client calculates the aggregate of those detailed records.
The client sends a command to update the invoices table (C) with the calculated aggregate.
The client sends a COMMIT TRANSACTION statement.
|
|
Why doesn't the ISAM-style application perform well? The problems with this style of coding are:
Excessive network traffic.
The ISAM‑style moves data unnecessarily across the network. This example application moved the master and detail records to the client to calculate an aggregate, a task that could have been done at the server. More importantly, this example required at least seven roundtrips between client and server to accomplish a simple task. Network roundtrips are usually the number one factor for poor performance in a client/server application, an even greater factor than the amount of data transferred between server and client.
Excessive use of cursors.
Cursors are a useful tool in relational databases; however, it is almost always more expensive to use a cursor than to use set-oriented SQL to accomplish a task. In set-oriented SQL, the client application tells the server to update the set of records that meet specified criteria. The server figures out how to accomplish the update as a single unit of work. When updating through a cursor, the client application requires the server to maintain row locks or version information for every row, just in case the client asks to update the row after it has been fetched. Also, using a cursor implies that the server is maintaining client "state" information such as the user's current rowset at the server, usually in temporary storage. Maintaining this state for a large number of clients is an expensive use of server resources. A better strategy with a relational database is for the client application to get in and out quickly, maintaining no client state at the server between calls. Set-oriented SQL supports this strategy.
Unnecessarily long transactions.
The ISAM‑style application example uses a "conversational" style of communicating with the server that involves many network roundtrips within a single transaction. The effect is that transactions get longer in duration. Transactions handled this way can span seconds or minutes or even tens of minutes between the BEGIN TRANSACTION and the COMMIT TRANSACTION statements. These long-running transactions can be fine for a single user, but they scale poorly to multiple users. To support transactional consistency, the database must hold locks on shared resources from the time they are first acquired within the transaction until the transaction commits. If other users need access to the same resources, they must wait. As individual transactions get longer, the queue and other users waiting for locks gets longer and system throughput decreases. Long transactions also increase the chances of a deadlock, which occurs when two or more users are simultaneously waiting on locks held by each other.
The problems that result from running an ISAM-style application on SQL Server stem from its failure to take advantage of the capabilities of SQL Server. In contrast, an application that is well designed for SQL Server:
Uses SQL effectively.
Minimizes network roundtrips to the server during a transaction.
Uses stored procedures.
Incorporates the essential indexing and configuration steps for SQL Server.
These characteristics don't have to be applied with an all-or-nothing approach. They can be incorporated into an application over time.
Structured query language (SQL) is the language of Microsoft SQL Server. It makes sense that application developers learn to "speak" this language fluently if they want their applications to communicate effectively with the server. By using SQL effectively, an application can ask the server to perform tasks rather than requiring application code and processing cycles to achieve the same result. More importantly, effective use of SQL can minimize the amount of data that must be read from and written to disk devices at the server. Finally, effective use of SQL can minimize the amount of data shipped to and from SQL Server across the network. Saving disk I/O and network I/O are the most important factors for improving application performance.
Using SQL effectively begins with a normalized database design. Normalization is the process of removing redundancies from the data. When converting from an ISAM-style application, normalization often involves breaking data in a single file into two or more logical tables in a relational database. SQL queries then recombine the table data by using relational join operations. By avoiding the need to update the same data in multiple places, normalization improves the efficiency of an application and reduces the opportunities for introducing errors due to inconsistent data.
There are sometimes trade-offs to normalization: A database that is used primarily for decision support (as opposed to update-intensive transaction processing) may not have redundant updates and may be more understandable and efficient for queries if the design is not fully normalized. Nevertheless, unnormalized data is a more common design problem in SQL Server applications than over-normalized data. Starting with a normalized design and then selectively denormalizing tables for specific reasons is a good strategy.
Whatever the database design, you should take advantage of the features in SQL Server to automatically maintain the integrity of the data. The CREATE TABLE statement supports data integrity:
CHECK constraints ensure that column values are valid.
DEFAULT and NOT NULL constraints avoid the complexities (and opportunities for hidden application bugs) caused by missing column values.
PRIMARY KEY and UNIQUE constraints enforce the uniqueness of rows (and implicitly create an index to do so).
FOREIGN KEY constraints ensure that rows in dependent tables always have a matching master record.
IDENTITY columns efficiently generate unique row identifiers.
TIMESTAMP columns ensure efficient concurrency checking between multiple user updates.
User-defined data types ensure consistency of column definitions across the database.
By taking advantage of these CREATE TABLE options, you can make the data rules visible to all users of the database, rather than hide them in application logic. These server-enforced rules help avoid errors in the data that can arise from incomplete enforcement of integrity rules by the application itself. Using these facilities also ensures that data integrity is enforced as efficiently as possible.
One of the capabilities of SQL is its ability to filter data at the server so that only the minimum data required is returned to the client. Using these facilities minimizes expensive network traffic between the server and client. This means that WHERE clauses must be restrictive enough to get only the data that is required by the application.
It is always more efficient to filter data at the server than to send it to the client and filter it in the application. This also applies to columns requested from the server. An application that issues a SELECT * FROM statement requires the server to return all column data to the client, whether or not the client application has bound these columns for use in program variables. Selecting only the necessary columns by name will avoid unnecessary network traffic. It will also make your application more robust in the event of table definition changes, because newly added columns won't be returned to the client application.
Beyond the SQL syntax itself, performance also depends on
how your application requests a result set from the server. In an application
using ODBC, the "how" is determined by the statement options set prior to
executing a SELECT. When you leave the statement options at default values, SQL
Server sends the result set the most efficient way. SQL Server assumes
that your application will fetch all the rows from a default result set
immediately. Therefore, your application must buffer any rows that are not used
immediately but may be needed later. This buffering requirement makes it
especially important for you to specify (by using SQL) only the data you need.
It may seem economical to request a default result set and fetch rows only as your application logic or your application user needs them, but this is false economy. Unfetched rows from a default result set can tie up your connection to the server, blocking other work in the same transaction. Still worse, unfetched rows from a default result set can cause SQL Server to hold locks at the server, possibly preventing other users from updating. This concurrency problem may not show up in small-scale testing, but it can appear later when the application is deployed. The lesson here is simple-immediately fetch all rows from a default result set.
Some applications cannot buffer all the data they request of the server. For example, an application that queries a large table and allows the user to specify the selection criteria may return no rows or millions of rows. The user is unlikely to want to see millions of rows. Instead, the user is more likely to re-execute the query with narrower selection criteria. In this case, fetching and buffering millions of rows only to have them thrown away by the user would be a waste of time and resources.
For applications like these, SQL Server offers server cursors that allow an application to fetch a small subset or block of rows from an arbitrarily large result set. If the user wants to see other records from the same result set, a server cursor allows the application to fetch any other block of rows from the result set, including the next n rows, the previous n rows, or n rows starting at a certain row number in the result set. SQL Server does the work to fulfill each block fetch request only as needed, and SQL Server does not normally hold locks between block fetches on server cursors. Server cursors also allow an application to do a positioned update or delete of a fetched row without having to figure out the source table and primary key of the row. If the row data changes between the time it is fetched and the time the update is requested, SQL Server detects the problem and prevents a lost update.
All of these features of server cursors come at a cost. If all the results from a given SELECT statement are going to be used in your application, a server cursor is always going to be more expensive than a default result set. A default result set always requires just one roundtrip between client and server, whereas each call to fetch a block of rows from a server cursor results in a roundtrip. Moreover, some types of server cursors (those declared as dynamic) are restricted to using unique indexes only, while other types (keyset and static cursors) make heavy use of temporary storage at the server. For these reasons, only use server cursors where your application needs their features. If a particular task requests a single row by primary key, use a default result set. If another task requires an unpredictably large or updatable result set, use a server cursor and fetch rows in reasonably sized blocks (for example, one screen of rows at a time).
Structured query language (SQL) goes far beyond the basics of creating tables, inserting records, and retrieving data from tables. Your application will perform better if it requests the server to perform a task with a more sophisticated SQL statement than if it performs the same task using simple SQL statements combined with application logic. Therefore, learning the full capabilities of SQL is a wise investment of your time. For SQL Server, these capabilities include:
An UPDATE statement that can modify rows in one table based on related data in other tables.
Rich JOIN capabilities, including INNER, CROSS, LEFT OUTER, RIGHT OUTER, and FULL OUTER joins, as well as combinations of these join types.
Subqueries that can be used in any expression context.
A CASE expression that provides a powerful conditional logic capability in an ANSI‑standard syntax.
Sophisticated aggregation functions, including the CUBE and ROLLUP operators to produce multidimensional aggregates in decision support applications.
An ISAM‑style application will use few or none of these advanced SQL capabilities and, as a result, will be less efficient than an application designed to take advantage of them when performing equivalent tasks.
A primary goal of using SQL appropriately is to reduce the amount of data transferred between server and client. Reducing the amount of data transferred will usually reduce the time it takes to accomplish a logical task or transaction. As discussed earlier, long transactions may work fine for a single user, but they can cause concurrency problems and scale poorly for multiple users. Techniques you can use to reduce transaction duration include:
Commit transactional changes as soon as possible within the requirements of the application.
Applications often perform large batch jobs, such as month-end summary calculations, as a single unit of work (and thus one transaction). With many of these applications, individual steps of the job can be committed without compromising database consistency. Committing changes as quickly as possible means that locks are released as quickly as possible. Because SQL Server uses page locks for most operations, releasing locks quickly minimizes their impact on other users who may need access to rows on the same data pages.
Take advantage of SQL Server statement batches.
Statement batches are a way of sending multiple SQL statements to the server at one time, thereby reducing the number of roundtrips to the server. If the statement batch contains multiple SELECT statements, the server will return multiple result sets to the client in a single data stream.
Use parameter arrays for repeated operations.
The ODBC SQLParamOptions function allows multiple parameter sets for a single SQL statement to be sent to the server in a batch, again reducing the number of roundtrips.
Use SQL Trace to diagnose application traffic.
SQL Trace can monitor, filter, and record all of the calls sent from client applications to the server. It will often reveal unexpected application overhead due to unnecessary calls to the server. SQL Trace can also reveal opportunities for batching statements that are currently being sent separately to the server.
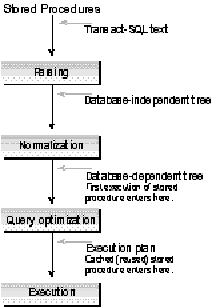
All well-designed SQL Server applications should use stored procedures. This is true whether or not the application's business logic is written into stored procedures. Even standard SQL statements with no business logic component gain a performance advantage when "packaged" as stored procedures with parameters.
When they are created, stored procedures go through the parsing and normalization steps that SQL Server performs on any SQL statement. The stored procedure is then saved to disk in the parsed, normalized form of a query tree. At first execution, SQL Server retrieves the saved query tree and optimizes the execution of the SQL based on the values of parameters passed in and the available statistics of the referenced tables and their indexes. On subsequent executions of the same stored procedure by any user, SQL Server looks to the procedure cache first to see if a matching optimized execution plan is available for use with a new set of parameters. SQL statements compiled into stored procedures can thus save a significant amount of processing at execution time.
|
|
Another advantage of stored procedures is that client execution requests use the network more efficiently than equivalent SQL statements sent to the server. For example, suppose an application needs to insert a large binary value into an image data field. To send the data in an INSERT statement, the application must convert the binary value to a character string (doubling its size) and then send it to the server. The server then converts the value back into a binary format for storage in the image column. In contrast, the application can create a stored procedure of the form:
CREATE PROCEDURE P(@p1 image) AS INSERT T VALUES (@p1)
When the client application requests an execution of procedure P, the image parameter value will stay in its native binary format all the way to the server, thereby saving processing time and network traffic.
SQL Server stored procedures can provide even greater performance gains when they include business services logic. As described earlier, this "fat server" implementation yields outstanding performance because it moves the processing to the data, rather than moving the data to the processing. Nevertheless, using stored procedures is not restricted to the fat server development model. Stored procedures that encapsulate predefined SQL statements provide performance benefits in any implementation. Furthermore, you can easily configure the SQL Server ODBC driver to create and use temporary stored procedures automatically, any time your application calls the SQLPrepare API. These temporary stored procedures are not (currently) as efficient as permanent stored procedures created by the application itself, but they can yield good performance gains when an application executes the same prepared SQL statement multiple times. If you write an application to use the ODBC prepare/execute combination, you enable it to selectively take advantage of the current automatic stored procedure option as well as future enhanced versions of this option.
Indexing and configuring a SQL Server database for optimal performance is usually considered a database administrator's job, not a development task. However, as a developer, you should know the fundamentals of SQL Server indexes and configuration so that:
Database designs incorporate clustered indexes in the original creation scripts.
Development computers execute test scenarios as efficiently as possible.
Your application can automatically configure the database as part of the installation process, reducing the complexity for the end user.
There are books, self-study courses, and classroom courses that teach SQL Server configuration and tuning in great depth. The following sections, however, cover basic configuration steps that are often overlooked. If an application is well written and these configuration guidelines are followed, SQL Server will perform optimally. Additional tuning can yield small performance gains, but there probably won't be configuration changes that will result in dramatic performance boosts.
SQL Server has two types of indexes: clustered and nonclustered. A clustered index keeps the data rows of a table physically stored in index order. Because there is only one physical order to the rows in a table, there can be a maximum of one clustered index per table. All other indexes on a table are nonclustered. A clustered index is usually the most efficient method to finding a row or set of rows in a table, so choosing the column(s) by which to define the clustered index is an important part of application tuning. But if you don't know what columns to use, don't leave off a clustered index entirely. In SQL Server version 6.5, it is rarely a benefit to have no clustered index on a table. For an application in which the query patterns are not well known, you can define the clustered index on the primary key columns. Subsequent analysis of some tables may suggest that the most common queries perform better with the clustered index on a nonkey column such as a foreign key column, in which case the default could be overridden for those tables only.
An index includes distribution statistics about the data values in the index. The SQL Server cost-based query optimizer uses these statistics to determine if a particular index will be useful to solve a query. When a large number of rows are added or changed after an index is defined on a table, these statistics will be inaccurate until you run an UPDATE STATISTICS statement. This can mislead SQL Server into using a poor index or a table scan to resolve a query, which can cause poor query performance and reduced concurrency. An update operation that uses a table scan instead of an index, for example, will lock the entire table for the duration of the transaction.
It is therefore important to update statistics regularly on the active tables in your application. You should also learn how to use the SHOWPLAN feature of SQL Server. It reports information such as the optimizer's index selections and join orderings, and shows you whether the indexes are being used for your application's queries. Every unused nonclustered index slows down inserts, updates, and deletes on a table, so make sure that you are using only the indexes you need.
The axiom of SQL Server disk management is that spreading the database out over multiple physical disk drives improves performance. In almost all cases, the log for a database should be placed on a separate physical disk from the data portion of the database. The data portion of the database should be "striped" across multiple physical devices to achieve maximum throughput. Striping is easy to configure with the disk management facilities built into the Microsoft Windows NT operating system. For the operating system to spread out the data randomly with striping usually yields equivalent performance to placing database tables and indexes on specific devices, and at a fraction of the effort. Windows NT also offers disk configurations (RAID levels) that can protect a database against the failure of a hard disk. All SQL Server databases should take advantage of these capabilities.
SQL Server uses memory for data cache and procedure cache, among other things. Using data or a procedure from cache is an order of magnitude faster than reading it from disk. Therefore, allowing SQL Server to use as much of the physical memory of the server computer as practical will yield better performance. On the other hand, assigning too much memory to SQL Server can conflict with other applications on the server. This can cause the Windows NT operating system to start paging real memory out to disk, resulting in worse performance for SQL Server. SQL Server memory usage is not automatically configured at installation. You must manually configure SQL Server memory usage based on published guidelines, and check it with performance monitoring tools. The procedure is simple, and it is essential to achieving optimal throughput on a computer.
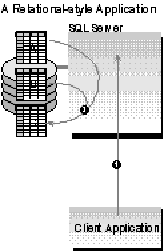
The following SQL application performs the same task as the previous ISAM‑style example. This time, however, the application task has been rewritten to use the principles of relation-style database access. The application task now uses a stored procedure, P, that takes one ID parameter. Procedure P is created as follows:
CREATE PROCEDURE P (@p1 int) AS
UPDATE C SET c1 =
(select sum(B.qty)
from A, B
where A.pk=C.id
and A.fk=B.pk)
WHERE C.id = @id
|
|
This procedure updates the summary table C for a passed-in customer ID, using the detailed customer and order records for that customer ID from tables A and B. This stored procedure uses only ANSI-standard SQL; it does not involve writing business logic in Transact‑SQL. Yet it reduces the transaction to a single roundtrip to the server; data stays at the server, rather than moving unnecessarily across the network. Because the action is an atomic SQL statement, the procedure doesn't even need to wrap the statement in a BEGIN TRANSACTION/COMMIT TRANSACTION pair-the statement is automatically its own transaction. This transaction will be significantly shorter in duration than the equivalent ISAM‑style transaction. The user of this SQL application is going to have less impact on other users because the application holds locks for much shorter duration.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 1362
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved