| CATEGORII DOCUMENTE |
| Astronomie | Biofizica | Biologie | Botanica | Carti | Chimie | Copii |
| Educatie civica | Fabule ghicitori | Fizica | Gramatica | Joc | Literatura romana | Logica |
| Matematica | Poezii | Psihologie psihiatrie | Sociologie |
UNIVERSITATEA DIN ORADEA
FACULTATEA DE STIINTE ECONOMICE
SPECIALIZAREA MARKETING
Modelul econometric pentru..y..
CUPRINS
Introducere
Dispunem de 36 observatii asupra marimii lui y si x.
|
luna |
yt |
X1t |
X2t |
|
| |||
Reprezentam grafic norul de puncte:
Cometarii privind aspectul norului de puncte.
Pentru analiza exportului am ales urmatorul model:
![]()
unde:
yt = din luna t
xt = in luna t
εt = variabila reziduala
Ecuatia (1) se poate scrie sub forma matriciala:
![]()
cu 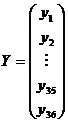 ,
, 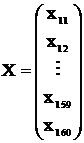
Am notat:
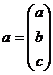
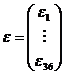
1. Ipoteze fundamentale
H0 : Ipoteza de liniaritate: modelul este liniar in Xt
H1 : Ipoteze asupra variabilelor X si Y:
(i) xt si yt reprezinta valori numerice ale variabilelor X si Y rezultate prin observarea statistica, neafectate de erori sistematice;
(ii) Y este variabila endogena aleatoare, pentru ca este functie de
(iii) X, variabila explicativa, este considerata ca fiind o variabila determinista in model, nealeatoare;
H2 : Ipoteze asupra erorilor ε:
(i) ε are o distributie independenta de timp, de speranta matematica nula, respectiv:
E (εt) = 0, ( ) t = 0, 1, 2, ., T
V (εt) = E[εt - E(εt)]2
= ![]() =
= ![]()
altfel spus, modelul este homoscedastic.
(ii) Independenta erorilor. Doua erori εt si εt' sunt independente liniar intre ele, adica
![]()
respectiv
![]()
(iii) Variabila ε are o distributie normala.
H3 : Ipoteze privind variabila exogena X:
(i)
cov(xt,
εt) = 0, ![]() t - erorile
sunt independente de X;
t - erorile
sunt independente de X;
(ii) Se presupune ca pentru T , primele doua momente empirice ale variabilei X sunt finite, respectiv
Speranta
matematica ![]()
Varianta
![]()
2. Determinarea estimatorilor de regresie liniara prin metoda celor mai mici patrate
Aplicam metoda celor mai mici patrate pentru determinarea coeficientilor.
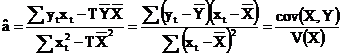 =
=
![]() =
=
Ecuatia de regresie se prezinta astfel:
Y= *X-
3. Testarea validitatii modelului
Testarea validitatii modelului presupune parcurgerea urmatoarelor etape:
Testarea validitatii modelului de regresie folosind metoda descompunerii variantei;
Calculul raportului de corelatie si testarea semnificatiei lui;
Inferenta statistica pentru parametrii modelului de regresie;
Verificarea ipotezelor modelului de regresie.
Testarea validitatii modelului de regresie folosind metoda descompunerii variantei
Dispersia totala verifica urmatoarea relatie:
![]()
Termenii relatiei se definesc prin:
![]() - varianta
totala a variabilei Y determinata de toti factorii
sai de influenta;
- varianta
totala a variabilei Y determinata de toti factorii
sai de influenta;
![]() - varianta
fenomenului Y determinata
numai de variatia factorului X,
considerat factorul principal al variabilei Y, adica variatia lui Y explicata de modelul
econometric;
- varianta
fenomenului Y determinata
numai de variatia factorului X,
considerat factorul principal al variabilei Y, adica variatia lui Y explicata de modelul
econometric;
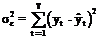 - variatia
reziduala, sau variatia fenomenului Y generata de catre factorii nespecificati in
model, acesti factori fiind considerati - in etapa de specificare -
drept factori cu influenta intamplatoare, neesentiali
pentru a explica variatia fenomenului Y
- variatia
reziduala, sau variatia fenomenului Y generata de catre factorii nespecificati in
model, acesti factori fiind considerati - in etapa de specificare -
drept factori cu influenta intamplatoare, neesentiali
pentru a explica variatia fenomenului Y
Descompunerea variantei - Metoda ANOVA
|
Sursa de variatie |
Masura variatiei |
Numarul gr. de libertate |
Dispersii corectate |
Valoarea testului F |
|
|
Fcalc |
Fα;v1;v2 |
||||
|
Varianta explicata de model, datorata factorului X |
|
k = 1 |
|
| |
|
Varianta Reziduala, datorata factorilor neesentiali |
|
T - k - 1 |
| ||
|
Varianta totala |
|
T - 1 |
| ||
Pe baza datelor din tabel se pot testa urmatoarele ipoteze:
H : s2Y/X s2 , cele doua dispersii sunt aproximativ egale, influenta factorului X nu difera semnificativ de influenta factorilor intamplatori.
H : s2Y/X s2 , influenta factorului X si a factorilor intamplatori - masurata prin cele doua dispersii - difera semnificativ si, deci, se poate trece la discutia similitudinii, a verosimilitatii modelului teoretic in raport cu modelul real.
Acceptarea ipotezei H0 este echivalenta cu respingerea modelului (modelul nu este valid).
Testarea semnificatiei dintre doua dispersii se face cu ajutorul distributiei teoretice Fisher-Snedecor, respectiv cu testul F.
Cunoscand cele doua valori, ![]() =
=
si Fα,v1,v2=4.17 valoarea teoretica a variabilei F, preluata din tabelul repartitiei Fisher - Snedecor, in functie de un prag de semnificatie α si un numarul gradelor de libertate = k; = n-k-1, regula de decizie se scrie:
- se accepta H1 si se respinge H0 daca Fcalc >Fα, , deci modelul este valid.
3.2. Calcularea coeficientului de corelatie R2, a coeficientului de corelatie corectat si testarea reprezentativitatii lui
Coeficientul de corelatie R2 exprima rolul jucat de ansamblul variabilelor exogene asupra variabilei endogene. Cu cat valoarea acestuia este mai apropiata de 1, cu atat legatura dintre variabile este mai intensa.
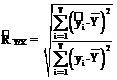 =
=
Aceasta expresie nu tine cont de numarul observatiilor si nici de numarul variabilelor explicative din model. O definitie mai precisa a lui R2 , care tine cont de numarul observatiilor t = 36 si numarul variabilelor exogene p = 1 este urmatoarea (R2 corectat):
Testarea
reprezentativitatii lui ![]()
H0:
![]() = 0
= 0
H1:
![]() ≠ 0
≠ 0
![]()
Se compara valoarea calculata a lui F cu cea tabelara (din anexa 6, in functie de t-p-1 si p grade de liberate, si probabilitatea 95%). Regulile de decizie sunt urmatoarele:
- daca Fcalc > Ftab, ipoteza nula este cea care se respinge, acceptandu-se cea alternativa.
Intrucat Fcalc>Ftab rezulta ca si la nivelul populatiei totale intre variabile exista legatura, iar aceasta legatura este de intensitate medie.
3.3. Teste si regiuni de incredere
3.3.1.Testarea validitatii estimatiei coeficientilor
Pentru testarea validitatii estimatiei coeficientilor ai se utilizeaza testul Student. In general :
H0 : ai = 0, cu alternativa
H1 : ai ≠ 0
Daca 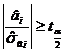 atunci H0
se respinge, iar coeficientul ai este semnificativ diferit de 0.
atunci H0
se respinge, iar coeficientul ai este semnificativ diferit de 0.
Pentru parametrul a emitem ipotezele:
H0 : a = 0, cu alternativa
H1 : a ≠ 0
Dupa efectuarea calculelor, obtinem:
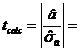
si stim ca ttab = 1.96
Comparam cele doua valori si tragem concluzia ca se accepta ipoteza H1 cu o probabilitate de 95%, ceea ce inseamna ca modelul este valid.
H0 : b = 0, cu alternativa
H1 : b ≠ 0
Dupa efectuarea calculelor, obtinem:
si stim ca ttab = 1.96
Comparam cele doua valori si tragem concluzia ca se accepta ipoteza H1 cu o probabilitate de 95%, ceea ce inseamna ca modelul este valid.
3.3.2. Intervale de incredere pentru coeficienti
Acestea se stabilesc cu un prag de semnificatie α = 0,05.
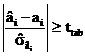 deci
deci ![]()
Dupa efectuarea calculelor obtinem urmatoarele intervale de incredere, cu o probabilitate de 95%:
0.54≤a≤0.96
-8254.8≤b≤-4324.7
3.4. Testarea ipotezelor fundamentale referitoare la variabila aleatoare ε
Pe langa influenta factorilor esentiali, asupra marimii .. (Y) isi exercita influenta si alti factori, care sunt surprinsi prin variabila ε. Acesti factori ar putea fi:..
. Ipoteza de homoscedasticitate a variabilei reziduale - Testul White
Testul White - etape:
- estimarea parametrilor modelului initial si calculul valorilor estimate ale variabilei reziduale, εt
- construirea unei regresii auxiliare, bazata pe prespunerea existentei unei relatii de dependenta intre patratul valorilor erorii, variabila exogena inclusa in modelul initial si patratul valorilor acesteia:
![]()
- calcularea coeficientului de corelatie estimat, corespunzator acestei regresii auxiliare
- testarea semnificatiei raportului de corelatie. Daca acesta este semnificativ diferit de zero, atunci ipoteza de heteroscedasticitate a erorilor este acceptata.
![]()
![]()
LMcalc = TR2
![]()
Daca LMcalc > (k grade de libertate, k - numarul de variabile exogene) , erorile sunt heteroscedastice, in caz contrar, sunt homoscedastice.
3.4.2. Ipoteza independentei valorilor variabilei reziduale εt
Aceasta ipoteza presupune verificarea relatiei:
![]()
Depistarea autocorelarii erorilor se poate face utilizand Testul Durbin - Watson. Functia de autocorelatie descrie intensitatea analogiei dintre doi termeni yt si yt-k .In ceea ce priveste autocorelarea valorilor variabilei reziduale, a fost elaborat in 1950, de catre Durbin J. si Watson G. S. un test intens utilizat si in prezent. Se obtine:
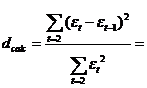
Valoarea empirica, dcalc, se compara cu doua valori teoretice, d1 si d2, citite din tabelul distributiei Durbin - Watson in functie de un prag de semnificatie , convenabil ales, ( = 0,05 sau = 0,01), de numarul de variabile exogene, k si de valorile observate T, T
Regulile de decizie a testului sunt:
|
< DWcalc < d1 |
d1 DWcalc d2 |
d2 < DWcalc < 4 - d2 |
4 - d2 DWcalc 4 - d1 |
4 - d1 < DWcalc < 4 |
|
Autocorelare pozitiva |
Indecizie |
Erorile sunt independente |
Indecizie |
Autocorelare negativa |
3.4.2.Testarea normalitatii distributiei variabilei aleatoare ε
O modalitate de verificare a ipotezei de normalitate a erorilor o constituie testul Jarque - Berra, care estel un test asimptotic, valabil in cazul unui esantion de volum mare, ce urmeaza o distributie hipatrat cu cu 2 grade de libertate, avand urmatoarea forma:
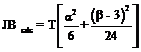
unde:
n - numarul de observatii;
coeficientul de asimetrie (skewness), ce masoara simetria distributiei erorilor in jurul mediei acestora (medie care este nula), avand urmatoarea relatie de calcul:
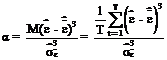
β - coeficientul de boltire al lui Pearson (kurtosis), ce masoara boltirea distributiei in raport cu distributia normala, ce are urmatoarea relatie de calcul:
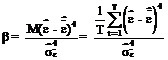
Testul Jarque - Berra se bazeaza pe ipoteza ca distributia normala are un coeficient de asimetrie egal cu zero, = 0, si un coeficient de aplatizare egal cu trei, β = 3.
Daca ![]() , atunci ipoteza de normalitate a erorilor este
respinsa.
, atunci ipoteza de normalitate a erorilor este
respinsa.
4. Previziunea variabilei y
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 1402
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved