| CATEGORII DOCUMENTE |
| Asp | Autocad | C | Dot net | Excel | Fox pro | Html | Java |
| Linux | Mathcad | Photoshop | Php | Sql | Visual studio | Windows | Xml |
The previous chapters have constructed a world in which types, objects, and values are dynamically brought into existence and can be referenced, created, and, in some cases, destroyed. However, the most interesting thing one can do with a type, object, or value, is invoke a method because that is the primary way that the three entities can interact.
The CLR executes only native machine code. If a method body consists of CIL, it must be translated to native machine code prior to invocation. As discussed briefly in Chapter 1, there are two options for converting CIL to native machine code. The default scenario is to postpone the translation until sometime after the component is loaded into memory. This approach is called just-in-time (JIT) compilation, or JIT-compiling for short. An alternative scenario is to generate a native image when the component is first installed on the deployment machine. This approach is called precompiling. The CLR provides a deployment tool (NGEN.EXE) and an underlying library (MSCORPE.DLL) to generate native images at deployment time.
When NGEN.EXE and MSCORPE.DLL generate a native image, it is stored on disk in a machine-wide code cache so that the loader can find it. When the loader tries to load a CIL-based version of an assembly, it also looks in the cache for the corresponding native image and will use the native machine code if possible. If no suitable native image is found, the CLR will use the CIL-based version that it initially loaded.
Although generating native images at deployment time sounds attractive, it is not without its downsides. One reason not to cache native images on disk has to do with code size. As a rule, native IA-32 machine code is larger than the corresponding CIL. For a typical component, the application in its steady state is likely to use only a small number of methods. When the CLR generates a native image, the new DLL will contain the native code for every method, including methods that may never be called or, at best, are called only occasionally, such as initialization or termination code or error-handling code. The inclusion of every method implementation causes the overall in-memory code size to grow needlessly. Worse, the placement of individual method bodies does not take into account the dynamics of the running program. Because one cannot change the method locations in the NGEN.EXE-generated image after the code is generated, each of the handful of needed methods may wind up occupying a different virtual memory page. This fragmentation has a negative impact on the working set size of the application.
A second issue related to caching native images has to do with cross-component contracts. For the CLR to generate native code, all types that are used by a method must be visible to the translator, because the native code must contain nonvirtualized offsets a la classic C, C++, COM, and Win32 contracts. This cross-component dependency can be problematic when a method relies on types in another component because any changes whatsoever to the other component will invalidate the cached native code. For that reason, every module is assigned a module version identifier (MVID) when it is compiled. The MVID is simply a unique identifier that is guaranteed to be unique for a particular compilation of a module.
When the CLR generates and caches a native image, the MVID of every module used to generate the native image (including those from external assemblies) is stored with the native code. When the CLR loader tries to load a cached native image, it first checks the MVIDs of the components used during the CIL-to-native generation process to verify that none of them has been recompiled. If a recompilation has taken place, the CLR ignores the cached native image and falls back to the version of the component that contains CIL.
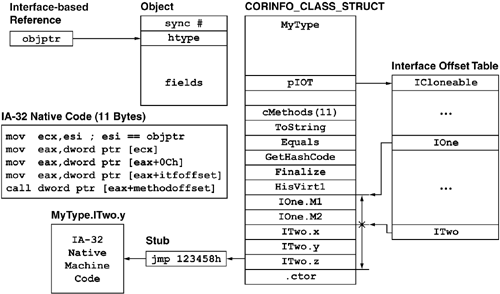
If a native image cannot be found in the cache (or is stale because of recompilation of dependencies), the CLR loads a CIL-based version of the component. In this scenario, the CLR JIT-compiles methods just before they are first executed. When a method is JIT-compiled, the CLR must load any types that the method uses as parameters or local variables. The CLR may or may not need to JIT-compile any subordinate methods that are to be called by this method at that time. To understand how JIT compilation works, let's examine a small amount of grunge code. Recall from the discussion of casting in Chapter 4 that the CLR allocates an in-memory data structure for each type that it initializes. Under version 1.0 of the CLR, this data structure is internally called a CORINFO_CLASS_STRUCT and is referenced by the RuntimeTypeHandle stored in every object. On an IA-32 processor, a CORINFO_CLASS_STRUCT has 40 bytes of header information followed by the method table. The method table is a length-prefixed array of memory addresses, one entry per method. Unlike those in C++ and COM, a CLR method table contains entries for both instance and static methods.
The CLR routes all method calls through the method table of the method's declaring type. For example, given the following simple class, the call from Bob.f to Bob.c will always go through Bob's method table.
class BobIn fact, the native IA-32 code for Bob.f would look like this:
; set up stack frameThe addresses used in the IA-32 call instructions correspond to the method table entries for Bob.c, Bob.b, and Bob.a, respectively.
Every entry in a type's method table points to a unique stub routine. Initially, each stub routine contains a call to the CLR's JIT compiler (which is exposed via the internal PreStubWorker routine). After the JIT compiler produces the native machine code, the JIT compiler overwrites the stub routine, inserting a jmp instruction that jumps to the freshly JIT-compiled code. This means that the second and subsequent calls to the method will not incur any overhead other than the single jmp instruction that sits between the call site and the method body. This technique is extremely similar to the delay-load feature added to Visual C++ 6.0. This feature was completely explained by Matt Peitrek and Jeff Richter in two articles in the December 1998 issue of Microsoft Systems Journal.
Figure 6.1 shows our simple C# class as it is being JIT-compiled. Specifically, this figure shows a snapshot of Bob's method table during a call to Bob.f after f has called Bob.c but before f has called b or a. Note that because the Bob.c method has already been called, the stub for c is a jmp instruction that simply passes control to the native code for Bob.c. In contrast, Bob.a and Bob.b have yet to be called, so the stub routines for a and b contain the generic call statement that passes control to the JIT compiler.
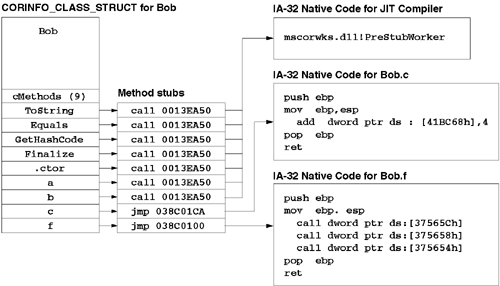
Technically, Figure 6.1 doesn't tell the whole story. Specifically, each method stub initially contains both a call statement and the address of the specific method's CIL. The method stub calls into a small amount of prolog code that extracts the address of the method's CIL from the code stream and then passes that address to PreStubWorker (the JIT compiler). Figure 6.2 shows this process in detail.
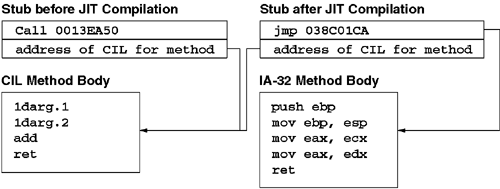
That single jmp instruction may have performance wonks concerned. However, the level of indirection provided by the extra jmp instruction allows the CLR to tune the working set of an application on-the-fly. If the CLR determines that a given method will no longer be needed, it can 'pitch' the native method body and reset the jmp instruction to point to the JIT routine. Conceivably, native method bodies could even be relocated in memory to put frequently accessed methods in the same (or adjacent) virtual memory pages. Because all invocations go through the jmp instruction, making this change requires the CLR to rewrite only one memory location, no matter how many call sites refer to the relocated method.
Based on the discussion of JIT compilation and invocation, it is apparent that type is involved in method invocation. Specifically, the CLR uses the method table for a type to locate the address of the target method. Consider the following simple type definition:
public class BobIgnoring method prolog and epilog, the JIT compiler would generate the following IA-32 native code for the UseBob method:
mov ecx, esiThe first instruction moves the target object reference into the ecx register. This is because the JIT compiler typically uses the __fastcall stack discipline, and that causes the first two parameters to be passed in the ecx and edx registers, if possible. The second instruction calls the target method indirectly. The indirection uses a specific slot in the method table for Bob-in this case, dword ptr [352108h].
Note that in the IA-32 call statement just shown, the exact address of Bob's method table slot is baked into the JIT-compiled method. That means that even in the presence of a derived type (shown in the following code snippet), the UseIt method always dispatches to Bob.f, even if the derived type has a method whose name and signature match exactly.
public class Steve : BobTo cause the JIT compiler to consider the concrete type of the object, one needs to declare the method as virtual.
A virtual method is an instance method whose implementation can be replaced or overridden by a derived type. Virtual methods are identified by the presence of the virtual metadata attribute. At development time, when a compiler encounters a call to a virtual method in source code, it emits a callvirt CIL opcode rather than the traditional call opcode. The corresponding native code for a callvirt instruction is different than that for a call instruction. As described in the previous section, a CIL call instruction statically binds the native IA-32 call instruction to the method table of a particular type. In contrast, a CIL callvirt instruction results in an extra IA-32 instruction that determines which method table to use based on the target object's RuntimeTypeHandle. This allows the concrete type of the target object to determine which method will be invoked. Because the CLR needs the concrete type of an object to determine which method table to use, the virtual method mechanism is not available for static methods. Additionally, if a callvirt instruction is executed against a null reference, a System.NullReferenceException will be thrown.
The CLR allocates entries in the method table differently for virtual methods than for nonvirtual methods. Specifically, the method table has two contiguous regions. The first region is used for virtual methods. The second region is used for nonvirtual methods. The first region will contain one entry for each method that has been declared virtual, both in the current type and in all base types and interfaces. The second region will contain one entry for each non-virtual method that is declared in the current type. This separation allows a derived type's method table to replace a base type's method table for virtual method dispatch, because the indices used for a particular virtual method will be the same up and down the inheritance hierarchy.
The CLR dispatches calls to virtual methods by accessing the method table referenced by the target object's type handle. This allows the object's concrete type to determine exactly which code will execute. Had the Bob.f method in the previous example been declared virtual, the Bob.UseIt method would look like this:
move ecx, esiThe first mov instruction simply stores the target object reference in the IA-32 ecx register. This instruction is required for both virtual and nonvirtual calls because the CLR's calling convention requires that the this pointer be stored in ecx prior to invocation. The second mov instruction is unique to virtual method dispatching. This instruction stores the object's type handle in the IA-32 eax register. The type handle is then used by the IA-32 call instruction to locate the actual address of the target method. Figure 6.3 shows what this call looks like in memory.
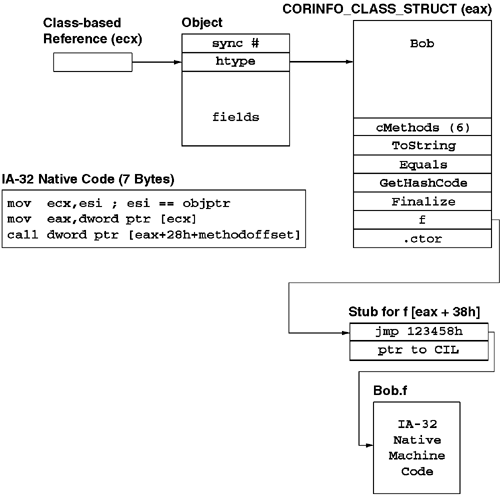
Note that in the IA-32 call instruction just described, the CLR indexes the type's method table based on a fixed methodoffset. For a particular virtual method, this offset may be different for different executions of the program; however, it will be constant for the lifetime of a running program. Like field offsets, method table offsets are calculated at type load time. Each virtual method's metadata attributes control the offsets chosen. Table 6.1 shows the metadata attributes that influence the method table. The attribute that has the greatest influence on method offsets is newslot.
The CLR assigns each virtual method a slot in the method table that will contain a pointer to the method's code. The CLR assumes that virtual methods that are declared as newslot are unrelated to any methods declared in the base type. The CLR assigns virtual methods declared as newslot a new methodoffset that is at least 1 greater than the highest methodoffset used by the base type. Because System.Object, the ultimate base type of all concrete types, has four virtual methods, the first four slots in every method table correspond to these four methods.
If a virtual method does not have the newslot metadata attribute set, the CLR assumes that this method is a replacement for a virtual method in the base type. In this case, the CLR will look in the base type's metadata for a virtual method whose name and signature match the derived method. If it finds a match, then that method's methodoffset will be reused, and the corresponding slot in the derived type's method table will point to the derived replacement method. Because calls through references of the base type use this index, calls to the derived type will be dispatched to the derived type's method and not the base's method; the fact that the call may be issued through a base-type reference is immaterial.
Table 6.1. Metadata Attributes and Virtual Methods |
||
|
Metadata Attribute |
Present (1) |
Absent (0) |
|
virtual |
Method table index in virtual range |
Method table index in nonvirtual range |
|
newslot |
Allocate a new virtual method table index |
Reuse index from base type method if possible |
|
abstract |
Require replacement in derived type |
Allow replacement in derived type |
|
final |
Prohibit replacement in derived type |
Allow replacement in derived type |
final and abstract are mutually exclusive.
A virtual method that is not marked with the newslot metadata attribute is assumed to be a replacement for a virtual method of the base type. However, if the CLR finds no matching method in the base, then it treats the method as if it were declared as newslot.
It is possible to mandate or prohibit replacement of a virtual method using the abstract and final attributes, respectively. The abstract attribute mandates replacement of a virtual method by a derived type. Abstract methods are only declarations and do not have method implementations because their replacement by a derived type is mandatory. By inference, types that contain one or more abstract methods must themselves be marked abstract because the type specification is incomplete until a replacement for the abstract method is made available. All instance methods declared by an interface are required to be marked as abstract, and most programming languages do this for you implicitly.
When one replaces a virtual method in a base type, one can suppress further replacement by any downstream derived types. One does this by setting the final metadata attribute. Applying the final attribute to a method tells the CLR to disallow replacement of the method for all derived types. Obviously, one cannot combine the final attribute with the newslot abstract attribute, which mandates method replacement by the derived type.
Each programming language provides its own syntax for specifying the virtual, abstract, newslot, and final metadata attributes. Table 6.2 shows the keywords used by C#. As mentioned previously, marking a method as new in C# does not affect the generated code or metadata; rather, the keyword simply suppresses a compiler warning.
When a derived type provides an implementation overriding a base type's method, all invocations of that method will dispatch to the derived type's code. Consider the type hierarchy shown in Listing 6.1, which does not use virtual methods. Note that when a program calls the base type's DoIt method, the method ignores the existence of the DoItForReal method in the derived type and simply calls the base type's version. Because the DoItForReal method was not declared as virtual in the base type, the method code for Base.DoIt is statically bound to call Base.DoItForReal, independent of what any derived type may indicate. However, had the DoItForReal method been declared as virtual in the base type, as shown in Listing 6.2, Base.DoIt method would always invoke the DoItForReal method via the virtual function mechanism, allowing the derived type to replace the base type's method by overriding it.
Table 6.2. Metadata Attribute Combinations |
|||||
|
Metadata Attribute |
C# Syntax |
Meaning |
|||
|
virtual |
final |
abstract |
newslot |
||
|
override |
Replace virtual method from base and allow replacment in derived |
||||
|
virtual |
Introduce new virtual method and allow replacement in derived |
||||
|
override abstract |
Require replacement of existing virtual method from base |
||||
|
abstract |
Introduce new virtual method and require replacement in derived |
||||
|
override sealed |
Replace virtual method from base and prohibit further replacement |
||||
final and abstract are mutually exclusive.
By default, when you override a virtual method, there is nothing to stop new types that derive from your type from replacing your implementation of the method with their own. If you want to prevent this, you can mark your override as being final. Final methods replace a virtual or abstract method in their base but prevent further replacement by more-derived types. In C#, you can mark a method as final by combining the sealed keyword with the override keyword. Listing 6.3 shows an example of this technique.
In the previous examples of overriding methods, the method implementation of the most-derived type completely replaces the implementation in the base type. If the derived type wanted to augment rather than replace the base method implementation, then the derived type's method would need to explicitly invoke the base method using a language-specific qualifier (base in C#, MyBase in VB.NET). Listing 6.4 shows such an implementation. Whether or not the derived type should actually dispatch to the base type-as well as whether it should do this dispatching before or after its own work-has been one of the primary arguments against using virtual method replacement as a reuse technique, because it is rarely possible to know which approach to use without incestuous knowledge of the inner workings of the base type.
Interfaces, Virtual Methods, and Abstract MethodsThe CLR deals with objects and interface types differently than its predecessors (C++ and COM). In C++ and COM, a given concrete type has one method table per base type or supported interface. In contrast, a given concrete type in the CLR has exactly one method table. By inference, a CLR-based object has exactly one type handle. This is in stark contrast to C++ and COM, where an object would routinely have one vptr per base type or interface. For this reason, the CLR's castclass does not result in a second pointer value in the same way as C++'s dynamic_cast or COM's QueryInterface. Each CLR type has a single method table independent of its type hierarchy. The initial slots in the method table will correspond to virtual methods declared by the base type. These slots are then followed by entries that correspond to new virtual methods introduced by the derived type. The CLR arranges this region of the method table such that all of the method table slots for a particular declared interface are arranged contiguously with one another. However, because different concrete types may support different interfaces, the absolute offset of this range of entries will not be the same for all types that support a given interface. To deal with this variability, the CLR adds a second level of indirection when invoking virtual methods through an interface-based object reference. The CORINFO_CLASS_STRUCT contains pointers to two tables that describe the interfaces the type supports. The isinst and castclass opcodes use one of these tables to determine whether a type supports a given interface. The second of these tables is an interface offset table that the CLR uses when dispatching virtual method calls made against interface-based object references. As shown in Figure 6.4, the interface offset table is an array of offsets into the type's method table. There is one entry in this table for every interface type that has been initialized by the CLR independent of whether or not the type supports the interface. As the CLR initializes interface types, it assigns them a zero-based index into this table. When the CLR initializes a concrete type, the CLR allocates a new interface offset table for the type. The interface offset table will be sparsely populated, but it must be at least as long as the index of any of its declared interfaces. When the CLR initializes a concrete type, the CLR populates its interface offset table by storing the appropriate method table offsets into the entries for supported interfaces. Because the CLR's verifier ensures that interface-based references refer only to objects that support the declared type, interface offset table entries for unsupported interfaces are never used and their contents are immaterial. Figure 6.4. Virtual Functions Using Interface-Based References
As shown in Figure 6.4, a method invocation through an interface-based reference must first locate the range of entries in the method table that corresponds to the interface. After the CLR finds this offset, the CLR adds the method-specific offset and dispatches the call. When compared with calling virtual methods through class-based references, the interface-based reference approach results in code that is slightly larger and slower because an additional level of indirection is used. It is conceivable, however, for the JIT compiler to optimize away this extra indirection if the same object reference is used multiple times. The C# language supports two techniques for implementing an interface method. Either one can implement the interface method as a public method with the same name and signature, or one can implement a private method with the same signature but with a name that follows the InterfaceName.MethodName convention. For example, for a method named Display on an interface named IDrawable, the implementation's method name would be IDrawable.Display. The primary difference between these two techniques is that with the former, the method also becomes part of the class's public signature. With the latter approach, the method is visible only via an up-cast to the corresponding interface type. For that exact reason, the latter technique is indispensable when one must overload a given method name based on the scope of the reference used to invoke the method. One might need to do this when one desires a more type-safe version of the method for the class's contract. For example, consider the following class, which implements System.ICloneable: using System;public class Patient : ICloneable // this is private and accessible only via ICloneable Object ICloneable.Clone() Note that the public contract for the Patient type contains a strongly typed Clone method that returns the precise reference type. This makes it more convenient for callers using references of type Patient to perform the clone because the second object reference is already cast to the anticipated type. In contrast, callers using ICloneable references to access the object still get correct behavior, but those clients will likely need to do a down-cast prior to using the result of the ICloneable.Clone method. Another advantage of using scoped method names to implement the abstract members of an interface is that it lets one easily handle name collisions across interfaces. These collisions can occur when a class implements two or more interfaces with identical method declarations but differing semantics, something that is rare but in fact possible. Consider the following canonical example: public interface ICowboypublic interface IArtist public class AcePowell : ICowboy, IArtist void IArtist.Draw() public void Draw() Note that the AcePowell class has three Draw methods. The CLR will determine the one selected by what kind of reference is used to invoke the method. In each of the examples shown so far, the implementation of an interface method is implicitly final, just as if the sealed and override modifiers were present. As illustrated in Table 6.3, when the implementation of an interface method is marked as public, it can also be marked as virtual or abstract, making the method nonfinal. This allows a derived type to override the method. Such an override would replace both class-based and interface-based uses of the base type's method. It is also possible for a derived type to replace any or all of the base type's interface implementation methods simply by redeclaring support for the interface. After this is done, the derived class is free to provide new implementations of any of the interface methods no matter how the base type declared them. Listing 6.5 shows an example C# program in which the base type Base implements three interface methods using the techniques just described. Note that the derived type Derived1 can replace only the base type's Turn method. This is because the base type did not declare any other methods as virtual. In contrast, the Derived2 class can replace all of the interface methods. This is because Derived2 explicitly redeclares support for the IVehicle interface. In this example, programs will never call the base type's implementations of Start on an instance of Derived2. This is because the only way the Start method can be invoked is via the IVehicle interface, for which the Derived2 class has explicitly provided a Start method. Programs may invoke the base type's Stop and Turn methods on instances of Derived2. This can occur when a reference of type Base refers to an instance of Derived2. When such a reference is used, the Stop method in Base was nonvirtual, so no virtual method invocation (or derived-type overloading) is in effect. What is odd (but expected) is that the Turn method will still dispatch to the implementation in Base. This occurs because the developer did not use the override keyword in declaring the implementation of Turn in Derived2. The lack of an override keyword informs the C# compiler to emit the method declaration using the newslot attribute, an action that causes compilers to consider the Turn method in Derived2 unrelated to the Turn method in Base.
Listing 6.5 Interfaces and Base Typespublic interface IVehiclepublic class Base : IVehicle public void Stop() public virtual void Turn() public class Derived1 : Base // illegal - Base.Stop not virtual public override void Stop() // legal, replaces Base.Turn + IVehicle.Turn public override void Turn() public class Derived2 : Base, IVehicle // legal - we redeclared IVehicle support public void Stop() // legal - replaces IVehicle.Turn (but not Base.Turn) public void Turn() If the previous discussion
has left you confused, consider the example shown in Listing 6.6. This example exercises
most if not all combinations of overriding, overloading, and interfaces. Try
to figure out what this program does. In particular, try to figure out which
of the six DoIt method declarations the compiler and/or
the CLR will choose for each of the four method invocations in Listing 6.6 Inheritance Abusepublic interface ICommonpublic class Base : ICommon public virtual void DoIt() public class Derived : Base, ICommon { void ICommon.DoIt() public new virtual void DoIt() public class ReallyDerived : Derived { public override void DoIt() public static void The first call would dispatch to e because the concrete type of the object has a public method named DoIt. The second call would dispatch to e because Derived.DoIt is declared as virtual. The third call would dispatch to b because even though Base.DoIt was declared as virtual, the subsequent derived methods overloaded its use. The fourth call would dispatch to c because ICommon.DoIt is implicitly virtual. No, you don't want to write code like this, but it may (or may not) be comforting to know that the CLR supports this without flinching.
|
||||||||||||||||||||||||||||||||||||||||||||||||
The previous discussion looked at how virtual methods introduce a level of indirection between the call site and the actual method that is executed. This level of indirection is largely transparent to the caller, with the CLR using the concrete type of the target object to automatically determine which method to use. In addition to virtual methods, the CLR provides facilities to make method invocation even more flexible, to the point where one can discover and invoke arbitrary methods without a priori knowledge of their signature or even their name. This facility-explicit method invocation-is critical for building highly dynamic systems.
Recall that one makes CLR metadata accessible through System.Type and friends. One of the facilities of System.Type is the ability to discover the methods of a given type. The System.Reflection.MethodInfo type exposes the metadata for a method. As described in Chapter 4, the MethodInfo type makes the signature of the method available, including the types and names of the parameters. What was not discussed, however, is the MethodInfo type's capabilities for invoking the underlying method. One exposes this functionality via the MethodInfo.Invoke method.
MethodInfo.Invoke has two overloads. The more complex of the two overloads allows the caller to provide mapping code to deal with parameter type mismatches and overload resolution. This version of the MethodInfo.Invoke method is used primarily by support plumbing in dynamically typed languages and is outside the scope of this discussion. The simpler of the two methods assumes that the caller is capable of providing the parameters exactly as the underlying method expects them to appear. Listing 6.7 shows both prototypes.
To use the simpler form of MethodInfo.Invoke, one needs to provide two parameters. This usage is shown in Figure 6.5. The first parameter is a reference to the target object. If the underlying method is declared static, then this reference is ignored. If the underlying method is not static, this reference must refer to an object that is type-compatible with MethodInfo's reflected type. If an incompatible object is passed for this parameter, MethodInfo.Invoke will throw a System.Reflection.TargetException exception.
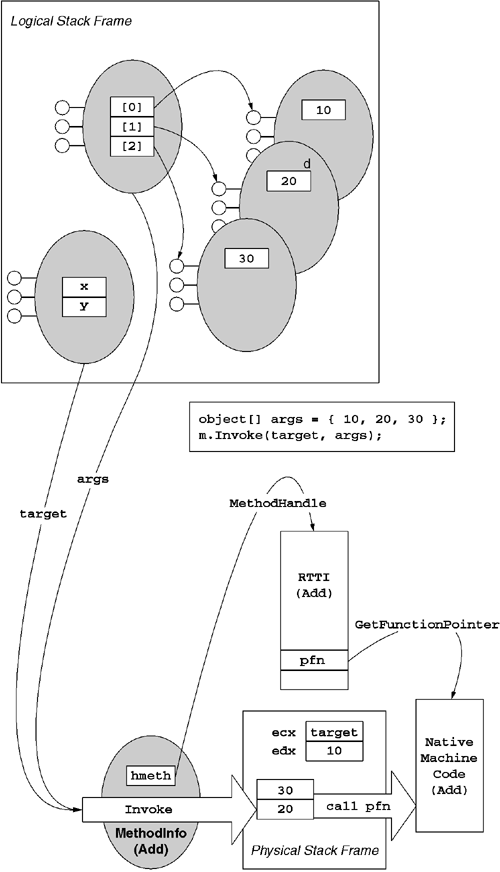
The second parameter to MethodInfo.Invoke accepts an array of object references, one array element per parameter. The length of this array must match the number of parameters expected. The type of each referenced object in the array must be type-compatible with the type of the corresponding parameter. If either of these is not the case, MethodInfo.Invoke will throw a System.Reflection.TargetParameterCountException or System.ArgumentException exception, respectively.
The implementation of MethodInfo.Invoke will call the underlying method using the parameter values and target object reference provided. To accomplish this, MethodInfo.Invoke will form a stack frame based on the underlying method declaration and the processor architecture under which the CLR is running. MethodInfo.Invoke will then copy the parameter values from the array of object references onto the stack. When the stack frame is properly formed, the MethodInfo.Invoke code makes a processor-specific call (e.g., call in IA-32) to the target method. When the method has completed execution, MethodInfo.Invoke will then identify any parameters that were passed by reference and copy them back to the presented array of parameter values. Finally, if the method returns a value, that value will be returned as the result of the MethodInfo.Invoke call.
The example in Listing 6.8 shows a C# routine that calls a method named 'Add' on an arbitrary object. This code assumes that the object's underlying type has an Add method. Moreover, this example also assumes that the Add method takes exactly three System.Int32s as arguments and that the underlying method will return a System.Int32. As an aside, this particular example uses the BindingFlags.NonPublic flag to indicate that nonpublic methods are to be considered. Yes, this facility allows you to circumvent the method's access modifier (e.g., private); however, only trusted code can violate this encapsulation.
Figure 6.5 shows how the MethodInfo object relates to the underlying method and target object. Note that there is an underlying System.RuntimeMethodHandle that points to CLR-managed data structures that describe the method. One can use the System.RuntimeMethodHandle.GetFunctionPointer method to access the address of the underlying method code. After this address is found, programmers who are comfortable with low-level programming techniques can invoke the method directly without going through the overhead of MethodInfo.Invoke.
The address returned by GetFunctionPointer is meant to be invoked using the CIL calli instruction. Unlike the call and callvirt instructions-which encode the metadata token of the target method directly into the instruction stream-the calli instruction expects the address of the target method to be pushed onto the stack at runtime. This level of indirection allows the CLR to support C-style function pointers. For example, suppose one has the following C# type definition:
public class TargetOne should be able to write the following C++ code:
using namespace System;Unfortunately, under version 1.0 of the .NET framework, the C++ compiler's CLR-compliant mode (/CLR) does not support the declaration of function pointers that use the __fastcall stack discipline, which is the discipline typically used internally by the CLR. Although constructing the proper IA-32 machine code is possible, the C++ compiler also prohibits inline assembly in managed methods. This leaves the industrious developer little choice except to use ILASM, the CIL assembler that ships with the .NET framework SDK, to write the necessary CIL to invoke the function.
The following ILASM method definition demonstrates how to invoke the Add method shown in the previous example:
.method public hidebysig static int32This method would generate the same machine code that the desired C++ function pointer would generate if the C++ compiler allowed __fastcall function pointers.
To invoke the instance method Subtract, one could use this ILASM method:
.method public hidebysig static int32In both cases, the first parameter to Call will be a function pointer as returned by MethodBase.GetFunctionPointer. It is important to note that in both of these examples, even though it appears that every argument is passed on the stack, when the JIT compiler translates this CIL into machine code, the first two parameters will be passed in the ecx and edx registers, as per the __fastcall calling convention.
The previous discussion looked at how MethodInfo objects give developers the capability of invoking a specific method on any type-compatible object. Because a MethodInfo object is affiliated with a type but not an object, invocation using MethodInfo requires that one supply the target object reference explicitly each time one invokes a method. In many cases, this is perfectly acceptable. However, it is often desirable to bind to a particular method on a specific object, and that is the role of delegates.
Delegates provide a mechanism for binding to a specific method on a specific target object. Binding to a specific target object eliminates the need to explicitly supply the target object reference at invocation time, something that is required by MethodInfo.Invoke. To that end, delegates can do very little interesting work other than invoke their underlying method.
Delegates are used in CLR-based libraries to represent the capability of calling a particular method. To that end, delegates are similar to a single-method interface, the primary difference being that interfaces require the target method's type to have predeclared compatibility with the interface type. In contrast, delegates can be bound to methods on any type, provided that the method signature matches what is expected by the delegate type.
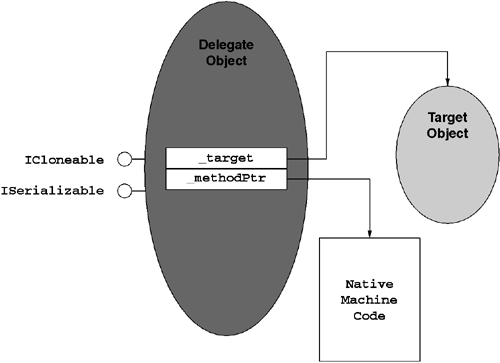
As shown in Figure 6.6, delegates are objects that maintain two fields: a method pointer and a target object reference. The method pointer is simply a C++-style function pointer such as the address returned by System.RuntimeMethodHandle.GetFunctionPointer. The target object reference is a reference of type System.Object that refers to the target object. When a delegate is bound to a static method, this reference is null.
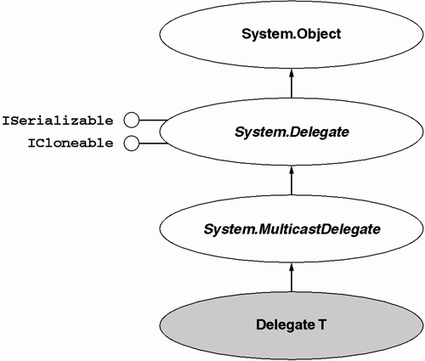
Unlike the MethodInfo type, which is used no matter what the underlying method signature is, a delegate object must be affiliated with a delegate type that is specific to the underlying method signature. As shown in Figure 6.7, delegate types always derive directly from System.MulticastDelegate, which in turn derives from System.Delegate. These two base types provide a variety of base functions as well as signal to the CLR that the type is in fact a delegate type.
Like any other CLR type, a delegate type has a type name and can have members. However, the members of a delegate type are restricted to a finite set of methods with fixed names. The most important of these is the Invoke method.
The Invoke method must be a public instance method. Additionally, one must mark the Invoke method as runtime, which means that the CLR will synthesize its implementation rather than JIT-compile it from CIL in the type's module. Although the name and metadata attributes are hard-wired, the actual signature of the method can be any CLR-compliant signature. The signature of the Invoke method determines how the delegate type can be used. In particular, any method that is bound to the delegate must have a signature that is identical to that of the delegate's Invoke method. The CLR enforces this signature matching both at compile time and at runtime.
In addition to the Invoke method, delegate types must provide an instance constructor method that takes two parameters. The first parameter is of type System.Object and specifies the target object reference being bound. The second parameter is of type System.IntPtr and must point to the code for the method being bound. As with the Invoke method, the constructor must be marked as runtime because the CLR will synthesize the implementation at runtime.
Each programming language provides its own syntax for defining delegate types. C#, C++, and VB.NET all share a similar syntax, which looks like a method declaration but is in fact a type definition statement. Consider the following C# statement:
public delegate int AddProc(int x, int y);This statement defines a new delegate type named AddProc whose Invoke method will accept two System.Int32s as parameters and will return a System.Int32 as a result. The following is the ILASM that corresponds to this C# type definition:
.class public auto ansi sealed AddProcAs just described, the signature of the Invoke method corresponds to the type definition statement in C#.
To instantiate a delegate, one needs a method and optionally a target object reference. One needs the target object reference only when one is binding to an instance method; it is not used when one is binding to a static method. The System.Delegate type provides the CreateDelegate static method for creating new delegates that are bound to a particular method and object. There are four overloads of CreateDelegate, as shown here:
namespace SystemThe first pair of overloads are for binding a new delegate object to a static method. The second pair are for binding to an instance method on a particular object. In all cases, the first parameter is a System.Type object that describes the desired delegate type. The specified target method must exactly match the signature of the delegate type's Invoke method.
The following C# code uses the CreateDelegate method to bind a delegate to a static method and an instance method:
using System;Calling CreateDelegate is an indirect way to invoke the delegate type's constructor. Each programming language provides syntax for invoking the constructor directly. In the case of C#, one can simply specify the symbolic name of the method qualified either by the type name or by an object reference. The following Main method is equivalent to the previous example:
static voidThe C# compiler will translate these new expressions to use the underlying CIL ldftn or ldvirtftn opcode to fetch the address of the target method prior to invoking the delegate type's constructor. This technique for binding a delegate is considerably faster than calling Delegate.CreateDelegate because the method handle does not need to be looked up via metadata traversal.
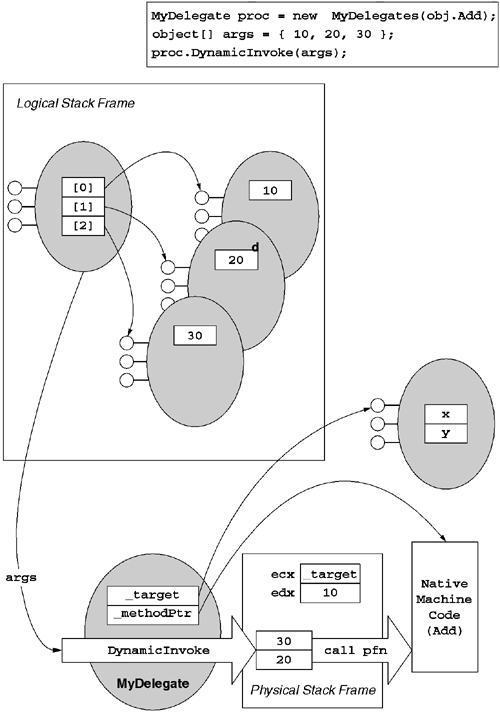
After the CLR has instantiated and bound a delegate to a method and object, the delegate's primary purpose is to support invocation. One can invoke using a delegate in one of two ways. If one needs a generic mechanism (a la MethodInfo.Invoke), the System.Delegate type provides a DynamicInvoke method:
namespace SystemNote that the signature for DynamicInvoke is identical to that of MethodInfo.Invoke except that the target object reference is not passed explicitly. Rather, the _target field of the delegate acts as the implicit target of the invocation. This is illustrated in Figure 6.8.
The far more common way to invoke against a delegate is to use the type-specific Invoke method. Unlike DynamicInvoke, the Invoke method is strongly typed and yields much better performance because of its lack of generality. The CLR-synthesized Invoke implementation for IA-32 is simply an eight-instruction shim that replaces the this pointer in ecx with that of the target object reference. The shim then jmps directly to the target method address. After the jmp occurs, the target method begins execution as if it were invoked directly by the caller. In fact, because the caller's return address is still on the stack, the target method will return directly to the caller, bypassing the delegate machinery altogether.
The shim used by the Invoke method is capable of working generically because the signature of the target method is guaranteed to match that of the Invoke method exactly. As shown in Figure 6.9, this allows one to reuse the stack frame from the call to Invoke when dispatching to the target method.
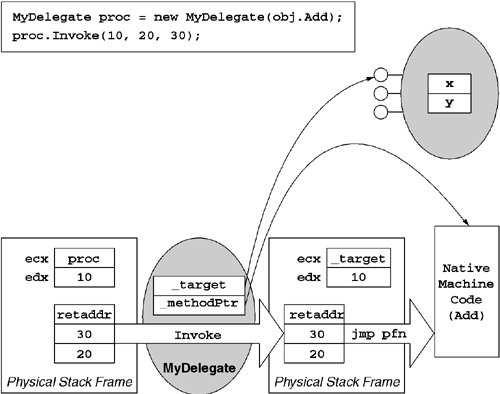
The C# programming language handles delegate invocation somewhat strangely. A C# program cannot access the Invoke method explicitly by name. Rather, one omits the Invoke name, resulting in a usage model that resembles C-style function pointers:
static voidIn my opinion, this slight obfuscation adds little to the usability of delegates. Fortunately, C++ and VB.NET allow developers to use the Invoke method explicitly.
The CLR's implementation of Invoke supports chaining together multiple delegates so that a single Invoke call can trigger calls to more than one method at a time. As shown in Figure 6.10, the System.MulticastDelegate type adds support for chaining delegate objects into a singly linked list. When one makes a call to Invoke on the head of the list, the CLR-synthesized code walks the list in order, invoking the target method on each delegate in the list. Because these calls are made in sequence, any changes to pass-by-reference parameters made by one method will be visible to the next target in the chain. Additionally, if the Invoke method returns a typed value, only the last method's value will be returned to the caller. Finally, if any of the methods throws an exception, then the invocation will stop at that point and the exception will be thrown to the caller.
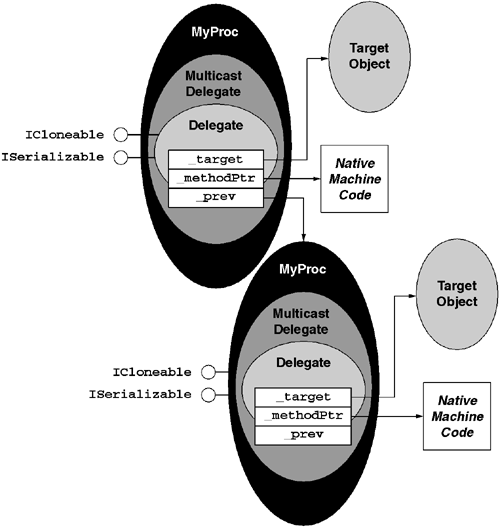
The System.Delegate type supports two methods for managing delegate chains: Combine and Remove.
namespace SystemBoth of these methods return a new delegate reference that references the updated delegate chain. This reference may or may not refer to the exact delegate passed as a parameter.
Listing 6.9 shows an example that uses Delegate.Combine to conjoin two delegates into a chain. Note that the order in which the delegates are conjoined is significant because the Invoke method will walk the chain in order.
It is possible to alter the way invocation works against a delegate chain. The System.Delegate type provides a method (GetInvocationList) that returns all of the delegates in a chain as an array. When you have access to this array, you can then decide exactly how to perform the individual invocations. Listing 6.10 shows an example that walks the list of delegates backward. This example also looks at the intermediate results of each individual invocation. In this case, an average is taken of the results of each invocation.
All of the invocation techniques shown so far simply route the stream of execution from one method to another. It is often desirable to fork the stream of execution into two branches, allowing one branch to execute the instructions of a given method while the remaining branch independently continues its normal processing. Figure 6.11 illustrates this concept. On a multiprocessor machine, the two branches can actually execute concurrently. On a single-processor machine, the CLR will preemptively schedule two branches of execution for execution on the shared CPU.
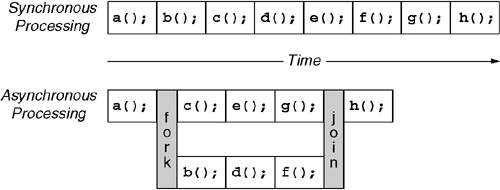
The primary motivation for forking execution is to allow processing to continue while part of the program is blocked, waiting for I/O to complete or for the user to enter a command. Forking execution can also increase throughput on a multi-CPU machine due to parallelism; however, this requires a very deliberate design style that avoids excessive contention for shared resources.
The primary mechanism for forking the instruction stream is to make an asynchronous method call. An asynchronous method call forks execution into two streams. The new stream executes the body of the target method. The original stream continues its normal processing.
The CLR implements asynchronous method invocation by using a work queue. When invoking a method asynchronously, the CLR packages the method parameters and the target method address into a request message. The CLR then queues this message onto a process-wide work queue. The CLR maintains an OS-level thread pool that is responsible for listening on the work queue. When a request arrives on the queue, the CLR dispatches a thread from its thread pool to perform the work. In the case of an asynchronous method call, the work is simply to invoke the target method.
One always performs asynchronous method invocation via a delegate object. Recall that a delegate type has two compiler-generated methods: Invoke and a constructor. Delegate types may also have two additional methods to enable asynchronous method invocation: BeginInvoke and EndInvoke. Like Invoke, these two methods must be marked as runtime because the CLR will provide their implementations at runtime based on their signatures.
The CLR uses the BeginInvoke method to issue an asynchronous method request. The CLR-synthesized implementation of BeginInvoke simply creates a work request containing the parameter values and queues the request onto the work queue. BeginInvoke typically returns before the target method begins to execute on the thread pool thread, but, because of the unpredictability of the underlying thread scheduler, it is possible (although unlikely) for the target method to actually complete before the calling thread returns from BeginInvoke.
The signature for BeginInvoke is similar to the signature for Invoke. Consider the following C# delegate type definition:
public delegate doubleThis delegate type would have an Invoke method signature that looks like this:
public double Invoke(double x, double y,The corresponding BeginInvoke would look like this:
public System.IAsyncResultNote that BeginInvoke's signature differs in two ways. For one thing, BeginInvoke accepts two additional parameters that are used to tailor how the call will be processed. These two parameters are described later in this section. The other difference between the signatures of Invoke and BeginInvoke is that BeginInvoke always returns a reference to a call object. The call object represents the pending execution of the method and can be used to control and interrogate the call in progress. The call object always implements the System.IAsyncResult interface.
As shown in Listing 6.11, IAsyncResult has four members. The CompletedSynchronously property indicates whether or not execution took place during BeginInvoke. Although the CLR's asynchronous invocation plumbing will never do this, objects that implement asynchronous methods explicitly may elect to process an asynchronous request synchronously.
The IAsyncResult.IsCompleted property indicates whether or not the method has completed execution. This allows the caller to poll the call object to determine when the call has actually completed execution:
static void f(Add add)As an alternative to polling, the AsyncWaitHandle property returns a System.Threading.WaitHandle object that one can use to wait via thread synchronization techniques.
static void f(Add add)This variation is considerably more efficient because the caller's underlying OS thread is put to sleep until the call is complete, giving other threads in the system more access to the CPU.
Finally, one uses the last parameter of a BeginInvoke signature to allow the caller to associate an arbitrary object with the method call. One then makes this user-provided object available via the AsyncState property of the call object. This facility is especially useful when one will use the call object outside the scope of the issuing method, because it allows the caller to provide additional information to the code that will ultimately process the completion of the call.
When an asynchronous method has completed execution, one needs some mechanism to allow the results of the call to be harvested for further processing. This mechanism is the EndInvoke method. The EndInvoke method is the fourth method of a delegate type. As with BeginInvoke, the signature of EndInvoke is related to the signature of the delegate type's Invoke method. Consider the C# delegate type used throughout this discussion:
public double Add(double x, double y,The corresponding EndInvoke would look like this:
public double EndInvoke(out double z, ref bool overflow,There are three ways in which the two method signatures relate. For one thing, EndInvoke returns the same typed value as Invoke. This is possible because EndInvoke will not return until the underlying method has completed execution and the return value is actually available. Second, EndInvoke omits any pass-by-value parameters that appear in Invoke. This is because the pass-by-value parameters were needed only to issue the call, and they do not represent the results of method execution. Finally, EndInvoke accepts an additional parameter of type IAsyncResult. This parameter allows the caller to indicate which call it is interested in harvesting results from. This parameter is necessary because one can issue multiple asynchronous calls against the same delegate object. The IAsyncResult parameter indicates which of the calls you are interested in.
Figure 6.12 shows how BeginInvoke and EndInvoke allow the caller's thread to continue processing while the target method executes. This diagram illustrates a couple of interesting points. For one thing, the CLR invokes the target method using the synchronous Invoke method, but one invokes it from a CLR-managed worker thread and not the caller's thread. Second, after the call has completed execution, the worker thread returns to the work queue after signaling call completion. By reusing the worker thread for additional asynchronous calls, one amortizes the thread creation costs over the lifetime of the process.
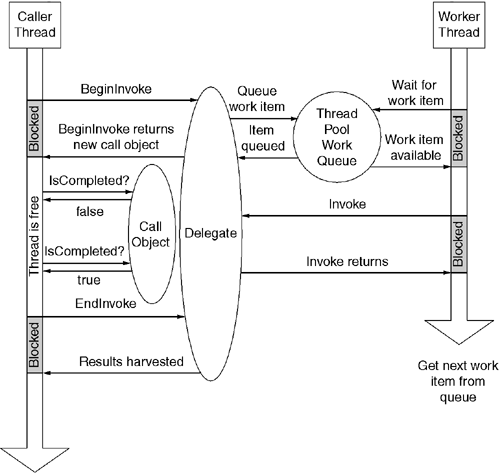
The number of threads in the thread pool will grow and shrink over time. When a work request arrives in the queue, the CLR will try to dispatch the call to an existing worker thread. If every worker thread is currently busy servicing a previous request, the CLR will start up a new thread to service the new request. To avoid saturating the system, the CLR places an upper bound on the number of worker threads it will create. The default upper bound is 25 threads per CPU, but processes that host the CLR manually can change this default using the ICorThreadpool::CorSetMaxThreads method. You can interrogate the upper bound from CLR-based programs by calling the System.Threading.ThreadPool.GetMaxThreads method.
It is possible that when a burst of work appears in the system, the number of threads can reach its upper bound. However, if that burst is a transient spike that does not represent the steady state of the application, it would be wasteful to keep every thread alive when a smaller number could accomplish the same results more efficiently. To that end, the worker threads decay after a period of time if they are not used. At the time of this writing, the decay period for a worker thread is 30 seconds.
The previous examples of asynchronous method invocation showed the caller's thread eventually making a rendezvous with the call object to process the results of the asynchronous call. Technically, it is legal to omit the call to EndInvoke if the results of the call are not important. This mode of invocation is sometimes called fire-and-forget, or one-way invocation. One typically uses this invocation style only with methods that do not have a return value and have no pass-by-reference parameters. One also uses this invocation style only when one can safely ignore method failure, because any exceptions thrown by the target method will be swallowed by the CLR in fire-and-forget scenarios.
One can process the results of an asynchronous method call without using an explicit rendezvous with the call object. One accomplishes this by passing an asynchronous completion routine to the BeginInvoke method when one issues the call.
Completion routines must match the prototype for the System.AsyncCallback delegate, which was shown in Listing 6.11. One passes the completion routine as the second-to-last argument to BeginInvoke. When present, the completion routine will be called by the worker thread immediately following the execution of the target method. Your completion routine will be passed the call object as its lone parameter. Typically, any state that is needed to properly process the call's completion would be passed as the last parameter to BeginInvoke; the completion routine would then retrieve this state via the IAsyncResult.AsyncState property.
Listing 6.12 shows an asynchronous method call that uses a completion routine. Note that in this example, the Completed method is responsible for calling EndInvoke to harvest any results from the method call. To allow EndInvoke to be called at completion time, a reference to the delegate object was passed as the last parameter to BeginInvoke. Had more sophisticated processing been required, a more complex object could have been passed instead.
As shown in Figure 6.13, the completion routine executes on the worker thread and not the caller's thread. Because the number of worker threads is limited, completion routines should avoid any long-running processing. If prolonged execution is needed, the completion routine should attempt to break the work into smaller chunks, which themselves can be executed asynchronously.
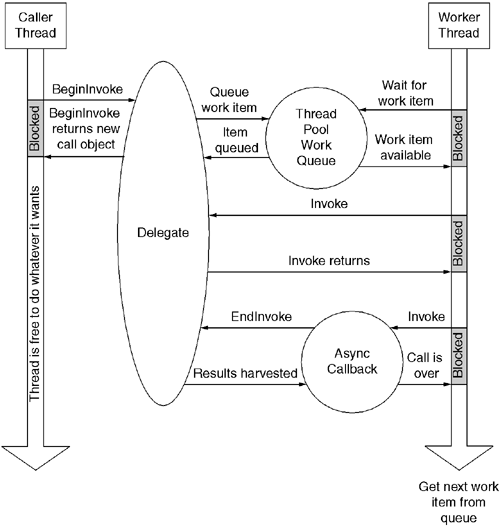
It is difficult to talk about asynchronous execution without addressing concurrency issues. Issuing an asynchronous method call inherently introduces concurrency into your programs. Although concurrency can allow your program to take advantage of multiple CPUs and gracefully deal with blocking system calls, concurrency can also introduce insidious problems that are extremely difficult to diagnose, debug, and repair. These problems are inevitably caused by locking.
It is a natural instinct to want to use locks to solve concurrency problems; most texts on multithreaded programming dedicate a great deal of space to lock primitives. However, locks introduce as many problems as they solve, and one should use them with great care and avoid them if possible. In particular, systems that use locks are often prone to deadlock, which can freeze the system altogether. Another common problem one encounters when using locks is poor scalability due to lock contention. This can happen when lock acquisition occurs on the critical path of an application, especially when the lock is held for a significant amount of time.
The best way to avoid using locks is to ensure that concurrent tasks do not need to share any resources. This means that asynchronous methods need to be careful not to access static fields that may also be accessed by the caller's thread. Also, if the call to BeginInvoke conveyed any object references, the calling thread should take care not to access the referenced object while the asynchronous method is still executing. By avoiding access to these (and other) shared resources, one can achieve lock-free concurrency.
If a resource in fact needs to be shared, one can use at least one technique short of locking. If the shared resource is simply a System.Int32 or System.Single, the System.Threading.Interlocked type has methods that one can use to overwrite, increment, or decrement the shared value in a thread-safe fashion. These methods use processor-specific instructions to perform the operation atomically. The use of these methods is considerably faster than locking and will never result in deadlock because no locks are taken.
The CLR does support locking for cases when it is absolutely necessary. The CLR provides two basic types of locks. Locks based on System.Threading.WaitHandle mirror the Win32 event and mutex synchronization primitives and are suitable for cross-process synchronization. The more interesting locks are the monitor and ReaderWriterLock.
Both the monitor and ReaderWriterLock are limited to use within a single process (actually, within a single AppDomain). The monitor supports exclusive locking, which allows only one thread at a time to gain access to the lock. The ReaderWriterLock supports both exclusive and shared locking, which allows multiple threads to gain access to the lock provided that they require only read access to the resource the lock protects.
The monitor lets one associate a lock with any object in the system. However, because relatively few objects will be used with locks, objects do not have a lock when they are instantiated. Instead, the CLR lazily allocates the lock the first time a monitor tries to apply a lock to an object. To allow an object's lock to be found efficiently, the CLR stores an index into a table of sync blocks in the object's header. Objects that have no sync block have zero for a sync block index. The first time a monitor is used on an object, a sync block will be allocated for the object, and its index will be stored in the object's header.
One exposes monitor-based locking via the System.Threading.Monitor type. This type has two static methods (Enter and Exit), which acquire and release an object's lock, respectively. This lock is an exclusive lock, and only one thread at a time can acquire it. If a second thread attempts to acquire a lock on an object that is already locked, the second thread will block until the lock becomes available. C# provides an exception-safe construct for using the two monitor methods via its lock statement. For example, consider the following method:
static void UseIt(Bob bob)This method is equivalent to the following:
static void UseIt(Bob bob)The CLR's monitor also offers Java-style pulse-and-wait capabilities for performing low-level thread synchronization. Readers are encouraged to look at Doug Lea's most excellent Concurrent Programming in Java (Addison-Wesley, 1999) for the definitive discussion of this facility.
The majority of this chapter has focused on how to enter a method in the CLR. Before concluding this chapter, it seems appropriate to look at how methods are left once they are invoked.
Barring termination of a process, AppDomain, or thread, there are two ways to leave a method after it has been entered: normal termination and abnormal termination. This is illustrated in Figure 6.14. The CIL ret instruction, which invariably terminates every method's instruction stream, triggers normal termination. The ret instruction may also appear in other locations in the instruction stream, typically due to return statements in C#, C++, or VB.NET. When a method terminates normally, the typed return value is available to the caller, and the CLR guarantees that any pass-by-reference parameters will reflect the changes made by the method.
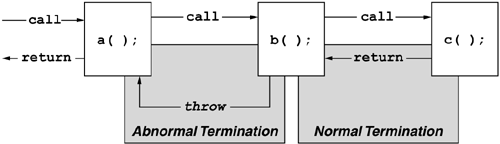
Abnormal termination differs from normal termination in two ways. For one thing, the typed return value is not available to the caller when a method terminates abnormally. Second, the values of pass-by-reference parameters may or may not have been affected by the method body. Although the results of a method call are not available under abnormal termination, there is an alternative medium for conveying output to the callee. That medium is the exception object.
The raising of an exception triggers abnormal termination. The CLR itself can raise exceptions in response to any number of abnormal conditions (e.g., using a null reference, division by zero). Application code can also raise exceptions via the CIL throw instruction (which is triggered by the throw statement in C#, C++, and VB.NET). Ultimately, exception processing works the same whether the CLR or the application throws the exception, so the remainder of this discussion will focus on exceptions raised using the throw instruction.
The throw instruction requires a reference to an exception object that will convey the reason for abnormal termination. An exception object is an instance of System.Exception or a derived type. Rather than rely on error numbers, the CLR (like C++ and Java) uses the type of the exception to convey the reason for the error. To that end, the CLR defines two commonly used subtypes of System.Exception: The CLR uses System.SystemException as a base type for the CLR-defined system-level exception types, and the CLR uses System.ApplicationException as a base type for application-specific exception types. Figure 6.15 shows many of the system-level exceptions.
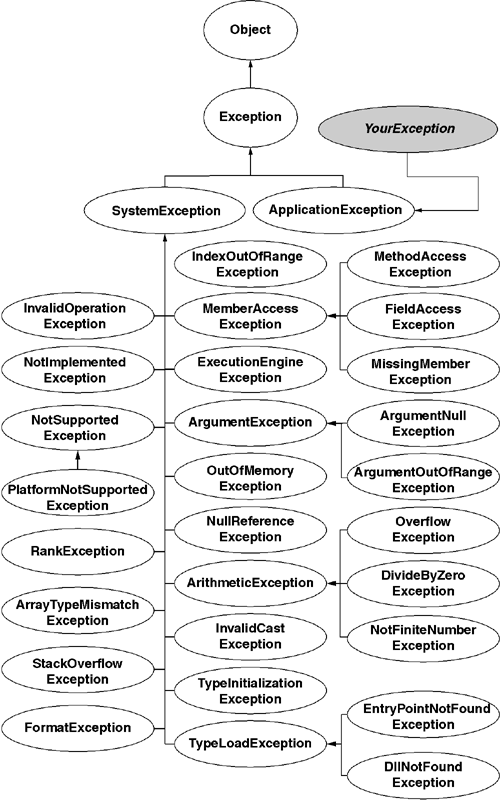
Not only do exceptions carry an alternate result from a method or instruction, but also the throwing of an exception causes the CLR to change the course of normal execution. In particular, the CLR will look for an appropriate exception handler by traversing the stack of the currently executing thread. Each stack frame has an exception table that indicates where that method's exception handlers are located as well as which range of instructions they apply to. The CLR looks at the instruction counter for that stack frame to determine which handlers are applicable.
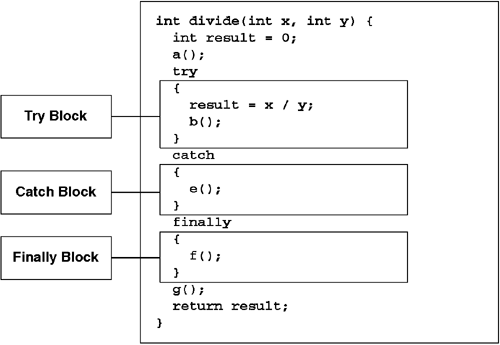
Each programming language provides its own syntax for populating the exception table of a method. Figure 6.16 shows the simplest C# exception handler. In this example, the divide method will have exactly one entry in its exception table. The protected body will span the assignment statement and the call to b. The handler will span the call to e. This handler is an unconditional handler, and if any exception is thrown while the method is executing in the protected body, the handler code will execute and the exception will be considered handled. After the exception is handled, execution will resume at the instructions that form the call to g.
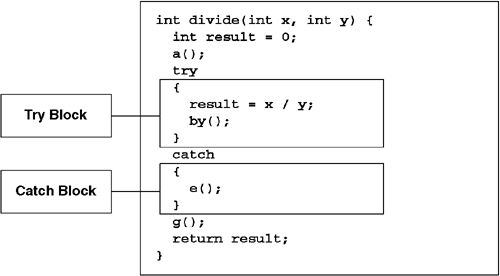
The CLR will use the exception handler no matter what the type of the exception object may be. It is also possible to add a predicate to an exception handler that restricts the handler to exceptions that are compatible with a given type. For example, consider the C# exception handler shown in Figure 6.17. This method has an exception table with three entries. Each entry in the exception table has an identical protected range, which will correspond to the try block shown here. However, the first entry in the table will have a type-based predicate that causes the handler to be ignored if the current exception is not compatible with FancyException. The second entry in the table will have a predicate that causes the handler to be ignored if the current exception is not compatible with NormalException.
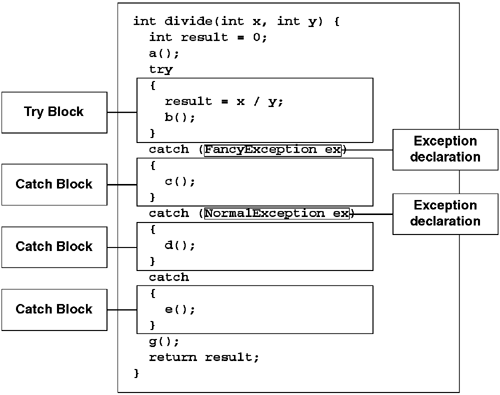
Finally, the third entry in the exception table has a type-based predicate that requires the exception to be compatible with System.Object, something that in essence makes the third entry an unconditional handler. It is important to note that the CLR will walk the exception table in order, so it is critical that handlers with more-specific types in their predicates appear before handlers that use generic types. The C# compiler will enforce this by way of compiler errors; your language's compiler may not be so watchful.
The exception table also contains entries for termination handlers. A termination handler fires whenever control leaves a protected range of instructions. The CLR will run termination handlers when an exception causes a protected body to be left. The CLR also runs termination handlers when a protected range of instructions completes execution normally. In C#, one creates termination handlers using the try-finally statement, as shown in Figure 6.18. In this example, the instructions in the protected range are the assignment statement and the call to b. After execution begins in this range of instructions, the CLR will guarantee that the handler clause (in this case, the call to f) will execute. If no exceptions are thrown, then the call to f will occur immediately after the call to b. If an exception is thrown while the method is executing in the protected range of instructions, the call to f will be made prior to the CLR's unwinding the method's stack frame.
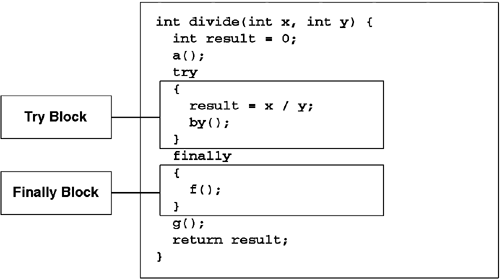
Just as it was possible to specify multiple exception handlers for a given C# try block, one can also specify a termination handler after the list of exception handlers. This is shown in Figure 6.19. Again, each handler (be it a termination or an exception handler) will have its own entry in the method's exception table.
The CLR provides a variety of mechanisms to trigger the execution of method code. Each of these mechanisms allows the developer to control the exact method that will be invoked as well as the way the parameters will be specified. Some of the mechanisms assume that method invocation will be an implicit action, whereas others make method invocation explicit. To that end, the CLR allows developers to explicitly invoke methods either synchronously or asynchronously based on the desired concurrency characteristics.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 1459
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2024 . All rights reserved