| CATEGORII DOCUMENTE |
| Bulgara | Ceha slovaca | Croata | Engleza | Estona | Finlandeza | Franceza |
| Germana | Italiana | Letona | Lituaniana | Maghiara | Olandeza | Poloneza |
| Sarba | Slovena | Spaniola | Suedeza | Turca | Ucraineana |
DOCUMENTE SIMILARE |
||||
|
||||
TERMENI importanti pentru acest document |
||||
| : | ||||
COMS W4701x: Artificial Intelligence
MIDTERM EXAM
October 26th, 2006
This exam is closed book and closed notes. It consists of three parts. Each part is labeled with the amount of time you should expect to spend on it. If you are spending too much time, skip it and go on to the next section, coming back if you have time.
The first part is multiple choice. The second part is short answer and problem solving. The third part is an essay question.
Important: Answer Part I by circling answers on the test sheets and turn in the test itself. Answer Part II and Part III in separate blue books. In other words, you should be handing in the test and at least two blue books.
Part I - Multiple Choice. 20 points total. 15 minutes.
Circle the one answer that best answers the question.
Searle defines strong AI as
a. a computer program that produces the strongest possible rational for a decision
b. a computer program that models human cognitive reasoning
c. a computer program that can outperform a human on the Turing test
d. a computer program that can speak Chinese
b
Which of the following search algorithms finds the optimal solution?
a. breadth first c. depth first
b. hill climbing d. greedy search
a
A search algorithm is complete if it
a. always finds the optimal solution
b. always finds a solution if there is one
c. finds all possible solutions
d. never finds a solution
b
Which of the following techniques uses randomness for avoiding getting trapped in local maxima?
a. Best first search
b. Local beam search
c. Simulated annealing
d. Gradient descent
c
Which of the following is a problem that occurs in hill climbing?
a. Cliff
b. Ridge
c. Valley
d. Rock slide
b
. Given that
P(a) = 0.2
and
P(b) = 0.6
in which of the following joint probability tables are P(A) and P(B) absolutely independent?
a) |
b)
|
||||||||||||||||||
c) |
d) |
c
Inference by enumeration
(a) is based on conditional probabilities between atomic events
(b) is based on .circumstantial evidence derived from atomic events
(c) is based on the full joint distribution of atomic events
(d) is based on a list of atomic events alone
c
A greedy search uses a heuristic function to
a. expand the node that appears to be closest to the goal
b. expand the node that is closest to the goal
c. expand the node that is the most expensive
d. expand the leftmost node
a
What is the difference between the cost function and heuristic function portions of the A* evaluation function?
a. A cost function returns the actual cost from current node to goal, while the heuristic function returns the estimated cost from current node to goal
b. A cost function returns the estimated cost from start node to current node, while the heuristic function returns the estimated cost from current node to goal
c. A cost function returns the estimated cost from current node to goal, while the heuristic function returns the actual cost from start node to current node
d. A cost function returns the actual cost from start node to current node, while the heuristic function returns the estimated cost from current node to goal.
d
10. An utility function is used in game playing to
a. estimate the expected utility of the game from a given position
b. compute the winner of the game based on number of pieces left
c. compute the utility of a terminal leaf in a game tree
d. compute the best move for the successor function
c
Part II. Problem Solving. 60 points. 45 minutes.
1. [20 points Constraint Satisfaction. Consider the crossword puzzle given below:

Suppose we have the following words in our dictionary: ant, ape, big, bus, car, has, bard, book, buys, hold, lane, year, rank, browns, ginger, symbol, syntax. The goal is to fill the puzzle with words from the dictionary.
(10 pts) Formalize the problem as a constraint satisfaction problem. Be sure to specify the variables, their domains, constraints and give a sketch of how the problem would be solved.
Variables will be positions in the crossword puzzle: (2)
e.g., 4 across, 1 down, etc.
Domain of each variable will be the set of words that can fit in that slot.
So: (3)
1A,4A: ant, ape, big, bus, car, has
1D, 3A: bard, book, buys, hold, lane, year, rank
2D: browns, ginger, symbol, syntax
Constraints: at each place where two words intersect, the letters must be equal. So, the first letter of 1A = 1D. last letter of 1A = 1st letter of 2D, etc. (2)
Sketch of how problem will be solved: (3 initial state, successor function, backtracking, heuristics)
The initial state will have an empty assignment of values to variable.
The successor function will chose a variable to assign a value to and check whether all the constraints are met as it assigns a value. If there is no value which can be assigned without breaking the constraints, the algorithm will backtrack to the last choice point.
When choosing a variable, the successor function will use the MRV to select the variable which has the minimum remaining valueson it. If more than variable have the same # of constraints, the algorithm will choose the variable with the most constraints on remaining variables
(5 pts) Show the resulting constraint network.
Here, you need to show the graph for these constraints.
1A(1) = 1D(1)
1A(3) = 2D(1)
1D(3) = 3A(1)
3A(3) = 2D(3)
4A(1) = 2D (5)
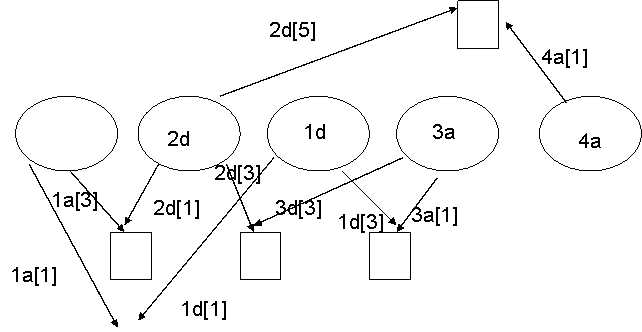
(5 pts) Show how the Minimum Remaining Values heuristic would be used, showing how the first two words would be selected.
The first variable to be selected will be 2D because it has the fewest possible values in its domain.
The value will be chosen as the one which rules out the fewest possible remaining values for other variables. So, the choices are:
browns, ginger, symbol, syntax
Choosing browns, leaves 1 choice for 3A, 0 for 4A, 0 for 1A
Choosing ginger leaves 2 choices for 3A, 0 for 4A, 1 for 1A
Choosing symbol leaves 0 choices for 3A, 0 for 4A, 2 for 1A
Choosing syntax leaves 2 choices for 3A, 2 for 4A, 2 for 1A
So syntax will be chosen.
The second variable to be selected will be either 3A, 1A or 4A by MRV. Given a tie, the one that places the most constraints on remaining variables is either 1A or 3A. So lets say 1A chosen next (either one is OK). The value will be chosen as the one which rules out the fewest possible remaining values for other variables. So the choices are:
ant, ape, big, bus, car, has
it must be a word that ends in s since 2D begins with s
Choosing bus leaves 3 choices for 1 D
Chososing has leaves 1 choice for 1D
Bus is chosen.
Forward checking would not change the choices for any of these variables at this point in time.
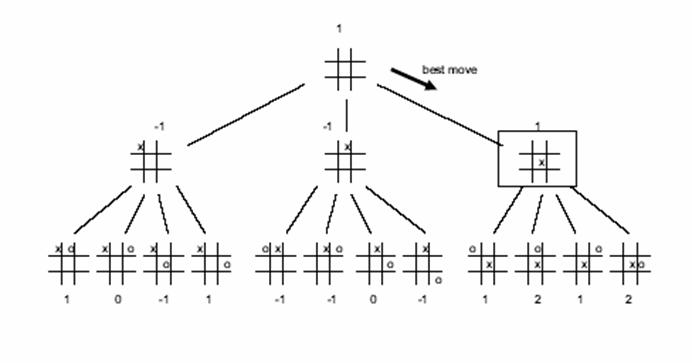
2. [20 points] Game playing and alpha beta pruning
Consider the game of tic-tac-toe (also sometimes called noughts and crosses). We define Xn as the number of rows, columns, or diagonals with exactly n X's and no O's. Similarly, On is the number of rows, columns, or diagonals with exactly n O's and no X's. The utility function assigns +1 to any position with X3 = 1 and -1 to any position with O3 = 1. All other terminal positions have utility 0. For non-terminal positions, we use a linear evaluation function defined as Eval(s)= 3X2(s) + X1(s) - (3O2(s) + O1(s)).
The figure below shows a partial game tree to depth 2.
(10 pts) Given the partial game tree, use the minimax agorithm to choose the best starting move. Mark on the tree the minimax value associated with every node in the tree.
(10 pts) Circle the nodes that would not be evaluated if alpha-beta pruning were applied, assuming the nodes are generated in the optimal order for alpha-beta pruning. (This means that it's ok to (virtually) reorder the leaves and associated internal nodes if they are not in the optimal order.)
For alpha-beta pruning, the best leaf for Max is one of the 1's in the
rightmost branch. So the optimal ordering for alpha-beta pruning
would be to evaluate this branch first (i.e. as if it were the
left-most branch). None of the nodes in this branch can be pruned.
The ordering of the other branches doesn't matter. Within the
1-0-(-1)-1 branch, one of the 1's must be visited, but the remaining 3
leaves will be pruned by alpha-beta pruning. Within the
(-1)-(-1)-0-(-1) branch, (any) one of the leaves must be visited, but
then the rest will be pruned by alph-beta pruning.
Optimal ordering: 2
No pruning of right-most branch: 2
3 branches pruned in left-most: 3
3 branches pruned in middle: 3
Best move: 1
1st levels: 1 each (or 3)
Bottom level: 2 per branch or .5 per evaluation fn.
3. [20 points] Consider the search space below, where S is the start node and G1 and G2 are goal nodes. Arcs are labeled with the value of a cost function; the number gives the cost of traversing the arc. Above each node is the value of a heuristic function; the number gives the estimate of the distance to the goal. Assume that uninformed search algorithms always choose the left branch first when there is a choice. Assume that the algorithms do not keep track of and recognize repeated states.
For each of the following search strategies,
(a) indicate which goal state is reached first (if any) and
(b) list in order, all the states that are popped off the OPEN list.
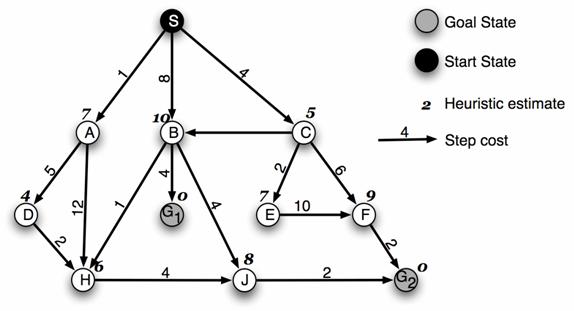
SOLUTION
Depth-first
(a) G2 (2 pt)
(b) S, A, D, H, J, G2 (2pt)
Iterative Deepening
(a) G1
(b) S, A, B, C, S, A, D, H, H, B, H, G1
Breadth-first
(a) G1
(b) S, A, B, C, D, H, H, G1
Greedy
(a) G2
(b) S, C, A, D, H, E, J, G2
A*
(a) G1
(b) S, A, C, D, E, H, B, G1
SOLUTION
Depth-first
(a) G2
(b) S, A, D, H, J, G2
Iterative Deepening
(a) G1
(b) S, A, B, C, S, A, D, H, H, B, H, G1
Breadth-first
(a) G1
(b) S, A, B, C, D, H, H, G1
Greedy
(a) G2
(b) S, C, A, D, H, E, J, G2
A*
(a) G1
(b) S, A, C, D, E, H, B, G1
SOLUTION
Depth-first
(a) G2
(b) S, A, D, H, J, G2
Iterative Deepening
(a) G1
(b) S, A, B, C, S, A, D, H, H, B, H, G1
Breadth-first
(a) G1
(b) S, A, B, C, D, H, H, G1
Greedy
(a) G2
(b) S, C, A, D, H, E, J, G2
A*
(a) G1
(b) S, A, C, D, E, H, B, G1
Part III. 20 points. 15 minutes.
Short Answer. Answer 4 out of the following 6 problems. Use no more than 2 sentences for each question. Each question is worth 5 points. You may put your answer on the test sheet.
1. Under
what conditions does A* produce the optimal solution?
When the heuristic that A* uses is admissible (i.e. an underestimate of the true cost to the goal)
2. Could we apply the Turing test to a computer that plays chess? Why or why not?
If we restricted the questions asked to the chess playing computer to be questions about what is the best move to make next, then we could use the Turing test by comparing the computers answers to a human playing the same game. If we allow any questions, then the chess playing computer would most definitely lose the Turing test.
3. How is information gain used to select the best attribute for decision tree learning? Describe metrics (but no need to give formulae) and effect of using information gain on the resulting tree.
Two metrics would be used: entropy and information gain. Entropy measures the homogeneity of a class of examples. If all are the same it returns a value of 0, if they are equally split, it returns a value of 1. In between this, it will return a value between 0 and 1, being closer to 1 if they are more equally split than not. Information gain measures the difference between entropy of the original set and entropy of the subsets obtained after choosing an attribute. The attribute that gives the largest information gain is chosen.
Calculate the value of P(C,L,ØM,ØB) for the Bayesian net shown below. It is sufficient to show how you would calculate it without actually doing the arithmetic.
|
L |
M |
P(B=true|L,M) |
|
True |
True | |
|
True |
False | |
|
False |
True | |
|
False |
False |
|
C |
P(L=true|C) |
|
True | |
|
False |
P(C=true) = 0.1 0.20.20.2

|
C |
P(M=true|C) |
|
True | |
|
False |
P(C,L,ØM,ØB) = .1*.6*.2*.1
5. Describe 3 sources of knowledge that IBMs Deep Blue uses to select good moves.
Book of opening moves, end game database, and heuristics
6. Describe how hill-climbing is used for machine translation, including the evaluation function that is used to determine the best next state.
We start off with a translation based on individual word translations. This is the initial state. Then the successor function proposes modifications to the initial translation, which may include substituting a word, deleting a word, adding a word, among others. The different possible new translations (note that there are many) are then scored using a language model and the best one is accepted.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 2045
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved