| CATEGORII DOCUMENTE |
| Aeronautica | Comunicatii | Electronica electricitate | Merceologie | Tehnica mecanica |
Aplicatia "Wave to text". Metoda de lucru folosind coeficientii LPC
Reprezentarea digitala a sunetului.
Formatul de compresie audio Wav.
Comprimarea unui wav folosind un
algoritm lossless clasic este o operatie destul de ineficienta. Prin wav ne
referim la un fisier cu extensia .wav, ce contine muzica, o copie fidela a unui
CD audio.
Un
fisier wav contine un numar imens de esantioane (sample-uri), fiecare fiind
codificat pe 2 bytes (16 biti). Intre aceste sample-uri se poate trasa o
functie sinusoidala, care reprezinta unda
Explicatia
pentru cele 44100 de esantioane pe secunda sta in faptul ca omul poate percepe,
in cel mai bun caz, frecvente de pana la 22 KHz. Pentru functia sinusoidala
necesara formarii sunetului trebuie sa avem un numar suficient de puncte
descriptive, care reprezinta niste maxime si minime locale. Strictul necesar
(dar nu si suficient) pentru ca functia sa poata fi reconstituita este un numar
de sample-uri egal cu dublul frecventei dorite (cate un sample pentru minim si
cate unul pentru maxim). Sa luam exemplul unui ton perfect, care este redat
grafic printr-o functie sinus perfecta, ca in figura de mai jos :
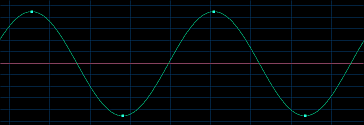
Fig. 22. Functia sinus
Imaginea reprezinta un ton cu frecventa de 22050 Hz la o rata de esantionare de 44100 Hz. Scaderea cu 1 Hz a esantionarii duce la imposibilitatea pastrarii sunetului la frecventa dorita, fiind redate doar cele inferioare (inexistente in acest exemplu). Regula descrisa anterior poarta numele de Legea lui Nyquist.
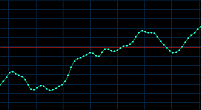
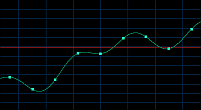
44 kHz 6 kHz
Fig. 23. Esantionarea unei secventa audio la 44kHz, respectiv la 6kHz
Am exemplificat in imaginile de mai sus o secventa audio complexa, reprezentata in 44 KHz si respectiv 6 KHz. Numarul de esantioane fiind mult mai mic in cel de-al doilea caz, sunetul este puternic denaturat, fiind pastrate doar frecventele joase. Prin upsampling (cresterea fortata a ratei de esantionare) se poate obtine, prin interpolare, un sunet mai bun, dar totusi departe de original deoarece o mare parte din informatia audio este pierduta iremediabil. Aceasta intrucat curba rezultata este foarte aproximativa, cu mai putine "urcusuri" si "coborasuri", mai aproape de reprezentarea unei functii trigonometrice simple.
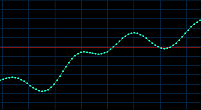
44 kHz -> 6 kHz -> 44 kHz
Fig. 24. Esantionarea pe 44kHz
Putem face o analogie intre
rezolutia unei imagini si rata de esantionare a unui sunet: la o rezolutie
mare, exista un numar mai mare de pixeli care descriu imaginea, deci nivelul de
detaliere este mai ridicat.
Alta caracteristica a unui fisier wav este rezolutia sa. Ca si in cazul adancimii
de culoare a imaginilor, unde mai multe culori inseamna o imagine mai aproape
de realitate, mai multi biti alocati unui sample inseamna un sunet mai
"precis". In cazul uzual, sunt folositi 16 biti (2 bytes); pentru domeniul
Hi-Fi este folosita rata de 24 sau chiar si 32 de biti (3, respecitiv 4 bytes).
In trecut era utilizata rezolutia de 8 biti, deci fiecarui esantion ii era
alocat un singur byte.
Daca in
cazul trecerii de la 16 la 24 sau 32 de biti diferentele nu se observa asa de usor,
odata cu scaderea la 8 biti va aparea un zgomot de fond suparator. Cu alte
cuvinte, un sample poate lua 65536 de valori (2 la puterea 16) in cazul
rezolutiei de 16 biti si doar 256 de valori in cazul al doilea.
O metoda de a imbunatati calitatea slaba datorata acestei scaderi de rezolutie este dithering-ul, adica generarea unui alt zgomot de fond, care sa "niveleze" sunetul; chiar daca zgomotul final va fi mai puternic, el va fi constant, oferind senzatia ca exista doua surse sonore: sunetul propriu zis si generatorul de zgomot.
In primul caz, fara
dithering, apare des senzatia unui sunet neclar, fenomen de multe ori mai
suparator decat dithering-ul.
Nivelul de dithering poate fi ales dupa necesitati, un nivel prea mare crescand zgomotul de fond, ceea ce evident ca nu este de dorit.
Putem afirma ca, din
anumite puncte de vedere, scaderea ratei de esantionare sau a rezolutiei
reprezinta o compresie a sunetului cu pierdere de calitate pentru ca sunt
eliminate o serie de aspecte ale sunetului astfel incat rezultatul final nu
difera in mod fundamental de original. Cine doreste sa pastreze doar informatia
redata de vocea umana, poate seta fara grija 8 KHz cu 8 biti si mesajul
transmis va fi inteles fara probleme.
Spatiul ocupat de un fisier wav necomprimat intr-o
secunda este calculat astfel (in paranteza am trecut valorile standard in cazul
unui CD audio): sampling rate (44100) * numarul de biti (16) * numar de canale
(2 = stereo). Avem, astfel, 1.411.200 biti (sau 176.400 bytes) pentru muzica de
pe un CD audio, ceea ce inseamna 1378,125 kilobiti/s. Am ajuns aici pentru a
defini unitatea de masura acceptata in compresia audio: numarul de kilobiti pe
secunda (kbps), numit si bitrate.
5.2 Aplicatia "Wave to text"
Programul permite realizarea conversiei de voce in text, aceasta facandu-se in timp real. Pentru aceasta avem nevoie de instrumente performante pentru a-l putea utiliza.
Wave-to-text este o aplicatie complexa de sinteza vocala. Se pot inregistra fisiere wav, care apoi sa fie transformate in fisiere txt prin recunoastere vocala.
Aplicatia contine si o sectiune de dictare care permite convertirea vocii in text in timp real, aceasta dictare este probabil cea mai rapida cale de afisare in format text a cuvintelor rostite,care depinde mult de zgomotul ambiental si de viteza de rostire.
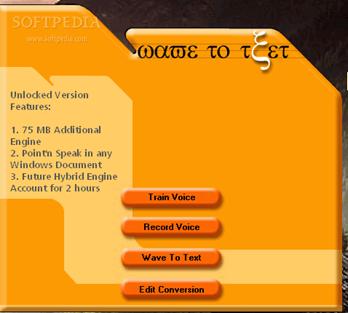
Pe langa utilitatea uneltelor deja implementate in cadrul aplicatiei aceasta isi demonstreaza viabilitatea si prin usurinta unei dezvoltari ulterioare, datorita faptului ca modularitatea ridicata a aplicatiei permite utilizatorului adaugarea cu usurinta a propriilor unelte in oricare din modulele de prelucrare.
Ne vom opri insa asupra algoritmilor proprii in ce priveste localizarea vorbirii folosind spectru de frecvente, asupra performantei algoritmilor de recunoastere a cuvintelor folosind coeficienti LPC si cepstrali, si respectiv a algoritmilor de recunoastere a vorbitorului.
In ce priveste algoritmul de localizare a vorbirii singura limitare este data de posibilitatea utilizatorului de a determina pe baza unor semnale vocale anterioare apartinand aceluiasi vorbitor a limitelor intervalului in care este localizata vorbirea respectivului in domeniul frecventa. In ce priveste algoritmul de recunoastere a vorbitorului bazat pe frecventa fundamentala si N-1 formanti performantele au fost foarte bune megandu-se pana la 95 % in conditii de relativa lipsa a perturbatiilor si o rostire normala in toate cazurile a cuvintelor.
5.2.1 Formatul intern al semnalului audio
Formatul intern al semnalului audio are o componenta comuna pentru formatul Microsoft Wave PCM , componenta in care se specifica elemente ca numarul de esantioane pe secunda, numarul de bytes pe secunda etc. Dupa aceste caracteristici urmeaza esantioanele propri-zise care in functie de caracteristicile semnalului vocal sunt memorate pe 8 sau 16 biti. Aplicatia "Wave to text " lucreaza cu semnale vocale memorate pe 16biti, ceea ce este de altfel suficient pentru scopurile propuse ale aplicatiei.
Stocarea interna in cadrul aplicatiei a unui semnal vocal respecta in mare parte structura interna a fisierelor in format Microsoft Wave PCM.
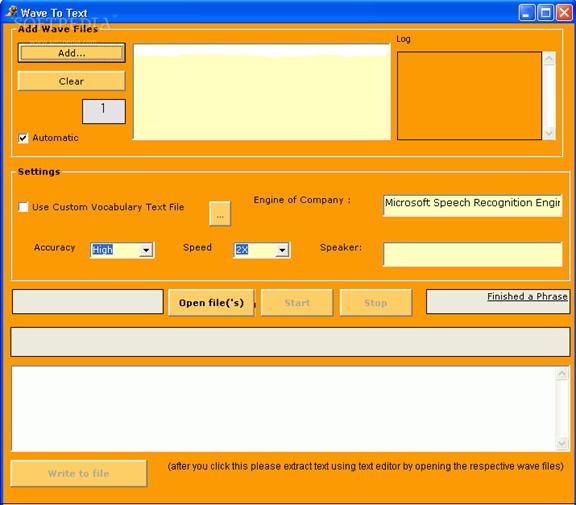
Toate informatiile legate de un semnal vocal, fie inregistrat cu prezenta aplicatie, fie deschis dintr-un fisier de pe disc sunt incarcate in aplicatie si apoi convertite in text cu ajutorul Microsoft Speech Recognition Engine.
Atributele asupra carora ma voi opri , sunt matricile de coeficienti cepstrali si LPC. Matricile sunt implementate in cadrul clasei CMatrix. Cele doua atribute ce stocheaza coeficientii respectivi sunt mtxLPCCoefs si mtxCepsCoefs , atribute ce apar atat in clasa CFrameArray cat si in CFrame . Calcularea coeficientilor are loc in metodele Cepstral si LPC din CFrame, in metodele omonime din CFrameArray avand loc doar o combinare a rezultatelor.
O metoda asemanatoare ca structura si functionalitate este metoda de determinare a spectrului de frecventa prin aplicarea Transformatei Fourier Rapide, DoFFT.
Aplicarea transformatei FFT asupra unui semnal da un rezultat continuu, dar se poate aplica aceasta functie si discret in n puncte fara o pierdere de informatie. In acest caz transformata ar avea urmatoarea forma:
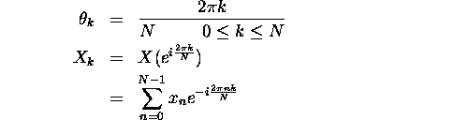
iar transformata inversa:
![]()
In aplicatiea "Wave to text", calculul transformatei Fourier se face utilizand algoritmul butterfly de calcul al FFT. Caracteristica principala a acestui algoritm este ca lucreaza cu operatii pe biti ceea ce ii asigura o viteza ridicata dar si ii determina cateva limitari. Printre acestea cele mai importante ar fi faptul ca numarul de frecvente determinate trebuie sa fie de forma "2 la puterea x", iar domeniul in care sunt calculate frecventele nu este cel real. Oricum aceste doua limitari nu reprezinta niste inconveniente in cadrul aplicatiei noastre, primul deoarece oricum numai primele frecvente prezinta interes iar al doilea pentru ca acest spectru este calculat in vedea comparatiei cu spectre de acelasi fel, in acest caz contand diferenta intre doua spectre si nu valorile absolute ale frecventelor.
Determinarea spectrului se face in fiecare cadru de semnal in metoda DoFFT din CFrame , pentru ca mai apoi aceste spectre sa fie combinate in cadrul metodei DoFFT din CFrameArray . Combinarea spectrelor consta de fapt in adunarea valorilor de pe indici corespunzatori din vectorii ce contin spectrul frecventelor in fiecare frame.
Spectrul de frecvente este memorat tot in cadrul unei matrici numita mtxFFTFreqs .
5.2.2 Implementarea metodei de lucru cu coeficientii LPC
Pentru asigurarea unei omogenitati in lucrul cu diferitele tipuri de coeficienti s-a ales implementarea unei singure clase care sa fie fie folosita indiferent de tipul de coeficienti. Acceasi structura este folosita si pentru lucrul cu spectrele de frecvente.
Daca e sa vorbim despre coeficientii LPC sau cepstrali se stie ca pentru fiecare cadru dintr-un semnal se determina cate un set de coeficienti. Asfel pentru o mai usoara abordare a problemei s-a ales o reprezentare asemanatoare celei de la CFrameArray si CFrame. In mod similar aici vom avea o clasa cu setul de coeficienti pentru un frame, numita CCoefs, si o clasa care va reuni toate aceste seturi de coeficienti, numita CCoefsArray.
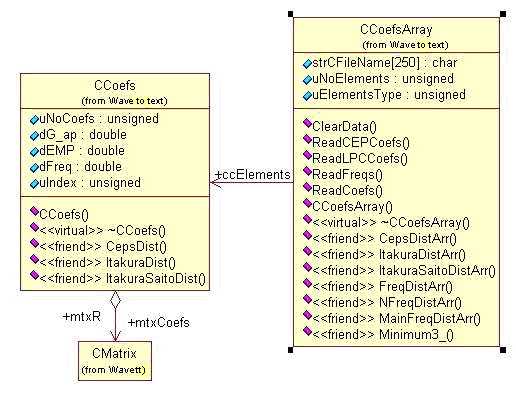
Fig. 25. Structura claselor de coeficienti cepstrali
Chiar daca nu este o asemanare intre aceste multimi de seturi de coeficienti si un spectru de frecvente reprezentat de un vector uni-dimensional, pentru consistenta s-a ales solutia stocarii acestui vector folosind aceleasi clase sub urmatoarea forma: fiecare element de frecventa este stocat intr-un obiect CCoefs in atributul dFreq .
Coeficientii cepstrali si LPC sunt memorati in cadrul matricei mtxCoefs . Totusi in cazul coeficientilor LPC, pe langa acestia in cadrul obiectului CCoefs se memoreaza si matricea R ,intr-o structura CMatrix, numita mtxR.
Pentru a se putea face diferenta intre atatea tipuri de date stocate in cadrul acestor structuri, clasa CCoefsArray contine un atribut numit uElementsType care in functie de valoarea sa va stabili tipul de date stocate: coeficienti LPC, coeficienti cepstrali, spectru de frecvente.
Legatura intre CCoefs si CCoefsArray este realizata prin intermediul atributului ccElements care reprezinta un pointer din CCoefsArray spre CCoefs.
Incarcarea continutului obiectelor CCoefs se face din fisiere intr-un format specific ce in prealabil au fost salvate pe disc dupa prelucrari cu unelte standard din aplicatia "Wave to text". Dat fiind acest fapt clasa CCoefsArray dispune de o interfata de lucru cu fisierele "Wave to text" bine pusa la punct.
Prin intermediul metodelor acestei interfete se vor citi diferitele tipuri de coeficienti. Metodele sunt: ReadCoefs (metoda "parinte" din care se cheama celalalte in functie de tipul fisierului deschis), ReadCEPCoefs, ReadLPCCoefs, ReadFreqs .
In cazul in care clasa CCoefs este folosita pentru coeficienti LPC, pe langa coeficientii propriu-zisi, mai sunt stocate si castigul filtrului, in atributul d_Gap si eroarea medie patratica in dEMP .
In fiecare obiect CCoefs va exista un index ce memoreaza pozitia in CCoefsArray.
Motivatia pentru care s-a ales memorarea coeficientilor in cadrul acestor structuri este in calculul distantei intre doua seturi de coeficienti sau respectiv doua spectre de frecvente. Aceste operatii pentru calculul diferentei sunt implementate la nivelul claselor prin metode specifice fiecarui tip de coeficienti. La fel ca in cazul claselor CFrame si CFrameArray si aici avem o corespondenta intre metodele-operatii din CCoefs si CCoefsArray. Diferenta semnificativa fiind ca in acest din urma caz operatiile sunt implementate in metode <<friend>>.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 2058
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2026 . All rights reserved