| CATEGORII DOCUMENTE |
| Bulgara | Ceha slovaca | Croata | Engleza | Estona | Finlandeza | Franceza |
| Germana | Italiana | Letona | Lituaniana | Maghiara | Olandeza | Poloneza |
| Sarba | Slovena | Spaniola | Suedeza | Turca | Ucraineana |
DOCUMENTE SIMILARE |
|
TERMENI importanti pentru acest document |
|
Datová komprese – definice prefixového kódu, Kraftova nerovnost, kompresní poměr, průměrná délka slova, Huffmanova konstrukce kódu
Blokové kódování
Blokové kódování délky n, je takové prosté kódování, při kterém všechna kódová sloma mají stejnou délku a to n. Každé blokové kódování je jednoznačně dekódovatelné.
Prefixové kódování
Kódování se nazývá prefixové, jestliže je prosté a žádné kódové slovo není prefixem jiného kódového slova. Prefixové kódování je vždy jednoznačně dekódovatelné. Každé blokové kódování je prefixové. Prefixové kódy jsou jediné kódy, které lze dekódovat znak po znaku.
Př.:
|
A | |
|
B | |
|
C | |
|
D | |
|
E | |
|
F |
Zpráva 1 1 221 1 221 1 -> Dekódování: B B F B F B
Kraftova nerovnost
Při kódování n znaky můžeme sestavit prefixový kód s délkami slov d1, d2, …, di právě když platí tzv. Kraftova nerovnost:
![]()
Z existence prefixového kódu plyne Kraftova nerovnost. Kraftova nerovnost nezaručuje, že daný kód je prefixový. Pouze zaručuje, že prefixový kód s danými délkami kódových slov musí existovat.
Věta McMilianova: „Pro každé jednoznačně dekódovatelné kódování platí Kraftova nerovnost.“
Kompresní poměr
Cílem datové komprese je převést data z původní reprezentace do nové úspornější a zároveň umožnit kdykoliv opět získat originál nebo jeho aproximaci. Na vyjádření efektivnosti metod komprimace mžeme zavést tzv. poměr komprimace nebo jeho převrácenou hodnotu tzv. faktor komprimace:

Metody komprese lze dělit podle mnoha kritérií. Jedním z možných je rozhodování na základě použitých technik, nebo na základě kvality reprodukce původních dat:
Bezeztrátová komprimace – zaručuje 100% rekonstrukci původních nezkomprimovaných dat, má horší poměr komprimace. Př. Morseův princip, Huffmanovy kódy, metoda potlačení nul, metody proudového kódování RLE,…(ARJ, ZIP, RAR, pkzip, zip, …)
Ztrátová komprimace – vypouští některé méně významné informace. Po dekompresi tak získáváme jen aproximaci originálu. Př. Komprimace zvukových souborů, komprimace videa, obrazových souborů, fraktální komprimace, …
Průměrná délka slova
Předpokládáme, že jsme zjistili přesnou frekvenci znaků
zdrojové abecedy a1a2a3…ar.
To znamená, že pro každý znak ai
známe pravděpodobnost pi toho, že na náhodně zvoleném
místě zdrojové zprávy je zapsáno ai.
Platí ![]() a 0 ≤ pi ≤ 1. Označme délky
kódových slov pro dané kódování d1,
d2, …, dr a odpovídající pravděpodobnosti
výskytu těchto slov p1, p2,
…, pr. Našim cílem je najít nejkratší kód, přesněji
prefixový kód, jehož průměrná délka slova d je nejmenší možná:
a 0 ≤ pi ≤ 1. Označme délky
kódových slov pro dané kódování d1,
d2, …, dr a odpovídající pravděpodobnosti
výskytu těchto slov p1, p2,
…, pr. Našim cílem je najít nejkratší kód, přesněji
prefixový kód, jehož průměrná délka slova d je nejmenší možná:
![]()
Nejkratším n znakovým kódováním zdrojové abecedy a1, a2, …, ar
s pravděpodobnostmi výskytu p1,
p2, …, pr se rozumí prefixové kódování této abecedy
pomocí n znaků, které má nejmenší možnou průměrnou délku slova ![]() .
.
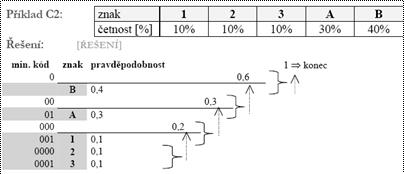
Huffmanova konstrukce kódu
D.A. Huffman objevil algoritmus, který při zadané
pravděpodobnosti výskytu zdrojových symbolů pi vytvoří kód
minimální délky ![]() . Huffmanovo kódování je užíváno pro bezeztrátovou kompresi
dat. Existují dva typy Huffmanova kódování: statické a dynamické. Základní
myšlenkou je tedy zakódování znaků podle počtu jejich výskytu tak, že
znaky, které se vyskytují nejčastěji, mají nejkratší kód.
. Huffmanovo kódování je užíváno pro bezeztrátovou kompresi
dat. Existují dva typy Huffmanova kódování: statické a dynamické. Základní
myšlenkou je tedy zakódování znaků podle počtu jejich výskytu tak, že
znaky, které se vyskytují nejčastěji, mají nejkratší kód.
algoritmus generuje binární stromy, kde uzly cesty z počátečního do koncového uzlu umožňují vytvořit kódová slova
kódy jsou prefixové kódy minimální délky
algoritmus přiřazuje slova dle Morseova principu
algoritmus není a nebyl patentován
Algoritmus:
Zdrojové znaky uspořádáme tak, aby platilo: p1 ≥ p2 ≥ … ≥ pr (nerostoucí posloupnost)
Znaky a1, a2, …, ar napíšeme pod sebe a vedle nich jejich pravděpodobnosti
Sečteme poslední dvě pravděpodobnosti a výsledek zařadíme do posloupnosti bodu 2.
Sečteme poslední dvě dosud nesečtené pravděpodobnosti a výsledek opět zařadíme
Krok 4. opakujeme až do součtu pravděpodobností = 1
Poté přiřazujeme kódová slova od prvního znaku a1 směrem k dalším dle prefixového principu. Nekódová slova využíváme jako použitelné prefixy mimo poslední součet.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 1083
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2026 . All rights reserved